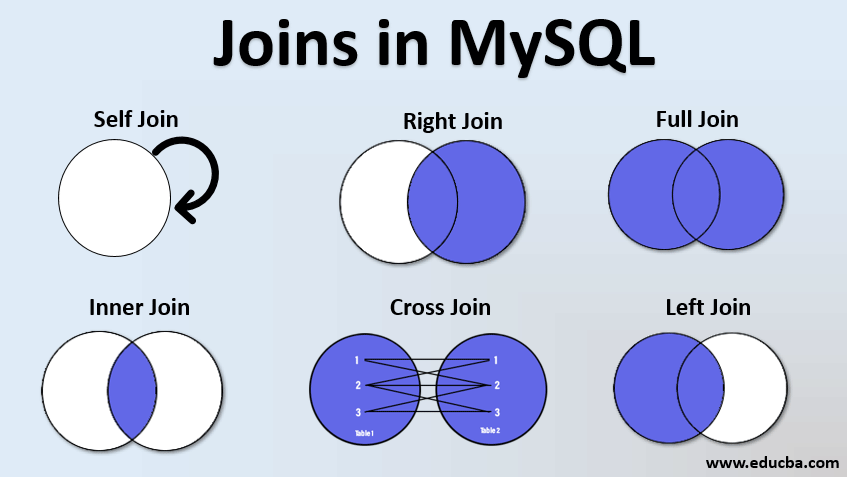
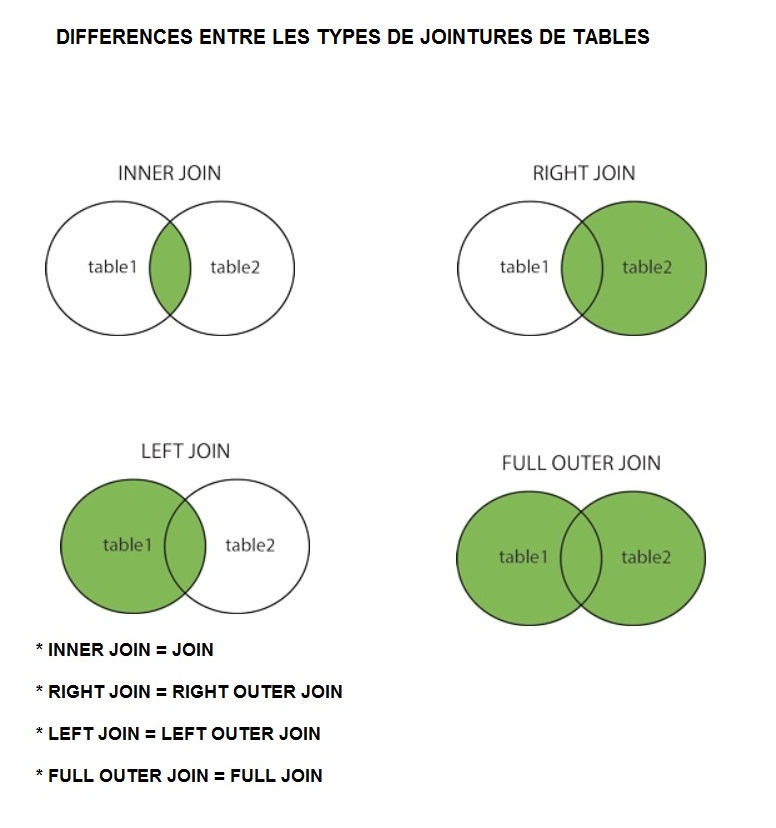
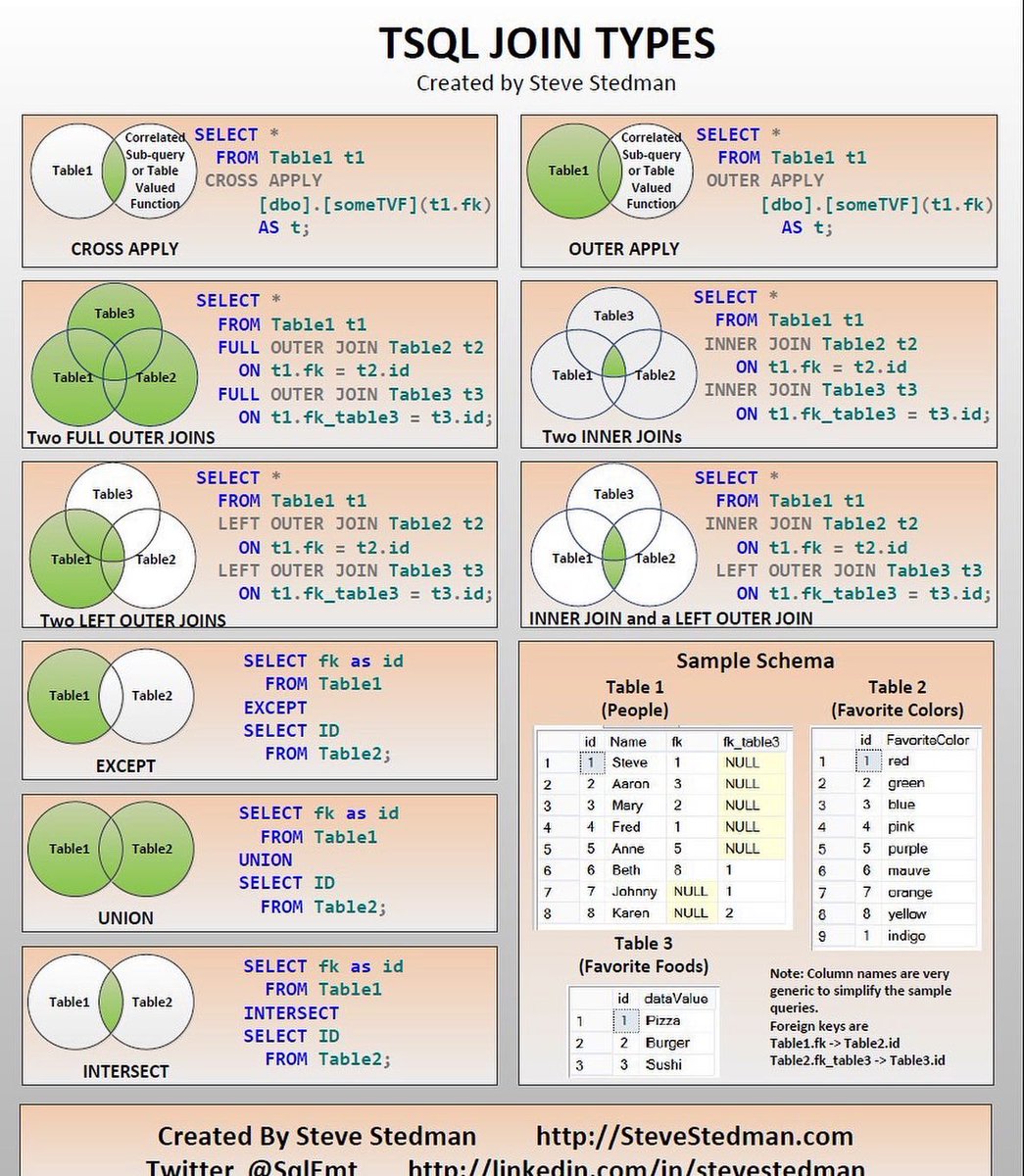
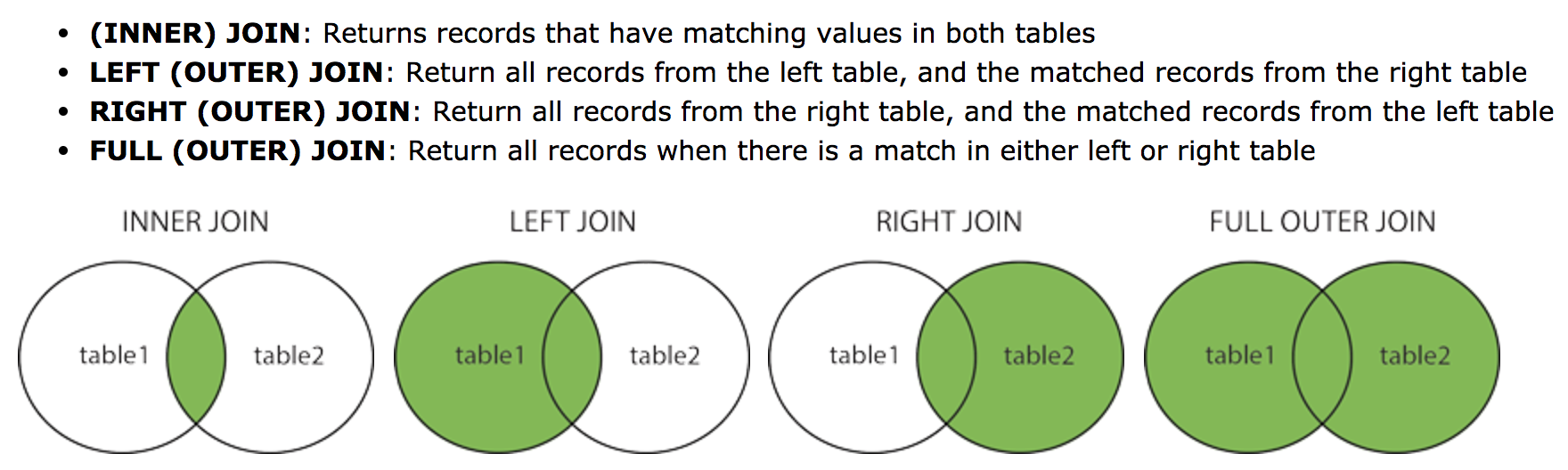
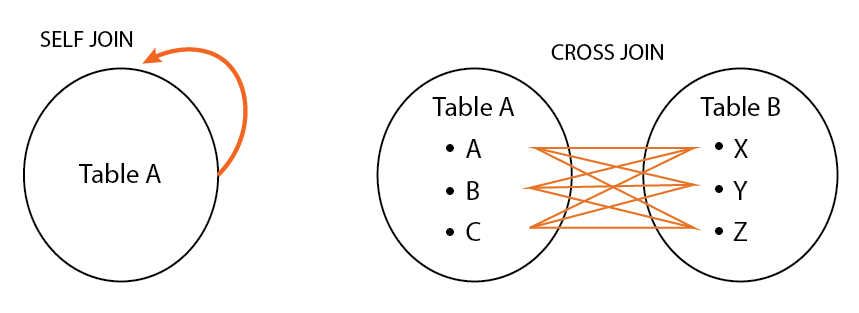
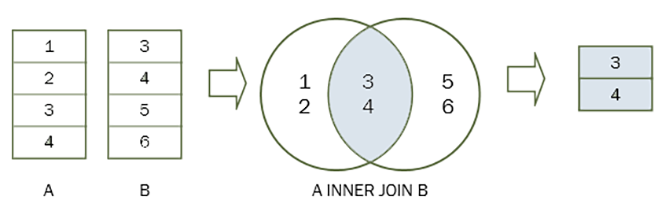
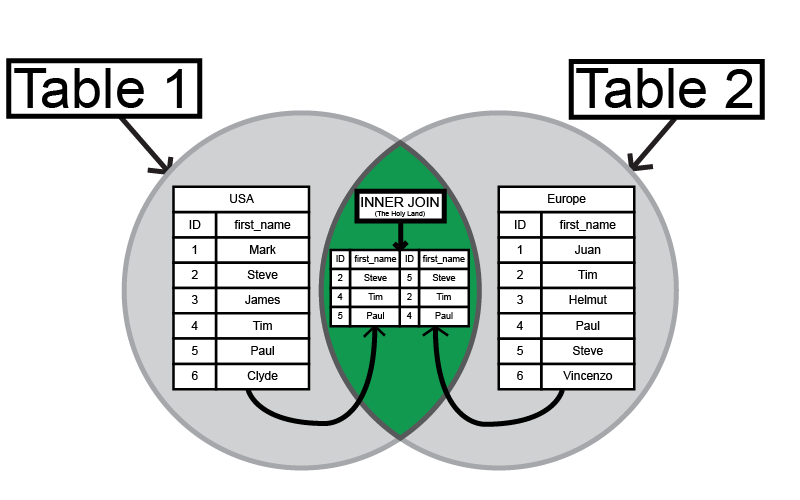
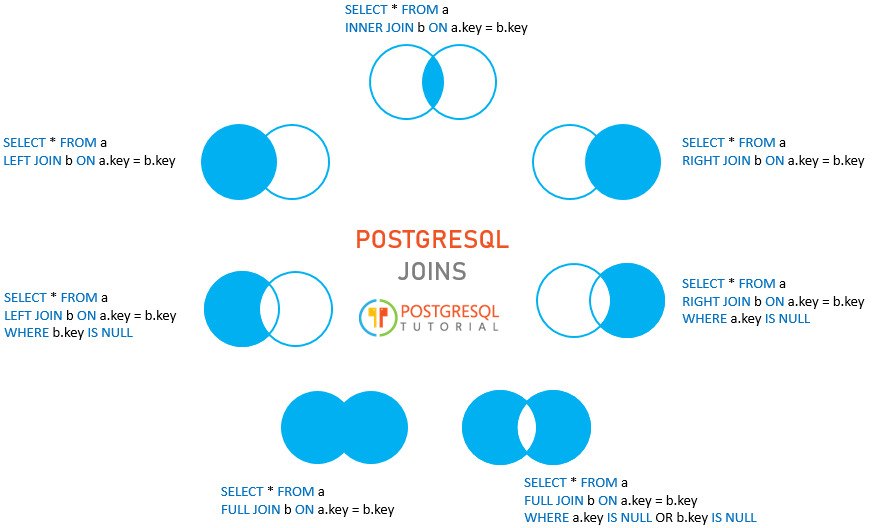
