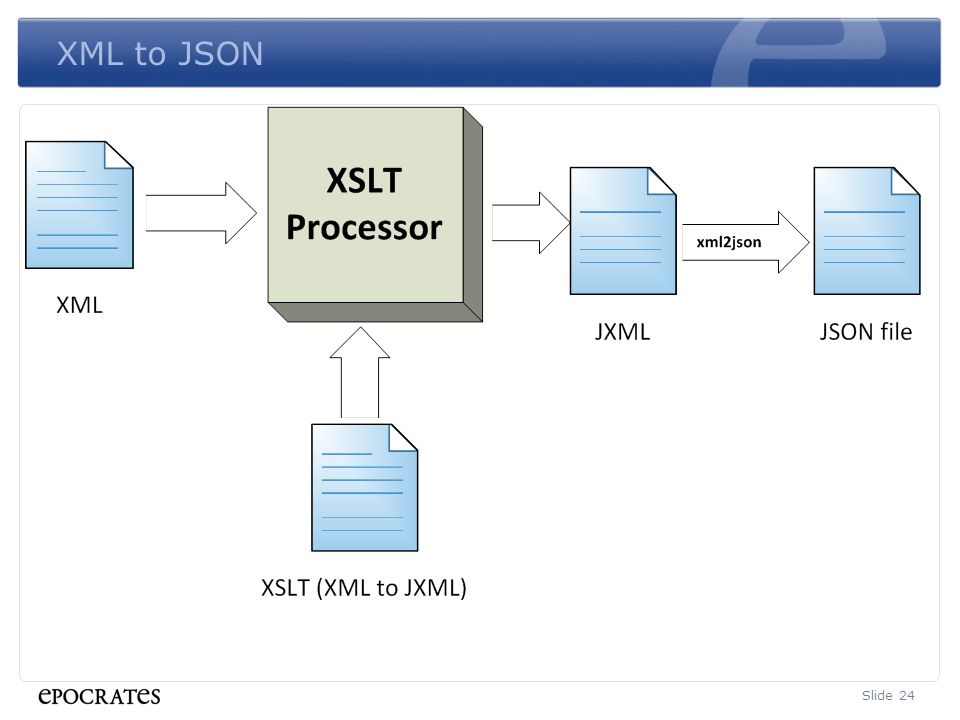
Auto Rollback transactions in SQL Server
Generally, the transactions include more than one query. In this manner, if one of the SQL statements returns an
error all modifications are erased, and the remaining statements are not executed. This process is called
Auto Rollback Transaction in SQL. Now let’s explain this principle with a very
simple example.
|
1 |
BEGINTRAN INSERTINTOPerson VALUES(‘Bunny’,’Bugs’,’742 Evergreen Terrace’,’Springfield’,54) UPDATEPersonSETAge=’MiddleAge’WHEREPersonID=7 SELECT*FROMPerson COMMITTRAN |
As we can see from the above image, there was an error that occurred in the update statement due to the data type
conversion issue. In this case, the inserted data is erased and the select statement did not execute.
Регулярные выражения
И последнее и наименее рекомендованное — можно извлекать данные из HTML с помощью регулярных выражений . В целом использование регулярных выражений в HTML не рекомендуется.
Большинство фрагментов кода, которые вы найдете в интернете для соответствия разметке, некорректны. В большинстве случаев они работают только с определенными фрагментами HTML. Небольшие изменения разметки, такие как добавление пробелов, добавление или изменение атрибутов в теге, могут привести к сбою RegEx, если он неправильно написан. Вы должны знать, что делаете, прежде чем использовать RegEx в HTML.
Парсеры HTML уже имеют синтаксические правила HTML. Регулярные выражения необходимо обучать для каждого конкретного случая. В некоторых случаях RegEx подходят, но это действительно зависит от вашего варианта использования.
