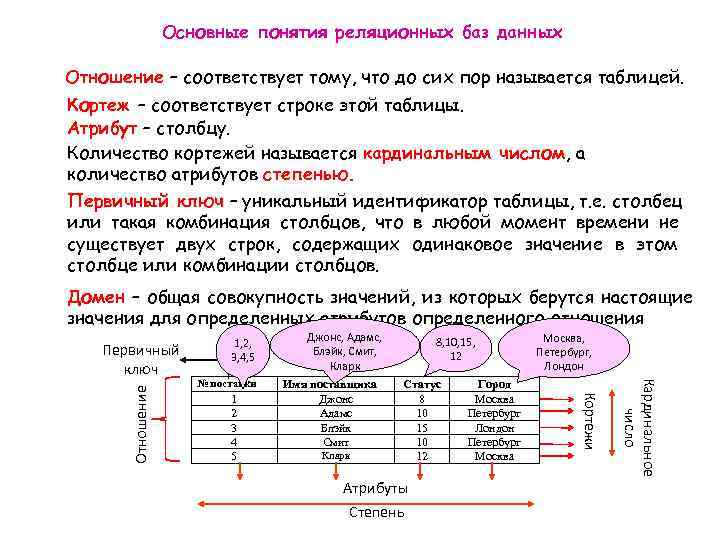
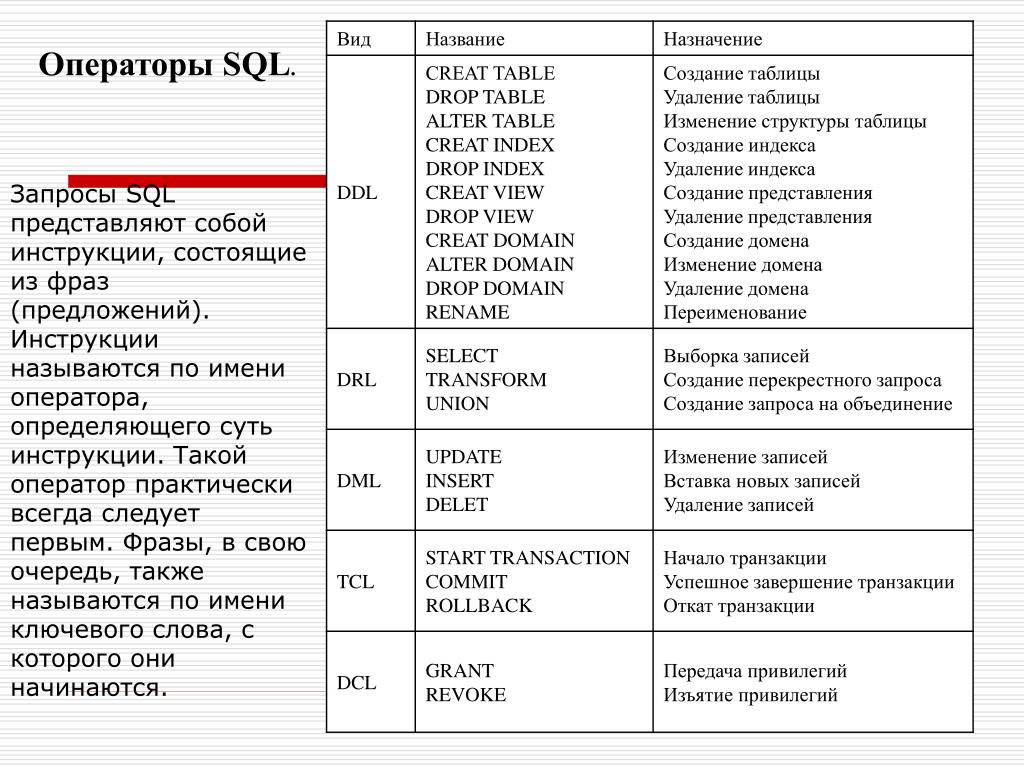
Модификаторы запроса SELECT
Вы можете использовать следующие модификаторы в запросах .
APPLY
Вызывает указанную функцию для каждой строки, возвращаемой внешним табличным выражением запроса.
Синтаксис:
Пример:
Исключает из результата запроса один или несколько столбцов.
Синтаксис:
Пример:
REPLACE
Определяет одно или несколько . Каждый алиас должен соответствовать имени столбца из запроса . В списке столбцов результата запроса имя столбца, соответствующее алиасу, заменяется выражением в модификаторе .
Этот модификатор не изменяет имена или порядок столбцов. Однако он может изменить значение и тип значения.
Синтаксис:
Пример:
Комбинации модификаторов
Вы можете использовать каждый модификатор отдельно или комбинировать их.
Примеры:
Использование одного и того же модификатора несколько раз.
Использование нескольких модификаторов в одном запросе.
Функции ранжирования и нумерации в Transact-SQL — ROW_NUMBER, RANK, DENSE_RANK, NTILE | Info-Comp.ru
Изучение Transact-SQL продолжается и на очереди у нас функции ранжирования ROW_NUMBER, RANK, DENSE_RANK и NTILE, сейчас мы узнаем, что делают эти функции и зачем вообще они нужны, все как обычно будем рассматривать на примерах.
