
Как выбрать место работы для Junior DBA
В начале вашей карьеры следует обращать больше внимание не на зарплату, а на коллектив. Вам необходимо найти такое место работы, где вы сможете перенять опыт у ваших коллег
Вам очень повезёт, если вы сможете найти достойного наставника, тогда ваш карьерный рост будет стремительным. Если вы устраиваетесь на работу где нет других ДБА, то вам придётся самостоятельно проходить все сложности обучения и очень вероятно что это обучение будет сопровождаться авариями и другими сложностями, в таком случае будет полезно иметь знакомых, опытных администраторов БД, которым можно задать вопросы по телефону.
Чтобы стать Senior DBA вам необходимо постоянно развиваться. Вот несколько вариантов как вы можете это делать:
- Посещать курсы
- Посещать мероприятия
- Читать сайты и форумы
- Задавать вопросы на форумах и сайтах
- Смотреть обучающее видео
- Старайтесь делать на работе больше, чем вас просят (изучать каждую тему глубже)
Пора переходить к нашей теме.
Примеры полнотекстовых запросов
Более подробно полнотекстовые запросы мы будем рассматривать в отдельном материале, а пока, в качестве примера и подтверждения того, что наш полнотекстовый поиск работает, давайте напишем пару простых полнотекстовых запросов.
Если помните, наша таблица TestTable содержит определения технологий, языков программирования, в общем, определений, связанных со сферой IT. Допустим, что мы хотим получить все записи, где есть упоминание о компании Microsoft, для этого мы пишем полнотекстовый запрос с ключевым словом CONTAINS, например
Мы получили результат, но допустим, нам также необходимо отсортировать его по релевантности, другими словами, какие строки больше соответствуют нашему запросу. Для этого мы будем использовать функцию CONTAINSTABLE, которая проставляет ранг для каждой найденной записи.
Как видим, ранг проставлен и по нему отсортированы строки. Сам алгоритм ранжирования, как и более подробную информацию о полнотекстовом поиске, можно найти в электронной документации по SQL Server.
5 последних уроков рубрики «Разное»
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
Разработка веб-сайтов с помощью онлайн платформы Wrike
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
Небольшая подборка провайдеров бесплатного хостинга с подробным описанием.
Быстрая заметка: массовый UPDATE в MySQL
Ни для кого не секрет как в MySQL реализовать массовый INSERT, а вот с UPDATE-ом могут возникнуть сложности. Чтобы не прибегать к манипуляциям события ON_DUPLICATE можно воспользоваться специальной конструкцией CASE … WHEN … THEN.
Установка компонента «Полнотекстовый поиск» в Microsoft SQL Server
Чтобы установить компонент Full-Text Search, необходимо в процессе установки Microsoft SQL Server поставить галочку напротив Full—Text and Semantic Extractions for Search.
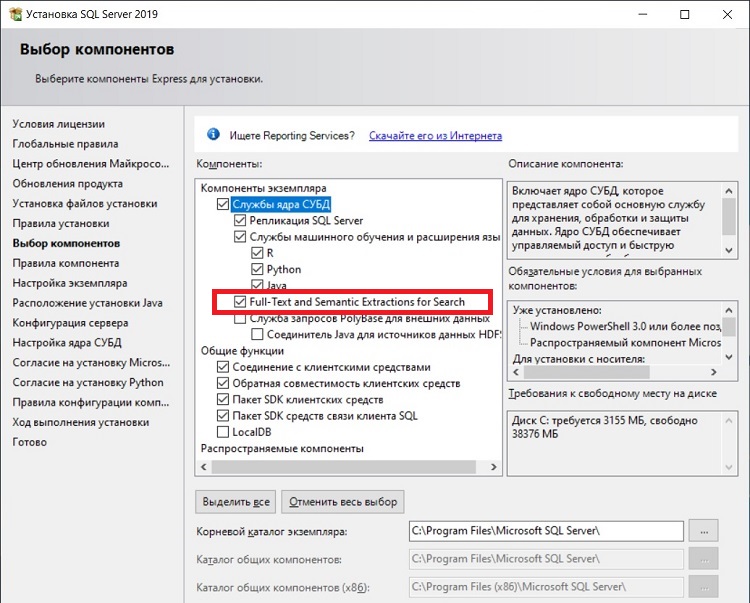
В случае если в процессе установки SQL Server компонент Вы не отметили, то это можно сделать и потом, т.е. доустановить необходимый компонент. Для этого запустите «Центр установки SQL Server», так же, как и в процессе установки SQL Server, выберите «Новая установка изолированного экземпляра SQL Server или добавление компонентов к существующей установке» и на этапе выбора компонентов поставьте соответствующую галочку.
