
Введение
В этом руководстве вы узнаете об основных столпах «структуры абстракции транзакций» (transaction abstraction framework — запутанный термин, не так ли?) ядра Спринга (Spring core) — описанных с большим количеством примеров кода:
-
(декларативное управление транзакциями) против программного управления транзакциями.
-
Физические и логические транзакции.
-
Интеграция Спринга и «Джэйпиэй» (JPA) / Гибернэйтом .
-
Интеграция Спринга и Спринг-бута (Spring Boot) или Спринга МВС (Spring MVC).
-
Откаты, прокси, общие проблемы и многое другое.
В отличие, скажем, от официальной документации по Спрингу это руководство не запутает вас, погрузившись сразу в тему Spring-first.
Вместо этого вы будете изучать управление транзакциями Спринга нетрадиционным способом: с нуля, шаг за шагом. Это означает, что вы начнёте со старого доброго управления транзакциями СБДЯ (JDBC).
Почему?
Потому что всё, что делает Спринг, построено на этих самых основах СБДЯ (соединение с базами данных на Яве, JDBC). И вы сэкономите кучу времени при работе с аннотацией от Спринга, если усвоите эти начала.
Содержание
-
- Транзакции баз данных
- Транзакции вручную
- Автоматические транзакции
Введение
Транзакция — это последовательность операций, выполняемых как единое
целое. Благодаря объединению взаимосвязанных операций в транзакцию
гарантируется согласованность и целостность данных в системе, несмотря
на любые ошибки, которые могли возникнуть в ходе транзакции. Для
успешного выполнения транзакции необходимо успешное завершение всех
ее операций.
У транзакции есть начало и конец, определяющие ее границы
(transaction boundaries), внутри которых транзакция может охватывать
различные процессы и компьютеры. Все ресурсы, используемые в ходе данной
транзакции, считаются участвующими в этой транзакции. Для поддержания
целостности используемых ресурсов транзакция должна обладать свойствами
ACID: Atomicity (атомарность), Consistency (целостность), Isolation
(изоляция) и Durability (отказоустойчивость). Подробнее об основах
обработки транзакций см.
Processing Transactions (EN)
в Microsoft .NET Framework SDK и Transaction Processing в Microsoft
Platform SDK.
В этой статье мы покажем, как выполнять локальные и распределенные
транзакции в приложениях Microsoft .NET.
Локальные и распределенные транзакции
Локальной называется транзакция, областью действия которой является
один ресурс, поддерживающий транзакции, — база данных Microsoft
SQL Server, очередь сообщений MSMQ и др. Например, отдельно взятая СУБД
может вводить в действие правила ACID, когда в ее распоряжении имеются
все данные, участвующие в транзакции. В SQL Server предусмотрен
внутренний диспетчер транзакций (transaction manager), предоставляющий
функциональность для фиксации (commit) и отката (rollback) транзакций.
Распределенные транзакции могут использовать гетерогенные ресурсы,
поддерживающие транзакции, включать самые разнообразные операции,
например выборку информации из базы данных SQL Server, считывание
сообщений Message Queue Server и запись в другие базы данных.
Программирование распределенных приложений упрощается программным
обеспечением, способным координировать фиксацию и откат, а также
восстановление данных, хранящихся в различных ресурсах. Одной из таких
технологий является DTC (Microsoft Distributed Transaction Coordinator).
DTC реализует протокол двухфазной фиксации (two-phase
commit protocol), гарантирующий непротиворечивость результатов
транзакции во всех ресурсах, участвующих в этой транзакции. DTC
поддерживает только приложения, в которых реализуются совместимые с ним
интерфейсы управления транзакциями. Эти приложения называются
диспетчерами ресурсов (Resource Managers) (дополнительную информацию
по этой теме см. в Distributed
Transactions (EN) в .NET Framework
Developer’s Guide). В настоящее время существует довольно много таких
приложений — MSMQ, Microsoft SQL Server, Oracle, Sybase и др.
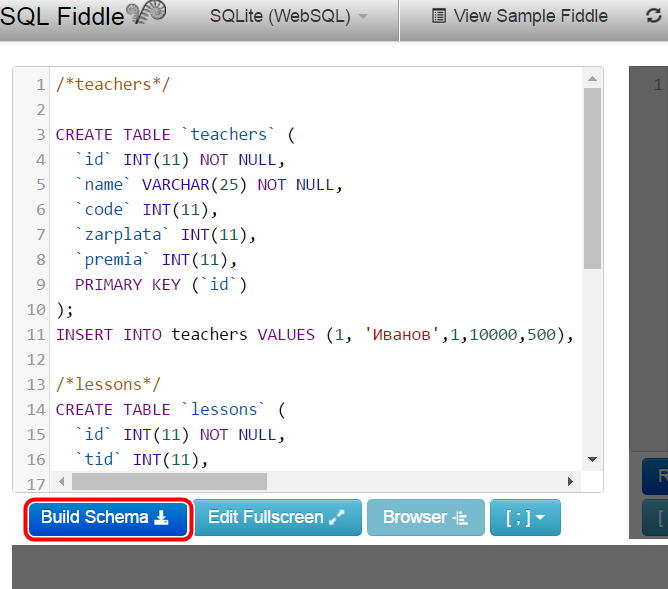
Использование пакета DBMS_SQL
Пакет DBMS_SQL предоставляет возможность использования в PL/SQL динамического SQL для выполнения DML- или DDL-операций.
