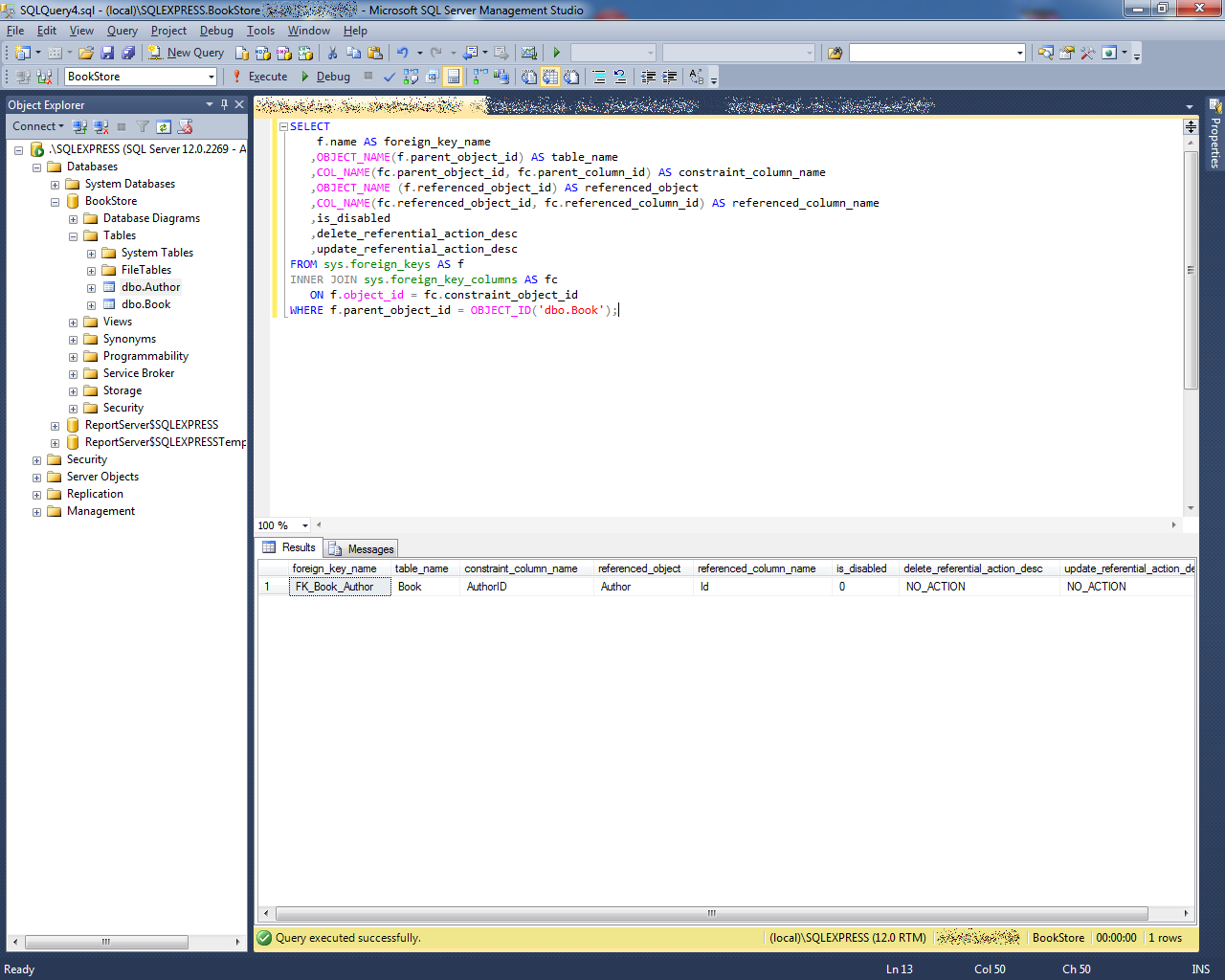
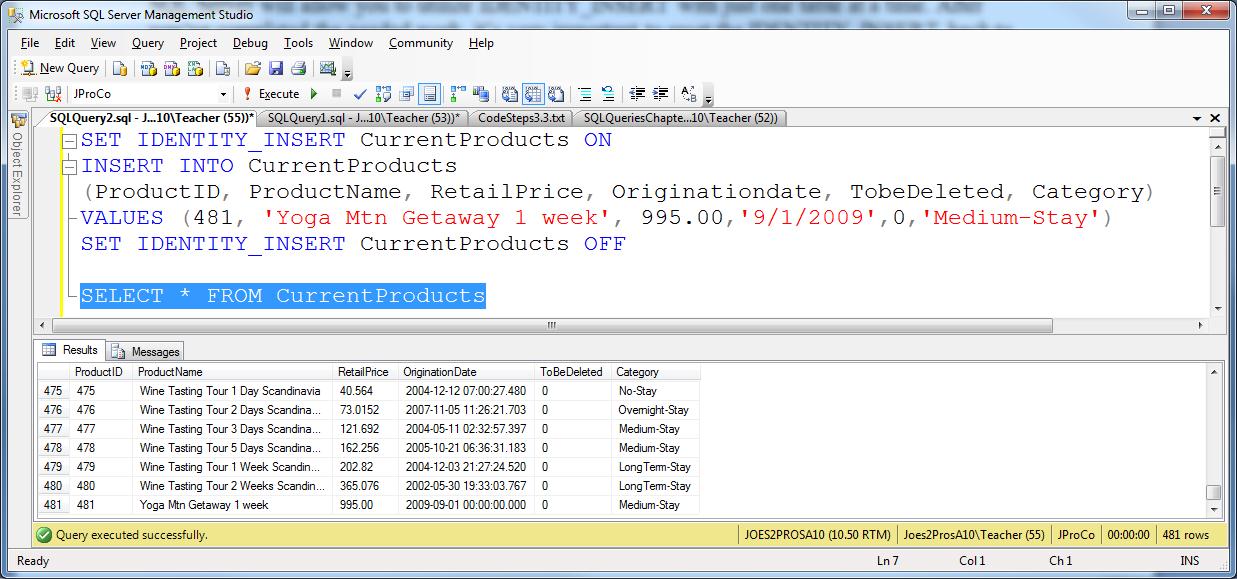
IDENTITY_INSERT property in Microsoft SQL Server
IDENTITY_INSERT is a table property that allows you to insert explicit values into the column of table identifiers, i.e. into the column with IDENTITY. The value of the inserted identifier can be either less than the current value or more, for example, to skip a certain interval of values.