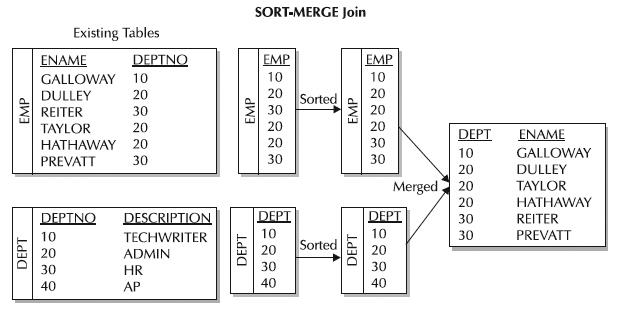
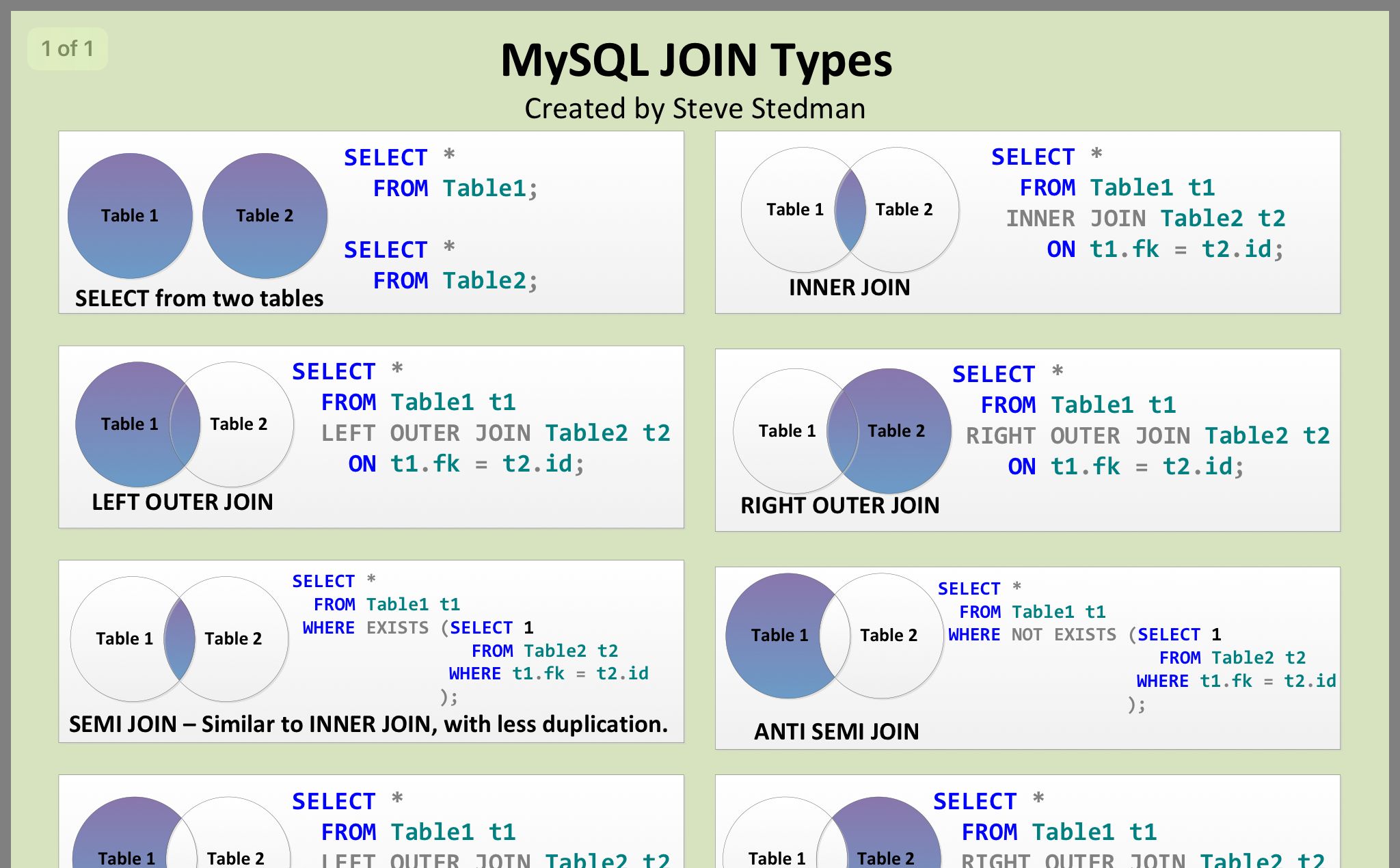
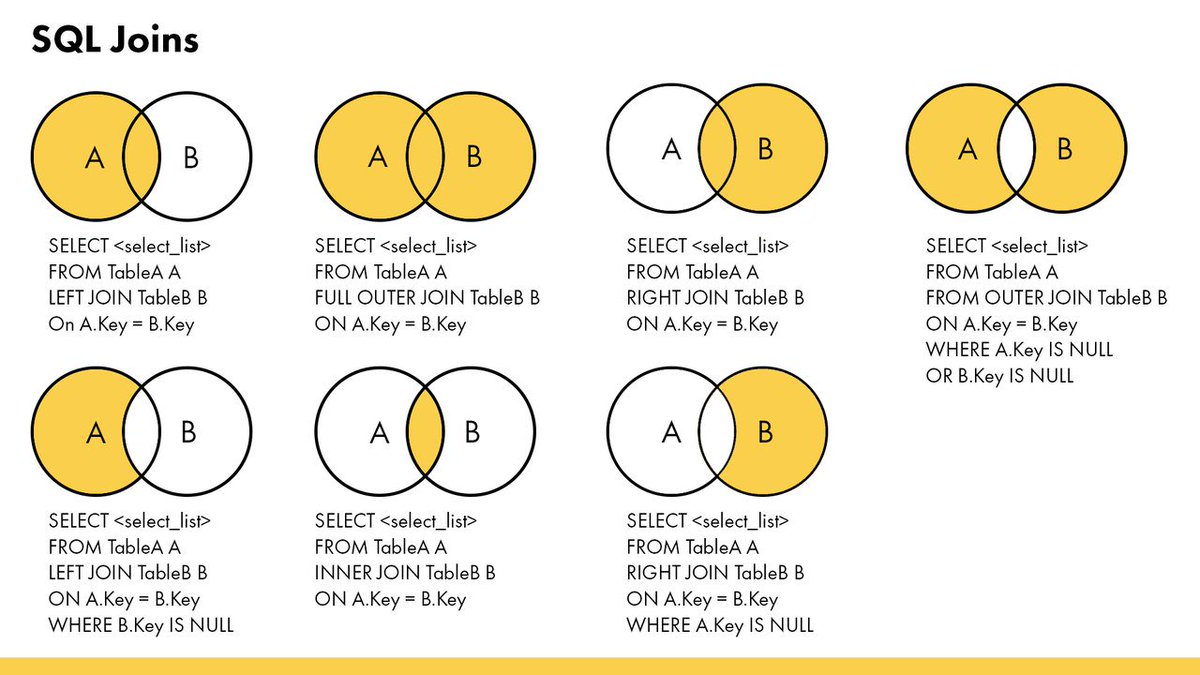
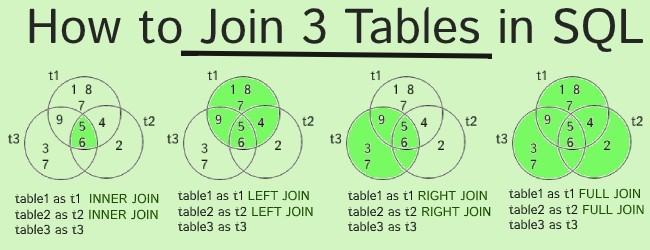
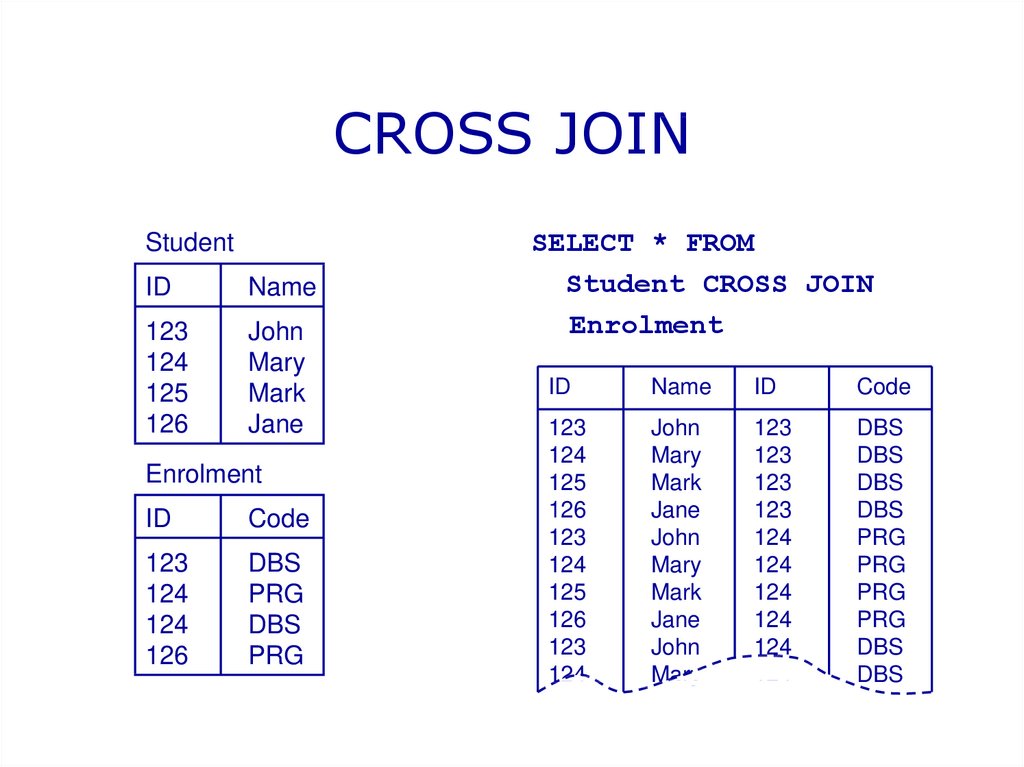
Using a JSON Path
To query the characters value directly, a JSON path can be passed into the OPENJSON function. A path always begins with $.
