Links
There is a great book called T-SQL querying that you should get your hands on. It contains absolutely everything you need to know about querying SQL Server databases, including everything about window functions. You won’t regret owning this book, trust me. I reference it all the time. Get it today!
If you don’t want to buy the book, you should at least…
Download the Simple SQL Window Functions EBook!
This EBook discusses absolutely everything you need to know about window functions in SQL Server, including everything discussed in this tutorial. A proper understanding of window functions is essential for anyone looking to enter the field of data science. This eBook will definitely be a great resource for you to reference throughout your career. Get it today!
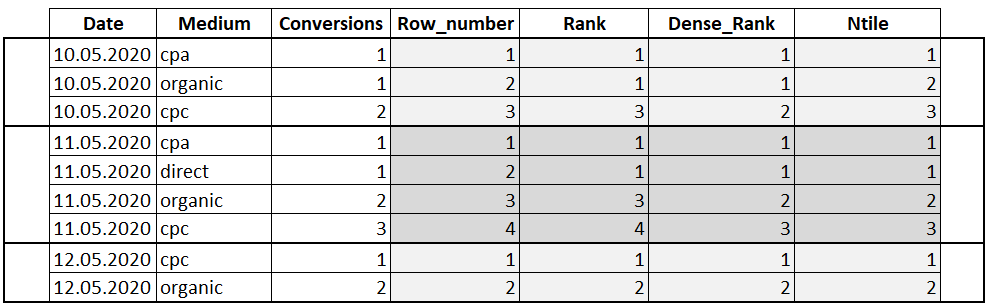
Функции ранжирования и нумерации в Transact-SQL — ROW_NUMBER, RANK, DENSE_RANK, NTILE | Info-Comp.ru
Изучение Transact-SQL продолжается и на очереди у нас функции ранжирования ROW_NUMBER, RANK, DENSE_RANK и NTILE, сейчас мы узнаем, что делают эти функции и зачем вообще они нужны, все как обычно будем рассматривать на примерах.
В языке Transact-SQL очень много различных функций, конструкций, например, PIVOT или INTERSECT, которые в принципе редко используются, их мы даже в нашем мини справочнике Transact-SQL не указывали, но знать, где и как их можно использовать нужно, так же как и функции ранжирования или их также называют функции нумерации. Поэтому сегодня давайте поговорим именно об этих функция и если говорить конкретно, то это функции: ROW_NUMBER, RANK, DENSE_RANK, NTILE.
И начнем мы, конечно же, с определения, что же вообще это за ранжирующие функции.
Ранжирующие функции в T-SQL
Ранжирующие функции — это функции, которые возвращают значение для каждой строки группы в результирующем наборе данных. На практике они могут быть использованы, например, для простой нумерации списка, составления рейтинга или постраничной выборки.
И для того чтобы лучше усвоить работу и применение этих функций, давайте рассмотрим все их по очереди, и параллельно будем сравнивать их друг с другом, т.е. таким образом, мы еще и узнаем в чем их отличие. Но для того чтобы начать рассматривать примеры, необходимо определится с исходными данными.
Примечание! Для детального изучения языка T-SQL, рекомендую почитать книгу «Путь программиста T-SQL», в ней я подробно, с большим количеством примеров, рассказываю основы программирования на языке T-SQL.
Исходные данные для примеров
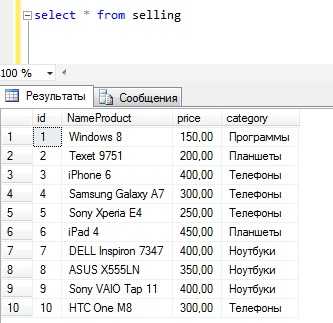
Использовать мы будем MS SQL Server Express 2014, а запросы будем писать в Management Studio Express. В качестве тестовых данных будем использовать таблицу selling, которая будет содержать различные товары (телефоны, планшеты, ноутбуки, программы) с выдуманными ценами.
Наша тестовая таблица
Заполним ее тестовыми данными, в итоге получим следующее (для выборки пишем простой запрос select)
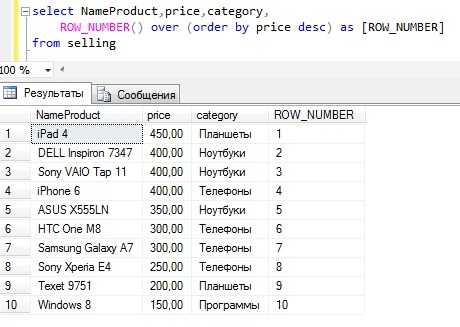
ROW_NUMBER
ROW_NUMBER – функция нумерации в Transact-SQL, которая возвращает просто номер строки.
Синтаксис
ROW_NUMBER () OVER ( ORDER BY столбец сортировки)
где, partition by — это не обязательное ключевое слово, после которого указывается столбец или столбцы, по которым группировать данные, а order by столбец для сортировки, т.е. по данному столбцу будут отсортированы данные, а потом пронумерованы, он уже обязателен. Сразу скажу, чтобы не возвращаться, что эти ключевые слова относятся ко всем функциям ранжирования, которые мы будем сегодня использовать.
Текст запроса
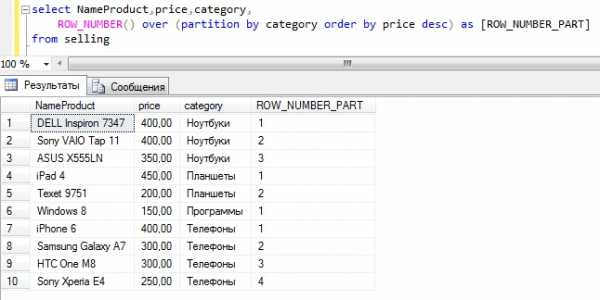
Текст запроса
Как видите, здесь уже нумерация идет в каждой категории.
