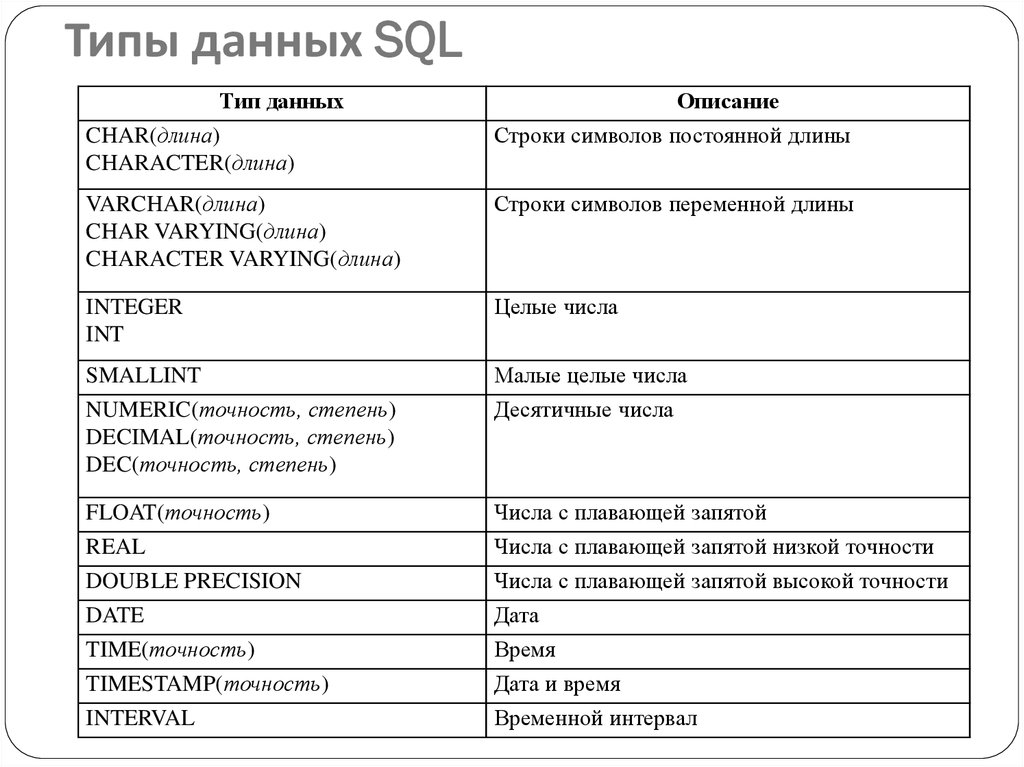
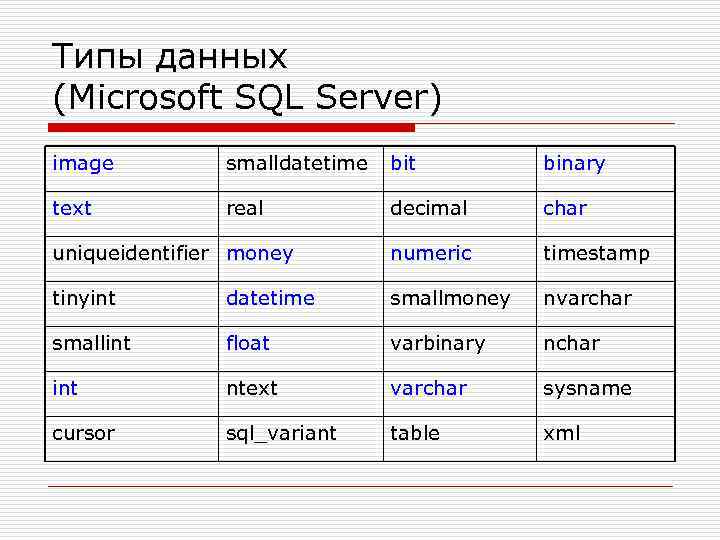
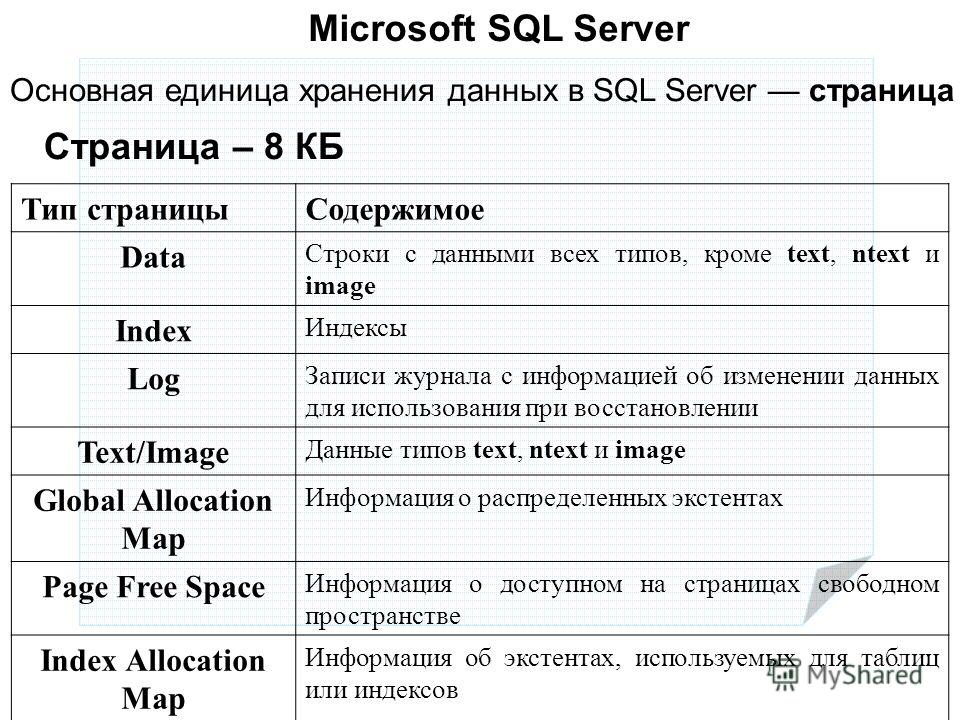
SQL запросы: возможности SQL для создания запросов в Excel и напрямую к таблицам Excel
Порой таблицы Excel постепенно разрастаются настолько, что с ними становится неудобно работать. Поиск дубликатов, группировка, сложная сортировка, объединение нескольких таблиц в одну, т.д. — превращаются в действительно трудоёмкие задачи. Теоретически эти задачи можно легко решить с помощью языка запросов SQL… если бы только можно было составлять запросы напрямую к данным Excel.
