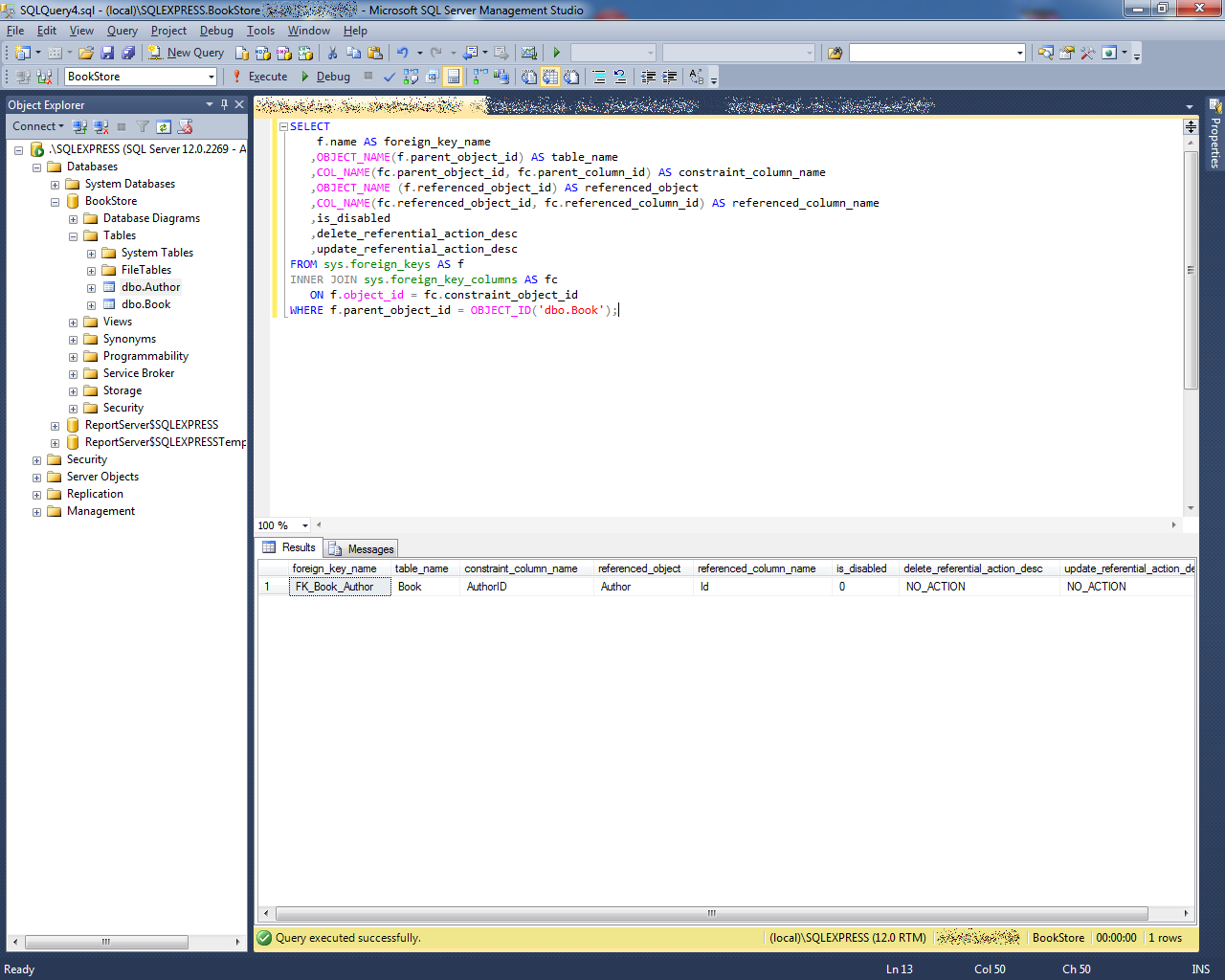
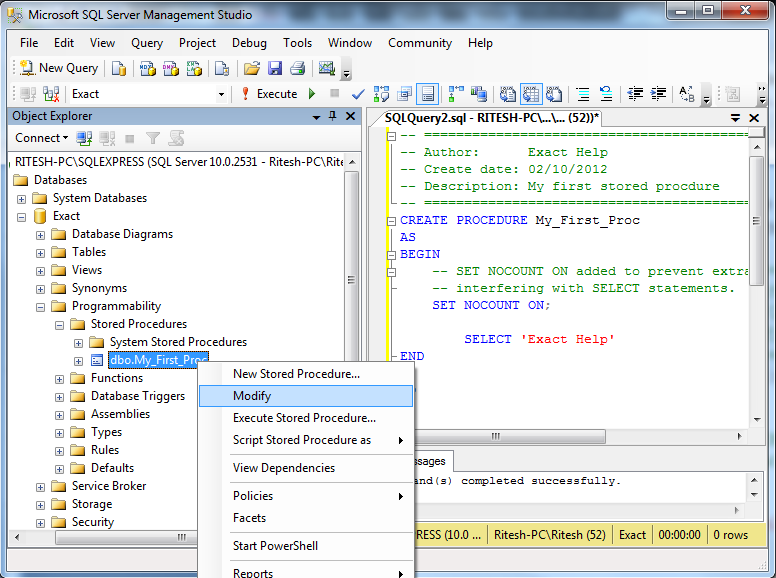
ТОП 10 популярных хинтов
Давайте рассмотрим 10 популярных хинтов, которые чаще других можно встретить в production, и которые мы чаще используем для Ad Hoc запросов.
NOLOCK
Данный хинт разрешает «грязное чтение». Поведение становится похоже на уровень изоляции READ UNCOMMITTED. Хинт NOLOCK равнозначен хинту READUNCOMMITTED.
