The Data Model and the general idea
In the previous article, Intro to SQL Server loops, we talked about SQL Server loops, but we haven’t used data from the database. That was odd, but that should become much clearer now. Today, while explaining cursors, we’ll use the data from the database to show when (not) to use cursors. The data model we’ll be using is the same one we’re using throughout this series.
SQL Server supports 3 different implementations of cursors – Transact-SQL cursors, API cursors, and Client cursors. In this article, we’ll focus on Transact-SQL cursors. You’ll easily recognize them because they are based on the DECLARE CURSOR syntax.
Предоставлять, отзывать и запрещать разрешения для базы данных
Язык управления данными (DCL) является подмножеством языка структурированных запросов (SQL) и позволяет администраторам баз данных настраивать безопасный доступ к реляционным базам данных. Он дополняет язык определения данных (DDL), который используется для добавления и удаления объектов базы данных, и язык манипулирования данными (DML), используемый для извлечения, вставки и изменения содержимого базы данных.
DCL является самым простым из подмножеств SQL, поскольку он состоит только из трех команд: GRANT, REVOKE и DENY. В совокупности эти три команды предоставляют администраторам возможность гибко устанавливать и удалять разрешения для базы данных.
Добавление разрешений с помощью команды GRANT
Команда GRANT используется администраторами для добавления новых разрешений пользователю базы данных. У него очень простой синтаксис, определенный следующим образом:
GRANT ON TO
Вот краткое описание каждого из параметров, которые вы можете указать с помощью этой команды:
Привилегия – может быть ключевым словом ALL (для предоставления широкого спектра разрешений) или определенным разрешением базы данных или набором разрешений. Примеры включают CREATE DATABASE, SELECT, INSERT, UPDATE, DELETE, EXECUTE и CREATE VIEW.
Объект – может быть любым объектом базы данных. Допустимые параметры привилегий зависят от типа объекта базы данных, который вы включаете в это предложение. Как правило, объект будет либо базой данных, функцией, хранимой процедурой, таблицей или представлением.
Пользователь – может быть любым пользователем базы данных. Вы также можете заменить роль для пользователя в этом пункте, если хотите использовать безопасность баз данных на основе ролей.
Если вы добавите необязательное условие WITH GRANT OPTION в конце команды GRANT, вы не только предоставите указанному пользователю разрешения, определенные в операторе SQL, но и дадите пользователю возможность предоставить те же разрешения. другим пользователям базы данных
По этой причине используйте этот пункт с осторожностью.
Например, предположим, что вы хотите предоставить пользователю Джо возможность извлекать информацию из таблицы сотрудников в базе данных под названием HR. Вы можете использовать следующую команду SQL:
ВЫБРАТЬ ГРАНТ НА HR.employees TO Джо
Теперь у Джо будет возможность извлекать информацию из таблицы сотрудников. Однако он не сможет предоставить другим пользователям разрешение на извлечение информации из этой таблицы, поскольку вы не включили условие WITH GRANT OPTION в оператор GRANT.
Отмена доступа к базе данных
Команда REVOKE используется для удаления доступа к базе данных у пользователя, ранее предоставившего такой доступ. Синтаксис этой команды определяется следующим образом:
REVOKE ON FROM
Вот краткое описание параметров команды REVOKE:
- Разрешение – указывает разрешения для базы данных, которые необходимо удалить для указанного пользователя. Команда отменяет оба утверждения GRANT и DENY, ранее сделанные для указанного разрешения.
- Объект – может быть любым объектом базы данных. Допустимые параметры привилегий зависят от типа объекта базы данных, который вы включаете в это предложение. Как правило, объект будет либо базой данных, функцией, хранимой процедурой, таблицей или представлением.
- Пользователь – может быть любым пользователем базы данных. Вы также можете заменить роль для пользователя в этом пункте, если хотите использовать безопасность баз данных на основе ролей.
- Предложение GRANT OPTION FOR устраняет возможность указанного пользователя предоставлять указанное разрешение другим пользователям. Примечание . Если вы включите условие GRANT OPTION FOR в оператор REVOKE, основное разрешение будет не отменено. Этот пункт отменяет только возможность предоставления.
- Параметр CASCADE также отменяет указанное разрешение у всех пользователей, которым указанный пользователь предоставил разрешение.
Например, следующая команда отзывает разрешение, предоставленное Джо в предыдущем примере:
ОТМЕНИТЬ ВЫБРАТЬ НА HR.employees ОТ Джо
Явный отказ в доступе к базе данных
Команда DENY используется для явного запрета пользователю получать определенное разрешение. Это полезно, когда пользователь является участником роли или группы, которой предоставлено разрешение, и вы хотите запретить этому отдельному пользователю наследовать разрешение путем создания исключения. Синтаксис этой команды следующий:
DENY ON TO
Параметры для команды DENY идентичны параметрам, используемым для команды GRANT.Например, если вы хотите, чтобы Мэтью никогда не получал возможность удалять информацию из таблицы сотрудников, введите следующую команду:
УДАЛЕНИЕ ДЕНИ НА HR.employees TO Matthew
How to Create a SQL Server Cursor
Creating a SQL Server cursor is a consistent process, so once you learn the
steps you are easily able to duplicate them with various sets of logic to loop
through data. Let»s walk through the steps:
- First, you declare your variables that you need in the logic.
- Second you declare cursor with a specific name that you will use
throughout the logic. This is immediately followed by opening the cursor. - Third, you fetch a record from cursor to begin the data processing.
- Fourth, is the data process that is unique to each set of logic.
This could be inserting, updating, deleting, etc. for each row of data that
was fetched. This is the most important set of logic during this process
that is performed on each row. - Fifth, you fetch the next record from cursor as you did in step 3 and
then step 4 is repeated again by processing the selected data. - Sixth, once all of the data has been processed, then you close cursor.
