Дефрагментация индекса (реорганизация или перестроение).
В процессе работы базы данных 1С Предприятия, в результате постоянной записи и удаления данных, образуются пустые (фрагментированные) области. По этой причине может увеличиваться бесполезный объем БД и замедляться скорость взаимодействия с ней.
Для устранения фрагментированных областей баз данных в MS SQL существует возможность проведения Реорганизации индекса и Перестроение индекса.
В чем разница между реорганизацией и перестроением?
Перестроение индекса означает, что фрагментация будет устранена путем удаления и пересоздания индексов.
При Реорганизации индекска происходит перестроение индексов в соответствии с логическим порядком. Этот способ наименее ресурсозатратный и является более предпочтительным для регулярного обслуживания баз данных.
В каких случаях требуется реорганизация индекса?
- Уровень фрагментации от 5% до 30%, то проводим реорганизацию.
- Фрагментация свыше 30% необходимо проводить перестроение индекса
Под выполнение этих задач очень подходит инструкция Transact-SQL со следующим содержимым:
Создаем вложенный план с названием «Дефрагментация индекса и обновление статистики» с расписанием раз в день в 4:00 и перетаскиваем в него из Панели элементов Задачу «Выполнение инструкции T-SQL».
Вставляем в задачу приведенную выше инструкцию T-SQL.
When to Create or Update Statistics
When to Create Statistics
Often columns being used in JOIN, WHERE, ORDER BY, or GROUP clauses are good candidate to have up-to-date statistics on them. Though the SQL Server Query Optimizer creates single column statistics when the AUTO_CREATE_STATISTICS database property is set to ON or when you create indexes on the table or views (statistics are created on the key columns of the indexes), there might be times when you need to create additional statistics using the CREATE STATISTICS command to capture cardinality, statistical correlations so that it enables the SQL Server Query Optimizer to create improved query plans.
When you find a query predicate containing multiple columns with cross column relationships and dependencies you should create multi-column statistics. These multi-column statistics contain cross-column correlation statistics, often referred to as densities, to improve the cardinality estimates when query results depend on data relationships among multiple columns.
When creating multi-column statistics, be sure to put columns in the right order as this impacts the effectiveness of densities for making cardinality estimates. For example, a statistic created on these columns and in order – Name, Age, and Salary. In this case, the statistics object will have densities for the following column prefixes: (Name), (Name, Age), and (Name, Age, Salary). Now if your query uses Name and Salary without using Age, the density is not available for cardinality estimates.
When to Update Statistics
Substantial data change operations (like insert, update, delete, or merge) change the data distribution in the table or indexed view and make the statistics goes stale or out-of-date, as it might not reflect the correct data distribution in a given column or index. SQL Server Query Optimizer identifies these stale statistics before compiling a query and before executing a cached query plan. The identification of stale statistics are done by counting the number of data modifications since the last statistics update and comparing the number of modifications to a threshold as mentioned below.
- A database table with no rows gets a row
- A database table had fewer than 500 rows when statistics was last created or updated and is increased by another 500 or more rows
- A database table had more than 500 rows when statistics was last created or updated and is increased by 500 rows + 20 percent of the number of rows in the table when statistics was last created or updated.
You can find when each statistics object of a database table was updated using the below query:
SELECT name AS StatisticsName, STATS_DATE(object_id, stats_id) AS StatisticsUpdatedDate FROM sys.stats WHERE OBJECT_NAME(object_id) = 'SalesOrderHeader' ORDER BY name; GO
You can also use below query, which uses the dynamic management function (sys.dm_db_stats_properties) to retrieve statistics properties with further details; for example, modification_counter, which shows the total number of modifications on the leading statistics column (the column on which the histogram is built) since the last statistics update.:
SELECT OBJECT_NAME(stats.object_id) AS TableName, stats.name AS StatisticsName, stats_properties.last_updated, stats_properties.rows_sampled, stats_properties.rows, stats_properties.unfiltered_rows, stats_properties.steps, stats_properties.modification_counter FROM sys.stats stats OUTER APPLY sys.dm_db_stats_properties(stats.object_id, stats.stats_id) as stats_properties WHERE OBJECT_NAME(stats.object_id) = 'SalesOrderHeader' ORDER BY stats.name;
Отфильтрованный индекс
Отфильтрованный
индекс был
представлен
в
SQL
Server
2008, — это
оптимизированная
разновидность
некластеризованного
индекса.
Индекс
применяется
только к
подмножеству
информации в таблице
и полезен для
покрытия
запросов, что
возвращают
малый
процент
информации
из строго
определенного
подмножества
информации и
таблице.
В
этом примере,
мы создадим
отфильтрованный
индекс на
поле
ContactName
для всех
клиентов в
городе
Seattle
.
Шаг 1
Откройте
новое окно
запроса. В
новом окне запроса,
напишите
следующий
запрос, что
бы создать
отфильтрованный
индекс на
поле в таблице
Customers
CREATE
NONCLUSTERED INDEX idx_filtered_ctnm_city
ON
Customers (ContactName)
WHERE
City = ‘Seattle’
GO
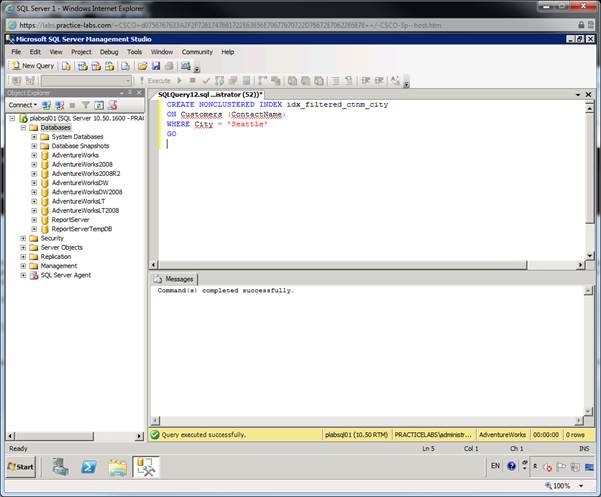
Выполните
запрос.
