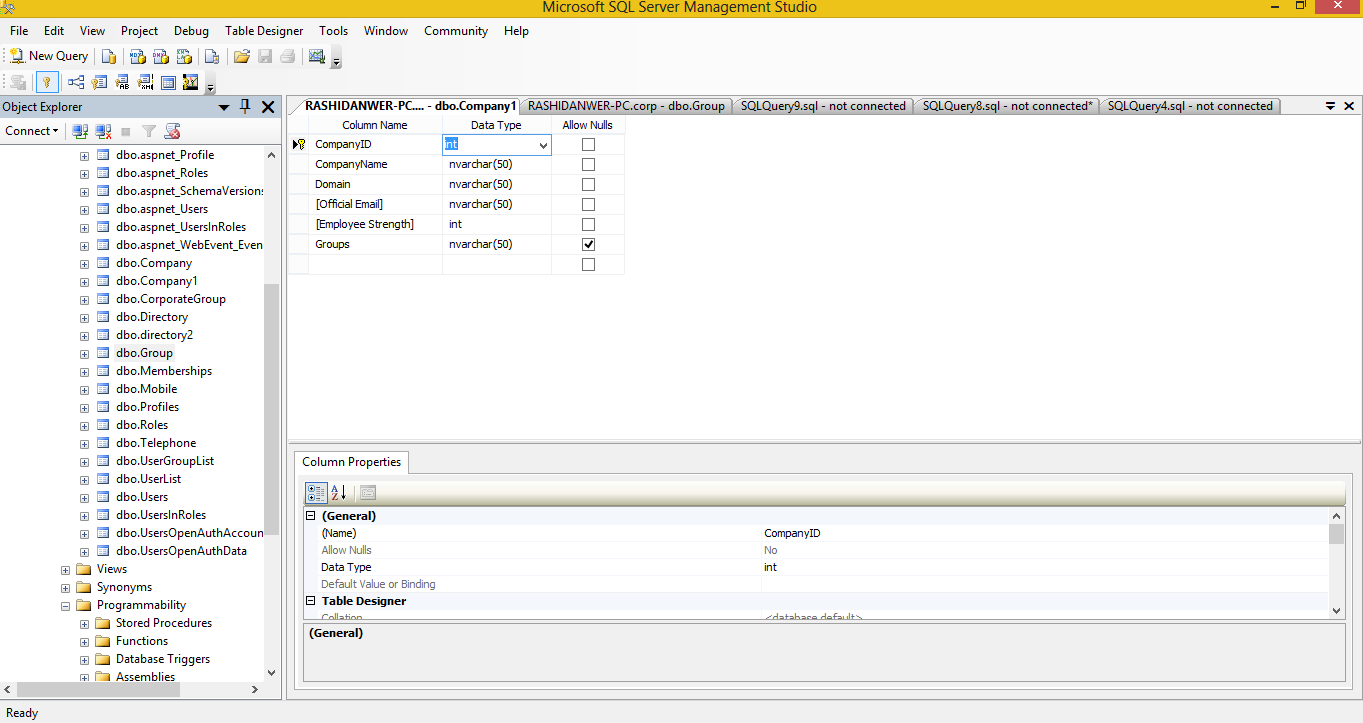
Examples
A. Using @@IDENTITY and SCOPE_IDENTITY with triggers
The following example creates two tables, and , and an INSERT trigger on . When a row is inserted to table , the trigger () fires and inserts a row in .
USE tempdb;
GO
CREATE TABLE TZ (
Z_id INT IDENTITY(1,1)PRIMARY KEY,
Z_name VARCHAR(20) NOT NULL);
INSERT TZ
VALUES ('Lisa'),('Mike'),('Carla');
SELECT * FROM TZ;
Result set: This is how table TZ looks.
CREATE TABLE TY (
Y_id INT IDENTITY(100,5)PRIMARY KEY,
Y_name VARCHAR(20) NULL);
INSERT TY (Y_name)
VALUES ('boathouse'), ('rocks'), ('elevator');
SELECT * FROM TY;
Result set: This is how TY looks:
Create the trigger that inserts a row in table TY when a row is inserted in table TZ.
CREATE TRIGGER Ztrig
ON TZ
FOR INSERT AS
BEGIN
INSERT TY VALUES ('')
END;
FIRE the trigger and determine what identity values you obtain with the @@IDENTITY and SCOPE_IDENTITY functions.
INSERT TZ VALUES ('Rosalie');
SELECT SCOPE_IDENTITY() AS ;
GO
SELECT @@IDENTITY AS ;
GO
B. Using @@IDENTITY and SCOPE_IDENTITY() with replication
The following examples show how to use and for inserts in a database that is published for merge replication. Both tables in the examples are in the sample database: is not published, and is published. Merge replication adds triggers to tables that are published. Therefore, can return the value from the insert into a replication system table instead of the insert into a user table.
The table has a maximum identity value of 20. If you insert a row into the table, and return the same value.
USE AdventureWorks2012;
GO
INSERT INTO Person.ContactType () VALUES ('Assistant to the Manager');
GO
SELECT SCOPE_IDENTITY() AS ;
GO
SELECT @@IDENTITY AS ;
GO
The table has a maximum identity value of 29483. If you insert a row into the table, and return different values. returns the value from the insert into the user table, whereas returns the value from the insert into the replication system table. Use for applications that require access to the inserted identity value.
