
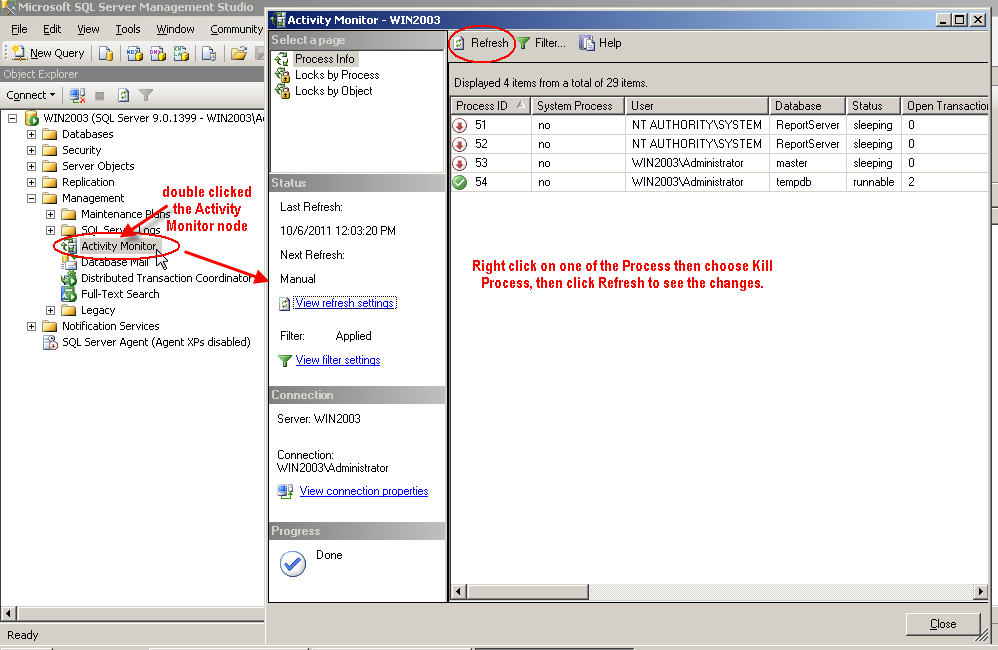
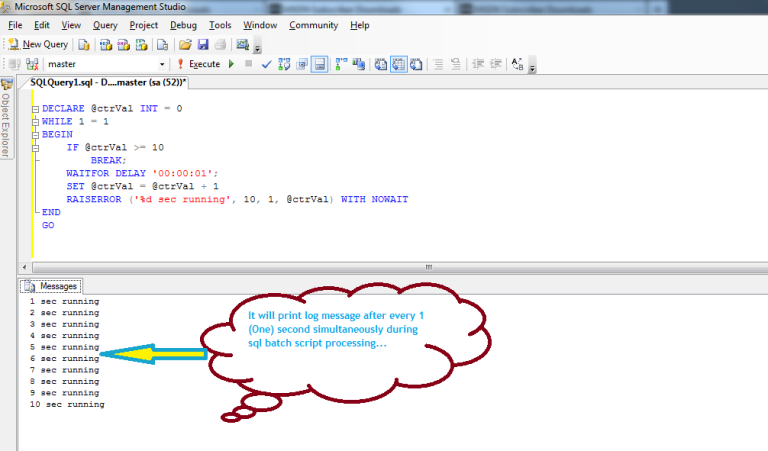
Using system_health extended event to monitor SQL Server blocking problems
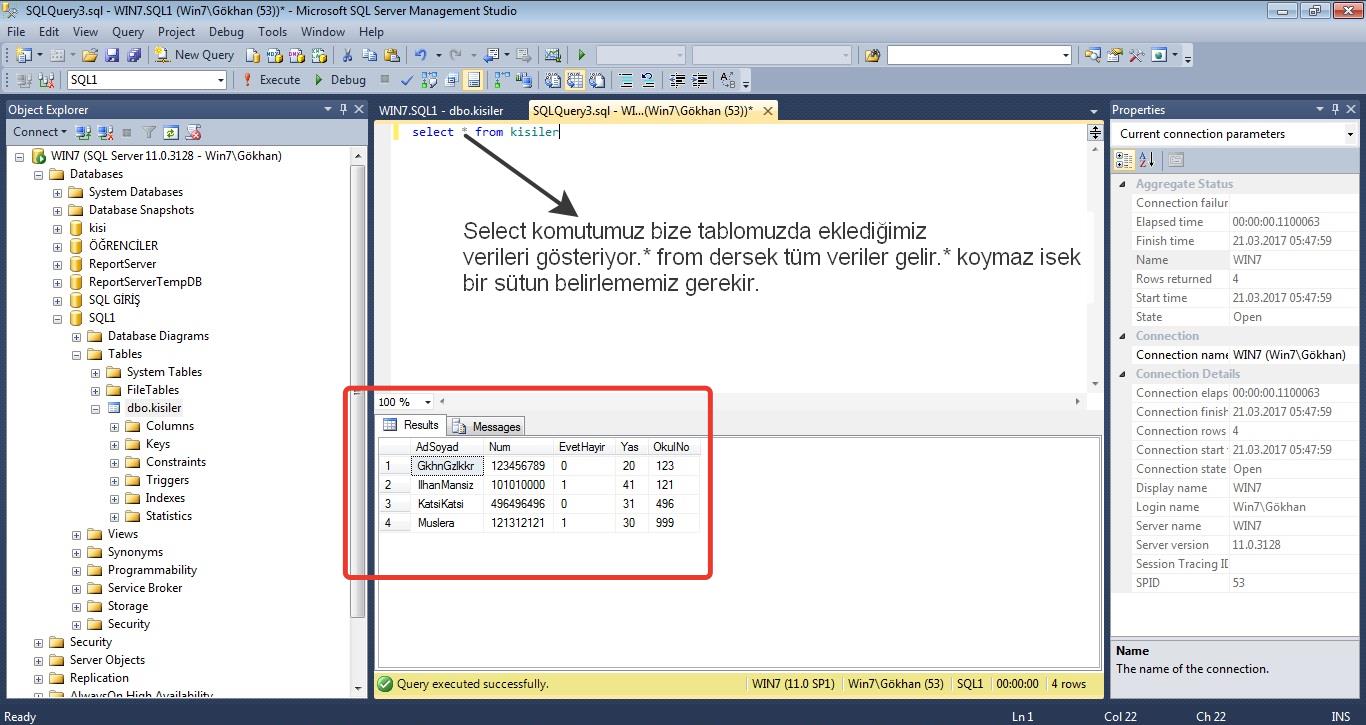
The system_health is the default extended event session of the SQL Server. It is started automatically when the database engine is started. The system_health captures any session that has waited in the blocked status for over 30 seconds. We can report the blocked queries which are over 30 seconds with the help of the following query. This query finds the system_health file stored location and then parses this XML data only for the lock wait types.
