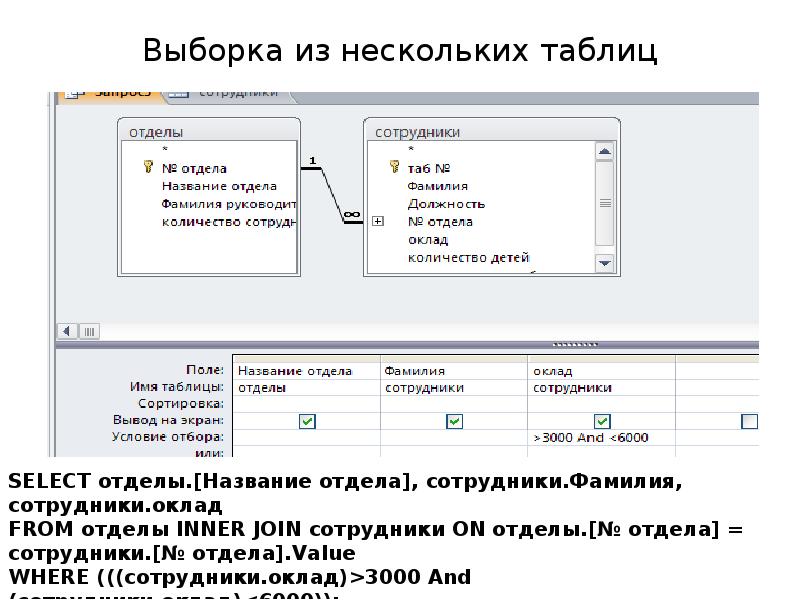
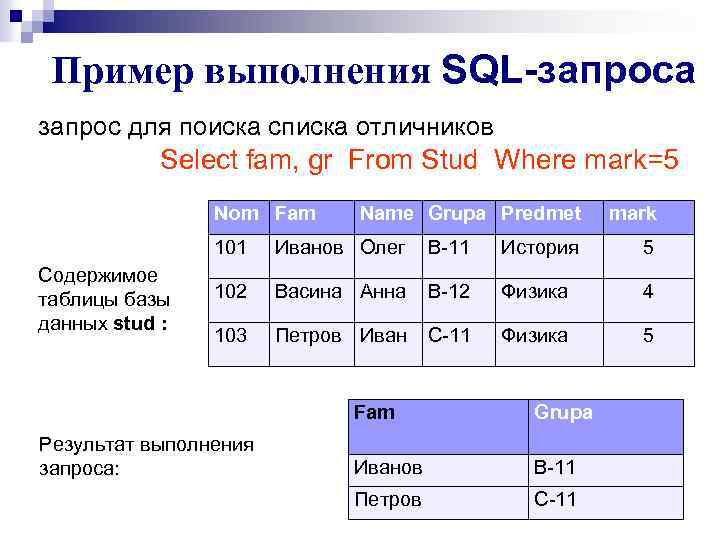
Контекст сеанса с базой данных DBContext
Контекст баз данных представляется классом DBContext, необходимым для взаимодействия с базами данных. Объект класса производного от DBContext позволяет выполнять запросы и сохранять изменения, произведенные над свойствами экземпляров модели.
Во время взаимодействия с базой данных класс контекста наполняет классы модели информацией из таблиц базы данных. Сеанс взаимодействия контекста с базой данных краток, и состоит из одного цикла:
- Создание объекта класса контекста
- Получение данных (сохранение изменений)
- Закрытие сеанса и удаление экземпляра контекста
Для наполнения классов модели информацией из базы в классе контекста необходимо определить свойства DbSet<TEntity>, где роль сущности (Entity) будут исполнять классы модели.
Класс DbSet<TEntity> — это оболочка для сущности (типа объекта таблицы базы данных), которой являются классы модели. Включение экземпляра класса DbSet<TEntity> в контекст означает, что он включен в модель Entity Framework Core. Свойства DbSet<TEntity> автоматически инициализируются при создании экземпляра класса контекста. Имена свойств, представляющих классы модели, должны быть идентичны названиям соответствующих таблиц в базе данных.
В принципе этих определений уже достаточно для работы с базами данных. Вся черновая работа скрыта инкапсуляцией, что вызывает приятное созерцание минимализма программного кода.
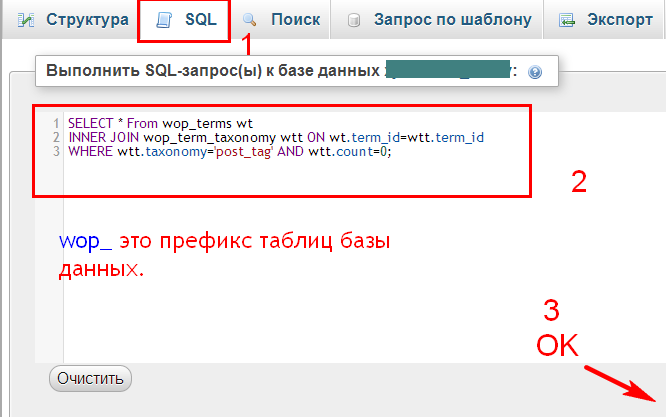
Перенос базы данных доступа на SQL Server
Откройте SQL Server Management Studio и подключитесь к серверу базы данных, в который вы хотите импортировать базу данных Access. Под Базы данныхщелкните правой кнопкой мыши и выберите Новая база данных, Если у вас уже есть база данных, и вы просто хотите импортировать пару таблиц из Access, просто пропустите это и перейдите к Импорт данных шаг ниже. Просто щелкните правой кнопкой мыши на вашей текущей базе данных вместо создания новой.
Если вы создаете новую базу данных, продолжайте, дайте ей имя и настройте параметры, если вы хотите изменить их по умолчанию.
Теперь нам нужно щелкнуть правой кнопкой мыши на тестовой базе данных, которую мы только что создали, и выбрать Задания а потом Импорт данных,
На Выберите источник данных диалоговое окно, выберите Microsoft Access (ядро базы данных Microsoft Jet) из выпадающего списка.
