Кросс-коммутация
Существует также особый случай в операции соединения, то есть соединение продукта Kaskov, которое является соединением без предиката соединения. Продукт Касселя этих двух таблиц является перекрестным произведением записей в этих двух таблицах, то есть каждая запись в таблице должна быть сшита с каждой записью в другой таблице, поэтому таблица результатов часто очень велика.
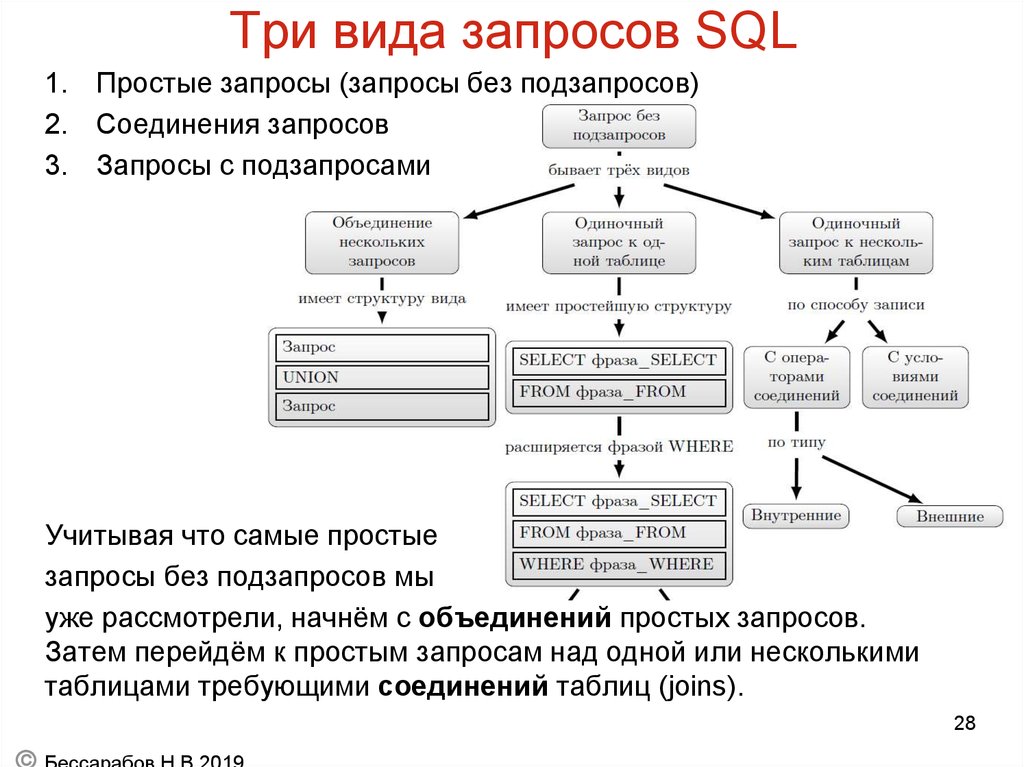
2. Подзапрос
На языке SQL оператор SELECT-FROM-WHERE называется блоком запроса. Запрос, который вкладывает один блок запроса в предложение WHERE или фразу HAVING другого блока запроса, называется вложенным запросом или подзапросом.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
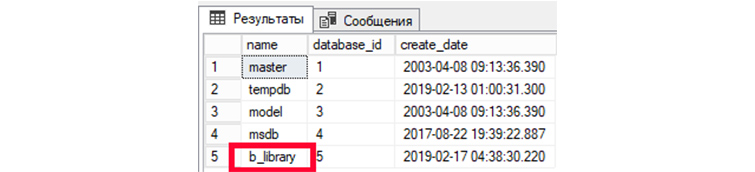
1) Выведем все имеющиеся у нас БД:
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
 3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
 4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
 5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
 6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
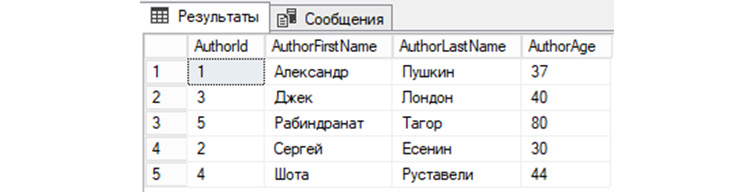 7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
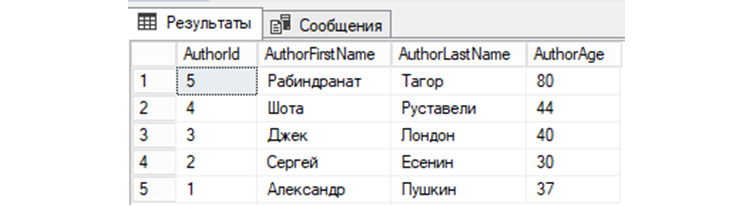
![]() Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
 9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
 10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
 11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
 12) Выберем в «tAuthors» такую запись AuthorAge, значение которой – наибольшее:
12) Выберем в «tAuthors» такую запись AuthorAge, значение которой – наибольшее:
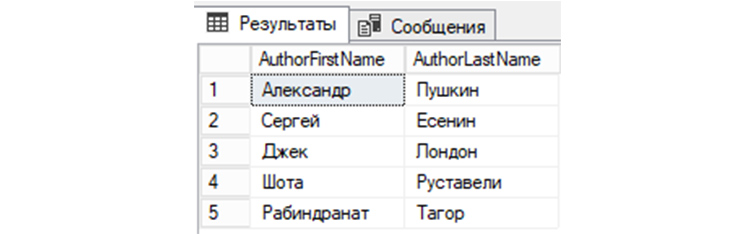
 13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
 14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:

INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД.
Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.

UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (Author >
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
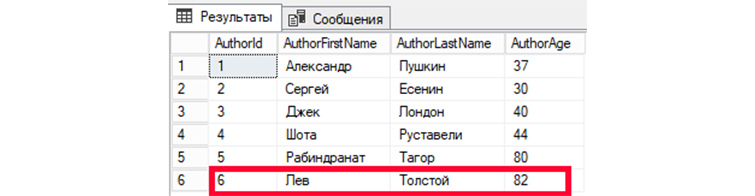
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где Author >
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
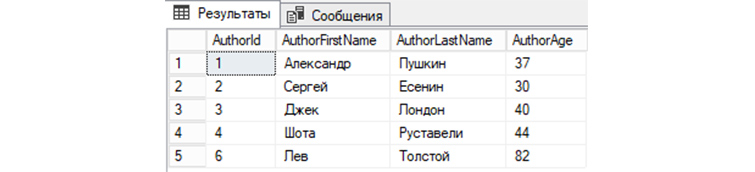
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors целиком, выполнив простой SQL запрос:
Далее рассмотрим сложные запросы SQL.