В языке Transact-SQL очень много различных функций, конструкций, например, PIVOT или INTERSECT, которые в принципе редко используются, их мы даже в нашем мини справочнике Transact-SQL не указывали, но знать, где и как их можно использовать нужно, так же как и функции ранжирования или их также называют функции нумерации. Поэтому сегодня давайте поговорим именно об этих функция и если говорить конкретно, то это функции: ROW_NUMBER, RANK, DENSE_RANK, NTILE.
И начнем мы, конечно же, с определения, что же вообще это за ранжирующие функции.
Ранжирующие функции в T-SQL
Ранжирующие функции — это функции, которые возвращают значение для каждой строки группы в результирующем наборе данных. На практике они могут быть использованы, например, для простой нумерации списка, составления рейтинга или постраничной выборки.
И для того чтобы лучше усвоить работу и применение этих функций, давайте рассмотрим все их по очереди, и параллельно будем сравнивать их друг с другом, т.е. таким образом, мы еще и узнаем в чем их отличие. Но для того чтобы начать рассматривать примеры, необходимо определится с исходными данными.
Примечание! Для детального изучения языка T-SQL, рекомендую почитать книгу «Путь программиста T-SQL», в ней я подробно, с большим количеством примеров, рассказываю основы программирования на языке T-SQL.
Исходные данные для примеров
Использовать мы будем MS SQL Server Express 2014, а запросы будем писать в Management Studio Express. В качестве тестовых данных будем использовать таблицу selling, которая будет содержать различные товары (телефоны, планшеты, ноутбуки, программы) с выдуманными ценами.
Наша тестовая таблица
Заполним ее тестовыми данными, в итоге получим следующее (для выборки пишем простой запрос select)
ROW_NUMBER
ROW_NUMBER – функция нумерации в Transact-SQL, которая возвращает просто номер строки.
Синтаксис
ROW_NUMBER () OVER ( ORDER BY столбец сортировки)
где, partition by — это не обязательное ключевое слово, после которого указывается столбец или столбцы, по которым группировать данные, а order by столбец для сортировки, т.е. по данному столбцу будут отсортированы данные, а потом пронумерованы, он уже обязателен. Сразу скажу, чтобы не возвращаться, что эти ключевые слова относятся ко всем функциям ранжирования, которые мы будем сегодня использовать.
Текст запроса
Текст запроса
Как видите, здесь уже нумерация идет в каждой категории.
RANK
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
Текст запроса
Текст запроса
DENSE_RANK
DENSE_RANK — ранжирующая функция, которая возвращает ранг каждой строки, но в отличие от rank, в случае нахождения одинаковых значений, возвращает ранг без пропуска следующего.
Текст запроса
NTILE
NTILE – функция Transact-SQL, которая делит результирующий набор на группы по определенному столбцу. Количество групп указывается в качестве параметра. В случае если в группах получается не одинаковое количество строк, то в первой группе будет наибольшее количество, например, в нашем случае строк 10 и если мы поделим на три группы, то в первой будет 4 строки, а во второй и третей по 3.
Пример
Текст запроса
В заключение давайте приведем пример, в котором мы наглядно увидим различия в работе всех функций, например, вот такой
Текст запроса
На этом я думаю по ранжирующим функциям достаточно, в следующих статьях мы продолжим изучение Transact-SQL, а на этом пока все. Удачи!
Выбор некоторых полей из двух таблиц
Когда нужно выбрать данные, находящиеся в разных таблицах, применяют объединение таблиц. Пусть, например, необходимо выбрать данные, находящиеся в таблицах Books и Authors.
Простейший шаблон объединения двух таблиц выглядит следующим образом:
SELECT * FROM <таблица1> <тип объединения> <таблица2> ON <таблица1>.<столбец1> = <таблица2>.<столбец2>
Есть 4 типа объединения.
Внутреннее объединение (INNER JOIN)
При внутреннем объединении в таблицах А и В соединяются только те строки, для которых найдено совпадение, указанное в критерии объединения (после ключевого слова ON). Это наиболее подходящий в нашем случае вариант. Следующий запрос объединяет две таблицы Books и Authors, связанные по полю Code_author.
