
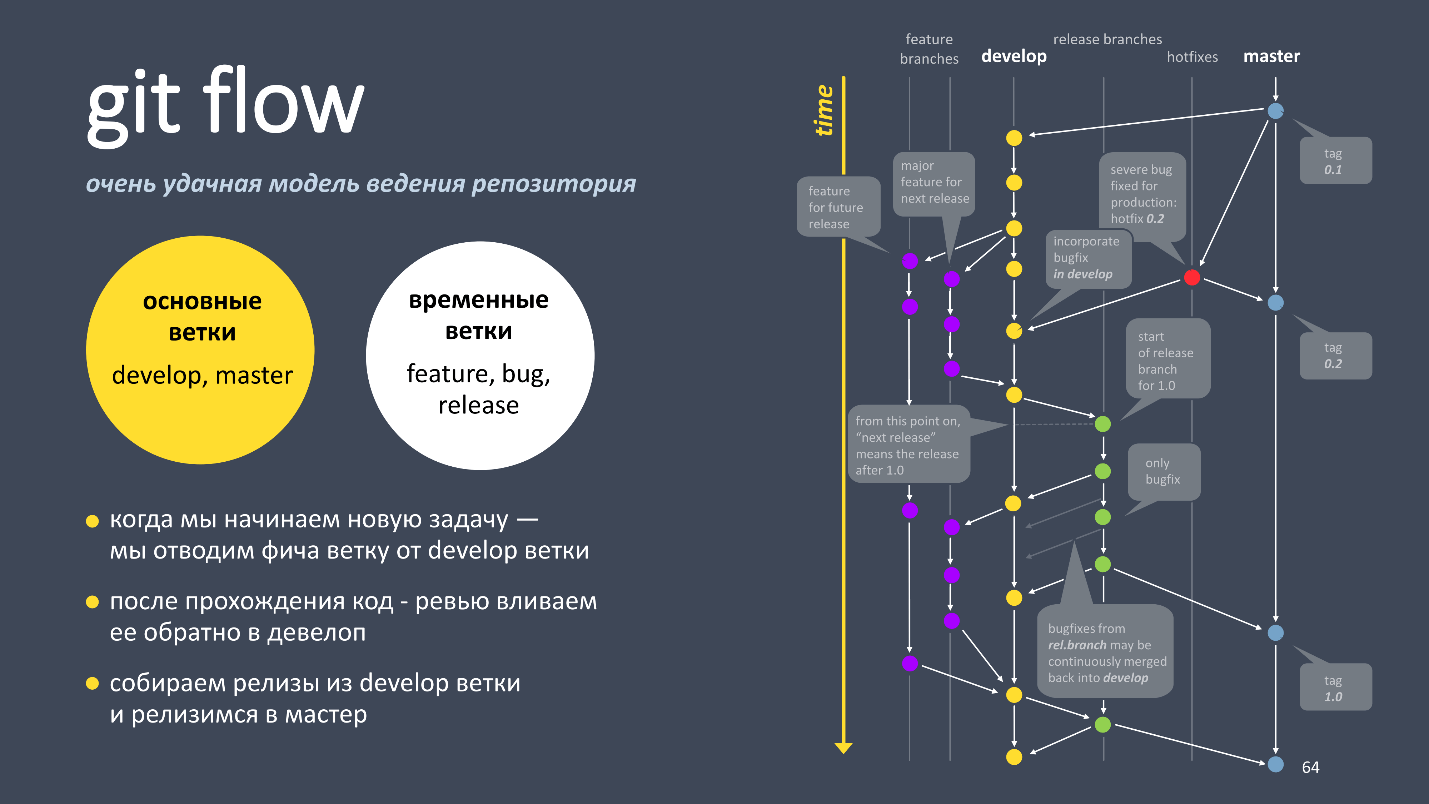
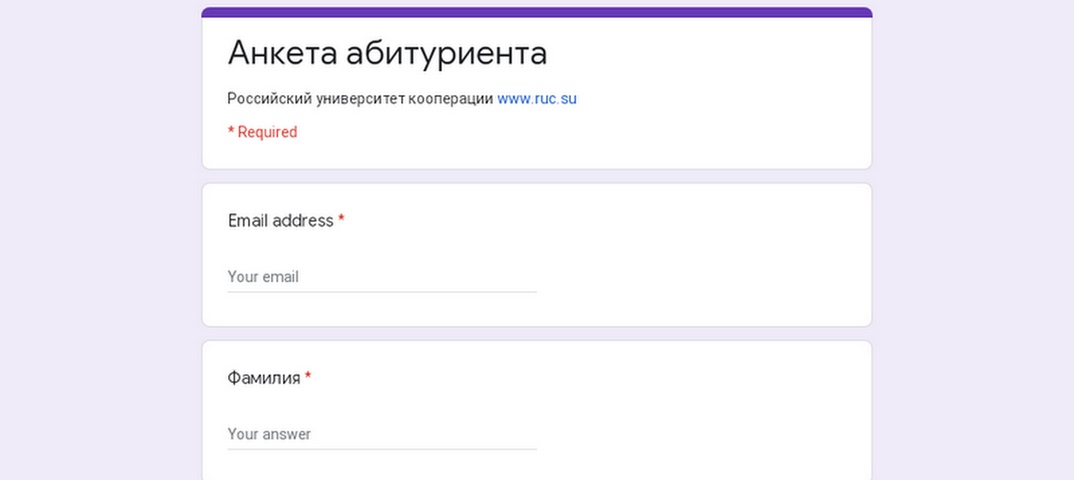
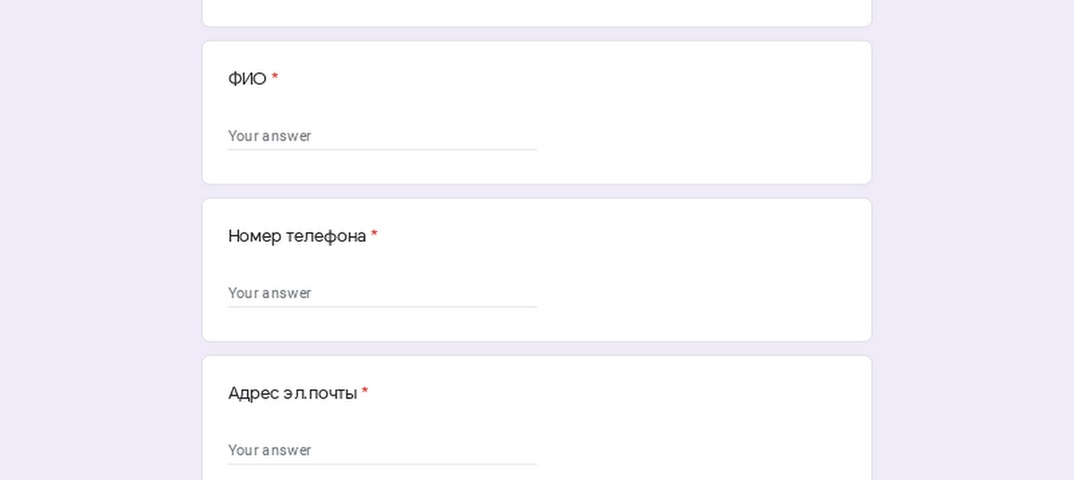
Введение
Сразу оговорюсь, что считаю данную тему абсолютно ненужной, а обсуждаю ее только потому, что она требуется для всевозможных «тупопроверочных» работ.
В основе моей нелюбви лежит высосанность из пальца.
Как и во многих других областях знаний, теория в основном развивалась значительно позднее (1970-е гг.) накопленной практики применения (примерно с середины 1960 гг. по 1970 г, IBM).
Фактически она была навязыванием теоретической наукообразной «скорлупы», сложно сочетаемой с практикой.
Хуже того, на планете нет ни одной БД, соответствующей всем нормальным формам.
Еще хуже, что сами формы в некоторых формулировках своих определений содержат обсуждение своей же абсурдности.
И, напоследок, ещё камень.
Беседуя с преподавателями, разглагольствующими о бесценности изучения понятия нормализации в их учебных курсах, я заметил одну закономерность.
Большинство из них вообще никогда не имели дел с программированием БД, либо делали это лишь несколько раз.
Успешно, как они полагают.
Само собой, что кроме аргументов «это же и так понятно/очевидно», «все/каждый это знает/понимает», «без этого вообще никак не управиться» и т.п.,
ответа на мой простой вопрос о прикладном назначении нормальных форм я не получил ни разу.
Найдёте — пришлите, буду безмерно благодарен.
Так вот, в связи с бессмысленностью и теоретизированностью, данная страница изобилует незавершенными тезисами и обрывочными мыслями, за что приношу отдельные извинения.
Нормальная форма — требование, предъявляемое к структуре таблиц в теории реляционных баз данных для устранения из базы избыточных функциональных зависимостей между атрибутами.
