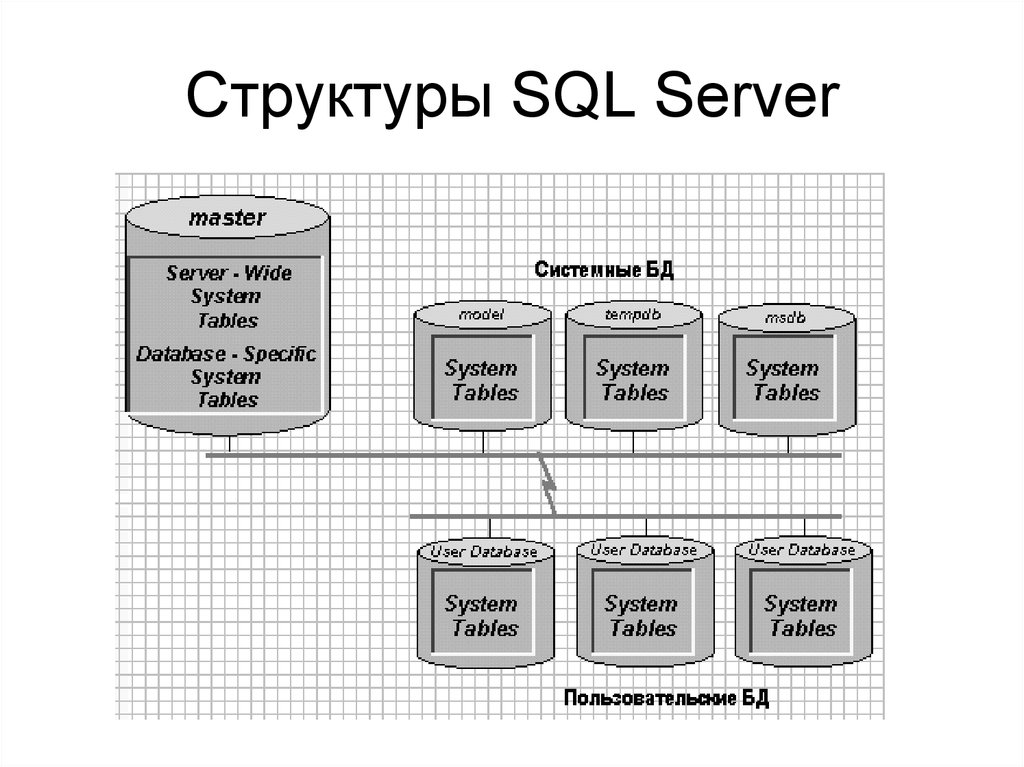
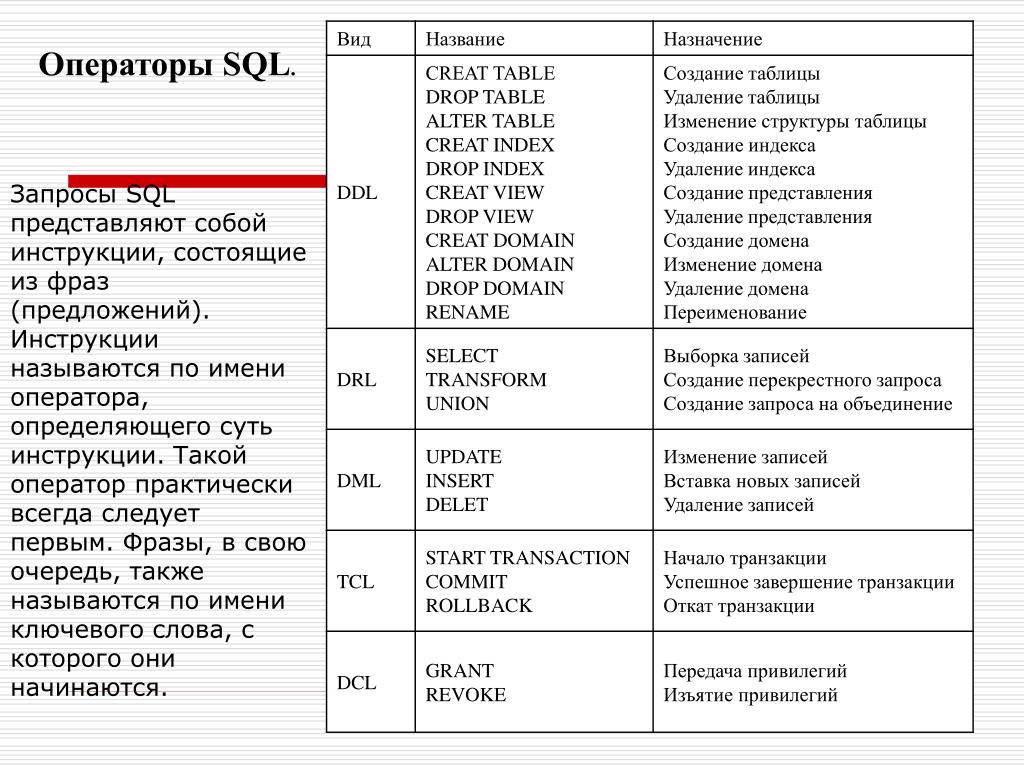
В каких базах данных используют SQL
Все БД можно поделить на два вида: реляционные и нереляционные. Язык SQL нужен для работы с первыми.
SQL настолько тесно связан с реляционными БД, что все нереляционные БД в противовес стали называть NoSQL. Вот и получилось, что SQL — это язык программирования, а NoSQL — тип баз данных.
Про реляционные БД часто говорят, что это набор двумерных таблиц. Прямо как в Excel: со столбцами, строками и ячейками. Это понятная визуализация, хотя и не совсем точная.