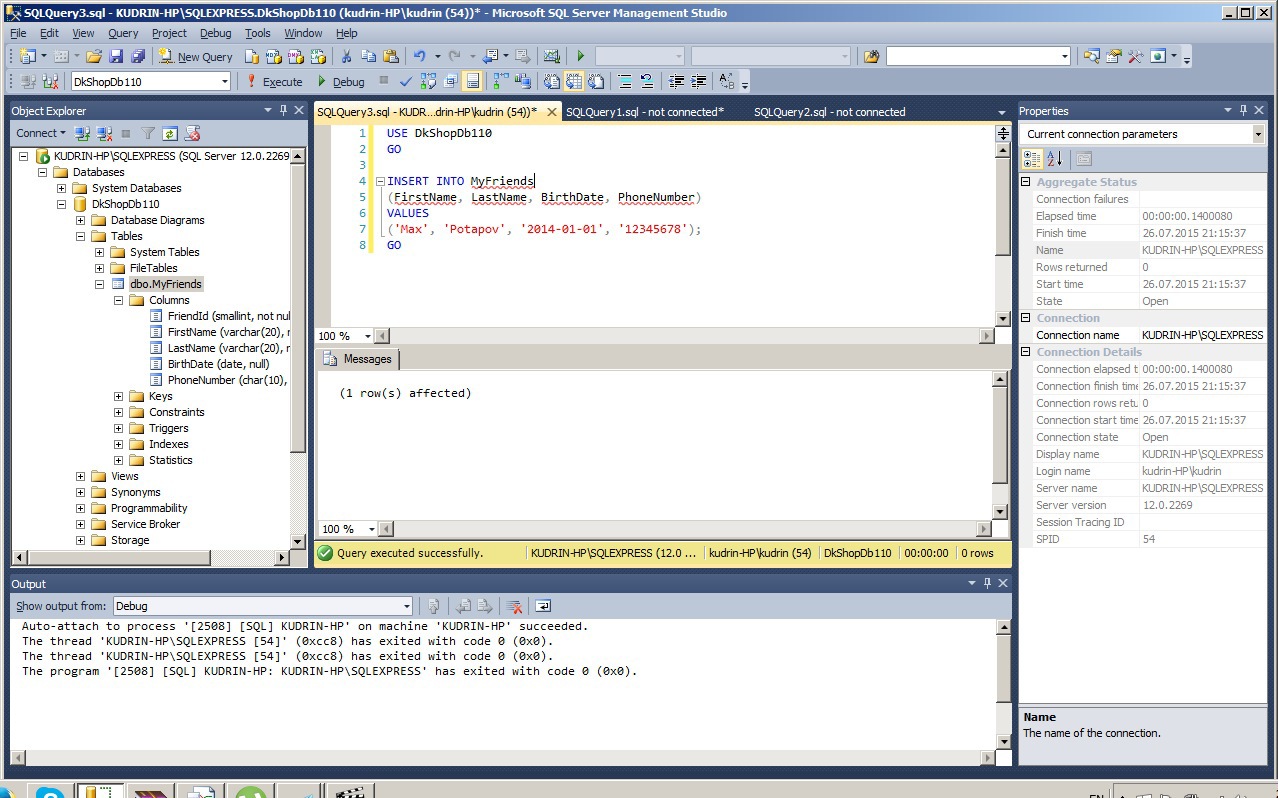
Этот хинт очень часто встречается в аналитических системах или в процедурах, которые выполняют какие-то аналитические действия, с целью ускорения выборок, т.е. ускорения получения данных. При этом, как Вы понимаете, актуальность данных с точностью до секунд не так важна.
NOEXPAND
Этот хинт указывает, что при обработке запроса индексированное представление не расширяется для доступа к базовым таблицам. Оптимизатор запросов обрабатывает представление так же, как и таблицу с кластеризованным индексом.
Хинт NOEXPAND применяется также с целью ускорения выборки данных.
RECOMPILE
Данный параметр указывает SQL Server, что план выполнения запроса должен строиться каждый раз при запуске этого запроса.
Этот хинт применяется в тех случаях, когда в кэше находится план запроса, неподходящий для текущих параметров или данных.
RECOMPILE создает определенную нагрузку на процессор и в случае высоконагруженных систем может значительно нагрузить сервер, поэтому желательно находить другие варианты оптимизации.
OPTIMIZE FOR
Данный хинт указывает оптимизатору запросов, что при компиляции и оптимизации запросов нужно использовать конкретное значение для локальной переменной. Значение используется только в процессе оптимизации запроса, но не в процессе выполнения.
Данный хинт часто используют, когда сталкиваются с проблемой «Parameter sniffing», чтобы оптимизировать процедуру под конкретное значение параметра или в случае OPTIMIZE FOR UNKNOWN под среднее значение.
TABLOCK
Данный хинт указывает оптимизатору, что полученная блокировка применяется на уровне таблицы.
Хинт TABLOCK часто можно встретить в инструкциях по массовой вставке данных в таблицу (INSERT), так как это позволяет оптимизировать и, как следствие, ускорить процесс вставки данных.
ROWLOCK
Этот хинт указывает, что вместо блокировки страниц или таблиц применяются блокировки на уровне строк.
Данный хинт можно встреть в инструкциях обновления данных (UPDATE), его часто применяют с целью снижения гранулярности блокировки, что в теории способствует ускорению инструкции.
READPAST
Хинт указывает SQL Server, что не нужно считывать строки, которые заблокированы другими транзакциями. Иными словами, если указан хинт READPAST, блокировки уровня строк будут пропускаться, т.е. SQL Server будет пропускать строки вместо блокировки текущей транзакции до тех пор, пока блокировки не будут сняты.
