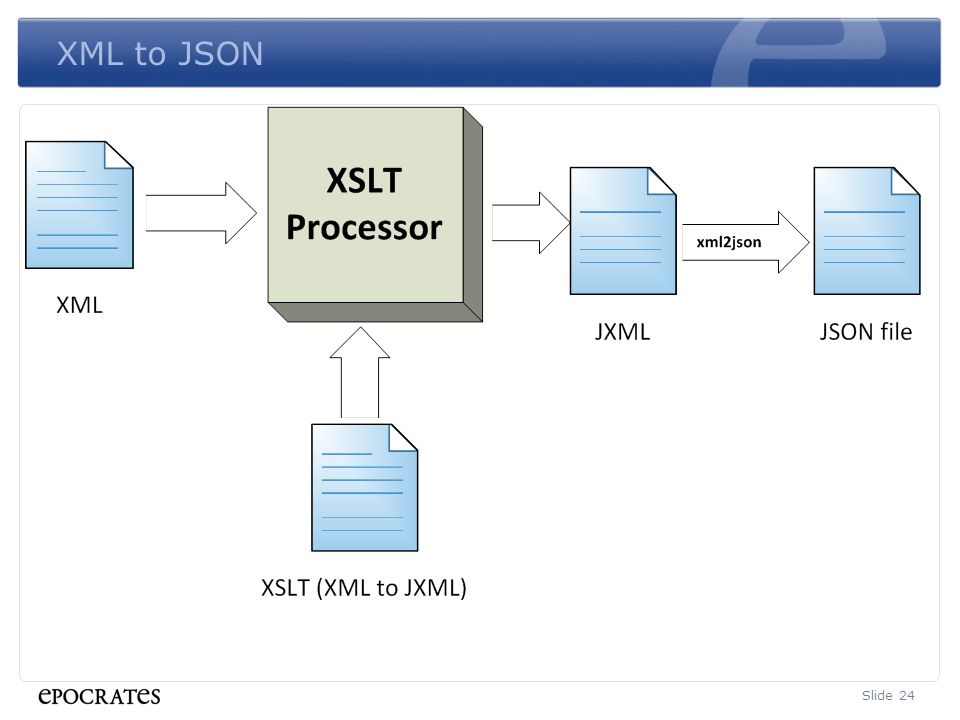
XML Editors
There are several XML editors available. Any text editor (such as notepad and so on) can use as an XML editor.
The following list shows some of the popular XML editors in 2021.
1) XML Notepad:
XML Notepad is an open-source editor for XML . It has a tree view and XSL Output on the left pane and node text on the right. It has an error-debugging window at the bottom.
Key Statistics:
- Type – XML editor
- Developer – Microsoft
- Supported operating system – Microsoft Windows.
- Price – Free
Link: http://microsoft.github.io/XmlNotepad/
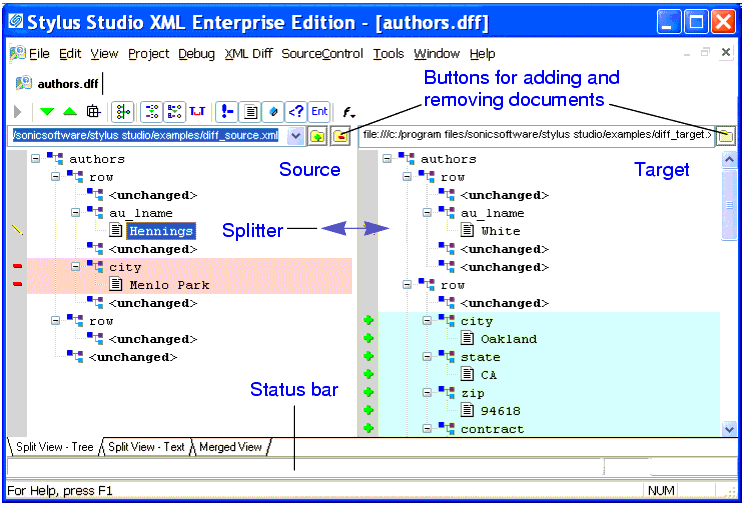
2) Stylus Studio:
Stylus Studio is an IDE written in C++ for Extensible Markup Language ( XML ). It allows a user to edit and transform XML documents, data such as electronic data interchange(EDI), CSV, and relational data.
