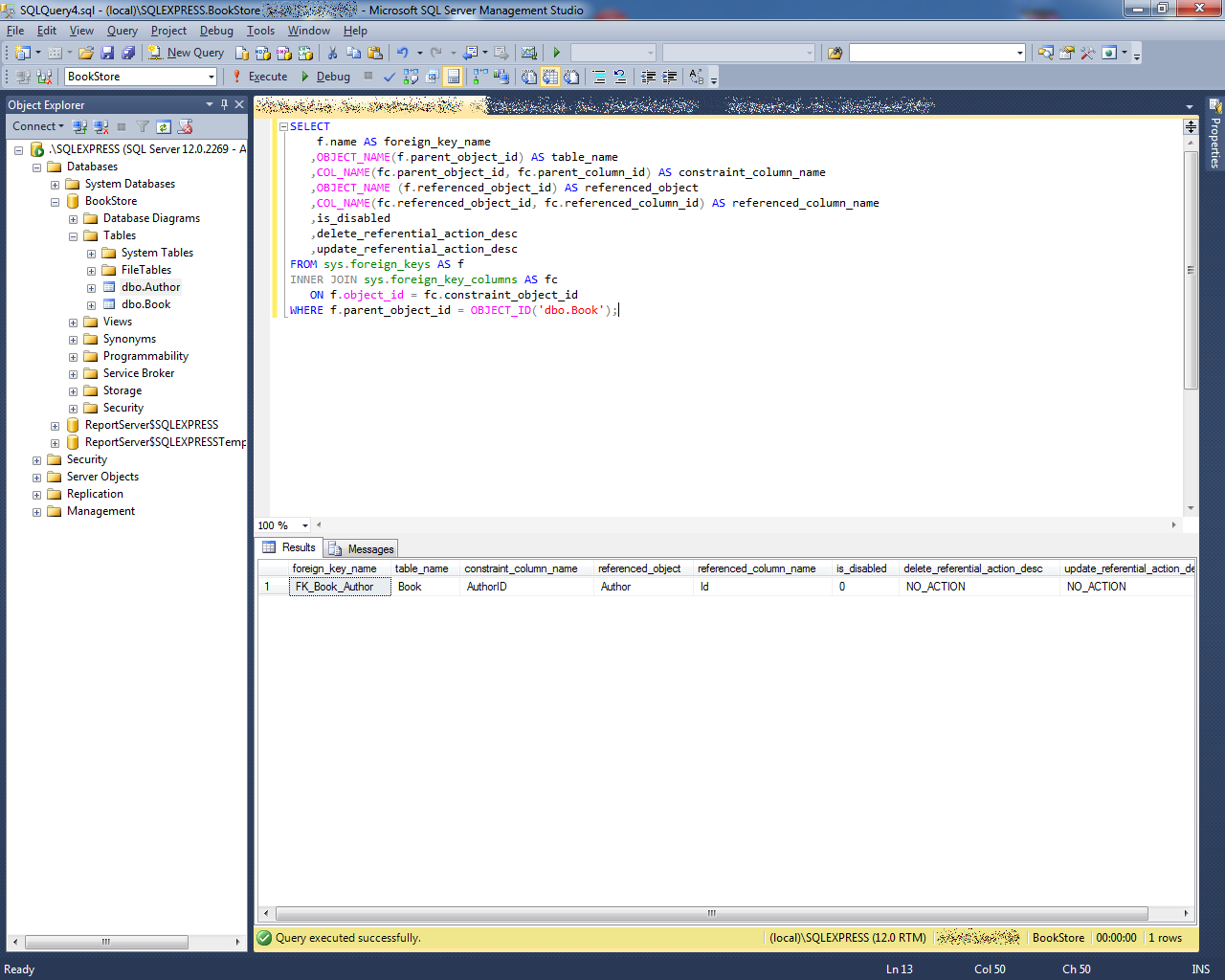
«Введение в базы данных» от Stepik
Язык: русский.
Длительность: 7 часов видеоуроков.
Формат обучения: 23 видеоурока + 80 тестов.
Уровень сложности: для студентов, обучающихся по направлениям, связанным с Computer Science (информатикой).
Обратная связь: нет.
Программа обучения:
- Термины и определения.
- Базовые операции SQL.
- Агрегация данных.
- Основы реляционных баз данных.
- Введение в реляционную модель данных.
- Архитектура ANSI/SPARC.
- Выборки из нескольких источников.
- Триггеры и хранимые процедуры.
- Проектирование баз данных.
- Задача проектирования баз данных.
- Концептуальное проектирование.
- Логическое и физическое проектирование.
- Инструмент проектирования MySQL Workbench.
- SQL-DDL.
- Нормализация реляционной базы данных.
- Термины нормализации.
- Основные нормальные формы: 1НФ, 2НФ, 3НФ, НФБК.
- Прочие нормальные формы: 4NF, 5NF, DKNF, 6NF.
- Использование ORM.
- Моделирование данных с использованием ORM.
- Администрирование MySQL и оптимизация запросов.
- Сложность выполнения запросов. EXPLAIN.
- Индексы.
- Практическая работа с индексами.
- Нереляционные СУБД.
- Термины и характеристики NoSQL.
- Обзор key-value СУБД Redis.