SELECT * FROM Books INNER JOIN Authors ON Books.Code_author = Authors.Code_author
Левое внешнее объединение (LEFT OUTER JOIN)
Левое внешнее объединение таблиц А и В включает в себя все строки из левой таблицы А и те строки из правой таблицы В, для которых обнаружено совпадение, указанное в критерии объединения (после ключевого слова ON). Для строк из таблицы А, для которых не найдено соответствия в таблице В, в столбцы, извлекаемые из таблицы В, заносятся значения NULL. Пример запроса:
SELECT * FROM Books LEFT OUTER JOIN Authors ON Books.Code_author = Authors.Code_author
Правое внешнее объединение (RIGHT OUTER JOIN)
Правое внешнее объединение таблиц А и В включает в себя все строки из правой таблицы В и те строки из левой таблицы А, для которых обнаружено совпадение, указанное в критерии объединения (после ключевого слова ON). Для строк из таблицы В, для которых не найдено соответствия в таблице А, в столбцы, извлекаемые из таблицы А заносятся значения NULL. Пример запроса:

![Sql [айти бубен]](https://wudgleyd.ru/wp-content/uploads/8/4/b/84ba53757a9af071eb535103a1ba9cf2.jpeg)



SELECT * FROM Books RIGHT OUTER JOIN Authors ON Books.Code_author = Authors.Code_author
Полное объединение (FULL JOIN)
Это комбинация левого и правого объединений. В полное объединение таблиц включаются все строки из обеих таблиц. Для совпадающих строк поля заполняются реальными значениями, для несовпадающих строк поля заполняются в соответствии с правилами левого и правого соединений. Пример запроса:
SELECT * FROM Books FULL JOIN Authors ON Books.Code_author = Authors.Code_author
Если необходимо вывести не все столбцы, например, два столбца из таблицы Books (Title_book и Authors) и один столбец из таблицы Authors. Для этого нужные столбцы надо явно указать (с учетом идентификатора таблицы, к которой они принадлежат):
SELECT Books.Title_book, Books.Pages, Authors.Name_author FROM Books INNER JOIN Authors ON Books.Code_author = Authors.Code_author
Самостоятельно:
- Выбрать из таблицы Books названия книг и количество страниц (поля Title_book и Pages), а из таблицы Deliveries выбрать имя соответствующего поставщика книги (поле Name_delivery).
- Выбрать из таблицы Books названия книг и количество страниц (поля Title_book и Pages), а из таблицы Publishing_house выбрать название соответствующего издательства и места издания (поля Publish и City).
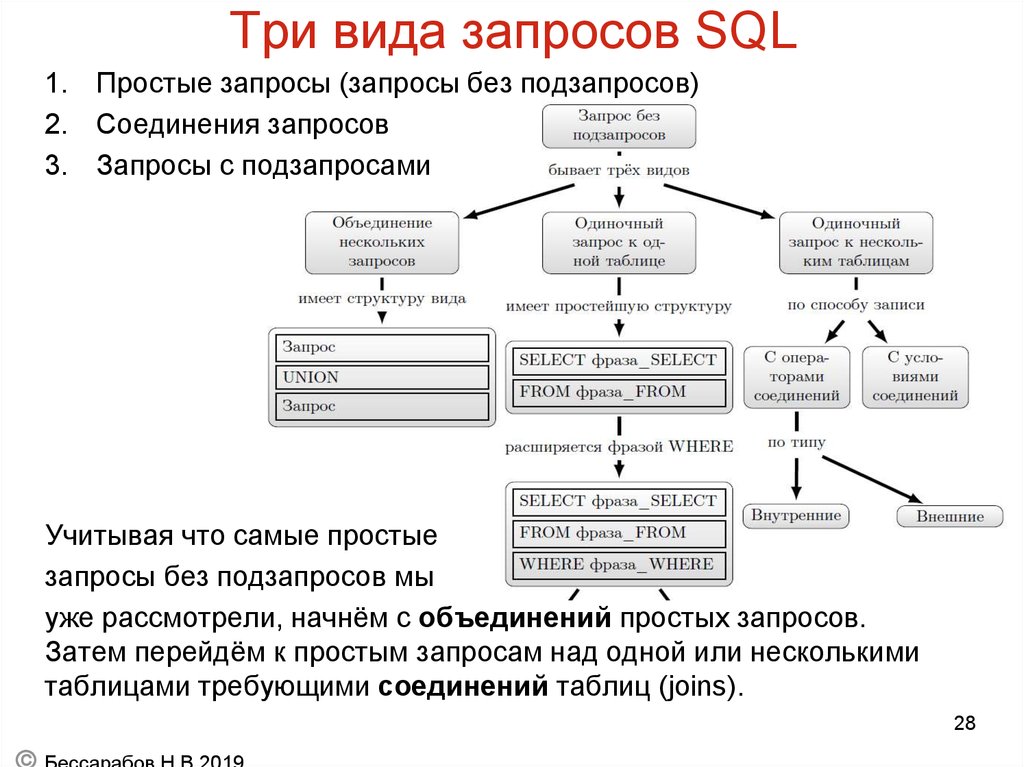
Используем фильтры и сортировку (Where, Order by)
Переходим на лист Level_2. Выберем только некоторые нужные нам поля и зададим условия фильтрации и сортировки. Например, используем данные только по кампаниям Campaign_1 и Campaign_2 за период 22-25 октября 2015 года. Отсортируем их в порядке убывания по сумме сеансов. Для фильтра и сортировки в текст запроса необходимо добавить описание кляуз Where и Order. Для вывода в результирующую таблицу описанного выше примера нам понадобятся поля Campaign, Date и Sessions. Именно их и нужно перечислить в кляузе Select.
Обращение к полям базы данных осуществляется через названия столбцов рабочего листа, на котором располагается база данных.
В нашем случае данные, расположенные на листе DB, и обращение к определенным полям прописываются как название столбцов листа. Таким образом, нужные поля располагается в следующих столбцах:
- поле Date — столбец A;
- поле Campaign — столбец B;
- поле Sessions — столбец G.