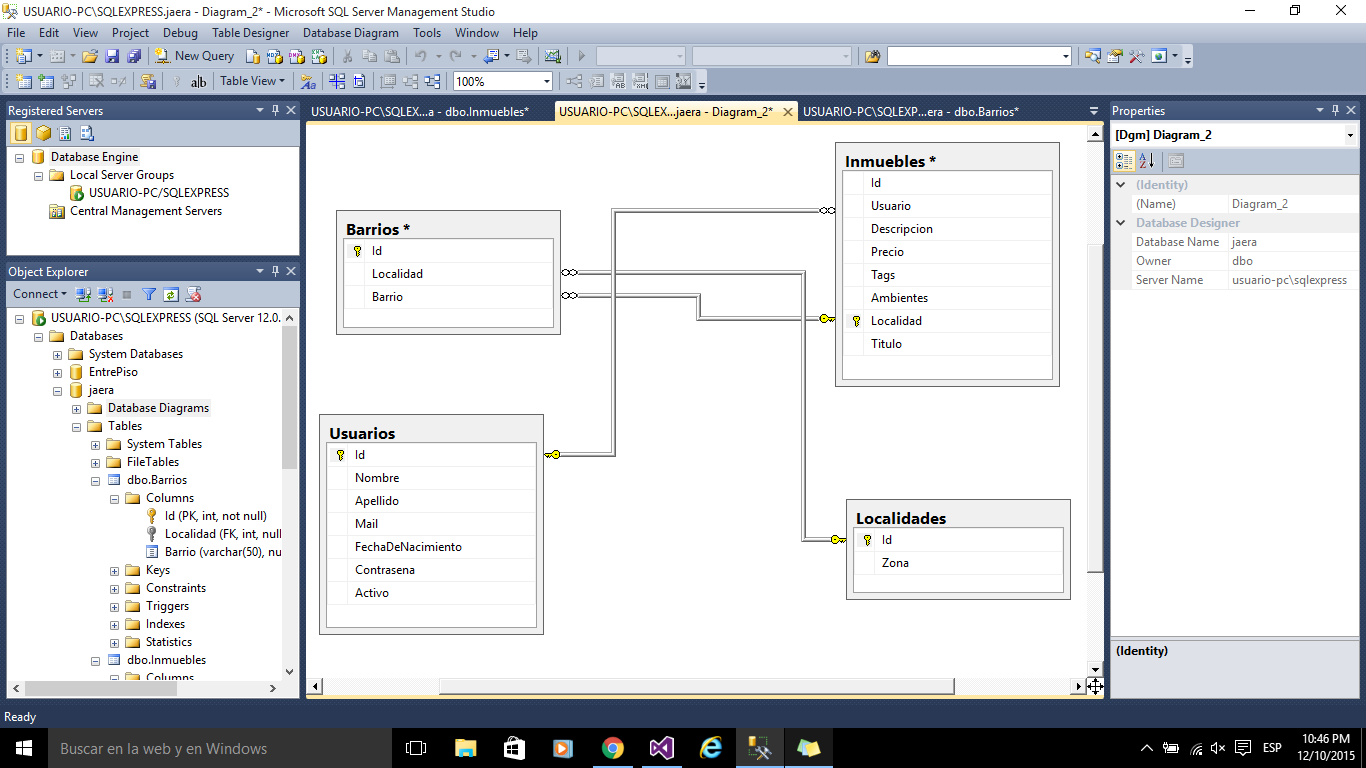
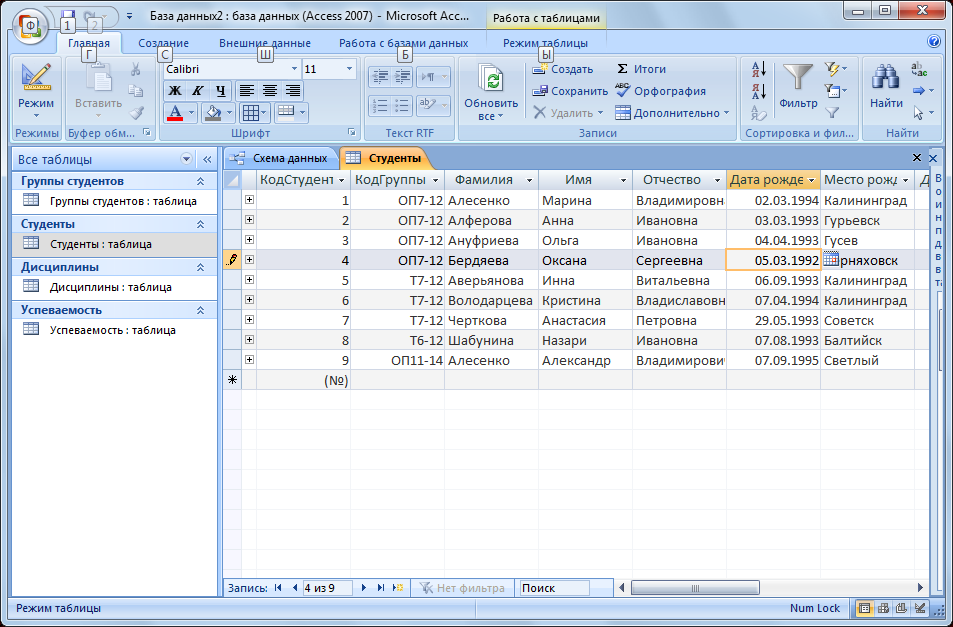
Представим, что мы создаём базу данных для небольшой строительной фирмы. Она проектирует загородные дома и передаёт проекты подрядчикам, которые занимаются самим строительством:
Примерная база данных воображаемой строительной фирмыСкриншот: Skillbox Media
Чем же база данных отличается от таблицы? Тем, что в базе:
- У столбцов и строк нет определённого положения. Нельзя сказать, что столбец status находится до или после столбца num_floors, а имя Анастасии Романиной — до или после имени Дмитрия Пожарова.
- Каждый столбец диктует свой домен, то есть тип данных, к которому могут относиться его значения. Например, в столбцах cost и num_floors могут храниться только числа, а в столбце client — только строки.
- Каждая строка должна быть уникальной и не может повторять какую-то другую строку.
Конкатенация полей
Конкатенация — «склеивание» нескольких строк в одну.
Допустим, мы создаём список студентов участвующих в творческом конкурсе, и нам требуется указать их возраст в виде Фамилия (возраст). В PostgreSQL соединить значения двух столбцов и добавить скобки мы можем с помощью оператора ||:
SELECT student_surname || ' (' || student_age || ')'
FROM Students
ORDER BY student_surname;
Получим:
------------------------------------ Адамченко (21 ) Грошев (20 ) Егорова (19 ) Колобков (22 ) Легран (24 ) Петрашевский (22 ) Распопов (22 ) Римский (21 ) Сейдинай (25 ) Шульгина (23 )
Как вы можете увидеть, в результате мы имеем все 4 части, склеенные в одну строку. Но мешают пробелы, которыми было заполнено поле. Чтобы их убрать, воспользуемся функцией RTRIM(), которая удаляет все пробелы, справа от значения. Также, в случае необходимости, можете использовать LTRIM() и TRIM(), удаляющие соответственно пробелы слева от строки или пробелы и слева, и справа.
SELECT RTRIM(student_surname) || ' (' || RTRIM(student_age) || ')'
FROM Students
ORDER BY student_surname;
------------------------------------
Адамченко (21)
Грошев (20)
Егорова (19)
Колобков (22)
Легран (24)
Петрашевский (22)
Распопов (22)
Римский (21)
Сейдинай (25)
Шульгина (23)
В некоторых других СУБД для конкатенации вместо «||» используется «+».
В MySQL конкатенацию можно осуществить с помощью функции CONCAT().
Псевдонимы вычисляемых полей
Наверное вы заметили, что новый столбец, который мы получили «на лету», не имеет имени. В таком случае мы не сможем обратиться к нему на стороне клиентского приложения. Чтобы решить эту проблему, дадим столбцу псевдоним. Для этого используется ключевое слово AS:
SELECT RTRIM(student_surname) || ' (' || RTRIM(student_age) || ')'
AS student_data
FROM Students
ORDER BY student_surname;
Получим:
student_data ------------------------------------ Адамченко (21) Грошев (20) Егорова (19) Колобков (22) Легран (24) Петрашевский (22) Распопов (22) Римский (21) Сейдинай (25) Шульгина (23)
Теперь мы сможем обращаться к результату данного запроса по имени, так, как если бы это был реальный столбец.