Key Statistics:
- Type – Integrated development environment (IDE) for XML
- Developer – Progress Software Corporation
- Supported operating system – Microsoft Windows.
- Price – Paid (Please refer to the website given below for the latest price), Free trial available.
Link: http://www.stylusstudio.com/
3) Altova XMLSpy:
XMLSpy is primarily marketed as a JSON and XML Editor. It has a built-in schema designer and editor. It includes Visual Studio And Eclipse integration.
Key Statistics:
- Type – XML Editor
- Developer – Altova
- Supported operating system – Microsoft Windows.
- Price – Paid (Please refer to the website given below for the latest price), Free trial available.
Link: https://www.altova.com/xmlspy-xml-editor
4) Oxygen XML Editor:
Oxygen XML is a cross-platform editor developed in Java. It helps to validate schemas like DTD, W3C XML Schema, RELAX NG, Schematron, NRL, and NVDL schemas.
Key Statistics:
- Type – XML editor
- Developer – SyncRO Soft Ltd
- Supported operating system – Windows, Linux, and Mac OS X
- Price – Paid (Please refer to the website given below for the latest price
Link: https://www.oxygenxml.com/
5) Xmplify:
Xmplify XML Editor provides a fully XML-aware editing environment with DTD and XML Schema-based auto, automatic document validation, etc.
Key Statistics:
- Type – XML Editor
- Developer – MOSO Corporation
- Supported operating system – Mac OS.
- Price – Paid (Please refer to the website given below for the latest price
Link: http://xmplifyapp.com/
Advantages of XML
Here, pros/benefits of XML:
- It made it easy to transport and share data.
- XML improves the exchange of data between various platforms.
- It is a markup language, which is a set of characters or/and symbols placed in a text document.
- XML indicates how the XML document should look after it is displayed.
- It simplifies the platform change process.
- It enhances data availability.
- It supports multilingual documents and Unicode.
- Provide relatively easy to learn and code.
- It is a markup language, which is a set of characters or/and symbols placed in a text document.
- It performs validation using DTD and Schema.
- Makes documents transportable across systems and applications. With the help of XML, you can exchange data quickly between different platforms.
- XML separates the data from HTML.
Теоретические сведения
Устройство XML документа
Синтаксически в XML, по сравнению с HTML, нет ничего нового. Это такой же текст, размеченный тэгами, но с той
лишь разницей, что в HTML существует ограниченный набор тэгов, которые можно использовать в документах, в то
время, как XML позволяет создавать и использовать любую разметку, которая может понадобиться для разметки
данных.
Несомненным достоинством XML является и то, что это достаточно простой язык. Основных конструкций в XML мало, но,
несмотря на это, с их помощью можно создавать разметку документов практически любой сложности.
Для демонстрации структуры XML документа лучше обратиться к какому нибуть примеру. Рассмотрим следующий XML
документ:
<?xml version="1.0" ?> <корневой_элемент> <элемент> Текст <еще_элемент атрибут="значение" /> текст ... </элемент> Текст текст текст <элемент>текст текст... </элемент> ... </корневой_элемент>
Рассмотрим данный пример подробно. Первая строка документа определяет его как XML документ, построенный в
соответствии с первой версией языка (version=»1.0″). В этой же конструкции можно указать и
кодировку, в которой создан документ:
Кодировкой по умолчанию для XML является unicode. Далее находится открывающий тэг корневого
(главного) элемента <корневой_элемент>, содержащий элемент
<элемент>, который, в свою очередь, содержит элемент <еще_элемент
атрибут=»значение» /> с атрибутом атрибут. Как видно из примера, правила
записи элементов, атрибутов и их значений в XML ничем не отличаются от правил записи элементов атрибутов и их
значений в HTML (также есть открывающие и закрывающие тэги элементов, элементы с содержимым и без и т.д.),
только набор элементов несколько расширен, благодаря чему мы и можем «нагрузить» разметку семантикой.