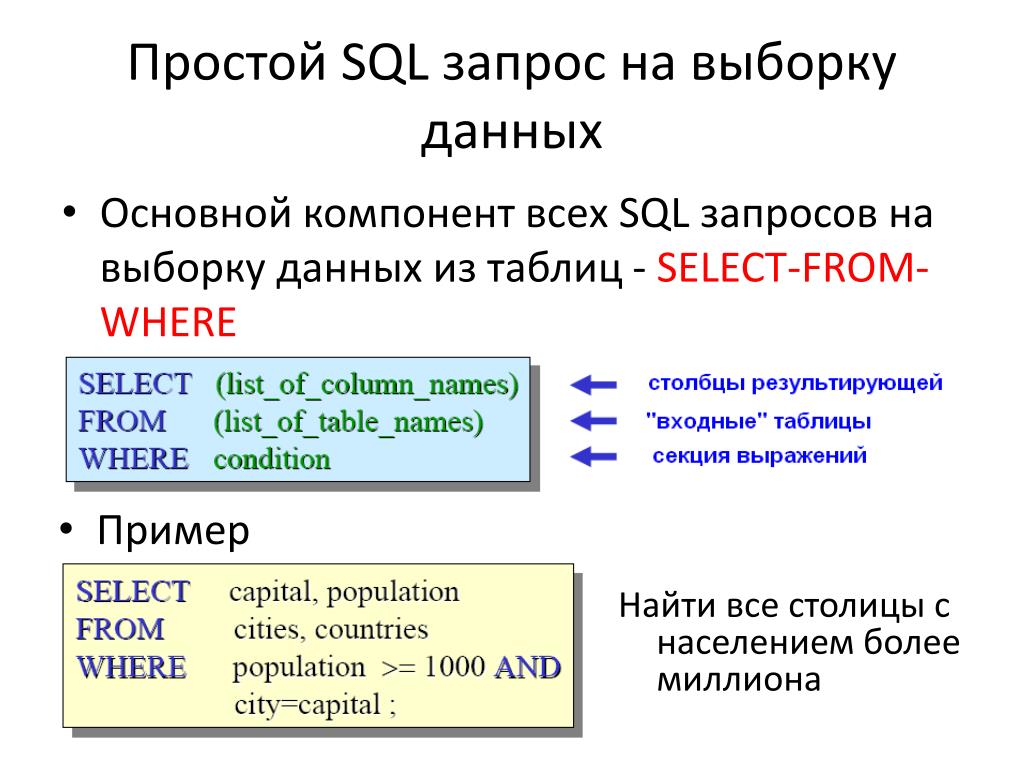
 Соответственно, часть запроса, отвечающая за перечень выводимых в результате данных, будет выглядеть так:
Соответственно, часть запроса, отвечающая за перечень выводимых в результате данных, будет выглядеть так:
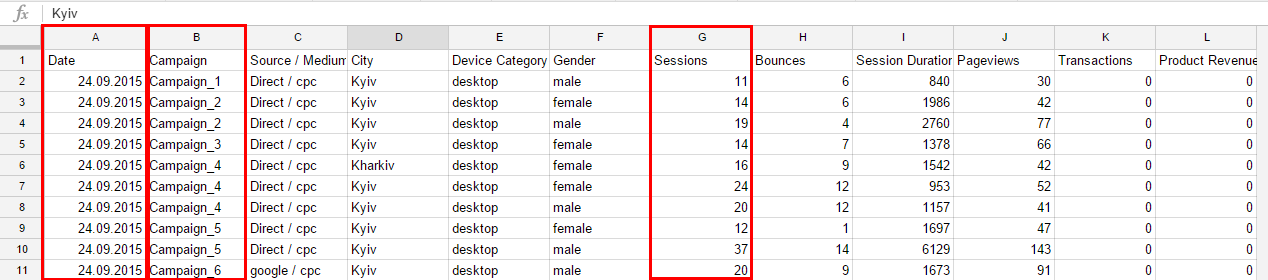
Далее в запросе идет кляуза Where. При написании запроса кляузы обязательно должны располагаться в таком порядке, в котором были описаны в первом разделе этой статьи. После объявления Where нам необходимо перечислить условия фильтрации. В данном случае мы фильтруем данные по названию кампании (Campaign) и дате (Date). Мы используем несколько условий фильтрации. В тексте запроса между всеми условиями должен стоять логический оператор OR или AND. Фильтрация по датам немного отличается от фильтрации по числовым и текстовым значениям, для ее применения необходимо использовать оператор Date. Часть запроса, отвечающая за фильтрацию данных, будет выглядеть так:
Мы разбили с помощью скобок фильтрацию данных на две логических части: первая фильтрует по датам, вторая — по названию кампании. На данном этапе формула, описывающая данные, которые необходимо выбрать, и условия фильтрации данных, выглядит так:
Вы можете скопировать ее и вставить, например, на новый лист документа, который используется в качестве примера в этом посте, и получите следующий результат:
Помимо обычных логических операторов (=, <, >) блок WHERE поддерживает дополнительные операторы фильтрации:
- contains — проверяет содержание определённых символов в строке. Например, WHERE A contains ‘John’ вернёт в фильтр все значения из столбца A, в которых встречается John, например, John Adams, Long John Silver;
- starts with — фильтрует значения по префиксу, то есть проверяет символы в начале строки. Например, starts with ‘en’ вернёт значения engineering и english;
- ends with — фильтрует значения по окончанию строки. Например, строка ‘cowboy’ будет возвращена конструкцией «ends with ‘boy’» или «ends with ‘y’»;
- matches — соответствует регулярному выражению. Например: where matches ‘.*ia’ вернёт значения India и Nigeria.
