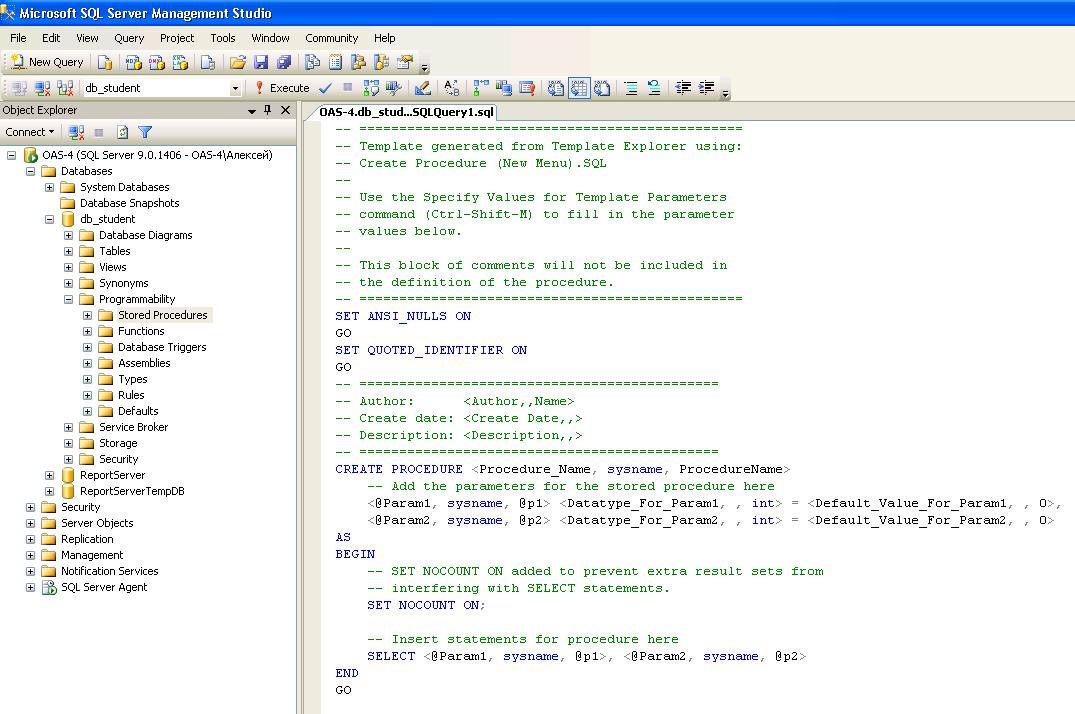
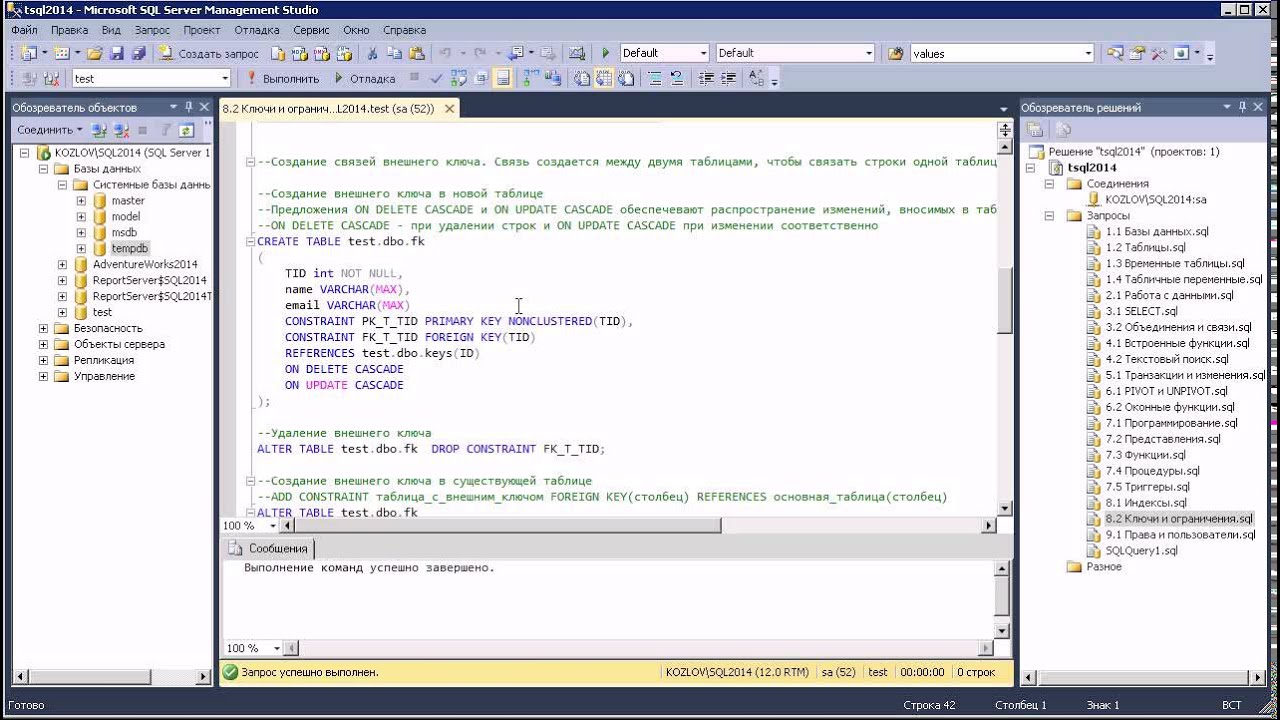
Основная грамматика
1. Создайте хранимую процедуру
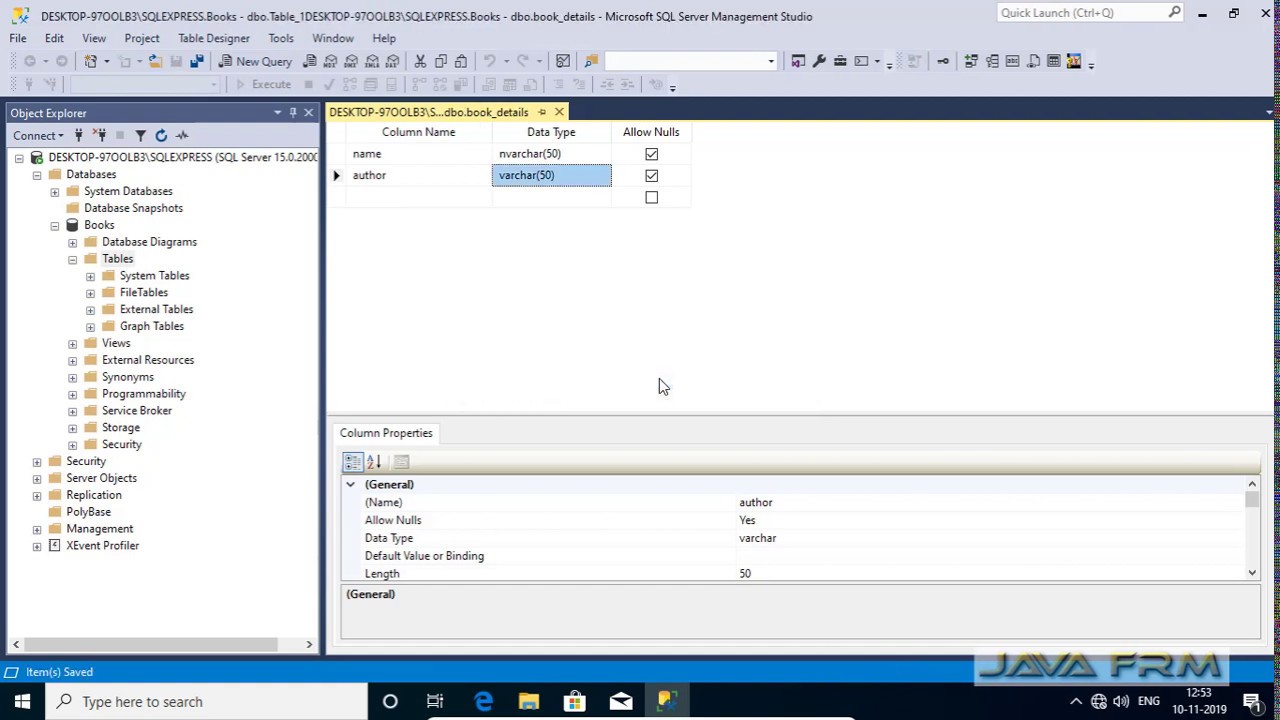
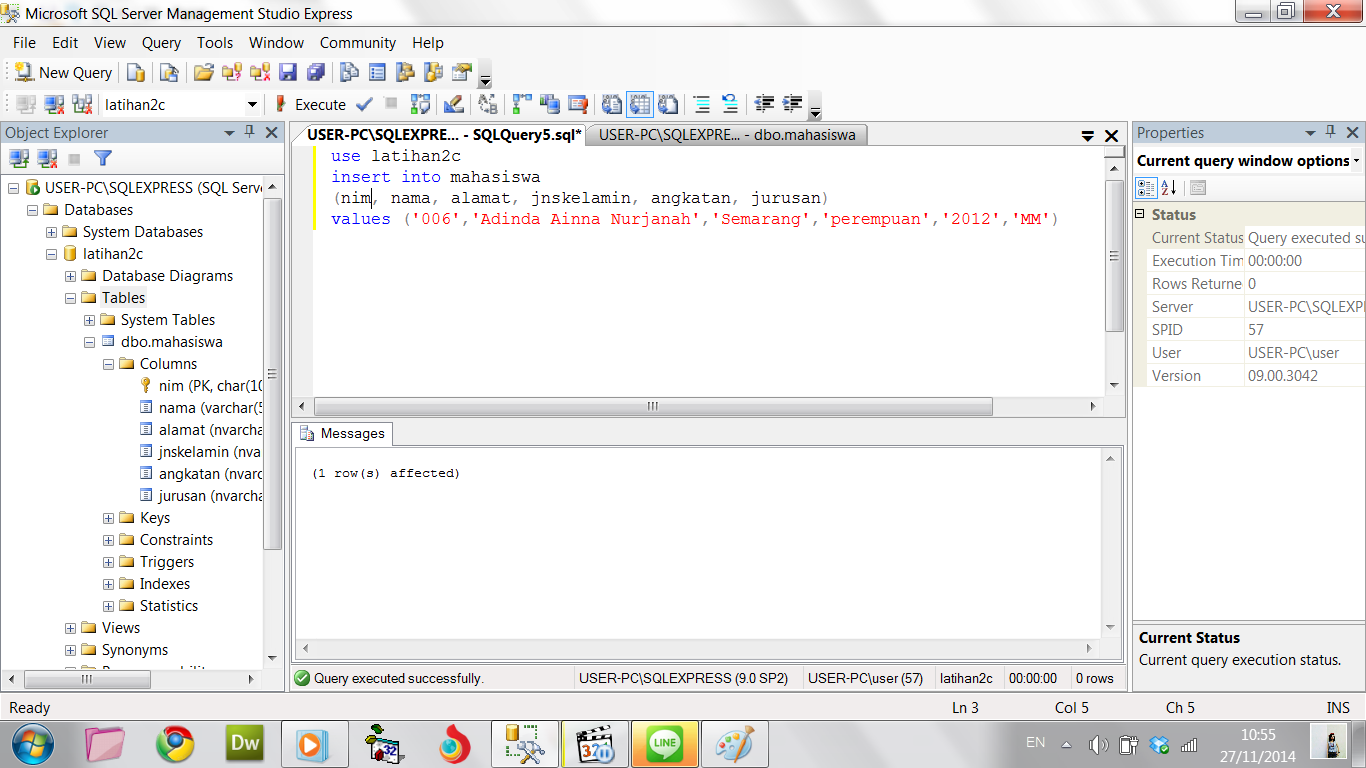
Создайте хранимую процедуру с именем selectData.
create procedure selectData()
начало — это начало выполнения, конец — это конец, а две строки кода — это логика хранимой процедуры.
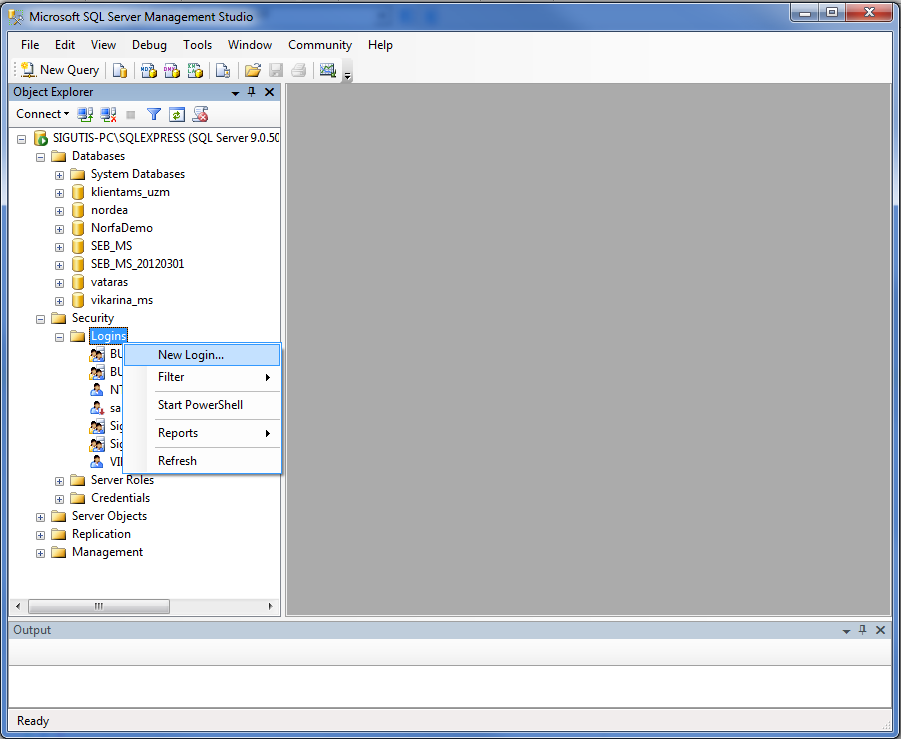
Вызов хранимых процедур
После создания, как вы вызываете хранимую процедуру?
Примечание. Независимо от того, имеет ли хранимая процедура параметры, вы должны добавить круглые скобки. Похоже на вызовы методов в Java.
3. Удалить хранимые процедуры
Почему у нас есть этот синтаксис? После того, как мы создали хранимую процедуру, если логику в ней нужно изменить, нам нужно выполнить синтаксис процедуры создания после модификации. Если вы не удалили и не выполнили синтаксис create, вам будет неправильно сказано, что хранимая процедура уже существует. Вы можете только удалить или изменить имена наших хранимых процедур.
Примечание. Не вызывайте синтаксис удаления в другой хранимой процедуре.
4, другой широко используемый синтаксис
Где применяют SQL
В индексе TOPDB популярность СУБД определяется по тому, как часто их гуглят. В декабре 2022 года первые пять мест в нём занимают именно реляционные СУБД — вместе они дают больше 70% поисковых запросов.
