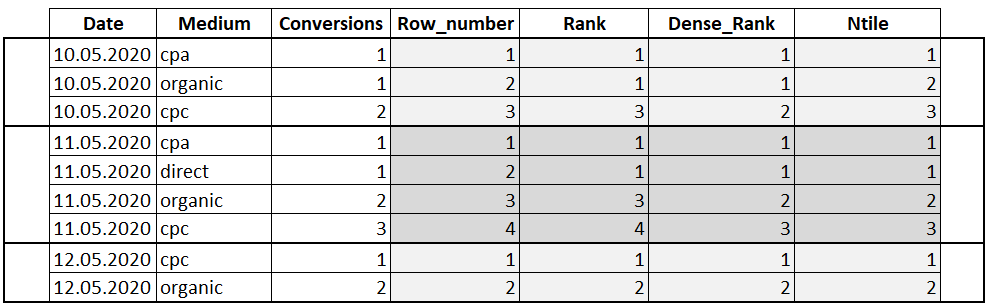
Введение
В Microsoft SQL Server 2005 появился новый функционал — он интегрирован со средой CLR платформы Microsoft.NET Framework. Это позволяет использовать функции и классы .NET Framework в инструкциях и запросах Transact-SQL.
Существует несколько механизмов интеграции с CLR. Это:
- CLR-функции , создаваемые пользователем (в том числе функции, возвращающие табличные значения);
- определяемые пользователем CLR-типы;
- хранимые процедуры, исполняемые CLR;
- триггеры, исполняемые CLR.
В этом документе показано, как использовать CLR-функции, возвращающие табличные значения, чтобы получать данные для отчетов из различных источников (в дополнение к базам данных) и создавать эффективные отчеты средствами Reporting Services.
Example — Sorting Results in Ascending Order
To sort your results in ascending order, you can specify the ASC attribute. If no value (ASC or DESC) is provided after a field in the ORDER BY clause, the sort order will default to ascending order. Let’s explore this further.
In this example, we have a table called customers with the following data:
| customer_id | last_name | first_name | favorite_website |
|---|---|---|---|
| 4000 | Jackson | Joe | techonthenet.com |
| 5000 | Smith | Jane | digminecraft.com |
| 6000 | Ferguson | Samantha | bigactivities.com |
| 7000 | Reynolds | Allen | checkyourmath.com |
| 8000 | Anderson | Paige | NULL |
| 9000 | Johnson | Derek | techonthenet.com |
Enter the following SQL statement:
Try It
SELECT * FROM customers ORDER BY last_name;
There will be 6 records selected. These are the results that you should see:
| customer_id | last_name | first_name | favorite_website |
|---|---|---|---|
| 8000 | Anderson | Paige | NULL |
| 6000 | Ferguson | Samantha | bigactivities.com |
| 4000 | Jackson | Joe | techonthenet.com |
| 9000 | Johnson | Derek | techonthenet.com |
| 7000 | Reynolds | Allen | checkyourmath.com |
| 5000 | Smith | Jane | digminecraft.com |
This example would return all records from the customers sorted by the last_name field in ascending order and would be equivalent to the following SQL ORDER BY clause:
Try It
SELECT * FROM customers ORDER BY last_name ASC;
3.3.7. Изменение функций
Вы можете изменять функцию с помощью оператора ALTER FUNCTION. Общий вид для каждого варианта функции отличается. Давайте рассмотрим каждый из них.
1. Общий вид команды изменения скалярной функции:
ALTER FUNCTION function_name
( } ] )
RETURNS scalar_return_data_type
]
BEGIN
function_body
RETURN scalar_expression
END
2. Общий вид изменения функции, возвращающей таблицу:
ALTER FUNCTION function_name
( } ] )
RETURNS TABLE
]
RETURN select-stmt
3. Общий вид команды изменения функции с множеством операторов, возвращающей таблицу.
ALTER FUNCTION function_name
( } ] )
RETURNS @return_variable TABLE
]
BEGIN
function_body
RETURN
END
::=
{ ENCRYPTION | SCHEMABINDING }
:: =
( { column_definition | table_constraint } )
Следующий пример показывает упрощенный вариант команды, изменяющей функцию:
ALTER FUNCTION dbo.tbPeoples AS -- Новое тело функции
Агрегация
Агрегация — это когда мы считаем суммарные или средние показатели. Например, среднюю зарплату по каждому региону или количество золотых медалей у каждой страны в зачете Олимпийских игр.