When working with this property, it is necessary to take into account some nuances, let’s consider them:
- The IDENTITY_INSERT property can only take ON for one table in a session, i.e. IDENTITY_INSERT cannot be set to ON for two or more tables in a session simultaneously. If it is necessary to use IDENTITY_INSERT ON for several tables in one SQL instruction, you must first set the value to OFF for the table that has already been processed, and then set IDENTITY_INSERT to ON for the next table;
- If the IDENTITY value to be inserted is greater than the current value, the SQL server will automatically use the inserted value as the current value, i.e. if, for example, the next IDENTITY INSERT value is 5, and you use IDENTITY INSERT to insert an ID with a value of 6, then automatically the next ID value will be 7;
- In order to use IDENTITY_INSERT, a user must have the appropriate rights, i.e. to be the owner of the object or to be part of the sysadmin server role, the db_own or db_ddladm database role.
Changing the increment used by auto-increment in a SQL query
Unless you’re building a new app from scratch, chances are you’ll be importing or working within an existing dataset. This means that you’ll need to adjust the starting point of your auto-increment to account for the existing values (and possibly the increment between values depending on naming conventions).
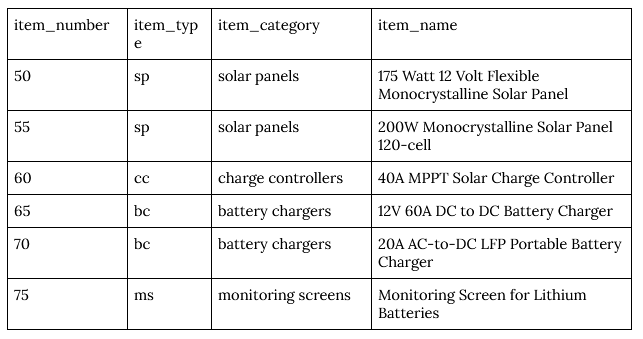
Working within our inventory dataset example, let’s say you were migrating and updating the records from your first product release into a new table before adding new and improved products. For simplicity’s sake, let’s say your company just happens to have released 49 different items in the first go-round, which means you’ll need to start your new values at 50.
Also, for whatever reason (nobody documented it), your predecessors created past in increments of five, so you’ll want to keep the vernacular correct and increment by five with each new product added. Thankfully, this change is easy to make in (just about) every DBMS.
➞ PostgreSQL
Postgres is kind of weird here: changing the auto-increment start and increment values in Postgres involves the keyword and requires you to create a custom as a separate, single-row table that you’ll then insert into your employee table.
First, create a custom using:
Note: make sure that this sequence name is distinct (i.e. doesn’t share the name of any other tables, sequences, indexes, views, or foreign tables within your existing schema) to avoid conflicts.
In our example, we want item_number to start at 50 and go up by five with each new value. The code for that would look like:
Then, you insert this record into the inventory table we created earlier and set the value to this new item like so:
Each time you add a value to your table (see below), you’ll need to call out that the value is:
If you’re only looking to change the starting value of your IDs (and not the increment value), you can just use and save yourself some of the legwork. The basic syntax for this looks like:
For our example, this looks like:
➞ MySQL
If you’re using MySQL, you can run to set new auto-increment starting values. Unfortunately, MySQL doesn’t support changes to the default increment value, so you’re stuck there.
The basic syntax for this looks like:
Using our inventory table example, your adjustment to the auto-increment start value would be:
After running this code, future item IDs will start at an item_number of 50 and increment by 1.
➞ SQL Server
To change the starting increment value and increment in SQL Server, set your non-default values during table creation. Looking back at our base syntax from the previous section:
In our example, where we want to start at 50 and go up by five with each new value, the code would look like:
If you’re looking to add auto increment to an existing table by changing an existing column to , SQL Server will fight you. You’ll have to either:
- Add a new column all together with new your auto-incremented primary key, or
- Drop your old column and then add a new right after
In the second scenario, you’ll want to make sure your new starts at +1 the value of the last id in your dropped column to avoid duplicate primary keys down the road.
To do this, you’d use the following code:
With our example, this would look like:
Regardless of what DBMS you end up using, though, if you’re following along with our example scenario, your output should resemble the following table (MySQL notwithstanding since it doesn’t support non-default increments of 5). We’ll get into adding the values seen below in the next section.
Syntax for Oracle
In Oracle the code is a little bit more tricky.
You will have to create an auto-increment field with the sequence object (this object generates a number sequence).
Use the following syntax:
CREATE SEQUENCE seq_person
MINVALUE 1
START WITH 1
INCREMENT BY 1
CACHE 10;
The code above creates a sequence object called seq_person, that starts with 1 and will increment by 1.
It will also cache up to 10 values for performance. The cache option specifies how many sequence values will be stored in memory for faster access.