Оператор UNION
Оператор UNION объединяет результаты двух или более запросов в один результирующий набор, в который входят все строки, принадлежащие всем запросам в объединении:
Transact-SQL
select_1 UNION select_2 { select_3]}…
| 1 | select_1UNIONALLselect_2{UNIONALLselect_3}… |
Параметры select_1, select_2, … представляют собой инструкции SELECT, которые создают объединение. Если используется параметр ALL, отображаются все строки, включая дубликаты. По умолчанию дубликаты удаляются.
Объединять с помощью инструкции UNION можно только совместимые таблицы. Под совместимыми таблицами имеется в виду, что оба списка столбцов выборки должны содержать одинаковое число столбцов, а соответствующие столбцы должны иметь совместимые типы данных. Результат объединения можно упорядочить, только используя предложение ORDER BY в последней инструкции SELECT. Предложения GROUP BY и HAVING можно применять с отдельными инструкциями SELECT, но не в самом объединении.
Два других оператора для работы с наборами:
- INTERSECT — пересечение — набор строк, которые принадлежат к обеим таблицам
- EXCEPT — разность двух таблиц — все значения, которые принадлежат к первой таблице и не присутствуют во второй
Проверка на соответствие шаблону (LIKE)
Для выборки строк, в которых содержимое некоторого текстового столбца совпадает с заданным текстом, можно использовать простое сравнение. Например, следующий запрос извлекает строку из таблицы по имени.
Показать лимит кредита для Smithson Corp.
Однако очень легко можно забыть, какое именно название носит интересующая нас компания: «Smith», «Smithson» или «Smithsonian». Проверка на соответствие шаблону позволяет выбрать из базы данных строки на основе частичного соответствия имени клиента.