На примере нашей таблички сотрудников:
Сравнение с фондом оплаты труда
У каждого департамента есть фонд оплаты труда — денежная сумма, которая ежемесячно уходит на выплату зарплат сотрудникам. Посмотрим, какой процент от этого фонда составляет зарплата каждого сотрудника:
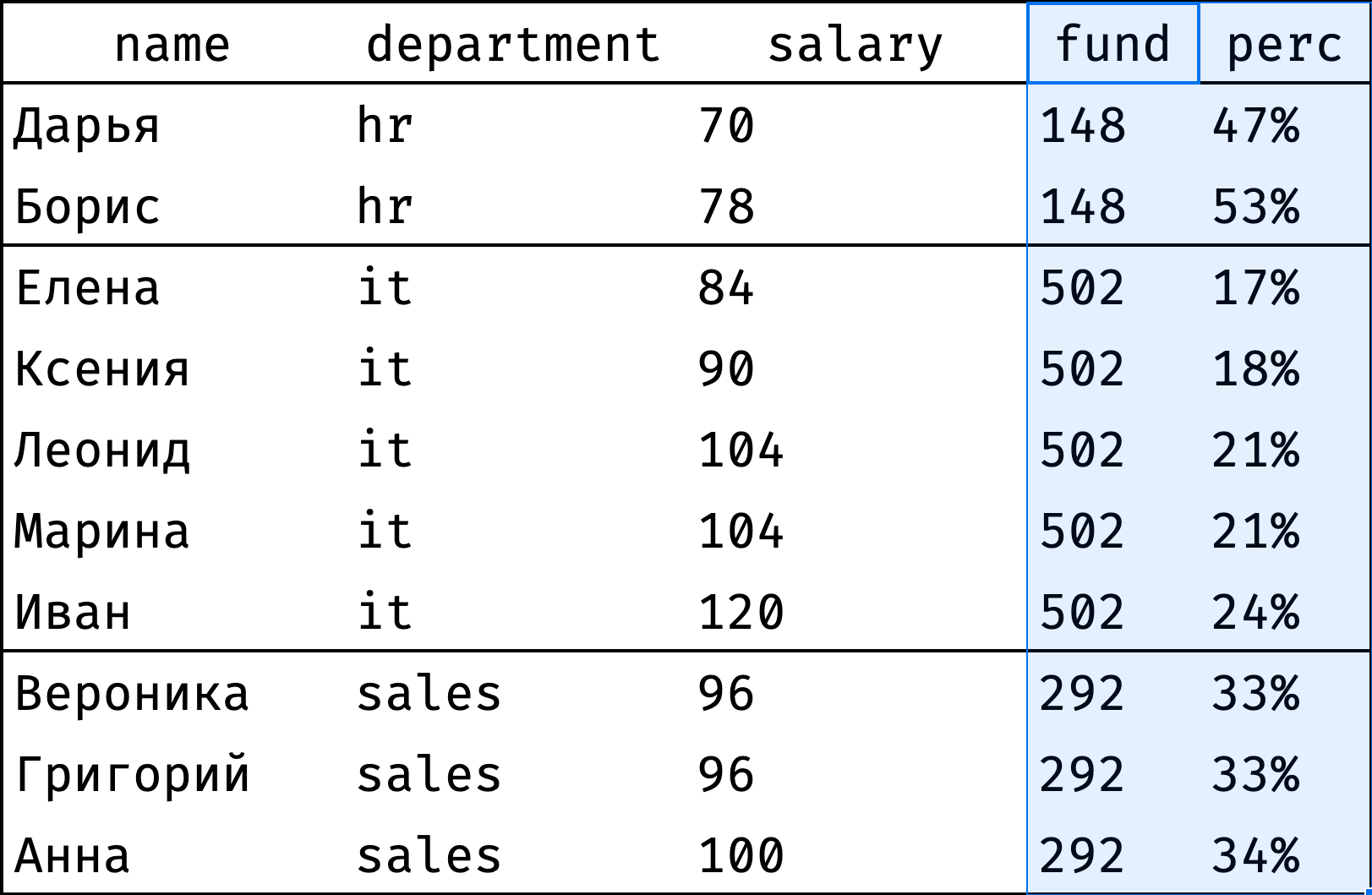
Столбец показывает фонд оплаты труда отдела, а — долю зарплаты сотрудника от этого фонда. Видно, что в HR и продажах все более-менее ровно, а у айтишников есть заметный разброс зарплат.
Сравнение со средней зарплатой
Интересно, велик ли разброс зарплат в департаментах. Проверим: посчитаем отклонение зарплаты каждого сотрудника от средней по департаменту:
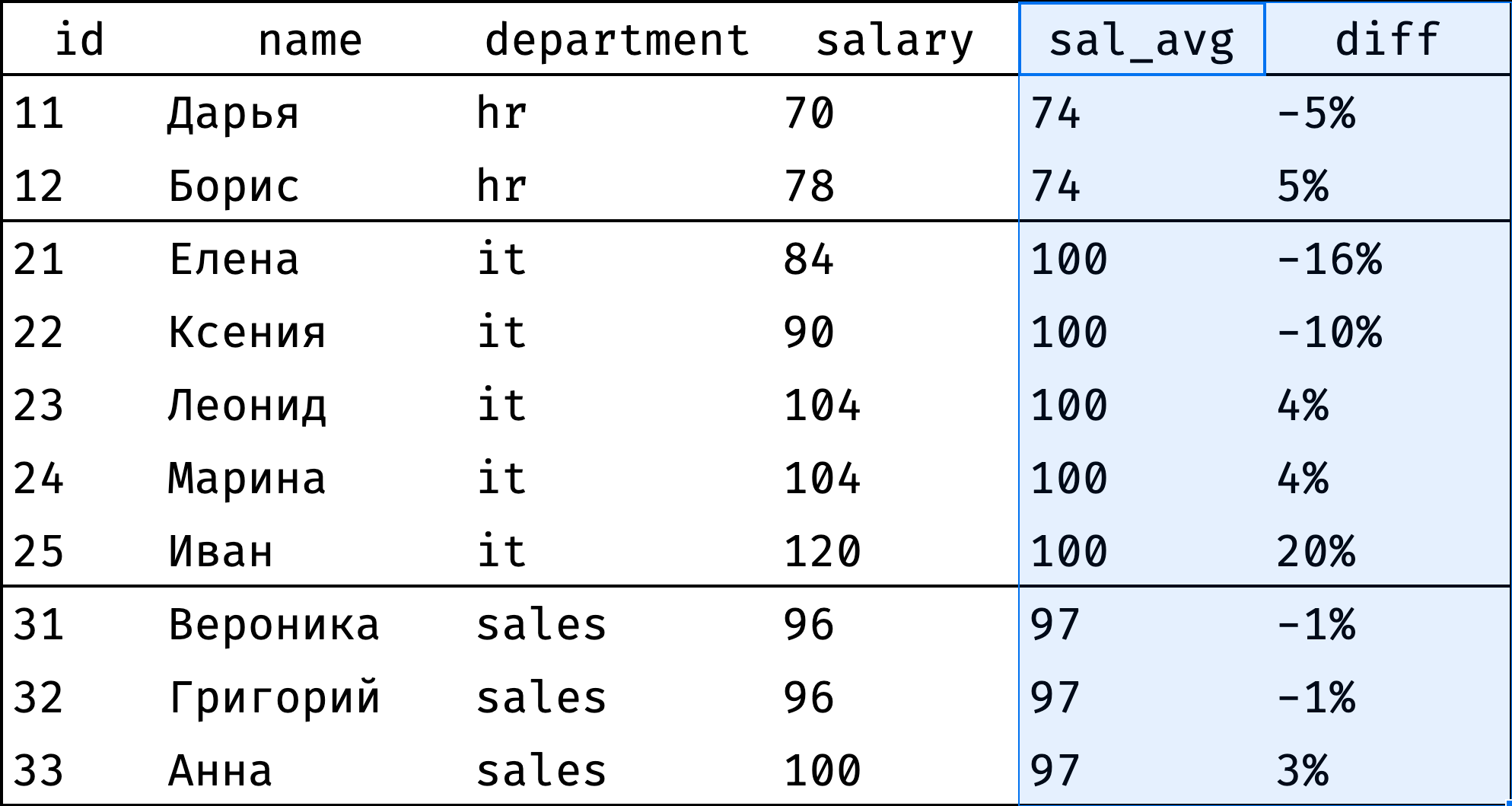
Результат подтверждает предыдущие наблюдения: у айтишников зарплаты колеблются от -16% до +20% от среднего, а у остальных департаментов отклонение в пределах 5%.
