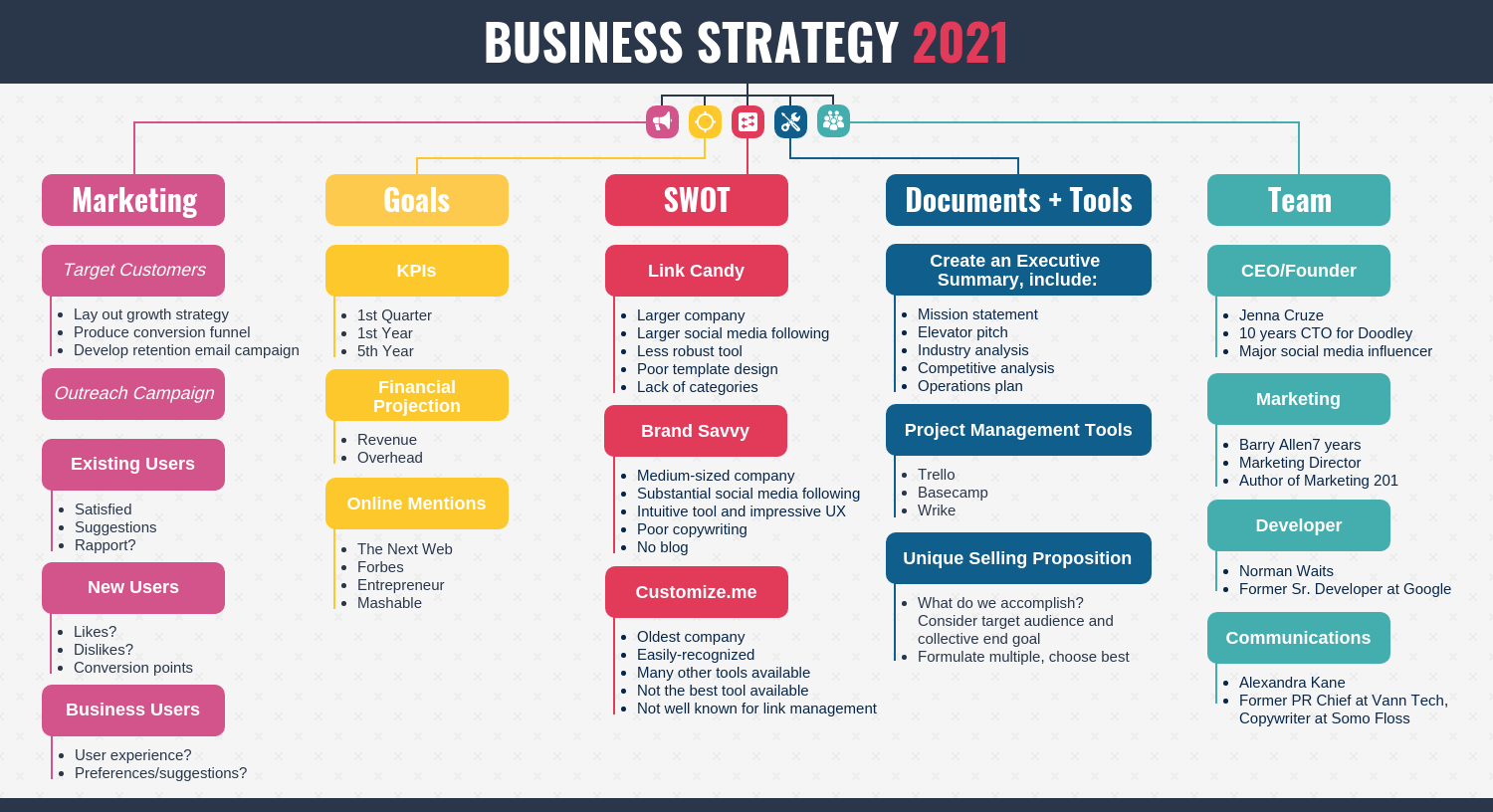
How to install full-text search in SQL Server Express
In the case of SQL Server Express Edition, we have to download the Express Edition with advanced services. Here are some of the additional steps that we need to follow in the case of SQL Server Express Edition.
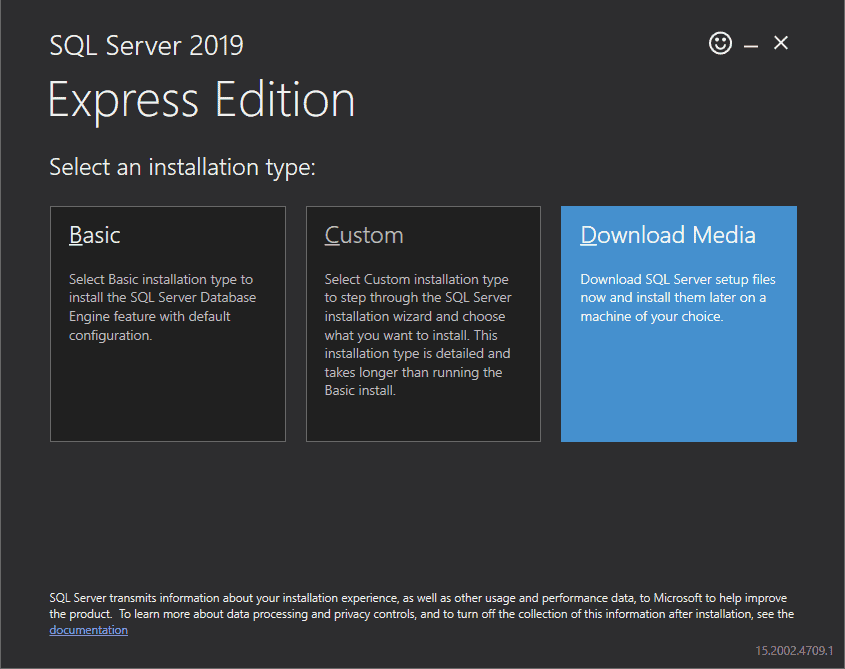
- First, we need to download the installer for SQL Server Express Edition. To download it, open this link and click on “Download” option. It will start downloading the installer.
