
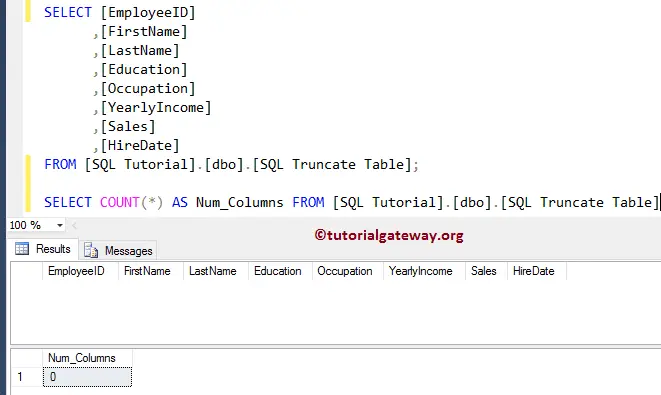
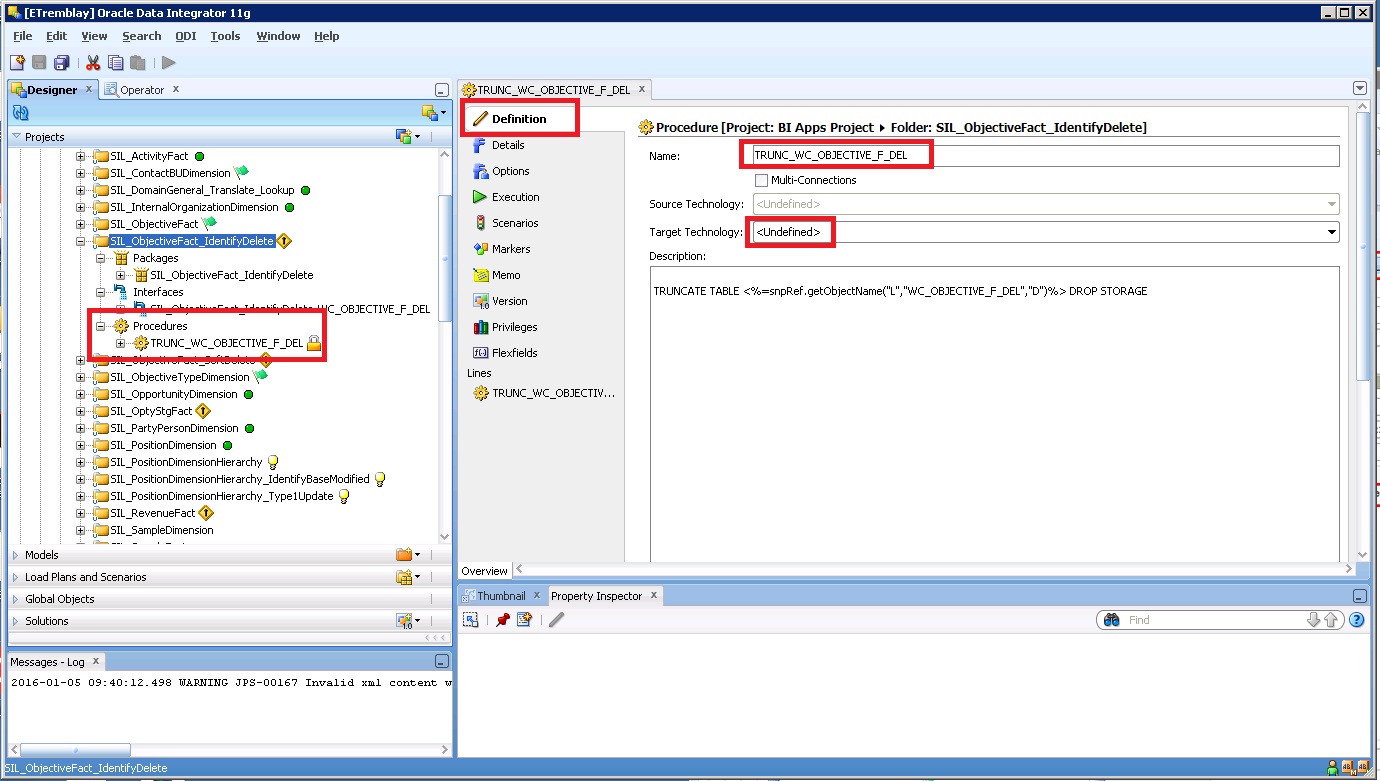
Сводка
Существует два распространенных метода, которые можно использовать для удаления дублирующихся записей из SQL Server таблицы. Для демонстрации сначала создайте пример таблицы и данных:
Затем попробуйте следующие методы, чтобы удалить дублирующиеся строки из таблицы.
Способ 1
Запустите следующий сценарий:
Этот скрипт принимает следующие действия в данном порядке:
- Перемещает один экземпляр любой дублирующейся строки в исходной таблице в дублирующую таблицу.
- Удаляет все строки из исходной таблицы, которые также находятся в дублирующей таблице.
- Перемещает строки в таблицу дубликатов обратно в исходную таблицу.
- Сбрасывает таблицу дубликата.
Этот метод прост. Однако для создания дублирующей таблицы в базе данных необходимо иметь достаточно места. Этот метод также накладные расходы, так как данные перемещаются.
Кроме того, если в вашей таблице есть столбец IDENTITY, при восстановлении данных в исходной таблице необходимо использовать set IDENTITY_INSERT ON.
Способ 2
Функция ROW_NUMBER, которая была представлена в Microsoft SQL Server 2005 г., значительно упрощает эту операцию:
Этот скрипт принимает следующие действия в данном порядке:
- Использует функцию для раздела данных на основе которых может быть один или несколько столбцов, разделенных запятой.
- Удаляет все записи, которые получили значение больше 1. Это значение указывает на то, что записи являются дубликатами.
Из-за выражения скрипт не сортировать разделимые данные на основе каких-либо условий. Если в логике удаления дубликатов необходимо выбрать, какие записи удалять, а какие хранить в соответствии с порядком сортировки других столбцов, для этого можно использовать выражение ORDER BY.
