Нормализация базы данных и ее формы
Примечание: Во всех статьях текущей категории уроков по SQL используются примеры и задачи, основанные на учебной базе данных.
Приступая к изучению данного материала, рекомендуется ознакомиться с описанием учебной БД.
Материал этой статьи напрямую не относиться к изучению языка SQL, так как имеет отношение к проектированию баз данных (БД), но для общего понимания взаимосвязи хранимой в системе информации она будет полезна.
По поводу того, как должна быть спроектирована база нет 100% решения, потому что конкретный вариант может удовлетворять либо не удовлетворять различным бизнес-процессам и целям
Но не принимать во внимание элементарные правила нельзя, так как их соблюдение сохранит много времени, нервов и денег при работе с данными
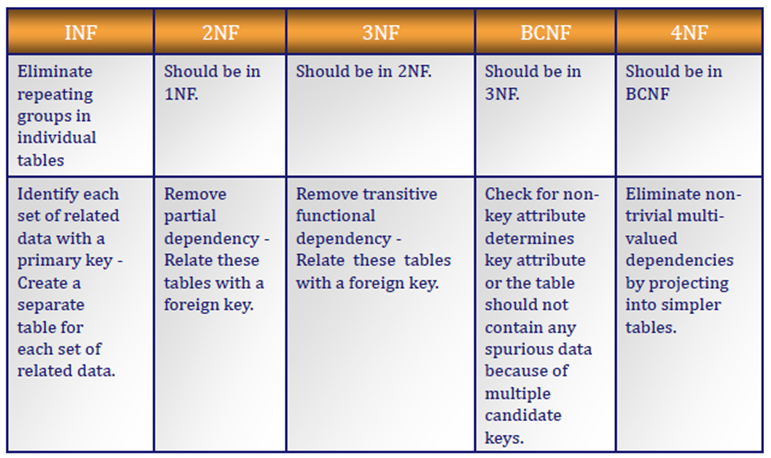
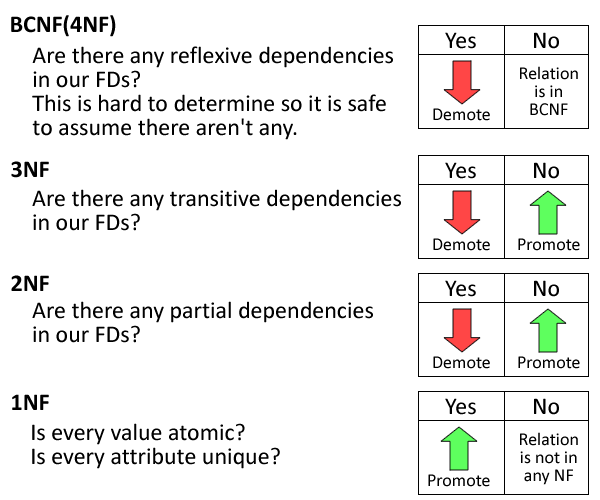
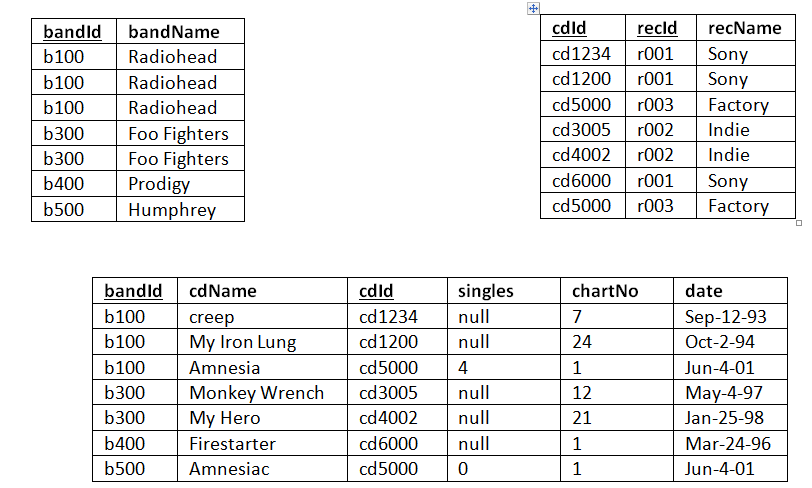
Нормализация баз данных заключается в приведении структуры хранения данных к нормальным формам (NF). Всего таких форм существует 8, но часто достаточным является соблюдение первых трех. Рассмотрим их более подробно на примере учебной базы данных. Примеры будут строится по принципу «что было бы, если было иначе, чем сейчас».
Первая нормальная форма
Основным правилом первой формы является необходимость неделимости значения в каждом поле (столбце) строки – атомарность значений.
Рассмотрим таблицы сотрудников и телефонных линий.
Чтобы избавиться от связывающей таблицы «Сотрудники_Линии», мы могли бы записать идентификаторы сотрудников для каждой линии в виде перечня в дополнительном столбце:
Но подобная структура не является надежной. Представьте, что Вам необходимо поменять некоторым сотрудникам подключенные линии. Потребуется осуществить разбор составного поля, чтобы определить наличие id сотрудника в каждой записи линий, затем скорректировать перечень. Получается слишком сложный и долгий процесс для такой простой операции.
Организации структуры таблиц с применением дополнительной связывающей избавляет от подобных проблем.
Помимо атомарности к первой нормальной форме относятся следующие правила:
- Строки таблиц не должны зависеть друг от друга, т.е. первая запись не должна влиять на вторую и наоборот, вторая на третью и т.д. Размещение записей в таблице не имеет никакого значения.
- Аналогичная ситуация со столбцами записей. Их порядок не должен влиять на понимание информации.
- Каждая строка должна быть уникальна, поэтому для нее определяется первичный ключ, состоящий из одного либо нескольких полей (составной ключ). Первичный ключ не может повторяться в пределах таблицы и служит идентификатором записи.