|
1 |
SELECTs.name,CAST(t.target_dataASXML).value(‘(EventFileTarget/File/@name)’,’VARCHAR(MAX)’)ASfileName INTO#EX_FilePath FROMsys.dm_xe_sessionsASs INNERJOIN sys.dm_xe_session_targetsASt ONs.address=t.event_session_address WHEREt.target_name=’event_file’; DECLARE@EventFileTargetASNVARCHAR(500); SELECT@EventFileTarget=fileName FROM#EX_FilePath WHEREname=’system_health’; SELECT* FROM(SELECTn.value(‘(@name)’,’varchar(50)’)ASevent_name, n.value(‘(@package)’,’varchar(50)’)ASpackage_name, n.value(‘(@timestamp)’,’datetime2′)ASutc_timestamp, n.value(‘(data/text)’,’nvarchar(max)’)ASwait_type, n.value(‘(action/value)’,’bigint’)ASsession_id, n.value(‘(data/value)’,’bigint’)1000ASduration_ms, n.value(‘(action/value)’,’nvarchar(max)’)ASsql_text FROM ( SELECTCAST(event_dataASXML)ASevent_data FROMsys.fn_xe_file_target_read_file(@EventFileTarget,NULL,NULL,NULL) )ASed CROSSAPPLY ed.event_data.nodes(‘event’)ASq(n))ASTMP_TBL WHEREevent_name=’wait_info’ ANDwait_typeLIKE’LCK%’ ORDERBYutc_timestampDESC;
|
The advantage of this option is to see the problematic queries and lock wait types without extra effort. Despite that, the drawback of system_health is that it only captures the blocking issues that take longer than 30 seconds.
Методы блокировок Oracle
Oracle использует блокировки для контроля двух обширных типов объектов: пользовательских объектов, к которым относятся таблицы, и системных объектов, к которым могут относится структуры разделяемой памяти и объекты словаря данных. Oracle следует пессимистическому подходу к блокировкам, который исключает потенциальные конфликты и блокирует некоторые транзакции от взаимного влияния других транзакций, чтобы исключить конфликты между ними.
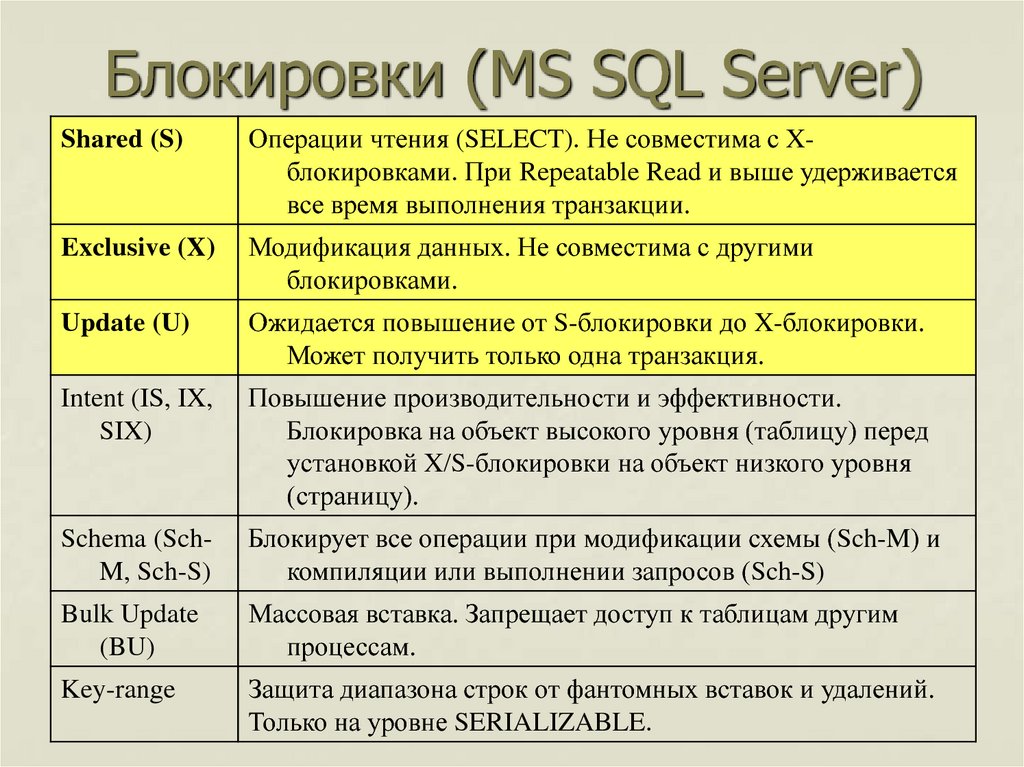
Гранулированностью (granularity) в контексте блокировок называется размер единицы данных, заблокированный механизмом блокировки. Oracle использует гранулированность уровня строки для блокировки объектов, которая представляет собой наиболее мелкий уровень гранулированности (наиболее крупный уровень — блокировка таблицы). Некоторые базы данных, включая Microsoft SQL Server, предлагают только блокировку уровня страницы, а не строки. Страница — это нечто похожее на блок данных Oracle, и она может хранить группу строк, поэтому блокировка уровня страницы означает, что на время обновления несколько строк будут заблокированы в дополнение к тем, что подлежат обновлению; если другим пользователям понадобятся заблокированные строки, которые не участвуют в обновлении, им придется ждать, пока блокировка страницы не будет снята. Например, если размер страницы составляет 8 Кбайт, а средняя длина строки — 100 байт, то в страницу уместится 80 строк. Если одна из них будет обновляться, то блокировка уровня страницы также распространится на остальные 79 строк. Блокировка на уровне выше строки ограничивает параллельный доступ к данным.