INSERT INTO Sales.Customer (,) VALUES (8,NULL); GO SELECT SCOPE_IDENTITY() AS ; GO SELECT @@IDENTITY AS ; GO
SQL IDENTITY Function
In my previous article, we explored SQL SELECT INTO Statement, to create a new table and inserted data into it from the existing table. We can use the SQL IDENTITY function to insert identity values in the table created by SQL SELECT INTO statement.
By default, if a source table contains an IDENTITY column, then the table created using a SELECT INTO statement inherits it. Consider a scenario in which you want to create a table using the SELECT INTO statement from the output of a view or join from multiple tables. In this case, you want to create an IDENTITY column in a new table as well.
Note: SQL IDENTITY function is different from the IDENTITY property we use while creating any table.
We need to specify a data type for a column to use SQL Identity function. We also need to specify SEED and Step values to define an identity configuration.
We cannot use SQL IDENTITY Function in a Select statement. We get the following error message.
Msg 177, Level 15, State 1, Line 2
The IDENTITY function can only be used when the SELECT statement has an INTO clause.
Let’s create a table using the SQL SELECT INTO statement with the following query.
|
1 |
SELECTTOP(10)IDENTITY(INT,100,2)ASNEW_ID, PersonType, NameStyle, Title, FirstName, MiddleName, LastName, Suffix INTOTEMPTABLE FROMAdventureWorks2017.Person.Person; |
Once the statement executes, check the table properties using sp_help command.
| 1 | sp_help’TEMPTABLE’ |
You can see the IDENTITY column in the TEMPTABLE properties as per the specified conditions.
Let’s look at another example. Execute the following command.
|
1 |
SELECTIDENTITY(INT,100,2)ASNEW_ID, ID, Name INTOtemp2 FROMemployeedata; |
We already have an IDENTITY column in the EmployeeData table. The new table temp2 also inherits the IDENTITY column. We cannot have multiple IDENTITY columns in a table. Due to this, we get the following error message.
Msg 8108, Level 16, State 1, Line 1
Cannot add identity column, using the SELECT INTO statement, to table ‘temp2’, which already has column ‘ID’ that inherits the identity property.
Introduction
SQL Identity columns are often used as a way to auto-number some data element when we have no need to assign any specific values to it. Either the values are arbitrary, the column is a surrogate key, or we wish to generate numbers for use in other processes downstream.
For most applications, identity columns are set-it-and-forget-it. For an integer, which can contain 2,147,483,647 positive values, it’s easy to assume that a number so large is out-of-reach for a fledgling table. As time goes on, though, and applications grow larger, two billion can quickly seem like a much smaller number. It’s important to understand our data usage, predict identity consumption over time, and proactively manage data type changes before an emergency arises.
How to find the last IDENTITY value that was created
There are three functions you should use to determine the last IDENTITY value that was created:
- SCOPE_IDENTITY()
- @@IDENTITY
- IDENT_CURRENT(‘<tablename>’)
Which one you use depends on your needs. Let’s walk through how to use each one.
SCOPE_IDENTITY() will tell you the last IDENTITY value that was created in the current scope. The scope of your code is important most of the time, so this function should be the one you’ll want to think about using first.
@@IDENTITY will tell you the last IDENTITY value that was generated in the current session, regardless of scope.
As an example, think about a stored procedure that calls another stored procedure, each doing inserts into different tables that each have the IDENTITY property. When you call the first procedure, it will be in a different scope than the second. In that case, SCOPE_IDENTITY() will return a different value depending on which procedure you’re in. The @@IDENTITY tool, on the other hand, will return the last identity value that was created overall, regardless of where it came from.
In that scenario, @@IDENTITY will tell you the identity value created from the second procedure because it was more recent.
Scope usually matters
But again, I don’t want to get too bogged down with @@IDENTITY. It’s more likely your scope will matter, so SCOPE_IDENTITY() should be your go-to function to use if you need to know the last identity value created.



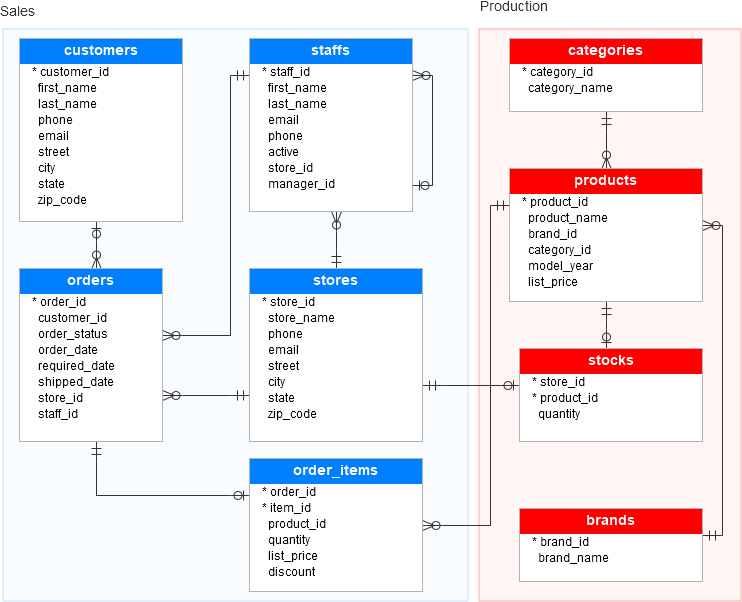
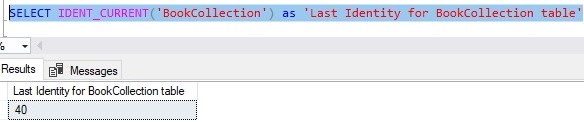
Finally, there is the IDENT_CURRENT(‘<tablename>’) function. This function very simply tells you the last identity value that was created for a table whose name you pass in as an argument. Here is an example:
As an example of when you might need to know the last identity value generated, think about two tables that have a foreign key link to one another.