- Обзор документоориентированной СУБД MongoDB.
- Заключительный модуль.
- Финальный урок.
Особенности курса:
Для прохождения курса необходимы навыки работы с командно-строковыми интерфейсами, желательно знание формы Бэкуса — Наура, знание английского языка на уровне чтения сообщений интерпретатора SQL, общие знания о типах данных в программировании.
Взаимосвязь PHP и MySQL
Приложения на базе языка программирования PHP, применяющие базу данных как способ хранения информации, функционируют значительно быстрее и эффективнее аналогов, построенных на файловой системе хранения. MySQL в этом случае выполняет необходимую работу с данными. Базы данных берут на себя заботу о безопасности информации и ее хранении и обработке. Извлечение и размещение контента осуществляется посредством использования всего одной строчки.
С аналогичной легкостью решаются задачи поиска в рамках сайта, разбиения на страницы, регистрации и авторизации пользователей. Несмотря на значительнее количество базовых систем, на основе которых могут быть сформированы веб-приложения, MySQL остается наиболее предпочтительной. Поддержка сервера MySQL составляет стандартный комплект поставки PHP. Поэтому связка PHP+MySQL воспринимается как неразрывная.
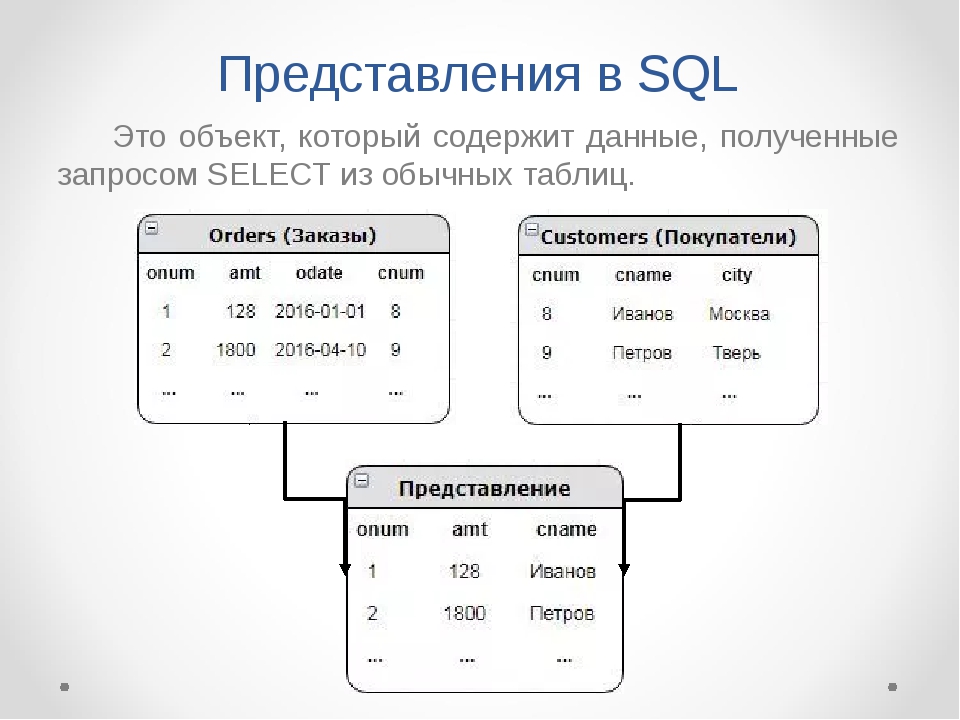
В каких базах данных используют SQL
Все БД можно поделить на два вида: реляционные и нереляционные. Язык SQL нужен для работы с первыми.
SQL настолько тесно связан с реляционными БД, что все нереляционные БД в противовес стали называть NoSQL. Вот и получилось, что SQL — это язык программирования, а NoSQL — тип баз данных.
Про реляционные БД часто говорят, что это набор двумерных таблиц. Прямо как в Excel: со столбцами, строками и ячейками. Это понятная визуализация, хотя и не совсем точная.
Представим, что мы создаём базу данных для небольшой строительной фирмы. Она проектирует загородные дома и передаёт проекты подрядчикам, которые занимаются самим строительством:
Примерная база данных воображаемой строительной фирмыСкриншот: Skillbox Media
Чем же база данных отличается от таблицы? Тем, что в базе:
- У столбцов и строк нет определённого положения. Нельзя сказать, что столбец status находится до или после столбца num_floors, а имя Анастасии Романиной — до или после имени Дмитрия Пожарова.
- Каждый столбец диктует свой домен, то есть тип данных, к которому могут относиться его значения. Например, в столбцах cost и num_floors могут храниться только числа, а в столбце client — только строки.
- Каждая строка должна быть уникальной и не может повторять какую-то другую строку.
Благодарности
Работа над книгой – это достаточно тяжелый труд, который отнимает очень много сил. Каждую свою работу я стремлюсь сделать лучше предыдущей, а это уже затраты не только сил, но и времени. Если бы не моя семья, то выход этой книги задержался бы наверно на месяц. Лето 2005-го, когда писалась эта книга, выдалось для меня достаточно тяжелым, потому что за три месяца к нам по очереди приезжали гости и родственники из разных городов. В это время дом превращался в сумасшедший, и работать приходилось по ночам. Если бы не помощь семьи с детьми и домашними обязанностями, то книга точно была бы задержана.
