Введение в sp_executesql
Вы можете использовать sp_executeslq для выполнения транзакционного SQL, хранящегося в переменной. Форма инструкции:
EXECUTE sp_executesql @statement.
Если вам интересно, sp_executesql — это системная хранимая процедура. Системные хранимые процедуры расширяют язык и предоставляют больше возможностей для использования.
Вот простой пример:
DECLARE @statement NVARCHAR(4000)
SET @statement = N’SELECT getdate()’
EXECUTE sp_executesql @statement
Если вы запустите это в окне запроса, вы получите подобный результат:
2018-01-24 18:49:30.143
Теперь, когда вы поняли, как работает sp_executeslq, давайте перейдем к практике. Предположим, вас попросили написать хранимую процедуру, которая возвращает либо среднее значение LineTotal, либо сумму LineTotal по ProductID для продуктов, отправленных в 2011 году.
Ваше руководство хотело бы, чтобы это было написано как хранимая процедура. Хранимая процедура должна принимать один параметр @ReturnAverage. Если это истинно, то вы вернете среднее значение, в противном случае сумму.
Конечно, вы могли бы написать это в виде двух отдельных запросов, как показано в следующей хранимой процедуре, но это было бы не очень весело, поскольку это предполагало бы слишком много ручного ввода и возможных ошибок.
CREATE PROCEDURE uspCalcuateSalesSummaryStatic
@returnAverage bit
AS
IF (@returnAverage = 1)
BEGIN
SELECT SOD.ProductID,
AVG(SOD.LineTotal) as ResultAvg
FROM Sales.SalesOrderDetail SOD
INNER JOIN Sales.SalesOrderHEader SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
WHERE YEAR(SOH.ShipDate) = 2011
GROUP BY SOD.ProductID
END
ELSE
BEGIN
SELECT SOD.ProductID,
SUM(SOD.LineTotal) as ResultSum
FROM Sales.SalesOrderDetail SOD
INNER JOIN Sales.SalesOrderHEader SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
WHERE YEAR(SOH.ShipDate) = 2011
GROUP BY SOD.ProductID
END
Что здесь является слабым местом, так это много дублированного кода, который я выделил жирным шрифтом. Существует не так много уникального кода, но имеющийся выделен курсивом.
При всей этой избыточности у нас есть прекрасная возможность продемонстрировать некоторый динамический SQL. Давайте сделаем это!
CREATE PROCEDURE uspCalcuateSalesSummaryDynamic
@returnAverage bit
AS
DECLARE @statement NVARCHAR(4000),
@function NVARCHAR(10)
IF (@returnAverage = 1) SET @function = ‘Avg’
ELSE SET @function = ‘Sum’
SET @statement =
‘SELECT SOD.ProductID,’ +
@function + + ‘(SOD.LineTotal) as Result’ + @function + ‘
FROM Sales.SalesOrderDetail SOD
INNER JOIN Sales.SalesOrderHEader SOH
ON SOH.SalesOrderID = SOD.SalesOrderID




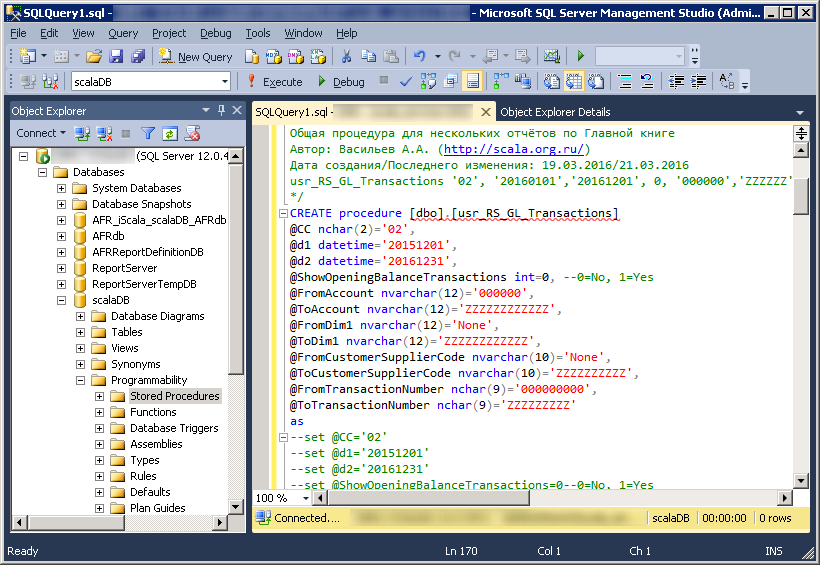
WHERE YEAR(SOH.ShipDate) = 2011
GROUP BY SOD.ProductID’
EXECUTE sp_executesql @statement
Здесь вместо двух полных версий SQL, один для AVG, другой для SUM, мы создаем запрошенную версию «на лету».