На заметку!
Все блокировки, полученные операторами в транзакции, удерживаются Oracle до тех пор, пока транзакция не завершится. Когда транзакция явно или неявно выдает команду или , Oracle освобождает все блокировки, которые удерживали операторы, входящие в транзакцию. Если Oracle выполняет откат к точке сохранения, то освобождаются все блокировки, установленные после этой точки.
И снова о скорости работы 1с 8.х + тест от Гилева (конфигурация TPС_1C_GILV_A) + как Выбрать сервер для 1С 8.х Промо
Предыстория:
Есть в конторе, где я работаю, пара практически ОДИНАКОВЫХ по железу сервера…
так вот заметили что на одном из них 1С 8.2 работает значительно быстрей что в Клиент-Серверном, что в файловом варианте…
и что именно удивило так это что медленней работал сервер с большим количеством Оперативной памяти + RAID10 на SSD.
Проводили много тестов на работу дисковой системы + различные тесты SQL — ВЫВОД: ничего непонятно где тормоза.
И вот попала ко мне конфигурация 1С для оценки производительности 1С от Гилева http://infostart.ru/public/57204/
Подробности в Описании…
2 стартмани
13.08.2012
661364
661
sanfoto
2561
301
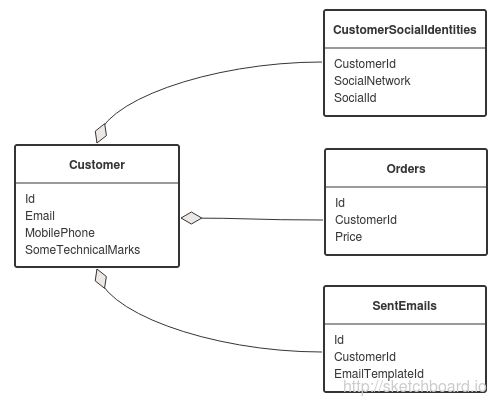
Получение информации о текущих блокировках в СУБД MS SQL Server
Продолжая тему динамических представлений MS SQL Server, в данной статье будет описано как получить информацию о текущих блокировках СУБД.
Для большей информативности, текущая статья использует материал представленный в статье «Получение информации о текущих исполняемых запросах MS SQL Server», поэтому рекомендуется с ней ознакомиться.
Эксперимент
Произведем те же действия что и в приведенной выше статье, а именно:
- Создадим тестовую базу и обработку
- Выполним запись в регистр сведений через обработку и встанем на ожидании, не завершив транзакцию
- В Management Studio выполним запрос выборки всех данных из таблицы регистра сведений
- Получим текущие исполняемые запросы в СУБД
Получение информации о текущих блокировках СУБД
Текущее состояние нашей системы дает возможность выполнить запрос, который вернет информацию о текущих блокировках СУБД. В моем запросе будут использованы следующие представления:
| Представление | Описание |
|---|---|
| dm_tran_locks | Возвращает сведения об активных в данный момент в SQL Server ресурсах диспетчера блокировок |
| partitions | Возвращает информацию о секциях |
| indexes | Возвращает информацию об индексах |
Текст запроса приведен ниже, а также доступен во вложении к статье:
В условии отбора «MyBase» — имя базы данных в СУБД; «_InfoRg243» — условие по таблице.