Следующий на Имя файлае, нажмите на Просматривать и перейдите к базе данных Access, которую вы хотите импортировать, и нажмите открыто, Обратите внимание, что база данных не может быть в Access 2007 или более высоком формате (ACCDB) как SQL Server не распознает это! Поэтому, если у вас есть база данных Access с 2007 по 2016, сначала преобразуйте ее в База данных 2002-2003 формат (MDB) зайдя в Файл — Сохранить как,
Идите вперед и нажмите следующий выбрать пункт назначения. Поскольку вы щелкнули правой кнопкой мыши базу данных, в которую хотите импортировать данные, она уже должна быть выбрана в списке. Если нет, выберите Собственный клиент SQL от Пункт назначения падать. Вы должны увидеть экземпляр базы данных под Название сервера и затем сможете выбрать конкретную базу данных внизу, как только вы выберете метод аутентификации.
щелчок следующий а затем укажите способ передачи данных из Access в SQL, выбрав Скопируйте данные из одной или нескольких таблиц или Напишите запрос, чтобы указать данные для передачи,
Если вы хотите скопировать все таблицы или только некоторые таблицы из базы данных Access без каких-либо манипуляций с данными, выберите первый вариант. Если вам нужно скопировать только определенные строки и столбцы данных из таблицы, выберите второй вариант и напишите SQL-запрос.
По умолчанию все таблицы должны быть выбраны, и если вы нажмете редактировать Отображения Кнопка, вы можете настроить, как поля отображаются между двумя таблицами. Если вы создали новую базу данных для импорта, то она будет точной копией.
Здесь у меня есть только одна таблица в моей базе данных Access. Нажмите Далее, и вы увидите Запустить пакет экран где Беги немедленно должны быть проверены.
щелчок следующий а затем нажмите Конец, Затем вы увидите, как происходит процесс передачи данных. После его завершения вы увидите количество строк, переданных для каждой таблицы в Сообщение колонка.
щелчок близко и вы сделали. Теперь вы можете запустить SELECT для ваших таблиц, чтобы убедиться, что все данные были импортированы. Теперь вы можете использовать возможности SQL Server для управления вашей базой данных.
Есть проблемы с импортом данных из Access в SQL Server? Если да, оставьте комментарий, и я постараюсь помочь. Наслаждайтесь!
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
Колоночные
Колоночные БД отличаются от реляционных тем, что информация в них хранится столбцами, а не построчно. Значение атрибута любого из объектов прочитывается сразу. Используются они в качестве хранилищ данных с большим (от ста миллионов записей) объёмом информации, и при обработке скромных объёмов не способны продемонстрировать свои преимущества.
Колоночные СУБД удобны тем, что позволяют действительно быстро выполнять сложные аналитические запросы на больших объёмах данных. При этом структура таблиц с данными легко меняются, а эффективная компрессия позволяет экономить занимаемый БД объём памяти. Среди популярных СУБД этого типа можно назвать Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra, SAP IQ.
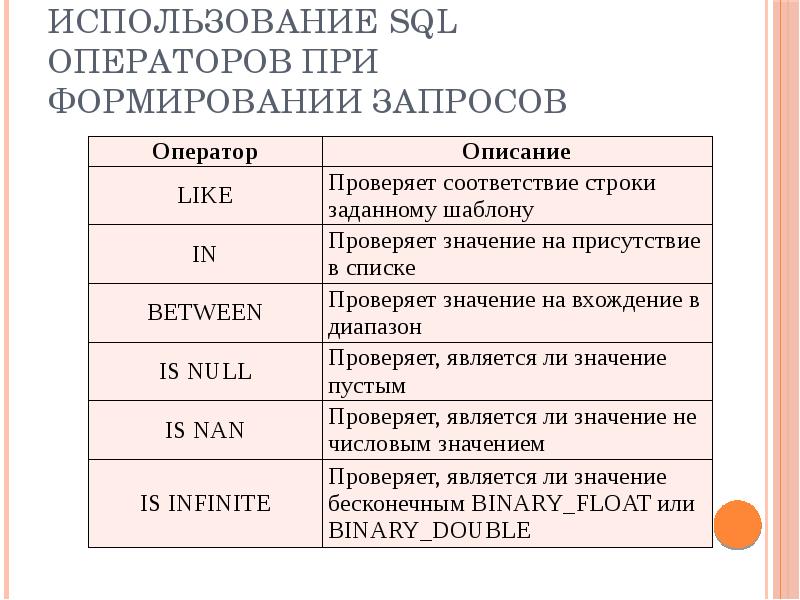
Как работать с SQL: основные операторы
Запросы в SQL похожи на естественный английский язык и выглядят как полноценные предложения.
Например, если мы захотим в базе данных нашей строительной фирмы получить номер телефона ООО «Коттеджи», нам нужно написать такую команду:
Перевести на русский её можно так: «Выбери значение из столбца tel в таблице contractors, где значение столбца id равно единице». Символ ; означает конец команды.
SQL-инструкции общаются не напрямую с базой данных, а с СУБД. Многие производители СУБД хотели расширить функциональность запросов, поэтому добавляли к языку собственные расширения.
Так у SQL появились несовместимые между собой диалекты. Например, PL/SQL, PL/pgSQL, T-SQL. Но структура запросов и основные «встроенные» команды от диалекта к диалекту неизменны.