RANK
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
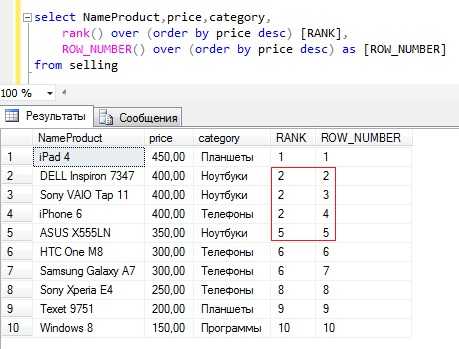
Текст запроса
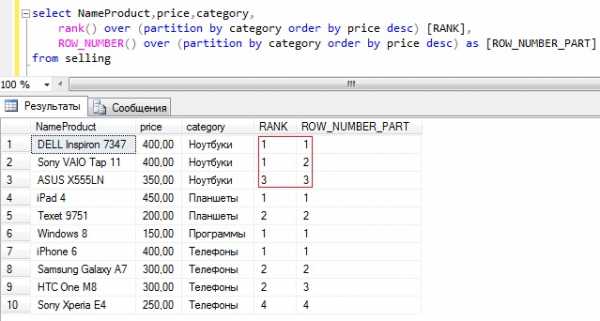
Текст запроса
DENSE_RANK
DENSE_RANK — ранжирующая функция, которая возвращает ранг каждой строки, но в отличие от rank, в случае нахождения одинаковых значений, возвращает ранг без пропуска следующего.
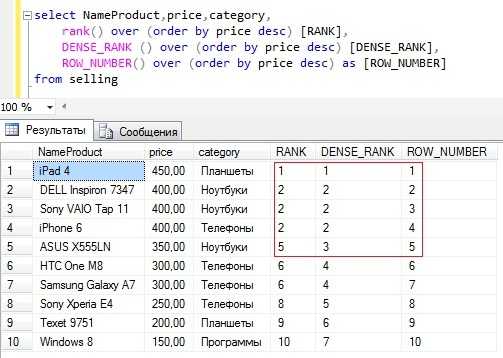
Текст запроса
NTILE
NTILE – функция Transact-SQL, которая делит результирующий набор на группы по определенному столбцу. Количество групп указывается в качестве параметра. В случае если в группах получается не одинаковое количество строк, то в первой группе будет наибольшее количество, например, в нашем случае строк 10 и если мы поделим на три группы, то в первой будет 4 строки, а во второй и третей по 3.
Пример
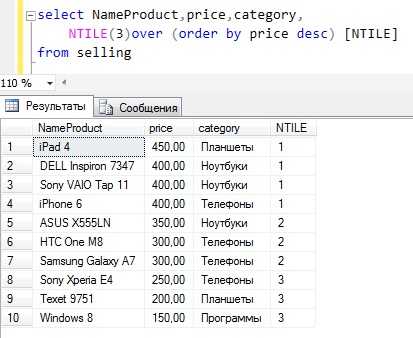
Текст запроса
В заключение давайте приведем пример, в котором мы наглядно увидим различия в работе всех функций, например, вот такой
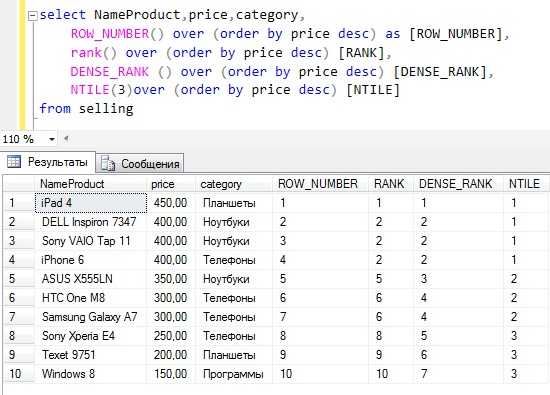
Текст запроса
На этом я думаю по ранжирующим функциям достаточно, в следующих статьях мы продолжим изучение Transact-SQL, а на этом пока все. Удачи!
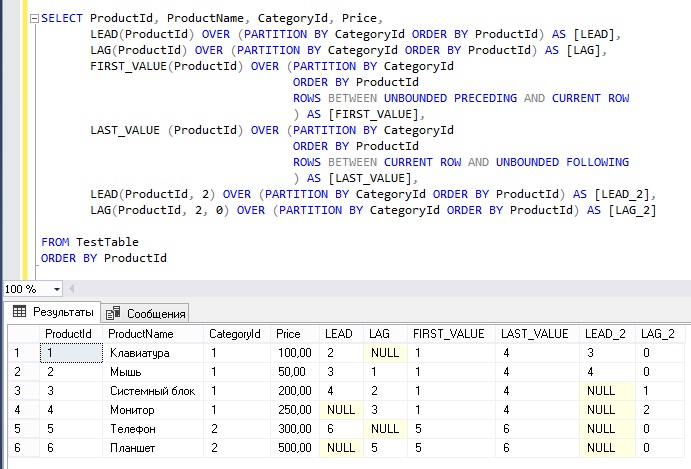
LAG, LEAD
Недавно прошла аттестация и сотрудникам повысили зарплату. В таблице Assessments есть информация о зарплатах сотрудников по каждому году, руководству для анализа необходимо узнать сумму, на которую каждому сотруднику сделали повышение. Обычно это решается соединением таблицы на саму себя с использованием смещения, в нашем случае — по году:
Ожидаемый результат:

Меняя выражение Year + 1 мы можем посмотреть повышение за последние 1, 2 и т.д. лет. При этом, если мы хотим одним запросом узнать повышение за год и за 5 лет, то нам придется сделать 2 соединения соответственно.Функция LAG позволяет получить значение предыдущей строки, LEAD — следующей. При этом, как параметр можно указать, на сколько строк нужно «вернуться» назад или вперед:
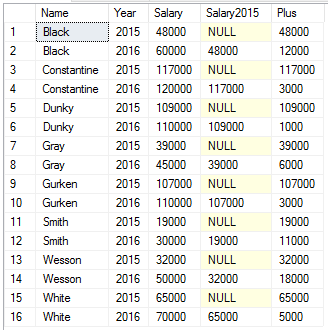
И так, мы указали в функции LAG, что нужно «вернуться» на 1 строку назад в отсортированном наборе. Мы разделили наш набор по сотрудникам и отсортировали по году. Естественно, для первой строки не будет предыдущего набора (а для последней — следующего), поэтому третий параметр функции как раз определяет это отсутствующее значение.Мы получили необходимый результат и еще строки за 2015 год. Мы не можем их отфильтровать в этом же запросе, т.к. это повлияет на результат выполнения функции LAG (для строк только из 2016 года нет предыдущего значения года, очевидно), поэтому обернем это еще в один запрос и отфильтруем:
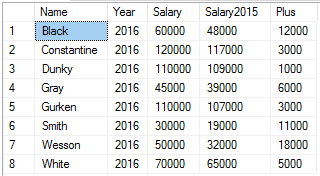
И мы получили аналогичный результат. Здесь преимущество функции LAG над соединением в том, что мы можем легко сравнивать текущее значение со значением 1, 2, 3 или 5 лет назад просто поменяв одно значение параметра, при этом, можем все это вычислить одним запросом, который будет исполнен за один проход по таблице без соединений. Функция LEAD работает аналогично, но выбирает следующие строки.