Результат запроса к представлению dm_exec_requests (запрос из статьи, указанной в начале):

Текущие запросы СУБД
Результат запроса к представлению dm_tran_locks:

Запрошенные и установленные блокировки СУБД
Описания колонок результата запроса представлены ниже:
| Имя колонки | Описание |
|---|---|
| DB_Name | Имя базы данных к которой выполняется запрос |
| TableName | Имя сущности в базе данных, с которой связан ресурс (в примере ожидается имя таблицы) |
| IndexID | Идентификатор индекса, связанного с таблицей |
| IndexName | Имя индекса, связанного с таблицей |
| ResourceType | Тип ресурса |
| RequestMode | Запрашиваемый/предоставленный режим запроса |
| RequestType | Тип запроса |
| RequestStatus | Текущее состояние запроса |
| RequestSessionID | Идентификатор сеанса, которому принадлежит этот запрос |
| ResourceDescription | Описание ресурса |
Анализ полученного результата
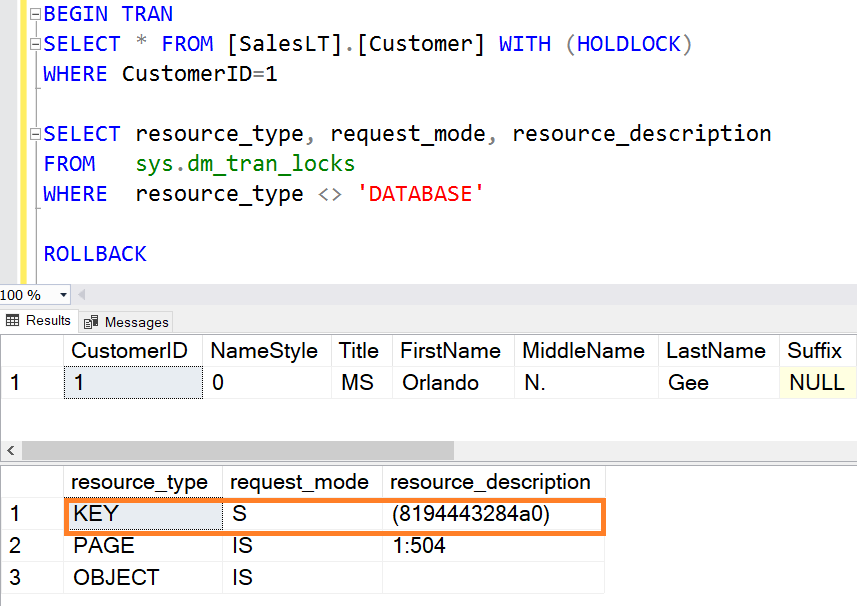
Во-первых, интерпретируем результат запроса к представлению dm_tran_locks независимо от dm_exec_requests:
Как видно, сессия с идентификатором «65» установила (GRANT) на единственный индекс таблицы «_InfoRg243» следующие блокировки: IX на уровне страницы индекса и X на уровне ключа индекса. Как можно догадаться, это тот сеанс, который производит запись в регистр из 1С:Предприятие. Сессия с номером «55» установила (GRANT) блокировку IS на уровне страницы единственного индекса таблицы «_InfoRg243», а S блокировку на уровне ключа записи установить не удалось и поэтому она находится в ожидание (WAIT) до момента освобождения ресурса (или таймаута).
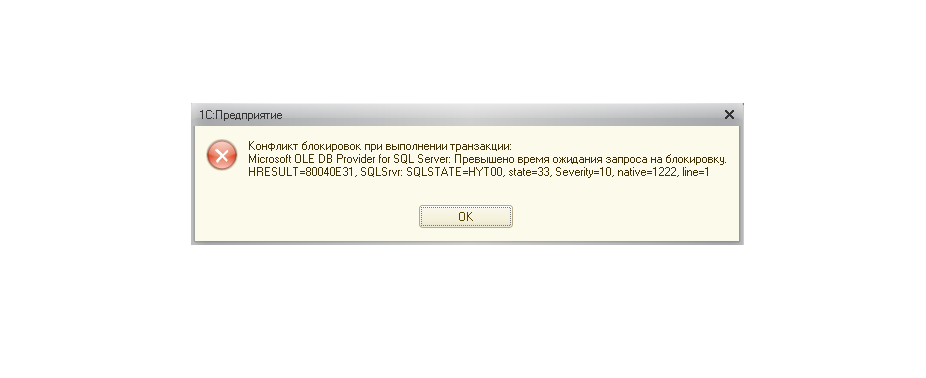

В результате данного запроса нет явного указания на связь заблокированного и блокирующего сеанса, хотя, при желании, сопоставив описания ресурсов, можно сделать вывод об этом. Поэтому, на мой взгляд, при разборе конфликтов блокировок логичнее сначала получить информацию по представлению dm_exec_requests, а затем уже получить информацию о том какие блокировки были установлены/запрошены источником и жертвой.
При таком подходе (сначала dm_exec_requests, затем dm_tran_locks) получим следующую интерпретацию:
| Представление | Интерпретация результата |
|---|---|
| dm_exec_requests | Сеансом с идентификатором «55» (жертва) был отправлен запрос «Select * from dbo._InfoRg243», который встал на ожидании получения S блокировки по ресурсу «KEY: 9:72057594051559424 (227b7397de24)». Блокирующим является сеанс с идентификатором «65» (источник) |
| dm_tran_locks | Запрашиваемая блокировка сеанса «55» по ресурсу «227b7397de24»: S блокировка по ключу индекса «_InfoRg243_ByDims_N» таблицы «_InfoRg243». Как видно, причина по которой жертве не удается установить блокировку заключается в том что источник уже установил исключительную блокировку на данный ресурс. Установленная источником блокировка (X) несовместима с блокировкой жертвы (S) |
Причина почему не возникает конфликта блокировок на уровне страниц индекса, несмотря на то что ситуация схожа с блокировкой на уровне ключей, заключается в том что блокировки IS и IX совместимы.
Настройка блокировок
Настройку блокировок можно осуществлять, используя подсказки блокировок (locking hints) или параметр LOCK_TIMEOUT инструкции SET. Эти возможности описываются в следующих разделах.
Подсказки блокировок (locking hints)
Подсказки блокировок задают тип блокировки, используемой компонентом Database Engine для блокировки табличных данных. Подсказки блокировки уровня таблиц применяются, когда требуется более точное управление типами блокировок, накладываемых на ресурс. (Подсказки блокировок перекрывают текущий уровень изоляции для сеанса.)