Псевдонимы могут быть использованы и для переименования существующих столбцов таблицы. Обычно это делают для сокращения длинных неудобочитаемых заголовков, но причина может быть и любая другая
Важно помнить, что если вы хотите дать столбцу сложный псевдоним из нескольких слов, его надо будет заключить в кавычки
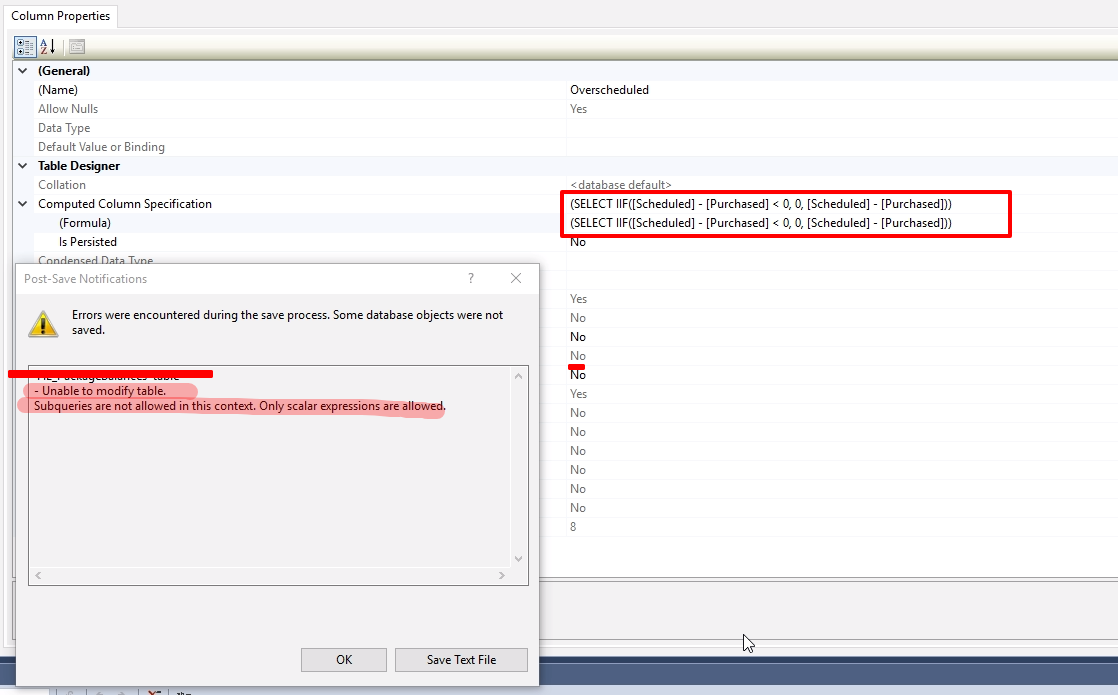
Добавление вычисляемого столбца в существующую таблицу в Microsoft SQL Server
А сейчас давайте допустим, что возникла необходимость знать еще и сумму с учетом некого статического коэффициента (например, 1,7). Но нам об этом сказали уже после того, как мы создали таблицу, иными словами, нам нужно добавить вычисляемый столбец в существующую таблицу.
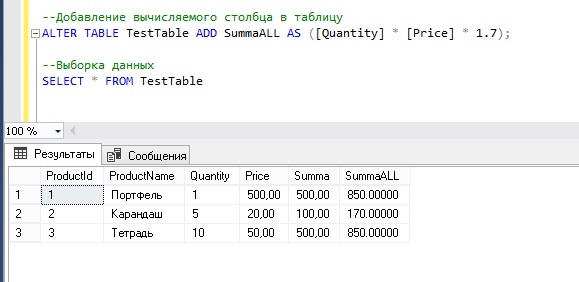
Добавление вычисляемых столбцов доступно также и в графической среде SQL Server Management Studio. Для этого Вам нужно просто в обозревателе объектов найти нужную таблицу и щелкнуть правой кнопкой мыши по контейнеру «Столбцы» и выбрать «Создать столбец», т.е. все как обычно.

Затем указать название столбца и тип данных (тип данных временно), а для того чтобы определить вычисляемый столбец, в «Свойствах столбца» нужно найти раздел «Спецификация вычисляемого столбца» и в поле «Формула» указать соответствующую формулу.
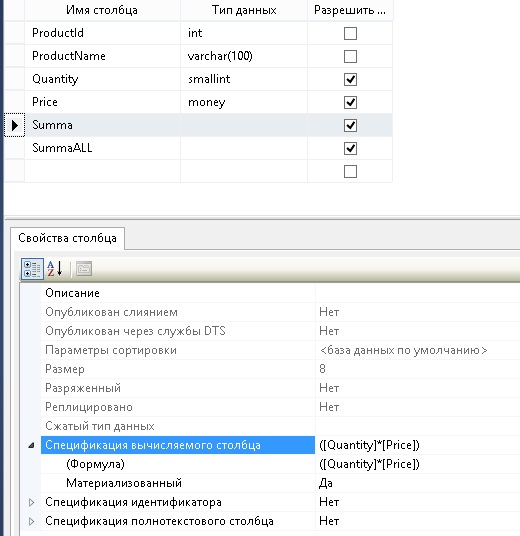
Точно также определяется вычисляемый столбец и при создании таблицы с помощью Management Studio, т.е. просто в соответствующем разделе указывается формула.
Агрегатные функции
Последнее обновление: 19.07.2017
Агрегатные функции выполняют вычисления над значениями в наборе строк. В T-SQL имеются следующие агрегатные функции:
-
AVG: находит среднее значение
-
SUM: находит сумму значений
-
MIN: находит наименьшее значение
-
MAX: находит наибольшее значение
-
COUNT: находит количество строк в запросе
В качестве аргумента все агрегатные функции принимают выражение, которое представляет критерий дя определения значений. Зачастую, в качестве
выражения выступает название столбца, над значениями которого надо проводить вычисления.
Выражения в функциях AVG и SUM должно представлять числовое значение. Выражение в функциях
MIN, MAX и COUNT может представлять числовое или строковое значение или дату.
Все агрегатные функции за исключением игнорируют значения NULL.
Avg
Функция Avg возвращает среднее значение на диапазоне значений столбца таблицы.
Пусть в базе данных у нас есть таблица товаров Products, которая описывается следующими выражениями:
CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
INSERT INTO Products
VALUES
('iPhone 6', 'Apple', 3, 36000),
('iPhone 6S', 'Apple', 2, 41000),
('iPhone 7', 'Apple', 5, 52000),
('Galaxy S8', 'Samsung', 2, 46000),
('Galaxy S8 Plus', 'Samsung', 1, 56000),
('Mi6', 'Xiaomi', 5, 28000),
('OnePlus 5', 'OnePlus', 6, 38000)
Найдем среднюю цену товаров из базы данных:
SELECT AVG(Price) AS Average_Price FROM Products
Для поиска среднего значения в качестве выражения в функцию передается столбец Price. Для получаемого значения устанавливается псевдоним Average_Price, хотя можно его и не
устанавливать.
Также мы можем применить фильтрацию. Например, найти среднюю цену для товаров какого-то определенного производителя:
SELECT AVG(Price) FROM Products WHERE Manufacturer='Apple'
И, кроме того, мы можем находить среднее значение для более сложных выражений.
Например, найдем среднюю сумму всех товаров, учитывая их количество:
SELECT AVG(Price * ProductCount) FROM Products
Count
Функция Count вычисляет количество строк в выборке. Есть две формы этой функции.
Первая форма подсчитывает число строк в выборке:
SELECT COUNT(*) FROM Products
Вторая форма функции вычисляет количество строк по определенному столбцу, при этом строки со значениями NULL игнорируются:
SELECT COUNT(Manufacturer) FROM Products
Min и Max
Функции Min и Max возвращают соответственно минимальное и максимальное значение по столбцу.
Например, найдем минимальную цену среди товаров:
SELECT MIN(Price) FROM Products
Поиск максимальной цены:
SELECT MAX(Price) FROM Products
Данные функции также игнорируют значения NULL и не учитывают их при подсчете.
Sum
Функция Sum вычисляет сумму значений столбца. Например, подсчитаем общее количество товаров:
SELECT SUM(ProductCount) FROM Products
Также вместо имени столбца может передаваться вычисляемое выражение. Например, найдем общую стоимость всех имеющихся товаров:
SELECT SUM(ProductCount * Price) FROM Products
All и Distinct
По умолчанию все вышеперечисленных пять функций учитывают все строки выборки для вычисления результата. Но выборка может содержать повторяющие значения.