- After downloading the installer, run the installer and first, it will ask for installation. In this case, we have to select the “Download Media” option.
Installing full-text search in SQL Server Express
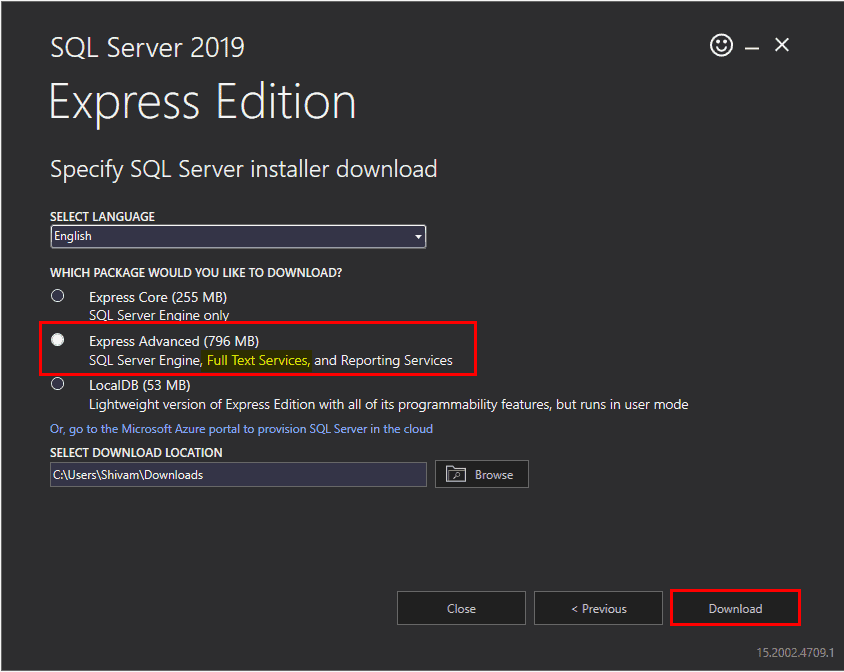
In the next page, we have to select the package type that we want to download. So, we have to select the “Express Advanced” package and click on “Download“.
Installing full-text search in SQL Server Express
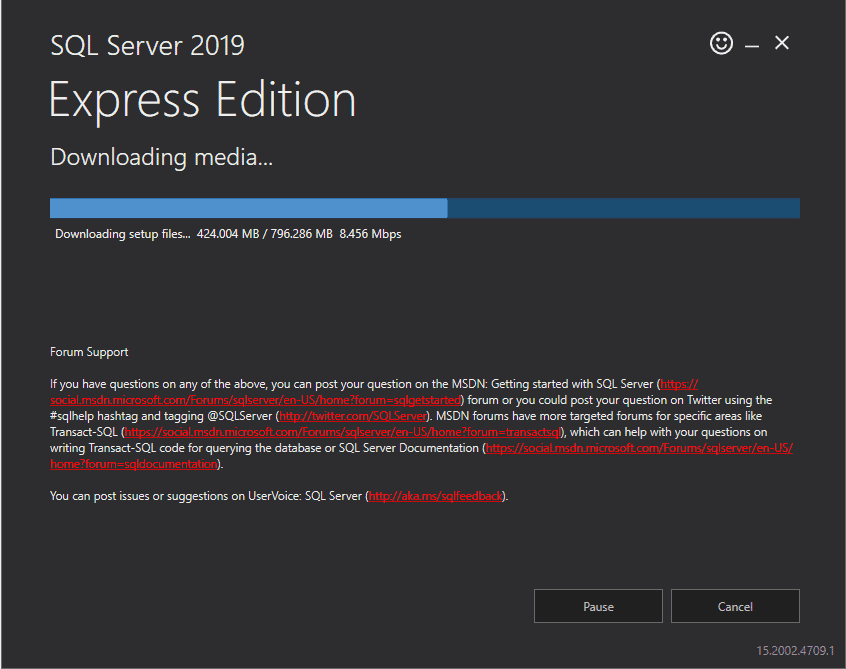
Once we click on download, it will start download of the Express Advanced package at the specified location.
Downloading full-text search for SQL Server Express
- Now, once the download is completed, open the location where we have downloaded the package. And run the downloaded file. It will extract the Express Advanced package to the specified directory.
- Now, we simply need to open that directory and run the installation media. And then, we can follow the steps given in the previous section to install the Full-Text Search feature.
Read: SQL Server create stored procedure
Создание полнотекстового индекса в Microsoft SQL Server
После того как полнотекстовый каталог мы создали, мы можем переходить к созданию полнотекстового индекса. В нашем случае для столбца TextData нашей тестовой таблицы.
Создание полнотекстового индекса на T-SQL
Для того чтобы создать полнотекстовый индекс, мы пишем инструкцию CREATE FULLTEXT INDEX.
- CREATE FULLTEXT INDEX – команда создания полнотекстового индекса;
- TestTable(TextData) – таблица и столбец, включенные в индекс;
- KEY INDEX PK_TestTable – имя уникального индекса таблицы TestTable;
- ON (TestCatalog) – указываем, что полнотекстовый индекс будет создан в полнотекстовом каталоге TestCatalog. Если не указать этот параметр, то индекс будет создан в полнотекстовом каталоге по умолчанию;
- WITH (CHANGE_TRACKING AUTO) – это мы говорим, что все изменения, которые будут вноситься в базовую таблицу (TestTable), автоматически отобразятся и в нашем полнотекстовом индексе, т.е. автоматическое заполнение.
