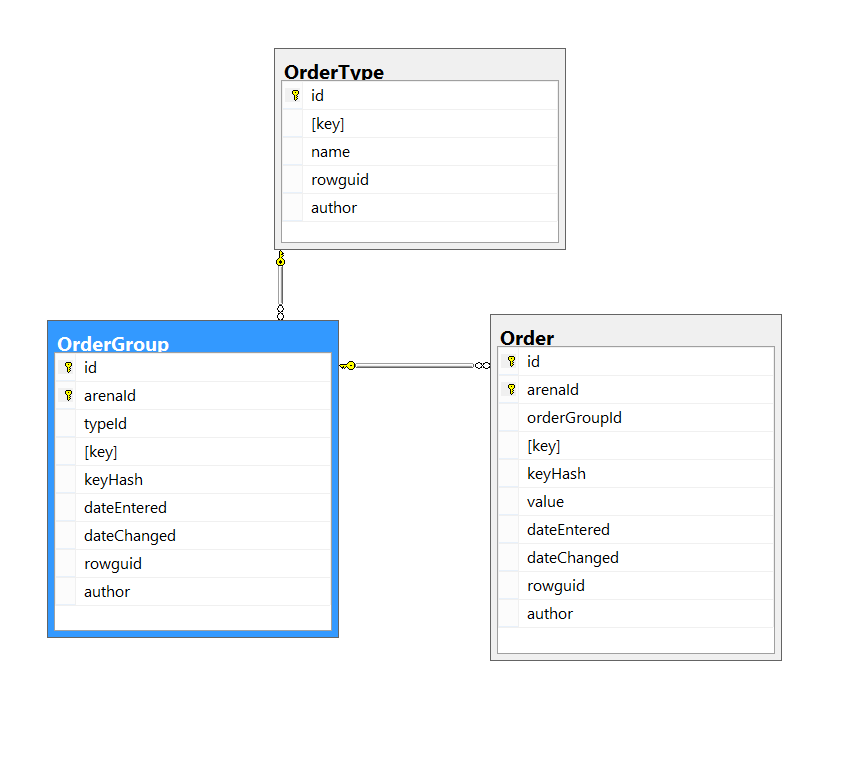
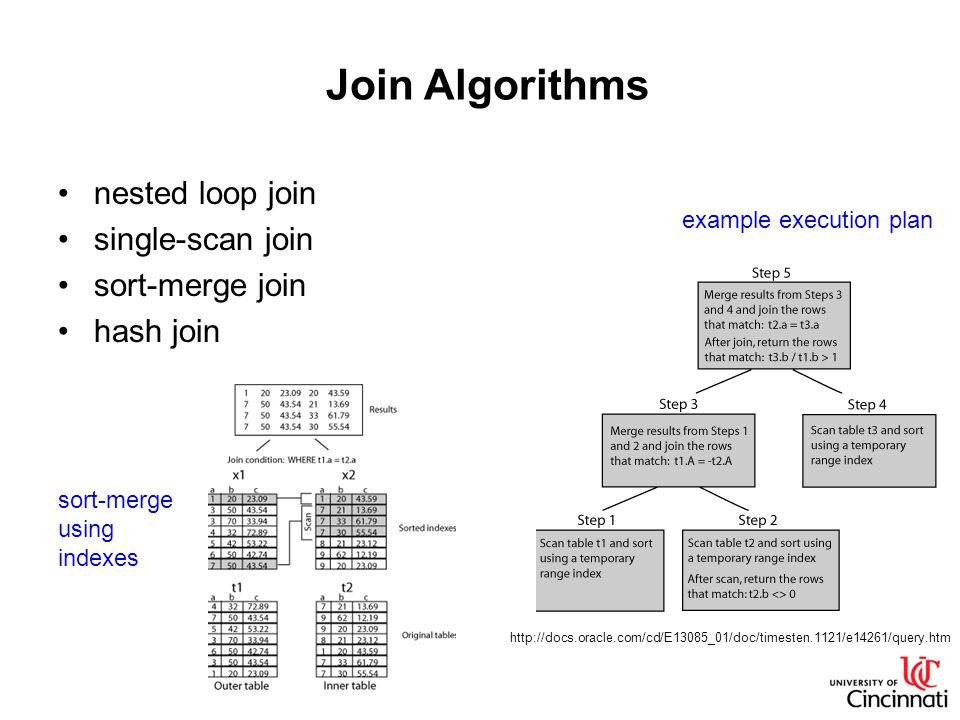
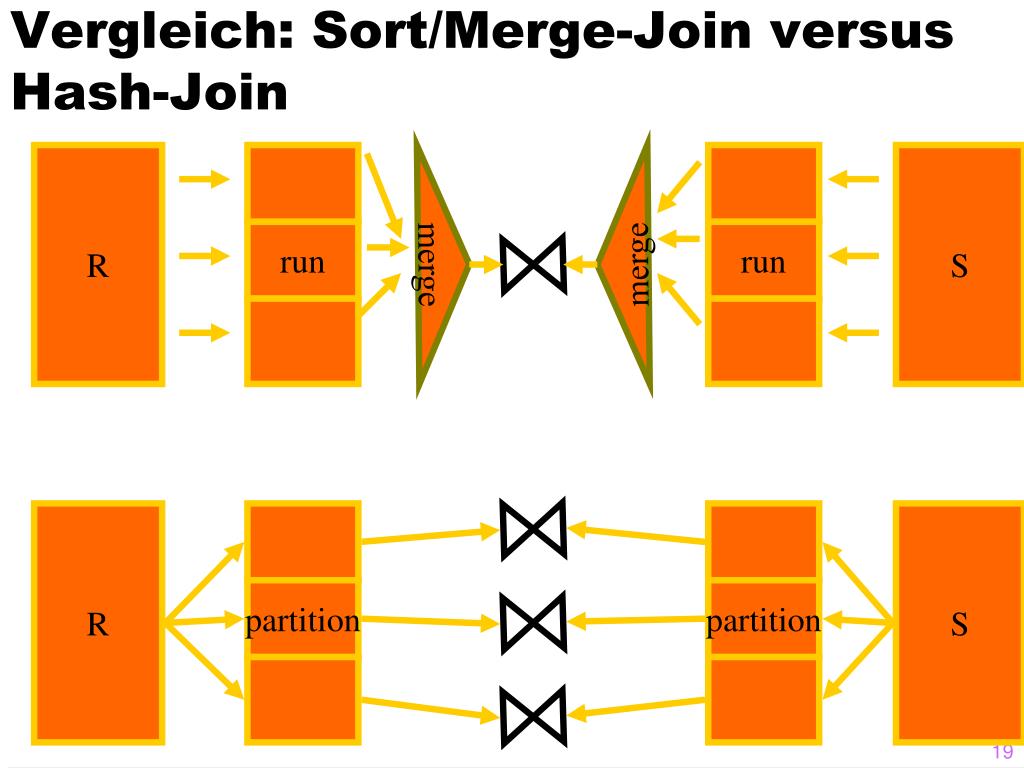
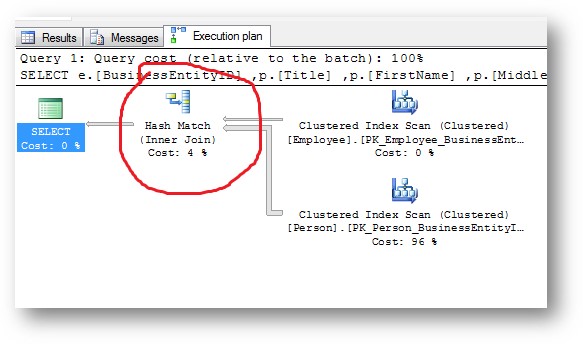
Spool Rules
There are a number of rules that explore logical nested loops join or apply alternatives. Some of these rules can produce one or more substitutes with a particular type of performance spool. Other rules that match nested loops join or apply never generate a spool alternative.