Если необходимо выполнить вычисления только над уникальными значениями, исключив из набора значений повторяющиеся данные, то для
этого применяется оператор DISTINCT.



SELECT AVG(DISTINCT ProductCount) AS Average_Price FROM Products
По умолчанию вместо DISTINCT применяется оператор ALL, который выбирает все строки:
SELECT AVG(ALL ProductCount) AS Average_Price FROM Products
Так как этот оператор неявно подразумевается при отсутствии DISTINCT, то его можно не указывать.
Комбинирование функций
Объединим применение нескольких функций:
SELECT COUNT(*) AS ProdCount, SUM(ProductCount) AS TotalCount, MIN(Price) AS MinPrice, MAX(Price) AS MaxPrice, AVG(Price) AS AvgPrice FROM Products
НазадВперед
Видео-инструкция по изменению таблиц в Microsoft SQL Server
У меня на этом все, надеюсь, материал был Вам полезен, пока!
Изменение данных Для изменения значений столбцов таблицы применяется оператор UPDATE (изменить, обновить). Чтобы изменить значения в одном столбце таблицы в тех записях, которые удовлетворяют некоторому условию, следует выполнить такой запрос.
UPDATE имяТаблицы SET имяСтолбца = значение WHERE условие;
За ключевым словом SET (установить) следует выражение равенства, в левой части которого указывается имя столбца, а в правой — выражение, значение которого следует сделать значением данного столбца. Эти установки будут выполнены в тех записях, которые удовлетворяют условию в операторе WHERE. Чтобы одним оператором UPDATE установить новые значения сразу для нескольких столбцов, вслед за ключевым словом SET записываются соответствующие выражения равенства, разделенные запятыми.
UPDATE имяТаблицы SET имяСтолбца1 = значение1, имяСтолбца2 = значение2, . , имяСтолбцаN = значениеN WHERE условие;
Например, следующий запрос изменяет фамилию и имя клиента с кодом 5.
UPDATE Customer SET FName= ‘Иван’ , LName= ‘Иванов’ WHERE >
Использование оператора WHERE в инструкции UPDATE не обязательно. Если он отсутствует, то указанные в SET изменения будут произведены для всех записей таблицы.
Так же как и в инструкции DELETE условие в операторе WHERE инструкции UPDATE может содержать подзапросы, в том числе и связанные. Transact-SQL расширяет стандартный SQL, позволяя использовать в инструкции UPDATE предложение FROM (по аналогии с DELETE). Это расширение, в котором задается соединение, может быть использовано вместо вложенного запроса в предложении WHERE для указания обновляемых строк.
Если обновляемый объект тот же самый, что и объект в предложении FROM, и в предложении FROM имеется только одна ссылка на этот объект, псевдоним объекта указывать необязательно. Если обновляемый объект встречается в предложении FROM несколько раз, одна и только одна ссылка на этот объект не должна указывать псевдоним таблицы. Все остальные ссылки на объект в предложении FROM должны включать псевдоним объекта. Предположим, что требуется сделать 5% скидку по тем заказам клиентов, суммарная стоимость которых превышает 1000. Для этого следует изменить значения столбца Price, просто умножить их на 0,95. Однако эти изменения должны быть выполнены, только если суммарная стоимость заказа превышает 1000. Таким образом, в качестве критерия обновления записей в таблице OrdItem может быть задан запрос возвращающий список всех заказов с суммарной стоимостью более 1000.
UPDATE OrdItem SET Price = Price * 0.95 FROM OrdItem o INNER JOIN ( SELECT >FROM OrdItem GROUP BY >HAVING SUM (Qty*Price) > 1000) a ON o. >
Операция изменения записей, как и их удаление, связана с риском необратимых потерь данных в случае семантических ошибок при формулировке SQL-выражения. Например, стоит только забыть написать оператор WHERE, и будут обновлены значения во всех записях таблицы. Чтобы избежать подобных неприятностей, перед обновлением записей рекомендуется выполнить соответствующий запрос на выборку, чтобы просмотреть, какие записи будут изменены. Например, перед выполнением приведенного ранее запроса на обновление данных не помешает выполнить соответствующий запрос на выборку данных.
SELECT * FROM OrdItem o INNER JOIN ( SELECT >FROM OrdItem GROUP BY >HAVING SUM (Qty*Price) > 1000) a ON o. >
Задание для самостоятельной работы: Сформулируйте на языке SQL запрос имитирующий поступление на склад новой партий определенного товара (Обновление столбца InStock в таблице Product).
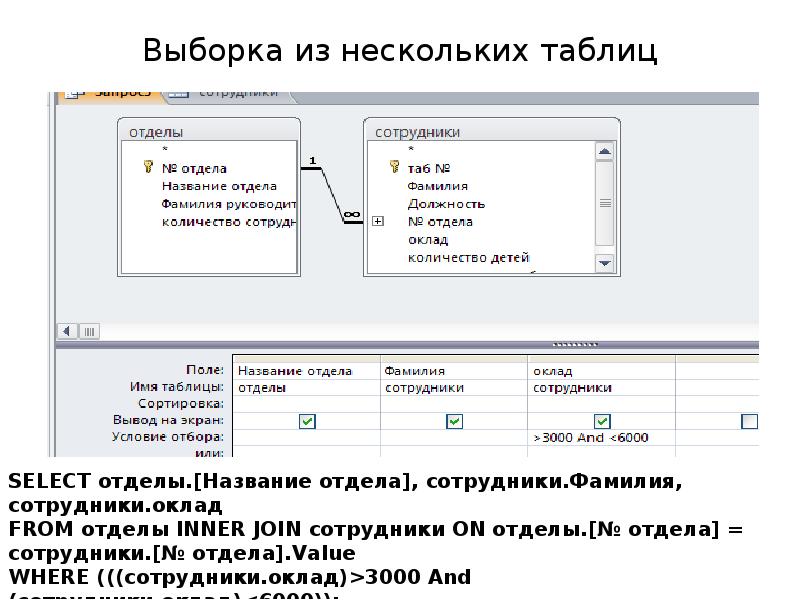
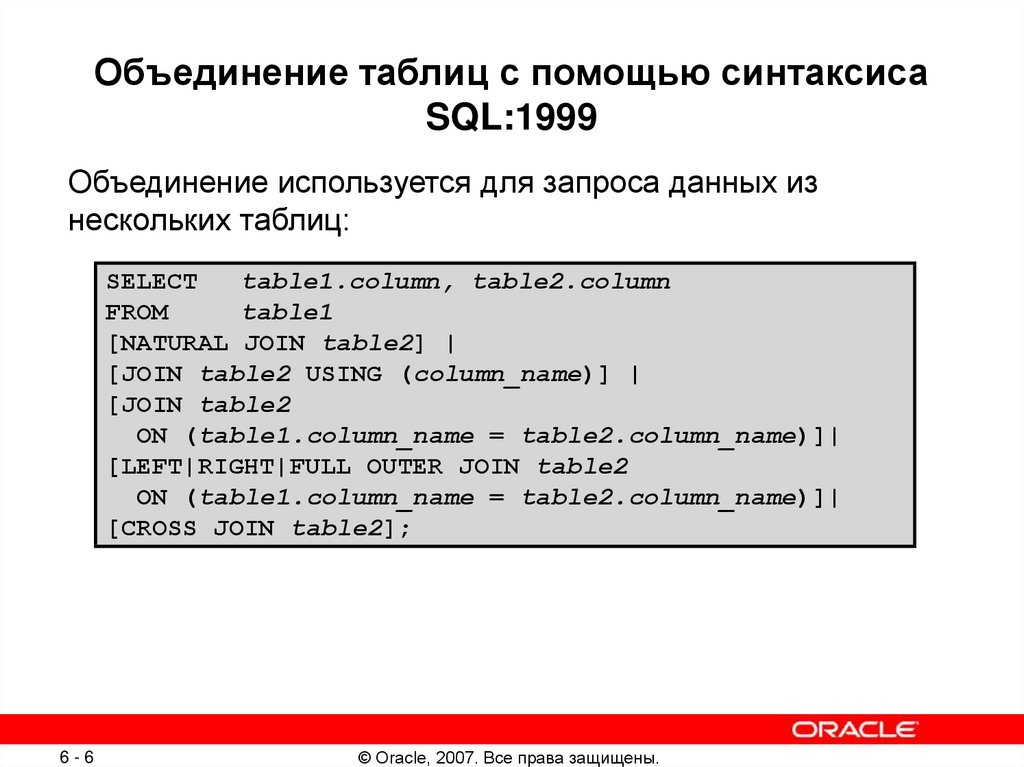
Выборка сводных данных (из двух и более таблиц)
При формировании сводной выборки данные беруться из нескольких таблиц. В операторе FROM исходные таблицы перечисляются через запятую. Также им могут быть присвоены алиасы. Синтаксис запроса выглядит следующийм образом:
SELECT
.Название_поля1, .Название_поля2,...