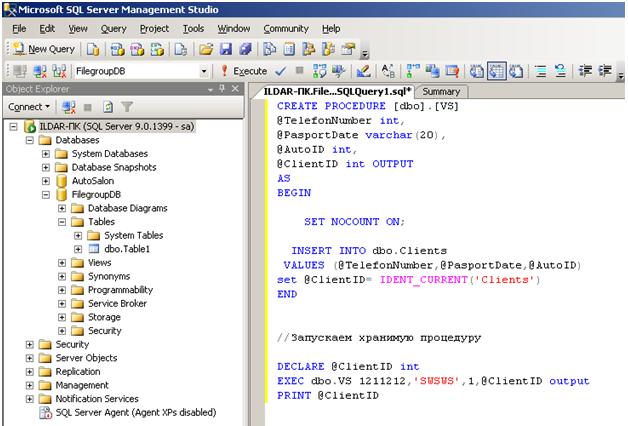
Добавление выходных параметров в хранимой процедуре
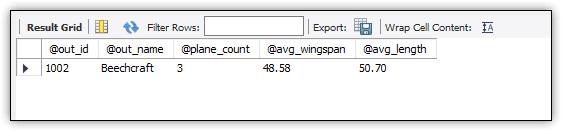
DROP PROCEDURE IF EXISTS get_plane_info; DELIMITER // CREATE PROCEDURE get_plane_info( IN in_name VARCHAR(50), OUT out_id INT UNSIGNED, OUT out_name VARCHAR(50), OUT plane_count SMALLINT UNSIGNED, OUT avg_wingspan DECIMAL(5,2), OUT avg_length DECIMAL(5,2)) COMMENT 'retrieves aggregated airplane information' BEGIN SELECT a.manufacturer_id, m.manufacturer, COUNT(*), ROUND(AVG(a.wingspan), 2), ROUND(AVG(a.plane_length), 2) INTO out_id, out_name, plane_count, avg_wingspan, avg_length FROM airplanes a INNER JOIN manufacturers m ON a.manufacturer_id = m.manufacturer_id WHERE m.manufacturer = in_name; END// DELIMITER ;
CALL get_plane_info ('beechcraft', @out_id, @out_name,
@plane_count, @avg_wingspan, @avg_length);
SELECT @out_id, @out_name, @plane_count, @avg_wingspan, @avg_length;

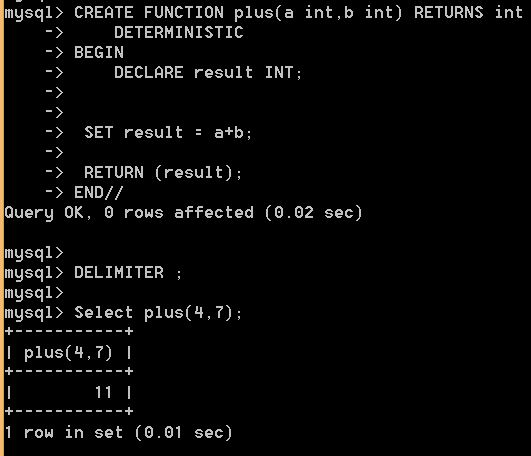
3.3.2. Скалярные функции в Transact-SQL
Давайте для примера создадим функцию, которая будет возвращать скалярное значение. Например, результат перемножение цены на количество указанного товара. Товар будет идентифицироваться по названию и дате, ведь мы договорились, что сочетание этих полей дает уникальность. Но будьте осторожны, при тестировании запроса, если в разделе 3.2.8 вы выполнили запрос на изменение данных и создали дубликаты покупок за 1.1.2005-го года.