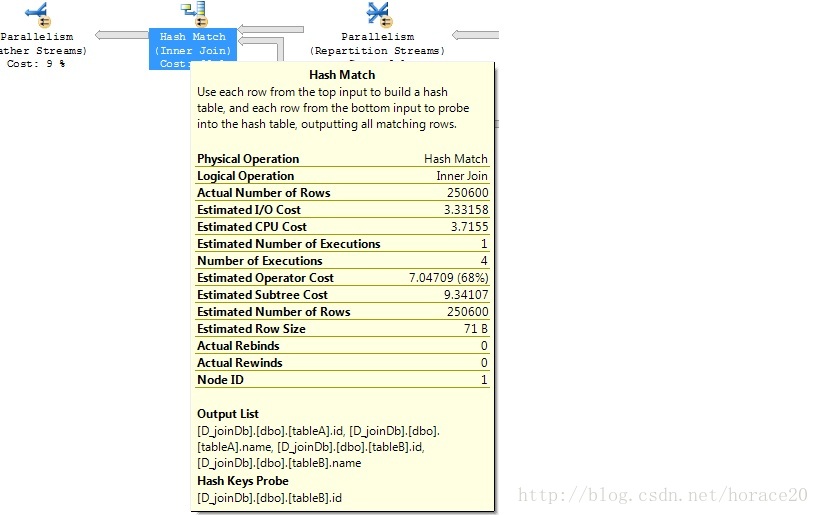
For example, the rule implements a logical apply as a physical loops join with outer references. This rule may generate several alternatives each time it runs. In addition to the physical join operator, each substitute may contain a lazy table spool, a lazy index spool, or no spool at all. The logical spool substitutes are later individually implemented and costed as the appropriately-typed physical spools, by another rule called .
As a second example, the rule implements a logical join as a physical apply, with an index seek immediately on the inner side. This rule never generates an alternative with a spool component. is evaluated early and returns a high promise value when it matches, so simple index-lookup plans are found quickly.
When the optimizer finds a low-cost alternative like this early on, more complex alternatives may be aggressively pruned out or skipped entirely. The reasoning is that it does not make sense to pursue options that are unlikely to improve on a low cost alternate already found. Equally, it is not worth exploring further if the current best complete plan has a low enough total cost already.
A third rule example: The rule is similar to , but it only implements physical nested loop join, with either a lazy table spool, or no spool at all. This rule never generates an index spool because that type of spool requires an apply.
Морализаторское послесловие
Если вы дочитали досюда, значит, статья показалась вам интересной. А значит, вы простите мне небольшую порцию нравоучений.