To insert a new record into the «Persons» table, we will have to use the nextval function (this function retrieves the next value from seq_person
sequence):
INSERT INTO Persons (Personid,FirstName,LastName)
VALUES (seq_person.nextval,’Lars’,’Monsen’);
The SQL statement above would insert a new record into the «Persons» table. The «Personid» column would be assigned the next number from the seq_person
sequence. The «FirstName» column would be set to «Lars» and the «LastName» column would be set to «Monsen».
❮ Previous
Next ❯
Глобальный идентификатор
Идентификатор в пределах таблицы – это конечно здорово,
но отнюдь не предел мечтаний. В некоторых случаях вовсе не лишней была бы
возможность получить запись, гарантировано уникальную в пределах базы данных,
экземпляра сервера или даже в пределах всех серверов предприятия. Для
уникальности в пределах БД тип данных int, может еще и сгодится, но вот если
брать что-то более глобальное, то четырех миллиардов уникальных значений может
и не хватить. Max(int) – это много, но не так много как хотелось бы, проблема в
том, что назначая новое автоинкрементное поле, которое по идее должно быть
гарантировано уникальным при любых обстоятельствах, приходится думать о других
уникальных полях, чтобы ни коим образом диапазоны их идентификаторов не
пересеклись, а отсюда и совершенно неестественные ограничения.
Для выхода из подобной ситуации Microsoft предлагает
использовать тип данных uniqueidentifier — 16 байтное число, которое, будучи
сгенеренным с помощью специальной функции, является гарантировано уникальным
при любых обстоятельствах. Вся прелесть такого подхода заключается в том, что
такой идентификатор, будучи полученным на одном сервере, заведомо не
пересечется с другими подобными же идентификаторами, полученными на других
серверах. Уникальный идентификатор получается с помощью функции NewID().
Типичный сценарий работы с таким идентификатором выглядит примерно так:
|
DECLARE @PrimaryKey uniqueidentifier BEGIN TRAN SET @PrimaryKey = NewID() INSERT INTO MasterTbl (PrimaryKey, <… some fields …>) VALUES INSERT INTO DetailTbl (ForeignKey, <… some other fields …>) COMMIT |
Для разработчиков под ADO.Net есть еще один удобный
повод использовать подобный идентификатор. Поскольку, на самом деле, это
обычный GUID, то при добавлении записей в отсоединенный набор данных (Dataset),
можно совершенно спокойно получить этот идентификатор на клиенте и быть
уверенным, что на сервере такого нет.
Таким образом, использовать обычный автоинкремент
удобно только в пределах таблицы, а GUID, во всех остальных случаях. Если же,
хотя бы в отдаленной перспективе, предвидится какое-нибудь подобие репликации
или синхронизации данных между различными базами или серверами, то лучше в
качестве идентификатора сразу использовать GUID. Это серьезно уменьшит
количество головной боли.
Intro: auto-incrementing fields and primary keys
Imagine you’re working with product data for the inventory of a new solar panel manufacturer and distributor. You need to create a unique for each order placed from today on (think: thousands of orders). Item numbers cannot be duplicated in order to distinguish between each item in your inventory. If you’re creating these primary keys as a composite of table column values, your work is likely slow and cumbersome. You don’t have to suffer. There’s a better way.




When you use auto-incremented fields to assign integer values in your databases, you improve your database stability, limit errors caused by changing values, improve performance and uniformity, increase compatibility, and streamline validation. You can then use auto-increment in SQL queries to assign values in the primary key column automatically.
In short: you make your life—and database management—easier. In the example throughout this article, your table will need to include the following fields:
- : generated using auto-increment
- : manually entered as a variable string
- : manually entered as a variable string, too
- : also manually entered as a variable string
These values will be used to reference products in internal databases that will need to be pulled when customers place an order.
Before we jump into syntax and our example, we want to take a minute to talk about why you should use auto-increment in your database (especially for primary keys). (If you just want to get to the point, click here to jump down to the syntax summary.)
Using auto-incrementing IDs in SQL brings with it a lot of benefits, chief among them saving a bit of your sanity. But it also helps you:
- Retrieve data faster and easier because each primary key is a simple, sequential integer rather than a complex mix of other string values.
- Avoid breaking code if other values in your table change as would happen if your primary key was a compound of other column values.
- Ensure the uniqueness of each key within your table without locking or race conditions as auto-incremented IDs automatically avoid repetition and duplication.
- Improve system performance because they’re a compact data type, which allows for highly optimized code paths that avoid skipping between columns to create keys.
Additionally, primary keys can be used across many systems and drivers to support object-to-row mapping and database-system-agnostic operations.
Having said all of that, using an auto-incremented primary key isn’t appropriate for every use case. Read up on this before really jumping in.
Syntax for SQL Server
The following SQL statement defines the «Personid» column to be an auto-increment primary key field in the «Persons» table:
CREATE TABLE Persons
(
Personid int IDENTITY(1,1) PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int
);
The MS SQL Server uses the keyword to perform an auto-increment feature.
In the example above, the starting value for is 1, and it will increment by 1 for each new record.
Tip: To specify that the «Personid» column should start at value 10 and increment by 5, change
it to .
To insert a new record into the «Persons» table, we will NOT have to specify a value for the «Personid» column (a unique value will be added automatically):
INSERT INTO Persons (FirstName,LastName)
VALUES (‘Lars’,’Monsen’);
The SQL statement above would insert a new record into the «Persons» table. The
«Personid» column would be assigned a unique value. The «FirstName» column would be set to
«Lars» and the «LastName» column would be set to «Monsen».
Как вставить значение из другой таблицы INSERT INTO … SELECT …
Допустим у нас есть еще одна таблица которая по структуре точно такая же как и первая. Нам в таблицу table2 нужно вставить все строки из table1.