- like — упрощённая версия регулярных выражений, проверяет соответствия строки заданному выражению с использованиям символов подстановки. На данный момент like поддерживает два символа подстановки: «%» означает любое количество любых символов в строке, и «_» — означает один любой символ. Например, «where name like ‘fre%’» будет соответствовать строкам ‘fre’, ‘fred’, и ‘freddy’.
Запрос уже отфильтровал данные за определенный период и оставил только нужные нам кампании. Остается только отсортировать результат по убыванию в зависимости от количества сеансов. Сортировка в данных запросах осуществляется традиционно для SQL с помощью кляузы Order by. По синтаксису она довольна простая: необходимо только перечислить поля, по которым требуется отсортировать результат, а также указать порядок сортировки. По умолчанию — порядок asc, то есть по возрастанию. Если укажете после название поле параметр desc, запрос вернет результат в порядке убывания указанных в кляузе Order by полей.
В нашем случае за фильтрацию будет отвечать строчка в тексте запроса:
Соответственно, окончательный результат формулы на листе Level_2, решающий нужную нам задачу, выглядит так:
Теперь вы умеете с помощью простейшего SQL синтаксиса и функции QUERY фильтровать и сортировать данные.
Анализ данных на языке SQL
Этот курс в нашем Центре успешно закончили 7936 человек!
Data analysis with SQL.
Язык SQL – самый мощный инструмент для обработки данных, придуманный человеком. Этот простой и выразительный язык запросов поддерживается всеми современными базами данных (в том числе Microsoft, Oracle, IBM) и инструментами анализа и программирования (в том числе Excel).
На данном курсе Вы познакомитесь с базами данных и языком запросов SQL. Цель курса – научиться свободно и уверенно пользоваться современными базами данных, в том числе анализировать данные и строить отчёты.
Аудитория курса: аналитики и разработчики отчётов, работающие с базами данных.
Учебный курс «Язык SQL»
На ФКН ВШЭ и ВМК МГУ с 10 сентября по 19 октября будет проводиться чтение нового курса «Язык SQL», ориентированного на СУБД PostgreSQL. Слушатели без предварительной подготовки смогут разобраться что такое системы баз данных и научиться с ними работать. Курс начинается с разработки простых запросов на языке SQL, а в конце будут рассмотрены такие конструкции как общие табличные выражения, агрегатные и оконные функции. Учебные примеры используют демонстрационную базу данных «Авиаперевозки», содержимое которой максимально приближено к реальным данным.
Курс создан по инициативе компании Postgres Professional — вендора СУБД PostgreSQL в России. Автор и преподаватель курса, доцент СИбГУ Е.П. Моргунов, является также автором используемого в курсе учебного пособия «Язык SQL. Базовый курс». Овладев материалом курса, студент получит практические знания, востребованные IT-рынком в области СУБД.
Курс состоит из 36 часов лекционных и практических занятий.
The SQL SELECT TOP Clause
The clause is used to specify the number of records to return.
The clause is useful on large tables with thousands of
records. Returning a large number of records can impact performance.
Note: Not all database systems support the clause. MySQL
supports the clause to select a limited number of records, while Oracle uses and .
SQL Server / MS Access Syntax:
SELECT TOP number|percent column_name(s)
FROM table_nameWHERE condition;
MySQL Syntax:
SELECT column_name(s)
FROM table_nameWHERE condition
LIMIT number;
Oracle 12 Syntax:
SELECT column_name(s)
FROM table_nameORDER BY
column_name(s)
FETCH FIRST number ROWS ONLY;
Older Oracle Syntax:
SELECT column_name(s)
FROM table_name
WHERE ROWNUM <= number;
Older Oracle Syntax (with ORDER BY):
SELECT *FROM (SELECT column_name(s) FROM table_name
ORDER BY column_name(s))
WHERE ROWNUM <= number;
SQL TOP
В SQL Server и MS Access предложение SQL TOP используется для ограничения количества строк, возвращаемых запросом. Вот синтаксис SQL-запроса, в котором используется TOP:
Вот пример запроса, который вернёт двух самых высокооплачиваемых сотрудников из таблицы сотрудников:
Наш запрос возвращает следующее:
| имя |
| Иона Эмма |
(2 ряда)
За предложением TOP может следовать ключевое слово PERCENT, которое извлекает процент строк вместо количества фиксированных строк. Итак, если вы хотите получить 25% лучших сотрудников на основе их заработной платы, вы можете использовать этот запрос:
Наш запрос к базе данных с восемью записями возвращает следующее:
| имя |
| Иона Эмма |
(2 ряда)
Как вывести последние строки SQL запроса?
Если Вам нужно получить не первые строки результирующего набора данных, а последние (например, последние записи в таблице), причем с той же самой сортировкой, то Вы также можете использовать два способа, т.е. и TOP, и OFFSET. В обоих случаях нам нужно будет немного усложнить запросы.