Расчет выражения SQL
предикат
Предикат в SQL относится к логическому выражению, результатом операции которого является Истина, Ложь или Неизвестно. Предикаты в T-SQL включают IN, BETWEEN, LIKE и т. Д.
Используйте LIKE для нечеткого сопоставления и поддержки регулярных выражений:
Следует отметить, что если нечеткое сопоставление LIKE начинается с%, индекс использовать нельзя. Такие как:
Оператор
Операторы в SQL аналогичны языкам программирования высокого уровня (C #, JAVA). Когда несколько операторов появляются в одном выражении, SQL Server будет производить вычисления в соответствии с приоритетом операторов. Используйте скобки, если не знаете приоритета, и сравните следующие два предложения SQL:
Оператор AND имеет более высокий приоритет, чем OR, поэтому два приведенных выше предложения SQL логически эквивалентны. Однако очевидно, что условие WHERE во втором предложении логически яснее.
Трехзначная логика
В результате операции выражения в SQL могут быть три ситуации:。
В фильтре запроса возвращаются только данные, результат работы которых условного выражения (WHERE, HAVING, ON) равен True.
Ограничение CHECK, возвращает результат операции выражения, не Ложь.
Двузначная логика
В отличие от большинства предикатов в T-SQL, EXISTS использует двузначную логику (True / False) вместо трехзначной логики;
вВ предикат EXISTS заботится только о существовании совпадающих строк, независимо от атрибутов, указанных в SELECT,Так же, как все предложение SELECT является избыточным. Ядро SQL Server игнорирует предложение SELECT при оптимизации запроса. Следовательно, звездочка (*) в предложении SELECT не оказывает отрицательного влияния на производительность.
Чтобы сэкономить тривиальные дополнительные расходы, связанные с синтаксическим анализом звездочки (*), не стоит жертвовать удобочитаемостью кода.
NULL & Unknown
NULL указывает, что значение неизвестно., Различные языковые элементы в SQL имеют разные способы обработки NULL.
Обратите внимание на следующие моменты при использовании значений NULL:
-
Сравните NULL с другими значениями, независимо от того, является ли значение NULL, результат будет неизвестен
-
Следует использовать IS NULL или IS NOT NULL, чтобы определить, является ли значение NULL
-
INSERT не указывает значение для столбца, вставьте NULL
-
Предложения GROUP BY и ORDER BY будут рассматривать несколько значений NULL как равные
-
Ограничение UNIQUE стандартного SQL считает, что NULL отличаются друг от друга
-
Ограничение UNIQUE в T-SQL считает, что несколько значений NULL равны
-
Особенности COUNT (*)
Если столбец с именем tag существует в примереНесколько строк данных, затем COUNT (*) вернет 4, а COUNT (tag) вернет 3
Результатом логической операции, в которой участвует NULL, скорее всего, будет Неизвестный (трехзначная логика также является важной причиной ошибок приложения), если только результат операции не зависит от Неизвестно, как показано ниже. Неизвестный участвует в результате операции И:
Неизвестный участвует в результате операции И:
| Expression 1 | Expression 2 | Result |
|---|---|---|
| TRUE | UNKNOWN | UNKNOWN |
| UNKNOWN | UNKNOWN | UNKNOWN |
| FALSE | UNKNOWN | FALSE |
Участие неизвестного в результатах бюджета OR:
| Expression 1 | Expression 2 | Result |
|---|---|---|
| TRUE | UNKNOWN | TRUE |
| UNKNOWN | UNKNOWN | UNKNOWN |
| FALSE | UNKNOWN | UNKNOWN |
Общие замечания General Remarks
Нет гарантии того, что строки, возвращенные запросом, использующим ROW_NUMBER() , будут расставлены в одинаковом порядке после каждого выполнения, если не соблюдены указанные ниже условия. There is no guarantee that the rows returned by a query using ROW_NUMBER() will be ordered exactly the same with each execution unless the following conditions are true.