Проверка на соответствие шаблону (оператор ), схематически изображенная на рис. 9, позволяет определить, соответствует ли значение данных в столбце некоторому шаблону. Шаблон представляет собой строку, в которую может входить один или несколько подстановочных символов. Эти символы интерпретируются особым образом.

Рис. 9. Синтаксическая диаграмма проверки на соответствие шаблону (LIKE)



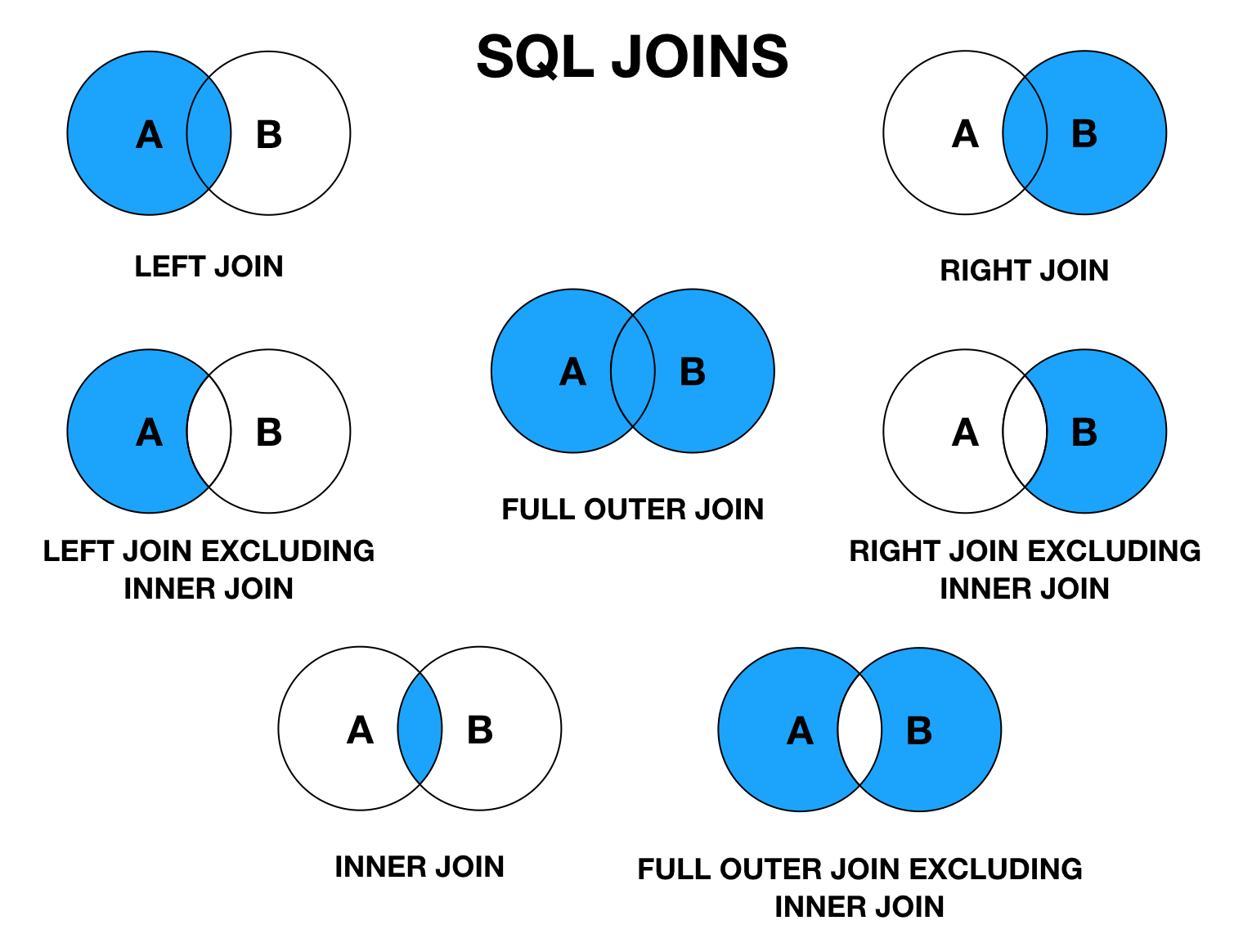
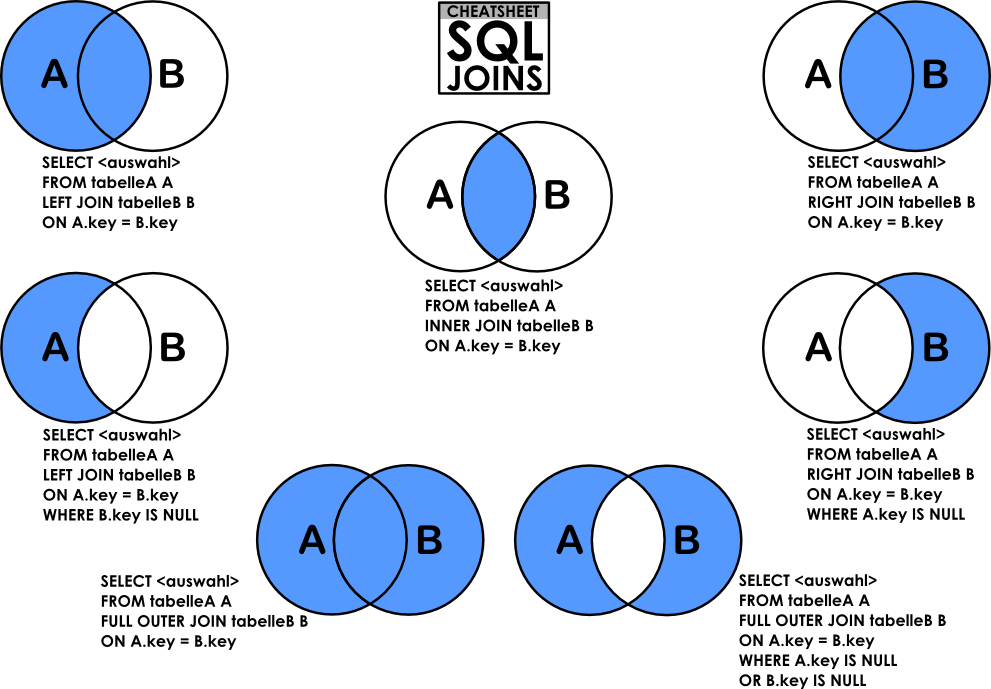

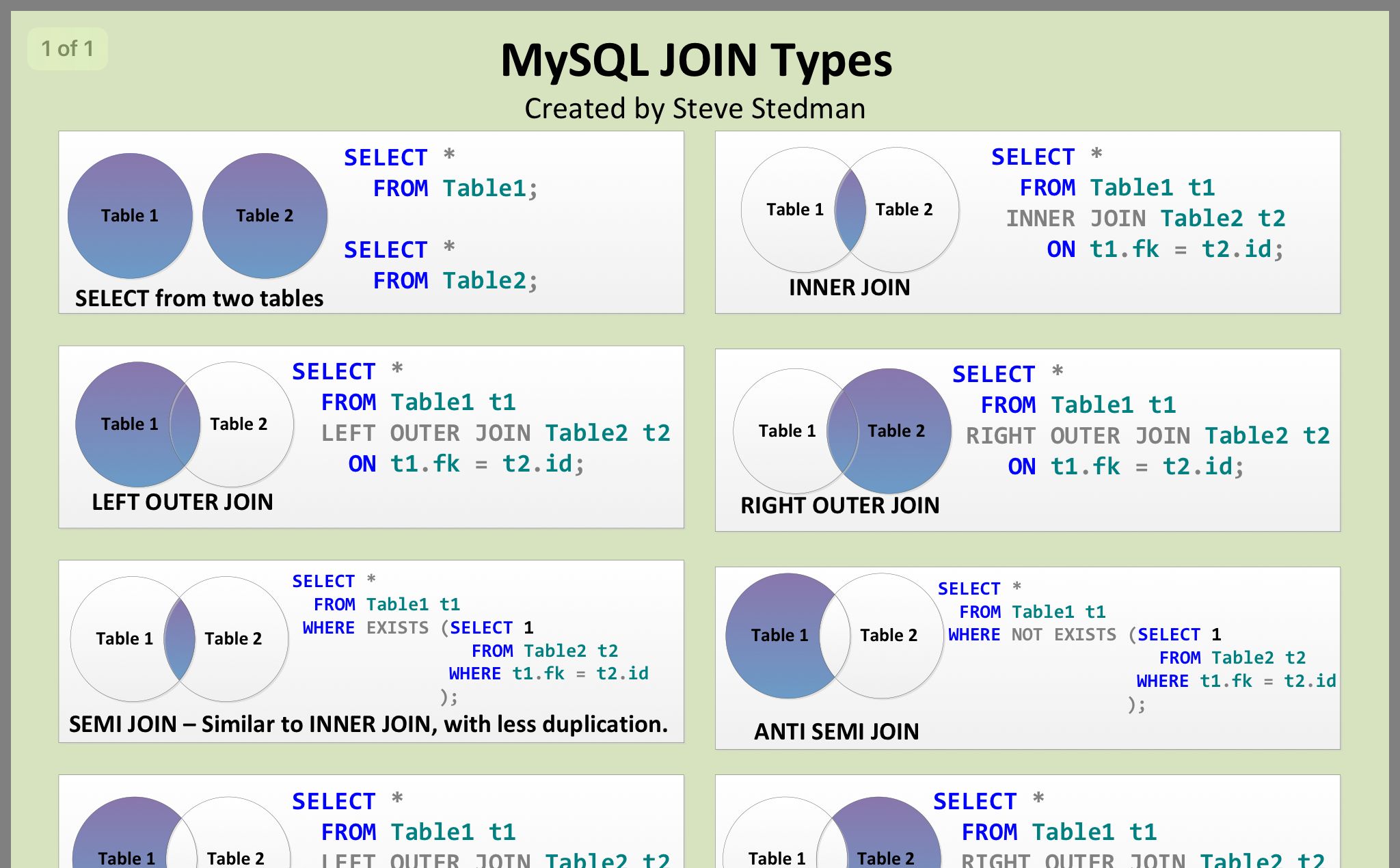
Реализуем FULL JOIN в MySQL
Реализовать FULL JOIN на самом деле достаточно просто, ведь, как было уже отмечено ранее, это по сути объединённое соединение LEFT и RIGHT. Поэтому, чтобы получить точно такой же результат, как и при соединении FULL JOIN, мы должны объединить два результирующих набора данных, в одном использовать LEFT JOIN, а в другом RIGHT JOIN.
Для объединения нескольких результирующих наборов в SQL используются операторы UNION и UNION ALL. Именно их мы и будем использовать.
Исходные данные для примера
Чтобы было наглядно видно, как работает соединение FULL JOIN, давайте создадим тестовые данные, в частности две таблицы, данные которых мы и будем объединять с помощью FULL JOIN.
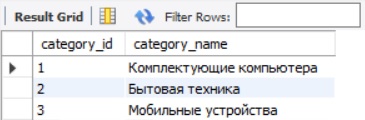
Давайте представим, что у нас есть таблица с товарами, а также таблица с категориями товаров:
- products – товары;
- categories – категории товаров.
В таблице с товарами будет ссылка на таблицу с категориями, при этом у нас будут товары, для которых категория еще не определена, кроме этого в таблице с категориями у нас будут категории, в которых нет еще ни одного товара.
Инструкция для создания таких данных.