Все подсказки блокировок указываются в предложении FROM инструкции SELECT. Далее приводится список и краткое описание доступных подсказок блокировок:
- UPDLOCK
-
Устанавливается блокировка обновления для каждой строки таблицы при операции чтения. Все блокировки обновления удерживаются до окончания транзакции.
- TABLOCK
-
Устанавливается разделяемая (или монопольная) блокировка для таблицы. Все блокировки удерживаются до окончания транзакции.
- ROWLOCK
-
Существующая разделяемая блокировка таблицы заменяется разделяемой блокировкой строк для каждой отвечающей требованиям строки таблицы.
- PAGLOCK
-
Разделяемая блокировка таблицы заменяется разделяемой блокировкой страницы для каждой страницы, содержащей указанные строки.
- NOLOCK
-
Синоним для READUNCOMMITTED, который мы рассмотрим при обсуждении уровней изоляции.
- HOLDLOCK
-
Синоним для REPEATABLEREAD.
- XLOCK
-
Устанавливается монопольная блокировка, удерживаемая до завершения транзакции. Если подсказка xlock указывается с подсказкой rowlock, paglock или tablock, монопольные блокировки устанавливаются на соответствующем уровне гранулярности.
- READPAST
-
Указывает, что компонент Database Engine не должен считывать строки, заблокированные другими транзакциями.
Все эти параметры можно объединять вместе в любом имеющем смысл порядке. Например, комбинация подсказок TABLOCK с PAGLOCK не имеет смысла, поскольку каждая из них применяется для разных ресурсов.
Параметр LOCK_TIMEOUT
Чтобы процесс не ожидал освобождения блокируемого объекта до бесконечности, можно в инструкции SET использовать параметр LOCK_TIMEOUT. Этот параметр задает период в миллисекундах, в течение которого транзакция будет ожидать снятия блокировки с объекта. Например, если вы хотите чтобы период ожидания был равен восемь секунд, то это следует указать следующим образом:
Если данный ресурс не может быть предоставлен процессу в течение этого периода времени, инструкция завершается аварийно и выдается соответствующее сообщение об ошибке. Значение LOCK_TIMEOUT равное -1 (значение по умолчанию) указывает отсутствие периода ожидания, т.е. транзакция не будет ожидать освобождения ресурса совсем. (Подсказка блокировки READPAST предоставляет альтернативу параметру LOCK_TIMEOUT.)
Блокировка вредоносных клиентов
Теперь давайте рассмотрим код, который фактически обнаруживает попытки взлома входа в систему и управляет нашими блочными списками и правилами брандмауэра. Я поместил этот код в одну хранимую процедуру, которую можно планировать на регулярной основе. Это можно сделать с помощью агента SQL Server или SQL Server CLI и планировщика заданий Windows (если используется версия Express, у которой нет агента SQL Server). Я рекомендую запускать это каждые 30 секунд до минуты. Убедитесь, что параметр «Время в секундах, чтобы посмотреть назад на неудавшиеся логины» в Config больше, этого времени, иначе появится окно неконтролируемого времени, когда неудачный вход в систему останется незамеченным.
Убедитесь, что учетная запись пользователя, запускающая сценарий, является локальным администратором на компьютере, на котором запущен SQL Server (если используется агент SQL Server, служба должна работать под учетной записью администратора локального компьютера). Доступ к машинным администраторам необходим для запуска команд netsh для добавления или удаления правил брандмауэра.
CREATE PROCEDURE CheckFailedLoginsASBEGIN SET NOCOUNT ON; DECLARE @UnblockDate DATETIME DECLARE @LookbackDate DATETIME DECLARE @MaxFailedLogins INT DECLARE @FailedLogins TABLE ( LogDate datetime, ProcessInfo varchar(50), Message text ); SELECT @LookbackDate = dateadd(second, -ConfigValue, getdate()) FROM Config WHERE ConfigID = 1
SELECT @MaxFailedLogins = ConfigValue FROM Config WHERE ConfigID = 2
SELECT @UnblockDate = CASE WHEN ConfigValue > 0 THEN DATEADD(hour, -ConfigValue, getdate()) END FROM Config WHERE ConfigID = 3
INSERT INTO @FailedLogins — Read current log exec sp_readerrorlog 0, 1, ‘Login failed’;
INSERT INTO BlockedClient(IPAddress, LastFailedLogin, FailedLogins) SELECT IPAddress, MAX(LogDate) AS LastFailedLogin, COUNT(*) AS FailedLogins FROM ( SELECT LogDate, ProcessInfo, Message, ltrim(rtrim(substring(CONVERT(varchar(1000), Message), — Extract client IP charindex(», CONVERT(varchar(1000), Message)) — 9 — charindex(‘[CLIENT: ‘, CONVERT(varchar(1000), Message))))) as IPAddress FROM @FailedLogins WHERE (Message like ‘%Reason: An error occurred while evaluating the password.%’ — Some filter criteria OR Message like ‘%Reason: Could not find a login matching the name provided.%’ OR Message like ‘%Reason: Password did not match that for the login provided.%’ OR Message LIKE ‘%Login failed. The login is from an untrusted domain and cannot be used with Windows authentication.%’) AND LogDate >= @LookbackDate ) AS t WHERE NOT EXISTS (SELECT * FROM Whitelist l — Check against whitelist WHERE l.IPAddress = t.IPAddress) AND NOT EXISTS (SELECT * FROM BlockedClient c — ignore already blocked clients WHERE c.IPAddress = t.IPAddress) AND IPAddress <> ‘<local machine>’ — ignore failed logins from local machine GROUP BY IPAddress HAVING COUNT(*) >= @MaxFailedLogins — Check against number of failed logins config AND MAX(LogDate) >= COALESCE(@UnblockDate, MAX(LogDate)) — Check that new entries meet delete config criteria so we don’t unnecessarily — add a rule that would then get deleted.