Let’s say we have a Customers table with a CustID column that has the IDENTITY property. Here is an example of the rows in that table:
Then we have a ContactInfo table that has a foreign key column also called CustID.

The number in this column matches back to the CustID column back in the Customers table.
This CustID column in the ContactInfo table does NOT have the IDENTITY property.
Inserting corresponding rows into multiple tables is difficult
Great, but what must we do if we need to add a new Customer?
We need to add a new row to the Customers table (of course), but we also need to add a corresponding row to the ContactInfo table. And again, the way we correspond them is through the CustID column.
So, first we do our insert into the Customer table, which is easy:

Great. We see the row that was inserted, and we see it’s identity value, which appears to be 27. If we’re doing things the hard way, we can manually enter that identity value into our next insert statement into ContactInfo, like so:
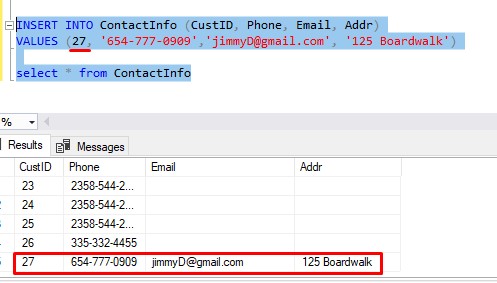
But again, that’s the hard way. Who has time to run an insert statement, figure out the key, type it into a second insert, then run the second insert?
Not me.
What if we could do it all at once?:

SCOPE_IDENTITY: A very useful function
We can use SCOPE_IDENTITY() to basically skip a couple steps, which means we’re less likely to make a mistake. We use SCOPE_IDENTITY() to figure out the last identity value created from our first INSERT into the Customers table, then we write that value to a variable (@identVal), then use that variable in our second INSERT statement.
Pretty slick, right?
If you’re being really cool, you could use SCOPE_IDENTITY() directly in your second INSERT statement. That way you don’t even need to use a variable:

To make this process even easier, you could contain all this work into a simple stored procedure:

See how this is done in my Stored Procedure tutorial here:
Инструкция INSERT в T-SQL
INSERT – это инструкция языка T-SQL, которая предназначена для добавления данных в таблицу, т.е. создания новых записей. Данную инструкцию можно использовать как для добавления одной строки в таблицу, так и для массовой вставки данных. Для выполнения инструкции INSERT требуется разрешение на вставку данных (INSERT) в целевую таблицу.
Существует несколько способов использования инструкции INSERT в части данных, которые необходимо вставить:
- Перечисление конкретных значений для вставки;
- Указание набора данных в виде запроса SELECT;
- Указание набора данных в виде вызова процедуры, которая возвращает табличные данные.
Упрощённый синтаксис
INSERT (список столбцов, …) VALUES (список значений, …) Или SELECT запрос на выборку Или EXECUTE процедура
Где,
- INSERT INTO – это команда добавления данных в таблицу;
- Таблица – это имя целевой таблицы, в которую необходимо вставить новые записи;
- Список столбцов – это перечень имен столбцов таблицы, в которую будут вставлены данные, разделенные запятыми;
- VALUES – это конструктор табличных значений, с помощью которого мы указываем значения, которые будем вставлять в таблицу;
- Список значений – это значения, которые будут вставлены, разделенные запятыми. Они перечисляются в том порядке, в котором указаны столбцы в списке столбцов;
- SELECT – это запрос на выборку данных для вставки в таблицу. Результирующий набор данных, который вернет запрос, должен соответствовать списку столбцов;
- EXECUTE – это вызов процедуры на получение данных для вставки в таблицу. Результирующий набор данных, который вернет хранимая процедура, должен соответствовать списку столбцов.
Вот примерно так и выглядит упрощённый синтаксис инструкции INSERT INTO, в большинстве случаев именно так Вы и будете добавлять новые записи в таблицы.
Список столбцов, в которые Вы будете вставлять данные, можно и не писать, в таком случае их порядок будет определен на основе фактического порядка столбцов в таблице. При этом необходимо помнить этот порядок, когда Вы будете указывать значения для вставки или писать запрос на выборку. Лично я Вам рекомендую все-таки указывать список столбцов, в которые Вы планируете добавлять данные.