Аргументы Arguments
PARTITION BY value_expression PARTITION BY value_expression Делит результирующий набор, полученный от предложения FROM, на секции, к которым применяется функция ROW_NUMBER. Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied. value_expression определяет столбец, по которому секционируется результирующий набор. value_expression specifies the column by which the result set is partitioned. Если параметр PARTITION BY не указан, функция обрабатывает все строки результирующего набора запроса как одну группу. If PARTITION BY is not specified, the function treats all rows of the query result set as a single group. Дополнительные сведения см. в статье Предложение OVER (Transact-SQL). For more information, see OVER Clause (Transact-SQL).
order_by_clause order_by_clause Предложение ORDER BY определяет последовательность, в которой строкам назначаются уникальные номера с помощью функции ROW_NUMBER в пределах указанной секции. The ORDER BY clause determines the sequence in which the rows are assigned their unique ROW_NUMBER within a specified partition. Оно должно указываться обязательно. It is required. Дополнительные сведения см. в статье Предложение OVER (Transact-SQL). For more information, see OVER Clause (Transact-SQL).
Как пронумеровать строки в результате SQL-запроса?
G.A.SH. Например делаем запросSELECT Name, Price FROM ProductКоторый возвращает намNotebook 1000Printer 500…Как получить результат с номерами строк1 Notebook 10002 Printer 500n…
SETdream В Postgresql можно так
CREATE SEQUENCE serial START 1;
select nextval(‘serial’), title from page;
Это так к примеру.
intlex Напрямую вроде никак, только через процедуру или запрос с обращением к генератору (последний придется обнулять перед самой выборкой)
Гость В приведенном примере проще добавить в таблицу Product номер записи (с авто-инкрементом, если нужно).
Можно сгенерировать порядковый номер на стандартном SQL с помощью подзапросов или представлений, если в таблице присутствует уникальное поле, по которому можно сортировать записи. Но для больших выборок это может оказаться неэффективным — O(n^2).

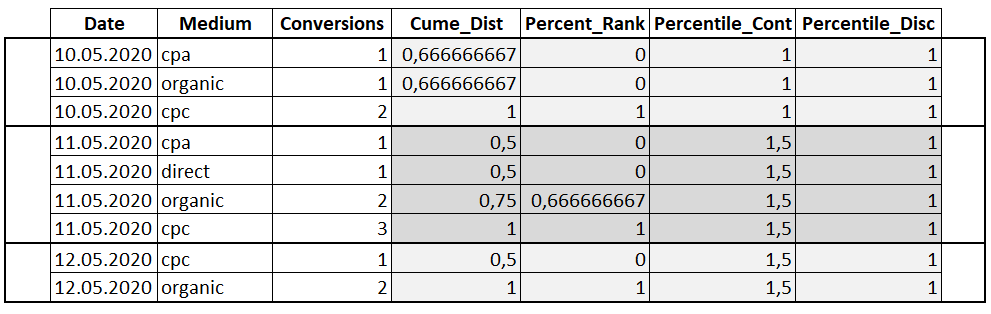







В большинстве практических случаев самый эффективный способ — добавить номер на стадии обработки результата (на PHP или C или на чем там программа написана).
ValWлучший ответ Если СУБД MSSQL, то там вообще нет такого понятия, как номер строки, но суррогатный номер все-таки можно ввести, используя конструкцию «ROW_NUMBER() OVER(ORDER BY»:
select ROW_NUMBER() OVER(ORDER BY Name), Name, Price, FROM Product
только использовать его нужно осторожно, так как Этот номер не будет точно идентифицировать запись, а будет только указывать номер записи в КАЖДЫЙ МОМЕНТ выполнения запроса.то есть в случае, если между моментами выполнения двух запросов в таблице появится запись, которая «сдвинет» весь набор по установленной сортировке (в нашем случае сортировка по полю Name), то записи как бы «перенумеруются»:-)
Примеры Examples
A. A. Простые примеры Simple examples
Приведенный ниже запрос возвращает четыре системные таблицы в алфавитном порядке. The following query returns the four system tables in alphabetic order.
Ниже приводится результирующий набор. Here is the result set.
| name name | recovery_model_desc recovery_model_desc |
|---|---|
| master master | SIMPLE SIMPLE |
| model model | FULL FULL |
| msdb msdb | SIMPLE SIMPLE |
| tempdb tempdb | SIMPLE SIMPLE |
Чтобы добавить столбец с номерами строк перед каждой строкой, добавьте столбец с помощью функции ROW_NUMBER , в данном случае с именем Row# . To add a row number column in front of each row, add a column with the ROW_NUMBER function, in this case named Row# . Предложение ORDER BY необходимо переместить к предложению OVER . You must move the ORDER BY clause up to the OVER clause.
Ниже приводится результирующий набор. Here is the result set.
| Номер строки Row# | name name | recovery_model_desc recovery_model_desc |
|---|---|---|
| 1 1 | master master | SIMPLE SIMPLE |
| 2 2 | model model | FULL FULL |
| 3 3 | msdb msdb | SIMPLE SIMPLE |
| 4 4 | tempdb tempdb | SIMPLE SIMPLE |
Добавление предложения PARTITION BY для столбца recovery_model_desc приведет к тому, что нумерация начнется заново при изменении значения recovery_model_desc . Adding a PARTITION BY clause on the recovery_model_desc column, will restart the numbering when the recovery_model_desc value changes.