Реиндексация таблиц базы данных
Реиндексация таблиц включает полное перестроение индексов таблиц базы данных, что приводит к существенной оптимизации их работы. Рекомендуется выполнять регулярную переиндексацию таблиц базы данных. Для реиндексации всех таблиц базы данных необходимо выполнить следующий SQL запрос:
sp_msforeachtable N’DBCC DBREINDEX (»?»)’
Реиндексация таблиц блокирует их на все время своей работы, что может существенно сказаться на работе пользователей. В связи с этим реиндексацию рекомендуется выполнять во время минимальной загрузки системы.
После выполнения реиндексации нет необходимости делать дефрагментацию индексов.
Настройка реиндексации таблиц (MS SQL 2005)
В ранее созданном плане обслуживания создайте новый субплан с именем «Реиндексация». Добавьте в него задачу Rebuild Index Task:
Задайте расписание выполнения для задачи реиндексирования таблиц. Рекомендуется выполнять задачу во время минимальной нагрузки на систему, не реже одного раза в неделю.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.
Какие счётчики SQL Server необходимо отслеживать?
Любые метрики, которые вам необходимо отслеживать, зависят в первую очередь от ваших целей. Тем не менее, есть целый ряд показателей, которых достаточно для выполнения базовой диагностики. На основании их значений можно получить первые сигналы и уже с помощью дополнительных показателей найти причину падения производительности.
These commonly monitored SQL Server performance metrics are memory and processor usage, network traffic, and disk activity.
Среди основных показателей эффективности SQL Server необходимо контролировать память, процессор, сетевой трафик и активность дисковой подсистемы. Кроме того, параметры SQL Server и операционной системы Windows.
Основные счётчики: processor time (процессорное время), processor queue length (длина очереди), page reads and writes per second (чтение и запись страниц в секунду), page life expectancy (время жизни страницы), target and total server memory (память), buffer cache hit ratio (буферный кэш), batch requests (число команд), processor utilization (утилизация процессора), lazy writes (сбрасывание страниц на диск), network usage (сеть), paging (подкачка), user connections (подключения) и т.д.
В SQL Server есть два встроенных инструмента мониторинга: Activity Monitor и Data Collector.
Update STATISTICS using SQL Server Maintenance Plan
We can configure a SQL Server maintenance plan to update the statistics regularly. Connect to SQL Server instance in SSMS. Right-click on the Maintenance Plans and go to Maintenance Plan Wizard.
Select the Update Statistics maintenance task from the list of tasks.
Click Next, and you can define the Update Statistics task.
In this page, we can select the database (specific database or all databases), objects (specific or all objects). We can also specify to update all, column or index statistics only.
We can further choose the scan type as a Full Scan or sample by. In the Sample by, we need to specify the sample percentage or sample rows as well.
Как работать с Data Collector
Убедитесь, что SQL Server Integration Services установлен, а SQL Server Agent, Management Data Warehouse и Data Collection включены.
- В Object Explorer среды SQL Server Management Studio раскройте папку Management.
- В контекстном меню Data Collection выберите Configure Management Data Warehouse.
-
Укажите Set up data collection.
-
Нажмите далее (Next).
-
Выберите имя экземпляра SQL Server и базу данных, где будет размещаться хранилище данных управления, и локальную папку, где будет храниться кэш собранных данных.
-
Нажмите Next, проверьте все параметры и затем Finish.
Data Collection имеет три предустановленных набора мониторинга в папке System Data Collection Sets (Object Explorer -> Management -> Data Collection): Disk Usage, Query Statistics и Server Activity. Кроме того, они имеют встроенные отчёты.
Набор Disk Usage показывает информацию по файлам данных (MDF и NDF) и файлам лога транзакций (LDF). Статистику ввода/вывода.
В контекстном меню Data Collection имеется отчёт Disk Usage built-in, который показывает размер файлов, их прирост, в том числе и ежедневный.
Набор Query Statistics показывает статистику, активность и планы 10 самых «тяжёлых» запросов.
Набор Server Activity показывает общую нагрузку на процессор, память, сеть и дисковую подсистему. В отчётах можно увидеть активность экземпляра SQL Server и операционной системы, ЦПУ, память, сеть, ввод\вывод.
Data Collection мощный инструмент, который необходимо сконфигурировать, прежде чем начать использовать. Он имеет три встроенных набора для мониторинга и адекватные отчёты. К сожалению, нет мастера для настройки своих показателей мониторинга и это необходимо делать с помощью кода.
Ещё одним преимуществом инструмента является то, что он не нагружает систему постоянно, а сбор данных осуществляет по указанному расписанию. В качестве недостатка стоит отменить отсутствие фильтра по БД. К сожалению, статистика собирается сразу со всех баз данных, а это лишняя информация, дополнительная нагрузка на сервер и потребность в дополнительном дисковом пространстве.
Функционал не поддерживается в версиях SQL Server ниже 2008-ого. И присутствует только в редакциях Enterprise, Standard, Business Intelligence, и Web.
В отличие от Activity Monitor, нет возможности просматривать графики в реальном времени, но собранная информация может храниться на протяжении нескольких дней. В базовом наборе представлены только основные показатели, а для расширения необходимы знания средств разработки.
