
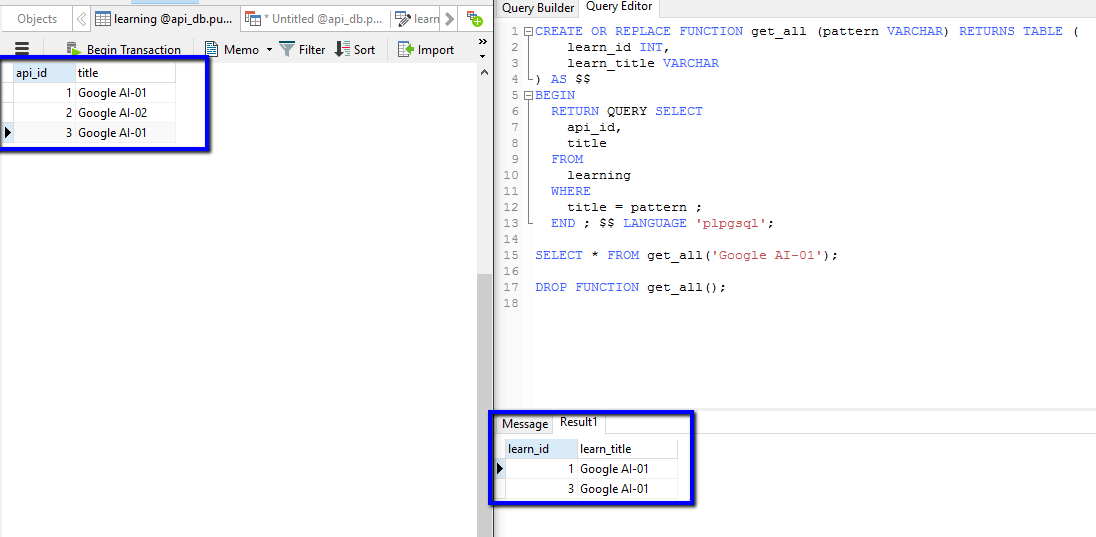
Кейс «Считаем средний чек, выбирая данные с определенной даты»
На скриншоте массив данных, с которым мы будем работать:
Наша задача: отобрать строки с продажами начиная с 1 апреля и посчитать по ним средний чек, используя количество клиентов, то есть получить среднее взвешенное.
Начнем. Создадим QUERY с умножением количества клиентов (столбец B) на средний чек (столбец С) начиная с определенной даты:
Правильно использовать дату в формуле QUERY так:
- QUERY работает с датой только в формате yyyy-mm-dd. Чтобы перевести дату из ячейки Е1 в этот вид, используем формулу ТЕКСТ (TEXT) с условием «yyyy-mm-dd»;
- перед датой и перед апострофом нужно написать date;
- можно и не делать ссылку на ячейку с датой, а написать ее сразу в QUERY, тогда формула будет выглядеть так:
дата с двух сторон обрамляется одиночными кавычками (‘).
Вернемся к тому, что у нас получилось. Наша формула выдала вот такой массив данных:
Это построчные произведения количества клиентов на средний чек. Нам нужно просуммировать их, для этого введем перед формулой СУММ (SUM):
Чтобы получить средний чек, получившееся число нужно разделить на общую сумму клиентов в отобранных строках. Чтобы закрепить использование QUERY, опять воспользуемся этой формулой.
Берем предыдущую формулу, меняем B*C на sum(B) и получаем такую конструкцию:
Наконец, совмещаем формулы:
Все работает, ура! 53 (этот результат видно на всплывающей подсказке в верхнем левом углу) — средний чек с учетом количества клиентов, рассчитанный через среднее взвешенное.
Создание потоковой функции
Потоковая функция получает параметр с результирующим набором (через выражение CURSOR ) и возвращает результат в форме коллекции. Так как к коллекции можно применить оператор TABLE , а затем запросить данные командой SELECT , эти функции позволяют выполнить одно или несколько преобразований данных в одной команде SQL . Потоковые функции, поддержка которых добавилась в Oracle9i Database , позволяют скрыть алгоритмическую сложность за интерфейсом функции, и упростить SQL приложения. Приведенный ниже пример объясняет различные действия, которые необходимо выполнить для такого использования табличных функций.
Представьте следующую ситуацию: имеется таблица с информацией биржевых котировок, которая содержит строки с ценами на моменты открытия и закрытия биржи:
Эту информацию необходимо преобразовать в другую таблицу:
Иначе говоря, одна строка stocktable превращается в две строки tickertable . Эту задачу можно решить многими способами. Самое элементарное и традиционное решение на PL/SQL выглядит примерно так:
Также возможны решения, полностью основанные на SQL :
А теперь предположим, что для перемещения данных из stocktable в tickertable требуется выполнить очень сложное преобразование, требующее использования PL/ SQL . В такой ситуации табличная функция, используемая для передачи преобразуемых данных, потребует намного более эффективного решения.
