
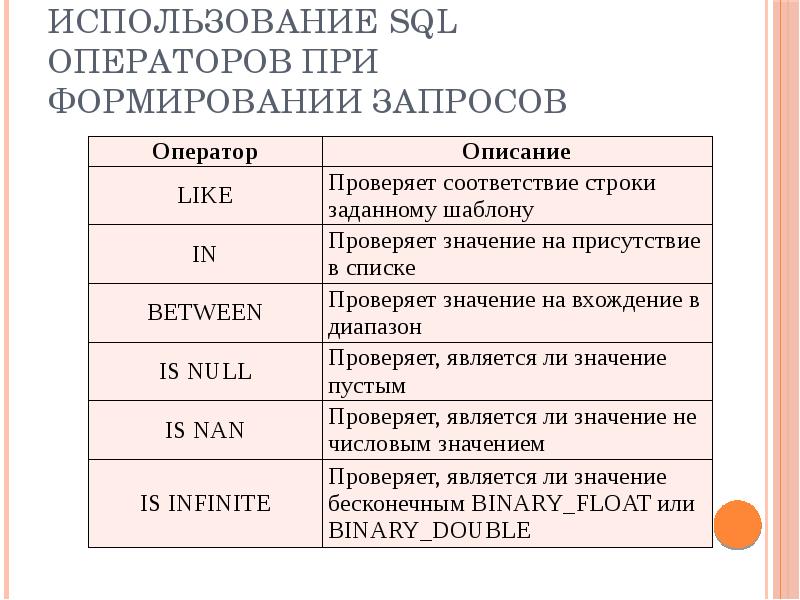
Введение в sp_executesql
Вы можете использовать sp_executeslq для выполнения транзакционного SQL, хранящегося в переменной. Форма инструкции:
EXECUTE sp_executesql @statement.
Если вам интересно, sp_executesql — это системная хранимая процедура. Системные хранимые процедуры расширяют язык и предоставляют больше возможностей для использования.
Вот простой пример:
DECLARE @statement NVARCHAR(4000)
SET @statement = N’SELECT getdate()’
EXECUTE sp_executesql @statement
Если вы запустите это в окне запроса, вы получите подобный результат:
2018-01-24 18:49:30.143
Теперь, когда вы поняли, как работает sp_executeslq, давайте перейдем к практике. Предположим, вас попросили написать хранимую процедуру, которая возвращает либо среднее значение LineTotal, либо сумму LineTotal по ProductID для продуктов, отправленных в 2011 году.
Ваше руководство хотело бы, чтобы это было написано как хранимая процедура. Хранимая процедура должна принимать один параметр @ReturnAverage. Если это истинно, то вы вернете среднее значение, в противном случае сумму.
Конечно, вы могли бы написать это в виде двух отдельных запросов, как показано в следующей хранимой процедуре, но это было бы не очень весело, поскольку это предполагало бы слишком много ручного ввода и возможных ошибок.
CREATE PROCEDURE uspCalcuateSalesSummaryStatic
@returnAverage bit
AS
IF (@returnAverage = 1)
BEGIN
SELECT SOD.ProductID,
AVG(SOD.LineTotal) as ResultAvg
FROM Sales.SalesOrderDetail SOD
INNER JOIN Sales.SalesOrderHEader SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
WHERE YEAR(SOH.ShipDate) = 2011
GROUP BY SOD.ProductID
END
ELSE
BEGIN
SELECT SOD.ProductID,
SUM(SOD.LineTotal) as ResultSum
FROM Sales.SalesOrderDetail SOD
INNER JOIN Sales.SalesOrderHEader SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
WHERE YEAR(SOH.ShipDate) = 2011
GROUP BY SOD.ProductID
END
Что здесь является слабым местом, так это много дублированного кода, который я выделил жирным шрифтом. Существует не так много уникального кода, но имеющийся выделен курсивом.
При всей этой избыточности у нас есть прекрасная возможность продемонстрировать некоторый динамический SQL. Давайте сделаем это!
CREATE PROCEDURE uspCalcuateSalesSummaryDynamic
@returnAverage bit
AS
DECLARE @statement NVARCHAR(4000),
@function NVARCHAR(10)
IF (@returnAverage = 1) SET @function = ‘Avg’
ELSE SET @function = ‘Sum’
SET @statement =
‘SELECT SOD.ProductID,’ +
@function + + ‘(SOD.LineTotal) as Result’ + @function + ‘
FROM Sales.SalesOrderDetail SOD
INNER JOIN Sales.SalesOrderHEader SOH
ON SOH.SalesOrderID = SOD.SalesOrderID




WHERE YEAR(SOH.ShipDate) = 2011
GROUP BY SOD.ProductID’
EXECUTE sp_executesql @statement
Здесь вместо двух полных версий SQL, один для AVG, другой для SUM, мы создаем запрошенную версию «на лету».
SQL построен и сохраняется в переменной @statement. Эта переменная построена на основе значения параметра @returnAverage. Если установлено значение 1, то @function представляет Среднее; в противном случае — Суммирование.