DELETE FROM BlockedClient — Delete entries older than the delete config WHERE LastFailedLogin < @UnblockDateENDGO
Вторая часть процедуры ищет клиентов, заблокированных дольше, чем 24-часовой период времени, который мы установили, и удаляет их, чтобы наш список не выходил из-под контроля.
Наконец, глядя на брандмауэр Windows, мы можем видеть наши правила блоков, созданные автоматически!
Явное блокирование таблицы
Каждый раз, когда вы добавляете столбец к таблице, база данных должна установить монопольную DML-блокировку на этой таблице. Можно указать, что команда DDL должна ожидать определенный период времени перед отказом, когда не удается установить блокировку DML. Оператор позволяет специфицировать максимальный период времени, который оператор DDL может ожидать возможности захвата DML-блокировки таблицы. Применяйте это средство при добавлении столбца, часто обновляемого пользователями.




Ниже приведен синтаксис оператора :
В операторе значения и параметр означают следующее.
- Если вы хотите, чтобы база данных вернула управления немедленно, обнаружив,что требуемая таблица уже заблокирована другим пользователем, укажите опцию .
- С помощью параметра можно задать количество секунд, в течение которых оператор может ожидать возможности установки DML-блокировки. Значение этого параметра является целочисленным и на него не накладывается никаких ограничений.
- Если не указано ни , ни , база данных будет ожидать до тех пор, пока заблокированная таблица не станет доступной, и затем заблокирует ее перед возвратом управления.
Как написать курсор в SQL Server
Объявите ваши переменные (для имен файлов, имен баз данных, номеров счетов и т.д.), которые вам нужны для реализации логики, и присвойте им начальные значения. Эта логика будет меняться в зависимости от задачи.
Объявите курсор с конкретным именем (как db_cursor в этом примере), которое вы будете использовать на протяжении всей логики вместе с бизнес-логикой (оператор SELECT) для наполнения курсора требуемыми записями. Имя курсора может быть осмысленным. Сразу после этого следует открытие курсора. Эта логика будет меняться в зависимости от задачи.
Извлеките запись из курсора, чтобы начать обработку.Замечание. Число переменных, объявленных для курсора, число столбцов в операторе SELECT и число переменных в операторе FETCH одинаково. В рассматриваемом примере имеется только одна переменная для извлечения данных из единственного столбца. Однако если должно быть пять элементов данных в курсоре, то необходимо также указать пять переменных в операторе FETCH.
Обработка данных уникальна для каждого набора логики. Это может быть вставка, обновление, удаление и т.д. для каждой извлекаемой строки данных. Это самый важный набор логики в данном процессе, который выполняется для каждой строки. Эта логика будет меняться в зависимости от задачи
Извлечение следующей записи из курсора, как это делалось на шаге 3, а затем шаг 4 снова повторяется при обработке выбранных данных.
По завершению обработки всех данных курсор закрывается.
На последнем и важном шаге вам необходимо освободить курсор, т.е. освободить все удерживаемые внутренние ресурсы SQL Server.
-- 1 - Объявление переменных
-- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД *
DECLARE @name VARCHAR(50) -- имя базы данных
DECLARE @path VARCHAR(256) -- путь в файлам резервных копий
DECLARE @fileName VARCHAR(256) -- имя файла бэкапа
DECLARE @fileDate VARCHAR(20) -- используется для имени файла
-- Инициализация переменных
-- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД *
SET @path = 'C:\Backup\'
SELECT @fileDate = CONVERT(VARCHAR(20),GETDATE(),112)
-- 2 - Объявление курсора
DECLARE db_cursor CURSOR FOR
-- Наполнить курсор вашей логикой
-- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД *
SELECT name
FROM MASTER.dbo.sysdatabases
WHERE name NOT IN ('master','model','msdb','tempdb')
-- Открыть курсор
OPEN db_cursor
-- 3 - Извлечь следующую запись из курсора
FETCH NEXT FROM db_cursor INTO @name
-- Проверить состояние курсора
WHILE @@FETCH_STATUS = 0
BEGIN
-- 4 - Начало настраиваемой бизнес-логики
-- * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД *
SET @fileName = @path + @name + '_' + @fileDate + '.BAK'
BACKUP DATABASE @name TO DISK = @fileName
-- 5 - Извлечь следующую запись из курсора
FETCH NEXT FROM db_cursor INTO @name
END
-- 6 - Закрыть курсор
CLOSE db_cursor
-- 7 - Освободить ресурсы
DEALLOCATE db_cursor
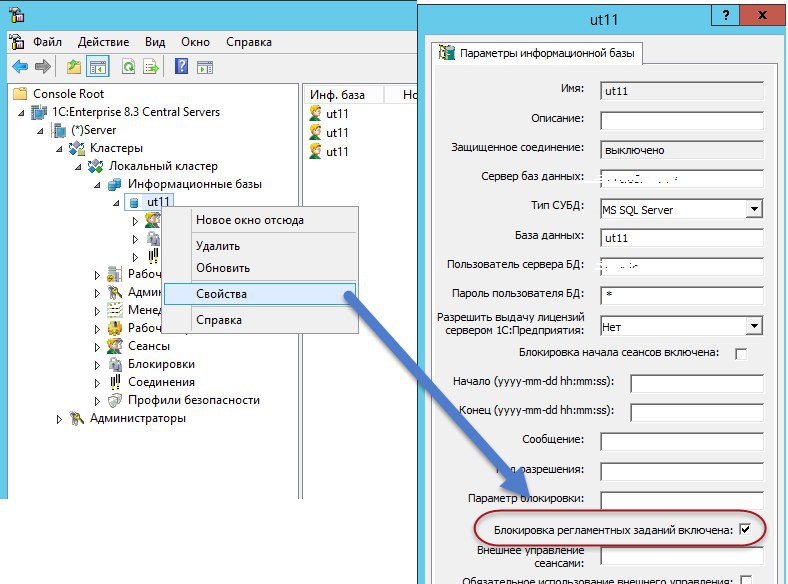
Использование SQL для анализа блокировок
Текущую ситуацию с блокировками в экземпляре можно проверять с помощью сценариев SQL. Прежде чем впервые выполнить в базе данных любой относящийся к блокировкам сценарий, может понадобиться сначала запустить сценарий находящийся в каталоге . Этот сценарий создаст несколько важных представлений, относящихся к блокировкам, таких как и .
