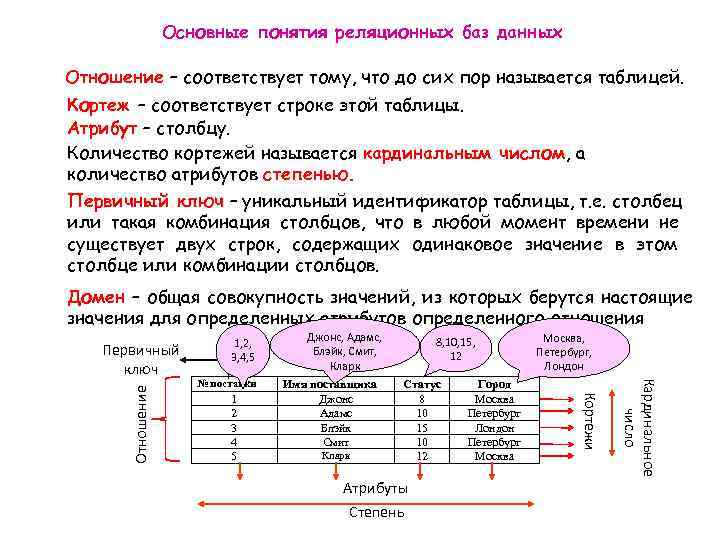
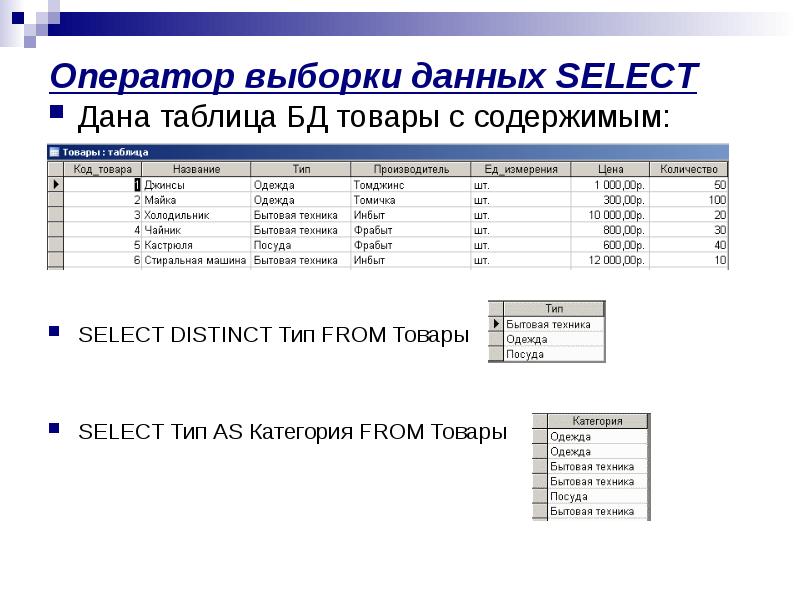
Преобразование типов данных
На самом деле, типы редко меняются. Самый простой вариант: , но начать нужно с функции . Она может сказать, возможно ли преобразовать тип данных. Пример использования: . Вместо значения можно указать название колонки: .
Если нужно добавить данных, то вот пример:
Строковые функции: мы уже знаем , но существует и простой , который склеивает строки внутри функции. . С виду простая операция, но позволяет склеивать столбцы с абстрактными значениями, что часто помогает. Но такой код преобразует все в строку, даже числа. Функции лучше смотреть в документации, такие как , .
Но маленький нюанс я бы хотел рассказать
Важно понять, что для понимания разницы в двух датах можно использовать. Но правильнее использовать , , эта функция поможет вычислить возраст пользователя
SPACE
С помощью функции SPACE можно создавать пробелы. В качестве единственного параметра нужно указать число, которое определяет количество возвращаемых пробелов. Работа функции идентична REPLICATE, если в качестве клонируемого символа указать пробел.
Допустим, что нам нужно вывести на экран поля фамилию и имя, разделенные 5-ю пробелами. Можно сделать так:
SELECT vcFamil+' '+vcName FROM tbPeoples
А можно воспользоваться функцией SPACE:
SELECT vcFamil+SPACE(5)+vcName FROM tbPeoples
Зачем нужна функция, когда можно воспользоваться без нее? Допустим, что вам нужно использовать 5 пробелов в нескольких местах большого сценария. Все легко решается без функций, но в последствии оказалось, что количество пробелов должно быть не 5, а 10. Придется пересматривать весь сценарий и корректировать пробелы. А если бы мы использовали SPACE в сочетании с переменными, то проблема решилась бы намного проще.
Рассмотрим пример, в котором множественные пробелы используются дважды и для задания количества используется переменная:
DECLARE @sp int SET @sp=10 SELECT vcFamil+SPACE(@sp)+vcName+SPACE(@sp)+vcSurName FROM tbPeoples
Теперь, достаточно только изменить значение переменной, и количество пробелов изменено во всем сценарии. А главное – что количество пробелов может быть определено динамически, на основе запросов к таблице.
Исходные данные для примеров
Сначала давайте я расскажу, какие данные я буду использовать в статье, чтобы Вы четко понимали и видели, какие результаты будут возвращаться, если выполнять те или иные действия.
Сразу скажу, что все данные тестовые.
Следующей инструкцией мы создаем таблицу Goods и добавляем в нее несколько строк, в некоторых из которых значение столбца Price будет повторяться.
Останавливаться на том, что делает та или иная инструкция, я не буду, так как это другая тема, если Вам интересно, можете более подробно посмотреть в следующих статьях:
- Создание таблиц в Microsoft SQL Server (CREATE TABLE);
- Добавление данных в таблицы Microsoft SQL Server (INSERT INTO).
