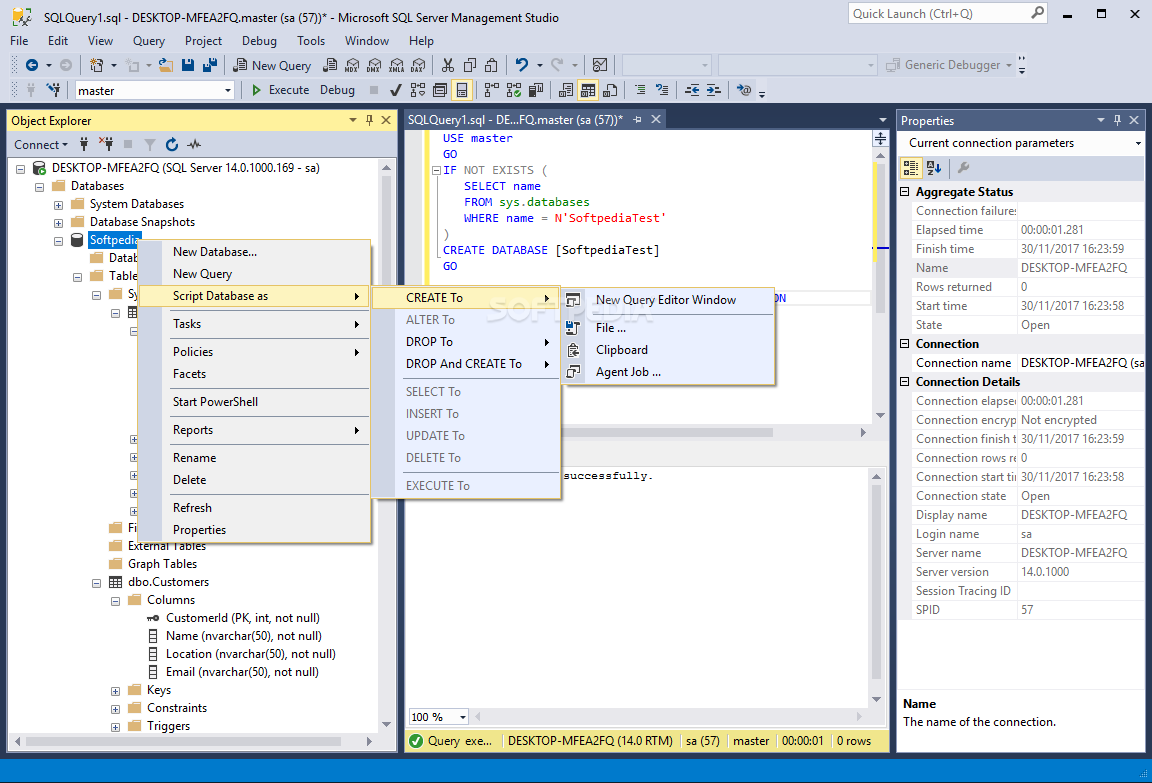
Какие СУБД бывают
На самом деле, существует достаточно много различных СУБД, некоторые из них платные и стоят немалых денег, если говорить о полнофункциональных версиях, но даже у самых, так скажем, «крутых» есть бесплатные редакции, которые, кстати, отлично подходят для обучения.
- Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях. И это не просто СУБД – это целый комплекс приложений, позволяющий хранить и модифицировать данные, анализировать их, осуществлять безопасность этих данных и многое другое;
- Oracle Database – это система управления базами данных от компании Oracle. Это также очень популярная СУБД, и также среди крупных компаний. По своим возможностям и функциональности Oracle Database и Microsoft SQL Server сопоставимы, поэтому являются серьезными конкурентами друг другу, и стоимость их полнофункциональных версий очень высока;
- MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила очень широкую популярность в интернет сегменте, т.е. именно на MySQL работают чуть ли не все сайты в интернете, иными словами, большинство сайтов в интернете используют эту СУБД как средство хранения данных;
- PostgreSQL – эта система управления базами данных также является бесплатной, и она очень популярна и функциональна.