SQL построен и сохраняется в переменной @statement. Эта переменная построена на основе значения параметра @returnAverage. Если установлено значение 1, то @function представляет Среднее; в противном случае — Суммирование.
Шаг 5: Структуры управления потоками
MySQL поддерживает конструкции IF, CASE, ITERATE, LEAVE LOOP, WHILE и REPEAT для управления потоками в пределах хранимой процедуры. Мы рассмотрим, как использовать IF, CASE и WHILE, так как они наиболее часто используются.
Конструкция IF
С помощью конструкции IF, мы можем выполнять задачи, содержащие условия:
DELIMITER //
CREATE PROCEDURE `proc_IF` (IN param1 INT)
BEGIN
DECLARE variable1 INT;
SET variable1 = param1 + 1;
IF variable1 = 0 THEN
SELECT variable1;
END IF;
IF param1 = 0 THEN
SELECT 'Parameter value = 0';
ELSE
SELECT 'Parameter value <> 0';
END IF;
END //
Конструкция CASE
CASE — это еще один метод проверки условий и выбора подходящего решения. Это отличный способ замены множества конструкций IF. Конструкцию можно описать двумя способами, предоставляя гибкость в управлении множеством условных выражений.
DELIMITER //
CREATE PROCEDURE `proc_CASE` (IN param1 INT)
BEGIN
DECLARE variable1 INT;
SET variable1 = param1 + 1;
CASE variable1
WHEN 0 THEN
INSERT INTO table1 VALUES (param1);
WHEN 1 THEN
INSERT INTO table1 VALUES (variable1);
ELSE
INSERT INTO table1 VALUES (99);
END CASE;
END //
или:
DELIMITER //
CREATE PROCEDURE `proc_CASE` (IN param1 INT)
BEGIN
DECLARE variable1 INT;
SET variable1 = param1 + 1;
CASE
WHEN variable1 = 0 THEN
INSERT INTO table1 VALUES (param1);
WHEN variable1 = 1 THEN
INSERT INTO table1 VALUES (variable1);
ELSE
INSERT INTO table1 VALUES (99);
END CASE;
END //
Конструкция WHILE
Технически, существует три вида циклов: цикл WHILE, цикл LOOP и цикл REPEAT. Вы также можете организовать цикл с помощью техники программирования “Дарта Вейдера”: выражения GOTO. Вот пример цикла:
DELIMITER //
CREATE PROCEDURE `proc_WHILE` (IN param1 INT)
BEGIN
DECLARE variable1, variable2 INT;
SET variable1 = 0;
WHILE variable1 < param1 DO
INSERT INTO table1 VALUES (param1);
SELECT COUNT(*) INTO variable2 FROM table1;
SET variable1 = variable1 + 1;
END WHILE;
END //
Шаг 6: Курсоры
Курсоры используются для прохождения по набору строк, возвращенному запросом, а также обработки каждой строки.
MySQL поддерживает курсоры в хранимых процедурах. Вот краткий синтаксис создания и использования курсора.