--Создание таблицы Goods
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_ProductId PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
GO
--Добавление строк в таблицу Goods
INSERT INTO Goods(ProductName, Price)
VALUES ('Системный блок', 100),
('Монитор', 200),
('Сканер', 150),
('Принтер', 200),
('Клавиатура', 50),
('Смартфон', 300),
('Мышь', 20),
('Планшет', 300),
('Процессор', 200);
GO
--Выборка данных
SELECT ProductId, ProductName, Price
FROM Goods;
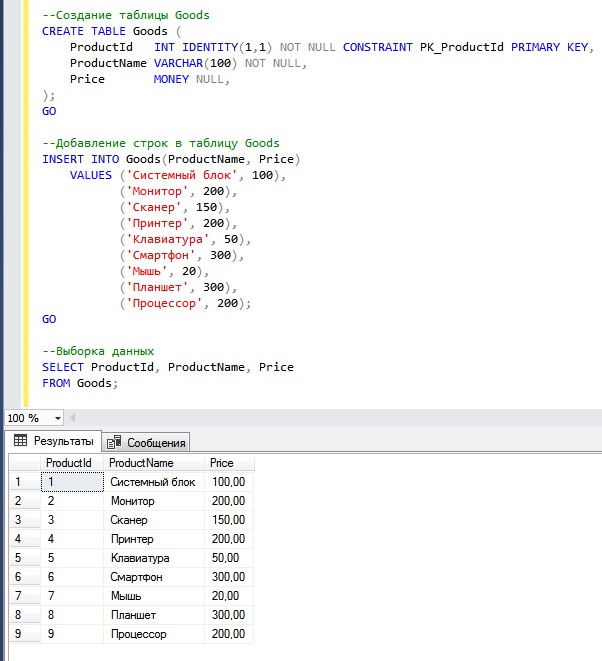
Вы видите, какие данные есть, именно к ним я буду посылать SQL запрос, который будет определять и выводить повторяющиеся значения в столбце Price.
Основные моменты при изучении Sql
Как уже отмечалось выше, запросы применяются для обработки и ввода новой информации в БД, состоящую из таблиц. Каждая ее строка — это отдельная запись. Итак, создадим БД. Для этого напишите команду:
Create database ‘bazaname’
В кавычках пишем имя БД на латинице. Старайтесь придумать для нее понятное имя. Не создавайте базу типа «111», «www» и тому подобное.
После создания БД устанавливаем кодировку windows-1251:
Это нужно чтобы контент на сайте правильно отображаться.
Теперь создаем таблицу:
CREATE TABLE ‘bazaname’ . ‘table’ (
id INT(8) NOT NULL AUTO_INCREMENT PRIMARY KEY,
Во второй строке мы прописали три атрибута. Посмотрим, что они означают:
- Атрибут NOT NULL означает, что ячейка не будет пустой (поле обязательное для заполнения);
- Значение AUTO_INCREMENT — автозаполнение;
- PRIMARY KEY — первичный ключ.
Добавление целых строк
Как видно из названия, оператор INSERT используется для вставки (добавления) строк в таблицу базы данных. Добавление можно осуществить несколькими способами:
- — добавить одну полную строку
- — добавить часть строки
- — добавить результаты запроса.
Итак, чтобы добавить новую строку в таблицу, нам необходимо указать название таблицы, перечислить названия колонок и указать значение для каждой колонки с помощью конструкции INSERT INTO название_таблицы (поле1, поле2 … ) VALUES (значение1, значение2 …). Рассмотрим на примере.
INSERT INTO Sellers (ID, Address, City, Seller_name, Country) VALUES (‘6’, ‘1st Street’, ‘Los Angeles’, ‘Harry Monroe’, ‘USA’)

Также можно изменять порядок указания названий колонок, однако одновременно нужно менять и порядок значений в параметре VALUES.
2. Добавление части строк
В предыдущем примере при использовании оператора INSERT мы явно отмечали имена столбцов таблицы. Используя данный синтаксис, мы можем пропустить некоторые столбцы. Это значит, что вы вводите значение для одних столбцов но не предлагаете их для других. Например:
INSERT INTO Sellers (ID, City, Seller_name) VALUES (‘6’, ‘Los Angeles’, ‘Harry Monroe’)
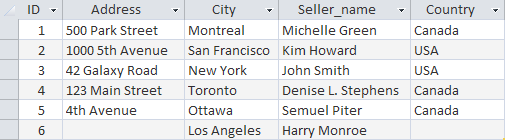
В данном примере мы не указали значение для двух столбцов Address и Country . Вы можете исключать некоторые столбцы из оператора INSERT INTO, если это позволяет производить определение таблицы. В этом случае должно соблюдаться одно из условий: этот столбец определен как допускающий значение NULL (отсутствие какого-либо значения) или в определение таблицы указанное значение по умолчанию. Это означает, что, если не указано никакое значение, будет использовано значение по умолчанию. Если вы пропускаете столбец таблицы, которая не допускает появления в своих строках значений NULL и не имеет значения, определенного для использования по умолчанию, СУБД выдаст сообщение об ошибке, и это строка не будет добавлена.