Данный хинт часто используется для устранения конфликта блокировок при реализации какой-либо очереди, использующей таблицу SQL Server, т.е. когда записи в таблице периодически обрабатываются и пропуск некоторых записей неважен, так как они могут попасть в следующей поток обработки.
MAXDOP
Хинт переопределяет параметр конфигурации, задающий максимальный уровень параллелизма.
MAXDOP можно часто встретить в запросах с целью отключения параллелизма (MAXDOP 1).
INDEX
Этот хинт указывает индекс, который будет принудительно использован оптимизатором запросов при обработке инструкции, иными словами, фактически мы привязываем индекс к запросу.
INDEX используют для того, чтобы SQL Server всегда применял один и тот же индекс при построении плана запроса.
Однако, как уже было отмечено, со временем индекс может стать неэффективным, поэтому периодически необходимо проверять запросы с хинтом INDEX на предмет их производительности, т.е. этот индекс еще эффективен или нет.
FORCE ORDER
Данный хинт указывает, что при оптимизации запроса сохраняется порядок соединения, заданный синтаксисом запроса.
FORCE ORDER часто используется в запросах, когда SQL Server по каким-либо причинам применяет не тот порядок соединения, который был бы самым эффективным.
А сегодня это все, пока!
Нравится11Не нравится
ограничения
Для переменных Table не предусмотрена статистика распределения. Они не будут вызывать перекомпиляцию. Во многих случаях оптимизатор строит план запроса на предположении, что у табличной переменной нет строк
По этой причине следует проявлять осторожность относительно использования табличной переменной, если ожидается большое число строк (больше 100). В этом случае временные таблицы могут быть предпочтительным решением. Для запросов, которые объединяют табличную переменную с другими таблицами, используйте указание RECOMPILE, чтобы оптимизатор использовал правильную кратность для табличной переменной
Для запросов, которые объединяют табличную переменную с другими таблицами, используйте указание RECOMPILE, чтобы оптимизатор использовал правильную кратность для табличной переменной.
Переменные table не поддерживаются в модели выбора на основе затрат оптимизатора SQL Server. Поэтому их не нужно использовать, если требуется принять решение на основе затрат, чтобы получить эффективный план запроса. Временные таблицы являются предпочтительными при необходимости осуществления выбора с учетом затрат. Этот план обычно включает запросы с соединениями, решения в отношении параллелизма и варианты выбора индекса.
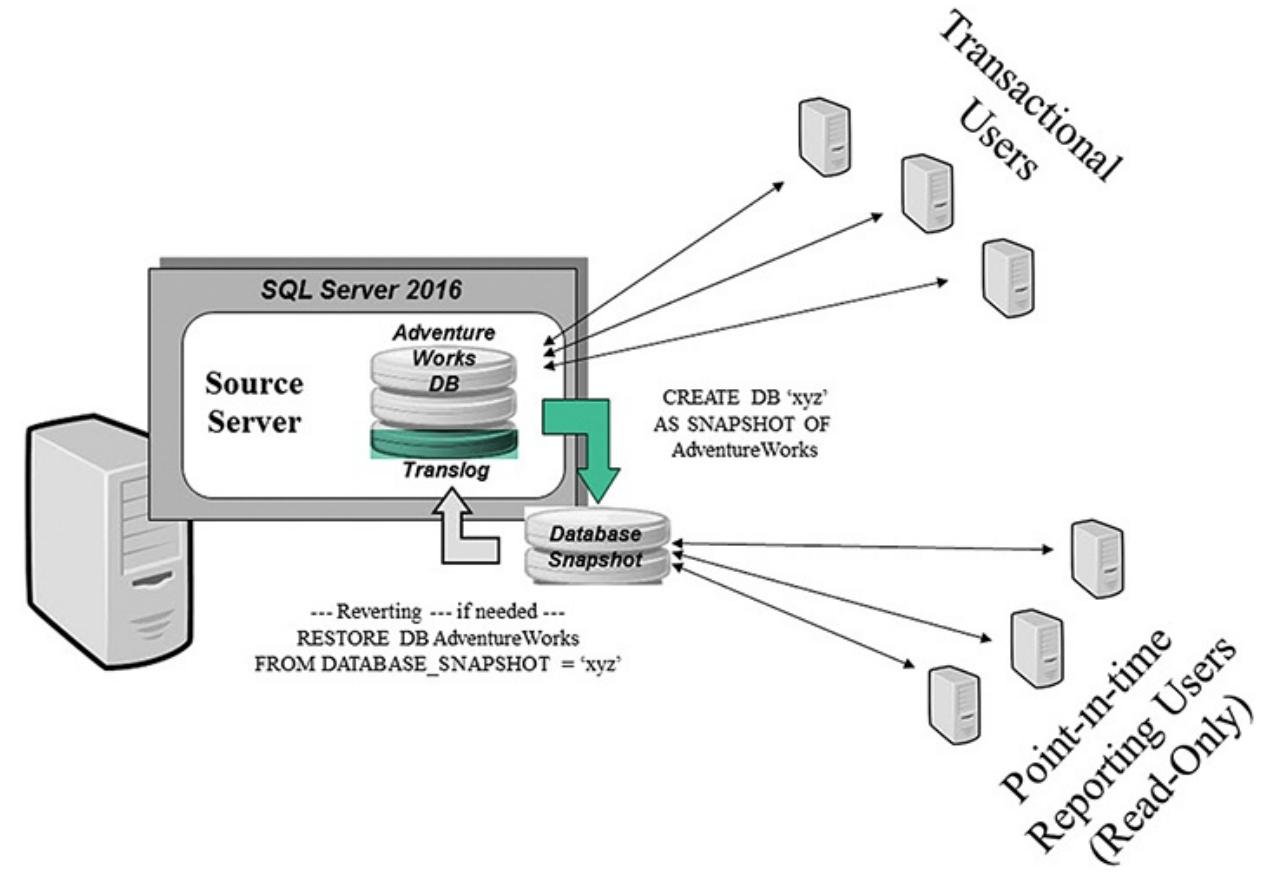

Запросы, изменяющие переменные table, не создают параллельных планов выполнения запроса. При изменении больших переменных table или переменных table в сложных запросах может снизиться производительность. В ситуациях с изменением переменных table мы рекомендуем использовать временные таблицы. Дополнительные сведения см. в разделе CREATE TABLE (Transact-SQL). Запросы, которые считывают переменные table, не изменяя их, могут выполняться параллельно.