Итак, посмотрим сначала на код создание скалярной функции:
CREATE FUNCTION GetSumm
(@name varchar(50), @date datetime)
RETURNS numeric(10,2)
BEGIN
DECLARE @Summ numeric(10,2)
SELECT @Summ = Цена*Количество
FROM Товары
WHERE =@name
AND Дата=@date;
RETURN @Summ
END
После оператора CREATE FUNCTION мы указываем имя функции. Далее, в скобках идут параметры, которые необходимо передать. Да, параметры должны передаваться через запятую в круглых скобках. В этом объявление отличается от процедур и эту разницу необходимо помнить.
Далее указывается ключевое слово RETURNS, за которым идет описание типа возвращаемого значения. Для скалярной функции это могут быть любые типы (строки, числа, даты и т.д.).
Код, который должна выполнять функция пишется между ключевыми словами BEGIN (начало) и END (конец). В коде можно использовать любые операторы Transact-SQL, которые мы изучали ранее. Итак, объявление нашей функции в упрощенном виде можно описать следующим образом:
CREATE FUNCTION GetSumm (@name varchar(50), @date datetime) RETURNS numeric(10,2) BEGIN -- Код функции END
Между ключевыми словами BEGIN и END у нас выполняется следующий код:
-- Объявление переменной DECLARE @Summ numeric(10,2) -- Выполнение запроса на выборку суммы SELECT @Summ = Цена*Количество FROM Товары WHERE =@name AND Дата=@date; -- Возврат результата RETURN @Summ
В первой строке объявляется переменная @Summ. Она нужна для хранения промежуточного результата расчетов. Далее выполняется запрос SELECT, в котором происходит поиск строки по дате и названию товара в таблице товаров. В найденной строке перемножаются поля цены и количества, и результат записывается в переменную @Summ.







Обратите внимание, что в конце запроса стоит знак точки с запятой. Каждый запрос должен заканчиваться этим символом, но в большинстве примеров мы этим пренебрегали, но в функции отсутствие символа «;» может привести к ошибке
В последней строке возвращаем результат. Для этого нужно написать ключевое слово RETURN, после которого пишется возвращаемое значение или переменная. В данном случае, возвращаться будет содержимое переменной @Summ.
Так как функция скалярная, то и возвращаемое значение должно быть скалярным и при этом соответствовать типу, описанному после ключевого слова RETURNS.
PostgreSQL. Добавляем not null constraints в большие таблицы
Проекты развиваются, клиентская база увеличивается, базы данных разрастаются, и наступает момент, когда мы начинаем замечать, что некогда простые манипуляции над базами данных требуют более сложных действий, а цена ошибки сильно повышается. Уже нельзя за раз промигрировать данные с одного столбца в другой, индексы лучше накатывать асинхронно, добавлять столбцы с default значениями теперь нельзя.
Одной из команд, с которой надо быть осторожным на таблицах с большим количеством записей, является добавление not null constraint на столбец. При добавлении данного constraint PostgreSQL приобретает access exclusive lock на таблицу, в результате чего другие сессии не могут временно даже читать таблицу; затем БД проверяет, что в столбце действительно ни одного null нет, и только после этого вносятся изменения. Под катом я рассмотрю различные варианты, как можно добавить not null constraint , лоча таблицу на минимально возможное время или даже не лоча ее совсем.
Создание полнотекстового индекса в Microsoft SQL Server
После того как полнотекстовый каталог мы создали, мы можем переходить к созданию полнотекстового индекса. В нашем случае для столбца TextData нашей тестовой таблицы.
Создание полнотекстового индекса на T-SQL
Для того чтобы создать полнотекстовый индекс, мы пишем инструкцию CREATE FULLTEXT INDEX.