Таблица products
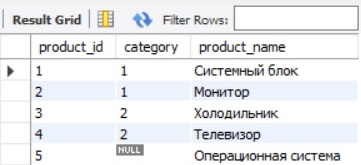
Таблица categories
Соединение LEFT JOIN и RIGHT JOIN
Теперь давайте посмотрим, как будет происходить объединение данных при помощи LEFT JOIN и RIGHT JOIN.
LEFT JOIN

Как видим, у нас вывелись все записи из таблицы с товарами, а у товаров, у которых категория еще не определена, из таблицы categories вывелось значение NULL.
RIGHT JOIN
Теперь изменим LEFT на RIGHT и посмотрим на результат.
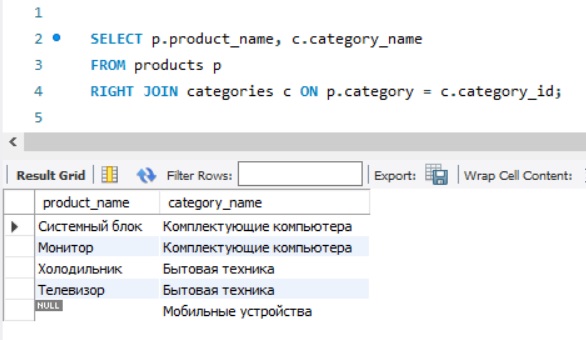
В данном случае у нас вывелись все записи из таблицы с категориями, а рядом с теми категориями, в которых нет ни одного товара, в столбцах из таблицы товаров вывелось значение NULL.
Как Вы понимаете, в первом случая с LEFT JOIN мы не видим категории, в которых нет еще товаров, а во втором с RIGHT JOIN, мы не видим товары, не относящиеся ни к одной категории.
FULL JOIN
Теперь представим, что нам потребовалось сформировать такие данные, чтобы было видно и товары без категорий и категории без единого товара.
В других СУБД мы могли бы легко заменить LEFT или RIGHT на FULL и тем самым получили бы тот результат, который нам нужен.
Пример FULL JOIN в Microsoft SQL Server (те же самые данные)
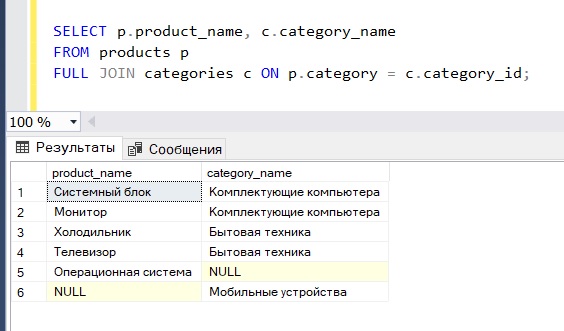
Теперь мы видим, какие товары без категорий, и какие категории без товаров.
Давайте попробуем реализовать то же самое, но в MySQL.
Реализация FULL JOIN в MySQL с помощью UNION
Как было уже отмечено ранее, мы можем реализовать FULL JOIN, объединив два запроса при помощи UNION, в первом мы будем использовать LEFT JOIN, а во втором RIGHT JOIN.
По факту мы берем те же самые запросы, которые мы использовали чуть ранее, и объединяем их с помощью UNION.

Как видим, мы получили точно такой же результат, как и в случае с FULL JOIN.
Реализация FULL JOIN в MySQL с помощью UNION ALL
Как Вы, наверное, знаете, запросы с UNION выполняются достаточно медленно, за счет сортировки и удаления дублирующих строк.
Чтобы немного увеличить производительность, мы можем использовать оператор UNION ALL. Однако он выведет все данные двух запросов, что приведет к наличию дублированных строк, но это мы можем легко исправить, если во втором запросе с RIGHT JOIN мы поставим условие, которое уберет повторяющиеся строки, и в итоге мы получим тот же самый результат.
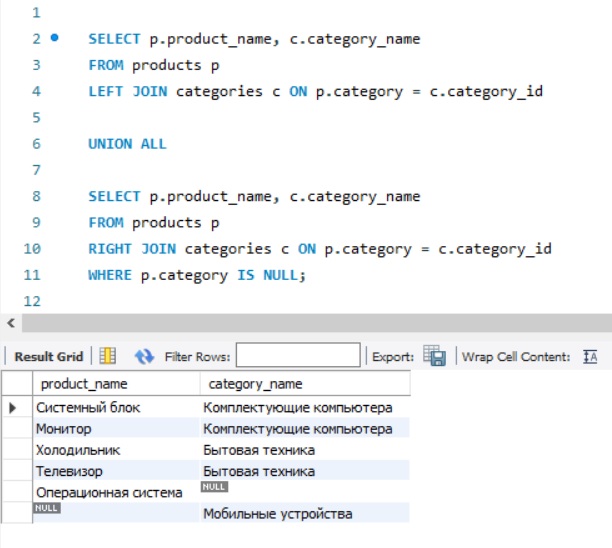
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Источник
9. SQL SELECT в реляционной алгебре называется проекцией
Мне лично нравится термин «проекция», так как он используется в реляционной алгебре. После того как вы создали ссылку на таблицу, отфильтровали и преобразовали ее, можете переходить к проецированию в другую форму. Предложение SELECT подобно проектору. Табличная функция использующет выражение значения строки для преобразования каждой записи из ранее созданной ссылки на таблицу в конечный результат.
В предложении SELECT можно работать со столбцами, создавая сложные выражения столбцов как части записи/строки.
Есть много специальных правил в отношении характера доступных выражений, функций и т.д. Главное, нужно помнить следующее:
- Можно использовать только ссылки на столбцы, полученные из ссылки на таблицу в «output».
- Если у вас есть предложение GROUP BY, вы можете ссылаться только на столбцы из этого предложения или агрегатные функции.
- Если нет предложения GROUP BY вместо агрегатных можно использовать оконные функции.
- Если нет предложения GROUP BY, нельзя сочетать агрегатные и неагрегатные функции.
- Существуют некоторые правила, касающиеся переноса регулярных функций в агрегатные функции и наоборот.
- Есть…
Много сложных правил. Которыми можно заполнить еще один урок. Например, причина почему нельзя комбинировать агрегатные функции с неагрегатными функциями в проекции инструкции SELECT без предложения GROUP BY (правило № 4), такова:
- Это не имеет смысла. Интуитивно.
- Если не помогает интуиция (например, новичкам в SQL), выручают синтаксические правила. В SQL:1999 реализован оператор GROUPING SETS, а в SQL:2003 — пустой оператор grouping sets: GROUP BY (). Всякий раз, когда присутствует агрегатная функция и нет явного предложения GROUP BY, применяется неявный пустой GROUPING SET (правило №2). Следовательно, исходные правила о логическом упорядочении больше не являются верными, и проекция (SELECT) влияет на результат логически предшествующего, но лексически последовательного предложения (GROUP BY).