Ниже приводится результирующий набор. Here is the result set.
| Номер строки Row# | name name | recovery_model_desc recovery_model_desc |
|---|---|---|
| 1 1 | model model | FULL FULL |
| 1 1 | master master | SIMPLE SIMPLE |
| 2 2 | msdb msdb | SIMPLE SIMPLE |
| 3 3 | tempdb tempdb | SIMPLE SIMPLE |
Б. B. Возврат номера строки для salespeople Returning the row number for salespeople
В следующем примере показан расчет номера строки для salespeople в Компания Adventure Works Cycles Adventure Works Cycles , выполняемый на основе ранжирования продаж за текущий год. The following example calculates a row number for the salespeople in Компания Adventure Works Cycles Adventure Works Cycles based on their year-to-date sales ranking.
Ниже приводится результирующий набор. Here is the result set.
В. C. Возврат подмножества строк Returning a subset of rows
В следующем примере показан расчет номеров всех строк в таблице SalesOrderHeader в порядке OrderDate с последующим возвращением строк с номерами от 50 до 60 включительно. The following example calculates row numbers for all rows in the SalesOrderHeader table in the order of the OrderDate and returns only rows 50 to 60 inclusive.
Г. D. Использование ROW_NUMBER() с PARTITION Using ROW_NUMBER() with PARTITION
В следующем примере аргумент PARTITION BY используется для секционирования результирующего набора запроса по столбцу TerritoryName . The following example uses the PARTITION BY argument to partition the query result set by the column TerritoryName . Предложение ORDER BY , указанное в предложении OVER , упорядочивает строки каждой секции по столбцу SalesYTD . The ORDER BY clause specified in the OVER clause orders the rows in each partition by the column SalesYTD . Предложение ORDER BY в инструкции SELECT упорядочивает полный результирующий набор запроса по TerritoryName . The ORDER BY clause in the SELECT statement orders the entire query result set by TerritoryName .
Ниже приводится результирующий набор. Here is the result set.
SQL Server Row_Number without over
The Row_Number() function in SQL Server 2019/2017 is used to generate a serial number for a given recordset. However, we must always include the ORDER BY clause with the Row_Number function to ensure that the numbers are assigned to the correct order.
Now it is always mandatory to use the OVER clause with Order By argument, and if we don’t include the OVER clause with Row_Number, the SQL Server will return an error.
In the above code, we have not included the OVER clause with Row_number() function, and now if we try to execute this code, it will return the following error.
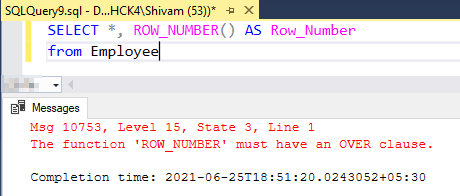
SQL Server Row_Number without Order
Summary
There are 4 ranking functions ROW_NUMBER(), RANK(), DENSE_RANK(), and NTILE() are in MS SQL. These are used to perform some ranking operation on result data set.
- ROW_NUMBER() gives unique sequential numbers for each row.
- RANK()returns a unique rank number for each distinct row. It behaves like ROW_NUMBER() except for the rows with equal values, where it will rank with the same rank ID and generate a gap after it.
- DENSE_RANK() is similar to RANK() but the only difference is DENSE_RANK() does not skip any rank, i.e. leaving no gap(s) between the gap(s).
- NTILE() is used to distribute the rows in to the rows set with a specific number of groups.
Here, I have described each one with real practical examples and also given the difference between theme in the last section.
Now, I believe you will be able to know the key important things about ranking functions ROW_NUMBER(), RANK(), DENSE_RANK(), and NTILE() are in MS SQL.
Examples of the DENSE_RANK Function
Here are some examples of the SQL DENSE_RANK function.
Sample Data
We’re using a student database table for the examples here. You can get the SQL scripts for this sample data in my GitHub repository here.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | FEES_REQUIRED | FEES_PAID | GENDER |
| 6 | Julie | Armstrong | 100 | F | |
| 5 | Steven | Webber | 100 | 80 | M |
| 1 | John | Smith | 500 | 100 | M |
| 9 | Robert | Pickering | 110 | 100 | M |
| 10 | Tanya | Hall | 150 | 150 | F |
| 2 | Susan | Johnson | 150 | 150 | F |
| 3 | Tom | Capper | 350 | 320 | M |
| 8 | Andrew | Cooper | 800 | 400 | M |
| 4 | Mark | Holloway | 500 | 410 | M |
| 7 | Michelle | Randall | 250 | F |
Example 1 (Aggregate) – Basic
This example ranks the value of 100 in the fees_paid column.
Result:
| RANK_VAL |
| 3 |
It shows 3 because the value of 100 is the 3rd lowest in the fees_paid column.
Example 2 (Aggregate) – Duplicate Value
This example uses a value that is duplicated in the fees_paid column.
Result:
| RANK_VAL |
| 4 |
It shows 4 because 150 is the 4th lowest in the fees_paid column in the student table.
Example 3 (Aggregate) – Second column
This example uses the same duplicated value but searches for a second column.
Result:
| RANK_VAL |
| 7 |
It shows 7 because even though the value of 150 is the 4th lowest in the fees_paid column in the student table, it also searches by last_name, which comes after Armstrong but before Randall.
Example 4 (Aggregate) – Use a text value
This example performs a DENSE_RANK function using a text value (the first_name).
Result:
| RANK_VAL |
| 3 |
The result is 3 because the name Julie is 3rd in the list when ordered by first_name.
Example 5 (Aggregate) – Use a text value that is not in the database
This example ranks a first_name value that is not in the database table.
Result:
| RANK_VAL |
| 2 |
The result is 2. This is because Boris is not in the table, but if he was, he would be ranked number 2.
Example 6 (Window) – Partition by Gender
This example partitions (groups) the data by gender, and then ranks the values according to fees_paid.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | GENDER | FEES_PAID | RANK_VAL |
| 6 | Julie | Armstrong | F | 1 | |
| 2 | Susan | Johnson | F | 150 | 2 |
| 10 | Tanya | Hall | F | 150 | 2 |
| 7 | Michelle | Randall | F | 3 | |
| 5 | Steven | Webber | M | 80 | 1 |
| 1 | John | Smith | M | 100 | 2 |
| 9 | Robert | Pickering | M | 100 | 2 |
| 3 | Tom | Capper | M | 320 | 3 |
| 8 | Andrew | Cooper | M | 400 | 4 |
| 4 | Mark | Holloway | M | 410 | 5 |
As you can see, each row has a DENSE_RANK value. There is a duplicate within the gender of F, as that is expected in the SQL DENSE_RANK function. The DENSE_RANK values are separated for M and F gender values.