Перед сдачей книги из-за отсутствия времени я иногда срывался на своих родных (жену, родителей). Сейчас, оглядываясь на прошлое, хочется попросить прощения за мои срывы.
Пять лет назад я знакомился с MS SQL Server в МГТУ им. Баумана в г. Москве, где курс читал Гилев Алексей Вячеславович. Хочется поблагодарить этого специалиста за то, что дал мне основные знания программирования на языке Transact-SQL. До этого момента я работал только с классическим ANSI SQL, а этот курс помог мне расширить знания.
Хочется поблагодарить Олега (не помню фамилию), который обучает программистов в МВ «Офисная Техника». Этот человек помог мне постигнуть еще одно расширение языка SQL – PL/SQL, который отличается от рассматриваемого в данной книге Transact-SQL, но его знания, помогло мне понять некоторые тонкости классического ANSI SQL.
Отдельное спасибо редакции БХВ-Петербург за то, что помогают в издании моих работ. Редакторам и корректорам за то, что выискивают мои багги и делают мой технический русский немного более литературным и читаемым.
Всех друзей по моему блогу www.flenov.info. C каждым годом количество друзей растет и чтобы поблагодарить всех понадобиться целая книга, а ведь каждый помогает мне своими знаниями, поддержкой и просто советом. Поэтому, если я кого-то упустил, то хочу попросить прощения.
Виды СУБД
Основы SQL – это базы данных и таблицы без программного обеспечения не могут выполнить никакую операцию. Их функционал обеспечивается СУБД. В системе пользователь может удалять ненужные элементы, обрабатывать запросы, настраивать ключи и пр.
СУБД разрабатываются с открытым и закрытым кодом. Первыми могут пользоваться все программисты, вторые придется покупать за отдельную плату.
К основным видам систем относят:
- PostgreSQL. Способна обрабатывать данные как абстрактные объекты. Каждый из них здесь имеет собственные характеристики и методы взаимодействия с остальными элементами. Применяется для обработки сложных структур данных (пример – Яндекс.Почта).
- MySQL. Отличается простотой и функциональностью. Способна работать с сайтами и веб-приложениями. Применяется в системе управления контентом. Считается безопасной и высокоскоростной.
- SQLte. Встраиваемая версия системы. Здесь нельзя делиться правами доступа, но благодаря встроенным инструментам – это одна из мощнейших СУБД. Применяется как обработчик запросов на сайтах с низким и высоким трафиком.
- Oracle. Старейшая СУБД, разработанная в 1977 году. Не потеряла актуальности и 21 веке. Кроссплатформенная система, работающая на всех ОС. Применяется в коммерческих проектах (МТС, Теле2, ВТБ и пр.).
- Google Cloud Spanner. Облачная система разработанная для управления сервисами Google. С 2017 года является общедоступной.
Это основные виды СУБД, которые применяются программистами при веб-разработках.
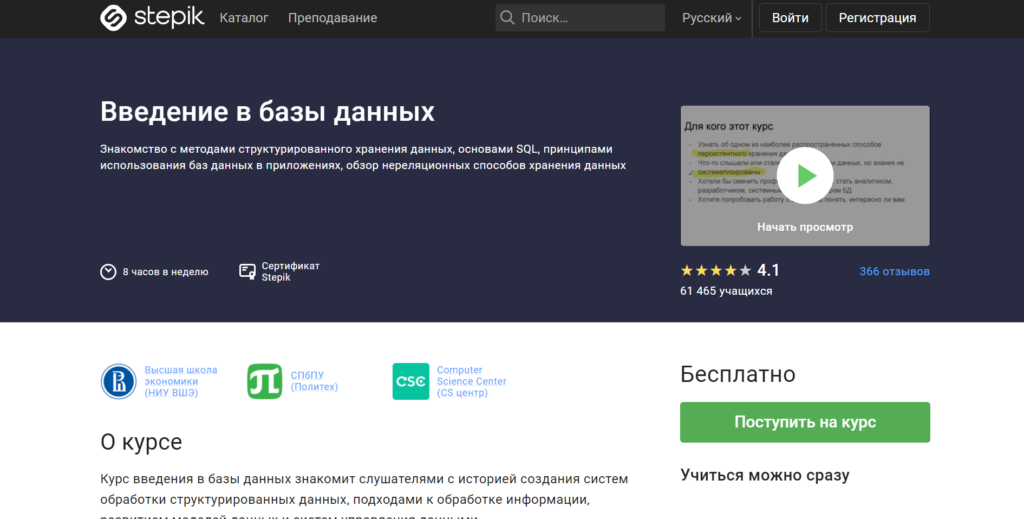
Операторы управления схемой данных
Операторы создания элементов схемы в общем называются .
Операторы создания
Создание базы данных
Создание таблицы
Здесь может иметь следующие значения (или их комбинации):
- – не может быть “пустым”
- – значение уникально
- – комбинация первых двух
- – указание внешнего ключа
- – значение должно удовлетворять условию
- – значение по умолчанию
Присутствуют некоторые разночтения в разных реализациях.
Если первичный ключ состоит из нескольких столбцов, необходимо выносить его после объявления столбцов в виде
где – уникальное название ограничения.