Полезные ресурсы:Activity MonitorData CollectionMonitoring SQL Server Performance
РазницамеждуинструкциямиCREATE INDEX иCREATE STATISTICS
Инструкция
CREATEINDEX
в первую
очередь
генерирует
объявленный индекс
и также
создает один
набор
статистики
для
комбинации
полей
составляющих
ключи индекса(но
не для
включенных
полей).
Инструкция
CREATESTATISTICS
только
генерирует
статистику
для данного
поля или
комбинации
полей.
В этом
примере вы
создадите
статистику(
CREATESTATISTICS
) для
таблицы
Customers
и
используете
опцию
Sample
, что бы
указать
приблизительный
процент количества
записей
таблицы или
индексированного
представления
для
оптимизатора
запросов, что
используется
когда
статистика
создается.
Шаг 1
Откройте
новое окно
запросов в
SQL Server
Management Studio(SSMS
). В новом окне
запроса
напишите
следующий
запрос, что
бы создать
статистику
для таблицы
Customers
CREATE
STATISTICS CustomerId
ON
Customers (CustomerID, SocialSecurityNumber)
WITH
SAMPLE 50 PERCENT
Выполните
запрос.
Просмотр и редактирование таблиц SQL Server в графическом режиме
Иногда бывает необходимо произвести некоторые элементарные действия с базой данных, например найти некое значение и\или изменить его. Для тех, кто постоянно работает с базами и владеет языком запросов, эта задача не составит труда, но если вы видите SQL Server в первый раз, то проще всего просмотреть и отредактировать данные в графическом режиме.
Для этого надо открыть SQL Server Management Studio, найти в разделе «Databases» нужную базу и раскрыть ее. Затем в разделе «Tables» выбрать таблицу и правой клавишей мыши вызвать контекстное меню. В этом меню есть два пункта — «Select Top 1000 Rows» и «Edit Top 200 Rows».
Select Top 1000 Rows, как следует из названия, выводит первые 1000 строк таблицы
а Edit Top 200 Rows открывает для редактирования первые 200 строк таблицы. Это очень удобно, так как таблицу можно быстро пролистать, найти требуемую информацию и изменить ее.
При необходимости дефолтные значения 200\1000 можно изменить. Для этого надо открыть меню «Tools», перейти к пункту «Options»
открыть вкладку «SQL Server Object Explorer» и в разделе «Table and View Options» установить необходимые значения. А если поставить 0, то будет выводиться все содержимое базы без ограничений.
Все вышеописаное применимо ко всем более-менее актуальным версиям, начиная с SQL Server 2008 и заканчивая SQL Server 2016.
Подготовка
Суть примера заключается в том чтобы получить ожидание на блокировке СУБД. Для этого нам потребуется тестовая база данных, а также информация об имени таблицы в базе для составления SQL-запроса. С помощью обработки выполним запись в регистр и встанем на ожидании, не завершив транзакцию. В Management Studio выполним запрос чтения данных из регистра. Поскольку в предлагаемом примере уровень изоляции Read Committed, запрос на чтение будет ожидать освобождения ресурса, который заблокирован транзакцией записи.
Создание базы данных
Создадим базу данных, в которой установим режим управления блокировкой «Управляемый», основной режим запуска «Обычное приложение», режим использования модальных окон в «Использовать», режим совместимости «8.2.13». Добавим в базу регистр сведений «ТекущиеИсполняемыеЗапросы» (непериодический, независимый). В регистре добавим измерение: «Измерение1» (тип Число) и ресурс: «Ресурс1» (тип Число). Также создадим обработку «ЗаписьВРегистрВТранзакции» со следующим кодом:
НачатьТранзакцию();
НаборЗаписей = РегистрыСведений.ТекущиеИсполняемыеЗапросы.СоздатьНаборЗаписей();
НаборЗаписей.Отбор.Измерение1.Установить(1);
НоваяЗапись = НаборЗаписей.Добавить();
НоваяЗапись.Измерение1 = 1;
НоваяЗапись.Ресурс1 = 1;
НаборЗаписей.Записать(Истина);
Предупреждение(«Ожидание»);
ЗафиксироватьТранзакцию();
|
1 |
НачатьТранзакцию(); НаборЗаписей= РегистрыСведений.ТекущиеИсполняемыеЗапросы.СоздатьНаборЗаписей(); НаборЗаписей.Отбор.Измерение1.Установить(1); НоваяЗапись= НаборЗаписей.Добавить(); НоваяЗапись.Измерение1= 1; НоваяЗапись.Ресурс1= 1; НаборЗаписей.Записать(Истина); Предупреждение(«Ожидание»); ЗафиксироватьТранзакцию(); |
SQL-запрос
Для составления SQL-запроса нам потребуется имя таблицы базы данных, соответствующее регистру сведений. Для этого воспользуемся обработкой из статьи «Получение информации о структуре хранения базы данных в терминах 1С:Предприятие и СУБД». В моей базе данных имя этой таблицы: «_InfoRg243», напишем следующий запрос выборки всех данных из таблицы:
SELECT
*
FROM
dbo._InfoRg243
|
1 |
SELECT * FROM dbo._InfoRg243 |
5.3Резервное копирование базы данных ПО «Луч»
5.3.1Резервное копирование
К сожалению, в SQL Server Express отсутствуют средства автоматического резервного копирования данных, поэтому данный раздел содержит описание резервного копирования вручную, через интерфейс SQL Server Management Studio Express.
Запустите SSMSE через меню Пуск/Программы/MS SQL Server/Среда SQL Server Management Studio Express.
Для соединения с SQL Server используйте проверку подлинности Windows или введите имя и пароль администратора SQL Server, если используется другой режим проверки.