DECLARE cursor-name CURSOR FOR SELECT ...; /*Объявление курсора и его заполнение */ DECLARE CONTINUE HANDLER FOR NOT FOUND /*Что делать, когда больше нет записей*/ OPEN cursor-name; /*Открыть курсор*/ FETCH cursor-name INTO variable ; /*Назначить значение переменной, равной текущему значению столбца*/ CLOSE cursor-name; /*Закрыть курсор*/
В этом примере мы проведем кое-какие простые операции с использованием курсора:
DELIMITER //
CREATE PROCEDURE `proc_CURSOR` (OUT param1 INT)
BEGIN
DECLARE a, b, c INT;
DECLARE cur1 CURSOR FOR SELECT col1 FROM table1;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET b = 1;
OPEN cur1;
SET b = 0;
SET c = 0;
WHILE b = 0 DO
FETCH cur1 INTO a;
IF b = 0 THEN
SET c = c + a;
END IF;
END WHILE;
CLOSE cur1;
SET param1 = c;
END //
У курсоров есть три свойства, которые вам необходимо понять, чтобы избежать получения неожиданных результатов:
- Не чувствительный: открывшийся однажды курсор не будет отображать изменения в таблице, происшедшие позже. В действительности, MySQL не гарантирует то, что курсор обновится, так что не надейтесь на это.
- Доступен только для чтения: курсоры нельзя изменять.
- Без перемотки: курсор способен проходить только в одном направлении — вперед, вы не сможете пропускать строки, не выбирая их.
Переходим к делу
Для примера возьмем задачу по автоматизации отчета по эффективности контекстной рекламы.
К данному отчету заказчиком предъявляются следующие требования:
- Отчет должен содержать исторические данные по вчерашний день;
- Отчет должен обновляться ежедневно в автоматизированном режиме;
- Помимо Power BI, должна быть возможность подключения к отчету через Excel.
Также отчет должен содержать следующие параметры и показатели:
- Дата;
- Источник/Канал
- Кампания
- Сумма расходов;
- Кол-во показов;
- Кол-во кликов;
- Кол-во сеансов;
- Кол-во заказов;
- Доход;
- Рассчитываемые показатели — CPC, CR и ROMI.
Естественно, все данные должны быть предварительно загружены в хранилище, но это тема отдельного поста и обычно этим занимаются data-инженеры. Мы же с вами аналитики и используем те данные, которые для нас любезно сложили в DWH (хранилище данных).
В моем случае DWH работает на базе MS SQL Server и содержит следующие таблицы:
- sessions — данные из Google Analytics загруженные посредством коннектора к Reporting API v4;
- costs — данные по расходам, предварительно загруженные в Google Analytics;
- orders — данные по заказам и доходу из внутренней CRM-системы.
Для работы нам потребуется установить:
- SQL Server Management Studio — для подключения к DWH;
- Power BI Desktop — для создания отчета.
Опущу совсем уж базовые вещи, такие как регистрация аккаунтов и установка программ, с этим вы без проблем справитесь и сами.
Почему именно эти технологии?
За время работы аналитиком, я перепробовал различные варианты сбора отчетности. Начиная с ручной выгрузки данных из кабинетов рекламных систем, с последующим сведением в Excel, и заканчивая созданием специальных отчетов в Google Analytics или дашбордов в Data Studio.
Но ни один из вариантов не был идеальным и каждый имел свои недостатки. Все изменилось, когда я открыл для себя Power BI.
Microsoft Power BI — это один из самых технологичных на данный момент инструментов по визуализации данных, обладающий большим набором коннекторов к различным системам.
Но и Power BI сам по себе не идеален и без грамотного использования будет работать медленно и неэффективно. Приведу два примера:
- Если вы попытаетесь собрать модель данных из различных источников, с большим количеством связей и рассчитываемых показателей на стороне Power BI, то отчет будет жутко тормозить, а ведь именно таким принципам работы учит большое количество курсов по данному инструменту.
- Еще пример, если вы пытаетесь загрузить в модель данные из Google Analytics при помощи встроенного коннектора, то столкнетесь как минимум с двумя проблемами — ограничениями API GA и долгой выгрузкой данных.
Вышеописанные проблемы привели меня к мысли о загрузке всех данных сначала в базу, моделировании отчета при помощи SQL и только потом их визуализации в Power BI.
Обновление статистик
MS SQL Server строит план запроса на основании статистической информации о распределении значений в индексах и таблицах. Статистическая информация собирается на основании части (образца) данных и автоматически обновляется при изменении этих данных. Иногда этого оказывается недостаточно для того, что MS SQL Server стабильно строил наиболее оптимальный план выполнения всех запросов.