Ниже приводятся несколько правил построения XML документа. Итак:
- любой XML документ должен начинаться строкой <?xml version=»1.0″ ?>
- любой XML документ должен иметь единственный (не более, не менее!) корневой элемент; например, в HTML для
этих целей использовался элемент <html>, в примере выше — это
<корневой_элемент>. - кодировкой по умолчанию для символов XML документа
является Unicode кодировка UTF-8, поэтому XML файлы должны
быть сохранены в соответствующей кодировкой или в 1-й строке документа должна быть задана кодировка
документа, например encoding=»Windows-1251″ (при работе только с латиницей это никак
себя не проявляет, так как кодировка этих символов в ASCIIсовпадает
с UTF-8). - правила записи большинства конструкций языка совпадает с правилами XHTML, изучавшемся
вами ранее (более подробно речь об основных конструкциях языка пойдет далее в уроке).
XML документ представляет собой обыкновенный текстовый файл с расширением .xml.
Единственная особенность их заключается в том, что для символов файла рекомендуется использовать
кодировку Unicode.
Объявления атрибутов
Объявление списка атрибутов определяет имена атрибутов, устанавливает тип для каждого атрибута и задаёт
востребованность для каждого атрибута, в частности, может задавать значение атрибута по умолчанию. Объявление
списка атрибутов имеет следующую форму записи:
<!ATTLIST Имя ОпрАтр>
Здесь «Имя» — имя элемента, для которого задаются атрибуты. «ОпрАтр» — это одно или несколько определений атрибутов.
Определение атрибута имеет следующую форму записи:
Имя ОпрАтр ОбъявУмолч
Здесь «Имя» — имя атрибута. ОпрАтр представляет собой тип атрибута. ОбъявУмолч — это объявление значения по
умолчанию, которое указывает на востребованность атрибута и содержит некоторую дополнительную информацию. Пример
объявления:
<!ATTLIST PRODUCT Retail CDATA «retail» Title CDATA #REQUIRED>
Вышеприведённое объявление означает, что вы можете присвоить атрибуту Retail любую строку в кавычках (ключевое
слово CDATA); если этот атрибут опущен, ему будет присвоено значение по умолчанию «retail». Вы можете присвоить
атрибуту Title любую строку в кавычках; этот атрибут должен быть обязательно задан для каждого элемента PRODUCT
(ключевое слово #REQUIRED) и не имеет значения по умолчанию.
Объявления атрибутов просто включаются в DTD наряду с объявлениями типов элементов, например:
…
<!ELEMENT PRODUCT (#PCDATA)>
<!ATTLIST PRODUCT Retail CDATA «retail» Title CDATA #REQUIRED>
…
Вы можете задавать тип атрибута тремя различными способами:
- Строковый тип (ключевое слово CDATA, что означает символьные данные, Character Data).
- Маркерный тип.
- Нумерованный тип.