Example 7 (Window) – Partition by fees paid
This example partitions the data by fees_paid, and ranks according to the last name, and first name.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | GENDER | FEES_PAID | RANK_VAL |
| 6 | Julie | Armstrong | F | 1 | |
| 5 | Steven | Webber | M | 80 | 1 |
| 9 | Robert | Pickering | M | 100 | 1 |
| 1 | John | Smith | M | 100 | 2 |
| 10 | Tanya | Hall | F | 150 | 1 |
| 2 | Susan | Johnson | F | 150 | 2 |
| 3 | Tom | Capper | M | 320 | 1 |
| 8 | Andrew | Cooper | M | 400 | 1 |
| 4 | Mark | Holloway | M | 410 | 1 |
| 7 | Michelle | Randall | F | 1 |
As you can see, most of the DENSE_RANK values are 1 because the fees_paid values are mostly unique. Where the fees_paid is not unique, it has been ranked based on last_name and then first_name, causing a value of 2 for Michelle Randall.
Example 8 (Window) – No partition
This example uses the SQL DENSE_RANK function without a partition clause.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | GENDER | FEES_PAID | RANK_VAL |
| 6 | Julie | Armstrong | F | 1 | |
| 5 | Steven | Webber | M | 80 | 2 |
| 1 | John | Smith | M | 100 | 3 |
| 9 | Robert | Pickering | M | 100 | 3 |
| 10 | Tanya | Hall | F | 150 | 4 |
| 2 | Susan | Johnson | F | 150 | 4 |
| 3 | Tom | Capper | M | 320 | 5 |
| 8 | Andrew | Cooper | M | 400 | 6 |
| 4 | Mark | Holloway | M | 410 | 7 |
| 7 | Michelle | Randall | F | 8 |
Each row has been assigned a DENSE_RANK value, according to fees_paid.
Example 9 – Compare RANK and DENSE_RANK
This example is similar to example 8, but we are using both RANK and DENSE_RANK to see the differences.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | GENDER | FEES_PAID | RANK_VAL | DENSE_RANK_VAL |
| 6 | Julie | Armstrong | F | 1 | 1 | |
| 2 | Susan | Johnson | F | 150 | 2 | 2 |
| 10 | Tanya | Hall | F | 150 | 2 | 2 |
| 7 | Michelle | Randall | F | 4 | 3 | |
| 5 | Steven | Webber | M | 80 | 1 | 1 |
| 1 | John | Smith | M | 100 | 2 | 2 |
| 9 | Robert | Pickering | M | 100 | 2 | 2 |
| 3 | Tom | Capper | M | 320 | 4 | 3 |
| 8 | Andrew | Cooper | M | 400 | 5 | 4 |
| 4 | Mark | Holloway | M | 410 | 6 | 5 |
Both the RANK and DENSE_RANK take the same parameters, but you can see the output is different. RANK leaves some numbers out of the sequence, but DENSE_RANK does not show any gaps.






What’s the Difference between RANK and DENSE_RANK and ROW_NUMBER?
The RANK and DENSE_RANK functions are slightly different from each other as well as the ROW_NUMBER function:
- RANK numbers are skipped so there may be a gap in rankings, and may not be unique.
- DENSE_RANK numbers are not skipped so there will not be a gap in rankings, and may not be unique.
- ROW_NUMBER is generated once for each row so there are no duplicates or gaps.
For example:
- RANK: a list of results could use the RANK function and show values of 1, 2, 2, 4, and 5. The number 3 is skipped because the rank of 2 is tied.
- DENSE_RANK: a list of results could use the DENSE_RANK function and show values of 1, 2, 2, 3, and 4. The number 3 is still used, even if rank of 2 is tied.
- ROW_NUMBER: a list of results could use the ROW_NUMBER function and show values of 1, 2, 3, 4, and 5. All of the numbers are unique.
SQL Server Row_Number without order by
We define the ORDER BY clause with Row_Number() function to ensure that the numbers are assigned to the correct order. But what if we want the row numbers to be generated in the same order as the data is entered?
Is it possible to skip the ORDER BY clause?
The answer to this question is NO, we cannot skip the ORDER BY clause. The SQL Server will raise an error if we try to ignore the ORDER BY clause.
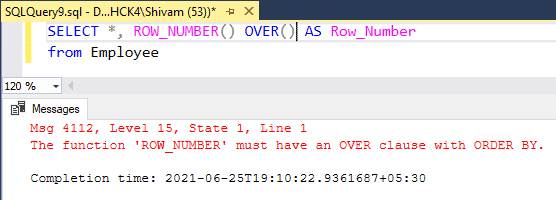
SQL Server Row_Number without Order By clause
Still, there is a solution if we want the row numbers to be generated in the same order as the data is entered. For this implementation, we can use any literal value instead of using the column name in the ORDER BY clause.
In the above query, we are using the “SELECT 100” statement instead of defining any column name with Order By clause. Now the query will add the Row_Number column without ordering any table value.
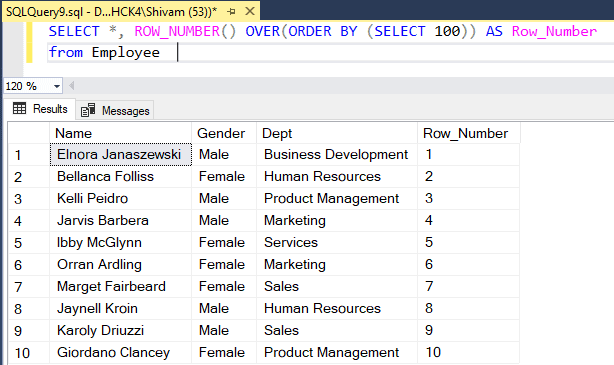
Using Row_Number without ordering table values
Read: SQL Server Agent won’t start
Ranking Functions | ROW_NUMBER, RANK, DENSE_RANK, NTILE
August 9, 2010
SQL Server 2005 provides functionality for using Ranking Functions with your result set. One can select a number of Ranking algorithms which are applied to a column of your table that you want to classify in a scope of your executing query. This feature is Dynamic and upon change of data (addition or removal of rows) it gives desired results the next time query is run.