Пример
Рассмотрим некоторые примеры SQL Server функции CONVERT, чтобы понять, как использовать функцию CONVERT в SQL Server (Transact-SQL). Например:
Transact-SQL
SELECT CONVERT(int, 15.49);
—Результат: 15 (Результат усекается)
SELECT CONVERT(float, 15.49);
—Результат: 15,49 (Результат не усекается)
SELECT CONVERT(varchar, 23.7);
—Результат: ‘23.7’
SELECT CONVERT(varchar(4), 23.7);
—Результат: ‘23.7’
SELECT CONVERT(float, ‘52.4’);
—Результат: 52,4
SELECT CONVERT(datetime, ‘01.12.2017’);
—Результат: ‘2017-12-01 00:00:00.000’
SELECT CONVERT(varchar, ‘01.12.2017’, 101);
—Результат: ‘01.12.2017’
|
1 |
SELECTCONVERT(int,15.49); SELECTCONVERT(float,15.49); SELECTCONVERT(varchar,23.7); SELECTCONVERT(varchar(4),23.7); SELECTCONVERT(float,’52.4′); SELECTCONVERT(datetime,’01.12.2017′); SELECTCONVERT(varchar,’01.12.2017′,101); |
Tag-Based XML
This example uses tag-based XML, where each data element for an employee is surrounded by its own start and end tag.
First we create a table to hold our XML document and populate it with a document containing multiple rows of data. Using gives us a separate tag for each column in the query.
CREATE TABLE xml_tab (
id NUMBER,
xml_data XMLTYPE
);
DECLARE
l_xmltype XMLTYPE;
BEGIN
SELECT XMLELEMENT("employees",
XMLAGG(
XMLELEMENT("employee",
XMLFOREST(
e.empno AS "empno",
e.ename AS "ename",
e.job AS "job",
TO_CHAR(e.hiredate, 'DD-MON-YYYY') AS "hiredate"
)
)
)
)
INTO l_xmltype
FROM emp e;
INSERT INTO xml_tab VALUES (1, l_xmltype);
COMMIT;
END;
/
We can see the resulting row containing the tag-based XML using the following query.
SET LONG 5000
SELECT x.xml_data.getClobVal()
FROM xml_tab x;
X.XML_DATA.GETCLOBVAL()
--------------------------------------------------------------------------------
<employees>
<employee>
<empno>7369</empno>
<ename>SMITH</ename>
<job>CLERK</job>
<hiredate>17-DEC-1980</hiredate>
</employee>
<employee>
<empno>7499</empno>
<ename>ALLEN</ename>
<job>SALESMAN</job>
<hiredate>20-FEB-1981</hiredate>
</employee>
<employee>
<empno>7521</empno>
<ename>WARD</ename>
<job>SALESMAN</job>
<hiredate>22-FEB-1981</hiredate>
</employee>
<employee>
<empno>7566</empno>
<ename>JONES</ename>
<job>MANAGER</job>
<hiredate>02-APR-1981</hiredate>
</employee>
<employee>
<empno>7654</empno>
<ename>MARTIN</ename>
<job>SALESMAN</job>
<hiredate>28-SEP-1981</hiredate>
</employee>
<employee>
<empno>7698</empno>
<ename>BLAKE</ename>
<job>MANAGER</job>
<hiredate>01-MAY-1981</hiredate>
</employee>
<employee>
<empno>7782</empno>
<ename>CLARK</ename>
<job>MANAGER</job>
<hiredate>09-JUN-1981</hiredate>
</employee>
<employee>
<empno>7788</empno>
<ename>SCOTT</ename>
<job>ANALYST</job>
<hiredate>19-APR-1987</hiredate>
</employee>
<employee>
<empno>7839</empno>
<ename>KING</ename>
<job>PRESIDENT</job>
<hiredate>17-NOV-1981</hiredate>
</employee>
<employee>
<empno>7844</empno>
<ename>TURNER</ename>
<job>SALESMAN</job>
<hiredate>08-SEP-1981</hiredate>
</employee>
<employee>
<empno>7876</empno>
<ename>ADAMS</ename>
<job>CLERK</job>
<hiredate>23-MAY-1987</hiredate>
</employee>
<employee>
<empno>7900</empno>
<ename>JAMES</ename>
<job>CLERK</job>
<hiredate>03-DEC-1981</hiredate>
</employee>
<employee>
<empno>7902</empno>
<ename>FORD</ename>
<job>ANALYST</job>
<hiredate>03-DEC-1981</hiredate>
</employee>
<employee>
<empno>7934</empno>
<ename>MILLER</ename>
<job>CLERK</job>
<hiredate>23-JAN-1982</hiredate>
</employee>
</employees>
1 row selected.