Remember, JSON arrays use zero-based array indexing. That means they start at 0, not 1. So if I want to see the key value pairs within the character object, I need to pass the position into the path. Since I want to see the first position, my path is ‘$.characters’
select * from OPENJSON( (select description from superHero where heroID = 1), '$.characters' )
$.characters results
Using that same path pattern, if I wanted to explore the second friend of the first character, the path would be ‘$.characters.friends’
$.characters.friends results
Querying Nested Hierarchical JSON Sub-arrays
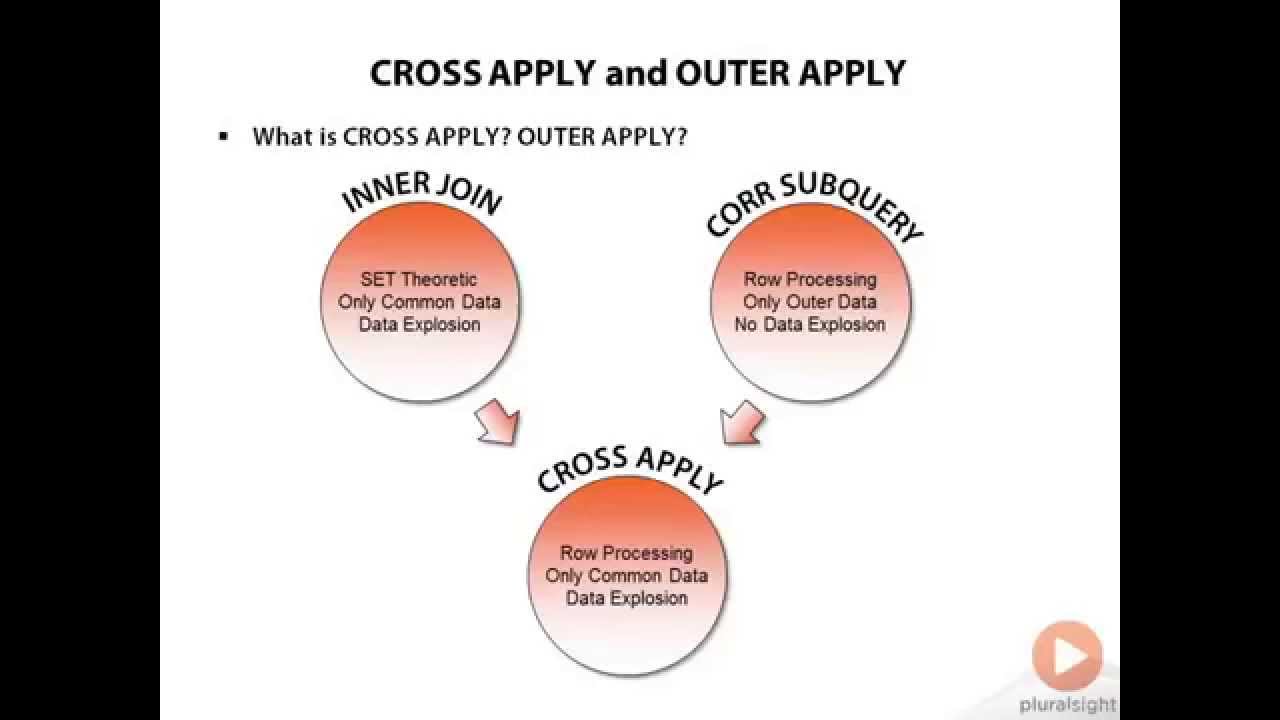
Supplying a path to OPENJSON is useful for digging into individual JSON levels, but not ideal for returning multiple nested hierarchies at once. In SQL Server, CROSS APPLY and OUTER APPLY can be used flatten the nested JSON. While it might look confusing at first, SQL Server makes opening JSON hierarchies fairly intuitive.
To flatten the superHero JSON, start by selecting from the superHero table. Then CROSS APPLY OPENJSON on the description field.
select *from superHero sCROSS APPLY OPENJSON(s.description)
Cross apply results
The CROSS APPLY joins each key value pair onto the row in superHero. Since the OPENJSON is opening the root object, the two keys are universe and characters.
Using the WITH keyword in the SQL query, the key value pair can be pivoted into a column instead of a row:
select *from superHero sCROSS APPLY OPENJSON(s.description)WITH (universe varchar(10))
WITH results
Notice only one row returns and now has a universe column instead of a key column and a value column.
To open the nested characters level, in the WITH statement, cast the characters as JSON. Then add another CROSS APPLY OPENJSON to the query, opening the JSON.
select *from superHero sCROSS APPLY OPENJSON(s.description)WITH (universe varchar(10), characters nvarchar(max) as JSON) c CROSS apply OPENJSON(c.characters)
To flatten characters, use the WITH and include the keys within characters. Do the same thing for the friends object.
select heroID, universe, f.hero, f.alias, powers, g.hero as friendHero, g.alias as friendAliasfrom superHero sCROSS APPLY OPENJSON(s.description)WITH (universe varchar(10), characters nvarchar(max) as JSON) c CROSS apply OPENJSON(c.characters) WITH (hero varchar(20), alias varchar(20),powers nvarchar(max)as JSON, friends nvarchar(max)as JSON) f OUTER APPLY OPENJSON(f.friends) WITH(hero varchar(20), alias varchar(20)) g
The query selects fields from the superHero table and cross joins them with the ROOT objects. Using the WITH operator, the query knows to select the value from the supplied key. In the query, I have selected universe from the OPENJSON call on the Root object. Casting the characters value AS JSON allows it to be passed into another OPENJSON. By chaining together OPENJSON using CROSS APPLY and OUTER APPLY, the query parses each of the nested hierarchies and returns the flattened data in tabular format.
Query Nested JSON sub-arrays
Congratulations! You just transformed nested JSON into a flattened result set!
Final Thoughts
As JSON is used more and more due to the popularity of JavaScript, understanding how to work with it is a fantastic skill to have. Although it might have seemed intimidating, working with JSON in SQL Server is fairly straightforward thanks to the OPENJSON function. In a few lines of SQL, you can transform JSON into columns and rows. For more information on OPENJSON I recommend reviewing the official Microsoft documentation.
Thank You!
- If you enjoyed my work, follow me on Medium for more!
- Get FULL ACCESS and help support my content by subscribing!
- Let’s connect on LinkedIn
- Analyze Data using Python? Check out my website!
FROM
The FROM clause specifies the tables or views used in the SELECT, DELETE, and UPDATE statements. It is required unless a SELECT list contains only constants, variables or arithmetic expressions, or an UPDATE clause does not contain references to other tables other than the target. It can be a single table, a derived table, a Table-Valued Function (TVF), or it can be several tables and/or views joined together.