3.3.2. Скалярные функции в Transact-SQL
Давайте для примера создадим функцию, которая будет возвращать скалярное значение. Например, результат перемножение цены на количество указанного товара. Товар будет идентифицироваться по названию и дате, ведь мы договорились, что сочетание этих полей дает уникальность. Но будьте осторожны, при тестировании запроса, если в разделе 3.2.8 вы выполнили запрос на изменение данных и создали дубликаты покупок за 1.1.2005-го года.
Итак, посмотрим сначала на код создание скалярной функции:
CREATE FUNCTION GetSumm
(@name varchar(50), @date datetime)
RETURNS numeric(10,2)
BEGIN
DECLARE @Summ numeric(10,2)
SELECT @Summ = Цена*Количество
FROM Товары
WHERE =@name
AND Дата=@date;
RETURN @Summ
END
После оператора CREATE FUNCTION мы указываем имя функции. Далее, в скобках идут параметры, которые необходимо передать. Да, параметры должны передаваться через запятую в круглых скобках. В этом объявление отличается от процедур и эту разницу необходимо помнить.
Далее указывается ключевое слово RETURNS, за которым идет описание типа возвращаемого значения. Для скалярной функции это могут быть любые типы (строки, числа, даты и т.д.).
Код, который должна выполнять функция пишется между ключевыми словами BEGIN (начало) и END (конец). В коде можно использовать любые операторы Transact-SQL, которые мы изучали ранее. Итак, объявление нашей функции в упрощенном виде можно описать следующим образом:
CREATE FUNCTION GetSumm (@name varchar(50), @date datetime) RETURNS numeric(10,2) BEGIN -- Код функции END
Между ключевыми словами BEGIN и END у нас выполняется следующий код:
-- Объявление переменной DECLARE @Summ numeric(10,2) -- Выполнение запроса на выборку суммы SELECT @Summ = Цена*Количество FROM Товары WHERE =@name AND Дата=@date; -- Возврат результата RETURN @Summ
В первой строке объявляется переменная @Summ. Она нужна для хранения промежуточного результата расчетов. Далее выполняется запрос SELECT, в котором происходит поиск строки по дате и названию товара в таблице товаров. В найденной строке перемножаются поля цены и количества, и результат записывается в переменную @Summ.
Обратите внимание, что в конце запроса стоит знак точки с запятой. Каждый запрос должен заканчиваться этим символом, но в большинстве примеров мы этим пренебрегали, но в функции отсутствие символа «;» может привести к ошибке
В последней строке возвращаем результат. Для этого нужно написать ключевое слово RETURN, после которого пишется возвращаемое значение или переменная. В данном случае, возвращаться будет содержимое переменной @Summ.
Так как функция скалярная, то и возвращаемое значение должно быть скалярным и при этом соответствовать типу, описанному после ключевого слова RETURNS.
Запуск динамического SQL с помощью EXECUTE ()
Вы также можете использовать команду EXEC или EXECUTE для запуска динамического SQL. Формат этой команды:
EXECUTE (@statement)
Вот простой пример:
DECLARE @statement NVARCHAR(4000)
SET @statement = N’SELECT getdate()’
EXECUTE (@statement)
Важно заключить @statement в круглые скобки. Если вы этого не сделаете, инструкция EXECUTE принимает @statement, и вместо запуска динамического SQL она решит, что значение переменной является именем хранимой процедуры
Вы получите следующую ошибку:
Msg 2812, Level 16, State 62, Line 3
Could not find stored procedure ‘SELECT getdate()’.
Конечно, это дает отличную подсказку! Если хотите, можете использовать переменные, чтобы указать, какие хранимые процедуры вызывать.
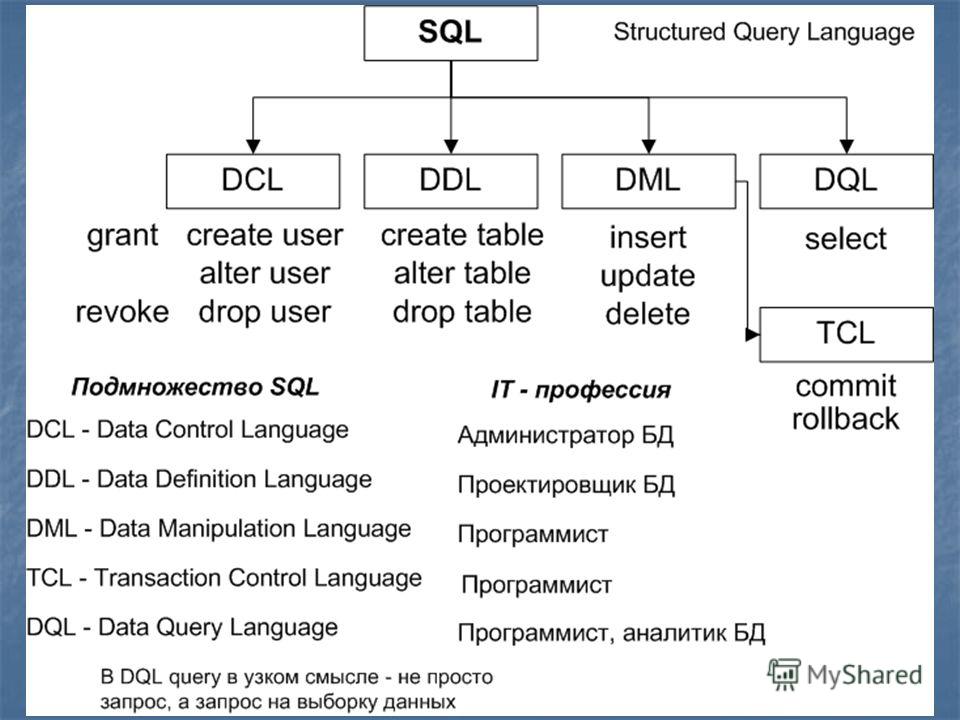
Определение данных
Существует набор команд, использующихся для определения данных, включенных
в язык
SQL.