Функции LOWER и UPPER
LOWER(<строковое выражение>)
UPPER(<строковое выражение>)
преобразуют все символы аргумента соответственно к нижнему и верхнему регистру. Эти функции оказываются полезными при сравнении регистрозависимых строк.
Пара интересных функций SOUNDEX и DIFFERENCE:
SOUNDEX(<строковое выражение>)
DIFFERENCE (<строковое выражение_1>, <строковое выражение_2>)
Позволяют определить близость звучания слов. При этом SOUNDEX возвращает четырехсимвольный код, используемый для сравнения, а DIFFERENCE собственно и оценивает близость звучания двух сравниваемых строковых выражений. Поскольку эти функции не поддерживают кириллицы, отсылаю интересующихся к BOL за примерами их использования.
В заключение приведем функции и несколько примеров использования юникода.
Индексы
Это объект базы данных, который повышает производительность поиска данных, за счет сортировки данных по определенному полю. Если провести аналогию то, например, искать определенную информацию в книге намного легче и быстрей по его оглавлению, чем, если бы этого оглавления не было. В СУБД MS SQL Server существует следующие типы индексов:
Кластеризованный индекс — при таком индексе строки в таблице сортируются с заданным ключом, т.е. указанным полем. Данный тип индексов у таблицы в MS SQL сервере может быть только один и, начиная с MS SQL 2000, он автоматически создается при указании в таблице первичного ключа (PRIMARY KEY).
Некластеризованный индекс – при использовании такого типа индексов в индексе содержатся отсортированные по указанному полю указатели строк, а не сами строки, за счет чего происходит быстрый поиск необходимой строки. Таких индексов у таблицы может быть несколько.
Колоночный индекс (columnstore index) – данный тип индексов основан на технологии хранения данных таблиц не виде строк, а виде столбцов (отсюда и название), у таблицы может быть один columnstore индекс.
При использовании такого типа индексов таблица сразу становится только для чтения, другими словами, добавить или изменить данные в таблице уже будет нельзя, для этого придется отключать индекс, добавлять/изменять данные, затем включать индекс обратно.
Такие индексы подходят для очень большого набора данных, используемых в хранилищах.
Операции, в которых используются агрегатные функции с использованием группировки, выполняются намного быстрей (в несколько раз!) при наличии такого индекса.
Columnstore index доступен начиная с 2012 версии SQL сервера в редакциях Enterprise, Developer и Evaluation.
Создание
Кластеризованного индекса
CREATE CLUSTERED INDEX idx_clus_one
ON test_table(id)
GO
Где, CREATE CLUSTERED INDEX — это инструкция к созданию кластеризованного индекса, idx_clus_one название индекса, test_table(id) соответственно таблица и ключевое поле для сортировки.
Некластеризованного индекса
CREATE INDEX idx_no_clus
ON test_table(summa)
GO
Columnstore index
CREATE columnstore INDEX idx_columnstore
ON test_table(date_create)
GO
Отключение
--отключение ALTER INDEX idx_no_clus ON test_table DISABLE --включение, перестроение ALTER INDEX idx_no_clus ON test_table REBUILD
USE HINT и новые указания запросов в SQL Server 2016 SP1
Published on 01.02.2017 by Dmitry Pilugin
in SQL Server (все заметки), оптимизатор
«Query Hints» в документации переводится как «указания запросов», кто-то называет их «подсказками», но чаще говорят просто «хинты». Я буду использовать в заметке именно последнее выражение, т.к. оно более распространено в повседневной жизни и сразу дает понять, о чем идет речь. Эта публикация — введение, она открывает цикл заметок по новым хинтам, которые появились в SQL Server 2016 SP1.
Существуют разные мнения по поводу использования хинтов в запросах от «никогда их не используйте» до «если что-то работает плохо, все решается хинтом».