Вот список ключевых слов, которые вы можете использовать в определении маркерных типов атрибутов:
| ID | Для каждого элемента атрибут должен иметь уникальное значение. Элемент может иметь только один атрибут типа ID. В объявлении значения по умолчанию такого атрибута должно фигурировать #REQUIRED или #IMPLIED. |
| IDREF | Значение такого атрибута является ссылкой на атрибут типа ID другого элемента . |
| IDREFS | Этот тип атрибута похож на IDREF, но его значение может включать ссылки на несколько идентификаторов — разделённых пробелами — внутри строки в кавычках. |
| ENTITY | Значение атрибута должно совпадать с именем примитива, объявленного в DTD. Такой примитив ссылается на внешний файл, обычно содержащий не XML-данные. Таким способом, например, определяют путь к файлу, содержащему графические данные (рисунок). |
| ENTITIES | Этот тип атрибута похож на ENTITY, но его значение может включать ссылки на несколько идентификаторов, разделённых пробелами — внутри строки в кавычках. Таким способом, например, определяют пути к файлам, содержащим графические данные (рисунки) в альтернативных форматах. |
| NMTOKEN | Элементарное имя. |
| NMTOKENS | Этот тип атрибута похож на NMTOKEN, но его значение может включать несколько элементарных имён, разделённых пробелами — внутри строки в кавычках.. |
Два способа, которые вы можете использовать в определении нумерованных типов атрибутов:
-
Если вы хотите ограничить значение атрибута «Mass» словами «net» и «gross», вы можете написать следующее:
<!ATTLIST PRODUCT Mass (net | gross) «net»>
-
Нумерованный тип можно определить с помощью ключевого слова NOTATION. Каждая из указанных нотаций должна точно
соответствовать имени нотации, объявленному в DTD. Нотация описывает формат данных или идентифицирует программу,
применяемую для обработки определённого формата данных:<!ATTLIST PRODUCT Description NOTATION (HTML | SGML | RTF) #REQUIRED>
Объявление значения атрибута по умолчанию может иметь четыре формы:
| #REQUIRED | Вы должны задать значение атрибута для каждого элемента. |
| #IMPLIED | Вы можете опустить атрибут, но никакое значение по умолчанию назначено не будет. |
| AttValue | Собственно значение по умолчанию. Вы можете опустить атрибут, и ему будет назначено это значение по умолчанию. |
| #FIXED AttValue | Вы можете опустить атрибут, и ему будет назначено это значение по умолчанию (AttValue). Если вы не опускаете атрибут, вы обязаны назначить ему это значение по умолчанию. При таком объявлении указывать атрибут в элементе имеет смысл только для того, чтобы сделать документ более понятным для восприятия. |
Структура XML-документа:
-
XML-документ содержит ровно один корневой элемент: начальный тег XML-документа, а также все остальные элементы.
1
2
3
4
5
6
7
8
9
10
11<root>
<section>
<sub-section><sub-section>
<sub-section><sub-section>
<section>
<section>
<sub-section><sub-section>
<sub-section><sub-section>
<section>
<root>
-
XML-документы могут начинаться с пролога, стоящего перед корневым элементом. Он содержит метаданные о XML-документе, такие как кодировка символов, структура документа и таблицы стилей. Например,
1 <?xml version=»1.0″encoding=»UTF-8″?> - Тег в XML — это чувствительная к регистру конструкция разметки, начинающаяся с и заканчивается . Тег может быть:
- Начальный тег, например
- Конечный тег, например
- Тег пустого элемента, например
- Элемент в XML формируется символами между начальным и конечным тегами. Например, . Он также может состоять только из тега пустого элемента. Например, .
-
Элементы XML могут иметь атрибуты, существующие в начальном теге или теге пустого элемента.
Атрибут состоит из пары имя-значение. Например,1 <img src=»screenshot.png»alt=»screenshot»> Здесь имена атрибутов источник а также альтернативный, а их значения screenshot.png а также Скриншот, соответственно.
-




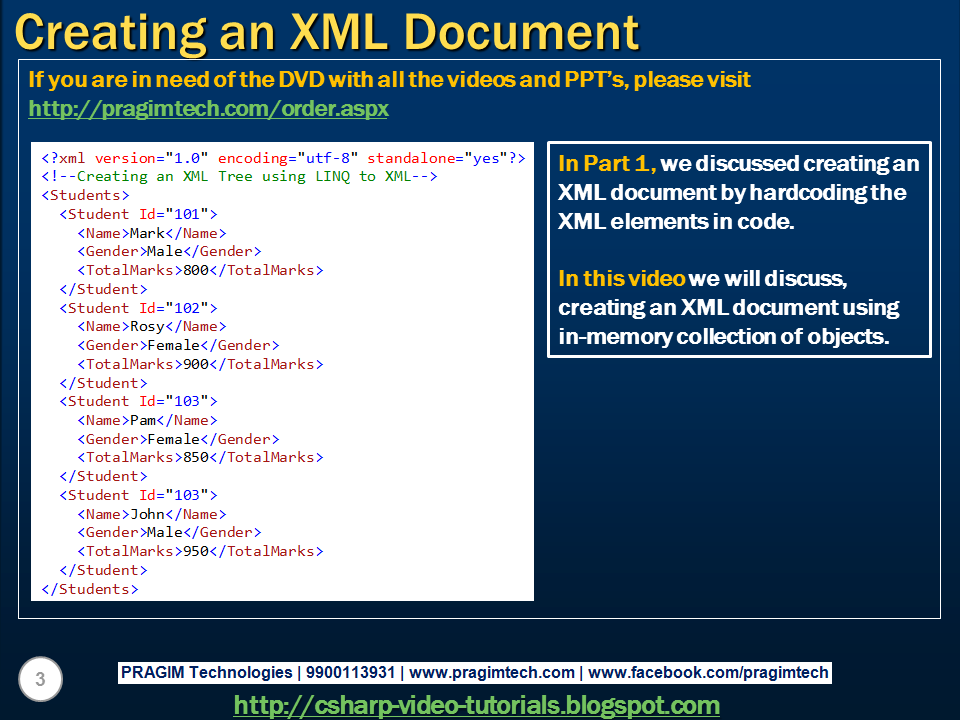


Disadvantages of XML
Here are the cons/drawback of using XML:
- XML requires a processing application.