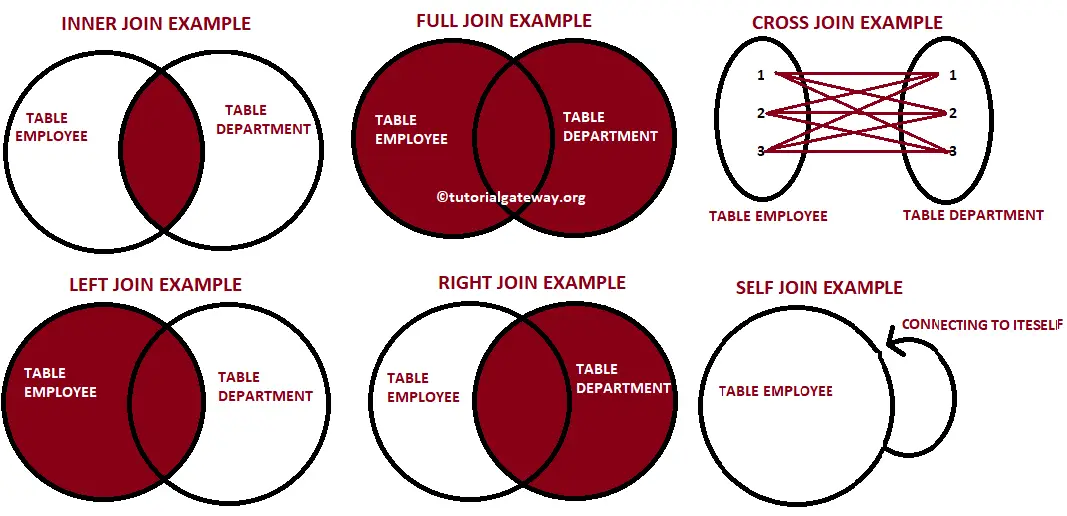
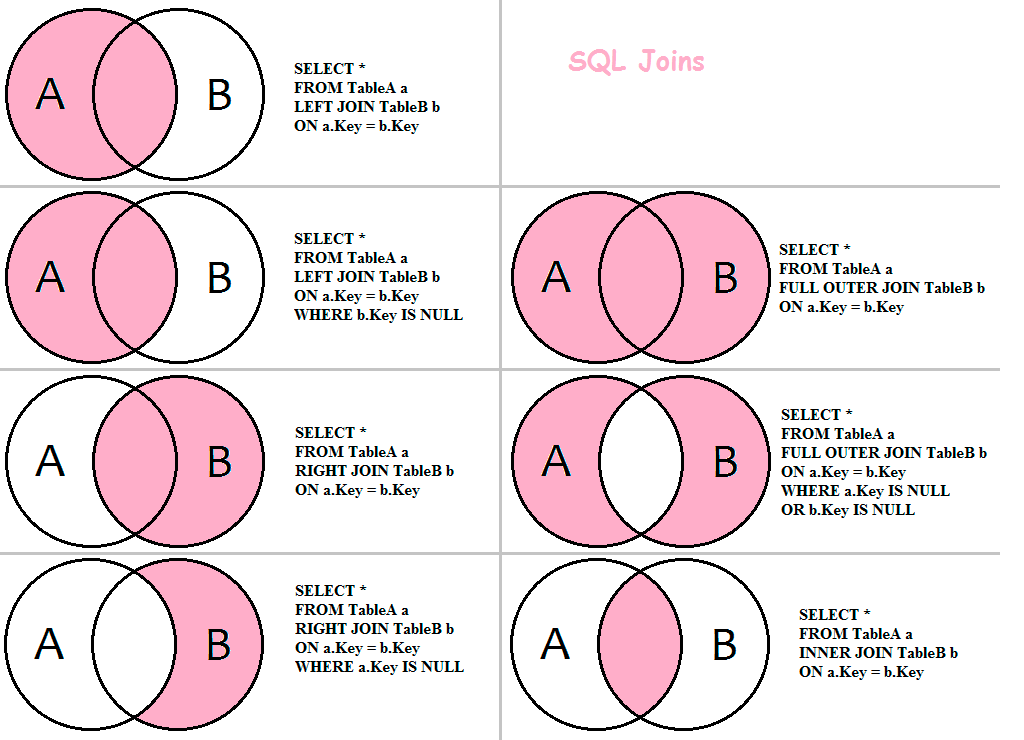
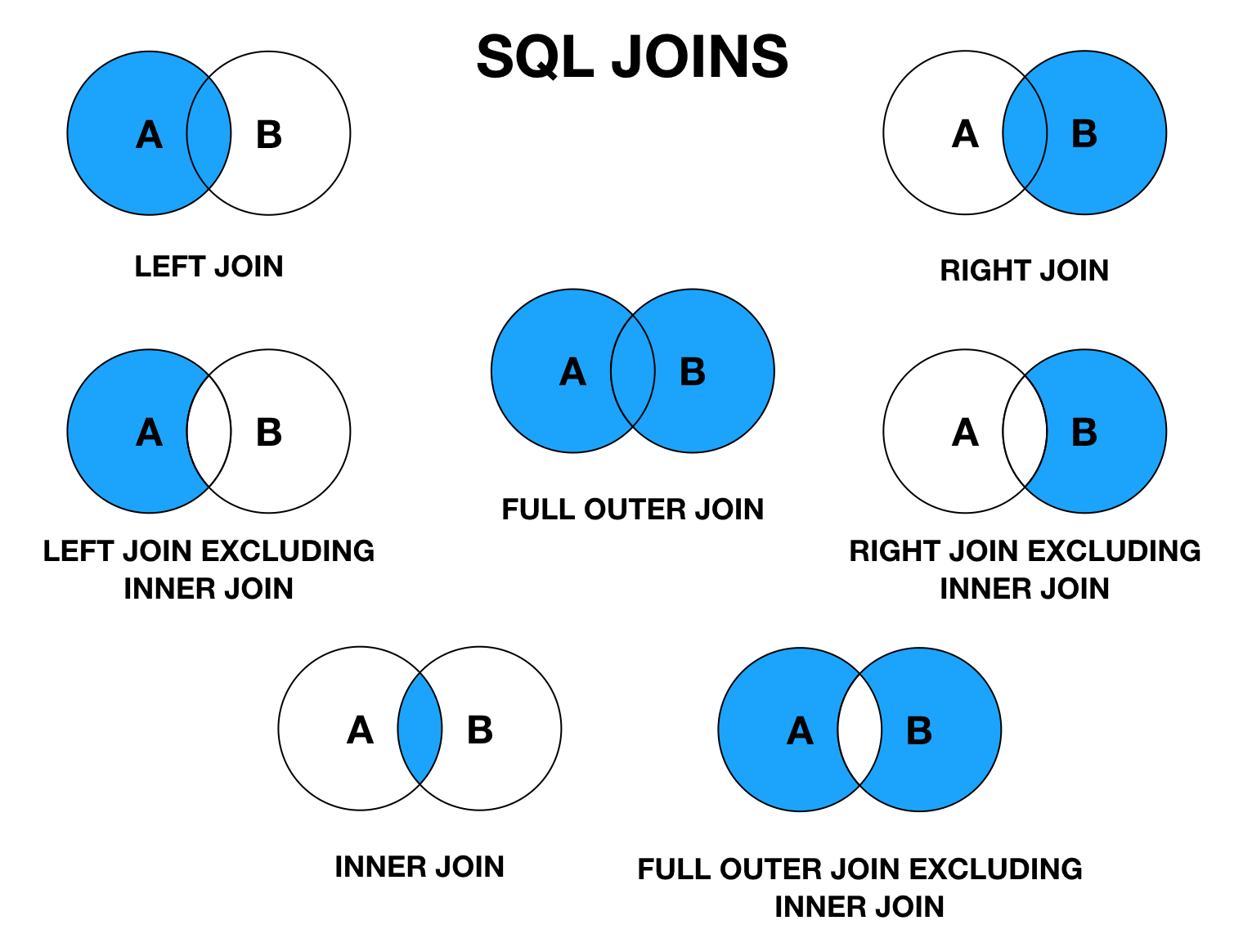
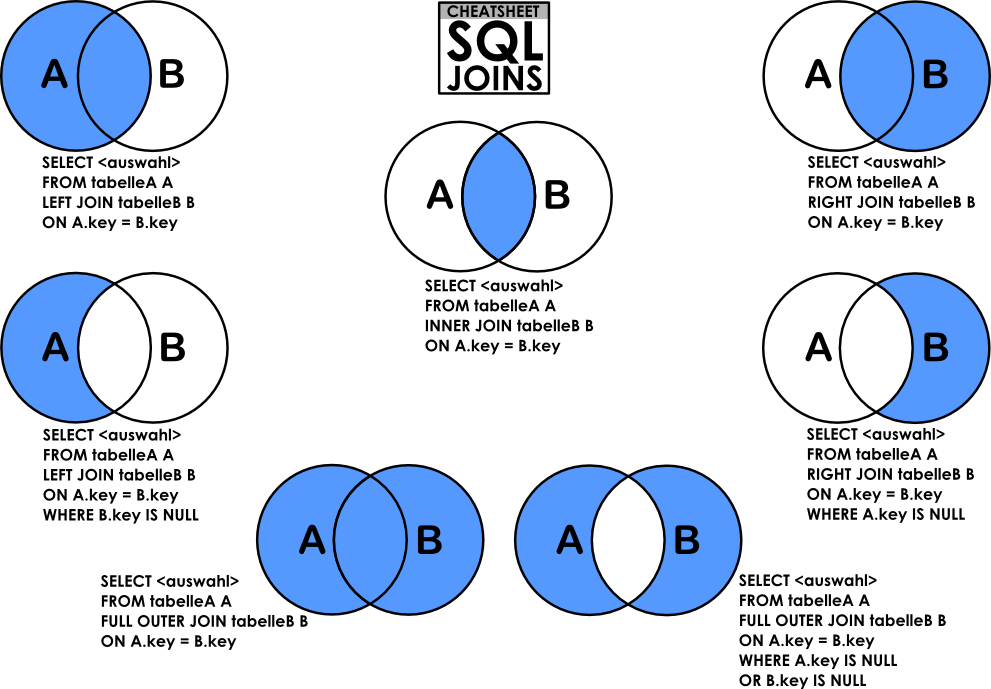
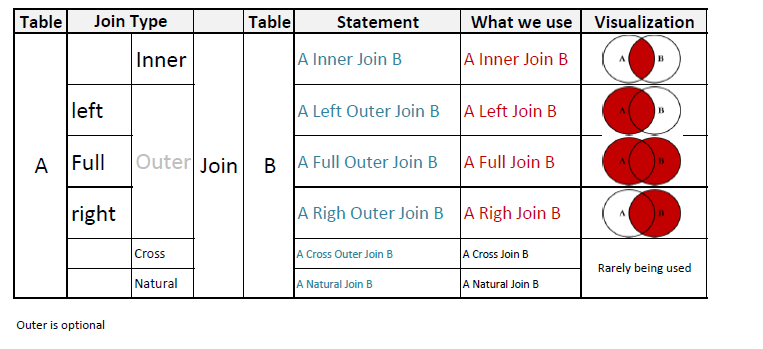
If the desired result set contains data from more than one table or view, joins can be used to link rows from one table to another. There are essentially the following three types of logical joins that are expressed when writing a query:
CROSS APPLY vs OUTER APPLY operators in SQL Server
December 11, 2010
In my we learnt about UDFs, their types and implementations. UDFs can be used in queries at column level, table levels and on column definition while creating tables.
They can also be joined with other tables, but not by simple joins. They use special join-keyword called APPLY operator.
According to MS BOL an APPLY operator allows you to invoke a table-valued function for each row returned by an outer table expression of a query. The table-valued function acts as the right input and the outer table expression acts as the left input. The right input is evaluated for each row from the left input and the rows produced are combined for the final output. The list of columns produced by the APPLY operator is the set of columns in the left input followed by the list of columns returned by the right input.
–> There are 2 forms of APPLY operators:
1. CROSS APPLY acts as INNER JOIN, returns only rows from the outer table that produce a result set from the table-valued function.
2. OUTER APPLY acts as OUTER JOIN, returns both rows that produce a result set, and rows that do not, with NULL values in the columns produced by the table-valued function.
Lets take 2 tables: Person.Contact & Sales.SalesOrderHeader
SELECT * FROM Person.Contact WHERE ContactID = 100 SELECT * FROM Sales.SalesOrderHeader WHERE ContactID = 100
You have a UDF that returns Sales Order Details of a Particular Contact. Now you want to use that UDF to know what all Contacts have Ordered what with other details, let’s see:
–> First creating a UDF to test with JOINS & APPLY:
--// Create Multiline UserDefinedFunction .
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE FUNCTION .(@ContactID int)
RETURNS @retSalesInfo TABLE (
INT NOT NULL,
INT NULL,
INT NULL,
NVARCHAR(50) NULL,
DATETIME NULL,
DATETIME NULL,
DATETIME NULL,
MONEY NULL,
TINYINT NULL,
INT NULL)
AS
BEGIN
IF @ContactID IS NOT NULL
BEGIN
INSERT @retSalesInfo
SELECT h., h., p., p., h., h.,
h., h., h., h.