В этом случае возможно проявление проблем с производительностью запросов. При этом в планах запросов наблюдаются характерные признаки неоптимальной работы (неоптимальные операции).
Для того, чтобы гарантировать максимально правильную работу оптимизатора MS SQL Server рекомендуется регулярно обновлять статистики базы данных MS SQL.
Для обновления статистик по всем таблицам базы данных необходимо выполнить следующий SQL запрос:
exec sp_msforeachtable N'UPDATE STATISTICS ? WITH FULLSCAN'
Обновление статистик не приводит к блокировке таблиц, и не будет мешать работе других пользователей. Статистика может обновляться настолько часто, насколько это необходимо. Следует учитывать, что нагрузка на сервер СУБД во время обновления статистик возрастет, что может негативно сказаться на общей производительности системы.
Оптимальная частота обновления статистик зависит от величины и характера нагрузки на систему и определяется экспериментальным путем. Рекомендуется обновлять статистики не реже одного раза в день.
Приведенный выше запрос обновляет статистики для всех таблиц базы данных. В реально работающей системе разные таблицы требуют различной частоты обновления статистик. Путем анализа планов запроса можно установить, какие таблицы больше других нуждаются в частом обновлении статистик, и настроить две (или более) различных регламентных процедуры: для часто обновляемых таблиц и для всех остальных таблиц. Такой подход позволит существенно снизить время обновления статистик и влияние процесса обновления статистики на работу системы в целом.
Настройка автоматического обновления статистик (MS SQL 2005)
Запустите MS SQL Server Management Studio и подключитесь к серверу СУБД. Откройте папку Management и создайте новый план обслуживания:

Создайте субплан (Add Subplan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:
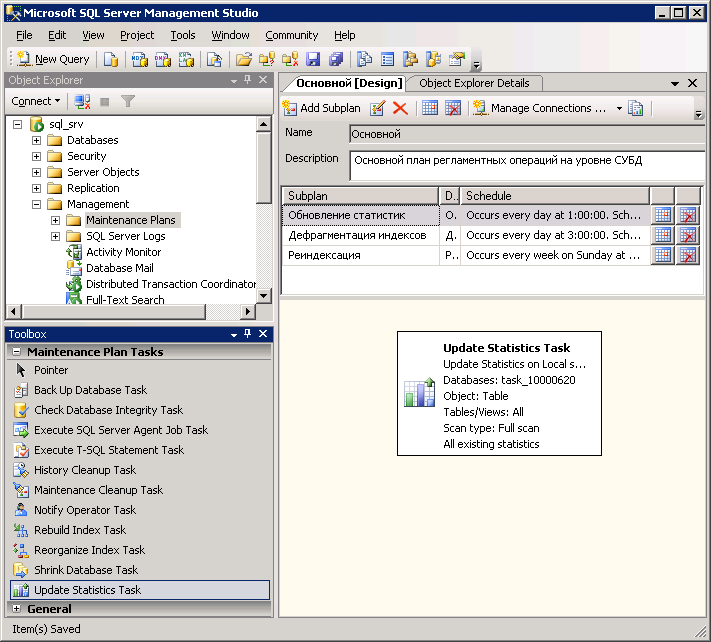
Настройте расписание обновления статистик. Рекомендуется обновлять статистики не реже одного раза в день. При необходимости частота обновления статистик может быть увеличена.
Настройте параметры задачи. Для этого следует два раза кликнуть на задачу в правом нижнем углу окна. В появившейся форме укажите имя базу данных (или несколько баз данных) для которых будет выполняться обновление статистик. Кроме этого вы можете указать для каких таблиц обновлять статистики (если точно неизвестно, какие таблицы требуется указать, то устанавливайте значение All).
Обновление статистик необходимо проводить с включенной опцией Full Scan.

Сохраните созданный план. При наступлении указанного в расписании срока обновление статистик будет запущено автоматически.
