
SQL | Команды DDL, DQL, DML, DCL и TCL
SQL | Команды DDL, DQL, DML, DCL и TCL
Язык структурированных запросов (SQL), как мы все знаем, является языком баз данных, с помощью которого мы можем выполнять определенные операции с существующей базой данных, а также мы можем использовать этот язык для создания базы данных.SQL использует определенные команды, такие как Create, Drop, Insert и т. Д., Для выполнения необходимых задач.
Эти команды SQL в основном делятся на четыре категории:
- DDL — язык определения данных
- DQl — язык запросов данных
- DML — язык обработки данных
- DCL — язык управления данными
Хотя многие ресурсы утверждают, что существует еще одна категория предложений SQL TCL — Transaction Control Language . Так что мы также подробно рассмотрим TCL.
- DDL (язык определения данных): DDL или язык определения данных фактически состоит из команд SQL, которые можно использовать для определения схемы базы данных. Он просто занимается описанием схемы базы данных и используется для создания и изменения структуры объектов базы данных в базе данных.
Примеры команд DDL:
- CREATE — используется для создания базы данных или ее объектов (таких как таблица, индекс, функция, представления, процедура хранения и триггеры).
- DROP — используется для удаления объектов из базы данных.
- ALTER — используется для изменения структуры базы данных.
- TRUNCATE –используется для удаления всех записей из таблицы, включая удаление всех пространств, выделенных для записей.
- КОММЕНТАРИЙ — используется для добавления комментариев в словарь данных.
- RENAME –используется для переименования объекта, существующего в базе данных.
-
DQL (язык запросов данных):
Операторы
DML используются для выполнения запросов к данным в объектах схемы.Цель команды DQL — получить некоторое отношение схемы на основе переданного ей запроса.
Пример DQL:
SELECT — используется для извлечения данных из базы данных.
- DML (язык манипулирования данными): Команды SQL, которые имеют дело с манипуляциями с данными, присутствующими в базе данных, принадлежат DML или языку манипулирования данными, и это включает большинство операторов SQL.
Примеры DML:
- INSERT — используется для вставки данных в таблицу.
- ОБНОВЛЕНИЕ — используется для обновления существующих данных в таблице.
- DELETE — используется для удаления записей из таблицы базы данных.
- DCL (язык управления данными): DCL включает такие команды, как GRANT и REVOKE, которые в основном имеют дело с правами, разрешениями и другими элементами управления системы баз данных.
Примеры команд DCL:
- GRANT — дает пользователю права доступа к базе данных.
- REVOKE — отменить права доступа пользователя, предоставленные с помощью команды GRANT.
- TCL (язык управления транзакциями): команды TCL работают с транзакцией в базе данных.
Примеры команд TCL:
- COMMIT — совершает транзакцию.
- ROLLBACK — откатывает транзакцию в случае возникновения ошибки.
- SAVEPOINT — устанавливает точку сохранения в транзакции.
- SET TRANSACTION — указать характеристики транзакции.
Уровни изоляции в MS SQL Server
Уровень изоляции задает степень защищенности выбираемых транзакцией данных от возможности изменения другими транзакциями. Другими словами, они позволяют указать, какие аномалии транзакций могут иметь место, а какие необходимо избежать.
Read Uncommitted
Самая простая форма изоляции между транзакциями. Этот уровень не использует никакие блокировки, и, следовательно, совершенно не изолирует операции чтения от других транзакций. Из описанных в начале поста аномалий Read Uncommitted допускает три: грязное чтение, неповторяемое чтение и фантомы.
Read Committed
Существует две формы уровня изоляции Read Committed — для пессимистичной и оптимистичной моделей выполнения. В этом подразделе описывается пессимистичный вариант, оптимистичному соответствует уровень Read Committed Snapshot.
На этом уровне изоляции транзакция, читающая строку, проверяет только наличие монопольной блокировки для данной строки. В случае отсутствия блокировки транзакция извлекает строку с использованием уже разделяемой блокировки. Таким образом предотвращается чтение транзакцией данных, которые не были подтверждены и которые могут быть позже отменены. После того, как данные были прочитаны, их можно изменять другими транзакциями.
Применяемые этим уровнем изоляции разделяемые блокировки отменяются сразу же после обработки данных. При таком подходе к параллельному выполнению транзакций остаются аномалии неповторяемого и фантомного чтения.
Repeatable Read
В отличие от предыдущего уровня изоляции, Repeatable Read вешает разделяемые блокировки на все считываемые данные и удерживает их до тех пор, пока транзакция не будет подтверждена или отменена. Поэтому в этом случае многократное выполнение запроса внутри транзакции всегда будет возвращать один и тот же результат. Недостатком этого уровня изоляции является дальнейшее ухудшение одновременного конкурентного доступа, поскольку период времени, в течение которого другие транзакции не могут обновлять те же самые данные, значительно дольше, чем в случае уровня Read Committed.
Тем не менее, этот уровень изоляции не препятствует другим инструкциям вставлять новые строки, которые включаются в последующие операции чтения, вследствие чего могут появляться фантомы.