Я придерживаюсь мнения, что хинт – это прежде всего инструмент, и, если его использовать к месту, то он может быть полезен, если же использовать его бездумно, то может навредить. В своей практике я прибегаю к хинтам при соблюдении двух условий. Первое – мне полностью понятна причина плохого плана, второе – других способов устранить эту причину нет.
Кроме того, важно помнить, что хинты, в плане ограничения свободы оптимизатора, бывают более жесткие и менее жесткие. По возможности, лучше использовать менее жесткие
Например, для ограничения типов соединений, лучше использовать хинт запроса, чем хинт в соединении, т.к. последний ограничивает еще и порядок соединений.
Хинтов запроса существует довольно много, но мы остановимся на тех, что появились в SQL Server 2016 SP1, и которые можно использовать при помощи ключевого слова USE HINT. Они могут быть получены при помощи нового представления sys.dm_exec_valid_use_hints. Ниже приведена таблица доступных хинтов с кратким описанием.
| Hint | Описание | TF |
| DISABLE_OPTIMIZED_NESTED_LOOP | Отключает оптимизацию batch sort в соединении вложенными циклами | 2340* |
| FORCE_LEGACY_CARDINALITY_ESTIMATION | Включает «старый» механизм оценки (версия 70, применялся до SQL Server 2014) | 9481 |
| ENABLE_QUERY_OPTIMIZER_HOTFIXES | Включить исправления оптимизатора | 4199 |
| DISABLE_PARAMETER_SNIFFING | Отключить прослушивание параметров | 4136 |
| ASSUME_MIN_SELECTIVITY_FOR_FILTER_ESTIMATES | При оценке комплексных предикатов использовать предположение минимальной селективности | 4137 (<2014) 9471 (>=2014) |
| ASSUME_JOIN_PREDICATE_DEPENDS_ON_FILTERS | Включает зависимость селективности соединения от предикатов по таблицам | 9476 |
| ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS | Включить автоматическое дополнение гистограммы статистики при оценке предиката по колонке, вне зависимости возрастания/убывания ее значений | 4139 |
| DISABLE_OPTIMIZER_ROWGOAL | Отключить механизм учета целевого числа строк при построении плана запроса | 4138 |
| FORCE_DEFAULT_CARDINALITY_ESTIMATION | Установить версию модели оценки, соответствующую уровню совместимости БД |
Чтобы применить хинт к запросу, необходимо в предложении OPTION указать ключевое слово USE HINT и в скобках перечислить один или несколько хинтов, например:
select name from sys.all_columns option( use hint( 'FORCE_LEGACY_CARDINALITY_ESTIMATION', 'ENABLE_QUERY_OPTIMIZER_HOTFIXES' ) );
Многое из того что позволяют делать хинты USE HINT было ранее доступно при помощи флагов трассировки, они перечислены в последнем столбце таблицы. Минус подходов с флагами это – слабая самодокументированность (нужно помнить, какой номер флага за что отвечает), и необходимость привилегий SA, и, хотя для последнего есть обходной путь, это не очень удобно.
Из краткого описания в документации может быть трудно понять, на что влияют эти хинты, поэтому, в дальнейших заметках, мы разберем что означает каждый из них и как он влияет на план запроса.
В следующей заметке, мы поговорим про хинт DISABLE_OPTIMIZED_NESTED_LOOP.
Примеры полнотекстовых запросов
Более подробно полнотекстовые запросы мы будем рассматривать в отдельном материале, а пока, в качестве примера и подтверждения того, что наш полнотекстовый поиск работает, давайте напишем пару простых полнотекстовых запросов.
Если помните, наша таблица TestTable содержит определения технологий, языков программирования, в общем, определений, связанных со сферой IT. Допустим, что мы хотим получить все записи, где есть упоминание о компании Microsoft, для этого мы пишем полнотекстовый запрос с ключевым словом CONTAINS, например
Мы получили результат, но допустим, нам также необходимо отсортировать его по релевантности, другими словами, какие строки больше соответствуют нашему запросу. Для этого мы будем использовать функцию CONTAINSTABLE, которая проставляет ранг для каждой найденной записи.