Создание полнотекстового индекса в графическом интерфейсе Management Studio
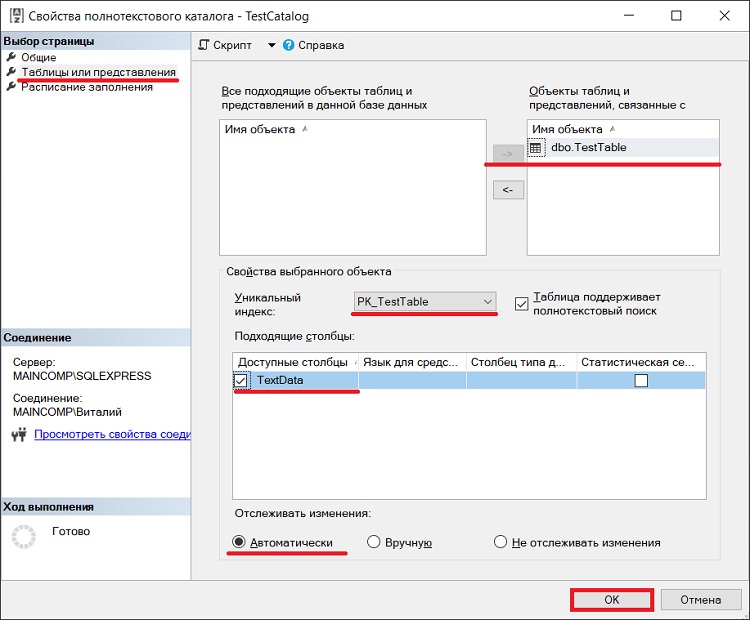
Полнотекстовый индекс можно создать, используя и графические инструменты, для этого открываем свойства полнотекстового каталога и переходим в пункт «Таблицы или представления», выбираем нужную таблицу, столбец, уникальный индекс и способ отслеживания изменений. В нашем случае у нас всего одна доступная таблица и один столбец. Нажимаем «ОК».
Overview of SQL Contains
The SQL contains is the SQL predicate Boolean function used with WHERE clause in the SQL Select statement to perform full-text search operations like search for a word, the prefix of a word, a word near another word, synonym of a word, etc… On full-text indexed columns containing character-based data types like string, char, and so on
Although SQL contains is not a standard SQL function, many of the database SQL Contains function argument depending on which database system we are using with,
For Microsoft SQL Server, SQL Contains function used to searches a text search in text column value-based criteria that are specified in a search argument and returns a number with either a true or false result, it will be 1 (true) if it finds a match and 0 (false) if it doesn’t. The first argument is the name of the table column you want to be searched; the second argument is the substring you want to find in the first argument column value
CROSS JOIN (перекрестное соединение)
Использование оператора SQL CROSS JOIN в наиболее простой форме — без условия соединения —
реализует операцию .
Результатом такого соединения будет сцепление каждой строки первой таблицы с каждой строкой второй таблицы. Таблицы
могут быть записаны в запросе либо через оператор CROSS JOIN, либо через запятую между ними.
Пример 9. База данных — всё та же, таблицы — Categories и Parts.
Реализовать операцию декартова произведения этих двух таблиц.
Запрос будет следующим:
SELECT (*) Categories CROSS JOIN Parts
Или без явного указания CROSS JOIN — через запятую:
SELECT (*) Categories, Parts
Запрос вернёт таблицу из 5 * 5 = 25 строк, фрагмент которой приведён ниже:
| Catnumb | Cat_name | Price | Part_ID | Part | Cat |
| 10 | Стройматериалы | 105,00 | 1 | Квартиры | 505 |
| 10 | Стройматериалы | 105,00 | 2 | Автомашины | 205 |
| 10 | Стройматериалы | 105,00 | 3 | Доски | 10 |
| 10 | Стройматериалы | 105,00 | 4 | Шкафы | 30 |
| 10 | Стройматериалы | 105,00 | 5 | Книги | 160 |
| … | … | … | … | … | … |
| 45 | Техника | 65,00 | 1 | Квартиры | 505 |
| 45 | Техника | 65,00 | 2 | Автомашины | 205 |
| 45 | Техника | 65,00 | 3 | Доски | 10 |
| 45 | Техника | 65,00 | 4 | Шкафы | 30 |
| 45 | Техника | 65,00 | 5 | Книги | 160 |
Как видно из примера, если результат такого запроса и имеет какую-либо ценность, то
это, возможно, наглядная ценность в некоторых случаях, когда не требуется вывести структурированную информацию,
тем более, даже самую простейшую аналитическую выборку. Кстати, можно указать выводимые столбцы из каждой
таблицы, но и тогда информационная ценность такого запроса не повысится.
Но для CROSS JOIN можно задать условие соединения! Результат будет совсем иным. При
использовании оператора «запятая» вместо явного указания CROSS JOIN условие соединения задаётся не
словом ON, а словом WHERE.
Пример 10. Та же база данных портала объявлений, таблицы Categories и Parts.
Используя перекрестное соединение, соединить таблицы так, чтобы данные полностью пересекались по
условию. Условие — совпадение идентификатора категории в таблице Categories и ссылки на категорию в таблице Parts.
Запрос будет следующим:
SELECT P.Part, C.Catnumb AS Cat, C.Price
FROM Parts P, Categories C
WHERE P.Cat = C.Cat_ID
Запрос вернёт то же самое, что и запрос в примере 1:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
И это совпадение не случайно. Запрос c перекрестным соединением по условию соединения полностью
аналогичен запросу с внутренним соединением — INNER JOIN — или, учитывая, что слово INNER — не обязательное,
просто JOIN.