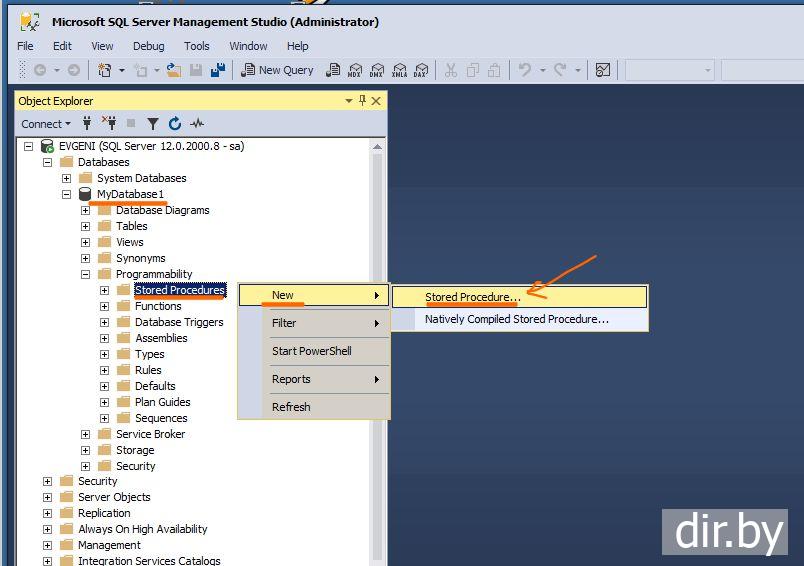

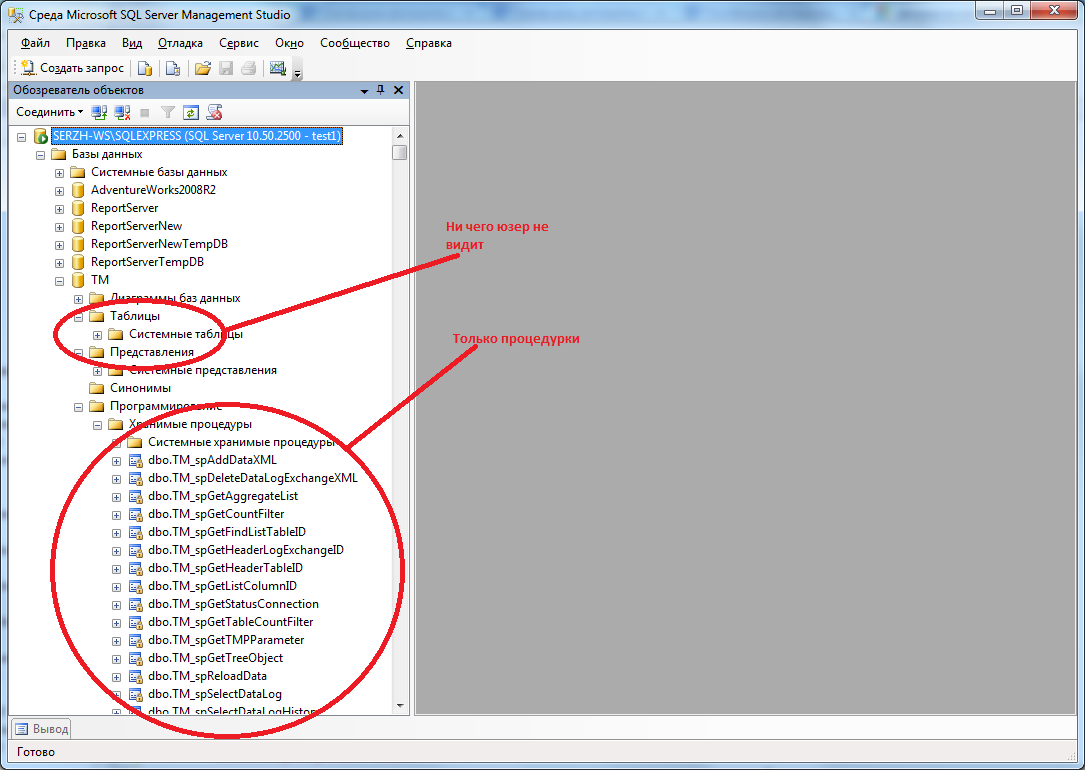


Типы хранимых процедур
Системные хранимые процедуры предназначены для выполнения раз-
личных административных действий. Практически все действия по адми-
нистрированию сервера выполняются с их помощью. Можно сказать, что
системные хранимые процедуры являются интерфейсом, обеспечивающим
работу с системными таблицами. Системные хранимые процедуры имеют
префикс sp_, хранятся в системной базе данных и могут быть вызваны в
контексте любой другой базы данных.
