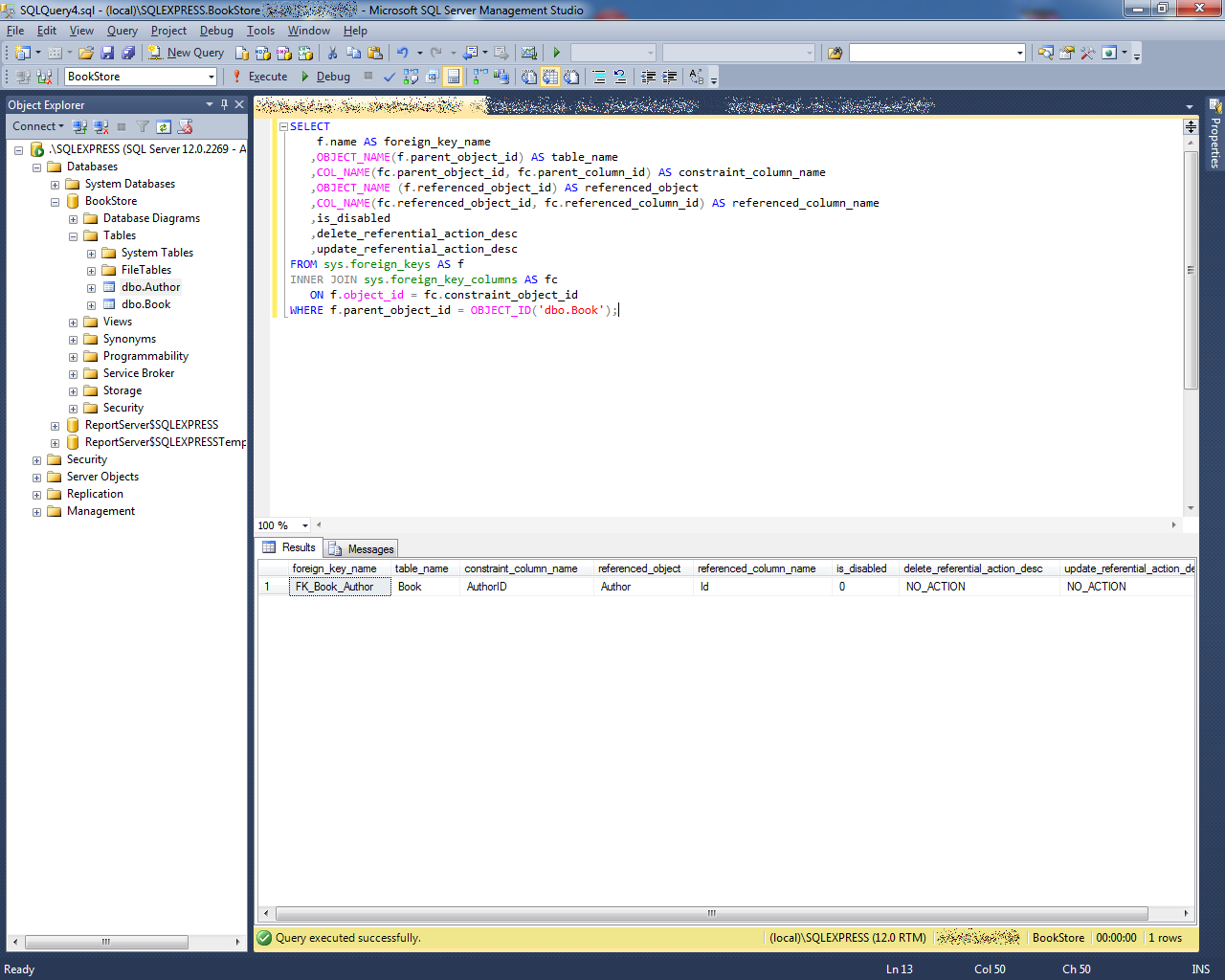
Состояния ограничений целостности
Как было показано в предыдущем выше, ограничения целостности определяются на таблицах для гарантии, что данные, нарушающие заранее установленные правила,в таблицу не попадут. Однако иногда, например, при загрузке данных, ограничения целостности не должны поддерживаться в действительном состоянии, поскольку это приведет к определенным проблемам. При необходимости Oracle позволяет отключать ограничения и затем включать их, когда они снова понадобятся. Давайте рассмотрим некоторые способы изменения состояния ограничений таблиц.
При загрузке больших объемов данных с использованием SQL*Loader или утилиты Import может потребоваться значительное время на загрузку данных, каждую строку которых нужно проверять на предмет нарушения целостности. Более эффективная стратегия предусматривает отключение ограничения, загрузку данных и последующую проверку корректности загруженных данных. После завершения загрузки ограничения вновь вводятся в действие посредством включения. Когда ограничение отключается,как описано здесь, база данных уничтожает индекс. Подобным образом реализуется лучшая стратегия — предварительное создание неуникальных индексов для ограничений, которые база данных не должна уничтожать, поскольку они обрабатывают дублированные записи.
На заметку! Состояние enabled (включено) — это состояние ограничений Oracle по умолчанию
Отключаются ограничения двумя способами: указание в качестве состояния ограничения либо disable validate (отключить с проверкой), либо disable no validate (отключить без проверки) с использованием конструкции DISABLE VALIDATE и DISABLE NO VALIDATE, соответственно. Аналогично, для включения ограничения применяются конструкции ENABLE VALIDATE и ENABLE NO VALIDATE. Ниже кратко обсуждаются различные способы включения и отключения ограничений.
Состояние Disable Validate
В случае использования команды DISABLE VALIDATE выполняются следующие два действия сразу. Во-первых, конструкция VALIDATE гарантирует, что все данные в таблице удовлетворяют условию ограничения. Во-вторых, конструкция DISABLE избавляет от необходимости поддерживать ограничение. Oracle сбрасывает индекс ограничения,но сохраняет его действительным. Вот пример:
SQL> ALTER TABLE sales_data ADD CONSTRAINT quantity_unique UNIQUE (prod_id,customer_id) DISABLE VALIDATE;
После выдачи приведенного выше оператора SQL наличие только уникальных комбинаций уникальных ключей prod_id и customer_id в таблице гарантируется, однако уникальный индекс не поддерживается.
Обратите внимание, что поскольку было решено сохранить ограничение в отключенном состоянии, никаких DML-действий в отношении таблицы выполнять нельзя. Эта опция идеально подходит для крупных таблиц хранилищ данных, которые обычно используются только для извлечения данных по запросам
Состояние Disable No Validate
При отключении ограничения без проверки ограничение отключается, и нет никаких гарантий соответствия данных требованиям ограничения, поскольку Oracle не предпринимает проверку его действительности. Это по существу то же самое, что команда DISABLE CONSTRAINT.