Запутались? Да. Я тоже. Давайте вернемся к более простым вещам.
Что мы из этого узнаем?
Предложение SELECT может быть одним из самых сложных предложений в SQL, даже если оно выглядит просто. Все другие предложения только переносят ссылки на таблицы от одного к другому. Предложение SELECT портит всю красоту этих ссылок, полностью их преобразовывая путем применения к ним правил.
Чтобы понять SQL, перед использованием оператора SELECT нужно усвоить все остальное. Даже если SELECT является первым предложением в лексической упорядоченности, он должен быть последним.
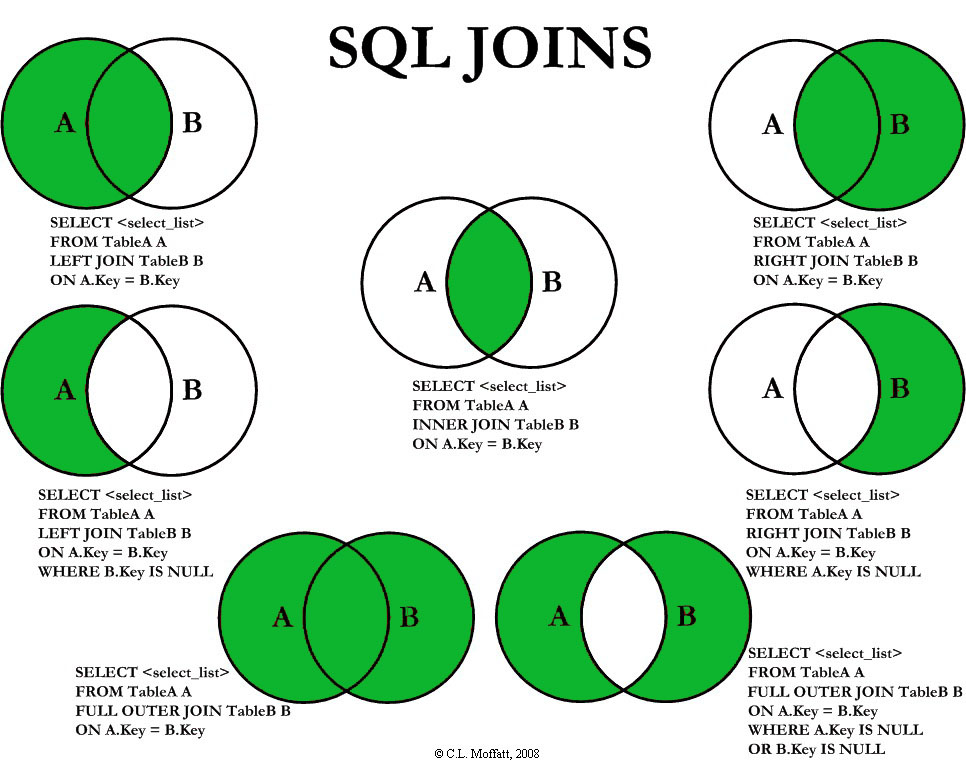