Важно!
Уровень совместимости базы данных 150 повышает производительность табличных переменных с введением отложенной компиляции табличных переменных. См. дополнительные сведения об .
Для переменных table нельзя явно создавать индексы, при этом статистика для переменных table не сохраняется. Начиная с SQL Server 2014 (12.x), реализован новый синтаксис, который позволяет создавать определенные встроенные типы индекса с использованием определения таблицы. С помощью этого нового синтаксиса можно создавать индексы в переменной table как часть определения таблицы. В некоторых случаях можно добиться повышения производительности за счет использования временных таблиц, которые позволяют работать с индексами и статистикой. Дополнительные сведения о временных таблицах и создании встроенных индексов см. в руководстве по использованию CREATE TABLE (Transact-SQL).
Ограничения CHECK, значения DEFAULT и вычисляемые столбцы в объявлении типа table не могут вызывать определяемые пользователем функции.
Операция присвоения между переменными table не поддерживается.
Так как переменные table имеют ограниченную область действия и не являются частью постоянной базы данных, они не изменяются при откатах транзакций.
Табличные переменные нельзя изменить после их создания.
Структура
Все индексы имеют одинаковую структуру (structure). Они состоят из:
- наборов страниц;
- узлов, имеющих древовидную структуру, иерархическую по природе.
Все они хранятся в виде сбалансированных B-деревьев (B-tree). Начало такого дерева расположено в корневом узле (находящимся на вершине иерархии) и по сути является «входной дверью». Этот узел имеет одну страницу, в которой содержатся указатели на ключи последующих уровней.
В нижней части иерархии расположены листья дерева (являющиеся конечными узлами). Длины веток одинаковы.
В таком дереве сбалансирована каждая ветка. Благодаря внутреннему механизму при любых изменениях в таблице дерево снова становится сбалансированным.
При формировании запроса к индексированному столбцу подсистема начинает процесс поиска с верхнего узла к нижним, проходя промежуточные и обрабатывая их. На каждом уровне располагается все более развернутая информация о запрашиваемых данных. Как только достигается нижний уровень листьев (leaf level) поиск прекращается, т.к. подсистема запросов находит необходимое значение.
Как работать с Data Collector
Убедитесь, что SQL Server Integration Services установлен, а SQL Server Agent, Management Data Warehouse и Data Collection включены.
- В Object Explorer среды SQL Server Management Studio раскройте папку Management.
- В контекстном меню Data Collection выберите Configure Management Data Warehouse.
-
Укажите Set up data collection.
-
Нажмите далее (Next).
-
Выберите имя экземпляра SQL Server и базу данных, где будет размещаться хранилище данных управления, и локальную папку, где будет храниться кэш собранных данных.
-
Нажмите Next, проверьте все параметры и затем Finish.
Data Collection имеет три предустановленных набора мониторинга в папке System Data Collection Sets (Object Explorer -> Management -> Data Collection): Disk Usage, Query Statistics и Server Activity. Кроме того, они имеют встроенные отчёты.
Набор Disk Usage показывает информацию по файлам данных (MDF и NDF) и файлам лога транзакций (LDF). Статистику ввода/вывода.
В контекстном меню Data Collection имеется отчёт Disk Usage built-in, который показывает размер файлов, их прирост, в том числе и ежедневный.
Набор Query Statistics показывает статистику, активность и планы 10 самых «тяжёлых» запросов.
Набор Server Activity показывает общую нагрузку на процессор, память, сеть и дисковую подсистему. В отчётах можно увидеть активность экземпляра SQL Server и операционной системы, ЦПУ, память, сеть, ввод\вывод.
Data Collection мощный инструмент, который необходимо сконфигурировать, прежде чем начать использовать. Он имеет три встроенных набора для мониторинга и адекватные отчёты. К сожалению, нет мастера для настройки своих показателей мониторинга и это необходимо делать с помощью кода.

Ещё одним преимуществом инструмента является то, что он не нагружает систему постоянно, а сбор данных осуществляет по указанному расписанию. В качестве недостатка стоит отменить отсутствие фильтра по БД. К сожалению, статистика собирается сразу со всех баз данных, а это лишняя информация, дополнительная нагрузка на сервер и потребность в дополнительном дисковом пространстве.
Функционал не поддерживается в версиях SQL Server ниже 2008-ого. И присутствует только в редакциях Enterprise, Standard, Business Intelligence, и Web.
В отличие от Activity Monitor, нет возможности просматривать графики в реальном времени, но собранная информация может храниться на протяжении нескольких дней. В базовом наборе представлены только основные показатели, а для расширения необходимы знания средств разработки.
Полезные ресурсы:Activity MonitorData CollectionMonitoring SQL Server Performance
Как написать курсор в SQL Server
Объявите ваши переменные (для имен файлов, имен баз данных, номеров счетов и т.д.), которые вам нужны для реализации логики, и присвойте им начальные значения. Эта логика будет меняться в зависимости от задачи.