Oracle поставляет сценарий по имени , строящий древовидный граф блокирующих сеансов, которые удерживают блокировки, затрагивающие другие сеансы. Используя этот сценарий, можно посмотреть, освобождения какой блокировки может ожидать сеанс, и какой сеанс удерживает эту блокировку. Этот сценарий находится в каталоге . Ниже приведен пример выполнения сценария :
На заметку!
В предыдущем примере идентификатор сеанса слева, равный 682, указывает на сеанс, которого ждет сеанс 363. Информация, выводимая справа от каждого сеанса,описывает блокировку, снятия которой он ожидает. Таким образом, сеанс 682, хотя и удерживающий блокировку, не показывает ничего (None) в столбцах, описывающих блокировки, потому что он никого не ждет. Однако строка сеанса 363 говорит о том, что этот сеанс запросил разделяемую (S) блокировку и ожидает от сеанса 682 освобождения его монопольной (X) блокировки строки таблицы.
В следующем примере из сценария сеанс 9 ожидает сеанса 8, сеанс 7 ждет сеанса 9, а сеанс 10 ждет сеанса 9.
Информация блокировки справа от идентификатора сеанса описывает блокировку,освобождения которой ждет сеанс (а не которую удерживает он сам).
Представления и очень полезны для анализа блокировок в экземпляре, но иногда запросы к ним требуют длительного времени. Представление может быстро дать информацию для идентификации пользователя, удерживающего блокировку. Столбец представления указывает на то, действительны ли данные . Например,наличие значения в столбце означает, что в столбце находится системный идентификатор (SID) блокирующего пользователя.
Рассмотрим пример простого запроса, который продемонстрирует использование представления для определения того, кто блокирует определенный сеанс:
Приведенный выше запрос показывает, что пользователь с SID 24 заблокирован пользователем с SID 32. Столбец указывает тип блокировки, которую удерживает блокирующий сеанс.
На заметку! Таблицы словаря данных, которые следует проверить, чтобы найти информацию о блокировках — это представления , и . Если по какой-то причине вы не видите представления , запустите сценарий ,находящийся в каталоге , чтобы создать его.
Пути устранения взаимоблокировок
- Использовать одинаковый порядок доступа к одинаковым данным в различных процедурах
- Уменьшать сложность и продолжительность транзакций
- Использовать индексный поиск записей для чтения/модификации/удаления
- Избегать внутри транзакции повторных обращений к уже заблокированным ресурсам с более сильной блокировкой
- Использовать минимальный уровень изоляции транзакций (уменьшение блокировок – уменьшение ожиданий освобождения ресурсов – уменьшение вероятности взаимоблокировок). Однако следует помнить, что последствия рассогласованности данных гораздо серьёзнее, чем последствия взаимоблокировок.
- Как «последний рубеж» по защите нервов пользователя, в приложениях рекомендуется перехват ошибки сервера 1205 (взаимоблокировка) и пытаться перезапускать транзакцию, однако рекомендуется делать это (скрытно от пользователя) не более 3 раз подряд, т.к. этот шаг не устраняет первопричины явления, а лишь маскирует его.
#it #sql #sql для новичков #блокировки
Финальные замечания
Вы изучили основной образец для обработки ошибок и транзакций в хранимых процедурах. Он не идеален, но он должен работать в 90-95% вашего кода
Есть несколько ограничений, на которые стоит обратить внимание:
- Как мы видели, ошибки компиляции не могут быть перехвачены в той же процедуре, в которой они возникли, а только во внешней процедуре.
- Пример не работает с пользовательскими функциями, так как ни TRY-CATCH, ни RAISERROR нельзя в них использовать.
- Когда хранимая процедура на Linked Server вызывает ошибку, эта ошибка может миновать обработчик в хранимой процедуре на локальном сервере и отправиться напрямую клиенту.
- Когда процедура вызвана как INSERT-EXEC, вы получите неприятную ошибку, потому что ROLLBACK TRANSACTION не допускается в данном случае.
- Как упомянуто выше, если вы используете error_handler_sp или SqlEventLog, мы потеряете одно сообщение, когда SQL Server выдаст два сообщения для одной ошибки. При использовании ;THROW такой проблемы нет.
Я рассказываю об этих ситуациях более подробно в других статьях этой серии.
Перед тем как закончить, я хочу кратко коснуться триггеров и клиентского кода.