Получаем последние строки SQL запроса с помощью TOP
В случае с TOP нам дополнительно потребуется использовать конструкцию WITH (CTE – обобщенное табличное выражение), для того чтобы выполнить сортировку по идентификатору для применения фильтра TOP, т.е. отобрать самые последние записи. А после этого мы уже можем отсортировать строки так, как нам нужно.
Как видите, нам вывелись 5 последних строк.
Получаем последние строки SQL запроса с помощью OFFSET-FETCH
Для получения последних строк с помощью OFFSET-FETCH нам потребуется предварительно узнать общее количество строк, для того чтобы определить, сколько строк нужно пропустить. Это можно сделать как с помощью вложенного запроса, так и с помощью предварительного сохранения нужного нам значения в переменной. Я покажу способ с использованием переменной.
Итоговый результат такой же, как и в запросе с TOP.
Теперь Вы знаете, как с помощью TOP и OFFSET получать первые и последние строки результирующего набора данных, который возвращает SQL запрос.
В данной статье мы затронули одну очень маленькую возможность языка T-SQL, но их, как Вы понимаете, гораздо больше, поэтому, если Вы начинающий программист и хотите изучить язык T-SQL, то рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать на T-SQL.
У меня на этом все, удачи в освоении языка T-SQL!
Источник статьи: http://info-comp.ru/obucheniest/672-get-first-query-records-sql.html
4. Ссылки на таблицы SQL могут быть довольно функциональными
Ссылка на таблицу — мощная штука. Примером их силы является ключевое слово JOIN, которое в действительности не является выражением SELECT, а частью специальной ссылки на таблицу. Объединенная таблица, как определено в стандарте SQL (упрощенный):








Вернемся к нашему примеру:
a может по сути быть объединенной таблицей:
Развивая предыдущее выражение, получим:
Хотя не рекомендуется объединять синтаксис, где приводится разделенный запятыми список ссылок на таблицы, с синтаксисом объединенных таблиц, но так можно делать. В результате, объединенная ссылка будет содержать величины a1+a2+b.
Производные таблицы еще мощнее, чем объединенные таблицы. Мы до этого еще дойдем.
Что мы из этого узнаем?
Всегда нужно думать категориями ссылок на таблицы. Это поможет не только понять, как данные переходят в предложениях SQL, (смотрите предыдущий раздел), но и как создаются сложные ссылки на таблицы.
И, что важно, понять, JOIN является ключевым словом для построения соединенных таблиц. А не частью оператора SELECT
Некоторые базы данных позволяют использование JOIN в операторах INSERT, UPDATE, DELETE
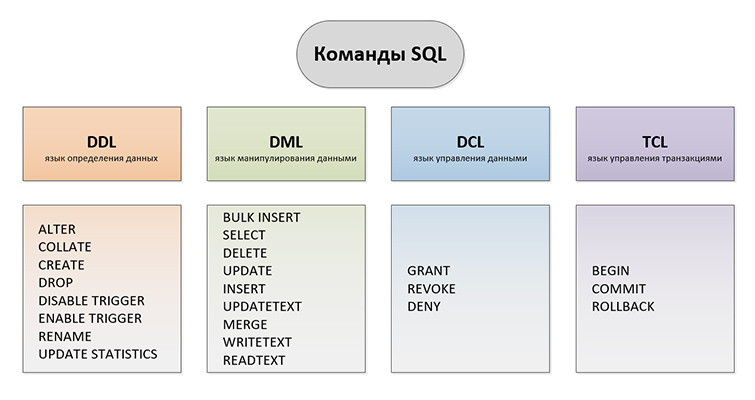
Для чего изучать MySQL
SQL представляет собой язык структурированных запросов, с помощью которого осуществляется управление реляционными базами данных. На их основе могут работать как простые любительские блоги, так и сложные высоконагруженные системы. Поэтому система управления базами данных (далее СУБД) MySQL входит в арсенал основных инструментов веб-разработчика.
В процессе обучения MySQL с нуля вы узнаете, что включено в понятие реляционной базы данных, как правильно составлять запрос и прочие тонкости языка SQL.
Достаточный уровень владения языком SQL входит в перечень профессиональных требований со стороны большинства работодателей в области веб-разработки.
Эффективное использование MySQL требует владения его инструментарием, знаниями функциональных возможностей и особенностей. Наши уроки MySQL для начинающих охватывает ключевые аспекты языка и позволяет овладеть им с нуля. В учебную программу включены наиболее важные для веб-разработчиков темы.
«Классическое» решение
Это решение опирается на алгоритм нумерации строк, возвращаемых запросом. Т.е. мы нумеруем строки, а потом выбираем те их них, которые имеют номера, меньшие заданного числа. Следуя упомянутому алгоритму, запрос, который нумерует упорядоченный по возрастанию номера модели весь набор строк в таблице, можно записать так:
Только для решения нашей задачи нужно пронумеровать не весь набор, а каждую группу в отдельности. Этого легко добиться, если в условие соединения таблиц добавить условие совпадения типов продукции, а также добавить группировку по типу:
в соответствии с условием задачи ограничивает тремя количество строк в каждой группе. Фактически мы уже решили задачу. Осталось лишь добавить производителя (maker), что также можно сделать разными способами. Например, еще раз соединить по номеру модели приведенный выше запрос с таблицей Product, или использовать коррелирующий подзапрос в предложении SELECT. В учебных целях приведу оба подхода.
