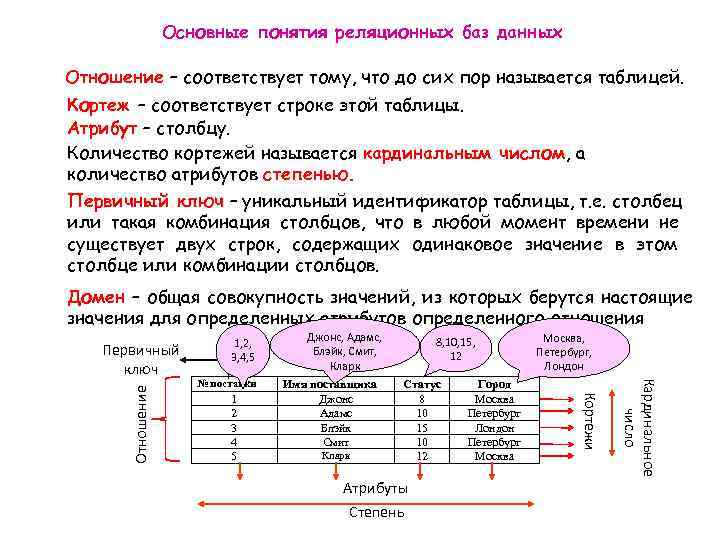
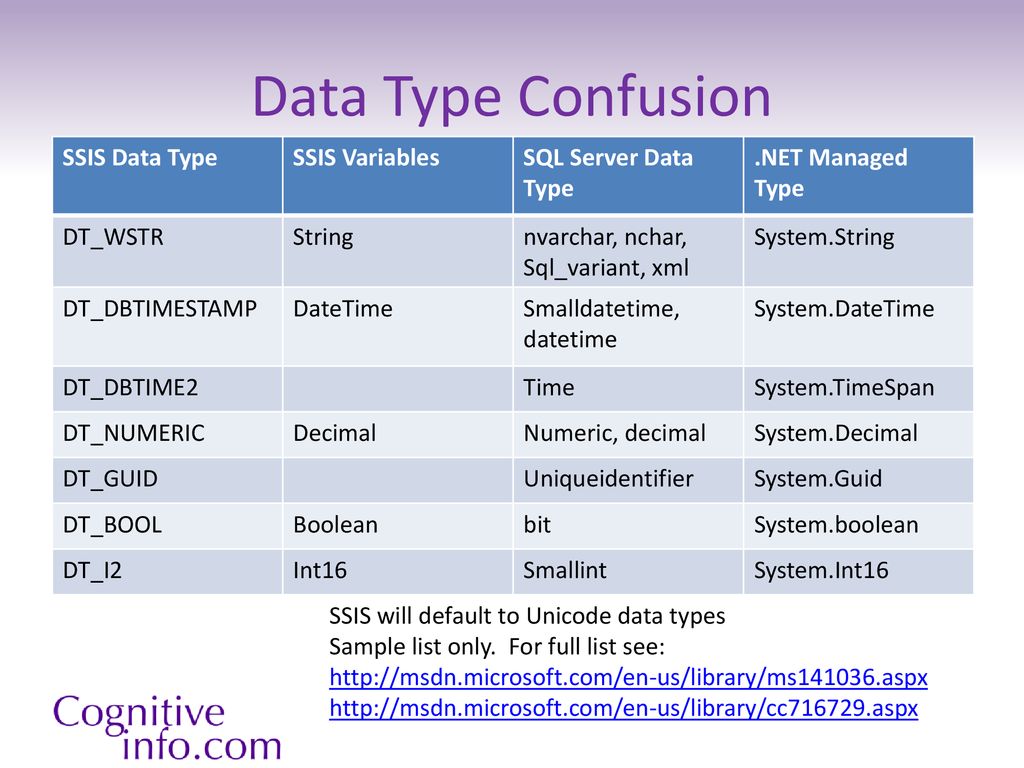
Exact numeric data types
Exact numeric data types store exact numbers such as integer, decimal, or monetary amount.
- The bit store one of three values 0, 1, and NULL
- The int, bigint, smallint, and tinyint data types store integer data.
- The decimal and numeric data types store numbers that have fixed precision and scale. Note that decimal and numeric are synonyms.
- The money and smallmoney data type store currency values.
The following table illustrates the characteristics of the exact numeric data types:
| Data Type | Lower limit | Upper limit | Memory |
|---|---|---|---|
| bigint | −2^63 (−9,223,372, 036,854,775,808) | 2^63−1 (−9,223,372, 036,854,775,807) | 8 bytes |
| int | −2^31 (−2,147, 483,648) | 2^31−1 (−2,147, 483,647) | 4 bytes |
| smallint | −2^15 (−32,767) | 2^15 (−32,768) | 2 bytes |
| tinyint | 255 | 1 byte | |
| bit | 1 | 1 byte/8bit column | |
| decimal | −10^38+1 | 10^381−1 | 5 to 17 bytes |
| numeric | −10^38+1 | 10^381−1 | 5 to 17 bytes |
| money | −922,337, 203, 685,477.5808 | +922,337, 203, 685,477.5807 | 8 bytes |
| smallmoney | −214,478.3648 | +214,478.3647 | 4 bytes |
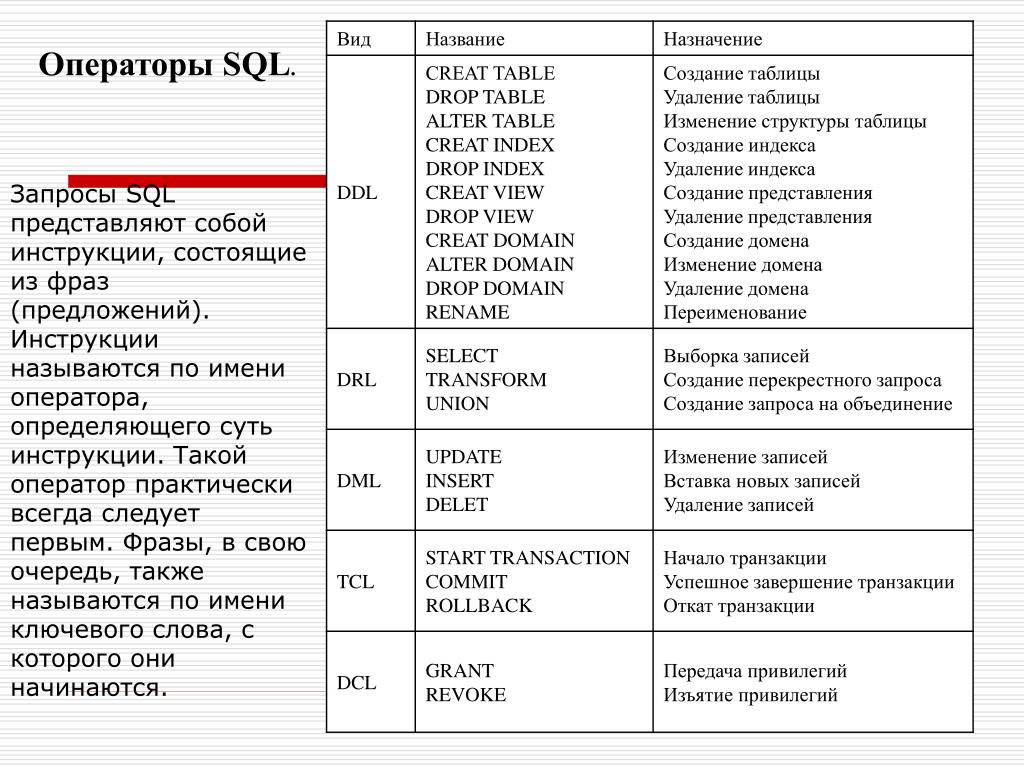
Предоставлять, отзывать и запрещать разрешения для базы данных
Язык управления данными (DCL) является подмножеством языка структурированных запросов (SQL) и позволяет администраторам баз данных настраивать безопасный доступ к реляционным базам данных. Он дополняет язык определения данных (DDL), который используется для добавления и удаления объектов базы данных, и язык манипулирования данными (DML), используемый для извлечения, вставки и изменения содержимого базы данных.
DCL является самым простым из подмножеств SQL, поскольку он состоит только из трех команд: GRANT, REVOKE и DENY. В совокупности эти три команды предоставляют администраторам возможность гибко устанавливать и удалять разрешения для базы данных.
Добавление разрешений с помощью команды GRANT
Команда GRANT используется администраторами для добавления новых разрешений пользователю базы данных. У него очень простой синтаксис, определенный следующим образом:
GRANT ON TO
Вот краткое описание каждого из параметров, которые вы можете указать с помощью этой команды:
Привилегия – может быть ключевым словом ALL (для предоставления широкого спектра разрешений) или определенным разрешением базы данных или набором разрешений. Примеры включают CREATE DATABASE, SELECT, INSERT, UPDATE, DELETE, EXECUTE и CREATE VIEW.
Объект – может быть любым объектом базы данных. Допустимые параметры привилегий зависят от типа объекта базы данных, который вы включаете в это предложение. Как правило, объект будет либо базой данных, функцией, хранимой процедурой, таблицей или представлением.
Пользователь – может быть любым пользователем базы данных. Вы также можете заменить роль для пользователя в этом пункте, если хотите использовать безопасность баз данных на основе ролей.