Пользовательские хранимые процедуры реализуют те или иные дейст-
вия. Хранимые процедуры – полноценный объект базы данных. Вследствие
этого каждая хранимая процедура располагается в конкретной базе дан-
ных, где и выполняется.
Временные хранимые процедуры существуют лишь некоторое время,
после чего автоматически уничтожаются сервером. Они делятся на ло-
кальные и глобальные. Локальные временные хранимые процедуры могут
быть вызваны только из того соединения, в котором созданы. При созда-
нии такой процедуры ей необходимо дать имя, начинающееся с одного
символа #. Как и все временные объекты, хранимые процедуры этого типа
автоматически удаляются при отключении пользователя, перезапуске или
остановке сервера. Глобальные временные хранимые процедуры доступны
для любых соединений сервера, на котором имеется такая же процедура.
Для ее определения достаточно дать ей имя, начинающееся с символов ##.
Удаляются эти процедуры при перезапуске или остановке сервера, а также
при закрытии соединения, в контексте которого они были созданы.
3.3.6. Опции функций
При создании функций могут использоваться следующие опции SCHEMABINDING (привязать к схеме) и/или ENCRYPTION (шифровать текст функции). Если вторая опция нам уже известна по вьюшкам и процедурам (позволяет шифровать исходный код функции в системных таблицах), то вторая встречается впервые, но при этом предоставляет удобное средство защиты данных.
Если функция создана с опцией SCHEMABINDING, то объекты базы данных, на которые ссылается функция, не могут быть изменены (с использованием оператора ALTER) или удалены (с помощью оператора DROP). Например, следующая функция использует таблицу tbPeoples и при этом используется опция SCHEMABINDING:
CREATE FUNCTION GetPeoples2(@Famil varchar(50)) RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM dbo.tbPeoples WHERE vcFamil=@Famil )
Функция может быть связанной со схемой, только если следующие ограничения истины:
- все функции объявленные пользователем и просмотрщики на которые ссылается функция, также связаны со схемой с помощью опции SCHEMABINDING;
- объекты, на которые ссылается функция, должны использовать имя из двух частей именования: owner.objectname. При создании функции GetPeoples2 ссылка на таблицу указана именно в таком формате – dbo.tbPeoples;
- Функция и объекты должны быть расположены в одной базе данных;
- Пользователь, который создает функцию, имеет право доступа ко всем объектам, на которые ссылается функция.
Создайте функцию и попробуйте после этого удалить таблицу tbPeoples.
DROP TABLE tbPeoples
В ответ на это сервер выдаст сообщение с ошибкой о том, что объект не может быть удален, из-за присутствия внешнего ключа. Даже если избавиться от ключа, удаление будет невозможно, потому что на таблицу ссылается функция, привязанная к схеме.
Чтобы увидеть сообщение без удаления ключа, давайте добавим к таблице колонку, а потом попробуем ее удалить:
-- Добавим колонку ALTER TABLE dbo.tbPeoples ADD vcTemp VARCHAR(30) NOT NULL default '' -- Попробуем ее удалить ALTER TABLE dbo.tbPeoples DROP COLUMN vcTemp
Создание пройдет успешно, а вот во время удаления произойдет ошибка, с сообщением о том, что существует ограничение, которое зависит от колонки. Мы же не создавали никаких ограничений, а просто добавили колонку и попытались ее удалить. Ограничение уже давно существует, но не на отдельную колонку, а на все колонки таблицы и это ограничение создано функцией GetPeoples2, которая связана со схемой.
SQL Server select from stored procedure return table
Now in this section, we will try to understand how to select some data from a table returned using stored procedure.
A stored procedure in SQL Server does not return a table directly neither we can directly select data from a stored procedure. But, for this implementation, we can use a SELECT statement within a stored procedure to return table data, and then we can use table variables to store the data returned from a stored procedure. After this, we can select data from a table variable.