–> Its 4 gems are:
1. ROW_NUMBER: Returns the sequential number of a row within a partition of a result set, starting at 1 for the first row in each partition.
Syntax:
ROW_NUMBER() OVER ( < order_by_clause > )
2. RANK: Returns the rank of each row within the partition of a result set. The rank of a row is one plus the number of ranks that come before the row in question.
Syntax:
RANK() OVER ( < order_by_clause > )
3. DENSE_RANK: Returns the rank of rows within the partition of a result set, without any gaps in the ranking. The rank of a row is one plus the number of distinct ranks that come before the row in question.
Syntax:
DENSE_RANK() OVER( < order_by_clause > )
4. NTILE: Distributes the rows in an ordered partition into a specified number of groups. The groups are numbered, starting at one. For each row, NTILE returns the number of the group to which the row belongs.
Syntax:
NTILE(integer_expression) OVER( < order_by_clause > )
–> Now lets take an example, simple one of a class of students, their marks & class:
select 'A' , 80 , 'manoj' stuName into #tempTable UNION select 'A', 70 ,'harish' stuName UNION select 'A', 80 ,'kanchan' stuName UNION select 'A', 90 ,'pooja' stuName UNION select 'A', 90 ,'saurabh' stuName UNION select 'A', 50 ,'anita' stuName UNION select 'B', 60 ,'nitin' stuName UNION select 'B', 50 ,'kamar' stuName UNION select 'B', 80 ,'dinesh' stuName UNION select 'B', 90 ,'paras' stuName UNION select 'B', 50 ,'lalit' stuName UNION select 'B', 70 ,'hema' stuName select * from #tempTable
Now on selection this gives you: class marks name A 50 anita A 70 harish A 80 kanchan A 80 manoj A 90 pooja A 90 saurabh B 50 kamar B 50 lalit B 60 nitin B 70 hema B 80 dinesh B 90 paras
–> The following query shows you how each function works:
select marks, stuName,
ROW_NUMBER() over(order by marks desc) as ,
RANK() over(order by marks desc) as ,
DENSE_RANK() over(order by marks desc) as ,
NTILE(3) over(order by marks desc) as
from #tempTable
Result: marks stuName RowNum Rank DenseRank nTile 90 pooja 1 1 1 1 90 saurabh 2 1 1 1 90 paras 3 1 1 1 80 dinesh 4 4 2 1 80 kanchan 5 4 2 2 80 manoj 6 4 2 2 70 harish 7 7 3 2 70 hema 8 7 3 2 60 nitin 9 9 4 3 50 anita 10 10 5 3 50 kamar 11 10 5 3 50 lalit 12 10 5 3
–> Here:– RowNum column lists unique ID’s of students, like Roll Numbers.– Rank lists student rank with equal ranks those secured equal marks, thus there is no 2nd or 3rd.– DenseRank lists student ranks with no gaps, so here 3 students came 1st &2nd and only 2 3rd.– nTile listed students in different but equal groups, can be thought of as different sections.
–> Now, lets use the PARTITION BY option, its same as group by clause. Lets group/partition the students group by their classes A&B:
select class, marks, stuName,
ROW_NUMBER() over(partition by class order by marks desc) as ,
RANK() over(partition by class order by marks desc) as ,
DENSE_RANK() over(partition by class order by marks desc) as ,
NTILE(3) over(partition by class order by marks desc) as
from #tempTable
Result: class marks stuName RowNum Rank DenseRank nTile A 90 pooja 1 1 1 1 A 90 saurabh 2 1 1 1 A 80 kanchan 3 3 2 2 A 80 manoj 4 3 2 2 A 70 harish 5 5 3 3 A 50 anita 6 6 4 3 B 90 paras 1 1 1 1 B 80 dinesh 2 2 2 1 B 70 hema 3 3 3 2 B 60 nitin 4 4 4 2 B 50 kamar 5 5 5 3 B 50 lalit 6 5 5 3
You can clearly see that our query has grouped students in 2 Partitions (classes) and then Ranked them.
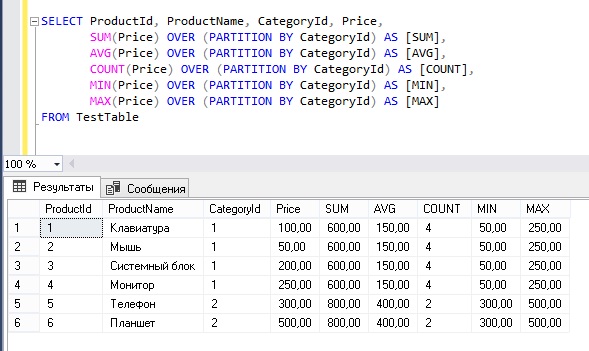
In my check how to use OVER Clause & Partition By option with Aggregate functions like, SUM, AVG, MIN, MAX, etc.
–> Check the same demo on YouTube:
Advertisement
Categories: SQL Server 2005
DENSE_RANK, NTILE, OVER, PARTITION BY, RANK, RANKING FUNCTIONS, ROW_NUMBER
Общие замечания General Remarks
Нет гарантии того, что строки, возвращенные запросом, использующим ROW_NUMBER() , будут расставлены в одинаковом порядке после каждого выполнения, если не соблюдены указанные ниже условия. There is no guarantee that the rows returned by a query using ROW_NUMBER() will be ordered exactly the same with each execution unless the following conditions are true.
Все значения в секционированном столбце являются уникальными. Values of the partitioned column are unique.
Все значения в столбцах ORDER BY являются уникальными. Values of the ORDER BY columns are unique.
Сочетания значений из столбца секционирования и столбцов ORDER BY являются уникальными. Combinations of values of the partition column and ORDER BY columns are unique.