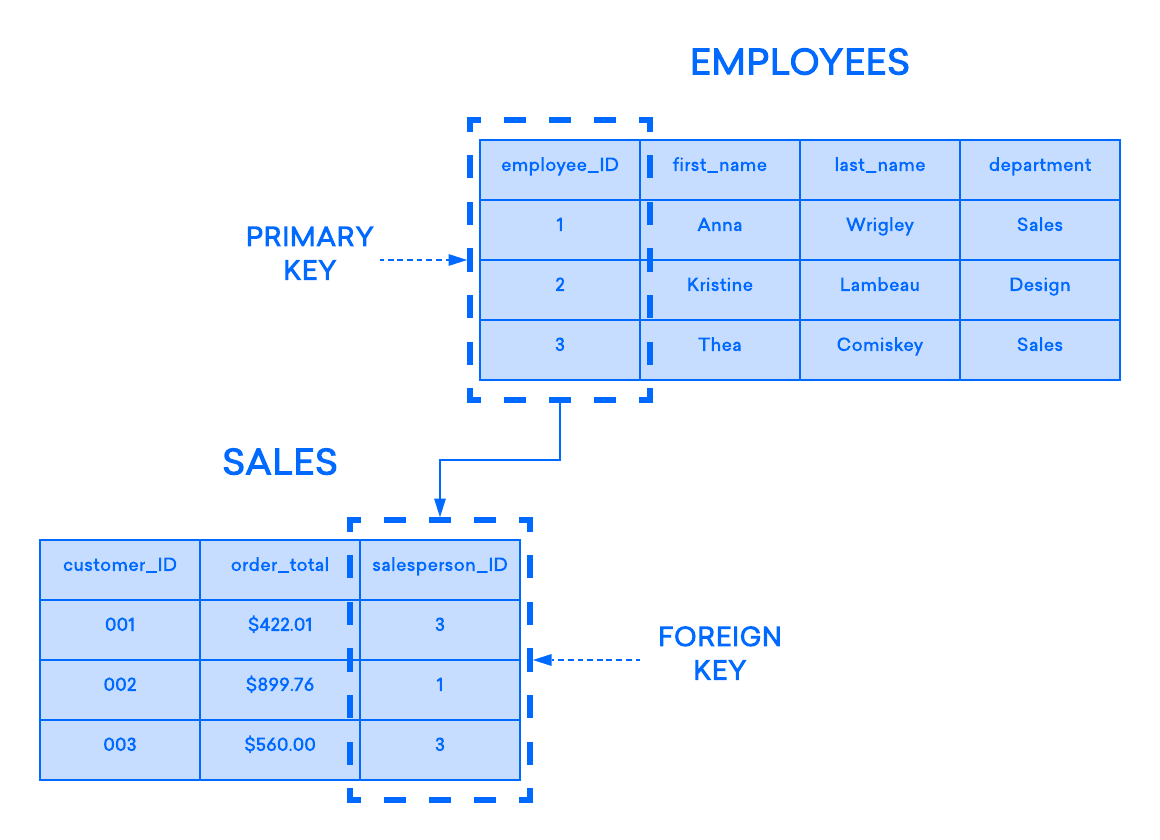
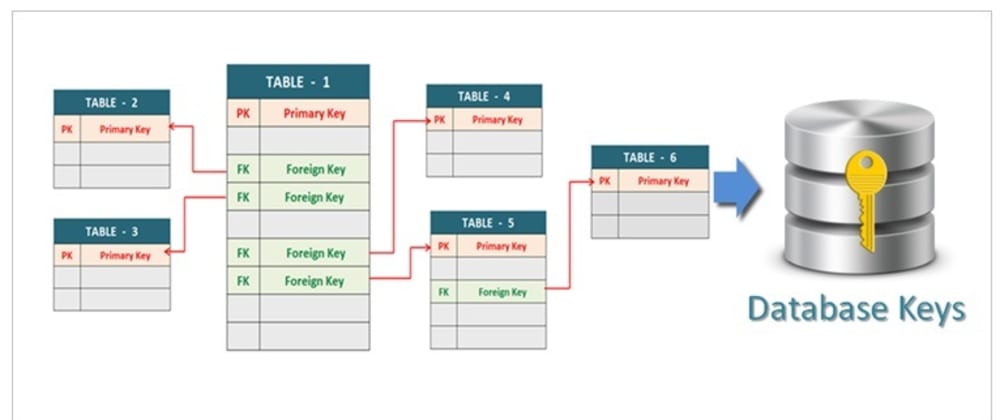
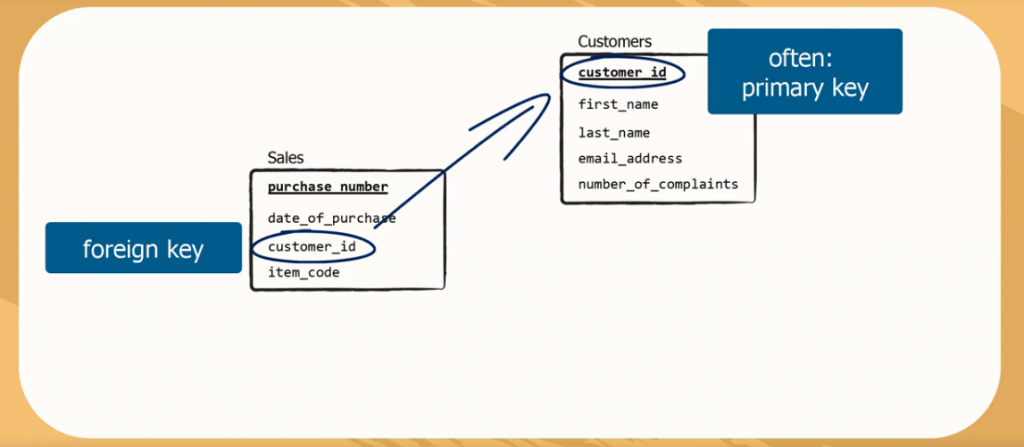
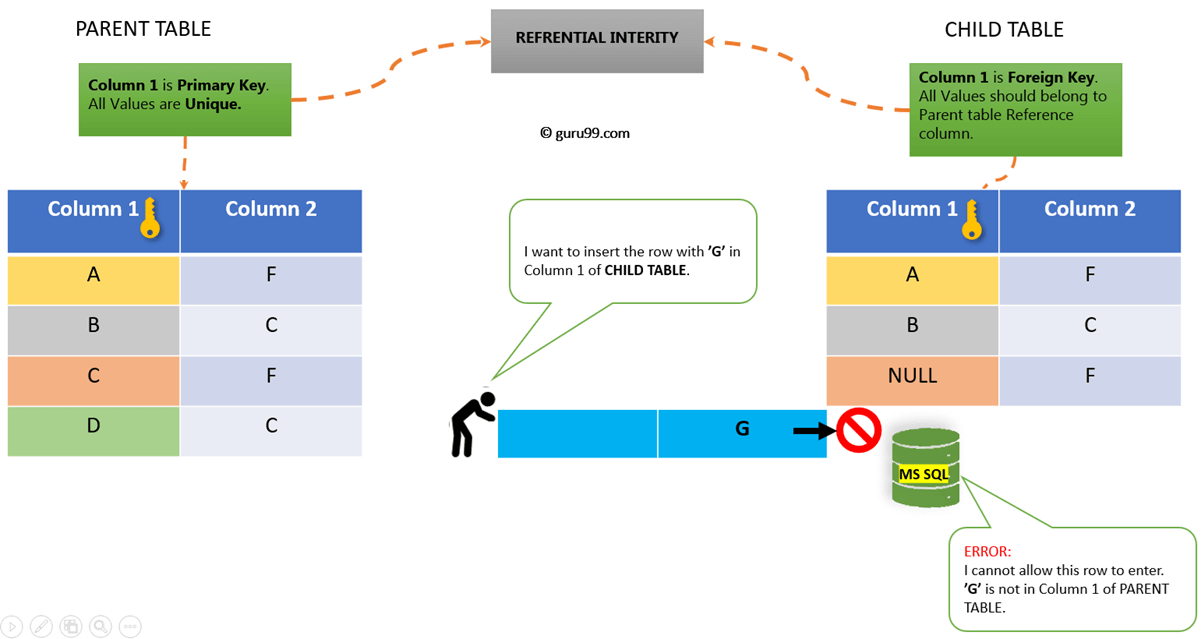
SQL FOREIGN KEY Constraint
The constraint is used to prevent actions that would destroy links between tables.