Now for demonstration, consider the following code given below, used to create a stored procedure.
In the query, first, we are using the IF block to check whether the procedure name is not used. After this, we are creating a procedure with the name “TableRetuen” and in the procedure, we are using the SELECT statement to return 3 columns from the sample table.
Next, we are going to execute the following query given below.
In the above example, first, we are creating a table variable and inserting values in the table variable using a stored procedure. After this, we are using the SELECT statement to select values inserted in the table variable.
After executing the above-mentioned example, we will get the following result-set as an output.
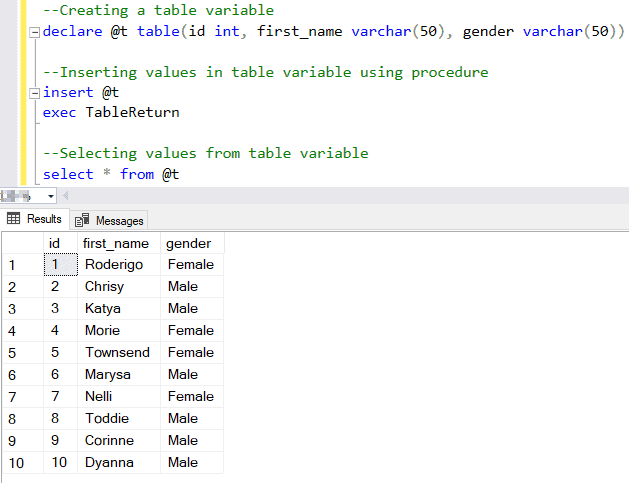
Final Output
Read SQL Server stored procedure output parameter
Сохранение результатов с заголовками в Sql Server Management Studio
Я выбираю «сохранить как», а затем сохраняю в файл CSV, который можно открыть в Excel. Все хорошо, за исключением того, что мне не хватает заголовков столбцов, есть идеи, как их экспортировать?
10 ответов
Tools > Options > Query Results > SQL Server > Results to Text (or Grid if you want) > Include columns headers in the result set
После изменения этого параметра вам может потребоваться закрыть и снова открыть SSMS.
На панели инструментов редактора SQL вы можете выбрать сохранение в файл без перезапуска SSMS
Я тоже сталкиваюсь с той же проблемой. Когда я использовал правый щелчок в окне запроса и выбрал Параметры запроса. Но строки заголовка не отображаются в выходном CSV-файле.
Затем я выхожу из сервера, снова вхожу в систему и запускаю сценарий. Тогда это сработало.
В SQL Server 2014 Management Studio этот параметр находится по адресу:
Инструменты> Параметры> Результаты запроса> SQL Server> Результаты в текст> Включить заголовки столбцов в набор результатов.
Попал сюда, когда искал способ заставить SSMS правильно экранировать разделители CSV при экспорте результатов.
Угадай, что? — это действительно опция, и она не отмечена по умолчанию . Таким образом, по умолчанию вы получаете битые CSV-файлы (и можете даже не осознавать этого, особенно если ваш экспорт большой и ваши данные обычно не содержат запятых) — и вам нужно войти и установить флажок, чтобы ваши CSV-файлы экспортировались правильно!
Мне это кажется монументально глупым дизайнерским выбором и подходящей метафорой подхода Microsoft к программному обеспечению в целом («сломано по умолчанию, требует бессмысленных ритуальных действий, чтобы заставить тривиальную функциональность работать»).
Но я с радостью пожертвую 100 долларов в благотворительную организацию по выбору респондента, если кто-нибудь может назвать мне одну действительную реальную причину существования этого варианта (то есть реальный сценарий, в котором он был полезен).
Параметры, которые было рекомендовано изменить в принятом ответе @Diego, могут быть хорошими, если вы хотите установить этот параметр постоянно для всех будущих сеансов запросов, которые вы открываете в SQL Server Management Studio (SSMS). Обычно это не . Кроме того, изменение этого параметра требует перезапуска приложения SQL Server Management Studio (SSMS). Это снова «не очень приятный» опыт, если у вас много несохраненных открытых окон сеанса запросов и вы находитесь в процессе некоторой отладки.