3. Добавление отобранных данных
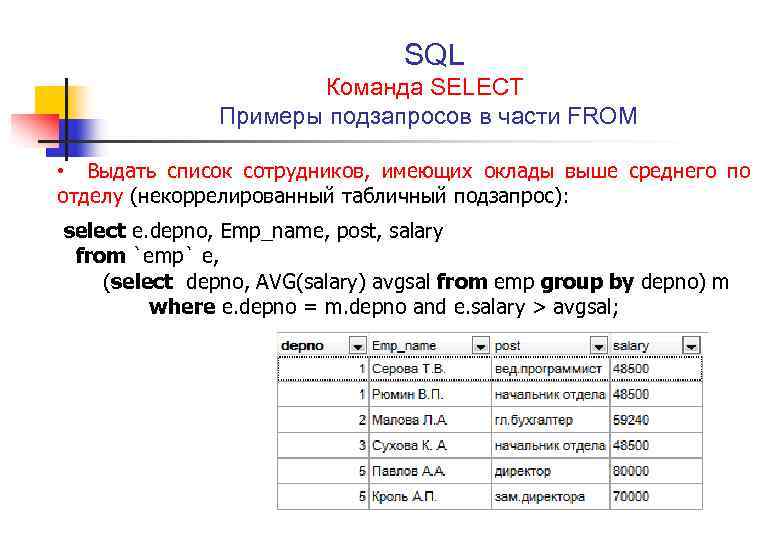
В предыдущей примерах мы вставляли данные в таблицы, прописывая их вручную в запросе. Однако оператор INSERT INTO позволяет автоматизировать этот процесс, если мы хотим вставлять данные из другой таблицы. Для этого в SQL существует такая кострукция как INSERT INTO … SELECT … . Данная конструкция позволяет одновременно выбирать данные из одной таблицы, и вставить их в другую. Предположим мы имеем еще одну таблицу Sellers_EU с перечнем продавцов нашего товара в Европе и нам нужно их добавить в общую таблицу Sellers. Структура этих таблиц одинакова (то же количество колонок и те же их названия), однако другие данные. Для этого мы можем прописать следующий запрос:
INSERT INTO Sellers (ID, Address, City, Seller_name, Country) SELECT ID, Address, City, Seller_name, Country FROM Sellers_EU
Нужно обратить внимание, чтобы значение внутренних ключей не повторялись (поле ID), в противном случае произойдет ошибка. Оператор SELECT также может включать предложения WHERE для фильтрации данных
Также следует отметить, что СУБД не обращает внимания на названия колонок, которые содержатся в операторе SELECT, для нее важно только порядок их расположения. Поэтому данные в первом указанном столбце, что были выбраны из-за SELECT, будут в любом случае заполнены в первый столбец таблицы Sellers, указанной после оператора INSERT INTO, независимо от названия поля
4. Копирование данных из одной таблицы в другую
Часто при работе с базами данных возникает необходимость в создании копий любых таблиц, с целью резервирования или модификации. Чтобы сделать полную копию таблицы в SQL предусмотрен отдельный оператор SELECT INTO. Например, нам нужно создать копию таблицы Sellers, нужно будет прописать запрос следующим образом:
SELECT * INTO Sellers_new FROM Sellers

В отличие от предыдущей конструкции INSERT INTO … SELECT … , когда данные добавляются в существующую таблицу, конструкция SELECT … INTO … FROM … копирует данные в новую таблицу. Также можно сказать, что первая конструкция импортирует данные, а вторая — экспортирует. При использовании конструкции SELECT … INTO … FROM … следует учитывать следующее:
- — можно использовать любые предложения в операторе SELECT, такие как GROUP BY и HAVING
- — для добавления данных из нескольких таблиц можно использовать объединение
- — данные возможно добавить только одну таблицу, независимо от того, из скольких таблиц они были взяты.
Функция COUNT (Transact-SQL)
Эта функция возвращает количество элементов, найденных в группе. Функция COUNT работает подобно функции COUNT_BIG. Эти функции различаются только типами данных в возвращаемых значениях. Функция COUNT всегда возвращает значение типа данных int. Функция COUNT_BIG всегда возвращает значение типа данных bigint.
Синтаксис
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
ALL Применяет агрегатную функцию ко всем значениям. Аргумент ALL используется по умолчанию.
DISTINCT Указывает, что функция COUNT возвращает количество уникальных значений, не равных NULL.
expression Выражение любого типа, кроме image, ntext и text
Обратите внимание, что функция COUNT не поддерживает агрегатные функции и вложенные запросы в выражении
* Указывает, что функция COUNT должна учитывать все строки, чтобы определить общее количество строк таблицы для возврата. Функция COUNT(*) не принимает параметры и не поддерживает использование аргумента DISTINCT. Для функции COUNT(*) не требуется параметр expression, так как по определению она не использует сведения о конкретном столбце. Функция COUNT(*) возвращает количество строк в указанной таблице с учетом повторяющихся строк. Она подсчитывает каждую строку отдельно. При этом учитываются и строки, содержащие значения NULL.
OVER ( ) partition_by_clause делит результирующий набор, полученный с помощью предложения FROM , на секции, к которым применяется функция COUNT . Если этот параметр не указан, функция обрабатывает все строки результирующего набора запроса как отдельные группы. order_by_clause определяет логический порядок выполнения операции. Дополнительные сведения см. в статье SELECT — предложение OVER (Transact-SQL).
Remarks
Функция COUNT(*) возвращает количество элементов в группе. Сюда входят значения NULL и повторяющиеся значения.
Функция COUNT(ALL expression) вычисляет expression для каждой строки в группе и возвращает количество значений, не равных NULL.
Функция COUNT(DISTINCT expression) вычисляет expression для каждой строки в группе и возвращает количество уникальных значений, не равных NULL.
Для возвращаемых значений, которые превышают значение 2^31-1, функция COUNT возвращает ошибку. В таких случаях используйте вместо нее функцию COUNT_BIG .
COUNT — это детерминированная функция, если она используется без _ предложений OVER и ORDER BY. Она не детерминирована при использовании _ с предложениями OVER и ORDER BY. Дополнительные сведения см. в статье Детерминированные и недетерминированные функции.