FROM
Table1 ,
Table2
...
При выборке сводных таблиц нужно учитывать, что исходные таблицы перемножаются. Т.е. если на входе у нас были таблицы:
| id | Name |
|---|---|
| 1 | Иванов |
| 2 | Петров |
| id | Name | Phone |
|---|---|---|
| 1 | Иванов | 322223 |
| 2 | Петров | 111111 |
То при простом запросе без условий
SELECT a.*, b.*
FROM
Table1 a, Table2 b
Получим примерно следующее:
| id | Name | id2 | Name2 | Phone |
|---|---|---|---|---|
| 1 | Иванов | 1 | Иванов | 322223 |
| 1 | Иванов | 2 | Петров | 111111 |
| 2 | Петров | 1 | Иванов | 322223 |
| 2 | Петров | 2 | Петров | 111111 |
Чтобы выбрать уникальные значения, нам нужно использовать оператор WHERE для связи этих таблиц
SELECT a.*, b.Phone
FROM
Table1 a, Table2 b
WHERE
a.Name=b.Name
| id | Name | Phone |
|---|---|---|
| 1 | Иванов | 322223 |
| 2 | Петров | 111111 |
Сводные выборки нужны при импорте данных в базу. Сначала вы выделяете из таблиц импорта словари. А потом из таблиц импорта и словарей формируете запрос для записи данных в основную таблицу.
Функция SQL MIN
Функция SQL MIN также действует в отношении столбцов, значениями которых являются числа и возвращает
минимальное среди всех значений столбца. Эта функция имеет синтаксис аналогичный синтаксису функции SUM.
Пример 3.
База данных и таблица —
те же, что и в примере 1.
Требуется узнать минимальную заработную плату сотрудников отдела с номером 42.
Для этого пишем следующий запрос:
Запрос вернёт значение 10505,90.
И вновь упражнение для самостоятельного решения
. В этом и некоторых
других упражнениях потребуется уже не только таблица Staff, но и таблица Org, содержащая данные о
подразделениях фирмы:
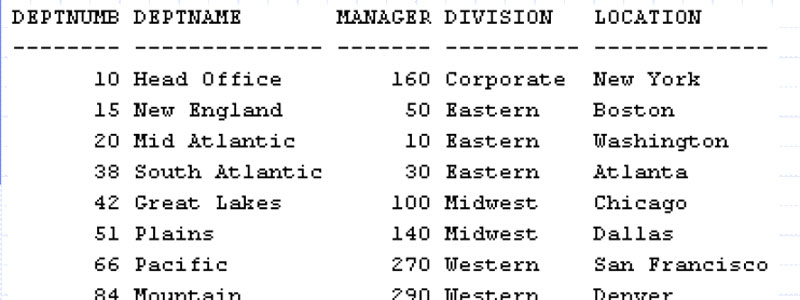
Пример 4.
К таблице Staff добавляется таблица Org, содержащая данные
о подразделениях фирмы. Вывести минимальное количество лет, проработанных одним сотрудником в отделе,
расположенном в Бостоне.
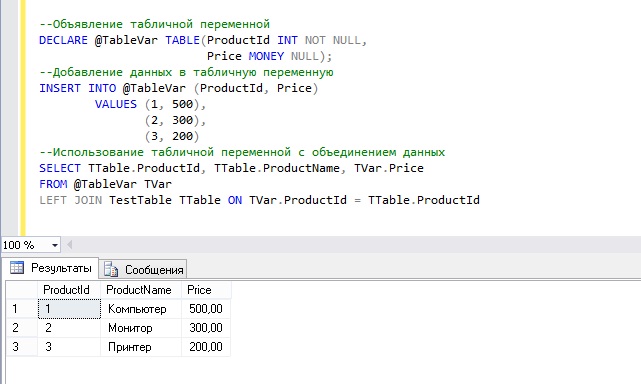
Примеры использования табличных переменных в Microsoft SQL Server
Сейчас давайте перейдем к практике, и для начала хотелось бы отметить, что в качестве сервера у меня выступает Microsoft SQL Server 2016 Express, другими словами все запросы ниже запускались на данной версии СУБД.
Сначала давайте создадим тестовую таблицу и заполним ее тестовыми данными, для того чтобы посмотреть, как можно использовать табличные переменные вместе с обычными таблицами.
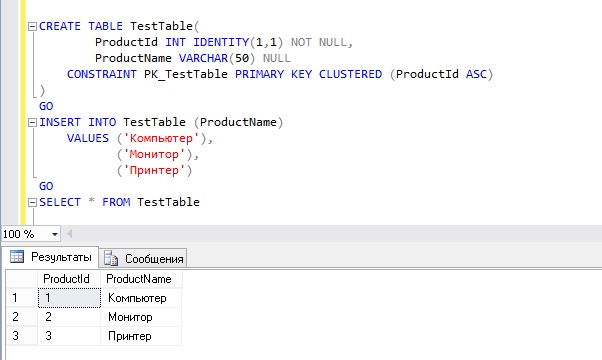
С помощью инструкции CREATE TABLE я создал таблицу TestTable, затем для добавления данных в таблицу я использовал инструкцию INSERT совместно с конструктором табличных значений VALUES, затем с помощью SELECT сделал выборку из только что созданной таблицы.
Объявление табличной переменной и ее использование
В данном примере мы объявим табличную переменную, добавим в нее данных, и сделаем выборку из двух таблиц (табличной переменной и обычной таблицы) с объединением.