Таким образом, какой вариант запроса использовать — вопрос стиля или даже привычки
специалиста по работе с базой данных. Возможно, перекрёстное соединение с условием для двух таблиц
может представляться более компактным. Но преимущество перекрестного соединения для более чем двух
таблиц (это также возможно) весьма спорно. В этом случае WHERE-условия пересечения перечисляются через
слово AND. Такая конструкция может быть громоздкой и трудной для чтения, если в конце запроса есть
также секция WHERE с условиями выборки.
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
FTS architecture
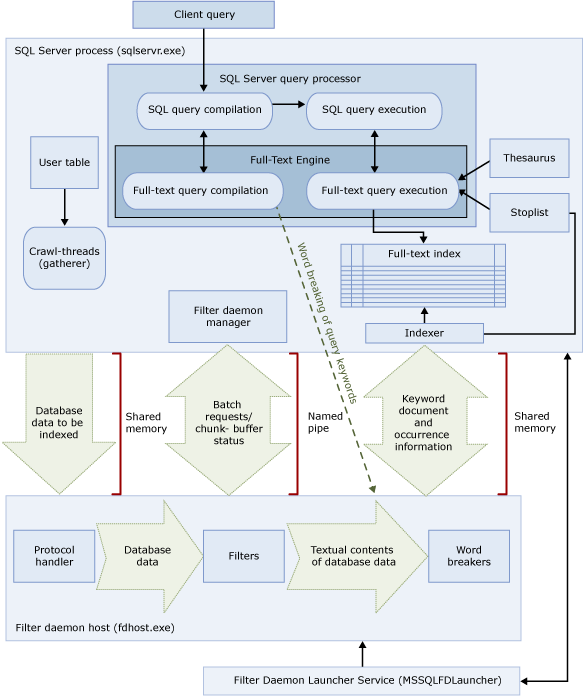
The architecture of the FTS has several components working in conjunction with the SQL Server query processor to perform textual research efficiently. The Figure 1 illustrates the major components of the architecture of the FTS. Let’s look at some of them:
- Client Consultation: The client application sends the textual queries to the SQL Server query processor. It is the responsibility of the client application to ensure that the textual queries are written in the right way by following the syntax of FTS;
- SQL Server Process (sqlservr.exe): The SQL Server process contains the query processor and also the engine of the FTS, which compiles and executes the textual queries. The integration between SQL Server and process the FTS offers a significant performance boost because it allows the query processor lot more efficient execution plans for textual searches;
- SQL Server Query Processor: The query processor has multiple subcomponents that are responsible for validating the syntax, compile, generate execution plans and execute the SQL queries;
- Full-Text Engine: When the SQL Server query processor receives a query FTS, it forwards the request to the FTS Engine. The Engine is responsible for validating FTS the FTS query syntax, check the full-text index, and then work together with the SQL Server query processor to return the textual search results;
- Indexer: The indexer works in conjunction with other components to populate the full-text index;
- Full-Text Index: The full-text index contains the most relevant words and their respective positions within the columns included in the index;
- Stoplist: A stoplist is a list of stopwords for textual research. The indexer stoplist query during the indexing process and implementation of textual research to eliminate the words that don’t add value to the survey. SQL Server 2014 stores the stoplists within the database itself, thus facilitating their administration;
- Thesaurus: The thesaurus is an XML file (stored externally to the database) in which you can define a list of synonyms that can be used for the textual research. The thesaurus must be based on the language that will be used in the search. The full-text engine reads the thesaurus file at the time of execution of research to verify the existence of synonyms that can increase the quality and comprehensiveness of the same;
- Filter daemon host (fdhost.exe): Is responsible for managing the processes of filtering, word breaker and stemmer;
- SQL Full-Text Filter Daemon Launcher (fdlauncher.exe): Is the process that starts the Filter daemon host (Fdhost.exe) when the full-text engine needs to use some of the processes managed by the same.
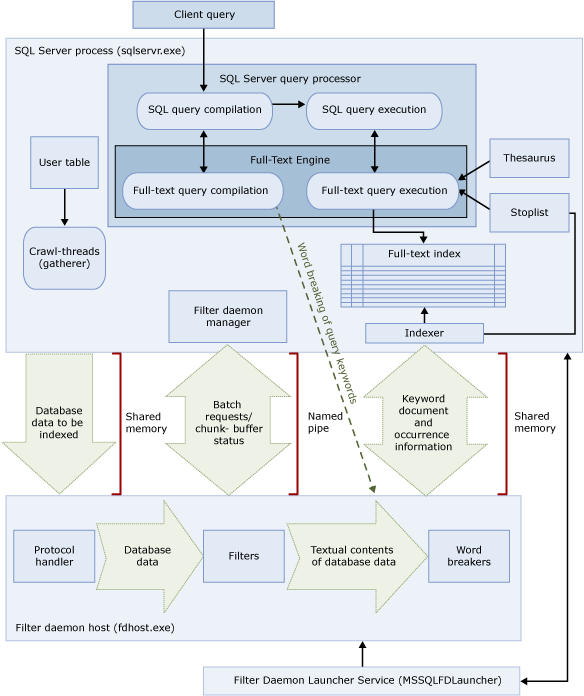
Figure 1. Architecture of FTS.
For the better understanding of the process of creation, use and maintenance of the structure of full-text indexes, you must also know the meaning of some important concepts. They are:
- Term: The word, phrase or character used in textual research;
- Full-Text Catalog: A group of full-text indexes;
- Word breaker: The process that is the barrier every word in a sentence, based on the grammar rules of the language selected for the creation of full-text index;
- Token: A word, phrase or character defined by the word breaker;
- Stemmer: The process that generates different verb forms for the words, based on the grammar rules of the language selected for the creation of full-text index;
- Filter: Component responsible for extracting textual information from documents stored with the data type varbinary(max) and send this information to the process word breaker.