Триггеры
Пример для обработки ошибок в триггерах не сильно отличается от того, что используется в хранимых процедурах, за исключением одной маленькой детали: вы не должны использовать выражение RETURN (потому что RETURN не допускается использовать в триггерах).
С триггерами важно понимать, что они являются частью команды, которая запустила триггер, и в триггере вы находитесь внутри транзакции, даже если не используете BEGIN TRANSACTION. Иногда я вижу на форумах людей, которые спрашивают, могут ли они написать триггер, который не откатывает в случае падения запустившую его команду
Ответ таков: нет способа сделать это надежно, поэтому не стоит даже пытаться. Если в этом есть необходимость, по возможности не следует использовать триггер вообще, а найти другое решение. Во второй и третьей частях я рассматриваю обработку ошибок в триггерах более подробно.
Клиентский код
У вас должна быть обработка ошибок в коде клиента, если он имеет доступ к базе. То есть вы должны всегда предполагать, что при любом вызове что-то может пойти не так. Как именно внедрить обработку ошибок, зависит от конкретной среды.
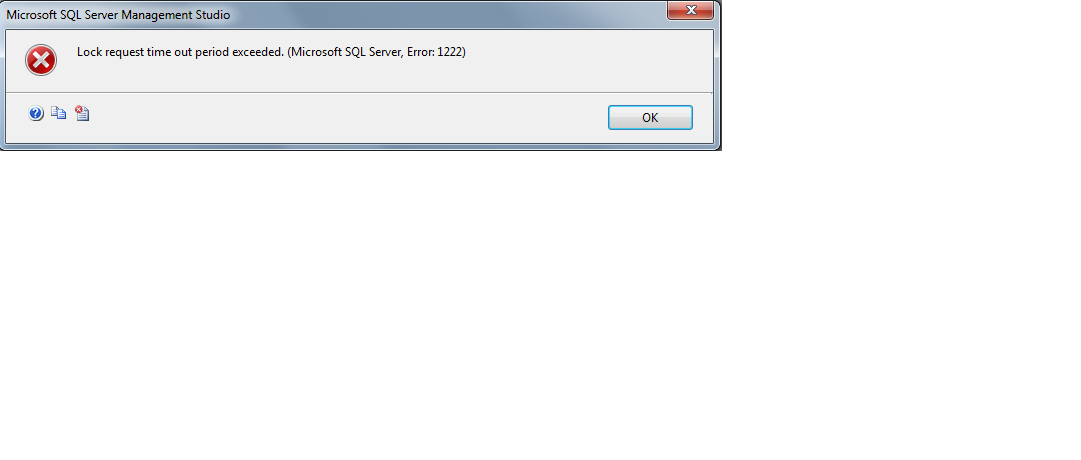

Здесь я только обращу внимание на важную вещь: реакцией на ошибку, возвращенную SQL Server, должно быть завершение запроса во избежание открытых бесхозных транзакций:
Это также применимо к знаменитому сообщению Timeout expired (которое является не сообщением от SQL Server, а от API).
Выводы
- Если есть возможность использовать Центр Управления Производительностью, лучше использовать его, т.к. он позволит вам сэкономить существенное время при расследовании ожиданий на блокировках.
- Стоит помнить, что сбор необходимой для анализа информации в нагруженной системе не является бесплатным (с точки зрения затрат памяти, процессорного времени, дисков). Поэтому нужно рассматривать каждый сбор информации как серьезное вмешательство в работу информационной системы, которое может существенно сказаться на качестве работы пользователей. Число таких вмешательств нужно стараться минимизировать. Для этого требуется заранее готовиться и стараться понимать, какие данные должны быть собраны на следующем шаге расследования.
- Ожидания на блокировках всегда являются проблемой. Если ожидания происходят при работе с одними и теми же данными, что-то не так с построенными бизнес-процессами. Если ожидания происходят, когда пользователи (со своей точки зрения) работают с разными данными, то это всегда ошибки программирования, которые необходимо устранять. Необходимо учитывать, что проблемой являются не только ошибки, но и избыточные впустую потраченные ресурсы в результате отката транзакции с ошибкой и возможного повтора транзакции с самого начала.
- Длительное выполнение операции с точки зрения пользователя не всегда является следствием ожидания на блокировках, но совершенно точно нужно уметь выявлять и исключать эту составляющую путем исправления найденных проблем.
- При выполнении тестов по методикам нагрузочного тестирования скорость выполнения операций одним пользователем и в нагрузочном тесте отличается в первую очередь в результате ожиданий. При этом производительность под нагрузкой никогда не будет выше, чем производительность одного пользователя. Ожидания на блокировках (управляемых и транзакционных на уровне СУБД) могут быть только частью всех имеющихся ожиданий.
Выводы
Механизм версионности при одинаковых нагрузках требует больше памяти. Если нет памяти, лучше решить вопрос установкой большего LOCK TIMEOUT (если приложение его выставляет).
Вопрос «что лучше: версионность или блокировки?» не решается, очевидно, в пользу версионности, вот почему:
Если памяти для СУБД мало — версионность работать будет, но пользоваться приложением будет нельзя (будет работать слишком медленно).Если памяти для СУБД много — время блокировок само по себе сократится (из-за ускорения записи и сокращения очередей на дисках) и преимущество неблокирующего чтения сойдет на нет.
В итоге, версионная у вас СУБД или блокирующая неважно, требуется адекватный объем памяти. Единственный плюс блокирующей СУБД, во всяком случае SQL Server перед Oracle в том, что при маленькой нагрузке можно работать на небольшом объеме памяти



