
Денормализация базы данных
Для баз данных, предназначенных для аналитики, часто выполняют денормализацию, чтобы укорить выполнение запросов.
Статья расскажет о том, что такое нормализация баз данных, для чего она нужна, и какие виды нормализации существуют. Для наилучшего понимания отношений между таблицами в нормализованной базе данных будут приведены практические примеры.
При создании базы нужно учитывать некоторые правила. Исходя из вышесказанного, можно привести следующую формулировку: нормализация БД — это процесс организации данных определенным образом и рекомендации по проектированию. То есть таблицы и связи между ними (отношения) создаются в соответствии с правилами. В результате обеспечивается нужный уровень безопасности данных, а сама база становится более гибкой. Также устраняются несогласованные зависимости и избыточность.
Чем управление базами данных отличается от управления электронными таблицами
Если бегло посмотреть на базу данных и электронную таблицу, можно не увидеть разницы. Но она есть — и сейчас мы о ней расскажем.
Представим, что у нас есть Excel-таблица, в которой мы ведём учёт всех клиентов нашей компании — отмечаем, как их зовут, где они работают, зачем к нам обращались и когда в последний раз мы с ними общались. Этот Excel-файл единый для всей компании, и каждый день им пользуются десятки человек.
Вот вы садитесь за работу, открываете эту таблицу и вносите в неё какие-то изменения. Параллельно с этим ваш коллега тоже открыл её и начал вносить изменения — причём в те же колонки или строки, в которых работаете вы. Вы доделали работу, сохранили файл и закрыли его. Данные перезаписались в таблицу. Но ваш коллега не увидит эти изменения, потому что он открыл файл раньше. Поэтому когда он сохранит свой файл, то перезапишет ваши данные своими, а ваши изменения пропадут.
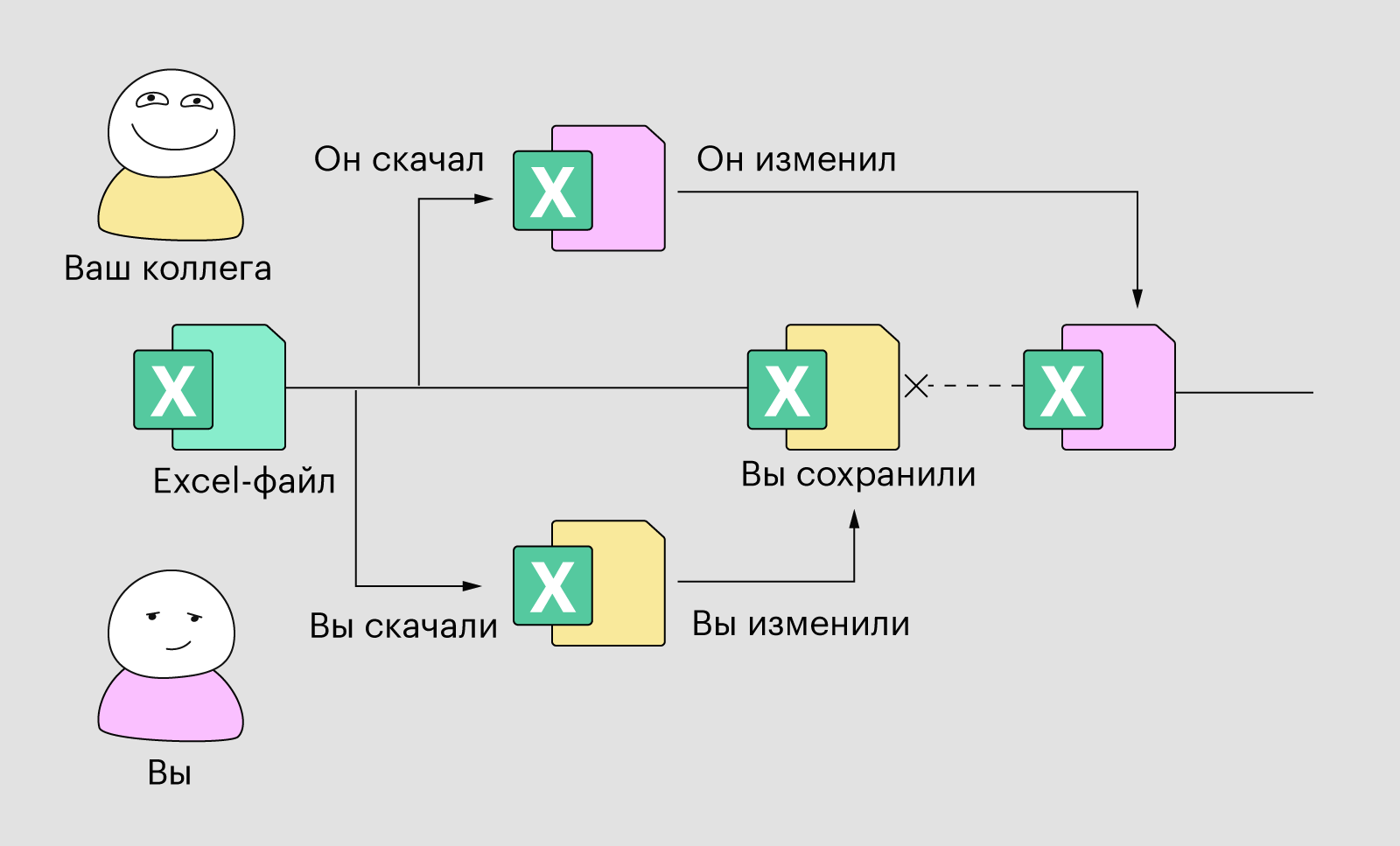
Если работать без базы данных, легко потерять эти данныеИллюстрация: Polina Vari для Skillbox Media
С базой данных такой ситуации не произойдёт. Пусть у нас та же ситуация, но таблица — это база данных, которая управляется с помощью какой-то СУБД. Теперь каждый раз, когда вы вносите изменения, они отправляются в виде запросов в СУБД. И даже если ваш коллега будет работать с вами одновременно и тоже отправит запрос, то он встанет в очередь и будет ждать, пока не обработается предыдущий.
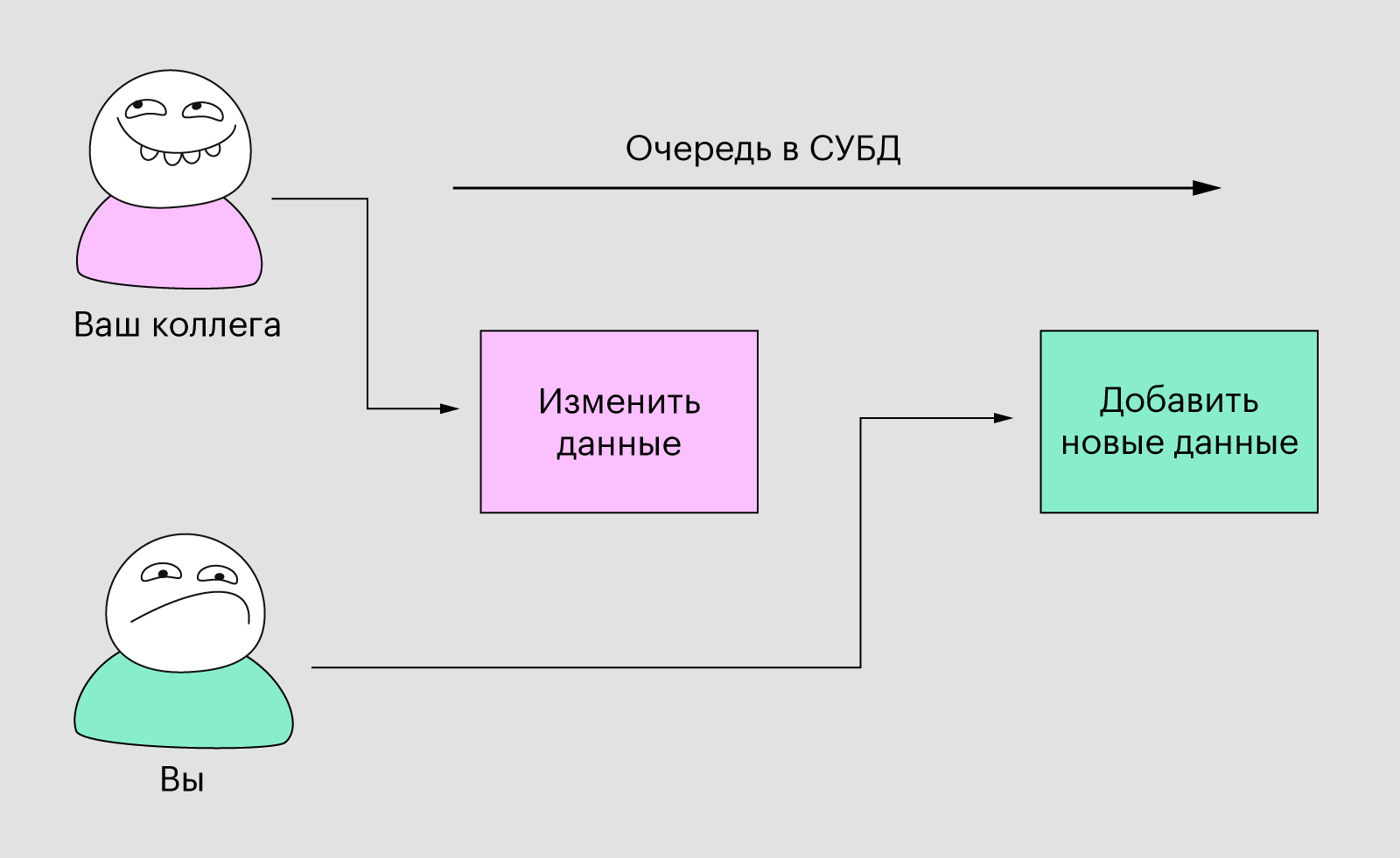
С СУБД всё будет работать в режиме очереди, и никто не потеряет данныеИллюстрация: Polina Vari для Skillbox Media
Комплексный графический механизм для руководителя на базе СКД