Функция ROW_NUMBER() не детерминирована. ROW_NUMBER() is nondeterministic. Дополнительные сведения см. в разделе Deterministic and Nondeterministic Functions. For more information, see Deterministic and Nondeterministic Functions.
ROW_NUMBER with Other Ranking Functions in SQL
ROW_NUMBER is a function in the database language Transact-SQL that assigns a unique sequential number to each row in the result set of a query. It is typically used in conjunction with other ranking functions such as DENSE_RANK, RANK, and NTILE to perform various types of ranking analysis. ROW_NUMBER is also used in reporting applications to display a sequential number for each row in the report. This can help sort by criteria that don’t appear in the information or for debugging complex statements.
This paper aims to analyze the usage of ROW_NUMBER along with other ranking functions in SQL databases. Our goal is to explore the various options available and to understand their advantages and disadvantages in the context of data retrieval. We will also explore how different ranking functions can be combined to create a comprehensive solution for data retrieval. To do this, we will provide examples of how ROW_NUMBER and other ranking functions can be used and discuss their respective strengths and weaknesses.
4. SQL ROW_NUMBER () FUNCTION
SQL ROW_NUMBER() function will assign the count row numbers the output of a result set, function assign the sequential number of a records within a partition of a result set, starting at 1 for the first row in each partition
Advertisement
SQL ROW_NUMBER () Values of the partitioned column are unique. SQL Rank () function assign Values of the ORDER BY columns are unique also the combinations of values of the partition column and ORDER BY columns are unique
SQL ROW_NUMBER() Syntax
Here,
- PARTITION BY column_name: Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied. If PARTITION BY is not specified, the function treats all rows of the query result set as a single group. For more information, see OVER Clause (Transact-SQL).
- ORDER BY column_name : The ORDER BY clause determines the sequence in which the rows are assigned their unique ROW_NUMBER within a specified partition. It is required
Example-8: SQL ROW_NUMBER() Function with ORDER BY
Write SQL query to assign the count row number to the student list in the order of city name
In the above query, SQL ROW_NUMBER() function used to assign the record number value to each record order of city name
OUTPUT:
Example-9: SQL ROW_NUMBER() Function with PARTITION BY
Write SQL query to assign the record counting number of student city wise in the order of enrollment number
- In the above query, SQL RANK_NUMBER() function is used to assign the record count number of student based on city name
- Partition by clause is used to make partition of student records city wise and order by clause is used to display resulting records in the ascending order of enrollment number
OUTPUT:
DENSE_RANK()
It is similar to RANK() but the only difference is DENSE_RANK() does not skip any rank, i.e. leaving no gap(s) between the gap(s).
Generally, DENSE_RANK() is used to provide ranking to the records as mentioned in Example-6.
Syntax
DENSE_RANK () OVER (] ORDER BY_clause)
Example 6
How to display member names in rank given by their points. For example highest point will come first and lowest last?
- SELECT DENSE_RANK() OVER( ORDERBY Point desc) AS , Name, Point FROM Member
Output
As you can see here, the default order is ascending order.
Example 7
How to display third highest point?
- select Point from (
- SELECT DENSE_RANK() OVER( ORDERBY Point desc) AS , Name, Point FROM Member
- ) as tmp where tmp. = 3
Output
Note that, generally, this question is asked in interview question such as how to get second highest salary.
Partition By clause
You can also use partition by clause with it to divide result with some specified partition.
Examples of the SQL RANK Function
Here are some examples of the SQL RANK function.
Sample data
This is the student table that is being used for these examples. You can get the SQL scripts for this sample data in my GitHub repository here.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | FEES_PAID | GENDER |
| 5 | Steven | Webber | M | |
| 10 | Tanya | Hall | 50 | F |
| 4 | Mark | Holloway | 100 | M |
| 6 | Julie | Armstrong | 150 | F |
| 7 | Michelle | Randall | 150 | F |
| 1 | John | Smith | 200 | M |
| 3 | Tom | Capper | 350 | M |
| 2 | Susan | Johnson | 500 | F |
| 8 | Andrew | Cooper | 800 | M |
| 9 | Robert | Pickering | 900 | M |
Example 1 (Aggregate) – Basic
This example ranks the value of 200 in the fees_paid column.
Result:
| RANK_VAL |
| 6 |
It shows 6 because the value of 200 is the 6th lowest in the fees_paid column in the student table.
Example 2 (Aggregate) – Duplicate value
This example uses a value that is duplicated in the fees_paid column
Result:
| RANK_VAL |
| 4 |
It shows 4, because the value of 150 is the 4th lowest in the fees_paid column in the student table.
Example 3 (Aggregate) – Second column
This example uses the same duplicated value but searches for a second column.
Result:
| RANK_VAL |
| 5 |
It shows 5, because even though the value of 150 is the 4th lowest in the fees_paid column in the student table, it also searches by last_name, which comes after Armstrong but before Randall.
Example 4 (Aggregate) – Use a text value
This example performs a RANK function using a text value (the first_name).
Result:
| RANK_VAL |
| 7 |
The result is 7 because the name Steven is 7th in the list when ordered by first_name.
Example 5 (Aggregate) – Use a text value that is not in the database.
This example ranks a first_name value that is not in the database table.
Result:
| RANK_VAL |
| 2 |
The result is 2. Even though Brad is not a record in the table, it would still have been ranked #2.

![Sql ranking functions explained [practical examples] | golinuxcloud](https://wudgleyd.ru/wp-content/uploads/1/2/d/12d7bec80573e14f255506194c3024c3.jpeg)




Example 6 (Window) – Partition by Gender
This example partitions (groups) the data by gender, and then ranks the values according to fees_paid.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | GENDER | FEES_PAID | RANK_VAL |
| 10 | Tanya | Hall | F | 50 | 1 |
| 7 | Michelle | Randall | F | 150 | 2 |
| 6 | Julie | Armstrong | F | 150 | 2 |
| 2 | Susan | Johnson | F | 500 | 4 |
| 5 | Steven | Webber | M | 1 | |
| 4 | Mark | Holloway | M | 100 | 2 |
| 1 | John | Smith | M | 200 | 3 |
| 3 | Tom | Capper | M | 350 | 4 |
| 8 | Andrew | Cooper | M | 800 | 5 |
| 9 | Robert | Pickering | M | 900 | 6 |
As you can see, each row has a RANK value. There is a duplicate within the gender of F, as that is expected in the SQL RANK function. The RANK values are separated for M and F gender values.