Если вы добавите необязательное условие WITH GRANT OPTION в конце команды GRANT, вы не только предоставите указанному пользователю разрешения, определенные в операторе SQL, но и дадите пользователю возможность предоставить те же разрешения. другим пользователям базы данных
По этой причине используйте этот пункт с осторожностью.
Например, предположим, что вы хотите предоставить пользователю Джо возможность извлекать информацию из таблицы сотрудников в базе данных под названием HR. Вы можете использовать следующую команду SQL:
ВЫБРАТЬ ГРАНТ НА HR.employees TO Джо
Теперь у Джо будет возможность извлекать информацию из таблицы сотрудников. Однако он не сможет предоставить другим пользователям разрешение на извлечение информации из этой таблицы, поскольку вы не включили условие WITH GRANT OPTION в оператор GRANT.
Отмена доступа к базе данных
Команда REVOKE используется для удаления доступа к базе данных у пользователя, ранее предоставившего такой доступ. Синтаксис этой команды определяется следующим образом:
REVOKE ON FROM
Вот краткое описание параметров команды REVOKE:
- Разрешение – указывает разрешения для базы данных, которые необходимо удалить для указанного пользователя. Команда отменяет оба утверждения GRANT и DENY, ранее сделанные для указанного разрешения.
- Объект – может быть любым объектом базы данных. Допустимые параметры привилегий зависят от типа объекта базы данных, который вы включаете в это предложение. Как правило, объект будет либо базой данных, функцией, хранимой процедурой, таблицей или представлением.
- Пользователь – может быть любым пользователем базы данных. Вы также можете заменить роль для пользователя в этом пункте, если хотите использовать безопасность баз данных на основе ролей.
- Предложение GRANT OPTION FOR устраняет возможность указанного пользователя предоставлять указанное разрешение другим пользователям. Примечание . Если вы включите условие GRANT OPTION FOR в оператор REVOKE, основное разрешение будет не отменено. Этот пункт отменяет только возможность предоставления.
- Параметр CASCADE также отменяет указанное разрешение у всех пользователей, которым указанный пользователь предоставил разрешение.
Например, следующая команда отзывает разрешение, предоставленное Джо в предыдущем примере:
ОТМЕНИТЬ ВЫБРАТЬ НА HR.employees ОТ Джо
Явный отказ в доступе к базе данных
Команда DENY используется для явного запрета пользователю получать определенное разрешение. Это полезно, когда пользователь является участником роли или группы, которой предоставлено разрешение, и вы хотите запретить этому отдельному пользователю наследовать разрешение путем создания исключения. Синтаксис этой команды следующий:
DENY ON TO