Предлагаемый механизм был реализован под собственные нужды. Демонстрирует возможности использования механизма СКД при графической интерпретации бизнес-процессов на предприятии. Особенностью данного механизма является универсальность, т.е. с помощью этого отчета можно отобразить множество различных показателей, используя произвольные отборы, измерения, периоды, типы графиков и т.д. Эксплуатация данной системы в течение полугода на холдинге показала, что графическое отображение бизнес-процессов способствует более быстрому принятию необходимых управленческих решений.
Механизм реализован с использованием справочника «Произвольные отчеты», который был адаптирован в УТ из КА (такой же механизм существует и в УПП), изначально для запуска инструмента «Монитор эффективности».
1 стартмани
33
2НФ – вторая нормальная форма
Вторая нормальная форма (2НФ) означает, что выполнены требования 1НФ, при этом все атрибуты целиком зависят от составного ключа и не зависят ни от какой его части.
На первый взгляд кажется, что нарушения 2НФ практически невозможны, потому что чаще всего в качестве первичных ключей используются автоинкрементные целочисленные значения или иные суррогаты для реализации ссылок. Однако, в определении говорится о ключах вообще, а не только о первичных. В отношении может быть несколько ключей, и некоторые из них могут являться составными. Такие ключи следует подвергнуть проверке в первую очередь.