- CREATE FULLTEXT INDEX – команда создания полнотекстового индекса;
- TestTable(TextData) – таблица и столбец, включенные в индекс;
- KEY INDEX PK_TestTable – имя уникального индекса таблицы TestTable;
- ON (TestCatalog) – указываем, что полнотекстовый индекс будет создан в полнотекстовом каталоге TestCatalog. Если не указать этот параметр, то индекс будет создан в полнотекстовом каталоге по умолчанию;
- WITH (CHANGE_TRACKING AUTO) – это мы говорим, что все изменения, которые будут вноситься в базовую таблицу (TestTable), автоматически отобразятся и в нашем полнотекстовом индексе, т.е. автоматическое заполнение.
Создание полнотекстового индекса в графическом интерфейсе Management Studio
Полнотекстовый индекс можно создать, используя и графические инструменты, для этого открываем свойства полнотекстового каталога и переходим в пункт «Таблицы или представления», выбираем нужную таблицу, столбец, уникальный индекс и способ отслеживания изменений. В нашем случае у нас всего одна доступная таблица и один столбец. Нажимаем «ОК».
Против
- Повышение нагрузки на сервер баз данных в связи с тем, что большая часть работы выполняется на серверной части, а меньшая — на клиентской.
- Придется много чего подучить. Вам понадобится выучить синтаксис MySQL выражений для написания своих хранимых процедур.
- Вы дублируете логику своего приложения в двух местах: серверный код и код для хранимых процедур, тем самым усложняя процесс манипулирования данными.
- Миграция с одной СУБД на другую (DB2, SQL Server и др.) может привести к проблемам.
Инструмент, в котором я работаю, называется MySQL Query Browser, он достаточно стандартен для взаимодействия с базами данных. Инструмент командной строки MySQL — это еще один превосходный выбор. Я рассказываю вам об этом по той причине, что всеми любимый phpMyAdmin не поддерживает выполнение хранимых процедур.
Кстати, я использую элементарную структуру таблиц, чтобы вам было легче разобраться в этой теме. Я ведь рассказываю о хранимых процедурах, а они достаточно сложны, чтобы вникать еще и в громоздкую структуру таблиц.
Примеры работы с хранимыми процедурами в Microsoft SQL Server
Исходные данные для примеров
Все примеры ниже будут выполнены в Microsoft SQL Server 2016 Express. Для того чтобы продемонстрировать, как работают хранимые процедуры с реальными данными, нам нужны эти данные, давайте их создадим. Например, давайте создадим тестовую таблицу и добавим в нее несколько записей, допустим, что это будет таблица, содержащая список товаров с их ценой.
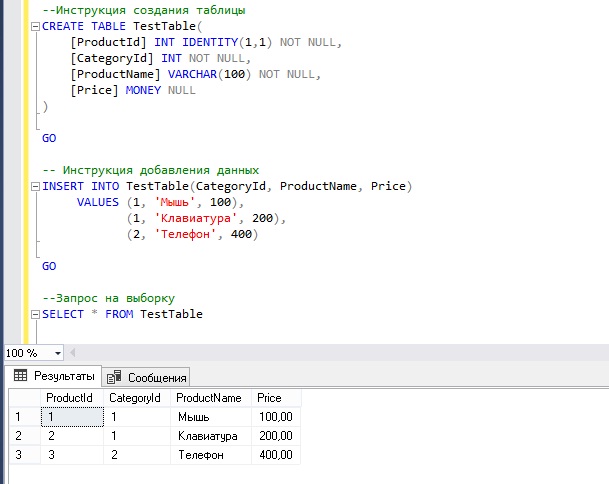
Данные есть, теперь давайте переходить к созданию хранимых процедур.
Создание хранимой процедуры на T-SQL – инструкция CREATE PROCEDURE
Хранимые процедуры создаются с помощью инструкции CREATE PROCEDURE, после данной инструкции Вы должны написать название Вашей процедуры, затем в случае необходимости в скобочках определить входные и выходные параметры. После этого Вы пишите ключевое слово AS и открываете блок инструкций ключевым словом BEGIN, закрываете данный блок словом END. Внутри данного блока Вы пишите все инструкции, которые реализуют Ваш алгоритм или какой-то последовательный расчет, иными словами, программируете на T-SQL.