Параметры для команды DENY идентичны параметрам, используемым для команды GRANT.Например, если вы хотите, чтобы Мэтью никогда не получал возможность удалять информацию из таблицы сотрудников, введите следующую команду:
УДАЛЕНИЕ ДЕНИ НА HR.employees TO Matthew
Примеры
A. Отображение значения по умолчанию n при использовании в объявлении переменной
В приведенном ниже примере показано, что значение по умолчанию n равно 1 для типов данных и , если они используются в объявлении переменной.
В. Преобразование данных для отображения
В следующем примере два столбца преобразуются в символьные типы, после чего к ним применяется стиль, применяющий к отображаемым данным конкретный формат. Тип money преобразуется в символьные данные. К нему применяется стиль 1, отображающий значения с запятыми между каждой группой из трех цифр, отсчитывая влево от десятичной точи, и каждой группой из двух цифр, отсчитывая вправо от десятичной точки. Тип datetime преобразуется в символьные данные. К нему применяется стиль 3, отображающий данные в формате дд/мм/гг. В предложении WHERE тип money приводится к символьному типу для выполнения операции сравнения строк.
Результирующий набор:
Г. Преобразование данных uniqueidentifier
В следующем примере значение преобразуется в тип данных .
Следующий пример показывает усечение данных, когда значение является слишком длинным для преобразования в заданный тип данных. Так как тип данных uniqueidentifier ограничен 36 символами, все символы, выходящие за пределы этой длины, будут усечены.
Результирующий набор:
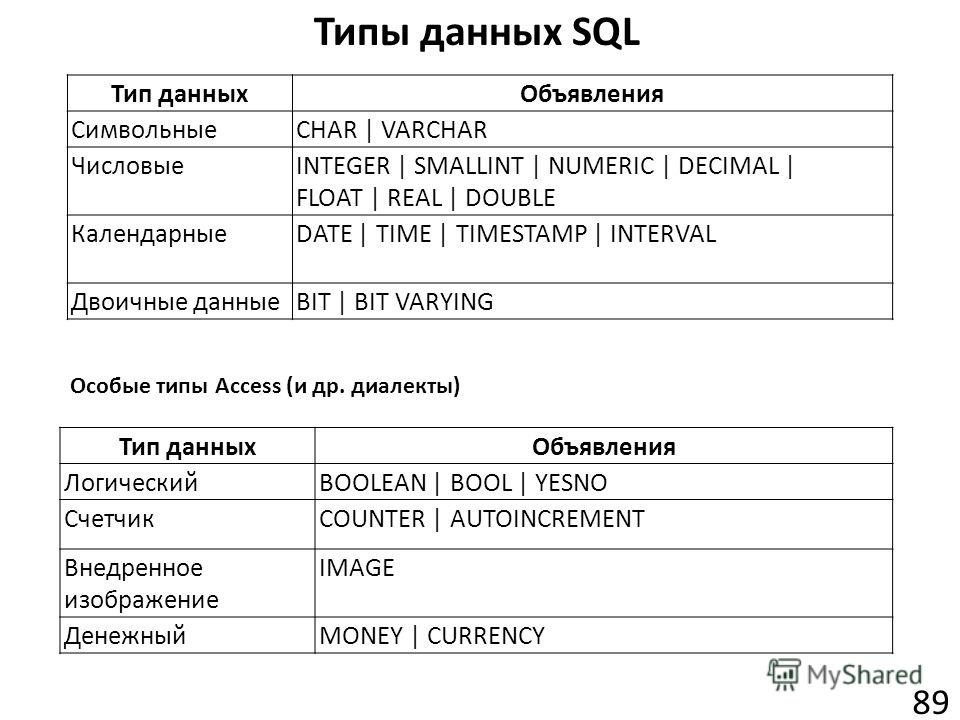
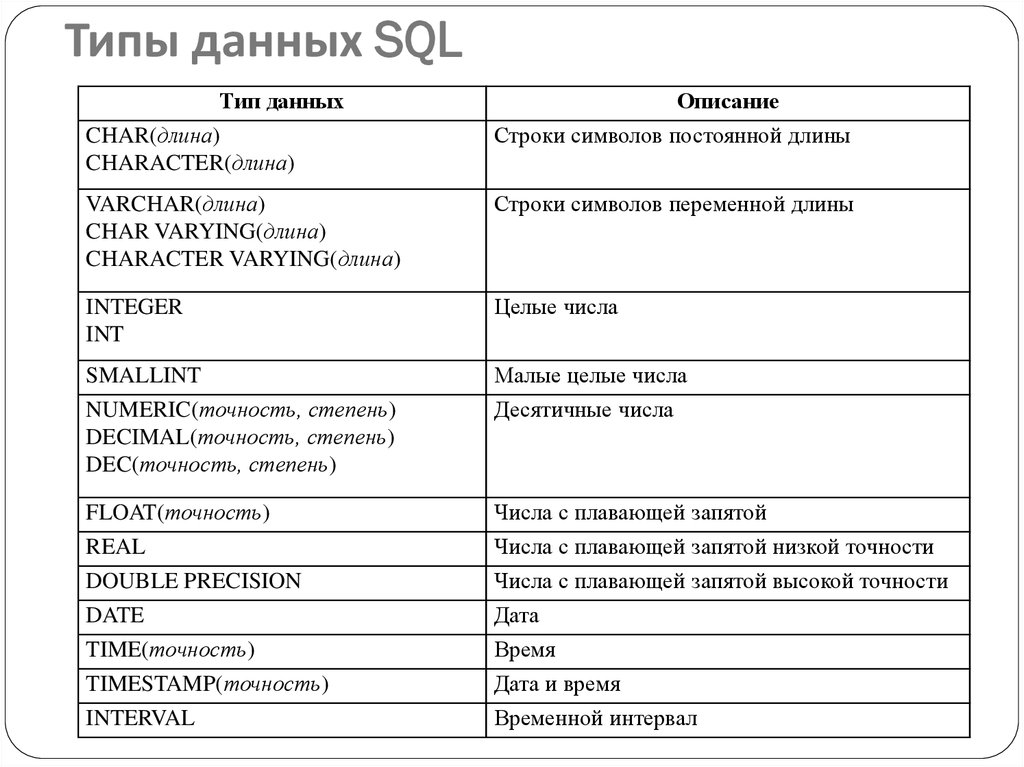
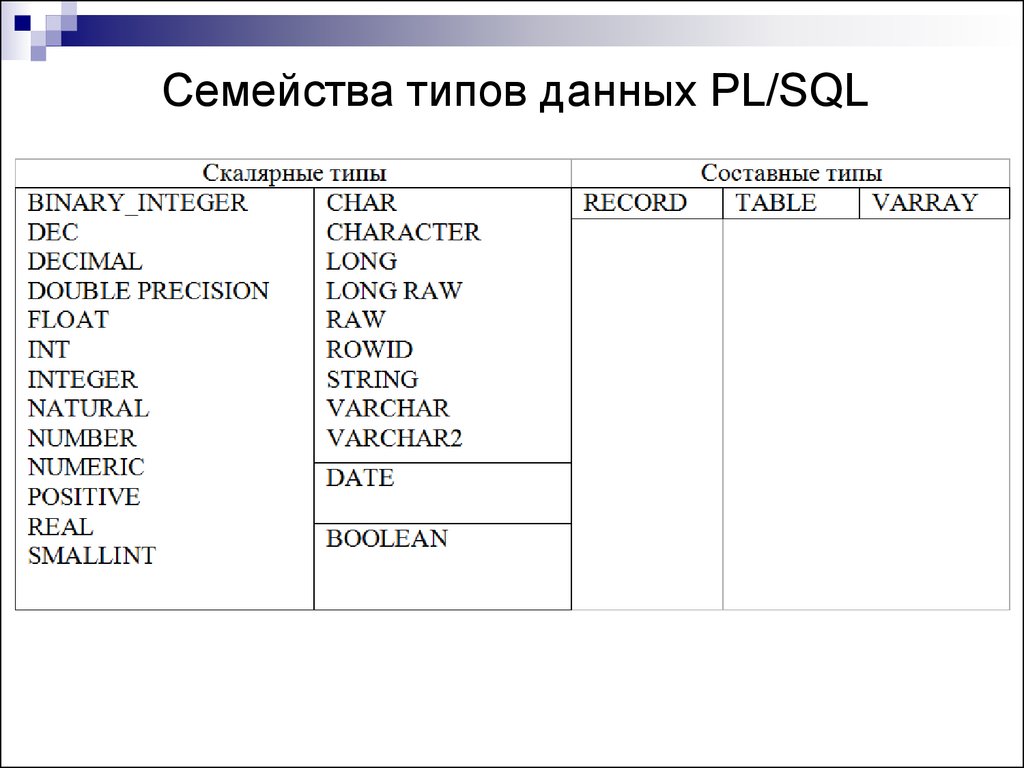
Простые типы данных
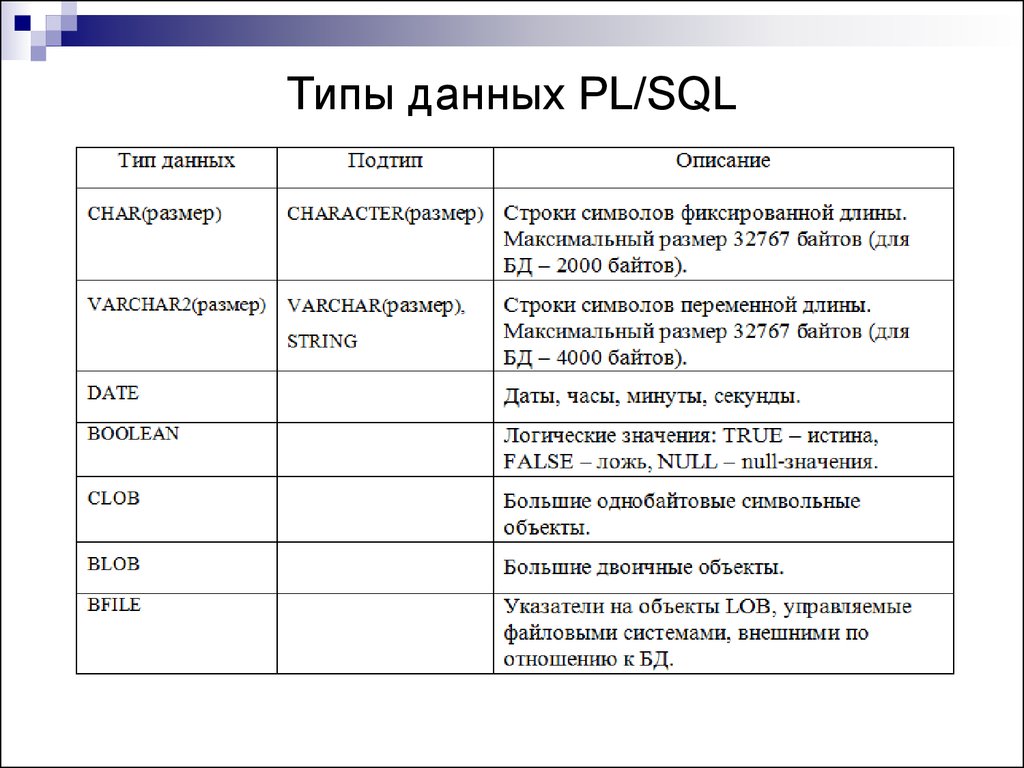
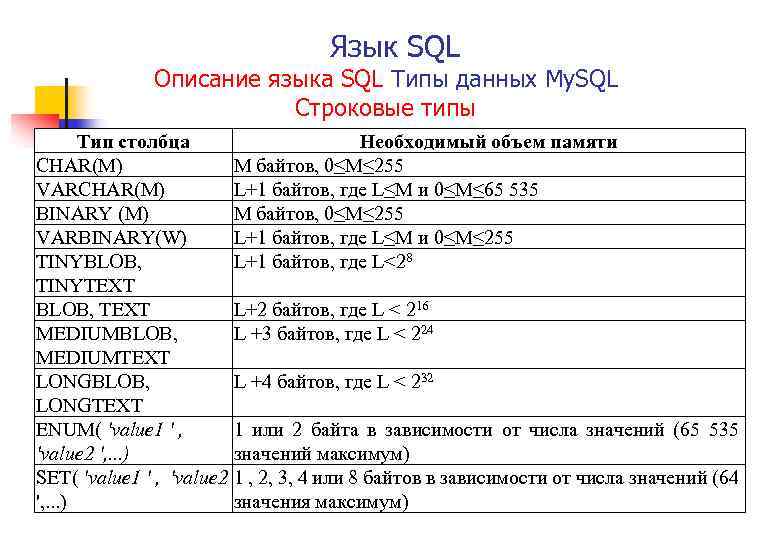
1.1. Символьные типы
1) Строки постоянной длиныCHAR() – строка текста в формате, определенном разработчиком. Натуральное число задает строки. На практике максимальное число символов бывает в диапазоне от 256 в MS SQL Server до 32767 в InterBase. CHAR трактуется как CHAR(1)
2) Строки переменной длиныVARCHAR|CHAR VARYING – строка текста переменной длины в формате, определенном разработчиком. Натуральное число задает максимальную строки, но в таблице отводится место только под реальную длину строки.
3) Особенности символьных типов ряда СУБД В ряде СУБД, например, MS SQL Server, если CHAR допускает значение NULL, то от трактуется как VARCHAR. В Oracle для полей типа VARCHAR2 можно зарезервировать в каждом блоке место для будущих обновлений поля, определив опцию PCTFREE.
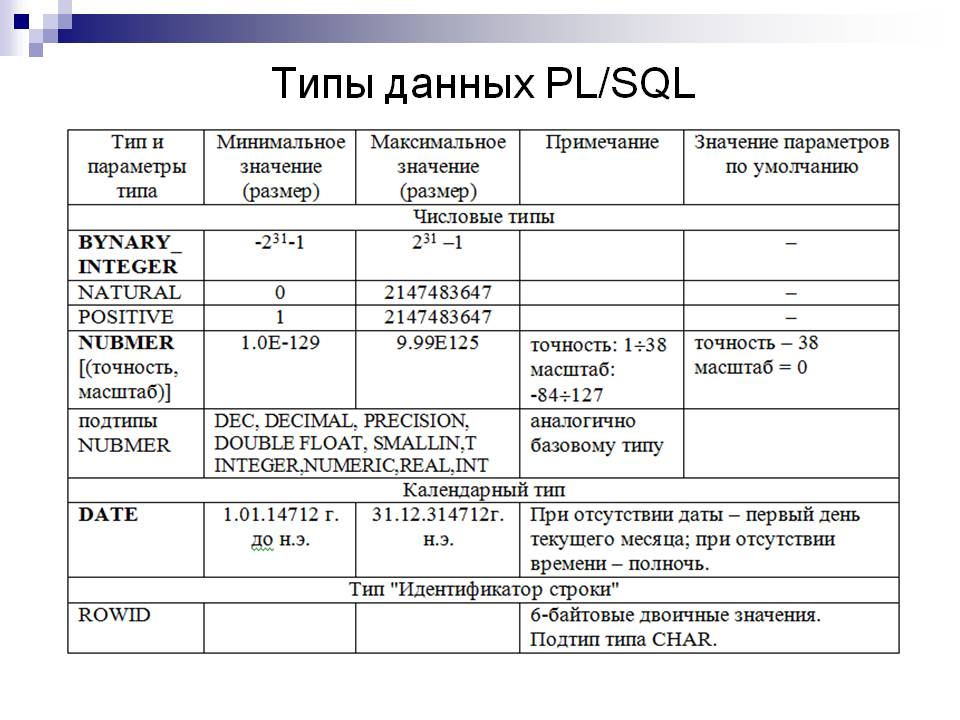
1.2. Числовые типы
1) Целые типы данныхINT – число без десятичной точки. Размер зависит от конкретного варианта реализации. Часто это 4 байта.SMALLINT – совпадает с INT, но обычно меньше по размеру. Часто 2 байта.BIGINT – совпадает с INT, но обычно больше по размеру. Это 4 или более байта.