Выполнение одного динамического оператора с использованием пакета DBMS_SQL состоит, как правило, из следующих шагов:
-
Связывание текста динамического оператора с курсором и его синтаксический анализ и разбор;
-
Связывание входных аргументов с переменными, содержащими реальные значения;
-
Связывание выходных значений с переменными вызывающего блока;
-
Указание переменных, в которые будут сохраняться выходные значения;
-
Выполнение оператора;
-
Извлечение строк;
-
Получение значений переменных, извлеченных запросом;
-
Закрытие курсора.
Ниже приведен перечень функций и процедур пакета DBMS_SQL:
|
Функции |
|
|
EXECUTE |
Executes a given cursor |
|
EXECUTE_AND_FETCH |
Executes a given cursor and fetch rows |
|
FETCH_ROWS |
Fetches a row from a given cursor |
|
IS_OPEN |
Returns TRUE if given cursor is open |
|
LAST_ERROR_POSITION |
Returns byte offset in the SQL statement text where the error occurred |
|
LAST_ROW_COUNT |
Returns cumulative count of the number of rows fetched |
|
LAST_ROW_ID |
Returns ROWID of last row processed |
|
LAST_SQL_FUNCTION_CODE |
Returns SQL function code for statement |
|
OPEN_CURSOR |
Returns cursor ID number of new cursor |
|
TO_CURSOR_NUMBER |
Takes an OPENed strongly or weakly-typed ref cursor and transforms it into a DBMS_SQL cursor number |
|
TO_REFCURSOR |
Takes an OPENed, PARSEd, and EXECUTEd cursor and transforms/migrates it into a PL/SQL manageable REF CURSOR (a weakly-typed cursor) that can be consumed by PL/SQL native dynamic SQL switched to use native dynamic SQL |
|
Процедуры |
|
|
BIND_ARRAY |
Binds a given value to a given collection |
|
BIND_VARIABLE |
Binds a given value to a given variable |
|
CLOSE_CURSOR |
Closes given cursor and frees memory |
|
COLUMN_VALUE |
Returns value of the cursor element for a given position in a cursor |
|
COLUMN_VALUE_LONG |
Returns a selected part of a LONG column, that has been defined using DEFINE_COLUMN_LONG |
|
DEFINE_ARRAY |
Defines a collection to be selected from the given cursor, used only with SELECT statements |
|
DEFINE_COLUMN |
Defines a column to be selected from the given cursor, used only with SELECT statements |
|
DEFINE_COLUMN_CHAR |
Defines a column of type CHAR to be selected from the given cursor, used only with SELECT statements |
|
DEFINE_COLUMN_LONG |
Defines a LONG column to be selected from the given cursor, used only with SELECT statements |
|
DEFINE_COLUMN_RAW |
Defines a column of type RAW to be selected from the given cursor, used only with SELECT statements |
|
DEFINE_COLUMN_ROWID |
Defines a column of type ROWID to be selected from the given cursor, used only with SELECT statements |
|
DESCRIBE_COLUMNS |
Describes the columns for a cursor opened and parsed through DBMS_SQL |
|
DESCRIBE_COLUMNS2 |
Describes the specified column, an alternative to DESCRIBE_COLUMNS |
|
DESCRIBE_COLUMNS3 |
Describes the specified column, an alternative to DESCRIBE_COLUMNS |
|
PARSE |
Parses given statement |
|
VARIABLE_VALUE |
Returns value of named variable for given cursor |
Основные команды
2.1 TRY-CATCH
Как правило, в CATCH откатывают любую открытую транзакцию и повторно вызывают ошибку. Таким образом, вызывающая клиентская программа понимает, что что-то пошло не так. Повторный вызов ошибки мы обсудим позже в этой статье.
Вот очень быстрый пример:
Мы вернемся к функции error_message() позднее. Стоит отметить, что использование PRINT в обработчике CATCH приводится только в рамках экспериментов и не следует делать так в коде реального приложения.
Если вызывает хранимую процедуру или запускает триггеры, то любая ошибка, которая в них возникнет, передаст выполнение в блок CATCH. Если более точно, то, когда возникает ошибка, SQL Server раскручивает стек до тех пор, пока не найдёт обработчик CATCH. И если такого обработчика нет, SQL Server отправляет сообщение об ошибке напрямую клиенту.