Объявите курсор с конкретным именем (как db_cursor в этом примере), которое вы будете использовать на протяжении всей логики вместе с бизнес-логикой (оператор SELECT) для наполнения курсора требуемыми записями. Имя курсора может быть осмысленным. Сразу после этого следует открытие курсора. Эта логика будет меняться в зависимости от задачи.
Извлеките запись из курсора, чтобы начать обработку.Замечание. Число переменных, объявленных для курсора, число столбцов в операторе SELECT и число переменных в операторе FETCH одинаково. В рассматриваемом примере имеется только одна переменная для извлечения данных из единственного столбца. Однако если должно быть пять элементов данных в курсоре, то необходимо также указать пять переменных в операторе FETCH.
Обработка данных уникальна для каждого набора логики. Это может быть вставка, обновление, удаление и т.д. для каждой извлекаемой строки данных. Это самый важный набор логики в данном процессе, который выполняется для каждой строки. Эта логика будет меняться в зависимости от задачи
Извлечение следующей записи из курсора, как это делалось на шаге 3, а затем шаг 4 снова повторяется при обработке выбранных данных.
По завершению обработки всех данных курсор закрывается.
На последнем и важном шаге вам необходимо освободить курсор, т.е. освободить все удерживаемые внутренние ресурсы SQL Server.
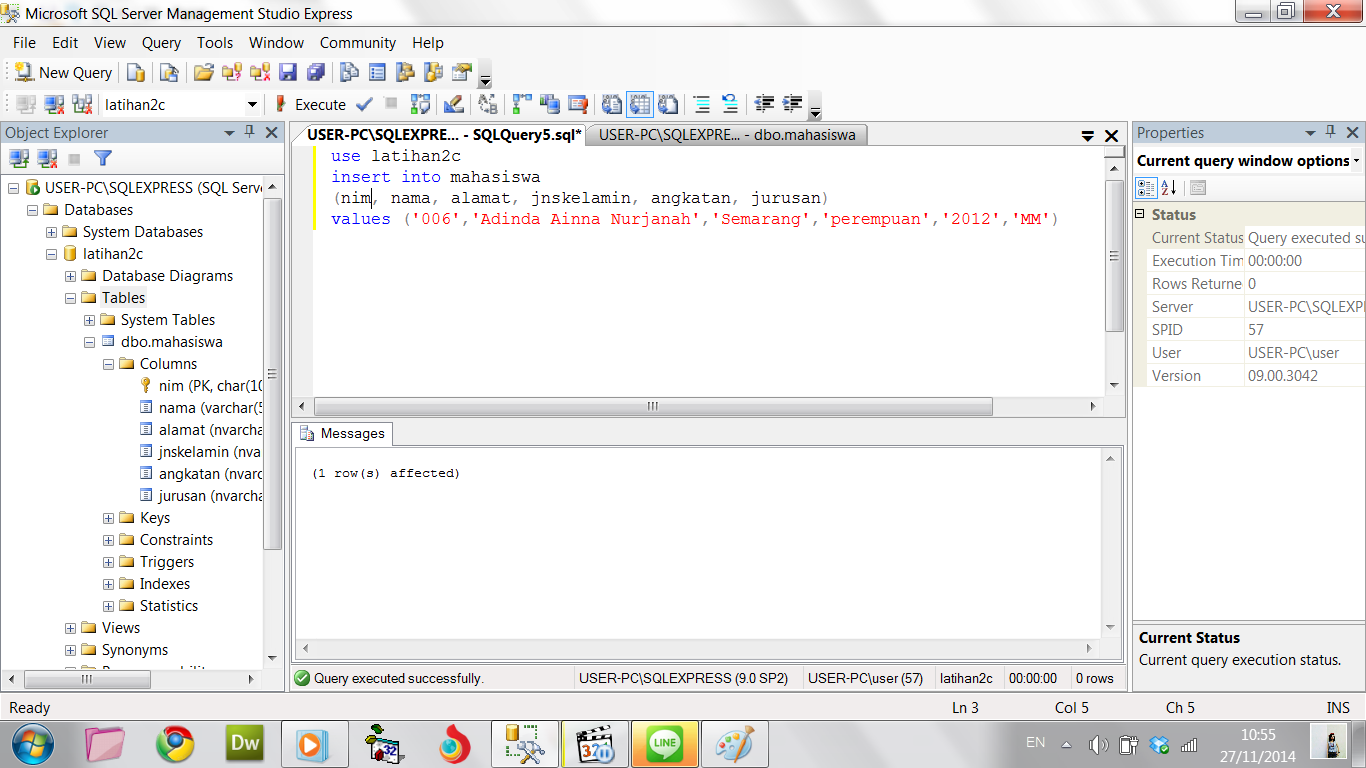
-- 1 - Объявление переменных -- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД * DECLARE @name VARCHAR(50) -- имя базы данных DECLARE @path VARCHAR(256) -- путь в файлам резервных копий DECLARE @fileName VARCHAR(256) -- имя файла бэкапа DECLARE @fileDate VARCHAR(20) -- используется для имени файла -- Инициализация переменных -- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД * SET @path = 'C:\Backup\' SELECT @fileDate = CONVERT(VARCHAR(20),GETDATE(),112) -- 2 - Объявление курсора DECLARE db_cursor CURSOR FOR -- Наполнить курсор вашей логикой -- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД * SELECT name FROM MASTER.dbo.sysdatabases WHERE name NOT IN ('master','model','msdb','tempdb') -- Открыть курсор OPEN db_cursor -- 3 - Извлечь следующую запись из курсора FETCH NEXT FROM db_cursor INTO @name -- Проверить состояние курсора WHILE @@FETCH_STATUS = 0 BEGIN -- 4 - Начало настраиваемой бизнес-логики -- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД * SET @fileName = @path + @name + '_' + @fileDate + '.BAK' BACKUP DATABASE @name TO DISK = @fileName -- 5 - Извлечь следующую запись из курсора FETCH NEXT FROM db_cursor INTO @name END -- 6 - Закрыть курсор CLOSE db_cursor -- 7 - Освободить ресурсы DEALLOCATE db_cursor
Как работать с Activity Monitor
Activity Monitor можно открыть в SQL Server Management Studio toolbar используя иконку Activity Monitor на панели, сочетанием клавиш Ctrl+Alt+A или через контекстное меню в Object Explorer.