A is a field (or collection of fields) in one table, that refers to
the in another table.
The table with the foreign key is called the child table, and the table
with the primary key is called the referenced or parent table.
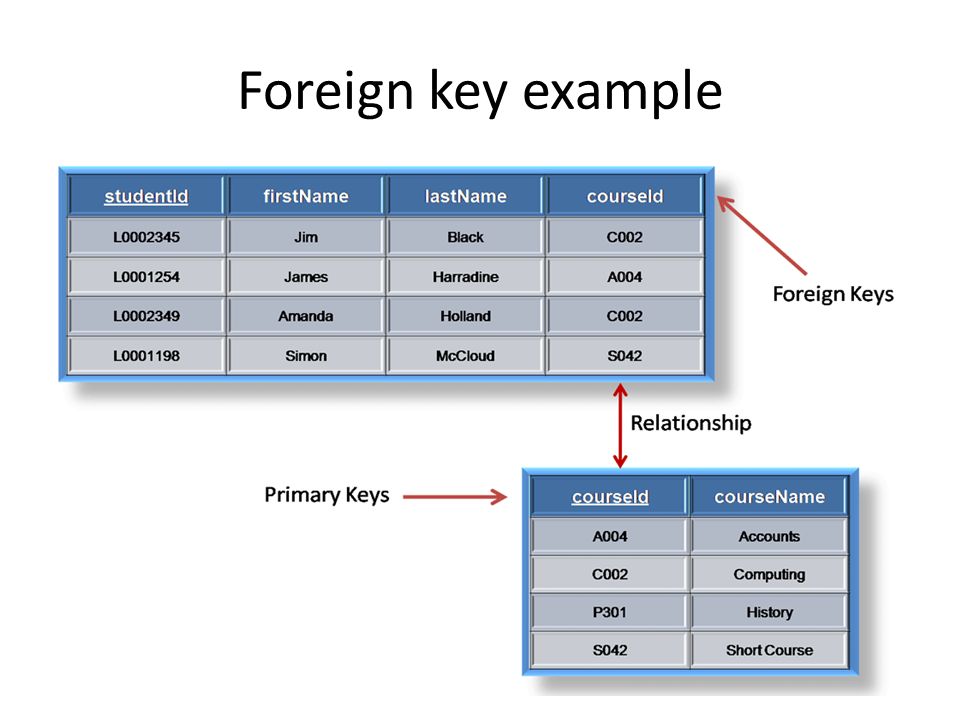
Look at the following two tables:
Orders Table
| OrderID | OrderNumber | PersonID |
|---|---|---|
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 2 |
| 4 | 24562 | 1 |
Notice that the «PersonID» column in the «Orders» table points to the «PersonID» column in the «Persons» table.
The «PersonID» column in the «Persons» table is the in the «Persons» table.
The «PersonID» column in the «Orders» table is a in the «Orders» table.
The constraint prevents invalid data from being inserted into the foreign key column,
because it has to be one of the values contained in the parent table.
Где хранятся данные mysql?
По аналогии с остальными настройками (php, apache, nginx), предвкушал долгие поиски и не ошибся. В итоге выяснил, что хранятся они в файле /etc/mysql/conf. d/bvat.
Как просмотреть базу данных MySQL?
Чтобы получить список таблиц в базе данных MySQL, используйте клиентский инструмент mysql для подключения к серверу MySQL и выполните команду SHOW TABLES. Необязательный модификатор FULL покажет тип таблицы в качестве второго выходного столбца.
Где найти базу данных сайта?
По умолчанию сама БД сайта находится в каталоге data на веб-сервере интернет-проекта. К примеру, если БД имеет название bd, то все ее значения находятся в data/bd. Как правило, на хостинге доступ к файлам БД закрыт, их следует “вытягивать” посредством запросов SQL через консоль.
Куда сохраняется база данных SQL Server?
По умолчанию и файлы баз данных, и файлы журналов помещаются в каталог С:\Program Files\Microsoft SQL Server\MSSQL. X\MSSQL\Data (где X — номер экземпляра SQL Server 2005).
Где Битрикс хранит подключения к базе данных?
- u77777_dbuser — пользователь, от имени которого сайт подключается к базе данных;
- password — пароль, с которым сайт подключается к базе данных;
- u77777_database — база данных, которую использует сайт.
Как посмотреть список пользователей MySQL?
MySQL список пользователей
Теперь мы можем вывести список пользователей, созданных в MySQL, с помощью следующей команды: mysql> SELECT user FROM mysql. user; В результате мы сможем посмотреть всех пользователей, которые были созданы в MySQL.
Как скопировать базу данных с сайта?
Для переноса базы данных необходимо сначала создать ее дамп, то есть разместить содержимое в отдельный sql-файл. Делается это в меню phpMyAdmin на хостинге, откуда вы переносите сайт. Зайдите в phpMyAdmin, выделите слева базу данных, которую необходимо перенести, и нажмите на кнопку «Экспорт» в верхнем меню.
Что можно делать с базами данных?
База данных (БД) — это программа, которая позволяет хранить и обрабатывать информацию в структурированном виде. БД это отдельная независимая программа, которая не входит в состав языка программирования. В базе данных можно сохранять любую информацию, чтобы позже получать к ней доступ.
Как узнать имя сервера базы данных MySQL?
Запустите классическое приложение Windows “Службы” на вашем компьютере и найдите в списке служб объект SQL Server. В скобках будет указано имя экземпляра. В этом же меню можно остановить, запустить и перезапустить экземпляр установленного Microsoft SQL Server.
Где находится SQL Server Management Studio?
На панели задач нажмите кнопку Пуск, выберите Все программы, Microsoft SQL Server SQL Server 2008, а затем щелкните SQL Server Management Studio.
Ограничения и индексы
Это единственные объекты в БД, где можно и даже рекомендовано использовать префиксы или суффиксы. Но, снова повторюсь, Вы должны выработать определённые правила с самого начала разработки, зафиксировать их, и придерживаться этих правил должны все и всегда.
В случае с ограничениями Вы можете придерживаться общепризнанных префиксов, которые используем в SQL Server:
PK_ — ограничение первичного ключа;
FK_ — ограничение внешнего ключа;
CK_ — проверочное ограничение;
UQ_ — ограничение, обеспечивающее уникальность значений;
DF_ — значение по умолчанию.
При этом само имя в любом случае должно четко отражать суть этого ограничения, так например, по имени ограничения DF_First_Column непонятно, что это за ограничение, а вот DF_Category уже более понятно имя, т.е. это значение по умолчанию для столбца Category. Иногда можно встретить и такое, что к этому имени ограничения могут добавлять еще и имя таблицы, например, DF_Goods_Category, но данный принцип лучше использовать для ограничения внешнего ключа, показывая тем самым название внешней таблицы, в случае со значением по умолчанию — это избыточно.
Кроме того, имя ограничения отображается в сообщении об ошибке, когда это ограничение нарушено. Поэтому понятное имя ограничения даст Вам нужную информацию для того, чтобы быстро диагностировать ошибку.
В индексах можно использовать префикс IX_ или суффикс _idx, это также общепринятые обозначения этого типа объектов в Microsoft SQL Server.
Syntax for creating a primary key constraint
Ok, now we have a better idea of why we need a primary key constraint. Let’s talk about how you would create one.
There are a few different ways we can create a primary key constraint when creating or modifying a table. We’ll go over each one.
1. Simply using the keywords “PRIMARY KEY” next to the column you want set to be the primary key.
This is the easiest way to set a primary key constraint on a specific column. Here’s an example of a Products table with a primary key constraint on the ProductID column:
CREATE TABLE Products ( ProductID INT PRIMARY KEY, ProductName VARCHAR(20), Price DECIMAL(5,2) )
Fairly straightforward, right?