Есть одно очень важное ограничение у конструкции TRY-CATCH, которое нужно знать: она не ловит ошибки компиляции, которые возникают в той же области видимости. Рассмотрим пример:. Эти ошибки не являются полностью неуловимыми; вы не можете поймать их в области, в которой они возникают, но вы можете поймать их во внешней области
Добавим такой код к предыдущему примеру:
Эти ошибки не являются полностью неуловимыми; вы не можете поймать их в области, в которой они возникают, но вы можете поймать их во внешней области. Добавим такой код к предыдущему примеру:
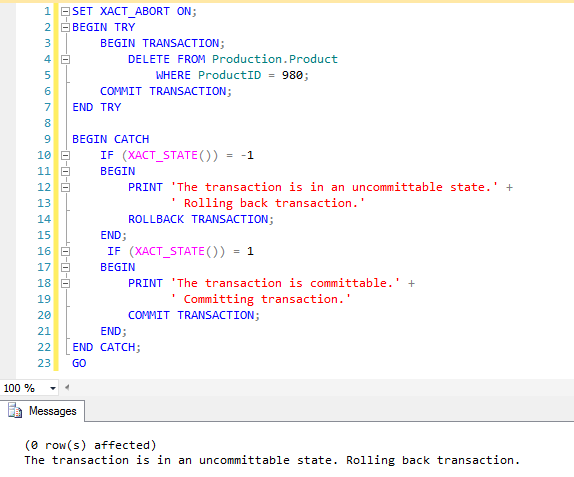
2.2 SET XACT_ABORT ON
Параметр XACT_ABORT необходим для более надежной обработки ошибок и транзакций. В частности, при настройках по умолчанию есть несколько ситуаций, когда выполнение может быть прервано без какого-либо отката транзакции, даже если у вас есть TRY-CATCH. Мы видели такой пример в предыдущем разделе, где мы выяснили, что TRY-CATCH не перехватывает ошибки компиляции, возникшие в той же области. Открытая транзакция, которая не была откачена из-за ошибки, может вызвать серьезные проблемы, если приложение работает дальше без завершения транзакции или ее отката.
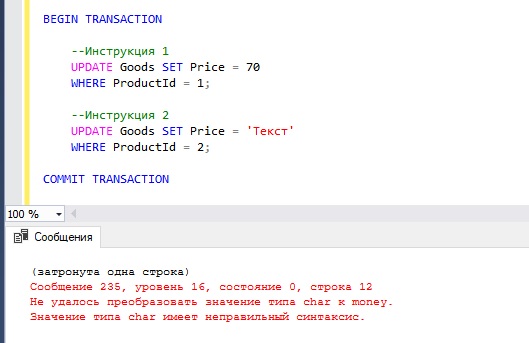



Для надежной обработки ошибок в SQL Server вам необходимы как TRY-CATCH, так и SET XACT_ABORT ON. Среди них инструкция SET XACT_ABORT ON наиболее важна. Если для кода на промышленной среде только на нее полагаться не стоит, то для быстрых и простых решений она вполне подходит.
Параметр NOCOUNT не имеет к обработке ошибок никакого отношения, но включение его в код является хорошей практикой. NOCOUNT подавляет сообщения вида (1 row(s) affected), которые вы можете видеть в панели Message в SQL Server Management Studio. В то время как эти сообщения могут быть полезны при работе c SSMS, они могут негативно повлиять на производительность в приложении, так как увеличивают сетевой трафик. Сообщение о количестве строк также может привести к ошибке в плохо написанных клиентских приложениях, которые могут подумать, что это данные, которые вернул запрос.
Выше я использовал синтаксис, который немного необычен. Большинство людей написали бы два отдельных выражения:
Вместо заключения
Все, что написано выше, не является правильным подходом при разработке и поддержке баз данных. Но иногда просто нет выхода и приходится искать альтернативные пути решения проблем производительности и стабильности. То, что в мире больших баз считается нормой, для баз 1С применять очень сложно. Вспомните хотя бы сегментирование или простое использование файловых групп. Для 1С — это боль.
Цель всего этого донести, что имеется огромный потенциал для улучшения производительности и обслуживания баз данных 1С, но чтобы его использовать сейчас требуется некоторая хитрость и смекалка. Я очень надеюсь, что в одной из версий платформы 1С появится возможность использовать больше настроек баз данных для индексов, сегментирования, файловых групп и т.д., и в один прекрасный момент такие костыли станут уже больше не нужны.
Обработка исключений в PL/SQL
PL/SQL перехватывает ошибки и реагирует на них при помощи так называемых обработчиков исключений. Механизм функционирования обработчиков исключений позволяет четко отделить код обработки ошибок от исполняемых операторов, дает возможность реализовать обработку ошибок, управляемую событиями, отказавшись от устаревшей линейной модели программирования.
Независимо от того, как и по какой причине было инициировано конкретное исключение, оно обрабатывается одним и тем же обработчиком в разделе исключений.
Любая ошибка может быть обработана только одним обработчиком.
Для обработки исключений в блоке PL/SQL предназначается необязательный раздел EXCEPTION
BEGIN
операторы
EXCEPTION
WHEN THEN …..;
WHEN THEN …..;
…
WHEN THEN …..;
WHEN OTHERS THEN …..;
END;
Если в исполняемом блоке PL/SQL инициируется исключение, то выполнение блока прерывается и управление передается в раздел обработки исключений (если таковой имеется). После обработки исключения возврат в исполняемый блок уже невозможен, поэтому управление передается в родительский блок.