Для примера давайте напишем хранимую процедуру, которая будет добавлять новую запись, т.е. новый товар в нашу тестовую таблицу. Для этого мы определим три входящих параметра: @CategoryId – идентификатор категории товара, @ProductName — наименование товара и @Price – цена товара, данный параметр будет у нас необязательный, т.е. его можно будет не передавать в процедуру (например, мы не знаем еще цену), для этого в его определении мы зададим значение по умолчанию. Эти параметры в теле процедуры, т.е. в блоке BEGIN…END можно использовать, так же как и обычные переменные (как Вы знаете, переменные обозначаются знаком @). В случае если Вам нужно указать выходные параметры, то после названия параметра указывайте ключевое слово OUTPUT (или сокращённо OUT).
В блоке BEGIN…END мы напишем инструкцию добавления данных, а также в завершении процедуры инструкцию SELECT, чтобы хранимая процедура вернула нам табличные данные о товарах в указанной категории с учетом нового, только что добавленного товара. Также в этой хранимой процедуре я добавил обработку входящего параметра, а именно удаление лишних пробелов в начале и в конце текстовой строки с целью исключения ситуаций, когда случайно занесли несколько пробелов.
Вот код данной процедуры (его я также прокомментировал).

Запуск хранимой процедуры на T-SQL – команда EXECUTE
Запустить хранимую процедуру, как я уже отмечал, можно с помощью команды EXECUTE или EXEC. Входящие параметры передаются в процедуры путем простого их перечисления и указания соответствующих значений после названия процедуры (для выходных параметров также нужно указывать команду OUTPUT). Однако название параметров можно и не указывать, но в этом случае необходимо соблюдать последовательность указания значений, т.е. указывать значения в том порядке, в котором определены входные параметры (это относится и к выходным параметрам).
Параметры, которые имеют значения по умолчанию, можно и не указывать, это так называемые необязательные параметры.
Вот несколько разных, но эквивалентных способов запуска хранимых процедур, в частности нашей тестовой процедуры.
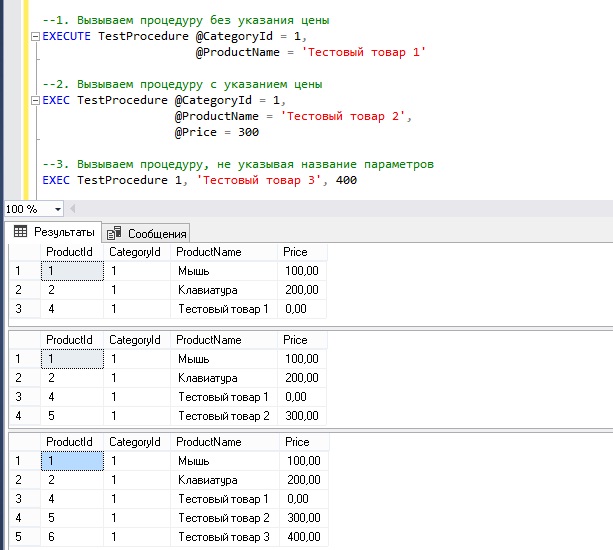
Изменение хранимой процедуры на T-SQL – инструкция ALTER PROCEDURE
Внести изменения в алгоритм работы процедуры можно с помощью инструкции ALTER PROCEDURE. Иными словами, для того чтобы изменить уже существующую процедуру, Вам достаточно вместо CREATE PROCEDURE написать ALTER PROCEDURE, а все остальное изменять по необходимости.
Допустим, нам необходимо внести изменения в нашу тестовую процедуру, скажем, параметр @Price, т.е. цену, мы сделаем обязательным, для этого уберём значение по умолчанию, а также представим, что у нас пропала необходимость в получении результирующего набора данных, для этого мы просто уберем инструкцию SELECT из хранимой процедуры.