На данном этапе развития мысли теоретиков, выделено 6 основных и 2 дополнительных формы нормализации.
Для упрощения формулировок договоримся, что каждая последующая форма должна отвечать требованиям всех предыдущих.
- 1. (1970) Отношение находится в первой нормальной форме когда весь набор каждого атрибута содержит только простейшее (атомарное, неделимое без потери смысла) значения
и значение каждого атрибута содержит только единичное значение от набора данных. - 2. (1971) Каждый неключевой атрибут таблицы функционально зависит от ее потенциального ключа.
- 3. (1971) Каждый неключевой атрибут транзитивно независим от потенциального ключа таблицы. Атрибуты, которые не соответствуют описанию первичного ключа, удаляются из таблицы. (Все понятно?)
- 3a. Бойса–Кодда (1974) Каждая непростейшая функциональная зависимость в таблице является зависимостью от суперключа.
- 4. (1977) Каждая непростейшая множественная зависимость в таблице является зависимостью от суперключа.
- 5. (1979) Каждая непростейшая объединенная зависимость в таблице определяется суперключом таблицы.
- 5а. DKNF (domain-key normal form) (1981) База данных не содержит ограничений, отличных от доменных и ключевых.
(По большому счету, считается, что данная форма обобщает три предыдущих из данного списка.) - 6. (2002) Таблица соответствует всем нетривиальным зависимостям объединения.
Для первой нормальной формы имеет смысл обсуждать некоторые основополагающие (базовые) условия.
- Нет упорядочивания строк, то есть порядок строк не имеет значения и смысла.
- Столбцы также следуют в произвольном порядке.
- Отсутствуют повторяющиеся строки.
- Каждое пересечение строки и столбца содержит ровно одно значение из соответствующего набора данных.
- Все столбцы не являются составными.
Также важнейший смысл несет атомарность значения, то есть невозможность, а, скорее, ненужность дальнейшего деления.
Так, полный телефонный номер содержит код страны и код региона. Если не предполагается поиск по этим критериям и привязка к ним ввода данных, то такой номер будет атомарным.
В противном случае номер должен быть разделен на три части.
(Последнее решение будет всегда актуально для больших БД.)
Доступ к этим материалам предоставляется только зарегистрированным пользователям!
Какие существуют уровни изолированности транзакций?
В порядке увеличения изолированности транзакций и, соответственно, надёжности работы с данными:
- Чтение неподтверждённых данных (грязное чтение) (read uncommitted, dirty read) — чтение незафиксированных изменений как своей транзакции, так и параллельных транзакций. Нет гарантии, что данные, изменённые другими транзакциями, не будут в любой момент изменены в результате их отката, поэтому такое чтение является потенциальным источником ошибок. Невозможны потерянные изменения, возможны неповторяемое чтение и фантомы.
- Чтение подтверждённых данных (read committed) — чтение всех изменений своей транзакции и зафиксированных изменений параллельных транзакций. Потерянные изменения и грязное чтение не допускается, возможны неповторяемое чтение и фантомы.
- Повторяемость чтения (repeatable read, snapshot) — чтение всех изменений своей транзакции, любые изменения, внесённые параллельными транзакциями после начала своей, недоступны. Потерянные изменения, грязное и неповторяемое чтение невозможны, возможны фантомы.
- Сериализация (serializable) — результат параллельного выполнения сериализуемой транзакции с другими транзакциями должен быть логически эквивалентен результату их какого-либо последовательного выполнения. Проблемы синхронизации не возникают.
Что такое «индексы»? Для чего их используют? В чём заключаются их преимущества и недостатки?
Индекс (index) — объект базы данных, создаваемый с целью повышения производительности выборки данных.
Наборы данных могут иметь большое количество записей, которые хранятся в произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра набора данных запись за записью может занимать много времени. Индекс формируется из значений одного или нескольких полей и указателей на соответствующие записи набора данных, — таким образом, достигается значительный прирост скорости выборки из этих данных.
Преимущества
- ускорение поиска и сортировки по определенному полю или набору полей.
- обеспечение уникальности данных.
Недостатки
- требование дополнительного места на диске и в оперативной памяти и чем больше/длиннее ключ, тем больше размер индекса.
- замедление операций вставки, обновления и удаления записей, поскольку при этом приходится обновлять сами индексы.