Я действительно считаю, что знания РСУБД на уровне SQL абсолютно не достаточно, чтобы считать себя профессиональным разработчиком ПО. Профессионал должен знать не только свой код, но и примерное устройство соседей по стеку, т.е. 3rd-party систем, которые он использует — баз данных, фреймворков, сетевых протоколов, файловых систем. Без этого разработчик вырождается до кодера или оператора ЭВМ, и в по настоящему сложных масштабных задачах становится бесполезен.
UPD. Несмотря на это послесловие, статья, на самом деле, про JOIN’ы.
Languages with no films
In this example, we’ll see if there are any languages with no films by
- Joining the language table with film table using language_id. The left join ensures languages without any films are also includes.
- Filtering records where film_id IS NULL.
SELECT *FROM language lLEFT JOIN film fUSING (language_id)WHERE f.film_id IS NULL;
Image by author
We see a few languages with no films in the database. We’ll make sure that it’s not an error by selecting the films with language_id in (2,3,4,5,6) from the film table. The query result should return no records.
SELECT * FROM filmWHERE language_id IN (2,3,4,5,6);
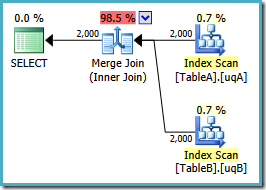
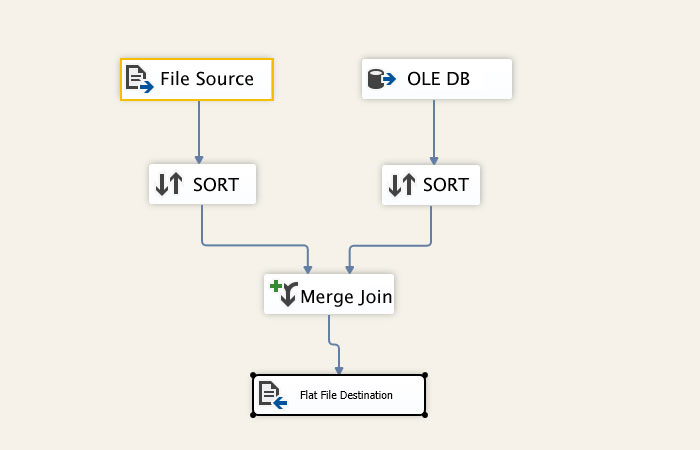
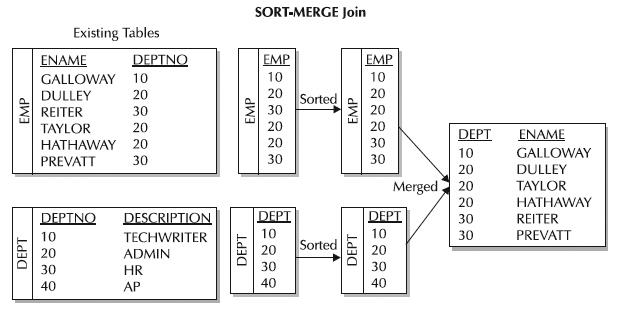
Merge joins
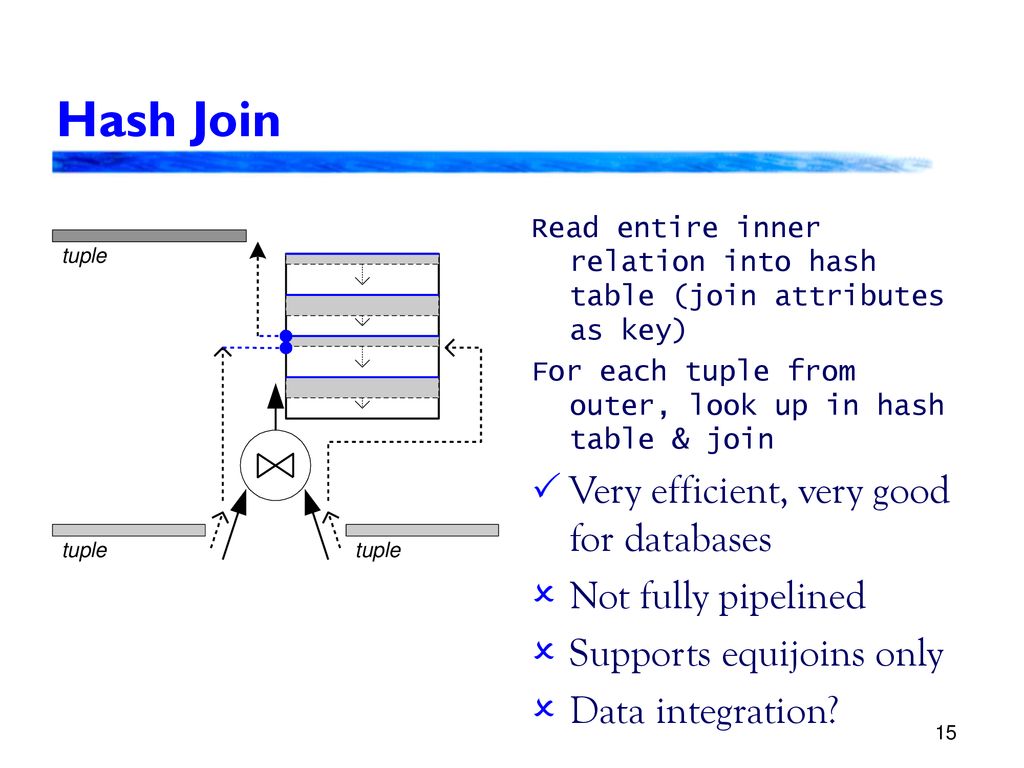
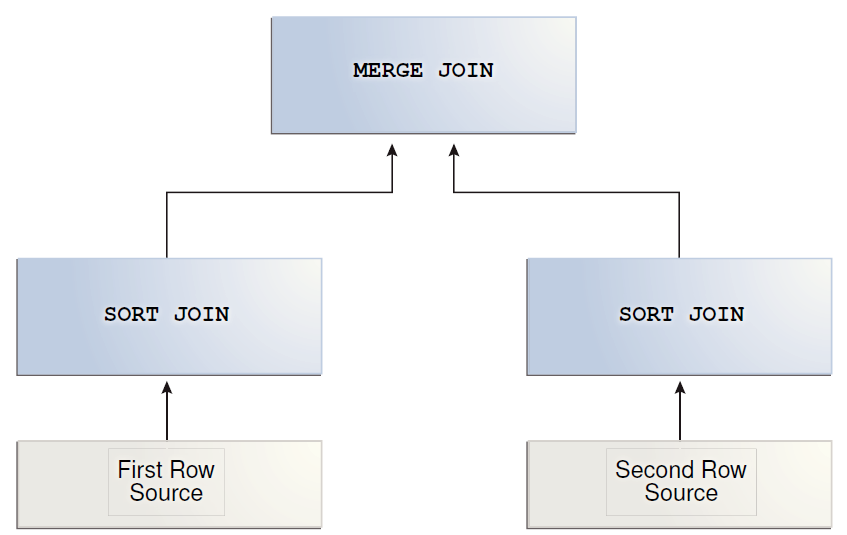
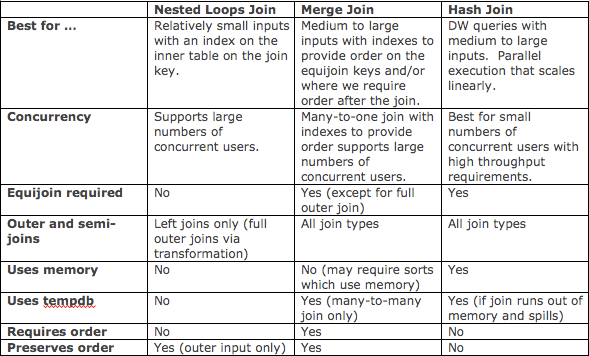
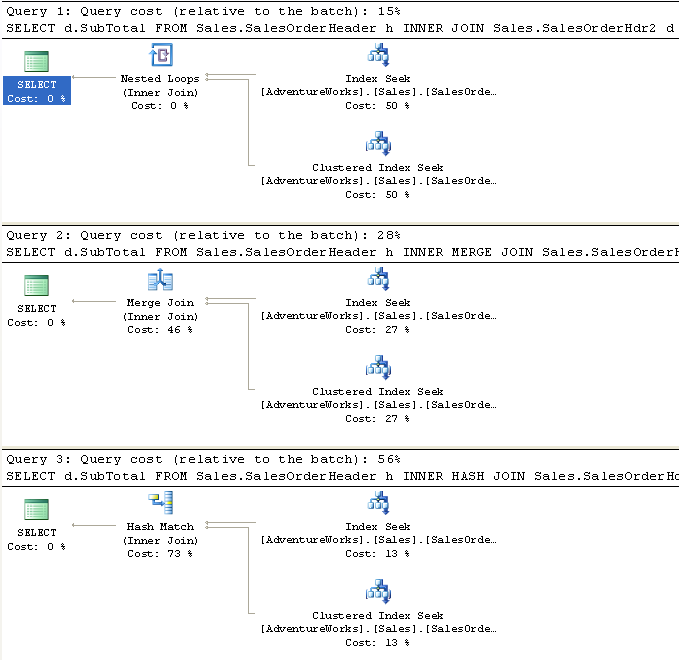
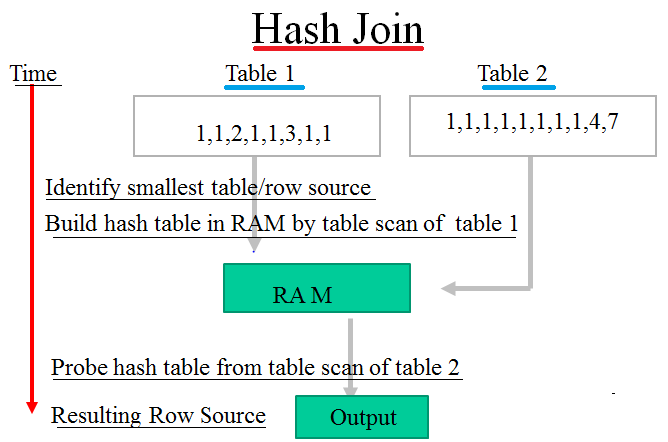
If the two join inputs are not small but are sorted on their join column (for example, if they were obtained by scanning sorted indexes), a merge join is the fastest join operation. If both join inputs are large and the two inputs are of similar sizes, a merge join with prior sorting and a hash join offer similar performance. However, hash join operations are often much faster if the two input sizes differ significantly from each other.