Serializable
Уровень изоляции Serializable является самым строгим, потому что он не допускает возникновения всех четырех аномалий конкурентного доступа, перечисленных в начале поста. Этот уровень устанавливает блокировку на всю область данных, считываемых соответствующей транзакцией. Поэтому этот уровень изоляции также предотвращает вставку новых строк другой транзакцией до тех пор, пока первая транзакция не будет подтверждена или отменена.
Read Committed Snapshot
Последние два уровня используются в оптимистичном контексте. Read Committed Snapshot применяется на уровне инструкции, что означает, что что любая другая транзакция будет читать зафиксированные значения в том виде, в каком они существуют на момент начала этой инструкции. Для выборки строк для обновлений этот уровень изоляции возвращает версии строк в фактические данные и устанавливает на выбранных строках блокировки обновлений. Реальные строки данных, которые требуется изменить, получают монопольные блокировки.
Snapshot
Уровень изоляции Snapshot предоставляет изоляцию на уровне транзакций, что означает, что любая другая транзакция будет читать подтвержденные значения в том виде, в каком они существовали непосредственно перед началом выполнения транзакции этого уровня изоляции. Кроме этого, транзакция уровня изоляции Snapshot будет возвращать исходное значение данных до завершения своего выполнения, даже если в течение этого времени оно будет изменено другой транзакцией. Поэтому другая транзакция сможет читать модифицированное значение только после завершения выполнения транзакции уровня изоляции Snapshot.
Как начать работу с SQL
Синтаксис операторов SQL является очень простым. Чтобы работать с ними, хватит базовых познаний в Еxcel и начального уровня английского языка. Ведь в основном операторам SQL задаются очень простые команды:
- SELECT — выбор данных.
- FROM — источник информации, откуда брать данные.
- JOIN — добавление таблиц.
- WHERE — при каком условии.
- GROUP BY — сформируй группу данных по заданному признаку.
- ORDER BY — сортировка данных по нужному признаку.
- LIMIT —количество результатов.
- ; — конец предложения
Популярные статьи
Высокооплачиваемые профессии сегодня и в ближайшем будущем
Дополнительный заработок в Интернете: варианты для новичков и специалистов
Востребованные удаленные профессии: зарабатывайте, не выходя из дома
Разработчик игр: чем занимается, сколько зарабатывает и где учится
Как выбрать профессию по душе: детальное руководство + ценные советы
Все системы, работающие с SQL операторами, имеют подобную структуру. Они включают в себя базу данных в виде таблицы, из которой пользователь черпает информацию, возможность отправки запросов и получения результата.
Как начать работу с SQL
Можно изучить язык SQL самостоятельно. Для этого существует множество видео на на YouTube, а также большое количество статей от специалистов в данной сфере. Конечно, как и в любой другой области, для наиболее полного получения информации и лучшего её усвоения стоит пройти курс у компетентного специалиста.
Как вы можете видеть, в настоящее время язык операторов SQL используется повсеместно. Он помогает в разработке сайтов, программ и мобильных приложений, а также в редактировании уже имеющихся данных.
Сложная задача про календарь
Решил предыдущие задачи и они слишком простые? Ок, давай возьмемся за действительно сложную задачу. Напиши SQL-код, выводящий календарь на текущий месяц в виде:
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Подсказка: ты можешь делать запросы без таблиц, например
- Подсказка: здесь не надо использовать циклы или процедуры
- Подсказка: функции работы с датой и временем ты можешь найти тут http://dev.mysql.com/doc/refman/5.0/en/date-and-time-functions.html (англ.)
- Подсказка: для сокращения объема кода ты можешь использовать переменные (создаются командой )
Transaction Types
SQL transactions can be run in the following modes.
| Transaction mode | Description |
|---|---|
| Autocommit transaction | Each individual statement is a transaction. |
| Implicit transaction | A new transaction is implicitly started when the prior transaction completes, but each transaction is explicitly completed, typically with a or statement depending on the DBMS. |
| Explicit transaction | Explicitly started with a line such as , or similar, depending on the DBMS, and explicitly committed or rolled back with the relevant statements. |
| Batch-scoped transaction | Applicable only to multiple active result sets (MARS). An explicit or implicit transaction that starts under a MARS session becomes a batch-scoped transaction. |
The exact modes and options available may depend on the DBMS. This table outlines the transaction modes available in SQL Server.
In this article, we’re mainly focussed on explicit transactions.
See How Implicit Transactions Work in SQL Server for a discussion of the difference between implicit transactions and autocommit.
Marked transactions in SQL Server
SQL Server allows us to mark and add a description to a specific transaction in the log files. In this way, we can
generate a recovery point that is independent of the time. Such as, when an accidental data modification occurs
in the database and we don’t know the exact time of the data modification, the data recovery effort can be taken a
long time. For this reason, marked transactions can be a useful solution to find out the exact time of the data
modifications. In order to create a marked transaction, we need to give a name to the transaction and we also need
to add WITH MARK syntax. In the following query, we will delete some rows and we will also mark the
modifications in the log file.