SQL>
The operator allows us to split the XML data into rows and project columns on to it. We effectively make a cartesian product between the data table and the call, which allows to split a XML document in a single row into multiple rows in the final result set. The table column is identified as the source of the data using the clause. The rows are identified using a XQuery expression, in this case ‘/employees/employee’. Columns are projected onto the resulting XML fragments using the clause, which identifies the relevant tags using the expression and assigns the desired column names and data types. Be careful with the names of the columns in the clause. If you use anything other than upper case, they will need to be quoted to make direct reference to them. Notice we are querying using the alias of the call, rather than the regular table alias.
SELECT xt.*
FROM xml_tab x,
XMLTABLE('/employees/employee'
PASSING x.xml_data
COLUMNS
empno VARCHAR2(4) PATH 'empno',
ename VARCHAR2(10) PATH 'ename',
job VARCHAR2(9) PATH 'job',
hiredate VARCHAR2(11) PATH 'hiredate'
) xt;
EMPN ENAME JOB HIREDATE
---- ---------- --------- -----------
7369 SMITH CLERK 17-DEC-1980
7499 ALLEN SALESMAN 20-FEB-1981
7521 WARD SALESMAN 22-FEB-1981
7566 JONES MANAGER 02-APR-1981
7654 MARTIN SALESMAN 28-SEP-1981
7698 BLAKE MANAGER 01-MAY-1981
7782 CLARK MANAGER 09-JUN-1981
7788 SCOTT ANALYST 19-APR-1987
7839 KING PRESIDENT 17-NOV-1981
7844 TURNER SALESMAN 08-SEP-1981
7876 ADAMS CLERK 23-MAY-1987
7900 JAMES CLERK 03-DEC-1981
7902 FORD ANALYST 03-DEC-1981
7934 MILLER CLERK 23-JAN-1982
14 rows selected.
SQL>
Modes of the Transactions in SQL Server
SQL Server can operate 3 different transactions modes and these are:
-
Autocommit Transaction mode is the default transaction for the SQL Server. In this mode, each
T-SQL statement is evaluated as a transaction and they are committed or rolled back according to their results.
The successful statements are committed and the failed statements are rolled back immediately -
Implicit transaction mode enables to SQL Server to start an implicit
transaction for every DML statement but we need to use the commit or rolled back commands explicitly at the end
of the statements -
Explicit transaction mode provides to define a transaction exactly with the starting and ending
points of the transaction
Оптимизация индексов
После выполнения любых действий с табличными данными sql сервером в тот же момент производятся соответствующие правки в индексах. Спустя некоторое время все подобные исправления могут спровоцировать фрагментацию данных. В результате, их может разбросать по всей базе.
Подобная фрагментация данных может стать причиной понижения производительности
Потому крайне важно время от времени проводить дефрагментацию. К подобным операциям по обслуживанию индексов относят реорганизацию и перестроение индексов
Чтобы понять, какую именно операцию требуется провести – реорганизацию или перестроение, следует выяснить степень фрагментации данных. Она поможет понять, какой способ дефрагментации будет наиболее эффективным и что выбрать.
Чтобы выяснить уровень фрагментации следует воспользоваться системной табличной функцией sys.dm_db_index_physical_stats. Для определения уровня фрагментации всего перечня таблиц для выбранной базы, можете воспользоваться следующим запросом:
SELECT OBJECT_NAME(T1.object_id) AS NameTable,
T1.index_id AS IndexId,
T2.name AS IndexName,
T1.avg_fragmentation_in_percent AS Fragmentation
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS T1
LEFT JOIN sys.indexes AS T2 ON T1.object_id = T2.object_id AND T1.index_id = T2.index_id
Согласно рекомендациям Microsoft, последующие действия будут зависеть от уровня фрагментации:
- меньше 5% – о дефрагментации следует пока забыть;
- от 5 до 30% – требуется выполнить реорганизацию индекса. Это потребует минимального количества ресурсов системы и ее можно провести без долговременной блокировки;
- свыше 30% – следует выполнить перестроение индекса. При значительном уровне фрагментации это наиболее эффективно.