Вставляем значения из table1 в таблицу table2:
INSERT INTO table2 (a, b, c) SELECT a, b, c FROM table1;
Вам следует позаботиться об уникальности ключей, если они есть в таблице, в которую мы вставляем. Например при дублировании PRIMARY KEY мы получим следующее сообщение об ошибке:
/* ERROR 1062 (23000): Duplicate entry '100' for key 'PRIMARY' */
Если вы делаете не какую-то единичную вставку при переносе данных, а где-то сохраните этот запрос, например в вашем PHP скрипте, то всегда перечисляйте столбцы.
Как не рекомендуется делать (без перечисления столбцов):
INSERT INTO table2 SELECT * FROM table1;
Если у вас со временем изменится количество столбцов в таблице, то запрос перестанет работать. При выполнении запроса MySQL в лучшем случае просто будет возвращать ошибку:
/* Ошибка SQL (1136): Column count doesn't match value count at row 1 */
Либо еще хуже: значения вставятся не в те столбцы.
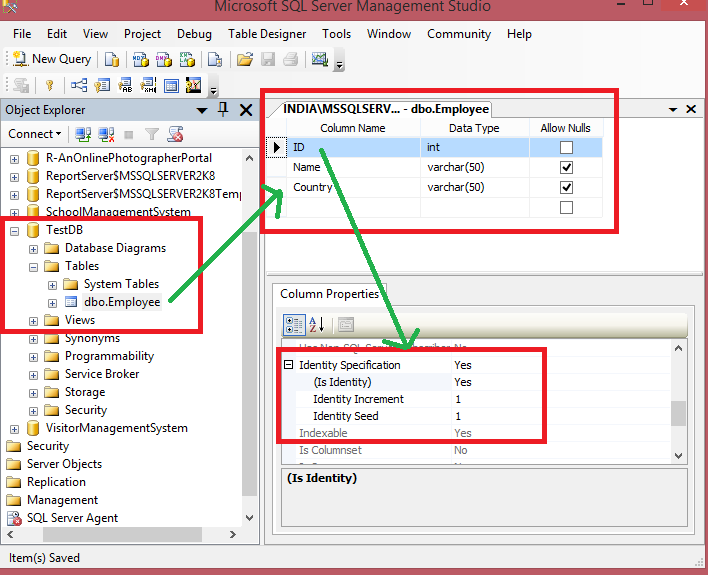
IDENTITY_INSERT
One key characteristic of an IDENTITY column is that SQL Server does not allow manual inserts by default. In order to manually insert rows in a table with such a column, you need to
- Set IDENTITY_INSERT ON
- Ensure all columns matching the values being inserted are listed in the insert statement (See Listing 3).
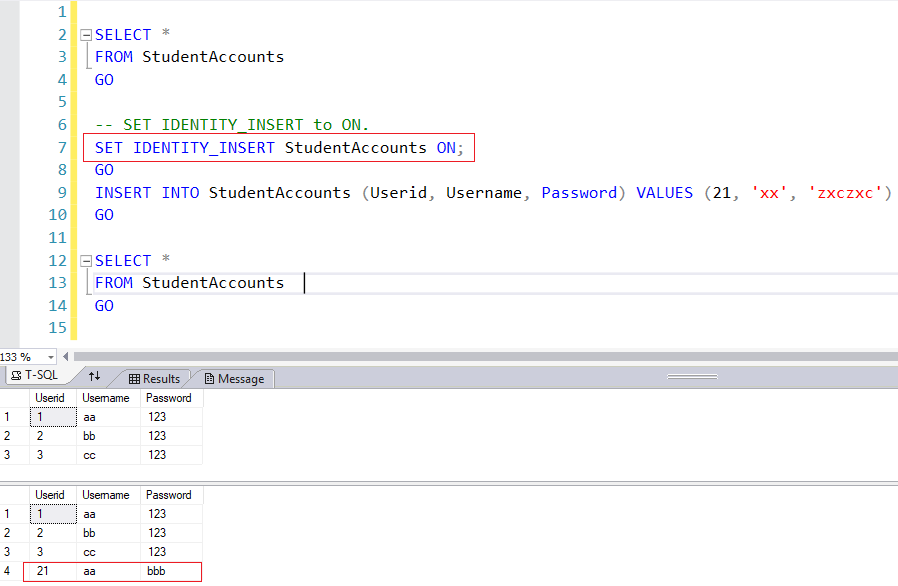
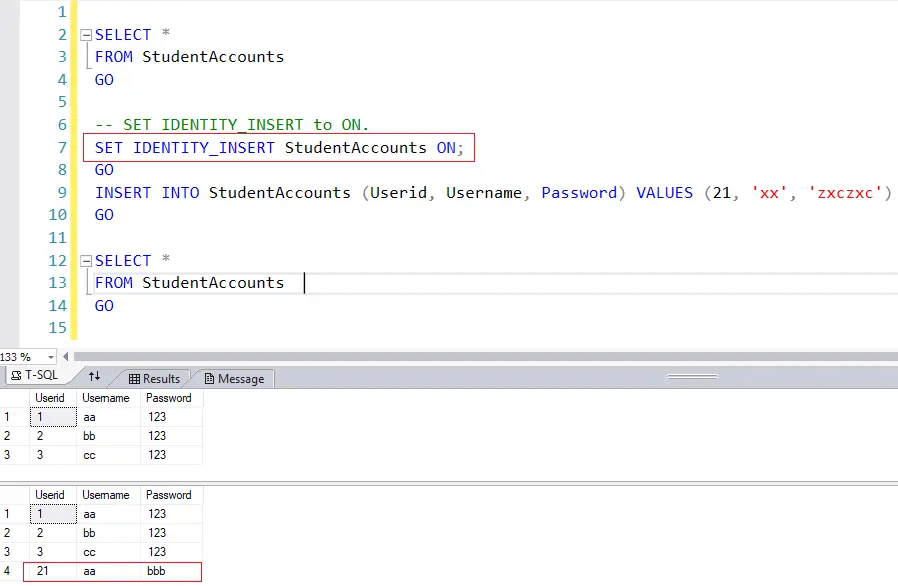
SET IDENTITY_INSERT EMPLOYEE ON; GO INSERT INTO EMPLOYEE (ID, FNAME, LNAME, HIREDATE) VALUES (6,'Ernest','Ofori','20020210'); GO SET IDENTITY_INSERT EMPLOYEE OFF; GO
Listing 3: Setting IDENTITY_INSERT ON
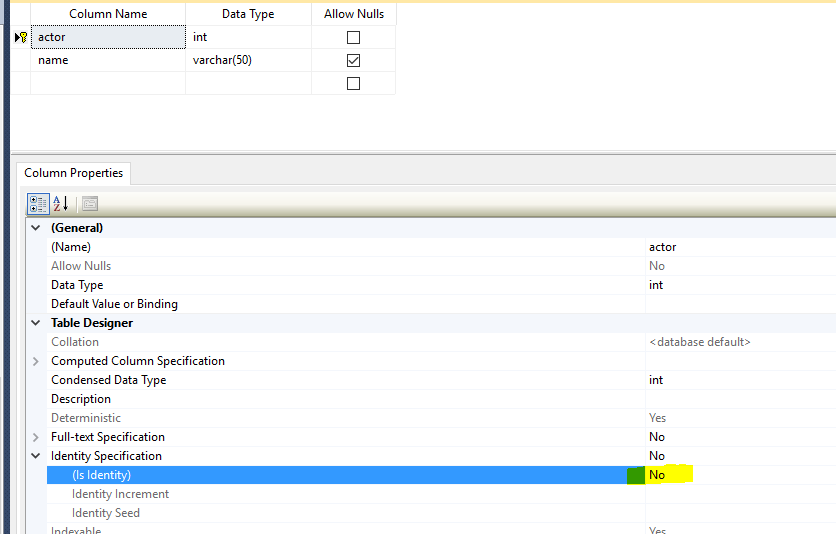
It is also important to know that you cannot set IDENTITY_INSERT ON for two tables in the same session (See Fig. 4). We discuss this further in the next section. When dealing with tables having an identity column, consider turning IDENTITY_INSERT ON as a temporary action. Be sure to revert to the normal by issuing SET IDENTITY_INSERT .<Table_Name> OFF when done with manual inserts.
Figure 4: Error Message on Attempt to Turn IDENTITY_INSERT ON Twice in the Same Session
identity_insert имеет значение off (11)