Примеры
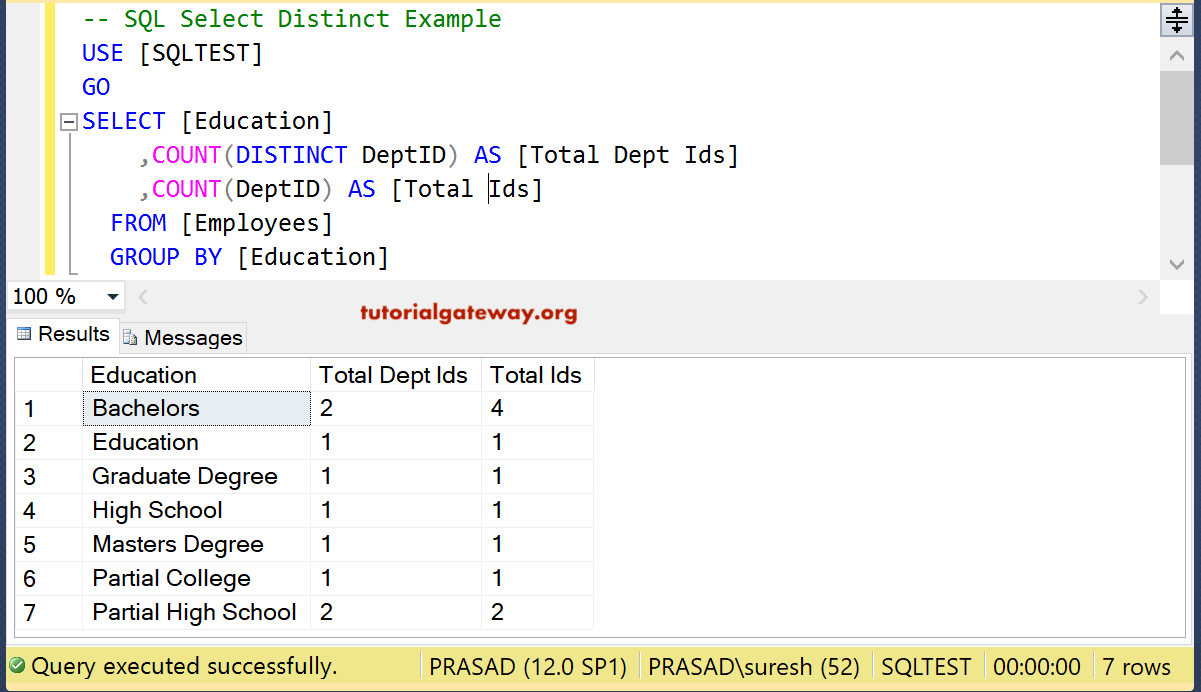
A. Использование функции COUNT и параметра DISTINCT
В этом примере функция возвращает количество различных должностей, которые может иметь сотрудник Компания Adventure Works Cycles.
В. Использование функции COUNT(*) совместно с другими статистическими функциями
В этом примере показано, что функция COUNT(*) работает с другими статистическими функциями в списке SELECT . В этом примере используется база данных AdventureWorks2012.
Г. Использование предложения OVER
В этом примере функции MIN , MAX , AVG и COUNT используются с предложением OVER , чтобы получить статистические значения для каждого из отделов в таблице HumanResources.Department базы данных AdventureWorks2012.
Примеры: Azure Synapse Analytics и Система платформы аналитики (PDW)
Д. Использование функции COUNT и параметра DISTINCT
В этом примере функция возвращает количество различных должностей, которые может иметь конкретный сотрудник компании.
Ж. Использование функции COUNT(*) совместно с другими статистическими функциями
В этом примере функция COUNT(*) работает с другими статистическими функциями в списке SELECT . Запрос возвращает количество торговых представителей с годовой квотой продаж более 500 000 долл. США и их среднюю квоту продаж.
З. Использование функции COUNT с предложением HAVING
В этом примере функция COUNT используется с предложением HAVING , чтобы получить список подразделений компании, в каждом из которых работает более 15 сотрудников.
И. Использование функции COUNT с предложением OVER
В этом примере функция COUNT используется с предложением OVER , чтобы получить количество продуктов, содержащихся в каждом из указанных заказов на продажу.
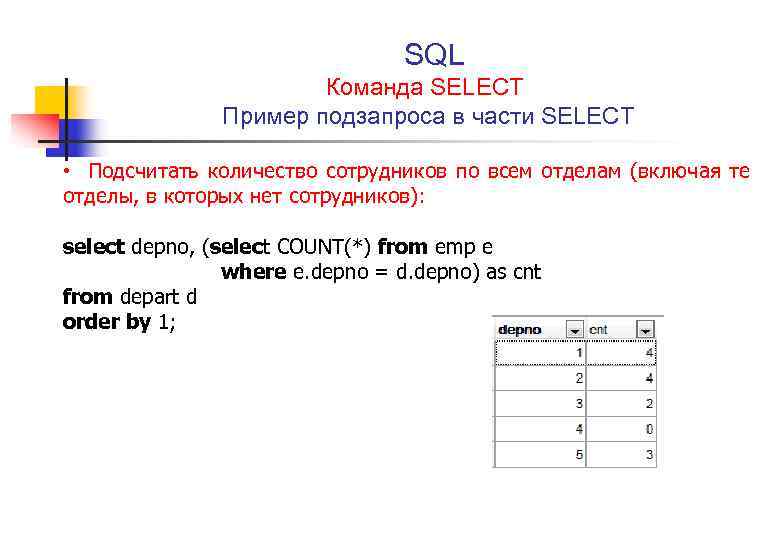
Подзапросы
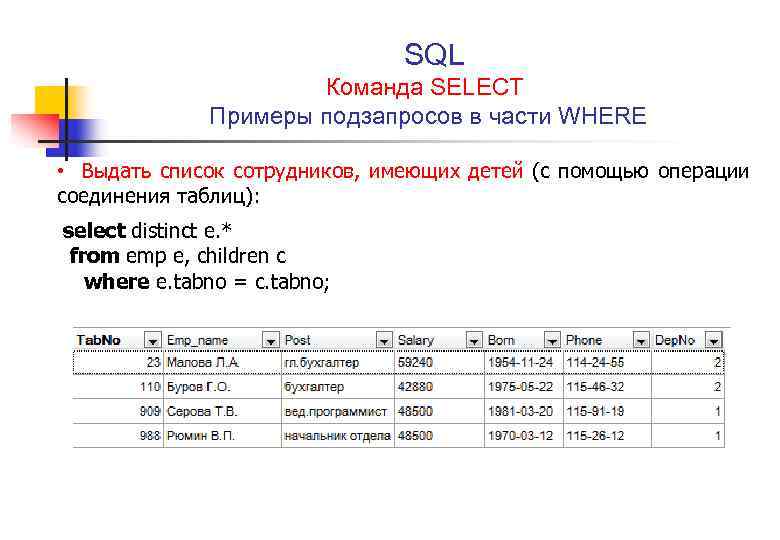
На выходе подзапрос должен возвращать одно единственное значение (для страховки можно принудительно указывать LIMIT 1). Допускается использование подзапросов, которые на выходе выдают ряд значений, для оператора IN.