Прежде всего, при использовании табличной функции нужно будет возвращать вложенную таблицу или массив VARRAY с данными. Я выбрал вложенную таблицу, потому что для VARRAY нужно задать максимальный размер, а я не хочу устанавливать это ограничение в своей реализации. Тип вложенной таблицы должен быть определен как тип на уровне схемы или в спецификации пакета, чтобы ядро SQL могло разрешить ссылку на коллекцию этого типа. Конечно, хотелось бы вернуть вложенную таблицу, основанную на самом определении таблицы, — то есть чтобы определение выглядело примерно так:
К сожалению, эта команда завершится неудачей, потому что %ROWTYPE не относится к числу типов, распознаваемых SQL. Этот атрибут доступен только в разделе объявлений PL/SQL . Следовательно, вместо этого придется создать объектный тип, который воспроизводит структуру реляционной таблицы, а затем определить тип вложенной таблицы на базе этого объектного типа:
Чтобы табличная функция передавала данные с одной стадии преобразования на другую, она должна получать аргумент с набором данных — фактически запрос. Это можно сделать только одним способом — передачей курсорной переменной, поэтому в списке параметров функции необходимо будет использовать тип REF CURSOR.
Я создал пакет для типа REF CURSOR , основанного на новом типе вложенной таблицы:
Работа завершается написанием функции преобразования:
Как и в случае с функцией pet_family , конкретный код не важен; в ваших программах логика преобразований будет качественно сложнее. Впрочем, основная последовательность действий с большой вероятностью будет повторена в вашем коде, поэтому я приведу краткую сводку в следующей таблице.
Итак, теперь у меня имеется функция, которая будет проделывать всю нетривиальную, но необходимую работу, и я могу использовать ее в запросе для передачи данных между таблицами:
Внутренняя команда SELECT извлекает все строки таблицы stocktable . Выражение CURSOR , в которое заключен запрос, преобразует итоговый набор в курсорную переменную, которая передается stockpivot. Функция возвращает вложенную таблицу, а оператор TABLE преобразует ее к формату реляционной таблицы, к которой можно обращаться с запросами.
Никакого волшебства, и все же выглядит немного волшебно, правда? Но вас ждет нечто еще более интересное — конвейерные функции!