SQL Server предоставляет очень удобную возможность изменять его для каждого сеанса, что очень быстро, удобно и удобно . Я подробно описываю шаги ниже, используя окно параметров запроса:
- Щелкните правой кнопкой мыши в окне редактора запросов> щелкните Query Options. в нижней части контекстного меню, как показано ниже:

- Выберите Results > Grid на левой панели навигации. Установите флажок Include column headers when copying or saving the results на правой панели, как показано ниже:

Вот и все. В текущем сеансе ваши настройки сразу же вступят в силу без перезапуска SSMS. Кроме того, этот параметр не будет распространен на любой будущий сеанс. Эффективное изменение этого параметра для каждого сеанса гораздо менее шумно.
Выберите результаты, щелкнув в верхнем левом углу, щелкните правой кнопкой мыши и выберите «Копировать с заголовками». Вставить в Excel. Готово!
Та же проблема существует в Visual Studio, вот как ее исправить:
Теперь установите флажок в значение true: «Включить заголовки столбцов при копировании или сохранении результатов».
По крайней мере, в SQL Server 2012 вы можете щелкнуть правой кнопкой мыши в окне запроса и выбрать Параметры запроса. Оттуда вы можете выбрать Включить заголовки для сетки и / или текста, и сохранить как нужно работать так, как вы хотите, без перезапуска SSMS.
Вам все равно нужно будет изменить его в Инструменты-> Параметры в строке меню, чтобы новые окна запросов использовали эти настройки по умолчанию.
Другая возможность — использовать буфер обмена для копирования и вставки результатов непосредственно в Excel. Просто будьте осторожны со столбцами Excel общего типа, поскольку иногда они могут давать непредсказуемые результаты в зависимости от ваших данных. CTL-A в любом месте таблицы результатов, а затем щелкните правой кнопкой мыши:





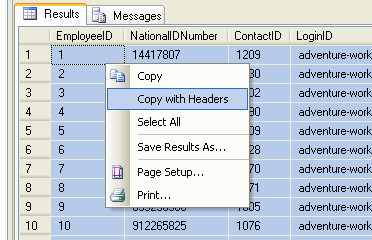
Если у вас возникли проблемы с общим форматом Excel при выполнении нежелательных преобразований, выберите пустые столбцы в Excel перед вставкой и измените формат на «текст».
Попробуйте Мастер экспорта. В этом примере я выбираю всю таблицу, но вы можете так же легко указать запрос:
Выводы
Есть много других способов экспортировать результаты. Однако эти параметры вдохновят вас на использование других.
В заключение, вот несколько советов о том, когда их использовать:
1. Назначение SSMS для файла вариант – это самый простой вариант. Используется, если вам не нужно ничего автоматизировать и вы сразу получаете только один текстовый отчет.
2. SQLCMD – используйте его, когда у вас есть командный файл или если вы используете командную строку для автоматизации нескольких задания.
3. PowerShell – используйте его, когда вы автоматизируете задачи с помощью PowerShell или когда используете инструменты для вызова сценариев PowerShell.
4. Мастер импорта/экспорта в SSMS – используйте его, когда у вас есть миллионы строк для копирования файлы. Это очень быстрый вариант, специализирующийся на экспорте и импорте данных из нескольких источников.
5. Мастер SSIS (почти такой же, как номер 4, но мы используем SSDT вместо SSMS для создания пакета. ). Он похож на 4, но его можно настроить, и вы можете создавать действительно сложные пакеты, интегрированные с веб-службами, отправлять почту, PowerShell и многое другое. Используйте его, если вам нужно сложное решение, требующее интеграции между несколькими инструментами.
6. C # – используйте его, когда у вас есть код для других задач и вам необходимо интегрироваться с другими строками кода на C #.
7. SSRS – SSRS полезен для создания красивого настраиваемого отчета. Используйте его, когда презентация важна.
8. BCP – это очень быстрый вариант. Используйте его для больших объемов данных.
Ссылки
- Задача сценария SSIS
- Руководства по службам Reporting Services
- Решения PowerShell – несколько советов для повседневных задач