Операторы EXISTS, ANY(ANY и SOME абсолютно идентичны и являются взаимозаменяемыми),ALL умеют работать с множеством значений.
-
Пример. Использования подзапроса с оператором INSERT. В таблицу df_lcr_list передаются два значения(datestart и dateend), login_id ищется подзапросом по заранее известному имени пользователя, в таблицу вставляется текущее время.
INSERT INTO df_lcr_list (datestart,dateend,login_id, date_event) SELECT '20120405','20120405',id, now() FROM users WHERE login='username';
-
Пример. Использования подзапроса(subquery) с оператором UPDATE. Subquery выводит множество значений.
UPDATE accounts SET balance=0 WHERE uid IN (SELECT id FROM users WHERE email LIKE 'ltaixp1%');
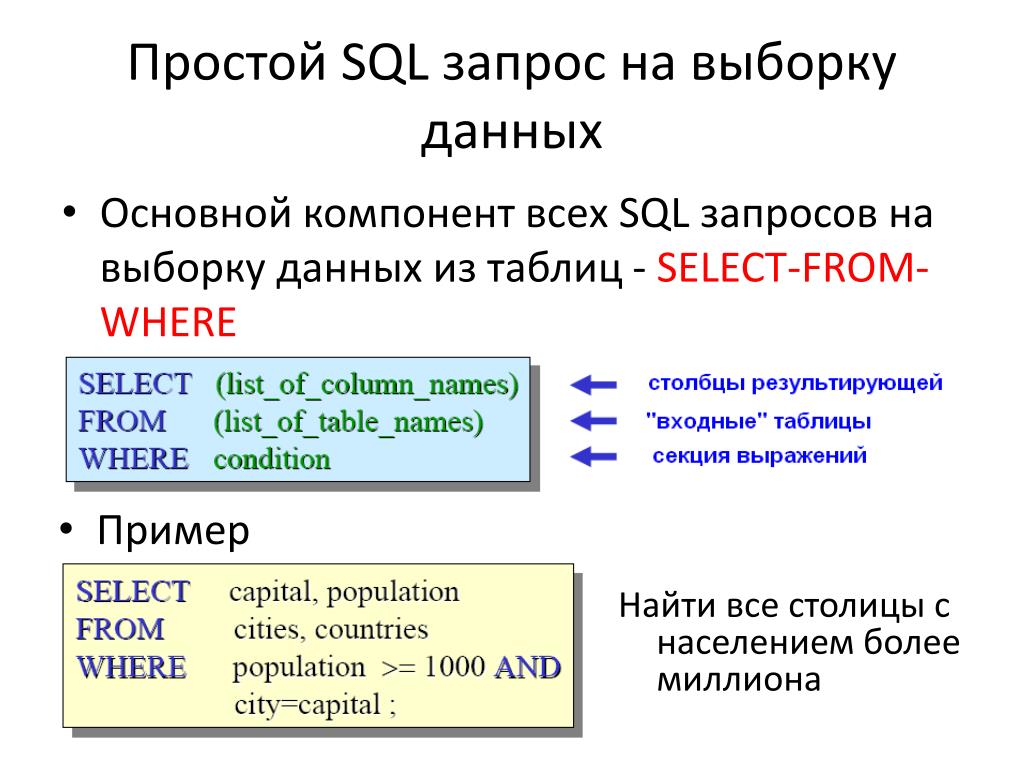
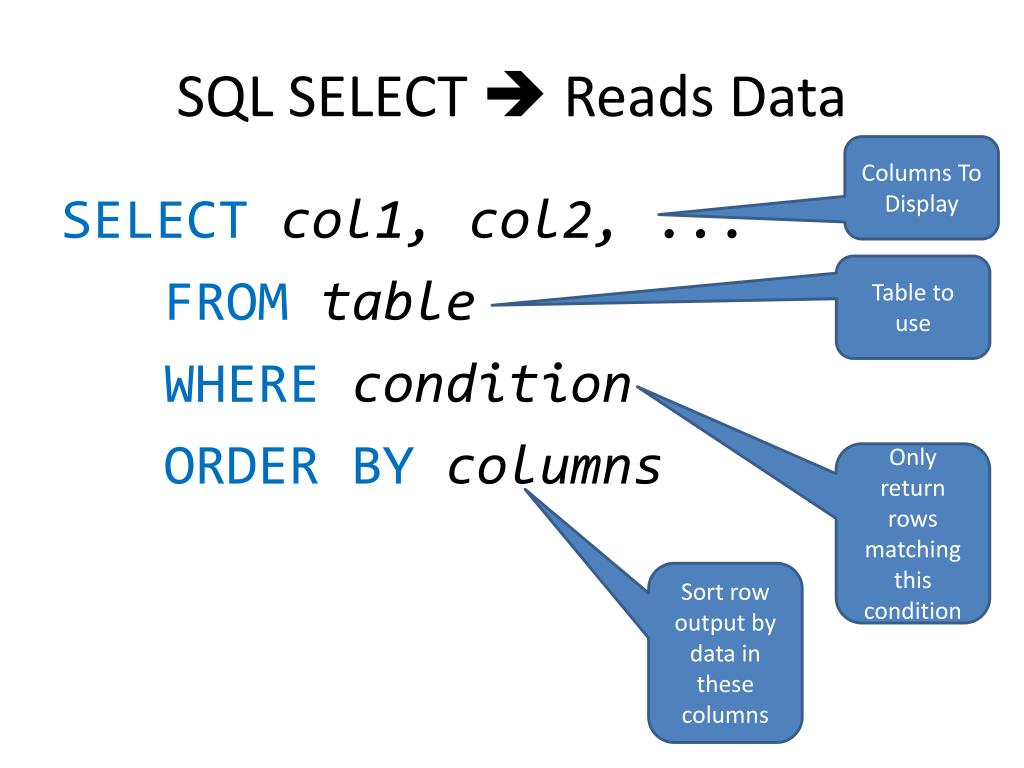
SELECT раздел ORDER BY
ORDER BY используется для того, чтобы упорядочить строки, извлекаемые запросом.