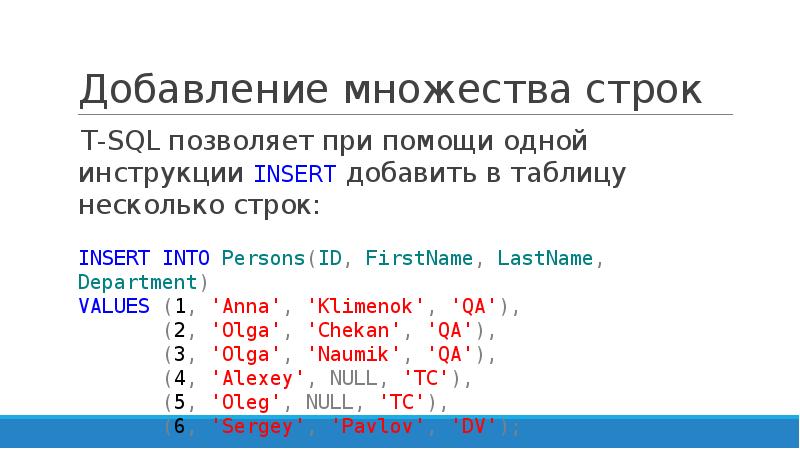
Вставка нескольких строк в таблицу
Применение рассмотренного выше механизма автоматического приращения позволяет вставлять в таблицу базы данных сразу несколько строк, не заботясь об уникальности значений первичного ключа.
Для этого применяется либо однострочный, либо многострочный оператор INSERT. Рассмотрим сначала синтаксис однострочного варианта.
Пример 7. Если используется механизм автоматического приращения значений первичного ключа, то на MySQL вставить новые строки в таблицу можно, применив несколько раз оператор INSERT и указав в качестве значений первичного ключа 0 или NULL:
Допустим, перед вставкой новых строк записи в таблице завершались строкой со значением первичного ключа 5. В результате выполнения запроса в таблице появятся новые строки:
| 6 | Электротехника | Телевизоры | 127 | 8255 |
| 7 | Электротехника | Холодильники | 137 | 8905 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
| 9 | Досуг | Книги | 96 | 6240 |
На MS SQL Server нет необходимости указывать значения столбца Id. Аналогичный запрос будет следующим:
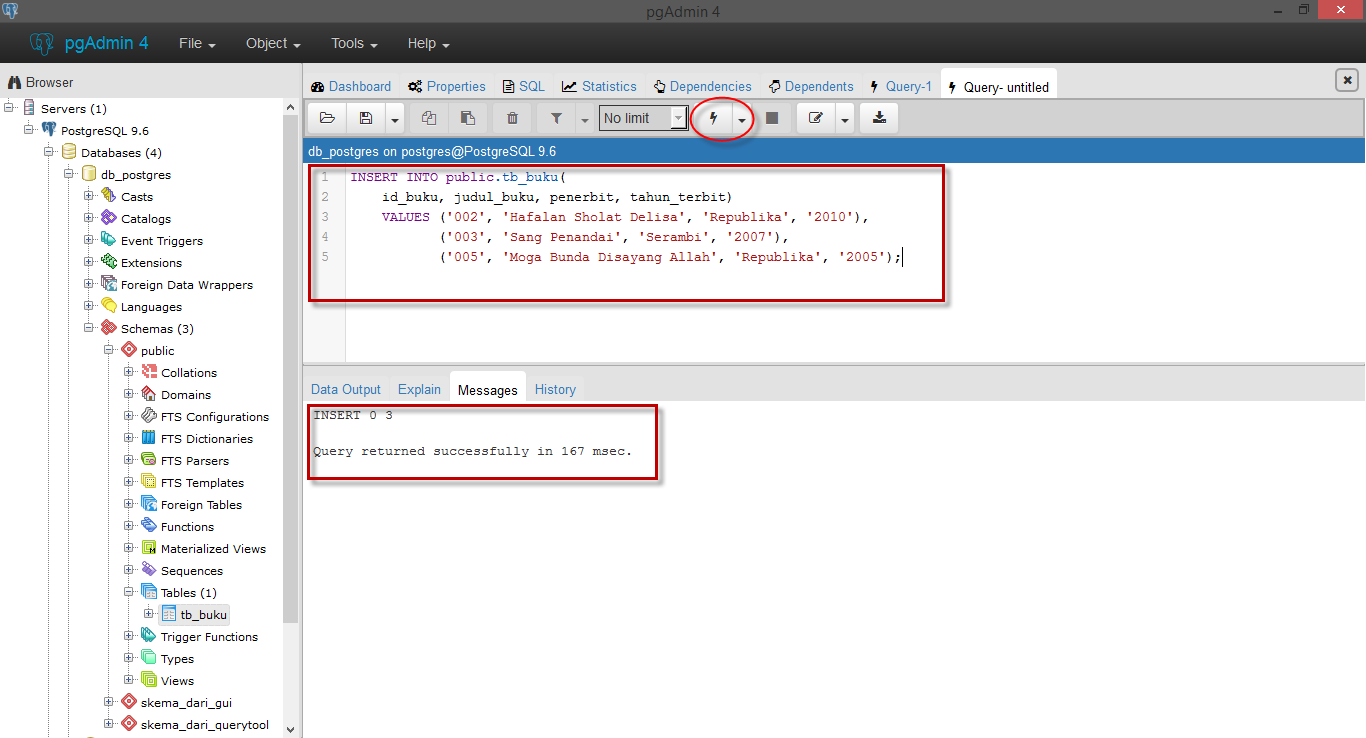
В MySQL и SQL Server существует многострочный оператор INSERT. Его отличие от однострочного варианта в том, что для вставки нескольких строк он используется один раз, а после ключевого слова VALUES указывается не один, а несколько списков значений добавляемых строк.
Пример 8. Вставим строки с теми же значениями, что и в предыдущем примере, используя многострочный оператор INSERT.
Запрос на MySQL:
Запрос на MS SQL Server:
Результат применения — тот же, что и в предыдущем примере.
Примеры запросов к базе данных «Портал объявлений-1» есть также в уроках об операторах UPDATE, DELETE, HAVING и UNION.
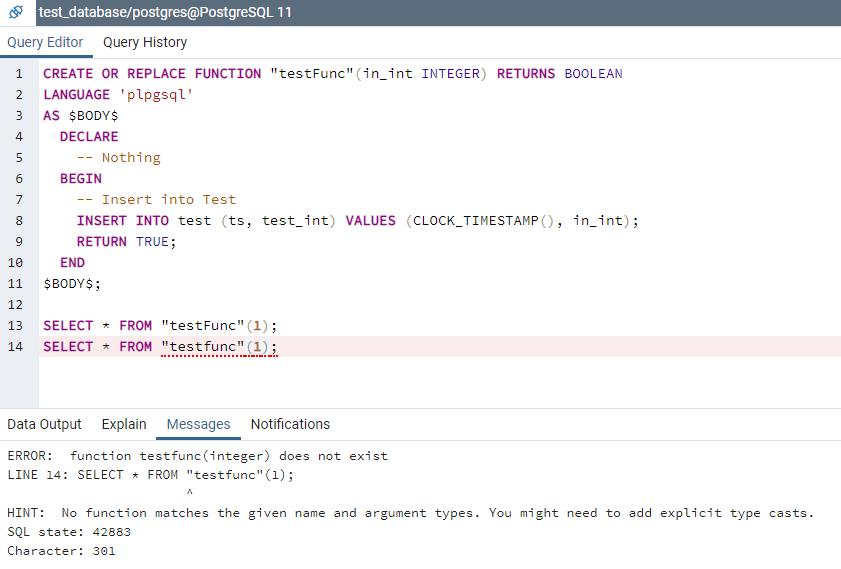
Всем доброго времени суток. Помогите пожалуйста. Я использую Oracle9i. Создал следующую функцию:


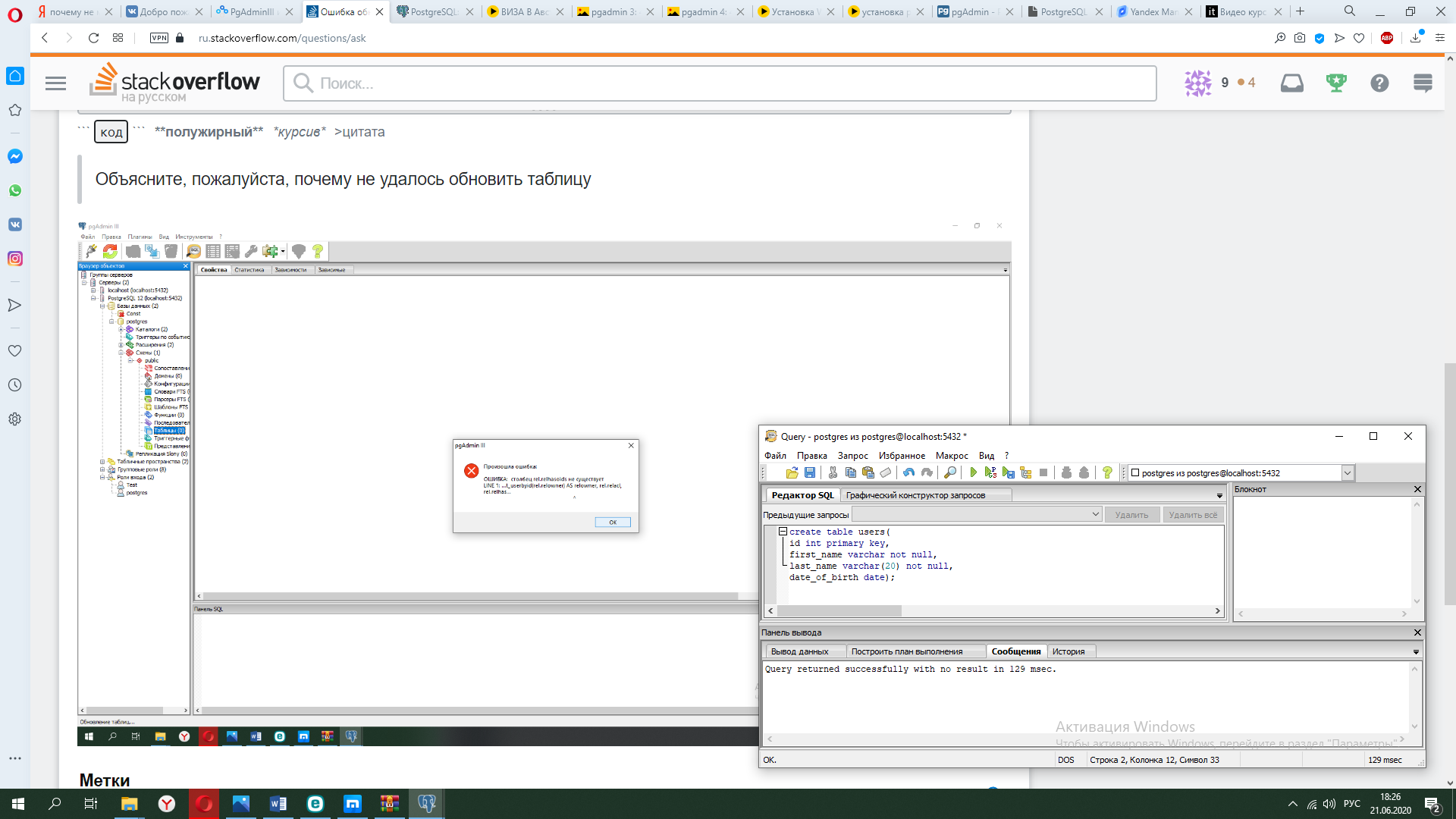

Эта функция обрабатывает цены ценных бумаг и возвращает, но при этом должен был вставить другую запись в таблицу. в этом и вся проблема.
и вызываю эту функцию следующим образом:
ORA-14551: «невозможно выполнение операции DML внутри запроса»
Как решить проблему, подскажите. Но мне нужно, чтобы DML опреации проводились внутри функции и эту функцию объязательно вызывать в запросе как вышерасположенным образом. Иначе нельзя. Есть решение? Спасибо.