- As a final and important step, you need to deallocate the cursor to
release all of the internal resources SQL Server is holding.
From here, check out the examples below to get started on knowing when to use
SQL Server cursors and how to do so.
Cursors
Cursors are a looping construct built inside the database engine and come with a wide variety of features. Cursors allow you to fetch a set of data, loop through each record, and modify the values as necessary; then, you can easily assign these values to variables and perform processing on these values. Depending on the type of cursor you request, you can even fetch records that you’ve previously fetched.
Because a cursor is an actual object inside the database engine, there is a little overhead involved in creating the cursor and destroying it. Also, a majority of cursor operations occur in tempdb, so a heavily used tempdb will be even more overloaded with the use of cursors.
The types of cursors used are very important in terms of performance. Below is a list of the available cursor types as listed on Microsoft’s SQL Server Books Online.
FORWARD_ONLYSpecifies that the cursor can only be scrolled from the first to the last row. FETCH NEXT is the only supported fetch option. If FORWARD_ONLY is specified without the STATIC, KEYSET, or DYNAMIC keywords, the cursor operates as a DYNAMIC cursor. When neither FORWARD_ONLY nor SCROLL is specified, FORWARD_ONLY is the default, unless the keywords STATIC, KEYSET, or DYNAMIC are specified. STATIC, KEYSET, and DYNAMIC cursors default to SCROLL. Unlike database APIs such as ODBC and ADO, FORWARD_ONLY is supported with STATIC, KEYSET, and DYNAMIC Transact-SQL cursors.
STATICDefines a cursor that makes a temporary copy of the data to be used by the cursor. All requests to the cursor are answered from this temporary table in tempdb; therefore, modifications made to base tables are not reflected in the data returned by fetches made to this cursor, and this cursor does not allow modifications.
KEYSETSpecifies that the membership and order of rows in the cursor are fixed when the cursor is opened. The set of keys that uniquely identify the rows is built into a table in tempdb known as the keyset. Changes to nonkey values in the base tables, either made by the cursor owner or committed by other users, are visible as the owner scrolls around the cursor. Inserts made by other users are not visible (inserts cannot be made through a Transact-SQL server cursor). If a row is deleted, an attempt to fetch the row returns an @@FETCH_STATUS of -2. Updates of key values from outside the cursor resemble a delete of the old row followed by an insert of the new row. The row with the new values is not visible, and attempts to fetch the row with the old values return an @@FETCH_STATUS of -2. The new values are visible if the update is done through the cursor by specifying the WHERE CURRENT OF clause.
DYNAMICDefines a cursor that reflects all data changes made to the rows in its result set as you scroll around the cursor. The data values, order, and membership of the rows can change on each fetch. The ABSOLUTE fetch option is not supported with dynamic cursors.




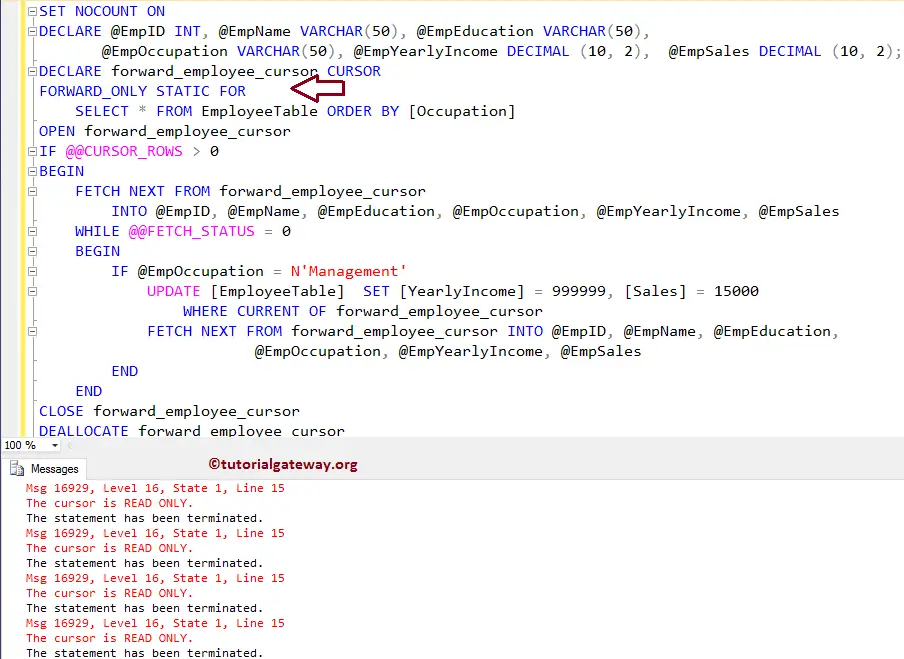



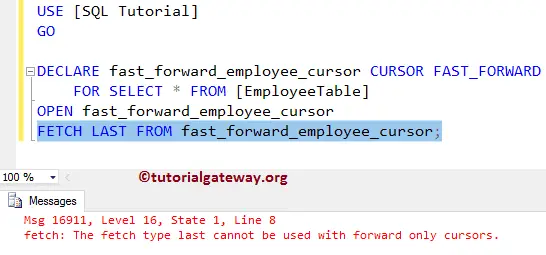
- FAST_FORWARDSpecifies a FORWARD_ONLY, READ_ONLY cursor with performance optimizations enabled. FAST_FORWARD cannot be specified if SCROLL or FOR_UPDATE is also specified.
- READ_ONLYPrevents updates made through this cursor. The cursor cannot be referenced in a WHERE CURRENT OF clause in an UPDATE or DELETE statement. This option overrides the default capability of a cursor to be updated.