Во многих реализациях, часть можно опустить. В таком случае имя будет сгенерировано автоматически.




Внешний ключ в любом случае объявляется после объявления колонок.
Синтаксис:
где – уникальное название ограничения, – названия колонок данной таблицы, входящих во внешний ключ, – таблица, для которой указанный внешний ключ является первичным, – названия соответствующих колонок в . и определяют, как БД реагирует на изменение и удаление записей из , и могут принимать одно из значений:
- – ссылающиеся колонки устанавливается в NULL
- – если есть записи, ссылающиеся на обновляемое/удаляемое значение, обновление/удаление завершается ошибкой
- – обновляет/удаляет все ссылающиеся записи
- – ничего не делать
Во многих реализациях, часть можно опустить. В таком случае имя будет сгенерировано автоматически.
Создание индекса
Индексы ускоряют выборку по индексированным колонкам, но замедляют добавление и удаление записей.
Операторы удаления элементов схемы в общем называются .
Удаление базы данных
Удаление таблицы
Удаление индекса
Операторы изменения
Изменение таблицы
Здесь может быть одним из:
- – позволяет указать или убрать значение по умолчанию
- – позволяет переименовать, и изменить определение
- – позволяет изменить определение
- и т.д.
Introduction
As an example, if we want to list customers who bought something last week, in T-SQL, we will write a SELECT query on a Customers table, join it to an Invoices table and filter on an InvoiceDate column. In regular programming language, we would have to write a program which does everything that is performed by SQL Server database engine plus what we want to get: open Invoices and Customers list files, read it one row at a time and create the results set then close it.
This means that operations in SQL Server are performed on a complete set of rows and returns a subset of the rows it manipulated.
As a SQL Server professional, we must be aware of the power of a database engine and get the best out of it, not simply see Transact SQL as another procedural language! Furthermore, if T-SQL is designed for set manipulation, we could expect performance improvement using this « set-based » approach.
This article is the first part of a series of three articles that will deal with set-based programming. In this article, we will focus on the simple “problem” of getting the minimum and maximum values of a column, so as its sum. We will first discuss about different T-SQL instructions and objects that we will use to actually implement solutions using both approaches. Then we will have a look at details of these implementations. While this “problem” can be easily solved by a complete T-SQL beginners, even not aware of set-based programming approach, it will help us to reveal some points of interest in building a deeper knowledge on set-based approach.
Перенос базы данных доступа на SQL Server
Откройте SQL Server Management Studio и подключитесь к серверу базы данных, в который вы хотите импортировать базу данных Access. Под Базы данныхщелкните правой кнопкой мыши и выберите Новая база данных, Если у вас уже есть база данных, и вы просто хотите импортировать пару таблиц из Access, просто пропустите это и перейдите к Импорт данных шаг ниже. Просто щелкните правой кнопкой мыши на вашей текущей базе данных вместо создания новой.
Если вы создаете новую базу данных, продолжайте, дайте ей имя и настройте параметры, если вы хотите изменить их по умолчанию.
Теперь нам нужно щелкнуть правой кнопкой мыши на тестовой базе данных, которую мы только что создали, и выбрать Задания а потом Импорт данных,
На Выберите источник данных диалоговое окно, выберите Microsoft Access (ядро базы данных Microsoft Jet) из выпадающего списка.
Следующий на Имя файлае, нажмите на Просматривать и перейдите к базе данных Access, которую вы хотите импортировать, и нажмите открыто, Обратите внимание, что база данных не может быть в Access 2007 или более высоком формате (ACCDB) как SQL Server не распознает это! Поэтому, если у вас есть база данных Access с 2007 по 2016, сначала преобразуйте ее в База данных 2002-2003 формат (MDB) зайдя в Файл — Сохранить как,
Идите вперед и нажмите следующий выбрать пункт назначения. Поскольку вы щелкнули правой кнопкой мыши базу данных, в которую хотите импортировать данные, она уже должна быть выбрана в списке. Если нет, выберите Собственный клиент SQL от Пункт назначения падать. Вы должны увидеть экземпляр базы данных под Название сервера и затем сможете выбрать конкретную базу данных внизу, как только вы выберете метод аутентификации.
щелчок следующий а затем укажите способ передачи данных из Access в SQL, выбрав Скопируйте данные из одной или нескольких таблиц или Напишите запрос, чтобы указать данные для передачи,
Если вы хотите скопировать все таблицы или только некоторые таблицы из базы данных Access без каких-либо манипуляций с данными, выберите первый вариант. Если вам нужно скопировать только определенные строки и столбцы данных из таблицы, выберите второй вариант и напишите SQL-запрос.
По умолчанию все таблицы должны быть выбраны, и если вы нажмете редактировать Отображения Кнопка, вы можете настроить, как поля отображаются между двумя таблицами. Если вы создали новую базу данных для импорта, то она будет точной копией.
Здесь у меня есть только одна таблица в моей базе данных Access. Нажмите Далее, и вы увидите Запустить пакет экран где Беги немедленно должны быть проверены.






щелчок следующий а затем нажмите Конец, Затем вы увидите, как происходит процесс передачи данных. После его завершения вы увидите количество строк, переданных для каждой таблицы в Сообщение колонка.