FROM Sales.SalesOrderHeader AS h
JOIN Sales.SalesOrderDetail AS d ON d.SalesOrderID = h.SalesOrderID
JOIN Production.Product AS p ON p.ProductID = d.ProductID
WHERE ContactID = @ContactID
END
-- Return the recordsets
RETURN
END
--// Test the UDF
SELECT * FROM dbo.ufn_mtv_GetContactSales(100)
–> Trying to JOIN UDF with a table, problem is you need to apply a parameter and it can’t be a column, but a value:
--// UDF with JOIN, try it out!!! SELECT * FROM Person.Contact c JOIN dbo.ufn_mtv_GetContactSales(100) f -- You will have to pass the ContactID parameter, so no use of joining. ON f.ContactID = c.ContactID
–> Testing with CROSS APPLY:
--// CROSS APPLY -- 279 records (All matched records, 1 missing out of 280) SELECT c., c., c., c., c., s.* FROM Person.Contact AS c CROSS APPLY ufn_mtv_GetContactSales(c.ContactID) AS s WHERE c.ContactID between 100 and 105 -- Same equivalent query without cross apply, using JOINs -- 279 records SELECT c., c., c., c., c., h., h., p., p., h., h., h., h., h., h. FROM Person.Contact AS c JOIN Sales.SalesOrderHeader AS h ON c.ContactID = h.ContactID JOIN Sales.SalesOrderDetail AS d ON d.SalesOrderID = h.SalesOrderID JOIN Production.Product AS p ON p.ProductID = d.ProductID WHERE c.ContactID between 100 and 105
–> Testing with OUTER APPLY:
--// OUTER APPLY -- 280 records (All 280 records with 1 not matched) SELECT c., c., c., c., c., s.* FROM Person.Contact AS c OUTER APPLY ufn_mtv_GetContactSales(c.ContactID) AS s WHERE c.ContactID between 100 and 105 -- Same equivalent query without OUTER APPLY, using LEFT JOINs -- 280 records SELECT c., c., c., c., c., h., h., p., p., h., h., h., h., h., h. FROM Person.Contact AS c LEFT JOIN Sales.SalesOrderHeader AS h ON c.ContactID = h.ContactID LEFT JOIN Sales.SalesOrderDetail AS d ON d.SalesOrderID = h.SalesOrderID LEFT JOIN Production.Product AS p ON p.ProductID = d.ProductID WHERE c.ContactID between 100 and 105
>> Check & Subscribe my on SQL Server.
Advertisement
Categories: Differences
APPLY Operator, CROSS APPLY, OUTER APPLY
CROSS APPLY and OUTER APPLY clause in SQL-SERVER 2005
March 3, 2009 — riteshshah
CROSS APPLY and OUTER APPLY clause in SQL-SERVER 2005
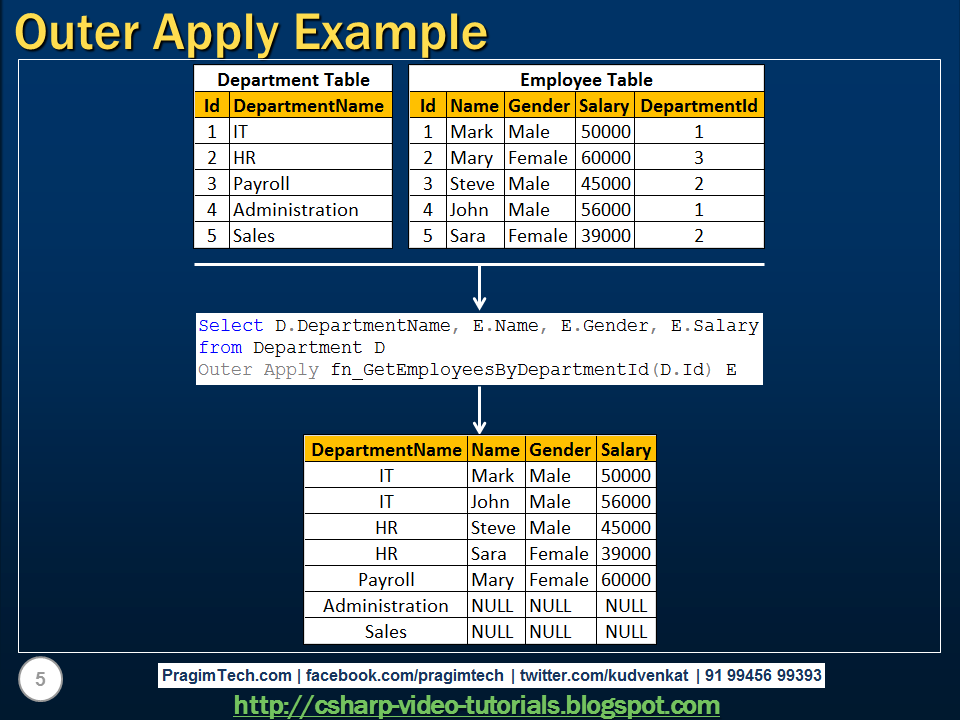
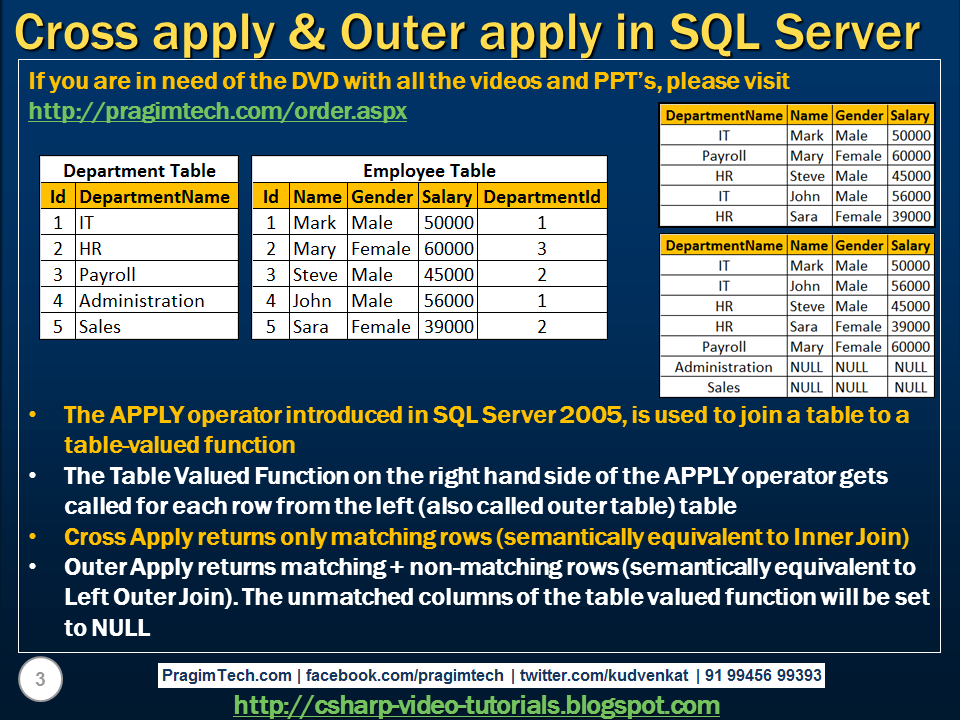
I will be introducing you with magical feature of Microsoft SQL-Server 2005, called CROSS APPLY and OUTER APPLY. If you want to get top 2 or 3 maximum inventory quantity of each product or all product of AdventureWorks database then it is bit difficult in SQL-Server 2000 as it doesn’t support CROSS APPLY or OUTER APPLY. You can use UDF or sub query for CROSS APPY or OUTER APPLY.
BTW, you can consider CROSS APPLY clause as INNER APPLY also as it will use outer (main) query as an input of subquery or function and will return the result set. In CROSS APPLY we will be getting full set of left side query (main query) and its corresponding value from right side query or function, if it is not available in right side query or function, it will return NULL.
First let us see use of CROSS APPLY:
We are going to create one function which will return top row from production.productinventory table of AdventureWorks database based on supplied productID and row number.
CREATE FUNCTION dbo.fn_GetMax_ProductItem(@Productid AS int, @rownum AS INT)
RETURNS TABLE
AS
RETURN
SELECT TOP(@rownum) *
FROM Production.ProductInventory
WHERE ProductID = @Productid
ORDER BY Quantity DESC
GO
You can run above UDF and test it with following query.
select * from dbo.fn_GetMax_ProductItem(1,2)
It will return top two row of productID 1.
Note: I strongly recommend not using “*” in query in live production environment due to performance issue, this is ok in this example.
As function is ready, we will start using that function in our CROSS APPLY example.
SELECT
p.ProductID,
p.Name,
p.ProductNumber,
pmi.Quantity,
pmi.locationID
FROM
Production.Product AS p
CROSS APPLY
dbo.fn_GetMax_ProductItem(p.productid, 2) AS pmi


WHERE
p.ProductID in (1,2,3,531,706)
ORDER BY
p.productid ASC
As soon as you run above query, you will get 8 rows. Two rows for each productID (1,2,3,531). You will not get any row for ProductID 706 as it is not available in Production.Product table.This proves that CROSS APPLY clause works like INNER APPLY.
Now let us tweak above query a bit with OUTER APPLY instead of CROSS APPLY.
SELECT
p.ProductID,
p.Name,
p.ProductNumber,
pmi.Quantity,
pmi.locationID
FROM
Production.Product AS p
OUTER APPLY
dbo.fn_GetMax_ProductItem(p.productid, 2) AS pmi
WHERE
p.ProductID in (1,2,3,531,706)
ORDER BY
p.productid ASC
This time you will get records for 706 productID as well but it will come with NULL in Quantity and LocationID.
Reference: Ritesh Shah
Advertisement
Use case 1: TOP N Rows
These queries now do the same thing and the is easier to write and remember, so why on earth would we use instead?
Let’s say that instead of all mileage log entries for every vehicle we now only want the last 5 entries for every vehicle. One way of doing this is with , and a nested query:
SQL
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY ML.VehicleID ORDER BY ML.EntryDate DESC) RN FROM Vehicles V INNER JOIN MileageLog ML ON V.ID = ML.VehicleID ) IQ WHERE IQ.RN <= 5
Which would only return the first 5 entries for every vehicle. To do so using a statement:
SQL
SELECT * FROM Vehicles V CROSS APPLY ( SELECT TOP 5 * FROM MileageLog ML WHERE V.ID = ML.VehicleID ORDER BY ML.EntryDate DESC) ML
The are a few important things to take note of here:
- We can use inside a statement: Since works row-by-row it will select the 5 items for every row of the Vehicles table.
- We don’t have to specify partitioning since is always row-by-row. Think of it as a built in clause that is always there.
- The approach will add a new field where does not.
SQL
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY ML.VehicleID ORDER BY ML.EntryDate DESC) RN FROM Vehicles V INNER JOIN MileageLog ML ON V.ID = ML.VehicleID ) IQ INNER JOIN ( SELECT ML.VehicleID, COUNT(*) AS RowCount FROM MileageLog ML GROUP BY ML.VehicleID ) MLCount ON IQ.VehicleID = MLCount.VehicleID WHERE RN / cast(MLCount.RowCount as float) <= .1
As you can see this becomes a more complex query since we now require aggregates and single-row expressions in order to calculate our own percentages. It also very quickly becomes unclear what we were trying to do.
If we use doing this is simply:
SQL
SELECT * FROM Vehicles V CROSS APPLY ( SELECT TOP 10 PERCENT * FROM MileageLog ML WHERE V.ID = ML.VehicleID ORDER BY ML.EntryDate DESC) ML
Are you starting to see how can make your life easier?