- SCROLL_LOCKSSpecifies that positioned updates or deletes made through the cursor are guaranteed to succeed. SQL Server locks the rows as they are read into the cursor to ensure their availability for later modifications. SCROLL_LOCKS cannot be specified if FAST_FORWARD or STATIC is also specified.
OPTIMISTICSpecifies that positioned updates or deletes made through the cursor do not succeed if the row has been updated since it was read into the cursor. SQL Server does not lock rows as they are read into the cursor. It instead uses comparisons of timestamp column values, or a checksum value if the table has no timestamp column, to determine whether the row was modified after it was read into the cursor. If the row was modified, the attempted positioned update or delete fails. OPTIMISTIC cannot be specified if FAST_FORWARD is also specified.
SQL Server Cursor Components
Based on the example above, cursors include these components:
- DECLARE statements — Declare variables used in the code block
- SET\SELECT statements — Initialize the variables to a specific value
- DECLARE CURSOR statement — Populate the cursor with values that will be
evaluated - OPEN statement — Open the cursor to begin data processing
- FETCH NEXT statements — Assign the specific values from the cursor to the
variables - WHILE statement — Condition to begin and continue data processing
- BEGIN…END statement — Start and end of the code block
- Data processing — In this example, this logic is to backup a database to
a specific path and file name, but this could be just about any DML or administrative
logic - CLOSE statement — Releases the current data and associated locks, but permits
the cursor to be re-opened - DEALLOCATE statement — Destroys the cursor
Что дальше
- Когда вам нужно принять решение об обработке данных, определите, где вы можете столкнуться с использованием курсоров. Это может иметь место в вашем приложении или в операционных процессах. Существует много способов решить задачу. Использование курсора может оказаться разумной альтернативой в некоторых случаях. Решать вам.
- Если вы сталкиваетесь в проблемами при другом способе кодирования, и необходимо сделать что-то быстро, использование курсора может быть надежной альтернативой. Она может привести к более продолжительной обработке данных, но время написания кода может стать значительно быстрей. Если вам требуется одноразовый процесс или процесс, выполняемый в ночное время, это может помочь.
- Если в вашей среде избегают курсоров, выберите другое надежное решение. Просто убедитесь, что этот процесс не вызовет других проблем. Например, если используется курсор и обрабатываются миллионы строк, не приведет ли это к удалению всех данных из кеша и не спровоцирует ли дальнейшие конфликты? Или при большом наборе данных не будут ли данные сброшены на диск или записаны во временную директорию?
- Оценивая подход на основе курсора по сравнению с другими альтернативами, проведите честное сравнение методов с точки зрения времени, возможности конфликтов и необходимых ресурсов. Надеюсь, что эти факторы приведут вас к правильному способу.
Выбор между явным и неявным курсорами
Все последние годы знатоки Oracle (включая и авторов данной книги) убежденно доказывали, что для однострочной выборки данных никогда не следует использовать неявные курсоры. Это мотивировалось тем, что неявные курсоры, соответствуя стандарту , всегда выполняют две выборки, из-за чего они уступают по эффективности явным курсорам.
Так утверждалось и в первых двух изданиях этой книги, но пришло время нарушить эту традицию (вместе со многими другими). Начиная с Oracle8, в результате целенаправленных оптимизаций неявные курсоры выполняются даже эффективнее эквивалентных явных курсоров.
Означает ли это, что теперь всегда лучше пользоваться неявными курсорами? Вовсе нет. В пользу применения явных курсоров существуют убедительные доводы.
- В некоторых случаях явные курсоры эффективнее неявных. Часто выполняемые критические запросы лучше протестировать в обеих формах, чтобы точно выяснить, как лучше выполнять каждый из них в каждом конкретном случае.
- Явными курсорами проще управлять из программы. Например, если строка не найдена, Oracle не инициирует исключение, а просто принудительно завершает выполняемый блок.
Поэтому вместо формулировки «явный или неявный?» лучше спросить: «инкапсулированный или открытый?» И ответ будет таким: всегда инкапсулируйте однострочные запросы, скрывая их за интерфейсом функции (желательно пакетной) и возвращая данные через .
Не жалейте времени на инкапсуляцию запросов в функциях, желательно пакетных. Это позволит вам и всем остальным разработчикам вашей группы просто вызвать функцию, когда появится необходимость в данных. Если Oracle изменит правила обработки запросов, а ваши предыдущие наработки станут бесполезными, достаточно будет изменить реализацию всего одной функции.
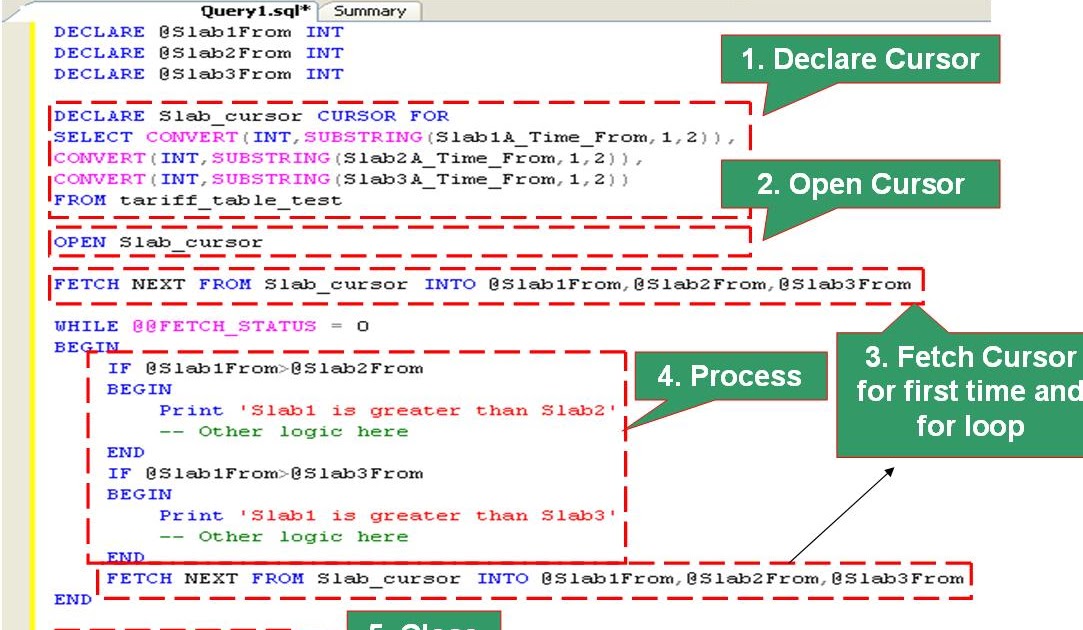
Opening a Cursor
Once a cursor has been declared, you must open it to fetch data from it.