Обработчик WHEN OTHERS должен быть последним обработчиком в блоке, иначе возникнет ошибка компиляции. Этот обработчик не является обязательным. Если он отсутствует, то все необработанные исключения передадутся в родительский блок, либо в вызывающую хост-систему.
В одном предложении WHEN, можно объединить несколько исключений, используя оператор OR:
WHEN invalid_company_id OR negative_balance THEN
Также в одном о6ра6отчике можно ком6инировать имена пользовательских и системных исключений:
WHEN balance_too_low OR zero_divide OR dbms_ldap.invalid_session THEN
Nested Transactions
SQL Server technically supports nested transactions; however, they are primarily intended to simplify transaction management during nested stored procedure calls. In practice, it means that the code needs to explicitly commit all nested transactions and the number of COMMIT calls should match the number of BEGIN TRAN calls. The ROLLBACK statement, however, rolls back entire transaction regardless of the current nested level.
The code below demonstrates this behavior. As I already mentioned, system variable @@TRANCOUNT returns the nested level of the transaction.
select @@TRANCOUNT as ;
begin tran
select @@TRANCOUNT as ;
begin tran
select @@TRANCOUNT as ;
commit
select @@TRANCOUNT as ;
begin tran
select @@TRANCOUNT as ;
rollback
select @@TRANCOUNT as ;
rollback; -- This ROLLBACK generates the error
You can see the output of the code in Figure 7 below.
07. Nested Transactions
You can save the state of transaction and create a savepoint by using SAVE TRANSACTION statement. This will allow you to partially rollback a transaction returning to the most recent savepoint. The transaction will remain active and needs to be completed with explicit COMMIT or ROLLBACK statement later.
It is worth noting that uncommittable transactions with XACT_STATE() = -1 cannot be rolled back to savepoint. In practice, it means that you cannot rollback to savepoint after an error if XACT_ABORT is set to ON.
The code below illustrates savepoints in action. The stored procedure creates the savepoint when it runs in active transaction and rolls back to this savepoint in case of committable error.
create proc dbo.TryDeleteCustomer
(
@CustomerId int
)
as
begin
-- Setting XACT_ABORT to OFF for rollback to savepoint to work
set xact_abort off
declare
@ActiveTran bit
-- Check if SP is calling in context of active transaction
set @ActiveTran = IIF(@@TranCount > 0, 1, 0);
if @ActiveTran = 0
begin tran;
else
save transaction TryDeleteCustomer;
begin try
delete dbo.Customers where CustomerId = @CustomerId;
if @ActiveTran = 0
commit;
return 0;
end try
begin catch
if @ActiveTran = 0 or XACT_STATE() = -1
begin
-- Rollback entire transaction
rollback tran;
return -1;
end
else begin
-- Rollback to savepoint
rollback tran TryDeleteCustomer;
return 1;
end
end catch;
end;
go
-- Test
declare
@ReturnCode int
exec dbo.ResetData;
begin tran
exec @ReturnCode = TryDeleteCustomer @CustomerId = 1;
select
1 as
,@ReturnCode as
,XACT_STATE() as ;
if @ReturnCode >= 0
begin
exec @ReturnCode = TryDeleteCustomer @CustomerId = 2;
select
2 as
,@ReturnCode as
,XACT_STATE() as ;
end
if @ReturnCode >= 0
commit;
else
if @@TRANCOUNT > 0
rollback;
go
select * from dbo.Customers;
The test triggered foreign key violation during the second dbo.TryDeleteCustomer call. This is non-critical error and, therefore, the code is able to commit after it as shown in Figure 8.
08. Transaction Has Been Committed After Rollback to Savepoint
It is worth noting that this example is shown for demonstration purposes only. From efficiency standpoint, it would be better to validate referential integrity and existence of the orders before deletion occurred rather than catching exception and rolling back to savepoint in case of an error.
I hope that those examples provided you the good overview of transaction management and error handling strategies in the system. If you want to dive deeper, I would strongly recommend you to read the great article by Erland Sommarskog, which provides you much more details on the subject.
Source code is available for download.