Также следует помнить и то, что в списке столбцов и в списке значений, соответственно, должны присутствовать так называемые обязательные столбцы, это те, которые не могут содержать значение NULL. Если их не указать, и при этом у столбца отсутствует значение по умолчанию, будет ошибка.
Еще хотелось бы отметить, что тип данных значений, которые Вы будете вставлять, должен соответствовать типу данных столбца, в который будет вставлено это значение, ну или, хотя бы, поддерживал неявное преобразование. Но я Вам советую контролировать тип данных (формат) значений, как в списке значений, так и в запросе SELECT.
Хватит теории, переходим к практике.
SQL SCOPE_IDENTITY() function
We use SCOPE_IDENTITY() function to return the last IDENTITY value in a table under the current scope. A scope can be a module, trigger, function or a stored procedure. We can consider SQL SCOPE_IDENTITY() function similar to the @@IDENTITY function, but it is limited to a specific scope. It returns the NULL value if this function is involved before an insert statement generates value under the same scope.
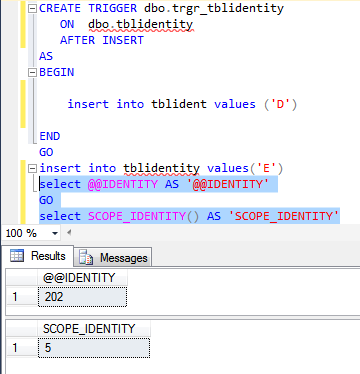
In the following example, we see that both the @@IDENTITY and SCOPE_IDENTITY() return the same value in the current session and similar scope.
Let’s understand the difference between SCOPE_IDENTITY() and @@IDENTITY with another example.
Let’s consider we have two tables EmployeeData and Departments table. We create an INSERT trigger on the EmployeeData table. Once we insert any row on EmployeeData, it calls to defined trigger for inserting a row in Departments.
|
1 |
DroptableEmployeeData DroptableDepartments CREATETABLEEmployeeData (idTINYINTIDENTITY(100,1)PRIMARYKEYNOTNULL, NameNVARCHAR(20)NULL ) CREATETABLEDepartments (DepartmentIDINTIDENTITY(100,5)PRIMARYKEY, DepartmentnameVARCHAR(20)NULL ); Go |
In the following query, we create a trigger to insert default value ‘IT’ in the departments table for every insert in the EmployeeData table.
|
1 |
CREATETRIGGERT_INSERT_DEPARTMENT ONEmployeeData FORINSERTAS BEGIN INSERTDepartmentsVALUES(‘IT’) END; |
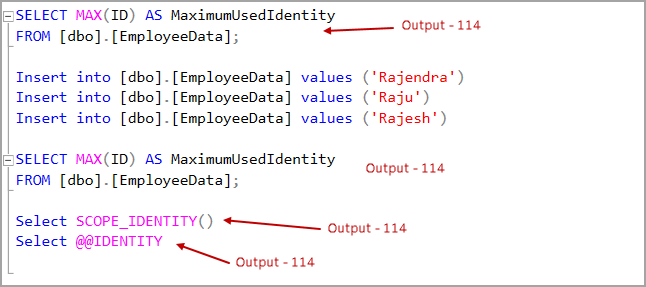
Let’s insert value in the Employee data table and view the output of both @@IDENTITY and SCOPE_IDENTITY() functions.
In the current session, we inserted data into the EmployeeData table. It generates an identity in this table. The identity seed value is 1 for the EmployeeData table.
Once we insert value in the EmployeeData table, it fires a trigger to insert value in the Departments table. The identity seed value is 100 for the Departments table.
- We get the output 100 for the SELECT @@IDENTITY function
- SCOPE_IDENTITY function returns identity value under the current scope only. It gives output 1 for this function
Timestamp (rowvesion)
Строго говоря, существует еще один тип данных,
предназначенный для идентификации, но идентификации несколько другого рода. Тип
данных rowversion предназначен для идентификации версии строки в пределах базы
данных.
|
ПРИМЕЧАНИЕ Вообще можно указывать как timestamp |
Если в таблице имеется поле типа rowversion (оно, как
и identity, может быть только одно на таблицу), то значение в этом поле будет
автоматически меняться, при изменении любого другого поля в записи. Таким
образом, запомнив предыдущее значение, можно определить — менялась запись, или
нет, не проверяя всех полей. Для каждой базы SQL сервер ведет отдельный счетчик
rowversion. При внесении изменения в любую таблицу со столбцом такого типа,
счетчик увеличивается на единицу, после чего новое значение сохраняется в
измененной строке. Текущее значение счетчика в базе данных хранится в
переменной @@DBTS. Для хранения данных rowversion используется 8 байт, посему
этот тип вполне может быть представлен, как varbinary(8) или binary(8).
Overview of IDENTITY columns
In SQL Server, we create an identity column to auto-generate incremental values. It generates values based on predefined seed (Initial value) and step (increment) value. For example, suppose we have an Employee table and we want to generate EmployeeID automatically. We have a starting employee ID 100 and further want to increment each new EmpID by one. In this case, we need to define the following values.