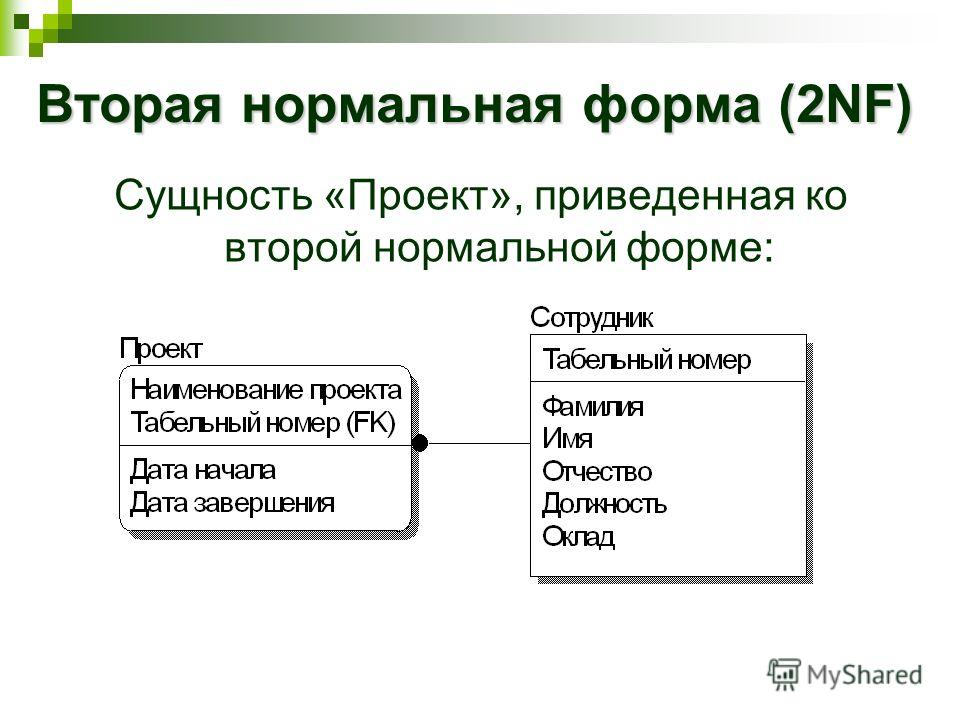
Вторая нормальная форма
Условием этой формы является отсутствие зависимости неключевых полей от части составного ключа.
Так как составной ключ в учебной базе наблюдается только в таблице «Сотрудники_Линии», то рассмотрим пример на ней.
На представленной диаграмме столбцы описания и приоритета зависят от столбца «Линия», входящего в составной ключ. Это значит, что для каждой линии, подключенной разным сотрудникам, потребуется повторно указывать описание и приоритетность. Подобная структура приводит к избыточности данных.
Также велика вероятность возникновения противоречивой информации. Изменяя приоритет или описание для линии, можно по ошибке оставить некоторые строки не обработанными. В таком случае, для одного и того же идентификатора линии значения зависимых полей будут различными.
Если соблюдены правила первой нормальной формы, то создание таблицы «Линии» и перенос в нее зависимых столбцов удовлетворяет второй нормальной форме.
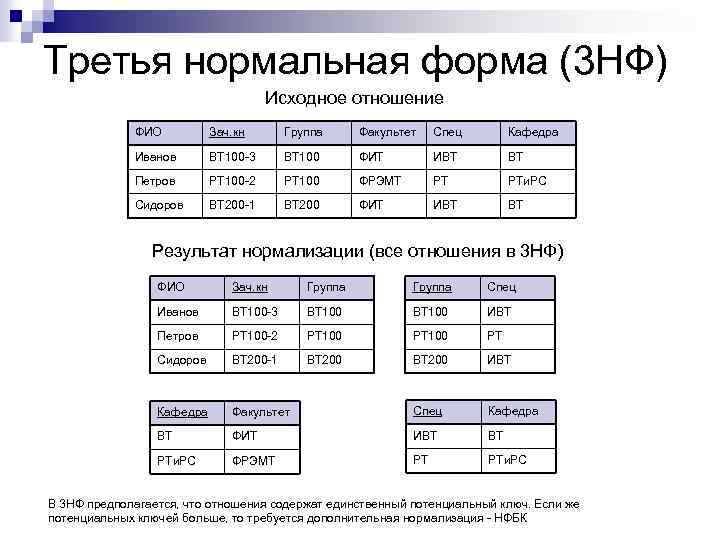
Третья нормальная форма
3NF схожа по логике с 2NF, но с некоторым отличием. Если 2 форма ликвидирует зависимости неключевых полей от части ключа, то третья нормальная форма исключает зависимость неключевых полей от других неключевых полей.
На приведенном примере таблицы сотрудников видно, что столбец «Супервайзер» имеет зависимость от столбца «Группа», а это значит, что при изменении значения поля группы, потребуется изменить значение поля супервайзера.
Все риски, которые были рассмотрены для 2NF, так же относятся к 3NF и устраняются переносом зависимых полей в отдельную таблицу.
Денормализация базы данных
Теория нормальных форм не всегда применима на практике. Например, неатомарные значения не всегда являются «злом», а иногда наоборот. Связано это с необходимостью дополнительного объединения (следовательно, затрат производительности системы) при выполнении запросов, особенно когда производится обработка большого массива информации.
Для баз данных, предназначенных для аналитики, часто выполняют денормализацию, чтобы укорить выполнение запросов.
Первая нормальная форма
Как писалось выше, нормализация — это приведение структуры бд в порядок в соответствии с несколькими правилами. Правилам нужно следовать точно, и приводить к формам нужно в порядке их следования.
Чтобы привести таблицу к 1НФ, нужно соблюсти два правила:
- Атомарность или неделимость. Каждая колонка должна содержать одно неделимое значение.
- Таблица не должна содержать повторяющихся колонок или групп данных.
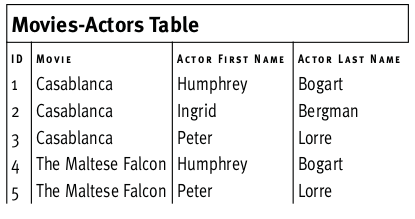
Например, если таблица содержит в одном поле полный адрес человека (улица, город, почтовый код), не будет отвечать правилам 1НФ, поскольку будет содержать различные значения в одном столбце, что будет нарушением правила об атомарности. Или если бд содержит данные о фильмах и в ней есть столбцы актер1, актер2, актер3, также не будет отвечать правилам, поскольку будет иметь место повторению данных.
Начинать нормализацию следует с проверки структуры бд на совместимость с 1НФ. Все столбцы, которые не являются атомарными, должны быть разбиты на составляющие их столбцы. Если в таблице есть повторяющиеся столбцы, то им нужно выделить отдельную таблицу.
Чтобы привести таблицу к первой нормальной форме, следует:
- Найти все поля, которые содержат многосоставные части информации. На рисунке выше, поле message date содержит день, месяц, год и время, которое можно разбить на составные части, но в данном примере такая детализация даты не нужна. Mysql может работать и с таким форматом — благодаря типу DATETIME. В этом примере разбито имя пользователя на имя и фамилию. Еще примерами неудачных решений могут быть поля, в которых хранятся сразу все телефоны человека (мобильный, рабочий) или его интересы (готовка, танцы).
- Те данные, которые можно разбить на составные части, нужно выносить в отдельные поля. На рисунке выше так разнесено полное имя на имя и фамилию.