- The XML syntax is similar to another alternative ‘text-based’ data transmission formats, which is sometimes confusing.
- No intrinsic data type support
- The XML syntax is redundant.
- Does not allow the user to create his tags.
Summary
- XML stands for eXtensible Markup Language. XML is a language (not a programming language) that uses the markup and can extend.
- The main goal is to transport data, not to display data.
- XML 1.1 is the latest version. Yet, XML 1.0 is the most used version.
- Tags work as pairs except for declarations.
- Opening tag + content + closing tag = an element
- Entities are a way of representing special characters.
- DTD stands for Document Type Definition. It defines the structure of an XML document using some legal elements. XML DTD is optional.
- DOM stands for Document Object Model. It defines a standard manner of accessing and manipulating XML documents.
- Well-formed XML documents are XML documents with correct syntax.
- Valid XML documents are well-formed and also conform to the DTD rules.
- Namespaces help to avoid element name conflicts.
XML DTD
What is DTD?
DTD stands for Document Type Definition. It defines the structure of an XML document using some legal elements. XML DTD is optional.
DTD Rules
Following list shows DTD rules.
- If DTD is present, it must appear at the start of the document (only the XML declaration can appear above the DTD).
- The element declaration must start with an ! mark.
- The DTD name and element type of the root element must be the same.
Examples of DTD
Example of an internal DTD:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE student >
<student>
<firstname>Mark</firstname>
<lastname>Wood</lastname>
<school>Hills College</school>
</student>
In the above example,
- !DOCTYPE student indicates the beginning of the DTD declaration. And the student is the root element of the XML document.
- !ELEMENT student indicates the student element must contain firstname, lastname and school elements.
- !ELEMENT firstname indicates the firstname element is of type #PCDATA (Parsed Character Data).
- !ELEMENT lastname indicates the lastname element is of type #PCDATA.
- !ELEMENT school indicates the school element is of type #PCDATA.
Example of an external DTD:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE student SYSTEM "student.dtd">
<student>
<firstname>Mark</firstname>
<lastname>Wood</lastname>
<school>Hills College</school>
</student>
The DTD file content (student.dtd) as follows.
<!ELEMENT student (firstname,lastname,school)> <!ELEMENT firstname (#PCDATA)> <!ELEMENT lastname (#PCDATA)> <!ELEMENT school (#PCDATA)>
Задание на лабораторную работу
Создать XML документ, содержащий информацию о какой-либо предметной области. Название предметной области
согласовать с преподавателем. Для оформления XML документа использовать знания и пользоваться правилами,
указаными в теоретических сведениях. Проверить документ на действительность.
The Apache Software Foundation создала набор ПО,
представляющего собой парсеры и другое обеспечение для работы с XML.
Одним из таких известных парсеров является Xerces.
Он существует в виде отдельного ПО, реализованного на С++ или Java. Чтобы не ограничивать Вас в выборе
инструментальной среды и ОС, будем использовать Java реализацию ввиду ее кроссплатформенности и простоты
использования.