Удаление хранимой процедуры на T-SQL – инструкция DROP PROCEDURE
В случае необходимости можно удалить хранимую процедуру, это делается с помощью инструкции DROP PROCEDURE.
Например, давайте удалим созданную нами тестовую процедуру.
При удалении хранимых процедур стоит помнить о том, что, если на процедуру будут ссылаться другие процедуры или SQL инструкции, после ее удаления они будут завершаться с ошибкой, так как процедуры, на которую они ссылаются, больше нет.
У меня все, надеюсь, материал был Вам интересен и полезен, пока!
В MySQL 5 есть много новых функций, одной из самых весомых из которых является создание хранимых процедур. В этом уроке я расскажу о том, что они из себя представляют, а также о том, как они могут облегчить вам жизнь.








sql-server — Курсор SQL медленный
Я начинаю с первого использования курсора в хранимой процедуре в sql server 2008. Я сделал предварительное чтение, и я понимаю, что они имеют значительные ограничения производительности. В моем текущем случае я думаю, что они необходимы (я хочу запустить несколько хранимых процедур для каждого символа запаса в таблице символов.
Изменить:
Скроки, которые я буду называть каждым символом, в большинстве случаев будут выполнять операции вставки для вычисления значений, зависящих от символа, таких как 5-дневная скользящая средняя, средний дневной объем, ATR (средний истинный диапазон). Большинство из этих значений будут вычисляться по данным ежедневной таблицы цен и томов… Я хотел бы упорядочить поиск значений данных, которые будут извлекаться избыточно в противном случае… например, я хотел бы получить для каждого символ ежедневных данных о ценах и объемах в переменную таблицы… эта временная таблица будет передана в хранимую процедуру, которая вызывает каждую из агрегированных функций, о которых я только что упомянул. Надеюсь, что это имеет смысл…
Итак, моя начальная хранимая процедура на основе курсора «внешний цикл» находится ниже.. он истекает через несколько минут, не возвращая ничего в окно вывода.
Когда я запускаю его без локальной переменной @symbol и исключаю его назначение в цикле while, он, кажется, работает нормально. Существует ли явное нарушение лучших практик в рамках этого задания? Спасибо..
Практика обновления версий PostgreSQL. Андрей Сальников
Предлагаю ознакомиться с расшифровкой доклада 2018 года Андрея Сальникова «Практика обновления версий PostgreSQL»
В большинстве своем, системные администраторы и ДБА бояться как огня делать мажорные обновления версий баз данных (RDBMS), особенно если эта база данных в эксплуатации и имеет достаточно высокую нагрузку. Главной причиной тому некоторый даунтайм базы данных, который всегда подразумевается при планировании таких работ.
На практике, такого рода upgrade занимает довольно длительное время и зачастую администраторам с малым опытом подобных операций приходится откатываться на старую версию баз данных из-за достаточно банальных ошибок, которые можно было бы избежать еще на этапе подготовки.
В Data Egret мы накопили огромный опыт проведения мажорных апгрейдов PostgreSQL в проектах, где нет права на ошибку. Я поделюсь своим опытом и расскажу о следующих шагах процесса: как правильно подготовиться к upgrade-у PostgreSQL? что необходимо сделать на этапе подготовки? как запланировать последовательность действий на сам upgrade? как провести процедуру upgrade-а успешно, без возврата на предыдущую версию бд? как минимизировать или вообще избежать простоя всей системы во время upgrade-а? какие действия необходимо выполнить после успешного upgrade-а PostgreSQL? Я также расскажу про две наиболее популярные процедуры апгрейда PostgreSQL — pg_upgrade и pg_dump/pg_restore, плюсы и минусы каждого из методов и расскажу про все типичные проблемы на всех этапах этой процедуры, и как их избежать.
Доклад будет интересен как новичкам так и тем ДБА которые уже давно работают с PostgreSQL, но хотят побольше узнать о том как правильно планировать и проводить upgrade максимально безболезненно.
Kilor 31 марта 2020 в 09:45
Оптимизация SQL Server при работе с курсорами
Здравствуй, человек-читатель блогов на Community.