Индексы предпочтительней для:
- Поля-счетчика, чтобы в том числе избежать и повторения значений в этом поле;
- Поля, по которому проводится сортировка данных;
- Полей, по которым часто проводится соединение наборов данных. Поскольку в этом случае данные располагаются в порядке возрастания индекса и соединение происходит значительно быстрее;
- Поля, которое объявлено первичным ключом (primary key);
- Поля, в котором данные выбираются из некоторого диапазона. В этом случае как только будет найдена первая запись с нужным значением, все последующие значения будут расположены рядом.
Использование индексов нецелесообразно для:
- Полей, которые редко используются в запросах;
- Полей, которые содержат всего два или три значения, например: мужской, женский пол или значения «да», «нет».
Отношение один-ко-многим
Хорошим примером отношения между таблицами
один-ко-многим является отношение между авторами
и названиями книг (таблицы AUTHORS и TITLES), так как
каждый автор может иметь отношение к созданию
нескольких книг. Связь между таблицами AUTHORS и TITLES
осуществляется с помощью совпадающих полей Au_ID в
обеих таблицах.
Аналогичное отношение существует между
издательствами и названиями изданных книг,
организацией и работающими в ней сотрудниками,
автомобилем и деталями, из которых он состоит и
т.п. Понятно, что подобный тип отношения между
таблицами наиболее часто встречается при
проектировании структуры баз данных.
Перед началом…
Перед тем, как мы начнем изучать правила нормализации и применять их, мы должны разобраться со следующими понятиями.
Избыточность
Одним из основных моментов, который нужно учитывать при проектировании таблиц — уменьшение пространства для хранения данных. Таблицы должны быть спроектированы таким образом, чтобы повторяющиеся данные хранились отдельно, в одной или нескольких таблицах. Хранение повторяющихся данных не только требует больше места, но также приводит к более серьезным проблемам.
Таблица с данными о сотрудниках из разных отделов, содержит избыточные данные
Обратите внимание, что данные в полях DNAME и DNO неоднократно повторяются в таблице. Такой вид избыточности данных приводит к аномалиям обновления, вставки и удаления
Аномалии вставки
Если нам понадобится добавить в таблицу информацию о новом сотруднике, который не «привязан» к какому-либо отделу, данные об отделе в добавляемой записи окажутся пустыми, а это явно неоправданная трата пространства. Кроме того, при вставке данных нового сотрудника, скажем, в отдел с идентификатором ‘4’, другие поля, относящиеся к отделу, также должны будут повториться. Пример: отдел 4, поле DNAME должно содержать значение ‘Administrator’, а поле MGR_SSN — содержимое должно быть равно ‘234567890’.
Аномалии обновления
Если мы изменим значение какого-либо поля, относящегося к отделу, например, DNAME или MGR_SSN, мы должны будем изменить это значение у записей всех сотрудников, которые работают в этом отделе. Иначе, база данных будет находиться в несогласованном состоянии.

Аномалии удаления
Предположим, мы удалим информацию об одном сотруднике, например, последнюю запись из представленной выше таблицы. Только у этой записи значение в поле DNO равно ‘1’, в результате этого действия получится, что информация об отделе будет потеряна. Это нелепо, потому что мы хотим удалить информацию о сотруднике, а не обо всем отделе.
Функциональные зависимости
Функциональные зависимости — основа нормализации баз данных. Под функциональной зависимостью подразумевается зависимость значения одного поля (столбца) от другого. Например, по значению поля SSN определенного работника, мы сможем найти его адрес. Это значит, что поле адрес функционально зависимо от поля SSN. Символическая запись этой зависимости выглядит так:
{SSN} → {ADDRESS}
Аналогично,
{SSN} → {ENAME, ADDRESS} {SSN, DNO} → {MGR_SSN}
Когда значение одного или нескольких полей точно идентифицируют запись, значение такого поля называется «первичным ключом».
Определение атрибутов
Атрибут представляет свойство, описывающее сущность. Атрибуты часто бывают числом, датой или текстом. Все данные, хранящиеся в атрибуте, должны иметь одинаковый тип и обладать одинаковыми свойствами.
В физической модели атрибуты называют колонками.
После определения сущностей необходимо определить все атрибуты этих сущностей.
На диаграммах атрибуты обычно перечисляются внутри прямоугольника сущности. На рисунке вы найдете пример базы данных «Дома», только теперь для сущностей из этой базы определены некоторые атрибуты.
Для каждого атрибута определяется тип данных, их размер, допустимые значения и любые другие правила. К их числу относятся правила обязательности заполнения, изменяемости и уникальности.