Ассоциативная таблица — таблица, имеющая ключевые связи с двумя и более таблицами
Например, если каждая операция сбыта мебельной продукции в таблице продаж однозначно характеризуется колонками идентификатора товарной позиции, даты продажи и идентификатором покупателя, то нахождение в той же таблице столбца «Тип материала», зависящего непосредственно от товарной позиции, должно немедленно привлечь ваше внимание. Аномалия в данном случае приведёт только к избыточности хранения в виде размера идентификатора, помноженного на число строк таблицы (без учёта индексов)
Но если в той же таблице обнаружится ещё и колонка «Контактный телефон», присущая атрибутике покупателя, то последствия окажутся более серьёзными. Кроме избыточности хранения при ошибке ввода придётся исправлять номер телефона во всех записях о продажах данному покупателю
Аномалия в данном случае приведёт только к избыточности хранения в виде размера идентификатора, помноженного на число строк таблицы (без учёта индексов). Но если в той же таблице обнаружится ещё и колонка «Контактный телефон», присущая атрибутике покупателя, то последствия окажутся более серьёзными. Кроме избыточности хранения при ошибке ввода придётся исправлять номер телефона во всех записях о продажах данному покупателю.
Кроме приведённых примеров, при наличии в таблицах нескольких ключей необходимо, с позиций логики предметной области, определить, являются ли эти ключи присущими данной сущности или же они суть внешние ключи другой сущности, пока ещё не выделенной в процессе проектирования.
Зачем нужны базы данных

- Зачем нужны базы данных
- Как пользоваться телефонными базами данных
- Что такое база данных
База данных представляет собой определенным образом структурированную совокупность данных, совместно хранящихся и обрабатывающихся в соответствии с некоторыми правилами. Как правило, база данных моделирует некоторую предметную область или ее фрагмент. Очень часто в качестве постоянного хранилища информации баз данных выступают файлы.
Программа, производящая манипуляции с информацией в базе данных, называется СУБД (система управления базами данных). Она может осуществлять выборки по различным критериям и выводить запрашиваемую информацию в том виде, который удобен пользователю. Основными составляющими информационных систем, построенных на основе баз данных, являются файлы БД, СУБД и программное обеспечение (клиентские приложения), позволяющие пользователю манипулировать информацией и совершать необходимые для решения его задач действия.








Структурирование информации производится по характерным признакам, физическим и техническим параметрам абстрактных объектов, которые хранятся в данной базе. Информация в базе данных может быть представлена как текст, растровое или векторное изображение, таблица или объектно-ориентированная модель. Структурирование информации позволяет производить ее анализ и обработку: делать пользовательские запросы, выборки, сортировки, производить математические и логические операции.
Информация, которая хранится в базе данных, может постоянно пополняться. От того, как часто это делается, зависит ее актуальность. Информацию об объектах также можно изменять и дополнять.
Базы данных, как способ хранения больших объемов информации и эффективного манипулирования ею, используются практически во всех областях человеческой деятельности. В них хранят документы, изображения, сведения об объектах недвижимости, физических и юридических лицах. Существуют правовые базы данных, автомобильные, адресные и пр.
Базы данных используются в информационных системах, например, в тех, которые позволяют обеспечивать контроль и управление территориями на уровне государства. В базах данных таких систем хранятся сведения обо всех объектах недвижимости, расположенных на данных территориях: земельных участках, растительности, строениях, гидрографии, дорогах и пр. Базы данных позволяют анализировать информацию и осуществлять управление информационными потоками, использовать их для статистики, прогнозирования и учета.
Первая нормальная форма
Основным правилом первой формы является необходимость неделимости значения в каждом поле (столбце) строки – атомарность значений.
Рассмотрим таблицы сотрудников и телефонных линий.
Но подобная структура не является надежной. Представьте, что Вам необходимо поменять некоторым сотрудникам подключенные линии. Потребуется осуществить разбор составного поля, чтобы определить наличие id сотрудника в каждой записи линий, затем скорректировать перечень. Получается слишком сложный и долгий процесс для такой простой операции.
Организации структуры таблиц с применением дополнительной связывающей избавляет от подобных проблем.
Помимо атомарности к первой нормальной форме относятся следующие правила:
- Строки таблиц не должны зависеть друг от друга, т.е. первая запись не должна влиять на вторую и наоборот, вторая на третью и т.д. Размещение записей в таблице не имеет никакого значения.
- Аналогичная ситуация со столбцами записей. Их порядок не должен влиять на понимание информации.