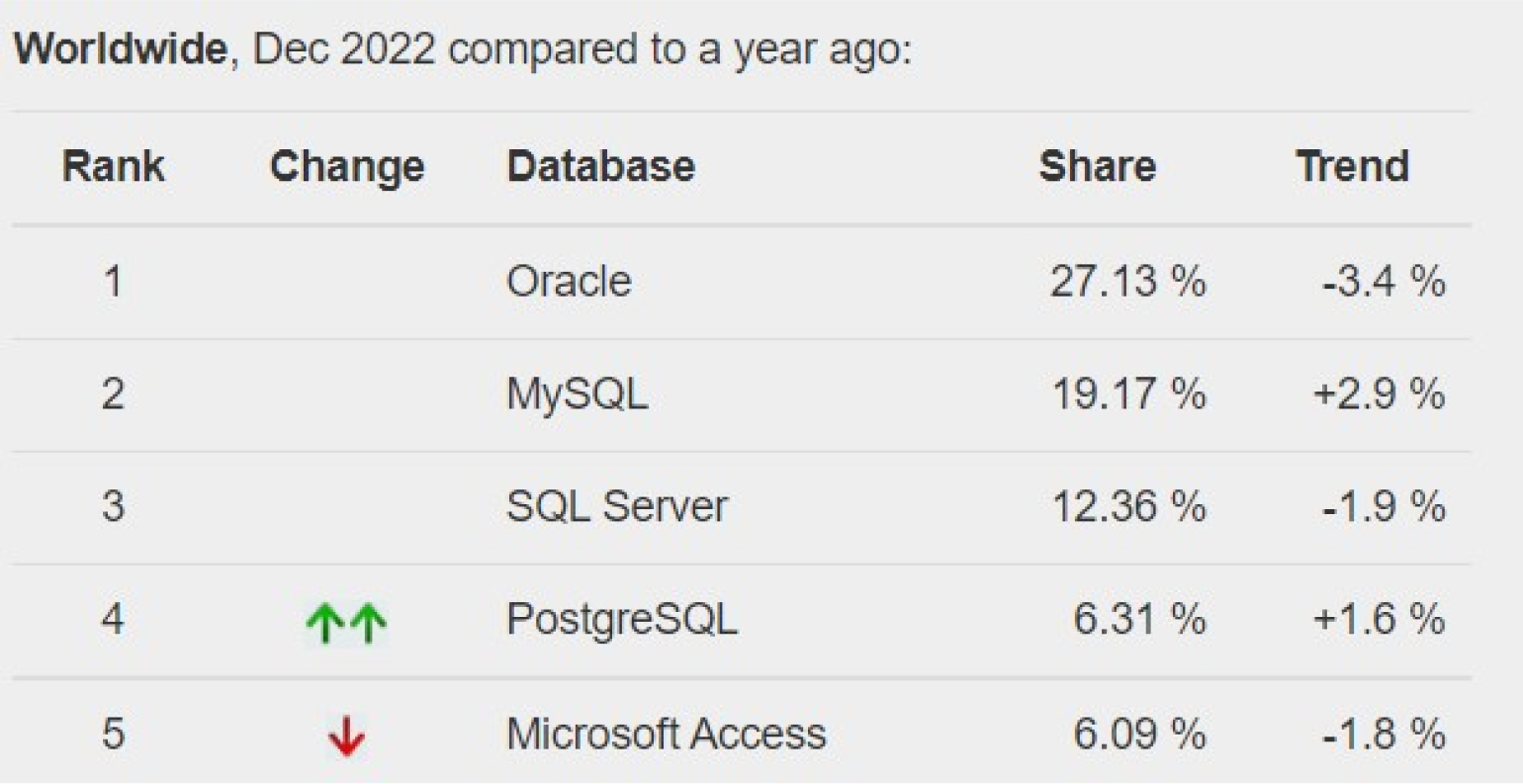
Скриншот: Top Database index / GitHub
Рейтинг DB-Engines даёт похожие цифры. В декабре 2022 года доля реляционных СУБД составляет 71,7%.
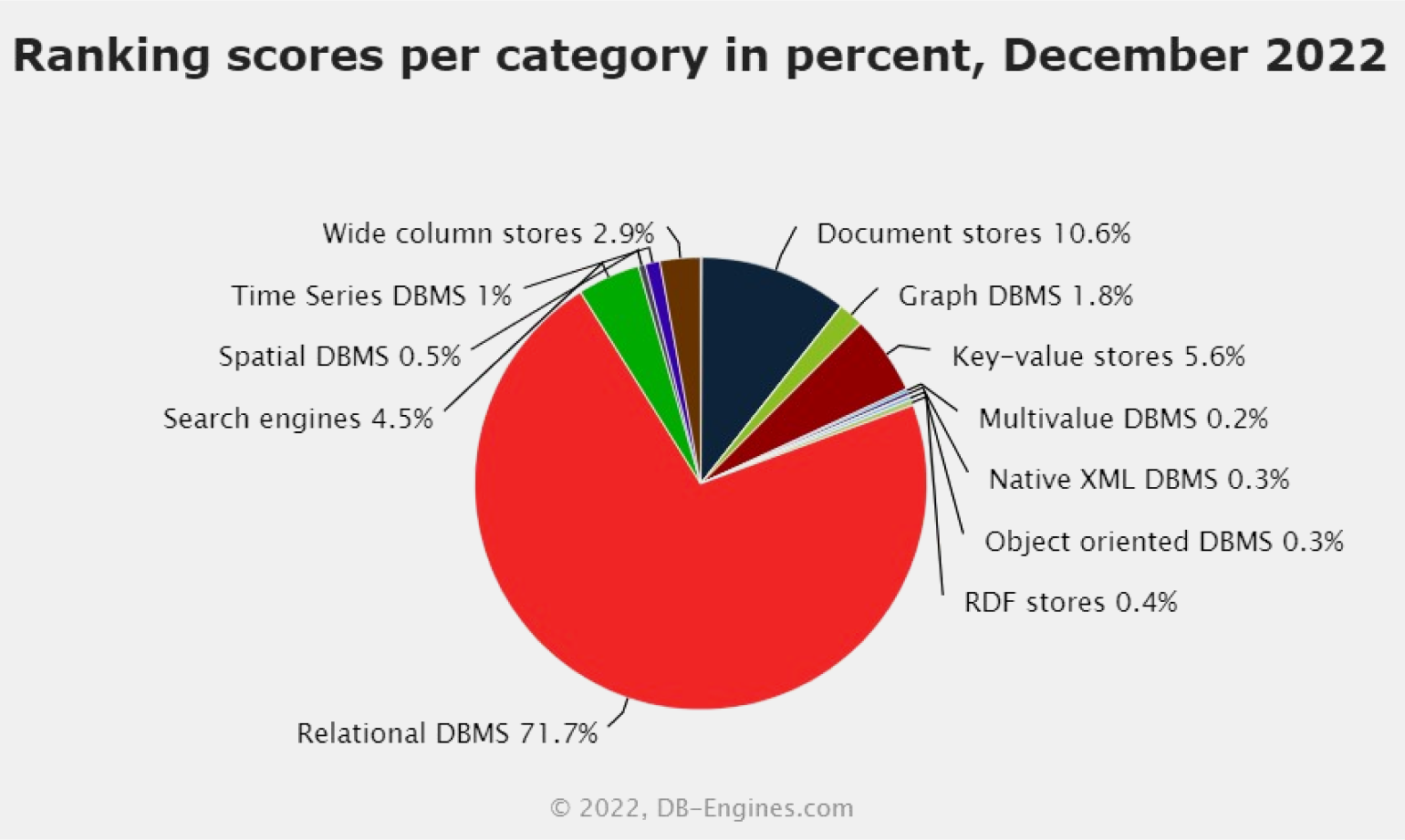
Скриншот: DB-Engines
Без баз данных не будет ни сайтов, ни сетевых приложений, ни крупных информационных систем — нужно же где-то хранить всю информацию. При этом реляционных БД — большинство, а чтобы управлять ими, нужен SQL. Поэтому мало какая вакансия бэкенд-разработчика обходится без требования владеть SQL. По крайней мере, мы такой не нашли.