В предложении ORDER BY SQL можно задавать несколько выражений. Сначала сортируются строки, основываясь на их значениях для первого выражения. Строки с одним и тем же значением для первого выражения затем сортируются по второму выражению и так далее. NULL- значения располагает после всех других при упорядочивании в порядке возрастания и перед всеми другими при сортировке в убывающем порядке.
ORDER BY подчинено следующим ограничениям:
- Если в утверждении SELECT используются и оператор ORDER BY и оператор DISTINCT, то предложение ORDER BY не может ссылаться на столбцы, не упоминаемые в списке выбора выбираемых столбцов.
- Предложение ORDER BY не может появляться в подзапросах внутри других утверждений.
Пример. ORDER BY в возрастающем (ASC по умолчанию ) и убывающем (DESC) порядке. Выбрать из таблицы peers записи, упорядоченные сначала по возрастанию данных в столбце code, а затем по убыванию данных в столбце sale:
![Sql [айти бубен]](https://wudgleyd.ru/wp-content/uploads/7/0/2/7028624551899361f74c259220b1c5b7.jpeg)



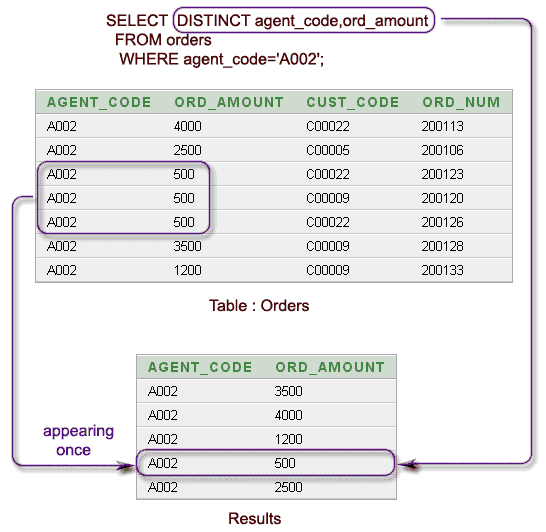

SELECT ename, deptno, sal FROM peers ORDER BY code ASC, sale DESC;
При задании в операторе ORDER BY числовой константы сортировка осуществляется по столбцу с за данным в списке SELECT порядковым номером. Когда в ORDER BY задается функция, сортировке подвергается результат, возвращаемый функцией для каждой строки.
Как вывести повторяющиеся значения в столбце на T-SQL? Microsoft SQL Server
Приветствую всех на сайте Info-Comp.ru! В этой небольшой заметке я покажу, как можно на SQL вывести повторяющиеся значения в столбце таблицы в Microsoft SQL Server. Все будет рассмотрено очень подробно и с примерами.

Исходные данные для примеров
Сначала давайте я расскажу, какие данные я буду использовать в статье, чтобы Вы четко понимали и видели, какие результаты будут возвращаться, если выполнять те или иные действия.
Сразу скажу, что все данные тестовые.
Следующей инструкцией мы создаем таблицу Goods и добавляем в нее несколько строк, в некоторых из которых значение столбца Price будет повторяться.
Останавливаться на том, что делает та или иная инструкция, я не буду, так как это другая тема, если Вам интересно, можете более подробно посмотреть в следующих статьях:
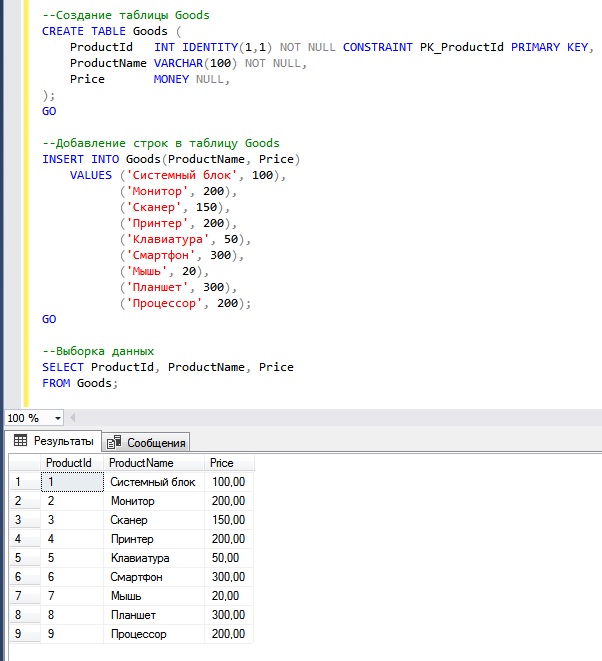
Вы видите, какие данные есть, именно к ним я буду посылать SQL запрос, который будет определять и выводить повторяющиеся значения в столбце Price.
Выводим повторяющиеся значения в столбце на T-SQL
Основной алгоритм определения повторяющихся значений в столбце состоит в том, что нам нужно сгруппировать все строки по столбцу, в котором необходимо найти повторяющиеся значения, и подсчитать количество строк в каждой сгруппированной строке, а затем просто поставить фильтр (>1) на итоговое количество, отбросив тем самым строки со значением 1, т.е. если значение встречается всего один раз, значит, оно не повторяется, и нам не нужно.