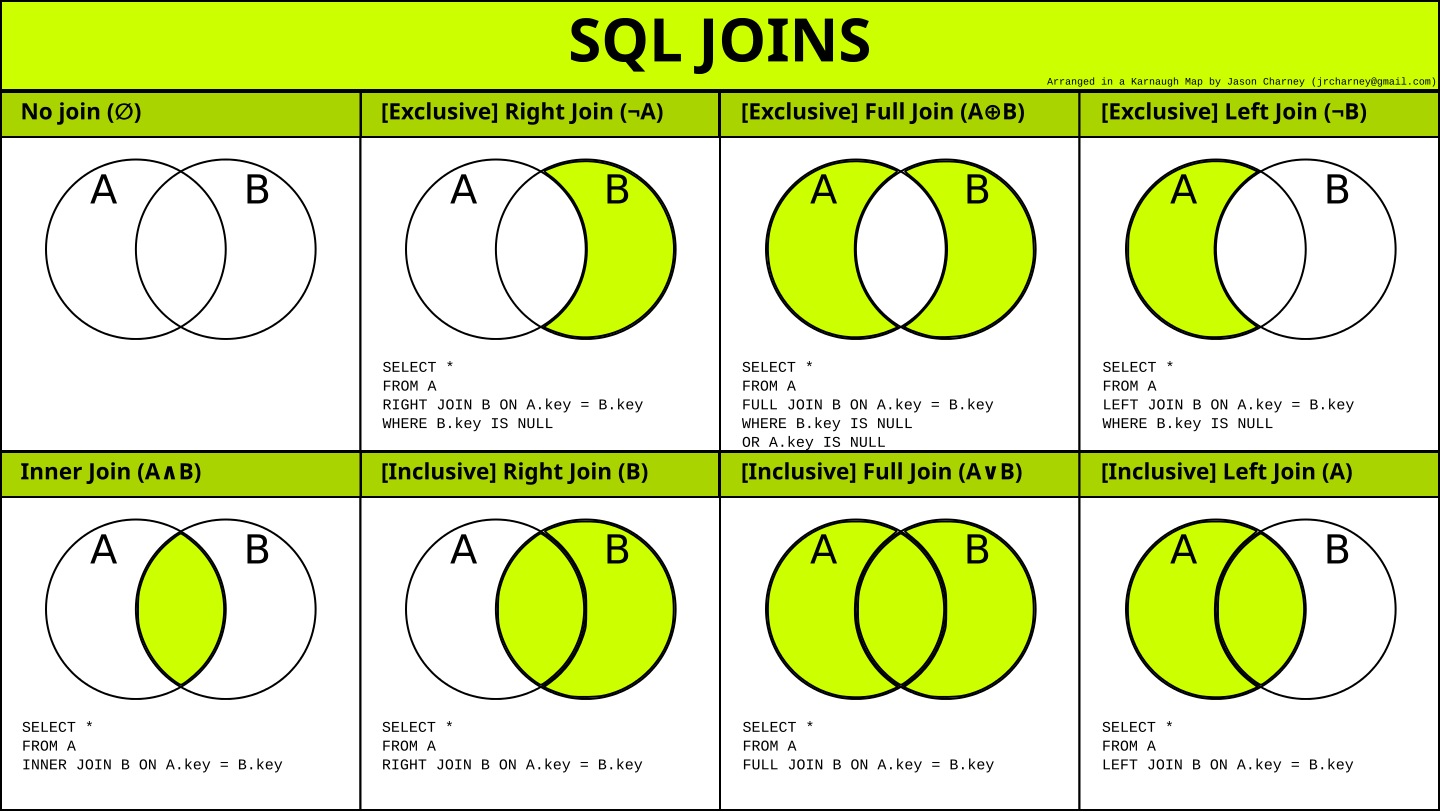
Соединяем данные нескольких таблиц
Чтобы достроить нашу воронку до конца, необходимо соединить данные из таблиц и . А для этого нужно использовать оператор , который соединяет данные из разных таблиц по какому-либо единому для этих таблиц идентификатору.
Чтобы связать две таблицы в предложении нужно написать:
table_1 table_2 table_1.id = table_2.id
Виды оператора :
- — при помощи этого соединения, вы получите записи присутствующие в обеих таблицах.
-
— соединение, в результат которого входят все записи либо одной, либо обеих таблиц:
- — возвращает все записи из таблицы слева и соединяет их со связанными записями из правой таблицы (именно такое соединение мы используем).
- — тоже самое, что и предыдущее соединение, только все записи возвращаются из присоединяемой таблицы.
- — возвращает все записи обеих таблиц, там где нет пересечений возвращается .
- — перекрестное соединение при котором каждая запись одной таблицы соединяется с каждой записью второй таблицы, давая тем самым в результате все возможные сочетания строк двух таблиц.
Визуально это выглядит так:
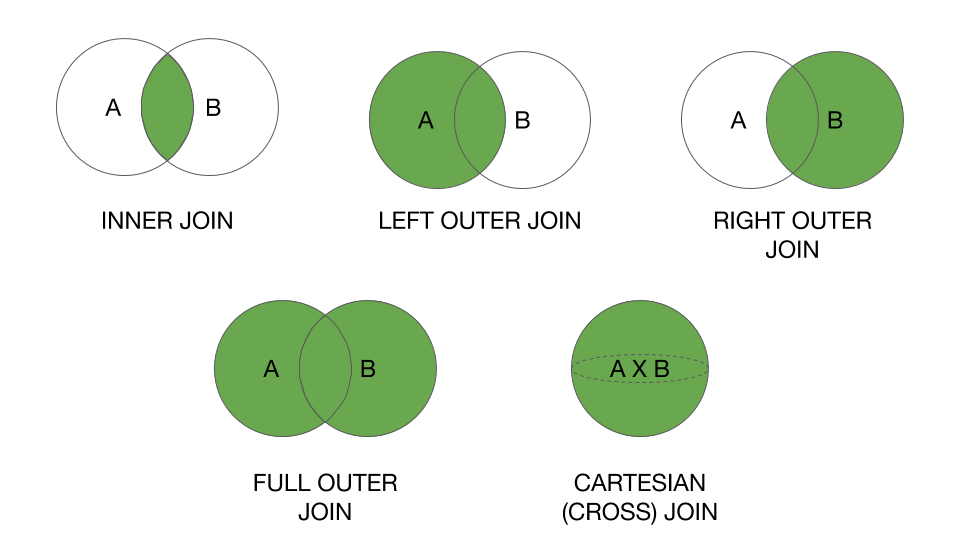
Подробнее читайте в .
Теперь можем смело добавить в нашу воронку статусы заказов.
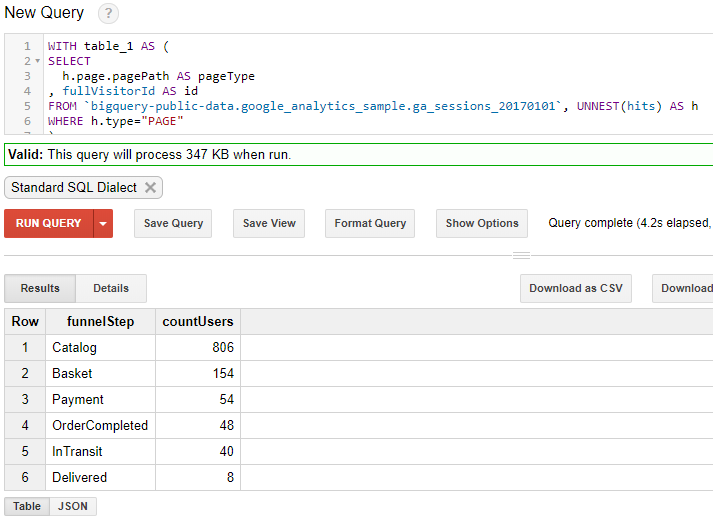
SELECT CASE WHEN h.page.pagePath LIKE '/google+redesign%' THEN 'Catalog' WHEN h.page.pagePath LIKE '/basket%' THEN 'Basket' WHEN h.page.pagePath LIKE '/payment%' THEN 'Payment' WHEN h.page.pagePath LIKE '/ordercompleted%' THEN 'OrderCompleted' WHEN deliveryStatus = 'inTransit' THEN 'InTransit' WHEN deliveryStatus = 'delivered' THEN 'Delivered' ELSE 'Other' END AS funnelStep , COUNT (DISTINCT `bigquery-public-data.google_analytics_sample.ga_sessions_20170101`.fullVisitorId) AS countUsers FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170101`, UNNEST(hits) AS h LEFT JOIN `alert-snowfall-167320.crm_data.delivery_data` ON `bigquery-public-data.google_analytics_sample.ga_sessions_20170101`.fullVisitorId = `alert-snowfall-167320.crm_data.delivery_data`.fullVisitorId WHERE h.type="PAGE" GROUP BY funnelStep ORDER BY countUsers DESC
Получилось:
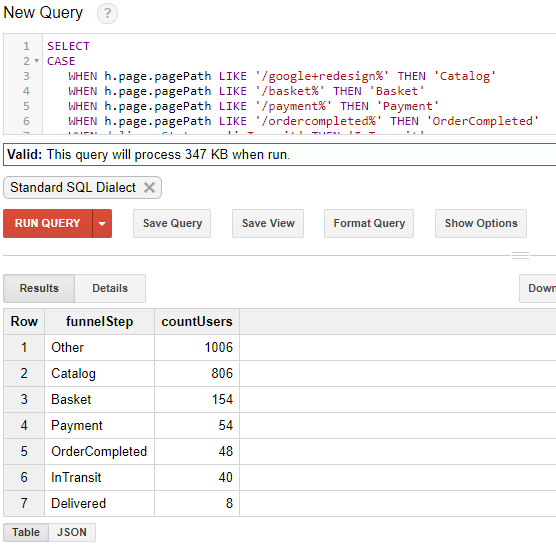
Осталось только немного оптимизировать запрос, так как в текущем виде он работает достаточно медленно. Для этого разобьем наш сложный запрос на более простые подзапросы, а также воспользуемся оператором , который позволяет именовать подзапросы (подробнее и ).


WITH table_1 AS ( SELECT h.page.pagePath AS pageType , fullVisitorId AS id FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170101`, UNNEST(hits) AS h WHERE h.type="PAGE" ), table_2 AS ( SELECT deliveryStatus , fullVisitorId as id FROM `alert-snowfall-167320.crm_data.delivery_data` ), table_join AS ( SELECT CASE WHEN pageType LIKE '/google+redesign%' THEN 'Catalog' WHEN pageType LIKE '/basket%' THEN 'Basket' WHEN pageType LIKE '/payment%' THEN 'Payment' WHEN pageType LIKE '/ordercompleted%' THEN 'OrderCompleted' WHEN deliveryStatus = 'inTransit' THEN 'InTransit' WHEN deliveryStatus = 'delivered' THEN 'Delivered' ELSE 'Other' END AS funnelStep , COUNT (DISTINCT table_1.id) AS countUsers FROM table_1 LEFT JOIN table_2 ON table_1.id = table_2.id GROUP BY funnelStep ORDER BY countUsers DESC ) SELECT * FROM table_join WHERE funnelStep <> 'Other'
Окончательная воронка:
MSTVF vs. Inline TVFs
While inline TVFs and MSTVFs are highly similar in how they’re called and the results they return to the end-user, they’re not compatible objects. For example, if I try to ALTER the inline TVF I created above, I receive the following syntax error:

So, I’ll drop the previous inline TVF and replace it with the MSTVF.
The MSTVF is called the same way as the inline TVF—by using the APPLY operator. The example below passes each value from Production.Product into the MSFTF and returns all product values having associated records returned from the function call.