В качестве имени сервера укажите имя компьютера, на котором установлен SQL Server Express, и далее через обратный слэш — имя экземпляра. Для экземпляра по умолчанию SQL Server Express это SQLEXPRESS.
В обозревателе объектов разверните дерево выбранного сервера, щелкнув имя сервера, раскройте узел «Базы данных» и выберите базу данных ПО «Луч»:
Из контекстного меню «Задачи» выберите пункт «Создать резервную копию».
В окне «Резервное копирование базы данных» убедитесь, что выбрана база данных ПО «Луч» и тип резервной копии «Полное». Полная резервная копия содержит все данные заданной базы данных и журналов с возможностью последующего восстановления этих данных.
В поле «Назначение» оставьте путь по умолчанию или укажите новые пути к файлу с копией базы данных с помощью кнопки «Добавить».
Если будет задано несколько путей назначения, резервная копия будет разделена таким образом, что восстановление будет возможно только при указании всех этих путей.
Введите путь и имя файла резервной копии. Расширение файла может быть произвольным, но чаще всего это bak.
Нажмите «ОК».
Подождите, пока осуществляется копирование:
В случае успешного копирования будет выдано сообщение:
Файлы с копией базы данных появятся во всех папках, указанных в поле «Назначение».
5.3.2Восстановление
В окне «Восстановление базы данных» выберите опцию «С устройства» и нажмите кнопку для выбора файла с резервной копией.
Нажмите кнопку «Добавить», чтобы указать путь к файлу с резервной копией.
Если резервное копирование было осуществлено в несколько файлов, все они должны быть указаны при восстановлении.
Нажмите «ОК».
Отметьте флажком имя резервного набора и нажмите кнопку «ОК», чтобы начать восстановление:
По завершении восстановления появится сообщение об успешном восстановлении базы данных:
Создание представления с шифрованием
Свойство
WITHENCRYPTION
шифрует
данные в
sys
.syscomments
что хранит
текст
создания
представления.
Использование
свойства
WITHENCRYPTION
предотвращает
представление
от
публикации в рамках репликации
SQL Server.
В этом
примере, вы
создадите
представление,
что бы
показать
детали
отклоненных
заказов.
Шаг 1
В SQL
Server
Management
Studio
откройте
новое окно запросов.
В новом окне
запросов, напишите
следующий
запрос что бы
создать новое
представление
в базе данных
AdventureWorks
с
шифрованием:
USE
AdventureWorks
GO
CREATE
VIEW Purchasing.PurchaseOrderReject
WITH
ENCRYPTION
AS
SELECT
PurchaseOrderID, ReceivedQty, RejectedQty, RejectedQty / ReceivedQty AS
RejectRatio, DueDate
FROM
Purchasing.PurchaseOrderDetail
WHERE
RejectedQty / ReceivedQty> 0
GO
Запустите
запрос на
выполнение.
Шаг 2
Попытайтесь
просмотреть
SQL
код
представления
используя
sp
_helptext
sp_helptext
‘Purchasing.PurchaseOrderReject’
Что такое MS SQL Server
Чтобы упростить работу с такими хранилищами данных и повысить эффективность их применения, создаются специализированные системы управления. Одной из наиболее популярных является разработка от Microsoft – SQL Server. Первый релиз платформы опубликован еще в 1989 году, а последняя версия выпущена в 2019 году (проект продолжает развиваться).
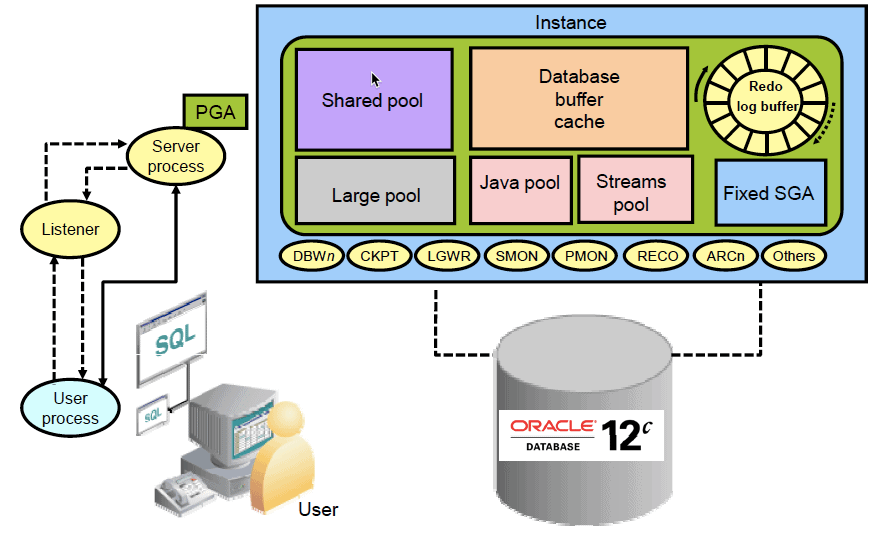


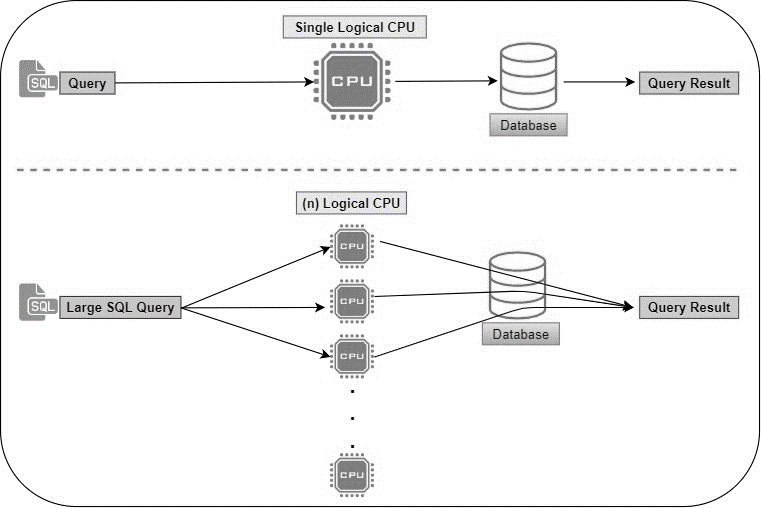

Преимущества решения:
- Тесная интеграция с операционной системой Windows.