Вот пример всего вышесказанного.
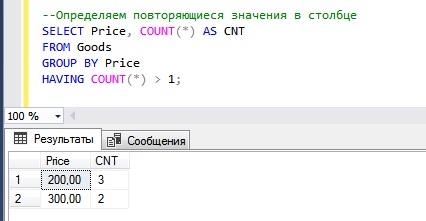
Мы видим, что у нас есть всего два значения, которые повторяются — это 200 и 300. Первое значение, т.е. 200, повторяется 3 раза, второе — 2 раза.
Данные сгруппировали мы конструкцией GROUP BY, подсчитали количество значений встроенной функцией COUNT, а отфильтровали сгруппированные строки конструкцией HAVING.
Выводим все строки с повторяющимися значениями на T-SQL
Но в большинстве случаев просто узнать повторяющиеся в столбце значения недостаточно, иногда необходимо вывести все записи в этой таблице, которые содержат эти повторяющиеся значения.
Это можно реализовать с помощью подзапроса, но использовать подзапрос, в котором будет группировка, не очень удобно, и уж точно неудобочитаемо. Поэтому мне нравится в каких-то подобных случаях использовать CTE (обобщённое табличное выражение) для повышения читабельности кода. Также чтобы сделать результирующий набор данных более наглядным, его можно отсортировать по целевому столбцу, тем самым мы сразу увидим строки с повторяющимися значениями.
Вот пример, в котором мы выводим все строки с повторяющимися значениями в столбце, отсортированные по столбцу Price.
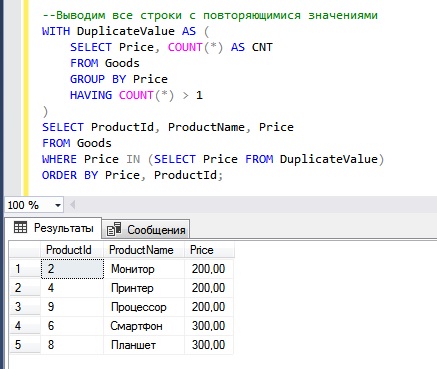
Как видим, сначала у нас идут все строки со значением 200, а затем строки со значением 300. Сортировку мы осуществили конструкцией ORDER BY. Если у Вас возникает вопрос, что такое DuplicateValue, то это всего лишь название CTE выражения, в принципе Вы его можете назвать и по-другому.
Заметка!
Для комплексного изучения языка T-SQL рекомендую почитать мои книги и пройти курсы:
Инструкция INSERT в T-SQL
INSERT – это инструкция языка T-SQL, которая предназначена для добавления данных в таблицу, т.е. создания новых записей. Данную инструкцию можно использовать как для добавления одной строки в таблицу, так и для массовой вставки данных. Для выполнения инструкции INSERT требуется разрешение на вставку данных (INSERT) в целевую таблицу.
Существует несколько способов использования инструкции INSERT в части данных, которые необходимо вставить:
- Перечисление конкретных значений для вставки;
- Указание набора данных в виде запроса SELECT;
- Указание набора данных в виде вызова процедуры, которая возвращает табличные данные.
Упрощённый синтаксис
INSERT (список столбцов, …) VALUES (список значений, …) Или SELECT запрос на выборку Или EXECUTE процедура
Где,
- INSERT INTO – это команда добавления данных в таблицу;
- Таблица – это имя целевой таблицы, в которую необходимо вставить новые записи;
- Список столбцов – это перечень имен столбцов таблицы, в которую будут вставлены данные, разделенные запятыми;
- VALUES – это конструктор табличных значений, с помощью которого мы указываем значения, которые будем вставлять в таблицу;
- Список значений – это значения, которые будут вставлены, разделенные запятыми. Они перечисляются в том порядке, в котором указаны столбцы в списке столбцов;
- SELECT – это запрос на выборку данных для вставки в таблицу. Результирующий набор данных, который вернет запрос, должен соответствовать списку столбцов;
- EXECUTE – это вызов процедуры на получение данных для вставки в таблицу. Результирующий набор данных, который вернет хранимая процедура, должен соответствовать списку столбцов.
Вот примерно так и выглядит упрощённый синтаксис инструкции INSERT INTO, в большинстве случаев именно так Вы и будете добавлять новые записи в таблицы.
Список столбцов, в которые Вы будете вставлять данные, можно и не писать, в таком случае их порядок будет определен на основе фактического порядка столбцов в таблице. При этом необходимо помнить этот порядок, когда Вы будете указывать значения для вставки или писать запрос на выборку. Лично я Вам рекомендую все-таки указывать список столбцов, в которые Вы планируете добавлять данные.
Также следует помнить и то, что в списке столбцов и в списке значений, соответственно, должны присутствовать так называемые обязательные столбцы, это те, которые не могут содержать значение NULL. Если их не указать, и при этом у столбца отсутствует значение по умолчанию, будет ошибка.
Еще хотелось бы отметить, что тип данных значений, которые Вы будете вставлять, должен соответствовать типу данных столбца, в который будет вставлено это значение, ну или, хотя бы, поддерживал неявное преобразование. Но я Вам советую контролировать тип данных (формат) значений, как в списке значений, так и в запросе SELECT.
Хватит теории, переходим к практике.
Поиск дубликатов в одной таблице с помощью INNER JOIN
Вот основной синтаксис для поиска дубликатов в одной таблице:
Вот описание служебного запроса:
- Col: имя столбца, который нужно проверить и выбрать для дублирования.
- Temp: ключевое слово для применения внутреннего соединения к столбцу.
- Таблица: имя проверяемой таблицы.
У нас есть новая таблица order2 с повторяющимися значениями в столбце OrderNo, как показано ниже.