Замечание. Для запуска Java приложения необходимо, чтобы на компьютере была установлена Java
машина от Sun. Желательно с Java SDK.
Проверить действительность My.XML можно командой
При необходимости нужно явно указать путь к архивам Xerces ключом -classpath
(замените PATH на свой путь к местоположению архивов)
Сам Xerces можно скачать отсюда или с официального сайта.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам
XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой
элемент (инструкция к дереву отношения не имеет).
У элемента дерева всегда существуют потомки и предки, кроме корневого
элемента, у которого предков нет, а также тупиковых элементов (листьев
дерева), у которых нет потомков. Каждый элемент дерева находится на
определенном уровне вложенности (далее — «уровень»). У элементов на
одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки
XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример
списка книг:
<?xml version="1.0" encoding="windows-1251"?>
<bookstore>
<book category="COOKING">
<title lang="it">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
XPath запрос вернет следующий результат:
<price>30.00</price> <price>29.99</price> <price>39.95</price>
Сокращенная форма этого запроса выглядит так: .
С помощью XPath запросов можно искать информацию по атрибутам. Например,
можно найти информацию о книге на итальянском языке: вернет .
Чтобы получить больше информации, необходимо модифицировать запрос вернет:
<book category="COOKING">
<title lang="it">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
В приведенной ниже таблице представлены некоторые выражения XPath и
результат их работы:
XML Tags and Elements
Tags work as pairs except for declarations. Every tag pair consists of an opening tag (also known as the start tag) and a closing tag (also known as the end tag).
Tag names are enclosed in <>. For a particular tag pair, the start and end tags must be identical except the end tag has after the <.
<name>...</name>
Anything between the opening and closing tags is referred to as content.
Opening tag, content, and closing tag, altogether, is referred to as an element.
Opening tag + content + closing tag = an element
Note: Elements may also contain attributes. You will learn the attributes very soon.




Let us consider the below element.
<age>20</age>
In the above element,
age is the name of the element.
Note: Tag name also referred to as an element or element name.
- <age> – opening tag
- 25 – content
- </age> – closing tag.
If there is no content between the tags, as shown below, it referred to as empty tags.
<result></result>
XML Tag and Element Rules
Following list shows XML tag and element rules.
Tags are case sensitive.
Example:
Correct:
<age>20</age>
Wrong:
<age>20</Age>
Note: AGE, Age, and age are three different names in XML.
- All XML documents must contain a single root element.
- All elements must have a closing tag (except for declarations).
- A tag name must begin with a letter or an underscore, and it cannot start with the XML.
- A tag name can contain letters, digits, hyphens, underscores, and periods. Hyphens underscore, and periods are the only punctuation marks allowed.
- A tag name cannot contain spaces.
- All elements must be nested properly.
Example:
Correct:
<b><u>This text is bold and italic</u></b>
Wrong:
<b><u>This text is bold and italic.</b></u>
What is XML?
XML stands for eXtensible Markup Language. It is a language (not> a programming language) that uses the markup and can extend. It is derived from Standard Generalized Markup Language(SGML). XML also uses DTDs (Document Type Definitions) to define the XML document structure.
XML is not for handling computational operations and algorithms. Thus, XML is not a programming language. The main goal is to transport data not to display information. XML bridges the gap between human readability and machine readability. Unlike HTML tags, XML tags are self-descriptive.
XML is an open format. The filename extension of XML is
In this XML tutorial, you will learn:
HTML versus XML
Similarities between HTML and XML
Following list shows the similarities between HTML and XML.
- Both are open formats.
- Both are markup languages.
- Both use tags and attributes to describe the content.
Differences between HTML and XML
Even though XML is like HTML, XML is not a replacement for HTML. There are some significant differences between HTML and XML as well.