щелчок близко и вы сделали. Теперь вы можете запустить SELECT для ваших таблиц, чтобы убедиться, что все данные были импортированы. Теперь вы можете использовать возможности SQL Server для управления вашей базой данных.
Есть проблемы с импортом данных из Access в SQL Server? Если да, оставьте комментарий, и я постараюсь помочь. Наслаждайтесь!
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
SELECT раздел ORDER BY
ORDER BY используется для того, чтобы упорядочить строки, извлекаемые запросом.
В предложении ORDER BY SQL можно задавать несколько выражений. Сначала сортируются строки, основываясь на их значениях для первого выражения. Строки с одним и тем же значением для первого выражения затем сортируются по второму выражению и так далее. NULL- значения располагает после всех других при упорядочивании в порядке возрастания и перед всеми другими при сортировке в убывающем порядке.
ORDER BY подчинено следующим ограничениям:
- Если в утверждении SELECT используются и оператор ORDER BY и оператор DISTINCT, то предложение ORDER BY не может ссылаться на столбцы, не упоминаемые в списке выбора выбираемых столбцов.
- Предложение ORDER BY не может появляться в подзапросах внутри других утверждений.
Пример. ORDER BY в возрастающем (ASC по умолчанию ) и убывающем (DESC) порядке. Выбрать из таблицы peers записи, упорядоченные сначала по возрастанию данных в столбце code, а затем по убыванию данных в столбце sale:
SELECT ename, deptno, sal FROM peers ORDER BY code ASC, sale DESC;
При задании в операторе ORDER BY числовой константы сортировка осуществляется по столбцу с за данным в списке SELECT порядковым номером. Когда в ORDER BY задается функция, сортировке подвергается результат, возвращаемый функцией для каждой строки.
Язык программирования T-SQL
Transact-SQL (T-SQL) – расширение языка SQL от компании Microsoft и используется в SQL Server для программирования баз данных.
SQL Server включает много конструкций, компонентов, функций которые расширяют возможности языка SQL стандарта ANSI, в том числе и классическое программирование, которое отличается от обычного написания запросов.
И сегодня мы с Вами рассмотрим ту часть основ языка T-SQL, которая подразумевает написание кода для реализации некого функционала (например, в процедуре или функции), а не просто какого-то запроса к базе данных.
Примечание! Код я буду писать в окне запроса среды SQL Server Management Studio, о том, как установить SQL Server и Management Studio в редакции Express мы с Вами разговаривали вот здесь.
Специальные знаки и простейшие операторы в Transact SQL
| Знак | Назначение | Знак | Назначение |
|---|---|---|---|
| * | Знак умножения | » » | В них заключают строковые значения, если SET QUOTED_IDENTIFIER OFF |
| — | Знак вычитания | ‘ ’ | В них заключают строковые значения* |
| % | Остаток от деления двух чисел | <> | Не равно |
| + | Знак сложения или конкатенации (объединение двух строк в одну) | Аналог кавычек, в них можнозаключать названия идентификаторов, если в их названиях встречаются пробелы | |
| = | Знак равенства или сравнения | !< | Не менее чем |
| ⇐ | Меньше или равно | !> | Не более чем |
| >= | Больше или равно | > | Больше |
| != | Не равно | < | Меньше |
| @ | Ставится перед именем переменной | . | Разделяет родительские и подчиненные объекты |
| @@ | Указывает на системные функции | Знак деления | |
| – | Однострочный комментарий или комментарий с текущей позиции и до конца строки | /* */ | Многострочный комментарий |
Работа с запросами
Для работы с первыми двумя главами вам понадобиться база данных, которая поддерживает стандарт SQL 1992-го года. На данный момент, это практически все, но не все четко следуют стандарту. Желательно, чтобы база данных поддерживала его максимально полно.
Лучшим вариантом будет MS SQL Server, потому что он максимально полно соответствует стандарту, но можно использовать и MS Access, хотя тут и есть отличия при установке связей между таблицами и поддерживается только SQL, а не Transact-SQL.
Начиная с 3-й главы, мы начнем углубляться в расширение языка SQL под названием Transact-SQL, и вот тут уже MS SQL Server окажется не заменимым, потому что только этот сервер баз данных поддерживает это расширение.
Для вашего удобства, на компакт диске в директориях ChapterX (где X – это номер главы) расположены файлы с текстом запросов и комментариями. Эти файлы позволят вам не набирать коды запросов на клавиатуре, а использовать текст из файлов.
Все возможности языка SQL мы будем рассматривать с одновременным рассмотрением примеров. Сначала я буду приводить общий вид команды, а потом постепенно будем изучать возможности команды на примерах, максимально приближенных к боевым условиям, т.е. такие примеры, которые вы можете встретить в реальных задачах во время решения реальных проблем. Это позволит вам на практике увидеть, как использовать те или иные возможности и иметь готовый багаж запросов для решения наиболее часто встречающихся задач.
APPLY
APPLY is like a cross join in the type of result set that it produces, but usable only with functions. In a cross join, both inputs (left and right) are tables or views that already exist in the database, with a fixed definition. However, APPLY is used in scenarios where a join cannot be used. In APPLY, one of the inputs (the right) is not physically materialized in the database because its output is dependent on input parameters, such as in the case of a table-valued function (TVF).