Хочу рассказать о своем недавнем опыте оптимизации курсора в SQL Server.
курсор – это не хорошо, а плохо
DECLARE cursor_name CURSOR FOR select_statement ] ]
Остановлюсь на первых трех строчках ключевых параметров. LOCAL или GLOBAL: если хотим, чтобы курсор был доступен другим процедурам, функциям, пакетам в рамках нашей сессии, то GLOBAL – в этом случае за удалением курсора следим сами (команда DEALLOCATE). Во всех остальных случаях (т.е. в подавляющем своем большинстве) – LOCAL
Внимание, по умолчанию создается именно GLOBAL курсор! FORWARD_ONLY или SCROLL: если хотим ходить по курсору, как ненормальные, туда-сюда, то SCROLL, иначе – FORWARD_ONLY. Внимание, по умолчанию создается SCROLL курсор! STATIC или KEYSET, DYNAMIC, FAST_FORWARD: если хотим, чтобы при проходе по курсору отображалась актуальная информация из таблицы (т.е., если после открытия курсора, мы поменяли информацию в одном из полей таблицы и хотим, чтобы при проходе по курсору в нужной строчке курсора была уже обновленная информация), то используем или KEYSET (если КАЖДАЯ таблица, участвующая в выборке, имеет уникальный индекс) или DYNAMIC (самый медленный тип)
Если же нам нужен снимок результата выборки после открытия курсора – STATIC (самый быстрый тип – копия результата выборки копируется в базу tempdb и работаем уже с ней). FAST_FORWARD = KEYSET+FORWARD_ONLY+READ_ONLY – пацаны из инета пишут, что STATIC дольше открывается (т.к. создается копия в tempdb), но быстрее работает, а FAST_FORWARD – наоборот. Так что если количество записей велико (насколько большое показывает практика), то применяем STATIC, иначе – FAST_FORWARD. Внимание, по умолчанию создается DYNAMIC курсор.
Таким образом, для большого кол-ва записей в большинстве случаев мой выбор:DECLARE cursor_name CURSOR LOCAL FORWARD_ONLY STATIC FORselect_statement
для небольшого кол-ва записей:DECLARE cursor_name CURSOR LOCAL FAST_FORWARD FORselect_statement
Теперь перейдем к практике (что собственно и подтолкнуло меня к писанине сего).Испокон веков при объявлении курсора я применял конструкцию DECLARE … CURSOR LOCAL FOR…При разработке интеграции с одной очень нехорошей базой, в которой нет ни одного индекса и не одного ключа, я применил тот же подход при объявлении курсоров, что и всегда. Выборка одного курсора содержала 225 000 записей. В результате процесс импорта данных из такой базы занял 15 часов 14 минут !!! И хотя импорт и был первичный (т.е. одноразовый), но даже для нормального тестирования такого импорта потребовалось бы несколько суток! После замены вышеназванной конструкции при объявлении курсора на DECLARE .. CURSOR LOCAL FORWARD_ONLY STATIC FOR.
весь процесс импорта занял … внимание … 10 минут 5 секунд !!! Так что игра точно стоит свеч.Хочу повториться, что идеальный вариант — это все же не использовать курсоры вообще — для СУБД MS SQL намного роднее реляционный, а не навигационный подход
4.1 Возврат значений хранимых процедур SQL
В этой методике процедура присваивает значение локальной переменной и возвращает его. Процедура может также непосредственно возвращать постоянное значение. В следующем примере, мы создали процедуру, которая возвращает общее число авторов. Если сравнить эту процедуру с предыдущими, вы можете увидеть, что значение для печати заменяется обратным.
Теперь давайте посмотрим, как выполнить процедуру и вывести значение, возвращаемое ей. Выполнение процедуры требует установления переменной и печати, которая проводится после всего этого процесса
Обратите внимание, что вместо оператора печати вы можете использовать Select-оператор, например, Select @RetValue, а также OutputValue
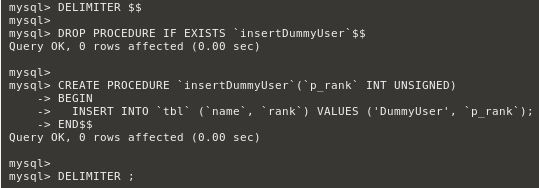
Триггеры
Поддержка триггеров появилась в MySQL начиная с версии 5.0.2.