Реорганизация индекса
Реорганизацией называют процесс устранения фрагментации индекса. В его ходе происходит дефрагментация конечного уровня кластерных и некластерных индексов по таблицам и представлениям. Говоря простым языком – выполняется простое переупорядочивание страниц. В основе переупорядочивания лежит логический порядок конечных узлов (выполняете слева направо).
Если хотите провести реорганизацию – воспользуйтесь:
- MSSQL Management Studio. На выбранном индексе следует щелкнуть мышкой, из списка выбрать и нажать «Реорганизовать»;
- соответствующими инструкциями T-SQL.
Перестроение индекса
Перестроением называется операция по устранению фрагментации индекса. Он заключается в устранении старого и формировании нового.
Перестроение индекс выполняется несколькими способами. В этом поможет:
- Management Studio. Для этого необходимо выбрать нужный индекс, мышкой кликнуть по нему и выбрать «Перестроить»;
- инструкция ALTER INDEX ix с предложением REBUILD, которая по сути является заменой инструкции DBCC DBREINDEX. Ею пользуются, когда возникла потребность в масштабной операции;
- инструкция CREATE NONCLUSTERED INDEX (CREATE INDEX) с предложением DROP_EXISTING. Подходит, чтобы перестроить индекс и изменить его определения (удалить либо добавить ключевые столбцы).
Это вся полезная информация по индексам в Microsoft SQL Server. Изучайте их, а если возникнут вопросы – задавайте. Удачи в изучении и применении indexes ms sql.











Introduction
Extensible Markup Language (XML) has been in existence for more than two decades. XML is a markup language for encoding documents in a format that is both human and machine readable. In XML, you define your own custom tags, elements and attributes to meet your specific needs. XML is case sensitive, allows comments and hierarchy is important. An XML file is a text file and can be opened with any text editor. The following is a sample of an XML document:
When we run a query against a relational database table, the resulting data is presented mostly in tabular format. Each horizontal row represents a record while the columns flow vertically and represent an attribute of the record.
In this post, I explore how MS SQL Server and PostgreSQL databases may be queried to output the data in an XML format instead of tabular format. Each of these databases contain inbuilt functionality to output XML. You can also manually write queries combining XML elements and data from the databases to create XML output. Manually created XML output is tedious, will be missing a root element and will therefore not conform to a .
Столбец is_directory в схеме FileTable The is_directory column in the FileTable schema
В приведенной ниже таблице описывается взаимодействие между столбцом is_directory и столбцом file_stream , в котором находятся данные FILESTREAM в таблице FileTable. The following table describes the interaction between the is_directory column and the file_stream column that contains the FILESTREAM data in a FileTable.
| is_directory значение is_directory value | file_stream значение file_stream value | Поведение Behavior |
| FALSE FALSE | NULL NULL | Это недопустимое сочетание, которое будет перехвачено системным ограничением. This is an invalid combination that will be caught by a system-defined constraint. |
| FALSE FALSE | Этот элемент представляет файл. The item represents a file. | |
| TRUE TRUE | NULL NULL | Этот элемент представляет каталог. The item represents a directory. |
| TRUE TRUE | Это недопустимое сочетание, которое будет перехвачено системным ограничением. This is an invalid combination that will be caught by a system-defined constraint. |
Создание, изменение хранимых процедур
Создание хранимой процедуры предполагает решение следующих за-
дач: планирование прав доступа. При создании хранимой процедуры следует учитывать, что она будет иметь те же права доступа к объектам базы
данных, что и создавший ее пользователь; определение параметров храни-
мой процедуры, хранимые процедуры могут обладать входными и выход-
ными параметрами; разработка кода хранимой процедуры. Код процедуры
может содержать последовательность любых команд SQL, включая вызов
других хранимых процедур.