2) Вещественные числа с фиксированной точкойDEC|)] – десятичное число с фиксированной точкой. Число имеет: — общее число значащих десятичных разрядов, — максимальное количество разрядов справа от десятичной точки.
3) Вещественные числа с плавающей точкойFLOAT – число с плавающей точкой, представленное в экспоненциальной форме по основанию 10. Задается максимальная точность.REAL – совпадает с FLOAT, но точность зависит от варианта реализации.DOUBE – совпадает с REAL, но точность может быть больше в конкретной реализации.
1.3. Даты и типы времени
DATE – дата в формате yyyy-mm-dd (ISO), mm/dd/yyyy (ANSI).TIME – время в формате hh.mm.ss (ISO), hh:mm am/pm (ANSI).INTERVAL – дата и время в формате yyyy-mm-dd-hh.mm.ss.nnnnn (ISO). (часто TIMESTAMP).
Примечание: Типы даты и времени могут задаваться в виде строковых литералов. Дата: ‘yyyy-mm-dd’, время: ‘hh.mm.ss’, Интервал: ‘yyyy-mm-dd-hh.mm.ss.n…n’.
1.4. Логический тип
BOOLEAN – логическое значение (TRUE, FALSE, UNKNOWN). Для правильного понимания таблицы истинности в трехзначной логике (3VL) можно условно считать, что FALSE — 0, TRUE -1, а UNKNOWN – 0.5. Тогда: — Оператор AND возвращает наименьшее. — Оператор OR – наибольшее из исходных значений. — NOT UNKNOWN = UNKNOWN.
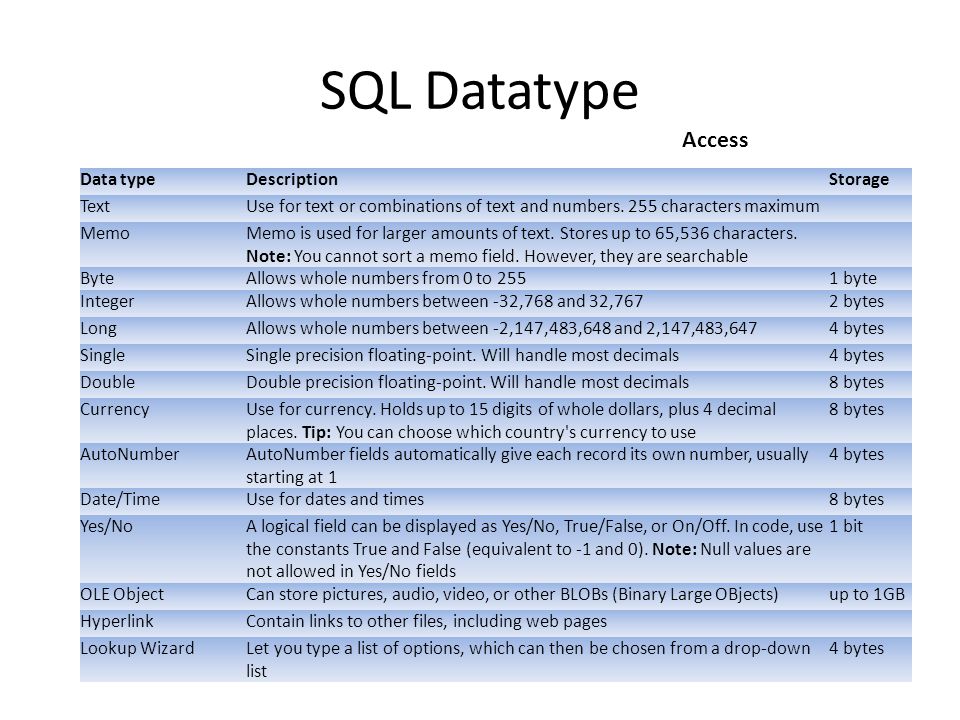
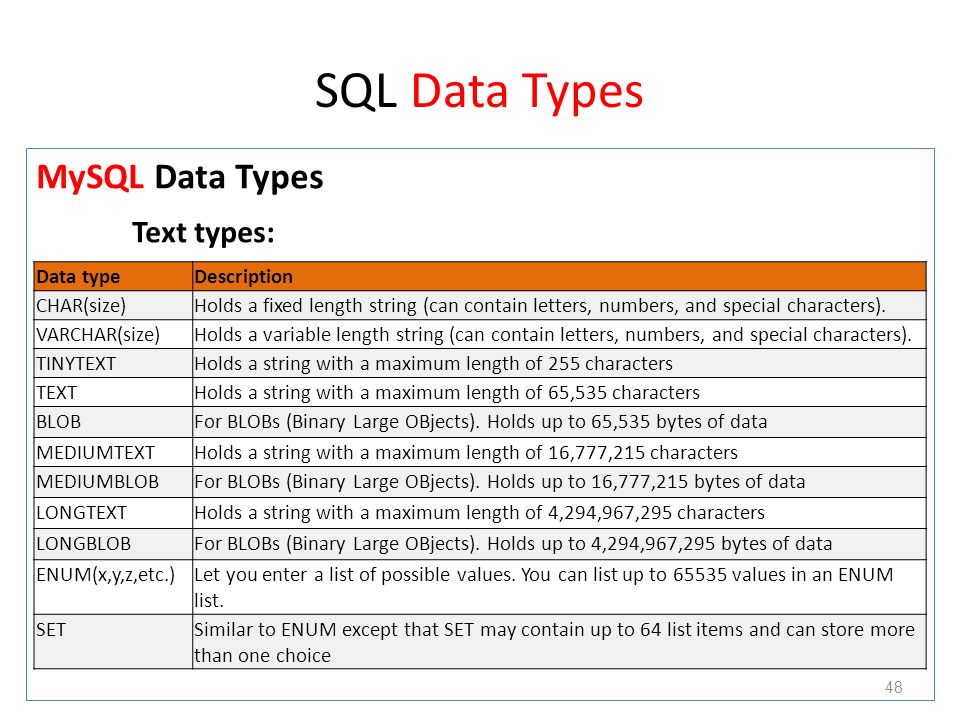
Типы данных Microsoft Access
| Тип данных | Описание | Хранения |
|---|---|---|
| Text | Используется для текста или комбинаций текста и чисел. 255 символов максимум | |
| Memo | MEMO используется для больших объемов текста. Хранит до 65 536 символов. Примечание: Поле MEMO нельзя сортировать. Тем не менее, они доступны для поиска | |
| Byte | Позволяет целые числа от 0 до 255 | 1 byte |
| Integer | Позволяет целые числа между-32 768 и 32 767 | 2 bytes |
| Long | Позволяет целые числа между-2 147 483 648 и 2 147 483 647 | 4 bytes |
| Single | Одинарная точность с плавающей запятой. Будет обрабатывать большинство десятичных знаков | 4 bytes |
| Double | Двойная точность с плавающей запятой. Будет обрабатывать большинство десятичных знаков | 8 bytes |
| Currency | Использовать для валюты. Вмещает до 15 цифр целых долларов, плюс 4 десятичных знака. Совет: Вы можете выбрать валюту страны для использования | 8 bytes |
| AutoNumber | Поля автонумерации автоматически дают каждой записи свой номер, обычно начиная с 1 | 4 bytes |
| Date/Time | Использовать для дат и времени | 8 bytes |
| Yes/No | Логическое поле может отображаться как Yes/No, true/false или вкл/выкл. В коде используйте Константы true и false (эквивалентно-1 и 0). Примечание: Значения NULL не разрешены в полях «да/нет» | 1 bit |
| Ole Object | Может хранить изображения, аудио, видео, или другие BLOB-объекты (двоичные больших объектов) | up to 1GB |
| Hyperlink | Содержать ссылки на другие файлы, включая веб-страницы | |
| Lookup Wizard | Позволяет ввести список опций, которые затем можно выбрать из раскрывающегося списка | 4 bytes |
❮ Назад
Дальше ❯
All the MS SQL Server Data Types in a Nutshell
That’s all there is! We’ve gone through all the data types available in SQL Server, comparing them and getting an idea of where to apply each one.
The basic data type categories – such as numerical, text, and date and time – are used on a daily basis. You should have them at your fingertips. However, the less-common data types are also important; they may not be used as often, but they can be very helpful in certain cases!
When you’re creating a database, it’s crucial to choose the right data types. Don’t miss our track on Creating Database Structure if you want to learn more about building databases and selecting data types. To get a sneak peek, check out an article about this track.
To deepen your knowledge of MS SQL Server data types, you might also want to try our course on Data Types in SQL.
Good luck!