Триггер – поименованный объект БД, который ассоциирован с таблицей и активируемый при наступлении определенного события, события связанного с этой таблицей.
Например, нижеприведенный код создает таблицу и INSERT триггер. Триггер суммирует значения, вставляемые в один из столбцов таблицы.





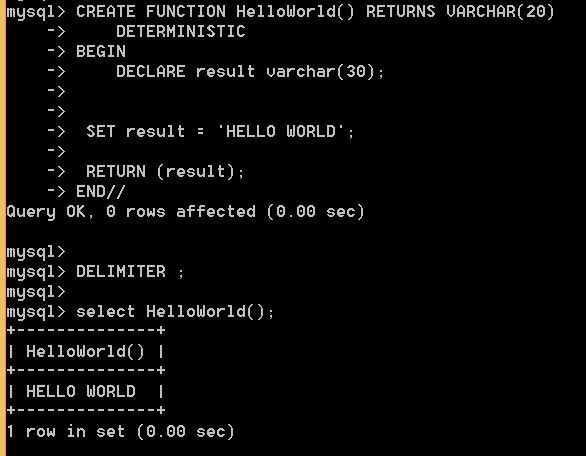

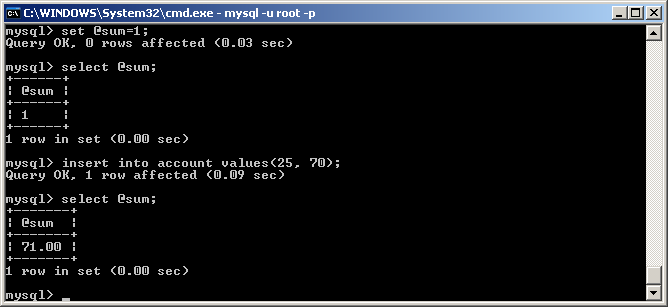
mysql> CREATE TABLE account (acct_num INT, amount DECIMAL(10,2));Query OK, 0 rows affected (0.03 sec)mysql> CREATE TRIGGER ins_sum BEFORE INSERT ON account-> FOR EACH ROW SET @sum = @sum + NEW.amount;Query OK, 0 rows affected (0.06 sec)

Объявим переменную sum и присвоим ей значение 1. После этого при каждой вставке в таблицу account значение этой переменной будет увеличивать согласно вставляемой части.
Замечание. Если значение переменной не инициализировано, то триггер работать не будет!
Синтаксис создания триггера
CREATETRIGGER имя_триггера время_триггера событие_срабатывания_триггераON имя_таблицы FOR EACH ROW выражение_выполняемое_при_срабатывании_триггера
Если с именем триггера и именем пользователя все понятно сразу, то о «времени триггера» и «событии» поговорим отдельно.
время_триггера
Определяет время свершения действия триггера. BEFORE означает, что триггер выполнится до завершения события срабатывания триггера, а AFTER означает, что после. Например, при вставке записей (см. пример выше) наш триггер срабатывал до фактической вставки записи и вычислял сумму. Такой вариант уместен при предварительном вычислении каких-то дополнительных полей в таблице или параллельной вставке в другую таблицу.
событие_срабатывания_триггера
Здесь все проще. Тут четко обозначается, при каком событии выполняется триггер.
- INSERT: т.е. при операциях вставки или аналогичных ей выражениях (INSERT, LOAD DATA, и REPLACE)
- UPDATE: когда сущность (строка) модифицирована
- DELETE: когда запись удаляется (запросы, содержащие выражения DELETE и/или REPLACE)
MySQL_dc.chm (1.7 MB) — подборка документации по MySQL.
- Chapter 19. Stored Programs and Views (англ.)
- (рус.)