Remarks Remarks
table — позволяет ссылаться на переменные по имени в пакетном предложении FROM, как показано в следующем примере: table Reference variables by name in a batch’s FROM clause, as shown the following example:
Вне предложения FROM на переменные table нужно ссылаться по псевдонимам, как показано в следующем примере: Outside a FROM clause, table variables must be referenced by using an alias, as shown in the following example:
Переменные table предоставляют указанные ниже преимущества для запросов малого масштаба, которые содержат неизменяющиеся планы запросов. Их также рекомендуется использовать при частой перекомпиляции. table variables provide the following benefits for small-scale queries that have query plans that don’t change and when recompilation concerns are dominant:
Переменная table ведет себя как локальная переменная. A table variable behaves like a local variable. Она имеет точно определенную область применения. It has a well-defined scope. Эта переменная представлена функцией, хранимой процедурой или пакетом, в котором она объявлена. This variable is the function, stored procedure, or batch that it’s declared in. Внутри этой области переменная table может использоваться как обычная таблица. Within its scope, a table variable can be used like a regular table. Она может быть применена в любом месте, где используется таблица или табличное выражение в инструкциях SELECT, INSERT, UPDATE и DELETE. It may be applied anywhere a table or table expression is used in SELECT, INSERT, UPDATE, and DELETE statements. Но переменную table нельзя использовать в следующей инструкции: However, table can’t be used in the following statement:
Переменные table автоматически очищаются в конце функции, хранимой процедуры или пакета, в котором они были определены. table variables are automatically cleaned up at the end of the function, stored procedure, or batch in which they’re defined.

- При использовании переменных table в хранимых процедурах приходится реже прибегать к перекомпиляциям, чем при использовании временных таблиц в тех случаях, когда не требуется делать выбор на основе затрат, который влияет на производительность. table variables that are used in stored procedures cause fewer stored procedure recompilations than when temporary tables are used when there are no cost-based choices that affect performance.
- Транзакции с использованием переменных table продолжаются только во время процесса обновления соответствующей переменной table. Transactions involving table variables last only for the duration of an update on the table variable. Поэтому переменные table реже подвергаются блокировке и требуют меньше ресурсов для ведения журналов. As such, table variables require less locking and logging resources.
Агрегатные функции вместе с SQL GROUP BY (группировкой)
Теперь рассмотрим применение агрегатных функций вместе с оператором SQL GROUP BY. Оператор SQL GROUP BY
служит для группировки результирующих значений по столбцам таблицы базы данных. На сайте есть урок,
посвящённый отдельно этому оператору
.
Пример 12.
Есть база данных портала объявлений. В ней есть
таблица Ads, содержащая данные об объявлениях, поданных за неделю. Столбец Category содержит
данные о больших категориях объявлений (например, Недвижимость), а столбец Parts — о более мелких
частях, входящих в категории (например, части Квартиры и Дачи являются частями категории Недвижимость).
Столбец Units содержит данные о количестве поданных объявлений, а столбец Money — о денежных суммах,
вырученных за подачу объявлений.
| Category | Part | Units | Money |
| Транспорт | Автомашины | 110 | 17600 |
| Недвижимость | Квартиры | 89 | 18690 |
| Недвижимость | Дачи | 57 | 11970 |
| Транспорт | Мотоциклы | 131 | 20960 |
| Стройматериалы | Доски | 68 | 7140 |
| Электротехника | Телевизоры | 127 | 8255 |
| Электротехника | Холодильники | 137 | 8905 |
| Стройматериалы | Регипс | 112 | 11760 |
| Досуг | Книги | 96 | 6240 |
| Недвижимость | Дома | 47 | 9870 |
| Досуг | Музыка | 117 | 7605 |
| Досуг | Игры | 41 | 2665 |
Используя оператор SQL GROUP BY, найти суммы денег, вырученных за подачу
объявлений в каждой категории. Пишем следующий запрос:
SELECT
Category, SUM
(Money) AS
Money
FROM
Ads
GROUP BY
Category
Пример 13.
База данных и таблица —
та же, что в предыдущем примере.
Используя оператор SQL GROUP BY, выяснить, в какой части каждой категории было
подано наибольшее число объявлений. Пишем следующий запрос:
SELECT
Category, Part, MAX
(Units) AS
Maximum
FROM
Ads
GROUP BY
Category
Результатом будет следующая таблица:
Итоговые и индивидуальные значения в одной таблице можно получить объединением
результатов запросов с помощью оператора UNION
.
Реляционные базы данных и язык SQL
Базы данных
Как сказано выше, производительность системы напрямую зависит от индексов. При поступлении запроса они могут увеличивать ее, обеспечивая быстрый поиск данных либо снижать, т.к. при каждой операции с данными будут изменяться и они, дабы отражать действия, производимые над данными
И не важно, что происходит с ними – добавление, удаление или обновление
Потому, при разработке плана стратегии по индексированию, необходимо придерживаться советов специалистов:
- Если предполагается частое обновление данных в таблице, то для нее нужно применять минимум индексов.
- Для таблицы со значительным количеством данных, которые предположительно будут редко изменяться, можно использовать то число индексов, которое улучшит производительность запросов. Но для таблиц небольшого объема не всегда целесообразно вообще их использовать. Такой поиск может выполняться дольше, чем обычное сканирование таблицы.
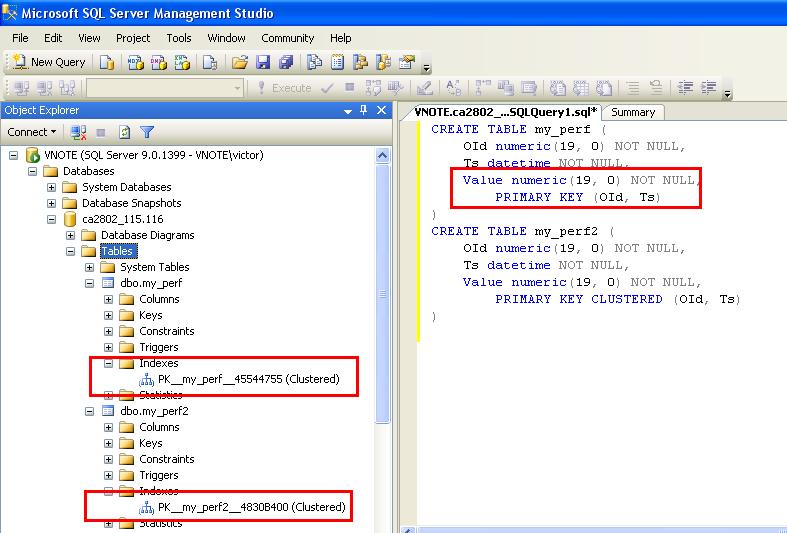
- Для Clustered indexes используйте самые короткие поля, которые только допустимы. Лучше всего их применять на столбцах с уникальными значениями и в которых не допускается использование NULL. По этой причине чаще всего PRIMARY KEY выступает в роли Clustered index.
- Производительность индекса напрямую зависит от того, насколько уникальны значения в столбце. Она снижается с увеличением дублей если в столбце и растет с уменьшением. Потому, при каждой возможности следует использовать уникальный индекс.
- Если используется составной индекс, то в нем нужно учитывать порядок столбцов. Первыми идут те, в которых в выражениях используется WHERE. За ними – столбцы с наивысшими показателями уникальных значений. Остальные выстраиваются по мере понижения этого показателя.
- Допускается использование индекса на вычисляемых столбцах таблицы, но лишь при условии соблюдения определенных требований (для вычисления значений такого столбца могут использоваться только детерминистические выражения, т.е. результат для определенного набора входящих параметров всегда должен быть одинаковым).
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER дает больше свободы, чем жесткий JOIN. Да и объем кода в итоге окажется гораздо меньше.
Как сделать вычисляемое поле в sql
Создание вычисляемых полей
До сих пор с помощью операторов SELECT мы отображали только содержащиеся в таблицах данные. Это полезно, но не всегда достаточно. Вам может понадобиться общая сумма, среднее значение или результаты других расчетов, основанные на данных, имеющихся в таблице. Именно здесь помогут вычисляемые поля. В отличие от всех выбранных нами ранее столбцов, вычисляемых полей на самом деле в таблице базы данных нет. Они создаются «на лету» оператором SELECT.