Если вы используете Liquibase для обновления вашего SQL Server, скорее всего, вы попытаетесь вставить ключ записи в поле autoIncrement. Удалив столбец из вставки, ваш скрипт должен работать.
…
Я выполняю следующий скрипт при ошибке ниже. Какова ошибка и как ее можно решить?
Например, если имя таблицы является учеником, тогда запрос выглядит так: SET IDENTITY_INSERT student ON
Проблема связана с использованием непечатаемого DBContext или DBSet, если вы используете интерфейс и реализуете метод savechanges в общем виде
Если это ваш случай, я предлагаю строго типизировать DBContex, например
MyDBContext.MyEntity.Add(mynewObject)
то. .Savechanges будут работать
не ставьте значение в OperationID, потому что оно будет автоматически сгенерировано. попробуй это:
Insert table(OpDescription,FilterID) values («Hierachy Update»,1)
вы можете просто использовать этот оператор, например, если ваше имя таблицы — школа
. Перед установкой убедитесь, что для параметра identity_insert установлено значение ON,
а после запроса вставки поверните идентификатор_интеста OFF
SET IDENTITY_INSERT School ON
/*
insert query
enter code here
*/
SET IDENTITY_INSERT School OFF
И если вы используете Oracle SQL Developer для подключения, не забудьте добавить / sqldev: stmt
/
/ sqldev: stmt
/ set identity_insert TABLE on;
Существуют два разных способа записи записей INSERT без ошибок:
1) Когда IDENTITY_INSERT выключен. ИДЕНТИФИКАТОР ПЕРВИЧНОГО КЛЮЧА НЕ ДОЛЖЕН БЫТЬ НАСТОЯЩИМ
2) Когда IDENTITY_INSERT установлен в положение ON. ИДЕНТИФИКАТОР ПЕРВИЧНОГО КЛЮЧА ДОЛЖЕН БЫТЬ НАСТОЯЩИМ
В соответствии с приведенным ниже примером из той же таблицы, созданной с основным ключом IDENTITY:
CREATE TABLE . (ID INT IDENTITY(1,1) PRIMARY KEY,
LastName VARCHAR(40) NOT NULL,
FirstName VARCHAR(40));
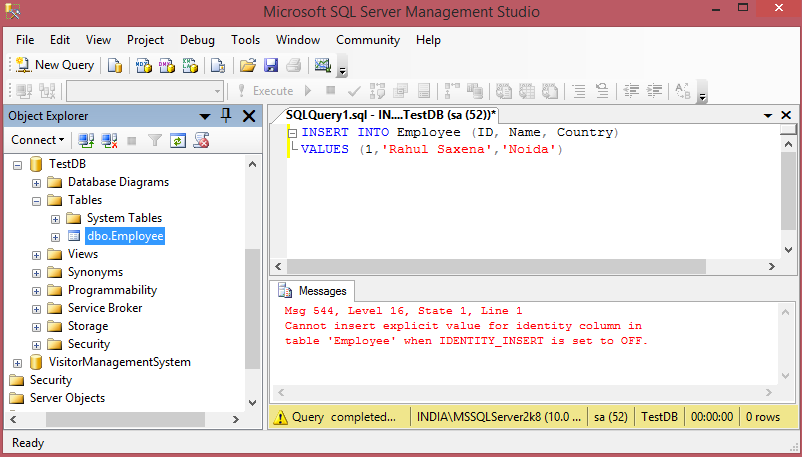
1) В первом примере вы можете вставить новые записи в таблицу, не получая ошибку, когда IDENTITY_INSERT выключен. «ИДЕНТИФИКАТОР ПЕРВИЧНОГО КЛЮЧА » НЕ ДОЛЖЕН БЫТЬ ПРИСУТСТВОВАНО
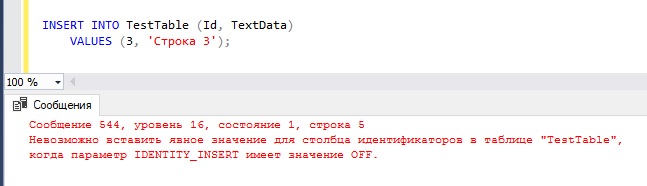
из утверждений «ВСТАВИТЬ В», а уникальное значение идентификатора будет добавляться автоматически:.