Правило обязательности заполнения определяет, является ли атрибут обязательной частью сущности. Если атрибут является необязательной частью сущности, то он может принимать NULL-значение, иначе — нет.
Также вы должны определить, является ли атрибут изменяемым. Значения некоторых атрибутов не могут измениться после создания записи.
И, наконец, вам нужно определить, является ли атрибут уникальным. Если это так, то значения атрибута не могут повторяться.
Что такое «нормализация»?
Нормализация — это процесс преобразования отношений базы данных к виду, отвечающему нормальным формам (пошаговый, обратимый процесс замены исходной схемы другой схемой, в которой наборы данных имеют более простую и логичную структуру).
Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную логическую избыточность, и не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение физического объёма базы данных. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в базе данных информации.
Вторая нормальная форма
Для приведения таблиц ко второй нормальной форме (2НФ), приводимые таблицы должны быть уже в 1НФ. Нормализация должна проходить по порядку.
Теперь, во второй нормальной форме, должно быть соблюдено условие — любой столбец, который не является ключом (в том числе внешним), должен зависеть от первичного ключа. Обычно такие столбцы, имеющие значения, который не зависят от ключа, легко определить. Если данные, содержащиеся в столбце, не имеют отношения к ключу, который описывает строку, то их следует отделять в свою отдельную таблицу. В старую таблицу надо возвращать первичный ключ.
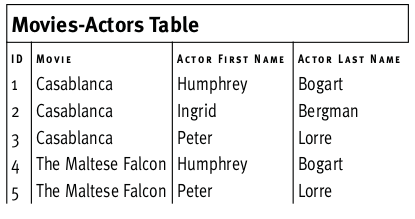
На рисунке выше и названия фильмов и имена актеров нарушают правила 2НФ (сами не являются ключами и не зависят от первичного ключа).
После всех преобразований, база данных с фильмами будет иметь минимум 4 таблицы.
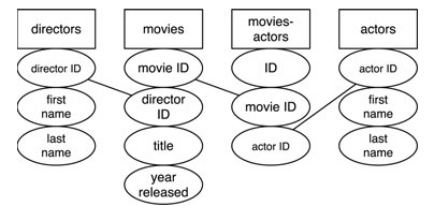
Каждое имя режиссёра, название картины и имя актера хранится только один раз и все неключевые поля зависят от первичного ключа их собственной таблицы.
По факту, нормализация может быть утрированно названа процессом создания все новых и новых таблиц до тех пор, пока избыточность и повторения не будут полностью уничтожены.
Чтобы привести базу ко второй нормальной форме, надо:
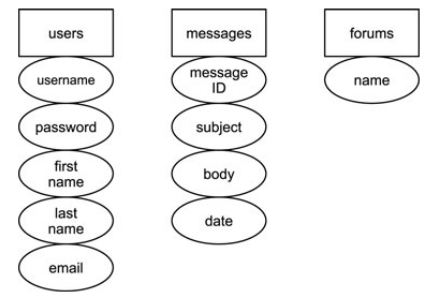
- Определить все столбцы, которые не находятся в прямой зависимости от первичного ключа этой таблицы. На рисунке выше у таблиц users и forums нет первичного ключа. У таблицы messages первичный ключ — message ID, от которого зависят все остальные поля этой таблицы.
- Создаем необходимые поля в таблицах users и forums, выделяем из существующих полей или создаем из новых первичные ключи.
- Создаем внешние ключи и обозначаем их отношения между таблицами. Конечным шагом нормализации до 2НФ будет являться выделение внешних ключей для связи с ассоциированными таблицами. Первичный ключ одной таблицы должен быть внешним ключом в другой. На рисунке снизу показана связь между ключами трех таблиц. Поле user ID таблицы messages является первичным ключом поля user ID таблицы users. Тип связи между ними — один ко многим. Один пользователь может оставить много сообщений, но у сообщения может быть только один пользователь. Такая же связь соединяет таблицы forums и messages через forum ID. У форума может быть много сообщений, но сообщение может находиться только в одном форуме.
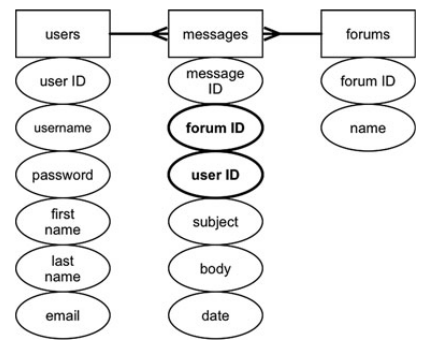
Подсказки:
- Другой способ приведения схемы к 2НФ — посмотреть на отношения между таблицами. Идеальный вариант — создать все отношения вида один-к-многим. Отношения вида многие-к-многим нуждаются в реструктуризации.