- Выносите повторяющиеся данные в отдельную таблицу. В примере с форумом такой проблемы нет, поэтому возьмем в качестве примера таблицу, содержащую информацию о фильмах. Там есть несколько полей actor, которые являются повторяемыми. Повторяемые поля тут несут две проблемы. Если хранить информацию об актерах таким образом, то их число будет лимитировано числом таблиц. Даже если их будет 100, то все равно это будет пределом для некоторых фильмов. И вторая проблема — будет большое количество пустых(NULL) ячеек для большинства остальных записей, чего также следует избегать. Решением этой проблемы станет создание отдельной таблицы для актеров, куда будет заносится информация обо всех необходимых фильмах. Имена актеров также разбиты, чтобы соблюсти атомарность. Также в этой таблице присутствует свой первичный ключ, что является необходимым условием для нормализации.
- Дважды проверьте, все ли таблицы подходят под условия первой нормальной формы.
Подсказки
- Простейший путь приведения к 1НФ — это пройтись глазами по всем столбцам. Проверьте каждый ряд на отсутствие повторения схожих данных и делимости.
- Разные источники трактуют процесс нормализации по своему, в основном более сухим, техническим языком. Более важен результат нормализации, а не повторение правил и умных слов.
Пример стандартизации
(Подчеркнутые атрибуты обозначают первичный ключ)
По трем основным типам нормальных форм:
первая нормальная форма, где каждый атрибут из объектов содержит атомарное значение (без соединения);
Пример:
| Продукт | Провайдер |
|---|---|
| Телевизор | ВИДЕО SA, HITEK LTD |
В этом случае значения провайдера многозначны и не атомарны. Чтобы это отношение было в первой нормальной форме, атрибуты столбца поставщика должны быть разбиты следующим образом
Решение:
| Продукт | Провайдер |
|---|---|
| Телевизор | VIDEO SA |
| Телевизор | ХИТЭК ООО |
вторая нормальная форма является отношением в первой нормальной форме, где каждый атрибут, который не принадлежит к ключу (набор атрибутов, позволяющих однозначно идентифицировать кортеж сущности) зависит не только от части ключа;
Пример:
| Продукт | Провайдер | Адрес поставщика |
|---|---|---|
| Телевизор | VIDEO SA | 13 rue du recherche-midi |
| плоский экран | VIDEO SA | 13 rue du recherche-midi |
| Телевизор | ХИТЭК ООО | 25 Bond Street |
Предположим, что ключ этой таблицы является составным ключом (товар — поставщик)
В случае изменения адреса поставщика следует проявлять особую осторожность, чтобы не забыть ни одно место, где указан адрес. Действительно, мы видим, что поле адреса зависит только от части ключа: поля поставщика, что создает возможность избыточности в таблице
Поэтому рекомендуется разделить таблицу на две части:
Решение во второй нормальной форме:
|
|
Таким образом, изменение адреса вызывает только одно изменение в таблице поставщиков.
третья нормальная форма является вторым нормальной формой соотношения где атрибуты, которые не являются частью ключа не зависят от атрибутов, которые не являются частью ключа либо (атрибуты, таким образом, полностью независимы друг от друга).
Пример:
| Провайдер | Адрес поставщика | Город | Страна |
|---|---|---|---|
| VIDEO SA | 13 rue du recherche-midi | ПАРИЖ | ФРАНЦИЯ |
| ХИТЭК ООО | 25 Bond Street | ЛОНДОН | АНГЛИЯ |
Страна адреса не зависит от ключа таблицы, а именно от имени поставщика, а зависит от города адреса. Опять же, лучше разделить таблицу на две части:
Стандартизированное решение:
|
|
Таким образом, изменение написания для страны (например: ENGLAND в ВЕЛИКОБРИТАНИИ) приведет только к одному изменению.
На практике тщательная идентификация всех элементарных объектов соответствующего приложения (страна, город, заказчик, поставщик, продукт, заказ, счет-фактура и т. Д.) Является первым шагом перед созданием каждой отдельной таблицы. Каждая таблица затем может быть подвергнута проверке на уважение / нет в той или иной нормальной форме. В общем, любое значение агрегированных данных и любое повторение значения данных в заполненном столбце потенциально являются нарушениями нормальной формы.





Настройка связи между таблицам
Для этого нам понадобится foreign keys (внешний ключ). Можно настраивать мышкой через клиента управления бд, а можно с помощью запроса. Вначале разберем вариант добавления через интерфейс.

Вначале выбираем общею таблицу, в моем случае это «valute», затем переходим в настройки таблицы и ищем там вкладку Foreign keys, там настраиваем поля как у меня на скриншоте выше.
- Name — название правила.
- Fields — выбираем колонку, для которой создаем это правило.
- Referenced Schema — выбираем БД.
- Referenced Table — выбираем таблицу для которой настраиваем связь.
- Referenced Fields — выбираем колонку в этой таблицу.
- On Delete — если cascade, то при удалении строки из таблице valute, удалится строчка и из связующей таблицы.
- On Update — …
Все клиенты плюс-минус одинаковы, так что можете воспользоваться любым. Теперь давайте рассмотрим то же самое с помощью запроса.
ALTER TABLE `parser_valute`.`valute` ADD CONSTRAINT `fk_id_valute` FOREIGN KEY (`id_valute`) REFERENCES `parser_valute`.`name_valute` (`id`) ON DELETE CASCADE ON UPDATE RESTRICT;
Теперь если выполнить обычный SELECT то получим таблицу следующего вида:
| id | id банк | id валюта | значение |
| 1 | 1 | 1 | 75 |
| 2 | 1 | 2 | 90 |
| 3 | 2 | 1 | 73 |
| 4 | 2 | 2 | 88 |
Не совсем информативно. Хотелось бы видеть названия банка и название валюты. Для этого есть INNER JOIN. Выполним следующий запрос.
SELECT valute.id, name_bank, name_valute, rezult FROM valute INNER JOIN name_banks ON valute.id_banks = name_banks.id INNER JOIN name_valute ON valute.id_valute = name_valute.id
Получаем таблицу в читаемом виде.
| id | name_bank | name_valute | rezult |
| 1 | Сбербанк | USD | 75,00 |
| 2 | ВТБ | USD | 73,00 |
| 3 | Сбербанк | EUR | 90,00 |
| 4 | ВТБ | EUR | 88,00 |
Примеры нарушения
(Подчеркнутые атрибуты обозначают первичный ключ)
1ФН — первая нормальная форма :
любой атрибут содержит атомарное значение
|
Атрибут CLIENT_ID состоит из двух атомарных атрибутов. |
|
Атрибут NOM состоит из двух атомарных атрибутов. |
все атрибуты не повторяются
|
Атрибут SUPPLIERS — это список. |
все атрибуты постоянны во времени.
|
Атрибут AGE не является постоянным во времени. |
2FN — вторая нормальная форма
все неключевые атрибуты функционально полностью зависят от всего первичного ключа.
|
Атрибут DESCRIPTION_ARTICLE зависит только от части первичного ключа. |
3FN — третья нормальная форма
любой атрибут, не принадлежащий ключу, не зависит от неключевого атрибута
|
Атрибут NOM_CLIENT зависит от CLIENT_ID. |
FNBC — Нормальная форма Бойса-Кодда
Если объект или отношение в третьей нормальной форме имеет составной ключ, ни одно из элементарных свойств этого ключа не должно функционально зависеть от другого свойства.
|
Если Дюран перестанет преподавать химию, линия будет удалена, и связь материи и комнаты будет потеряна. |
FNDC — домен ключа нормальной формы
Отношение находится в FNDC тогда и только тогда, когда все ограничения являются логическим следствием ограничений домена и ключевых ограничений, которые применяются к отношению.