Синтаксис оператора создания новой или изменения имеющейся хранимой процедуры в обозначениях MS SQL Server:
{CREATE | ALTER } PROCEDURE имя_процедуры ;номер
{@имя_параметра тип_данных } VARYING =DEFAULTOUTPUT ,...n
WITH { RECOMPILE | ENCRYPTION | RECOMPILE,
ENCRYPTION }
FOR REPLICATION
AS
sql_оператор ...n
Рассмотрим параметры данной команды.
Используя префиксы sp_, #, ##, создаваемую процедуру можно определить в качестве системной или временной. Как видно из синтаксиса команды, не допускается указывать имя владельца, которому будет принадлежать создаваемая процедура, а также имя базы данных, где она должна
быть размещена. Таким образом, чтобы разместить создаваемую хранимую
процедуру в конкретной базе данных, необходимо выполнить команду
CREATE PROCEDURE в контексте этой базы данных. При обращении из
тела хранимой процедуры к объектам той же базы данных можно использовать укороченные имена, т. е. без указания имени базы данных. Когда же
требуется обратиться к объектам, расположенным в других базах данных,
указание имени базы данных обязательно.
Для передачи входных и выходных данных в создаваемой хранимой
процедуре имена параметров должны начинаться с символа @. В одной
хранимой процедуре можно задать множество параметров, разделенных
запятыми. В теле процедуры не должны применяться локальные переменные, чьи имена совпадают с именами параметров этой процедуры.
Для определения типа данных параметров хранимой процедуры подходят любые типы данных SQL, включая определенные пользователем.
Однако тип данных CURSOR может быть использован только как выходной параметр хранимой процедуры, т.е. с указанием ключевого слова
OUTPUT.
Наличие ключевого слова OUTPUT означает, что соответствующий
параметр предназначен для возвращения данных из хранимой процедуры.
Однако это вовсе не означает, что параметр не подходит для передачи значений в хранимую процедуру. Указание ключевого слова OUTPUT предписывает серверу при выходе из хранимой процедуры присвоить текущее
значение параметра локальной переменной, которая была указана при вызове процедуры в качестве значения параметра. Отметим, что при указании ключевого слова OUTPUT значение соответствующего параметра при вызове процедуры может быть задано только с помощью локальной переменной. Не разрешается использование любых выражений или констант, допустимое для обычных параметров.
Ключевое слово VARYING применяется совместно с параметром
OUTPUT, имеющим тип CURSOR. Оно определяет, что выходным параметром будет результирующее множество.
Ключевое слово DEFAULT представляет собой значение, которое будет принимать соответствующий параметр по умолчанию. Таким образом,
при вызове процедуры можно не указывать явно значение соответствующего параметра.
Так как сервер кэширует план исполнения запроса и компилированный
код, при последующем вызове процедуры будут использоваться уже готовые значения. Однако в некоторых случаях все же требуется выполнять
перекомпиляцию кода процедуры. Указание ключевого слова RECOMPILE
предписывает системе создавать план выполнения хранимой процедуры
при каждом ее вызове.
Параметр FOR REPLICATION востребован при репликации данных и
включении создаваемой хранимой процедуры в качестве статьи в публикацию.
Ключевое слово ENCRYPTION предписывает серверу выполнить
шифрование кода хранимой процедуры, что может обеспечить защиту от
использования авторских алгоритмов, реализующих работу хранимой процедуры.
Ключевое слово AS размещается в начале собственно тела хранимой
процедуры. В теле процедуры могут применяться практически все команды SQL, объявляться транзакции, устанавливаться блокировки и вызываться другие хранимые процедуры. Выход из хранимой процедуры можно
осуществить посредством команды RETURN.
Настройка MS SQL Server
Перед установкой базы данных необходимо проверить аутентификацию сервера и настроить SQL Server для работы в сети.
Настройка аутентификации сервера
Для работы программ по сети нужно создать в Users Manager учетные записи пользователей. (Меню «Администрирование»). Перед тем как это сделать, необходимо изменить способ аутентификации в настройках сервера.
Запустите программу «Среда SQL Server Management Studio». Подключитесь к вашему серверу и затем кликните правой кнопкой по имени сервера и выберите пункт «Свойства»
Во вкладке «Безопасность» укажите «Проверка подлинности SQL Server и Windows»
Среда SQL Server Management Studio Express
Нажмите «Ок» и затем перезапустите службу SQL Server.