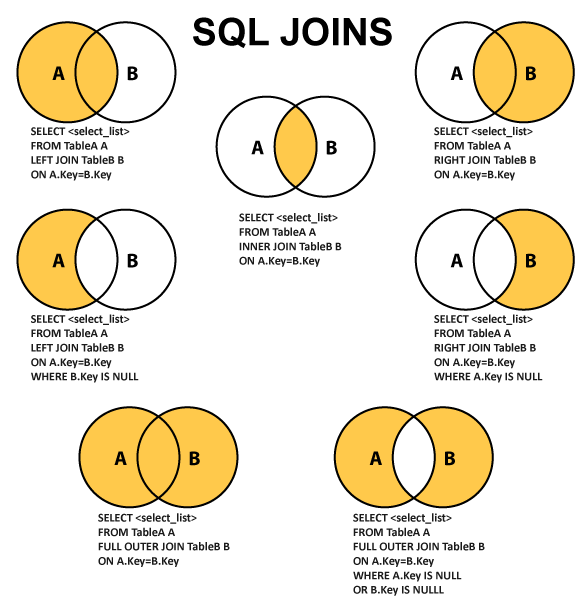
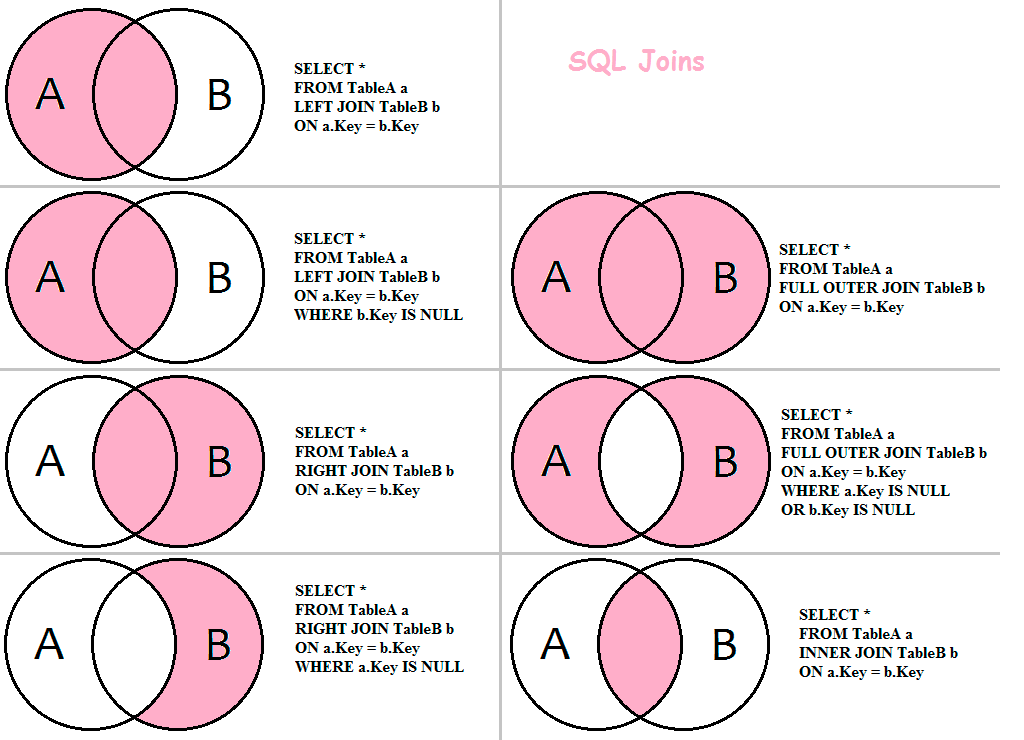
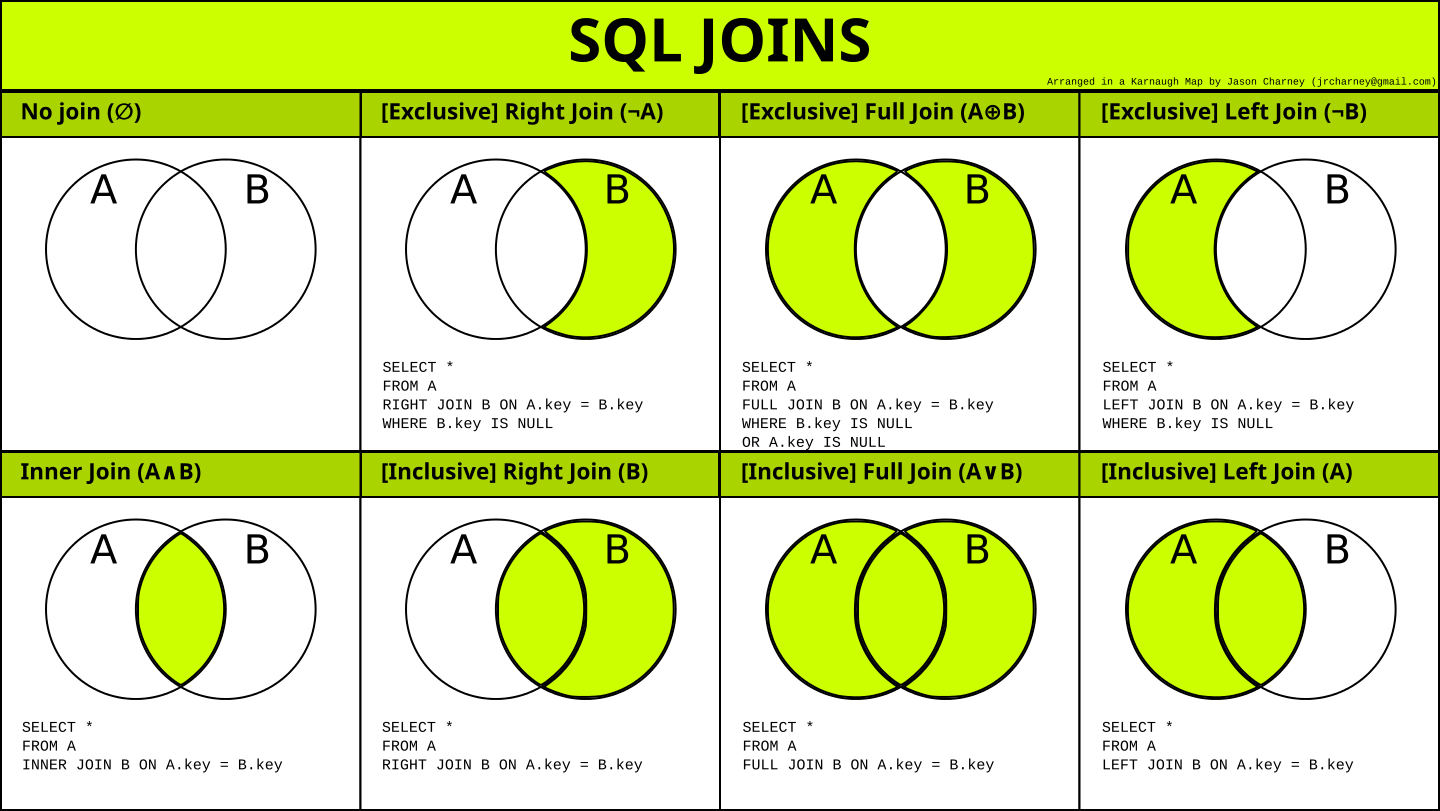
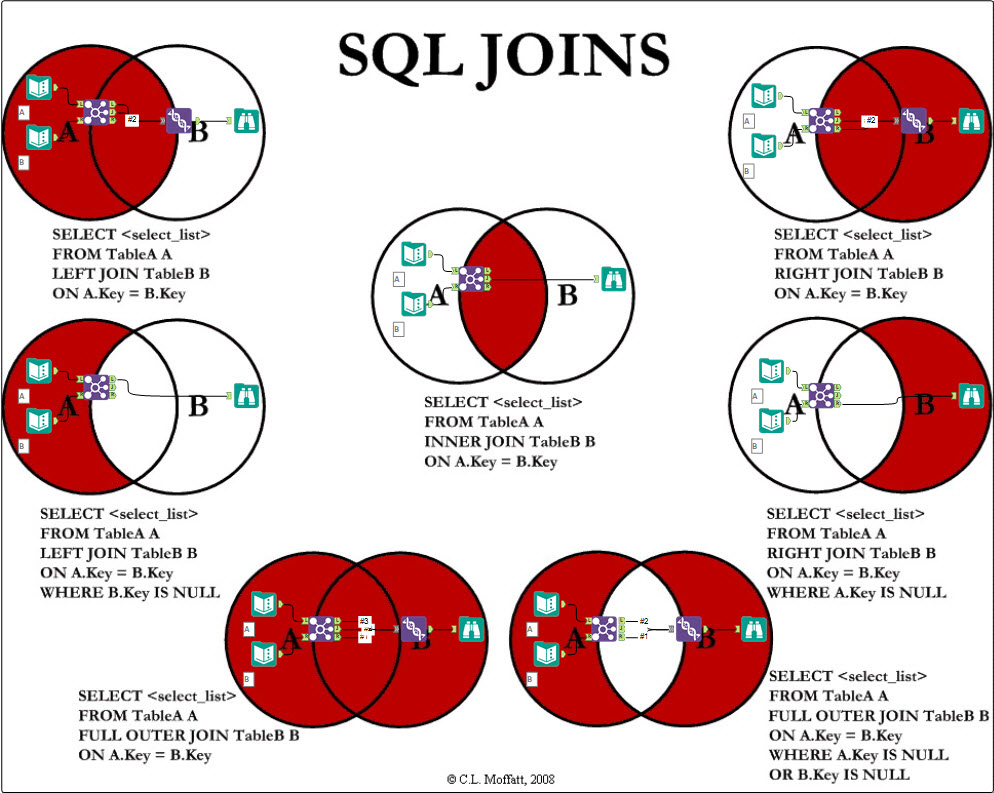
Внешнее соединение
В обычных операциях подключения в качестве результатов могут выводиться только записи, которые удовлетворяют условиям подключения.
1. Левое внешнее соединение
Левое внешнее объединение включает в себя все строки в первой именованной таблице («левая таблица», которая появляется в крайнем левом углу предложения JOIN), но не включает в себя строки в правой таблице, которые не удовлетворяют условиям.