- Seed: 100
- Step: 1
|
1 |
USESQLSHACKDEMO; GO CREATETABLEEmployeeData (idTINYINTIDENTITY(100,1)PRIMARYKEYNOTNULL, NameNVARCHAR(20)NULL ) ONPRIMARY; GO |
Let’s insert a few records in this table and view the records.
You can see the first employee gets an ID value 100 and each new records ID value gets an increment of one.
We have a few useful Identity functions in SQL Server to work with the IDENTITY columns in a table. Let’s explore the following IDENTITY functions with examples.
- SQL @@IDENTITY Function
- SQL SCOPE_IDENTITY() Function
- SQL IDENT_CURRENT Function
- SQL IDENTITY Function
2 ответа
1
Лучший ответ
вы можете попробовать использовать предложение OUTPUT в качестве работы:
этот единственный оператор будет вставлять строку и возвращать результирующий набор идентификационных значений.
рабочий образец:
OUTPUT:
это тоже хорошо, если вы вставляете сразу несколько строк:
ВЫВОД:
28 апр. 2010, в 15:39
Поделиться
Я не уверен, как вы выполняете фактический оператор insert, но scope_identity() возвращает только последнее значение удостоверения для этого сеанса, то есть тот же SPID.
Если вы подключаетесь к БД и выполняете вставку, а затем снова подключаетесь к БД, scope_identity() всегда возвращает NULL, поскольку они находятся в двух разных сеансах.
29 апр. 2010, в 06:02
Поделиться
Ещё вопросы
- Обертка шаблонных классов с другим аргументом шаблона
- Не знаю, какой плагин JQuery использовать
- Управлять результатами, хранящимися в «обещании»
- Добавление вертикального выравнивания: от среднего до запутанного div
- как получить доступ к переменной $ _SESSION в symfony2
- 1Панды сгруппированы по числовому условию
- Как справиться со смещением часового пояса с помощью летнего времени?
- 1Цепочка обещаний не в состоянии
- jQuery недооценивает ширину и высоту некоторых элементов на странице
- PHP сортирует массив ассоциативных массивов по размеру элемента / размеру строки
- MySQL Присоединиться к таблице на случайном Нравится
- Показывать окно оповещения, когда пользователь выбирает неприемлемый файл в плагине danialfarid / ng-file-upload
- Как gclid работает с Joomla
- JQuery доступ к динамическим селекторам классов
- Поведение динамически размещаемого массива классов
- Используйте push_back () для добавления элемента в вектор, размер вектора увеличивается, но не может прочитать значения из вектора
- Функция jquery bind с событием resize. ПОСЛЕ функции загружается с событием click.
- Добавить значение из поля ввода в пользовательский параметр href
- 1Сортировка массива для бинарного поиска
- Как получить Выбранное значение из выпадающего списка в Angularjs?
- 1отправить значения TextBox из FormB в DataGridView в FormA
- jQuery Waypoint — Хотите изменить функцию
- Как работает gulp and bower в asp.net mvc5
- 1Преобразование двойного 1.557760E12 в int
- 1java.lang.NoSuchFieldError: resources — ошибка синтаксического анализатора Eclipse AST
- OpenCV: количественная оценка различий между двумя изображениями
- Как обновить общую длину поля в таблице для базы данных MYSQL для всех таблиц?
- как получить внучку от родителя в php
- 1C # строки и VARCHAR и NVARCHAR
- 1Отказ запустить Tomcat от IntelliJ IDEA
- Должен ли я хранить настройки приложения в одном массиве столбцов? или создать таблицу из нескольких столбцов?
- 1Есть ли возможность конвертировать файл в формат .csv в Android?
- 1Tkinter / ttk — treeview не занимает полный кадр
- 1Невозможно отобразить несколько графиков с помощью chart.js.
- 1Невозможно войти в учетную запись openfire через XMPP
- Угловое обнаружение простоя пользователя
- 1Сторонняя библиотека связывает обратные вызовы, но мне нужно получить доступ к свойствам класса
- MySQL + PHP: получить группу фотографий каждого отдельного объекта другой таблицы
- Почему моя программа включается в функцию только в то время, когда не задействованы условные выражения?
- Как отправить функцию обратного вызова в угловом режиме после / во время http запроса?
- 1Вложенные просмотры в питоне или пандах
- Связь между родительским и дочерним окнами iFrame с помощью jQuery
- Функция jquery перезагружает страницу при клике
- 1Узел равен NULL, используя Xpath и HtmlAgilityPack
- Мне нужен трюк, чтобы имитировать каретку на этикетке
- Селекторы идентификатора jQuery застряли при переходе между <div>
- 1Проблема с Android в разных разрешениях
- 1сообщения сокетов разделяются по netty
- 1Нажмите ComboBox для нажатия клавиши со стрелкой
- Сервер разработки Webpack работает на другом порту
Timestamp (rowvesion)
Строго говоря, существует еще один тип данных,
предназначенный для идентификации, но идентификации несколько другого рода. Тип
данных rowversion предназначен для идентификации версии строки в пределах базы
данных.