Функция SQL DATE_TRUNC | Синтаксис и примеры BigQuery
Функция DATE_TRUNC в BigQuery усекает дату до заданной части date_part.
Где date_part может принимать любое из следующих значений:
WEEK (): усекает date_expression до границы предыдущей недели, где недели начинаются с WEEKDAY. Допустимые значения для WEEKDAY: ВОСКРЕСЕНЬЕ, ПОНЕДЕЛЬНИК, ВТОРНИК, СРЕДА, ЧЕТВЕРГ, ПЯТНИЦА и СУББОТА.
ISOWEEK: усекает date_expression до предыдущей границы недели ISO 8601. ISOWEEK начинается в понедельник. Первая НЕДЕЛЯ ISO каждого года по ISO содержит первый четверг соответствующего года по григорианскому календарю.Любое выражение date_expression до этого будет усечено до предыдущего понедельника.
ISOYEAR: усекает date_expression до предшествующей границы года нумерации недель ISO 8601. Граница года по ISO — это понедельник первой недели, четверг которой принадлежит соответствующему году по григорианскому календарю.
Возвращает: DATE
Всегда возвращает ДАТУ, поэтому даже если вы выполняете усечение до ГОДА, вы получите обратно первый день этого года .По этой причине его часто используют вместе с FORMAT_DATE, если вы хотите просто использовать год YYYY.
Будьте осторожны при работе с несколькими TRUNC — как показано в приведенном выше примере, дату в 2021 году можно считать в 2020 году, если там был первый день недели. Таким образом, если вы будете считать по ГОДУ и ГОДУ (НЕДЕЛЯ), вы получите разные результаты.
Как агрегировать данные по месяцам?
DATE_TRUNC очень удобен для агрегирования данных по определенной части date_part, например MONTH.См. Пример ниже, чтобы увидеть, как вы можете агрегировать по МЕСЯЦУ:
Убедитесь, что вы включили столбец DATE_TRUNC в свой GROUP BY!
Устранение неполадок Общие ошибки
Аргумент 1 DATE_TRUNC имеет неверный тип: ожидаемая дата, метка времени.
Убедитесь, что вы используете правильную функцию для вашего типа данных. Чтобы использовать DATE_TRUNC, вы должны работать с DATE, а не с DATETIME, TIMESTAMP или TIME.
Вы можете использовать CAST, чтобы изменить другие типы даты на DATE, или использовать одну из эквивалентных функций для других типов дат, например DATETIME_TRUNC.
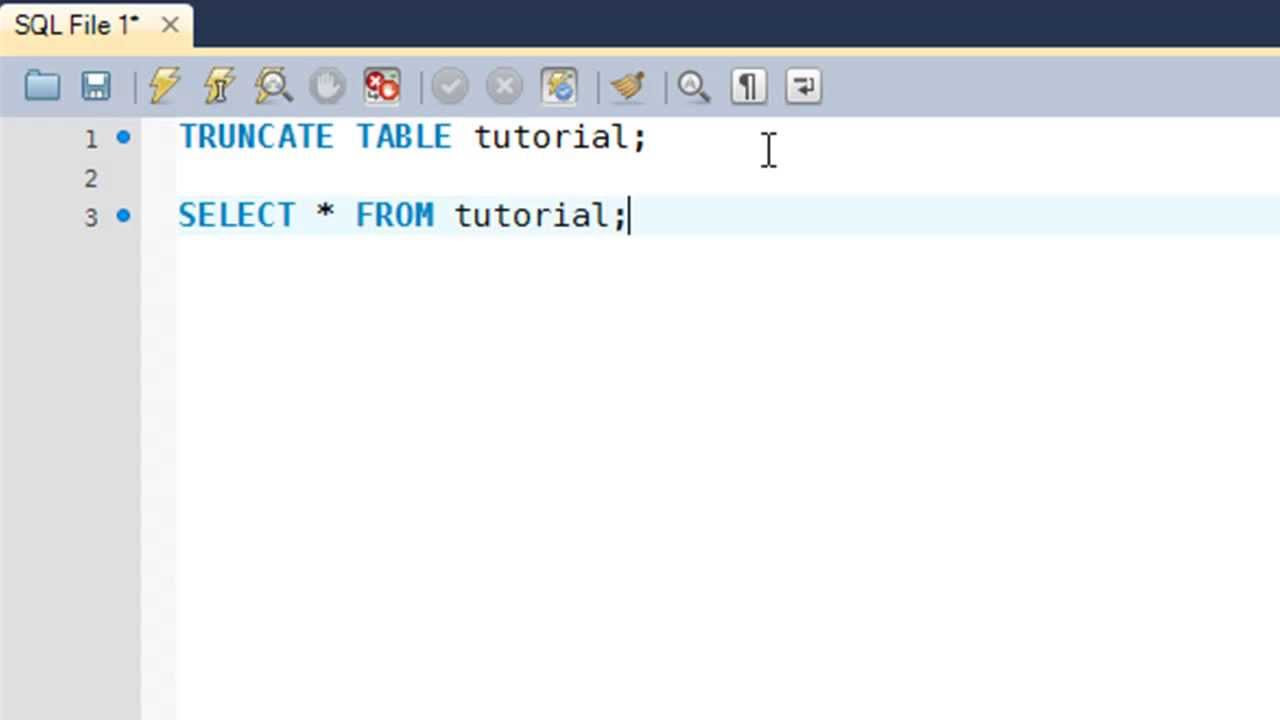
Инструкция TRUNCATE TABLE в Transact-SQL | Info-Comp.ru
В Microsoft SQL Server для удаления данных из таблицы можно использовать инструкцию DELETE, но также можно использовать и инструкцию TRUNCATE TABLE, поэтому сегодня мы поговорим о том, чем отличается TRUNCATE TABLE от DELETE и какие преимущества нам дает эта инструкция.
Если у Вас есть таблица в БД, данные которой Вы (или пользователи) периодически полностью удаляете с помощью инструкции DELETE, то данный материал будет Вам интересен, так как в нем мы рассмотрим альтернативную возможность удаления данных, а именно инструкцию TRUNCATE TABLE, которая в некоторых случаях будет предпочтительней, чем DELETE.