Table of Context
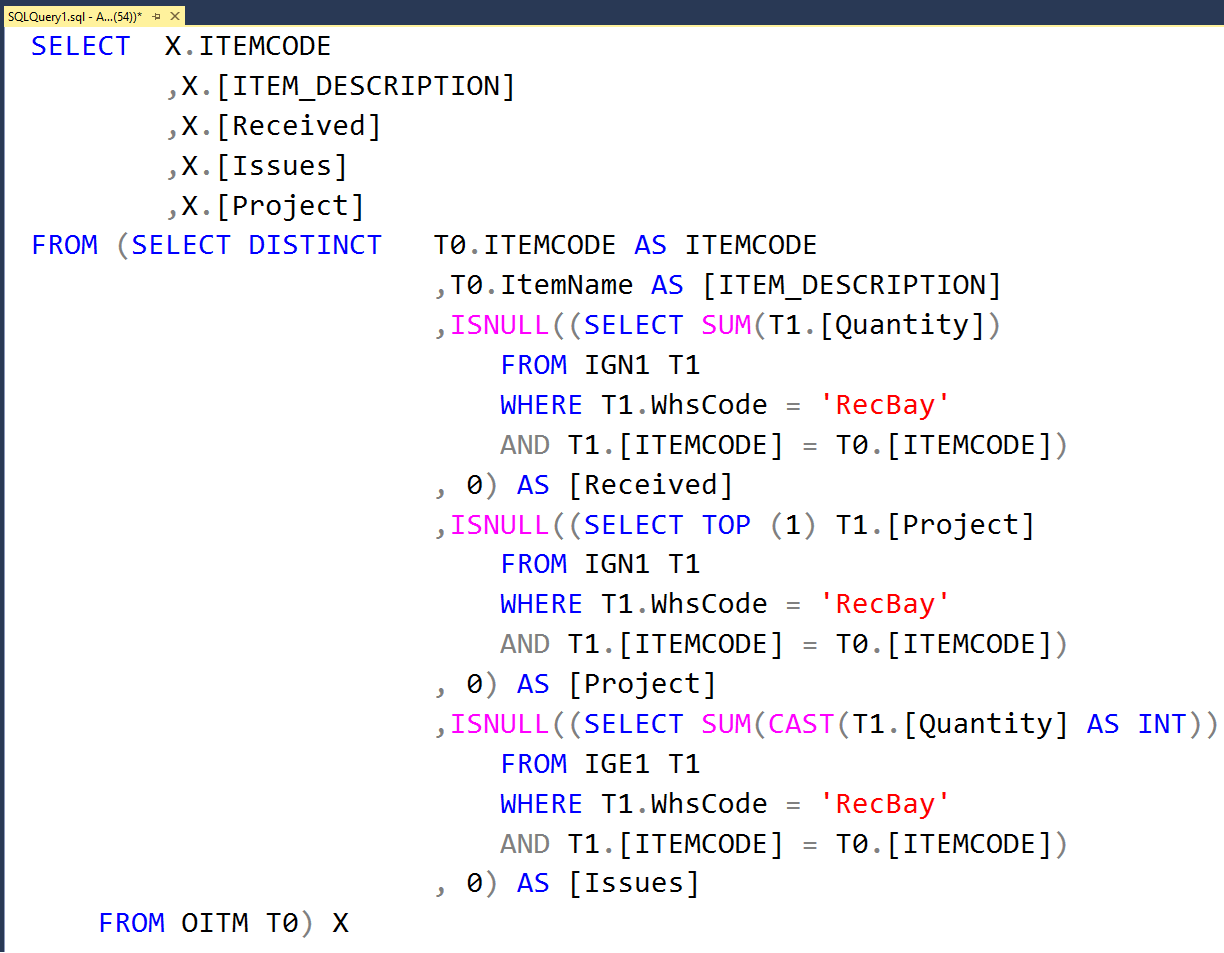
Инструкция EXECUTE IMMEDIATE
Инструкция ЕХЕСUТЕ IMMEDIATE, используемая для выполнения необходимой SQL-инструкции, имеет следующий синтаксис:
EXECUTE IMMEDIATE строка_SQL…| запись}] аргумент аргумент]…];
где
-
строка_SQL — строковое выражение, содержащее SQL-инструкцию или блок РL/SQL;
-
переменная — переменная, которой присваивается содержимое поля, возвращаемого запросом;
-
запись — запись, основаниая на типе данных который определяется пользавателем или объявляется с помощью атрибута %ROWTYPE, и принимающая всю возвращаемую запросом строку;
-
аргумент — выражение, значение которого передается SQL-инструкции или блоху РL/SQL, либо идентификатор, являющийся входной и/или выходной переменной для функции или процедуры, вызываемой из блока PL/SQL;
-
INTO — предложение, используемое для однострочных запросов (для каждого возвращаемого запросом столбца в этом предложении должна быть задана отдельная переменная или же ему должно соответствовать поле записи совместимого типа);
-
USING — предложение, определяющее параметры SQL-инструкции и используемое как в динамическом SQL, так и в динамическом РL/SQL (способ передачи параметра дается только в РL/SQL, причем по умолчанию для него установлен режим передачи IN).
Инструкция ЕХЕСUТЕ IMMEDIATE может использоваться для выполнения любой SQL-инструкции или PL/SQL-блока, за исключением многострочных запросов.
Если SQL-строка заканчивается точкой с запятой, она интерпретируется как блок РL/SQL. В противном случае воспринимается как DML- или DDL-инструкция.
Строка может содержать формальные параметры, но с их помощью не могут быть заданы имена объектов схемы, скажем, такие, как имена столбцов таблицы.