For example, the AdventureWorks sample database has a SalesPerson table that contains the BusinessEntityID and SalesYTD columns, and a ufnGetContactInformation TVF that returns the FirstName, LastName, and JobTitle columns. The TVF creates a runtime abstraction for columns that exist in multiple underlying tables, like building a table on-the-fly. To write a query that returns the year-to-date (YTD) sales per sales person, together with their name and job title, a cross apply can be used to return all rows from the SalesPerson table, and each of those rows is combined with the rows coming from the ufnGetContactInformation TVF.
The query would look like the following code block:
In the following screenshot, the results of the ufnGetContactInformation function are displayed alongside the SalesYTD column, just as if they came from another table using a simple inner or outer join:
However, the following query produces an error (ID 4104) because a join cannot be used directly with a TVF:
История языка SQL
Истоки SQL возвращают нас в 1970-е годы, когда в лабораториях IBM было создано новое программное обеспечение баз данных System R, а для управления язык SEQUEL. Сейчас это название применяется в качестве альтернативы произношения SQL.
В 1979 году в компании Oracle (на тот момент компания называлась Relational Software), распознали коммерческий потенциал языка SQL и выпустила собственную модифицированную версию.
Сегодня SQL стал стандартом языка запросов к базам данных. Он удовлетворяет как отраслевые, так и академические потребности и используется как на индивидуальных компьютерах, так и на корпоративных серверах. С развитием технологий баз данных приложения на основе SQL становятся все более доступными для обычного пользователя. В современной корпоративной культуре, знание SQL это одно из основных требований к аналитику.
Для чего изучать MySQL
SQL представляет собой язык структурированных запросов, с помощью которого осуществляется управление реляционными базами данных. На их основе могут работать как простые любительские блоги, так и сложные высоконагруженные системы. Поэтому система управления базами данных (далее СУБД) MySQL входит в арсенал основных инструментов веб-разработчика.
В процессе обучения MySQL с нуля вы узнаете, что включено в понятие реляционной базы данных, как правильно составлять запрос и прочие тонкости языка SQL.
Достаточный уровень владения языком SQL входит в перечень профессиональных требований со стороны большинства работодателей в области веб-разработки.
Эффективное использование MySQL требует владения его инструментарием, знаниями функциональных возможностей и особенностей. Наши уроки MySQL для начинающих охватывает ключевые аспекты языка и позволяет овладеть им с нуля. В учебную программу включены наиболее важные для веб-разработчиков темы.

![Топ-20 лучших бесплатных онлайн-курсов по sql [2023] для начинающих с нуля](https://wudgleyd.ru/wp-content/uploads/9/a/d/9adf616747b72c35e591eb1050064b63.jpeg)






Преимущества и недостатки
Преимущества
Независимость от конкретной СУБД
Несмотря на наличие диалектов и различий в синтаксисе, в большинстве своём тексты SQL-запросов могут быть достаточно легко перенесены из одной СУБД в другую. Существуют системы, разработчики которых изначально ориентировались на применение по меньшей мере нескольких СУБД (например: система электронного документооборота Documentum может работать как с Oracle Database, так и с Microsoft SQL Server и DB2). Естественно, что при применении некоторых специфичных для реализации возможностей такой переносимости добиться уже очень трудно.
Наличие стандартов
Наличие стандартов и набора тестов для выявления совместимости и соответствия конкретной реализации SQL общепринятому стандарту только способствует «стабилизации» языка
Правда, стоит обратить внимание, что сам по себе стандарт местами чересчур формализован и раздут в размерах (например, базовая часть стандарта SQL:2003 состоит из более 1300 страниц текста).
Декларативность
С помощью SQL программист описывает только то, какие данные нужно извлечь или модифицировать. То, каким образом это сделать, решает СУБД непосредственно при обработке SQL-запроса
Однако не стоит думать, что это полностью универсальный принцип — программист описывает набор данных для выборки или модификации, однако ему при этом полезно представлять, как СУБД будет разбирать текст его запроса. Чем сложнее сконструирован запрос, тем больше он допускает вариантов написания, различных по скорости выполнения, но одинаковых по итоговому набору данных.
Недостатки
- Несоответствие реляционной модели данных
-
Создатели реляционной модели данных Эдгар Кодд, Кристофер Дейт и их сторонники указывают на то, что SQL не является истинно реляционным языком. В частности, они указывают на следующие дефекты SQL с точки зрения реляционной теории:
- SQL разрешает в таблицах строки-дубликаты, что в рамках реляционной модели данных невозможно и недопустимо;
- SQL поддерживает неопределённые значения (NULL) и многозначную логику;
- SQL использует порядок колонок и ссылки на колонки по номерам;
- SQL разрешает колонки без имени и дублирующиеся имена колонок.
В опубликованном Кристофером Дейтом и Хью Дарвеном Третьем манифесте они излагают принципы СУБД следующего поколения и предлагают язык Tutorial D, который является подлинно реляционным.
- Сложность
- Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста.
- Отступления от стандартов
- Несмотря на наличие международного стандарта ANSI многие разработчики СУБД вносят изменения в язык SQL, применяемый в разрабатываемой СУБД, тем самым отступая от стандарта. Таким образом появляются специфичные для каждой конкретной СУБД диалекты языка SQL.