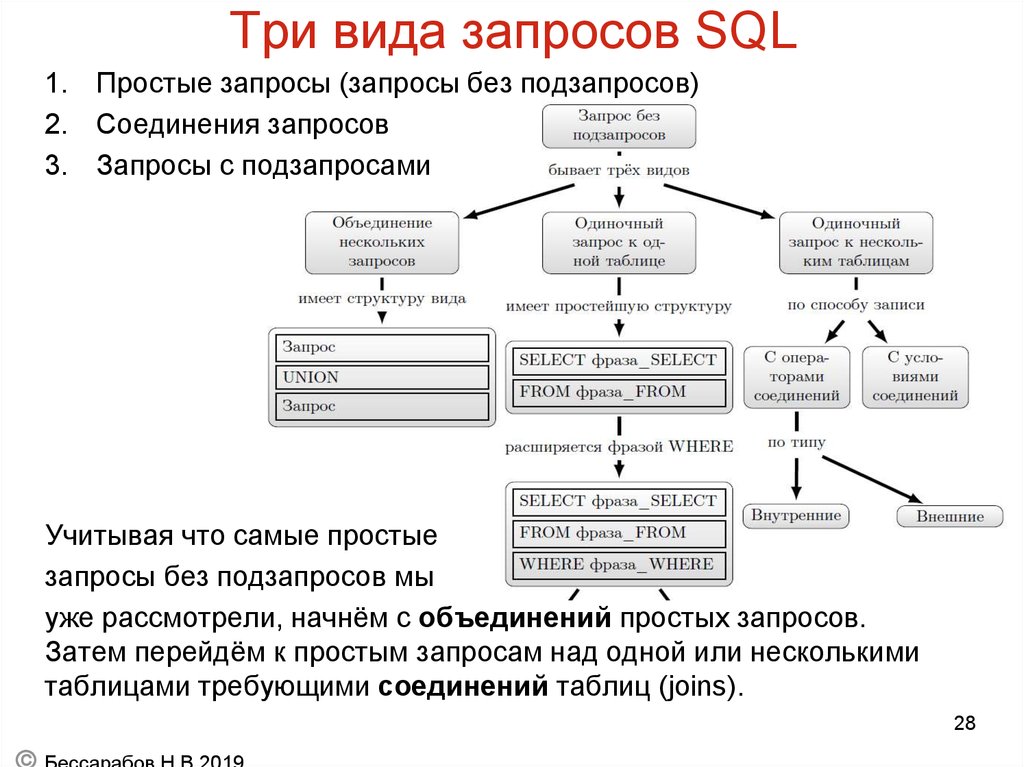
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_date FROM sys.databases;
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=’BASE TABLE’
3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
SELECT * FROM tAuthors;
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
SELECT count(*) FROM tAuthors;
5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
SELECT * FROM tAuthors ORDER BY AuthorId OFFSET 3 ROWS FETCH NEXT 2 ROWS ONLY;
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
SELECT * FROM tAuthors ORDER BY AuthorFirstName;
7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
SELECT * FROM tAuthors ORDER BY AuthorId DESC;
![]() Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
SELECT * FROM tAuthors WHERE AuthorFirstName=’Александр’;
9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘се%’;
10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘%ат’ ORDER BY AuthorId;
Видео курсы по схожей тематике:
SQL Базовый. Разбор ДЗ
Владимир Дымчук
MySQL Базовый
Андрей Бондаренко
How to SQL Базовый
Владимир Дымчук
11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
SELECT * FROM tAuthors WHERE AuthorId IN (2,4);
12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
SELECT max(AuthorAge) FROM tAuthors;
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
SELECT AuthorFirstName, AuthorLastName FROM tAuthors;
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
SELECT AuthorId, AuthorFirstName, AuthorLastName FROM tAuthors WHERE AuthorId!=’3′;
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД. Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.



INSERT INTO tAuthors VALUES (‘Уильям’, ‘Шекспир’, ’51’);
Проверим:
SELECT * FROM tAuthors;
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.
UPDATE tAuthors SET AuthorFirstName = ‘Лев’, AuthorLastName=’Толстой’, AuthorAge = ’82’ WHERE AuthorId = ‘6’;
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
SELECT * FROM tAuthors;
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
DELETE FROM tAuthors WHERE AuthorId = ‘5’;
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
SELECT * FROM tAuthors;
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors целиком, выполнив простой SQL запрос:
DROP TABLE tAuthors;
Далее рассмотрим сложные запросы SQL.
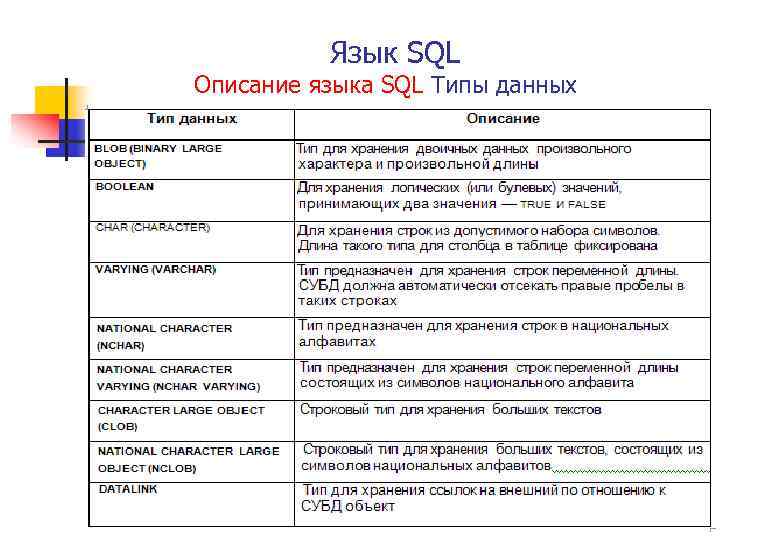
Типы LOB
CLOB (Character Large Object) – ведут себя во многом подобно символьным строкам, но их запрещено использовать: — В ограничениях Primary Key, Unique, Foreign Key. — В сравнениях, отличных от чистых равенств или неравенств, в разделах Order By и Group By.BLOB (Binary Large Object) – поток байт в формате, в котором пользователь сможет их записать в колонку БД.
3.1. Проблемы использования LOB
1) Проблемы хранения Хранение LOB прямо в таблицах вместе с другими данными нарушает работу оптимизатора, основанную на использовании страниц данных, размер которых соответствует размеру дисковых страниц. Поэтому LOB хранятся в отдельных областях (сегментах) дисковой памяти.
2) Проблемы обновления Поскольку размер LOB объектов может достигать десятков и сотен мегабайт, то их невозможно хранить в буферах целиком. Поэтому данные типа LOB обрабатываются по частям, например, группами страниц. В операторах INSERT и UPDATE для обработки по частям используются специальные технологии, позволяющие многократно вызывать одну и ту же API-функцию для одного поля. Аналогично и при считывании данных операторами SELECT и FETCH.
3) Проблемы выполнения транзакций Для поддержки транзакций большинство СУБД ведет журнал транзакций, в котором записываются копии данных до и после модификаций. Однако из-за больших размеров LOB не записываются в журнал.
4) Проблемы пересылки по сети Часто клиент и сервер работают на разных компьютерах, и пересылка LOB по сети может прервать работу всех, кто пользуется сетью в данных момент.
4.3 Генерация значений колонок
Различные
возможности позволяют вам генерировать значения колонок: тождеств (Identity), NEWID функция
и тип данных uniaueidentifier.
Использование свойства Identity
Вы можете
использовать свойство Identity (тождество) для
создания колонки, которая содержит сгенерированное системой следующее значение,
определяющее каждую строку, вставленную в таблицу. Тождественная колонка часто
используется в качестве значений первичного ключа.
Когда SQL Server
автоматически предоставляет значение ключа, можно уменьшить затраты на
улучшение производительности. Это облегчает программирование, делает первичный
ключ коротким и уменьшает пользовательские транзакции.
Рассмотрите
следующие рекомендации для использования свойства Identity:
Только одна тождественная колонка разрешена в таблице;
Она должна использоваться с целочисленными типами данных.;
Оно не может обновляться;
Вы можете использовать ключевое слово IDENTITYCOL в
месте с именем колонки в запросе. Это позволяет вам ссылаться на колонку в
таблице со свойством Identity, не зная имени
колонки;
Не разрешает нулевые значения.
Вы можете
получить информацию о свойстве Identity
несколькими путями:
Две системные функции возвращают информацию о тождественной
колонке: IDENT_SEED (возвращает начальное значение) и IDENT_INCR (возвращает значение приращения);
Вы можете получить информацию о Identity
колонке, используя глобальную переменную @@identity,
которая определяет значение последней вставленной строки в тождественную
колонку в течение сессии;
Функция SCOPE_IDENTITY
возвращает последнее значение, вставленное в колонку в некоторых рамках. Рамки
определяются процедурой, триггером, функцией или batch;
Функция IDENTITY_INSERT
возвращает последнее значение, сгенерированное для определённой таблицы в любой
сессии или рамке.
Вы можете
управлять свойством Identity несколькими путями:
Вы можете позволить явно вставлять значения в тождественную
колонку таблицы с помощью установки свойства IDENTITY_INSERT в
значение ON. Когда это свойство
установлена, оператор INSERT должен указывать значение колонки.



Для проверки возможности изменения текущего тождественного поля
таблицы, вы можете использовать оператор DBCC CHECKIDENT.
Он позволяет вам сравнить текущее тождественное значение с максимальным
значением в тождественной колонке.
Тождественное свойство не обеспечивает уникальности. Для
уникальности создавайте уникальный индекс.