|
1 |
BEGINTRANDeletePersonWITHMARK’MarkedTransactionDescription’ DELETEPersonWHEREPersonIDBETWEEN3AND4 COMMITTRANDeletePerson |
The logmarkhistory table stores details about each marked transactions that have been committed and
it is placed in the msdb database.
| 1 | SELECT*FROMmsdb.dbo.logmarkhistory |
As we can see in the above image the logmarkhistory gives all details about the marked transaction.
The following two options help to use marked transactions as a recovery point.
- STOPATMARK rolls forward to the mark and includes the marked transaction in the roll forward
- STOPBEFOREMARK rolls forward to the mark and excludes the marked transaction from the roll forward
You can read the following articles to learn more details about recovering a database from the transaction log backups:
- Recovering Data from the SQL Server Transaction Log
- Recovery of Related Databases That Contain Marked Transaction
Побочные эффекты параллелизма
Все операции в базе происходят не мгновенно и при одновременном изменении данных различными пользователями возможны следующие побочные эффекты:
- Потерянное обновление (lost update)
- «Грязное» чтение (dirty read)
- Неповторяющееся чтение (non-repeatable read)
- Фантомное чтение (phantom reads)
Далее, эти эффекты рассматриваются подробно и приводятся SQL скрипты, показывающие проблему на практике. Я настоятельно рекомендую попробовать выполнить их и увидеть проблему «в живую», но для этого нужно сначала подготовить ваш сервер. Шаги по подготовки и особенности запуска скриптов описаны ниже.
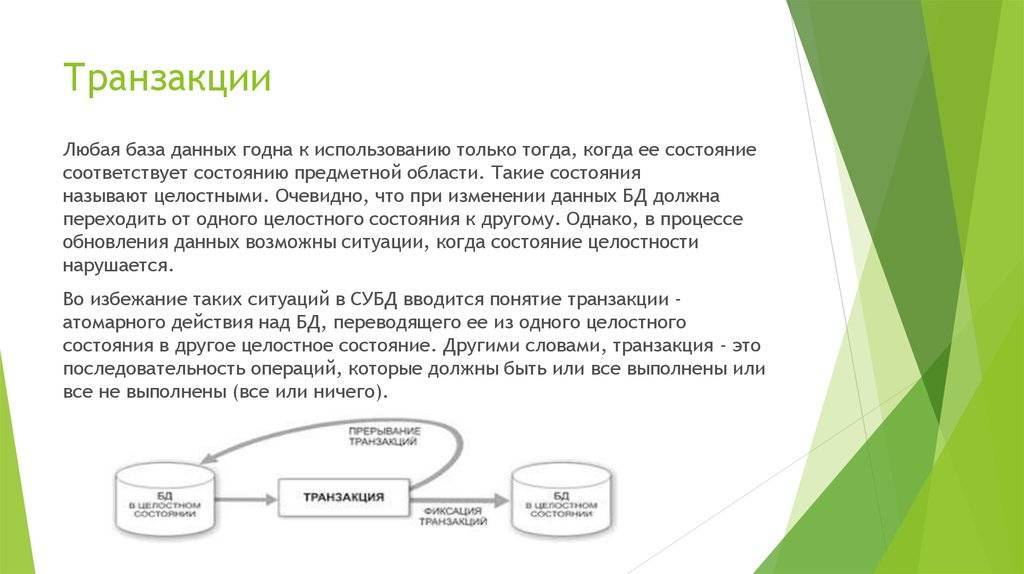
Определение транзакций
Существует несколько способов управления поведением транзакций. При этом пользователь должен указать только начало и конец транзакции. Транзакции определяются на уровне одного соединения с базой данных, и при закрытии этого соединения, автоматически закрываются. После того, как транзакция открыта, все команды, которые описаны внутри ее, выполняются как единое целое, пока не будет достигнут конец транзакции.
СУБД MS SQL Server поддерживает три вида транзакций:
• явное;
• автоматическое;
• подразумеваемое.
Если тип транзакции не указан явно, то по умолчанию используется режим автоматического определения начала и конца транзакции, при котором каждая команда рассматривается сервером как отдельная транзакция. Если указанные команды в транзакции выполняются успешно, то все внесенные в базу данных изменения фиксируются. Если же при выполнении команд произошли ошибки или сбои, то все сделанные изменения в базе отменяются.
Если необходимо передать серверу базы данных несколько команд внутри одной транзакции, то следует явно указать тип транзакции. Чтобы установить режим автоматического определения транзакций, необходимо выполнить команду:
SET IMPLICIT_TRANSACTIONS OFF
Если используется режим подразумевающегося начала транзакции, то сервер автоматически будет начинать новую транзакцию, только после того, как будет завершена предыдущая. Чтобы включить данный режим, используют команду:
SET IMPLICIT_TRANSACTIONS ON
Пример перевода средств
- Транзакция для перевода 1000 долларов со счета X на счет Y:
- чтения (X)
- X = X –1000
- записи (Х)
- готовы)
- Y = Y + 1000
- написать (Y)
- Требование атомарности — если транзакция завершится неудачей после шага 3 и до шага 6, система должна убедиться, что ее обновления не отражены в базе данных, иначе возникнет несогласованность.
- Требование согласованности — сумма X и Y не изменяется при выполнении транзакции.