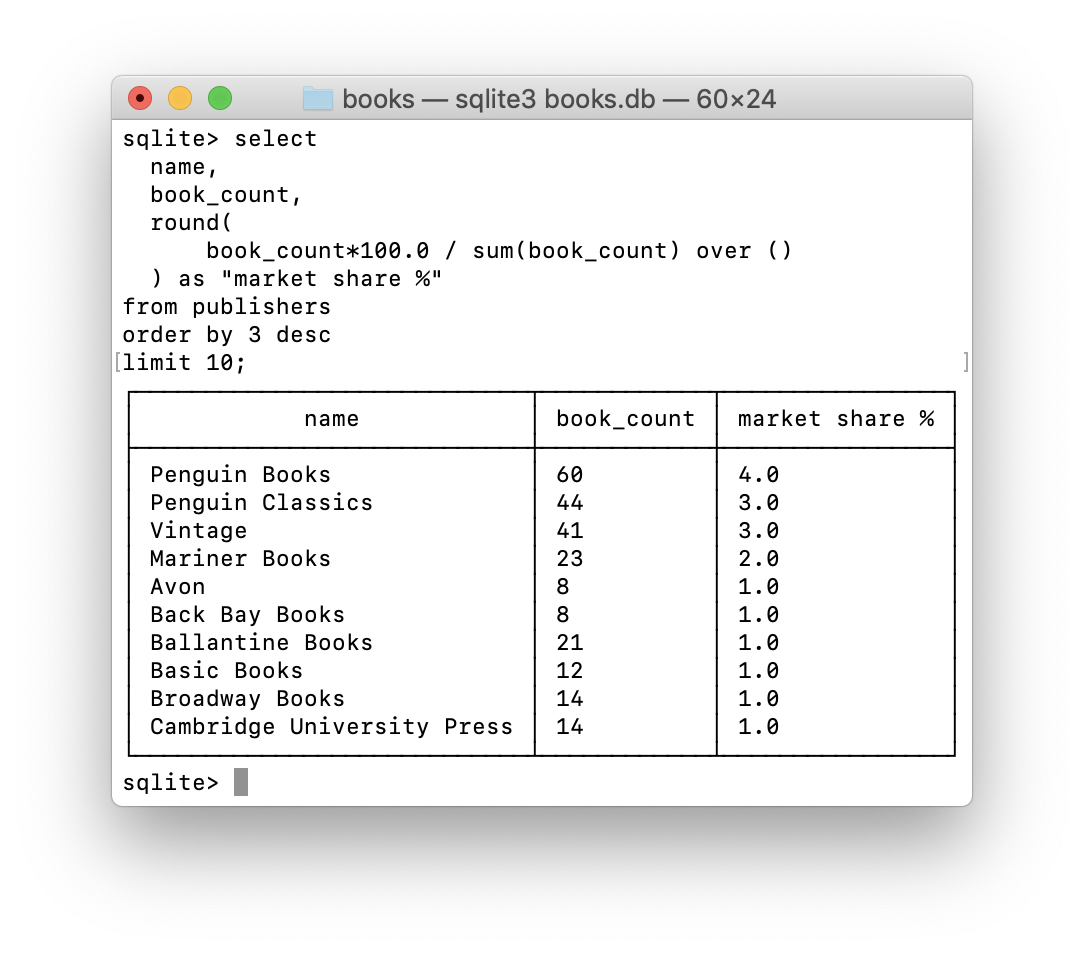
Все значения в секционированном столбце являются уникальными. Values of the partitioned column are unique.
Все значения в столбцах ORDER BY являются уникальными. Values of the ORDER BY columns are unique.
Сочетания значений из столбца секционирования и столбцов ORDER BY являются уникальными. Combinations of values of the partition column and ORDER BY columns are unique.
Функция ROW_NUMBER() не детерминирована. ROW_NUMBER() is nondeterministic. Дополнительные сведения см. в разделе Deterministic and Nondeterministic Functions. For more information, see Deterministic and Nondeterministic Functions.
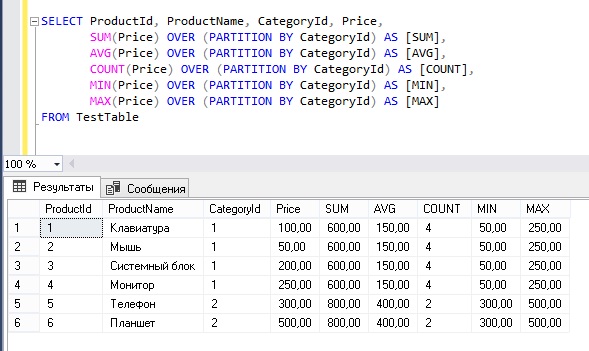
Window Aggregates
Window aggregates were also introduced with SQL Server 2005. These make writing some tricky queries easy but will often perform worse than older techniques. They allow you to add your favourite aggregate function to a non-aggregate query. Say, for example you would like to display all the customer orders along with the subtotal for each customer. By adding a SUM using the OVER clause, you can accomplish this very easily:
|
1 |
SELECTCustomerID,OrderDate,SalesOrderID,TotalDue, SUM(TotalDue)OVER(PARTITIONBYCustomerID)ASSubTotal FROMSales.SalesOrderHeader; |
By adding the PARTITION BY, a subtotal is calculated for each customer. Any aggregate function can be used, and ORDER BY in the OVER clause is not supported.
Ranking Functions
The most commonly used window functions, ranking functions, have been available since 2005. That’s when Microsoft introduced ROW_NUMBER, RANK, DENSE_RANK, and NTILE. ROW_NUMBER is used very frequently, to add unique row numbers to a partition or to the entire result set. Adding a row number, or one of the other ranking functions, is not usually the goal, but it is a step along the way to the solution.
ORDER BY is required in the OVER clause when using ROW_NUMBER and the other functions in this group. This tells the database engine the order in which the numbers should be applied. If the values of the columns or expressions used in the ORDER BY are not unique, then RANK and DENSE_RANK will deal with the ties, while ROW_NUMBER doesn’t care about ties. NTILE is used to divide the rows into buckets based on the ORDER BY.
One benefit of ROW_NUMBER is the ability to turn non-unique rows into unique rows. This could be used to eliminate duplicate rows, for example.