Как передать в функцию два односвязных списка так, чтобы внутри функции можно было эти списки редактировать?Мне нужно редактировать в функции два односвязных списка, как их передать в функцию, один.
Как быстро редактировать таблицу под стандартные настройкиНужно напечатать очень много страниц с книги с множеством данных и цифр, сначала я печатал, но.
Как редактировать таблицу из кода или сделать привязку?Доброго дня! Вопрос в следующем: Делаю приложение, которое готовит печатную форму. Где всё без.
Как сделать чтобы можно было редактировать таблицу через DataGridView?Заполняю таблицу таким способом. dataGridView1.ColumnHeadersDefaultCellStyle.Font = new.
Откуда Вы собрались вызывать функцию?
Из запроса? — Нельзя. Запрос придётся переписать в pl/sql.
Какой резон совмещать в одном блоке два действия (поиск цены и добавление имени акции)? Ответ на этот вопрос решит проблему.
Сделайте функцию процедурой или перенесите в пакет, задав правильно PRAGMA. Первое проще.
О! Я думал прагму можно только в пакете писать.
Ну я тоже не раз вызывал функции из запросов. Но в этом случае возникла ошибка. Как я уже понял нужно использовать прагмы. я попробую реализовать в свой проект код DLINNBLY. Если все успешно, то сообщу вам.
Для чего мне понадобился такой код? Использовать DML операцию внутри функции, которая вызывается из sql запросах. Я создаю отчет на CrystalReports XI. И в отчете использую параметр множественного выбора, т.е. значение multiple values = true. В 11 версии кристалла не возможно использовать подобный параметр в sql запросах. Например, в кристалле пишется обычный sql запрос:
-
Как взломать архикад 12
-
Как контролировать отдачу в apex legends на ps4
-
Электронная книга pocketbook 632 plus обзор
-
Как открыть файл yyz
- Как с компьютера ответить на комментарий в инстаграме
Общие замечания по поводу возврата из функции табличных значений
Сегодня опять циклы, но теперь мы возвращаем уже из функции таблицу — результат запроса. Напомню, что мы рассматриваем хранимые функции на языке PLpgSQL. В отличие от хранимых sql-функций, где просто выполняется запрос, здесь для возврата таблицы требуется соблюсти некоторые правила. Сегодня для возврата таблицы используем также тип данных RECORD (запись).