Либо отношение ТРАНСПОРТ со следующими атрибутами:
| ПРОИЗВОДИТЕЛЬ | МОДЕЛЬ | ТИП | PTAC (кг) |
|---|---|---|---|
| Renault | Диспетчерская | VL | 2500 |
| Iveco | Евростар 440 | PL | 19000 |
| Berliet | GDM 1934 г. | PL | 15000 |
| Фольксваген 2900 | комби | VL | 2 900 |
Обратите внимание, что тип VL (легковой автомобиль) или PL (тяжелый автомобиль) определяется значением PTAC. Таким образом, автомобиль массой более 3,5 тонн является PL
Ниже находится VL… Имеется избыточность данных типа, о которой можно судить по чтению значения PTAC. В случае изменения правил (для изменения может потребоваться стержень 3,5 тонны) необходимо обновить несколько кортежей.
— Чтобы устранить эту аномалию обновления, мы должны разделить отношение на два следующим образом:
1 ° АВТОМОБИЛЬ со следующими характеристиками:
| ПРОИЗВОДИТЕЛЬ | МОДЕЛЬ | PTAC (кг) |
|---|---|---|
| Renault | Диспетчерская | 2500 |
| Iveco | Евростар 440 | 19000 |
| Berliet | GDM 1934 г. | 15000 |
| Фольксваген 2900 | комби | 2 900 |
Типа транспортного средства больше нет в списке. Она будет вычтена из стоимости PTAC: более 3,5 тонн транспортное средство является грузовым автомобилем. Ниже это ВЛ.
2 ° ТИП АВТОМОБИЛЯ со следующими характеристиками:
| ТИП | PTAC (кг) |
|---|---|
| VL | |
| PL | 3500 |
Неравномерное соединение будет необходимо для восстановления исходной связи.
Ключи
Ключи являются составляющей частью нормализованных таблиц. Бывают двух видов — внешние и первичные.
Первичный ключ — это уникальный идентификатор, отвечающий следующим условиям:
- Он должен иметь значение, не NULL.
- Быть неизменным — значение ключа не должно меняться.
- Иметь уникальное значение для каждой строки.
Внешние ключи — это ссылки на первичные ключи других таблиц, которые удовлетворяют условиям выше.
Для начала нормализации следует указать хотя бы один первичный ключ. В примере это будет message ID.
Для указания первичного ключа, надо найти поле, которое будет подходить под все три условия. Если такого поля нет, его надо создать. В идеале, поле должно иметь тип integer.
Перед началом…
Перед тем, как мы начнем изучать правила нормализации и применять их, мы должны разобраться со следующими понятиями.
Избыточность
Одним из основных моментов, который нужно учитывать при проектировании таблиц — уменьшение пространства для хранения данных. Таблицы должны быть спроектированы таким образом, чтобы повторяющиеся данные хранились отдельно, в одной или нескольких таблицах. Хранение повторяющихся данных не только требует больше места, но также приводит к более серьезным проблемам.

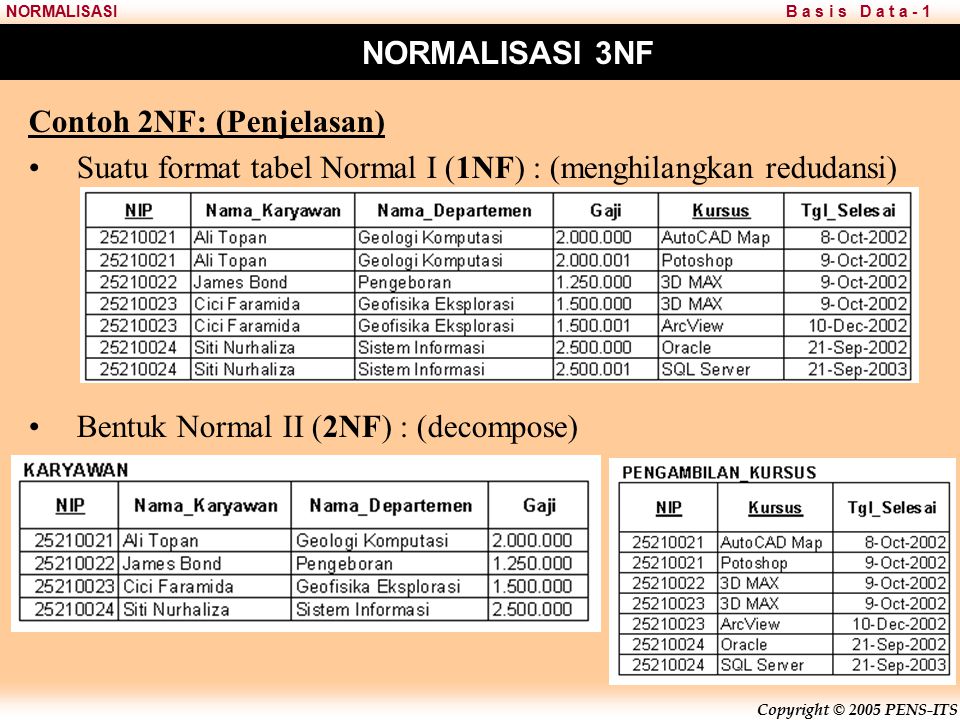
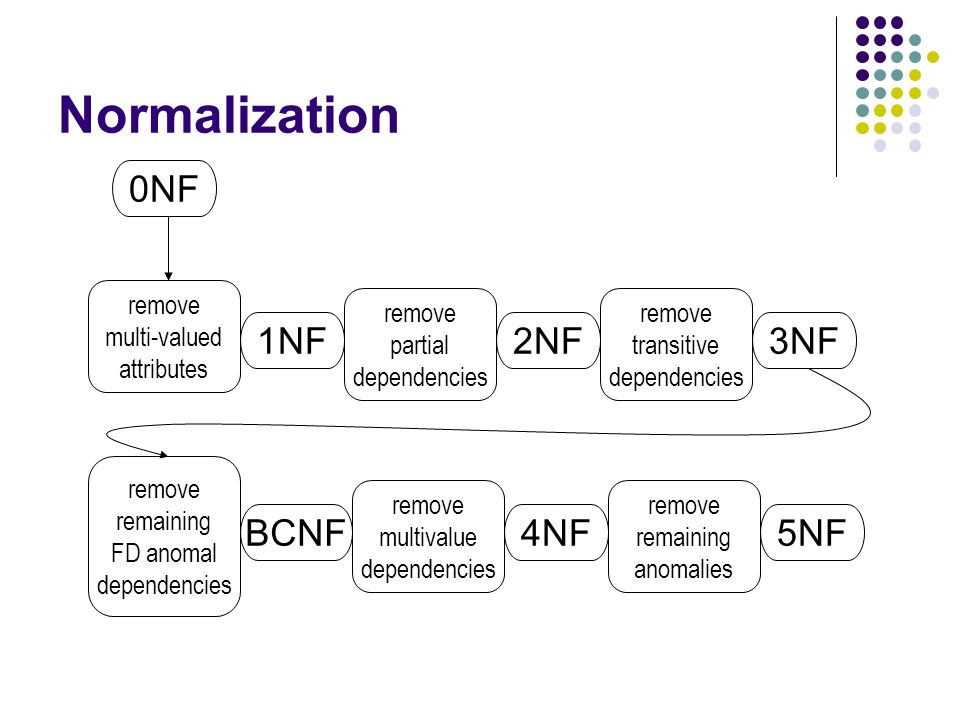

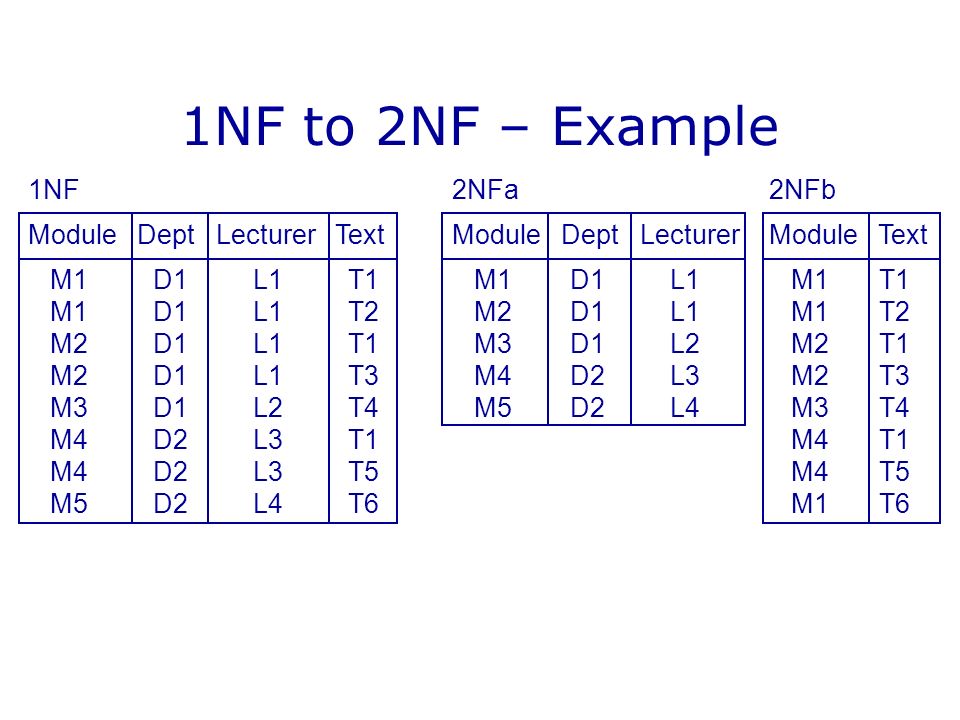




Таблица с данными о сотрудниках из разных отделов, содержит избыточные данные
Обратите внимание, что данные в полях DNAME и DNO неоднократно повторяются в таблице. Такой вид избыточности данных приводит к аномалиям обновления, вставки и удаления
Аномалии вставки