Мы выбираем три столбца: Item, Sales, OrderNo, которые будут отображаться в выводе. В то время как столбец OrderNo используется для проверки дубликатов. Внутреннее соединение выберет значения или строки, имеющие значения элементов более одного в таблице. После выполнения мы получим следующие результаты.
Как избежать курсоров в SQL Server
- Логика на основе множеств
- INSERT или SELECT INTO, или INSERT…SELECT для добавления записей в таблицу за одну транзакцию.
- UPDATE для модификации одной или многих строк в одной транзакции.
- DELETE или TRUNCATE для удаления записей из таблицы.
- Ветвящаяся логика MERGE для вставки, удаления или обновления данных на основе критериев.
- Рассмотрите возможность использования служб интеграции SQL Server (SSIS) для циклического перебора данных, в первую очередь, для извлечения, преобразования и загрузки данных из одной базы данных в другую.
- Команда WHILE для циклического обхода записей в последовательной манере.
- Команда COALESCE для обработки не-NULL значений.
- Системная хранимая процедура sp_MSforeachdb в SQL Server для перебора в цикле всех баз данных в экземпляре.
- Системная хранимая процедура sp_MSforeachtable в SQL Server для перебора в цикле всех таблиц в базе данных.
- Выражение CASE, которое может включать некоторую логику ветвления в обработку данных с помощью оператора SELECT.
- Повторение пакета с помощью команды GO.
SUBSTRING
Помниться, что мы добавили к значениям в колонке имен работников префикс ‘mr.’ (см. разд. 2.17). А как теперь от него избавится во время обращения к таблице? Достаточно просто, если воспользоваться функцией SUBSTRING, которая возвращает указанную часть строки. Этой функции необходимо передать три параметра:
- Поле, часть строки которого нужно получить;
- Первый символ;
- Количество интересующих нас символов.
Посмотрим, как вышесказанное можно реализовать в виде запроса:
SELECT idPeoples,
CASE SUBSTRING(vcFamil, 1, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END
FROM tbPeoples
В этом примере, мы выбираем только два поля: «idPeoples» и поле, результат которого зависит от проверки CASE. В данном случае CASE проверяет результат работы функции SUBSTRING, которая выбирает символы из поля «vcFamil» начиная с первого по третий. Если результат равен ‘mr.’, то необходимо обрезать этот префикс.






Для того, чтобы отбросить ненужные символы от значения поля, мы снова пользуемся функцией SUBSTRING, но теперь выбираем символы, начиная с четвертного (начиная с первого, после ‘mr.’). В качестве количества символов я указал число 255, что больше максимального значения поля, а значит, строка будет выбрана до конца, начиная 4-го.
Теперь попробуем обновить данные в таблице, чтобы в поле «vcName», чтобы в нем не было лишних символов ‘mr.’. Для этого выполняем следующий запрос:
UPDATE tbPeoples
SET vcFamil=(case SUBSTRING(vcFamil, 1, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END)
В этом примере полю «vcName»присваивается результат сравнения CASE, который мы уже рассмотрели выше. Таким образом, мы избавились от лишних букв в фамилиях.
Выводим все строки с повторяющимися значениями на T-SQL
Но в большинстве случаев просто узнать повторяющиеся в столбце значения недостаточно, иногда необходимо вывести все записи в этой таблице, которые содержат эти повторяющиеся значения.
Это можно реализовать с помощью подзапроса, но использовать подзапрос, в котором будет группировка, не очень удобно, и уж точно неудобочитаемо. Поэтому мне нравится в каких-то подобных случаях использовать CTE (обобщённое табличное выражение) для повышения читабельности кода. Также чтобы сделать результирующий набор данных более наглядным, его можно отсортировать по целевому столбцу, тем самым мы сразу увидим строки с повторяющимися значениями.
Вот пример, в котором мы выводим все строки с повторяющимися значениями в столбце, отсортированные по столбцу Price.
Как видим, сначала у нас идут все строки со значением 200, а затем строки со значением 300. Сортировку мы осуществили конструкцией ORDER BY. Если у Вас возникает вопрос, что такое DuplicateValue, то это всего лишь название CTE выражения, в принципе Вы его можете назвать и по-другому.
Заметка!
Для комплексного изучения языка T-SQL рекомендую почитать мои книги:
- Путь программиста T-SQL – самоучитель по языку Transact-SQL для начинающих;
- Стиль программирования на T-SQL – основы правильного написания кода. Книга, направленная на повышение качества T-SQL кода.
У меня на этом все, надеюсь, материал был Вам полезен. Удачи Вам, пока!
Новичок
как выбрать из таблицы все строки без повторений по одному полю
| id | name | description
| 1 | cat | animal1 | 2 | cat | animal2 | 3 | dog | animal3
мне нужны только 1 и 3 строка. Вторая отбрасывается так как ее name совпадает с name из первой строки. Как составить такой запрос?
Выводим повторяющиеся значения в столбце на T-SQL
Основной алгоритм определения повторяющихся значений в столбце состоит в том, что нам нужно сгруппировать все строки по столбцу, в котором необходимо найти повторяющиеся значения, и подсчитать количество строк в каждой сгруппированной строке, а затем просто поставить фильтр (>1) на итоговое количество, отбросив тем самым строки со значением 1, т.е. если значение встречается всего один раз, значит, оно не повторяется, и нам не нужно.
Вот пример всего вышесказанного.
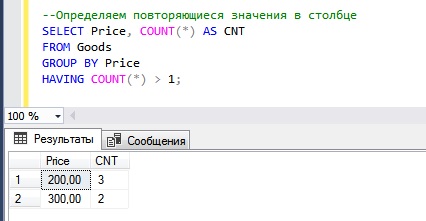
Мы видим, что у нас есть всего два значения, которые повторяются — это 200 и 300. Первое значение, т.е. 200, повторяется 3 раза, второе — 2 раза.
Данные сгруппировали мы конструкцией GROUP BY, подсчитали количество значений встроенной функцией COUNT, а отфильтровали сгруппированные строки конструкцией HAVING.