Создание таблицы
Самая основная команда определения данных — это та, которая создаёт
новое отношение (новую таблицу). Синтаксис команды CREATE TABLE:
CREATE TABLE table_name
(name_of_attr_1 type_of_attr_1
[, name_of_attr_2 type_of_attr_2
]);
Пример 2-10. Создание таблицы
Для создания таблиц, определённых в
, используются следующие SQL выражения:
CREATE TABLE SUPPLIER
(SNO INTEGER,
SNAME VARCHAR(20),
CITY VARCHAR(20));
CREATE TABLE PART
(PNO INTEGER,
PNAME VARCHAR(20),
PRICE DECIMAL(4 , 2));
CREATE TABLE SELLS
(SNO INTEGER,
PNO INTEGER);
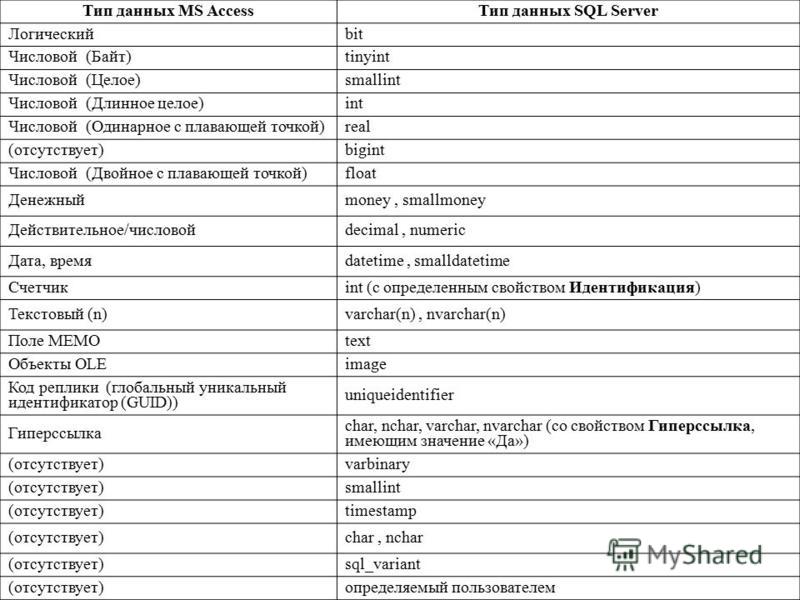
Типы данных SQL
Вот список некоторых типов данных, которые поддерживает
SQL:
-
INTEGER: знаковое полнословное двоичное целое (31 бит для представления данных).
-
SMALLINT: знаковое полсловное двоичное целое (15 бит для представления данных).
-
DECIMAL (p[,q]): знаковое упакованное десятичное число
с p знаками представления данных, с возможным
q знаками справа от десятичной точки.(15 ≥ p ≥ qq ≥ 0).
Если q опущено, то предполагается что оно равно 0.
-
FLOAT: знаковое двусловное число с плавающей точкой.
-
CHAR(n): символьная строка с постоянной длиной
n. -
VARCHAR(n): символьная строка с изменяемой длиной, максимальная длина
n.
Создание индекса
Индексы используются для ускорения доступа к отношению. Если отношение R проиндексировано по атрибуту A, то мы можем получить все кортежи t
имеющие
t(A) = a за время приблизительно пропорциональное числу таких кортежей t, в отличие от времени, пропорциональному размеру R.
Для создания индекса в SQL используется команда CREATE INDEX. Синтаксис:
CREATE INDEX index_name
ON table_name ( name_of_attribute );
Пример 2-11. Создание индекса
Для создания индекса с именем I по атрибуту SNAME отношения SUPPLIER
используем следующее выражение:
CREATE INDEX I
ON SUPPLIER (SNAME);
Созданный индекс обслуживается автоматически, т.е. при вставке ново
кортежа в отношение SUPPLIER, индекс I будет перестроен. Заметим, что
пользователь может ощутить изменения в при существовании индекса только по
увеличению скорости.
Создание представлений
Представление можно рассматривать как виртуальную таблицу, т.е. таблицу, которая в базе данных не существует физически, но для пользователя она как-бы там есть.