Если идентификатор присутствует в INSERT в этом случае, вы получите сообщение об ошибке «Невозможно вставить явное значение для идентификации столбца в таблице…»
SET IDENTITY_INSERT . OFF;
INSERT INTO . (FirstName,LastName)
VALUES («JANE»,»DOE»);
INSERT INTO Persons (FirstName,LastName)
VALUES («JOE»,»BROWN»);
2) Во втором примере вы можете вставить новые записи в таблицу, не получая ошибку, когда IDENTITY_INSERT включен. «ИДЕНТИФИКАТОР ПЕРВИЧНОГО КЛЮЧА » ДОЛЖЕН БЫТЬ НАСТОЯЩИМ
из заявлений «INSERT INTO», пока значение ID еще не существует
: если идентификатор НЕ присутствует от INSERT, в этом случае вы получите сообщение об ошибке «Явное значение должно быть для таблицы столбцов идентификаторов… «
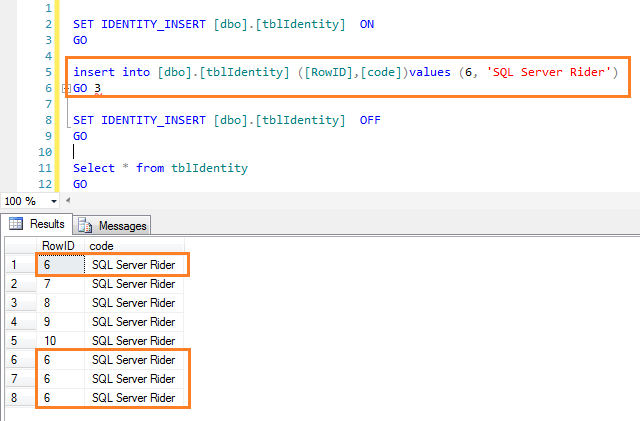




SET IDENTITY_INSERT . ON;
INSERT INTO . (ID,FirstName,LastName)
VALUES (5,»JOHN»,»WHITE»);
INSERT INTO . (ID,FirstName,LastName)
VALUES (3,»JACK»,»BLACK»);
ВЫВОД ТАБЛИЦЫ . будут:
Хорошо, я решил, что мой довольно простой. Убедитесь, что ваш первичный ключ с тем же именем совпадает с вашими классами, где единственное различие заключается в том, что ваш первичный ключ добавляет к нему ID или указывает на первичные ключи, которые не связаны с тем, как класс.
Вы вставляете значения для OperationId который является столбцом идентификации.
Вы можете включить идентификационную вставку в таблицу так, чтобы вы могли указать свои собственные значения идентичности.
SET IDENTITY_INSERT Table1 ON
INSERT INTO Table1
/*Note the column list is REQUIRED here, not optional*/
(OperationID,
OpDescription,
FilterID)
VALUES (20,
«Hierachy Update»,
1)
SET IDENTITY_INSERT Table1 OFF
Я не уверен, что использовать для «Вставить таблицу», но если вы просто пытаетесь вставить некоторые значения, попробуйте:
Insert Into (OpDescription,FilterID)
values («Hierachy Update»,1);
У меня было такое же сообщение об ошибке, но я думаю, что это должно сработать. Идентификатор должен автоматически увеличиваться автоматически, если это первичный ключ.
В запросе есть предварительно упомянутый OperationId, который не должен быть там, поскольку он автоматически увеличивается
Insert table(OperationID,OpDescription,FilterID)
values (20,»Hierachy Update»,1)
поэтому ваш запрос будет
Insert table(OpDescription,FilterID)
values («Hierachy Update»,1)
How to check identity_insert is on or off in SQL Server
In this section, you will learn how to check if the IDENTITY_INSERT option is ON or OFF. You will also see an example where we have implemented this.
You can check the IDENTITY_INSERT status of your table with the following script:
- In the above code, just add the database name, schema name, and the name of the table whose IDENTITY_INSERT status you want to check.
- Here we are creating a temporary table and try to turn the IDENTITY_INSERT option to ON.
- We know that only one table in a session can have this property on. Therefore, if your table’s IDENTITY_INSERT option is ON, it cannot be turned ON for another table in the same session.
- We are making the use of Exception Handling mechanism to find out the status.