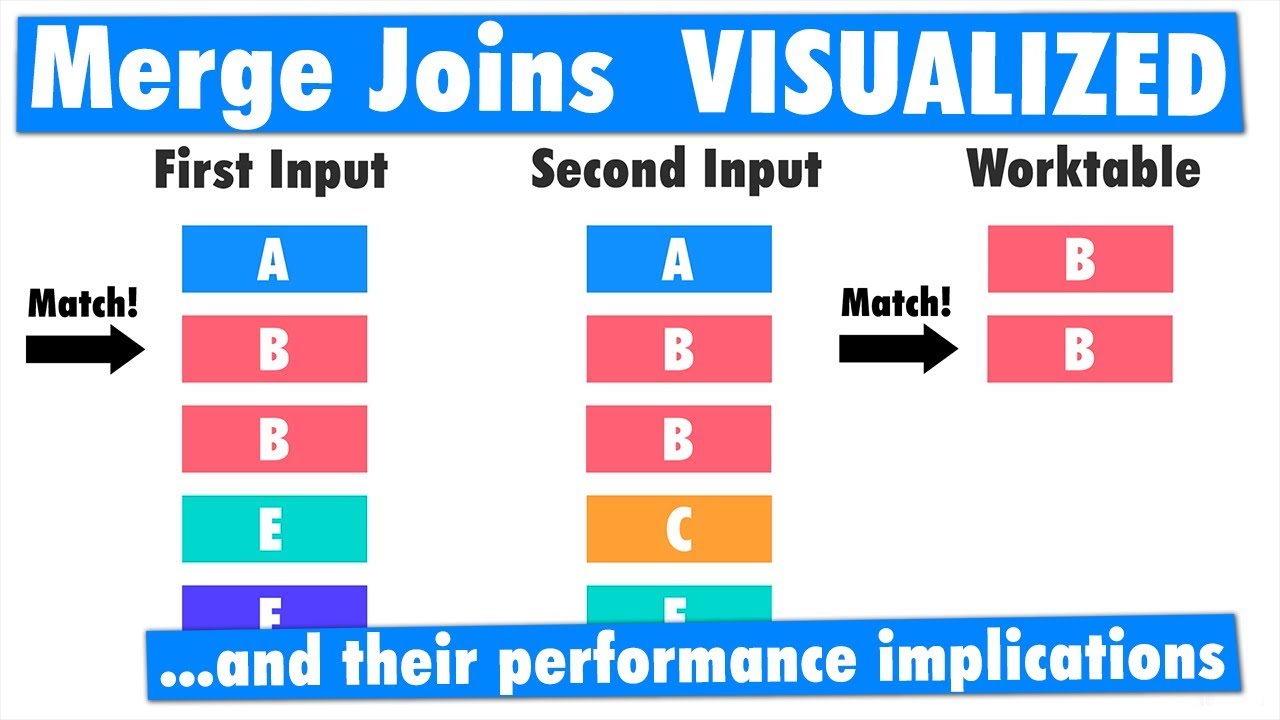
The merge join requires both inputs to be sorted on the merge columns, which are defined by the equality (ON) clauses of the join predicate. The query optimizer typically scans an index, if one exists on the proper set of columns, or it places a sort operator below the merge join. In rare cases, there may be multiple equality clauses, but the merge columns are taken from only some of the available equality clauses.
Because each input is sorted, the Merge Join operator gets a row from each input and compares them. For example, for inner join operations, the rows are returned if they are equal. If they are not equal, the lower-value row is discarded and another row is obtained from that input. This process repeats until all rows have been processed.
The merge join operation may be either a regular or a many-to-many operation. A many-to-many merge join uses a temporary table to store rows. If there are duplicate values from each input, one of the inputs will have to rewind to the start of the duplicates as each duplicate from the other input is processed.
If a residual predicate is present, all rows that satisfy the merge predicate evaluate the residual predicate, and only those rows that satisfy it are returned.
Merge join itself is very fast, but it can be an expensive choice if sort operations are required. However, if the data volume is large and the desired data can be obtained presorted from existing B-tree indexes, merge join is often the fastest available join algorithm.
Operator properties
The properties below are specific to the Nested Loops operator, or have a specific meaning when appearing on it. For all other properties, see Common properties. Properties that are included on the Common properties page but are also included below for their specific meaning for the Nested Loops operator are marked with a *.
| Property name | Description |
|---|---|
| Logical Operation * | The requested logical join type. Possible values are Inner Join, Left Outer Join, Left Semi Join, and Left Anti Semi Join. |
| Memory Fractions | Only used when Optimized is true. For any operator with a special memory requirement, this set of properties shows the fraction of the total available memory the operator can use, based on the optimizers understanding of which other operators are using memory at the same time.
|
| Optimized | When this property is true, use the optimized Nested Loops algorithm instead of the “normal” algorithm. See above for an explanation of the differences. |
| Outer References | Specifies a dynamic inner input. For each column listed here, the value this column has in the outer input will be pushed into the outer input whenever it (re)starts. |
| Output List * | If the Pass Through property is present, the Output List property may include a column named Passnnnn (where nnnn is a 4-digit number that is unique within the execution plan). This is a bit column that is set to 1 if the condition in the Pass Through property was met, and set to 0 otherwise. This Passnnnn column will also be in the Defined Values property (without definition). |
| Pass Through | When this property is present, it specifies a condition that is evaluated once for each row from the outer input. If the condition is met, the inner branch is not executed at all; the outer row is passed unchanged with NULL values for columns from the inner row. This property has thus far been observed for the Inner Join, Left Outer Join, and Left Semi Join operations. |
| Predicate | Specifies the logical condition that has to be met for a combination of rows from the outer and inner input to be considered a match. |
| Probe Column | Can be used with the Left Semi Join logical operation to change its behavior to that of a “probed’ Left Semi Join. This property lists the name of the generated column that will hold the probe result. This column will also be in the Defined Values property (without definition) and in the Output List property. |
| With Ordered Prefetch | This property is present (and set to true) when prefetching is requested, but the order of rows from the outer input has to be preserved. When neither this property nor With Unordered Prefetch is present, no prefetching is used. |
| With Unordered Prefetch | This property is present (and set to true) when prefetching is requested and order doesn’t need to be preserved. In this case the operator will start with the values for which the IOs completed first. When neither this property nor With Ordered Prefetch is present, no prefetching is used. |
Left Join
В отличие от предыдущего объединения, left join – это возврат всех строк из левой таблицы по установленным принципам. Это – левостороннее соединение, осуществляемое через условие ON. Вследствие обработки операции:
- проводится проверка на соответствие условия соединения;
- если оно выполняется – строчка из второй прибавляется к первой таблице.
Именно такое описание можно дать команде left join. Представив его в виде диаграмм, необходимо запомнить следующее представление:

Вся закрашенная область – это результат обработки команды left join в языке SQL.
Запись и пример
Указанным ранее вариантом соединения пользуются чаще всего. Но иногда, особенно при работе с большим количеством информации, может потребоваться левостороннее «слияние». Оно обладает такой формой записи:
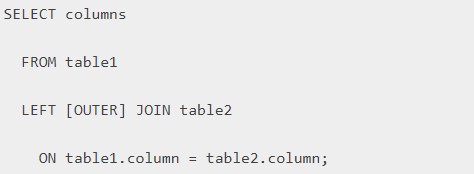
Ключевое слово OUTER может быть пропущено. Это нормальное явление, допускаемое некоторыми языками запросов. Помогает значительно сократить исходный код при его написании.
Для примера необходимо взять таблицу с информацией:

Вторая база данных:

Названия тут будут такими же, как и в прошлом случае. Теперь составляется запрос выполнения левостороннего слияния:

После обработки оного на экране появятся всего 6 записей:
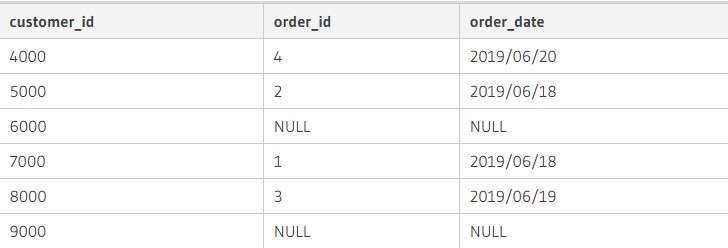
Так произошло, потому что left join произвел внутреннее объединение только строки customers и те строчки из orders, где объединенные поля обладают равными значениями. Также стоит запомнить следующие важные сведения:
- когда значение в customer_id из customers отсутствует в orders, поля «ордерс» отображаются в виде null;
- если выставленный параметр слияния не выполняется, поля/строчки «отбрасываются».
Ничего трудного. Такой тип объединения табличек в программировании и базах данных тоже встречается не слишком редко.
Outer Joins
Вы могли заметить, что написанный выше код имитирует только INNER JOIN, причем рассчитывает, что все ключи в обоих списках уникальные, т.е. встречаются не более, чем по одному разу. Я сделал так специально по двум причинам. Во-первых, так нагляднее — в коде содержится только логика самих джойнов и ничего лишнего. А во-вторых, мне очень хотелось спать. Но тем не менее, давайте хотя бы обсудим, что нужно изменить в коде, чтобы поддержать различные типы джойнов и неуникальные значения ключей.
