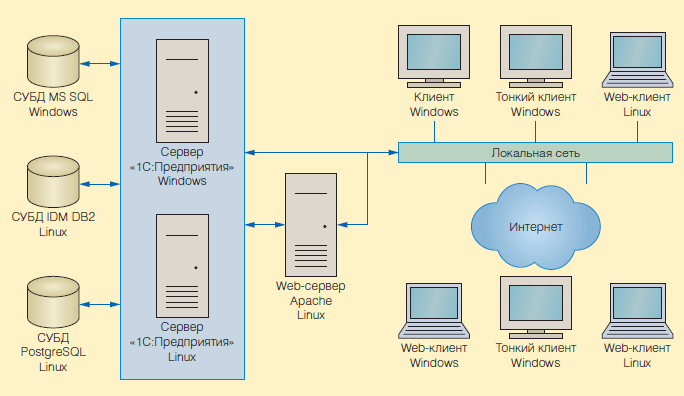
Перенос структуры базы данных
Загружаем с сайта Microsoft саму утилиту (версия для SQL Server 2008, версия для SQL Server 2005). Утилита бесплатна, но для ее активации нужно получить лицензионный код — сделать это можно через учетную запись Live ID.
Запускаем программу:
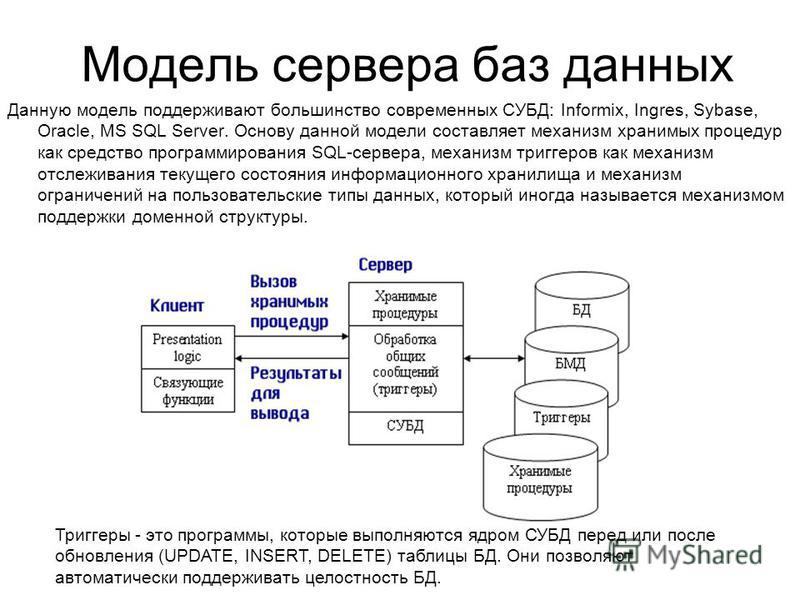
Слева от основной рабочей области видно два окна: просмотр метаданных у MySQL-сервера и у SQL Server. С ними мы будем активно работать.
Сверху над ними находятся кнопки подключения к серверам баз данных.
Для начала создаем новый проект:
Затем подключаемся к MySQL:

Далее подключаемся к SQL Server:
После подключения заполняются окна с метаданными обоих серверов:

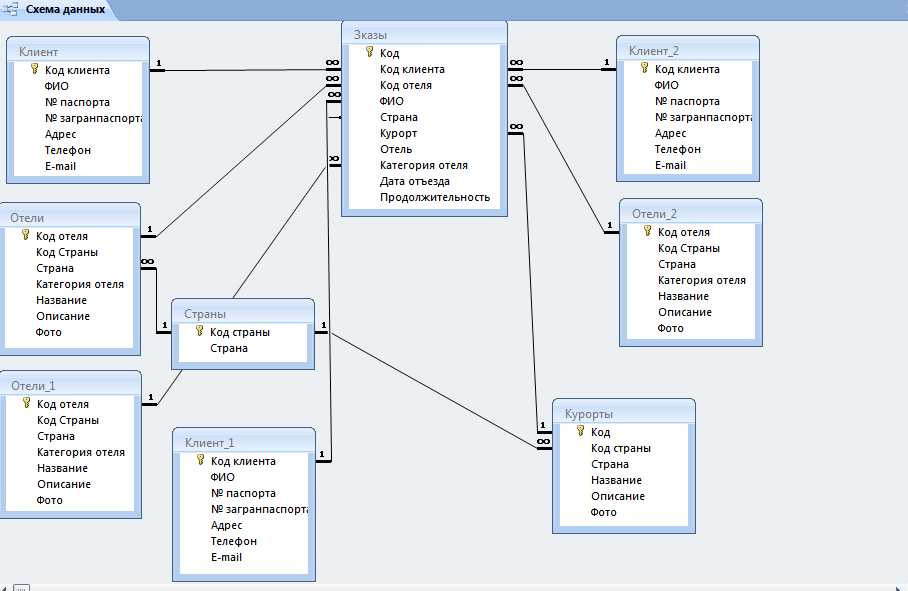
Можно видеть базу данных forum2 в MySQL, которую мы будем переносить, и базу данных forum в SQL Server, в которую будут записаны данные.
Отмечаем галочкой базу данных, которую хотим перенести:
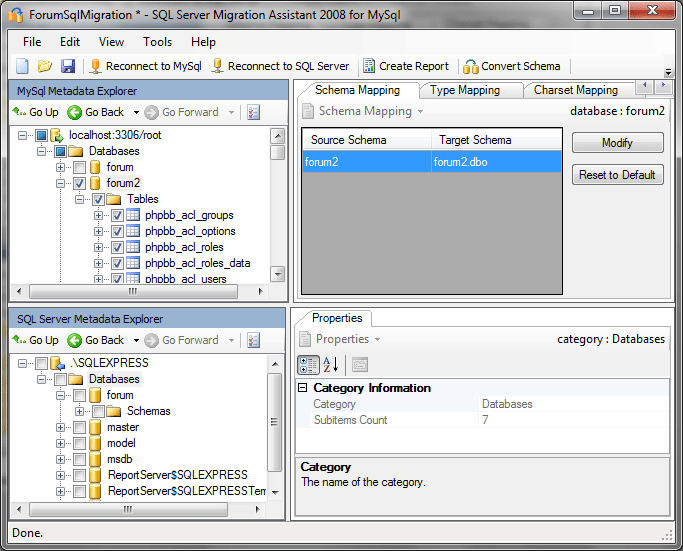
В основной рабочей области показывается главная вкладка: Schema Mapping. В ней показан план переноса — откуда и куда он будет выполнен.
Стоит отметить одну особенность: при работе с программой считается, что в понятие «схема» применительно к MySql входит название базы данных, а применительно к SQL Server — название базы данных и конкретная схема в ней (по умолчанию используется схема dbo).
Изначально утилита предлагает перенос в базу данных с таким же именем, как и исходная (forum2). Но, поскольку перенос будет осуществляться в базу данных с именем forum, а не forum2, нажимаем кнопку Modify и корректируем схему назначения:
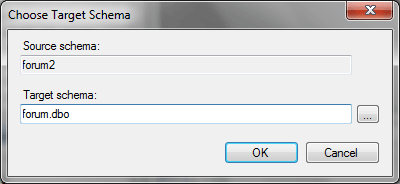
Кроме того, перейдя на вкладку Type Mapping можно посмотреть (и скорректировать) соответствие типов данных при переносе:
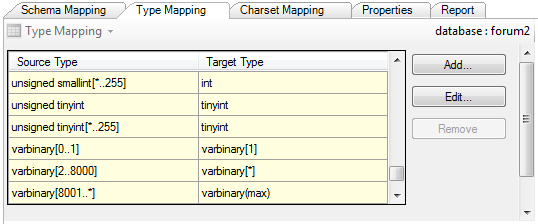
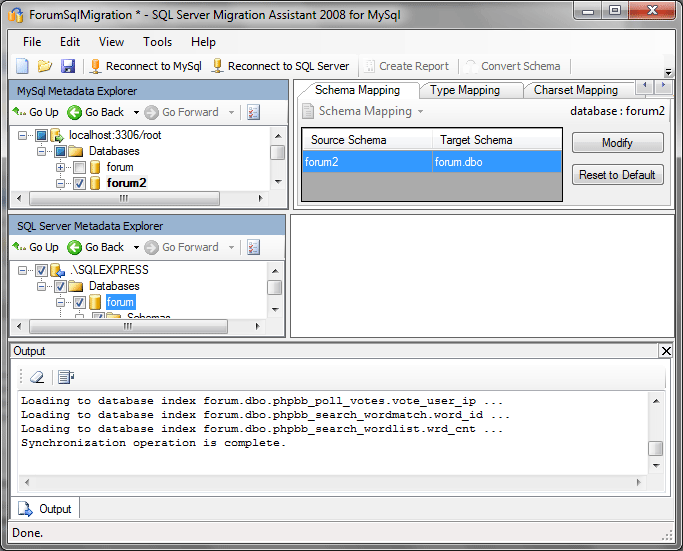
После этого можно приступать к конвертации. Кликнув правой кнопкой на объекте переноса (базе данных forum2), выбираем Convert Schema:
Программа приступает к конвертации:
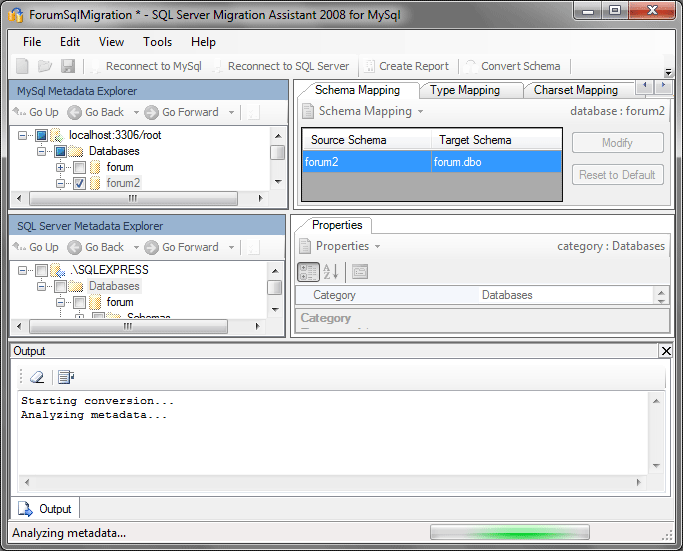
После завершения операции выводится отчет в стандартном стиле сред разработки:
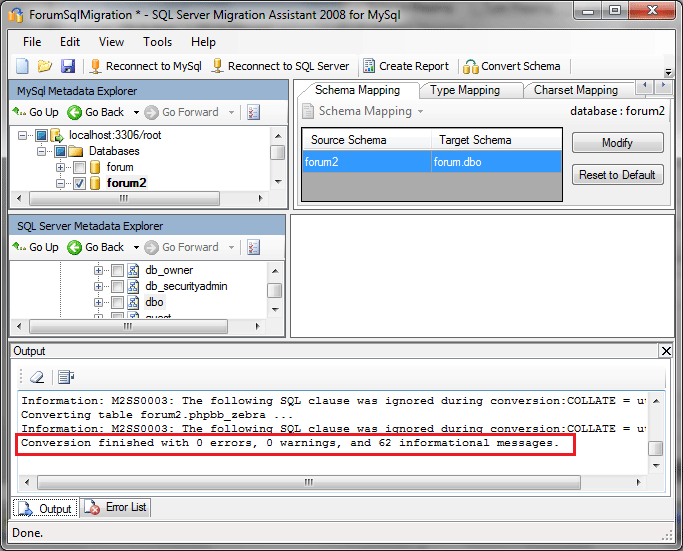
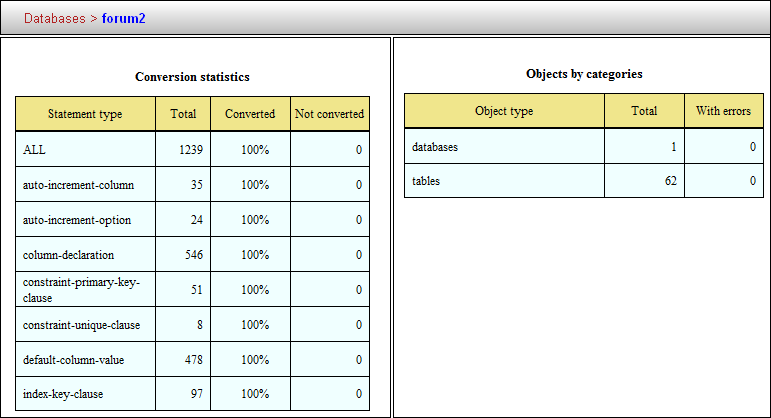
На данный момент сами таблицы физически еще не созданы — подготовлен лишь скрипт, который их создаст. Кликнув правой кнопкой по объекту переноса и выбрав Create Report, можно получить небольшой отчет:
Кроме того, можно сохранить и SQL-скрипт создания таблиц, выбрав пункт Save as Script все по тому же правому клику на переносимом объекте. Результат сохраняется в виде SQL-файла:

Как было сказано ранее, Convert Schema физически не проводит операцию создания таблиц в базе назначения. Чтобы выполнить физическое создание, кликнем по конечной базе данных правой кнопкой мыши и выберем Synchronize with Database. Эта операция выполнит сравнение структуры таблиц, находящихся в базе данных со структурой, созданной нами при конвертации, и создаст недостающие объекты.
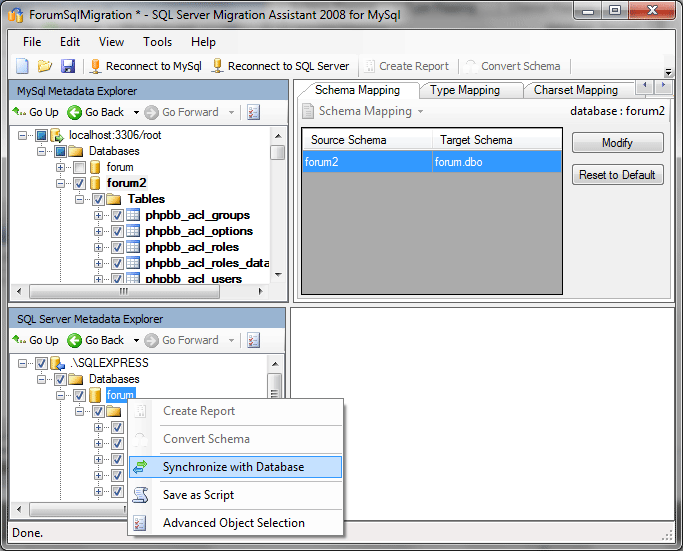
Кликнув на указанный пункт меню, получаем следующее диалоговое окно:
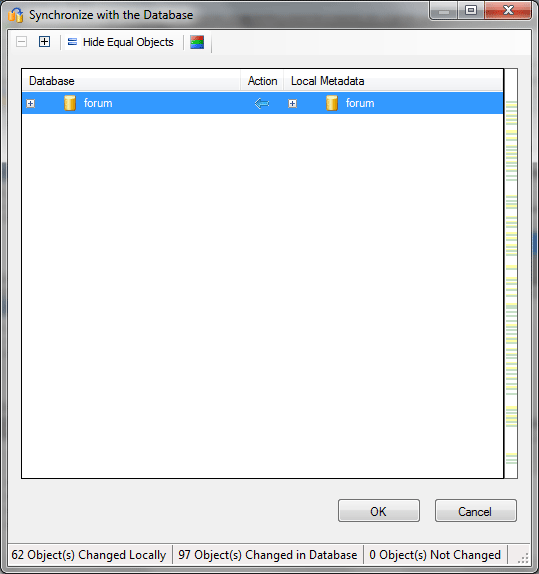
Синяя стрелка здесь обозначает, что будет выполнена операция отображения локальной структуры (то, что мы получили в результате конвертации) на базу данных назначения. Возможны и другие варианты — например, в случае, если часть таблиц уже существует. Расшифровку всех операций синхронизации можно получить, кликнув на кнопку с красно-зелено-синей полоской.
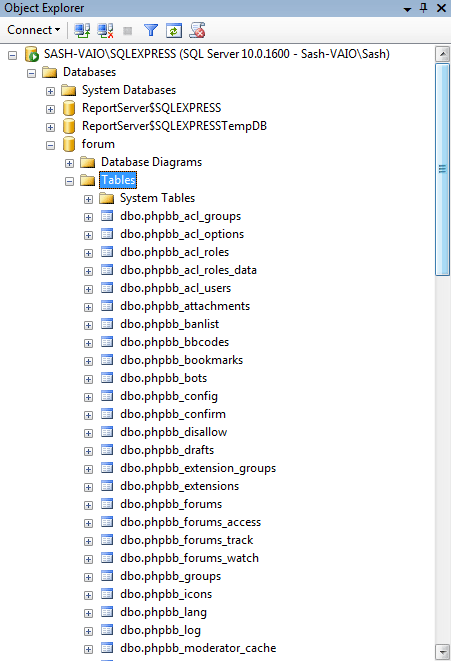
Нажав ОК, запускаем процесс создания таблиц:
Открыв базу данных forum в SQL Management Studio, убедимся, что таблицы появились:
Перенос данных
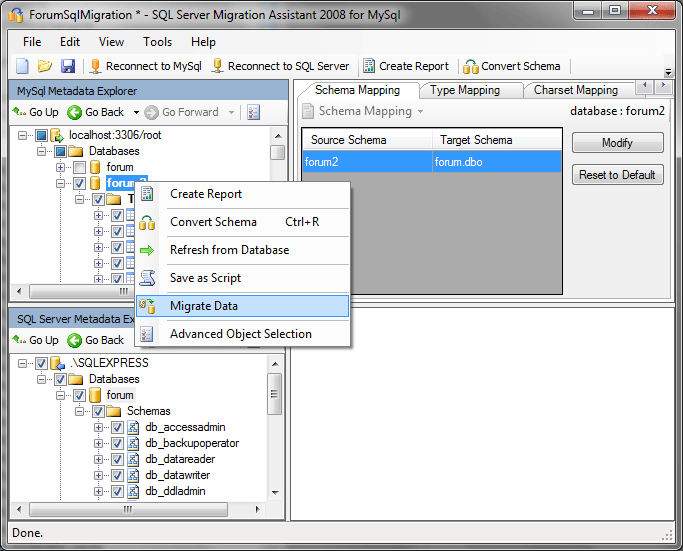
После того, как структура таблиц была перенесена, можно выполнить и перенос данных в таблицах.
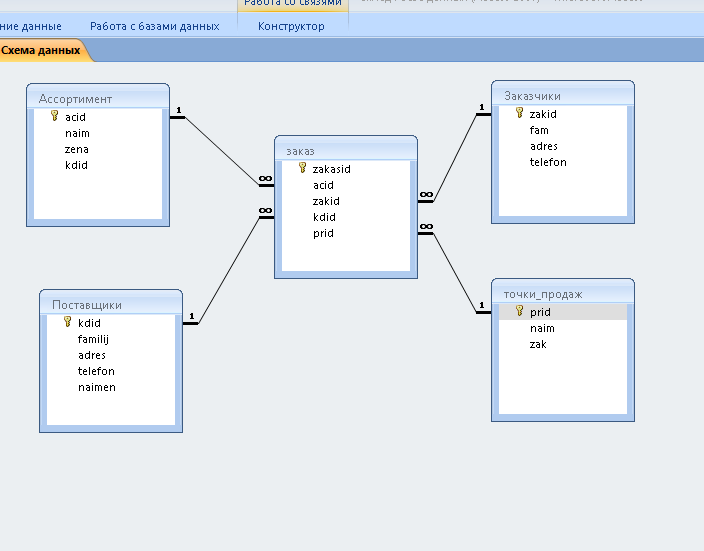
Для этого выбираем исходный объект (в нашем случае — базу данных), кликаем по нему правой кнопкой и используем пункт Migrate Data:
Для выполнения этой операции утилита должна заново выполнить подключение к базам данных. Соответствующие диалоги выводятся автоматически. Подключаемся к MySQL:

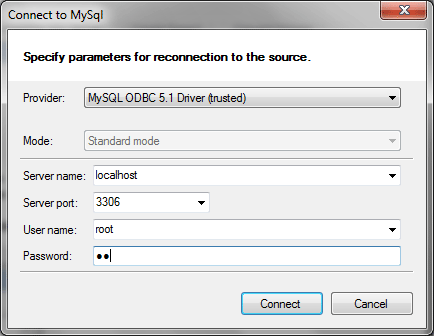
Подключаемся к SQL Server:
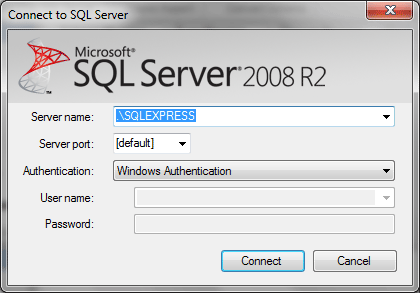
После этого утилита выполнит процедуру переноса данных автоматически. По завершению выводится отчет:

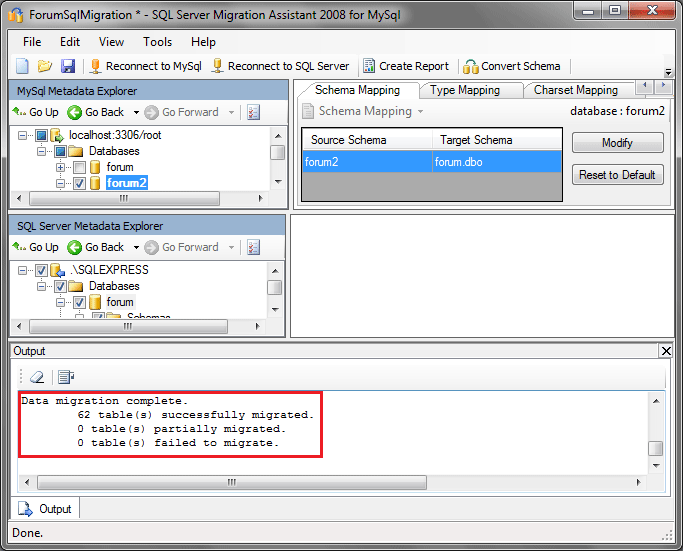
Используя SQL Management Studio, убедимся в том, что данные перенеслись:
Подход #0.1 проплаченный
Здесь бы мне могла заплатить компания RedGate. В общем-то, пару слов о них. У них есть огромное количество тулзов для упрощенной работы с базами данных (MS SQL), из мои любимых – это SQL Promt (IntelliSense для SQL кода), SQL Comparer (сравнение схем баз данных), SQL Data Comparer (сравнение данных), SQL Data Generator (генерирование тестовых данных). С того момента, как я начал пользоваться их продуктами, их SQL Toolbelt вырос с 5 до 15 продуктов. Цена у него тоже не маленькая. Среди не пользованных мною продуктов есть так же SQL Source Control, который, вроде как, облегчает работу с версионированием баз данных. Чтобы пользоваться, нужно, чтобы у всех участников была лицензия и установлен SQL Source Control, в общем, мы просто этот вариант откинули. Интересно, спасибо, но нам не настолько нужно это. Кстати, да, интересно, кто-то пользуется? Как впечатления? Есть ли ветвления?
Удаление схемы, DROP SCHEMA
Для удаления схемы необходимо использовать SQL скрипт drop schema.
Удаление схемы Oracle
Для удаление схемы СУБД Oracle необходимо удалить пользователя; объекты схемы удаляются автоматически :
Ключевое слово CASCADE означает удалить все связанное со схемой (пользователем) объекты.
Удаление схемы MSSQL
Удаляемая схема не должна содержать никаких объектов. Если схема содержит объекты, выполнение инструкции DROP заканчивается сбоем. Сведения о схемах можно увидеть в представлении каталога sys.schemas.
Удаление схемы PostgreSQL
Схема может быть удалена только её владельцем или superuser’ом. Необходимо помнить, что владелец owner может удалить схему и все содержащиеся в ней объекты даже если они ему не принадлежат.
При удалении схемы в PostgreSQL можно дополнительно включить параметры :
- IF EXISTS Проверка наличия схемы. Если схемы нет, то исключительная ситуация не возникнет.
- CASCADE Автоматически удалять объекты, содержащиеся в схеме.
- RESTRICT Не удалять схему, если она содержит объекты. Этот параметр используется по умолчанию.
Пример удаления схемы orders вместе с содержащимися в ней объектами :
Удаление базы данных MySQL
В СУБД MySQL удалить можно не только пустую базу данных.
Если не указать параметр IF EXISTS, то при попытке удаления не существующей базы данных, возникнет ошибка выполнения команды. Данный параметр доступен в MySQL 3.22 и более поздних версиях. При выполнении команды DROP DATABASE удаляется как сама база данных, так и все объекты, которые в ней находятся.
В следующем примере удаляется база данных «forum» :
Удаление схемы Derby
В СУБД Derby удалить можно только пустую схему. Схемы SYS и APP (схема пользователя по умолчанию) не могут быть удалены.
Ключевое слово RESTRICT является обязательным и обязывает выполнение проверки наличия объектов в удаляемой схеме.
Сравнить с
Сравнивать и синхронизировать структуру целевой базы данных со структурой шаблонной базы данных.
Шаблонная база данных, с которой сравнивать и синхронизировать. Вы можете установить подключение к базе данных онлайн или выбрать файл структуры базы данных. Также структура базы данных может быть взята из файла пакета (структура шаблонной базы данных в пакете).
Общие параметры
Изменять COLLATION базы данных
Используйте эту опцию вместе с опцией режима доступа SINGLE_USER для синхронизации параметров сортировки базы данных по умолчанию. Изменение параметров сортировки базы данных по умолчанию не изменяет параметры сортировки столбцов. Для приведения в соответствие параметров сортировки столбцов – используйте опцию для столбцов.
Если эта опция не установлена, то алгоритм сравнения обеспечивает сравнение баз данных, основываясь на параметрах сортировки по умолчанию целевой базы данных. В противном случае, он использует параметры сортировки шаблонной базы данных.
Изменять COLLATION по умолчанию в столбцах
Используйте эту опцию, чтобы привести в полное соответствие параметры сортировки всех столбцов с параметрами сортировки тех же столбцов в шаблонной базе данных. Если эта опция не установлена, то алгоритм сравнения будет считать равными различные параметры сортировки, если они совпадают с параметрами сортировки по умолчанию в их базах данных.
Применять режим доступа SINGLE_USER
Выключать AUTO_UPDATE_STATISTICS_ASYNC и применять режим доступа SINGLE_USER для целевой базы данных со значением ROLLBACK через 5 секунд. Все значения будут восстановлены в конце.
Устранять конфликты
Удалять объекты в целевой базе данных, которые конфликтуют с объектами в шаблонной, если последние необходимо создать или изменить. Этот параметр включает проверку на наличие конфликтов имен объектов, конфликтов кластерного ключа/индекса, конфликтов в назначении объектов (не может быть более одного кластерного ключа в таблице или ограничения по умолчанию для столбца, двух объектов с одинаковым именем и т.д.)
Перезаписовать таблицы представлениями или табличными функциями
Разрешить замену таблиц представлениями или табличными функциями, если они имеют одинаковые имена
Развязывать зависимости
Эта опция контролирует развязование зависимостей между зависимыми объектами. Всегда используйте ее, чтобы построить правильный скрипт синхронизации. Вы можете отключать эту опцию только в сравнительном анализе, чтобы получить отчет без перестроения зависимых объектов.
Часто, чтобы изменить один объект следует удалить (а затем заново создать) другие объекты, которые зависят от первого. Например: чтобы изменить столбец – следует предварительно удалить индекс; чтобы заново создать скалярную функцию – следует удалить констрейны по умолчанию, где она используется, и т.д.
Сравнение тела объектов
Дополнительные правила сравнения тела объектов.
Игнорировать любые пробелы и разрывы строк
Игнорировать любые пробелы и разрывы строк за пределами ‘строковых литералов’, «строковых литералов или идентификаторов в двойных кавычках» и .
Сравнивать согласно COLLATION
Сравнивать тела объектов на основе параметров сортировки базы данных по умолчанию, за исключением ‘строковых литералов’ и «строковых литералов или идентификаторов в двойных кавычках». В противном случае будет использоваться правило строгого соответствия.
Сравнение вычисляемых выражений
Дополнительные правила сравнения вычисляемых выражений.
Игнорировать внешние круглые скобки
Игнорировать внешние круглые скобки в начале и в конце.
DISABLED
Установите эту опцию, чтобы изменить свойство DISABLED объектов. Иначе алгоритм сравнения попытается унаследовать эти значения от существующих объектов.
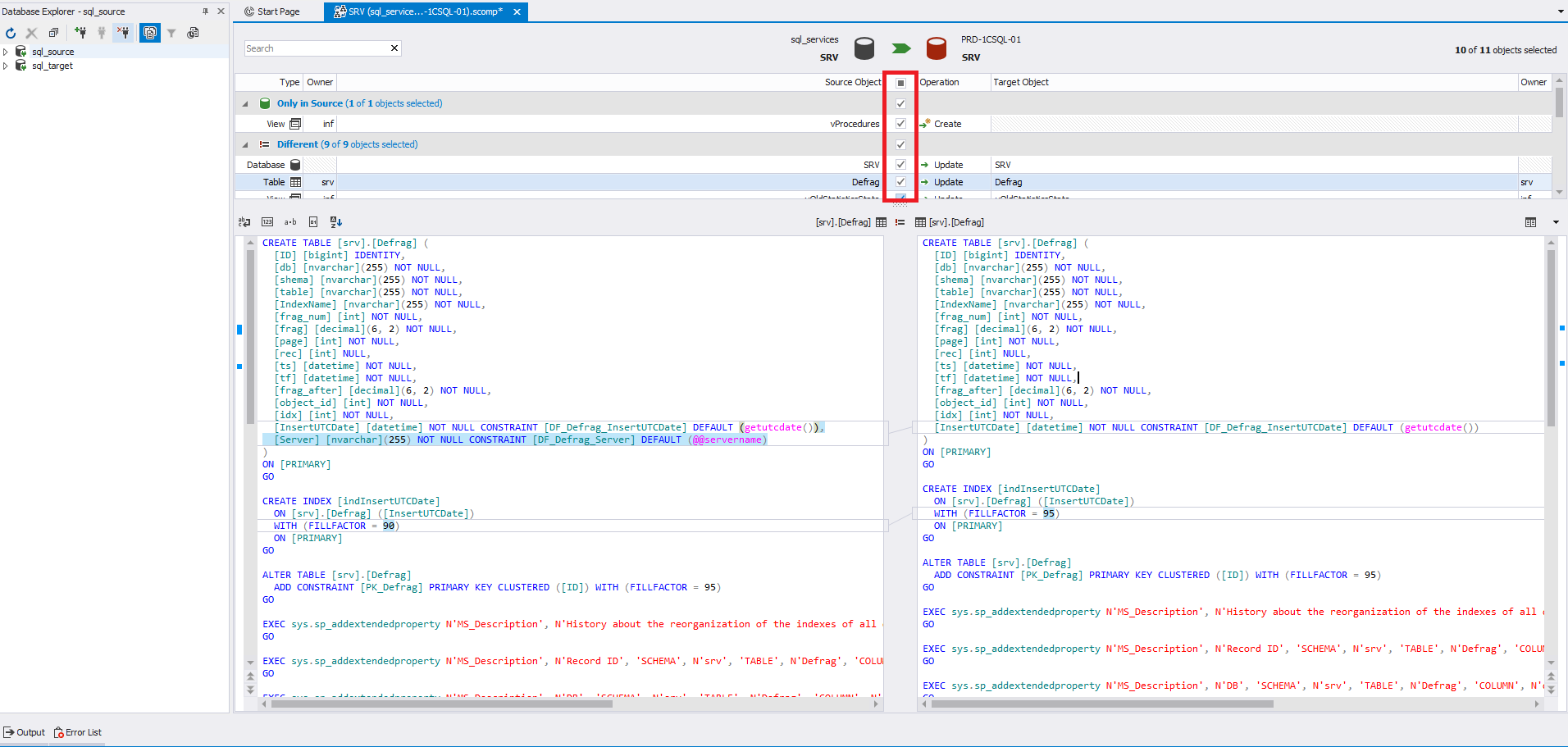
Не рекомендуется наличие отключенных ключевых ограничений и индексов в шаблонной базе данных. Они накладывают лишние зависимости на таблицы или представления, для которых были созданы, могут отключать другие зависимые индексы, и не всегда могут быть должным образом обработаны алгоритмом сравнения.
NOT FOR REPLICATION
Установите этот параметр, чтобы изменить свойство объектов NOT FOR REPLICATION. В противном случае алгоритм сравнения попытается унаследовать эти значения от существующих объектов.
- Предыдущая
- Следующая
Бесплатные проекты и образцы SQL Server
На странице Microsoft SQL Server Community Projects & Samples сайта CodePlex опубликованы сотни бесплатных проектов и примеров SQL Server 2008 и 2005 (www.codeplex.com/SqlServerSamples). Среди них — примеры баз данных (AdventureWorks, Northwind), примеры SQL Data Services и SQL Server Reporting Services (SSRS), SQL Server Analysis Services (SSAS) и SQL Server Integration Services (SSIS). На странице также приводятся ссылки на форумы и вопросы и ответы по SQL Server. Кроме того, можно загрузить AdventureWorks StoreFront со страницы SQL Server End to End Product Samples (www.codeplex.com/MSFTEEProdSamples).
Кто сказал, что бесплатный сыр бывает только в мышеловке?
Этот список, насчитывающий десятки бесплатных утилит SQL Server, еще далеко не полон. Если вам известна бесплатная утилита SQL Server, которой нет в нашем списке, сообщите нам: mkeller@sqlmag.com. Кроме того, посылайте отзывы об инструментах на форум Tool Time на сайте www.sqlmag.com/forums. Сведения о других бесплатных инструментах приведены во врезках «Бесплатные проекты и образцы SQL Server» и «Бесплатные сценарии PowerShell для SQL Server».
Меган Келлер (mkeller@sqlmag.com) — помощник редактора в журналах SQL Server Magazine и Windows IT Pro, специализируется на SQL Server
Соединение ADP-проектов Access с SQL Server Express
Ранее уже было рассказано, как использовать связанные таблицы для соединения баз данных Microsoft Access с SQL Server
. При таком подходе соединение ODBC связывает таблицы Access с таблицами SQL Server. Но еще более удачный способ связать Access и SQL Server Express — использовать проект базы данных Access. В сущности, в таких проектах Access используется для проектирования базы данных SQL Server, и пользователь получает преимущества обоих продуктов.
Проекты базы данных Access — отличное решение для многопользовательских приложений баз данных. Появляется возможность объединить производительные, простые в применении конструкторы форм, запросов и отчетов Access с более мощным ядром многопользовательской реляционной базы данных SQL Server. При использовании связанных таблиц для соединения с базой данных SQL Server изменить схему объектов базы данных SQL Server нельзя. Но в рамках проекта базы данных Access можно открывать, создавать, изменять и удалять объекты базы данных SQL Server Express, такие как таблицы, представления и хранимые процедуры. В сущности, благодаря проектам базы данных Access можно задействовать Access в качестве внешнего интерфейса разработки и управления базами данных для SQL Server Express.
Однако отыскать проекты базы данных в Access 2007 несколько сложнее, чем в предшествующих версиях. Не зная о поддержке проектов базы данных в Access 2007, можно даже никогда не обнаружить их.
Чтобы построить проект базы данных Access, откройте Access 2007, нажмите кнопку Office и выберите New. Щелкните на пиктограмме просмотра папок рядом с приглашением File Name, чтобы вывести на экран диалоговое окно New Database. Перейдите в каталог, в котором нужно сохранить проект, выберите пункт Microsoft Office Access Projects (*.adp) из раскрывающегося меню Save as type, а затем присвойте базе данных имя в поле File Name. Нажмите кнопку OK, чтобы вернуться в основное окно Access.
Затем нажмите кнопку Create. Access выведет приглашение Do you want to connect to an existing SQL Server database? Если предстоит построить новую базу данных, выберите ответ No, чтобы создать новую базу данных. Для подключения к существующей базе данных выберите ответ Yes.
В качестве примера установим соединение с тестовой базой данных Northwind. Нажмите кнопку Yes, чтобы вывести диалоговое окно Data Link Properties. Если экземпляр SQL Server Express установлен с использованием параметров по умолчанию, то выберите пункт SQLEXPRESS из раскрывающегося меню Select or enter a server name и щелкните Use Windows NT Integrated security. Из раскрывающегося меню Select the database on the server следует выбрать базу данных Northwind. По нажатию кнопки OK создается проект базы данных Access, и Access открывается, показывая таблицы Northwind. Структура проекта аналогична, но не полностью совпадает с собственным проектом базы данных Access. Открыв таблицу щелчком мыши, можно изменить ее схему и подготовить новые формы и отчеты Access.
Так можно создать проекты базы данных Access. Но что делать, если база данных Access уже сформирована с использованием связанных таблиц, и нужно перейти к проекту базы данных Access? Об этом будет рассказано в следующей статье.
Поделитесь материалом с коллегами и друзьями
Обновление схемы, ALTER SCHEMA
В SQL стандарте скрипт ALTER SCHEMA не определен.
В PostgreSQL владельца или наименование схемы можно изменить скриптом ALTER SCHEMA.
Чтобы использовать ALTER SCHEMA необходимо быть владельцем схемы и иметь соответствующие привилегии. При изменении наименования схемы нужно иметь привилегии CREATE для текущей базы данных. Чтобы сменить владельца, необходимо быть членом соответствующей роли и иметь в ней привилегии CREATE.
В СУБД MSSQL с помощью скрипта ALTER SCHEMA можно перенести объекты из одной схемы в другую.
Пользователи и схемы в MSSQL полностью разделены. Инструкция ALTER SCHEMA применяется только для перемещения объектов между схемами в пределах одной базы данных. В следующем примере схема Customers изменяется путем перемещения в нее таблицы Cities из схемы Persons.
Ответы 2
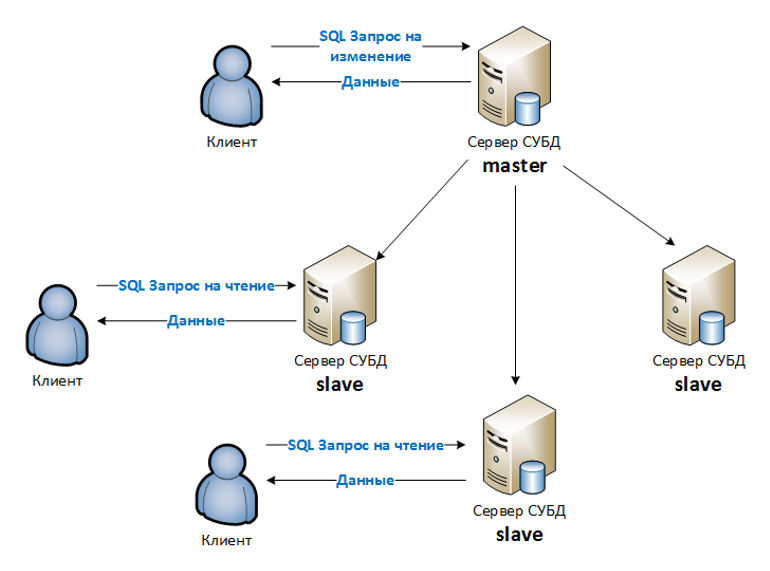
В зависимости от ваших требований вы можете просто попробовать резервное копирование и восстановление, который, кажется, удовлетворяет вашим требованиям. В качестве альтернативы попробуйте Репликация, но это значительно увеличивает сложность.
Существуют также различные инструменты, которые могут это сделать. Если вы можете заплатить за них, Редгейт работают очень хорошо. Я уверен, что есть и бесплатные, но у меня нет опыта работы с ними.
Я бы не рекомендовал катать самостоятельно.
Комментарии (1)
Вариантов много, я перечислил от самого простого до самого сложного.
- Бэкап с дальнейшим восстановлением
- Доставка журналов
- Моментальные снимки или репликации транзакций
- Зеркальное отображение базы данных
Автоматизацию первого варианта можно сделать с помощью командной оболочки:
https://blog.sqlauthority.com/2013/02/08/sql-server-backup-and-restore-database-using-command-prompt-sqlcmd/
Еще одна поразительная вещь:
вы запускаете RTM-версию SQL Server 2008 R2 на серверах:
- Он не исправлен, Microsoft выпустила 4 пакета обновлений. Версия RTM содержит серьезные ошибки
- Эта версия не поддерживается
Комментарии (3)
Другие вопросы по теме
Отобразить один столбец из базы данных в PHPКак отключить хэширование пароля cakephp3 по запросу перед его вставкой в базу данных?Подписчик события Symfony не реагирует на отправкуНе могу понять разницу между квантификаторами * и + в REGEXПочему функция curl возвращает неопределенный индекс при начальной загрузке страницы?PHP-скрипт работает в автономном режиме, но не работает в ИнтернетеКак написать код исходного тега платежной формы в codeigniter, который является формой javascriptПоиск DataTables на основе столбца со значкамиPHP сравнивает 2 массива и получает только не совпадающие значенияИзменить метод и действие внутри атрибута кнопки
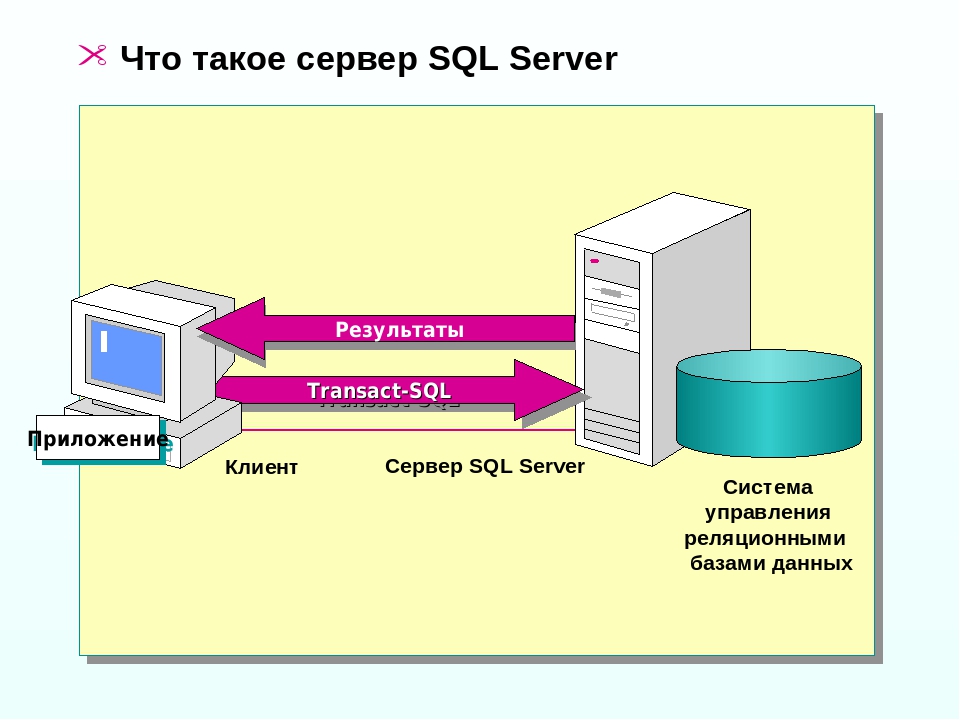
Системы реляционных баз данных
Компонент Database Engine сервера Microsoft SQL Server является системой реляционных баз данных. Понятие систем реляционных баз данных было впервые введено в 1970 г. Эдгаром Ф. Коддом в статье «A Relational Model of Data for Large Shared Data Banks». В отличие от предшествующих систем баз данных (сетевых и иерархических), реляционные системы баз данных основаны на реляционной модели данных, обладающей мощной математической теорией.
Модель данных — это набор концепций, взаимосвязей между ними и их ограничений, которые используются для представления данных в реальной задаче. Центральным понятием реляционной модели данных является таблица. Поэтому, с точки зрения пользователя, реляционная база данных содержит только таблицы и ничего больше. Таблицы состоят из столбцов (одного или нескольких) и строк (ни одной или нескольких). Каждое пресечение строки и столбца таблицы всегда содержит ровно одно значение данных.
Работа с демонстрационной базой данных в последующих статьях
Используемая в наших статьях база данных SampleDb представляет некую компанию, состоящую из отделов (department) и сотрудников (employee). Каждый сотрудник принадлежит только одному отделу, а отдел может содержать одного или нескольких сотрудников. Сотрудники работают над проектами (project): в любое время каждый сотрудник занят одновременно в одном или нескольких проектах, а над каждым проектом может работать один или несколько сотрудников.
Эта информация представлена в базе данных SampleDb (находится в исходниках) посредством четырех таблиц:
Department Employee Project Works_on
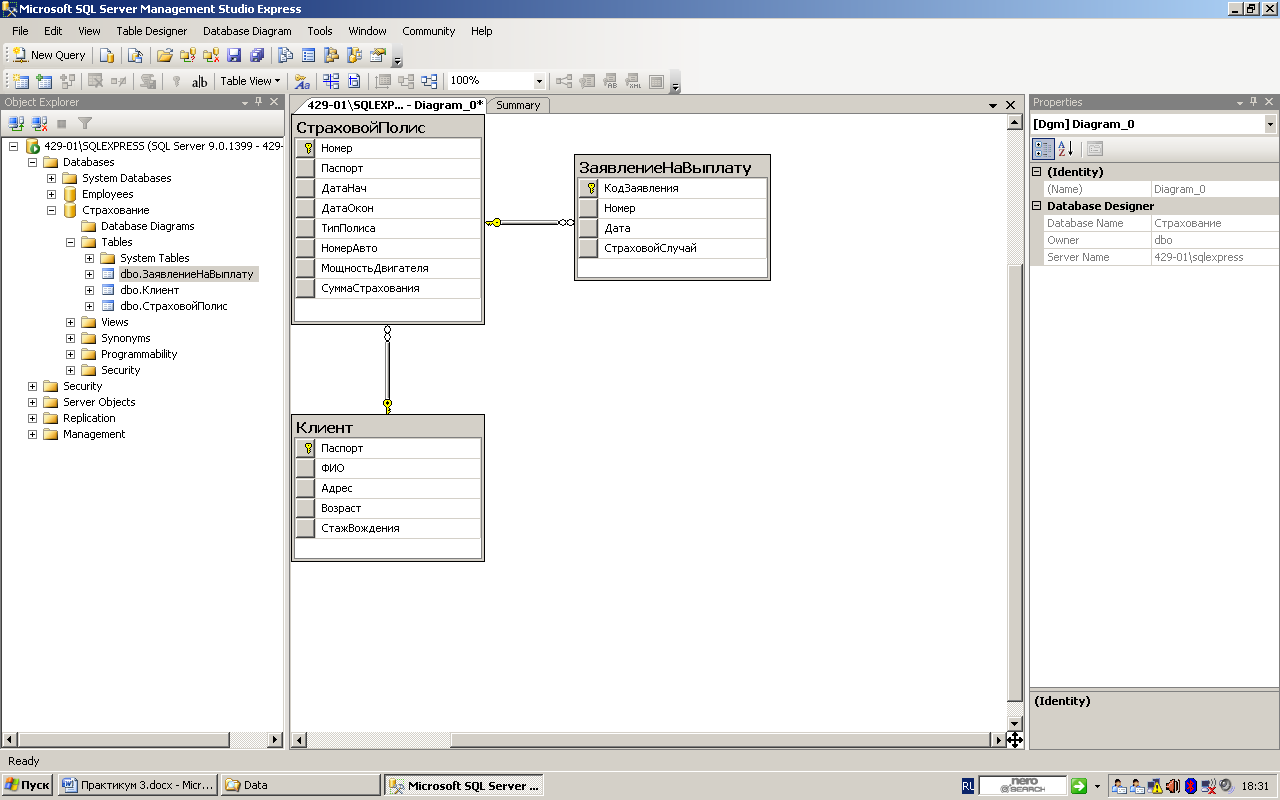
Организация этих таблиц показана на рисунках ниже. Таблица Department представляет все отделы компании. Каждый отдел обладает следующими атрибутами (столбцами):
Department (Number, DepartmentName, Location)
Атрибут Number представляет однозначный номер каждого отдела, атрибут DepartmentName — его название, а атрибут Location — расположение. Таблица Employee представляет всех работающих в компании сотрудников. Каждый сотрудник обладает следующими атрибутами (столбцами):
Employee (Id, FirstName, LastName, DepartmentNumber)
Атрибут Id представляет однозначный табельный номер каждого сотрудника, атрибуты FirstName и LastName — имя и фамилию сотрудника соответственно, а атрибут DepartmentNumber — номер отдела, в котором работает сотрудник.
Все проекты компании представлены в таблице проектов Project, состоящей из следующих столбцов (атрибутов):
Project (ProjectNumber, ProjectName, Budget)
В столбце ProjectNumber указывается однозначный номер проекта, а в столбцах ProjectName и Budget — название и бюджет проекта соответственно.
В таблице Works_on указывается связь между сотрудниками и проектами:
Works_on (EmpId, ProjectNumber, Job, EnterDate)
В столбце EmpId указывается табельный номер сотрудника, а в столбце ProjectNumber — номер проекта, в котором он принимает участие. Комбинация значений этих двух столбцов всегда однозначна. В столбцах Job и EnterDate указывается должность и начало работы сотрудника в данном проекте соответственно.


На примере базы данных SampleDb можно описать некоторые основные свойства реляционных систем баз данных:
-
Строки таблицы не организованы в каком-либо определенном порядке.
-
Также не организованы в каком-либо определенном порядке столбцы таблицы.
-
Каждый столбец таблицы должен иметь однозначное имя в любой данной таблице. Но разные таблицы могут содержать столбцы с одним и тем же именем. Например, таблица Department содержит столбец Number и столбец с таким же именем имеется в таблице Project.
-
Каждый элемент данных таблицы должен содержать одно значение. Это означает, что любая ячейка на пересечении строк и столбцов таблицы никогда не содержит какого-либо набора значений.
-
Каждая таблица содержит, по крайней мере, один столбец, значения которого определяют такое свойство, что никакие две строки не содержат одинаковой комбинации значений для всех столбцов таблицы. В реляционной модели данных такой столбец называться потенциальным ключом (candidate key). Если таблица содержит несколько потенциальных ключей, разработчик указывает один из них, как первичный ключ (primary key) данной таблицы. Например, первичным ключом таблицы Department будет столбец Number, а первичными ключами таблиц Employee будет Id. Наконец, первичным ключом таблицы Works_on будет комбинация столбцов EmpId и ProjectNumber.
-
Таблица никогда не содержит одинаковых строк. Но это свойство существует только в теории, т.к. компонент Database Engine и все другие реляционные системы баз данных допускают существование в таблице одинаковых строк.
Советы начинающим администраторам БД
- Делайте Backup перед любыми изменениями в БД
- Если вы выполняете добавление, обновление или удаление данных, то можно явно открыть транзакцию BEGIN TRANSACTION > выполнить ваш код > прочитать таблицу с параметром NOLOCK (позволяет читать незафиксированные данные) SELECT * FROM MyTable WITH (NOLOCK)> если всё прошло успешно, можно зафиксировать транзакцию — COMMIT TRANSACTION
- Пишите комментарии, они не раз помогут вам при разборе вашего кода, когда вы вернётесь к нему спустя некоторое время
- Скачайте для практики SQL Server Developer Edition (2014/16 бесплатны). Данная редакция имеет только одно ограничение — запрет на использование в продуктивных системах, что позволит вам практиковаться на всех компонентах SQL Server.
- Старайтесь отслеживать любые изменения на сервере БД, так как отвечать придётся именно вам, даже если изменения сделали другие
- Не вносите критические изменения, которые могут повлиять на производительность или доступность системы, без согласования с пользователями и вашим руководством
В конце хотелось бы добавить, что во время интенсивного обучения крайне важно отдыхать. Хороший сон позволит вам лучше усваивать материал, а периодические перерывы помогут по другому смотреть на ситуацию, но ни в коем случае не путайте полезные перерывы с ленью
Вам так же будет полезно изучить вопросы для собеседование на позицию Администратор MS SQL SERVER