Функция SUBSTRING
SUBSTRING (<выражение>, <начальная позиция>, <длина> )
Эта функция позволяет извлечь из выражения его часть заданной длины, начиная от заданной начальной позиции. Выражение может быть символьной или бинарной строкой, а также иметь тип text или image. Например, если нам потребуется получить 3 символа в названии корабля, начиная со 2-го символа, то сделать без помощи функции SUBSTRING будет не так просто. А так мы пишем:





В случае, когда нужно извлечь все символы, начиная с некоторого, мы также можем использовать эту функцию. Например,
даст нам все символы в названиях кораблей от второй буквы в имени
Обратите внимание на то, что для указания числа извлекаемых символов я использовал функцию LEN(name), которая возвращает число символов в имени. Понятно, что поскольку мне нужны символы, начиная со второго, то их число будет меньше общего количества символов в имени
Однако это не вызывает ошибки, поскольку если указанное число символов превышает возможное число, то будут извлечены все символы до конца строки. Поэтому я и беру их с запасом, не утруждая себя вычислениями.
Подготовка к реализации полнотекстового поиска в MS SQL Server
Перед тем как приступать к созданию полнотекстового поиска, необходимо знать несколько важных моментов:
- Для реализации полнотекстового поиска компонент Full-Text Search (Полнотекстовый поиск
) должен быть установлен; - У таблицы может быть только один полнотекстовый индекс;
- Чтобы создать полнотекстовый индекс, таблица должна содержать один уникальный индекс, который включает один столбец и не допускает значений NULL. Рекомендовано использовать уникальный кластеризованный индекс (или просто первичный ключ
), первый столбец которого должен иметь целочисленный тип данных; - Полнотекстовый индекс можно создавать на столбцах с типом данных: char, varchar, nchar, nvarchar, text, ntext, image, xml, varbinary или varbinary(max);
- Для того чтобы создать полнотекстовый индекс сначала необходимо создать полнотекстовый каталог. Начиная с SQL Server 2008 полнотекстовый каталог это логическое понятие, обозначающее группу полнотекстовых индексов, т.е. является виртуальным объектом и не входит в файловую группу (есть способ создания полнотекстового индекса, используя «Мастер», при котором каталог можно создать одновременно с индексом, этот способ мы будем рассматривать чуть ниже
).
В примерах ниже в качестве инструмента создания и управления полнотекстовыми каталогами и индексами я буду использовать SQL Server Management Studio.
Как найти слово в строке sql

PHP и MySQL с Нуля до Гуру 3.0
Данный курс научит Вас программировать на самом популярном Web-языке в мире — PHP. Курс состоит из 9 разделов, в которых с нуля рассказывается и показывается процесс написания различных скриптов на PHP.
В курсе Вы узнаете всю необходимую теоретическую часть, а также увидите массу практических примеров, в том числе, и из моей практики.
В Бонусе «Создание сайта для библиотеки» Вы увидите применение знаний из основного курса при создании полноценного проекта.
Просмотрев данный курс, Вы сможете создавать абсолютно любые PHP-сайты любой сложности.
Подпишитесь на мой канал на YouTube, где я регулярно публикую новые видео.
Подписаться
Подписаться
Добавляйтесь ко мне в друзья ! Отзывы о сайте и обо мне оставляйте в моей группе.
How to create a table with Full-Text enabled
Let’s say we have a table called . already created using following statement.
|
1 |
CREATE TABLEdbo.DM_OBJECT_FILE( FILE_IDintNOTNULL, FILE_FINintNOTNULL, FILE_TITLEVarchar(255), OBJ_IDintNOTNULL, FILE_ATTsmallintNOTNULL, FILE_PATHVarchar(500)NULL, FILE_EXTVarchar(50)NULL, FILE_TXTvarbinary(max)NULL, FILE_KEYWORDSVarchar(1000)NULL, FILE_STATUSsmallintNULL, FILE_TXT_SIZEIntdefault, OBJ_FILE_IDX_DOCTYPEVarchar(3)Null, CONSTRAINTPK_DM_OBJECT_FILEPRIMARY KEY CLUSTERED(FILE_ID) ) |
Each file imported into that table is uniquely identified by FILE_ID column, FILE_TXT column refers to the contents of this file and OBJ_FILE_IDX_DOCTYPE refers to the kind of document that is stored in the FILE_TXT column.
Now, we are willing to create a Full-Text Index on this table. This means that Full-Text feature should already be installed on our instance. To check whether it’s the case or not, we can use the following query:
|
1 |
CASEFULLTEXTSERVICEPROPERTY(‘IsFullTextInstalled’) WHEN1THEN’Full-Text installed.’ ELSE’Full-Text is NOT installed.’ END ; |
If it appears that Full-Text is not installed, you should consider to install it first.
As soon as you are sure that Full-Text feature is installed, we should check that FullText search is enabled for the database where our table is stored. We can check it with the following statement:
|
1 |
SELECT is_fulltext_enabled FROM sys.databases WHERE database_id=DB_ID()
|
We should get following output:
If we don’t, we should run following T-SQL statement:
|
1 |
exec sp_fulltext_database’enable’;
|
But this is not the end! We also want to check if there is already a full-text catalog, which is a virtual database object that does not belong to any filegroup and refers to a group of Full-Text indexes. To do so, we will run the following query:
|
1 |
FROM sys.fulltext_catalogs |
If this query did not return any row, then we have to create one or more fulltext catalogs and set one of them as default. To perform this action, we will use a statement based on CREATE FULLTEXT CATALOG as follows:
|
1 |
CREATE FULLTEXT CATALOG FullTextCatalog ASDEFAULT;
|
Now, we are ready to create the Full-Text index on . table. To create such an index we have to have some information:
- What is the key index to be used in order to uniquely identify records?