- Высокая производительность, отказоустойчивость.
- Поддержка многопользовательской среды.
- Расширенные функции резервирования данных.
- Работа с удаленным подключением.
Каждый выпуск включает в себя несколько специализированных редакций. Это снижает сложность внедрения и затраты на процесс разработки собственных решений, адаптированных для «узких» задач. При написании программного кода активно используется интеграция с продуктами Microsoft, например, с платформой Visual Studio.
Прямые конкуренты на рынке – Oracle Database, PostgreSQL. Первый проект коммерческий, он создан для поддержки крупных компаний, поэтому сопоставим по возможностям с MS SQL Server. Второй же распространяется на бесплатной основе и не «блещет» функциональностью, хотя весьма популярен среди многих разработчиков (аналог от Oracle MySQL).
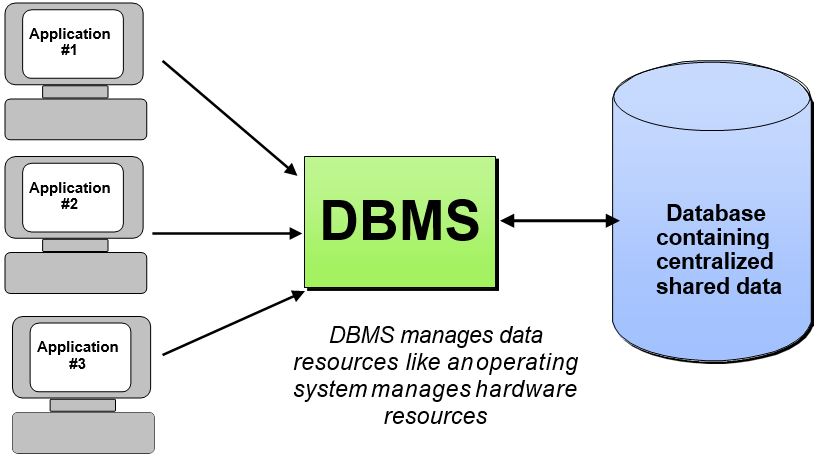
Что такое СУБД
Появление таких продуктов позволило объединить разное понимание БД (баз данных) со стороны пользователей и системных администраторов. Неискушенные в технических деталях люди «видят» таблицы как некий перечень данных с колонками и строками. Системный подход включает файлы с табличными данными, связанными друг с другом согласно определенному алгоритму.
Функции базы данных:
- Постоянное хранение информации.
- Поиск по ключевым критериям.
- Чтение и редактирование по запросу.
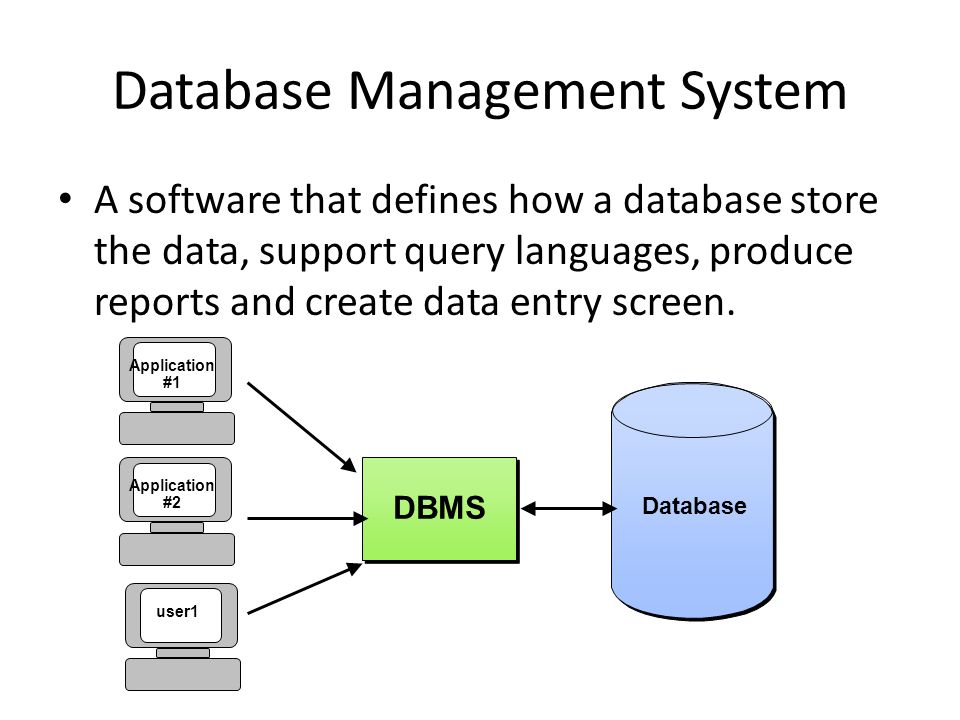
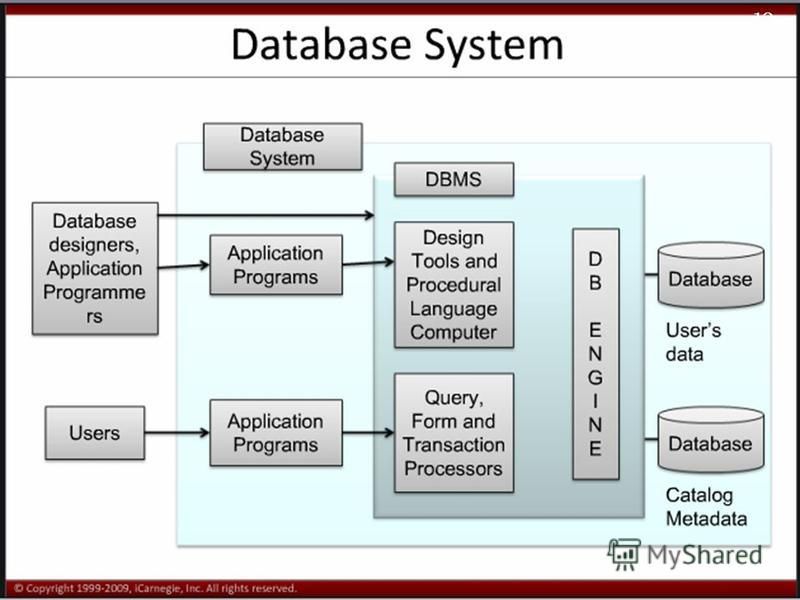
Клиентами БД являются прикладные программы, их интерфейс, различные интерактивные модули сайтов вроде калькуляторов и онлайн-редакторов. Но есть еще один компонент системы – СУБД. Он предназначен для ручного доступа к информации и позволяет извлекать данные на диск, работать с ними в памяти сервера, в том числе с применением структурированного языка SQL.