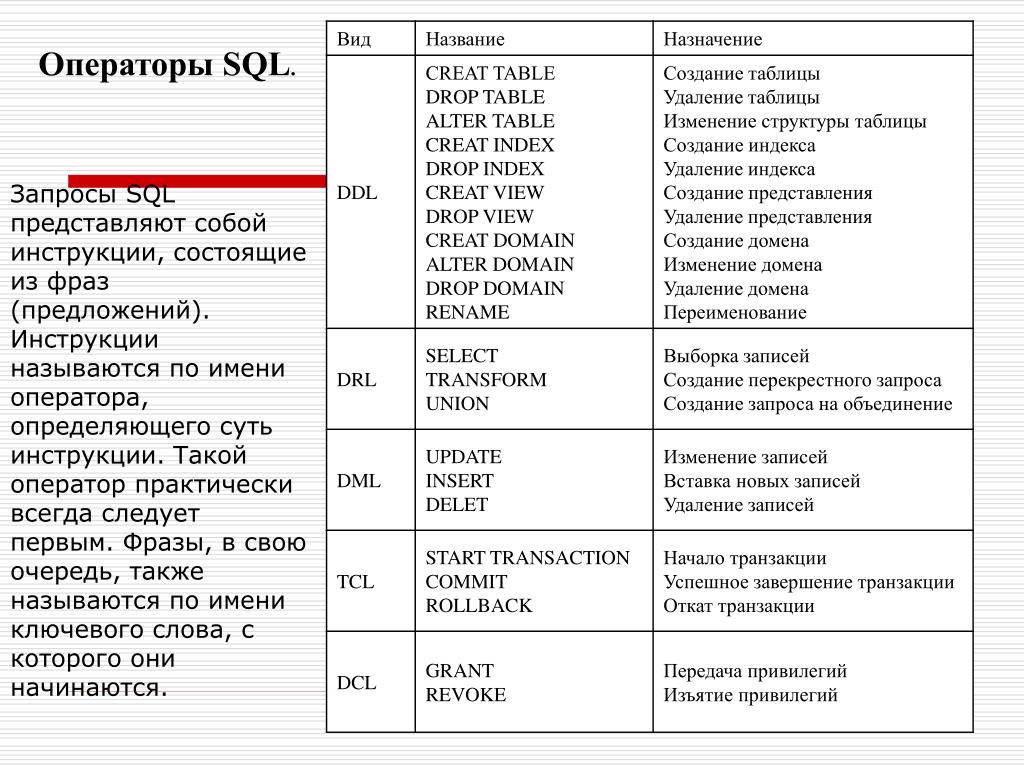
Вот список самых распространённых операторов SQL.
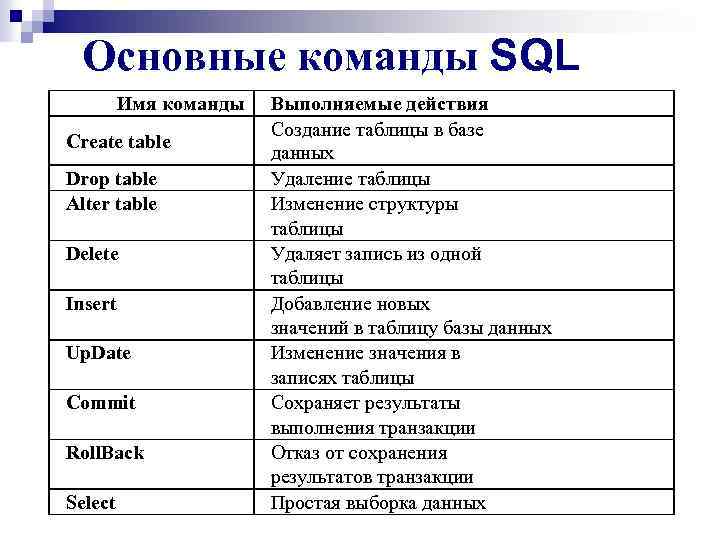
CREATE DATABASE — создаёт БД.
DROP DATABASE — удаляет БД.
USE — указывает СУБД, в какой БД работать в дальнейшем.
CREATE TABLE — создаёт новую таблицу внутри БД.
DROP TABLE — удаляет таблицу.
INSERT — добавляет данные в таблицу. Используется вместе с операторами INTO (указывает на таблицу) и VALUES (ему передают значения, которые нужно добавить).
UPDATE — обновляет данные в таблице. UPDATE указывает на саму таблицу, а потом используется оператор SET, после которого и прописываются новые значения для атрибутов. Чтобы указать на конкретную запись, используют оператор WHERE.
DELETE — удаляет данные из таблицы. Используется перед оператором FROM.
SELECT — выбирает данные. Ему передают название атрибута или атрибутов. Если нужно выбрать все атрибуты, то пишут SELECT *. Находится перед оператором FROM.
FROM — указывает на таблицу, к которой обращена команда.
WHERE — указывает на условие или условия, которым должна удовлетворять строка. Пишется после оператора FROM. Необязательный элемент инструкции. Если его не указывать, то команда применяется ко всем записям в таблице.
ORDER BY — сортирует результаты запроса. По умолчанию — в порядке возрастания. Для сортировки по убыванию можно использовать слово DESC.
JOIN — объединяет значения нескольких колонок. Бывает нескольких видов: внутренний (INNER), внешний (OUTER), левый (LEFT) и правый (RIGHT).
Давайте напишем какой-нибудь запрос к базе данных нашей строительной фирмы.
Он означает: выбери все столбцы из таблицы houses, чей status „Не построен“, и отсортируй их по убыванию атрибута cost. СУБД выдаст нам такую таблицу:

Пример выдачи по запросу status «Не построен» в столбце housesСкриншот: Skillbox Media
Также в SQL существуют агрегатные функции. Они позволяют производить с данными дополнительные операции и указываются вместо атрибутов. Агрегатные функции записываются в формате FUNCTION(ATTRIBUTE).
Вот некоторые из них.
COUNT — считает количество записей в колонке.
SUM — складывает содержимое значений колонки.
MIN — указывает на минимальное значение в колонке.
MAX — указывает на максимальное значение в колонке.
AVG — считает среднее значение в колонке.
ROUND — округляет значение в колонке.
Для работы с инструкциями, которые содержат агрегатные функции, есть специальные операторы.
GROUP BY — группирует выходные значения для колонок, к которым применили агрегатную функцию.
HAVING — работает как WHERE, но может применяться к агрегатным функциям.
Что такое база данных
И начну я с того, что под базой данных обычно принято понимать любой набор информации, которая хранится определенным образом, и ей можно воспользоваться. Но если говорить о каких-то автоматизированных базах данных, то здесь, конечно же, речь идет о так называемых реляционных базах данных.
Реляционная база данных – это упорядоченная информация, связанная между собой определёнными отношениями. Представлена она в виде таблиц, в которых и лежит вся эта информация
И это очень важно, так как теперь Вы должны представлять себе современную базу данных просто в виде таблиц (если говорить в контексте SQL), т.е. в общем смысле база данных – это набор таблиц
Безусловно, это сильно упрощенное определение, но оно дает некое практическое понимание базы данных.
Послесловие
Стоит знать, что каждая из баз данных позволяет использовать рассмотренные sql-запросы с расширенными возможностями. К примеру, одновременное удаление из нескольких таблиц или же вставка строк с использованием запросов выборки. Поэтому, если у вас возникает необходимость в чем-то специфическом, то стоит более подробно изучать возможности каждой базы данных.