Следующий
пример создаёт таблицу с двумя колонками, StudentID
и Name. Свойство Identity
используется для автоматического увеличения в каждой строке колонки StudentID. Начальное значение устанавливается в 100, а
приращение в 5. Значения для этой колонки будут генерироваться в виде 100, 105,
110, 115 …
CREATE
TABLE
Class
(StudentID INT IDENTITY(100,5) NOT NULL,
Namt varchar (16))
Использование функции NEWID и
уникального идентификатора
Тип данных uniqueidentifier (уникальный
идентификатор) и функция NEWID –
это две возможности, которые используются вместе. Используйте эти возможности,
когда данные сопоставляются из нескольких таблиц в одну большую таблице, когда
нужно обеспечить уникальность всех записей:
Тип данных uniqueidentifier хранит
число уникального идентификатора в виде 16-байт бинарной строки. Тип данных использует
для хранения глобальный уникальный идентификатор (GUID);
Функция NEWID
создаёт новое число уникального идентификатора, которое хранится в типе данных uniqueidentifier;
Тип данных uniqueidentifier не
генерирует автоматически новый ID для вставляемой
строки в отличие от свойства Identity.
Пример
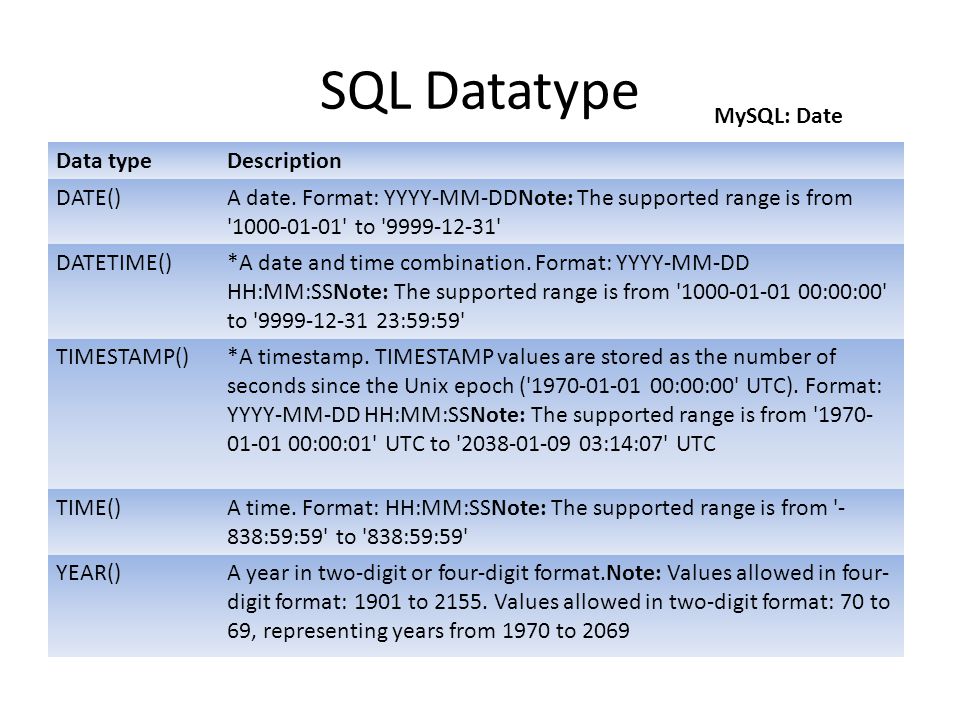
Календарные типы данных
| Тип данных | Объем памяти | Диапазон | Описание |
| DATE | 3 байта | от ‘1000-01-01’ до ‘9999-12-31’ | Предназначен для хранения даты. В качестве первого значения указывается год в формате «YYYY», через дефис — месяц в формате «ММ», а затем день в формате «DD». В качестве разделителя может выступать не только дефис, а любой символ отличный от цифры. |
| TIME | 3 байта | от ‘-838:59:59’ до ‘838:59:59’ | Предназначен для хранения времени суток. Значение вводится и хранится в привычном формате — hh:mm:ss, где hh — часы, mm — минуты, ss — секунды. В качестве разделителя может выступать любой символ отличный от цифры. |
| DATATIME | 8 байт | от ‘1000-01-01 00:00:00’ до ‘9999-12-31 23:59:59’ | Предназначен для хранения и даты и времени суток. Значение вводится и хранится в формате — YYYY-MM-DD hh:mm:ss. В качестве разделителей могут выступать любые символы отличные от цифры. |
| TIMESTAMP | 4 байта | от ‘1970-01-01 00:00:00’ до ‘2037-12-31 23:59:59’ | Предназначен для хранения даты и времени суток в виде количества секунд, прошедших с полуночи 1 января 1970 года (начало эпохи UNIX). |
| YEAR (M) | 1 байт | от 1970 до 2069 для М=2 и от 1901 до 2155 для М=4 | Предназначен для хранения года. М — задает формат года. Например, YEAR (2) — 70, а YEAR (4) — 1970. Если параметр М не указан, то по умолчанию считается, что он равен 4. |