При выполнении инструкции исполняющее ядро заменяет в SQL-строке формальные параметры (идентификаторы, начинающиеся с двоеточия) фактическими значениями параметров подстановки в предложении USING.В инструкции ЕХЕСUТЕ IMMEDIATE не разрешается передача литерального значения NULL — вместо него следует указывать переменную соответствующего типа, содержащую это значение.
Несколько примеров:
Создание индекса:
EXECUTE IMMEDIATE ‘CREATE INDEX emp_u_l ON employee (last_name)’;
Хранимую процедуру, выполняющую любую инструкцию DDL, можно создать так:CREATE OR REPLACE PROCEDURE execDDL(ddl_string in varchar2) isBEGIN EXECUTE IMMEDIATE ddl_string;END;
При наличии процедуры создание того же индекса выглядит так:BEGINexecDDL(‘CREATE INDEX emp_u_l ON employee (last_name)’);END;
DECLARE v_emp_last_name VARCHAR2(50); v_emp_first_name VARCHAR2(50); v_birth DATE;BEGIN EXECUTE IMMEDIATE ‘select emp_last_name, emp_first_name, birth ‘ || ’from EMPLOYEE where id = :id’ INTO v_emp_last_name, v_emp_first_name, v_birth USING 178; dbms_output.put_line(v_emp_last_name); dbms_output.put_line(v_emp_first_name); dbms_output.put_line(to_char(v_birth, ‘dd.mm.yyyy’));END;








Когда следует использовать DBMS_SQL
Хотя встроенный динамический SQL гораздо проще применять, а программный код более короткий и понятный, но все же бывают случаи, когда приходится использовать пакет DBMS_SQL.Это следующие случаи:
-
Разбор очень длинных строк.Если строка длиннее 32К, то EXECUTE IMMEDIATE не сможет ее выполнить;
-
Получение информации о столбцах запроса;
-
Минимальный разбор динамических курсоров.При каждом выполнении EXECUTE IMMEDIATE динамическая строка разбирается заново (производится синтаксический анализ, оптимизация и построение плана выполнения запроса), поэтому в некоторых ситуациях это обходится слишком дорого, и тогда DBMS_SQL может оказаться эффективнее.
Команда SET TRANSACTION
Команда позволяет начать сеанс чтения или чтения-записи, установить уровень изоляции или связать текущую транзакцию с заданным сегментом отката. Эта команда должна быть первой командой транзакции и дважды использоваться в ходе одной транзакции не может. У нее имеются четыре разновидности.
- — определяет текущую транзакцию доступной «только для чтения». В транзакциях этого типа всем запросам доступны лишь те изменения, которые были зафиксированы до начала транзакции. Они применяются, в частности, в медленно формируемых отчетах со множеством запросов, благодаря чему в них часто используются строго согласованные данные.
- — определяет текущую транзакцию как операцию чтения и записи данных в таблицу.
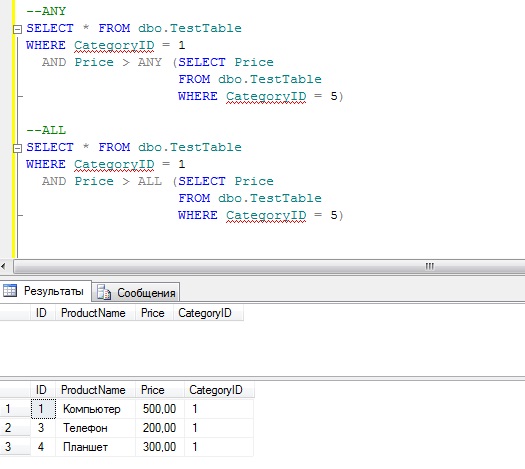
- — определяет способ выполнения транзакции, модифицирующей базу данных. С ее помощью можно задать один из двух уровней изоляции транзакции: или . В первом случае команде , пытающейся модифицировать таблицу, которая уже изменена незафиксированной транзакцией, будет отказано в этой операции. Для выполнения этой команды в инициализационном параметре COMPATIBLE базы данных должна быть задана версия 7.3.0 и выше.При установке уровня команда , которой требуется доступ к строке, заблокированной другой транзакцией, будет ждать снятия этой блокировки.
- имя сегмента — назначает текущей транзакции заданный сегмент отката и определяет ей доступ «только для чтения». Не может использоваться совместно с командой .
Механизм сегментов отката считается устаревшим; вместо него следует использовать средства автоматического управления отменой, введенные в Oracle9i.
Команда COMMIT
Фиксирует все изменения, внесенные в базу данных в ходе сеанса текущей транзакцией. После выполнения этой команды изменения становятся видимыми для других сеансов или пользователей. Синтаксис этой команды:
Ключевое слово не обязательно — оно только упрощает чтение кода.
Ключевое слово также не является обязательным; оно используется для задания комментария, который будет связан с текущей транзакцией. Текстом комментария должен быть заключенный в одинарные кавычки литерал длиной до 50 символов. Обычно комментарии задаются для распределенных транзакций с целью облегчения их анализа и разрешения сомнительных транзакций в среде с двухфазовой фиксацией. Они хранятся в словаре данных вместе с идентификаторами транзакций.