To show how this works, start with a temp table containing duplicate rows. The first step is to create the table and populate it.
|
1 |
CREATETABLE#Duplicates(Col1INT,Col2CHAR(1)); INSERTINTO#Duplicates(Col1,Col2) VALUES(1,’A’),(2,’B’),(2,’B’),(2,’B’), (3,’C’),(4,’D’),(4,’D’),(5,’E’), (5,’E’),(5,’E’); SELECT*FROM#Duplicates; |
Adding ROW_NUMBER and partitioning by each column will restart the row numbers for each unique set of rows. You can identify the unique rows by finding those with a row number equal to one.
|
1 |
SELECTCol1,Col2, ROW_NUMBER()OVER(PARTITIONBYCol1,Col2ORDERBYCol1)ASRowNum FROM#Duplicates; |
Now, all you have to do is to delete any rows that have a row number greater than one. The problem is that you cannot add window functions to the WHERE clause.
|
1 |
DELETE#Duplicates WHEREROW_NUMBER()OVER(PARTITIONBYCol1,Col2ORDERBYCol1)<>1; |
You’ll see this error message:
The way around this problem is to separate the logic using a common table expression (CTE). You can then delete the rows right from the CTE.
|
1 |
WITHDupesAS( SELECTCol1,Col2, ROW_NUMBER()OVER(PARTITIONBYCol1,Col2ORDERBYCol1)ASRowNum FROM#Duplicates) DELETEDupes WHERERowNum<>1; SELECT*FROM#Duplicates; |
Success! The extra rows were deleted, and a unique set of rows remains.
To see the difference between ROW_NUMBER, RANK, and DENSE_RANK, run this query:
|
1 |
USEAdventureworks2017;—Or whichever version you have GO SELECTSalesOrderID,OrderDate,CustomerID, ROW_NUMBER()OVER(ORDERBYOrderDate)AsRowNum, RANK()OVER(ORDERBYOrderDate)AsRnk, DENSE_RANK()OVER(ORDERBYOrderDate)AsDenseRnk FROMSales.SalesOrderHeader WHERECustomerID=11330; |
The ORDER BY for each OVER clause is OrderDate which is not unique. This customer placed two orders on 2013-10-24. ROW_NUMBER just continued assigning numbers and didn’t do anything different even though there is a duplicate date. RANK assigned 6 to both rows and then caught up to ROW_NUMBER with an 8 on the next row. DENSE_RANK also assigned 6 to the two rows but assigned 7 to the following row.
Two explain the difference, think of ROW_NUMBER as positional. RANK is both positional and logical. Those two rows are ranked logically the same, but the next row is ranked by the position in the set. DENSE_RANK ranks them logically. Order 2013-11-04 is the 7th unique date.
The final function in this group is called NTILE. It assigns bucket numbers to the rows instead of row numbers or ranks. Here is an example:
|
1 |
SELECTSP.FirstName,SP.LastName, SUM(SOH.TotalDue)ASTotalSales, NTILE(4)OVER(ORDERBYSUM(SOH.TotalDue))*1000ASBonus FROMSales.vSalesPersonSP JOINSales.SalesOrderHeaderSOH ONSP.BusinessEntityID=SOH.SalesPersonID WHERESOH.OrderDate>=’2012-01-01’ANDSOH.OrderDate<‘2013-01-01’ GROUPBYFirstName,LastName; |
NTILE has a parameter, in this case 4, which is the number of buckets you want to see in the results. The ORDER BY is applied to the sum of the sales. The rows with the lowest 25% are assigned 1, the rows with the highest 25% are assigned 4. Finally, the results of NTILE are multiplied by 1000 to come up with the bonus amount. Since 14 cannot be evenly divided by 4, an extra row goes into each of the first two buckets.
Example 3 – Find the Last Value Within a Range
This use of the RANGE clause allows you to find the last value within a defined range. For example, using the table , I can get the last value for every shop separately. The last value, in this case, means the last data available, which is the revenue for 2021-05-15. How do you get that data?
By using the clause, of course:
SELECT
shop,
date,
revenue_amount,
LAST_VALUE(revenue_amount) OVER (
PARTITION BY shop
ORDER BY date
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS last_value
FROM revenue_per_shop;
The window function I’ve used this time is . Once again, I’m using it on the column . I’ve partitioned the data by shop, same as before. And I ordered it by date, again the same as before. To get the last value, I used . Remember, the default range with the clause is . If you don’t change it, you’ll get the wrong result. The right result is:
| shop | date | revenue_amount | last_value |
|---|---|---|---|
| Shop 1 | 2021-05-01 | 12,573.25 | 19,874.26 |
| Shop 1 | 2021-05-02 | 14,388.14 | 19,874.26 |
| Shop 1 | 2021-05-03 | 9,845.29 | 19,874.26 |
| Shop 1 | 2021-05-04 | 11,500.63 | 19,874.26 |
| Shop 1 | 2021-05-05 | 9,634.56 | 19,874.26 |
| Shop 1 | 2021-05-06 | 11,248.33 | 19,874.26 |
| Shop 1 | 2021-05-07 | 14,448.65 | 19,874.26 |
| Shop 1 | 2021-05-08 | 6,874.23 | 19,874.26 |
| Shop 1 | 2021-05-09 | 9,784.33 | 19,874.26 |
| Shop 1 | 2021-05-10 | 12,235.50 | 19,874.26 |
| Shop 1 | 2021-05-11 | 14,800.65 | 19,874.26 |
| Shop 1 | 2021-05-12 | 18,845.69 | 19,874.26 |
| Shop 1 | 2021-05-13 | 13,250.69 | 19,874.26 |
| Shop 1 | 2021-05-14 | 17,784.25 | 19,874.26 |
| Shop 1 | 2021-05-15 | 19,874.26 | 19,874.26 |
| Shop 2 | 2021-05-01 | 11,348.22 | 15,489.36 |
| Shop 2 | 2021-05-02 | 18,847.54 | 15,489.36 |
| Shop 2 | 2021-05-03 | 14,574.56 | 15,489.36 |
| Shop 2 | 2021-05-04 | 16,897.21 | 15,489.36 |
| Shop 2 | 2021-05-05 | 14,255.87 | 15,489.36 |
| Shop 2 | 2021-05-06 | 21,489.22 | 15,489.36 |
| Shop 2 | 2021-05-07 | 15,517.22 | 15,489.36 |
| Shop 2 | 2021-05-08 | 12,500.00 | 15,489.36 |
| Shop 2 | 2021-05-09 | 15,321.89 | 15,489.36 |
| Shop 2 | 2021-05-10 | 22,222.22 | 15,489.36 |
| Shop 2 | 2021-05-11 | 5,894.12 | 15,489.36 |
| Shop 2 | 2021-05-12 | 9,966.66 | 15,489.36 |
| Shop 2 | 2021-05-13 | 4,987.56 | 15,489.36 |
| Shop 2 | 2021-05-14 | 12,567.45 | 15,489.36 |
| Shop 2 | 2021-05-15 | 15,489.36 | 15,489.36 |
Introduction to SQL ORDER BY clause
When you use the statement to query data from a table, the order which rows appear in the result set may not be what you expected.