- In our example, the database name is master, schema name is dbo and the table name is IdentityTable.
- Also, we will set the IdentityInsert option to on. The code now will be:
This is how to check identity_insert is on or off in SQL Server 2019.
Read SQL Server stored procedure if else
Создание баз данных и таблиц
Сначала создайте именованную базу данных.Создайте таблицу с именем «Человек», используя следующий код. Таблица создана с использованием «PRIMARY KEY IDENTITY»
Синтаксис для установки «identity_insert off | конечно»
«Отключить identity_insert | on »помогает нам исправить эту ошибку. Правильный синтаксис этого оператора следующий.
Обновление за январь 2023 года:
Теперь вы можете предотвратить проблемы с ПК с помощью этого инструмента, например, защитить вас от потери файлов и вредоносных программ. Кроме того, это отличный способ оптимизировать ваш компьютер для достижения максимальной производительности. Программа с легкостью исправляет типичные ошибки, которые могут возникнуть в системах Windows — нет необходимости часами искать и устранять неполадки, если у вас под рукой есть идеальное решение:
- Шаг 1: (Windows 10, 8, 7, XP, Vista — Microsoft Gold Certified).
- Шаг 2: Нажмите «Начать сканирование”, Чтобы найти проблемы реестра Windows, которые могут вызывать проблемы с ПК.
- Шаг 3: Нажмите «Починить все», Чтобы исправить все проблемы.

УСТАНОВИТЬ IDENTITY_INSERT. . {ВЫКЛ | КОНЕЧНО }Тогда как первый аргумент — это имя базы данных, в которой расположена таблица. Второй определяющий аргумент — это схема, к которой принадлежит эта таблица, значение идентификатора которой должно быть установлено на ON или OFF. Третий аргумент — это таблица со столбцом идентификаторов.
Есть два основных способа вставить данные в таблицу без ошибок. Они считаются решением этой ошибки и описаны ниже.
Сообщите SQL Server, каким должно быть значение идентификатора
Если вы хотите указать значения идентификаторов для вставляемых записей, вы должны запустить небольшую команду SQL, чтобы включить вставку идентификатора, перед выполнением оператора INSERT. Вставки идентификаторов позволяют вам заполнить значение столбца идентификаторов конкретным значением.
Разрешить SQL Server генерировать идентификатор
Если вам не нужны значения идентификаторов для этих записей, вы должны позволить SQL Server генерировать только значения идентификаторов для вас. Для этого просто введите столбцы таблицы и опустите столбец идентификаторов.
Совет экспертов:

Эд Мойес
CCNA, веб-разработчик, ПК для устранения неполадок
Я компьютерный энтузиаст и практикующий ИТ-специалист. У меня за плечами многолетний опыт работы в области компьютерного программирования, устранения неисправностей и ремонта оборудования. Я специализируюсь на веб-разработке и дизайне баз данных. У меня также есть сертификат CCNA для проектирования сетей и устранения неполадок.
Сообщение Просмотров: 228
Introduction
SQL Identity columns are often used as a way to auto-number some data element when we have no need to assign any specific values to it. Either the values are arbitrary, the column is a surrogate key, or we wish to generate numbers for use in other processes downstream.
For most applications, identity columns are set-it-and-forget-it. For an integer, which can contain 2,147,483,647 positive values, it’s easy to assume that a number so large is out-of-reach for a fledgling table. As time goes on, though, and applications grow larger, two billion can quickly seem like a much smaller number. It’s important to understand our data usage, predict identity consumption over time, and proactively manage data type changes before an emergency arises.
identity_insert имеет значение off ms sql (11)
Я не уверен, что использовать для «Вставить таблицу», но если вы просто пытаетесь вставить некоторые значения, попробуйте:
Insert Into (OpDescription,FilterID)
values («Hierachy Update»,1);
У меня было такое же сообщение об ошибке, но я думаю, что это должно сработать. Идентификатор должен автоматически увеличиваться автоматически, если это первичный ключ.
Я выполняю следующий скрипт при ошибке ниже. Какова ошибка и как ее можно решить?
И если вы используете Oracle SQL Developer для подключения, не забудьте добавить / sqldev: stmt
/
/ sqldev: stmt
/ set identity_insert TABLE on;
В вашей организации для этой таблицы добавьте атрибут DatabaseGenerated над столбцом, для которого установлен идентификатор:
Public int TaskId { get; set; }
не ставьте значение в OperationID, потому что оно будет автоматически сгенерировано. попробуй это:
Insert table(OpDescription,FilterID) values («Hierachy Update»,1)
Вы вставляете значения для OperationId который является столбцом идентификации.
Вы можете включить идентификационную вставку в таблицу так, чтобы вы могли указать свои собственные значения идентичности.
SET IDENTITY_INSERT Table1 ON
INSERT INTO Table1
/*Note the column list is REQUIRED here, not optional*/
(OperationID,
OpDescription,
FilterID)
VALUES (20,
«Hierachy Update»,
1)
SET IDENTITY_INSERT Table1 OFF
Проблема связана с использованием непечатаемого DBContext или DBSet, если вы используете интерфейс и реализуете метод savechanges в общем виде
Если это ваш случай, я предлагаю строго типизировать DBContex, например
MyDBContext.MyEntity.Add(mynewObject)



то. .Savechanges будут работать
Если вы используете Liquibase для обновления вашего SQL Server, скорее всего, вы попытаетесь вставить ключ записи в поле autoIncrement. Удалив столбец из вставки, ваш скрипт должен работать.
…
Будьте очень осторожны при установке IDENTITY_INSERT в положение ON. Это плохая практика, если база данных не находится в режиме обслуживания и не установлена на одного пользователя. Это влияет не только на вашу вставку, но и на тех, кто пытается получить доступ к таблице.