Обратите внимание: команда снимает все блокировки таблиц, установленные во время текущего сеанса (например, для команды). Кроме того, она удаляет все точки сохранения, установленные после выполнения последней команды или
После того как изменения будут закреплены, их откат становится невозможным.
Все команды в следующем фрагменте являются допустимыми применениями :
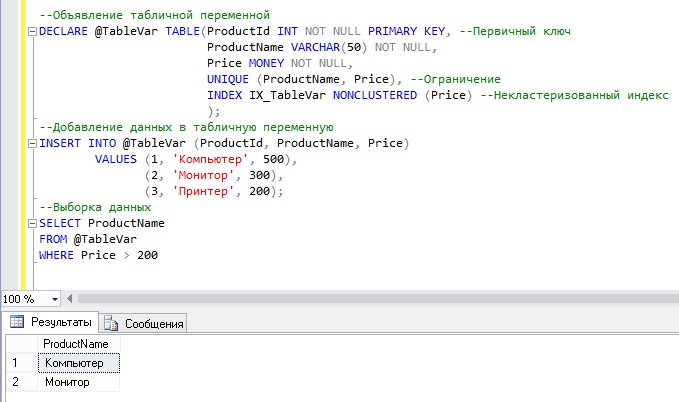
Основной пример обработки ошибок
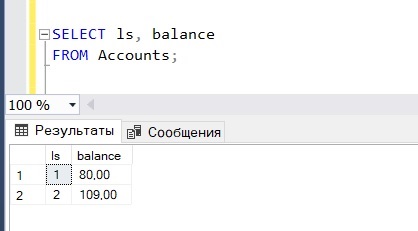
Для примера я буду использовать эту простую таблицу.
Причина, по которой я предпочитаю указывать SET XACT_ABORT и NOCOUNT перед BEGIN TRY, заключается в том, что я рассматриваю это как одну строку шума: она всегда должна быть там, но я не хочу, чтобы это мешало взгляду. Конечно же, это дело вкуса, и если вы предпочитаете ставить SET-команды после BEGIN TRY, ничего страшного
Важно то, что вам не следует ставить что-либо другое перед BEGIN TRY
Часть между BEGIN TRY и END TRY является основной составляющей процедуры. Поскольку я хотел использовать транзакцию, определенную пользователем, я ввел довольно надуманное бизнес-правило, в котором говорится, что если вы вставляете пару, то обратная пара также должна быть вставлена. Два выражения INSERT находятся внутри BEGIN и COMMIT TRANSACTION. Во многих случаях у вас будет много строк кода между BEGIN TRY и BEGIN TRANSACTION. Иногда у вас также будет код между COMMIT TRANSACTION и END TRY, хотя обычно это только финальный SELECT, возвращающий данные или присваивающий значения выходным параметрам. Если ваша процедура не выполняет каких-либо изменений или имеет только одно выражение INSERT/UPDATE/DELETE/MERGE, то обычно вам вообще не нужно явно указывать транзакцию.
В то время как блок TRY будет выглядеть по-разному от процедуры к процедуре, блок CATCH должен быть более или менее результатом копирования и вставки. То есть вы делаете что-то короткое и простое и затем используете повсюду, не особо задумываясь. Обработчик CATCH, приведенный выше, выполняет три действия:
- Откатывает любые открытые транзакции.
- Повторно вызывает ошибку.
- Убеждается, что возвращаемое процедурой значение отлично от нуля.
Код повторной генерации ошибки включает такую строку:
Замечание: синтаксис для присвоения начального значения переменной в DECLARE был внедрен в SQL Server 2008. Если у вас SQL Server 2005, вам нужно разбить строку на DECLARE и выражение SELECT.
Финальное выражение RETURN – это страховка. RAISERROR никогда не прерывает выполнение, поэтому выполнение следующего выражения будет продолжено. Пока все процедуры используют TRY-CATCH, а также весь клиентский код обрабатывает исключения, нет повода для беспокойства. Но ваша процедура может быть вызвана из старого кода, написанного до SQL Server 2005 и до внедрения TRY-CATCH. В те времена лучшее, что мы могли делать, это смотреть на возвращаемые значения. То, что вы возвращаете с помощью RETURN, не имеет особого значения, если это не нулевое значение (ноль обычно обозначает успешное завершение работы).
Последнее выражение в процедуре – это END CATCH. Никогда не следует помещать какой-либо код после END CATCH. Кто-нибудь, читающий процедуру, может не увидеть этот кусок кода.
После прочтения теории давайте попробуем тестовый пример:
Причины и симптомы
Если при выполнении распределенной транзакции с Microsoft SQL Server на сервере произошла ошибка I/O или произошло отключение сервера / базы данных, тогда транзакция в координаторе (DTC) и на других базах будет откачена (ROLLBACK), а в пострадавшей базе данных на SQL Server может не откатиться. Это потому, что в результате отключения / сбоя, СУБД технически не могла её откатить.