When I run this statement, the Products table will be created and a primary key constraint will also be created. The constraint is actually named, and we can see it in the object explorer (seen in the Keys folder and not the Constraints folder):
When we begin adding rows to this table, we need to make sure this ProductID column is given a unique value for every insert. If we don’t, SQL Server won’t let us add the row!
I’ll demonstrate. Let’s add a row, specifying a ProductID of 1:
-- First Insert INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Coffee Table', 198.00)
Then let’s check the data:

So far so good. Now let’s try to add the exact same row a second time.





-- Second Insert INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Coffee Table', 198.00)
We get an error message:
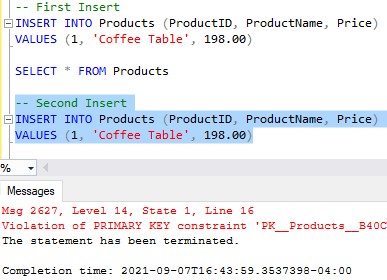
Here’s that full message:
Violation of PRIMARY KEY constraint ‘PK__Products__B40CC6EDAE880115’. Cannot insert duplicate key in object ‘dbo.Products’. The duplicate key value is (1).
Folks, this is exactly what the primary key constraint is there for. It’s there to basically force each row to be unique. I can’t enter a second row that contains exactly the same primary key value as an existing row!
But let’s try again with a different ProductID value:
-- Third Insert INSERT INTO Products (ProductID, ProductName, Price) VALUES (2, 'Coffee Table', 198.00)
Yep, that works:

All rows in this table are now unique, aren’t they? (say yes)
2. Specifying a constraint name
In the previous example, you might have noticed how the primary key constraint was given a very long name: PK__Products__B40CC6EDAE880115
While that name is fine if you don’t really care about the name of your constraint, there is another way to create the primary key constraint if you do care about the name.
Here is an example:
--Drop the old instance of Products DROP TABLE Products --Create new instance of Products table with Constraint name specified CREATE TABLE Products ( ProductID INT CONSTRAINT pk_Products PRIMARY KEY, ProductName VARCHAR(20), Price DECIMAL(5,2) )
Next to the column we want to use as the primary key, we outline the CONSTRAINT keyword, followed by whatever name we want to give the constraint, followed by the kind of constraint we want (in our case, a PRIMARY KEY constraint).
If we look at the constraint in object explorer, we see it was given the name!
3. Creating the primary key constraint after the column list
The final way we can create a SQL Server primary key constraint is by outlining the constraint after the column list, instead of directly next to the column we want to use as the primary key.
Here’s what it looks like:
--Drop old instance DROP TABLE Products --New instance CREATE TABLE Products ( ProductID INT, ProductName VARCHAR(20), Price DECIMAL(5,2), CONSTRAINT pk_Products PRIMARY KEY(ProductID) )
Notice it’s very similar to the previous example. We can still specify the name we want to give the constraint, which is great. But notice we needed to specify which column we wanted to set the constraint on.
This is how you would create what’s called a composite primary key (a primary key composed of multiple columns). For example, if we wanted to say our primary key was the combination of the ProductID and the ProductName, we could do that:
CREATE TABLE Products ( ProductID INT, ProductName VARCHAR(20), Price DECIMAL(5,2), CONSTRAINT pk_Products PRIMARY KEY(ProductID, ProductName) )
Easy peasy.
Об индексах и кучах
Как только таблица создана и в ней еще нет индексов, она выглядит как куча данных (Heap). В ней все записи хранятся хаотично, без определенного порядка. Потому их и называют «кучами».