По сравнению, если мы говорим о базовой таблице, то мы имеем в виду таблицу, физически хранящую каждую строку
где-то на физическом носителе.
Представления не имеют своих собственных, физически самостоятельных, различимых
хранящихся данных. Вместо этого, система хранит определение представления
(т.е. правила о доступе к физически хранящимся базовым таблицам
в порядке претворения их в представление) где-то в системных каталогах (смотри
). Обсуждение различных технологий реализации представлений смотри в
SIM98.
Для определения представлений в SQL используется команда CREATE VIEW. Синтаксис:
CREATE VIEW view_name
AS select_stmt
select_stmtselect_stmtсистемных каталогах
Пусть дано следующее определение представления (мы опять используем
таблицы из ):
CREATE VIEW London_Suppliers AS SELECT S.SNAME, P.PNAME FROM SUPPLIER S, PART P, SELLS SE WHERE S.SNO = SE.SNO AND P.PNO = SE.PNO AND S.CITY = 'London';
Теперь мы можем использовать это виртуальное отношение
London_Suppliers как если бы оно было ещё одной базовой таблицей:
SELECT *
FROM London_Suppliers
WHERE P.PNAME = 'Screw';
SNAME | PNAME
-------+-------
Smith | Screw
Для вычисления этого результата система базы данных в начале выполняет
скрытый доступ к базовым таблицам SUPPLIER, SELLS и PART. Это делается
с помощью выполнения заданных запросов в определении представления к этим
базовым таблицам. После, это дополнительное определедение (заданное в запросе
к представлению) можно использовать для получения результирующей таблицы.



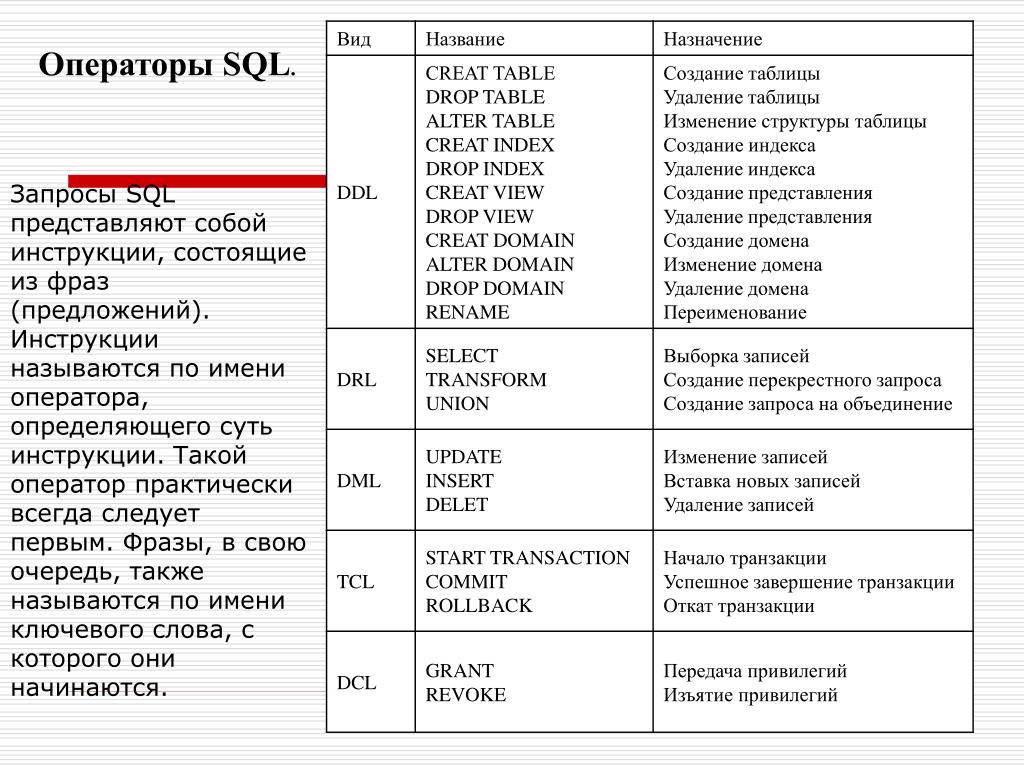

Drop Table, Drop Index, Drop View
Для уничтожения таблицы (включая все кортежи, хранящиеся в этой таблице)
используется команда DROP TABLE:
DROP TABLE table_name;
Для уничтожения таблицы SUPPLIER используется следующее выражение:
DROP TABLE SUPPLIER;
Команда DROP INDEX используется для уничтожения индекса:
DROP INDEX index_name;
Наконец, для уничтожения заданного представления используется
команда DROP VIEW:
DROP VIEW view_name;
Что такое MS SQL Server
Чтобы упростить работу с такими хранилищами данных и повысить эффективность их применения, создаются специализированные системы управления. Одной из наиболее популярных является разработка от Microsoft – SQL Server. Первый релиз платформы опубликован еще в 1989 году, а последняя версия выпущена в 2019 году (проект продолжает развиваться).