Что такое TRUNCATE TABLE?
TRUNCATE TABLE – это SQL инструкция в языке Transact-SQL, которая удаляет все строки в таблице, не записывая в журнал транзакций удаление отдельных строк данных. TRUNCATE TABLE похожа на инструкцию DELETE без предложения WHERE, но она выполняется быстрее и требует меньше ресурсов.
Преимущества TRUNCATE TABLE и отличия от DELETE
- TRUNCATE TABLE требуется меньший объем журнала транзакций, так как она в отличие от инструкции DELETE не заносит в журнал транзакций запись для каждой удаляемой строки, напомню что DELETE производит удаление по одной строке отражая все действия в журнале транзакций;
- TRUNCATE TABLE выполняется быстрее по сравнению с инструкцией DELETE также за счет меньшего использования журнала транзакций;
- Используется меньшее количество блокировок. Инструкция TRUNCATE TABLE в отличие от инструкции DELETE блокирует таблицу и страницу, а не каждую строку таблицы;
- Если инструкция TRUNCATE TABLE применяется к таблице, которая содержит столбец идентификаторов, счетчик этого столбца сбрасывается до начального значения. Инструкция DELETE не сбрасывает счетчик столбца идентификаторов;
- Инструкция TRUNCATE TABLE не активирует триггер, поскольку она не записывает в журнал удаление отдельных строк.
Примечание! Преимущества TRUNCATE TABLE в некоторых случаях, как Вы понимаете, могут быть и недостатками.
Инструкция TRUNCATE TABLE удаляет все строки (данные) таблицы, но структура таблицы: столбцы, ограничения, индексы и так далее сохраняются. Для того чтобы полностью удалить таблицу и ее определение, следует использовать инструкцию DROP TABLE.
Если таблица является частью индексированного представления, то TRUNCATE TABLE также нельзя использовать;
Если таблица опубликована с использованием репликации транзакций или репликации слиянием, то инструкцию TRUNCATE TABLE использовать нельзя.
Пример использования инструкции TRUNCATE TABLE
Для примера давайте создадим таблицу со столбцом идентификаторов, затем добавим в нее данные и удалим их инструкцией TRUNCATE TABLE, затем снова добавим данные и проверим, сбросился ли счетчик столбца идентификаторов на начальное значение.
--Создаем тестовую таблицу
CREATE TABLE TestTable(
ProductId INT IDENTITY(1,1) NOT NULL,
ProductName VARCHAR(100) NOT NULL
)
--Добавляем данные
INSERT INTO TestTable
VALUES ('Компьютер'),
('Монитор'),
('Принтер')
--Выборка данных
SELECT * FROM TestTable
--Удаляем все данные инструкцией TRUNCATE TABLE
TRUNCATE TABLE TestTable
--Снова добавляем данные
INSERT INTO TestTable
VALUES ('Компьютер'),
('Монитор'),
('Принтер')
--Выборка данных
SELECT * FROM TestTable
Как видим, счетчик сброшен, инструкция TRUNCATE TABLE отработала.
На этом у меня все, пока!
join + group by
Та же идея, что и в предыдущем случае, только реализована через самообъединение таблицы и группировку. Каждой строке сопоставляется набор строк с тем же user_id и большей или равной date_added, после группировки мы получаем для каждой строки (количество сообщений того же пользователя с большей датой добавления) + 1. Иными словами, если мы пронумеруем сообщения пользователя по убыванию date_added, то полученное число будет порядковым номером строки в этой нумерации.
select t1.* from
posts t1 join posts t2 on t1.user_id=t2.user_id and t2.date_added >= t1.date_addedgroup by t1.post_id having count(*) <=3;
Этот способ часто рекомендуют в интернете в качестве решения задачи (встречаются вариации с left join). Однако его производительность не самая оптимальная в сравнении с другими методами, рассмотренными в этой статье. Вероятно, причина популярности этого решения в том, что join многим интуитивно представляется более простым решением.
Обратите внимание: в режиме ONLY_FULL_GROUP_BY придется усложнять запрос: сначала выбрать нужные post_id, затем по ним дополнительным join извлечь остальные поля (подробнее см статью Группировка в MySQL). Простое перечисление всех полей в части group by в разы увеличивает время выполнения запроса. Строго говоря, этот способ как и предыдущий (с помощью зависимого подзапроса) можно использовать для выборки случайных строк из группы, но только в новых версиях, где есть поддержка обобщенных табличных выражений
Вместо исходной таблицы в запросе будет использоваться результат select posts.*, rand() new_col from posts, и сравнение не по полю date_added, а по new_col.