Как видите, основы баз данных не так уж сложны и их может освоить каждый. Тем не менее, пользы от их понимания много, так как все остальные сложные технические термины основываются или применяются для них. К примеру, ключи и индексы это не заумные вещи (хотя и могут быть непростыми), а лишь механизмы, которые позволяют быстрее осуществлять фильтрацию и поиск строк (например, из все той же простой таблички somedata). И это существенно легче понять и использовать, если знаешь как строится фундамент баз данных.
- PHP редирект — перенаправление на другую страницу
- Модульный принцип: несколько моментов
Зачем мне изучать SQL, если я занимаюсь данными?
SQL весьма далек от забвения – напротив, это один из самых востребованных навыков, который вы можете найти в описаниях вакансий в области обработки больших данных, независимо от того, хотите ли вы устроиться на должность аналитика данных, инженера по данным, научного сотрудника в области данных или в качестве еще кого-либо. Этот факт подтверждается результатами исследования рынка труда, проведенным O’Reilly в 2016 году: 70% респондентов, участвовавших в опросе, подтвердили, что в своей профессиональной деятельности они используют SQL. Более того, в обзоре результатов этого исследования язык SQL занимает более высокую позицию, по сравнению с другими языками программирования, такими как R (57%) и Python (54%).




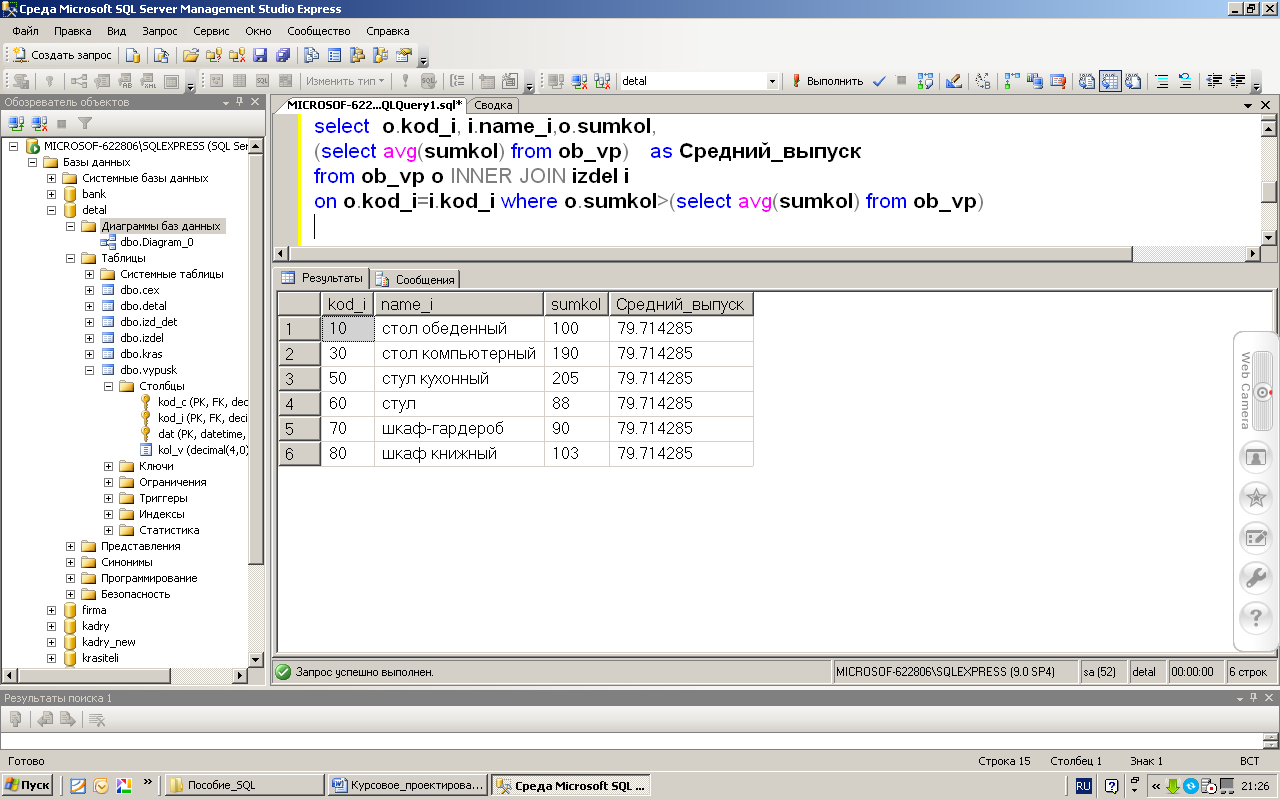


Теперь вы понимаете в чем тут дело: SQL является обязательным навыком, если вы хотите получить работу в сфере обработки больших данных.
Неплохо для языка, который был разработан еще в начале 1970-х годов прошлого века, не правда ли?
Но почему так часто используется именно этот язык? И почему он до сих пор не мертв, как многие другие языки того же поколения?
Для объяснения этого факта можно найти несколько причин: во-первых, компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в системах управления реляционными потоками данных (RDSMS), и SQL требуется для доступа к таким хранимым данным. SQL – это универсальный язык данных: он дает вам возможность взаимодействовать практически с любой базой данных или даже создавать свои локальные базы данных!
Только имейте в виду, что существует немало реализаций SQL, которые несовместимы между собой и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является обязательным для каждого, желающего найти свой путь в это наукоемкой отрасли.
Кроме того, можно с уверенностью сказать, что SQL также включается в новые технологии, такие как Hive, SQL-подобный язык запросов, ориентированный на запросы и управление большими наборами данных, или Spark SQL, которые вы можете использовать для выполнения SQL запросов. Но еще раз напоминаем, SQL, который вы найдете в этих технологиях, будет отличаться от стандартного, который вы, возможно, уже знаете, но разобраться в особенностях конкретной реализации, зная стандартный SQL, вам будет значительно проще.
Если хотите, можем привести такую аналогию с линейной алгеброй: сосредоточив все усилия только на этой одной области математики, вы сможете использовать полученные знания и как хорошую основу для овладения машинным обучением!
Короче говоря, вот причины, по которым вам следует изучить язык структурированных запросов:
- Он довольно прост в изучении, даже для новичков. Рост знаний и навыков происходит довольно быстро, и вы в кратчайшие сроки научитесь писать запросы.