- если между шагами 3 и 6 другой транзакции будет разрешен доступ к частично обновленной базе данных, он увидит несогласованную базу данных (сумма X + Y будет меньше, чем должна быть).
- Изоляция может быть обеспечена тривиально, последовательно выполняя транзакции, то есть одну за другой.
- Однако одновременное выполнение нескольких транзакций имеет значительные преимущества, как мы увидим позже.
- Требование долговечности — после того, как пользователь будет уведомлен о завершении транзакции (т. Е. Произошла передача 1000 долларов США), обновления базы данных транзакцией должны сохраняться, несмотря на сбои.
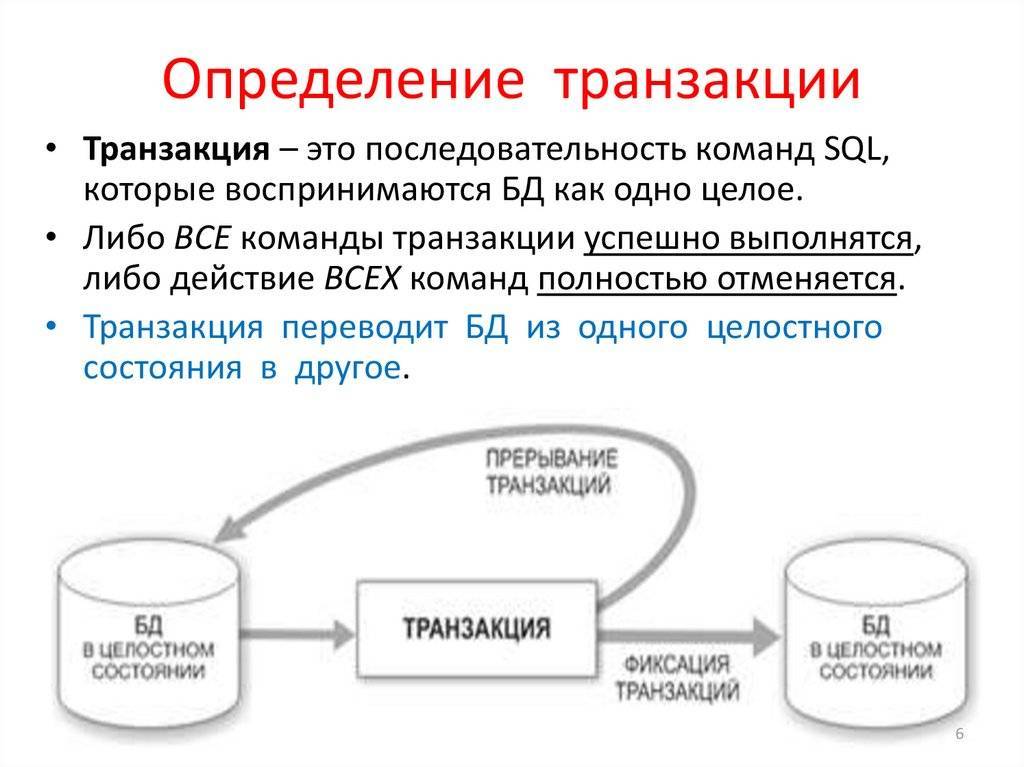
Что такое транзакция?
Транзакция — это набор операций, которые выполняются в базе данных как один логический блок. При использовании транзакций, SQL Server позволяет обеспечить целостность данных, и возможность восстановить удаленные или измененные данные. SQL Server использует внутренний журнал транзакций для возможности восстановления данных в случае произошедших ошибок или отказов системы.
Целостность самой транзакции зависит от программиста. Он должен правильно определить, когда следует начать и когда закончить транзакцию, в какой последовательности выполнять операции в транзакции, чтобы обеспечить логическую последовательность и содержательность данных.
Команды управления транзакциями в T-SQL
В T-SQL для управления транзакциями существуют следующие основные команды:
- BEGIN TRANSACTION (можно использовать сокращённую запись BEGIN TRAN) – команда служит для определения начала транзакции. В качестве параметра этой команде можно передать и название транзакции, полезно, если у Вас есть вложенные транзакции;
- COMMIT TRANSACTION (можно использовать сокращённую запись COMMIT TRAN) – с помощью данной команды мы сообщаем SQL серверу об успешном завершении транзакции, и о том, что все изменения, которые были выполнены, необходимо сохранить на постоянной основе;
- ROLLBACK TRANSACTION (можно использовать сокращённую запись ROLLBACK TRAN) – служит для отмены всех изменений, которые были внесены в процессе выполнения транзакции, например, в случае ошибки, мы откатываем все назад;
- SAVE TRANSACTION (можно использовать сокращённую запись SAVE TRAN) – данная команда устанавливает промежуточную точку сохранения внутри транзакции, к которой можно откатиться, в случае возникновения необходимости.
Проблемы взаимодействия транзакций
Существует, как известно, несколько проблем взаимодействия конкурирующих транзакций, для которых определены уровни изоляции:
1) Потеря результатов обновления Две транзакции с некоторым сдвигом по времени читают данные из одной и той же строки и затем изменяют данные в ней. После фиксации изменений первой по времени транзакции ее данные будут утеряны, поскольку тут же будут обновлены второй транзакцией.