Если нам понадобится добавить в таблицу информацию о новом сотруднике, который не «привязан» к какому-либо отделу, данные об отделе в добавляемой записи окажутся пустыми, а это явно неоправданная трата пространства. Кроме того, при вставке данных нового сотрудника, скажем, в отдел с идентификатором ‘4’, другие поля, относящиеся к отделу, также должны будут повториться. Пример: отдел 4, поле DNAME должно содержать значение ‘Administrator’, а поле MGR_SSN — содержимое должно быть равно ‘234567890’.
Аномалии обновления
Если мы изменим значение какого-либо поля, относящегося к отделу, например, DNAME или MGR_SSN, мы должны будем изменить это значение у записей всех сотрудников, которые работают в этом отделе. Иначе, база данных будет находиться в несогласованном состоянии.
Аномалии удаления
Предположим, мы удалим информацию об одном сотруднике, например, последнюю запись из представленной выше таблицы. Только у этой записи значение в поле DNO равно ‘1’, в результате этого действия получится, что информация об отделе будет потеряна. Это нелепо, потому что мы хотим удалить информацию о сотруднике, а не обо всем отделе.
Функциональные зависимости
Функциональные зависимости — основа нормализации баз данных. Под функциональной зависимостью подразумевается зависимость значения одного поля (столбца) от другого. Например, по значению поля SSN определенного работника, мы сможем найти его адрес. Это значит, что поле адрес функционально зависимо от поля SSN. Символическая запись этой зависимости выглядит так:
{SSN} → {ADDRESS}
Аналогично,
{SSN} → {ENAME, ADDRESS} {SSN, DNO} → {MGR_SSN}
Когда значение одного или нескольких полей точно идентифицируют запись, значение такого поля называется «первичным ключом».
Чтобы привести базу к третьей нормальной форме, надо:
1. Определить, в каких полях каких таблиц имеется взаимозависимость. Как только что говорилось, поля, которые зависят больше друг от друга (как город от штата), чем от ряда в целом. В базе форума такой проблемы нет. Взглянув на таблицу сообщений, увидите, что каждый заголовок, каждое тело сообщения относится к своему message ID.
2. Создайте соответствующие таблицы. Если есть проблемный столбец в шаге 1, создавайте раздельные таблицы для него. Как города и штаты, в примере с клиентами.
3. Создайте или выделите первичные ключи. Каждая таблица должна иметь первичный ключ. Для примера с клиентами это будут city ID и state ID.
4. Создайте необходимые внешние ключи, которые образуют любое из отношений. В нашем примере нужно добавить state ID в таблицу городов и city ID в таблицу клиентов. Это свяжет каждого клиента с городом и штатом, где они живут.
Подсказки:
Вообще, можно было бы и не нормализовывать базу с клиентами до такой степени. Если оставить города и штаты в таблице клиентов, самое страшное, что могло бы случиться — если бы город изменил название, нужно было бы менять его во всех записях о клиентах, которые живут в этом городе. Но города редко меняют свои имена.