- Изучение SQL подчиняется принципу «однажды изученное может применяться повсюду», поэтому это отличное вложение вашего времени и сил!
- Это отличное дополнение к языкам программирования. В некоторых случаях писать запрос даже предпочтительнее, чем писать код, потому что он более эффективен!
- …
И чего же ты все еще ждешь?
Начало работы в Microsoft SQL Server Management Studio
Для создания баз данных используем среду Microsoft SQL Server Management Studio. На запрос соединения с сервером выбираем (рис. 1):
Тип сервера: Компонент Database Engine
Имя сервера: SQL-MS.
Под таким именем в домене fizmat.vspu.ru. доступна машина, на которой установлены серверные компоненты MS SQL Server 2005. Можно попробовать выбрать сервер из выпадающего списка серверов. Можно также обратиться к этой машине по IP-адресу 192.168.10.152 из локальной сети.
Проверка подлинности: Проверка подлинности SQL Server.
Такая настройка позволяет создавать пользователей данного экземпляра SQL Server независимо от компьютера, с которого производится вход.
Имя входа: studentMBS21.
Пароль: student.
Рисунок 1. Окно входа в Microsoft SQL Server Management Studio 2005
Примечание. Пользователь studentMBS21 обладает большими полномочиями на этом сервере, поэтому пользоваться им надо очень аккуратно. Под этим пользователем мы создадим базу данных, а заполнять её и производить поиск по ней мы будем под другими пользователями. Предпочтительнее всего использовать свою учетную запись в домене fizmat.vspu.ru. В этом случае надо выбирать проверку подлинности Windows.
Теперь нажимаем кнопку «Параметры» и выбираем (рис. 2):
Соединение с базой данных → Обзор сервера… → Пользовательские базы данных → trial_base.
Сетевой протокол → TCP/IP
Нажимаем кнопку «Соединить».
Рисунок 2. Окно входа в Microsoft SQL Server Management Studio 2005 (вкладка Параметры)
Примечание. База данных trial_base является базой данной по умолчанию для пользователя studentMBS21, она была создана при регистрации этого пользователя. В случае, когда права доступа пользователя не ограничены (как в рассматриваемом случае), вкладку Параметры можно не открывать. Если же пользователь имеет доступ только к определенным базам данных, при подключении к серверу нужно одну из этих баз указывать.
После успешного соединения с базой данных на экране видим следующую картинку (рис. 3):
Рисунок 3. Подключение к SQL — серверу установлено
Среда MS SQL Management Studio предоставляет удобный инструментарий для создания, редактирования, заполнения баз данных. Но настоящие профессионалы в своей работе редко пользуются этой средой, а для выполнения своих задач используют SQL-запросы. Мы будем пользоваться, когда это удобно и наглядно, графическим режимом, но основной упор будем делать на освоении базы языка SQL.
На что стоит обратить внимание?
Вот список понятий, которые стоит знать если ты хочешь очень хорошо разбираться в MySQL:
- управление базами данных: CREATE DATABASE, DROP DATABASE, SHOW DATABASES
- управление таблицами: CREATE TABLE, ALTER TABLE, DROP TABLE, SHOW TABLES, SHOW CREATE TABLE, DESC table, TRUNCATE table
- управление правами доступа: GRANT, SHOW GRANTS
- типы колонок: ENUM, SET, CHAR, VARCHAR, TEXT, DATE, TIME, DATETIME, TIMESTAMP, INT, FLOAT, TINYINT, DECIMAL, MEDIUMTEXT, LONGTEXT. В чем разница между TIMESTAMP и DATETIME? Между FLOAT и DECIMAL? CHAR и VARCHAR?
- DECIMAL — тип с фиксированной точностью. В отличие от FLOAT/DOUBLE, которые приближенные и могут терять знаки после запятой, DECIMAL хранит заданное число знаков. Используется например, для хранения суммы денег.
- можно ли искать пустые поля условием WHERE x = NULL?
- при создании таблицы можно сделать поля обязательными для заполнения, указав NOT NULL
- SELECT/INSERT/DELETE/UPDATE
- порядок выполнения запроса выборки: FROM+JOIN, WHERE, GROUP, HAVING, ORDER, LIMIT, SELECT (его надо знать наизусть)
- REPLACE, INSERT IGNORE, INSERT .. ON DUPLICATE KEY UPDATE
- выборка данных: DISTINCT, JOIN, ORDER BY, GROUP BY, HAVING, LIMIT
- группировка и аггрегатные функции: GROUP BY, COUNT, MAX, MIN, AVG, SUM
- транзакции: BEGIN, ROLLBACK, COMMIT
- внешние ключи: FOREIGN KEY. Внешний ключ — это поле, которое хранит id записи в другой таблице
- первичный ключ: естественный и искуственный
- обычные и уникальные индексы (ключи)
- оптимизация запросов, команда EXPLAIN
- отличие InnoDB от MyISAM
Объектные
Данный тип СУБД предназначен для хранения и работы с объектами, у которых имеются свойства и методы. Основная задача таких СУБД заключается в избавлении разработчиков, использующих ООП, от необходимости трансформировать объекты в таблицы/строки и обратно. В объектных СУБД реализованы инкапсуляция и полиморфизм. Среди популярных СУБД этого типа можно назвать MongoDB Realm, InterSystems Caché, ObjectStore, Actian NoSQL DB, Objectivity/DB.
БД как сервис
- MS SQL Web;
- MS SQL Standard;
- PostgreSQL (typical);
- PostgreSQL (high availability);
- MySQL (typical);
- MySQL (high availability).
|
№ |
|
|
|
|
1 |
Реляционные |
Нужна транзакционность; высокая нормализация; большая доля операций на вставку |
Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2, SQLite |
|
2 |
Ключ-значение |
Задачи кэширования и брокеры сообщений |
Redis, Memcached, etcd |
|
3 |
Документные |
Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON |
Couchbase, MongoDB, Amazon DocumentDB |
|
4 |
Графовые |
Задачи подобные социальным сетям; системы оценок и рекомендаций |
Neo4j, Amazon Neptune, InfiniteGraph, TigerGraph |
|
5 |
Колоночные |
Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов |
Vertica, ClickHouse, Google BigQuery, Sybase \ SAP IQ, InfoBright |
|
6 |
Time series |
Системы мониторинга, сбора телеметрии, и финансовые системы, с привязкой к временным меткам или временным рядам |
InfluxDB, Kdb+, Prometheus, TimescaleDB, QuestDB, AWS Timestream, OpenTSDB, GridDB |
|
7 |
Объектные |
Высокопроизводительная обработка данных, имеющих сложную структуру, с использованием языков объектно ориентированного программирования |
MongoDB Realm, InterSystems Caché, ObjectStore, Actian NoSQL DB, Objectivity/DB |
|
8 |
Search engine |
Системы полнотекстового поиска |
Apache Solr, Elasticsearch, Splunk |
|
9 |
Spatial |
GIS-решения, работа с геометрическими объектами |
Oracle Spatial, Microsoft SQL, PostGIS, SpatialLite |
Что такое база данных?