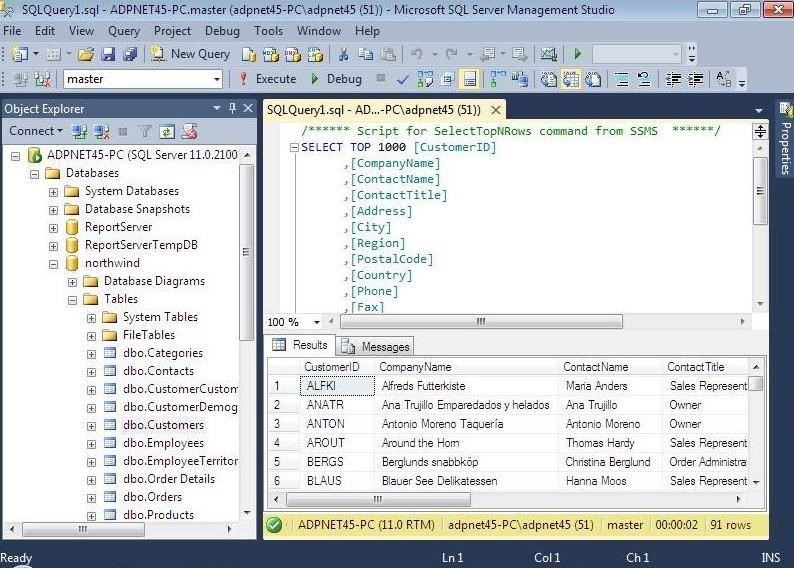
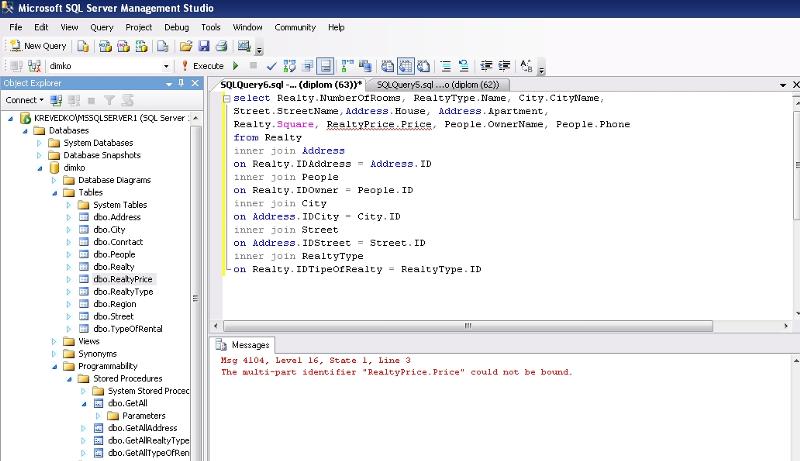
Как видим, ранг проставлен и по нему отсортированы строки. Сам алгоритм ранжирования, как и более подробную информацию о полнотекстовом поиске, можно найти в электронной документации по SQL Server.
Что такое DDL, DML, DCL и TCL в языке SQL
Приветствую всех посетителей сайта Info-Comp.ru! В этом материале я расскажу Вам о том, что такое DDL, DML, DCL и TCL в языке SQL. Если Вы не знаете, что означают эти непонятные наборы букв и при этом работаете с языком SQL, то Вам обязательно необходимо прочитать данный материал.

Для начала давайте вспомним, что такое SQL, и для чего он нужен.
SQL – Structured Query Language
Structured Query Language (SQL) — язык структурированных запросов, с помощью него пишутся специальные запросы (SQL инструкции) к базе данных с целью получения этих данных из базы и для манипулирования этими данными.
Иными словами, язык SQL нужен для работы с базами данных, более подробно о языке SQL можете почитать в отдельной моей статье – Что такое SQL. Назначение и основа.