Если в таблице необходимо найти определенные данные, sql server просканирует ее (Table scan). Пока в таблице не заданы индексы, поддерживающие ограничения (UNIQUE CONSTRAINT, UNIQUE INDEX или PRIMARY KEY), сервер прочитает все табличные записи (с первой до последней) и выберет те, которые удовлетворяют условиям поиска.
Это демонстрирует базовые функции indexes:
- повышение скорости поиска информации и производительности запросов;
- сохранение целостности данных через обеспечение уникальности строк таблицы.
Но не всегда индекс помогает ускорить поиск информации. Для таблиц небольших размеров обычный перебор данных может оказаться намного эффективнее выборки данных по индексам.
Indexes имеют и недостатки:
- требуется много места на дисковом пространстве и в оперативной памяти. Чем длиннее ключ, тем большего размера индекс и место для его хранения;
- замедляется производительность системы (медленнее выполняются операции вставок, обновления либо удаления записей).
Но современные методы их создания позволяют не только снижать негативный эффект для вышеперечисленных операций, но и увеличивать скорость выполнения.
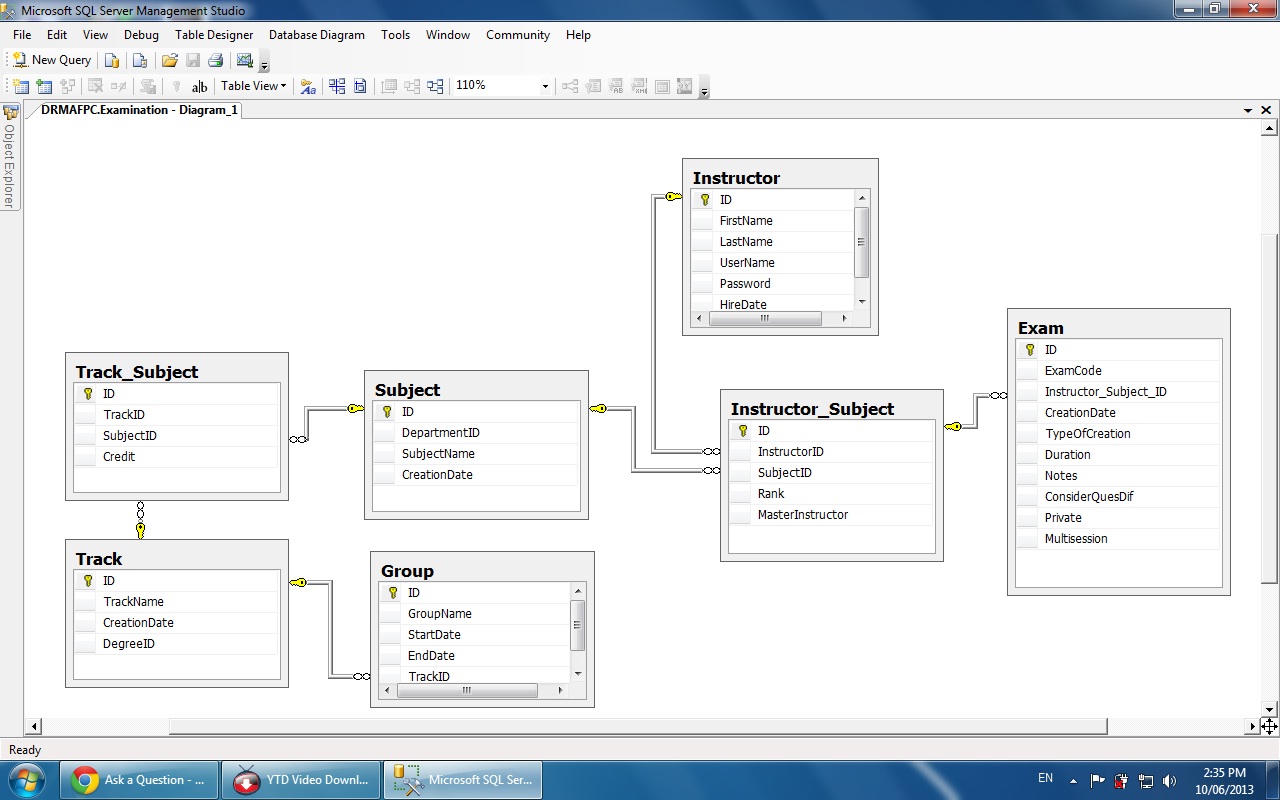
Ограничения внешнего ключа
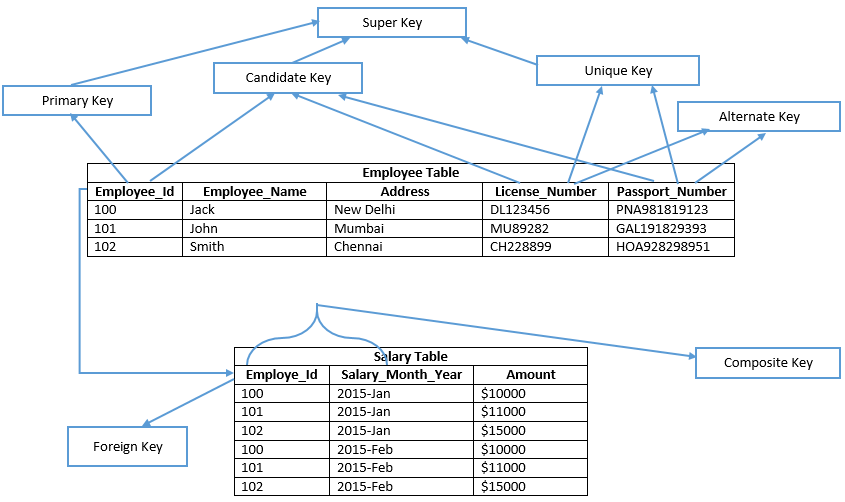
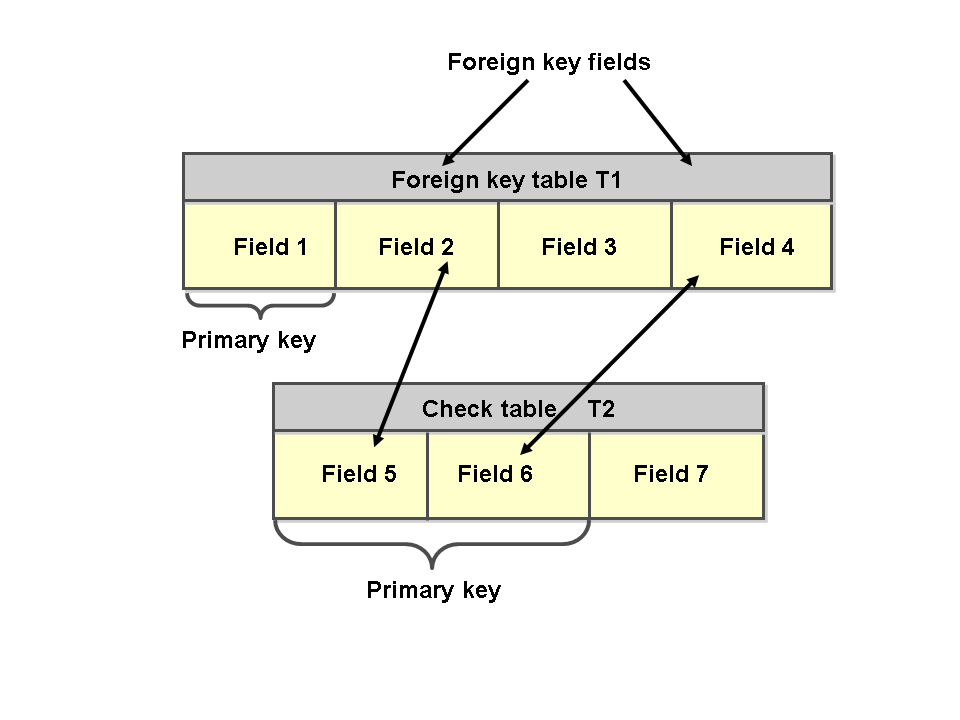
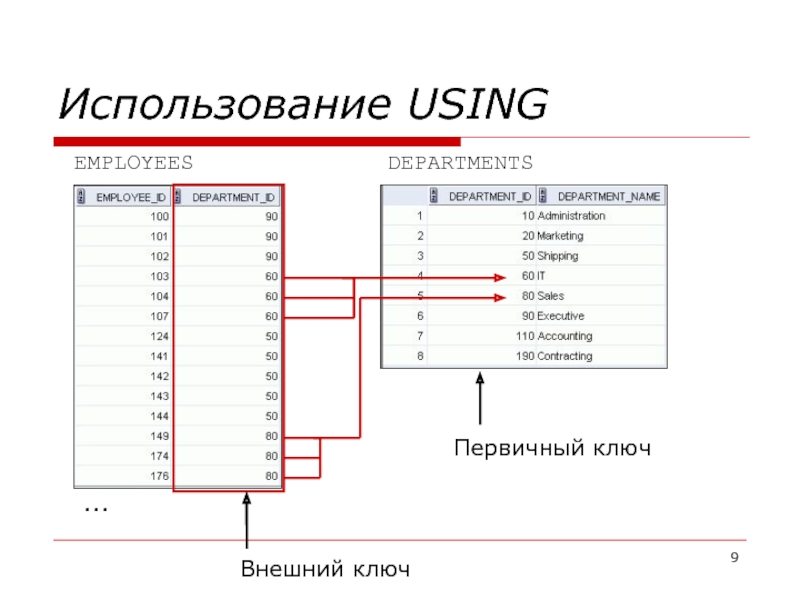
Внешний ключ (FK) — это столбец или сочетание столбцов, которое применяется для принудительного установления связи между данными в двух таблицах с целью контроля данных, которые могут храниться в таблице внешнего ключа. Если один или несколько столбцов, в которых находится первичный ключ для одной таблицы, упоминается в одном или нескольких столбцах другой таблицы, то в ссылке внешнего ключа создается связь между двумя таблицами. Этот столбец становится внешним ключом во второй таблице.
Например, таблица связана с таблицей с помощью внешнего ключа, так как существует логическая связь между заказами на продажу и менеджерами по продажам. Столбец в таблице соответствует столбцу первичного ключа таблицы . Столбец в таблице является внешним ключом таблицы . С помощью установления данной связи по внешнему ключу значение для не может быть вставлено в таблицу , если оно в настоящий момент не содержится в таблице .
Максимальное количество таблиц и столбцов, на которые может ссылаться таблица в качестве внешних ключей (исходящих ссылок), равно 253. SQL Server 2016 (13.x); увеличивает ограничение на количество других таблиц и столбцов, которые могут ссылаться на столбцы в одной таблице (входящие ссылки), с 253 до 10 000. (Требуется уровень совместимости не менее 130.) Увеличение имеет следующие ограничения:
Превышение 253 ссылок на внешние ключи поддерживается только для операций DML DELETE
Операции UPDATE и MERGE не поддерживаются.
Таблица со ссылкой внешнего ключа на саму себя по-прежнему ограничена 253 ссылками на внешние ключи.
Превышение 253 ссылок на внешние ключи в настоящее время недоступно для индексов columnstore, оптимизированных для памяти таблиц, базы данных Stretch или секционированных таблиц внешнего ключа.
Важно!
Службу Stretch Database не рекомендуется использовать в SQL Server 2022 (16.x). В будущей версии Microsoft SQL Server этот компонент будет удален
Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
There’s More to Learn About SQL’s Foreign Keys
In this article, we explained how foreign keys work in SQL and how to create them. We also showed some SQL codes for foreign key creation. And we explored some possible errors we can get when working with foreign keys.