Для определенности будем рассматривать базу данных, схема данных которой представлена на рисунке 1. Эта учебная база данных, где хранится информация об учащихся, их оценках, предметах, факультетах и преподавателях. Поставим задачу получить список учащихся с первичными ключами и их оценки.
Конвейерные табличные функции)(Pipelined Table Functions
Конвейерная обработка отменяет надобность в создании огромных наборов, передавая строки по каналу из функции по мере их создания, сохраняя память и позволяя запустить последующую обработку еще до окончания генерации всех строк.
Конвейерные табличные функции включают фразу PIPELINED и используют вызов PIPE ROW, чтобы вытолкнуть строки из функции, как только они создадутся, вместо построения табличной коллекции. Заметим, что вызов RETURN пустой, поскольку нет никакой коллекции, возвращаемой из функции.
Когда ETL-операции проводятся на большом хранилище данных, наблюдается существенное повышение производительности, поскольку загрузка данных из внешних таблиц производится табличными функциями непосредственно в таблицы хранилища, избегая промежуточного размещения данных.
Управление представлениями
Создаем представление:
CREATE OR REPLACE view_name AS query;
Создаем рекурсивное представление:
CREATE RECURSIVE VIEW view_name(column_list) AS SELECT column_list;
Создайте детализированное представление:
CREATE MATERIALIZED VIEW view_name AS query WITH DATA;
Обновление детализированного представления:
REFRESH MATERIALIZED VIEW CONCURRENTLY view_name;
Удаление существующего представления.
DROP VIEW view_name;
Удаление детализированного представления:
DROP MATERIALIZED VIEW view_name;
Переименование представления:
ALTER VIEW view_name RENAME TO new_name;
Изменение данных
Добавляет новую строку в таблицу:
INSERT INTO table(column1,column2,...) VALUES(value_1,value_2,...);
Добавляет несколько строк в таблицу:
INSERT INTO table_name(column1,column2,...)
VALUES(value_1,value_2,...),
(value_1,value_2,...),
(value_1,value_2,...)...
Обновление данных для всех строк:
UPDATE table_name
SET column_1 = value_1,
...;
Обновление данных для набора строк, заданных условием в предложении
UPDATE table
SET column_1 = value_1,
...
WHERE condition;
Удаление всех строк таблицы:
DELETE FROM table_name;
Удаление определенных строк на основе условия:
DELETE FROM table_name WHERE condition;
Postgresql function return table execute
In Postgresql, the function can return a table using the execute the command within a function, with help of executing the command, we can generate dynamic commands that can inset or fetch different kinds of information from the table, with different data types each time they are executed.
Let’s get the age of the employee by providing a name to function.
In the above code within BEGIN and END, we are using EXECUTE command to execute the dynamic Postgresql queries. The command string can use parameter values, which are denoted in the command as $1, etc. These symbols refer to values that we supplied in the USING clause
Syntax:
Where,
command-string: It is a string containing the command to be executed.
Using: It is an expression, values are supplied using this expression, that is inserted into the commands.
Call the above function to get the age of the employee named “Dan”.

Postgresql function return table execute
In the above code, we have found the age of Dan which is 45 years.
Read: PostgreSQL CREATE INDEX
Вставка значений по умолчанию (DEFAULT) и неопределённых значений (NULL)
Заметим, что при создании таблицы было предусмотрено, что значения столбцов могут иметь значения по умолчанию (DEFAULT). На MySQL для столбца Id можно предусмотреть значение 100. На MS SQL Server со строгим автоматическим приращением идентификатора это не допускается. В остальном же всё одинаково: для стобцов Category и Part значения по умолчанию — соответственно Some Category и Some Part, для столбцов Units и Money — значения NULL. Если в запросе на вставку данных на MySQL некоторые столбцы отсутствуют, то в них будут вставлены значения по умолчанию. На MS SQL в качестве значений нужно указать DEFAULT.



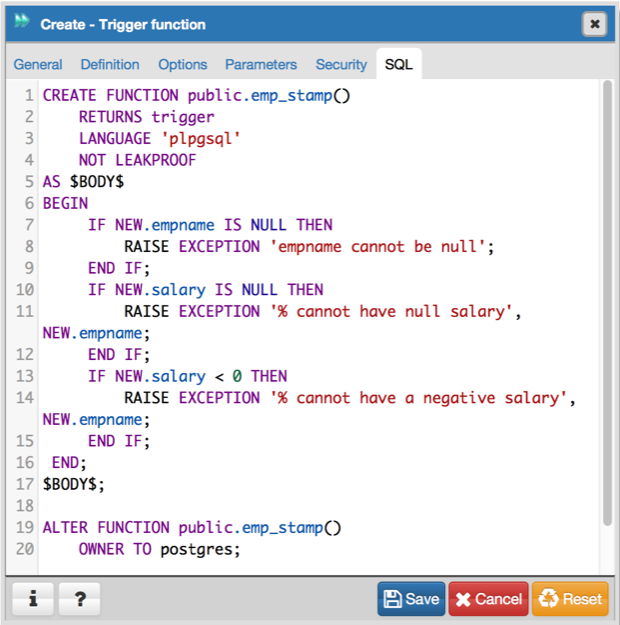
Пример 3. База данных и таблица — те же.