In some cases, the rows that appear in the result set are in the order that they are stored in the table physically. However, in case the query optimizer uses an index to process the query, the rows will appear as they are stored in the index key order. For this reason, the order of rows in the result set is undetermined or unpredictable.
The query optimizer is a built-in software component in the database system that determines the most efficient way for an SQL statement to query the requested data.
To specify exactly the order of rows in the result set, you add use an clause in the statement as follows:
In this syntax, the clause appears after the clause. In case the statement contains a clause, the clause must appear after the clause.
To sort the result set, you specify the column in which you want to sort and the kind of the sort order:
- Ascending ( )
- Descending ( )
If you don’t specify the sort order, the database system typically sorts the result set in ascending order ( ) by default.
When you include more than one column in the clause, the database system first sorts the result set based on the first column and then sort the sorted result set based on the second column, and so on.
MySQL Order By Ascending
To sort data in ascending order, we have to use Order By statement, followed by the ASC keyword. The following are the list of ways to sort data in ascending order. For example, as a Sales Manager, If you want to identify the low performing products (Products with No Sales, or fewer sales), then write the query as:
By seeing the result, you can understand that x is not performing well, and y has no sales at all. Using this data, you can try different strategies to improve sales.
MySQL Sort in Ascending Order Example
In this MySQL example, we are going to sort the Data in Ascending Order using Yearly Income. Please replace yearly income with any of your required columns in a Table.
From the below screenshot, you can see the Data was sorted by Yearly Income in Ascending order.
MySQL Sort in Ascending Order without using ASC
The ASC keyword is the default keyword in Order By statement, that’s why it is optional to use ASC. In this example, we are going to sort the customer’s data by First_Name in ascending order without using ASC Keyword.
MySQL Sort Numeric Position in Ascending Order
In this MySQL Order By ASC example, We are going to sort customers table in Ascending Order using Numerical Position of a Column Name.
The Numerical position of Last_Name is 2. So, data sorted by this column.
MySQL Order By Multiple Columns in Ascending Order
In this MySQL Order By ASC example, we are sorting the Data using multiple columns.
First, data sorted in Ascending Order by First Name. The Last Name then sorts it in Ascending Order.
MySQL Sort By ASC using Alias Column
In this MySQL Order by ASC example, we are going to sort the customer’s Data in Ascending Order using Alias Column Name.
We used the concat string function to concat the First Name, and Last_Name columns to create Name (an Alias Name). Next, we used the Alias name in the ORDER BY Clause. It means customer’s data sort by Name in Ascending Order.
Выражения значения
Выражение значения используются в различных контекстах, таких как список
целей команды SELECT, в качестве новых значений столбцов в INSERT или
UPDATE или в условиях поиска в ряде команд. Результат вычисления
выражения значений иногда называют скаляром, чтобы отличить его от
результата табличного выражения (которое является таблицей). Поэтому
выражения значений также называют скалярными выражениями (или даже
просто выражениями). Синтаксис выражения позволяет вычислять значения из
примитивных частей, используя арифметические, логические, множественные
и другие операции.





Выражением значения может быть:
-
Постоянное или буквальное значение;
-
Ссылка на столбец;
-
Ссылка на позиционный параметр в теле определения функции или
подготовленного оператора; -
Выражение подзапроса;
-
Выражение выбора поля;
-
Вызов оператора;
-
Вызов функции;
-
Агрегатное выражение;
-
Вызов оконной функции;
-
Приведение типа;
-
Сортировка выражения;
-
Скалярный подзапрос;
-
Конструктор массива;
-
Конструктор строк.
-
Другое выражение значения в скобках (используется для группировки
подвыражений и переопределения приоритета).
В дополнение к этому списку, существует ряд конструкций, которые могут
быть классифицированы как выражения, но не следуют никаким общим
правилам синтаксиса. Как правило, они имеют семантику функции или
оператора и объясняются в соответствующем месте в главе Функции и операторы. Примером
является предложение IS NULL.
Константы уже обсуждались в разделе . В следующих подразделах обсуждаются остальные варианты.
На столбец можно ссылаться в виде:
correlation — это имя таблицы (возможно, дополненной именем схемы) или
псевдонима для таблицы, определенного с помощью предложения FROM. Имя
таблицы и разделяющая точка могут быть опущены, если имя столбца
уникально во всех таблицах, используемых в текущем запросе. (См. также
главу Запросы).
Ссылка на позиционный параметр используется для указания значения,
которое подается извне в оператор SQL. Параметры используются в
определениях функций SQL и в подготовленных запросах. Некоторые
клиентские библиотеки также поддерживают указание значений данных
отдельно от командной строки SQL, и в этом случае параметры используются
для ссылки на внешние значения данных. Форма ссылки на параметр:
Например, рассмотрим определение функции dept как:
Здесь $1 ссылка на значение первого аргумента функции при каждом её
вызове.
Если выражение дает значение типа массива, то конкретный элемент
значения массива можно извлечь, написав
или несколько смежных элементов («срез массива») можно извлечь, написав
(Здесь скобки должны появляться буквально). Каждый подзапрос сам
по себе является выражением, которое должно давать целочисленное
значение.