2) «Грязное» чтение Одна транзакция модифицирует строку, а другая её читает перед тем, как изменения будут зафиксированы оператором COMMIT. Если первая транзакция отменяется, то окажется, что вторая транзакция считала неправильные данные.
3) «Неповторяемое» чтение Одна транзакция читает строку, а вторая затем её изменяет и фиксирует данные оператором COMMIT до того, как завершается первая. Если первая транзакция повторит чтение этой строки, то получит другие данные.
4) «Фантом» или «иллюзии» Одна транзакция читает группу строк, удовлетворяющих предикату. Вторая транзакция (INSERT или UPDATE) также удовлетворяет этому предикату. Первая транзакция получить другие данные при повторном чтении.
5) Особенности уровней изоляции
| Уровень изоляции | Потеря результатов обновления | Грязное чтение | Неповторяемое чтение | Фантом |
| READ UNCOMMITTED | Защищает | Нет | Нет | Нет |
| READ COMMITTED | Защищает | Защищает | Нет | Нет |
| REPEATABLE READ | Защищает | Защищает | Защищает | Нет |
| SERIALIZABLE | Защищает | Защищает | Защищает | Защищает |
6) Ключевые слова a) Read UnCommitted Уровень изоляции, называемый незавершенное чтение (READ UNCOMMITTED), не имеет ограничение на чтение данных, и при различных действиях над ними они будут видимы всеми пользователями.
Этот уровень обеспечивает максимальную параллельность и минимальную изоляцию (фактически они не изолируются).
Его целесообразно использовать в тех случаях, когда много операций чтения данных и не более одной транзакции изменения данных.
b) Read Committed Уровень изоляции, называемый завершенное чтение (READ COMMITTED), ограничивает только «грязное чтение», поэтому обеспечивает высокий уровень параллелизма и предпочтителен в тех случаях, когда модифицируется несколько данных.
Особенности завершенного чтения Если конкурирующие транзакции одновременно открыли набор данных (НД), то каждая из них не видит изменений, вносимых другой.
Если конкурирующие транзакции одновременно открыли НД и внесли изменения в него, то зафиксировать можно транзакцию, первой начавшую вносить изменения.
Если одна транзакция первой открыла НД для внесения изменений, то другая транзакция не сможет открыть этот же НД, пока первая транзакция не зафиксирует изменения.
c) Repeatable Read Уровень изоляции, называемый повторяемое чтение (REPEATABLE READ), ограничивает «грязное чтение» и «неповторяемое чтение», поэтому приемлем в тех случаях, когда возможны множественные изменения.
Этот уровень предполагает установку блокировок на множество строк и надо быть уверенным, что эти строки не выбираются другими пользователями.
d) Serializable Уровень изоляции, называемый последовательное преобразование (SERIALIZABLE), обеспечивает максимальную степень изоляции и, соответственно, целостности данных. Транзакции ведут себя так, как будто они выполняются последовательно друг за другом.