Запрос на MySQL. Вставим новые значения, указывая лишь столбец Id и его значение:
Все столбцы кроме Id получили значения по умолчанию. После выполнения этого запроса новая строка будет содержать следующие данные:
На MS SQL Server такой запрос недопустим.
Поскольку все столбцы могут иметь значения по умолчанию, можно использовать в запросе на вставку данных ключевое слово DEFAULT и не указывать имена столбцов.
Пример 4. Запрос на MySQL. Вставим новые значения, используя ключевое слово DEFAULT и не указывая имён столбцов:
Теперь все столбцы получили значения по умолчанию. После выполнения этого запроса новая строка будет содержать следующие данные:
Запрос на MS SQL Server (без указания столбца Id):
Вместо многократного использования слова DEFAULT можно использовать конструкцию DEFAULT VALUES, которая есть во многих диалектах SQL. Следует помнить, что в MySQL эта конструкция отсутствует.
Пример 5. Вставим новые значения, используя констукцию DEFAULT VALUES (запрос можно использовать и на MS SQL Server c предваряющей конструкцией USE adportal1):
После выполнения этого запроса новая строка будет содержать следующие данные:
3.3.6. Опции функций
При создании функций могут использоваться следующие опции SCHEMABINDING (привязать к схеме) и/или ENCRYPTION (шифровать текст функции). Если вторая опция нам уже известна по вьюшкам и процедурам (позволяет шифровать исходный код функции в системных таблицах), то вторая встречается впервые, но при этом предоставляет удобное средство защиты данных.
Если функция создана с опцией SCHEMABINDING, то объекты базы данных, на которые ссылается функция, не могут быть изменены (с использованием оператора ALTER) или удалены (с помощью оператора DROP). Например, следующая функция использует таблицу tbPeoples и при этом используется опция SCHEMABINDING:
CREATE FUNCTION GetPeoples2(@Famil varchar(50)) RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM dbo.tbPeoples WHERE vcFamil=@Famil )
Функция может быть связанной со схемой, только если следующие ограничения истины:
- все функции объявленные пользователем и просмотрщики на которые ссылается функция, также связаны со схемой с помощью опции SCHEMABINDING;
- объекты, на которые ссылается функция, должны использовать имя из двух частей именования: owner.objectname. При создании функции GetPeoples2 ссылка на таблицу указана именно в таком формате – dbo.tbPeoples;
- Функция и объекты должны быть расположены в одной базе данных;
- Пользователь, который создает функцию, имеет право доступа ко всем объектам, на которые ссылается функция.
Создайте функцию и попробуйте после этого удалить таблицу tbPeoples.
DROP TABLE tbPeoples
В ответ на это сервер выдаст сообщение с ошибкой о том, что объект не может быть удален, из-за присутствия внешнего ключа. Даже если избавиться от ключа, удаление будет невозможно, потому что на таблицу ссылается функция, привязанная к схеме.
Чтобы увидеть сообщение без удаления ключа, давайте добавим к таблице колонку, а потом попробуем ее удалить:
-- Добавим колонку ALTER TABLE dbo.tbPeoples ADD vcTemp VARCHAR(30) NOT NULL default '' -- Попробуем ее удалить ALTER TABLE dbo.tbPeoples DROP COLUMN vcTemp
Создание пройдет успешно, а вот во время удаления произойдет ошибка, с сообщением о том, что существует ограничение, которое зависит от колонки. Мы же не создавали никаких ограничений, а просто добавили колонку и попытались ее удалить. Ограничение уже давно существует, но не на отдельную колонку, а на все колонки таблицы и это ограничение создано функцией GetPeoples2, которая связана со схемой.
Создание и выполнение определяемых пользователем функций
Определяемые пользователем функции создаются посредством инструкции CREATE FUNCTION, которая имеет следующий синтаксис:
Параметр schema_name определяет имя схемы, которая назначается владельцем создаваемой UDF, а параметр function_name определяет имя этой функции. Параметр @param является входным параметром функции (формальным аргументом), чей тип данных определяется параметром type. Параметры функции – это значения, которые передаются вызывающим объектом определяемой пользователем функции для использования в ней. Параметр default определяет значение по умолчанию для соответствующего параметра функции. (Значением по умолчанию также может быть NULL.)
Предложение RETURNS определяет тип данных значения, возвращаемого UDF. Это может быть почти любой стандартный тип данных, поддерживаемый системой баз данных, включая тип данных TABLE. Единственным типом данных, который нельзя указывать, является тип данных timestamp.
Определяемые пользователем функции могут быть либо скалярными, либо табличными. Скалярные функции возвращают атомарное (скалярное) значение. Это означает, что в предложении RETURNS скалярной функции указывается один из стандартных типов данных. Функция является табличной, если предложение RETURNS возвращает набор строк.
Параметр WITH ENCRYPTION в системном каталоге кодирует информацию, содержащую текст инструкции CREATE FUNCTION. Таким образом, предотвращается несанкционированный просмотр текста, который был использован для создания функции. Данная опция позволяет повысить безопасность системы баз данных.