Несмотря на то, что имеются правила как нормализовывать базы данных, разные люди сделают это разными способами. Проектирование баз данных допускает личные предпочтения и интерпретации
Важно, чтобы в базе не было явных нарушений нормальных форм, которые могут привести в дальнейшем к проблемам
Первая нормальная форма
- Устраните повторяющиеся группы в отдельных таблицах.
- Создайте отдельную таблицу для каждого набора связанных данных.
- Идентифицируйте каждый набор связанных данных с помощью первичного ключа.
Не используйте несколько полей в одной таблице для хранения похожих данных. Например, для слежения за товаром, который закупается у двух разных поставщиков, можно создать запись с полями, определяющими код первого поставщика и код второго поставщика.
Что произойдет при добавлении третьего поставщика? Добавление третьего поля нежелательно, так как для этого нужно изменять программу и таблицу, поэтому данный способ плохо адаптируется к динамическому изменению числа поставщиков. Вместо этого можно поместить все сведения о поставщиках в отдельную таблицу Vendors (поставщики) и связать товары с поставщиками с помощью кодов товаров или поставщиков с товарами с помощью кодов поставщиков.
Определение сущностей
На этом этапе вам необходимо определить сущности, из которых будет состоять база данных.
Сущность — это объект в базе данных, в котором хранятся данные. Сущность может представлять собой нечто вещественное (дом, человек, предмет, место) или абстрактное (банковская операция, отдел компании, маршрут автобуса). В физической модели сущность называется таблицей.
Сущности состоят из атрибутов (столбцов таблицы) и записей (строк в таблице).
Обычно базы данных состоят из нескольких основных сущностей, связанных с большим количеством подчиненных сущностей. Основные сущности называются независимыми: они не зависят ни от какой-либо другой сущности. Подчиненные сущности называются зависимыми: для того чтобы существовала одна из них, должна существовать связанная с ней основная таблица.
На диаграммах сущности обычно представляются в виде прямоугольников. Имя сущности указывается внутри прямоугольника:
Любая таблица имеет следующие характеристики:
- в ней нет одинаковых строк;
- все столбцы (атрибуты) в таблице должны иметь разные имена;
- элементы в пределах одной колонки имеют одинаковый тип (строка, число, дата);
- порядок следования строк в таблице может быть произвольным.
На этом этапе вам необходимо выявить все категории информации (сущности), которые будут храниться в базе данных.
Как выполнить нормализацию?
Чтобы привести БД к нормальной форме, необходимо: 1. Объединить имеющиеся данные в группы. 2. Выяснить логические связи между группами. Чтобы обеспечить правильность связей, связываемые поля должны иметь один тип.
Если таблица не нормализована, она может хранить информацию о нескольких сущностях и включать в себя повторяющиеся столбцы, а они, в свою очередь, могут хранить дублируемые значения. Если же нормализована, то каждая таблица хранит информацию лишь об одной сущности.
Таких форм (уровней) — семь, однако на практике для большей части приложений вполне достаточно нормализовать БД до третьей нормальной формы (строго говоря, БД и будет считаться нормализованной, когда к ней применяется 3НФ и выше).
Да, обеспечить полное соответствие правилам и спецификациям — задача не всегда выполнимая, ведь для нормализации придется создавать дополнительные таблицы, а это не всегда приемлемо или не находит отклика у клиентов. Но если правила приходится нарушать, надо понимать, что все, связанные с этим проблемы, включая несогласованные зависимости и избыточность, будут учтены, и что это допустимо для приложения, не нарушит его работоспособность.
Определение атрибутов
Атрибут представляет свойство, описывающее сущность. Атрибуты часто бывают числом, датой или текстом. Все данные, хранящиеся в атрибуте, должны иметь одинаковый тип и обладать одинаковыми свойствами.
В физической модели атрибуты называют колонками.
После определения сущностей необходимо определить все атрибуты этих сущностей.
На диаграммах атрибуты обычно перечисляются внутри прямоугольника сущности. На рисунке вы найдете пример базы данных «Дома», только теперь для сущностей из этой базы определены некоторые атрибуты.
Для каждого атрибута определяется тип данных, их размер, допустимые значения и любые другие правила. К их числу относятся правила обязательности заполнения, изменяемости и уникальности.
Правило обязательности заполнения определяет, является ли атрибут обязательной частью сущности. Если атрибут является необязательной частью сущности, то он может принимать NULL-значение, иначе — нет.
Также вы должны определить, является ли атрибут изменяемым. Значения некоторых атрибутов не могут измениться после создания записи.
И, наконец, вам нужно определить, является ли атрибут уникальным. Если это так, то значения атрибута не могут повторяться.
Ключи
Ключом (key) называется набор атрибутов, однозначно определяющий запись. Ключи делятся на два класса: простые и составные.
Простой ключ состоит только из одного атрибута. Например, в базе «Паспорта граждан страны» номер паспорта будет простым ключом: ведь не бывает двух паспортов с одинаковым номером.
Составной ключ состоит из нескольких атрибутов. В той же базе «Паспорта граждан страны» может быть составной ключ со следующими атрибутами:
фамилия, имя, отчество, дата рождения. Это — как пример, т. к. этот составной ключ, теоретически, не обеспечивает гарантированной уникальности записи.
Также существует несколько типов ключей, о которых рассказано далее.
Возможный ключ
Возможный ключ представляет собой любой набор атрибутов, однозначно идентифицирующих запись в таблице. Возможный ключ может быть простым или составным.
Каждая сущность должна иметь, по крайней мере, один возможный ключ, хотя таких ключей может быть и несколько. Ни один из атрибутов первичного ключа не может принимать неопределенное (NULL) значение.
Возможный ключ называется также суррогатным.
Первичные ключи
Первичным ключом называется совокупность атрибутов, однозначно идентифицирующих запись в таблице (сущности). Один из возможных ключей становится первичным ключом. На диаграммах первичные ключи часто изображаются выше основного списка атрибутов или выделяются специальными символами. Сущность на рисунке имеет как ключевые, так и обычные атрибуты.
Альтернативные ключи
Любой возможный ключ, не являющийся первичным, называется альтернативным ключом. Сущность может иметь несколько альтернативных ключей.
Внешние ключи
Внешним ключом называется совокупность атрибутов, ссылающихся на первичный или альтернативный ключ другой сущности. Если внешний ключ не связан с первичной сущностью, то он может содержать только неопределенные значения. Если при этом ключ является составным, то все атрибуты внешнего ключа должны быть неопределенными.
На диаграммах атрибуты, объединяемые во внешние ключи, обозначаются специальными символами. На рисунке изображены две связанные сущности (Дома и их Хозяева) и образованные ими внешние ключи (ведь один человек может владеть больше, чем одним домом).