Анализ данных на языке SQL
Этот курс в нашем Центре успешно закончили 7936 человек!
Data analysis with SQL.
Язык SQL – самый мощный инструмент для обработки данных, придуманный человеком. Этот простой и выразительный язык запросов поддерживается всеми современными базами данных (в том числе Microsoft, Oracle, IBM) и инструментами анализа и программирования (в том числе Excel).
На данном курсе Вы познакомитесь с базами данных и языком запросов SQL. Цель курса – научиться свободно и уверенно пользоваться современными базами данных, в том числе анализировать данные и строить отчёты.
Аудитория курса: аналитики и разработчики отчётов, работающие с базами данных.
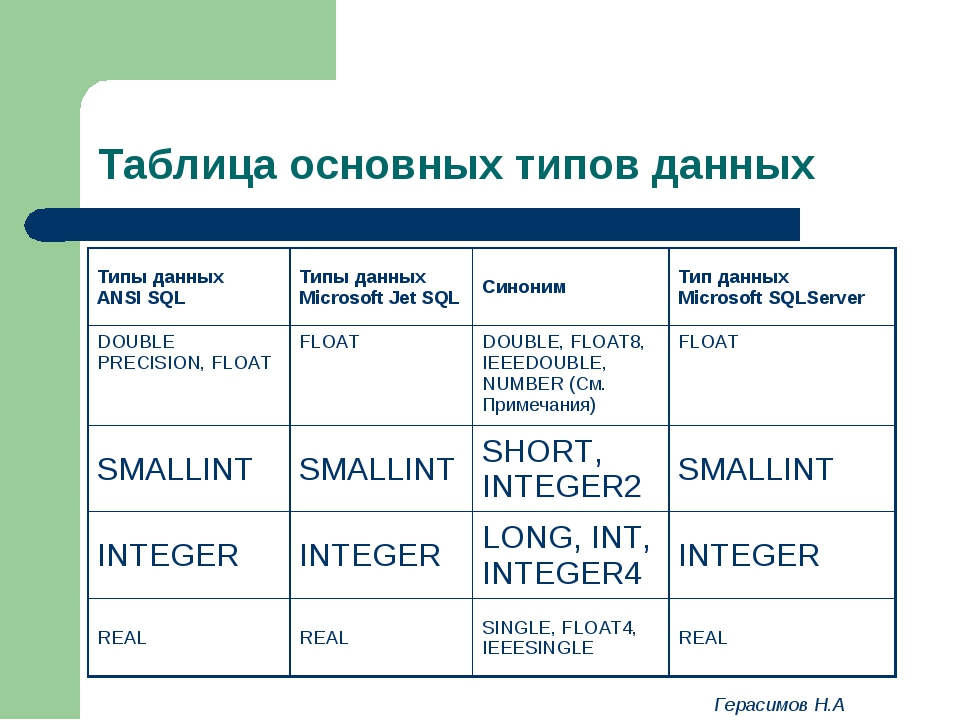
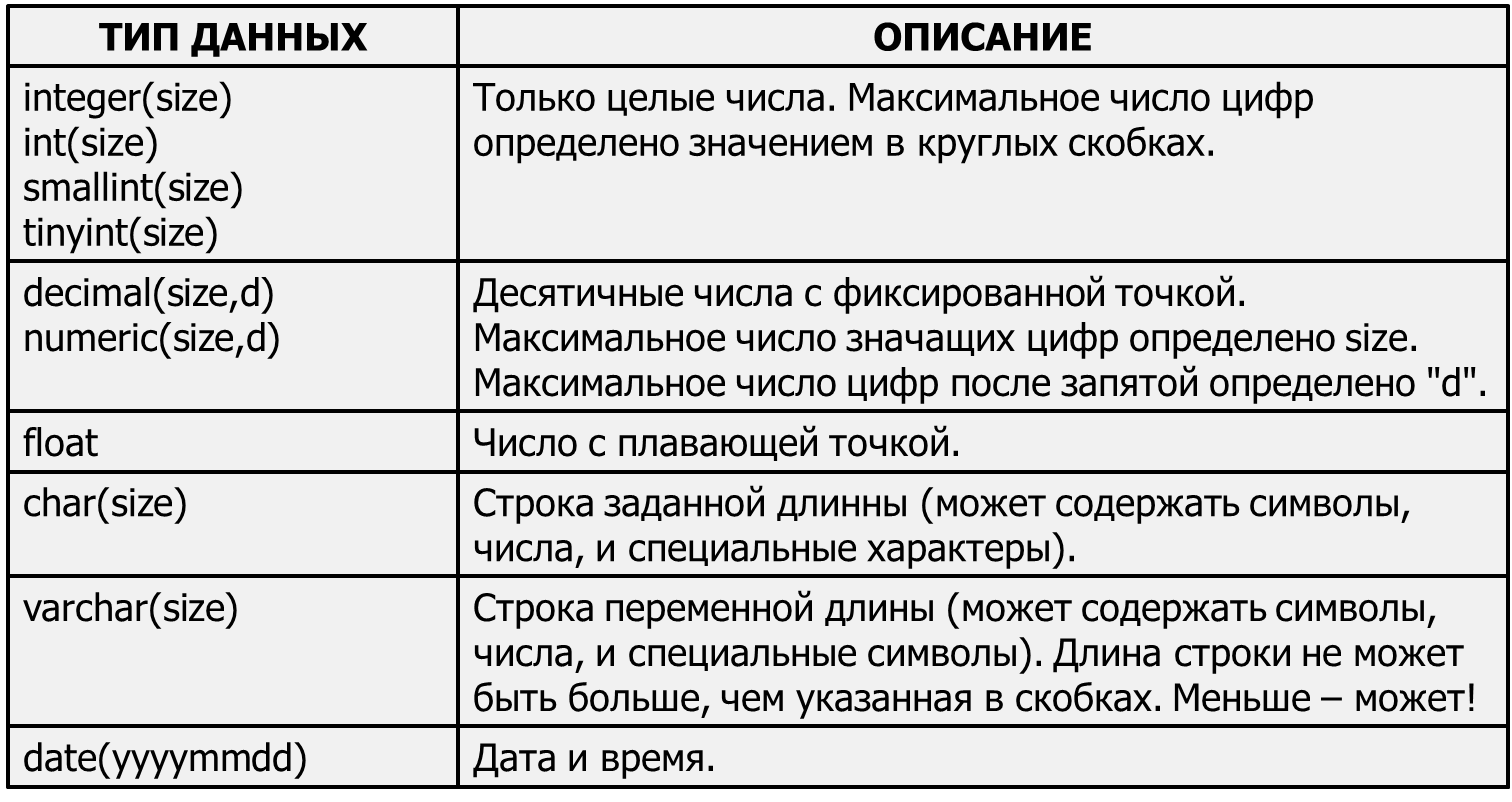
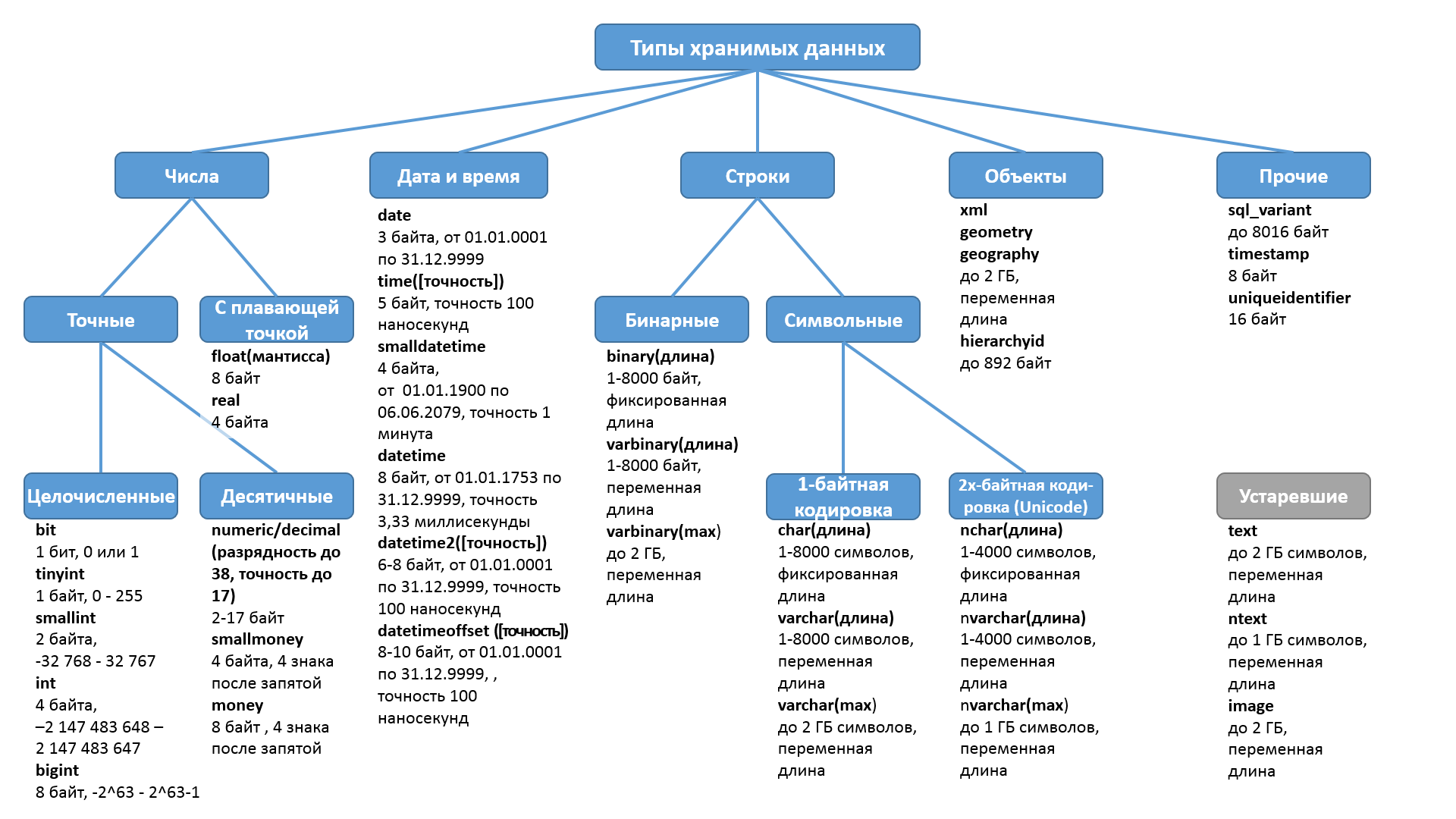
Что такое тип данных в SQL Server?
Тип данных – это характеристика, определяющая, какого рода данные будут храниться в объекте. Например: целые числа, числовые данные с плавающей запятой, данные денежного типа, дата, время, текст, двоичные данные и так далее. У каждого столбца, выражения, переменной или параметра есть определенный тип данных. В Microsoft SQL Server существует набор системных типов данных, который и определяет все доступные по умолчанию типы данных для использования. У разработчиков также существует возможность создавать псевдонимы типов данных основанные на системных типах, а также собственные пользовательские типы данных, о том, как реализовать псевдоним типа данных, мы разговаривали в материале – «Создание псевдонима типа данных в Microsoft SQL Server на T-SQL».
Типы данных в MS SQL Server делятся на следующие категории:
- Точные числа;
- Приблизительные числа;
- Символьные строки;
- Символьные строки в Юникоде;
- Дата и время;
- Двоичные данные;
- Прочие типы данных.
NoSQL как альтернатива традиционным БД
Мир меняется. В ходе цифровой трансформации перед бизнесом встают новые задачи. Компании решают их с помощью новых баз данных. Во-первых, чтобы не перегружать имеющиеся, во-вторых, не для всех современных задач подходят классические реляционные СУБД.
И вот, в начале 2000-х появились нереляционные базы. Помимо решения новых задач, их разработчики сделали упор на исправление главных недостатков реляционных баз — проблем с гибкостью, низкой производительностью и масштабируемостью.
В NoSQL нет таких понятий, как строки, столбцы, таблицы и их соединения. Данные в нереляционных базах хранятся как объекты с произвольными атрибутами: это могут быть пары «ключ-значение», документы в формате JSON, графы и так далее.