- Если взглянуть еще раз на таблицу movies-actors, то можно заметить, что она является промежуточной таблицей. Она превращает отношение многие-к-многим между movies и actors в один-к-многим. Можно вводить такие промежуточные таблицы, у которых все столбцы являются ключами. В таких таблицах не требуется свой собственный первичный ключ, поскольку он может быть комбинацией двух внешних ключей.
- Нормализованная должным образом таблица никогда не будет иметь повторяющихся рядов (двух и более рядов, значения которых не являются ключами и содержат совпадающие данные).
- Чтобы упростить нормализацию, помните, что при приведении к 1НФ вы ищете дубли горизонтально (дубли столбцов), а при приведении к 2НФ — вертикально (дубли рядов).
Значимость
Этот раздел также можно назвать, или альтернативные заголовки раздела:
При том, что идеи нормализации весьма полезны для проектирования баз данных, они отнюдь не являются универсальным или исчерпывающим средством повышения качества проекта БД. Это связано с тем, что существует слишком большое разнообразие возможных ошибок и недостатков в структуре БД, которые нормализацией не устраняются. Несмотря на эти рассуждения, теория нормализации является очень ценным достижением реляционной теории и практики, поскольку она даёт научно строгие и обоснованные критерии качества проекта БД и формальные методы для усовершенствования этого качества. Этим теория нормализации резко выделяется на фоне чисто эмпирических подходов к проектированию, которые предлагаются в других моделях данных. Более того, можно утверждать, что во всей сфере информационных технологий практически отсутствуют методы оценки и улучшения проектных решений, сопоставимые с теорией нормализации реляционных баз данных по уровню формальной строгости.
Нормализацию иногда упрекают на том основании, что «это просто здравый смысл», а любой компетентный профессионал и сам «естественным образом» спроектирует полностью нормализованную БД без необходимости применять теорию зависимостей. Однако, как указывает К. Дейт, нормализация в точности и является теми принципами здравого смысла, которыми руководствуется в своём сознании зрелый проектировщик, то есть принципы нормализации — это формализованный здравый смысл. Между тем, идентифицировать и формализовать принципы здравого смысла — весьма трудная задача, и успех в её решении является существенным достижением.
Третья нормальная форма.
База данных будет находиться в третьей нормальной форме, если она приведена ко второй нормальной форме и каждый не ключевой столбец независим друг от друга. Если следовать процессу нормализации правильно до этой точки, с приведением к 3НФ может и не возникнуть вопросов. Следует знать, что 3НФ нарушается, если изменив значение в одном столбце, потребуется изменение и в другом столбце. В примере с форумом (рисунок вверху), проблем с приведением к 3НФ не возникнет, но можно рассмотреть как образец гипотетическую ситуацию, где это может произойти.
Возьмём, как образец, одиночную таблицу, которая хранит некую информацию о бизнес клиентах: имя, фамилию, телефон, адрес, город, штат, почтовый индекс и все в этом духе. Такая таблица не будет находится в 3НФ, поскольку тут много полей будет взаимозависимо — улица будет зависеть от города, город от штата, почтовый индекс тоже под вопросом. Все эти поля будут подчинены друг другу, а не человеку, к которому относится эта запись.


Чтобы нормализовать такую базу, нужно создать по таблице для штатов, городов (с внешним ключом, ведущим в таблицу штатов) и для почтовых кодов. Все они будут ссылаться назад на клиентскую таблицу.
Если вы чувствуете, что все эти действия могут быть излишними, вы правы. Честно, в верхних уровнях нормализации часто нет необходимости. Смысл в том, что нужно стараться нормализовать базу данных, но иногда приходиться идти на уступки ради того, чтобы не допустить чрезмерного усложнения. Потребности приложения и структура данных в базе подскажут, насколько потребуется проводить процесс нормализации.
Как уже говорилось, пример с форумом уже достаточно нормализован, но все равно опишем шаги для нормализации для третьей нормальной формы, показав как исправить пример с клиентами.
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| key | value |
|---|---|
| user1 | {Кузнецов В., отдел маркетинга} |
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл. бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства — быстрый поиск и простое масштабирование.