Политика паролей
Если у Вас установлена Window Server любой версии, то откройте через меню «Пуск» — «Администрирование» — «Локальная политика безопасности».
Во вкладке «Политика паролей» посмотрите на значение пункта «Пароль должен отвечать требованиям …..».Если в строке стоит статус «Включен», то кликните по пункт 2-м щелчком и выберите галочку «Отключен».
После установки базы данных и создания в Users Manager учетных записей политику паролей можно включить обратно.
Настройка MS SQL Server 2005-2017 для работы в сети
После установки SQL Server, по умолчанию, он не доступен по сети. Если SQL сервер не доступен или при запуске программы (Деканат, ПК, Ведомости и т.д) возникает ошибка, то это может свидетельствовать о следующем:
— Не установлен режим подлинности Windows аутентификация; — Не включена возможность удаленного соединения (для SQL server 2005); — Не доступен протокол TCP/IP; — Отсутствует физическое подключение к сети; — Блокирование сервера Брандмауэром Windows.
После установки SQL Server необходимо настроить его для работы в сети. Настройки зависят от версии сервера.
Выберите в меню Пуск — Программы — Microsoft SQL Server 2005>Средства настройки> Настройка контактной зоны SQL Server. В открывшейся форме выберите «Настройка контактной зоны для служб и соединений» и нажмите «Сохранить»
Настройка контактной зоны
2.2. Укажите галочку «Использовать TCP/IP и именованные каналы». Нажмите кнопку «Применить».
Настройка контактной зоны
2.3 В списке компонентов перейдите на пункт «SQL Server Browser». Убедитесь, что служба запущена. Укажите режим запуска «Авто» и запустите службу.
Откройте меню «Пуск» – «Все программы» – «Microsoft Sql Server 2008/2012» – «Средства настройки» – «Диспетчер конфигурации SQL Server»
Во вкладке «Службы SQL Server» убедитесь, что служба «SQL Server, обозреватель» запущена. В колонке «Состояние» должно быть значение «Работает», а в колонке «Режим запуска» — «Авто». Также и для службы SQL Server (sqlexpress).










Агент SQL Server можно не включать
Перейдите в пункт «Сетевая конфигурация SQL Server». Проверьте состояние протокола TCP/IP (должна быть состояние «Включено»).
После смены состояния перезапустите службу SQL Server.
Настройка Брэндмаура
Если после выполнения всех перечисленных действий сервер не доступен по сети, то проверьте настройки брандмауэра/антивируса/сетевого экрана.
Если на серверном компьютере включен брандмауэр или установлен сетевой экран (Firewall), то это может препятствовать соединению с сервером. Для быстрого получения ответа можно временно выключить работу «защитной» программы (не рекомендуется).
Открытые порта 1433 в брандмауэре:
1. Откройте панель управления и выберите пункт Брандмауэр Windows.
2. Перейдите в дополнительные параметры
3. Выберите узел «Правила для входящих подключений» и затем, в правой панели — Создать правило
3. Выберите пункт «Для порта» и нажмите Далее
4. Укажите Протокол TCP и пункт «Определенные локальные порты». В поле укажите порт 1433 и нажмите Далее
5. В окне выбора профилей оставьте выбранными 3 галочки: доменный, частный, публичный. Нажмите кнопку Далее.
6. Укажите пункт «Разрешить подключение» и нажмите Далее
7. Укажите имя правилу (на свое усмотрение)
Удаление схем и пользователей
Данный пункт может применяться если у Вас уже была установлена БД Деканат. Данные действия надо выполнить, если не удается создать учетные записи программы.
1. Запустите «Среда SQL Server Management Studio»;
2. Откройте и перейдите во вкладку «Деканат» — «Безопасность» — «Схемы»;
3. Удалите следующие схемы: Abit, Dek, VedKaf, Kaf, Plany, Test, GraphGroups;
4. Отройте вкладку Деканат» — «Безопасность» — «Пользователи»
5. Удалите имена пользователей с именами: Abit, VedKaf, Kaf, Plany, Test, GraphGroups.