7) Управление транзакциями из клиента В Delphi управление транзакциями может производится с помощью свойств и методов компонента Database. a) Структурная схема подключения к БД
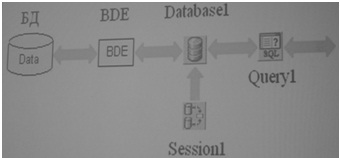
b) Компонент Database
c) Установка уровня изоляции транзакций Установка уровня изоляции транзакций с помощью компонента Database может производиться как во время проектирования приложения-клиента, так и в процессе его работы с помощью строки кода: Database1.TransIsolation:=tiReadCommitted; Старт и завершение транзакций можно выполнять с помощью вызова методов компонента Database:
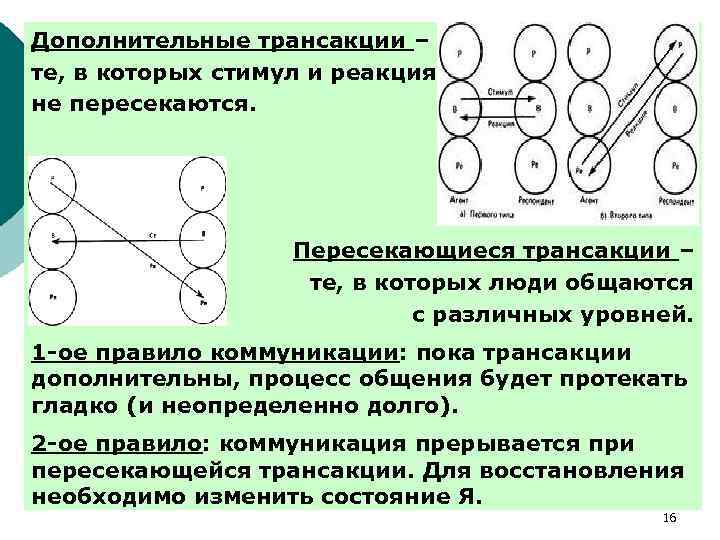
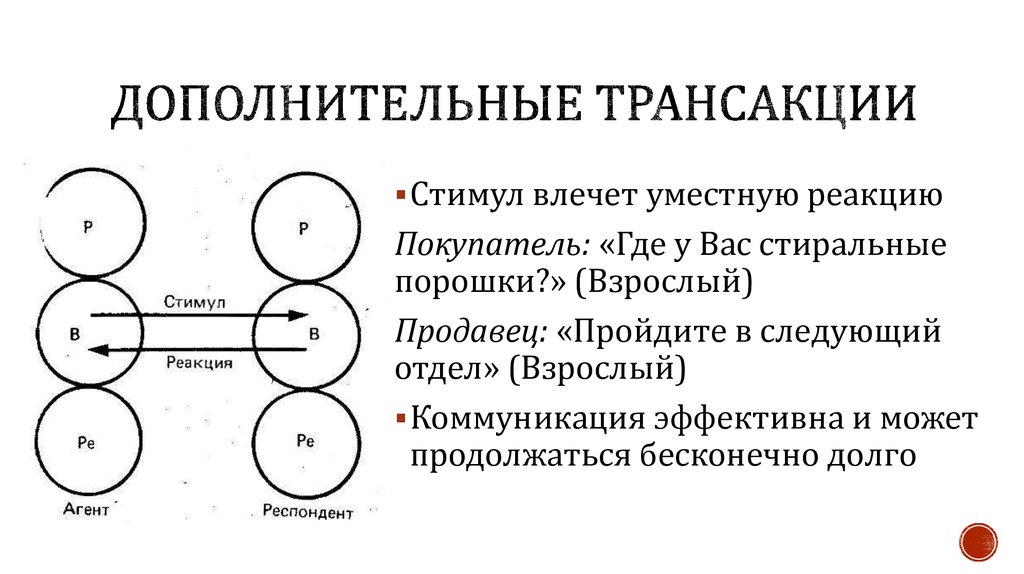
Неповторяющееся чтение (non-repeatable read)
Проявляется, когда при повторном чтении в рамках одной транзакции, ранее прочитанные данные, оказываются изменёнными. Данный эффект может наблюдаться при уровне изоляции ниже, чем REPEATABLE READ.






Transact-SQL
— Транзакция 1
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
—SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
BEGIN TRAN;
SELECT Value
FROM Table1
WHERE Id = 1;
WAITFOR DELAY ’00:00:10′;
SELECT Value
FROM Table1
WHERE Id = 1;
COMMIT;
— Результат для READ COMMITTED Value = 1 и Value = 42
— Результат для REPEATABLE READ Value = 1 и Value = 1
— Транзакция 2
BEGIN TRAN;
UPDATE Table1
SET Value = 42
WHERE Id = 1;
COMMIT TRAN;
— Результат для READ COMMITTED Мгновенное выполнение
— Результат для REPEATABLE READ Ожидание завершения транзакции 1
|
1 |
— Транзакция 1 SETTRANSACTIONISOLATIONLEVELREADCOMMITTED —SET TRANSACTION ISOLATION LEVEL REPEATABLE READ BEGINTRAN; SELECTValue FROMTable1 WHEREId=1; WAITFORDELAY’00:00:10′; SELECTValue FROMTable1 WHEREId=1; COMMIT; BEGINTRAN; UPDATETable1 SETValue=42 WHEREId=1; COMMITTRAN; |
Примеры транзакций в T-SQL
Давайте рассмотрим примеры транзакций, реализованные на языке T-SQL.
Исходные данные для примеров
Но сначала нам необходимо создать тестовые данные для нашего примера.
Для этого выполните следующую инструкцию.
--Создание таблицы
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL,
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
--Добавление данных в таблицу
INSERT INTO Goods(ProductName, Price)
VALUES ('Системный блок', 50),
('Клавиатура', 30),
('Монитор', 100);
SELECT ProductId, ProductName, Price
FROM Goods;
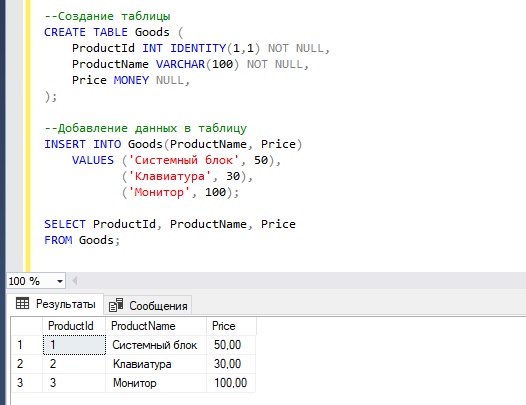
Простой пример транзакции в T-SQL
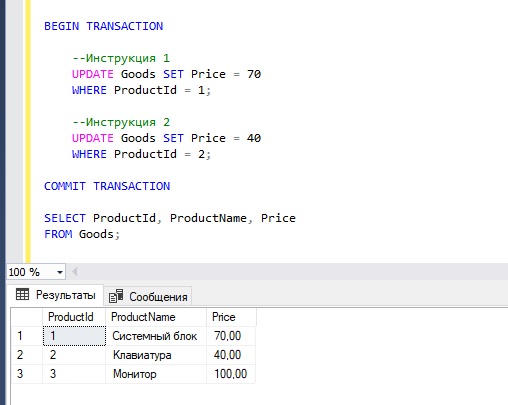
В данном примере у нас всего две инструкции, которые изменяют данные, но допустим, что они взаимосвязаны, т.е. они обе обязательно должны выполниться вместе или не выполниться также вместе.