- What columns should be part of the index? (Here: FILE_TXT column will be used)
- What type of document does the column represent and in which column this information is stored? (Here: OBJ_FILE_IDX_DOCTYPE column will be used)
- Which language is used in this column or is it preferable to be totally neutral regarding language interpretation?
- Do we enable change tracking and let the index update by itself or do we manage this part ourselves?
You will find below the create statement for a Full-Text Index on FILE_TXT column from table dbo.DM_OBJECT_FILE, with neutral language interpretation, automatic update and no stop list.
|
1 |
CREATE FULLTEXT INDEX ON dbo.DM_OBJECT_FILE( FILE_TXT TYPE COLUMN OBJ_FILE_IDX_DOCTYPE LANGUAGE )KEY INDEX PK_DM_OBJECT_FILE WITH CHANGE_TRACKING=AUTO, STOPLIST=OFF ; |
Фильтр синонимов токенов Elasticsearch с настраиваемыми сопоставлениями слов
Elasticsearch поддерживает настраиваемое сопоставление синонимов, если WordNet не соответствует вашим потребностям. Мы настраиваем фильтр токенов синонимов так, чтобы он сопоставлял ключевое слово «fruit» со списком ключевых слов — «banana», «pineapple», «date», «fig», «olive» и «citrus». Следовательно, поиск по ключевому слову «banana» будет соответствовать любым записям с «fruit».
 Анализатор Elasticsearch с настраиваемым фильтром токенов синонимов
Анализатор Elasticsearch с настраиваемым фильтром токенов синонимов
Отправьте этот запрос PUT, чтобы создать новый индекс и настраиваемый анализатор с фильтром токенов «synonym_filter».
После копирования данных во вновь созданный индекс отправьте этот запрос POST для поиска по ключевому слову «banana». Затем вы увидите, что результат содержит все записи, соответствующие ключевому слову «fruit».
Результат:
Elasticsearch — результат поиска отображается в Kibana
How to enable full-text search in SQL Server
In SQL Server, all the SQL Server databases are full-text enabled by default. But before implementing a full-text search on a table, we have to create a full-text catalog as well as the full-text index on the tables.






So, to enable a full-text search on a table, we should know how to create a full-text catalog and a full-text index on the table that we want to search. In this section, we will understand both the steps before start implementing a full-text search.
How to create Full-Text Catalog
A catalog in SQL Server is a virtual object that does not belong to any filegroup. And it is a logical concept that refers to the collection of full-text indexes. So, each full-text index must belong to a full-text catalog.
We can have a separate catalog for each full-text index and we can also have multiple indexes in one catalog.
Let’s understand how to create a full-text catalog using Transact-SQL in SQL Server. Here is the syntax for creating a full-text catalog.
In the above syntax, first, we have to specify the database in which we want to create a catalog. Next, we have used the “CREATE FULLTEXT CATALOG” statement to create a full-text catalog with a name that we will specify in place of catalog_name.
Let’s use the above syntax to create a new full-text catalog in SQL Server. And the code for the example is given below.
In the above example, we are creating a full-text catalog with the name “FullTextCatalog” in the “sqlserverguides” database. Now, if the above command is executed successfully then it simply means that the catalog is been created.
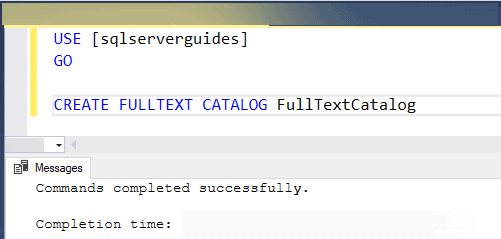
How to create Full-Text Catalog in SQL Server
How to create Full-Text Index
Before creating a full-text index, we have to assure that the table has a unique single-column, non-nullable index. And for this task, we have to follow the following syntax given below.
By using the above syntax, we can create an unclustered unique index on the specified column of the table. Let’s understand the syntax by executing a simple example. And the example is given below.
In the above example, we are using the CREATE UNIQUE INDEX statement to create a ui_Stud index on the id column in the Student table. Here is the screenshot of the above execution.

How to create Unique Index in SQL Server
Now, let’s understand how to create a full-text index in SQL Server. First, let’s see the syntax of creating a full-text index.
The above syntax accepts the following arguments.
- table_name: It is used to define the name of the table or view which consists of the column that needs to be indexed.
- column_name: It is used to define the column to be indexed.
- type_column_name: This argument is used to define the type column name. we only need to specify this argument when the column is of varbinary(max) or image data type.
- language_term: Here we need to specify the language in which the column data is stored.
- index_name: It is the name of the unique index in the table.
- catalog_filegroup_option: It is used to specify the catalog name.