- Каждая строка должна быть уникальна, поэтому для нее определяется первичный ключ, состоящий из одного либо нескольких полей (составной ключ). Первичный ключ не может повторяться в пределах таблицы и служит идентификатором записи.
Зачем нормализовать датасет для Data Mining и Machine Learning
Необходимость нормализации выборок данных обусловлена природой используемых алгоритмов и моделей Machine Learning. Исходные значения признаков могут изменяться в очень большом диапазоне и отличаться друг от друга на несколько порядков. Предположим, датасет содержит сведения о концентрации действующего вещества, измеряемой в десятых или сотых долях процентов, и показатели давления в сотнях тысяч атмосфер. Или, например, в одном входном векторе присутствует информация о возрасте и доходе клиента.
Будучи разными по физическому смыслу, данные сильно различаются между собой по абсолютным величинам . Работа аналитических моделей машинного обучения (нейронных сетей, карт Кохонена и т.д.) с такими показателями окажется некорректной: дисбаланс между значениями признаков может вызвать неустойчивость работы модели, ухудшить результаты обучения и замедлить процесс моделирования. В частности, параметрические методы машинного обучения (нейронные сети, растущие деревья) обычно требуют симметричного и унимодального распределения данных. Популярный метод ближайших соседей, часто используемый в задачах классификации и иногда в регрессионном анализе, также чувствителен к диапазону изменений входных переменных .
После нормализации все числовые значения входных признаков будут приведены к одинаковой области их изменения – некоторому узкому диапазону. Это позволит свести их вместе в одной модели Machine Learning и обеспечит корректную работу вычислительных алгоритмов [1.
Нормализованные данные в диапазоне
Практическим приемам Feature Transformation посвящена наша следующая статья, где мы рассказываем, как именно выполняется нормализация данных: формулы, методы и средства. Все эти и другие вопросы Data Preparation рассматриваются в нашем новом курсе обучения для аналитиков Big Data: подготовка данных для Data Mining. Оставайтесь с нами!
Смотреть расписание
Записаться на курс
Источники
- https://wiki.loginom.ru/articles/normalization.html
- http://molbiol.ru/forums/lofiversion/index.php/t460759.html
- https://btimes.ru/dictionary/normirovanie
- https://neuronus.com/theory/nn/925-sposoby-normalizatsii-peremennykh.html
- https://habr.com/ru/company/ods/blog/325422
Где их используют
Базы данных сейчас используются почти везде:
- На сайтах, чтобы хранить контент для страниц. Все статьи в «Коде» на самом деле хранятся в базе данных и извлекаются оттуда по вашему запросу.
- В смартфонах, чтобы хранить все ваши данные — фото, сообщения, заметки, контакты и музыку. Так как всего этого много, а доступ к этому должен быть молниеносный, используют разные виды СУБД.
- В почтовых сервисах, чтобы можно было найти нужное письмо. Там строятся сложные индексные массивы, по которым ваш почтовый клиент ищет данные.
- Везде, где есть личные кабинеты и регистрация, — чтобы запоминать пользователей и отличать их друг от друга.
- В соцсетях и блогах почти всё хранится в базах данных.
Если у вас в работе появляется много одинаковых или похожих данных, то самый надёжный способ не потерять ничего из них — поместить их в базу данных.
Что такое нормализация данных
(1) Определение парадигмы данных
В этой статье не будет конкретно вводиться определение парадигмы в базе данных. Обобщенная парадигма данных заключается в том, что в дополнение к внешним свойствам внешние ключи ссылаются на другие связанные свойства.
Преимущества нормализации данных: уменьшение избыточности данных.
(2) Примеры нормализации данных
Например, есть объект человека:
В приведенном выше объекте хобби вложено. Мы используем другие невложенные атрибуты perosn в качестве основного атрибута, а атрибут хобби представляет атрибут, на который должен ссылаться внешний ключ. Мы используем id в качестве имени внешнего ключа, а указанное выше Вложенные объекты можно нормализовать, чтобы получить:
Вышеупомянутый объект является результатом нормализации.Мы обнаружили, что атрибут хобби в главном объекте person становится массивом номеров идентификаторов в это время, а конкретное значение в другом хобби объекта индексируется идентификатором как внешний ключ.