Надстройка XLTools «SQL запросы» расширит Excel возможностями языка структурированных запросов:
- Создание запросов SQL в интерфейсе Excel и напрямую к Excel таблицам
- Автогенерация запросов SELECT и JOIN
- Доступны JOIN, ORDER BY, DISTINCT, GROUP BY, SUM и другие операторы SQLite
- Создание запросов в интуитивном редакторе с подстветкой синтаксиса
- Обращение к любым таблицам Excel из дерева данных
Подходит для: Microsoft Excel 2019 – 2010, desktop Office 365 (32-бит и 64-бит).
Скачать надстройку XLTools
Как превратить данные Excel в реляционную базу данных и подготовить их к работе с SQL запросами
По умолчанию Excel воспринимает данные как простые диапазоны. Но SQL применим только к реляционным базам данных. Поэтому, прежде чем создать запрос, преобразуйте диапазоны Excel в таблицу (именованный диапазон с применением стиля таблицы):
- Выделите диапазон данных > На вкладке «Главная» нажмите «Форматировать как таблицу» > Примените стиль таблицы.
-
Выберите эту таблицу > Откройте вкладку «Конструктор» > Напечатайте имя таблицы.
Напр., «КодТовара». -
Повторите эти шаги для каждого диапазона, который планируете использовать в запросах.
«КодТовара», «ЦенаРозн», «ОбъемПродаж», т.д. - Готово, теперь эти таблицы будут служить реляционной базой данных и готовы к SQL запросам.
Как создать и выполнить запрос SQL SELECT к таблицам Excel
Надстройка «SQL запросы» позволяет выполнять запросы к Excel таблицам на разных листах и в разных книгах. Для этого убедитесь, что эти книги открыты, а нужные данные отформатированы как именованные таблицы.
Нажмите кнопку «Выполнить SQL» на вкладке XLTools > Откроется окно редактора.
В левой части окна находится дерево данных со всеми доступными таблицами Excel.
Нажатием на узлы открываются/сворачиваются поля таблицы (столбцы).
Выберите целые талицы или конкретные поля.
По мере выбора полей, в правой части редактора автоматически генерируется запрос SELECT.
Обратите внимание: редактор запросов SQL автоматически подсвечивает систаксис.
Укажите, куда необходимо поместить результат запроса: на новый или существующий лист.
Нажмите кнопку «Выполнить» > Готово!
Операторы Left Join, Order By, Group By, Distinct и другие SQLite команды в Excel
XLTools использует стандарт SQLite. Пользователи, владеющие языком SQLite, могут создавать самые разнообразные запросы:
- LEFT JOIN – объединить две и более таблиц по общему ключевому столбцу
- ORDER BY – сортировка данных в выдаче запроса
- DISTINCT – удаление дубликатов из результата запроса
- GROUP BY – группировка данных в выдаче запроса
- SUM, COUNT, MIN, MAX, AVG и другие операторы
Совет: вместо набора названий таблиц вручную, просто перетягивайте названия из дерева данных в область редактора SQL запросов.
Как объединить две и более Excel таблиц с помощью надстройки «SQL запросы»
Вы можете объединить несколько таблиц Excel в одну, если у них есть общее ключевое поле. Предположим, вам нужно объединить несколько таблиц по общему столбцу «КодТовара»:
-
Нажмите «Выполнить SQL» на вкладке XLTools > Выберите поля, которые нужно включить в объединённую таблицу.
По мере выбора полей, автоматически генерируется запрос SELECT и LEFT JOIN. - Укажите, куда необходимо поместить результат запроса: на новый или существующий лист.
- Нажмите «Выполнить» > Готово! Объединённая таблица появится в считанные секунды.
Появились вопросы или предложения? Оставьте комментарий ниже.
Как получить список и описание всех колонок в таблице Microsoft SQL Server?
В данной заметке будет рассмотрено несколько способов получения информации о столбцах таблицы в базе данных Microsoft SQL Server, например, мы научимся получать список колонок таблицы, включая их тип данных, с помощью SQL запроса.

Начну с того, что если Вам нужно просто визуально посмотреть, какие колонки или какой тип данных у той или иной колонке в таблице, то Вы для этого можете использовать графический функционал SQL Server Management Studio, а именно «Обозреватель объектов». Например, для того чтобы посмотреть информацию о столбцах таблицы, необходимо плюсиком открыть соответствующий контейнер.