Following list table show a comparison between HTML and XML.
| HTML | XML | |
|---|---|---|
| Stands for | Hypertext Markup Language | Extensible Markup Language |
| Type of language | A predefined markup language. | A framework for specifying markup languages. |
| Structural details | Not provided. | Provided. |
| Purpose | Used to display data. | Used to transport data |
| Driven by | Format driven. | Content-driven. |
| Nature | Has a static nature. | Has a dynamic nature. |
| Tag type | Predefined tags. | User-defined tags. |
| Tag limit | A limited number of tags are available. | Tags are extensible. |
| Closing tags | It is not necessary to use closing tags (but recommended to use closing tags). | Closing tags are mandatory. |
| Namespace support | Not supported. | Supported. |
| Case sensitivity | Tags are not case-sensitive. | Tags are case-sensitive. |
| White space | White space cannot preserve (can ignore white space). | White space preserved (cannot ignore white space). |
| Parsing in JavaScript | Not needed any extra application. | Need DOM implementation. |
| Code nesting | Not necessarily needed. | Needed. |
| Errors | Can ignore small errors. | Errors are not allowed. |
| Filename Extension | .html or .htm | .xml |
| Size | Comparatively large. | Comparatively small. |
| Quotes | Quotes are not required for attribute values. | Required for XML attribute values. |
| Object support | Offers native object support. | Objects have to be expressed by conventions. |
| Null support | Natively recognizes the null value. | Need to use xsi:nil on elements. |
| Formatting decisions | Provides direct mapping for application data. | Require more significant effort. |
| Learning curve | Less steep learning curve compared to XML. | Steep learning curve. |
| Website | https://html.spec.whatwg.org/ | https://www.w3.org/TR/xml11/ |
Basic HTML Syntax
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
</html>
Same example with HTML and XML
With HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<p>Book</p>
<p>Name: Anna Karenina</p>
<p>Author: Leo Tolstoy</p>
<p>Publisher: The Russian Messenger</p>
</body>
</html>
With XML
<?xml version = "1.0" encoding = "UTF-8" ?>
<book>
<name>Anna Karenina</name>
<author>Leo Tolstoy</author>
<publisher>The Russian Messenger</publisher>
</book>
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор
символов.
Самыми распространенными кириллическими кодировками являются и . Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку .
В XML файле кодировка объявляется в декларации:
<?xml version="1.0" encoding="windows-1251"?>
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Правильно сформированный и действительный XML
Если вы создаете XML в соответствии со структурными правилами, легко реализовать хорошо структурированный XML.Правильно сформированный XMLТо есть XML создается в соответствии со всеми правилами XML: правильное именование элементов, вложение, именование атрибутов и т. Д.



Получение хорошо структурированного XML зависит от того, как обрабатывать XML. Но рассмотрим упомянутый ранее пример, который требует классификации по типу рецепта. Вы должны убедиться, что каждыйВсе элементы содержатАтрибуты для классификации рецептов
Очень важно уметь правильно проверять и обеспечивать наличие значений атрибутов (избегайте каламбуров)
проверкаЭто проверка структуры документа в соответствии с правилами элемента и определения дочерних элементов для каждого родительского элемента. Эти правила находятся вОпределение типа документа(Определение типа документа, DTD) или схема (схема) определены. Проверка требует, чтобы вы создали собственное DTD или схему, а затем ссылались на DTD или файл схемы в XML-файле.
Для обеспечения проверки тип документа должен быть указан в верхней части XML-документа (). Эта строка кода будет ссылаться на DTD или схему (список элементов и правил), используемую для проверки документа. Например,Может быть похож наЛистинг 5。
Листинг 5. DOCTYPE
- <!DOCTYPE MyDocs SYSTEM «filename.dtd»>
В этом примере предполагается, что имя файла списка элементовfilename.dtd, И находится на вашем компьютере (если указывает на расположение общедоступного файла, то с участиемОтносительно).
XML Declaration
XML declaration consists of the XML version, character encoding or/and standalone status. The declaration is optional.
Syntax for XML Declaration
The below code segment shows the syntax for XML declaration.
<?xml version="version_number," encoding="character_encoding" standalone="yes_or_no" ?>
XML Declaration Rules
Following are XML declaration rules.
- If the XML declaration is present, it must be the first thing that appears.
- The XML declaration is case sensitive, and it must start with the lowercased <?xml.
- It has no closing tag.
Example of XML Declaration
Following code segment shows an example of an XML declaration.
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>