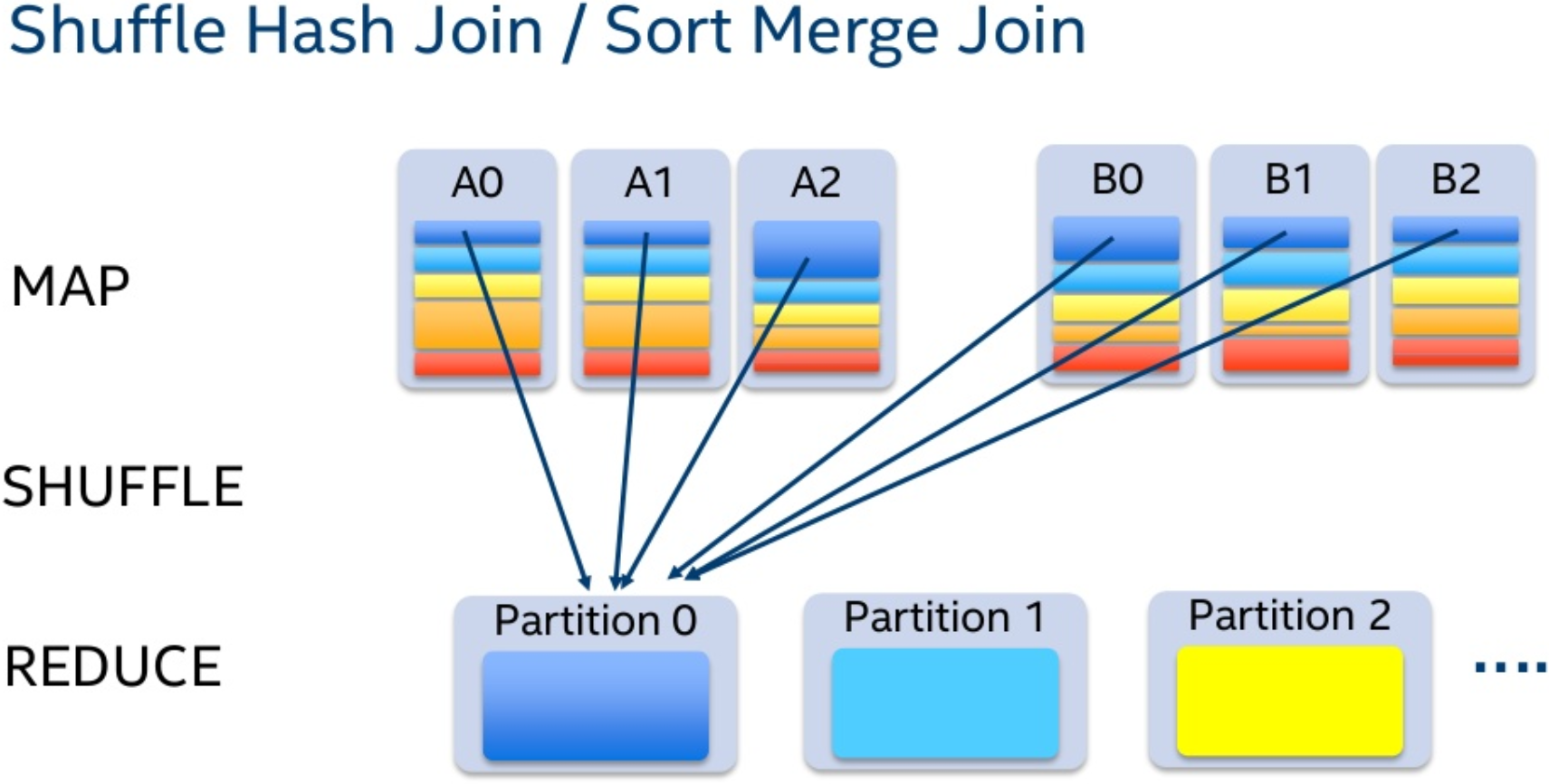
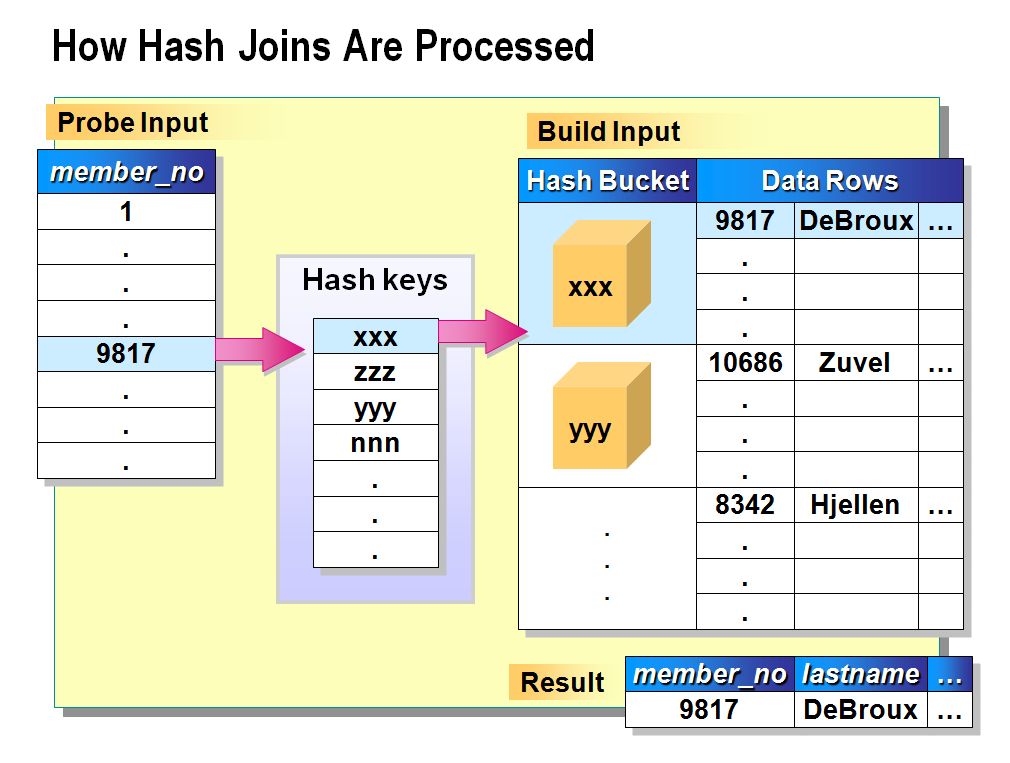
Первая проблема — неуникальные, т.е. повторяющиеся ключи. Для повторяющихся ключей нужно порождать декартово произведение всех соответствющих им значений. В Nested Loops Join почему-то это работает сразу. В Hash Join придется заменить HashMap на MultiHashMap. Для Merge Join ситуация гораздо более печальная — придется помнить, сколько элементов с одинаковым ключом мы видели.
Работа с неуникальными ключами увеличивает асимптотику до O(N*m+M*n), где n и m — среднее записей на ключ в таблицах. В вырожденном случае, когда n=N и m=M, операция превращается в CROSS JOIN.
Вторая проблема — надо следить за ключами, для которых не нашлось пары. Для Merge Join ключ без пары видно сразу для всех направлений JOIN’а. Для Hash Join сразу можно увидеть нехватку соответствующих ключей при джойне слева. Для того, чтобы фиксировать непарные ключи справа, придется завести отдельный флаг “есть пара!” для каждого элемента хеш-таблицы. После завершения основного джойна надо будет пройти по всей хеш-таблице и добавить в результат ключи без флага пары.