Но умение работать с базами данных пригодится не только программисту.
Аналитики данных напрямую работают с «сырой» информацией. Чем лучше и свободнее они общаются с БД, тем проще им добывать и обрабатывать нужные данные в нужном виде.
Маркетологам SQL тоже будет полезен для решения аналитических задач.
Тестировщикам понадобится обращаться к БД, потому что это важный компонент любого информационного продукта.
Распространенные ошибки при выборе типа данных в T-SQL
В начале статьи я говорил, что выбор неоптимального типа данных может сказаться на размере базы данных, так вот одной из самых распространенных ошибок при проектировании таблицы является выбор для столбца, который должен содержать тип данных Boolean (т.е. 0 или 1), тип SMALLINT или INT. Как Вы уже поняли, такого типа данных как Boolean в T-SQL нет, поэтому для этих целей разработчики используют похожие (подходящие) типы данных и в большинстве случаев их выбор неправильный. Если Вам нужно хранить только значения 0 или 1 (т.е. как Boolean), то в T-SQL существует специальный тип данных BIT, SQL сервер выделяет для хранения всего 1 байт, но в отличие от типа TINYINT, под который также отводится 1 байт, SQL сервер оптимизирует хранение бит столбцов. Если таблица содержит не больше 8 бит столбцов, столбцы хранятся как 1 байт, если таких столбцов от 9 до 16, то 2 байта и т.д.
Для сравнения давайте посмотрим на разницу.
Таблица 1
--В строке 16 байт
CREATE TABLE TestTable1 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled INT NOT NULL, --4 байта
IsTest INT NOT NULL, --4 байта
)
Таблица 2 (с использованием BIT столбцов)
--В строке 9 байт
CREATE TABLE TestTable2 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled BIT NOT NULL, --1 байта
IsTest BIT NOT NULL, --0 байта
)
Сравнение
| Количество строк | Размер в мегабайтах (MB) | ||
| Таблица 1 | Таблица 2 (с использованием BIT столбцов) | Разница | |
| 1 000 | 0,02 | 0,01 | 0,01 |
| 10 000 | 0,15 | 0,09 | 0,07 |
| 100 000 | 1,53 | 0,86 | 0,67 |
| 1 000 000 | 15,26 | 8,58 | 6,68 |
| 10 000 000 | 152,59 | 85,83 | 66,76 |
| 100 000 000 | 1525,88 | 858,31 | 667,57 |
Как видите, после добавления нескольких миллионов строк разница будет ощутимая, и это на простой, маленькой, тестовой таблице.
Про типы данных Microsoft SQL Server у меня все, надеюсь, материал был Вам полезен! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
Нравится8Не нравится1
Функции и хранимые процедуры T-SQL
В Microsoft SQL Server существуют такие объекты базы данных, как функции и хранимые процедуры, которые используются для хранения неких уже реализованных алгоритмов на языке T-SQL.
Функции и хранимые процедуры используются в языке T-SQL для реализации бизнес логики, упрощения сложных SQL запросов, а также для написания различных инструкций администрирования баз данных и сервера, которые периодически необходимо выполнять.
Иными словами, функции и хранимые процедуры – это своего рода мини программы внутри базы данных, они помогают нам реализовывать нужные нам алгоритмы и хранить их в базе данных. Кроме этого, функции и хранимые процедуры позволяют декомпозировать одну глобальную задачу на несколько мелких, тем самым упрощая решение этой задачи и дальнейшее сопровождение этого решения, так как весь алгоритм становится модульным и более гибким.
У начинающих может возникнуть вопрос – а чем отличаются функции от процедур? Или это одно и то же?
Конечно же, это не одно и то же, и между этими понятиями, в контексте языка T-SQL, есть нескольких ключевых отличный.
Отличия функций от хранимых процедур в T-SQL
Давайте перейдем к рассмотрению основных отличный функций от хранимых процедур, а чтобы было более наглядно, сделаем это в виде таблицы.
Отличия функций от хранимых процедур в T-SQL
Давайте перейдем к рассмотрению основных отличный функций от хранимых процедур, а чтобы было более наглядно, сделаем это в виде таблицы.
HAVING
HAVING — применяется для фильтрации функций и столбцов сгруппированных при помощи GROUP BY указанных в SELECT.
Другими словами применяется для агрегатных функций(COUNT(), MAX() . ) и столбцов указанных в выражении SELECT и обработанных GROUP BY. Если нужно использовать что-то, что не указанно в SELECT, то лучше использовать WHERE.
Порядок выполнения такой:1. В SELECT указываем нужные столбцы или агрегатные функции(то с чем будем работать в GROUP BY и HAVING)2. В GROUP BY пишем по какому столбцу или функции их группируем3. В HAVING пишем условие фильтровки результата GROUP BY
Применяется последним и не оптимизируется. При использовании не по назначению на больших таблицах будут жуткие тормоза.
HAVING SQL: описание, синтаксис, примеры
SQL представляет собой стандарт языка для работы с реляционными базами данных. Он имеет в своем арсенале множество мощных инструментов манипулирования данными, хранящихся в виде таблиц.

Несомненно, возможность группировать данные при их выборке по определенному признаку является одним из таких инструментов. Оператор SQL HAVING наряду с оператором WHERE позволяет определять условия выборки уже сгруппированных некоторым образом данных.
В чём же ключевое различие?
Во-первых, в HAVING и только в нём можно писать условия по агрегатным функциям (SUM, COUNT, MAX, MIN и т. д.). То есть если вы хотите сделать что-то вроде COUNT(*) > 10, то это возможно сделать только в HAVING.
«Почему бы не оставить только HAVING?» — спросите вы. Всё кроется в том, как SQL Server выполняет запрос, в каком порядке происходит его разбор и работа с данными. WHERE выполняется до формирования групп GROUP BY. Это нужно для того, чтобы можно было оперировать как можно меньшим количеством данных и сэкономить ресурсы сервера и время пользователя.
Следующим этапом формируются группы, которые указаны в GROUP BY. После того как сформированы группы, можно накладывать условия на результаты агрегатных функций. И тут как раз наступает очередь HAVING: выполняются условия, которые вы задали.
Главное отличие HAVING от WHERE в том, что в HAVING можно наложить условия на результаты группировки, потому что порядок исполнения запроса устроен таким образом, что на этапе, когда выполняется WHERE, ещё нет групп, а HAVING выполняется уже после формирования групп.
Чем отличаются функции от хранимых процедур в T-SQL (Microsoft SQL Server)
Приветствую всех посетителей сайта Info-Comp.ru! Сегодня мы с Вами поговорим о том, чем же отличаются функции от хранимых процедур в Microsoft SQL Server, и для наглядности сформируем итоговую таблицу отличий.

Функции и хранимые процедуры T-SQL
В Microsoft SQL Server существуют такие объекты базы данных, как функции и хранимые процедуры, которые используются для хранения неких уже реализованных алгоритмов на языке T-SQL.
Функции и хранимые процедуры используются в языке T-SQL для реализации бизнес логики, упрощения сложных SQL запросов, а также для написания различных инструкций администрирования баз данных и сервера, которые периодически необходимо выполнять.
Иными словами, функции и хранимые процедуры – это своего рода мини программы внутри базы данных, они помогают нам реализовывать нужные нам алгоритмы и хранить их в базе данных. Кроме этого, функции и хранимые процедуры позволяют декомпозировать одну глобальную задачу на несколько мелких, тем самым упрощая решение этой задачи и дальнейшее сопровождение этого решения, так как весь алгоритм становится модульным и более гибким.