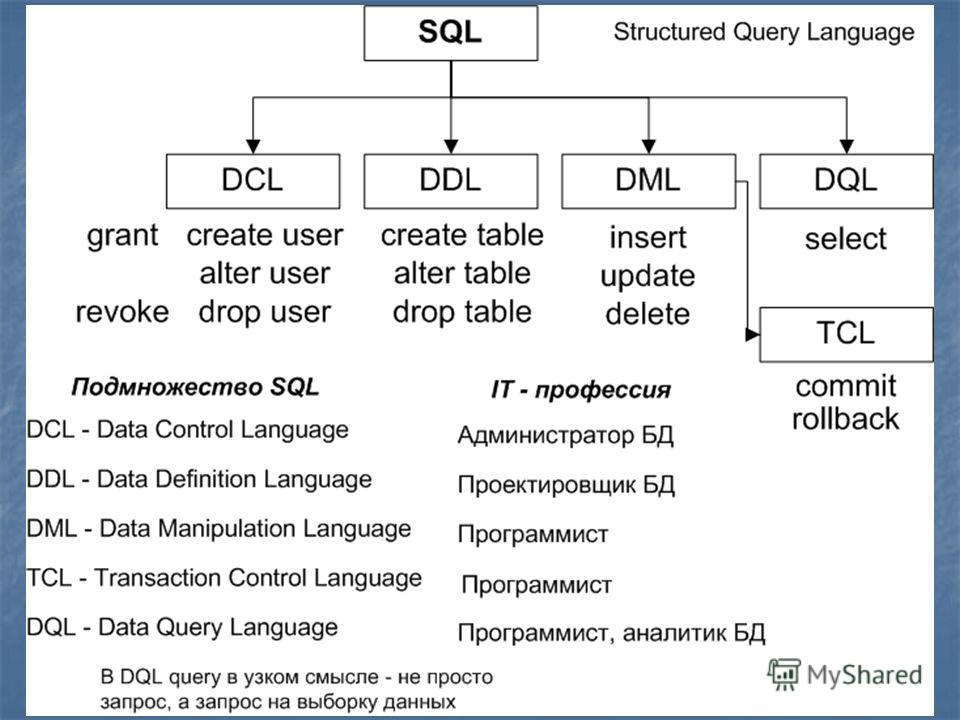
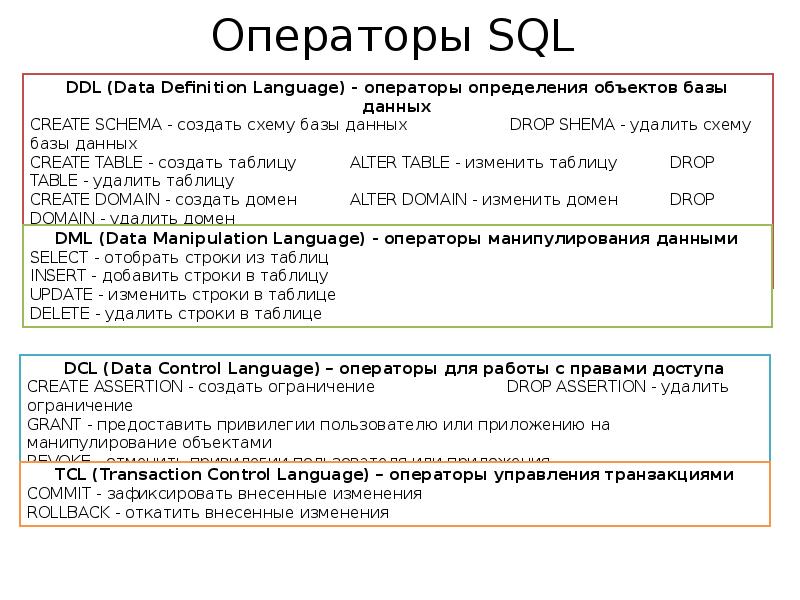
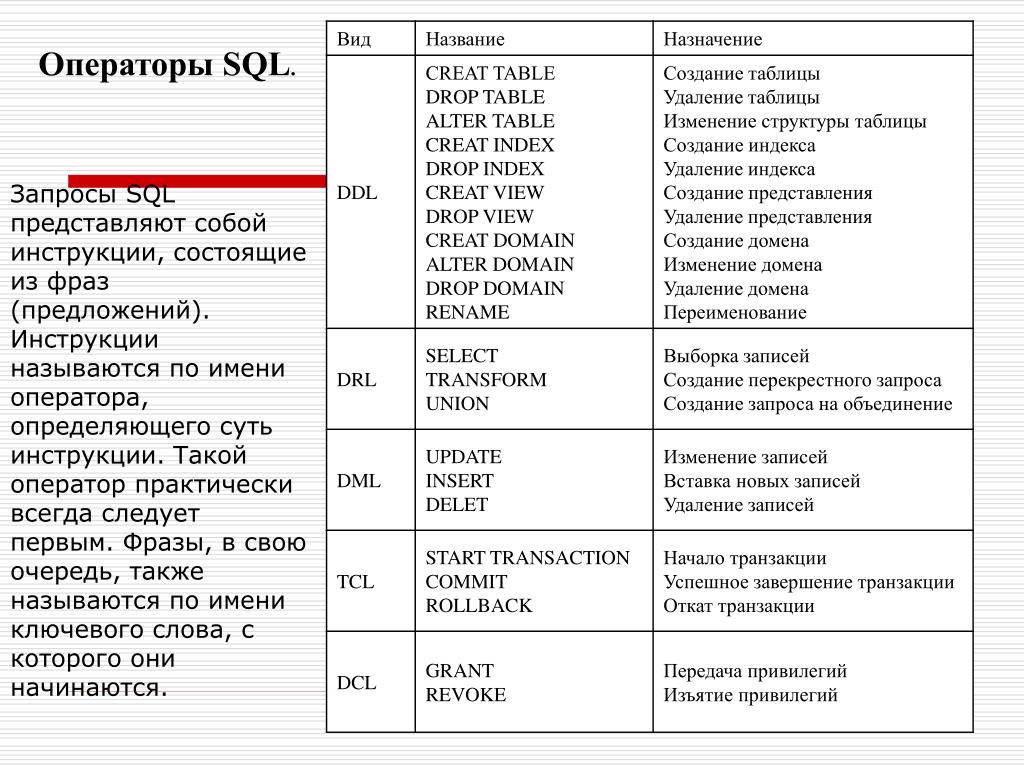
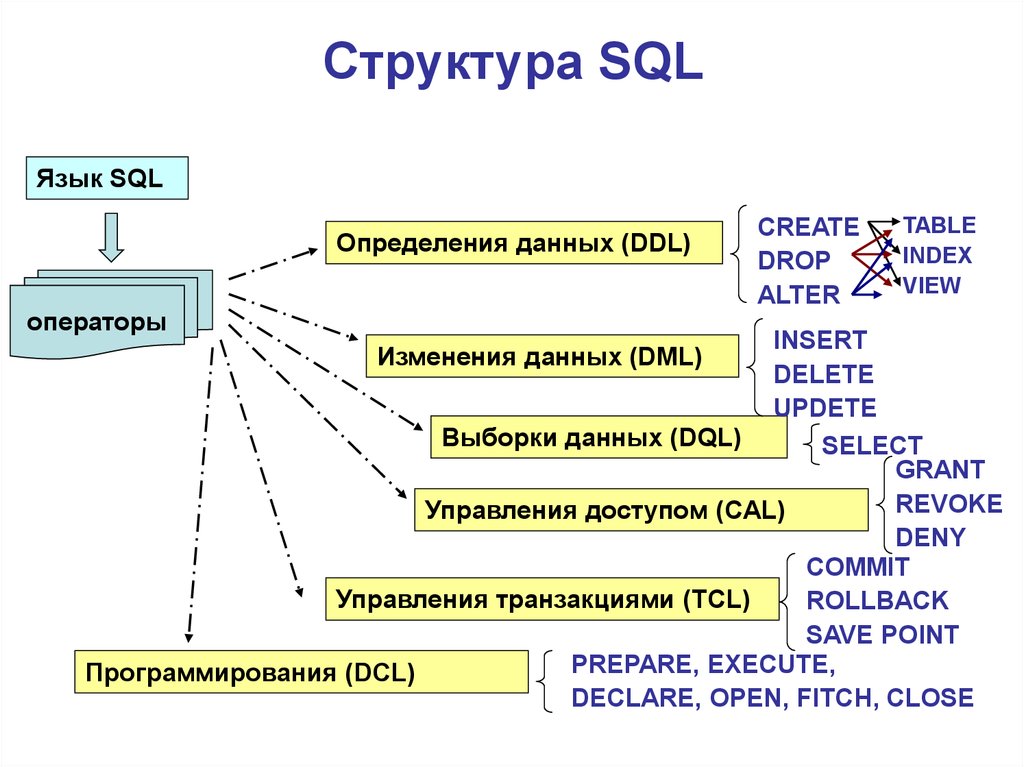
Основные операторы SQL
В SQL существует четыре больших группы операторов.
- Операторы управления схемой данных
-
это операторы, которые позволяют создавать, изменять и удалять таблицы (отношения), базы данных, ограничения, индексы и т.п., а так же получать информацию о существующей схеме данных.
- CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т. д.),
- ALTER изменяет объект,
- DROP удаляет объект;
- Операторы управления данными
-
это операторы, которые позволяют получать, создавать, изменять и удалять данные из созданных таблиц.
- SELECT считывает данные, удовлетворяющие заданным условиям,
- INSERT добавляет новые данные,
- UPDATE изменяет существующие данные,
- DELETE удаляет данные;
- Операторы управления СУБД
-
это операторы, позволяющие настраивать СУБД, управлять разрешениями, создавать пользователей, и т.п.
- GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом,
- REVOKE отзывает ранее выданные разрешения,
- DENY задает запрет, имеющий приоритет над разрешением;
- Операторы управления транзакциями
-
позволяют определять группы операций, которые могут быть отменены или совершены только “все вместе”. Т.е. при ошибке одной операции, автоматически отменяется вся транзакция.
- COMMIT применяет транзакцию,
- ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции,
- SAVEPOINT делит транзакцию на более мелкие участки.
Рассмотрим некоторые из них более подробно.