Как уже было сказано выше, Activity Monitor отслеживает только заранее определенный набор наиболее важных показателей производительности SQL Server. Дополнительных параметров указать нельзя, нельзя и удалить что-то из показателей. Мониторинг возможен только в режиме реального времени. Нет возможности сохранить результаты мониторинга для последующего анализа. Таким образом Activity Monitor – это полезный инструмент для беглого анализа и поиска неисправностей, но он не подходит для детального сбора информации, т.к. в нём отсутствует возможность гибкой настройки счётчиков производительности, указания пороговых значений и нет возможности сбора исторических данных.
Работа с индексами SQL Server
Советы по созданию кластерных индексов
- Первичный ключ не всегда должен быть кластерным индексом. Если Вы создаете первичный ключ, тогда SQL сервер автоматически делает первичный ключ кластерным индексом. Первичный ключ должен быть кластерным индексом, только если он отвечает одной из нижеследующих рекомендаций.
- Кластерные индексы идеальны для запросов, где есть выбор по диапазону или вы нуждаетесь в сортированных результатах. Так происходит потому, что данные в кластерном индексе физически отсортированы по какому-то столбцу. Запросы, получающие выгоду от кластерных индексов, обычно включают в себя операторы BETWEEN, <, >, GROUP BY, ORDER BY, и агрегативные операторы типа MAX, MIN, и COUNT.
- Кластерные индексы хороши для запросов, которые ищут запись с уникальным значением (типа номера служащего) и когда Вы должны вернуть большую часть данных из записи или всю запись. Так происходит потому, что запрос покрывается индексом.
- Кластерные индексы хороши для запросов, которые обращаются к столбцам с ограниченным числом значений, например столбцы, содержащие данные о странах или штатах. Но если данные столбца мало отличаются, например, значения типа «да/нет», «мужчина/женщина», то такие столбцы вообще не должны индексироваться.
- Кластерные индексы хороши для запросов, которые используют операторы GROUP BY или JOIN.
- Кластерные индексы хороши для запросов, которые возвращают много записей, потому что данные находятся в индексе, и нет необходимости искать их где-то еще.
- Избегайте помещать кластерный индекс в столбцы, в которых содержатся постоянно возрастающие величины, например, даты, подверженные частым вставкам в таблицу (INSERT). Так как данные в кластерном индексе должны быть отсортированы, кластерный индекс на инкрементирующемся столбце вынуждает новые данные быть вставленным в ту же самую страницу в таблице, что создает «горячую зону в таблице» и приводит к большому объему дискового ввода-вывода. Постарайтесь найти другой столбец, который мог бы стать кластерным индексом.
Советы по выбору некластерных индексов
- Некластерные индексы лучше подходят для запросов, которые возвращают немного записей (включая только одну запись) и где индекс имеет хорошую селективность (более чем 95 %).
- Если столбец в таблице не содержит по крайней мере 95% уникальных значений, тогда очень вероятно, что Оптимизатор Запроса SQL сервера не будет использовать некластерный индекс, основанный на этом столбце. Поэтому добавляйте некластерные индексы к столбцам, которые имеют хотя бы 95% уникальных записей. Например, столбец с «Да» или «Нет» не имеет 95% уникальных записей.
- Постарайтесь сделать ваши индексы как можно меньшего размера (особенно для многостолбцовых индексов). Это уменьшает размер индекса и уменьшает число чтений, необходимых, чтобы прочитать индекс, что увеличивает производительность.
- Если возможно, создавайте индексы на столбцах, которые имеют целочисленные значения вместо символов. Целочисленные значения имеют меньше потерь производительности, чем символьные значения.
- Если Вы знаете, что ваше приложение будет выполнять один и тот же запрос много раз на той же самой таблице, рассмотрите создание покрывающего индекса на таблице. Покрывающий индекс включает все столбцы, упомянутые в запросе. Из-за этого индекс содержит все данные, которые Вы ищете, и SQL сервер не должен искать фактические данные в таблице, что сокращает логический и/или физический ввод — вывод. С другой стороны, если индекс становится слишком большим (слишком много столбцов), это может увеличить объем ввода — вывода и ухудшить производительность.
- Индекс полезен для запроса только в том случае, если оператор WHERE запроса соответствует столбцу (столбцам), которые являются крайними левыми в индексе. Так, если Вы создаете составной индекс, типа «City, State», тогда запрос » WHERE City = ‘Хьюстон’ » будет использовать индекс, но запрос » WHERE State = ‘TX’ » не будет использовать индекс.
- Любая операция над полем в предикате поиска, которое лежит под индексом, сводит на нет его использование. where isnull(field,’’) = ‘’ здесь индекс не используется, where field = ‘’ and field is not null — здесь используется.
Бывает ли слишком много индексов?
Да. Проблема с лишними индексами состоит в том, что SQL сервер должен изменять их при любых изменениях таблицы (INSERT, UPDATE, DELETE).
Лучшим решением ставить сомнительный индекс или нет, будет подождать и собрать статистику по работе индексов.
Лучшие кандидаты на установку индекса
- Это поля, по которым идет Join
- Поля связи, участвующие в подзапросах
- Поля, по которым идет фильтрация в where
- Поля, по которым выполняется сортировка.