2. Правое внешнее соединение
Правое внешнее объединение включает все строки во второй именованной таблице («правая таблица», которая появляется в крайнем правом углу предложения JOIN), но не включает в себя строки в левой таблице, которые не удовлетворяют условиям.
3. Завершите внешнее соединение
Полное внешнее соединение будет включать все строки во всех связанных таблицах, независимо от того, совпадают ли они.
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.







Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library.
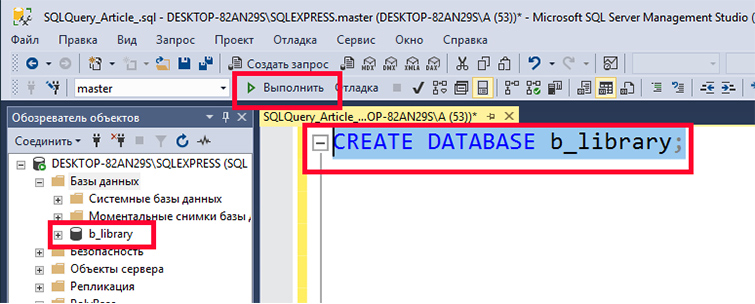
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
В БД «b_library создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
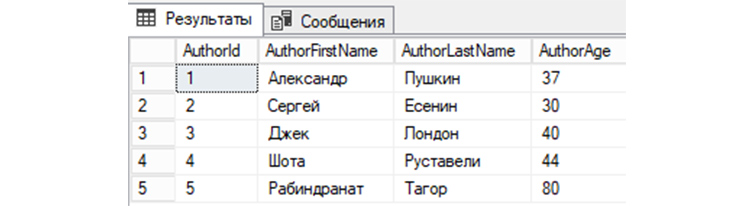
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
7. Производные таблицы SQL похожи на табличные переменные
Раньше мы узнали, что SQL является декларативным языком, и не имеет переменных (хотя в некоторых диалектах SQL они существуют). Но можно написать нечто похожее на переменные. Эти звери называются производными таблицами.
Производная таблица — это не что иное, как вложенный запрос, заключенный в круглые скобки.
Обратите внимание, что некоторые диалекты SQL требуют, чтобы производные таблицы имели корреляционное имя (также называемое псевдонимом). Производные таблицы великолепны, если необходимо обойти проблемы, вызванные логическим упорядочением предложений SQL
Например, если вы хотите повторно использовать выражение столбца в предложении SELECT и WHERE, просто напишите (диалект Oracle):
Производные таблицы великолепны, если необходимо обойти проблемы, вызванные логическим упорядочением предложений SQL. Например, если вы хотите повторно использовать выражение столбца в предложении SELECT и WHERE, просто напишите (диалект Oracle):
Обратите внимание, что некоторые базы данных и стандарт SQL:1999 подняли производные таблицы на следующий уровень введением обобщенных табличных выражений. Это позволит повторно использовать одну и ту же производную таблицу несколько раз в одной инструкции SQL SELECT
Приведенный выше запрос будет переведен на (почти) эквивалент:
Очевидно, что «a» можно также вывести в отдельное представление для более широкого использования общих подзапросов SQL. Подробнее о представлениях здесь.
Что мы из этого узнаем?
Снова, снова и снова. В SQL все завязано на ссылках, а не столбцах. Как этим воспользоваться. Не бойтесь написания производных таблиц или других сложных ссылок на таблицы.
пользовательские переменные
Та же идея, что и в предыдущем варианте, только реализована с помощью пользовательских переменных (user variables). Актуально для версий, в которых нет оконных функций.
select post_id, user_id, date_added, post_text from(select posts.*, if(@gr=user_id, @i:=@i+1, @i:=1 + least(@gr:=user_id,)) xfrom posts, (select @i:=, @gr:=) t order by user_id, date_added desc) t1 where x <=3;
Как и в примере с row_number(), мы нумеруем сообщения каждого пользователя в порядке убывания даты добавления (только делаем это с помощью пользовательских переменных), затем оставляем только те строки, у которых № меньше или равен 3.
Способ можно применять и для выборки нескольких случайных сообщений юзера. Однако простая замена сортировки по убыванию даты на случайную не даст нужного эффекта.
select post_id, user_id, date_added, post_text from(select t2.*, if(@gr=user_id, @i:=@i+1, @i:=1 + least(@gr:=user_id,)) xfrom (select posts.*, rand() q, @z:=1 from posts) t2, (select @i:=, @gr:=) t order by user_id, q) t1 where x <=3
Обратите внимание на добавление ещё одной переменной @z:=1, которая более нигде не применяется. С некоторых пор оптимизатор научился упрощать тривиальные с его точки зрения from-подзапросы, перенося условия из них во внешний запрос
Однако, если в подзапросе используются переменные, то пока оптимизатор материализует такие подзапросы.