Путь программиста T-SQL. Самоучитель по языку Transact-SQL
Самоучитель по языку T-SQL
Данная книга в первую очередь предназначена, как я уже сказал, для начинающих программистов SQL, в частности T-SQL. Если направление Вашей работы больше связано с администрированием Microsoft SQL Server, то Вам лучше выбрать другую книгу, так как книга «Путь программиста T-SQL» ориентирована все-таки на разработку, хотя, если Вы начинающий администратор, она будет Вам полезна, так как знания и умения писать SQL запросы требуется всем, кто работает с SQL сервером, к тому же тема базового администрирования в книге затронута.
Если говорить в целом, в книге затронуты все те моменты, с которыми Вы столкнетесь, когда будете разрабатывать инструкции на T-SQL, писать запросы на выборку, в общем, просто работать с Microsoft SQL Server. Книгу можно смело рекомендовать обычным администраторам, программистам, инженерам, в обязанности которых входит сопровождение Microsoft SQL Server.
В книге присутствуют примеры написания кода для каждой конструкции и оператора, поэтому могу с уверенностью сказать, что в книге очень много примеров T-SQL инструкций, все они несомненно помогут Вам в изучении языка T-SQL.
Конечно же, все знания, которые Вы получите, нельзя отнести к углубленным, так как книга посвящена основам T-SQL, самое главное, что эти знания у Вас будут, и после прочтения книги Вы без труда сможете писать SQL запросы, разрабатывать процедуры, функции и многое другое!
Кстати, после прочтения данной книги все те книги по T-SQL или SQL, которые Вы начинали читать, но так и не дочитали, будут для Вас не такими уж и сложными, ведь Вы уже будете обладать достаточными знаниями, чтобы понять все то, что пытаются донести до нас авторы этих книг.
Если Вы обычный администратор, программист, инженер, и сомневаетесь, что знания языка T-SQL и умение разрабатывать программы в базе данных Microsoft SQL Server будут Вам полезны, спешу Вам сообщить, что знания языка T-SQL и Microsoft SQL Server очень ценятся! И сотрудники, которые имеют опыт или навык работы с SQL Server, например, написание SQL запросов на выборку, ценятся в разы выше, чем сотрудники, у которых таких навыков нет! И соответственно у них выше зарплата, а если Вы профессионально займетесь T-SQL, то заработок будет в разы больше. Этим я хочу скачать, что в современном мире платформы по управлению базами данных, такие как Microsoft SQL Server, очень распространены, а умение работать с ними очень ценно!
Filtering Rows with XPath
We can limit the rows returned by altering the XPath expression. In the following example we only return rows with the job type of «CLERK».










SELECT xt.*
FROM xml_tab x,
XMLTABLE('/employees/employee'
PASSING x.xml_data
COLUMNS
empno VARCHAR2(4) PATH 'empno',
ename VARCHAR2(10) PATH 'ename',
job VARCHAR2(9) PATH 'job',
hiredate VARCHAR2(11) PATH 'hiredate'
) xt;
EMPN ENAME JOB HIREDATE
---- ---------- --------- -----------
7369 SMITH CLERK 17-DEC-1980
7876 ADAMS CLERK 23-MAY-1987
7900 JAMES CLERK 03-DEC-1981
7934 MILLER CLERK 23-JAN-1982
4 rows selected.
SQL>
We could parameterise the job type using variable in the XPath, which is prefixed with a «$». The value for this variable is then passed in the clause. The variable must be aliases using and double quoted to make sure the name and case matches that of the variable in the XPath expression.
VARIABLE v_job VARCHAR2(10);
EXEC :v_job := 'CLERK';
SELECT xt.*
FROM xml_tab x,
XMLTABLE('/employees/employee'
PASSING x.xml_data, :v_job AS "job"
COLUMNS
empno VARCHAR2(4) PATH 'empno',
ename VARCHAR2(10) PATH 'ename',
job VARCHAR2(9) PATH 'job',
hiredate VARCHAR2(11) PATH 'hiredate'
) xt;
EMPN ENAME JOB HIREDATE
---- ---------- --------- -----------
7369 SMITH CLERK 17-DEC-1980
7876 ADAMS CLERK 23-MAY-1987
7900 JAMES CLERK 03-DEC-1981
7934 MILLER CLERK 23-JAN-1982
4 rows selected.