Важно отметить, что только база данных «знает», какие столбцы в операторе SELECT являются реальными столбцами таблицы, а какие — вычисляемыми полями. С точки зрения клиента (например, вашего приложения), данные вычисляемого поля возвращаются точно так же, как и данные из любого другого столбца
В общем случае для создания вычисляемого поля в списке SELECT следует указать некоторое выражение языка SQL. В этих выражениях могут применяться операции сложения, вычитания, умножения и деления, а также встроенные функции СУБД. При построении сложных выражений могут использоваться круглые скобки.
Представленный запрос возвращает список услуг, с указанием их текущей стоимости и стоимости, увеличенной на 50%.
| service | price | price*1.5 |
| Equipment rental | 200,00 | 300.00 |
| Calling card service | 100,00 | 150.00 |
| Wireless service | 150,00 | 225.00 |
| Multiple lines | 320,00 | 480.00 |
| Voice mail | 50,00 | 75.00 |
| Paging service | 50,00 | 75.00 |
| Internet | 250,00 | 375.00 |
| Caller ID | 20,00 | 30.00 |
| Call waiting | 20,00 | 30.00 |
| Call forwarding | 20,00 | 30.00 |
| 3-way calling | 100,00 | 150.00 |
| Electronic billing | 50,00 | 75.00 |
Получить список, содержащий имя, фамилию и возраст клиентов:
SQL: SELECT lastname, name, TRUNCATE((TO_DAYS(CURRENT_DAY()) – TO_DAYS(d_birth)+364)/365,0) FROM tbl_clients
При построении выражения для вычисления возраста были использованы встроенные функции SQL.
При выводе результатов запроса каждый столбец по умолчанию получает заголовок, совпадающий с его именем в базе данных. У вычисляемых полей заголовки отсутствуют.
Для упрощения чтения и понимания результатов запроса можно переопределить заголовки столбцов. Чтобы получить необходимые имена заголовков, просто введите <column> <alias> или <column> as <alias> в списке выбора вместо обычных имен столбцов.
Запрос из предыдущего примера можно переписать следующим образом:
SQL: SELECT lastname, name, TRUNCATE((TO_DAYS(CURRENT_DAY()) – TO_DAYS(d_birth)+364)/365,0) AS age FROM tbl_clients
Вычисляемые столбцы в таблицах
Вычисляемый столбец
– это виртуальный столбец таблицы, который вычисляется на основе выражения, в этих выражениях могут участвовать другие столбцы этой же таблицы. Такие столбцы физически не хранятся, их значения рассчитываются каждый раз при обращении к ним. Это поведение по умолчанию, но можно сделать так, чтобы вычисляемые столбцы физически хранились, для этого нужно указать ключевое слово PERSISTED при создании подобного столбца. В данном случае значения данного столбца будут обновляться, когда будут вноситься любые изменения в столбцы, входящие в вычисляемое выражение.
Вычисляемые столбцы нужны для того, чтобы было проще и надежней получить результат каких-то постоянных вычислений. Например, при обращении к таблице, Вы всегда в SQL запросе применяете какую-нибудь формулу (один столбец перемножаете с другим или что-то в этом роде, хотя формула может быть и сложней
), так вот, если в таблице определить вычисляемый столбец, указав в его определении нужную формулу, Вам больше не нужно будет каждый раз писать эту формулу в SQL запросе в инструкции SELECT. Вам достаточно обратиться к определенному столбцу (вычисляемому столбцу
), который автоматически при выводе значений применяет эту формулу. При этом этот столбец можно использовать в запросах также как обычный столбец, например, в секциях WHEHE (в условии
) или в ORDER BY (в сортировке
).
Также важно понимать, что вычисляемый столбец не может быть указан в инструкциях INSERT или UPDATE в качестве целевого столбца
Сортировка
Для упорядочения данных по какому-то полю необходимо выполнить команду
ORDER BY <имя поля>
Записи можно упорядочивать в восходящем (параметр сортировки ASC) или в нисходящем (параметр сортировки DESC) порядке. Параметр сортировки ASC используется по умолчанию.
Пример. Выбрать все сведения о книгах из таблицы Books и отсортировать результат по коду книги (поле Code_book).
SELECT * FROM Books ORDER BY Code_book
Самостоятельно:
- Выбрать из таблицы Books коды книг, названия и количество страниц (поля Code_book, Title_book и Pages), отсортировать результат по названиям книг (поле Title_book по возрастанию) и по полю Pages (по убыванию).
- Выбрать из таблицы Deliveries список поставщиков (поля Name_delivery, Phone и INN), отсортировать результат по полю INN (по убыванию).
Переименование полей AS
Имена столбцов в запросах можно переименовывать. Это придает результатам более читабельный вид.
Рассмотрим пример переименования в SQL:
Пример БД «Институт»: Вывести фамилии учителей и их зарплаты, для тех преподавателей, у которых зарплата ниже 15000, переименовать поле на «низкая_зарплата»
Решение:
1 2 3 |
SELECT name, zarplata AS низкая_зарплата FROM teachers WHERE zarplata<15000; |
Результат:
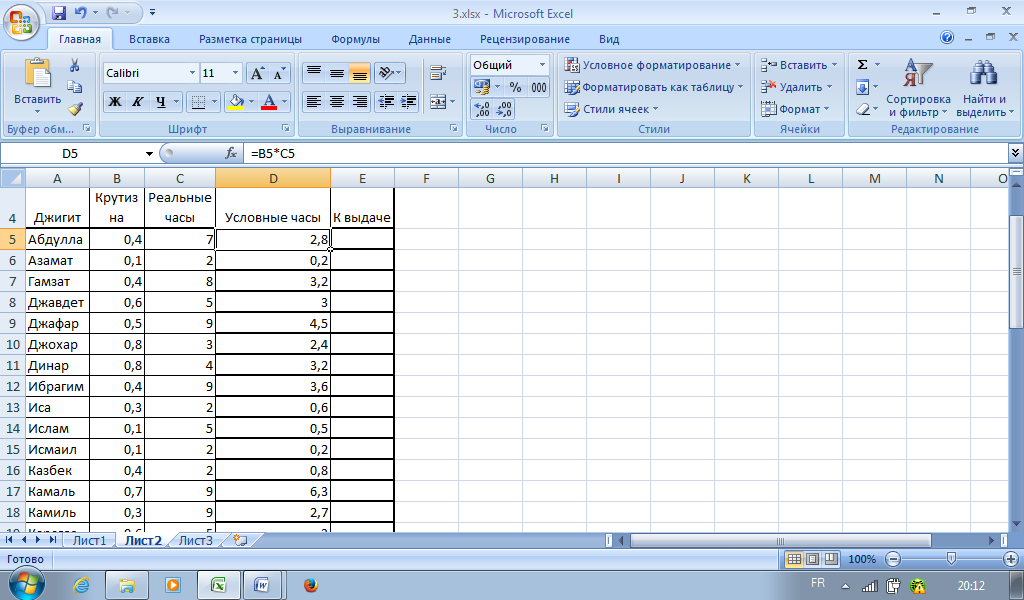
SQL As 2_1. . Вывести данные о компьютерах. Переименовать столбец Скорость в «Мб», а столбец HD в «Гб»

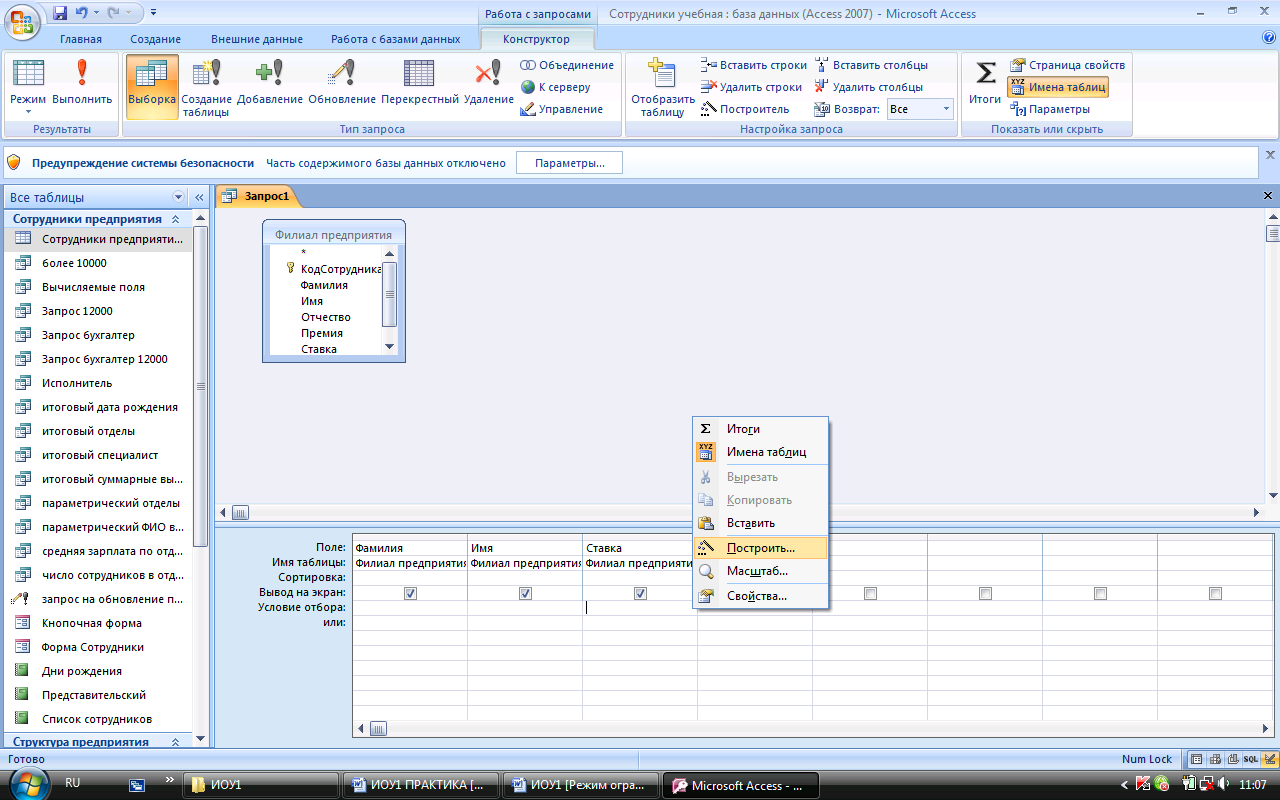

Переименование столбцов в SQL часто необходимо при вычислении значений, связанных с несколькими полями таблицы. Рассмотрим пример:
Пример БД «Институт»: Из таблицы вывести поле и вычислить сумму зарплаты и премии, назвав поле «зарплата_премия»
Решение:
1 2 |
SELECT name, (zarplata+premia) AS zarplata_premia FROM teachers; |
Результат:
SQL As 2_1. . Вывести фамилии учителей и разницу между их зарплатой и премией. Назвать вывод «зарплата_минус_премия»
Задание 2_1. . Из таблицы вывести значения полей , , , и вычислить среднее значение по полям , , , назвав поле «Среднее»
SQL As 2_2. . Вывести объем оперативной памяти в Килобайтах (из Мб получить Кб). Выводить и исходное и получившееся значение
Задание 2_2. . Вывести и оценки по студентов, успеваемость по курсу Word которых ниже 4 баллов, переименовать поле на Низкая успеваемость
Функция SQL MAX
Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда
требуется определить максимальное значение среди всех значений столбца.
Пример 5. База данных и таблица —
те же, что и в предыдущих примерах.
Требуется узнать максимальную заработную плату сотрудников отдела с номером 42.
Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT MAX(Salary)
FROM Staff WHERE Dept=42
Запрос вернёт значение 18352,80
Пришло время упражнения для самостоятельного решения.
Пример 6. Вновь работаем с двумя таблицами — Staff и Org.
Вывести название отдела и максимальное значение комиссионных, получаемых одним сотрудником в отделе,
относящемуся к группе отделов (Division) Eastern. Использовать JOIN (соединение таблиц).
- Агрегатные функции вместе с SQL GROUP BY (группировкой)
- Разрешены ли агрегатные функции от агрегатных функций?
Поделиться с друзьями
| Назад | Вперёд>>> |
SQL — Урок 11. Итоговые функции, вычисляемые столбцы и представления
Теперь, мы хотим узнать, на какую сумму нам привез товар поставщик «Дом печати» (id=2). Составить такой запрос не так просто. Давайте поразмышляем, как его составить:
1. Сначала надо из таблицы Поставки (incoming) выбрать идентификаторы (id_incoming) тех поставок, которые осуществлялись поставщиком «Дом печати» (id=2):
2. Теперь из таблицы Журнал поставок (magazine_incoming) надо выбрать товары (id_product) и их количества (quantity), которые осуществлялись в найденных в пункте 1 поставках. То есть запрос из пункта 1 становится вложенным:
3. Теперь нам надо добавить в результирующую таблицу цены на найденные товары, которые хранятся в таблице Цены (prices). То есть нам понадобится объединение таблиц Журнал поставок (magazine_incoming) и Цены (prices) по столбцу id_product:
4. В получившейся таблице явно не хватает столбца Сумма, то есть вычисляемого столбца . Возможность создания таких столбцов предусмотрена в MySQL. Для этого надо лишь указать в запросе имя вычисляемого столбца и что он должен вычислять. В нашем примере такой столбец будет называться summa, а вычислять он будет произведение столбцов quantity и price. Название нового столбца отделяется словом AS:
5. Отлично, нам осталось лишь просуммировать столбец summa и наконец-то узнаем, на какую сумму нам привез товар поставщик «Дом печати». Синтаксис для использования функции SUM() следущий:
Имя столбца нам известно — summa, а вот имени таблицы у нас нет, так как она является результатом запроса. Что же делать? Для таких случаев в MySQL существуют Представления . Представление — это запрос на выборку, которому присваивается уникальное имя и который можно сохранять в базе данных, для последующего использования.
Синтаксис создания представления следующий:
Вот мы и достигли результата, правда для этого нам пришлось использовать вложенные запросы, объединения, вычисляемые столбцы и представления. Да, иногда для получения результата приходится подумать, без этого никуда. Зато мы коснулись двух очень важных тем — вычисляемые столбцы и представления. Давайте поговорим о них поподробнее.
Представления
Синтаксис создания представлений мы уже рассматривали. После создания представлений, их можно использовать так же, как таблицы. То есть выполнять запросы к ним, фильтровать и сортировать данные, объединять одни представления с другими. С одной стороны это очень удобный способ хранения частоприменяемых сложных запросов (как в нашем примере).
Но следует помнить, что представления — это не таблицы, то есть они не хранят данные, а лишь извлекают их из других таблиц. Отсюда, во-первых, при изменении данных в таблицах, результаты представления так же будут меняться. А во-вторых, при запросе к представлению происходит поиск необходимых данных, то есть производительность СУБД снижается. Поэтому злоупотреблять ими не стоит.