To open a cursor, you can use the following syntax:
OPEN { { cursor_name } | cursor_variable_name}
|
where
GLOBAL – If this argument was not specified and both a global and
a local cursor exist with the same name, the local cursor
will be opened; otherwise, the global cursor will be opened.
cursor_name – The name of the server side cursor, must contain
from 1 to 128 characters.
cursor_variable_name – The name of a cursor variable that
references a cursor.
After a cursor is opening, you can determine the number of rows
that were found by the cursor. To get this number, you can use
@@CURSOR_ROWS scalar function.
Операторы для работы с курсором
Прежде чем обратиться к данным курсора, его нужно после объявления открыть.
Синтаксис оператора OPEN в обозначениях MS SQL Server:
Пример:
После прекращения работы с курсором, его нужно закрыть. Курсор остается доступным для последующего использования в рамках процедуры или триггера, в котором он создан.
Синтаксис оператора CLOSE в обозначенияхMS SQL Server:
Пример:
Если курсором больше не будут пользоваться, то его необходимо уничтожить и освободить переменную.
Синтаксис оператора DEALLOCATE в обозначениях MS SQL Server:
Пример:
FETCH – оператор движения по записям курсора и извлечения данных текущей записи в указанные переменные. Синтаксис оператора FETCH в обозначениях MS SQL Server:
Пример:
@@FETCH_STATUS – данная функция определяет признак конца или начала текущего курсора. Функция принимает одно из следующих значений:
Пример:
SQL Server Cursor – Examples
Let’s now take a look at two cursor examples. While they are pretty simple, they nicely explain how cursors work.
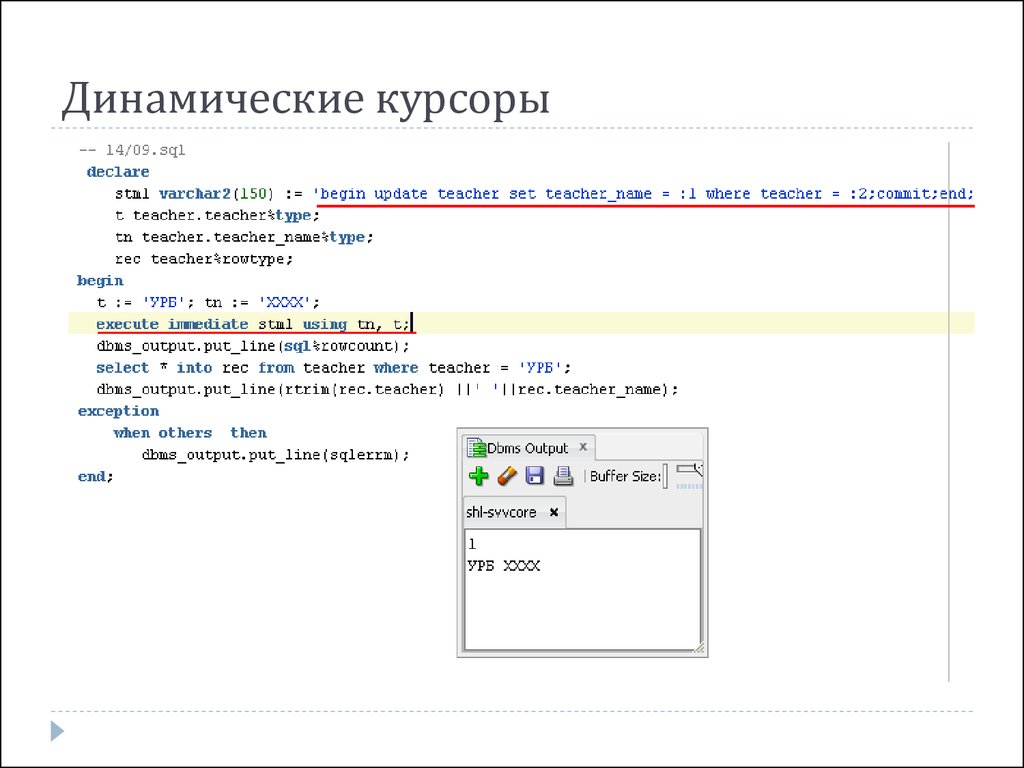







In the first example, we want to get all cities ids and names, together with their related country names. We’ll use the PRINT command to print combinations in each pass of the loop.
|
1 |
— declare variables used in cursor DECLARE@city_nameVARCHAR(128); DECLARE@country_nameVARCHAR(128); DECLARE@city_idINT; DECLAREcursor_city_countryCURSORFOR SELECTcity.id,TRIM(city.city_name),TRIM(country.country_name) FROMcity INNERJOINcountryONcity.country_id=country.id; OPENcursor_city_country; FETCHNEXTFROMcursor_city_countryINTO@city_id,@city_name,@country_name; WHILE@@FETCH_STATUS= BEGIN PRINTCONCAT(‘city id: ‘,@city_id,’ / city name: ‘,@city_name,’ / country name: ‘,@country_name); FETCHNEXTFROMcursor_city_countryINTO@city_id,@city_name,@country_name; END; CLOSEcursor_city_country; DEALLOCATEcursor_city_country; |
Using the SQL Server cursor and the while loop returned exactly what we’ve expected – ids and names of all cities, and related countries, we have in the database.