С точки зрения реализации язык SQL представляет собой набор операторов, которые делятся на определенные группы и у каждой группы есть свое назначение. В сокращенном виде эти группы называются DDL, DML, DCL и TCL.
Таким образом, эти непонятные буквы представляют собой аббревиатуру названий групп операторов языка SQL.
DDL – Data Definition Language
Data Definition Language (DDL) – это группа операторов определения данных. Другими словами, с помощью операторов, входящих в эту группы, мы определяем структуру базы данных и работаем с объектами этой базы, т.е. создаем, изменяем и удаляем их.
В эту группу входят следующие операторы:
- CREATE – используется для создания объектов базы данных;
- ALTER – используется для изменения объектов базы данных;
- DROP – используется для удаления объектов базы данных.
DML – Data Manipulation Language
Data Manipulation Language (DML) – это группа операторов для манипуляции данными. С помощью этих операторов мы можем добавлять, изменять, удалять и выгружать данные из базы, т.е. манипулировать ими.
В эту группу входят самые распространённые операторы языка SQL:
- SELECT – осуществляет выборку данных;
- INSERT – добавляет новые данные;
- UPDATE – изменяет существующие данные;
- DELETE – удаляет данные.
DCL – Data Control Language
Data Control Language (DCL) – группа операторов определения доступа к данным. Иными словами, это операторы для управления разрешениями, с помощью них мы можем разрешать или запрещать выполнение определенных операций над объектами базы данных.
- GRANT – предоставляет пользователю или группе разрешения на определённые операции с объектом;
- REVOKE – отзывает выданные разрешения;
- DENY– задаёт запрет, имеющий приоритет над разрешением.
TCL – Transaction Control Language
Transaction Control Language (TCL) – группа операторов для управления транзакциями. Транзакция – это команда или блок команд (инструкций), которые успешно завершаются как единое целое, при этом в базе данных все внесенные изменения фиксируются на постоянной основе или отменяются, т.е. все изменения, внесенные любой командой, входящей в транзакцию, будут отменены.
Группа операторов TCL предназначена как раз для реализации и управления транзакциями. Сюда можно отнести:
- BEGIN TRANSACTION – служит для определения начала транзакции;
- COMMIT TRANSACTION – применяет транзакцию;
- ROLLBACK TRANSACTION – откатывает все изменения, сделанные в контексте текущей транзакции;
- SAVE TRANSACTION – устанавливает промежуточную точку сохранения внутри транзакции.
Создание динамического SQL в хранимой процедуре
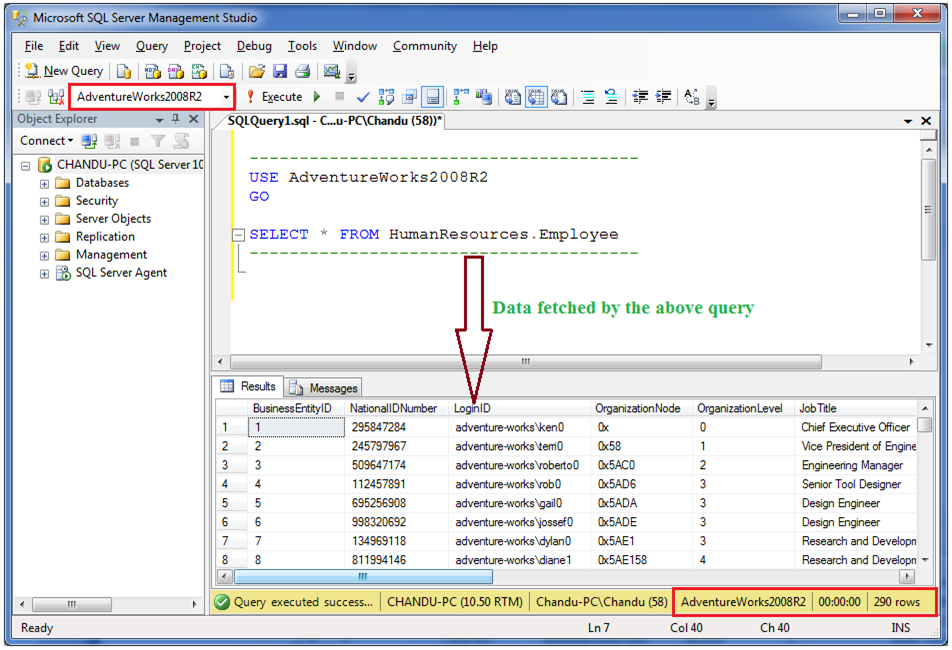