Всего различают три типа БД – клиент-серверные, файл-серверные и встраиваемые. MS SQL Server относится к первой категории. Плюс система является реляционной, т.е. адаптированной для хранения данных без избыточности, с минимальными рисками появления аномалий и нарушения целостности внутренних таблиц.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Общие сведения
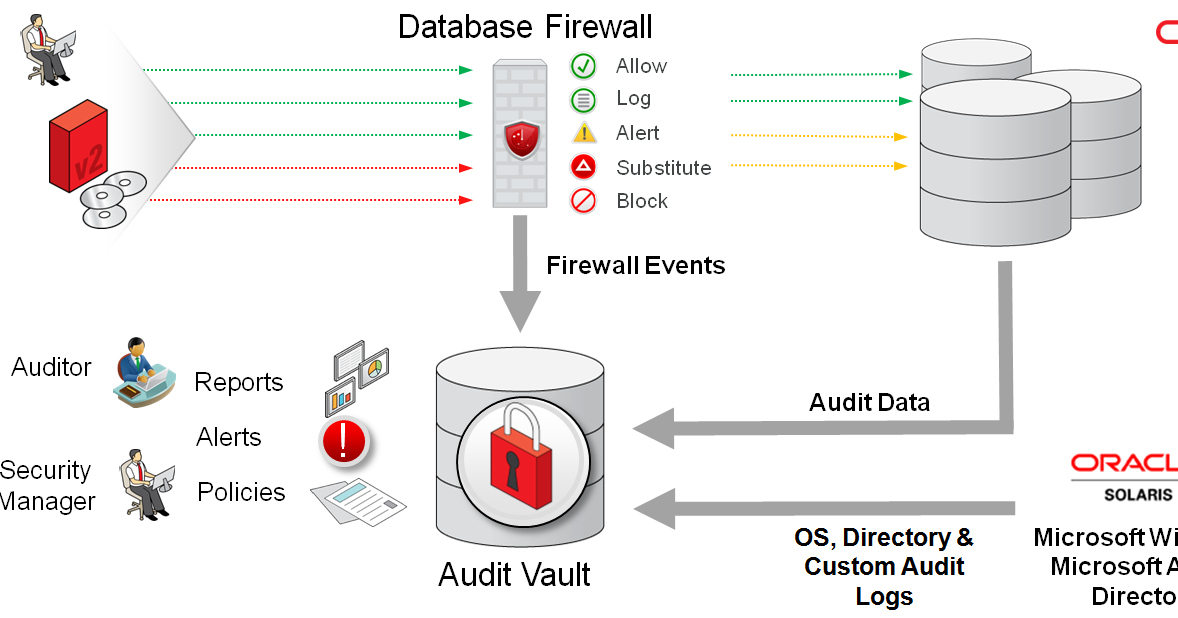
Одной из часто встречающихся причин неоптимальной работы системы является неправильное или несвоевременное выполнение регламентных операций на уровне СУБД
Особенно важно выполнять эти регламентные процедуры в крупных информационных системах, которые работают под значительной нагрузкой и обслуживают одновременно большое количество пользователей. Специфика таких систем в том, что обычных действий, выполняемых СУБД автоматически (на основании настроек) оказывает недостаточно для эффективной работы
Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Выполнение регламентных процедур должно быть автоматизировано. Для автоматизации этих операций рекомендуется использовать встроенное средства MS SQL Server: Maintenance Plan. Существуют так же другие способы автоматизации выполнения этих процедур. В настоящей статье для каждой регламентной процедуры дан пример ее настройки при помощи Maintenance Plan для MS SQL Server 2005.
Для MS SQL Server рекомендуется выполнять следующие регламентные операции:
Рекомендуется регулярно контролировать своевременность и правильность выполнения данных регламентных процедур.