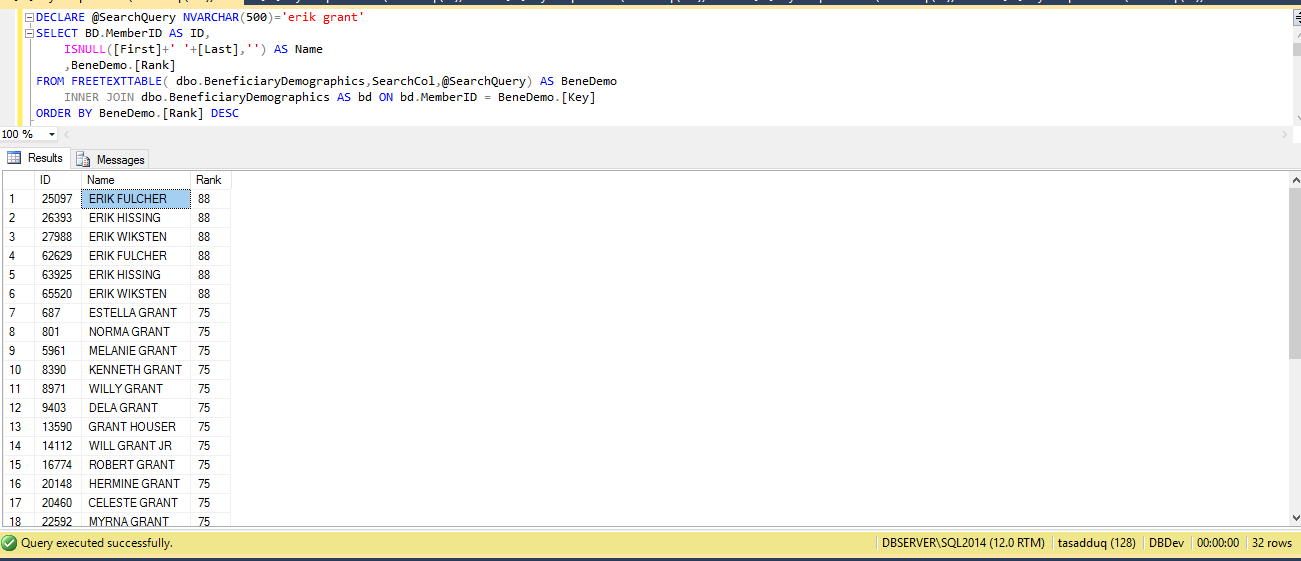
Now, let’s use this syntax to create a full-text index in the sqlserverguides database. And here is the SQL query for the example.
In the above example, we have created a full-text index on the “University_Name” column which is in the Student table. For the language, we have defined the LCID for American English. Here is the screenshot of the execution of the above example.
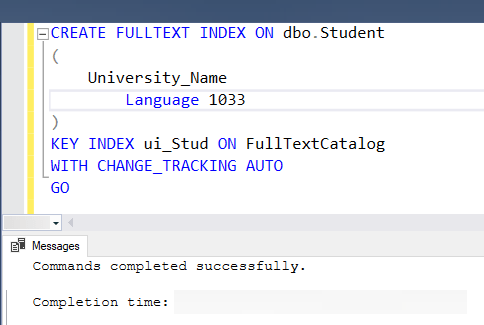
How to create Full-Text Index in SQL Server
Read: SQL Server trigger after insert
Что такое полнотекстовый поиск Full Text Search?
Определение
И кроме быстрой работы такой поиск может ранжировать найденные документы, это значит, что каждой строке присваивается ранг. Пользователю это нужно для того, чтобы найти наиболее релевантные записи, которые больше всего подходят пользователю.
Какие есть возможности полнотекстового поиска Microsoft SQL Server

Используя полнотекстовый поиск SQL сервера, пользователь может искать, используя не только слова и фразы, но и префиксные выражение, то есть искать текст сначала слова или фразы. Есть возможность искать слова по слова формам, это формы глаголов или существительные в единственном и множественном числе, это называется производные выражения.
Используя полнотекстовый поиск, пользователь может построить запрос таким образом, чтобы были найдены слова, которые находятся рядом с другими словами или фразами, это значит поиск выражения с учётом расположения. Также такой поиск даёт возможность производить поиск синонимических форм конкретного слова, thesaurus. Это значит, что если в тезаурусе указано, что автомобиль и машина являются синонимами, то при проведении поиска слова автомобиль в результате будут и строки, где есть слова «машина».
Если у пользователя есть необходимость, не учитывать в поиске определённые слова, то для этого есть список стоп слов. Это значит, по словам, которые включены в этот список, поиск проводиться не будет.
Процесс реализации полнотекстового поиска
Для создания полнотекстового индекса у таблицы должен быть один уникальный индекс, с одним столбцом, и без значения null.
Также важно, что полнотекстовый индекс можно создавать на столбцах с типом данных char, varchar, nchar, text, ntext, image, xml, varbinary
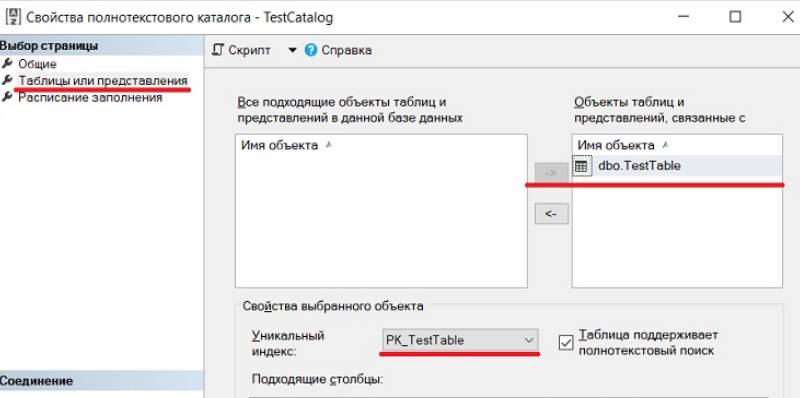
Для создания полнотекстового индекса пользователь должен создать полнотекстовый каталог. В программе SQL Server полнотекстовый каталог это логическое понятие, которое включает в себя группу полнотекстовых индексов, то есть это виртуальный объект, который не входит в файловую группу.
Типы индексов
В Microsoft SQL Server используются следующие индексы: кластерные и некластерные. Рассмотрим их подробнее.
Кластерный индекс
Основная его задача — сохранение табличных данных в виде, отсортированном по значению ключа. Таблице или представлению может быть присущ лишь единственный кластеризованный индекс (Clustered index), потому что табличные данные могут отсортировываться в едином возможном порядке – либо возрастания, либо убывания. По возможности, у каждой таблицы должен быть Clustered index.