Поэтому мы решили эти инструкции объединить в одну транзакцию.
Сначала мы открываем транзакцию командой BEGIN TRANSACTION, далее пишем все необходимые инструкции, которые мы хотим объединить в транзакцию.
После этого командой COMMIT TRANSACTION мы сохраняем все внесенные изменения.
В данном случае у нас нет никаких ошибок, все инструкции выполнились успешно. Как результат, транзакция завершена также успешно и все изменения сохранены на постоянной основе командой COMMIT TRANSACTION.
BEGIN TRANSACTION --Инструкция 1 UPDATE Goods SET Price = 70 WHERE ProductId = 1; --Инструкция 2 UPDATE Goods SET Price = 40 WHERE ProductId = 2; COMMIT TRANSACTION SELECT ProductId, ProductName, Price FROM Goods;
Однако, если в любой из инструкций возникнет ошибка, транзакция не завершится, и все изменения не сохранятся.
Например, если во второй инструкции мы попытаемся записать в столбец Price какое-нибудь текстовое значение, то у нас возникнет ошибка, и изменения, внесённые первой инструкцией, не зафиксируются на постоянной основе.
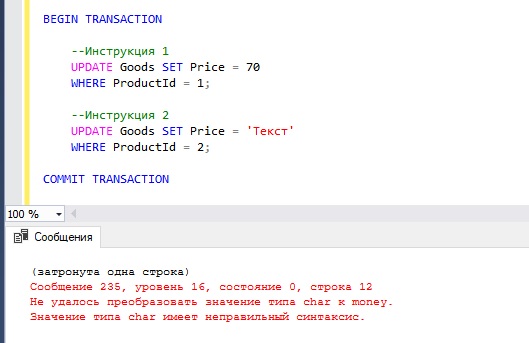
Пример транзакции в T-SQL с обработкой ошибок
В языке T-SQL существует механизм перехвата и обработки ошибок – конструкция TRY… CATCH.
Эту конструкцию можно использовать для отслеживания появления возможных ошибок внутри транзакции и в случае появления таких ошибок предпринять определенные действия.
Сначала мы открываем блок для обработки ошибок, затем открываем транзакцию командой BEGIN TRANSACTION, далее пишем наши инструкции, например, те же самые две инструкции UPDATE.
После этого закрываем блок TRY, открываем блок CATCH, в котором в случае возникновения ошибки мы откатываем все изменения командой ROLLBACK TRANSACTION. Также мы принудительно завершаем нашу инструкцию командой RETURN.
Если ошибок нет, то в блок CATCH мы, соответственно, не попадаем и у нас выполнится команда COMMIT TRANSACTION, которая сохранит все изменения.
В этом примере нет ошибок, поэтому транзакция завершена успешно.
BEGIN TRY
--Начало транзакции
BEGIN TRANSACTION
--Инструкция 1
UPDATE Goods SET Price = 70
WHERE ProductId = 1;
--Инструкция 2
UPDATE Goods SET Price = 40
WHERE ProductId = 2;
END TRY
BEGIN CATCH
--В случае непредвиденной ошибки
--Откат транзакции
ROLLBACK TRANSACTION
--Выводим сообщение об ошибке
SELECT ERROR_NUMBER() AS ,
ERROR_MESSAGE() AS
--Прекращаем выполнение инструкции
RETURN
END CATCH
--Если все хорошо. Сохраняем все изменения
COMMIT TRANSACTION
GO
SELECT ProductId, ProductName, Price
FROM Goods;
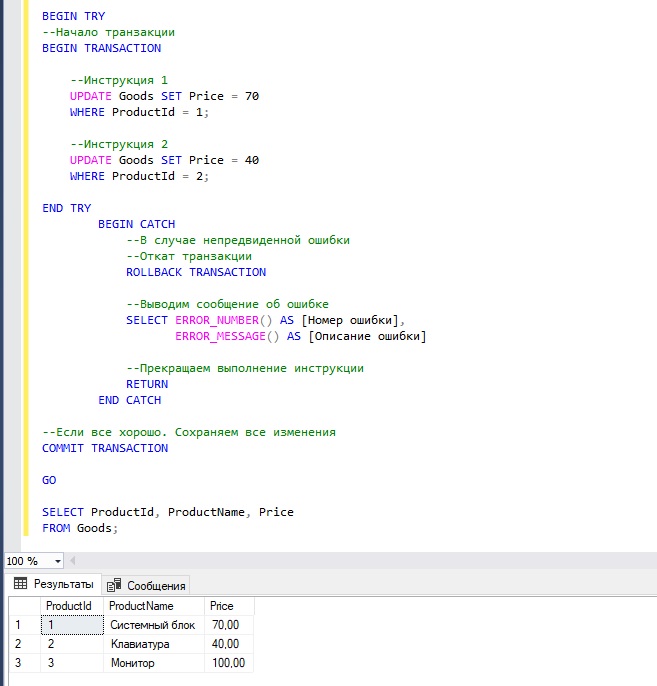
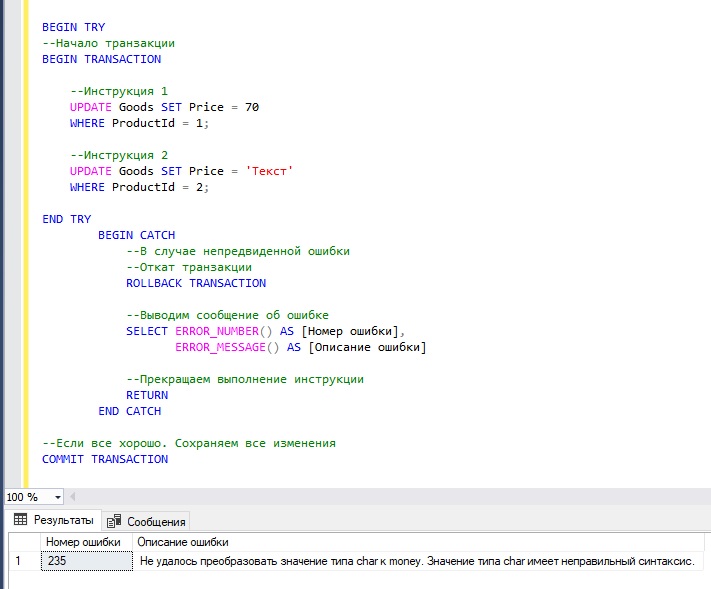
А в этом примере мы намерено допускаем ошибку во второй инструкции. Поэтому управление передается в блок CATCH, где мы откатываем все изменения, возвращаем номер и описание ошибки и принудительно завершаем всю инструкцию командой RETURN.









Первая инструкция отработала нормально, но ее изменения не были сохранены, так как вторая инструкция выполнена с ошибкой.