The execution plan shows a call against the Production.Product table and a call to the GetSalesByProduct MSTVF. This is a massive issue with looking at MSTVF calls in an execution plan because you can’t see what’s happening inside the MSTVF.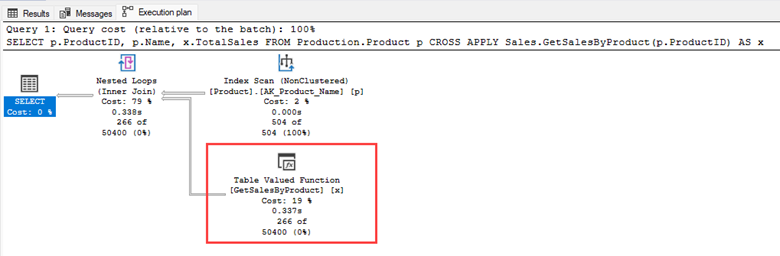
Also, looking at the output of STATISTICS IO isn’t much help as it doesn’t give any valuable information regarding the MSTVF:

To see the actual number of logical reads returned from the above query, I’ll use the Extended Event Profiler tool. To open this tool, expand the XEvent Profiler tool in SSMS Object Explorer and double click on the Standard profile, as shown below:
Once the tool is listening to events on the server, I can run the above query again and capture the output. Here you can see the logical number of reads from the query is slightly over 369K. Whoa!
A small change to using MSTVF can dramatically increase the number of logical reads for the query. Be aware of this common behavior when you see these in a production environment as they’re so commonly used. However, I still fix performance problems all the time by refactoring these problematic objects.
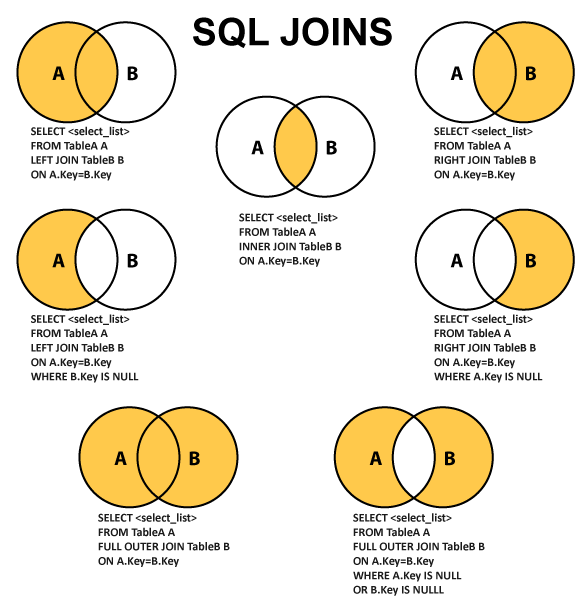
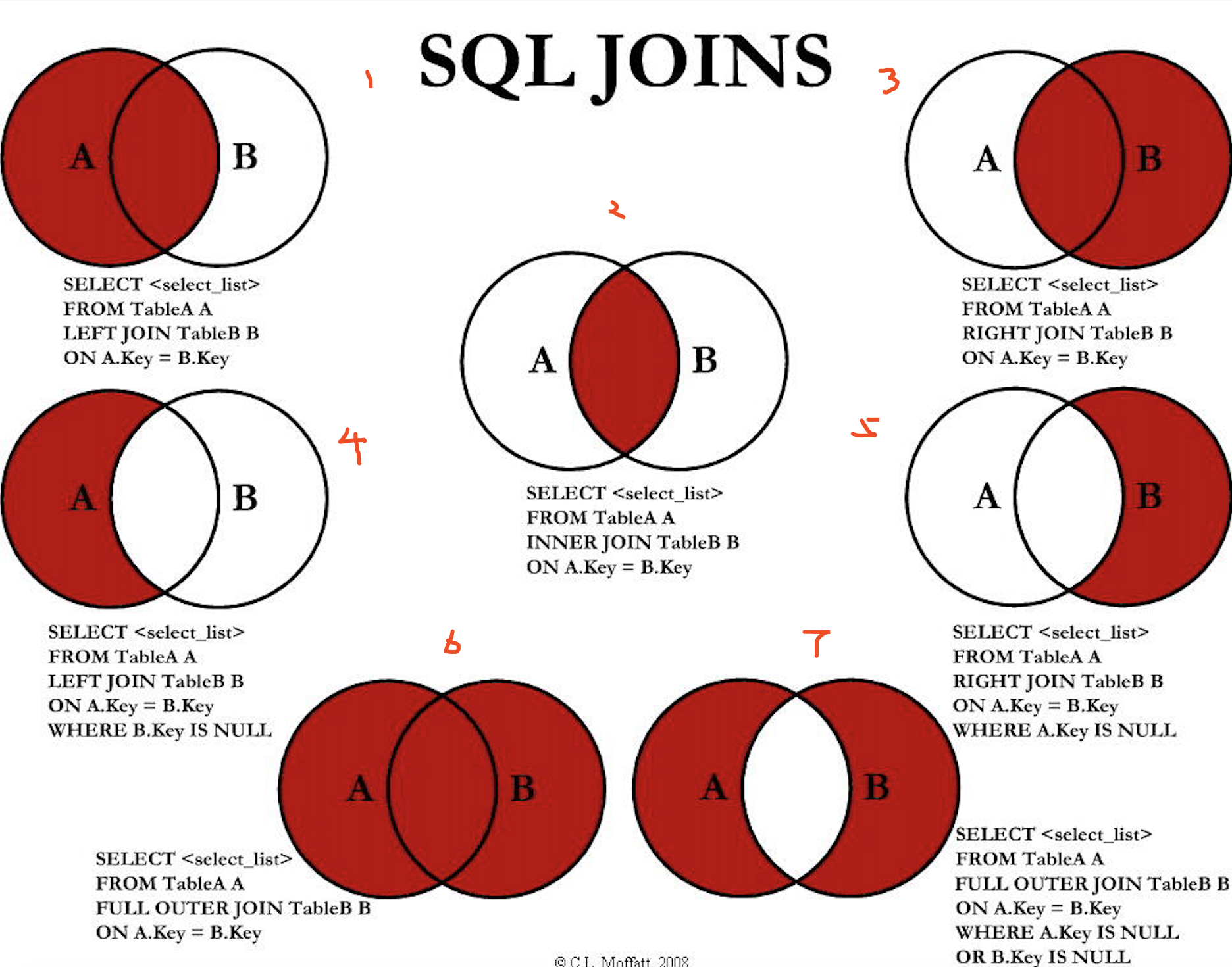
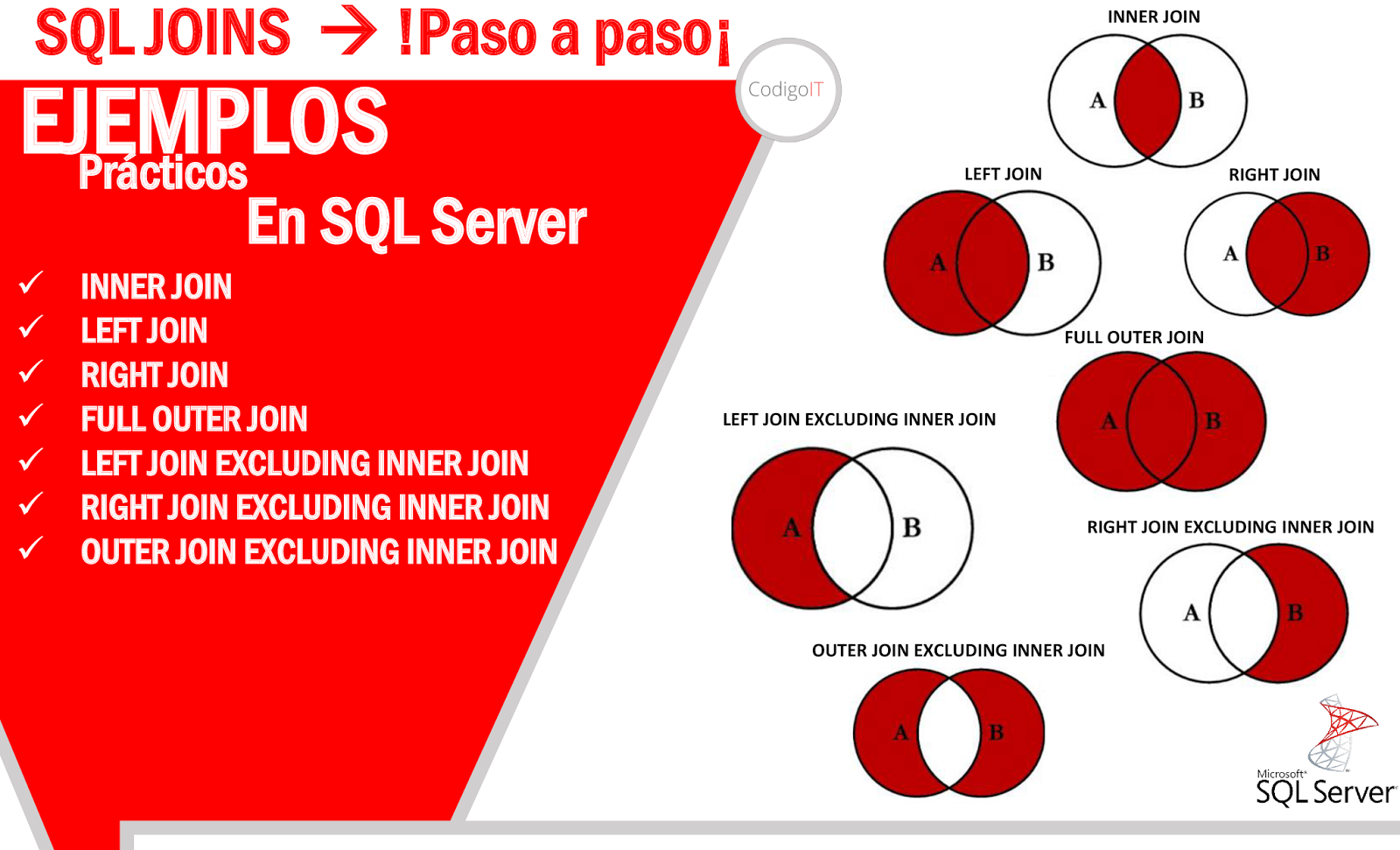
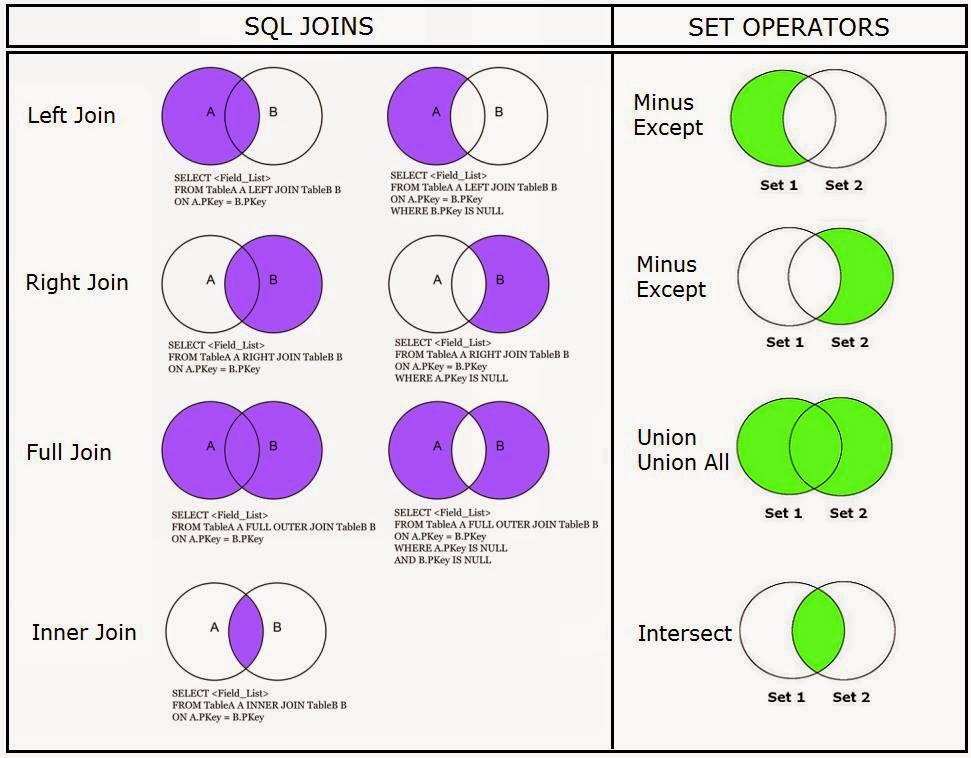
JOIN-соединения – операции горизонтального соединения данных
Если суть РДБ – разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.