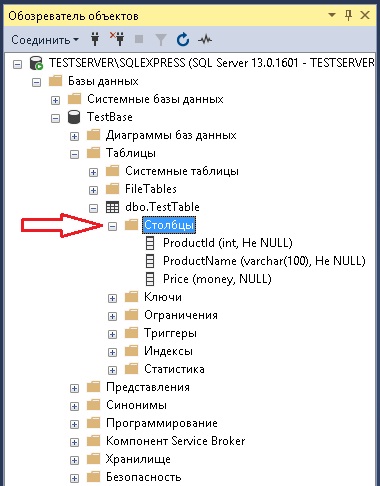
Но если Вам необходимо выгрузить эту информацию или обработать ее в SQL инструкции, то в этом случае необходимо обращаться к системным объектам SQL Server с помощью языка SQL, как и к каким именно объектам обращаться мы сейчас и рассмотрим.
Получаем список колонок таблицы с помощью представления информационной схемы
В Microsoft SQL Server существует специальная схема — INFORMATION_SCHEMA, которая содержит метаданные для всех объектов базы данных. В данной схеме есть представление COLUMNS, с помощью которого и можно получить информацию о колонках таблицы. Также в ней есть и другие полезные представления, о которых мы разговаривали в статье — «Представления информационной схемы Microsoft SQL Server».
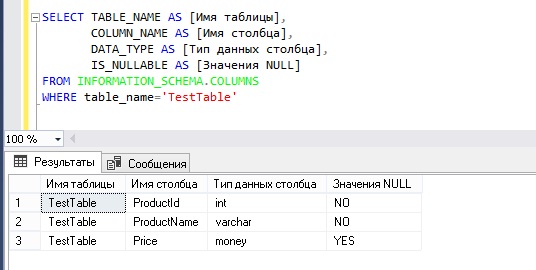
А теперь допустим, нам нужно получить информацию о столбцах в таблице, например, имя столбца, тип данных и возможность принятия значения NULL, для этого мы напишем следующий запрос, в котором обратимся к представлению COLUMNS информационной схемы.
Получаем список столбцов таблицы с помощью системного представления sys.columns
Также информацию о колонках таблицы можно получить с помощью системного представления sys.columns, но только в этом случае для получения точно такого же результата, как был выше, необходимо будет объединять несколько системных представлений, а именно sys.tables, sys.columns и sys.types, так как в представлении sys.columns есть только идентификаторы нужных нам данных.

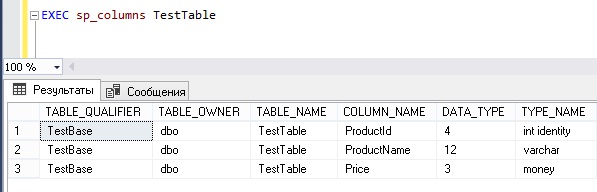
Получаем список колонок таблицы с помощью системной процедуры sp_columns
В SQL Server существует специальная системная процедура sp_columns, которая как раз и предназначена для получения информации о колонках таблицы.
Какой из рассмотренных выше способов Вам подойдет и окажется удобней решать Вам, а у меня на этом все, удачи!
Как найти нужные таблицы и отобразить всю информацию в одном запросе SQL
Где-то месяц назад ко мне обратился коллега с просьбой помочь составить комплексный запрос (если это можно так назвать), который можно было бы скопировать и вставить в phpMyAdmin, для выборки всех данных из таблиц плагина, оставшихся после удаления сайта/сайтов из сети WordPress.
Что? Объясняю. Допустим, у нас есть сеть на WordPress, в которой имеется N число сайтов. Установлен сетевой плагин, который для каждого сайта создает собственную таблицу в базе данных. Таблицы имеют следующие имена: wp_table для первого сайта и wp_N_table для N-го сайта (например, wp_10_table для десятого сайта в сети). В нашем случае, сайт X, Y и Z были удалены, но таблицы остались. Задача: одним запросом получить данные из этих таблиц для дальнейшего анализа.
Я не считаю себя огромным специалистом SQL и мне данная задача изначально показалась если не невыполнимой, то уж точно не той, которую я мог бы решить за пару минут. Пришлось покопаться в сети и найти как такое решают другие. Ниже представлено мое видение потенциального решения данной проблемы. Не беру на себя ответственность утверждать, что это самое оптимальное решение, но оно позволило мне поближе познакомиться с процедурным расширением SQL.
Итак, приступим. Изначально я разбил задачу на несколько этапов:
- Получить список всех таблиц от плагина
- Найти «таблицы-сироты»
- Получить данные из найденных таблиц
Чтобы всего этого добиться, мы будем использовать хранимые процедуры в SQL.
Базовый синтаксис для них следующий:
С помощью DELIMITER $$ мы задаем последовательность символов, которая будет завершать хранимую процедуру, без этого при наборе первой же строчки SQL будет исполнять набранный код. Данная последовательность может быть произвольной. В конце $$ укажет на завершение процедуры.
Создаем процедуру GetAllTables() с помощью CREATE PROCEDURE , она будет иметь начало BEGIN и конец END .
CALL GetAllTables(); — это выполнение всей процедуры.
В теле GetAllTables() мы объявляем переменные с помощью инструкции DECLARE , задаем тип и значение по умолчанию:
В переменной v_finished мы будем хранить статус обработки, в v_table — текущую таблицу.
Далее мы будем использовать курсор, чтобы осуществить построчную обработку нашего запроса. Задаем курсор table_cursor, который будет получать название таблиц из базы данных, соответствующих определенной маске.
Указываем что мы будем делать, когда не найдем больше результатов. Обработчик ошибок объявляется следующим образом:
Здесь action может принимать значение CONTINUE или EXIT , которые указывают на то что нужно продолжить или прекратить исполнение кода при достижении определенных условий. В нашем случае условием является NOT FOUND (результатов больше нет), при достижении которого мы задаем значение переменной v_finished равной 1.