Альтернативное предложение WITH SCHEMABINDING привязывает UDF к объектам базы данных, к которым эта функция обращается. После этого любая попытка модифицировать объект базы данных, к которому обращается функция, претерпевает неудачу. (Привязка функции к объектам базы данных, к которым она обращается, удаляется только при изменении функции, после чего параметр SCHEMABINDING больше не задан.)
Для того чтобы во время создания функции использовать предложение SCHEMABINDING, объекты базы данных, к которым обращается функция, должны удовлетворять следующим условиям:
все представления и другие UDF, к которым обращается определяемая функция, должны быть привязаны к схеме;
все объекты базы данных (таблицы, представления и UDF) должны быть в той же самой базе данных, что и определяемая функция.
Параметр block определяет блок BEGIN/END, содержащий реализацию функции. Последней инструкцией блока должна быть инструкция RETURN с аргументом. (Значением аргумента является возвращаемое функцией значение.) Внутри блока BEGIN/END разрешаются только следующие инструкции:
инструкции присвоения, такие как SET;
инструкции для управления ходом выполнения, такие как WHILE и IF;
инструкции DECLARE, объявляющие локальные переменные;
инструкции SELECT, содержащие списки столбцов выборки с выражениями, значения которых присваиваются переменным, являющимися локальными для данной функции;
инструкции INSERT, UPDATE и DELETE, которые изменяют переменные с типом данных TABLE, являющиеся локальными для данной функции.
По умолчанию инструкцию CREATE FUNCTION могут использовать только члены предопределенной роли сервера sysadmin и предопределенной роли базы данных db_owner или db_ddladmin. Но члены этих ролей могут присвоить это право другим пользователям с помощью инструкции GRANT CREATE FUNCTION.
В примере ниже показано создание функции ComputeCosts:
Функция ComputeCosts вычисляет дополнительные расходы, возникающие при увеличении бюджетов проектов. Единственный входной параметр, @percent, определяет процентное значение увеличения бюджетов. В блоке BEGIN/END сначала объявляются две локальные переменные: @addCosts и @sumBudget, а затем с помощью инструкции SELECT переменной @sumBudget присваивается общая сумма всех бюджетов. После этого функция вычисляет общие дополнительные расходы и посредством инструкции RETURN возвращает это значение.
Табличные функции в Transact-SQL – описание и примеры создания
Раньше мы уже знакомились с функциями, которые возвращают таблицу, правда, на языке PL/pgSQL для сервера PostgreSQL (Написание табличной функции на PL/pgSQL). Теперь пришло время поговорить о такой реализации на Transact-SQL.
Вспомним, а для чего нам вообще нужны такие функции. Самый простой ответ на этот вопрос это то, что в таких функциях можно программировать (объявлять переменные, выполнять какие-то расчеты) и передавать параметры внутрь этой функции, как в обычных скалярных функциях, а результат получать в виде таблицы. И это хорошо, ведь в представлениях (вьюхах) этого делать нельзя, а процедура ничего не возвращает (можно сделать, чтобы возвращала, но это в большинстве случае не очень удобно).
Пример создания простой табличной функции
Итак, приступим, для начала приведем самый простой вариант реализации такой функции. Допустим, нам нужно выбрать несколько полей из таблицы по определенному критерию.
Примечание! Данный пример можно реализовать и с помощью представления. Но мы пока только учимся писать такие функции.
--название нашей функции
CREATE FUNCTION .
(
--входящие параметры и их тип
@id INT
)
--возвращающее значение, т.е. таблица
RETURNS TABLE
AS
--сразу возвращаем результат
RETURN
(
--сам запрос
SELECT * FROM table WHERE id = @id
)
GO
В итоге мы создали функцию, в которую будем передавать один параметр id, его мы используем в условии исходного SQL запроса.
Получить данные из этой функции можно следующим образом:
SELECT * FROM dbo.fun_test_tabl (1)
Как видите все проще простого. Теперь давайте создадим функцию уже с использованием программирования в этой функции.
Пример создания табличной функции, в которой можно программировать
--название нашей функции
CREATE FUNCTION .
(
--входящие параметры
@number INT
)
--возвращающее значение, т.е. таблица с перечислением полей и их типов
RETURNS @tabl TABLE (id INT, number INT, summa MONEY)
AS
BEGIN
--объявляем переменные
DECLARE @var MONEY
--выполняем какие-то действия на Transact-SQL
IF @number >=0
BEGIN
SET @var=1000
END
ELSE
SET @var=0
--вставляем данные в возвращающий результат
INSERT @tabl
SELECT id, number, summa
FROM tabl
WHERE summa > @var
--возвращаем результат
RETURN
END
Здесь мы уже программируем и можем выполнять любые действия как в обычных функциях и процедурах, при этом получая результат в виде таблицы. В этом примере мы передаем один параметр внутрь нашей функции (их может быть несколько!), внутри функции мы уже смотрим, что за параметр к нам пришел, и на основе этого уже формируем условие для запроса. Как Вы понимаете это тоже простой пример, но можно писать очень и очень сложные алгоритмы как в процедурах, именно поэтому, и созданы эти табличные функции.
Теперь давайте обратимся к нашей функции, например, вот так
SELECT * FROM dbo.fun_test_tabl_new (1)
Postgresql function return table with columns
In Postgresql, the function can also return a table with specific columns or columns that we want from a table.
Now we will again modify the above function to return a table with columns.