Их недостаток — нельзя производить операции со значениями. Например — сортировать их или анализировать.
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
| name | волк | коза | капуста |
| color | серый | белая | зелёная |
| property | зубастый | рогатая |
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.
Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.




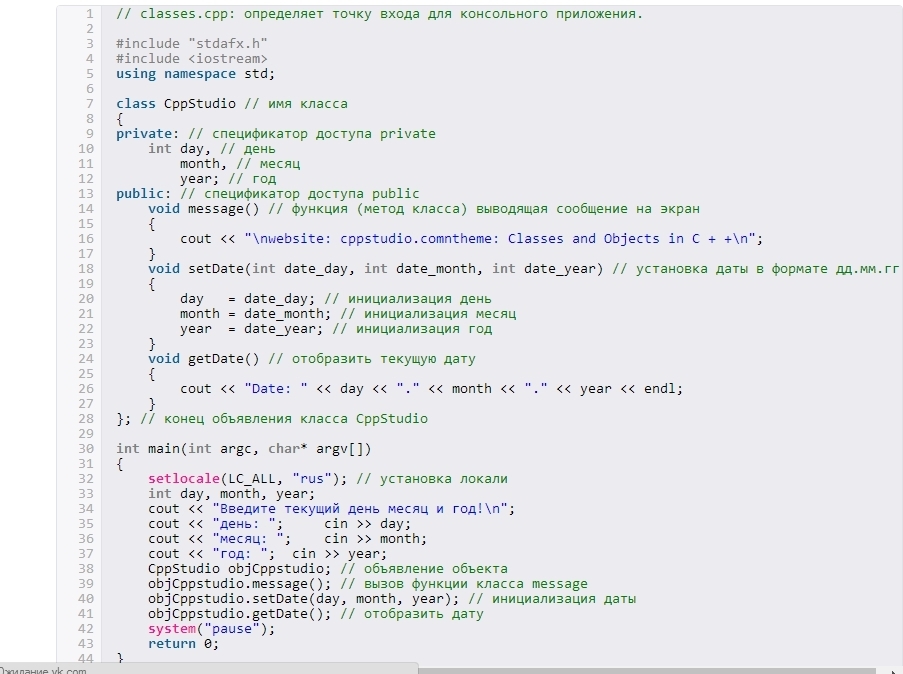
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.
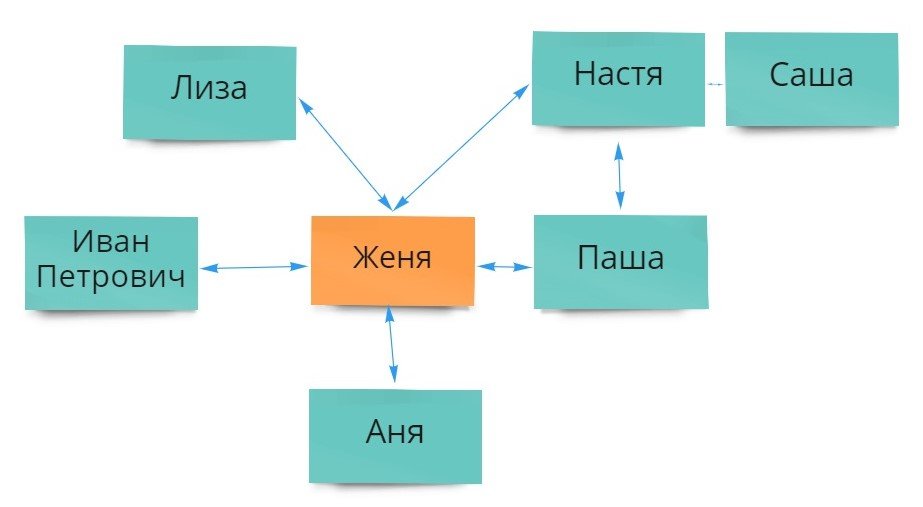
Типы баз данных
Есть много разных типов баз данных. Лучшая база данных для конкретной организации зависит от того, как организация намеревается использовать данные.
- Реляционные базы данных. Реляционные базы данных стали доминирующими в 1980-х годах. Элементы в реляционной базе данных организованы как набор таблиц со столбцами и строками. Технология реляционных баз данных обеспечивает наиболее эффективный и гибкий способ доступа к структурированной информации.
- Объектно-ориентированные базы данных. Информация в объектно-ориентированной базе данных представлена в виде объектов, как в объектно-ориентированном программировании.