Преимущества решения:
- Тесная интеграция с операционной системой Windows.
- Высокая производительность, отказоустойчивость.
- Поддержка многопользовательской среды.
- Расширенные функции резервирования данных.
- Работа с удаленным подключением.
Каждый выпуск включает в себя несколько специализированных редакций. Это снижает сложность внедрения и затраты на процесс разработки собственных решений, адаптированных для «узких» задач. При написании программного кода активно используется интеграция с продуктами Microsoft, например, с платформой Visual Studio.
Прямые конкуренты на рынке – Oracle Database, PostgreSQL. Первый проект коммерческий, он создан для поддержки крупных компаний, поэтому сопоставим по возможностям с MS SQL Server. Второй же распространяется на бесплатной основе и не «блещет» функциональностью, хотя весьма популярен среди многих разработчиков (аналог от Oracle MySQL).
Что такое СУБД
Появление таких продуктов позволило объединить разное понимание БД (баз данных) со стороны пользователей и системных администраторов. Неискушенные в технических деталях люди «видят» таблицы как некий перечень данных с колонками и строками. Системный подход включает файлы с табличными данными, связанными друг с другом согласно определенному алгоритму.
Функции базы данных:
- Постоянное хранение информации.
- Поиск по ключевым критериям.
- Чтение и редактирование по запросу.
Клиентами БД являются прикладные программы, их интерфейс, различные интерактивные модули сайтов вроде калькуляторов и онлайн-редакторов. Но есть еще один компонент системы – СУБД. Он предназначен для ручного доступа к информации и позволяет извлекать данные на диск, работать с ними в памяти сервера, в том числе с применением структурированного языка SQL.
Всего различают три типа БД – клиент-серверные, файл-серверные и встраиваемые. MS SQL Server относится к первой категории. Плюс система является реляционной, т.е. адаптированной для хранения данных без избыточности, с минимальными рисками появления аномалий и нарушения целостности внутренних таблиц.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Механизм заданий
Перейдем теперь к непосредственному механизму исполняющему Планы обслуживания. После сохранения плана обслуживания, на каждый из субпланов в ветке «Агент SQL Server» (SQL Server Agent) → «Задания» (Jobs) создаются элементы заданий.
 Задачи в Обозреватели объектов
Задачи в Обозреватели объектов
В свойствах Задания можно дополнительно настроить:
- Добавить/изменить шаги выполнения. При создании через Планы обслуживания задание состоит из одного шага — выполнение пакета служб SSIS
- Добавить дополнительные расписания в то же задание
- Настроить уведомления об успешном/ошибочном завершении
- Включить/отключить выполнение
Но главным удобством является то что задание можно запустить в ручном режиме в любой момент, для этого необходимо кликнуть правой клавишей мыши на нужном задании и в контекстном меню выбрать «Запустить задание на шаге» (Start Job at Step).
Шаг 3. Настройка рабочих баз данных Ms SQL
 Если база еще не развернута из .dt файла, и вы знаете примерный ее размер, то первичному файлу размер инициализации лучше сразу указать больший или равный размеру базы, но это дело вкуса, он все равно вырастет при развертке до нужных размеров. А вот Автоувеличение (Autogrowth) размера надо обязательно указать примерно по 200 МБ на базу и по 50 МБ на лог (можно увеличить/уменьшить, в зависимости от размера конечной базы и наличия места на диске), т.к. значения по умолчанию – рост по 1МБ и по 10% очень сильно тормозят работу сервера, когда ему при каждой 3й транзакции надо файл увеличивать. В этом же параметре можно ограничить размер файла лога, чтоб сильно не разрастался, хотя это очень спорный параметр…
Если база еще не развернута из .dt файла, и вы знаете примерный ее размер, то первичному файлу размер инициализации лучше сразу указать больший или равный размеру базы, но это дело вкуса, он все равно вырастет при развертке до нужных размеров. А вот Автоувеличение (Autogrowth) размера надо обязательно указать примерно по 200 МБ на базу и по 50 МБ на лог (можно увеличить/уменьшить, в зависимости от размера конечной базы и наличия места на диске), т.к. значения по умолчанию – рост по 1МБ и по 10% очень сильно тормозят работу сервера, когда ему при каждой 3й транзакции надо файл увеличивать. В этом же параметре можно ограничить размер файла лога, чтоб сильно не разрастался, хотя это очень спорный параметр…
Остальные параметры можно оставить по умолчанию, за исключением некоторых:
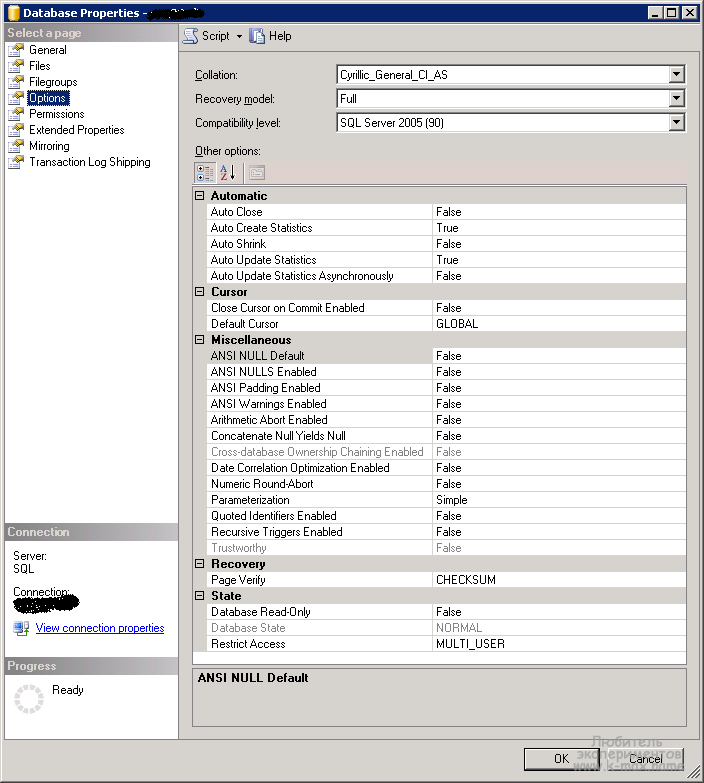 Например, параметр AutoShrink советуют отключить, ибо он приводит к постоянным скачкам размера лога. Лучше его держать в узде с помощью Планов обслуживания (они же Регламентные задания, они же Maintenance Plans).