У начинающих может возникнуть вопрос – а чем отличаются функции от процедур? Или это одно и то же?
Конечно же, это не одно и то же, и между этими понятиями, в контексте языка T-SQL, есть нескольких ключевых отличный.
Процедуры
Процедуры DECLARE SQL — это процедуры, полностью реализованные с использованием SQL, которые могут использоваться для инкапсуляции логики. Та же в свою очередь может быть вызвана как подпрограмма программирования.

В архитектуре базы данных существует много полезных приложений SQL-процедур. Они используются для создания простых сценариев для быстрого запроса на преобразование и обновление данных, генерации базовых отчетов, повышения производительности и модуляции приложений, а также для улучшения общего проектирования и обеспечения безопасности баз данных.
Существует множество функций процедур, которые делают их мощным инструментом обработки
Прежде чем принять решение о внедрении процедуры SQL, важно понять, какие аналоги находятся в контексте подпрограмм, как они реализованы и как их можно использовать
Диалекты языка SQL (расширения SQL)
Язык SQL – это стандарт, он реализован во всех реляционных базах данных, но у каждой СУБД есть расширение этого стандарта, есть собственный язык работы с данными, его обычно называют диалектом SQL, который, конечно же, основан на SQL, но предоставляет больше возможностей для полноценного программирования, кроме того, такой внутренний язык дает возможность получать системную информацию и упрощать SQL запросы.
Вот некоторые диалекты языка SQL:
- Transact-SQL (сокращенно T-SQL) – используется в Microsoft SQL Server;
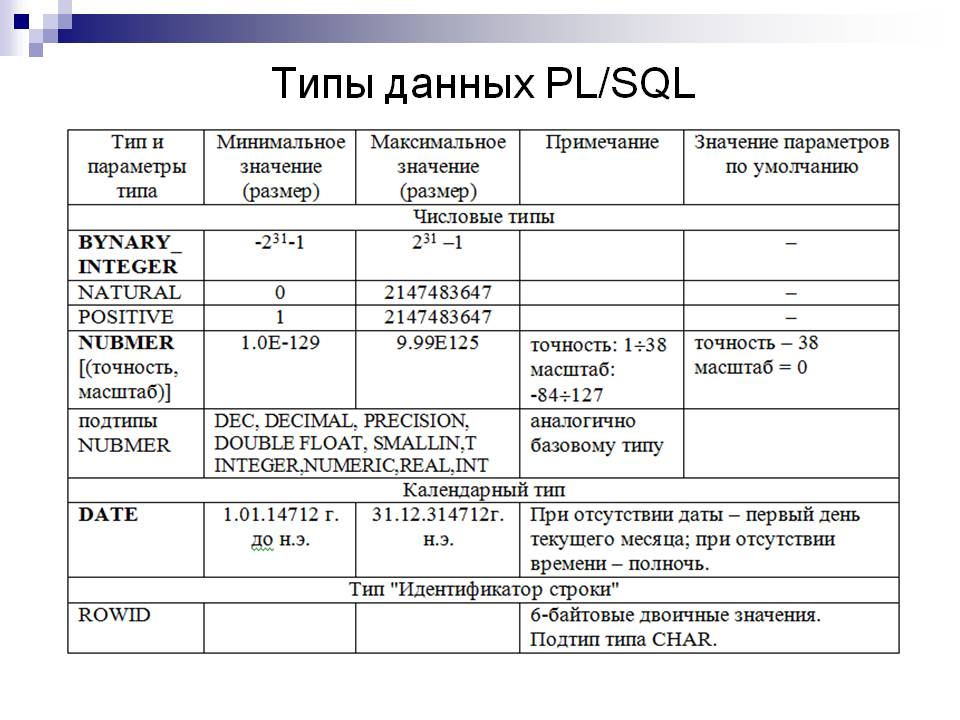
- PL/SQL (Procedural Language / Structured Query Language) – используется в Oracle Database;
- PL/pgSQL (Procedural Language/PostGres Structured Query Language) – используется в PostgreSQL.
Таким образом, от СУБД зависит, на каком расширении Вы будете писать SQL инструкции. Если говорить о простых SQL запросах, например,
то, безусловно, во всех СУБД такие запросы работать будут, ведь SQL — это стандарт.
Примечание! Это простой SQL запрос на выборку данных из одной таблицы, выводятся два столбца.
Однако если Вы собираетесь программировать, использовать все внутренние возможности СУБД (разрабатывать процедуры, использовать встроенные функции, получать системную информацию и т.д.), то Вам необходимо изучать конкретный диалект SQL и практиковаться соответственно в той СУБД, в которой используется этот диалект
Это важно, ведь синтаксис многих конструкций различается так же, как различаются возможности и многое другое. И если, допустим, Вы запустите SQL инструкцию, в которой использованы возможности определенного расширения SQL, на другой СУБД, то такая инструкция, конечно же, не выполнится
Например, лично я специализируюсь на языке T-SQL, и соответственно, работаю с Microsoft SQL Server, вот уже более 8 лет!
Хотя, конечно же, с другими СУБД я также работал, одно время я сопровождал два приложения, одно из которых работало с PostgreSQL, ну а второе, наверное, уже понятно, с Microsoft SQL Server.
С MySQL я работал, как, наверное, и многие, в рамках сопровождения сайтов и сервисов. Ну а с Oracle Database мне приходилось работать в рамках других проектов.
Весь свой накопленный опыт в части языка T-SQL я сгруппировал в одном месте и оформил в виде книг, поэтому, если у Вас есть желание изучить язык Transact-SQL (T-SQL), рекомендую почитать мои книги:
- Путь программиста T-SQL – самоучитель по языку Transact-SQL для начинающих. В ней я подробно рассказываю обо всех конструкциях языка и последовательно перехожу от простого к сложному. Подходит для комплексного изучения языка T-SQL;
- Стиль программирования на T-SQL – основы правильного написания кода. Книга, направленная на повышение качества T-SQL кода (для тех, кто уже знаком с языком T-SQL, т.е. знает хотя бы основы).
Русские Блоги
Первое реальное знакомство с хранимыми процедурами, в предыдущей работе, хотя я тоже был разоблачен, но все вызывают хранимые процедуры, написанные другими для выполнения. Не понял это в глубине. К счастью, в моей текущей работе, когда я использую sql для решения проблемы, я обнаружил, что единственное число sql не уверено. Моя первая реакция — использовать хранимые процедуры. Учитесь продавать сейчас, изучает простые хранимые процедуры и решает проблемы на работе. Тогда я поделюсь с вами шагами, которые я узнал. Как вы перешли от хранимой процедуры к новичку хранимой процедуры? Что касается Даниэля, он еще не достиг этого уровня. Тревожно есть горячий тофу, шаг за шагом. У начинающих не должно быть высоких глаз и низких рук .