1. Соединение
Здесь мы исключили лишний столбец num, который использовался в демонстрационных целях, поскольку нам не требуется выводить номер строки.
2. Подзапрос в предложении SELECT
Использование подзапроса в предложении SELECT допускается, если он возвращает всего одно значение для каждой строки основного запроса. Это условие у нас выполняется, т.к. мы выбираем производителя модели, которая передается из основного запроса и является уникальной (первичный ключ в таблице Product).
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
Пример использования агрегатных функций с оконной инструкцией OVER:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' , COUNT(Conversions) OVER(PARTITION BY Date) AS 'Count' , AVG(Conversions) OVER(PARTITION BY Date) AS 'Avg' , MAX(Conversions) OVER(PARTITION BY Date) AS 'Max' , MIN(Conversions) OVER(PARTITION BY Date) AS 'Min' FROM Orders
Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.
SELECT Date , Medium , Conversions , ROW_NUMBER() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Row_number' , RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Rank' , DENSE_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Dense_Rank' , NTILE(3) OVER(PARTITION BY Date ORDER BY Conversions) AS 'Ntile' FROM Orders
Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LAG или LEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.
SELECT Date , Medium , Conversions , LAG(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lag' , LEAD(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lead' , FIRST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'First_Value' , LAST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Last_Value' FROM Orders
Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP
SELECT Date , Medium , Conversions , CUME_DIST() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Cume_Dist' , PERCENT_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Percent_Rank' , PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Cont' , PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Disc' FROM Orders
Преимущества использования связки PHP+MySQL
Удобство использования. Язык PHP обеспечивает возможность разработки мощных веб-приложений в короткие сроки. Серверный язык программирования считается не лишком сложным для освоения. Работать с ним можно как с применением процедурного, так и объектно-ориентированного подхода. Языковые конструкции отличатся простотой построения и логичностью, благодаря чему легко запоминаются. MySQL характеризуется хорошей скоростью работы, гибкостью и высоким уровнем надежности. Графические инструментальные средства упрощают работу с базами данных.
Стабильность. В рамках этого понятия подразумевается отсутствие частой необходимости перезагрузки сервера и изменений в ПО принципиального характера. Оба аспекта термина стабильность в одинаковой степени относятся к СУБД MySQL и системе PHP. Постоянство состава средств и их продуманное усовершенствование – гарантия совместимости продуктов.
Кроссплатформенность и совместимость. MySQL, как и PHP, могут успешно использоваться на разных видах операционных систем:
Система PHP в одинаковой мере совместима с ведущими веб-серверами: HTTP-сервером Apache для Linux/Unix, Windows и IIS для Windows. Эксплуатация СУБД MySQL не требует обеспечения совместимости с конкретным веб-сервером – указанную функцию берет на себя интерпретатор PHP.
Стоимость. Важным фактором привлекательности является бесплатность систем. Распространение MySQL осуществляется на условиях общей лицензии GNU. Аналогичным преимуществом обладает и PHP, распространяемый на базе стратегии Open Source.
Общие положения
Создать новую базу данных с названием DB_Books с помощью оператора Create Database, создать в ней перечисленные таблицы c помощью
операторов Create table по примеру лабораторной работы №1. Сохранить файл программы с названием ФамилияСтудента_ЛАб_1_DB_Books. В
утилите SQL Server Management Studio с помощью кнопки «Создать запрос» создать отдельные программы по каждому запросу, которые сохранять на диске с названием: ФамилияСтудента_ЛАб_2_№_задания. В сами программы копировать текст задания в виде комментария. Можно сохранять все выполненные запросы в одном файле. Для проверки работы операторов SELECT предварительно создайте программу, которая с помощью операторов INSERT заполнит все таблицы БД DB_Books несколькими записями, сохраните программы с названием ФамилияСтудента_ЛАб_2_Insert.
Оператор Select используется для выбора данных из таблиц.
Для выбора данных из некоторой таблицы нет необходимости знать имена всех ее полей. Звездочка (*) после оператора SELECT означает выбор всех столбцов таблицы. Другими словами, эта команда просто выводит все данные таблицы. Синтаксис:
SELECT * FROM <имя таблицы>
Если необходимо выбрать только определенные столбцы, то нужно их непосредственно указать после слова Select.
Пример. Выбрать сведения о количестве страниц из таблицы Books (поле Pages).
SELECT Pages FROM Books
Пример. Выбрать все данные из таблицы Books.
SELECT * FROM Books
Удаление пробелов из строки
Для удаления лишних пробелов из начала и конца строки в языке SQL есть три функции.
Функция LTRIM:
string
LTRIM
(str string
)
Удаляет с начала строки str пробелы и возвращает результат.
Функция RTRIM:
string
RTRIM
(str string
)
Также удаляет пробелы из строки str, только с конца. Обе функции поддерживают многобайтовые символы.