Будем считать, что варианты 1 и 2 не применимы для поиска случайных строк в группах, потому что:
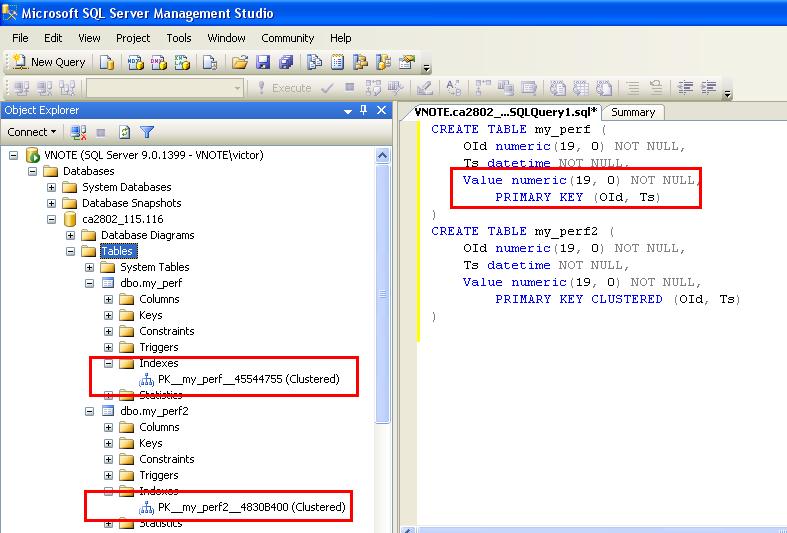


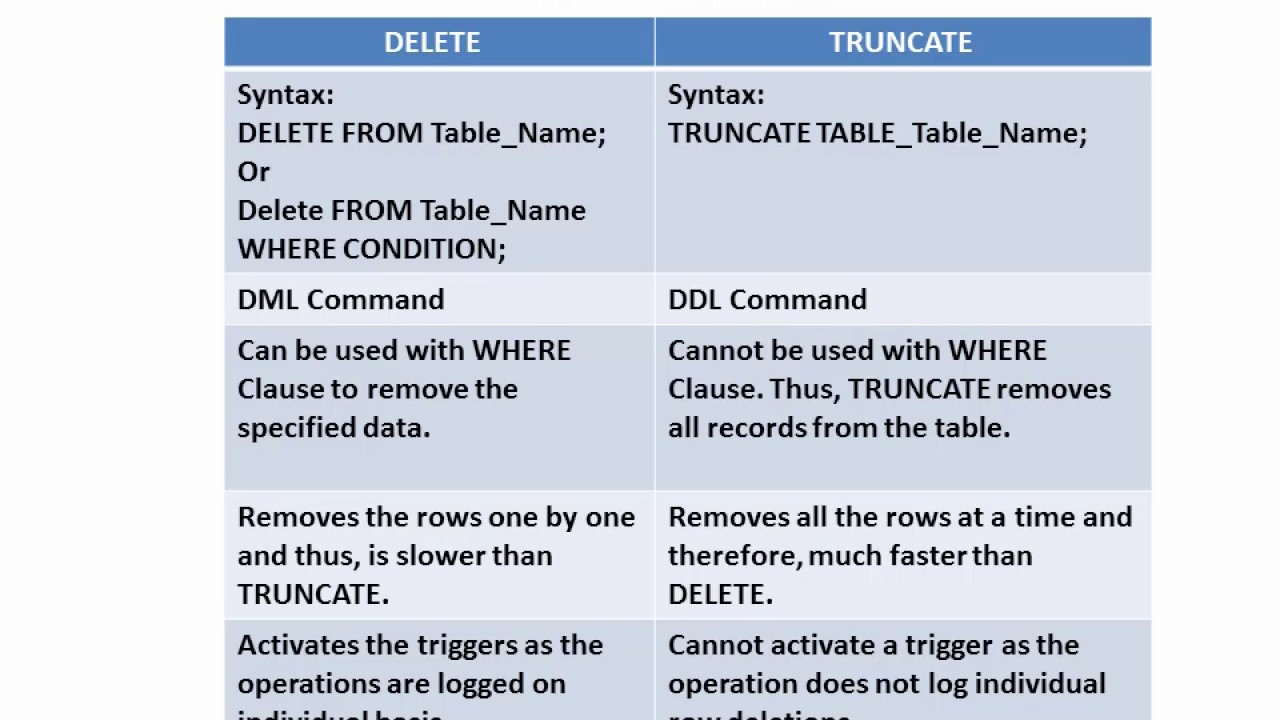

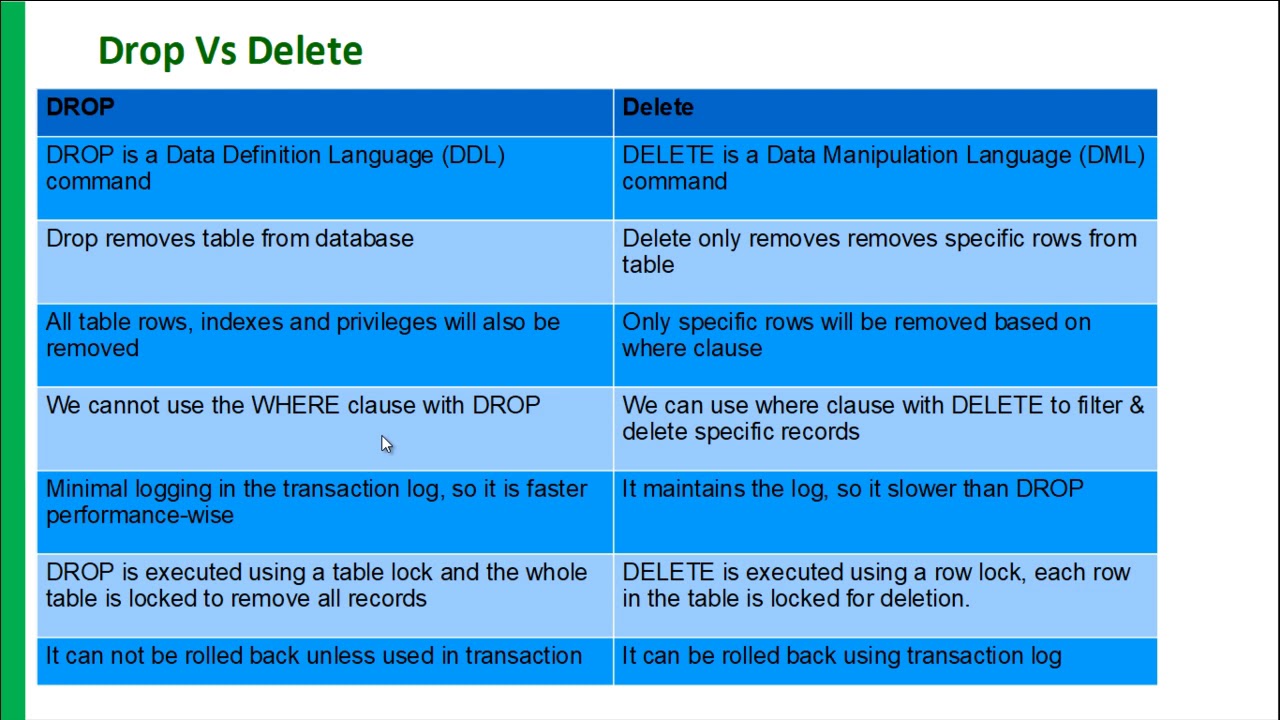
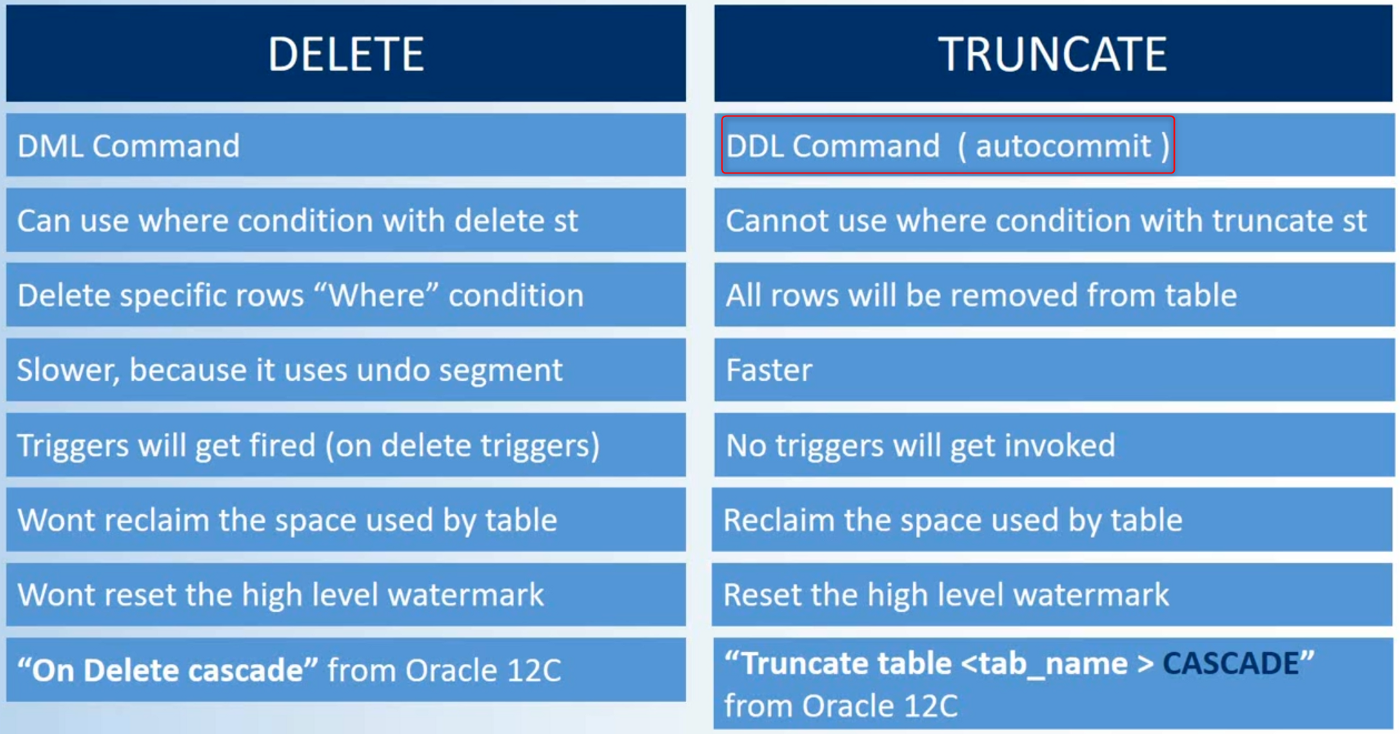
Строго говоря, этот способ как и предыдущий (с помощью зависимого подзапроса) можно использовать для выборки случайных строк из группы, но только в новых версиях, где есть поддержка обобщенных табличных выражений. Вместо исходной таблицы в запросе будет использоваться результат select posts.*, rand() new_col from posts, и сравнение не по полю date_added, а по new_col.
Будем считать, что варианты 1 и 2 не применимы для поиска случайных строк в группах, потому что:
- в старых версиях они действительно не применимы
- в новых их производительность будет существенно хуже по сравнению с иными доступными вариантами решений (см способы 4 и 6)
When to use the DELETE command
The DELETE command is used to remove records from a database. It is the most common way to do so. In its simplest form you can remove all the rows from a database or you can add a WHERE clause to remove only those meeting the criteria.
When execute the DELETE command,the DBMS logs all removed rows. This means it is easier to recover from a mistake, than it would a mistaken TRUNCATE.
The command
Will remove all employees from the employee table; whereas,
deletes all employees whose first name is Kris.
I would pretty much recommend using a DELETE statement in all cases, except for those special circumstances that merit a TRUNCATE.
Here are some things that happen during a DELETE that don’t during the TRUNCATE:
- Any deletion triggers are executed on the affected table.
- You are allowed to DELETE records that have foreign key constraints defined. A TRUNCATE cannot be executed if these same constraints are in place.
- Record deletions don’t reset identity keys. This is important when you need to guarantee each row uses a key that has never been used before. Perhaps, this need to happen for audit reasons.
- Depending on the locking you are using, row locks are placed on deleted rows. Unaffected rows remain unlocked.
Оператор SQL DELETE и удаление всех данных из таблицы
Для удаления всех строк из таблицы применяется оператор SQL DELETE без условий, заданных в секции WHERE и
без любых других ограничей и условий, например, диапазона удаляемых строк. Таким образом, для удаления
всех строк синтаксис оператора DELETE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ИМЯ_ТАБЛИЦЫ
Пример 4. Чтобы удалить все данные из таблицы ADS, достаточно
написать следующий запрос:
DELETE FROM ADS
Если после выполнения этого запроса обратиться к таблице ADS при помощи оператора
SELECT, применяемого для получения выборки данных, то будет выведено сообщение о том, что эта
таблица не содержит данных.
Оператору DELETE без условий и ограничений аналогичен оператор TRUNCATE TABLE. Он
также удаляет из таблицы все строки, но выполняется намного быстрее.
Пример 5. Запрос на удаление всех данных из таблицы ADS
при помощи оператора TRUNCATE TABLE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
TRUNCATE TABLE ADS
Примеры запросов к базе данных «Портал объявлений-1» есть также в уроках об
операторах INSERT, UPDATE, HAVING и UNION.