Теперь мы отобразим все таблицы, которые были найдены в базе данных по заданной маске. Для этого лишь надо выполнить SQL запрос:
Наверное, повторение одного запроса здесь и выше, когда мы задавали курсор, является не самым оптимальным решением, но зато оно понятно для начинающих и не требует каких-то углубленных знаний SQL.
Далее мы откроем установленный раннее курсор и задаем цикл get_data , где будем последовательно присваивать переменной v_table результаты нашего запроса.
Проверяем закончилась ли выборка и есть ли еще результаты. Напоминаю, что если результатов нет, то переменная v_finished будет равна 1. Это мы задавали выше. Если больше результатов нет, то мы выходим из цикла.
Здесь у меня возникла небольшая проблема: таблицы-то я нахожу, но как определить что именно данная таблица — это оставшаяся таблица от удаленного сайта. Как я писал выше, все таблицы в базе данных имеют вид wp_N_table. Нам лишь нужно получить значение N, присвоить его переменной v_id и посмотреть есть ли сайт с данным индексом в таблице wp_blogs. Но есть одно условие — у первого сайта в сети не будет индекса N, таблица будет иметь вид wp_table. Но, в то же время, сайт с индексом 1 все равно будет присутствовать в таблице wp_blogs. Чтобы избежать ошибок, мы сделаем небольшую проверку и установим v_id = 1 , если N не будет задана в названии таблицы:
Теперь осталось самое простое — для всех таблиц, индекс которых мы не нашли в wp_blogs, нужно выполнить запрос выборки данных и отобразить все это пользователю:
Чтобы подставить значение v_table в запрос, необходимо использовать команду concat, результат которой мы присваиваем переменной sql_query . Кстати, переменные в коде задаются с символом @ перед именем.
Какие СУБД бывают
На самом деле, существует достаточно много различных СУБД, некоторые из них платные и стоят немалых денег, если говорить о полнофункциональных версиях, но даже у самых, так скажем, «крутых» есть бесплатные редакции, которые, кстати, отлично подходят для обучения.
- Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях. И это не просто СУБД – это целый комплекс приложений, позволяющий хранить и модифицировать данные, анализировать их, осуществлять безопасность этих данных и многое другое;
- Oracle Database – это система управления базами данных от компании Oracle. Это также очень популярная СУБД, и также среди крупных компаний. По своим возможностям и функциональности Oracle Database и Microsoft SQL Server сопоставимы, поэтому являются серьезными конкурентами друг другу, и стоимость их полнофункциональных версий очень высока;
- MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила очень широкую популярность в интернет сегменте, т.е. именно на MySQL работают чуть ли не все сайты в интернете, иными словами, большинство сайтов в интернете используют эту СУБД как средство хранения данных;
- PostgreSQL – эта система управления базами данных также является бесплатной, и она очень популярна и функциональна.
Ответ 1
Лучше всего использовать виртуальную базу данных метаданных INFORMATION_SCHEMA. В частности, таблица INFORMATION_SCHEMA.COLUMNS…




SELECT `COLUMN_NAME`
FROM `INFORMATION_SCHEMA`.`COLUMNS`
WHERE `TABLE_SCHEMA`=’yourdatabasename’
AND `TABLE_NAME`=’yourtablename’;
Это ОЧЕНЬ мощный способ, и он может предоставить вам ТОННЫ информации без необходимости анализировать текст (например, тип столбца, наличие в нем значения NULL, максимальный размер столбца, набор символов и т. д.).
И это стандартный SQL (в то время как SHOW — это расширение для MySQL).
Для получения дополнительной информации о различиях между таблицами SHOW…и их использовании с INFORMATION_SCHEMA, ознакомьтесь с общей документацией INFORMATION_SCHEMA для MySQL.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_date FROM sys.databases;
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=’BASE TABLE’
3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
SELECT * FROM tAuthors;
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
SELECT count(*) FROM tAuthors;
5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
SELECT * FROM tAuthors ORDER BY AuthorId OFFSET 3 ROWS FETCH NEXT 2 ROWS ONLY;
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
SELECT * FROM tAuthors ORDER BY AuthorFirstName;
7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
SELECT * FROM tAuthors ORDER BY AuthorId DESC;
![]() Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
SELECT * FROM tAuthors WHERE AuthorFirstName=’Александр’;
9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘се%’;
10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘%ат’ ORDER BY AuthorId;
Видео курсы по схожей тематике:
SQL Базовый. Разбор ДЗ
Владимир Дымчук
MySQL Базовый
Андрей Бондаренко
How to SQL Базовый
Владимир Дымчук
11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
SELECT * FROM tAuthors WHERE AuthorId IN (2,4);
12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
SELECT max(AuthorAge) FROM tAuthors;
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
SELECT AuthorFirstName, AuthorLastName FROM tAuthors;
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
SELECT AuthorId, AuthorFirstName, AuthorLastName FROM tAuthors WHERE AuthorId!=’3′;
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД. Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
INSERT INTO tAuthors VALUES (‘Уильям’, ‘Шекспир’, ’51’);
Проверим:
SELECT * FROM tAuthors;
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.



UPDATE tAuthors SET AuthorFirstName = ‘Лев’, AuthorLastName=’Толстой’, AuthorAge = ’82’ WHERE AuthorId = ‘6’;
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
SELECT * FROM tAuthors;
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
DELETE FROM tAuthors WHERE AuthorId = ‘5’;
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
SELECT * FROM tAuthors;
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors целиком, выполнив простой SQL запрос:
DROP TABLE tAuthors;
Далее рассмотрим сложные запросы SQL.
Ответ 7
SHOW COLUMNS в mysql 5.1 (не 5.5) использует временную дисковую таблицу.