Зависшая распределенная транзакция будет проявляться, в том числе, тем, что в базе не будет обрезаться журнал (TRANSACTION LOG) даже в режиме восстановления SIMPLE.
Если транзакция провела много изменений в базе, все они так и не принятые будут лежать в журнале и увеличивать размер самого журнала и размер резервных копий. Если транзакция заблокировала ресурсы, по логике, они так же должны оказаться заблокированы до её отката (хотя я это не проверял).
А если нужен индекс по пометке удаления
Еще один наглядный пример — это индекс по пометке удаления. Средствами платформы добавить индекс по пометке удаления нет возможности, т.к. это стандартный реквизит и настройка “Индексирование” для него просто недоступна. Немного приблизим задачу к настоящей и скажем, что нужно отбирать помеченные на удаление элементы с учетом реквизита “ДатаСоздания”.
![Парсер хабра: [из песочницы] [перевод] обработка ошибок и транзакций в sql server. часть 1. обработка ошибок – быстрый старт](https://wudgleyd.ru/wp-content/uploads/c/9/d/c9d14cfa0a96c69466916ad6ee4ce0dd.jpeg)



И так, платформа не даст создать такой индекс, но мы то знаем решение!
Что это за условие “WHERE”? SQL Server поддерживает фильтрованные индексы, в которых можно ограничить какие данные в него попадут. Если нужна более подробная информация, то Welcome! Самое главное, что нужно знать — фильтрованные индексы улучшают производительность, качество плана выполнения, расходы на обслуживание и хранение. Очень жаль, что платформа 1С не использует такие возможности СУБД.
Проверим новый индекс запросом.
И вот план запроса.
То что надо! Подробно, как в прошлый раз, описывать план запроса не будем, но вот что стоит заметить: единственная значимая операция здесь — это “Index Seek”, которая как-раз и использует наш новый индекс “_ByDeletionMarkAndCreationDate”. Никаких обращений к основной таблице / кластерному индексу не выполнялось, то есть индекс полностью удовлетворяет условиям и полям выборки запроса, является покрывающим.
Итог:
- Время выполнения 7 миллисекунд
- Количество логических чтений = 459
- Время затраченное CPU 16 миллисекунд
- План запроса простейший, самая значимая часть — это поиск по индексу “_ByDeletionMarkAndCreationDate”
- Количество прочитанных строк — 3 (столько помеченных на удаление элементов за указанный период)
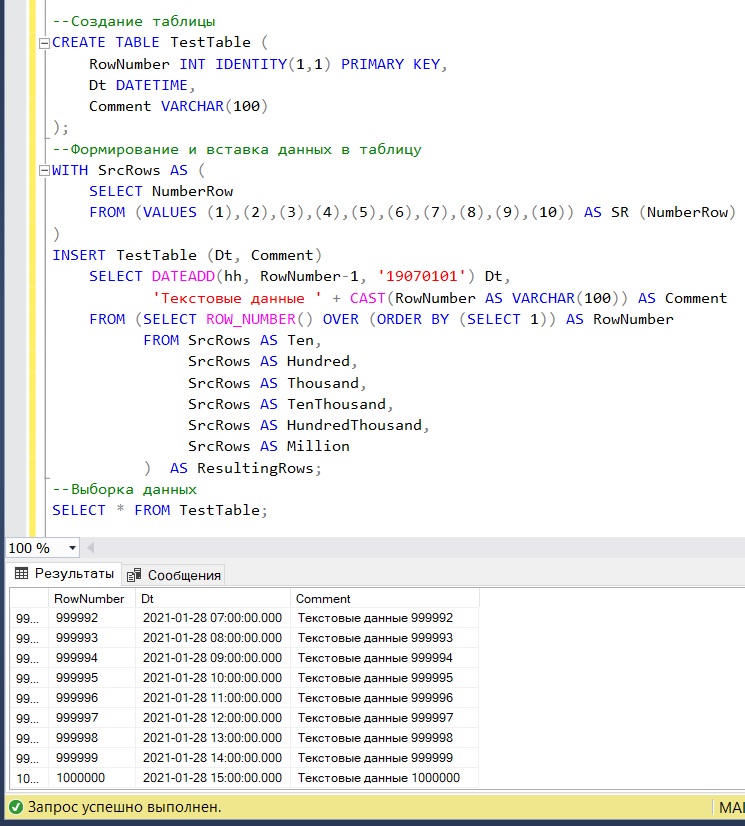
Для интереса создадим такой же индекс, но без фильтра по пометке удаления. Т.к. пример слишком простой, то разницы в результатах выполнения запроса мы не увидим, но размеры индексов будут разительно отличаться:
- фильтрованный индекс занимает 1 страницу и включает в себя 3 строки конечного уровня.
- полный индекс занимает 10319 страниц и содержит 2451400 строк конечного уровня.
А если не видно разницы, то зачем платить больше? ![]()
Таким же способом можно добавлять индексы для любых полей с типом “Булево” и это всегда будет эффективнее, чем добавлять индексы платформенными средствами.