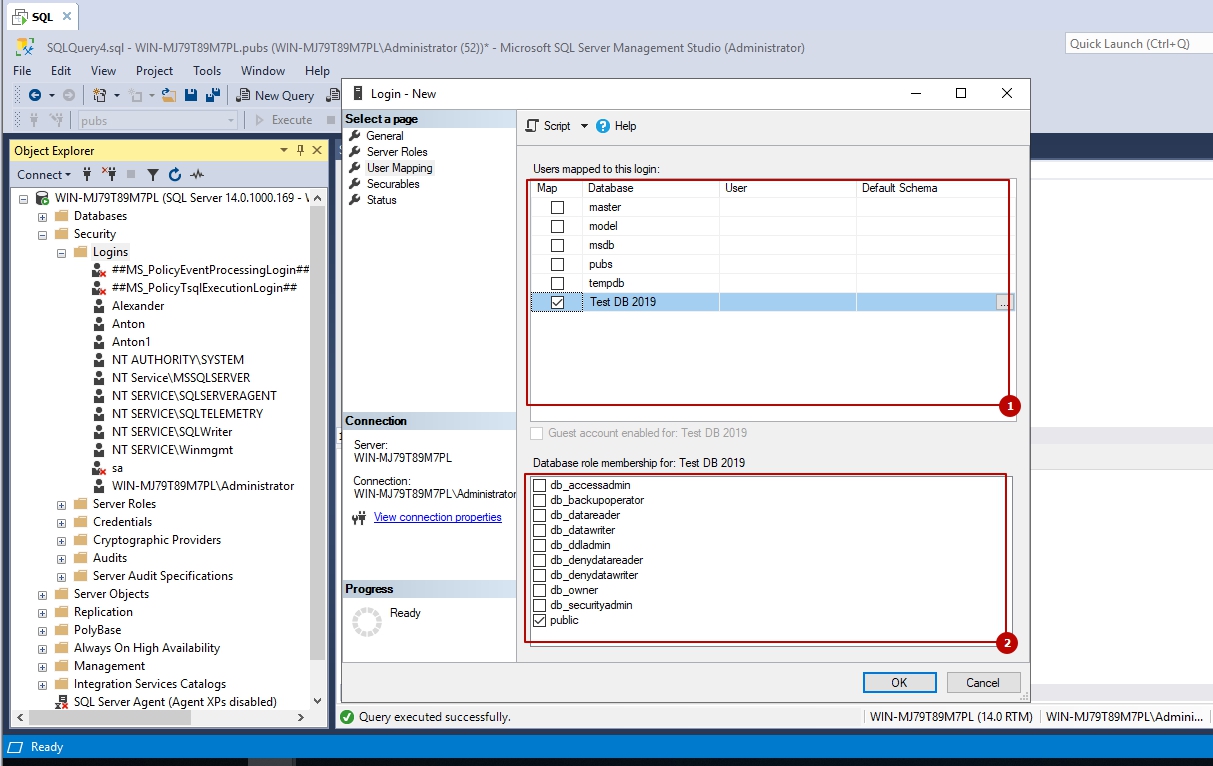
Указание параметров
Пользовательская функция может принимать 0 или более входных параметров и возвращать либо скалярное, либо табличное значение. Максимальное число входных параметров для функции равно 1024. Если для параметра функции установлено значение по умолчанию, необходимо указать ключевое слово DEFAULT при вызове функции, чтобы получить установленное по умолчанию значение. Это поведение отличается от использования параметров со значениями по умолчанию в пользовательских хранимых процедурах, в которых пропущенный параметр также принимает значение по умолчанию. Определяемые пользователем функции не поддерживают выходные параметры.
3.3.3. Использование функций
Как выполнить такую функцию? Да также, как и многие другие системные функции (например, GETDATE()). Например, следующий пример использует функцию в операторе SELECT:
SELECT dbo.GetSumm('Картофель', '03.03.2005')
В этом примере, оператор SELECT возвращает результат выполнения функции GetSumm. Функция принадлежит пользователю dbo, поэтому перед именем я указал владельца. После имени в скобках должны быть перечислены параметры в том же порядке, что и при объявлении функции. В данном примере я запрашиваю затраты на картофель, купленный 3.3.2005.
Выполните следующий запрос и убедитесь, что он вернул тот же результат, что и созданная нами функция:
SELECT Цена*Количество FROM Товары WHERE ='Картофель' AND Дата='03.03.2005'
Функции можно использовать не только в операторе SELECT, но и напрямую, присваивая значение переменной. Например:
DECLARE @Summ numeric(10,2)
SET @Summ=dbo.GetSumm('Картофель', '03.03.2005')
PRINT @Summ
В этом примере мы объявили переменную @Summ типа numeric(10,2). Именно такой тип возвращает функция. В следующей строке переменной присваивается результат выполнения Summ, с помощью SET.
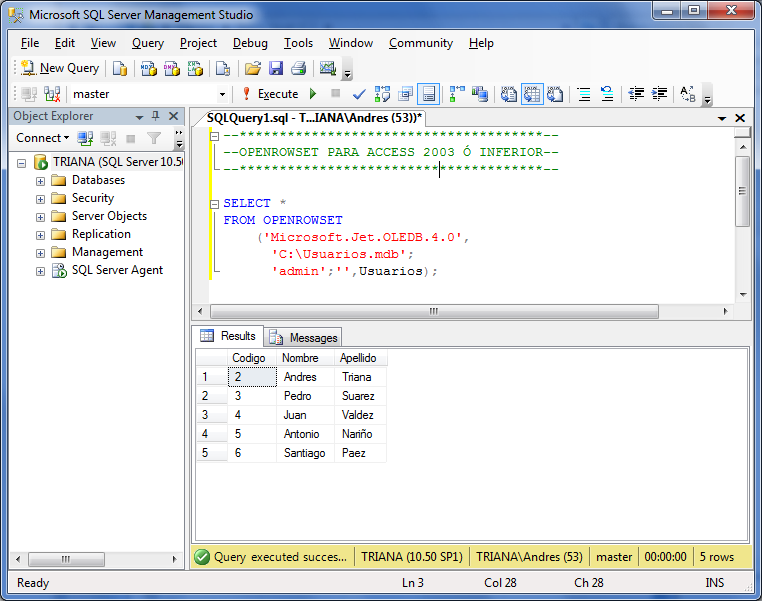
Давайте посмотрим, что произойдет, если передать функции такие параметры, при которых запрос функции вернет более одной строки. В нашей таблице товаров сочетание даты и название не дает уникальности, потому что мы ее нарушили. Первичного ключа в таблице также нет, и среди товаров у меня есть четыре строки, которые имеют свои точные копии. Это нарушает правило уникальности строк в реляционных базах, но очень наглядно показывает, что в реальной жизни нарушать его нельзя.
Итак, в моей таблице есть две покупки хлеба 1.1.2005-го числа. Попробую запросить у функцию сумму:
SELECT dbo.GetSumm('Хлеб', '01.01.2005')
Результатом будет только одно число, хотя строки две. А какую строку из двух вернул сервер? Никто точно сказать не может, потому что они обе одинаковые и без единого различия. Поэтому сервер скорей всего вернул первую из строк.
3.3.5. Много операторная функция возвращающая таблицу
Все функции, созданные в разделе 3.3.5 могут возвращать таблицу, сгенерированную только одним оператором SQL. А как же тогда сделать возможность выполнять несколько операций? Например, вы можете захотеть выполнять дополнительные проверки входных параметров для обеспечения безопасности. Проверки лишними не бывает, особенно входных данных и особенно, если эти входные данные указываются пользователем.
Следующий пример показывает, как создать функцию, которая может вернуть в качестве результата таблицу, и при этом, в теле функции могут выполняться несколько операторов:
CREATE FUNCTION имя (параметры) RETURNS имя_переменной TABLE (описание вида таблицы, в которой будет представлен результат) AS BEGIN Выполнение любого количества операций RETURN END
Это упрощенный вид создания процедуры. Более полный вид мы рассматривали в начале главы, а сейчас я упростил объявление, чтобы проще было его разбирать.
Объявление больше похоже на создание скалярных функций. Первая строка без изменений. В секции RETURNS объявляется переменная, которая имеет тип TABLE. После этого, в скобках нужно описать поля результирующей таблицы. После ключевого слова AS идtт пара операторов BEGIN и END, между которыми может выполняться какое угодно количество операций. Выполнение операций заканчивается ключевым словом RETURN.