Создание схемы базы данных используя SSMS
Шаг 1
Откройте
SQLServerManagementStudio
и войдите
на сервер баз
данных(
Database
Engine
).
Выберите
базу данных
AdventureWorks
и
разверните папку
Security
из
списка.
Нажмите
правой
кнопкой мыши
на
Schemas
и выберите
New
Schema
.
Шаг 2
На
вкладке
General
заполните
информацию
для новой
схемы. В этом
примере мы
назовем
схему
APerson
и
назначим
владельцем
схемы роль
db
_securityadmin.
Напишите
имя в поле
Schema
name
, потом
нажмите
кнопку
Search
рядом
с полем
Schema
Owner
.
В поле поиска,
напишите
db
_securityadmin
и нажмите
кнопку
Check
Names
.
Это должно
поместить
объект в
квадратные скобки.
Когда
сделаете
нажмите
OK
.
Выберите
страницу
Permissions
на
левой панели,
потом
нажмите
кнопку
Search
, нажмите
кнопу
Browse
и
добавьте к
схеме роль
Public
.
Нажмите
OK
,и
еще раз
OK
чтобы
вернуться.
Теперь вы
сможете
выбрать
необходимые
разрешения; в
этом примере
вы будете
устанавливать
такие
GRANT
разрешения:
Execute
Insert
Select
Нажмите
OK
чтобы
закрыть окно.
Итак, давайте знакомиться:
1.Sys.dm_exec_cached_plans возвращает закэшированные планы запросов. Очень полезное представление, чтобы посмотреть, например, варианты планов, которые строятся на различные выборки. Также позволяет проверить, сколько места в памяти занимают планы и насколько они одинаковы для разных запросов.
2.Sys.dm_exec_query_stats показывает суммарную статистику выполнения по планам запросов. Именно используя это DMV, вы можете собрать статистику самых ресурсоёмких запросов на сервере и начать оптимизацию именно с них.
3.Sys.dm_tran_locks хранит информацию о блокировках, которые в данный момент наложены на объекты в БД, покажет тип блокировки и заблокированный объект, а также уровень изоляции транзакции. При этом, если вы хотите собрать историю блокировок за какой-либо период, нужно будет вызывать периодически DMV и сохранять результаты, так как при снятии блокировки данные об этой блокировке перестанут отображаться.
4.Sys.dm_db_missing_index_. Набор DMV, который показывает, каких индексов не хватает в БД по мнению SQL Server
Осторожно, не стоит создавать все индексы из списка! Во-первых, SQL Server никак не анализирует уже существующие и, если на таблице есть индекс из 2-х полей , а сервер считает, что нужен индекс по , то он может только предложить создать новый, а не модифицировать существующий. Во-вторых, в предложения часто попадает длинный список INCLUDE полей, что далеко не всегда является хорошей практикой, так как предложенный индекс дублирует всю таблицу
5.Sys.dm_db_index_physical_stats покажет, сколько места занимают ваши индексы, а также уровень их фрагментации. Возможно, пора запустить процедуры обслуживания на некоторых индексах? Высокая фрагментация может быть причиной, по которой оптимизатор предпочтёт не использовать индекс, хотя по набору полей он может идеально подходить под запрос.
6.Sys.dm_io_pending_io_requests — список запросов на данный момент, которые висят в состоянии ожидания системы ввода-вывода
Можно обратить внимание на тот же уровень фрагментации, а также на объём возвращаемых данных
7.Sys.dm_os_performance_counters отображает счётчики производительности SQL Server. Выборка покажет сведения о том, насколько эффективно работает кэш, как часто приходится вычитывать данные с диска и многое-многое другое.
Обзор DMV получился весьма кратким, но я надеюсь, что вы познакомитесь с заинтересовавшими вас представлениями, и они помогут глубже понять причины проблем с производительностью, а также вычислить неидеально написанные запросы.
Сбор статистики для таблиц MS SQL Server.
Статьи —
oracle data integrator
Продолжим изучать описанный ранее подход сбора статистики для таблиц БД.
Моя цель — улучшить скрипт и разобраться немного с процессом сбора статистики для таблиц MS SQL Server. Статистику буду собирать по всем колонкам заданной таблицы.
Итак, документация дает следующее описание синтаксиса команды сбора статистики:
Второй момент, в котором необходимо разобраться — процесс получения списка колонок из метаданных БД. Согласно документации для этого существует представление sys.columns:
В результате получилась следующая процедура:
Вкладка Command On Target:
import string
import java.sql as sql
import java.lang as lang
sourceConnection = odiRef.getJDBCConnection(«SRC»)
stmt = sourceConnection.createStatement()
sql_use = «USE #s_Catalog; «
sql_columns = sql_use + «select col.name as CName, tab.name as TName from sys.all_columns col inner join sys.all_objects tab on col.object_id = tab.object_id and tab.name = » and tab.type = ‘U'»
col_result = stmt.executeQuery(sql_columns)
res = »
r_TableName = »
r_ColName = »
try:
while (col_result.next()):
r_TableName = str(col_result.getString(«TName»))
r_ColName = str(col_result.getString(«CName»))
sql_stats = sql_use + «IF EXISTS (SELECT name FROM sys.stats WHERE name = N'» + r_ColName + «‘ AND object_id = OBJECT_ID(N'» + r_TableName + «‘)) DROP STATISTICS » + r_TableName + «.» + r_ColName + «;»
sql_stats = sql_stats + ‘CREATE STATISTICS ‘ + r_ColName + ‘ on ‘ + r_TableName + ‘ (‘ + r_ColName + ‘);’
res = res + sql_stats + ‘\n’
#sql_stats = ‘select 1’
#stmt2.executeQuery(sql_stats)
except:
raise res, sql_stats
#sourceConnection.close()
Вкладка Command On Source:
select » as s_Catalog
С какими сложностями пришлось столкнуться:
- Я не нашел необходимого представления, которое бы возвращало список всех колонок всех таблиц одного сервера. Таким образом, селект по списку колонок возвращал пустой результат для заданного имени таблицы. Изменение представления на sys.all_columns не изменило ситуацию.