- Распределенные базы данных. Распределенная база данных состоит из двух или более файлов, расположенных на разных сайтах. База данных может храниться на нескольких компьютерах, находиться в одном физическом месте или разбросана по разным сетям.
- Хранилища данных. Централизованное хранилище данных, хранилище данных — это тип базы данных, специально разработанный для быстрого запроса и анализа.
- Базы данных NoSQL. NoSQL, или нереляционная база данных, позволяет хранить и обрабатывать неструктурированные и полуструктурированные данные (в отличие от реляционной базы данных, которая определяет, как должны быть составлены все данные, вставленные в базу данных). Базы данных NoSQL становились популярными по мере того, как веб-приложения становились все более распространенными и сложными.
- Графовые базы данных. База данных графов хранит данные в терминах сущностей и отношений между сущностями.
- Базы данных OLTP. База данных OLTP — это быстрая аналитическая база данных, предназначенная для большого количества транзакций, выполняемых несколькими пользователями.
Это лишь некоторые из нескольких десятков типов баз данных, используемых сегодня. Другие, менее распространенные базы данных предназначены для очень конкретных научных, финансовых или других функций. Помимо различных типов баз данных, изменения в подходах к разработке технологий и значительные достижения, такие как облачные технологии и автоматизация, продвигают базы данных в совершенно новых направлениях. Некоторые из последних баз данных включают:
- Базы данных с открытым исходным кодом (OpenSource). Система баз данных с открытым исходным кодом — это система с открытым исходным кодом; такие базы данных могут быть базами данных SQL или NoSQL.
- Облачные базы данных (Cloud Database). Облачная база данных — это набор структурированных или неструктурированных данных, который хранится на частной, общедоступной или гибридной платформе облачных вычислений. Существует два типа моделей облачных баз данных: традиционные и база данных как услуга (DBaaS). В случае DBaaS административные задачи и обслуживание выполняются поставщиком услуг.
- Многомодельная база данных. Мультимодельные базы данных объединяют различные типы моделей баз данных в единую интегрированную серверную часть. Это означает, что они могут поддерживать различные типы данных.
- База данных Документов / JSON. Базы данных документов, разработанные для хранения, извлечения и управления документально-ориентированной информацией, представляют собой современный способ хранения данных в формате JSON, а не в строках и столбцах.
- Автономные базы данных. Новейший и самый революционный тип базы данных, автономные базы данных (также известные как автономные базы данных) являются облачными и используют машинное обучение для автоматизации настройки базы данных, обеспечения безопасности, резервного копирования, обновления и других рутинных задач управления, традиционно выполняемых администраторами баз данных.
Отношения между таблицами
Отношения между таблицами устанавливают связь
между данными находящимися в разных таблицах
базы данных.
Отношения между таблицами определяются
отношением между группами объектов
соответствующего типа. Например, один автор
может написать несколько книг и издать их в
разных издательствах. Или издательство может
опубликовать несколько книг разных авторов.
Таким образом, между авторами и названиями книг
существует отношение один-ко-многим, а между
издательствами и авторами существует отношение
много-ко-многим.
Отношения между таблицами базы данных BIBLIO.MDB
показаны на рис.1.9.
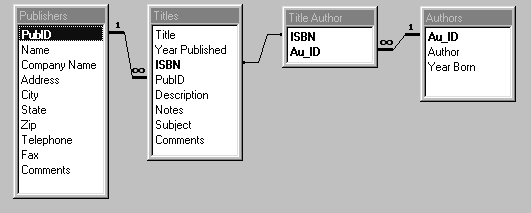 Рис.1.9. Отношения между таблицами базы данных BIBLIO.MDB.
Рис.1.9. Отношения между таблицами базы данных BIBLIO.MDB.Ключи
Ключи являются составляющей частью нормализованных таблиц. Бывают двух видов — внешние и первичные.
Первичный ключ — это уникальный идентификатор, отвечающий следующим условиям:
- Он должен иметь значение, не NULL.
- Быть неизменным — значение ключа не должно меняться.
- Иметь уникальное значение для каждой строки.
Внешние ключи — это ссылки на первичные ключи других таблиц, которые удовлетворяют условиям выше.
Для начала нормализации следует указать хотя бы один первичный ключ. В примере это будет message ID.

Для указания первичного ключа, надо найти поле, которое будет подходить под все три условия. Если такого поля нет, его надо создать. В идеале, поле должно иметь тип integer.