The most important thing to mention here is that we could simply return this result set using the original SQL query stored in the DECLARE part of the cursor, so there was no need for a cursor.
We’ll go with one more example. This time we’ll query the information schema database to return the first 5 tables ordered by table name. While there’s not much sense in using such a query, this example shows you:
- How to query the information schema database
- How to combine a few commands/statements we’ve mentioned in previous articles (IF … ELSE, WHILE loop, CONCAT)
|
1 |
— declare variables used in cursor DECLARE@table_nameVARCHAR(128); DECLARE@table_names_5VARCHAR(128); DECLAREcursor_table_namesCURSORFOR SELECTTOP5TABLE_NAME FROMINFORMATION_SCHEMA.TABLES ORDERBYTABLE_NAMEASC; SET@table_names_5=’first 5 tables are: ‘ — open cursor OPENcursor_table_names; FETCHNEXTFROMcursor_table_namesINTO@table_name; WHILE@@FETCH_STATUS= BEGIN IF@table_names_5=’first 5 tables are: ‘ SET@table_names_5=CONCAT(@table_names_5,@table_name) ELSE SET@table_names_5=CONCAT(@table_names_5,’, ‘,@table_name); FETCHNEXTFROMcursor_table_namesINTO@table_name; END; PRINT@table_names_5; CLOSEcursor_table_names; DEALLOCATEcursor_table_names; |
From the coding side, I would like to emphasize that this time, we haven’t printed anything in a loop but rather created a string using CONCAT. Also, we’ve used the IF statement to test if we’re in the first pass, and if so, we haven’t added “,”. Otherwise, we would add “,” to the string.
After the loop, we’ve printed the result string, closed and deallocated the cursor.
We could achieve this using the STRING_AGG function. This one is available starting from the SQL Server 2017 and is the equivalent of MySQL GROUP_CONCAT function.
General concepts
In this article, I want to tell you how to create and use server
side cursors and how you can optimize a cursor performance.
Cursor is a database object used by applications to manipulate data
in a set on a row-by-row basis, instead of the typical SQL commands
that operate on all the rows in the set at one time. For example,
you can use cursor to include a list of all user databases and make
multiple operations against each database by passing each database
name as a variable.
The server side cursors were first added in the SQL Server 6.0 release and
are now supported in all editions of SQL Server 7.0 and SQL Server 2000.
Before using cursor, you first must declare the cursor. Once a cursor
has been declared, you can open it and fetch from it. You can fetch
row by row and make multiple operations on the currently active row
in the cursor. When you have finished working with a cursor, you
should close cursor and deallocate it to release SQL Server resources.
Когда использовать курсоры
- OLTP (оперативная обработка транзакций) — в большинстве сред OLTP логика на основе множества строк (INSERT, UPDATE или DELETE) имеет наибольшее предпочтение для коротких транзакций. Наша команда выполняла стороннее приложение, которое использовало курсоры для любой обработки, что вызывало проблемы, но это случалось нечасто. Обычно логики на основе множеств более чем достаточно, и курсоры редко могут понадобиться.
- Отчеты — для проектирования отчетов курсоры обычно не нужны. Однако наша команда столкнулась с требованиями к отчетности, когда не существовало ссылочной целостности в используемой базе данных, и было необходимо использовать курсор для корректного вычисления отчетных значений. Мы имели подобный опыт при необходимости агрегировать данные для последующих процессов. Подход на основе курсора было быстро разработать и выполнить в приемлемой манере.
- Последовательная обработка — если вам необходимо выполнить процесс в последовательной манере, курсоры являются работоспособным вариантом.
- Административные задачи — многие административные задачи, подобные резервированию баз данных или проверки согласованности баз данных, требуется выполнять в последовательной манере, которая хорошо вписывается в основанную на курсорах логику. Но существуют и другие системные объекты, которые удовлетворяют эту потребность. В некоторых из этих случаев курсоры используются для завершения процесса.
- Большие наборы данных — при больших наборах данных вы можете столкнуться с одним или несколькими из следующих случаев:
- Логика на основе курсора может не масштабироваться в достаточной мере.
- Операции на основе множеств с большими объемами данных на сервере с минимальным количеством памяти могут привести к тому, что данные будут выгружаться, отнимая много времени и потенциально вызвая конфликты и проблемы с памятью. В этом случае, решение на базе курсора может оказаться приемлемым.
- Некоторые инструменты фактически кэшируют данные в файл, поэтому обработка данных в памяти может и не иметь места.
- Если данные могут быть обработаны на автономном SQL Server, то влияние на производственную среду будет оказываться только на финальной стадии обработки. Все ресурсы автономного сервера могут использоваться для процессов ETL, после чего полученные данные импортируются.
- SSIS поддерживает пакетную обработку наборов данных, которая может решить общую необходимость разбить большой набор данных на более мелкие и справиться с ними лучше, чем построчным методом на базе курсора.
- В зависимости от того, как закодирована логика курсора или SSIS, может иметься возможность перезапуска с точки сбоя на основе контрольных точек, или обработки каждой строки при помощи курсора. Однако при подходе на основе множеств это может оказаться недоступным, пока не будет обработан весь набор данных. В таком случае найти строку, которая вызвала сбой, будет более сложным.