Вот тут есть одно отличие от скалярных функций – после RETURN мы указывали имя переменной, значение которой должно стать результатом. В данном случае ничего указывать не надо. Мы уже объявили переменную в секции RETURNS и описали формат этой переменной. В теле функции мы можем и должны наполнить эту переменную значениями и именно это попадет в результат.
Теперь посмотрим на пример создания функции:
CREATE FUNCTION getFIO () RETURNS @ret TABLE (idPeoples int primary key, vcFIO varchar(100)) AS BEGIN INSERT @ret SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName FROM tbPeoples; RETURN END
В данном примере в качестве результата объявлена переменная @ret, которая является таблицей из двух полей «idPeoples» типа int и «vcFIO» типа varchar длинной в 50 символов. В теле функции в эту таблицу записываются значения из таблицы tbPeoples и выполняется оператор RETURN, завершающий выполнение функции.
В использовании, такая функция ничем не отличается от рассмотренных ранее. Например, следующий запрос выбирает все данные, которые возвращает функция:
SELECT * FROM GetFIO()
Что такое функция
Функция — это набор инструкций для выполнения конкретной задачи. Почти все языки программирования, такие как C ++, C, Java и Python, позволяют программисту писать функции. Функция позволяет снова и снова использовать один и тот же набор инструкций. Кроме того, он организует весь код.
Рисунок 2: Основная функция в C
Функция имеет следующий синтаксис.
return_type имя_функции (список параметров) {
// операторы внутри функции
}
Могут быть функции, которые принимают параметры и не принимают параметры. Обратитесь ниже функции.
void displayMessage () {
prinf («Hello World n»);
}
Выше простая функция C. Он не получает никаких параметров. Он просто выводит сообщение «Hello World» на консоль. Эта функция не возвращает никакого значения. Следовательно, тип возвращаемого значения void.
Функция также может принимать параметры. Смотрите приведенный ниже пример.
int calArea (int width, int length) {
int area = ширина * длина;
зона возврата;
}
Выше приведена функция с именем calArea. Он получает два целочисленных параметра, называемые шириной и длиной. Внутри функции создается локальная переменная с именем «area». Он присваивается с умножением двух значений. Наконец, рассчитанная площадь возвращается. Это целое число. Следовательно, тип возвращаемого значения — int.
About Daniel Calbimonte
Daniel Calbimonte is a Microsoft Most Valuable Professional, Microsoft Certified Trainer and Microsoft Certified IT Professional for SQL Server. He is an accomplished SSIS author, teacher at IT Academies and has over 13 years of experience working with different databases.
He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams.
He also helps with translating SQLShack articles to Spanish
View all posts by Daniel Calbimonte
Параметры установки
| Новые функции или обновления | Сведения |
|---|---|
| Новые параметры настройки памяти | Задает конфигурации минимальной памяти сервера (МБ) и максимальной памяти сервера (МБ) во время установки. См. статью , а также в описаниях параметров , и в разделе . Предложенное значение соответствует рекомендациям по настройке памяти, приведенным в разделе . |
| Новые параметры настройки параллелизма | Задает параметр максимального уровня параллелизма во время установки. См. статью и в описании параметра в разделе . Значение по умолчанию соответствует рекомендациям по максимальной степени параллелизма, приведенным в разделе . |
| Предупреждение при установке ключа продукта лицензии Server/CAL | Если вводится ключ продукта лицензии Enterprise Server или CAL и при включенной технологии Hyper-Threading на компьютере установлено более 20 физических ядер или 40 логических ядер, во время установки отобразится предупреждение. Пользователи по-прежнему могут подтвердить ограничение и продолжить установку, или ввести ключ лицензии, поддерживающий максимальное число процессоров операционной системы. |
Работа с индексами SQL Server
Советы по созданию кластерных индексов
- Первичный ключ не всегда должен быть кластерным индексом. Если Вы создаете первичный ключ, тогда SQL сервер автоматически делает первичный ключ кластерным индексом. Первичный ключ должен быть кластерным индексом, только если он отвечает одной из нижеследующих рекомендаций.
- Кластерные индексы идеальны для запросов, где есть выбор по диапазону или вы нуждаетесь в сортированных результатах. Так происходит потому, что данные в кластерном индексе физически отсортированы по какому-то столбцу. Запросы, получающие выгоду от кластерных индексов, обычно включают в себя операторы BETWEEN, <, >, GROUP BY, ORDER BY, и агрегативные операторы типа MAX, MIN, и COUNT.
- Кластерные индексы хороши для запросов, которые ищут запись с уникальным значением (типа номера служащего) и когда Вы должны вернуть большую часть данных из записи или всю запись. Так происходит потому, что запрос покрывается индексом.
- Кластерные индексы хороши для запросов, которые обращаются к столбцам с ограниченным числом значений, например столбцы, содержащие данные о странах или штатах. Но если данные столбца мало отличаются, например, значения типа «да/нет», «мужчина/женщина», то такие столбцы вообще не должны индексироваться.
- Кластерные индексы хороши для запросов, которые используют операторы GROUP BY или JOIN.
- Кластерные индексы хороши для запросов, которые возвращают много записей, потому что данные находятся в индексе, и нет необходимости искать их где-то еще.
- Избегайте помещать кластерный индекс в столбцы, в которых содержатся постоянно возрастающие величины, например, даты, подверженные частым вставкам в таблицу (INSERT). Так как данные в кластерном индексе должны быть отсортированы, кластерный индекс на инкрементирующемся столбце вынуждает новые данные быть вставленным в ту же самую страницу в таблице, что создает «горячую зону в таблице» и приводит к большому объему дискового ввода-вывода. Постарайтесь найти другой столбец, который мог бы стать кластерным индексом.
Советы по выбору некластерных индексов
- Некластерные индексы лучше подходят для запросов, которые возвращают немного записей (включая только одну запись) и где индекс имеет хорошую селективность (более чем 95 %).
- Если столбец в таблице не содержит по крайней мере 95% уникальных значений, тогда очень вероятно, что Оптимизатор Запроса SQL сервера не будет использовать некластерный индекс, основанный на этом столбце. Поэтому добавляйте некластерные индексы к столбцам, которые имеют хотя бы 95% уникальных записей. Например, столбец с «Да» или «Нет» не имеет 95% уникальных записей.
- Постарайтесь сделать ваши индексы как можно меньшего размера (особенно для многостолбцовых индексов). Это уменьшает размер индекса и уменьшает число чтений, необходимых, чтобы прочитать индекс, что увеличивает производительность.
- Если возможно, создавайте индексы на столбцах, которые имеют целочисленные значения вместо символов. Целочисленные значения имеют меньше потерь производительности, чем символьные значения.
- Если Вы знаете, что ваше приложение будет выполнять один и тот же запрос много раз на той же самой таблице, рассмотрите создание покрывающего индекса на таблице. Покрывающий индекс включает все столбцы, упомянутые в запросе. Из-за этого индекс содержит все данные, которые Вы ищете, и SQL сервер не должен искать фактические данные в таблице, что сокращает логический и/или физический ввод — вывод. С другой стороны, если индекс становится слишком большим (слишком много столбцов), это может увеличить объем ввода — вывода и ухудшить производительность.
- Индекс полезен для запроса только в том случае, если оператор WHERE запроса соответствует столбцу (столбцам), которые являются крайними левыми в индексе. Так, если Вы создаете составной индекс, типа «City, State», тогда запрос » WHERE City = ‘Хьюстон’ » будет использовать индекс, но запрос » WHERE State = ‘TX’ » не будет использовать индекс.
- Любая операция над полем в предикате поиска, которое лежит под индексом, сводит на нет его использование. where isnull(field,’’) = ‘’ здесь индекс не используется, where field = ‘’ and field is not null — здесь используется.
Бывает ли слишком много индексов?