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Examples
A. Truncate a Table
The following example removes all data from the table. statements are included before and after the statement to compare results.
USE AdventureWorks2012; GO SELECT COUNT(*) AS BeforeTruncateCount FROM HumanResources.JobCandidate; GO TRUNCATE TABLE HumanResources.JobCandidate; GO SELECT COUNT(*) AS AfterTruncateCount FROM HumanResources.JobCandidate; GO
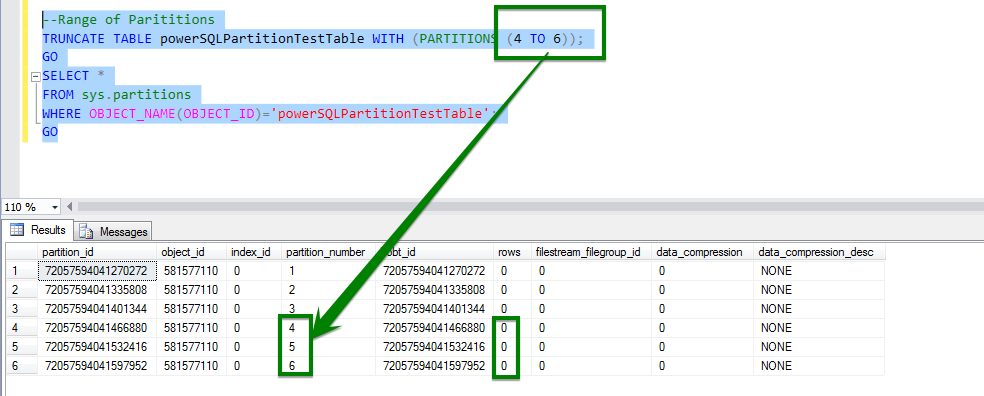
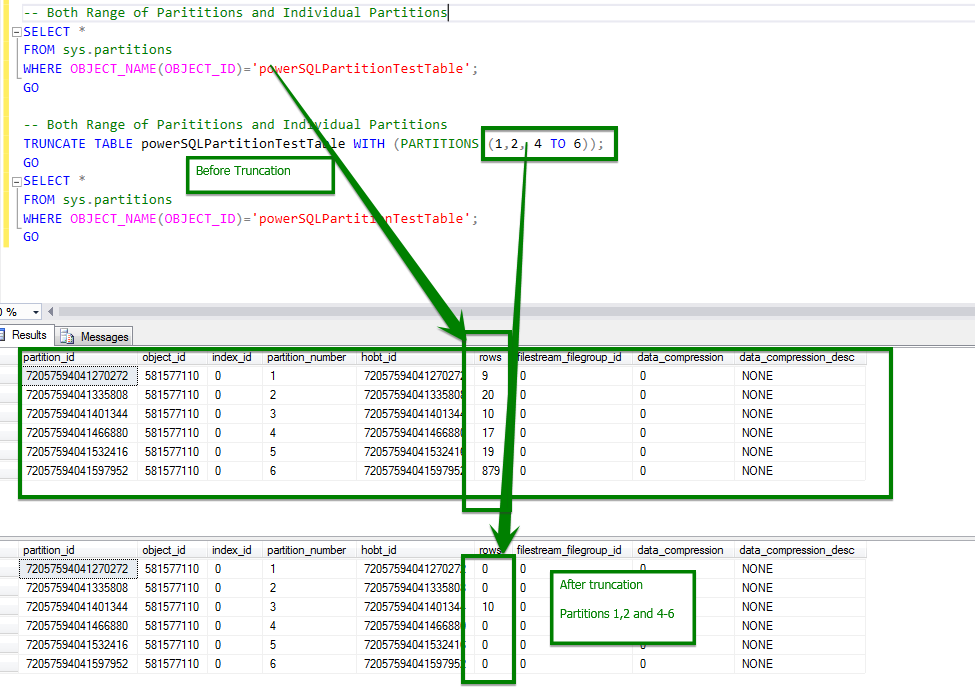
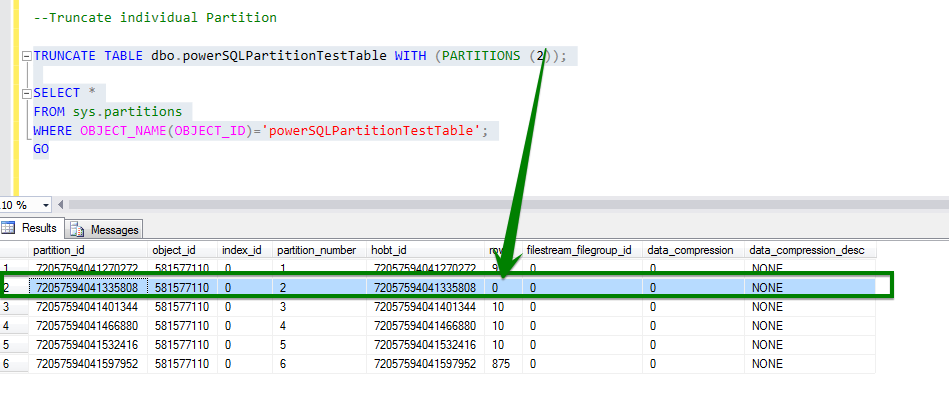
B. Truncate Table Partitions
Applies to: ( through current version)
The following example truncates specified partitions of a partitioned table. The syntax causes partition numbers 2, 4, 6, 7, and 8 to be truncated.
TRUNCATE TABLE PartitionTable1 WITH (PARTITIONS (2, 4, 6 TO 8)); GO
Другие инструкции и предложения Transact-SQL для модификации таблиц
Сервер SQL Server поддерживает следующие дополнительные инструкции и предложения для модификации таблиц:
-
инструкцию TRUNCATE TABLE;
-
инструкцию MERGE;
-
предложение OUTPUT.
Эти инструкции и предложение рассматриваются в последующих подразделах.