One kind of foreign key we didn’t cover are those that point to their own table. For example, we could have an table with the columns and , where is the primary key and is the foreign key.
Finally, I would like to suggest the LearnSQL track Create Database Structure, which includes a section on primary and foreign key constraints in a database. It’s a good place to practice the new concepts we’ve talked about.
Копирование числовых ячеек из 1С в Excel Промо
Решение проблемы, когда значения скопированных ячеек из табличных документов 1С в Excel воспринимаются последним как текст, т.е. без дополнительного форматирования значений невозможно применить арифметические операции. Поводом для публикации послужило понимание того, что целое предприятие с более сотней активных пользователей уже на протяжении года мучилось с такой, казалось бы на первый взгляд, тривиальной проблемой. Варианты решения, предложенные специалистами helpdesk, обслуживающими данное предприятие, а так же многочисленные обсуждения на форумах, только подтвердили убеждение в необходимости описания способа, который позволил мне качественно и быстро справиться с ситуацией.
33
Представления, относящиеся к ограничениям и индексам
Как определить, какие ограничения существуют на столбцах таблицы? Когда процесс завершается неудачей с сообщением о нарушении ссылочного ограничения целостности, как лучше всего определить, какого ограничения и какой таблицы это касается? Для решения подобных проблем необходимы представления словаря данных, относящиеся к ограничениям и индексам. Далее подробно рассматриваются ключевые ограничения такого рода.
DBA_CONSTRAINTS
Представление DBA_CONSTRAINTS предоставляет информацию обо всех типах ограничений таблицы в базе данных. Опрос этого представления делается, когда необходимо узнать, какого типа ограничения имеет таблица. Представление перечисляет несколько типов ограничений, как показано в следующем запросе:
SQL> SELECT DISTINCT constraint_type FROM DBA_CONSTRAINTS;
Constraint_type
--------------------
C /* check constraints */
/* ограничения проверки */
P /* primary key constraint */
/* ограничение первичного ключа */
R /* referential integrity (foreign key) constraint */
/* ограничение ссылочной целостности (внешний ключ) */
U /* unique key constraint */
/* ограничение уникального ключа */
SQL>
Следующий запрос позволит узнать, какие ограничения установлены для таблицы TESTD. Ответ на запрос показывает, что таблица имеет единственное ограничение CHECK. Префикс SYS в столбце NAME отражает тот факт, что CONSTRAINT_NAME — имя по умолчанию, а не явно указанное владельцем таблицы.
SQL> SELECT constraint_name, constraint_type 2 FROM DBA_CONSTRAINTS 3* WHHERE table_name='TESTD'; CONSTRAINT_NAME CONSTRAINT_TYPE ------------------- --------------- SYS_C005263 C SQL>
Обратите внимание, что если необходимо увидеть определенное ссылочное ограничение и правило удаления, то нужно применить следующую вариацию предыдущего запроса:
SQL> SELECT constraint_name, constraint_type, R_constraint_name, delete_rule FROM dba_constraints WHERE table_name='ORDERS'; CONSTRAINT_NAME TYPE R_CONSTRAINT_NAME DELETE_RULE ---------------------- ------ ----------------- ----------- ORDER_DATE_NN C ORDER_CUSTOMER_ID_NN C ORDER_MODE_LOV C ORDER_TOTAL_MIN C ORDER_PK P ORDERS_SALES_REP_FK R EMP_EMP_ID_PK SET NULL ORDERS_CUSTOMER_ID_FK R CUSTOMERS_PK SET NULL 7 rows selected. SQL>
DBA_CONS_COLUMNS
Представление DBA_CONS_COLUMNS показывает имя столбца и позицию в таблице,где определено ограничение:
SQL> DESC DBA_CONS_COLUMNS Name ---------------- OWNER CONSTRAINT_NAME TABLE_NAME COLUMN_NAME POSITION SQL>
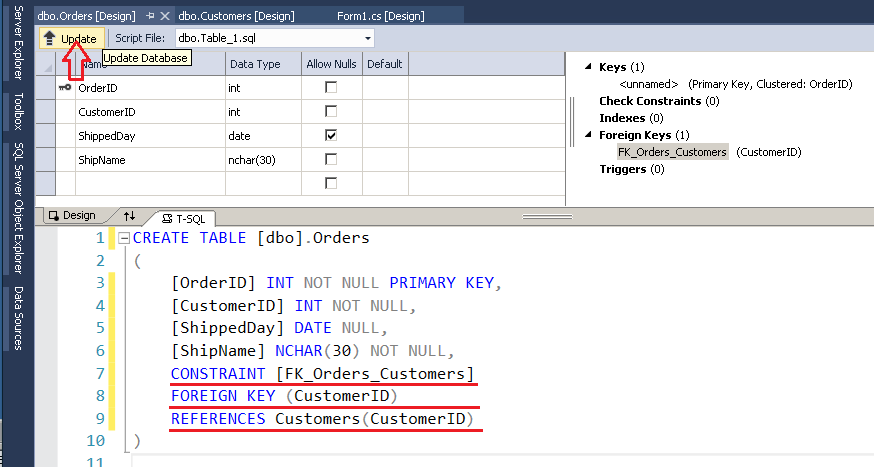
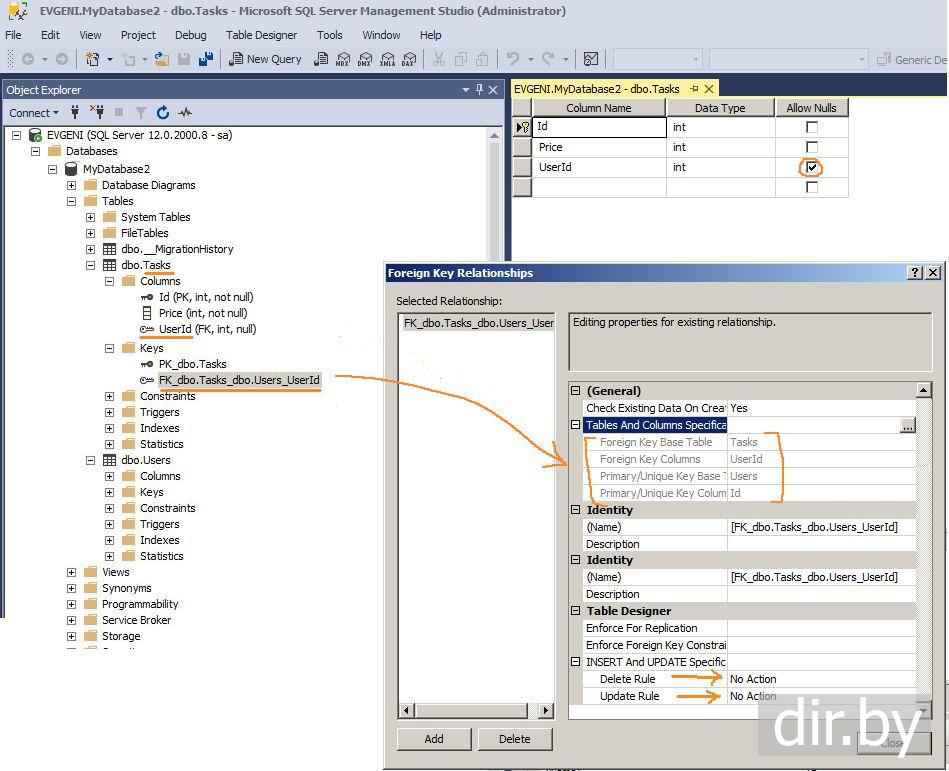
Создание внешнего ключа — использование оператора ALTER TABLE
Синтаксис
Синтаксис создания внешнего ключа с использованием оператора ALTER TABLE в SQL Server (Transact-SQL):
ALTER TABLE child_table
ADD CONSTRAINT fk_name
FOREIGN KEY (child_col1, child_col2, … child_col_n)
REFERENCES parent_table (parent_col1, parent_col2, … parent_col_n);
child_table — имя дочерней таблицы, которую вы хотите изменить.fk_name — имя ограничения внешнего ключа, которое вы хотите создать.child_col1, child_col2, … child_col_n — столбцы в child_table, которые будут ссылаться на первичный ключ в parent_table (родительской таблице).parent_table — имя родительской таблицы, первичный ключ которой будет использоваться в child_table.parent_col1, parent_col2, … parent_col3 — столбцы, которые составляют первичный ключ в родительской таблице. Внешний ключ будет обеспечивать связь между этими данными и столбцами child_col1, child_col2, … child_col_n в child_table.