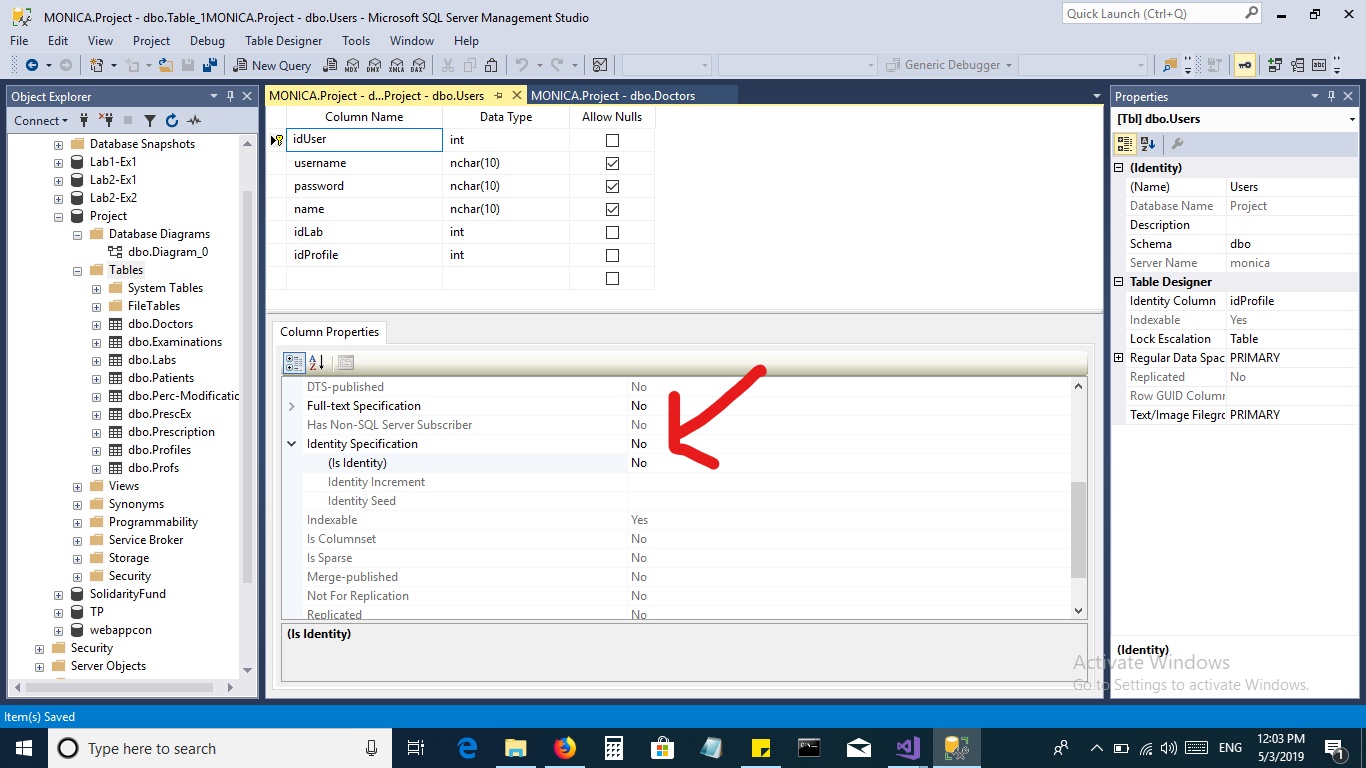


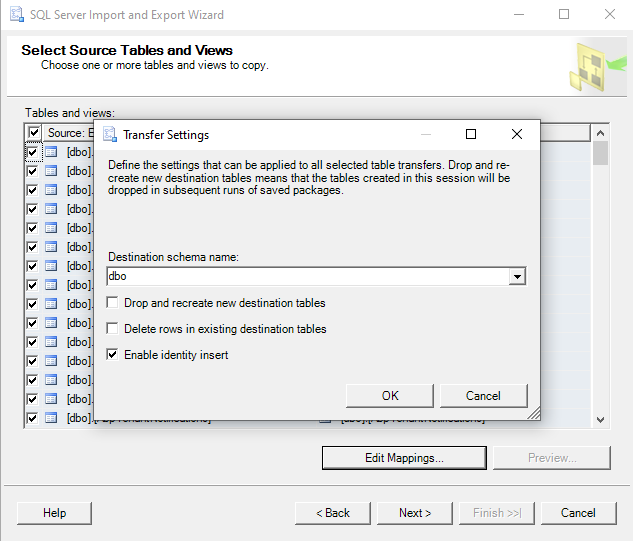

|
ПРИМЕЧАНИЕ Вообще можно указывать как timestamp |
Если в таблице имеется поле типа rowversion (оно, как
и identity, может быть только одно на таблицу), то значение в этом поле будет
автоматически меняться, при изменении любого другого поля в записи. Таким
образом, запомнив предыдущее значение, можно определить — менялась запись, или
нет, не проверяя всех полей. Для каждой базы SQL сервер ведет отдельный счетчик
rowversion. При внесении изменения в любую таблицу со столбцом такого типа,
счетчик увеличивается на единицу, после чего новое значение сохраняется в
измененной строке. Текущее значение счетчика в базе данных хранится в
переменной @@DBTS. Для хранения данных rowversion используется 8 байт, посему
этот тип вполне может быть представлен, как varbinary(8) или binary(8).