Ключи являются логическими конструкциями, а не физическими объектами. В реляционных базах данных предусмотрены механизмы, обеспечивающие сохранение ключей.
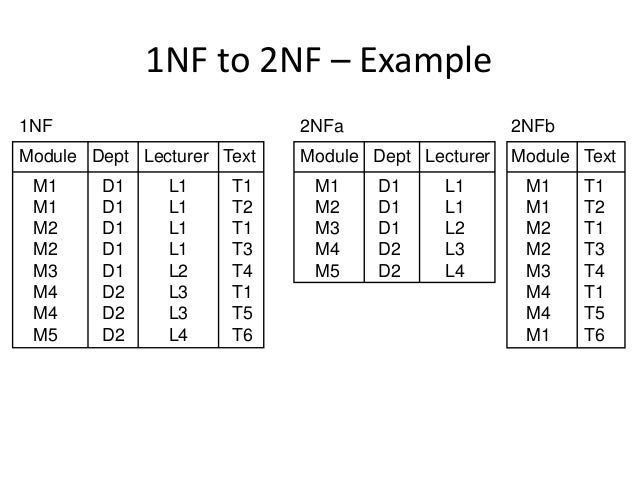
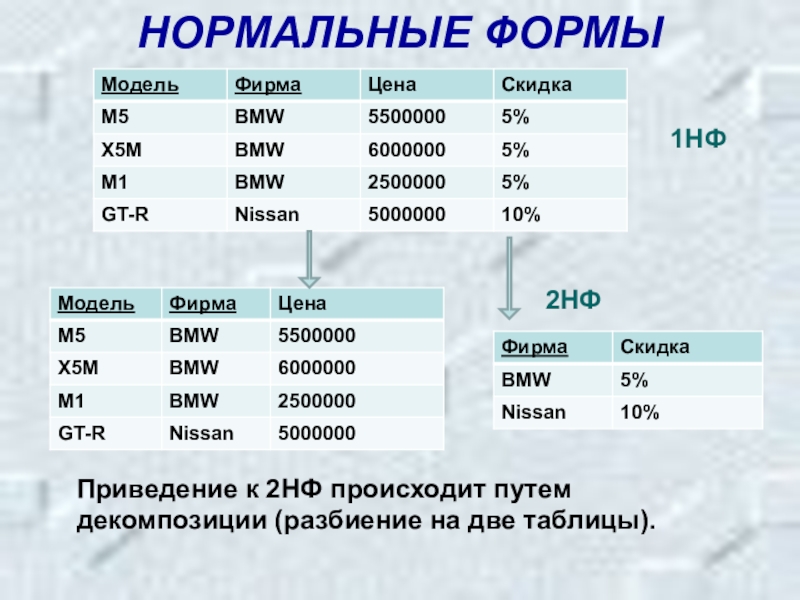
Вторая нормальная форма
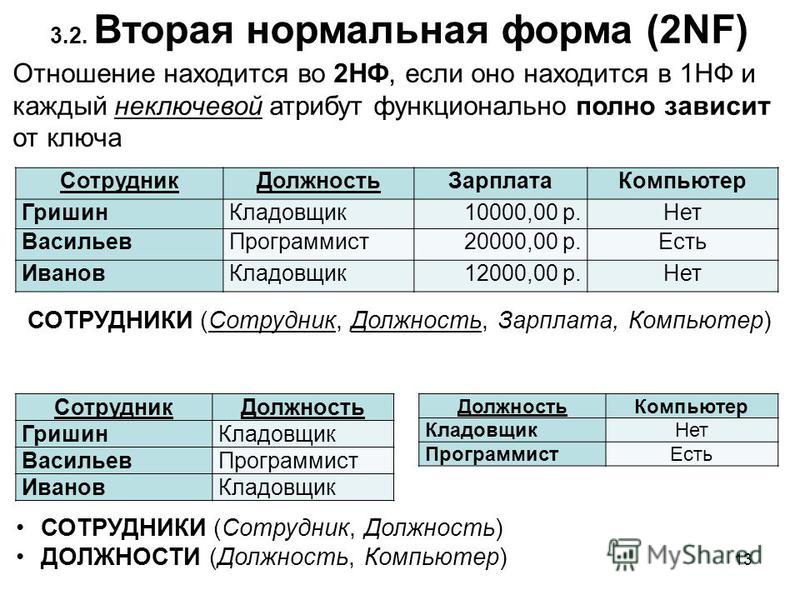
Определение 2
Отношение находится во второй нормальной форме (2NF), если находится в первой нормальной форме и каждый неключевой атрибут находится в полной функциональной зависимости от ключа.
Следовательно, вторая нормальная форма может быть нарушена лишь в том случае, если ключ является составным, т.е. ключ состоит из нескольких атрибутов.


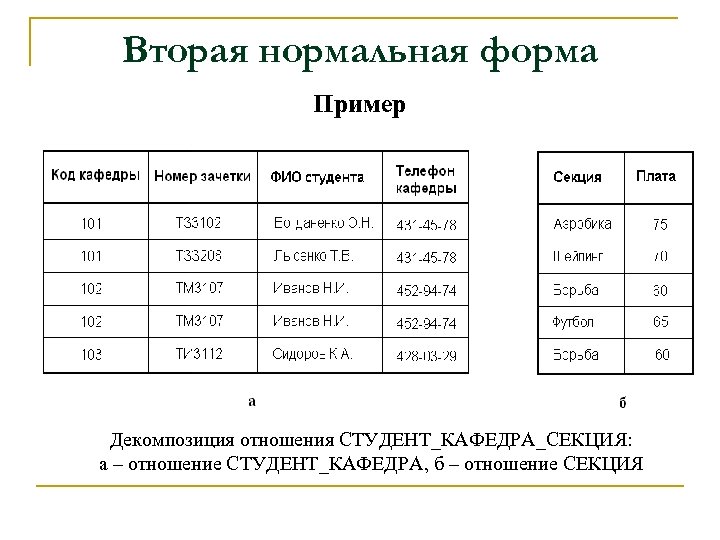

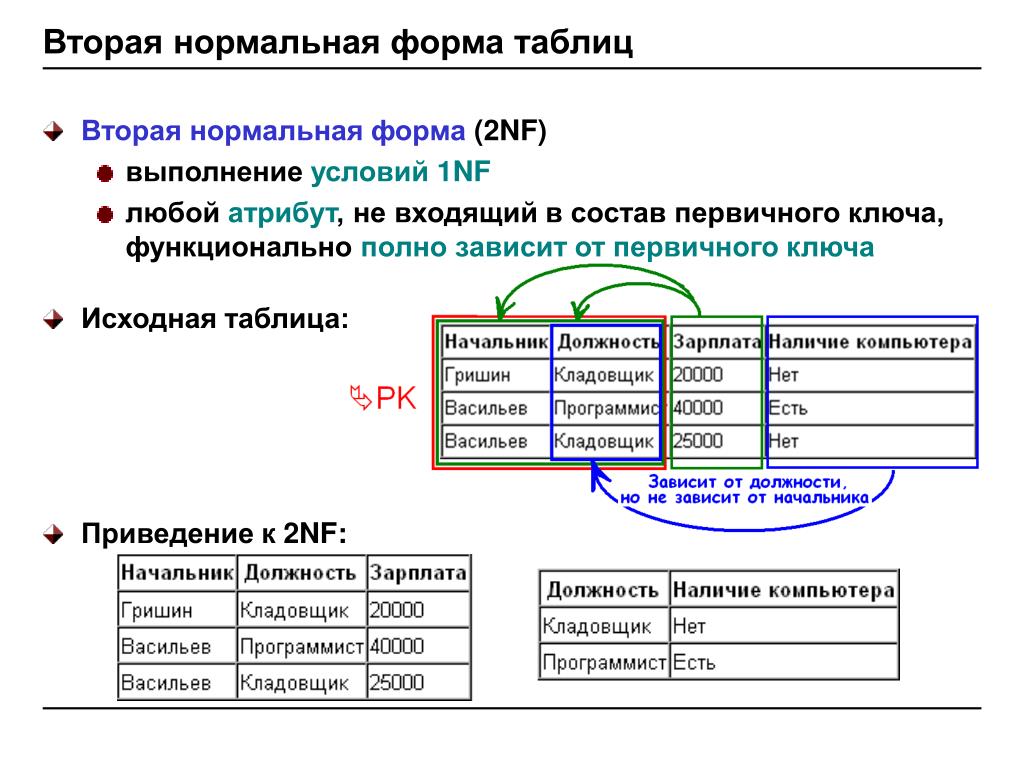
Рассмотрим таблицу «Назначение 1», представленную на рисунке 1. В таблице ключ состоит из набора атрибутов № здания и № работника. Атрибут Фамилия определяет атрибут № работника, а значит состоит в функциональной зависимости от части ключа. То есть для того, чтобы определить фамилию работника достаточно узнать № работника. Следовательно, таблица не удовлетворяет второй нормальной форме.
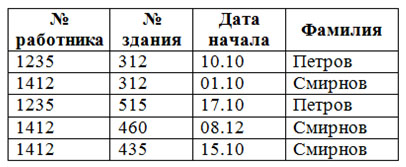
Если данную таблицу не приводить ко второй нормальной форме, могут появиться такие проблемы:
- Фамилия работника будет повторяться в каждой строке, которая относится к назначению данного работника.
- При изменении фамилии работника необходимо выполнить обновление всех строк, которые содержат записи о назначениях данного работника. Такая проблема называется аномалией изменения данных.
- Вследствие подобной избыточности возможно несоответствие данных – в разных строках для одного и того же работника могут содержаться разные имена.
- В ситуации, когда в какой-либо момент времени у работника нет назначений, может не быть строки, в которой будет храниться имя работника. Такая проблема называется аномалией ввода данных.
Для решения этих проблем необходимо выполнить разбиение таблицы на 2 реляционные таблицы, которые будут удовлетворять второй нормальной форме (рисунок 3).

Полученные реляционные таблицы «Работник» и «Назначение» находятся во второй нормальной форме и не содержат перечисленных выше проблем. Следовательно, 2NF уменьшает избыточность данных и исключает возможность аномалий.
Этапы разбиения на 2 таблицы в 2NF:
- Создание новой таблицы, которая состоит из атрибутов исходной таблицы. Детерминант функциональной зависимости станет ключом новой таблицы.
- Исключение атрибута, который стоит в правой части функциональной зависимости, из исходной таблицы.
- Повторение 1 и 2 шагов для каждой функциональной зависимости, которая нарушает 2NF.