Example 7 (Window) – Partition by fees paid
This example partitions the data by fees_paid, and ranks according to the last name, and first name.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | GENDER | FEES_PAID | RANK_VAL |
| 5 | Steven | Webber | M | 1 | |
| 10 | Tanya | Hall | F | 50 | 1 |
| 4 | Mark | Holloway | M | 100 | 1 |
| 6 | Julie | Armstrong | F | 150 | 1 |
| 7 | Michelle | Randall | F | 150 | 2 |
| 1 | John | Smith | M | 200 | 1 |
| 3 | Tom | Capper | M | 350 | 1 |
| 2 | Susan | Johnson | F | 500 | 1 |
| 8 | Andrew | Cooper | M | 800 | 1 |
| 9 | Robert | Pickering | M | 900 | 1 |
As you can see, most of the RANK values are 1 because the fees_paid values are mostly unique. Where the fees_paid is not unique, it has been ranked based on last_name and then first_name, causing a value of 2 for Michelle Randall.
Example 8 (Window) – No partition
This example uses the RANK function without a partition clause.
Result:
| STUDENT_ID | FIRST_NAME | LAST_NAME | GENDER | FEES_PAID | RANK_VAL |
| 5 | Steven | Webber | M | 1 | |
| 10 | Tanya | Hall | F | 50 | 2 |
| 4 | Mark | Holloway | M | 100 | 3 |
| 6 | Julie | Armstrong | F | 150 | 4 |
| 7 | Michelle | Randall | F | 150 | 4 |
| 1 | John | Smith | M | 200 | 6 |
| 3 | Tom | Capper | M | 350 | 7 |
| 2 | Susan | Johnson | F | 500 | 8 |
| 8 | Andrew | Cooper | M | 800 | 9 |
| 9 | Robert | Pickering | M | 900 | 10 |
Each row has been assigned a RANK value, according to fees_paid.
MySQL RANK()
Это метод, который дает ранг внутри раздела или массива результатов с пробелами в каждой строке. Хронологически ранжирование строк не распределяется постоянно (т. Е. Увеличивается на единицу по сравнению с предыдущей строкой). Даже если несколько значений совпадают, в этот момент утилита rank () применяет к нему такое же ранжирование. Кроме того, его предыдущий ранг плюс число повторяющихся чисел может быть последующим ранговым номером.
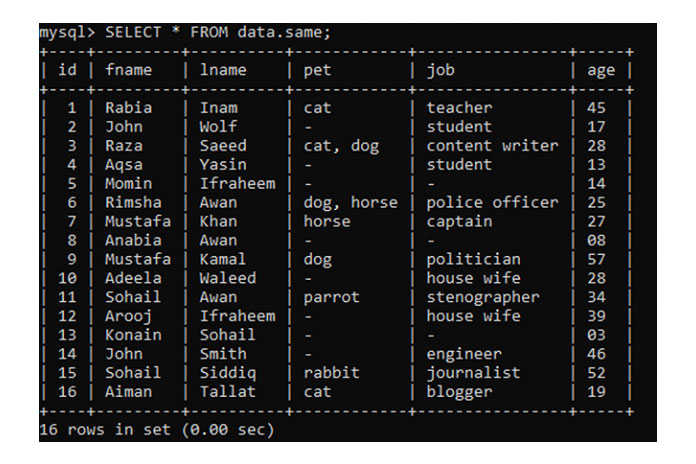
Чтобы понять ранжирование, откройте клиентскую оболочку командной строки и введите свой пароль MySQL, чтобы начать его использовать.
Предположим, что у нас есть приведенная ниже таблица с именем «same» в базе данных «data» с некоторыми записями.
Rules for ranking window functions
There are only a few rules you need to remember when working with ranking window functions:
- We use the OVER clause in all ranking window functions. This is actually true for all window functions. One could say the OVER clause is the heart of a window function.
- You can only specify a ranking window function in the SELECT list or an ORDER BY clause. This is also true for all window functions.
- They don’t take any arguments (except for NTILE which takes an integer as an argument)
- You don’t specify a window frame
- They do require the use of a window order clause
The use of a window order clause makes perfect sense, because how are you supposed to rank things if they aren’t in some kind of order?
Example 2 – Partitions
You can also divide the results into partitions. When you do this, the rank is calculated against each partition (so it starts over again with each new partition).
Example:
SELECT Genre, AlbumName, ArtistId, DENSE_RANK() OVER (PARTITION BY Genre ORDER BY ArtistId ASC) 'Rank' FROM Albums INNER JOIN Genres ON Albums.GenreId = Genres.GenreId;
Result:
+---------+--------------------------+------------+--------+ | Genre | AlbumName | ArtistId | Rank | |---------+--------------------------+------------+--------| | Country | Singing Down the Lane | 6 | 1 | | Country | Yo Wassup | 9 | 2 | | Country | Busted | 9 | 2 | | Jazz | All Night Wrong | 3 | 1 | | Jazz | The Sixteen Men of Tain | 3 | 1 | | Jazz | Big Swing Face | 4 | 2 | | Pop | Long Lost Suitcase | 7 | 1 | | Pop | Praise and Blame | 7 | 1 | | Pop | Along Came Jones | 7 | 1 | | Pop | No Sound Without Silence | 9 | 2 | | Pop | Blue Night | 12 | 3 | | Pop | Eternity | 12 | 3 | | Pop | Scandinavia | 12 | 3 | | Rock | Powerslave | 1 | 1 | | Rock | Somewhere in Time | 1 | 1 | | Rock | Piece of Mind | 1 | 1 | | Rock | Killers | 1 | 1 | | Rock | No Prayer for the Dying | 1 | 1 | | Rock | Powerage | 2 | 2 | | Rock | Ziltoid the Omniscient | 5 | 3 | | Rock | Casualties of Cool | 5 | 3 | | Rock | Epicloud | 5 | 3 | +---------+--------------------------+------------+--------+
In this case I partition by Genre. This causes each row to only be ranked against the other rows in the same partition. So each partition causes the ranking value to start at 1 again.