В общем случае массив expression должен быть заключен в скобки, но
круглые скобки могут быть опущены, когда выражение, которое должно быть
подписано, является просто ссылкой на столбец или позиционным
параметром. Кроме того, несколько подзапросов могут быть объединены,
если исходный массив является многомерным. Например:
Скобки в последнем примере обязательны. См. раздел для получения дополнительной информации о массивах.
Если выражение возвращает значение составного типа (тип строки), то
конкретное поле строки можно извлечь, написав
В общем случае expression строки должно быть заключено в скобки, но
скобки можно опустить, если выбранное выражение является просто ссылкой
на таблицу или позиционным параметром. Например:
(Таким образом, квалифицированная ссылка на столбец на самом деле
является просто частным случаем синтаксиса выбора поля). Важным частным
случаем является извлечение поля из столбца таблицы составного типа:
Скобки здесь обязательны для того, чтобы показать, что compositecol —
это имя столбца, а не имя таблицы, или что mytable — это имя таблицы, а
не имя схемы во втором случае.
Вы можете запросить все поля составного значения, написав :
Это обозначение ведет себя по-разному в зависимости от контекста; см. раздел для деталей.
Существует три возможных синтаксиса для вызова оператора:
где маркер operator следует синтаксическим правилам раздел , или
является одним из ключевых слов AND, OR и NOT, или является
квалифицированным именем оператора в форме:
Какие конкретные операторы существуют и являются ли они унарными или
двоичными, зависит от того, какие операторы были определены системой или
пользователем. В главе Функции и операторы описываются встроенные операторы.
Example 5 – Find the Maximum Value
This is not as simple as it may seem; I’m not talking about the common maximum value. To find that, you wouldn’t need the clause. But how about finding the maximum value (or revenue, in this case) across five days? Those five days will include the current date, up to three days before that, and one day after the current date. You probably already know the logic after all these examples of usage. Here’s my solution:
SELECT
shop,
date,
revenue_amount,
MAX(revenue_amount) OVER (
ORDER BY DATE
RANGE BETWEEN INTERVAL '3' DAY PRECEDING AND INTERVAL '1' DAY FOLLOWING
) AS max_revenue
FROM revenue_per_shop;
I’m using the function as a window function. Yet again, I’m using it with the column . There is no in the clause because I’m not interested in separating data on any level. Defining the range is not that difficult: . This will include the current date, three days before it, and one day after it. Here’s the result:
| shop | date | revenue_amount | max_revenue |
|---|---|---|---|
| Shop 1 | 2021-05-01 | 12,573.25 | 18,847.54 |
| Shop 2 | 2021-05-01 | 11,348.22 | 18,847.54 |
| Shop 1 | 2021-05-02 | 14,388.14 | 18,847.54 |
| Shop 2 | 2021-05-02 | 18,847.54 | 18,847.54 |
| Shop 1 | 2021-05-03 | 9,845.29 | 18,847.54 |
| Shop 2 | 2021-05-03 | 14,574.56 | 18,847.54 |
| Shop 1 | 2021-05-04 | 11,500.63 | 18,847.54 |
| Shop 2 | 2021-05-04 | 16,897.21 | 18,847.54 |
| Shop 1 | 2021-05-05 | 9,634.56 | 21,489.22 |
| Shop 2 | 2021-05-05 | 14,255.87 | 21,489.22 |
| Shop 1 | 2021-05-06 | 11,248.33 | 21,489.22 |
| Shop 2 | 2021-05-06 | 21,489.22 | 21,489.22 |
| Shop 2 | 2021-05-07 | 15,517.22 | 21,489.22 |
| Shop 1 | 2021-05-07 | 14,448.65 | 21,489.22 |
| Shop 2 | 2021-05-08 | 12,500.00 | 21,489.22 |
| Shop 1 | 2021-05-08 | 6,874.23 | 21,489.22 |
| Shop 2 | 2021-05-09 | 15,321.89 | 22,222.22 |
| Shop 1 | 2021-05-09 | 9,784.33 | 22,222.22 |
| Shop 1 | 2021-05-10 | 12,235.50 | 22,222.22 |
| Shop 2 | 2021-05-10 | 22,222.22 | 22,222.22 |
| Shop 1 | 2021-05-11 | 14,800.65 | 22,222.22 |
| Shop 2 | 2021-05-11 | 5,894.12 | 22,222.22 |
| Shop 2 | 2021-05-12 | 9,966.66 | 22,222.22 |
| Shop 1 | 2021-05-12 | 18,845.69 | 22,222.22 |
| Shop 1 | 2021-05-13 | 13,250.69 | 22,222.22 |
| Shop 2 | 2021-05-13 | 4,987.56 | 22,222.22 |
| Shop 1 | 2021-05-14 | 17,784.25 | 19,874.26 |
| Shop 2 | 2021-05-14 | 12,567.45 | 19,874.26 |
| Shop 2 | 2021-05-15 | 15,489.36 | 19,874.26 |
| Shop 1 | 2021-05-15 | 19,874.26 | 19,874.26 |
Let’s check the result for – marked in pink. The range is marked in yellow. To get the maximum revenue in that range, SQL will compare values: 14,388.14, 18,847.54, 9,845.29, 14,574.56, 11,500.63, 16,897.21, 9,634.56, 14,255.87, 11,248.33, 21,489.22. Which one is the highest? It’s 21,489.22.
After learning how to find maximum value using the clause, I’ve reached the maximum number of examples intended for this article. If you want more window functions examples, you can always read this article.