(3) Преимущества нормализации данных
Итак, каковы преимущества этого?
Например, теперь мы добавляем нового человека с id 2:
К счастью, его интерес также включает футбол, поэтому, если есть сложная форма вложенного объекта, объект становится следующей формы:
Вышеупомянутый объект имеет более глубокий уровень вложенности. Например, теперь мы обнаруживаем, что описание футбола в хобби изменилось, например:
desp: «Футбол» ——> desp: «Футбольный футбол»
Если вы меняете непосредственно в вышеупомянутом вложенном объекте, нам нужно изменить две позиции: одна — это хобби, идентификатор которого равен 30, у человека с идентификатором 1, а другой — идентификатор человека, чей идентификатор равен 2, 30. Деспот хобби.
Это по-прежнему тот случай, когда есть только два экземпляра человека. Если есть больше экземпляров человека, то если меняется только одно хобби, необходимо изменить несколько местоположений. Кажется, что операция относительно избыточна.
Каков будет эффект, если вы воспользуетесь нормализацией данных, чтобы справиться с этим? , Нормализуя вышеуказанный объект, чтобы получить:
Если то же самое произойдет в это время:
Такое изменение нужно изменить только после сопоставления, объект запроса — это хобби:
Таким образом, независимо от того, сколько экземпляров ссылается на хобби с идентификатором 30, операция, вызванная нашей модификацией, может выполняться только в одном месте.
(4) Недостатки нормализации данных
Так в чем же недостатки нормализации данных?
Одно предложение может резюмировать недостатки парадигмы данных: низкая производительность запросов.
Это видно из приведенных выше нормализованных данных:
В приведенных выше нормализованных данных хобби представлено идентификатором. Если вы хотите проиндексировать конкретное значение и объект каждого идентификатора, например, вам необходимо запросить объект «хобби» на верхнем уровне. Исходные вложенные объекты могут отображаться интуитивно, какой объект хобби соответствует каждому идентификатору.
Реализация DBA
Другой подход — денормализовать логический дизайн данных
При осторожном подходе можно добиться аналогичного улучшения ответа на запрос, но за счет затрат — теперь разработчик базы данных несет ответственность за то, чтобы денормализованная база данных не стала противоречивой. Это делается путем создания правил в базе данных под названием ограничения, которые определяют, как следует поддерживать синхронизацию избыточных копий информации, что может легко сделать процедуру денормализации бессмысленной
Это увеличение логического сложность структуры базы данных и дополнительной сложности из-за дополнительных ограничений, которые делают этот подход опасным. Кроме того, ограничения вводят компромисс, ускорение чтения ( в SQL) при замедлении записи (, , и ). Это означает, что денормализованная база данных при большой нагрузке записи может предложить хуже производительности, чем его функционально эквивалентный нормализованный аналог.
Определение сущностей
На этом этапе вам необходимо определить сущности, из которых будет состоять база данных.
Сущность — это объект в базе данных, в котором хранятся данные. Сущность может представлять собой нечто вещественное (дом, человек, предмет, место) или абстрактное (банковская операция, отдел компании, маршрут автобуса). В физической модели сущность называется таблицей.
Сущности состоят из атрибутов (столбцов таблицы) и записей (строк в таблице).
Обычно базы данных состоят из нескольких основных сущностей, связанных с большим количеством подчиненных сущностей. Основные сущности называются независимыми: они не зависят ни от какой-либо другой сущности. Подчиненные сущности называются зависимыми: для того чтобы существовала одна из них, должна существовать связанная с ней основная таблица.
На диаграммах сущности обычно представляются в виде прямоугольников. Имя сущности указывается внутри прямоугольника:
Любая таблица имеет следующие характеристики:
- в ней нет одинаковых строк;
- все столбцы (атрибуты) в таблице должны иметь разные имена;
- элементы в пределах одной колонки имеют одинаковый тип (строка, число, дата);
- порядок следования строк в таблице может быть произвольным.