Табличные данные будут храниться отсортированными лишь в том случае, когда таблица имеет кластеризованный индекс. Строки табличных данных Clustered index хранит в уровнях листьев.
Если у таблицы нет Clustered index, в момент формирования ограничений PRIMARY KEY и UNIQUE, он формируется автоматически. Когда для таблиц/ куч созданы Nonclustered indexes, то в процессе создания Clustered index все некластеризованные должны быть перестроены.
Содержание листьев зависит от того, индекс кластерный или некластерный. Они могут содержать как табличные данные, так и ссылки, указывающие на строки с ними.
Некластерный индекс
Некластеризованными (Nonclustered) называют такие индексы, которые содержат:
- значения ключей – ключевые столбцы, по которым они определены;
- указатели на строки в таблице, содержащие реальные данные (значения ключа).
Чтобы обнаружить и получить запрашиваемые данные, для системы подзапросов потребуется совершение дополнительных операций. Содержимое указателей на запрашиваемые данные полностью зависит от того, как они хранятся.


Он может указывать на:
- кучу и тем самым приводить к идентификатору строки с искомыми данными;
- таблицу с Clustered index, указывая, что именно он используется что для поиска действительных данных.
Nonclustered indexes могут быть расширены дополнительными столбцами (included column). А значит, листья будут сохранять значения индексированных и дополнительных неиндексированных столбцов. Это свойство дает возможность обойти определенные ограничения, возложенные на индекс. Данный подход позволяет включать неиндексируемые столбцы либо обходить ограничения на длину индекса.
Главные свойства Nonclustered indexes:
- их нельзя отсортировать;
- на таблицу или представление можно сформировать свыше одного (до 999) некластеризованных индексов. Но не стоит создавать максимальное количество Nonclustered indexes. Нужно помнить, что они способны как повысить, так и понизить производительность.
Nonclustered indexes могут создаваться на любых таблицах, в том числе и имеющих кластерный индекс.
MySql. Поиск слова или строки

Задание: Необходимо найти, в каких полях таблицы, встречается запрошенное слово или строка и запросить данные всех полей таблиц, удовлетворяющих запросу.
Решением этой задачи будет служить SQL запрос содержащий оператора LIKE.
Приведу примитивный пример.Представим, что у нас есть таблица с какими то данным:

Допустим нам нужно вывести все строки в поле text, которых содержится слово «статьи«.
Пишем запрос:Логика запроса: получить данные всех полей таблицы post, где в поле text встречается слово «статьи«.
Результат выполнения запроса:
Запрос для поиска слова в начале строки:Логика запроса: получить данные всех полей таблицы post, где в начале поля text встречается слово «статьи«.
Запрос для поиска слова в конце строки:Логика запроса: получить данные всех полей таблицы post, где в конце поля text встречается слово «статьи«.
Примеры полнотекстовых запросов
Более подробно полнотекстовые запросы мы будем рассматривать в отдельном материале, а пока, в качестве примера и подтверждения того, что наш полнотекстовый поиск работает, давайте напишем пару простых полнотекстовых запросов.
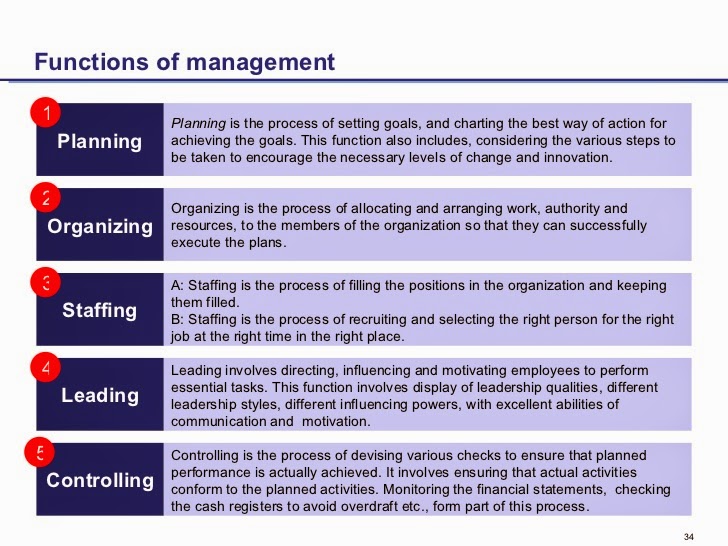
Если помните, наша таблица TestTable содержит определения технологий, языков программирования, в общем, определений, связанных со сферой IT. Допустим, что мы хотим получить все записи, где есть упоминание о компании Microsoft, для этого мы пишем полнотекстовый запрос с ключевым словом CONTAINS, например
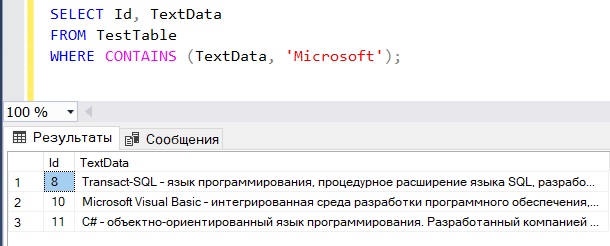
Мы получили результат, но допустим, нам также необходимо отсортировать его по релевантности, другими словами, какие строки больше соответствуют нашему запросу. Для этого мы будем использовать функцию CONTAINSTABLE, которая проставляет ранг для каждой найденной записи.
Как видим, ранг проставлен и по нему отсортированы строки. Сам алгоритм ранжирования, как и более подробную информацию о полнотекстовом поиске, можно найти в электронной документации по SQL Server.