SELECT LTRIM (» текст «);
Результат: «текст »
SELECT RTRIM (» текст «);
Результат: » текст»
И третья функция TRIM позволяет сразу удалять пробелы из начала и из конца строки:
string
TRIM
([ string
FROM] str string
)
Параметр str обязательный, остальные параметры не обязательные. В случае если задан только один параметр str, то возвращает строку str удалив пробелы из начала и конца строки одновременно.
SELECT TRIM (» текст «);
Результат: «текст»
С помощью пара метра remstr можно задавать символы или подстроки, которые будут удаляться из начала и конца строки. С помощью управляющих параметров BOTH, LEADING, TRAILING можно задавать откуда будут удаляться символы:
- BOTH — удаляет подстроку remstr с начала и с конца строки;
- LEADING — удаляет remstr с начала строки;
- TRAILING — удаляет remstr с конца строки.
SELECT TRIM (BOTH «а» FROM «текст»);
Результат: «текст»
SELECT TRIM (LEADING «а» FROM «текстааа»);
Результат: «текстааа»
SELECT TRIM (TRAILING «а» FROM «ааатекст»);
Результат: «ааатекст»
Функция SPACE позволяет получить строку состоящую из определенного количества пробелов:
string
SPACE
(n integer
)
Возвращает строку, которая состоит из n пробелов.
Функция REPLACE нужна для замены заданных символов в строке
:
string REPLACE
(str string
, from_str string
, to_str string
)
Функция заменяет в строке str все подстроки from_str на to_str и возвращает результат. Поддерживает многобайтные символы.








SELECT REPLACE («замена подстроки», «подстроки», «текста»)
Результат: «замена текста»
Функция REPEAT:
string
REPEAT
(str string
, count integer
)
Функция возвращает строку, которая состоит из count повторений строки str. Поддерживает многобайтовые символы.
SELECT REPEAT («w», 3);
Результат: «www»
Функция REVERSE переворачивает строку:
string
REVERSE
(str string
)
Переставляет в строке str все символы с последнего на первый и возвращает результат. Поддерживает многобайтовые символы.
SELECT REVERSE («текст»);
Результат: «тскет»
Функция INSERT для вставки подстроки в строку:
string
INSERT
(str string
, pos integer
, len integer
, newstr string
)
Возвращает строку полученную в результате вставки в строку str подстроки newstr с позиции pos. Параметр len указывает сколько символов будет удалено из строки str, начиная с позиции pos. Поддерживает многобайтовые символы.
SELECT INSERT («text», 2, 5, «MySQL»);
Результат: «tMySQL»
«SELECT INSERT («text», 2, 0, «MySQL»);
Результат: «tMySQLext»
SELECT INSERT («вставка текста», 2, 7, «MySQL»);
Результат: «SELECT INSERT («вставка текста», 2, 7, «MySQL»);»
Если вдруг понадобиться заеменить в тексте все заглавные буквы на прописные, то можно воспользоваться одной из двух функций:
string
LCASE
(str string
) и string
LOWER
(str string
)
Обе функции заменяют в строке str заглавные буквы на прописные и возвращают результат. И та и другая поддерживают многобайтовые символы.
SELCET LOWER («АБВГДеЖЗиКЛ»);
Результат:»абвгдежзикл»
Если же наоборот необходимо прописные буквы заменить заглавными, то также можно применить одну из двух функцийй:
string
UCASE
(str string
) и string
UPPER (str string
)
Функции возвращают строку str, заменив все прописные символы на заглавные. Также поддерживают многобайтовые символы.
Пример:
SELECT UPPER («Абвгдежз»);
Результат: «АБВГДЕЖЗ»
Строковых функций в языке SQL немного больше, чем рассмотрено в данной статье. Но так как даже большинство рассмотренных здесь функций используются редко, я закончу их рассмотрение. В следующих статьях я постараюсь рассмотреть реальные практические примеры использования строковых функций SQL. Поэтому не забудьте подписаться на обновления блога . До новых встреч!
Основные строковые функции и операторы предоставляют разнообразные возможности и возвращают в качестве результата строковое значение. Некоторые строковые функции являются двухэлементными, что означает, что они могут работать одновременно с двумя строками. Стандарт SQL 2003 поддерживает строковые функции.
Синтаксис
Синтаксис Oracle/PLSQL функции COUNT:
SELECT COUNT(aggregate_expression)
FROM tables
;
ИЛИ синтаксис функции COUNT с группировке результатов по одному или нескольким столбцам:
SELECT expression1, expression2, … expression_n,
COUNT(aggregate_expression)
FROM tables
GROUP BY expression1, expression2, … expression_n;
Параметры или аргументы
expression1, expression2, … expression_n Выражения, которые не инкапсулированы в функции COUNT и должны быть включены в оператор GROUP BY в конце SQL предложения.
aggregate_expression — это столбец или выражение, чьи ненулевые значения будут учитываться.
tables — таблицы, из которых вы хотите получить записи. В оперторе FROM должна быть указана хотя бы одна таблица.
WHERE conditions — необязательный. Это условия, которые должны быть соблюдены для выбранных записей.
Функция COUNT возвращает numeric значение.