На этом этапе вам необходимо выявить все категории информации (сущности), которые будут храниться в базе данных.
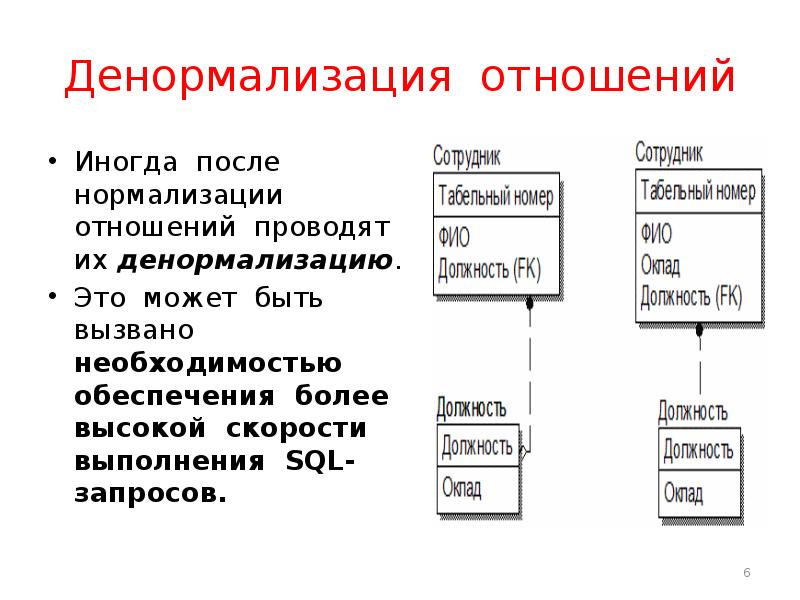
Демормализация в базе данных: «звезда» и «снежинка»
Как можно понять из вышеприведённых примеров, основными целями нормализации являются:
- устранение избыточности при хранении данных, приводящей к увеличению размера БД;
- исключение необходимости модификации данных в связных таблицах для минимизации времени и операций, проводящихся в одной транзакции. Или, как выражаются специалисты, уменьшить толщину транзакции, потому что толстые транзакции мешают при многопользовательской работе взаимными блокировками и увеличением времени отклика системы. Речь об этом пойдёт в отдельной главе.
Но список заявленных целей касается приложений транзакционных.
В приложениях интерактивной аналитической обработки приоритет меняется: на первый план выходит время отклика системы, в ущерб которому данные могут быть избыточны.
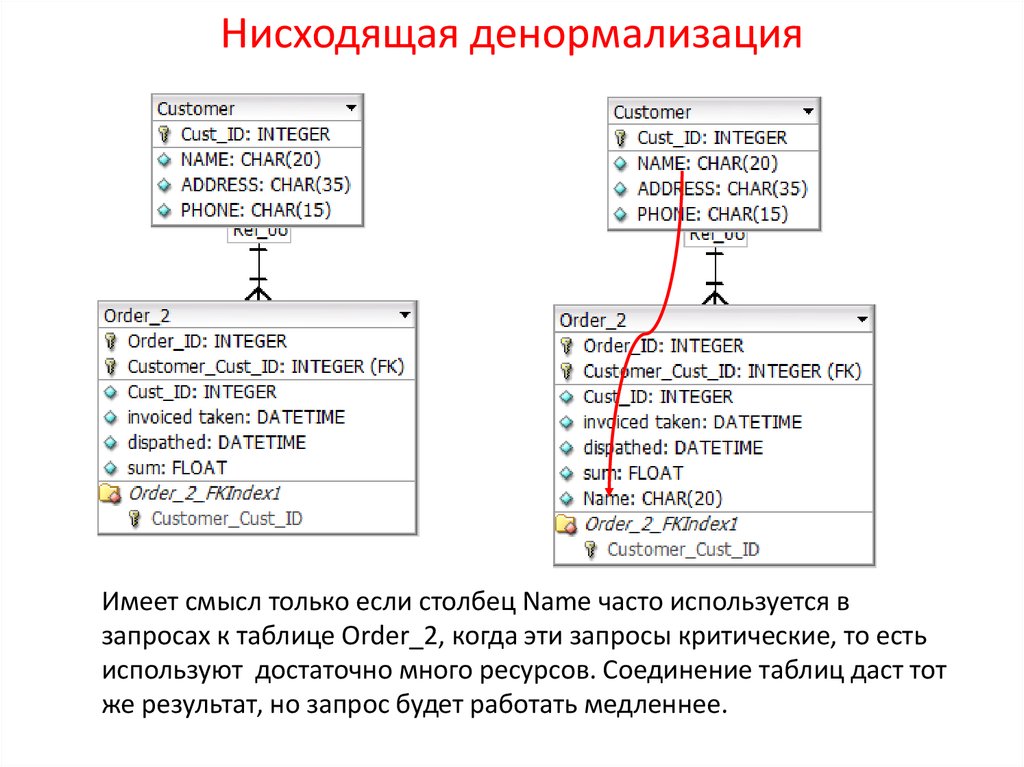
Как правильно проводить денормализацию
Проводя денормализацию, мы неизбежно создаем в базе данных избыточные, дублирующиеся данные. Поэтому перед разработчиками сразу возникает задача обеспечить непротиворечивость (а чаще – идентичность) дублирующихся данных. Как это реализовать?








В Oracle это делается достаточно просто – через механизм триггеров
К примеру, при добавлении вычисляемого поля на каждый из столбцов, от которых вычисляемое поле зависит, вешается триггер, вызывающий единую (это важно!) хранимую процедуру, которая и записывает нужные данные в вычисляемое поле. Надо только не пропустить ни один из столбцов, от которых зависит вычисляемое поле
С MySQL сложнее. В MySQL версии 4.1 (последняя на момент написания статьи стабильная версия) триггеров и хранимых процедур нет вообще. Поэтому заботиться об обеспечении непротиворечивости данных в денормализованной базе должны разработчики приложений.
Подведем итоги