- При вхождении одного и того же детерминанта в несколько функциональных зависимостей, все функционально зависящие от детерминанта атрибуты располагаются как неключевые атрибуты в таблицу, в которой детерминант будет ключом.
Пятая нормальная форма
Таблицу, находящуюся в четвертой нормальной форме и, казалось бы, уже нормализованную до предела, в некоторых случаях еще можно бывает разбить на три или более (но не на две!) таблиц, соединив которые, мы получим исходную таблицу. Получившиеся в результате такой, как правило, весьма искусственной, декомпозиции таблицы и называют находящимися в пятой нормальная форме. Формальное определение пятой нормальной формы таково: это форма, в которой устранены зависимости соединения. В большинстве случаев практической пользы от нормализации таблиц до пятой нормальной формы не наблюдается.
Такая вот теория… Разработаны специальные формальные математические методы нормализации таблиц реляционных баз данных. На практике же толковый проектировщик баз данных, детально познакомившись с предметной областью, как правило, достаточно быстро набросает структуру, в которой большинство таблиц находятся в четвертой нормальной форме:).
2NF и ключи-кандидаты
Функциональная зависимость от части любого ключа-кандидата является нарушением 2NF. В дополнение к первичному ключу отношение может содержать другие ключи-кандидаты; необходимо установить, что никакие непервичные атрибуты не имеют зависимостей частичного ключа от любого из этих ключей-кандидатов.
Следующее соотношение не удовлетворяет 2НФ, потому что:
- {Страна производителя} функционально зависит от {Производителя}.
- {Страна производителя} не является частью ключа-кандидата, поэтому это атрибут, не являющийся простым.
- {Производитель} — это правильное подмножество ключа-кандидата {Производитель, Модель}.
Поскольку {Страна-производитель} не является простым атрибутом, функционально зависящим от части ключа-кандидата, отношение нарушает 2NF.
| Производитель | Модель | Страна производитель |
|---|---|---|
| Форте | Икс-Прайм | Италия |
| Форте | Ультрачистый | Италия |
| Дент-о-Фреш | EZbrush | США |
| Мастер кисти | Суперкисть | США |
| Кобаяши | СТ-60 | Япония |
| Хох | зубной мастер | Германия |
| Хох | Икс-Прайм | Германия |
Отношение не во 2НФ. {Производитель, Модель} — это ключ-кандидат, и страна-производитель зависит от надлежащего его подмножества: Производитель. Чтобы проект соответствовал 2НФ, необходимо иметь два соотношения:
| Производитель | Страна производитель |
|---|---|
| Форте | Италия |
| Дент-о-Фреш | США |
| Мастер кисти | США |
| Кобаяши | Япония |
| Хох | Германия |
| Производитель | Модель |
|---|---|
| Форте | Икс-Прайм |
| Форте | Ультрачистый |
| Дент-о-Фреш | EZbrush |
| Мастер кисти | Суперкисть |
| Кобаяши | СТ-60 |
| Хох | зубной мастер |
| Хох | Икс-Прайм |