Why do table names in SQL Server start with «dbo»?
At least on my local instance, when I create tables, they are all prefixed with «dbo.». Why is that?








6 Answers 6
dbo is the default schema in SQL Server. You can create your own schemas to allow you to better manage your object namespace.
If you are using Sql Server Management Studio, you can create your own schema by browsing to Databases — Your Database — Security — Schemas.
To create one using a script is as easy as (for example):
You can use them to logically group your tables, for example by creating a schema for «Financial» information and another for «Personal» data. Your tables would then display as:
Financial.BankAccounts Financial.Transactions Personal.Address
Rather than using the default schema of dbo.

It’s new to SQL 2005 and offers a simplified way to group objects, especially for the purpose of securing the objects in that «group».
The following link offers a more in depth explanation as to what it is, why we would use it:

Microsoft introduced schema in version 2005. For those who didn’t know about schema, and those who didn’t care, objects were put into a default schema dbo .
dbo stands for DataBase Owner, but that’s not really important.
Think of a schema as you would a folder for files:
- You don’t need to refer to the schema if the object is in the same or default schema
- You can reference an object in a different schema by using the schema as a prefix, the way you can reference a file in a different folder.
- You can’t have two objects with the same name in a single schema, but you can in different schema
- Using schema can help you to organise a larger number of objects
- Schema can also be assigned to particular users and roles, so you can control access to who can do what.
You can generally access any object from any schema. However, it is possible to control which users have which access to particular schema, so you can use schema in your security model.
Because dbo is the default, you normally don’t need to specify it within a single database:
mean the same thing.
I am inclined to disagree with the notion of always using the dbo. prefix, since the more you clutter your code with unnecessary detail, the harder it is to read and manage.
For the most part, you can ignore the schema. However, the schema will make itself apparent in the following situations:
If you view the tables in either the object navigator or in an external application, such as Microsoft Excel or Access, you will see the dbo. prefix. You can still ignore it.
If you reference a table in another database, you will need its full name in the form database.schema.table :
For historical reasons, if you write a user defined scalar function, you will need to call it with the schema prefix:
This does not apply to other objects, such as table functions, procedures and views.
You can use schema to overcome naming conflicts. For example, if every user has a personal schema, they can create additional objects without having to fight with other users over the name.
Новое в T-SQL
Язык T-SQL также получил несколько новых функций, как больших, так и мелких. Рассмотрим лишь некоторые из них.
JSON — популярный формат текстовых данных для хранения неструктурированных данных и для обмена информацией в REST веб-службах. Некоторые сервисы Azure также используют JSON. До версии 2016 все задачи обработки JSON ложились на плечи разработчика, теперь разбор и хранение, импорт и экспорт данных, преобразование и форматирование запросов обеспечивает сам движок. Приложения и инструменты не видят разницы между значениями, взятыми из скалярных столбцов таблицы, и значениями, взятыми из столбцов в формате JSON.
Можно использовать значения из JSON-текста в любой части T-SQL-запроса (включая пункты WHERE, ORDER BY, GROUP BY). Отдельного типа данных не предусмотрено, для хранения используются стандартные varchar или nvarchar. Для работы с JSON реализовано несколько новых функций:
- ISJSON — проверка, является ли строка JSON;
- JSON_VALUE — извлечение скалярного значения;
- JSON_QUERY — извлечение объекта или массива;
- JSON_MODIFY — изменение части JSON-текста.
Функция OPENJSON преобразует массив JSON-объектов в таблицу, пригодную для импорта JSON-данных в SQL Server, в которой каждый объект представлен в виде одной строки, а пара ключ/значение возвращается в виде ячеек. Чтобы из реляционных данных сгенерировать JSON, следует использовать функцию , поддерживающую два варианта форматирования и . Дополнительная опция создает JSON без квадратных скобок. По умолчанию параметры, имеющие значение NULL, не будут включены в вывод. Если они нужны, следует в вызове FOR JSON использовать параметр .
При тестировании, да и в работе очень часто приходится многократно удалять и создавать объекты в базе данных. Чтобы скрипт отработал нормально, приходится проверять наличие/отсутствие объекта. До SQL 2016 эта процедура была полностью на разработчике:
Новая функция теперь позволяет очень просто проверить наличие объекта и упрощает написание кода:
поддерживается практически для всех объектов (баз данных, процедур, таблиц, индексов).
Две функции и обеспечивают встроенную поддержку Gzip. На входе они могут принимать несколько типов данных, на выходе .
В добавили возможность работы с отдельными секциями, а не только над всей таблицей. В можно использовать произвольную маску. Новая опция для позволит добавлять и удалять столбцы в режиме онлайн. При этом данные останутся доступны для чтения, а блокировка будет в конце операции. Процедура позволяет выполнять сценарии в SQL Server на другом языке. В настоящее время поддерживается только R.
Инструкция REVOKE
Инструкция REVOKE удаляет предоставленное или запрещенное ранее разрешение. Эта инструкция имеет следующий синтаксис:
Соглашения по синтаксису
Единственным новым параметром инструкции REVOKE является параметр GRANT OPTION FOR. Все другие параметры этой инструкции имеют точно такое же логическое значение, как и одноименные параметры инструкций GRANT или DENY. Параметр GRANT OPTION FOR используется для отмены эффекта предложения WITH GRANT OPTION в соответствующей инструкции GRANT. Это означает, что пользователь все еще будет иметь предоставленные ранее разрешения, но больше не сможет предоставлять их другим пользователям.
Инструкция REVOKE отменяет как «позитивные» разрешения, предоставленные инструкцией GRANT, так и «негативные» разрешения, предоставленные инструкцией DENY. Таким образом, его функцией является нейтрализация указанных ранее разрешений (позитивных и негативных).
Использование инструкции REVOKE показано в примере ниже:
Инструкция REVOKE в этом примере отменяет предоставленное разрешение выборки данных для роли public. При этом существующее запрещение разрешения этой инструкции для пользователя Vasya не удаляется, поскольку разрешения, предоставленные или запрещенные явно членам группы (или роли), не затрагиваются удалением этих разрешений (положительных или отрицательных) для данной группы.