Большинство SQL, которые мы пишем, записываются непосредственно в хранимую процедуру. Это то, что называется статическим SQL. Он называется так потому, что он не меняется. Как только он записан, его значение задано и не подлежит изменению.Ниже приведен пример статического SQL:
SELECT JobTitle, Count(BusinessEntityID)
FROM HumanResources.Employee
WHERE Year(BirthDate) = 1970
GROUP BY JobTitle
SELECT JobTitle, Count(BusinessEntityID)
FROM HumanResources.Employee
WHERE Year(BirthDate) = 1971
GROUP BY JobTitle
Обратите внимание, что есть две инструкции, каждая из которых возвращает резюме JobTitles для конкретного года рождения сотрудника. Если мы хотим добавить больше лет рождения, нам нужно добавить больше инструкций
Что нужно сделать, чтобы написать инструкцию единожды и изменять год на лету?
Именно здесь вступает в игру динамический SQL.
Динамический SQL — это SQL, который создается и выполняется во время исполнения. Это звучит сложно, но на самом деле это не так. Вместо того чтобы иметь инструкции, введенные непосредственно в хранимую процедуру, инструкции SQL сначала выстраиваются и определяются в переменных.
Затем в этих переменных выполняется код. Продолжая наш пример, вот тот же код с использованием динамического SQL:
DECLARE @birthYear int = 1970
DECLARE @statement NVARCHAR(4000)
WHILE @birthYear <= 1971
BEGIN
SET @statement = ‘
SELECT JobTitle, Count(BusinessEntityID)
FROM HumanResources.Employee
WHERE Year(BirthDate) = ‘ + CAST(@birthYear as NVARCHAR) +
‘ GROUP BY JobTitle’
EXECUTE sp_executesql @statement
SET @birthYear = @birthYear + 1
END
Динамический SQL выделен жирным шрифтом. Это SQL, который построен для каждого @birthYear. По мере создания SQL он сохраняется в @statement. Затем он выполняется с использованием sp_executesql, который мы объясним ниже.

Распространенные ошибки при выборе типа данных в T-SQL
В начале статьи я говорил, что выбор неоптимального типа данных может сказаться на размере базы данных, так вот одной из самых распространенных ошибок при проектировании таблицы является выбор для столбца, который должен содержать тип данных Boolean (т.е. 0 или 1), тип SMALLINT или INT. Как Вы уже поняли, такого типа данных как Boolean в T-SQL нет, поэтому для этих целей разработчики используют похожие (подходящие) типы данных и в большинстве случаев их выбор неправильный. Если Вам нужно хранить только значения 0 или 1 (т.е. как Boolean), то в T-SQL существует специальный тип данных BIT, SQL сервер выделяет для хранения всего 1 байт, но в отличие от типа TINYINT, под который также отводится 1 байт, SQL сервер оптимизирует хранение бит столбцов. Если таблица содержит не больше 8 бит столбцов, столбцы хранятся как 1 байт, если таких столбцов от 9 до 16, то 2 байта и т.д.
Для сравнения давайте посмотрим на разницу.