- Причиной этого стало, скорее всего, то, что для логина odi_dev, который был указан как пользователь для схемы Target использовалась БД по-умолчанию tempdb
- Чтобы можно было использовать эту процедуру для сбора статистики по любой таблице любой БД данного сервера я решил использовать команду USE перед запросом списка колонок из sys.all_columns
- Получить имя БД оказалось не совсем просто. Можно было бы его передавать как параметр, но я хотел попробовать провернуть такой же трюк, как и с получением подключения с помощью команды odiRef.getJDBCConnection(«SRC»).
- Мне нужно было узнать имя физической БД для выбранной на вкладке Command on Source логической схемы. Лучшее, что я смог сделать выглядит как селект имени каталога в переменную подстановки:
- Полученное имя каталога добавлялось к команде получения списка колонок таблицы.
- Так как MS SQL Server не имеет команды пересбора статистики, пришлось найти в хелпе команду определения, существует ли статистика для заданной колонки, и, в этом случае, удалять ее перед созданием.
- По прежнему темной частью джава материи остается для меня необходимость закрытия соединения в конце выполнения сбора статистики. В данном примере при наличии команды закрытия выдается сообщение об ошибке: 0 : null : com.microsoft.sqlserver.jdbc.SQLServerException: The connection is closed. Думаю вернуться к этому немного позже.
Изначально я планировал показать, как можно сделать сбор статистики частью модуля знаний. Для этого я собирался воспользоваться исключительно методами подстановки, в частности, методом GetColList().
К сожалению, я не смог его использовать, так как метод возвращает исключительно список всех столбцов всех таблиц источников, без названия этих самых таблиц. Поэтому идея собирать статистику с источников перед тем, как загружать данные в I$_ таблицу, сработала бы (с использованием GetColList()) только для интерфейсов с одним источником данных.
Добавление таблицы к новой схеме
Теперь,
когда у нас
есть новая
схема мы
можем
добавить в
нее объекты,
такие как
таблицы,
представления,
и хранимые
процедуры. В
этом примере,
мы будем
перемещать
существующую
таблицу в
схеме
dbo
в только
что
созданную
схему
APerson.
Шаг 1
Используя
инспектор объектов(
objectexplorer) вSQLServerManagementStudio
, разверните
Databases
>AdventureWorks
и нажмите
правой
кнопкой мыши
на таблице
ComputedColumnTest
(таблица
что ранее
создана) и
выберите
Design
В окне
Design
нажмите
F
4
чтобы
показать
окно
Properties
.
В
окне
Properties
, измените
схему на
созданную
вами схему:
Обратите
внимание, вы получите
подсказку о
том, что
изменение схемы
сбросит
текущие
разрешения
на объект,
нажмите
Yes.
Закройте
окно
Design
нажав
правой
кнопкой мыши
на вкладке и
выбрав
Close
, сохраните
изменения.
Create Schema, Database
Схема Schema с точки зрения базы данных представляет собой контейнер объектов типа таблиц, триггеров, хранимых процедур и т.п. В данной статье будут рассмотрены вопросы создания и удаления схемы БД следующих СУБД :




- Oracle : Schema привязывается к пользователю, т.е. наименование схемы, как правило, является учетной записью пользователя. Схема создается при создании пользователем первого объекта, и все последующие объекты созданные этим пользователем становятся частью этой схемы. Кроме этого Oracle позволяет создавать схему как контейнер одновременно с объектами базы данных.
- MSSQL : в Microsoft SQL Server начиная с версии 2005 жесткая связь между пользователями и схемами была отменена. Пользователи могут получить доступ на выполнение определенных операций с объектами схемы : чтение, запись, обновление или выполнение.
- PostgreSQL : Schema создается внутри объекта базы данных. Сервер может управлять несколькими базами данных, каждая из которых может включать несколько схем. То есть, как и в MSSQL, схема не связана с учетной записью пользователя.
- MySQL : понятие Schema имеет тождественный смысл с Database. База данных Database является контейнером объектов, к которым пользователь получает доступ.
- Derby : Schema не имеет жесткой связи с пользователем и является контейнером объектов, для доступа к которым пользователь должен иметь соответствующие привилегии.
Вставка значений в вычисляемое поле
Шаг 1
Вставьте
значения в
ранее
созданную
таблицу
используя
инструкцию
INSERTINTO
как
показано
ниже в коде.
Выполните
кодвновомокнезапросаNew
Query
вMicrosoftSQLServerManagementStudio:
USE
AdventureWorks
GO
INSERT
INTO ComputedColumnTest (EmpNumber, DOBirth)
VALUES
(1,
‘1977-12-23’),
(2,
‘1980-01-01’),
(3,
‘1968-03-23’),
(4,
‘1988-12-12’),
(5,
‘1975-06-15’)
GO
Нажмите
кнопку
Execute
чтобы
выполнить
SQL код.
Примечание:
Поскольку
поле
DORetirement
является
вычисляемым,
в него не
нужно вставлять
значения.
Шаг 2
Вы
можете
увидеть
вычисленные
значении для
поля
DORetirement
используя
предложение
SELECT
SELECT
*
FROM
dbo
.
ComputedColumnTest
GO
Когда
напечатаете
SQL
инструкции,
опят нажмите
кнопку
Execute
.