Например, параметр AutoShrink советуют отключить, ибо он приводит к постоянным скачкам размера лога. Лучше его держать в узде с помощью Планов обслуживания (они же Регламентные задания, они же Maintenance Plans).
What is Dynamic SQL?
Dynamic SQL is a technique in SQL that lets you construct an SQL statement dynamically as the code is being run. You can create a general SQL statement, where you don’t know the full statement when you write it, but is completed when the code is run.
One example of using this is where you don’t know what table you want to query until the code is run. You can use dynamic SQL to create a query that is run against a table you specify from code as you run the code.
Static SQL
The “regular” type of SQL, or the alternative to dynamic SQL is static SQL, which is the standard SQL or SQL that you create and execute at the same time.
If we wanted to select some data from a customer table using static SQL, our code could look like this:
This statement is simply run on the database and the results are returned.
Dynamic SQL
Dynamic SQL is created by placing the SQL statement inside a string variable and then running that as a statement.
The syntax is different for each database, but it generally looks like this:
The variable of “statement” is declared, set to a SELECT query, and is then executed.
The benefit of dynamic SQL is that you can construct the statement however you like, as it’s just a string value. You can use concatenation to add in different values, columns, or tables, for example.
Caution
Although I am not a huge fan of using dynamic SQL statements, I believe it is a great option to have in your tool belt.
If you decide to incorporate dynamic SQL into your production level code, be careful. The code is not parsed until it is executed, and it can potentially introduce security vulnerabilities that you do not want.
If you are careful with your dynamic SQL statement, it can help you create solutions to some pretty tricky problems.
—————————————————————————————–
Get database tips in your inbox
TechRepublic’s free Database Management newsletter, delivered each Tuesday, contains hands-on SQL Server and Oracle tips and resources. Automatically subscribe today!
Daily Tech Insider Newsletter
Stay up to date on the latest in technology with Daily Tech Insider. We bring you news on industry-leading companies, products, and people, as well as highlighted articles, downloads, and top resources. You’ll receive primers on hot tech topics that will help you stay ahead of the game.
Delivered Weekdays
Sign up today
Указание режимов параметров для переменных связывания в строках динамического SQL
С предложением USING режимом по умолчанию является IN, поэтому вам не нужно указывать режим параметров для аргументов связывания ввода.
С предложением RETURNING INTO режим имеет значение OUT, поэтому вы не можете указать режим параметров для выходных аргументов связывания.
Вы должны указать режим параметров в более сложных случаях, таких как этот, где вы вызываете процедуру из динамического блока PL/SQL:
Пример
Oracle PL/SQL
CREATE PROCEDURE create_dept (
deptno IN OUT NUMBER,
dname IN VARCHAR2,
loc IN VARCHAR2) AS
BEGIN
SELECT deptno_seq.NEXTVAL INTO deptno FROM dual;
INSERT INTO dept VALUES (deptno, dname, loc);
END;
|
1 |
CREATEPROCEDUREcreate_dept( deptnoINOUTNUMBER, dnameINVARCHAR2, locINVARCHAR2)AS BEGIN SELECTdeptno_seq.NEXTVALINTOdeptnoFROMdual; INSERTINTOdeptVALUES(deptno,dname,loc); END; |
Чтобы вызвать процедуру из динамического блока PL/SQL, необходимо указать режим IN OUT для аргумента связывания, связанного с формальным параметром deptno, следующим образом:
Oracle PL/SQL
DECLARE
plsql_block VARCHAR2(500);
new_deptno NUMBER(2);
new_dname VARCHAR2(14) := ‘ADVERTISING’;
new_loc VARCHAR2(13) := ‘NEW YORK’;
BEGIN
plsql_block := ‘BEGIN create_dept(:a, :b, :c); END;’;
EXECUTE IMMEDIATE plsql_block
USING IN OUT new_deptno, new_dname, new_loc;
IF new_deptno > 90 THEN …
END;
|
1 |
DECLARE plsql_blockVARCHAR2(500); new_deptnoNUMBER(2); new_dnameVARCHAR2(14):=’ADVERTISING’; new_locVARCHAR2(13):=’NEW YORK’; plsql_block:=’BEGIN create_dept(:a, :b, :c); END;’; EXECUTEIMMEDIATEplsql_block USINGINOUTnew_deptno,new_dname,new_loc; IFnew_deptno>90THEN… END; |
Создание и выполнение процедур
Последнее обновление: 14.08.2017
Нередко операция с данными представляет набор инструкций, которые необходимо выполнить в определенной последовательности. Например, при добавлении данных покупки товара
необходимо внести данные в таблицу заказов. Однако перед этим надо проверить, а есть ли покупаемый товар в наличии. Возможно, при этом понадобится проверить еще ряд дополнительных условий.