Способы создания индексов
Предусмотрено создание индексов ms sql server с помощью двух инструментов. В этом помогут:
- SSMS (MSSQL Management Studio);
- специальный язык Transact-SQL (T-SQL, поддерживающий Paging Queries).
Как создать кластеризованный индекс
Как отмечалось выше, создание кластеризованного индекса sql сервером происходит автоматически, когда определенный столбец выбирается в качестве первичного ключа (PRIMARY KEY). Когда такого не происходит, следует создать кластерный индекс своими руками.
Чтобы создать Clustered index воспользуемся Management Studio. Для этого следует:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать соответствующую таблицу.
- Остановившись на пункте «Индексы» кликнуть мышкой.
- Выбрать «Создать индекс» и соответствующий тип (выбираем «Кластеризованный»).
- В новом окне появится форма «Новый индекс». Здесь потребуется вписать наименование нового создаваемого индекса (в рамках одной таблицы требуется, чтобы оно было уникальным). Поставить галочку, что он уникальный.
- Выбрать столбец, который будет являться ключом индекса. Он ляжет в основу создаваемого Clustered index. Провести сортировку строк табличных данных кнопкой «Добавить».
- После ввода всех необходимых параметров кликнуть «ОК».
Результатом действий станет кластерный индекс.
Он может быть создан и с помощью инструкций Transact-SQL CREATRE INDEX.
Создание Nonclustered index с включенными столбцами
Коснемся вопроса, как создать Nonclustered index с условием, что в индекс включены столбцы, которые не являются ключевыми. Такой индекс принято использовать в тех случаях, когда индекс создается под конкретный запрос. К примеру, чтобы индексом покрывался запрос полностью, т.е. включал все столбцы. Вследствие того, что запрос покрыт, увеличивается производительность. Это становится возможным благодаря тому, что оптимизатор запросов может получить все значения столбцов в индексе без обращения к табличным данным. Это ведет к уменьшению числа операций ввода-вывода на диске.
Однако стоит учитывать, что с включением в индекс неключевых столбцов размер его увеличивается. А значит, для его хранения понадобится больше дискового пространства. Это также может снизить производительность операций INSERT, UPDATE, DELETE и MERGE в базовой таблице данных.
Для его создания также воспользуемся Management Studio:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать требуемую таблицу и щелкнуть мышкой по пункту «Индексы».
- Выбрать «Создать индекс», а затем «Некластеризованный» (не ставить галочку на уникальности).
- В открывшейся форме «Новый индекс» вписать наименование нового индекса, добавить один или несколько ключевых столбцов, воспользовавшись кнопкой «Добавить».
- Перейти во вкладку «Включено столбцы». Добавить все столбцы, которые должны быть включены в индекс, воспользовавшись кнопкой «Добавить».
- Когда введены все нужные параметры кликнуть «ОК».
Все готово!
При необходимости, можно легко создать фильтруемый Nonclustered index. Для этого следует воспользоваться T-SQL и в операторе CREATE NONCLUSTERED INDEX в WHERE указать условие фильтрации. Так можно отфильтровать практически любые данные, не важные в запросах.
Запросы к базе данных
При проектировании вторым важным пунктом является понимание и учет того, какие выполняются запросы к базе данных. Необходимо учитывать частоту изменения данных, а также требуется соблюдение определенных принципов:
- Предпочтительнее, чтобы один запрос содержал наибольшее число строк, нежели разбивать их на соответствующее число отдельных запросов.
- На столбцах, используемых в запросах с WHERE чаще всего, предпочтительнее создавать Nonclustered index в качестве условия поиска и соединения в JOIN.
- Следует воспользоваться возможностями индексирования столбцов, используемых в поисковых запросах на соответствие конкретным значениям.
17: используйте LAG и LEAD для последовательных строк
Функция позволяет запрашивать более одной строки в таблице, не вступая в таблицу к себе. Он возвращает значения из предыдущей строки таблицы.
Функция LEAD делает то же самое, но и для следующей строки.
Отказ от использования самостоятельных соединений повышает производительность, поскольку уменьшается количество операций чтения. Но, вы должны проверить, как LEAD и LAG влияют на производительность запросов.
Таким образом, рассмотренные нами моменты работы с SQL операторами и запросами значительно ускоряют работу с СУБД.
@data_analysis_ml – наш телеграм канал продвинутого анализа данных
+1
+1
+1
+1
+1
Просмотры: 1 140
Базы данных
Как сказано выше, производительность системы напрямую зависит от индексов. При поступлении запроса они могут увеличивать ее, обеспечивая быстрый поиск данных либо снижать, т.к. при каждой операции с данными будут изменяться и они, дабы отражать действия, производимые над данными
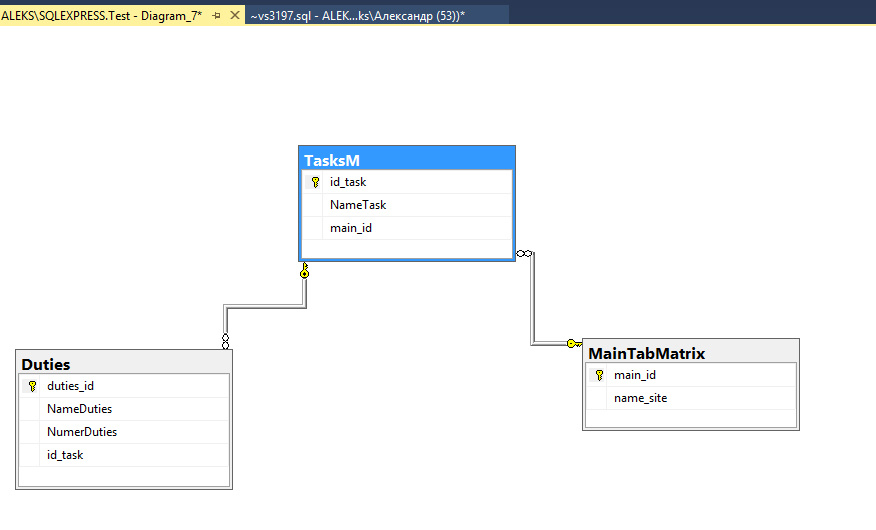


И не важно, что происходит с ними – добавление, удаление или обновление
Потому, при разработке плана стратегии по индексированию, необходимо придерживаться советов специалистов:
- Если предполагается частое обновление данных в таблице, то для нее нужно применять минимум индексов.