Таблица 1
--В строке 16 байт
CREATE TABLE TestTable1 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled INT NOT NULL, --4 байта
IsTest INT NOT NULL, --4 байта
)
Таблица 2 (с использованием BIT столбцов)
--В строке 9 байт
CREATE TABLE TestTable2 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled BIT NOT NULL, --1 байта
IsTest BIT NOT NULL, --0 байта
)
Сравнение
| Количество строк | Размер в мегабайтах (MB) | ||
| Таблица 1 | Таблица 2 (с использованием BIT столбцов) | Разница | |
| 1 000 | 0,02 | 0,01 | 0,01 |
| 10 000 | 0,15 | 0,09 | 0,07 |
| 100 000 | 1,53 | 0,86 | 0,67 |
| 1 000 000 | 15,26 | 8,58 | 6,68 |
| 10 000 000 | 152,59 | 85,83 | 66,76 |
| 100 000 000 | 1525,88 | 858,31 | 667,57 |
Как видите, после добавления нескольких миллионов строк разница будет ощутимая, и это на простой, маленькой, тестовой таблице.
Про типы данных Microsoft SQL Server у меня все, надеюсь, материал был Вам полезен! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
Нравится8Не нравится1
Примеры использования инструкции OUTPUT в T-SQL
Сейчас мы разберем примеры использования инструкции OUTPUT в сочетании с INSERT, UPDATE и DELETE, пример с MERGE мы подробно рассматривали в материале – Операция MERGE в языке Transact-SQL – описание и примеры, поэтому здесь я не буду повторяться.
Исходные данные для примеров
Сначала давайте создадим тестовые данные, а именно таблицу, с названием TestTable, именно данные в ней мы и будем изменять.
В качестве сервера у меня выступает Microsoft SQL Server 2016 Express.
--Создание таблицы
CREATE TABLE TestTable(
IDENTITY(1,1) NOT NULL,
NOT NULL,
(100) NOT NULL,
NULL
)
GO
Пример использования OUTPUT в сочетании с INSERT
В этом примере мы добавим три строки и сразу вернем результат (добавленные строки) инструкцией OUTPUT, для этого мы обратимся к таблице Inserted (т.е. укажем префикс).
Инструкция OUTPUT указывается после инструкции INSERT и определения целевой таблицы.
INSERT INTO TestTable
OUTPUT Inserted.ProductId,
Inserted.CategoryId,
Inserted.ProductName,
Inserted.Price
VALUES (1, 'Клавиатура', 150),
(1, 'Мышь', 50),
(2, 'Телефон', 300)
Пример использования OUTPUT в сочетании с UPDATE
В случае с обновлением данных (UPDATE) мы уже можем обращаться и к Inserted и к Deleted, для того чтобы получить как новые, так и старые значения. OUTPUT также указывается после модифицирующей инструкции, в этом случае после UPDATE, стоит отметить, что условие WHERE мы пишем после инструкции OUTPUT.
UPDATE TestTable SET Price = Price + 10
OUTPUT Inserted.ProductId AS ,
Deleted.Price AS ,
Inserted.Price AS
WHERE Price < 200
Пример использования OUTPUT в сочетании с UPDATE и конструкцией INTO
В данном примере я покажу, как можно сохранить результирующий набор, который нам возвращает инструкция OUTPUT, например, для того чтобы в дальнейшем проанализировать произведенные изменения. Это можно сделать с помощью указания конструкции INTO, принцип ее работы примерно такой же, как и у конструкции SELECT INTO, т.е. мы после указания списка выборки пишем INTO и название целевой таблицы (или табличной переменной).
В примере ниже результат сохраняется в табличной переменной, которая предварительно объявляется.
--Объявление табличной переменной
DECLARE @TmpTable TABLE (ProductId INT, PriceOld Money, PriceNew Money);
--Выполнение UPDATE с инструкцией OUTPUT
UPDATE TestTable SET Price = Price + 10
OUTPUT Inserted.ProductId AS ,
Deleted.Price AS ,
Inserted.Price AS
INTO @TmpTable (ProductId, PriceOld, PriceNew) --Сохраняем результат в табличной переменной
WHERE Price < 200
--Можем анализировать сохраненные данные
SELECT * FROM @TmpTable
Пример использования OUTPUT в сочетании с DELETE
Если в инструкции OUTPUT обратиться к таблицам Inserted или Deleted указав *, то, как и в случае с SELECT, выведутся все столбцы таблицы. В следующем примере, для того чтобы посмотреть значения всех столбцов удаленных строк, указан символ *.