- JOIN – левая_таблица JOIN правая_таблица ON условия_соединения
- LEFT JOIN – левая_таблица LEFT JOIN правая_таблица ON условия_соединения
- RIGHT JOIN – левая_таблица RIGHT JOIN правая_таблица ON условия_соединения
- FULL JOIN – левая_таблица FULL JOIN правая_таблица ON условия_соединения
- CROSS JOIN – левая_таблица CROSS JOIN правая_таблица
| Краткий синтаксис | Полный синтаксис | Описание (Это не всегда всем сразу понятно. Так что, если не понятно, то просто вернитесь сюда после рассмотрения примеров.) |
|---|---|---|
| JOIN | INNER JOIN | Из строк левой_таблицы и правой_таблицы объединяются и возвращаются только те строки, по которым выполняются условия_соединения. |
| LEFT JOIN | LEFT OUTER JOIN | Возвращаются все строки левой_таблицы (ключевое слово LEFT). Данными правой_таблицы дополняются только те строки левой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк правой_таблицы вставляются NULL-значения. |
| RIGHT JOIN | RIGHT OUTER JOIN | Возвращаются все строки правой_таблицы (ключевое слово RIGHT). Данными левой_таблицы дополняются только те строки правой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк левой_таблицы вставляются NULL-значения. |
| FULL JOIN | FULL OUTER JOIN | Возвращаются все строки левой_таблицы и правой_таблицы. Если для строк левой_таблицы и правой_таблицы выполняются условия_соединения, то они объединяются в одну строку. Для строк, для которых не выполняются условия_соединения, NULL-значения вставляются на место левой_таблицы, либо на место правой_таблицы, в зависимости от того данных какой таблицы в строке не имеется. |
| CROSS JOIN | — | Объединение каждой строки левой_таблицы со всеми строками правой_таблицы. Этот вид соединения иногда называют декартовым произведением. |
- Это короче и не засоряет запрос лишними словами;
- По словам LEFT, RIGHT, FULL и CROSS и так понятно о каком соединении идет речь, так же и в случае просто JOIN;
- Считаю слова INNER и OUTER в данном случае ненужными рудиментами, которые больше путают начинающих.
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 1 | Администрация |
| 1003 | Андреев А.А. | 3 | 1 | Администрация |
| 1004 | Николаев Н.Н. | 3 | 1 | Администрация |
| 1005 | Александров А.А. | NULL | 1 | Администрация |
| 1000 | Иванов И.И. | 1 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 2 | Бухгалтерия |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 2 | Бухгалтерия |
| 1004 | Николаев Н.Н. | 3 | 2 | Бухгалтерия |
| 1005 | Александров А.А. | NULL | 2 | Бухгалтерия |
| 1000 | Иванов И.И. | 1 | 3 | ИТ |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | 3 | ИТ |
| 1000 | Иванов И.И. | 1 | 4 | Маркетинг и реклама |
| 1001 | Петров П.П. | 3 | 4 | Маркетинг и реклама |
| 1002 | Сидоров С.С. | 2 | 4 | Маркетинг и реклама |
| 1003 | Андреев А.А. | 3 | 4 | Маркетинг и реклама |
| 1004 | Николаев Н.Н. | 3 | 4 | Маркетинг и реклама |
| 1005 | Александров А.А. | NULL | 4 | Маркетинг и реклама |
| 1000 | Иванов И.И. | 1 | 5 | Логистика |
| 1001 | Петров П.П. | 3 | 5 | Логистика |
| 1002 | Сидоров С.С. | 2 | 5 | Логистика |
| 1003 | Андреев А.А. | 3 | 5 | Логистика |
| 1004 | Николаев Н.Н. | 3 | 5 | Логистика |
| 1005 | Александров А.А. | NULL | 5 | Логистика |
WHERE
The WHERE clause specifies the search condition that determines whether a row should be returned in the result set. Rows will be returned only if the entire WHERE clause evaluates to TRUE. Each condition within the WHERE clause is referred to as a predicate. There is no limit to the number of predicates that can appear in a WHERE clause, and predicates are combined using the AND, OR, and NOT logical operators.
For example, the AdventureWorks sample database has a Product table that contains the Name and ProductID columns, a ProductInventory table that contains the Quantity, LocationID, and ProductID columns, and a Location table that contains the LocationID and Name columns. A query that returns the current product inventory per location, for the entire Touring line of products would look like the following code block:
The following screenshot shows that all the ProductName values in the result set begin with the word Touring:
Получайте только нужные данные
Идеология «чем больше данных, тем лучше» ‑ это не то, что вам нужно для написания SQL-запросов: вы рискуете не только затуманить свои идеи, получая данных на много больше, чем вам нужно, но также производительность вашего запроса может пострадать от того, что он будет выбираться слишком много данных.
Вот почему обычно рекомендуется заботиться об инструкции , операторах и .
Первое, что вы уже можете проверить, когда вы написали свой запрос, является ли оператор максимально возможно компактным. При этом ваша цель – удалить ненужные столбцы из оператора . Таким образом вы будете запрашивать только те данные, которые служат цели вашего запроса.
Помните, что коррелированный подзапрос – это подзапрос, который использует значения из внешнего запроса
И обратите внимание, что, хотя и может здесь использоваться в качестве «константы», это выглядит очень запутанно для понимания вашего запроса другими разработчиками!. Рассмотрим следующий пример, чтобы понять, что мы подразумеваем под использованием константы:
Рассмотрим следующий пример, чтобы понять, что мы подразумеваем под использованием константы:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS (SELECT '1' FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr);
Совет: полезно знать, что наличие коррелированного подзапроса не является хорошей идеей. Вы всегда можете отказаться от него, например, переписав запрос через :
SELECT driverslicensenr, name FROM drivers INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr;
Оператор используется для возврата только различных значений. – это условие, которого, при возможности, лучше всего избегать. Как вы можете видеть и на других примерах, время выполнения увеличивается только в том случае, если вы добавили это предложение в свой запрос. Поэтому всегда стоит подумать над тем, действительно ли вам нужна операция , чтобы получить нужный вам результат.
Когда вы используете оператор в запросе, индекс не используется, если шаблон начинается с или . Эти шаблоны запрещают использование индексов базы данных (если он имеются). Ну и конечно, с другой стороны, этот тип запроса потенциально оставляет открытой возможность для извлечения слишком большого количества записей, которые не обязательно могут удовлетворять цели вашего запроса.
Отметим еще раз – знания структуры хранимых данных могут помочь вам сформулировать шаблон, который будет правильно фильтровать все данные, чтобы выбрать из базы только те строки, которые действительно важны для вашего запроса.
Joining tables using JOIN operators
Therefore, Let’s first we will use the to retrieve matching rows from both of the tables. Execute the following script:
SELECT A.CarBrand_name, B.id, B.Car_name, B.price
FROM CarBrand A
INNER JOIN Car B
ON A.id = B.CarBrand_id
|
1 |
SELECTA.CarBrand_name,B.id,B.Car_name,B.price FROM CarBrandA INNER JOIN CarB ONA.id=B.CarBrand_id |
Output:
furthermore, as you can see that only those records have been selected from the table where there is a matching row in the table. so, to retrieve all those records from CarBrandr table can be used.
SELECT A.CarBrand_name, B.id, B.Car_name, B.price
FROM CarBrand A
LEFT JOIN Car B
ON A.id = B.CarBrand_id
|
1 |
SELECTA.CarBrand_name,B.id,B.Car_name,B.price FROM CarBrandA LEFT JOIN CarB ONA.id=B.CarBrand_id |
so, the output of the given above query, which looks like as:Output: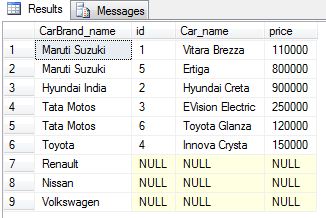
Therefore, you will see that all the records are retrieved from the table, therefore, the irrespective of there being any matching rows in the table.
Примеры использования CROSS APPLY
Для начала давайте определимся с исходными данными, допустим, у нас есть таблица товаров (Products) и таблица продаж (Sales) вот с такими данными:
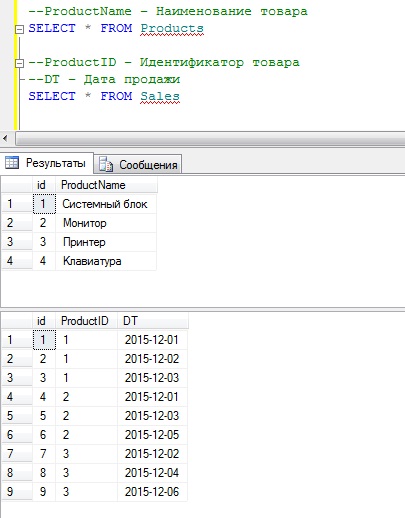
А также у нас есть функция (FT_GET_Sales), которая просто выводит список продаж по идентификатору товара.
Пример ее работы:
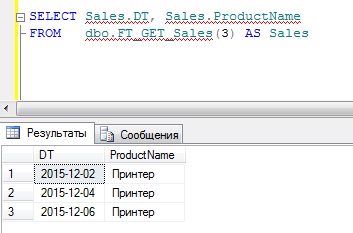
Пример использования CROSS APPLY с табличной функцией
Теперь допустим, нам необходимо получить продажи не только одного товара, но и других, для этого мы можем использовать оператор CROSS APPLY

Где как Вы понимаете, табличная функция FT_GET_Sales была вызвана для каждой строки таблицы Products.
Пример использования CROSS APPLY с подзапросом
Как уже было сказано выше, CROSS APPLY можно использовать и с подзапросом, для примера давайте допустим, что нам нужно получить последнюю дату продажи каждого товара.

Как видим, после CROSS APPLY у нас идет подзапрос.