База данных — это не что иное, как хранимый и организованный набор данных для будущего использования.
Система управления базами данных (СУБД) — это специальное программное обеспечение,
которое предоставляет нам необходимые инструменты для взаимодействия с хранимой информацией. Это позволяет нам:





- Создать(Create) новые данные
- Прочитать(Read) и получить информацию
- Обновить(Update) уже существующие данные с использованием новых значений
- Удалить(Delete) существующие данные, которые нам больше не нужны
Эти четыре основные операции сокращенно обозначаются как CRUD.
Этот термин ты будешь слышать еще много раз работая с системами баз данных и разрабатывая бекэнд системы.
Различные парадигмы баз данных
Существуют разные типы (или парадигмы) баз данных, такие как базы данных ключ-значение,
документно-ориентированные или реляционные базы данных.
Они различаются в основном тем, как хранят информацию и извлекают ее из памяти.
Наиболее часто используемый тип сегодня — это реляционные базы данных.
Эдгар Ф. Кодд описал эту парадигму в 1970 году в своей статье под названием
«Реляционная модель данных для больших общих банков данных».
В мире, где технологии появляются и устаревают в течение нескольких лет, впечатляет,
как эта модель — спустя более 50 лет — все еще существует и доминирует в мире баз данных.
В дальнейшем мы сосредоточимся в основном на модели реляционных баз данных.
Реляционная база данных состоит из таблиц. Эти таблицы состоят из столбцов (также называемых полями)
и строк (или записей). Каждый столбец имеет определенный тип данных, который определяет, что в него входит
(например, цифры, текст и т.д.).
Чтобы проиллюстрировать эти концепции на практическом примере, рассмотрим базу данных цифрового магазина.
Он может содержать несколько таблиц, например:
«продукты»: где мы храним список всего, что мы продаем в нашем магазине,
помимо любой другой соответствующей информации, такой как цена, доступное количество и т
д.
«клиенты»: здесь мы можем хранить и отслеживать клиентов, которые покупают в нашем магазине.
«покупки»: очень важно отслеживать покупки, сделанные вашими клиентами, чтобы впоследствии
выполнять аналитику и улучшать свой бизнес. В эту таблицу попадает любой продукт, купленный любым клиентом.
Что такое реляционная база данных
«Реляционная» часть в названии этой парадигмы относится к нашей способности создавать сущности,
которые имеют отношения друг с другом. Это дает нашим данным логическую структуру и связи.
Если ты вернешься и снова рассмотришь наш пример цифрового магазина, то увидишь, что любая покупка
совершается клиентом, который покупает продукт.
Каждая строка в таблице покупок должна иметь две ссылки:
- одна на другую строку в таблице клиентов (тот, кто совершил покупку)
- и вторая на строку в таблице продуктов (продукт, который был куплен)
Ссылка на другую таблицу в одной таблице называется внешним ключом.
Мы подробно рассмотрим эти отношения в следующих уроках.
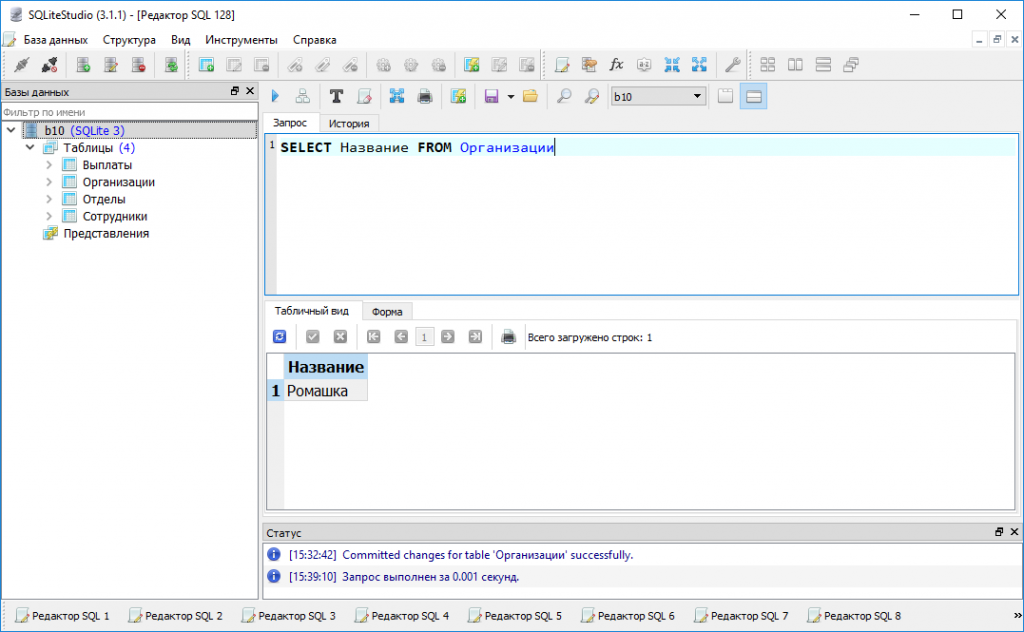
Простые примеры использования SELECT
Синтаксис:
> SELECT <fields1> FROM <table>
* где fields1 — поля для выборки через запятую, также можно указать все поля знаком *; table — имя таблицы, из которой вытаскиваем данные; conditions — условия выборки; fields2 — поле или поля через запятую, по которым выполнить сортировку; count — количество строк для выгрузки.
* запрос в квадратных скобках не является обязательным для выборки данных.
> SELECT * FROM users
* в данном примере мы получаем список всех записей из таблицы users.