То есть фактически процесс покупки товара охватывает несколько действий, которые должны выполняться в определенной последовательности.
И в этом случае более оптимально будет инкапсулировать все эти действия в один объект — хранимую процедуру (stored procedure).
То есть по сути хранимые процедуры представляют набор инструкций, которые выполняются как единое целое.
Тем самым хранимые процедуры позволяют упростить комплексные операции и вынести их в единый объект. Изменится процесс покупки товара, соответственно достаточно будет
изменить код процедуры. То есть процедура также упрощает управление кодом.
Также хранимые процедуры позволяют ограничить доступ к данным в таблицах и тем самым уменьшить вероятность преднамеренных или неосознанных
нежелательных действий в отношении этих данных.
И еще один важный аспект — производительность. Хранимые процедуры обычно выполняются быстрее, чем обычные SQL-инструкции. Все потому что код процедур компилируется один раз при первом ее запуске, а затем сохраняется в скомпилированной форме.






Для создания хранимой процедуры применяется команда CREATE PROCEDURE или CREATE PROC.
Таким образом, хранимая процедура имеет три ключевых особенности: упрощение кода, безопасность и производительность.
Например, пусть в базе данных есть таблица, которая хранит данные о товарах:
CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
Создадим хранимую процедуру для извлечения данных из этой таблицы:
USE productsdb; GO CREATE PROCEDURE ProductSummary AS SELECT ProductName AS Product, Manufacturer, Price FROM Products
Поскольку команда CREATE PROCEDURE должна вызываться в отдельном пакете, то после команды USE, которая устанавливает текущую базу данных, используется
команда GO для определения нового пакета.
После имени процедуры должно идти ключевое слово AS.
Для отделения тела процедуры от остальной части скрипта код процедуры нередко помещается в блок BEGIN…END:
USE productsdb; GO CREATE PROCEDURE ProductSummary AS BEGIN SELECT ProductName AS Product, Manufacturer, Price FROM Products END;
После добавления процедуры мы ее можем увидеть в узле базы данных в SQL Server Management Studio в подузле Programmability -> Stored Procedures:
И мы сможем управлять процедурой также и через визуальный интерфейс.
Для выполнения хранимой процедуры вызывается команда EXEC или EXECUTE:
EXEC ProductSummary
Примеры
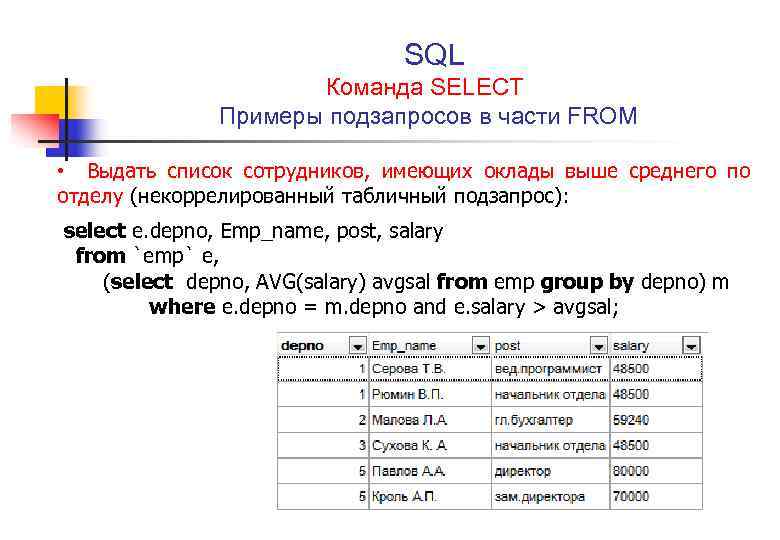
Б. Выполнение динамически построенной строки
В следующем примере показано использование процедуры для выполнения динамически построенной строки. В этом примере хранимая процедура вставляет данные в набор таблиц, использующихся для секционирования данных о продажах по одному году. Для каждого месяца года создается одна таблица следующего формата:
В этом образце хранимая процедура динамически строит и выполняет инструкцию для вставки новых заказов в соответствующую таблицу. В этом примере используется дата заказа для формирования имени таблицы, которая должна содержать данные, затем полученное имя вставляется в инструкцию .