SQL>
Ответ 2
- Простота и надежность
- Простые в использовании альтернативы ->find(«a img, a object, div a»)
- Правильное неэкранирование данных (по сравнению с grepping регулярным выражением)
Мы будем очень благодарны
Сформировать простой XML и распарсить его
Распарсить текстовый файл и сформировать HTML на его основеВсем привет! Направьте, пожалуйста, на путь истинный в решении такой вот задачки. Есть.
Во что лучше распарсить многоуровневый XML, чтобы потом его считать в GridСобственно вопрос в заголовке. Нужно распарсить XML, чтобы получилась плоская таблица, в которой.
Задача стоит дан XMl файл с фигурами надо его распарсить и создать массив фигур с их атрибутамиФайл распарсил , не могу создать массив чтобы в нем были все атрибуты . И проблема при выводе в гуи.
Распарсить xmlЗдравствуйте! Ребята, подскажите, каким образом можно корректно распарить xml документ при помощи.
Как просто распарсить XML в C#
Перед многими часто встаёт задача распарсить XML с помощью C#. В данной статье опишу простейшие методы разбора XML без излишней сложности и без подключения библиотек сторонних разработчиков. Описанных примеров хватит для большинства существующих задач.
Создадим в Visual Studio проект Windows Form и набросаем кнопки и текстовые поля и получим примерно такую форму:
По кнопке «Машина» мы будем получать из XML марку, номер и регион, в котором зарегистрирован автомобиль. По кнопке «Страна 2» мы будем получать из XML название второй страны и выводить данные в поле результата. По кнопке «Параметры Страна 1» мы будем получать из XML параметры первой страны (валюта, язык, столица) и выводить данные в поле результата.
Подключим к проекту:
Объявим пару переменных:
«XMLFileForParse.xml» — это XML-файл который мы будем разбирать, и который имеет следующую структуру:
Давайте получим из XML марку автомобиля, номер и регион. Все три значения мы будем получать разными способами, чтобы охватить шире тему. В коде все строки стараюсь комментировать подробно:
У нас в XML есть одинаковые теги «country», «name», «param». Давайте получим название второй страны, тег «name»:
До этого мы получали значения тегов, однако у тегов есть атрибуты. Далее рассмотрим получение значения атрибутов у тега «param». Давайте получим значения атрибутов тега «param» у первой страны:
Основы рассмотрели. Надеюсь в работе вам это поможет. Для наглядности приложил пример проекта с расширенными комментариями.
Типы хранимых процедур
Системные хранимые процедуры предназначены для выполнения раз-
личных административных действий. Практически все действия по адми-
нистрированию сервера выполняются с их помощью. Можно сказать, что
системные хранимые процедуры являются интерфейсом, обеспечивающим
работу с системными таблицами. Системные хранимые процедуры имеют
префикс sp_, хранятся в системной базе данных и могут быть вызваны в
контексте любой другой базы данных.
Пользовательские хранимые процедуры реализуют те или иные дейст-
вия. Хранимые процедуры – полноценный объект базы данных. Вследствие
этого каждая хранимая процедура располагается в конкретной базе дан-
ных, где и выполняется.
Временные хранимые процедуры существуют лишь некоторое время,
после чего автоматически уничтожаются сервером. Они делятся на ло-
кальные и глобальные. Локальные временные хранимые процедуры могут
быть вызваны только из того соединения, в котором созданы. При созда-
нии такой процедуры ей необходимо дать имя, начинающееся с одного
символа #. Как и все временные объекты, хранимые процедуры этого типа
автоматически удаляются при отключении пользователя, перезапуске или
остановке сервера. Глобальные временные хранимые процедуры доступны
для любых соединений сервера, на котором имеется такая же процедура.
Для ее определения достаточно дать ей имя, начинающееся с символов ##.
Удаляются эти процедуры при перезапуске или остановке сервера, а также
при закрытии соединения, в контексте которого они были созданы.