2. Выборка данных с объединением двух таблиц (JOIN)
SELECT u.name, r.* FROM users u JOIN users_rights r ON r.user_id=u.id
* в данном примере идет выборка данных с объединением таблиц users и users_rights. Объединяются они по полям user_id (в таблице users_rights) и id (users). Извлекается поле name из первой таблицы и все поля из второй.
3. Выборка с интервалом по времени и/или дате
Варианты запросов и примеров могут быть самые разные. Мы рассмотрим те, с которыми чаще всего приходилось иметь дело автору.
а) известна точка начала и определенный временной интервал:
> SELECT * FROM users WHERE date >= DATE_SUB(NOW(), INTERVAL 1 HOUR)
* будут выбраны данные за последний час (поле date).
б) известны дата начала и дата окончания:
> SELECT * FROM users WHERE date >= ‘2017-10-25’ AND date <= ‘2017-11-25’
* выбираем данные в промежутке между 25.10.2017 и 25.11.2017.
в) известны даты начала и окончания + время:
> SELECT * FROM users WHERE DATE(date) BETWEEN ‘2018-03-25 00:15:00’ AND ‘2018-04-25 15:33:09’;
* выбираем данные в промежутке между 25.03.2018 0 часов 15 минут и 25.04.2018 15 часов 33 минуты и 9 секунд.
г) вытаскиваем данные за определенные месяц и год:
> SELECT * FROM study WHERE MONTH(date) = 4 AND YEAR(date) = 2018
* извлечем данные, где в поле date присутствуют значения для апреля 2018 года.
д) текущая дата минут год:
> SELECT * FROM study WHERE date < (CURDATE() — INTERVAL 1 YEAR)
* мы получим данные, которые имеют в колонке date дату, старше одного года.
4. Выборка максимального, минимального и среднего значения
> SELECT max(area), min(area), avg(area) FROM country
* max — максимальное значение; min — минимальное; avg — среднее.
5. Использование длины строки
> SELECT * FROM users WHERE CHAR_LENGTH(name) = 5;
* данный запрос должен показать всех пользователей, имя которых состоит из 5 символов.
6. Использование лимитов (LIMIT)
Применяется для ограничения количества выводимых результатов. Синтаксис:
<основной запрос> LIMIT <число1>
* где число1 — сколько результатов вернуть; число2 — сколько результатов пропустить, необязательный параметр — если его не писать, то отсчет начнется с первой строки.
а) извлечь максимум 15 строк:
> SELECT * FROM users LIMIT 15;
б) выбрать строки с 16 по 25 (запрос со смещением):
> SELECT * FROM users LIMIT 15, 10;
* 15 строк пропускаем, 10 извлекаем.
Выполнение запросов
По умолчанию, если вы не устанавливали дополнительные программы, у MySQL нет графического интерфейса пользователя. Это значит, что единственный способ работы с ней — это использование командной строки.
- Откройте командную строку (Выполнить — ).
- Перейдите в каталог с установленной MySQL: .
- Выполните: .
- Введите пароль, заданный при установке.
Если вы всё выполнили верно, то в командной строке запустится клиент для работы с MySQL (вы поймете это по строке приглашения «mysql>»). С этого момента можно вводить любые SQL запросы, но каждый запрос обязательно должен заканчиваться точкой с запятой .
Установка ПО для работы
В данном разделе рассказывается как установить и настроить SQL Server на примере SQL Server 2016 Enterprise – самой новой версии.
Для начала скачайте установочный пакет SQL Server 2016 Enterprise с официальной страницы: https://www.microsoft.com/en-us/sql-server/sql-server-editions-express. Версия, которую вы скачали будет работать .
Вместо нее можно использовать SQL Server 2016 Developer Edition, если у вас есть подписка MSDN. Станица для скачивания: https://www.microsoft.com/en-us/sql-server/sql-server-editions-developers.
Прежде чем запускать скаченный установщик, создайте учетную запись. Она потребуется чтобы авторизовываться вас на сервере с клиентского компьютера. Поскольку у вас это один и тот же компьютер, то авторизовываться будет SQL Server через Management Studio, его мы скачаем позже.
Создание учетной записи
Выполните следующие инструкции чтобы создать учетную запись в Windows. Способ работает во всех ОС этого семейства начиная с 2000 и заканчивая 10.
Инструкции:
- Кликните правой кнопкой мышки по значку «Мой компьютер» на рабочем столе и выберите из списка пункт «Управление». Откроется оснастка «Управление компьютером».
- В окне оснастке выберите пункт меню «локальные пользователи», затем выделите пункт «пользователи». Окно приобретёт вот такой вид:
- Кликните правой кнопкой мыши по пустому пространству папки или по названию папки и выберите пункт «новый пользователь». Откроется такое окно:
- Придумайте имя пользователя и пароль заполните их в формы и нажмите кнопку создать. Рекомендуем использовать латинские символы.
Установка SQL Server
- Запустите скачанный ранее пакет установки. Установщик проверит подходит ли ваш компьютер по производительности и есть ли на нем все необходимое для установки программное обеспечение. Если последнего не окажется, он его скачает. После этого откроется SQL Server Installation Server:
- Выберите пункт «Установка».
- После изменения экраны кликните на пункте «Новая установка изолированного экземпляра SQL Server». Запустится установка и установщик попытается обновиться до последней версии. Щелкните кнопку «Далее», чтобы перейти к следующему шагу:
- На этапе «правил установки» проследите чтобы в окне не было красных крестиков. Если они появились, то щелкайте по выделенным строкам предупреждений и следуйте инструкциям по устранениям. Затем, щелкните кнопку «Далее». Окно установки снова изменится:
- В появившемся окне выберите «Выполнить новую установку SQL Server 2016» и нажмите «Далее». Откроется окно регистрации продукта:
- Введите лицензионный ключ продукта, если он у вас есть. Либо выберите Evaluation для активации 180 дневной копии.
- В следующем окне прочтите лицензионное соглашение, и примите его, установив флажок в поле «Я принимаю…». И нажмите «Далее»
- Откроется окно компонентов. Выберите пункты, установив галочки напротив:
• Службы ядра СУБД;
• Соединение с клиентскими средствами;
• Компоненты документации.
Нажмите «Далее» - В следующем окне выберите «экземпляр по умолчанию» если уже есть установленная копия SQL Server или именованный экземпляр, если устанавливаете первый раз. Введите в поле имя Экземпляра и нажмите «Далее».