Примечание
Это простой пример использования процедуры sp_executesql. Пример не включает в себя проверку ошибок и бизнес-правил, которые, например гарантируют то, что номера заказов не будут дублироваться в разных таблицах.
Применение процедуры sp_executesql в этом случае более эффективно, чем использование инструкции EXECUTE для выполнения строки. При использовании процедуры sp_executesql формируется только 12 версий инструкции INSERT, по одной для таблицы каждого месяца. При использовании EXECUTE каждая инструкция INSERT должна быть уникальной, так как значения параметров будут различными. И хотя с помощью обоих методов будет создано одинаковое число пакетов, подобие инструкций INSERT, сформированных sp_executesql, увеличивает вероятность того, что оптимизатор запросов повторно использует планы выполнения.
В. Использование параметра OUTPUT
В следующем примере используется параметр для хранения результирующий набор, созданный инструкцией в параметре . Затем выполняются две инструкции, использующие значение параметра .
3.3.4. Функция, возвращающая таблицу
В следующем примере мы создаем функцию, которая будет возвращать в качестве результата таблицу. В качестве примера, создадим функцию, которая будет возвращать таблицу товаров, и для каждой строки рассчитаем произведение колонок количества и цены:
CREATE FUNCTION GetPrice()
RETURNS TABLE
AS
RETURN
(
SELECT Дата, , Цена,
Количество, Цена*Количество AS Сумма
FROM Товары
)
Начало функции такое же, как у скалярной – указываем оператор CREATE FUNCTION и имя функции. Я специально создал эту функцию без параметров, чтобы вы увидели, как это делается. Не смотря на то, что параметров нет, после имени должны идти круглые скобки, в которых не надо ничего писать. Если не указать скобок, то сервер вернет ошибку и функция не будет создана.
Разница есть и в секции RETURNS, после которой указывается тип TABLE, что говорит о необходимости вернуть таблицу. После этого идет ключевое слово AS и RETURN, после которого должно идти возвращаемое значение. Для функции данного типа в секции RETURN нужно в скобках указать запрос, результат которого и будет возвращаться функцией.
Когда пишете запрос, то все его поля должны содержать имена. Если одно из полей не имеет имени, то результатом выполнения оператора CREATE FUNCTION будет ошибка. В нашем примере последнее поле является результатом перемножения полей «Цена» и «Количество», а такие поля не имеют имени, поэтому мы его задаем с помощью ключевого слова AS.
Посмотрим, как можно использовать такую функцию с помощью оператора SELECT:
SELECT * FROM GetPrice()
Так как мы используем простой оператор SELECT, то мы можем и ограничивать вывод определенными строками, с помощью ограничений в секции WHERE. Например, в следующем примере выбираем из результата функции только те строки, в которых поле «Количество» содержит значение 1:
SELECT * FROM GetPrice() WHERE Количество=1
Функция возвращает в качестве результата таблице, которую вы можете использовать как любую другую таблицу базы данных. Давайте создадим пример в котором можно будет увидеть использование функции в связи с таблицами. Для начала создадим функцию, которая будет возвращать идентификатор работников таблицы tbPeoples и объединенные в одно поле ФИО:
CREATE FUNCTION GetPeoples() RETURNS TABLE AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM tbPeoples )
Функция возвращает нам идентификатор строки, с помощью которого мы легко можем связать результат с таблицей телефонов. Попробуем сделать это с помощью простого SQL запроса:
SELECT * FROM GetPeoples() p, tbPhoneNumbers pn WHERE p.idPeoples=pn.idPeoples
Как видите, функции, возвращающие таблицы очень удобны. Они больше, чем процедуры похожи на объекты просмотра, но при этом позволяют принимать параметры. Таким образом, можно сделать так, чтобы сама функция возвращала нам только то, что нужно. Вьюшки такого не могут делать по определению. Чтобы получить нужные данные, вьюшка должна выполнить свой SELECT запрос, а потом уже во внешнем запросе мы пишем еще один оператор SELECT, с помощью которого ограничивается вывод до необходимого. Таким образом, выполняется два запроса SELECT, что для большой таблицы достаточно накладно. Функция же может сразу вернуть только то, что нужно.
Рассмотрим пример, функция GetPeoples у нас возвращает все строки таблицы. Чтобы получить только нужную фамилию, нужно писать запрос типа:
SELECT * FROM GetPeoples() WHERE FIO LIKE 'ПОЧЕЧКИН%'
В этом случае будут выполняться два запроса: этот и еще один внутри функции. Но если передавать фамилию в качестве параметра в функцию и там сделать секцию WHERE, то можно обойтись и одним запросом SELECT:
CREATE FUNCTION GetPeoples1(@Famil varchar(50)) RETURNS TABLE AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM tbPeoples WHERE vcFamil=@Famil )