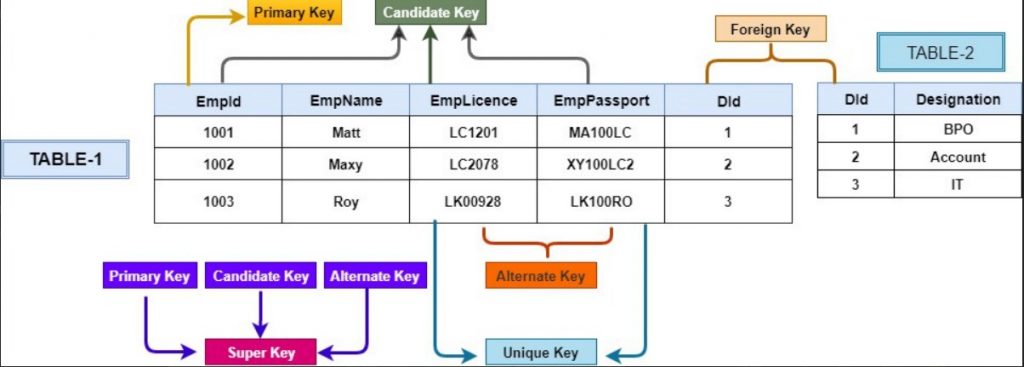
Ограничения первичного ключа
Обычно в таблице есть столбец или сочетание столбцов, содержащих значения, уникально определяющие каждую строку таблицы. Этот столбец, или столбцы, называются первичным ключом (PK) таблицы и обеспечивает целостность сущности таблицы. Ограничения первичного ключа часто определяются в столбце идентификаторов, поскольку гарантируют уникальность данных.
При задании ограничения первичного ключа для таблицы компонента Компонент Database Engine гарантирует уникальность данных путем автоматического создания уникального индекса для первичных ключевых столбцов. Этот индекс также обеспечивает быстрый доступ к данным при использовании первичного ключа в запросах. Если ограничение первичного ключа задано более чем для одного столбца, то значения могут дублироваться в пределах одного столбца, но каждое сочетание значений всех столбцов в определении ограничения первичного ключа должно быть уникальным.
Как показано на следующем рисунке, столбцы и в таблице формируют составное ограничение первичного ключа для этой таблицы. При этом гарантируется, что каждая строка в таблице имеет уникальное сочетание значений и . Это предотвращает вставку повторяющихся строк.
-
В таблице возможно наличие только одного ограничения по первичному ключу.
-
Первичный ключ не может включать больше 16 столбцов, а общая длина ключа не может превышать 900 байт.
-
Индекс, формируемый ограничением первичного ключа, не может повлечь за собой выход количества индексов в таблице за пределы в 999 некластеризованных индексов и 1 кластеризованный.
-
Если для ограничения первичного ключа не указано, является ли индекс кластеризованным или некластеризованным, то создается кластеризованный индекс, если таковой отсутствует в таблице.
-
Все столбцы с ограничением первичного ключа должны быть определены как не допускающие значения NULL. Если допустимость значения NULL не указана, то все столбцы c ограничением первичного ключа устанавливаются как не допускающие значения NULL.
-
-
Если первичный ключ определен на столбце определяемого пользователем типа данных CLR, реализация этого типа должна поддерживать двоичную сортировку.



SQL PRIMARY KEY Constraint
The PRIMARY KEY constraint consists of one column or multiple columns with values that uniquely identify each row in the table.
The SQL PRIMARY KEY constraint combines between the UNIQUE and SQL NOT NULL constraints, where the column or set of columns that are participating in the PRIMARY KEY cannot accept a NULL value. If the PRIMARY KEY is defined in multiple columns, you can insert duplicate values on each column individually, but the combination values of all PRIMARY KEY columns must be unique. Take into consideration that you can define only one PRIMARY KEY per each table, and it is recommended to use small or INT columns in the PRIMARY KEY.
In addition to providing fast access to the table data, the index that is automatically created, when defining the SQL PRIMARY KEY, will enforce the data uniqueness. The PRIMARY KEY is used mainly to enforce the entity integrity of the table. Entity integrity ensures that each row in the table is a uniquely identifiable entity.
PRIMARY KEY constraint differs from the UNIQUE constraint in that; you can create multiple UNIQUE constraints in a table, with the ability to define only one SQL PRIMARY KEY per each table. Another difference is that the UNIQUE constraint allows for one NULL value, but the PRIMARY KEY does not allow NULL values.
Assume that we have the below simple table with two columns; the ID and Name. The ID column is defined as a PRIMARY KEY for that table, that is used to identify each row on that table by ensuring that no NULL or duplicate values will be inserted to that ID column. The table is defined using the CREATE TABLE T-SQL script below:
|
1 |
USESQLShackDemo GO CREATE TABLE ConstraintDemo3 ( ID INTPRIMARY KEY, Name VARCHAR(50)NULL ) |
If you try to run the three INSERT statements below:
|
1 |
INSERT INTO ConstraintDemo3(ID,NAME)VALUES(1,’John’) GO INSERT INTO ConstraintDemo3(NAME)VALUES(‘Fadi’) GO INSERT INTO ConstraintDemo3(ID,NAME)VALUES(1,’Saeed’) GO |
You will see that the first record will be inserted successfully as both the ID and Name values are valid. The second insert operation will fail, as the ID column is mandatory and cannot be NULL, as the ID column is the SQL PRIMARY KEY. The last INSERT statement will fail too as the provided ID value already exists and the duplicate values are not allowed in the PRIMARY KEY, as shown in the error message below:
Checking the inserted values, you will see that only the first record is inserted successfully as below:
If you do not provide the SQL PRIMARY KEY constraint with a name during the table definition, the SQL Server Engine will provide it with a unique name as you can see from querying the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system object below:
|
1 |
SELECT CONSTRAINT_NAME, TABLE_SCHEMA, TABLE_NAME, CONSTRAINT_TYPE FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE TABLE_NAME=’ConstraintDemo3′
|
With the below result in our example:

The ALTER TABLE…DROP CONSTRAINT T-SQL statement can be used easily to drop the previously defined PRIMARY KEY using the name derived from the previous result:
|
1 |
ALTER TABLE ConstraintDemo3 DROP CONSTRAINT PK__Constrai__3214EC27E0BEB1C4;
|
If you try to execute the previously failed two INSERT statements, you will see that the first record will not be inserted as the ID column does not allow NULL values. The second record will be inserted successfully as these is nothing prevent the duplicate values from being inserted after dropping the SQL PRIMARY KEY, as shown below:

Trying to add the SQL PRIMARY KEY constraint again using the ALTER TABLE T-SQL query below:
|
1 |
ALTER TABLE ConstraintDemo3 ADD PRIMARY KEY(ID);
|
The operation will fail, as while checking the existing ID values first for any NULL or duplicate values, SQL Server finds a duplicate ID value of 1 as shown in the error message below:

Checking the table’s data will show you also the duplicate value:
In order to add the PRIMARY KEY constraint, we should clear the data first, by deleting or modifying the duplicate record. Here we will change the second record ID value using the UPDATE statement below:
|
1 |
UPDATE ConstraintDemo3 SET ID=2WHERE NAME=’Saeed’
|
Then trying to add the SQL PRIMARY KEY, which will be created successfully now:
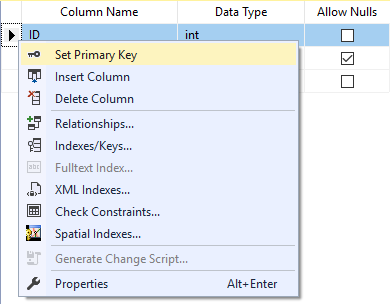
The SQL PRIMARY KEY constraint can be also defined and modified using SQL Server Management Studio. Right-click on your table and choose Design. From the Design window, right-click on the column or set of columns that will participate in the PRIMARY KEY constraint and Set PRIMARY KEY option, that will automatically uncheck the Allow NULLs checkbox, as shown below:
Please check the next article in the series Commonly used SQL Server Constraints: FOREIGN KEY, CHECK and DEFAULT that describes other three SQL Server constraints.