Поэтому в некоторых случаях его можно считать медленным. По крайней мере, это может увеличить значение created_tmp_disk_tables. Представьте себе одну временную дисковую таблицу на соединение или на каждый запрос страницы.
SHOW COLUMNS на самом деле не так медленна, возможно, потому что она использует кэш файловой системы. PhpMyAdmin постоянно говорит о ~0.5 мс. Это ничто, по сравнению с 500-1000 мс при обслуживании страницы wordpress. Но все же есть моменты, когда это имеет значение. Здесь задействована дисковая система; никогда не знаешь, что произойдет, когда сервер занят, кэш переполнен, hdd завис и т. д.
Получение имен колонок через SELECT * FROM … LIMIT 1 заняло около ~0.1 мс, и оно также может использовать кэш запросов.
Итак, вот мой небольшой оптимизированный код для получения имен столбцов из таблицы без использования show columns, если это возможно:
function db_columns_ar($table) {
//возвращает Array(‘col1name’=>’col1name’,’col2name’=>’col2name’,…)
if(!$table) return Array();
if(!is_string($table)) return Array();
global $db_columns_ar_cache;
if(!empty($db_columns_ar_cache))
return $db_columns_ar_cache;
$cols=Array();
$row=db_row_ar($q1=»SELECT * FROM `$table` LIMIT 1″);
if($row) {
foreach($row as $name=>$val)
$cols=$name;
} else {
$coldata=db_rows($q2=»SHOW COLUMNS FROM `$table`»);
if($coldata)
foreach($coldata as $row)
$cols=$row->Field;
}
$db_columns_ar_cache=$cols;
//debugexit($q1,$q2,$row,$coldata,$cols);
return $cols;
}
-
Пока первая строка вашей таблицы не содержит мегабайтного диапазона данных, она должна работать нормально.
-
Имена функций db_rows и db_row_ar должны быть заменены вашей конкретной настройкой базы данных.
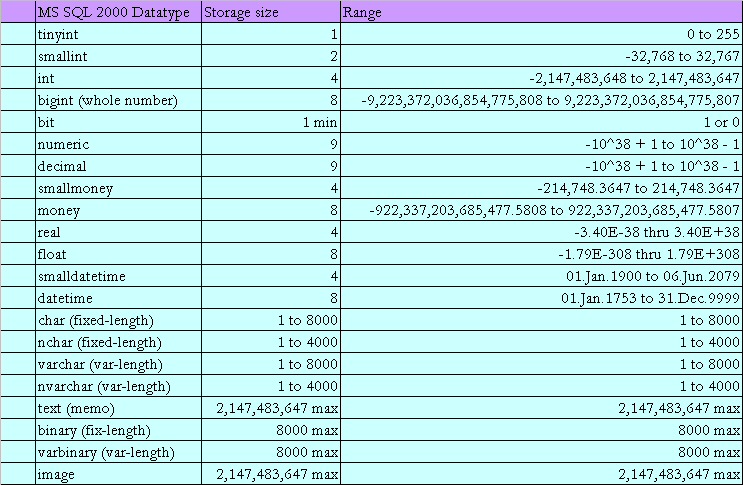
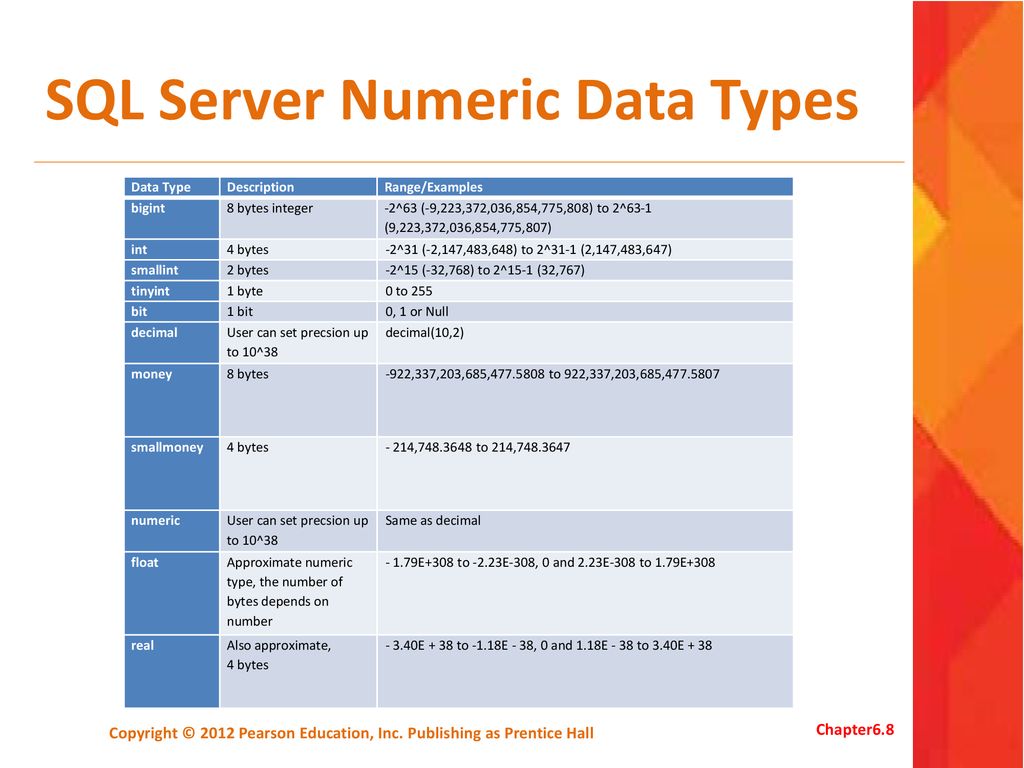
SQL Server Data Types Length
| General Type | Type | N value | Precision | Storage size, bytes | Range (in SQL Server) |
|---|---|---|---|---|---|
| Exact Numerics | bit | 1 | 1, 0 | ||
| Exact Numerics | tinyint | 1 | 0 to 255 | ||
| Exact Numerics | smallint | 2 | -2^15(-32768) to 2^15(32767) | ||
| Exact Numerics | int | 4 | -2^31(-2 147 483 648) to (2^31(2 147 483 647) | ||
| Exact Numerics | bigint | 8 | -2^63(-9 233 372 036 854 775 808) to 2^63(9 233 372 036 854 775 807) | ||
| Exact Numerics | decimal | 1-910-1920-2829-38 | 591317 | from -10^38 +1 through 10^38 -1 | |
| Exact Numerics | smallmoney | 4 | -214 748.3648 to 214 748.3647 | ||
| Exact Numerics | money | 8 | -922 337 203 685 477.5808 to 922 337 203 685 477.5807 | ||
| Approximate Numerics | float | 1-2425-53 | 715 | 48 | -3.40E+38 to -1.18E-38, 0 and 1.18E-38 to 3.40E+38-1.79E+308 to -2.23E-308, 0 and 2.23E-308 to 1.79E+308 |
| Date and Time | date | 3 | 0001-01-01 through 9999-12-31January 1, 1 CE through December 31, 9999 CE | ||
| Date and Time | smalldatetime | 4 | 1900-01-01 through 2079-06-06January 1, 1900 through June 6, 207900:00:00 through 23:59:59 | ||
| Date and Time | time | 8-1112-1314-16 | 345 | 00:00:00.0000000 through 23:59:59.9999999 | |
| Date and Time | datetime2 | 1-23-45-7 | 678 | 0001-01-01 through 9999-12-31January 1, 1 CE through December 31, 9999 CE00:00:00 through 23:59:59.9999999 | |
| Date and Time | datetime | 8 | anuary 1, 1753 through December 31, 999900:00:00 through 23:59:59.997 | ||
| Date and time | datetimeoffset | 26-2930-34 | 810 | 0001-01-01 through 9999-12-31January 1, 1 CE through December 31, 9999 CE00:00:00 through 23:59:59.9999999-14:00 throuth +14:00 | |
| Caracter Strings | char | 1-8000 | n | ||
| Caracter Strings | varchar | 1-8000 | n + 2 | ||
| Caracter Strings | varchar(max) | 1-(2^31 — 1) | 2^31 — 1 + 2 | ||
| Caracter Strings | nchar | 1-4000 | |||
| Caracter Strings | nvarchar | 1-4000 | |||
| Caracter Strings | nvarchar(max) | 1-(2^31 — 1) | |||
| Caracter Strings | ntext(*) | 1-(2^30 — 1) | n + n | ||
| Caracter Strings | text(*) | 1-(2^31 — 1) | |||
| Binary Strings | image(*) | 1-(2^31 — 1) | n | ||
| Binary Strings | binary | 1-8000 | n | ||
| Binary Strings | varbinary | 1-8000 | n | ||
| Binary Strings | varbinary(max) | 1-(2^31 — 1) | n + 2 | ||
| Other Data Types | cursor | ||||
| Other Data Types | sql_variant | max 8016 | |||
| Other Data Types | hierarchyid | max 892 | |||
| Other Data Types | rowversion | 8 | |||
| Other Data Types | timestamp(*) | ||||
| Other Data Types | uniqueidentifier | 16 | |||
| Other Data Types | xml | max 2Gb | |||
| Other Data Types | table | ||||
| Spatial Data Types | geometry | ||||
| Spatial Data Types | geography |
3 Scenarios to Get the Data Type of Columns in SQL Server
Scenario 1 – Get the data type of all columns in a particular database
To begin, select your desired database.
For example, let’s suppose that you have a database called the ‘test_database‘ which includes 3 tables.
You can then run the following query in order to get the data type of all the columns in the test_database:
SELECT TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS
Here is an example of the results that you may get, where the data type of each column is captured under the DATA_TYPE field:
| TABLE_CATALOG | TABLE_SCHEMA | TABLE_NAME | COLUMN_NAME | DATA_TYPE |
| test_database | dbo | cars | brand | nvarchar |
| test_database | dbo | cars | price | int |
| test_database | dbo | people | first_name | nvarchar |
| test_database | dbo | people | last_name | nvarchar |
| test_database | dbo | people | age | int |
| test_database | dbo | pets | name | nvarchar |
| test_database | dbo | pets | age | int |
Scenario 2 – Get the data type of all columns in a particular table
Let’s say that you want to find the data type of the columns under the ‘people‘ table. In that case, add where TABLE_NAME = ‘people’ at the bottom of the query:
SELECT TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS where TABLE_NAME = 'people'
There are 3 columns in the ‘people’ table. For the first two columns (first_name and last_name) the data type is nvarchar, while the data type for the last column (age) is int for integers
| TABLE_CATALOG | TABLE_SCHEMA | TABLE_NAME | COLUMN_NAME | DATA_TYPE |
| test_database | dbo | people | first_name | nvarchar |
| test_database | dbo | people | last_name | nvarchar |
| test_database | dbo | people | age | int |
Scenario 3 – Get the data type for a specific column
Lastly, let’s get the data type for the first_name column (under the people table):
SELECT TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS where TABLE_NAME = 'people' and COLUMN_NAME = 'first_name'
As you may see, the data type for the first_name column is nvarchar:
| TABLE_CATALOG | TABLE_SCHEMA | TABLE_NAME | COLUMN_NAME | DATA_TYPE |
| test_database | dbo | people | first_name | nvarchar |
Optionally, you can also include the CHARACTER_MAXIMUM_LENGTH field in the query:
SELECT TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, DATA_TYPE, CHARACTER_MAXIMUM_LENGTH FROM INFORMATION_SCHEMA.COLUMNS where TABLE_NAME = 'people' and COLUMN_NAME = 'first_name'
In this case, the CHARACTER_MAXIMUM_LENGTH is 50.
Тип данных TIMESTAMP
Тип данных TIMESTAMP указывает столбец, определяемый как VARBINARY(8) или BINARY(8) , в зависимости от свойства столбца принимать значения null. Для каждой базы данных система содержит счетчик, значение которого увеличивается всякий раз, когда вставляется или обновляется любая строка, содержащая ячейку типа TIMESTAMP, и присваивает этой ячейке данное значение. Таким образом, с помощью ячеек типа TIMESTAMP можно определить относительное время последнего изменения соответствующих строк таблицы. (ROWVERSION является синонимом TIMESTAMP.)







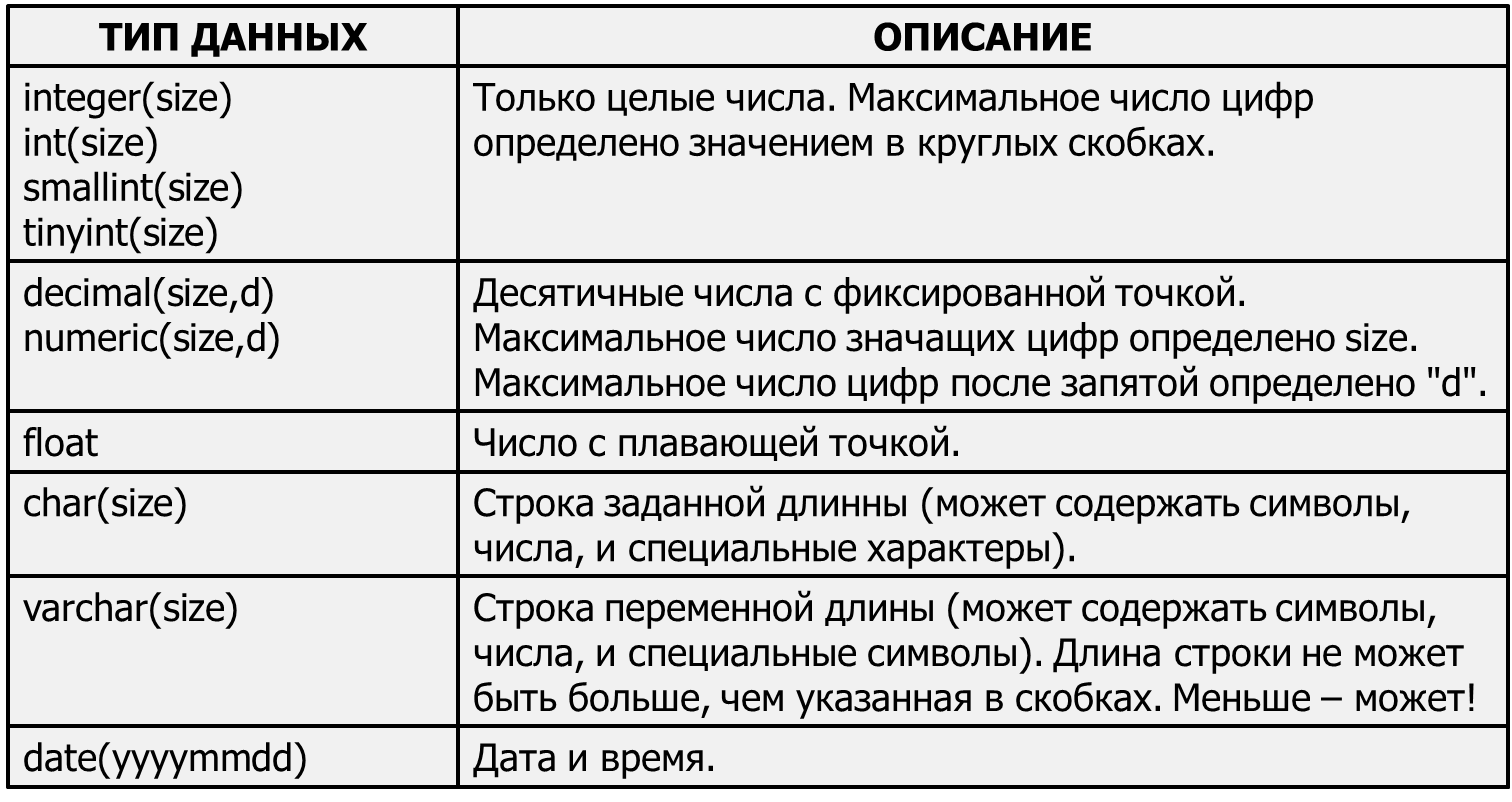
Само по себе значение, сохраняемое в столбце типа TIMESTAMP, не представляет никакой важности. Этот столбец обычно используется для определения, изменилась ли определенная строка таблицы со времени последнего обращения к ней
Как получить список и описание всех колонок в таблице Microsoft SQL Server?
В данной заметке будет рассмотрено несколько способов получения информации о столбцах таблицы в базе данных Microsoft SQL Server, например, мы научимся получать список колонок таблицы, включая их тип данных, с помощью SQL запроса.
Начну с того, что если Вам нужно просто визуально посмотреть, какие колонки или какой тип данных у той или иной колонке в таблице, то Вы для этого можете использовать графический функционал SQL Server Management Studio, а именно «Обозреватель объектов». Например, для того чтобы посмотреть информацию о столбцах таблицы, необходимо плюсиком открыть соответствующий контейнер.
Но если Вам необходимо выгрузить эту информацию или обработать ее в SQL инструкции, то в этом случае необходимо обращаться к системным объектам SQL Server с помощью языка SQL, как и к каким именно объектам обращаться мы сейчас и рассмотрим.
Получаем список колонок таблицы с помощью представления информационной схемы
В Microsoft SQL Server существует специальная схема — INFORMATION_SCHEMA, которая содержит метаданные для всех объектов базы данных. В данной схеме есть представление COLUMNS, с помощью которого и можно получить информацию о колонках таблицы. Также в ней есть и другие полезные представления, о которых мы разговаривали в статье — «Представления информационной схемы Microsoft SQL Server».
А теперь допустим, нам нужно получить информацию о столбцах в таблице, например, имя столбца, тип данных и возможность принятия значения NULL, для этого мы напишем следующий запрос, в котором обратимся к представлению COLUMNS информационной схемы.
Получаем список столбцов таблицы с помощью системного представления sys.columns
Также информацию о колонках таблицы можно получить с помощью системного представления sys.columns, но только в этом случае для получения точно такого же результата, как был выше, необходимо будет объединять несколько системных представлений, а именно sys.tables, sys.columns и sys.types, так как в представлении sys.columns есть только идентификаторы нужных нам данных.
Получаем список колонок таблицы с помощью системной процедуры sp_columns
В SQL Server существует специальная системная процедура sp_columns, которая как раз и предназначена для получения информации о колонках таблицы.
Какой из рассмотренных выше способов Вам подойдет и окажется удобней решать Вам, а у меня на этом все, удачи!
Точность, масштаб и длина (Transact-SQL)
Точность представляет собой количество цифр в числе. Масштаб представляет собой количество цифр справа от десятичной запятой в числе. Например: число 123,45 имеет точность 5 и масштаб 2.
В среде SQL Server максимальная точность типов данных numeric и decimal по умолчанию составляет 38 разрядов. В более ранних версиях SQL Server максимум по умолчанию составляет 28.
Длиной для числовых типов данных является количество байт, используемых для хранения числа. Длина символьной строки или данных в Юникоде равняется количеству символов. Длина для типов данных binary, varbinary и image равна количеству байт. Например, тип данных int может содержать 10 разрядов, храниться в 4 байтах и не должен содержать десятичный разделитель. Тип данных int имеет точность 10, длину 4 и масштаб 0.
При сцеплении двух выражений типа char, varchar, binary или varbinary длина результирующего выражения является суммой длин двух исходных выражений, но не превышает 8 000 символов.
При сцеплении двух выражений типа nchar или nvarchar длина результирующего выражения является суммой длин двух исходных выражений, но не превышает 4 000 символов.
Если два выражения одного и того же типа данных, но разной длины, сравниваются с помощью предложения UNION, EXCEPT или INTERSECT, длина результата будет равняться длине максимального из двух выражений.
Точность и масштаб числовых типов данных, кроме decimal, фиксированы. Если арифметический оператор объединяет два выражения одного и того же типа, результат будет иметь тот же тип данных с точностью и масштабом, определенными для этого типа. Если оператор объединяет два выражения с различными числовыми типами данных, тип данных результата будет определяться правилами старшинства типов данных. Результат имеет точность и масштаб, определенные для этого типа данных.
Следующая таблица определяет, как вычисляется точность и масштаб результата, если результат операции имеет тип decimal. Результат имеет тип decimal, если одно из следующих утверждений является истиной:
- Оба выражения имеют тип decimal.
- Одно выражение имеет тип decimal, а другое имеет тип данных со старшинством меньше, чем decimal.
Выражения операндов обозначены как выражение e1 с точностью p1 и масштабом s1 и выражение e2 с точностью p2 и масштабом s2. Точность и масштаб для любого выражения, отличного от decimal, соответствуют типу данных этого выражения
| Операция | Точность результата | Масштаб результата * |
|---|---|---|
| e1 + e2 | max(s1, s2) + max(p1-s1, p2-s2) + 1 | max(s1, s2) |
| e1 — e2 | max(s1, s2) + max(p1-s1, p2-s2) + 1 | max(s1, s2) |
| e1 * e2 | p1 + p2 + 1 | s1 + s2 |
| e1 / e2 | p1 — s1 + s2 + max(6, s1 + p2 + 1) | max(6, s1 + p2 + 1) |
| e1 { UNION | EXCEPT | INTERSECT } e2 | max(s1, s2) + max(p1-s1, p2-s2) | max(s1, s2) |
| e1 % e2 | min(p1-s1, p2 -s2) + max( s1,s2 ) | max(s1, s2) |
* Точность и масштаб результата имеют абсолютный максимум, равный 38. Если значение точности превышает 38, то соответствующее значение масштаба уменьшается, чтобы по возможности предотвратить усечение целой части результата.
A. Использование SELECT для получения строк и столбцов
В следующем примере приведены три примера кода. В ходе выполнения первого примера кода возвращаются все строки (предложение WHERE не указано), а также все столбцы (используется звездочка, ) таблицы базы данных .
В ходе выполнения данного примера кода происходит выдача всех строк (предложение WHERE не задано) и подмножества столбцов (, , ) таблицы базы данных . Дополнительно выведено название столбца.
В ходе выполнения данного примера кода происходит выдача всех строк таблицы , для которых линейки продуктов начинаются символом и для которых длительность изготовления не превышает дней.