DELETE TestTable
OUTPUT Deleted.*
WHERE ProductId < 3
Инструкцию OUTPUT языка T-SQL мы рассмотрели, надеюсь, материал был Вам полезен. Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL, удачи!
Нравится14Не нравится1
Точность, масштаб и длина (Transact-SQL)
Точность представляет собой количество цифр в числе. Масштаб представляет собой количество цифр справа от десятичной запятой в числе. Например: число 123,45 имеет точность 5 и масштаб 2.
В среде SQL Server максимальная точность типов данных numeric и decimal по умолчанию составляет 38 разрядов. В более ранних версиях SQL Server максимум по умолчанию составляет 28.
Длиной для числовых типов данных является количество байт, используемых для хранения числа. Длина символьной строки или данных в Юникоде равняется количеству символов. Длина для типов данных binary, varbinary и image равна количеству байт. Например, тип данных int может содержать 10 разрядов, храниться в 4 байтах и не должен содержать десятичный разделитель. Тип данных int имеет точность 10, длину 4 и масштаб 0.
При сцеплении двух выражений типа char, varchar, binary или varbinary длина результирующего выражения является суммой длин двух исходных выражений, но не превышает 8 000 символов.
При сцеплении двух выражений типа nchar или nvarchar длина результирующего выражения является суммой длин двух исходных выражений, но не превышает 4 000 символов.
Если два выражения одного и того же типа данных, но разной длины, сравниваются с помощью предложения UNION, EXCEPT или INTERSECT, длина результата будет равняться длине максимального из двух выражений.
Точность и масштаб числовых типов данных, кроме decimal, фиксированы. Если арифметический оператор объединяет два выражения одного и того же типа, результат будет иметь тот же тип данных с точностью и масштабом, определенными для этого типа. Если оператор объединяет два выражения с различными числовыми типами данных, тип данных результата будет определяться правилами старшинства типов данных. Результат имеет точность и масштаб, определенные для этого типа данных.
Следующая таблица определяет, как вычисляется точность и масштаб результата, если результат операции имеет тип decimal. Результат имеет тип decimal, если одно из следующих утверждений является истиной:
- Оба выражения имеют тип decimal.
- Одно выражение имеет тип decimal, а другое имеет тип данных со старшинством меньше, чем decimal.
Выражения операндов обозначены как выражение e1 с точностью p1 и масштабом s1 и выражение e2 с точностью p2 и масштабом s2. Точность и масштаб для любого выражения, отличного от decimal, соответствуют типу данных этого выражения
| Операция | Точность результата | Масштаб результата * |
|---|---|---|
| e1 + e2 | max(s1, s2) + max(p1-s1, p2-s2) + 1 | max(s1, s2) |
| e1 — e2 | max(s1, s2) + max(p1-s1, p2-s2) + 1 | max(s1, s2) |
| e1 * e2 | p1 + p2 + 1 | s1 + s2 |
| e1 / e2 | p1 — s1 + s2 + max(6, s1 + p2 + 1) | max(6, s1 + p2 + 1) |
| e1 { UNION | EXCEPT | INTERSECT } e2 | max(s1, s2) + max(p1-s1, p2-s2) | max(s1, s2) |
| e1 % e2 | min(p1-s1, p2 -s2) + max( s1,s2 ) | max(s1, s2) |
* Точность и масштаб результата имеют абсолютный максимум, равный 38. Если значение точности превышает 38, то соответствующее значение масштаба уменьшается, чтобы по возможности предотвратить усечение целой части результата.