Conclusion
SQL Identity columns are useful ways to generate sequential values with minimal effort or intervention. Checking periodically to ensure that identities have sufficient room to grow can help avert disaster and allow the problem to be solved preemptively without the need for last-minute panic.
Once identified, increasing the size of an identity column isn’t difficult, and we can choose from a variety of solutions based on the size, usage, and availability required of the table. Like many maintenance tasks, being able to perform this work on our terms saves immense time, effort, and stress. This not only makes us happier, but frees up more time so we can work on more important tasks!
SQL Tutorials / Topics
Best Practices for Creating Indexes
Collate
Collate Examples
Common Table Expressions
Contained Databases
DateDiff Examples
DATENAME
DATENAME Examples
DATETIME
DATETIME2
Dense_Rank
Dense_Rank & Row_Number
DENY & REVOKE
difference between CHAR and VARCHAR
Difference between DATETIME2 / DATETIME
Difference between GRANT
difference between isNull COALESCE
Difference Between Rank
Difference decimal / float
Difference Disable and Drop Indexes
Difference RAISERROR and THROW
Difference Server Instance / Database
Drop Indexes
Dynamic Data Masking
find indexes on table
Hash Join
how to use index in sql server
isNull Vs COALESCE
Join Hints
know indexes on a table
Merge Join
Multiple Choice
Multiple Choice Questions — UNION ALL
Partially Contained Databases
PATINDEX examples
Questions & Answers Hash Join
Rank
Row_Number
sparse columns
SQL Columnstore Indexes
SQL Data Types
SQL DateDiff
SQL decimal / float difference
SQL Delete
SQL Excel Linked Server
SQL EXISTS & IN
SQL Expressions
SQL GRANT
SQL HAVING / GROUP BY
SQL Identity Column Questions
SQL Inbuilt Functions
SQL Indexes
SQL Insert
SQL Insert and Update
SQL Interview Questions
SQL Join Questions
SQL Join Questions & Answers
SQL Joins & Nulls
SQL Keys
SQL Local Variables
SQL Merge
SQL Normalization
SQL NULL
SQL ORDER BY
SQL PL/SQL Interview Questions
SQL Server — WAITFOR
SQL Server ‘Like’
SQL Server Always Encrypted
SQL Server Backup & Restore
SQL Server Cast & Convert
SQL Server Collate
SQL Server Collation Examples
SQL Server Contained Databases
SQL Server Date / Time
SQL Server DateDiff
SQL Server DATENAME
SQL Server Exclusive Lock
SQL Server Files & Filegroups
SQL Server Inbuilt Functions
sql server index creation best practices
SQL Server Indexed Views
SQL Server Indexes
SQL Server Indexes best practices
SQL Server Interview
SQL Server Interview Questions
SQL Server Join Questions
SQL Server Linked Server
SQL Server Locks
SQL Server Permissions
SQL Server Questions
SQL Server Questions Answers
SQL Server Row Level Security
SQL Server Sequence Objects
SQL Server sparse columns
SQL Server Table Columns
SQL Server Update Lock
SQL Server Window Functions
SQL sparse columns
SQL Stored Procedures Questions Answers
SQL Subqueries
SQL Subquery
SQL Tables
SQL Temp Tables
SQL Truncate
SQL Union
SQL Views
SQL Where Clause
SQL Where with Wildcards
SQL XML Data Type & Columns
Subqueries in WHERE Clause
IDENTITY_INSERT property in Microsoft SQL Server
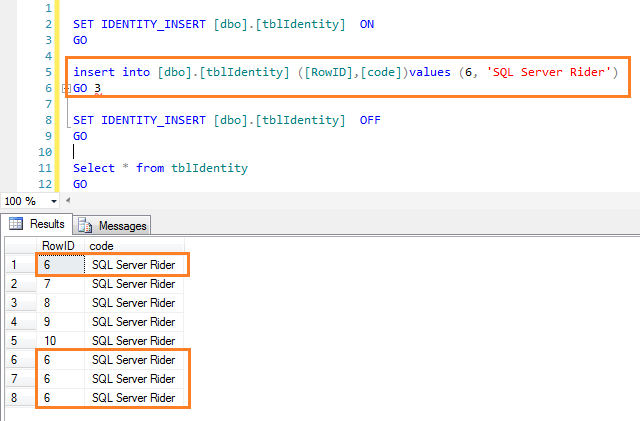
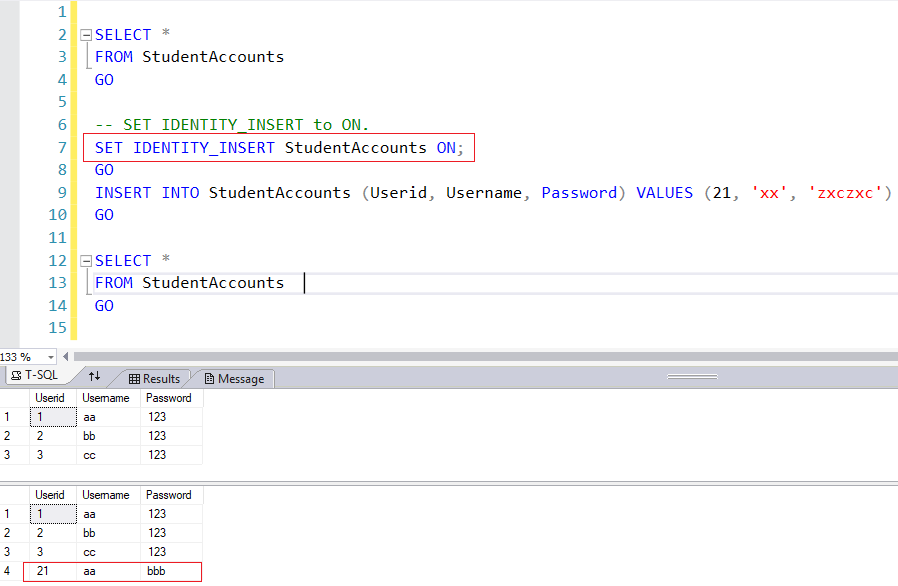
IDENTITY_INSERT is a table property that allows you to insert explicit values into the column of table identifiers, i.e. into the column with IDENTITY. The value of the inserted identifier can be either less than the current value or more, for example, to skip a certain interval of values.