Инструкция TRUNCATE TABLE
Инструкция TRUNCATE TABLE является более быстрой версией инструкции DELETE без предложения WHERE. Эта инструкция удаляет все строки таблицы более быстро, чем инструкция DELETE, поскольку она удаляет содержимое постранично, тогда как инструкция DELETE делает это построчно. Инструкция TRUNCATE TABLE является расширением Transact-SQL стандарта SQL. Еще одним важным отличием этой инструкции является то, что она сбрасывает индекс столбца, для которого указано свойство автоинкремента IDENTITY.
Инструкция TRUNCATE TABLE имеет следующий синтаксис:
Инструкция MERGE
Инструкция MERGE объединяет последовательность инструкций INSERT, UPDATE и DELETE в одну элементарную инструкцию, в зависимости от существования записи (строки). Иными словами, можно синхронизировать две разные таблицы, чтобы модифицировать содержимое таблицы назначения в зависимости от различий, обнаруженных в таблице-источнике.
Основной областью применения для инструкции MERGE является среда хранилищ данных, где таблицы необходимо периодически обновлять, чтобы отражать новые данные, прибывающие с систем оперативной обработки транзакций OLTP (On-Line Transaction Processing). Эти данные могут содержать изменения существующих строк таблиц и/или новый строки, которые нужно вставить в таблицы. Если строка в новых данных соответствует записи, которая уже имеется в таблице, выполняется инструкция UPDATE или DELETE. В противном случае выполняется инструкция INSERT.
Альтернативно, вместо инструкции MERGE можно использовать последовательность инструкций INSERT, UPDATE и DELETE, в которых для каждой строки решается, какую операцию выполнять: вставку, удаление или обновление. Но этот подход имеет значительный недостаток, связанный с производительностью: в нем требуется выполнять несколько проходов по данным, а данные обрабатываются по принципу «запись за записью».
Предложение OUTPUT
По умолчанию единым видимым результатом выполнения инструкции INSERT, UPDATE или DELETE является только сообщение о количестве модифицированных строк, например «3 rows DELETED» (удалены 3 строки) и система не сохраняет информацию о модифицированных данных. Если такой видимый результат не удовлетворяет вашим требованиям, то можно использовать предложение OUTPUT, которое выводит модифицированные, вставленные или удаленные строки.
Предложение OUTPUT также применимо с инструкцией MERGE, для которой оно выводит все модифицированные строки в виде таблицы.
Результаты выполненных операций соответствующих инструкций предложение OUTPUT выводит в таблицах inserted и deleted. Кроме этого, чтобы
заполнить таблицы, в предложении OUTPUT требуется использовать выражение INTO. Поэтому для сохранения результата используется табличная переменная.
В примере ниже показано использование инструкции OUTPUT с инструкцией DELETE:
При условии, что содержимое таблицы находится в исходном состоянии, выполнение запроса в примере дает следующий результат:
В этом примере сначала объявляется табличная переменная @deleteTable с двумя столбцами: Id и LastName. В этой таблице будут сохранены удаленные строки. Синтаксис инструкции DELETE расширен предложением OUTPUT: «OUTPUT deleted.Id, deleted.LastName INTO @deleteTable». Посредством этого предложения система сохраняет удаленные строки в таблице deleted, содержимое которой потом копируется в переменную @deleteTable.



В примере ниже показано использование предложения OUTPUT в инструкции UPDATE:
Результат выполнения этого запроса:
Команда DROP — DROP TABLE, TRUNCATE TABLE, DROP INDEX, DROP DATABASE, DROP SEQUENCE, DROP SYNONYM, DROP PUBLIC SYNONYM
Используя запрос DROP можно удалить таблицы (
TABLE), индексы (INDEX) и базы данных (DATABASE).
DROP TABLE
DROP TABLE, применяемый в базе данных Oracle.Обычно с таблицей в базе данных связано несколько объектов, например индекс, создаваемый первичным ключом, или ограничение UNIQUE, налагаемое на столбцы таблицы.При удалении таблицы Oracle автоматически удаляет и любой связанный с ней индекс. Для удаления таблицы из БД необходимо выполнить команду DROP TABLE:
DROP TABLE Пример 1Удаление таблицы:
Однако удалить таблицу не всегда столь просто. В любой момент мы можем создать таблицу с ограничениями целостности. Ограничение целостности (Integrityconstraint ) – это правило, устанавливаемое для таблицы и ограничивающее тип данных, которые можно вводить в эту таблицу. Если попытаться удалить таблицу с ограничениями целостности, возвращается сообщение об ошибке следующего вида: «
Unique/primary keys in table referenced by foreign keys» (на уникальные/первичные ключи таблицы ссылаются внешние ключи).
Когда существуют ограничения для других таблиц, на которые ссылается удаляемая таблица, можно пользоваться каскадной конструкцией CASCADE CONSTRAINTS:DROP TABLE. Пример 2Удаление таблицы с ограничениями целостности:
DROP TABLE, применяемый в mySQLDROP TABLE. Пример 3
Для удаления таблицы также используется запрос:
DROP TABLE. Пример 4
В случае, если необходимо установить проверку на существование таблицы при удалении (если существует удалить таблицу
Данный запрос будет выполнен в том случае, если удаляемая таблица существует в базе данных.
Данный запрос DROP INDEX используется для удаления индексов в таблице.
DROP INDEX, применяемый в базе данных Oracle:Когда индекс в базе данных больше не нужен, разработчик может удалить его командой DROP INDEX. После удаления индекса эффективность поиска с использованием столбца или столбцов, ограниченных индексом, больше не повышается и упоминание об индексе исчезает из словаря данных. Индекс, применяемый для первичного ключа, удалить нельзя.
Синтаксис оператора DROP INDEX одинаков для удаления индекса любого типа (уникальности, битовой карты или В-дерева). Чтобы каким-то образом улучшить индекс, нужно сначала удалить его, а потом создать новый.