Для Nested Loops Join ситуация аналогичная, причем все настолько просто, что я даже осилил это закодить:
IDE для SQL
IDE или интегрированная среда разработки — это графический инструмент, который позволяет вам управлять всеми файлами, связанными с вашим приложением, и работать с такими инструментами, как полезные пакеты, функции автозаполнения, подсветка синтаксиса и т. Д., Чтобы улучшить ваш опыт разработки.



Хотя это правда, что вы можете создавать базы данных и таблицы и управлять ими прямо из самой командной строки, однако использование IDE всегда будет полезно для получения обзора всех баз данных, запросов, таблиц и других компонентов с высоты птичьего полета. Фактически, есть IDE, в которых есть раздел справки, в котором объясняются основные команды и их использование. Вы можете просто заполнить текстовые поля, выбрать различные предварительно отформатированные команды, нажать кнопку «ОК», и ваша работа будет выполнена. Это так просто. Более того, существуют IDE, которые также позволяют создавать резервные копии и восстанавливать базы данных и таблицы.
Следовательно, всегда разумно выбрать среду IDE, которая удовлетворяет ваши требования, прежде чем вы запачкаете руки SQL. Вот список лучших IDE, которые вы можете использовать для составления сложных SQL-запросов.
1. DBeaver
DBeaver— это среда разработки баз данных на основе Java с открытым исходным кодом. Его можно использовать бесплатно, и в нем есть мощные функции, которые обеспечат бесперебойную разработку.
Функции —
- Он позволяет экспортировать таблицы в файлы CSV и дамп, а также восстанавливать таблицы.
- Он позволяет сохранять наиболее часто используемые команды SQL. Вы можете загрузить эти сохраненные команды позже для других проектов.
- Также есть несколько цветовых тем.
- Он имеет инструмент управления сеансом.
- Он позволяет сравнивать две таблицы БД и их структуры.
- Выполненные запросы эстетично отображаются в отдельном интерфейсе.
- Он позволяет графически редактировать ячейки таблиц базы данных и фиксировать их.
2. PHPMyAdmin
PHPMyAdmin — это многофункциональный инструмент с открытым исходным кодом на основе HTML, который вы можете использовать для управления своими базами данных.
Функции —
- Это позволяет вам управлять пользователями и разрешениями.
- Он может поддерживать множество языков.
- Это позволяет создавать и редактировать запросы и столбцы результирующих строк.
- Вы можете сохранить свои запросы на более позднее время.
- IDE обладает широкими возможностями настройки для скрытия или отображения таблиц, комментариев, кодировок, временных меток и т. Д.
- Вы можете создавать резервные копии баз данных, конвертировать их в файлы CSV, импортировать дампы SQL и т. Д.
- Это позволяет вам управлять несколькими серверами.
- Вы можете использовать QBE для создания сложных запросов.
3. Adminer
Adminer можно использовать как альтернативу PHPMyAdmin. Он основан на веб-интерфейсе, поддерживает множество плагинов, позволяет работать с несколькими базами данных, такими как Oracle, SQLite и т. Д.
Особенности —
- Подключайтесь к базам данных, создавайте новые и т. Д.
- Вы можете распечатать схемы баз данных, даже если они связаны внешними ключами.
- Вы можете устанавливать и управлять разрешениями и правами пользователей и даже изменять их как администратор.
- Раздел справки неплохой, можно отображать переменные, у которых есть реферальные ссылки на документацию.
- Вы можете легко управлять разделами таблиц и событий.
CROSS JOIN (перекрестное объединение)
Самое простое объединение, которое мы можем сделать, это CROSS JOIN (перекрестное объединение) или «декартово произведение».
При этом объединении мы берем каждую строку одной таблицы и соединяем ее с каждой строкой другой таблицы.
Если у нас есть два списка и в одном из них содержатся цифры 1, 2, 3, а в другом — буквы А, В, С, то декартово произведение этих списков будет выглядеть так:
1A, 1B, 1C 2A, 2B, 2C 3A, 3B, 3C
Каждое значение из первого списка соединено с каждым значением второго списка.
Давайте перепишем этот пример в виде SQL-запроса.
Для начала создадим две очень похожих таблицы и внесем в них данные:
CREATE TABLE letters( letter TEXT ); INSERT INTO letters(letter) VALUES (‘A’), (‘B’), (‘C’); CREATE TABLE numbers( number TEXT ); INSERT INTO numbers(number) VALUES (1), (2), (3);
Наши таблицы letters и numbers имеют по одному столбцу с простыми текстовыми полями.
Теперь давайте объединим эти таблицы, используя CROSS JOIN:
SELECT * FROM letters CROSS JOIN numbers; letter | number ———+——— A | 1 A | 2 A | 3 B | 1 B | 2 B | 3 C | 1 C | 2 C | 3 (9 rows)
Это наипростейший вид объединения, но даже на этом примере мы можем видеть, как работает JOIN. Две разных строки (одна из таблицы letters, другая — из numbers) объединяются друг с другом, образуя одну строку.
Хотя этот пример часто упоминается как чисто учебный, и для него есть практическое применение: покрытие диапазона дат.
CROSS JOIN с диапазонами дат
Хороший вариант использования CROSS JOIN — брать каждую строку таблицы и объединять ее с каждым днем из диапазона дат.
Скажем, вы создаете приложение, которое должно отслеживать ежедневную рутину (чистка зубов, завтрак, душ).
Если вы хотите генерировать запись для каждой задачи за каждый день прошлой недели, вы можете использовать CROSS JOIN с диапазоном дат.
Чтобы создать диапазон дат, мы можем воспользоваться функцией generate_series:
SELECT generate_series( (CURRENT_DATE — INTERVAL ‘5 day’), CURRENT_DATE, INTERVAL ‘1 day’ )::DATE AS day;
Функция generate_series принимает три параметра.
Первый параметр — стартовое значение. В этом примере мы использовали CURRENT_DATE — INTERVAL ‘5 day’, то есть текущая дата минус пять дней (или «пять последних дней»).
Второй параметр — текущая дата (CURRENT_DATE).
Третий параметр — шаг. То есть, на сколько мы хотим инкрементировать значение. Поскольку это ежедневные задачи, мы устанавливаем в качестве интервала один день (INTERVAL ‘1 day’).
Все вместе генерирует серию дат, начиная с даты пятидневной давности и заканчивая сегодняшним днем, по дню за раз.
Наконец, мы удаляем часть, касающуюся времени, преобразовывая вывод значений в дату при помощи ::DATE, и назначаем этому столбцу псевдоним (при помощи AS day), чтобы сделать вывод красивее.
Результат запроса за последние пять дней плюс сегодняшний:
day ———— 2020-08-19 2020-08-20 2020-08-21 2020-08-22 2020-08-23 2020-08-24 (6 rows)
Возвращаемся к нашему примеру с ежедневными задачами. Давайте создадим простую таблицу, в которой будут содержаться наши задачи (и добавим несколько):
CREATE TABLE tasks( name TEXT ); INSERT INTO tasks(name) VALUES (‘Brush teeth’), (‘Eat breakfast’), (‘Shower’), (‘Get dressed’);
В нашей таблице tasks есть только один столбец — name — в который мы добавили несколько задач.