Да. Проблема с лишними индексами состоит в том, что SQL сервер должен изменять их при любых изменениях таблицы (INSERT, UPDATE, DELETE).
Лучшим решением ставить сомнительный индекс или нет, будет подождать и собрать статистику по работе индексов.
Лучшие кандидаты на установку индекса
- Это поля, по которым идет Join
- Поля связи, участвующие в подзапросах
- Поля, по которым идет фильтрация в where
- Поля, по которым выполняется сортировка.
Функции и хранимые процедуры T-SQL
В Microsoft SQL Server существуют такие объекты базы данных, как функции и хранимые процедуры, которые используются для хранения неких уже реализованных алгоритмов на языке T-SQL.
Функции и хранимые процедуры используются в языке T-SQL для реализации бизнес логики, упрощения сложных SQL запросов, а также для написания различных инструкций администрирования баз данных и сервера, которые периодически необходимо выполнять.
Иными словами, функции и хранимые процедуры – это своего рода мини программы внутри базы данных, они помогают нам реализовывать нужные нам алгоритмы и хранить их в базе данных. Кроме этого, функции и хранимые процедуры позволяют декомпозировать одну глобальную задачу на несколько мелких, тем самым упрощая решение этой задачи и дальнейшее сопровождение этого решения, так как весь алгоритм становится модульным и более гибким.
У начинающих может возникнуть вопрос – а чем отличаются функции от процедур? Или это одно и то же?
Конечно же, это не одно и то же, и между этими понятиями, в контексте языка T-SQL, есть нескольких ключевых отличный.
Отличия функций от хранимых процедур в T-SQL
Давайте перейдем к рассмотрению основных отличный функций от хранимых процедур, а чтобы было более наглядно, сделаем это в виде таблицы.
Что такое СУБД
У Вас может возникнуть вопрос, если база данных это некая информация, которая хранится в таблицах, то как она выглядит физически? Как на нее посмотреть в целом?
Если очень коротко, то это просто файл, созданный в специальном формате, именно так и выглядит база данных (в большинстве случаев БД включает несколько файлов, но сейчас на этом уровне это не так важно). Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е
реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами
Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е. реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами.


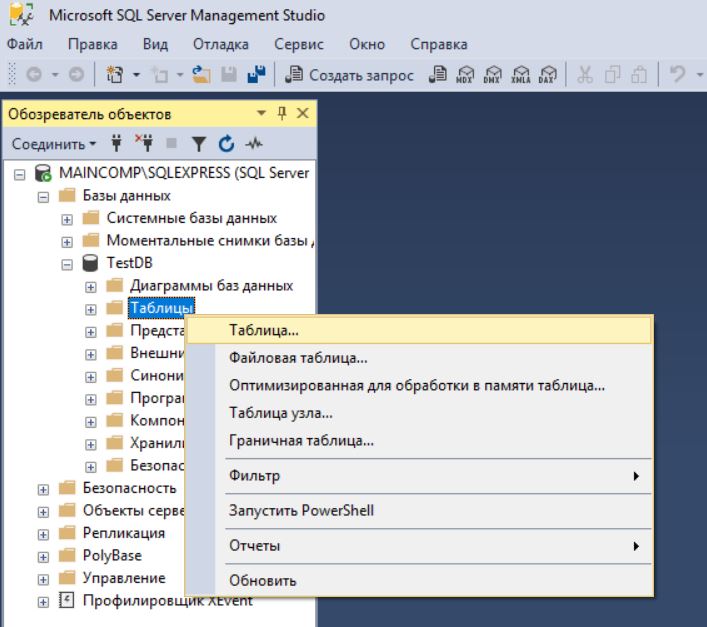

Таким инструментом как раз и выступает СУБД – это система управления базами данных, сокращенно СУБД.
Инструкции, допустимые в функциях
К типам инструкций, допустимым внутри функций, относятся следующие.
-
Инструкции , используемые для определения переменных и курсоров, локальных для данной функции.
-
Присвоение значений объектам, локальным для данной функции, например присвоение значений скалярным и табличным локальным переменным с помощью инструкции .
-
Операции над курсорами, обращающиеся к локальным курсорам и выполняющие их объявление, открытие, закрытие и освобождение внутри функции. Операторы, возвращающие данные клиенту, не допускаются. Разрешены только инструкции FETCH, присваивающие значения локальным переменным с помощью предложения .
-
Инструкции управления потоком, за исключением инструкций .
-
Инструкции , содержащие списки выборки с выражениями, присваивающими значения переменным, локальным для данной функции.
-
Инструкции , и , изменяющие табличные переменные, локальные для данной функции.
-
Инструкции , вызывающие расширенную хранимую процедуру.
Встроенные системные функции
Следующие недетерминированные встроенные функции могут быть использованы в определяемых пользователем функциях языка Transact-SQL.
- CURRENT_TIMESTAMP
- GET_TRANSMISSION_STATUS
- GETDATE
- GETUTCDATE
- @@CONNECTIONS
- @@CPU_BUSY
- @@DBTS
- @@IDLE
- @@IO_BUSY
- @@MAX_CONNECTIONS
- @@PACK_RECEIVED
- @@PACK_SENT
- @@PACKET_ERRORS
- @@TIMETICKS
- @@TOTAL_ERRORS
- @@TOTAL_READ
- @@TOTAL_WRITE
Следующие недетерминированные встроенные функции нельзя использовать в определяемых пользователем функциях на языке Transact-SQL.
- NEWID
- NEWSEQUENTIALID
- RAND
- TEXTPTR
Список детерминированных и недетерминированных встроенных системных функций см. в разделе Детерминированные и недетерминированные функции.
Типы данных SQL
Типы данных SQL разделяются на три группы: — строковые; — с плавающей точкой (дробные числа); — целые числа, дата и время.
1. Типы данных SQL строковые
| Типы данных SQL | Описание |
|---|---|
| Строки фиксированной длиной (могут содержать буквы, цифры и специальные символы). Фиксированный размер указан в скобках. Можно записать до 255 символов | |
| Может хранить не более 255 символов. | |
| Может хранить не более 255 символов. | |
| Может хранить не более 65 535 символов. | |
| Может хранить не более 65 535 символов. | |
| Может хранить не более 16 777 215 символов. | |
| Может хранить не более 16 777 215 символов. | |
| Может хранить не более 4 294 967 295 символов. | |
| Может хранить не более 4 294 967 295 символов. | |
| Позволяет вводить список допустимых значений. Можно ввести до 65535 значений в SQL Тип данных ENUM список. Если при вставке значения не будет присутствовать в списке ENUM, то мы получим пустое значение. Ввести возможные значения можно в таком формате: | |
| SQL Тип данных SET напоминает ENUM за исключением того, что SET может содержать до 64 значений. |
2. Типы данных SQL с плавающей точкой (дробные числа) и целые числа
| Типы данных SQL | Описание |
|---|---|
| Может хранить числа от -128 до 127 | |
| Диапазон от -32 768 до 32 767 | |
| Диапазон от -8 388 608 до 8 388 607 | |
| Диапазон от -2 147 483 648 до 2 147 483 647 | |
| Диапазон от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 | |
| Число с плавающей точкой небольшой точности. | |
| Число с плавающей точкой двойной точности. | |
| Дробное число, хранящееся в виде строки. |
3. Типы данных SQL — Дата и время
| Типы данных SQL | Описание |
|---|---|
| Дата в формате ГГГГ-ММ-ДД | |
| Дата и время в формате | |
| Дата и время в формате timestamp. Однако при получении значения поля оно отображается не в формате timestamp, а в виде ГГГГ-ММ-ДД ЧЧ:ММ:СС | |
| Время в формате | |
| Год в двух значной или в четырехзначном формате. |