In the above code, we are changing the function return type as a TABLE with the columns data type, because we want the function to return the table with specific columns, so we have specified the data type of two columns in the table function.
Between the BEGIN and END bodies, we using RETURN QUERY that appends the results of the SELECT statement to the function result set. Using the SELECT statement, we are fetching two columns named name, address from a table named emp_info.




Let’s execute the above function.

Postgresql function return table with columns
Read: Postgresql listen_addresses
Трансформация конвейеров(Transformation Pipelines)
В традиционных ETL-процессах необходимо сначала загрузить данные в промежуточную область, затем сделать по ней несколько проходов, чтобы преобразовать и переместить данные в область, откуда они будут загружены в схему назначения. Прохождение данных через промежуточные таблицы может потребовать значительного количества операций дискового ввода/вывода, как для загружаемых данных, так и для данных redo-журнала. Альтернативой должно стать выполнение преобразования конвейерными табличными функциями, поскольку данные читаются из внешней таблицы и вставляются непосредственно в таблицу назначения, сокращая большую часть операций дискового ввода/вывода.
В этой секции мы увидим и проэкзаменуем с использованием обсуждавшихся ранее методов трансформацию конвейера.
Сначала в виде плоского файла нужно выкачать из файловой системы сервера базы данных какие-либо тестовые данные.
Создаем объект «directory», где указывается местоположение этого файла, создаем внешнюю таблицу, чтобы прочитать файл, и создаем таблицу назначения.
Заметим, что в таблице назначения по сравнению с внешней таблицей есть два дополнительных столбца. Каждый из этих столбцов представляет шаг преобразования. Фактические преобразования в этом примере тривиальны, но следует представить, что они могут быть сложными и невыполнимыми одним SQL-предложением. Следовательно, имеет место потребность в табличных функциях.
Пакет ниже определяет два шага процесса преобразования и процедуры для его запуска.
Вставка внутри процедуры LOAD_DATA полностью выполняет загрузку данных, включая преобразования. Предложение выглядит довольно сложно, но оно состоит из следующих простых шагов.
- Строки запрашиваются из внешней таблицы.
- Строки конвертируются в ref-курсор с помощью функции CURSOR.
- Этот ref-курсор передается на первом этапе преобразования (STEP_1).
- Возвращаемая на шаге STEP_1 коллекция запрашивается, когда используется функция TABLE.
- Вывод этого запроса преобразуется в ref-курсор с помощью функции CURSOR.
- Этот ref-курсор передается на второй этап преобразования (STEP_2).
- Возвращаемая на шаге STEP_2 коллекция запрашивается, когда используется функция TABLE.
- Этот запрос используется для выполнения вставки в результирующую таблицу.
Применяя процедуру LOAD_DATA, можно как преобразовывать, так и загружать данные.
Заметим, что этот пример не содержит процедуры обработки ошибок и что в нем нет хинтов параллельности, чтобы упростить запрос в процедуре LOAD_DATA.
Для получения дополнительной информации обратитесь к документации:
Chaining Pipelined Table Functions for Multiple Transformations (11gR2)
Надеюсь, это вам поможет. С приветом Tim…
Предложение OVER (Transact-SQL)
Но есть особенности, которые не сразу ясны из официальной документации, либо, вообще, в ней не раскрываются.
Сразу скажу, что если есть возможность не делать партиционирование, то лучше его не делать. Зачастую дешевле увеличить размер памяти у вашего сервера БД, чтобы он начал запросто переваривать большие таблицы. И только когда вы упретесь в то, что такого количества памяти нет в продаже, стоит приступать к активным действиям.
Официальной документации вполне достаточно для того, чтобы партиционирование заработало. Более того, все дальнейшие рассуждения буду мало полезными для тех, кто официальную документацию не читал.
Во-первых, в должны быть IMMUTABLE функции. День у меня ушел на то, чтобы понять, что TIMESTAMP WITH TIME ZONE не является IMMUTABLE.
Пример того, как выглядит генерация триггера на вставку в партиционированную таблицу. Для этой статьи я добавил комментарии для больше понятности, но все равно выглядит громоздко.
После выполнения мы получим 36 новых таблиц в БД и триггер, похожий на этот.
При партиционировании перестает работать , а это значит, что при вставке новой записи нельзя узнать ее id. Для этого существует костыль, который на каждую вставку делает дополнительную вставку и удаление, чтобы получить id записи. Я не рискнул использовать его в бою, поскольку у нас и так очень интенсивная нагрузка на БД.
Более того, надо понимать, что в случае с партиционироваными таблицами, вы можете иметь одинаковые id для разных записей, так как уникальность id проверяется (если проверяется) только на уровне конкретной дочерней таблицы. Если вы вставляете данные только в главную таблицу , то id гарантированно будут отличаться, потому что триггер использует sequence от главной таблицы. Но ничего не запрещает вам вставить в дочернюю таблицу данные напрямую.
Какой выигрыш от такого усложнения? Во-первых, вместо одного большого индекса у вас будет теперь много маленьких, которые помещаются в память. Если вам надо сделать выборку по дате, то seq scan будет идти только по нужным партициям. В нашем случае, например, все запросы, в основном, делаются по последнему месяцу, поэтому она оказывается в кэше БД и, самое главное, помещается туда целиком. А как мы знаем, БД для web-проекта либо помещается в память, либо не работает, но об этом я напишу как-нибудь в другой раз.