Выборка сводных данных (из двух и более таблиц)
При формировании сводной выборки данные беруться из нескольких таблиц. В операторе FROM исходные таблицы перечисляются через запятую. Также им могут быть присвоены алиасы. Синтаксис запроса выглядит следующийм образом:
SELECT
.Название_поля1, .Название_поля2,...
FROM
Table1 ,
Table2
...
При выборке сводных таблиц нужно учитывать, что исходные таблицы перемножаются. Т.е. если на входе у нас были таблицы:
| id | Name |
|---|---|
| 1 | Иванов |
| 2 | Петров |
| id | Name | Phone |
|---|---|---|
| 1 | Иванов | 322223 |
| 2 | Петров | 111111 |
То при простом запросе без условий
SELECT a.*, b.*
FROM
Table1 a, Table2 b
Получим примерно следующее:
| id | Name | id2 | Name2 | Phone |
|---|---|---|---|---|
| 1 | Иванов | 1 | Иванов | 322223 |
| 1 | Иванов | 2 | Петров | 111111 |
| 2 | Петров | 1 | Иванов | 322223 |
| 2 | Петров | 2 | Петров | 111111 |
Чтобы выбрать уникальные значения, нам нужно использовать оператор WHERE для связи этих таблиц
SELECT a.*, b.Phone
FROM
Table1 a, Table2 b
WHERE
a.Name=b.Name
| id | Name | Phone |
|---|---|---|
| 1 | Иванов | 322223 |
| 2 | Петров | 111111 |
Сводные выборки нужны при импорте данных в базу. Сначала вы выделяете из таблиц импорта словари. А потом из таблиц импорта и словарей формируете запрос для записи данных в основную таблицу.
Задачка про кинотеатр
Вот дополнительная, более сложная задачка. Есть кинотеатр, в нем идут фильмы. У фильма есть название, длительность (пусть для простоты будет 60, 90 или 120 минут), цена билета (в разное время и дни может быть разная), время начала сеанса (один фильм может быть показан несколько раз в разное время за разную цену). Также, есть информация о купленных билетах (номер билета, на какой сеанс).
Задания:
составь грамотную нормализованную схему хранения этих данных в БД. Внеси в нее 4-5 фильмов, расписание на один день и несколько проданных билетов.
Сделай запросы, считающие и выводящие в понятном виде:
- ошибки в расписании (фильмы накладываются друг на друга), отсортированные по возрастанию времени. Выводить надо колонки «фильм 1», «время начала», «длительность», «фильм 2», «время начала», «длительность».
- перерывы больше или равные 30 минут между фильмами, выводятся по уменьшению длительности перерыва. Выводить надо колонки «фильм 1», «время начала», «длительность», «время начала второго фильма», «длительность перерыва».
- список фильмов, для каждого указано общее число посетителей за все время, среднее число зрителей за сеанс и общая сумма сбора по каждому, отсортированные по убыванию прибыли. Внизу таблицы должна быть строчка «итого», содержащая данные по всем фильмам сразу.
- число посетителей и кассовые сборы, сгруппированные по времени начала фильма: с 9 до 15, с 15 до 18, с 18 до 21, с 21 до 00:00. (то есть сколько посетителей пришло с 9 до 15 часов, сколько с 15 до 18 и т.д.).