- В следующем окне проверьте, хватает ли места на диске. Если нет, освободите его и нажмите «Далее».
- На этапе «Настройка Ядра СУБД» убедитесь, что выбрана строка «Проверка подлинности Windows». Если нет, выберите его. Затем добавьте в поле внизу пользователя, которого создавали перед установкой, либо добавьте текущего с помощью соответствующей кнопки Нажмите «Далее»
- На следующем окне перепроверьте все настройки установки и нажмите «далее»
- Понаблюдайте за установкой и нажмите «Закрыть», когда появится сообщение о завершении установки.
Установка
Последняя версия MySQL доступна для загрузки по ссылке: https://dev. mysql. com/downloads/mysql/. На этой странице следует выбрать MySQL Installer for Windows и нажать на кнопку Download для загрузки.
В процессе установки запомните директорию, куда вы устанавливаете MySQL (скрывается под ссылкой Advanced options). На шаге Accounts and Roles установщик попросит придумать пароль для доступа к БД (MySQL Root Password) — обязательно запомните или запишите этот пароль — он вам ещё понадобится.
Если для своей работы вы используете программную среду OpenServer, то этот раздел можно смело пропустить, так как в состав OpenServer уже входит свежая версия MySQL.
Подключения
“Плитка” подключения
При наведении курсора мыши на подключение, у “плитки” отгибается уголок. Если нажать на этот “уголок”, отобразится информация о подключении: версия СУБД, дата последнего использования, адрес сервера СУБД, логин, и т.п.





Информация о подключении
В правом нижнем углу есть кнопка ‘Connect’, которая откроет данное подключение.
Подключение так же можно открыть, нажав на саму “плитку”.
Откройте первое подключение в списке.
Редактор SQL-запросов
После открытия подключения, открывается окно редактора SQL-запросов.
Окно редактора SQL-запросов
В центре мы видим окно редактирования запроса.
Обратно к домашнему экрану можно вернуться, нажав на иконку в левом верхнем углу окна.
Слева находится навигатор, отображающий основные задачи и список объектов БД.
В левом нижнем углу находится окно информации о выбранном объекте.
Справа находится окно помощи.
Внизу – окно истории запросов.
В правом верхнем углу находятся элементы управления, позволяющие скрыть или отобразить боковые панели.
Примеры более сложных запросов или используемых редко
1. Объединение с группировкой выбранных данных в одну строку (GROUP_CONCAT)
> SELECT GROUP_CONCAT(DISTINCT CONVERT(id USING ‘utf8’) SEPARATOR ‘, ‘) as ids FROM users
* из таблицы users извлекаются данные по полю id, все они помещаются в одну строку, значения разделяются запятыми.
2. Группировка данных по двум и более полям
> SELECT * FROM users GROUP BY CONCAT(title, ‘::’, birth)
* итого, в данном примере мы сделаем выгрузку данных из таблицы users и сгруппируем их по полям title и birth. Перед группировкой мы делаем объединение полей в одну строку с разделителем ::.
3. Объединение результатов из двух и более таблиц (UNION)
а) простой вариант использования UNION:
> (SELECT id, fio, address, ‘Пользователи’ as type FROM users)
UNION
(SELECT id, fio, address, ‘Покупатели’ as type FROM customers)
* в данном примере идет выборка данных из таблиц users и customers.
б) если нам нужно использовать WHERE после UNION, запрос будет сложнее:
> SELECT * FROM (
(SELECT id, fio, address, ‘Пользователи’ as type FROM users)
UNION
(SELECT id, fio, address, ‘Покупатели’ as type FROM customers)
) as U
WHERE U.address LIKE «Садовая%»
4. Выборка средних значений, сгруппированных за каждый час
SELECT avg(temperature), DATE_FORMAT(datetimeupdate, ‘%Y-%m-%d %H’) as hour_datetime FROM archive GROUP BY DATE_FORMAT(datetimeupdate, ‘%Y-%m-%d %H’)
* здесь мы извлекаем среднее значение поля temperature из таблицы archive и группируем по полю datetimeupdate (с разделением времени за каждый час).
5. Использование операторов IF и CASE
Данные операторы позволяют определять исход запроса исходя из условия.
а) выбрать пол мужской или женский:
SELECT IF(sex = ‘m’, ‘мужчина’, ‘женщина’) as sex FROM people
* в данном примере мы возвращаем слово «мужчина», если поле sex равно ‘m’, иначе — «женщина».
б) заменяем идентификатор времени года более понятным человеку значением:
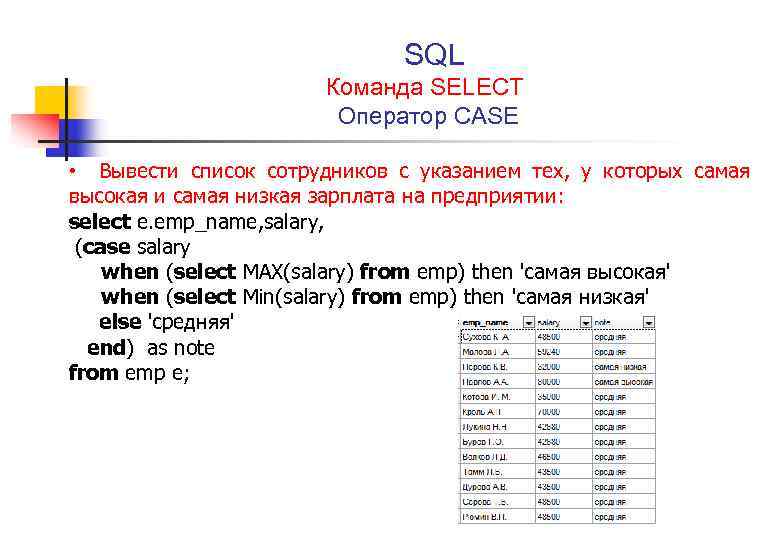
SELECT CASE season_id WHEN 1 THEN ‘зима’ WHEN 2 THEN ‘весна’ WHEN 3 THEN ‘лето’ WHEN 4 THEN ‘осень’ ELSE ‘неправильный идентификатор времени года’ END as season FROM ` seasons
* в данном примере мы используем оператор CASE. Если 1, то вернем слово «зима», если 2 — «весна» и так далее.