Теперь давайте осуществим перекрестное объединение наших задач с запросом на генерацию дат:
SELECT tasks.name, dates.day FROM tasks CROSS JOIN ( SELECT generate_series( (CURRENT_DATE — INTERVAL ‘5 day’), CURRENT_DATE, INTERVAL ‘1 day’ )::DATE AS day ) AS dates
(Поскольку наш запрос для генерации дат по сути не является таблицей, мы просто написали его в виде подзапроса).
В результате мы получаем название задачи и день. Выглядит это следующим образом:
name | day —————+———— Brush teeth | 2020-08-19 Brush teeth | 2020-08-20 Brush teeth | 2020-08-21 Brush teeth | 2020-08-22 Brush teeth | 2020-08-23 Brush teeth | 2020-08-24 Eat breakfast | 2020-08-19 Eat breakfast | 2020-08-20 Eat breakfast | 2020-08-21 Eat breakfast | 2020-08-22 … (24 rows)
Как и ожидалось, мы получили по строке для каждой задачи на каждый день из нашего диапазона дат.
CROSS JOIN это простейшее объединение. Дальнейшие примеры потребуют более «жизненной» настройки таблиц.





Внешнее соединение
В предшествующих примерах естественного соединения, результирующий набор содержал только те строки с одной таблицы, для которых имелись соответствующие строки в другой таблице. Но иногда кроме совпадающих строк бывает необходимым извлечь из одной или обеих таблиц строки без совпадений. Такая операция называется внешним соединением (outer join).
В примере ниже показана выборка всей информации для сотрудников, которые проживают и работают в одном и том же городе. Здесь используется таблица EmployeeEnh, которую мы создали в статье «Инструкция SELECT: расширенные возможности» при обсуждении оператора UNION.
Результат выполнения этого запроса:
В этом примере получение требуемых строк осуществляется посредством естественного соединения. Если бы в этот результат потребовалось включить сотрудников, проживающих в других местах, то нужно было применить левое внешнее соединение. Данное внешнее соединение называется левым потому, что оно возвращает все строки из таблицы с левой стороны оператора сравнения, независимо от того, имеются ли совпадающие строки в таблице с правой стороны. Иными словами, данное внешнее соединение возвратит строку с левой таблицы, даже если для нее нет совпадения в правой таблице, со значением NULL соответствующего столбца для всех строк с несовпадающим значением столбца другой, правой, таблицы. Для выполнения операции левого внешнего соединения компонент Database Engine использует оператор LEFT OUTER JOIN.
Операция правого внешнего соединения аналогична левому, но возвращаются все строки таблицы с правой части выражения. Для выполнения операции правого внешнего соединения компонент Database Engine использует оператор RIGHT OUTER JOIN.
В этом примере происходит выборка сотрудников (с включением полной информации) для таких городов, в которых сотрудники или только проживают (столбец City в таблице EmployeeEnh), или проживают и работают. Результат выполнения этого запроса:
Как можно видеть в результате выполнения запроса, когда для строки из левой таблицы (в данном случае EmployeeEnh) нет совпадающей строки в правой таблице (в данном случае Department), операция левого внешнего соединения все равно возвращает эту строку, заполняя значением NULL все ячейки соответствующего столбца для несовпадающего значения столбца правой таблицы. Применение правого внешнего соединения показано в примере ниже:
В этом примере происходит выборка отделов (с включением полной информации о них) для таких городов, в которых сотрудники или только работают, или проживают и работают. Результат выполнения этого запроса:
Кроме левого и правого внешнего соединения, также существует полное внешнее соединение, которое является объединением левого и правого внешних соединений. Иными словами, результирующий набор такого соединения состоит из всех строк обеих таблиц. Если для строки одной из таблиц нет соответствующей строки в другой таблице, всем ячейкам строки второй таблицы присваивается значение NULL. Для выполнения операции полного внешнего соединения используется оператор FULL OUTER JOIN.
Любую операцию внешнего соединения можно эмулировать, используя оператор UNION совместно с функцией NOT EXISTS. Таким образом, запрос, показанный в примере ниже, эквивалентен запросу левого внешнего соединения, показанному ранее. В данном запросе осуществляется выборка сотрудников (с включением полной информации) для таких городов, в которых сотрудники или только проживают или проживают и работают:
Первая инструкция SELECT объединения определяет естественное соединение таблиц EmployeeEnh и Department по столбцам соединения City и Location. Эта инструкция возвращает все города для всех сотрудников, в которых сотрудники и проживают и работают. Дополнительно, вторая инструкция SELECT объединения возвращает все строки таблицы EmployeeEnh, которые не отвечают условию в естественном соединении.
Определение SQL
Чтобы задействовать таблицы в приложениях, играх и прочем контенте, можно использовать SQL. Это – самый распространенный вариант развития событий.
Так называют язык структурированных запросов. Он дает возможность сохранять, управлять и извлекать информацию из реляционных баз данных.
Особенности – что умеет язык
При помощи SQL пользователь/разработчик сможет:
- заполучать доступ к информации в системах управления БД;
- производить описание данных, их структур;
- определять электронные материалы в «табличном хранилище», управляя оными;
- проводить взаимодействие с иными языками при помощи модулей, библиотек и компиляторов SQL;
- создавать новые таблички, удалять старые;
- заниматься созданием представлений, хранимых процедур и функций.
Также при работе с таблицами БД за счет SQL можно настраивать доступ к представлениям, таблицам и процедурам. Главное знать, каким именно образом действовать.
В SQL существуют всевозможные команды, использованием которых удается производить те или иные манипуляции
Далее будет рассказано всего об одном достаточно важном моменте. А именно – как использовать оператор Join
Он пригодится и новичкам, и тем, кто долгое время работает с таблицами и БД.
Постановка задачи
Людям, которые утверждают, что много и плотно работали с SQL, я задаю на собеседованиях вот такую задачу. Есть SQL команда
Нужно выполнить то же самое на Java, т.е. реализовать метод
Я не прошу прям закодить реализацию, но жду хотя бы устного объяснения алгоритма.
Дополнительно я спрашиваю, что нужно изменить в сигнатуре и реализации, чтобы сделать вид, что мы работаем с индексами.
- Знать теорию полезно из чисто познавательных соображений.
- Если вы различаете типы джойнов, то план выполнения запроса, который получается командой EXPLAIN, больше не выглядит для вас как набор непонятных английских слов. Вы можете видеть в плане потенциально медленные места и оптимизировать запрос переписыванием или хинтами.
- В новомодных аналитических инструментах поверх Hadoop планировщик запросов или малость туповат (см. Cloudera Impala), или его вообще нет (см. Twitter Scalding, Spark RDD). В последнем случае приходится собирать запрос вручную из примитивных операций.
-
Наконец, есть риск, что однажды вы попадете на собеседование ко мне или к другому зануде.Но на самом деле, статья не про собеседования, а про операцию JOIN.
Basic MERGE Structure
The MERGE statement combines INSERT, DELETE, and UPDATE operations into one table. Once you understand how it works, you’ll see it simplifies procedure with use all three statements separately to synchronize data.
Below is a generalized format for the merge statement.
The merge statement works using two tables, the sourceTable and targetTable. The targetTable is the table to be modified based in data contained within the sourceTable.
The two tables are compared using a mergeCondition. This condition specifies how rows from the sourceTable are matched to the targetTable. If your familiar with INNER JOINS, you can think of this as the join condition used to match rows.
Typically, you would match a unique identifier, such as a primary key. If the source table was NewProduct and target ProductMaster and the primary key for both ProductID, then a good merge condition to use would be:
A merge condition results in one of three states: MATCHED, NOT MATCHED, or NOT MATCHED BY SOURCE.
Popularity of films by category in India
In this example, we’ll find the number of rentals per film category in India by joining the required tables as discussed in the earlier examples and
- Grouping by country and category and filtering records from India and counting the film category name (as film_category_count).