Почему вы пытаетесь поместить значение в поле идентификации?
В запросе есть предварительно упомянутый OperationId, который не должен быть там, поскольку он автоматически увеличивается
Insert table(OperationID,OpDescription,FilterID)
values (20,»Hierachy Update»,1)
поэтому ваш запрос будет
Insert table(OpDescription,FilterID)
values («Hierachy Update»,1)
Хорошо, я решил, что мой довольно простой. Убедитесь, что ваш первичный ключ с тем же именем совпадает с вашими классами, где единственное различие заключается в том, что ваш первичный ключ добавляет к нему ID или указывает на первичные ключи, которые не связаны с тем, как класс.
Например, если имя таблицы является учеником, тогда запрос выглядит так: SET IDENTITY_INSERT student ON
Как видно из названия материала сегодня я расскажу о таком, в некоторых случаях, полезном свойстве таблицы в Microsoft SQL Server как IDENTITY_INSERT
, используя именно это свойство, можно вставить в автоинкрементное поле значение, которое ранее было удалено, т.е. заполнить или восстановить пропущенные значения идентификаторов.
Наверное, у многих программистов SQL сервера возникала ситуация, когда в таблице в которой определена спецификация идентификатора по какой-то причине удаляются некоторые записи, а затем возникает необходимость восстановить эти записи, причем со значениями старых идентификаторов. Первое, что приходит на ум это конечно удалить идентификацию, вставить строки с необходимыми значениями, а затем восстановить идентификацию, но для этого, как Вы понимаете, необходимо выполнить достаточно много манипуляций, которые могут повлиять на ход текущей работы, поэтому это нужно делать быстро, да и лучше в тот момент, когда в базе данных нет работающих пользователей.
Но на самом деле есть более простой, а главное правильный способ, который позволяет вставлять значения в столбец идентификаторов таблицы, он заключается в использование свойства IDENTITY INSERT
.
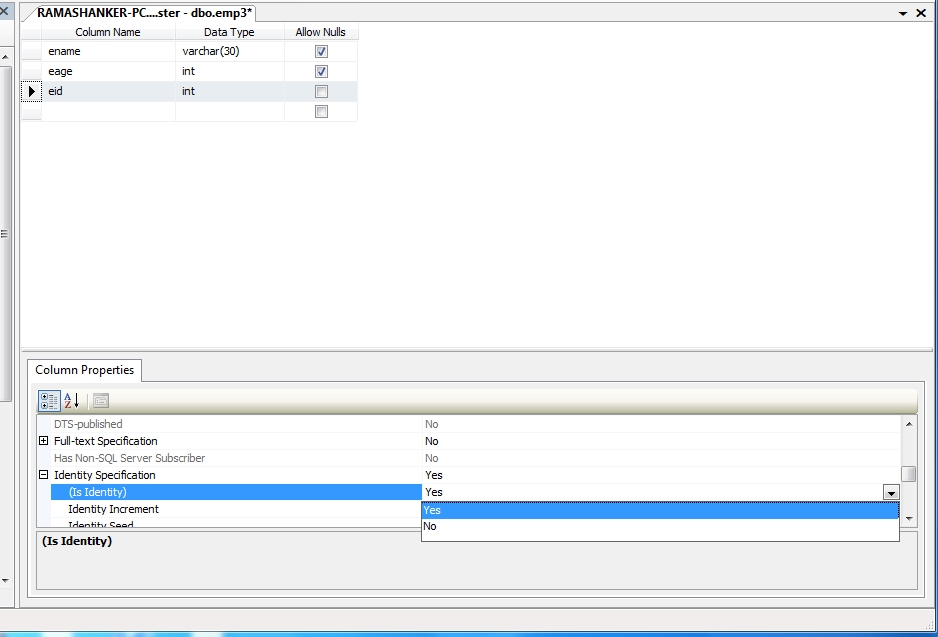
How to add the IDENTITY property to a column
It’s simple. When you create your column in your CREATE TABLE statement, you would just put the keyword IDENTITY next to your column you want to add the property to. Like so:
CREATE TABLE BookCollection ( BookID INT IDENTITY, Title VARCHAR(30), Author VARCHAR(15), PageCount INT )
There is also something called a seed and step value you can choose to specify when you use the IDENTITY property on a column. Here is the same example, but using a seed and step value with the IDENTITY property:
CREATE TABLE BookCollection ( BookID INT IDENTITY(10,5), Title VARCHAR(30), Author VARCHAR(15), PageCount INT )
Let’s talk about what this means. The first number in parentheses represents the seed value. This is the number at which the IDENTITY property will start. The second number is the step value, meaning how many digits are skipped between the previous identity number generated and the next identity number to be generated.
If you exclude the seed and step values (like I did in my first example), both the seed and step values will be 1.
We’ll see some examples in the next section.
What is an Identity Column?
An identity column is a feature in SQL Server that lets you auto-increment the column’s value. This is helpful for primary keys, where you don’t care what the number is, as long as it’s unique.
You can specify the word IDENTITY as a property after the data type when creating or altering a table.
For example:
This statement will create a new table called product.
The product_id has the word IDENTITY after it, which means new records will have an automatically generated value.
Let’s see an example of this.
We can check the value was inserted by selecting data from the table.
| product_id | product_name | price |
| 1 | Chair | 100 |
We can insert a second row into the table to see what the product_id identity column will be set to.
To see the records in the table, we can select from it.
| product_id | product_name | price |
| 1 | Chair | 100 |
| 2 | Desk | 250 |
Without specifying the product_id in the INSERT statements, the IDENTITY feature has generated a number and populated the row. A new number is created for each row.