LAG and LEAD
It can often be useful to compare rows to preceding or following rows, especially if you’ve got the data in an order that makes sense. You can use or to create columns that pull values from other rows—all you need to do is enter which column to pull from and how many rows away you’d like to do the pull. pulls from previous rows and pulls from following rows:
This is especially useful if you want to calculate differences between rows:
The first row of the column is null because there is no previous row from which to pull. Similarly, using will create nulls at the end of the dataset. If you’d like to make the results a bit cleaner, you can wrap it in an outer query to remove nulls:


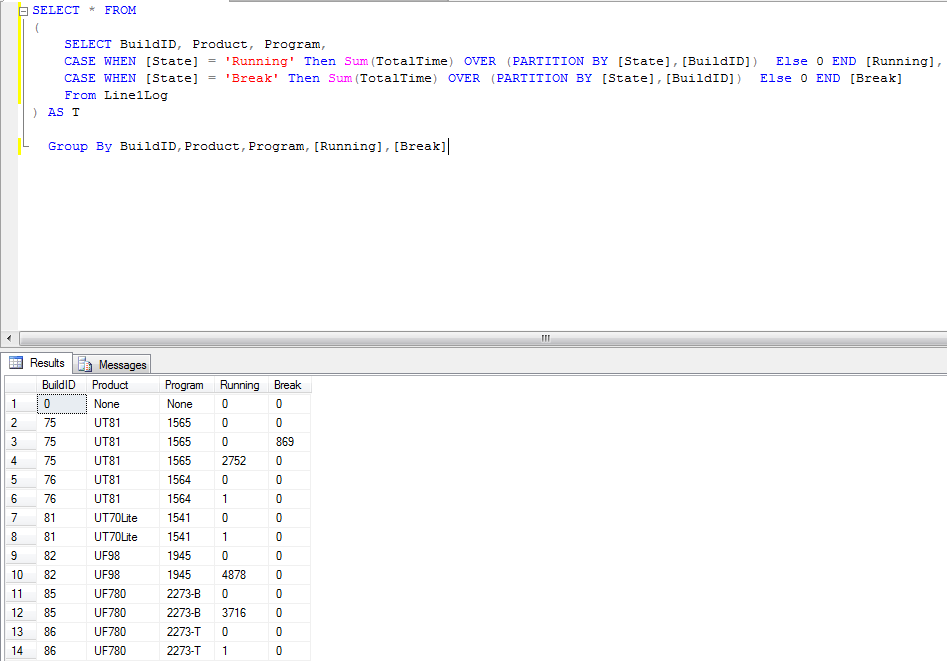
NTILE
NTILE – функция Transact-SQL, которая делит результирующий набор на группы по определенному столбцу. Количество групп указывается в качестве параметра. В случае если в группах получается не одинаковое количество строк, то в первой группе будет наибольшее количество, например, в нашем случае строк 10 и если мы поделим на три группы, то в первой будет 4 строки, а во второй и третей по 3.
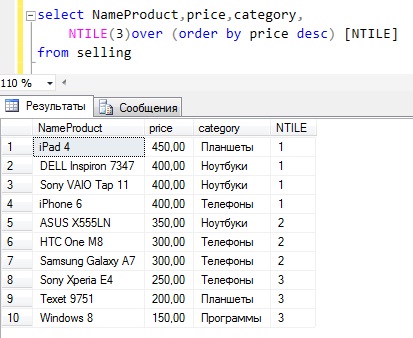
В заключение давайте приведем пример, в котором мы наглядно увидим различия в работе всех функций, например, вот такой
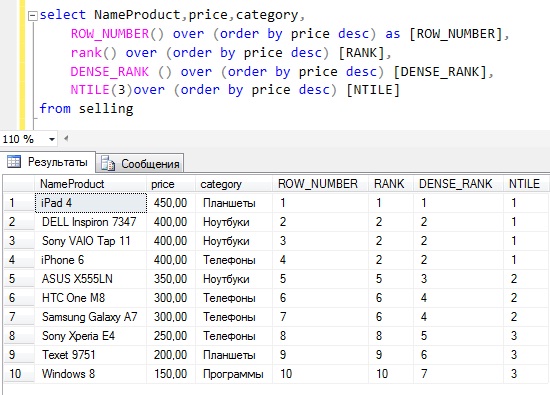
На этом я думаю по ранжирующим функциям достаточно, в следующих статьях мы продолжим изучение Transact-SQL, а на этом пока все. Удачи!
ОБЛАСТЬ ПРИМЕНЕНИЯ: SQL Server База данных SQL Azure Azure Synapse Analytics (хранилище данных SQL) Parallel Data Warehouse APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL DW) Parallel Data Warehouse
Нумерует выходные данные результирующего набора. Numbers the output of a result set. В частности, возвращает последовательный номер строки в секции результирующего набора, 1 соответствует первой строке в каждой из секций. More specifically, returns the sequential number of a row within a partition of a result set, starting at 1 for the first row in each partition.
Функции ROW_NUMBER и RANK похожи. ROW_NUMBER and RANK are similar. ROW_NUMBER нумерует все строки по порядку (например, 1, 2, 3, 4, 5). ROW_NUMBER numbers all rows sequentially (for example 1, 2, 3, 4, 5). RANK назначает одинаковое числовое значение строкам, претендующим на один ранг (например, 1, 2, 2, 4, 5). RANK provides the same numeric value for ties (for example 1, 2, 2, 4, 5).
ROW_NUMBER — это временное значение, вычисляемое во время выполнения запроса. ROW_NUMBER is a temporary value calculated when the query is run. Сведения о хранении номеров в таблице см. в разделах Свойство IDENTITY и SEQUENCE. To persist numbers in a table, see IDENTITY Property and SEQUENCE.
Синтаксические обозначения в Transact-SQL Transact-SQL Syntax Conventions
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. When you will include ALL it will count all values including duplicate ones. DISTINCT is not supported in window functions
expression
The target column or expression that the functions operates on. In other words, the name of the column for which we need an aggregated value. For example, a column containing order amount so that we can see total orders received.
OVER
Specifies the window clauses for aggregate functions.
PARTITION BY partition_list
Defines the window (set of rows on which window function operates) for window functions.
We need to provide a field or list of fields for the partition after PARTITION BY clause. Multiple fields need be separated by a comma as usual. If PARTITION BY is not specified, grouping will be done on entire table and values will be aggregated accordingly.
ORDER BY order_list
Sorts the rows within each partition. If ORDER BY is not specified, ORDER BY uses the entire table.