- Ordering the result by country in ascending order and film_category_count in descending order.
SELECT co.country, cat.name AS film_category,COUNT(cat.name) AS film_category_countFROM country coINNER JOIN city ciUSING (country_id)INNER JOIN address adUSING (city_id)INNER JOIN customer cuUSING (address_id)INNER JOIN rental reUSING (customer_id)INNER JOIN inventory invUSING (inventory_id)INNER JOIN film fiUSING (film_id)INNER JOIN film_category fcUSING (film_id)INNER JOIN category catUSING (category_id)/* Using WHERE co.country = 'India' here, instead of HAVING co.country = 'India' reduces the query execution time. */GROUP BY (co.country, cat.name)HAVING co.country = 'India'ORDER BY co.country ASC, COUNT(cat.name) DESC;
Right Join
Описание right join предельно простое – правостороннее соединение. Результатом будут служить строчки из второй таблицы, соответствующие выставленному условию слияния. Наглядно это выглядит так:
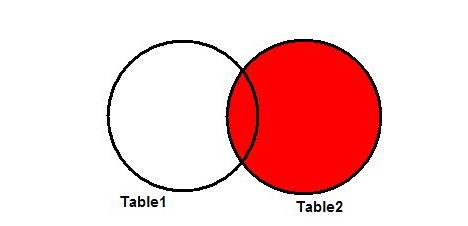
Результат запроса исключает поля левой таблицы, не соответствующие выставленным при составлении команды критериям.
О синтаксической записи и примерах
Синтаксис в команды будет иметь вид:
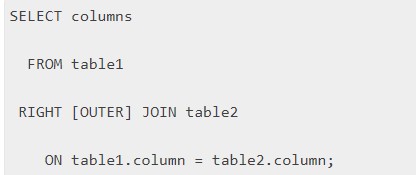
Чтобы понять, как работает right join в языке SQL, рекомендуется обратить внимание на наглядный пример. Он опять осуществляется с табличками customer и orders
Пример будет прописан в операторе SELECT.
Даны две таблицы с информацией:
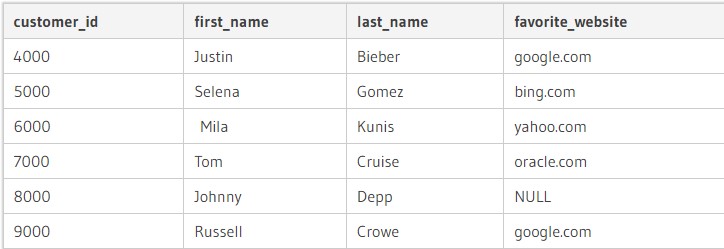
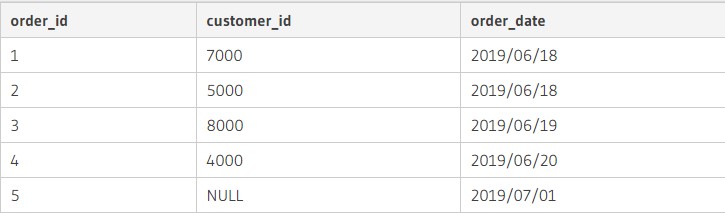
Далее, чтобы joined две таблички по правостороннему принципу, требуется отправить соответствующий запрос. Он обладает такой формой записи:

Как только операция пройдет обработку, на экране устройства появится результат. Он будет состоять из пяти элементов:
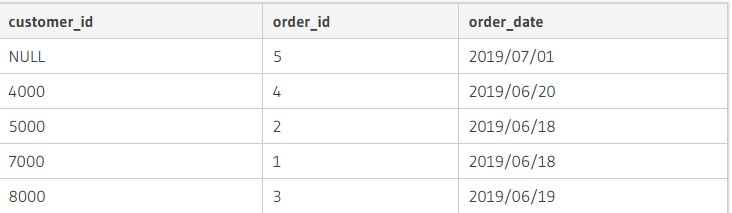
Здесь:
- возвращаются строки из orders – все;
- на экран дополнительно выводятся строчки из customers, которые имеют с «ордерс» одинаковые значения;
- если customers_id в orders отсутствует в «кастомерс», соответствующие поля имеют значение null.
Но и это еще не все. Для полного осознания запросов слияния электронных материалов, требуется в первую очередь изучить все доступные расклады. Их осталось еще 2. Встречаются на практике не слишком часто, из-за чего доставляют немалые хлопоты. Особенно тем, кто занимается запросовым языком относительно недавно.




Что такое СУБД
У Вас может возникнуть вопрос, если база данных это некая информация, которая хранится в таблицах, то как она выглядит физически? Как на нее посмотреть в целом?
Если очень коротко, то это просто файл, созданный в специальном формате, именно так и выглядит база данных (в большинстве случаев БД включает несколько файлов, но сейчас на этом уровне это не так важно). Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е
реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами
Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е. реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами.
Таким инструментом как раз и выступает СУБД – это система управления базами данных, сокращенно СУБД.
Number of films of an actor by category
In this example, we’ll find the number of films of an actor by film category by
- Creating a CTE named actor_cat_cnt that returns the number of films for each actor_id and category_id.
- Joining the above CTE with category table using category_id.
- Joining the resultant table with actor table using actor_id.
- Sort actor name (concatenation of first_name and last_name) in ascending order and film_count in descending order.
WITH actor_cat_cnt AS (SELECT fa.actor_id, fc.category_id, COUNT(f.film_id) AS film_count FROM film_actor faINNER JOIN film fUSING (film_id)INNER JOIN film_category fcUSING (film_id)GROUP BY fa.actor_id, fc.category_id )SELECT CONCAT(ac.first_name, ' ', ac.last_name) AS actor, ca.name AS category, film_countFROM actor_cat_cntINNER JOIN category caUSING (category_id)INNER JOIN actor acUSING (actor_id)ORDER BY CONCAT(ac.first_name, ' ', ac.last_name) ASC, film_count DESC;
Планы исполнения
Для того, чтобы грамотно использовать join в SQL, нужно учитывать планы исполнения запросов. То, как именно (в какой последовательности) будет происходить обработка операторов и необходимые вычисления.
Очередность такая:
- from;
- join;
- where.
Данный принцип актуален для всех СУБД
Если не принимать его во внимание, можно в конечном итоге получить таблички с неверной информацией
Важно: для того, чтобы ускорить обработку команд, важно использовать кластерные индексы. Они применяются Server Query Optimizer для обеих таблиц
Автоматическое создание кластерных индексов производится для первичных ключей. С остальными придется производить соответствующую настройку.
Описание join в языке SQL не должно вызывать вопросов. А если хочется лучше понять, что это такое, а также разобраться в принципах работы queries, стоит посетить дистанционные специализированные курсы. По окончанию обучения выдается сертификат, подтверждающий знания и навыки в выбранном направлении.

Заключение
Технология In-Memory довольно полезное дополнение, которое позволяет получить огромную производительность в базах данных на MS SQL Server. Но, как и везде, для этого нужно правильно организовать и построить вашу базу данных, просто взять и включить опцию In-Memory на ваших таблицах недостаточно, в некоторых случаях мы можем вообще получить деградацию.
Необходим глубокий анализ структуры таблиц и данных, запросов, а может и архитектуры ваших приложений. Для новых систем и приложений, лучше сразу планировать поддержку данной технологии, это будет легче чем потом пытаться подстроить базу под In-Memory технологию, тем более в MS SQL Server 2016 снято много ограничений.