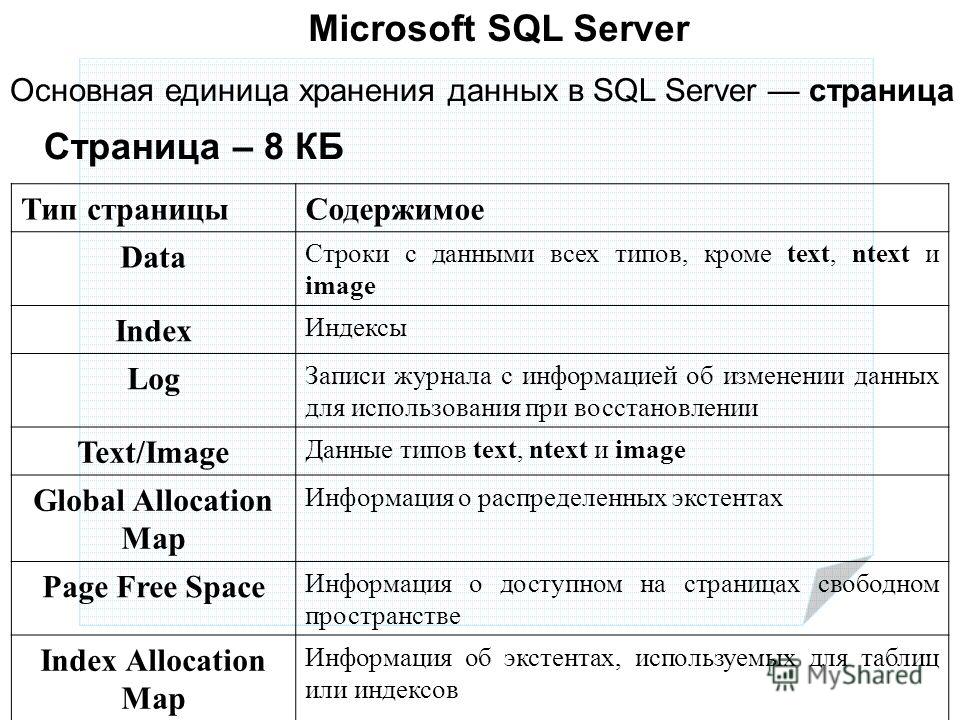
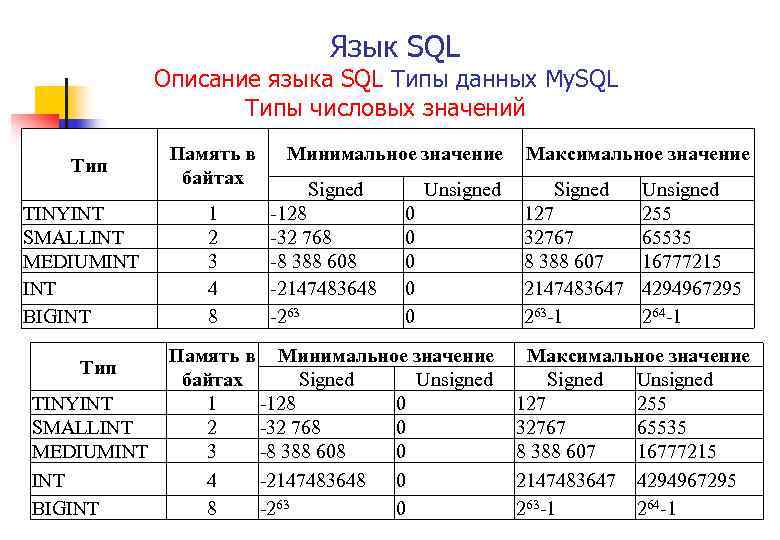
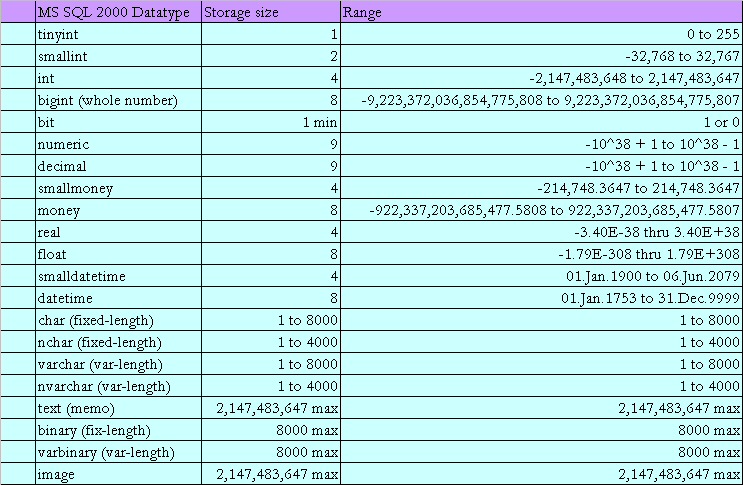
Типы данных
MS SQL Server поддерживает все основные простые типы данных, используемые в современных языках программирования. В версии MS SQL Server 2008 были добавлены несколько новых типов, а некоторые перестали рекомендоваться к использованию.
- Целые числа:
- Bit (1 байт). На самом деле первый бит в таблице будет занимать один байт, однако следующие семь бит в этой таблице будут храниться в том же байте.
- Bigint (8 байт). 64-разрядное целое число, позволяет хранить числа от –263 до +263–1.
- Int (4 байта). Диапазон значений от –2 147 483 648 до +2 147 483 647.
- SmallInt (2 байта). Диапазон значений от –32768 до +32767.
- TinyInt (1 байт). Диапазон значений от 0 до 255.
- Числа с фиксированной запятой:
- Decimal или Numeric. Диапазон значений от –1038–1 до +1038–1.
- Money (8 байт). Денежный формат, диапазон значений от –263 до +263 с четырьмя знаками после запятой.
-
SmallMoney (4 байта). Денежный формат, диапазон значений от
–214748,3648 до +214748,3647.
- Числа с плавающей запятой:
Float. Диапазон значений от –1,79E +308 до +1,79E +308.
- Дата и время:
- DateTime (8 байт). Диапазон значений от 1 января 1753 года до 31 декабря 9999 года с точностью до трех сотых секунды.
- DateTime2 (6-8 байт). Новый тип данных, поддерживает точность до 0,1 мс.
- SmallDateTime (4 байта). Диапазон значений от 1 января 1900 года до 6 июня 2079 года с точностью одна минута.
- DateTimeOffset (8-10 байт). Аналогичен типу DateTime, но хранит ещё сдвиг относительно времени UTC1.
- Date (3 байта). Хранит только дату. Диапазон значений от 1 января 0001 года до 31 декабря 9999 года.
- Time (3-5 байт). Хранит только время с точностью до 0,1 мс.
- Символьные строки:
- Char. Строка фиксированной длины. Максимальная длина строки 8000 символов.
- VarChar. Строка переменной длины. Максимальная длина строки 8000, но при использовании ключевого слова «max» может хранить до 231 байт.
- Text. Применялся для хранения больших строк, сейчас рекомендуется использование varchar(max) вместо text. Оставлен для обратной совместимости.
- Nchar. Строка фиксированной длины в Юникоде. Максимальная длина строки 4000 символов.
- NvarChar. Строка переменной длины в Юникоде. Максимальная длина строки 4000 символов, но при использовании ключевого слова «max» может хранить до 231 байт.
- Ntext. Аналогичен типу text, но предназначен для работы с Юникод. Сейчас рекомендуется использовать nvarchar(max). Оставлен для обратной совместимости.
- Двоичные данные:
- Binary. Позволяет хранить двоичные данные размером до 8000 байт.
- VarBinary. Тип данных переменной длины, позволяет хранить до 8000 байт, но при использовании ключевого слова «max» до 231 байт.
- Image. Использовался для хранения больших объемов данных, сейчас рекомендуется использовать varbinary(max). Оставлен для обратной совместимости.
- Прочие типы данных:
- Table. Особый тип данных, используемый в основном для временного хранения таблиц и для передачи в качестве параметра в функции.
- HierarchyID. Используется для представления положения в иерархической структуре.
- Sql_variant. Тип данных, хранящий значения различных типов данных, поддерживаемых MS SQL Server.
- XML. Позволяет хранить XML-данные.
- Cursor (1 байт). Тип данных для переменных или выходных параметров хранимых процедур, которые содержат ссылку на курсор.
- Timestamp/ rowversion (8 байт). Это тип данных, который представляет собой автоматически сформированные уникальные двоичные числа в базе данных. Значение данного типа генерируется БД автоматически при вставке или изменении записи.
- UniqueIdentifier (16 байт). Представляет собой GUID (Special Globally Unique Identifier). Гарантируется уникальность данного значения.
Распространенные ошибки при выборе типа данных в T-SQL
В начале статьи я говорил, что выбор неоптимального типа данных может сказаться на размере базы данных, так вот одной из самых распространенных ошибок при проектировании таблицы является выбор для столбца, который должен содержать тип данных Boolean (т.е. 0 или 1), тип SMALLINT или INT. Как Вы уже поняли, такого типа данных как Boolean в T-SQL нет, поэтому для этих целей разработчики используют похожие (подходящие) типы данных и в большинстве случаев их выбор неправильный. Если Вам нужно хранить только значения 0 или 1 (т.е. как Boolean), то в T-SQL существует специальный тип данных BIT, SQL сервер выделяет для хранения всего 1 байт, но в отличие от типа TINYINT, под который также отводится 1 байт, SQL сервер оптимизирует хранение бит столбцов. Если таблица содержит не больше 8 бит столбцов, столбцы хранятся как 1 байт, если таких столбцов от 9 до 16, то 2 байта и т.д.
Для сравнения давайте посмотрим на разницу.
Таблица 1
--В строке 16 байт
CREATE TABLE TestTable1 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled INT NOT NULL, --4 байта
IsTest INT NOT NULL, --4 байта
)
Таблица 2 (с использованием BIT столбцов)
--В строке 9 байт
CREATE TABLE TestTable2 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled BIT NOT NULL, --1 байта
IsTest BIT NOT NULL, --0 байта
)
Сравнение
| Количество строк | Размер в мегабайтах (MB) | ||
| Таблица 1 | Таблица 2 (с использованием BIT столбцов) | Разница | |
| 1 000 | 0,02 | 0,01 | 0,01 |
| 10 000 | 0,15 | 0,09 | 0,07 |
| 100 000 | 1,53 | 0,86 | 0,67 |
| 1 000 000 | 15,26 | 8,58 | 6,68 |
| 10 000 000 | 152,59 | 85,83 | 66,76 |
| 100 000 000 | 1525,88 | 858,31 | 667,57 |
Как видите, после добавления нескольких миллионов строк разница будет ощутимая, и это на простой, маленькой, тестовой таблице.
Про типы данных Microsoft SQL Server у меня все, надеюсь, материал был Вам полезен! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
Нравится8Не нравится1