- Для таблицы со значительным количеством данных, которые предположительно будут редко изменяться, можно использовать то число индексов, которое улучшит производительность запросов. Но для таблиц небольшого объема не всегда целесообразно вообще их использовать. Такой поиск может выполняться дольше, чем обычное сканирование таблицы.
- Для Clustered indexes используйте самые короткие поля, которые только допустимы. Лучше всего их применять на столбцах с уникальными значениями и в которых не допускается использование NULL. По этой причине чаще всего PRIMARY KEY выступает в роли Clustered index.
- Производительность индекса напрямую зависит от того, насколько уникальны значения в столбце. Она снижается с увеличением дублей если в столбце и растет с уменьшением. Потому, при каждой возможности следует использовать уникальный индекс.
- Если используется составной индекс, то в нем нужно учитывать порядок столбцов. Первыми идут те, в которых в выражениях используется WHERE. За ними – столбцы с наивысшими показателями уникальных значений. Остальные выстраиваются по мере понижения этого показателя.
- Допускается использование индекса на вычисляемых столбцах таблицы, но лишь при условии соблюдения определенных требований (для вычисления значений такого столбца могут использоваться только детерминистические выражения, т.е. результат для определенного набора входящих параметров всегда должен быть одинаковым).
3.3.4. Функция, возвращающая таблицу
В следующем примере мы создаем функцию, которая будет возвращать в качестве результата таблицу. В качестве примера, создадим функцию, которая будет возвращать таблицу товаров, и для каждой строки рассчитаем произведение колонок количества и цены:
CREATE FUNCTION GetPrice()
RETURNS TABLE
AS
RETURN
(
SELECT Дата, , Цена,
Количество, Цена*Количество AS Сумма
FROM Товары
)
Начало функции такое же, как у скалярной – указываем оператор CREATE FUNCTION и имя функции. Я специально создал эту функцию без параметров, чтобы вы увидели, как это делается. Не смотря на то, что параметров нет, после имени должны идти круглые скобки, в которых не надо ничего писать. Если не указать скобок, то сервер вернет ошибку и функция не будет создана.
Разница есть и в секции RETURNS, после которой указывается тип TABLE, что говорит о необходимости вернуть таблицу. После этого идет ключевое слово AS и RETURN, после которого должно идти возвращаемое значение. Для функции данного типа в секции RETURN нужно в скобках указать запрос, результат которого и будет возвращаться функцией.
Когда пишете запрос, то все его поля должны содержать имена. Если одно из полей не имеет имени, то результатом выполнения оператора CREATE FUNCTION будет ошибка. В нашем примере последнее поле является результатом перемножения полей «Цена» и «Количество», а такие поля не имеют имени, поэтому мы его задаем с помощью ключевого слова AS.
Посмотрим, как можно использовать такую функцию с помощью оператора SELECT:
SELECT * FROM GetPrice()
Так как мы используем простой оператор SELECT, то мы можем и ограничивать вывод определенными строками, с помощью ограничений в секции WHERE. Например, в следующем примере выбираем из результата функции только те строки, в которых поле «Количество» содержит значение 1:
SELECT * FROM GetPrice() WHERE Количество=1
Функция возвращает в качестве результата таблице, которую вы можете использовать как любую другую таблицу базы данных. Давайте создадим пример в котором можно будет увидеть использование функции в связи с таблицами. Для начала создадим функцию, которая будет возвращать идентификатор работников таблицы tbPeoples и объединенные в одно поле ФИО:
CREATE FUNCTION GetPeoples() RETURNS TABLE AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM tbPeoples )
Функция возвращает нам идентификатор строки, с помощью которого мы легко можем связать результат с таблицей телефонов. Попробуем сделать это с помощью простого SQL запроса:
SELECT * FROM GetPeoples() p, tbPhoneNumbers pn WHERE p.idPeoples=pn.idPeoples
Как видите, функции, возвращающие таблицы очень удобны. Они больше, чем процедуры похожи на объекты просмотра, но при этом позволяют принимать параметры. Таким образом, можно сделать так, чтобы сама функция возвращала нам только то, что нужно. Вьюшки такого не могут делать по определению. Чтобы получить нужные данные, вьюшка должна выполнить свой SELECT запрос, а потом уже во внешнем запросе мы пишем еще один оператор SELECT, с помощью которого ограничивается вывод до необходимого. Таким образом, выполняется два запроса SELECT, что для большой таблицы достаточно накладно. Функция же может сразу вернуть только то, что нужно.
Рассмотрим пример, функция GetPeoples у нас возвращает все строки таблицы. Чтобы получить только нужную фамилию, нужно писать запрос типа:
SELECT * FROM GetPeoples() WHERE FIO LIKE 'ПОЧЕЧКИН%'
В этом случае будут выполняться два запроса: этот и еще один внутри функции. Но если передавать фамилию в качестве параметра в функцию и там сделать секцию WHERE, то можно обойтись и одним запросом SELECT:
CREATE FUNCTION GetPeoples1(@Famil varchar(50)) RETURNS TABLE AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM tbPeoples WHERE vcFamil=@Famil )