Команды языка управления транзакциями
Команды языка управления транзакциями ( TCL (Тгаnsасtiоn Соntrol Language) ) команды позволяют определить исход транзакции. Команды управления транзакциями управляют изменениями в базе данных, которые осуществляются командами манипулирования данными.Транзакция (или логическая единица работы) – неделимая с точки зрения воздействия на базу данных последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.COMMIT — заканчивает («подтверждает») текущую транзакцию и делает постоянными (сохраняет в базе данных) изменения, осуществленные этой транзакцией. Также стирает точки сохранения этой транзакции и освобождает ее блокировки. Можно также использовать эту команду для того, чтобы вручную подтвердить сомнительную распределенную транзакцию.ROLLBACK — выполняет откат транзакции, т.е. отменяет все изменения, сделанные в текущей транзакции. Можно также использовать эту команду для того, чтобы вручную отменить работу, проделанную сомнительной распределенной транзакцией. Понятие транзакции имеет непосредственную связь с понятием целостности базы данных. Очень часто база данных может обладать такими ограничениями целостности, которые просто невозможно не нарушить, выполняя только один оператор изменения БД. Например, невозможно принять сотрудника в отдел, название и код которого отсутствует в базе данных. В системах с развитыми средствами ограничения и контроля целостности каждая транзакция начинается при целостном состоянии базы данных и должна оставить это состояние целостными после своего завершения. Несоблюдение этого условия приводит к тому, что вместо фиксации результатов транзакции происходит ее откат (т.е. вместо оператора COMMIT выполняется оператор ROLLBACK), и база данных остается в таком состоянии, в котором находилась к моменту начала транзакции, т.е. в целостном состоянии. В связи со свойством сохранения целостности БД транзакции являются подходящими единицами изолированности пользователей, т.е., если с каждым сеансом работы с базой данных ассоциируется транзакция, то каждый пользователь начинает работу с согласованным состоянием базы данных, т.е. с таким состоянием, в котором база данных могла бы находиться, даже если бы пользователь работал с ней в одиночку.
Закрытие явного курсора
Когда-то в детстве нас учили прибирать за собой, и эта привычка осталась у нас (хотя и не у всех) на всю жизнь. Оказывается, это правило играет исключительно важную роль и в программировании, и особенно когда дело доходит до управления курсорами. Никогда не забывайте закрыть курсор, если он вам больше не нужен!
Синтаксис команды CLOSE:
CLOSE имя_курсора;
Ниже приводится несколько важных советов и соображений, связанных с закрытием явных курсоров.
- Если курсор объявлен и открыт в процедуре, не забудьте его закрыть после завершения работы с ним; в противном случае в вашем коде возникнет утечка памяти. Теоретически курсор (как и любая структура данных) должен автоматически закрываться и уничтожаться при выходе из области действия. Как правило, при выходе из процедуры, функции или анонимного блока PL/SQL действительно закрывает все открытые в нем курсоры. Но этот процесс связан с определенными затратами ресурсов, поэтому по соображениям эффективности PL/SQL иногда откладывает выявление и закрытие открытых курсоров. Курсоры типа REF CURSOR по определению не могут быть закрыты неявно. Единственное, в чем можно быть уверенным, так это в том, что по завершении работы «самого внешнего» блока PL/SQL , когда управление будет возвращено SQL или другой вызывающей программе, PL/SQL неявно закроет все открытые этим блоком или вложенными блоками курсоры, кроме REF CURSOR . В статье «Cursor reuse in PL/SQL static SQL » из Oracle Technology Network приводится подробный анализ того, как и когда PL/SQL закрывает курсоры. Вложенные анонимные блоки — пример ситуации, в которой PL/SQL не осуществляет неявное закрытие курсоров. Интересная информация по этой теме приведена в статье Джонатана Генника « Does PL/SQL Implicitly Close Cursors ?».
- Если курсор объявлен в пакете на уровне пакета и открыт в некотором блоке или программе, он останется открытым до тех пор, пока вы его явно не закроете, или до завершения сеанса. Поэтому, завершив работу с курсором пакетного уровня, его следует немедленно закрыть командой CLOSE (и кстати, то же самое следует делать в разделе исключений):
Курсор можно закрывать только в том случае, если ранее он был открыт; в противном случае будет инициировано исключение INVALID_CURS0R . Состояние курсора проверяется с помощью атрибута %ISOPEN:
Если в программе останется слишком много открытых курсоров, их количество может превысить значение параметра базы данных OPEN_CURSORS . Получив сообщение об ошибке, прежде всего убедитесь в том, что объявленные в пакетах курсоры закрываются после того, как надобность в них отпадет.
SQL Server Cursor – Why people (don’t) use them?
The last question I would like to answer is: Why would anyone use a cursor? This is how I see it:
- People who’re using them for one-time jobs or regular actions where they won’t impact performance have the excuse. One of the reasons is that such code is procedural code, and if you’re used to it, it’s very readable
- On the other hand, those who started learning about databases, and are used to procedural programming might use cursors because, as mentioned, they are much closer to procedural programming than to databases. This is not a reason to use them, because the only excuse here would be that you simply don’t know the other (right) way how to get things done
- The most important thing about cursors is that they are slow when compared to SQL statements, and therefore you should avoid using them because they will sooner or later lead to performance issues (unless you know exactly what you’re doing and why)
I find it useful that you understand the concept of cursors because there is a great chance, you’ll meet them along the way. They were popular before some new options were added to SQL Server. Also, there is a chance you’ll continue working on a system where somebody before you used them, and you’ll have to continue where they stopped. Maybe you’ll need to replace the cursor (procedural code) with SQL (declarative code).
How to Create a SQL Server Cursor
Creating a SQL Server cursor is a consistent process, so once you learn the
steps you are easily able to duplicate them with various sets of logic to loop
through data. Let»s walk through the steps:
- First, you declare your variables that you need in the logic.