При денормализации важно сохранить баланс между повышением скорости работы базы и увеличением риска появления противоречивых данных, между облегчением жизни программистам, пишущим Select’ы, и усложнением задачи тех, кто обеспечивает наполнение базы и обновление данных. Поэтому проводить денормализацию базы надо очень аккуратно, очень выборочно, только там, где без этого никак не обойтись
И именно поэтому я и написал в начале статьи, что денормализация – это искусство.
Плюсы
Нормализация не является обязательной, но приносит следующие преимущества: — упрощается процесс выборки. Речь идет об упрощении работы по составлению запросов, то есть пользователь сможет получать нужную информацию относительно простыми запросами; — обеспечивается целостность данных. Можно говорить о минимизации искажения информации и снижении вероятности потери данных; — улучшается масштабируемость. При соблюдении правил нормализации формируются благоприятные предпосылки к росту БД; — отсутствует избыточность (data redundancy). Избыточность — известная проблема непродуктивного использования свободного места на жестком диске, затрудняющая обслуживание БД. В отдельных случаях эту проблему усугубляет и то, что в случае необходимости изменения записей однотипных данных, хранимых в нескольких местах (таблицах), пользователю придется вносить требуемые изменения везде, что весьма трудоемкое занятие. Гораздо проще сделать так, чтобы, к примеру, данные о городах хранились только в таблице Cities и нигде больше. Если подытожить вышесказанное, избыточность предполагает дублирование данных, а это не только усложняет работу с БД, но и увеличивает ее размер; — отсутствие несогласованных зависимостей. Несогласованные зависимости затрудняют доступ к данным, ведь путь к такой информации может быть неправилен и нелогичен. В той же таблице Cities логично искать города, количество жителей и т. п., но не адреса и имена жителей — для этой информации уже нужна другая таблица — Citizens.