When working with this property, it is necessary to take into account some nuances, let’s consider them:
- The IDENTITY_INSERT property can only take ON for one table in a session, i.e. IDENTITY_INSERT cannot be set to ON for two or more tables in a session simultaneously. If it is necessary to use IDENTITY_INSERT ON for several tables in one SQL instruction, you must first set the value to OFF for the table that has already been processed, and then set IDENTITY_INSERT to ON for the next table;
- If the IDENTITY value to be inserted is greater than the current value, the SQL server will automatically use the inserted value as the current value, i.e. if, for example, the next IDENTITY INSERT value is 5, and you use IDENTITY INSERT to insert an ID with a value of 6, then automatically the next ID value will be 7;
- In order to use IDENTITY_INSERT, a user must have the appropriate rights, i.e. to be the owner of the object or to be part of the sysadmin server role, the db_own or db_ddladm database role.
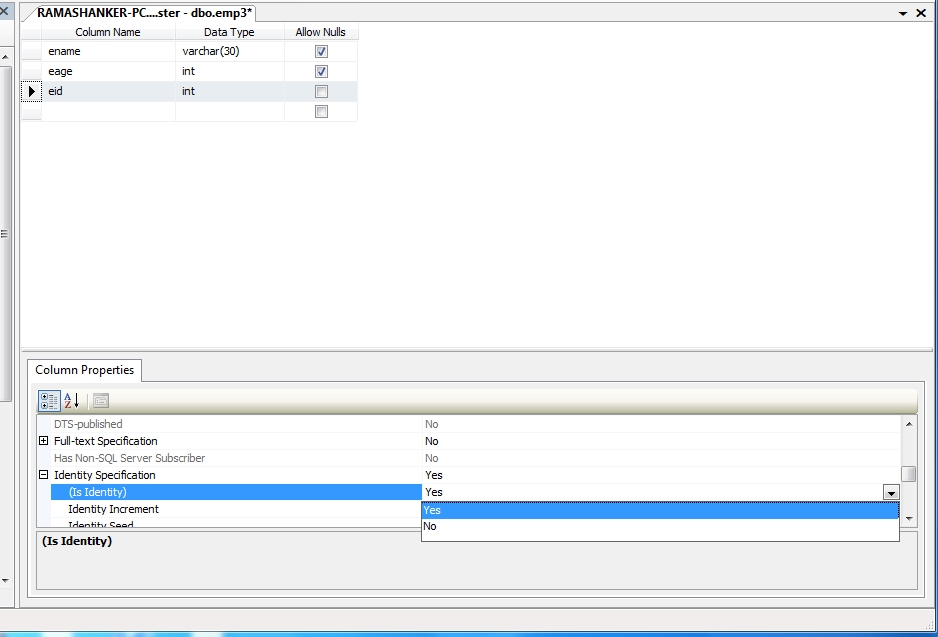
IDENTITY
The IDENTITY attribute allows you to make a column identifier. This attribute can be assigned to columns of numerical types INT, SMALLINT, BIGINT, TYNIINT, DECIMAL and NUMERIC. When adding new data to a table, SQL Server will increment the value of this column in the last record by one. Typically, the identifier role is the same column that is the primary key, although in principle this is not necessary.
You can also use the full form of the attribute:
Here, the seed parameter indicates the initial value from which the countdown will begin. And the increment parameter determines how much the next value will increase. By default, the attribute uses the following values:
So the countdown starts with 1. And the subsequent values are increased by one. But we can override that behavior. For example:
In this case, the countdown will start with 2, and the value of each subsequent record will increase by 3. That is, the first line will have the value of 2, the second – 5, the third – 8, etc.
Also note that in the table only one column should have this attribute.
Comments and Discussions
| You must Sign In to use this message board. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
General News Suggestion Question Bug Answer Joke Praise Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages.