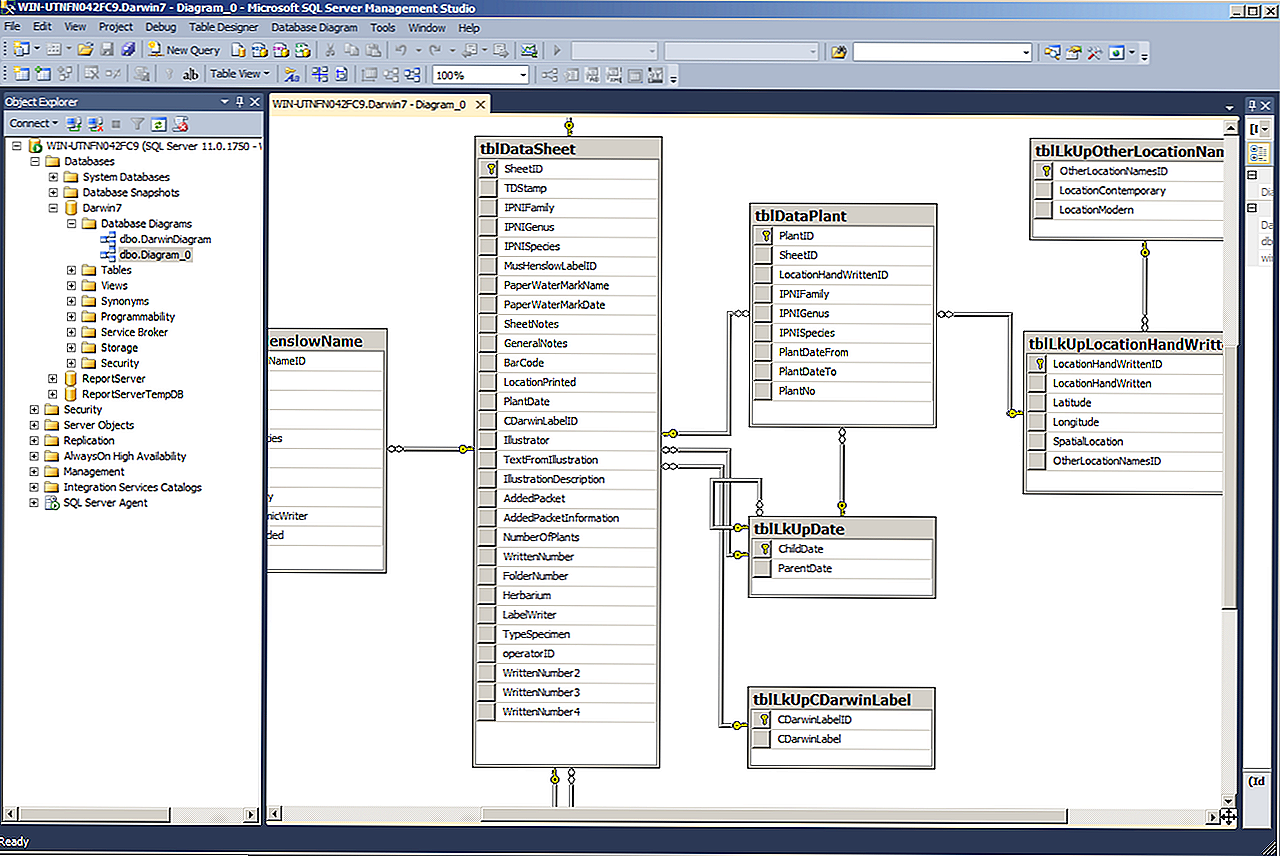
Пример статистики в Microsoft SQL Server
Информацию о статистике можно получить, например, с помощью команды DBCC SHOW_STATISTICS. В качестве параметра необходимо передать имя таблицы или индексированного представления, а также вторым параметром — имя индекса, статистики или столбца, для которого отображаются статистические данные.
В данном случае показан пример вывода информации о статистике некластеризованного индекса IX_Person_LastName_FirstName, который создан для столбцов LastName и FirstName таблицы Person в схеме Person.
DBCC SHOW_STATISTICS (N'Person.Person', N'IX_Person_LastName_FirstName');

Опыт оптимизации и контроля производительности в БД с 3000 пользователей Промо
Данная статья написана по материалам доклада, прочитанного на Конференции Инфостарта IE 2014 29-31 октября 2014 года.
Меня зовут Сергей, являюсь руководителем отдела оптимизации и производительности систем в компании «Деловые линии».
Цель этого доклада – поделиться информацией о нашем опыте работы с большой базой на платформе 1С, с чем пришлось столкнуться, как удалось обеспечить работоспособность.
Уверен, что вам будет интересно, так как подобной информацией мало кто делится, да и про само существование таких систем их владельцы стараются не рассказывать, максимум про это «краем глаза» упоминают участвовавшие в проекте вендоры.
**update от 04.03.2016 по вопросам из комментариев
328
Оптимизация индексов
После выполнения любых действий с табличными данными sql сервером в тот же момент производятся соответствующие правки в индексах. Спустя некоторое время все подобные исправления могут спровоцировать фрагментацию данных. В результате, их может разбросать по всей базе.
Подобная фрагментация данных может стать причиной понижения производительности
Потому крайне важно время от времени проводить дефрагментацию. К подобным операциям по обслуживанию индексов относят реорганизацию и перестроение индексов
Чтобы понять, какую именно операцию требуется провести – реорганизацию или перестроение, следует выяснить степень фрагментации данных. Она поможет понять, какой способ дефрагментации будет наиболее эффективным и что выбрать.
Чтобы выяснить уровень фрагментации следует воспользоваться системной табличной функцией sys.dm_db_index_physical_stats. Для определения уровня фрагментации всего перечня таблиц для выбранной базы, можете воспользоваться следующим запросом:
SELECT OBJECT_NAME(T1.object_id) AS NameTable,
T1.index_id AS IndexId,
T2.name AS IndexName,
T1.avg_fragmentation_in_percent AS Fragmentation
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS T1
LEFT JOIN sys.indexes AS T2 ON T1.object_id = T2.object_id AND T1.index_id = T2.index_id
Согласно рекомендациям Microsoft, последующие действия будут зависеть от уровня фрагментации:
- меньше 5% – о дефрагментации следует пока забыть;
- от 5 до 30% – требуется выполнить реорганизацию индекса. Это потребует минимального количества ресурсов системы и ее можно провести без долговременной блокировки;
- свыше 30% – следует выполнить перестроение индекса. При значительном уровне фрагментации это наиболее эффективно.
Реорганизация индекса
Реорганизацией называют процесс устранения фрагментации индекса. В его ходе происходит дефрагментация конечного уровня кластерных и некластерных индексов по таблицам и представлениям. Говоря простым языком – выполняется простое переупорядочивание страниц. В основе переупорядочивания лежит логический порядок конечных узлов (выполняете слева направо).
Если хотите провести реорганизацию – воспользуйтесь:
- MSSQL Management Studio. На выбранном индексе следует щелкнуть мышкой, из списка выбрать и нажать «Реорганизовать»;
- соответствующими инструкциями T-SQL.
Перестроение индекса
Перестроением называется операция по устранению фрагментации индекса. Он заключается в устранении старого и формировании нового.
Перестроение индекс выполняется несколькими способами. В этом поможет:
- Management Studio. Для этого необходимо выбрать нужный индекс, мышкой кликнуть по нему и выбрать «Перестроить»;
- инструкция ALTER INDEX ix с предложением REBUILD, которая по сути является заменой инструкции DBCC DBREINDEX. Ею пользуются, когда возникла потребность в масштабной операции;
- инструкция CREATE NONCLUSTERED INDEX (CREATE INDEX) с предложением DROP_EXISTING. Подходит, чтобы перестроить индекс и изменить его определения (удалить либо добавить ключевые столбцы).
Это вся полезная информация по индексам в Microsoft SQL Server. Изучайте их, а если возникнут вопросы – задавайте. Удачи в изучении и применении indexes ms sql.


╔༻ ━━━━━━━━━━━ ༺╗
9 февраля в OTUS состоится вебинар «Основы анализа производительности и оптимизации запросов в MS SQL Server».На занятии рассмотрим основы анализа производительности и оптимизации запросов в MS SQL Server.Не упусти возможность протестировать обучение на онлайн-курсе «MS SQL Server Developer».
Способы создания индексов
Предусмотрено создание индексов ms sql server с помощью двух инструментов. В этом помогут:
- SSMS (MSSQL Management Studio);
- специальный язык Transact-SQL (T-SQL, поддерживающий Paging Queries).
Как создать кластеризованный индекс
Как отмечалось выше, создание кластеризованного индекса sql сервером происходит автоматически, когда определенный столбец выбирается в качестве первичного ключа (PRIMARY KEY). Когда такого не происходит, следует создать кластерный индекс своими руками.
Чтобы создать Clustered index воспользуемся Management Studio. Для этого следует:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать соответствующую таблицу.
- Остановившись на пункте «Индексы» кликнуть мышкой.
- Выбрать «Создать индекс» и соответствующий тип (выбираем «Кластеризованный»).
- В новом окне появится форма «Новый индекс». Здесь потребуется вписать наименование нового создаваемого индекса (в рамках одной таблицы требуется, чтобы оно было уникальным). Поставить галочку, что он уникальный.
- Выбрать столбец, который будет являться ключом индекса. Он ляжет в основу создаваемого Clustered index. Провести сортировку строк табличных данных кнопкой «Добавить».
- После ввода всех необходимых параметров кликнуть «ОК».
Результатом действий станет кластерный индекс.
Он может быть создан и с помощью инструкций Transact-SQL CREATRE INDEX.
Создание Nonclustered index с включенными столбцами
Коснемся вопроса, как создать Nonclustered index с условием, что в индекс включены столбцы, которые не являются ключевыми. Такой индекс принято использовать в тех случаях, когда индекс создается под конкретный запрос. К примеру, чтобы индексом покрывался запрос полностью, т.е. включал все столбцы. Вследствие того, что запрос покрыт, увеличивается производительность. Это становится возможным благодаря тому, что оптимизатор запросов может получить все значения столбцов в индексе без обращения к табличным данным. Это ведет к уменьшению числа операций ввода-вывода на диске.
Однако стоит учитывать, что с включением в индекс неключевых столбцов размер его увеличивается. А значит, для его хранения понадобится больше дискового пространства. Это также может снизить производительность операций INSERT, UPDATE, DELETE и MERGE в базовой таблице данных.
Для его создания также воспользуемся Management Studio:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать требуемую таблицу и щелкнуть мышкой по пункту «Индексы».
- Выбрать «Создать индекс», а затем «Некластеризованный» (не ставить галочку на уникальности).
- В открывшейся форме «Новый индекс» вписать наименование нового индекса, добавить один или несколько ключевых столбцов, воспользовавшись кнопкой «Добавить».
- Перейти во вкладку «Включено столбцы». Добавить все столбцы, которые должны быть включены в индекс, воспользовавшись кнопкой «Добавить».
- Когда введены все нужные параметры кликнуть «ОК».
Все готово!
При необходимости, можно легко создать фильтруемый Nonclustered index. Для этого следует воспользоваться T-SQL и в операторе CREATE NONCLUSTERED INDEX в WHERE указать условие фильтрации. Так можно отфильтровать практически любые данные, не важные в запросах.
Достоинства и недостатки Microsoft Access
СУБД Access отличается простотой в изучении и применении. Данный системный продукт может с легкостью освоить любой пользователь, даже имеющий невысокий уровень квалификации. Программа включает широкий спектр средств, что позволяет создавать отчеты разной сложности и масштаба, которые формируются на основании табличных форматов. Обычно, Access используют для создания личных баз данных, которые не предназначены для коммерческого распространения.
- Реляционная база данных является комплексом взаимосвязанных двухмерных таблиц.
- СУБД позволяет создавать и обрабатывать локальные базы данных, а также применяется, как клиентское приложение, обеспечивающее доступ к удаленным и распределенным базам данных коллективного использования с SQL Server или Oracle.
- Базы данных, формы, запросы и отчеты формируются и используются по единой технологии.
- Опция совместной работы базы данных со сторонними источниками информации такими, как базы данных с СУБД Access и других типов СУБД, электронная таблица Excel, текстовые файлы.
- Возможность использования средств разработки пользовательских приложений для работы с другими СУБД, включая MS SQL Server, Oracle, в роли интегрированной среды разработки приложений, использующих для хранения данных базы с различными СУБД.
- Access включает разные мастера, конструкторы, построители.
- Полностью русифицированный интерфейс, в том числе перевод на русский язык имен полей и свойств, что упрощает работу с программой.
- Отсутствует опция создания приложения в виде исполняемого файла и одновременной непосредственной работы с несколькими базами с помощью окна базы.
- Собственный язык программирования не предусмотрен, используется Visual Basic.
- Возможность использования запроса наравне с таблицами, как источника записей для отчетов, форм и запросов.
- Базы данных, включая все объекты в виде таблиц, запросов, форм, отчетов, макросов, модулей, хранятся в одном файле.
Преимущества:
- простота;
- гибкость;
- русификация;
- большой выбор мастеров, конструкторов;
- надежность в применении.
Недостатки:
- низкоэффективная защита;
- слабые средства восстановления данных;
- ограничения по объему данных;
- отсутствует собственный язык программирования;
- длительное время обработки больших объемов информации.
Существуют некоторые ограничения при работе с Access:
- размер файла с расширением mdb составляет 2 Гб без учета объема системных объектов;
- фактический размер ограничен свободным дисковым пространством, по причине возможного наличия в базе данных присоединенных таблиц;
- количество объектов в базе данных — 32768;
- число пользователей, которые могут работать в одно время — 255;
- максимально допустимый размер таблицы — 2 Гбайт;
- максимально допустимое число полей в таблице — 255;
- максимально возможное число индексов в таблице — 32;
- максимально возможное количество символов в записи без учета поля Memo и полей объектов OLE — 2000;
- максимальное количество символов в поле Memo — 65 535 при вводе данных с помощью пользовательского интерфейса и 1 Гбайт при программном вводе данных;
- максимальный размер объекта OLE — 1 Гбайт;
- максимальное число таблиц в запросе — 32.
Примечание
Access целесообразно использовать при разработке несложных приложений и персональных баз данных, которые характеризуются ограниченным объемом сведений в несколько сотен тысяч записей. Подобные системы подходят для применения на небольших предприятиях.
Автокликер для 1С
Внешняя обработка, запускаемая в обычном (неуправляемом) режиме для автоматизации действий пользователя (кликер). ActiveX компонента, используемая в обработке, получает события от клавиатуры и мыши по всей области экрана в любом приложении и транслирует их в 1С, получает информацию о процессах, текущем активном приложении, выбранном языке в текущем приложении, умеет сохранять снимки произвольной области экрана, активных окон, буфера обмена, а также, в режиме воспроизведения умеет активировать описанные выше события. Все методы и свойства компоненты доступны при непосредственной интеграции в 1С. Примеры обращения к компоненте представлены в открытом коде обработки.
1 стартмани
03.04.2017
44312
87
slava_1c
67
74
Первый опыт работы с PostgreSQL на Windows
С чего мы начали? В 2014 году рискнули перевести 5 баз 1С общим объемом порядка 100 гигабайт на Postgres. Не сразу стали перепрыгивать бездну нашего незнания между Windows и Linux, а мир 1С, мне кажется, до сих пор на 80% это мир Windows. Поэтому сначала решили перепрыгнуть пропасть незнания между двумя базами данных: MS SQL и PostgreSQL.
Мы запустили Postgres на Windows. Сначала сильно удивились, что оно заработало. В целом все завелось, заработало, даже база открылась. Правда, потом начались бессонные ночи и дни без обеденного перерыва в попытках настроить Postgres так, чтобы он работал хорошо.

На момент 2014 года информации никакой нет. Есть английская документация, а в мире 1С английский язык не в почете: вы даже код пишете на русском. Поэтому читать тяжело, понимать еще тяжелее. И по сравнению с дружественным интерфейсным MS SQL, где вся настройка – это 5 галочек и 2 цифры, настройки в Postgres – это сотни параметров, слишком непонятно, как и на что отреагирует система, отреагирует ли вообще. Менять приходилось по одному параметру, потому что иначе вообще не поймешь, на что была реакция. А очень часто смена одного параметра не давала никакой реакции. Вот так мы и жили примерно полгода до момента обнаружения той самой ошибки, которая сейчас уже исправлена. О ней рассказывал Олег Бартунов.
Это была фантастика. Я на прошлой конференции по Postgres в Москве рассказывал об этом отдельно. Мы долго не верили своим глазам, будучи уверенными, что это мы неопытные и неправильно настроили систему. Потому что не может так база данных себя вести.
Там происходило очень чудесная вещь: у Postgres есть много файлов статистики. Один из них на весь сервер, и он переименовывается несколько десятков, может быть, сотен, может быть, тысяч раз в секунду. Так построена система: она создает рядом новый файл статистики, переименовывая его в действующий. А наша любимая Windows не дает так работать с файлами в своей файловой системе. Если файл кто-то читает, переименовать его нельзя. Postgres по-честному пишет, что у него нет доступа к статистике, поэтому он будет использовать старые файлы. Ладно, используй. Но нет, происходило 15-ти секундное торможение всего сервера, просто на 15 секунд останавливались все транзакции.
Мы долго не верили своим глазам, мы боялись рассказать это разработчикам. Что они бы подумали? Что какие-то дураки взялись за систему, и теперь непонятно, что от нас хотят. В итоге мы боролись-боролись, но не побороли. И все-таки написали письмо в Postgres Pro. Там тоже долго удивлялись, не верили, что такое может быть. Потом подтвердили, что, действительно, есть косяк. Пообещали исправить.
Как работать с SQL: основные операторы
Запросы в SQL похожи на естественный английский язык и выглядят как полноценные предложения.
Например, если мы захотим в базе данных нашей строительной фирмы получить номер телефона ООО «Коттеджи», нам нужно написать такую команду:
Перевести на русский её можно так: «Выбери значение из столбца tel в таблице contractors, где значение столбца id равно единице». Символ ; означает конец команды.
SQL-инструкции общаются не напрямую с базой данных, а с СУБД. Многие производители СУБД хотели расширить функциональность запросов, поэтому добавляли к языку собственные расширения.
Так у SQL появились несовместимые между собой диалекты. Например, PL/SQL, PL/pgSQL, T-SQL. Но структура запросов и основные «встроенные» команды от диалекта к диалекту неизменны.
Вот список самых распространённых операторов SQL.
CREATE DATABASE — создаёт БД.
DROP DATABASE — удаляет БД.
USE — указывает СУБД, в какой БД работать в дальнейшем.
CREATE TABLE — создаёт новую таблицу внутри БД.
DROP TABLE — удаляет таблицу.
INSERT — добавляет данные в таблицу. Используется вместе с операторами INTO (указывает на таблицу) и VALUES (ему передают значения, которые нужно добавить).
UPDATE — обновляет данные в таблице. UPDATE указывает на саму таблицу, а потом используется оператор SET, после которого и прописываются новые значения для атрибутов. Чтобы указать на конкретную запись, используют оператор WHERE.
DELETE — удаляет данные из таблицы. Используется перед оператором FROM.
SELECT — выбирает данные. Ему передают название атрибута или атрибутов. Если нужно выбрать все атрибуты, то пишут SELECT *. Находится перед оператором FROM.
FROM — указывает на таблицу, к которой обращена команда.
WHERE — указывает на условие или условия, которым должна удовлетворять строка. Пишется после оператора FROM. Необязательный элемент инструкции. Если его не указывать, то команда применяется ко всем записям в таблице.
ORDER BY — сортирует результаты запроса. По умолчанию — в порядке возрастания. Для сортировки по убыванию можно использовать слово DESC.
JOIN — объединяет значения нескольких колонок. Бывает нескольких видов: внутренний (INNER), внешний (OUTER), левый (LEFT) и правый (RIGHT).
Давайте напишем какой-нибудь запрос к базе данных нашей строительной фирмы.
Он означает: выбери все столбцы из таблицы houses, чей status „Не построен“, и отсортируй их по убыванию атрибута cost. СУБД выдаст нам такую таблицу:
Пример выдачи по запросу status «Не построен» в столбце housesСкриншот: Skillbox Media
Также в SQL существуют агрегатные функции. Они позволяют производить с данными дополнительные операции и указываются вместо атрибутов. Агрегатные функции записываются в формате FUNCTION(ATTRIBUTE).
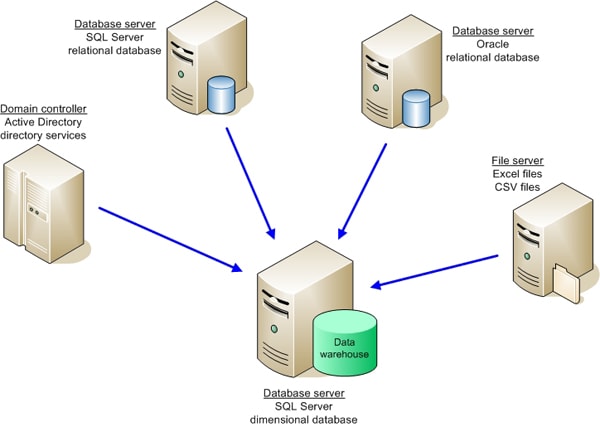
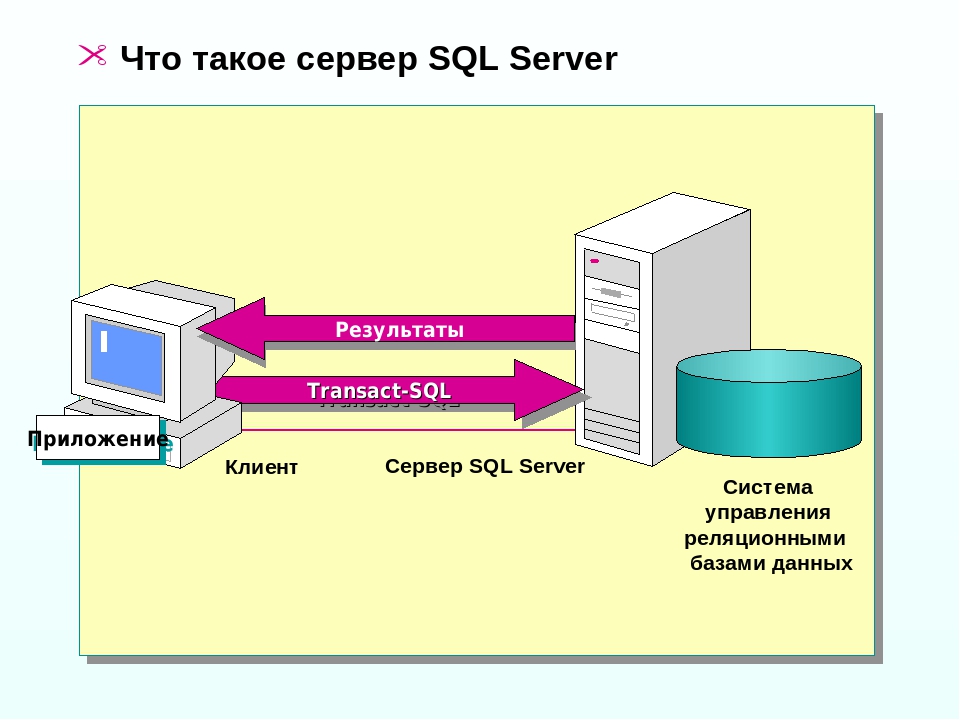

Вот некоторые из них.
COUNT — считает количество записей в колонке.
SUM — складывает содержимое значений колонки.
MIN — указывает на минимальное значение в колонке.
MAX — указывает на максимальное значение в колонке.
AVG — считает среднее значение в колонке.
ROUND — округляет значение в колонке.
Для работы с инструкциями, которые содержат агрегатные функции, есть специальные операторы.
GROUP BY — группирует выходные значения для колонок, к которым применили агрегатную функцию.
HAVING — работает как WHERE, но может применяться к агрегатным функциям.