- Second you declare cursor with a specific name that you will use
throughout the logic. This is immediately followed by opening the cursor. - Third, you fetch a record from cursor to begin the data processing.
- Fourth, is the data process that is unique to each set of logic.
This could be inserting, updating, deleting, etc. for each row of data that
was fetched. This is the most important set of logic during this process
that is performed on each row. - Fifth, you fetch the next record from cursor as you did in step 3 and
then step 4 is repeated again by processing the selected data. - Sixth, once all of the data has been processed, then you close cursor.
- As a final and important step, you need to deallocate the cursor to
release all of the internal resources SQL Server is holding.
From here, check out the examples below to get started on knowing when to use
SQL Server cursors and how to do so.
Освоение программирования с помощью встроенного языка Transact SQL
Цель работы – знакомство с основными приципами программирования в MS SQL Server средствами встроенного языка Transact SQL.
1. Знакомство с правилами обозначения синтаксиса команд в справочной системе MS SQL Server (утилита Books Online).
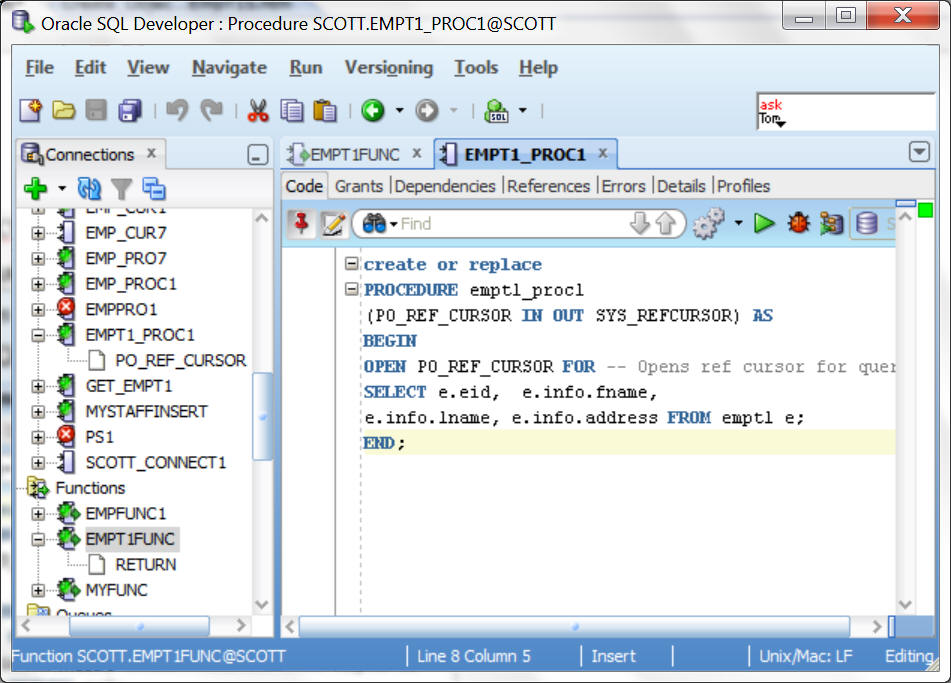



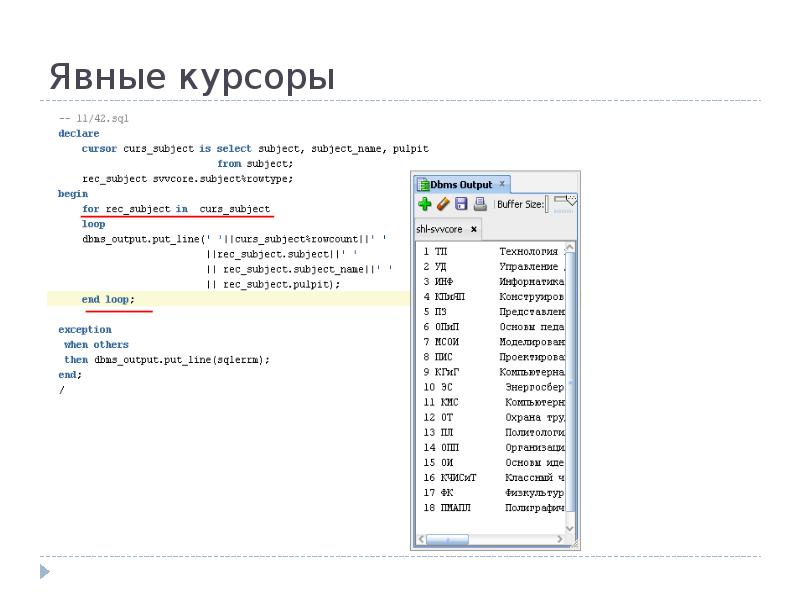
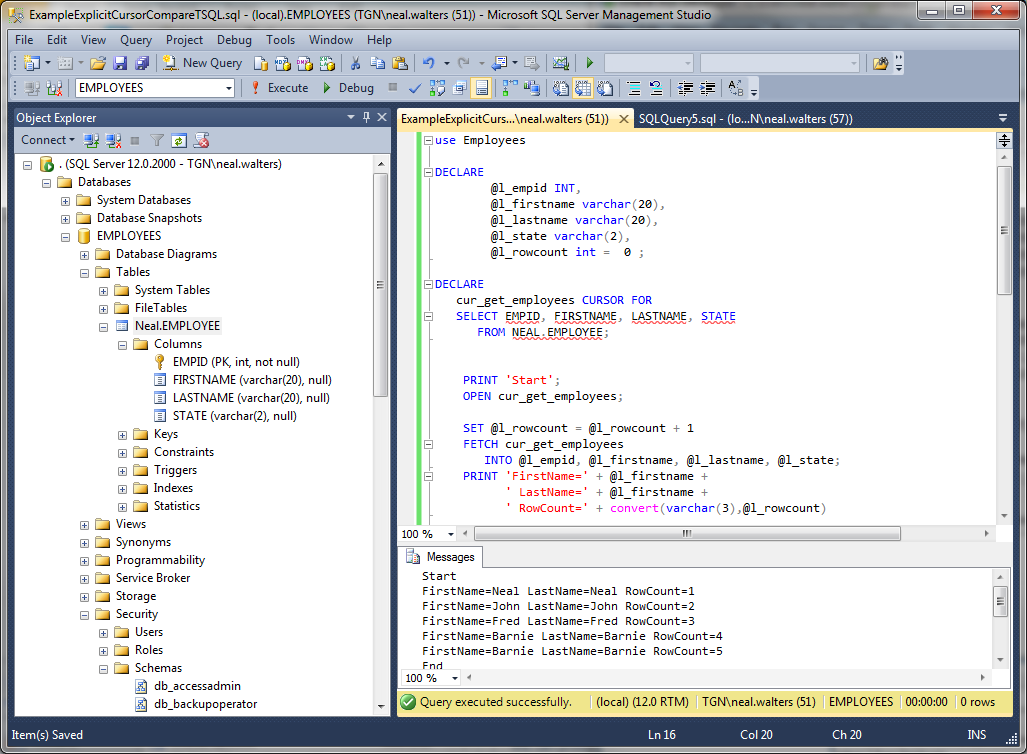
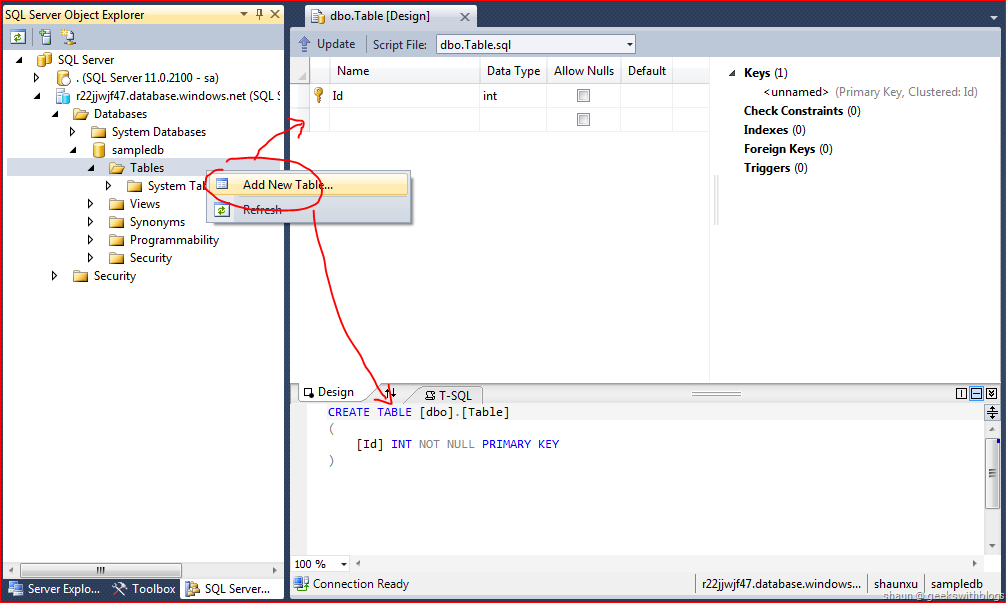
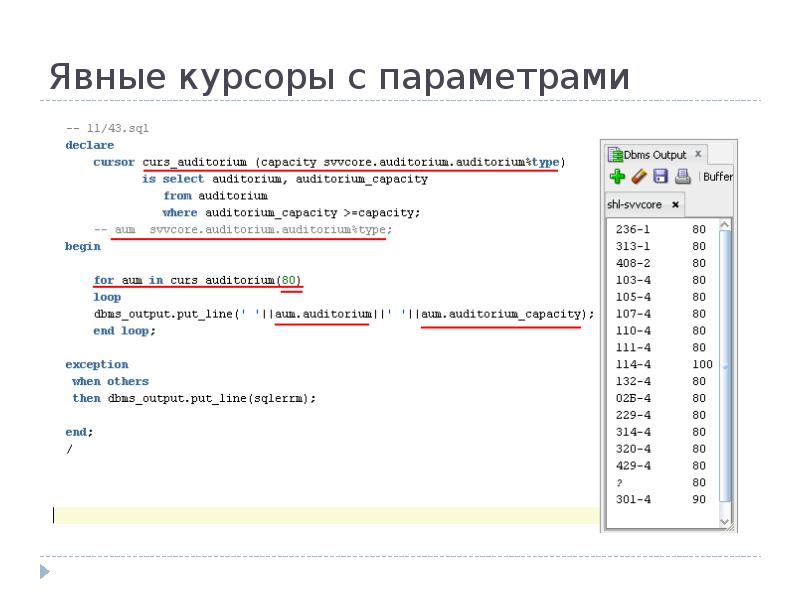

2. Изучение правил написания программ на Transact SQL.
3. Изучение правил построения идентификаторов, правил объявления переменных и их типов.
4. Изучение работы с циклами и ветвлениями.
5. Изучение работы с переменными типа Table и Cursor.
6. Проработка всех примеров, анализ результатов их выполнения.
7. Выполнение индивидуальных заданий по вариантам.
Пояснения к выполнению работы
Для освоения программирования используем пример базы данных c названием DB_Books, которая была создана в лабораторной работе №1.
При выполнении примеров и заданий обращайте внимание на соответствие названий БД, таблиц и других объектов проекта