DROP INDEX. Пример 1
DROP INDEX, применяемый в mySQL:
DROP INDEX. Пример 2Для удаления индексов (INDEX) используется запрос:
Данный запрос удаляет индексы, указанные в my_index из таблицы table, но она не работает в версиях MySQL до 3.22. В версиях 3.22 и более поздних используется команда:
DROP DATABASE
DROP DATABASE. Пример 1
Запрос DROP DATABASE удаляет базу данных database.
TRUNCATE TABLE
Запрос TRUNCATE TABLE
TRUNCATE TABLE
TRUNCATE TABLE, примеры использования TRUNCATE TABLETRUNCATE TABLE. Пример 1
DROP SEQUENCEDROP SEQUENCE используется для удаления последовательности.
DROP SEQUENCE. Пример 1
DROP SYNONYMDROP SYNONYM используется для удаления синонимов.
DROP SYNONYM. Пример 1
Для удаления общих синонимов необходимо воспользоваться командой DROP PUBLIC SYNONYM.
DROP SYNONYM. Пример 2
T-SQL + 1С: как правильно удалять очень много записей
Сразу скажу, что выполнять свёртку большой таблицы следующей командой, это очень плохая идея:
Дело в том, что если в выборку попадёт больше 5000 записей, то SQL Server может применить эскалацию блокировок до уровня таблицы и вся работа с ней для других транзакций будет невозможна. Однако блокировка всей таблицы может быть использована SQL Server не только по этой причине. Есть ещё ряд других условий, при которых это может произойти. Например, превышение определённого порога пямяти, используемого SQL Server. Подробнее об этом можно прочитать в онлайн документации Microsoft





Кто-то может сказать, что, как правило, администраторы баз данных 1С отключают возможность эскалации блокировок до уровня таблиц на уровне SQL Server. Да, это действительно так. Однако не все знают, что это не отменяет эскалации блокировок до уровня страниц пямяти SQL Server, размер которых равен 8 Кб.
Таким образом, правильным использованием команды DELETE является удаление больших объёмов данных небольшими порциями в цикле. Шаблоном такого кода может быть следующий скрипт:
Этот вариант значительно лучше первого, но он всё ещё может страдать от проблемы эскалации блокировок до уровня страниц (page locks). Если это то, что происходит в вашем случае, то можно попробовать использовать хинты (hints) SQL Server. Вкратце, хинты это специальные инструкции SQL Server, которые заставляют его для отдельных команд использовать поведение отличное от принятого по умолчанию. В русском переводе можно ещё встретить термин «табличные указания». Например таким хинтом является ROWLOCK. Это табличное указание заставляет SQL Server, использовать блокировку на уровне записей и не применять никаких эскалаций. Конечно же это может создать дополнительную нагрузку на «железо», но иногда без этого не обойтись. Использование этого хинта выглядит следующим образом:
Что интересно: я как-то использовал такую команду для свёртки таблицы, которая насчитывала десятки миллионов записей. Свёртка выполнялась в «боевой» базе в рабочее время. Иногда без этого тоже никак. Использование обычной команды DELETE давало множество блокировок на уровне страниц памяти SQL Server. Конфликт происходил в основном из-за интенсивного обмена данными, который имел место быть в этой базе и на код которого не было возможности повлиять в обозримом будущем. Всё было очень плохо. Было принято решение использовать «тяжёлую артиллерию» в виде хинтов.
По началу применение хинта ROWLOCK не дало прироста производительности, а даже наоборот ухудшило показатели. Правда блокировок на уровне страниц удалось избежать. На тот момент времени переменная @RowsToDelete имела значение 10000. Грубо говоря, команда выполнилась за 5 минут. Однако, увеличив это значение до 100000, команда выполнилась ровно за те же самые 5 минут! И это дало значительный прирост производительности по сравнению с вариантом без ROWLOCK! Затем это значение было увеличено до 500000 и эта история завершилась счастливым концом =)
Мораль этой истории заключается в том, что до тех пор, пока вы не попробовали все возможные варианты, не делайте окончательных выводов. Часто бывает так, что успех ждёт вас прямо за углом =)
В заключение я хотел бы поделиться ещё парой «хитростей» на тему массового удаления записей в таблицах SQL Server:
1. Иногда бывает выгоднее использовать команду TRUNCATE TABLE. Идея заключается в том, что сначала выполняется копирование тех записей, которые останутся после свёртки в какую-нибудь вспомогательную таблицу. Затем выполняется команда TRUNCATE, которая очень быстро очищает всю основную таблицу (гораздо быстрее команды DELETE). После этого сохранённые ранее записи возвращаются обратно в основную таблицу. Это выглядит примерно вот так:
2. Иногда есть возможность распараллелить удаление записей по нескольким соединениям (сессиям) SQL Server. Если быть кратким, то нужно найти какой-то разделитель для удаляемых записей таблицы, например, таким разделителем может быть месяц. То есть один поток (сессия) выполняет команду по удалению записей января, второй — февраля и так далее. Можно по типам регистраторов так делать и т.п. Зависит от ситуации. Единственное, о чём следует помнить, что слишком большое количество открываемых одновременно соединений SQL Server может в какой-то момент не понравиться и он их начнёт просто сбрасывать. Обычно рекомендуется использовать количество активных потоков (сессий) по количеству ядер сервера. Ну и, естественно, не следует забывать, что любое распараллеливание нагружает оборудование. Если нет свободных ресурсов по «железу», то не стоит этого делать.
DROP TABLE
The is another DDL (Data Definition Language) operation. But it is not used for simply removing data from a table; it deletes the table structure from the database, along with any data stored in the table.
Here is the syntax of this command:
DROP TABLE table_name;
All you need after is the name of the table you want to delete. For example, if you’d like to remove the entire table from the database, you’d write:
DROP TABLE product;
This removes all data in the table and the structure of the table.
How does DROP TABLE work?
The operation removes the table definition and data as well as the indexes, constraints, and triggers related to the table.
This command frees the memory space.
No triggers are fired when executing .
This operation cannot be rolled back in MySQL, but it can in Oracle, SQL Server, and PostgreSQL.
In SQL Server, requires permission in the schema to which the table belongs; MySQL requires the DROP privilege; Oracle the requires the privilege. In PostgreSQL, users can drop their own tables.