В общем, пользовательские переменные — мощный инструмент написания и оптимизации запросов, но нужно быть очень внимательными при работе с ними, понимать на каком эффекте основан, используемый вами трюк, и проверять работоспособность в новых версиях. Подробнее см Оптимизация запросов MySQL с использованием пользовательских переменных
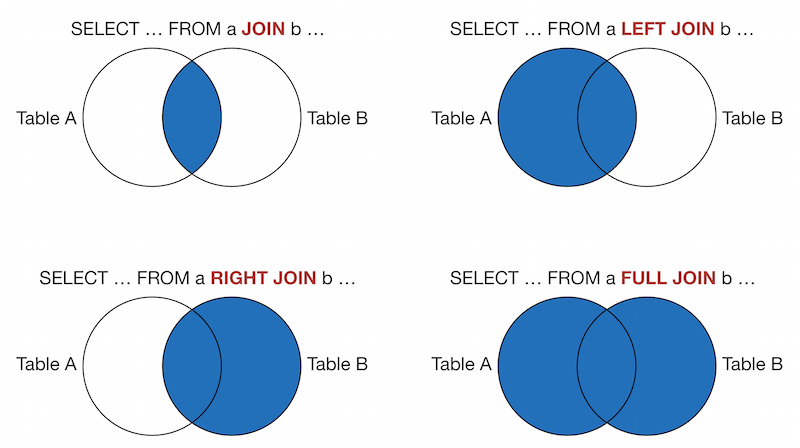
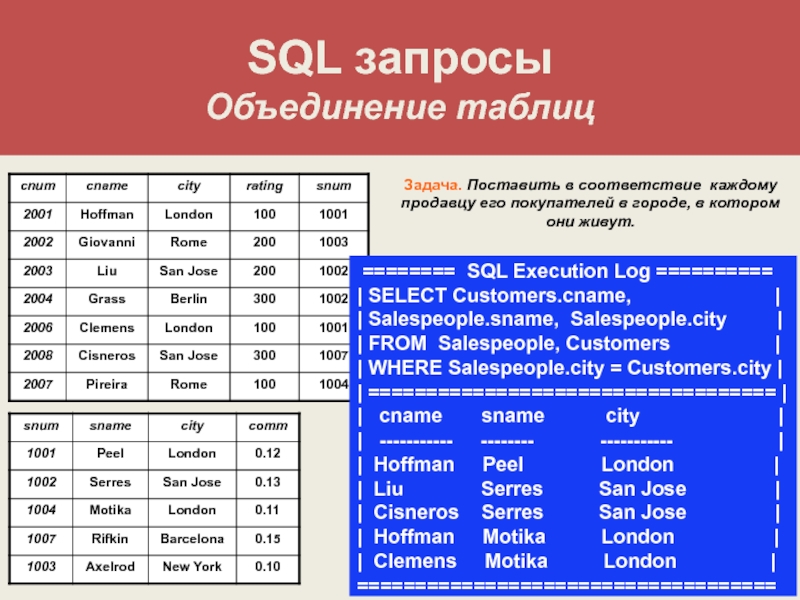
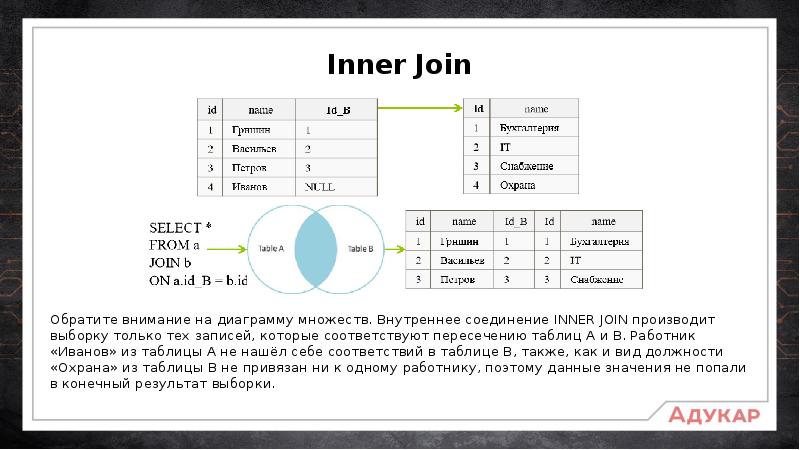
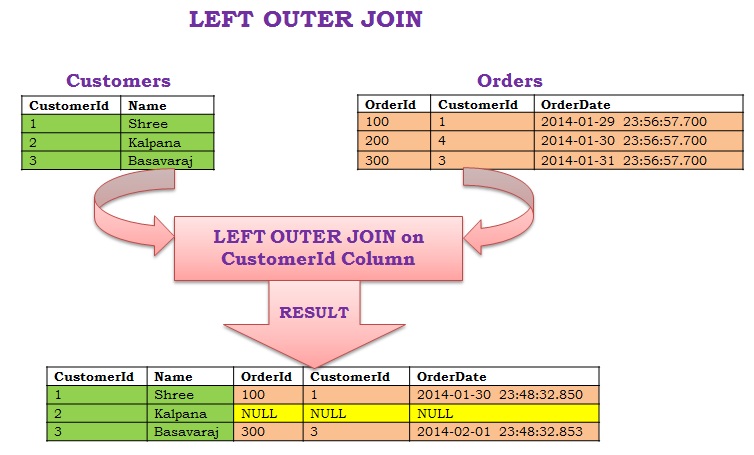
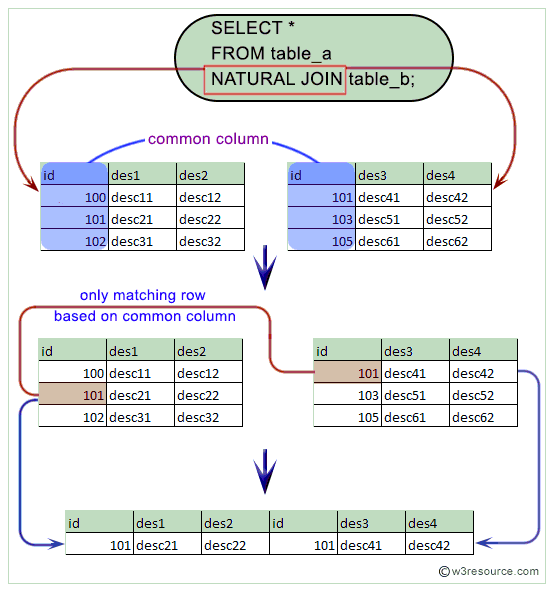
Что такое JOIN?
JOIN это операция объединения двух строк в одну. Эти строки обычно бывают из двух разных таблиц, но это не обязательно.
Прежде чем мы разберем, как писать JOIN-ы, давайте посмотрим, как выглядит объединение таблиц.
Возьмем для примера систему, в которой хранится информация о пользователях и их адресах.
Таблица, хранящая информацию о пользователях, может выглядеть следующим образом:
А таблица с адресами может быть такой:
id | street | city | state | user_id —-+——————-+—————+——-+——— 1 | 1234 Main Street | Oklahoma City | OK | 1 2 | 4444 Broadway Ave | Oklahoma City | OK | 2 3 | 5678 Party Ln | Tulsa | OK | 3 (3 rows)
Чтобы получить информацию и о пользователе, и о его адресе, мы можем написать два разных запроса. Но в идеале можно написать один запрос и получить все необходимые сведения в одном ответе.
Именно для этого, собственно, и нужны операции объединения!
Чуть позже мы рассмотрим, как составлять подобные запросы, а пока взгляните, как может вы глядеть результат объединения таблиц:
Мы видим всех наших пользователей сразу с их адресами.
Но операции объединения позволяют не просто выводить такие вот комбинированные сведения. У них есть еще одна важная функция: с их помощью можно получать отфильтрованные результаты.
Например, если мы хотим послать настоящие бумажные письма всем пользователям, живущим в Оклахоме, мы можем объединить таблицы и отфильтровать результаты по столбцу city.
Теперь, когда вы поняли, для чего вообще нужны операции объединения, давайте приступим к написанию запросов!
Перекрестный запрос
Перекрестный запрос позволяет представить данные в виде таблицы, в которой отображаются результаты вычислсний (сумма, количество записей, среднее значение и т.п.), выполненных по данным из какого-либо поля таблицы. Результаты вычислений группируются по двум наборам данных, один из которых располагается в лервом столбце таблицы, выступая в качестве заголовков строк, а второй — в верхней строке, образуя заголовки столбцов. Таким образом, при создании перекрестного запроса главная задача — определить роль и местопо ложение каждого поля таблицы.

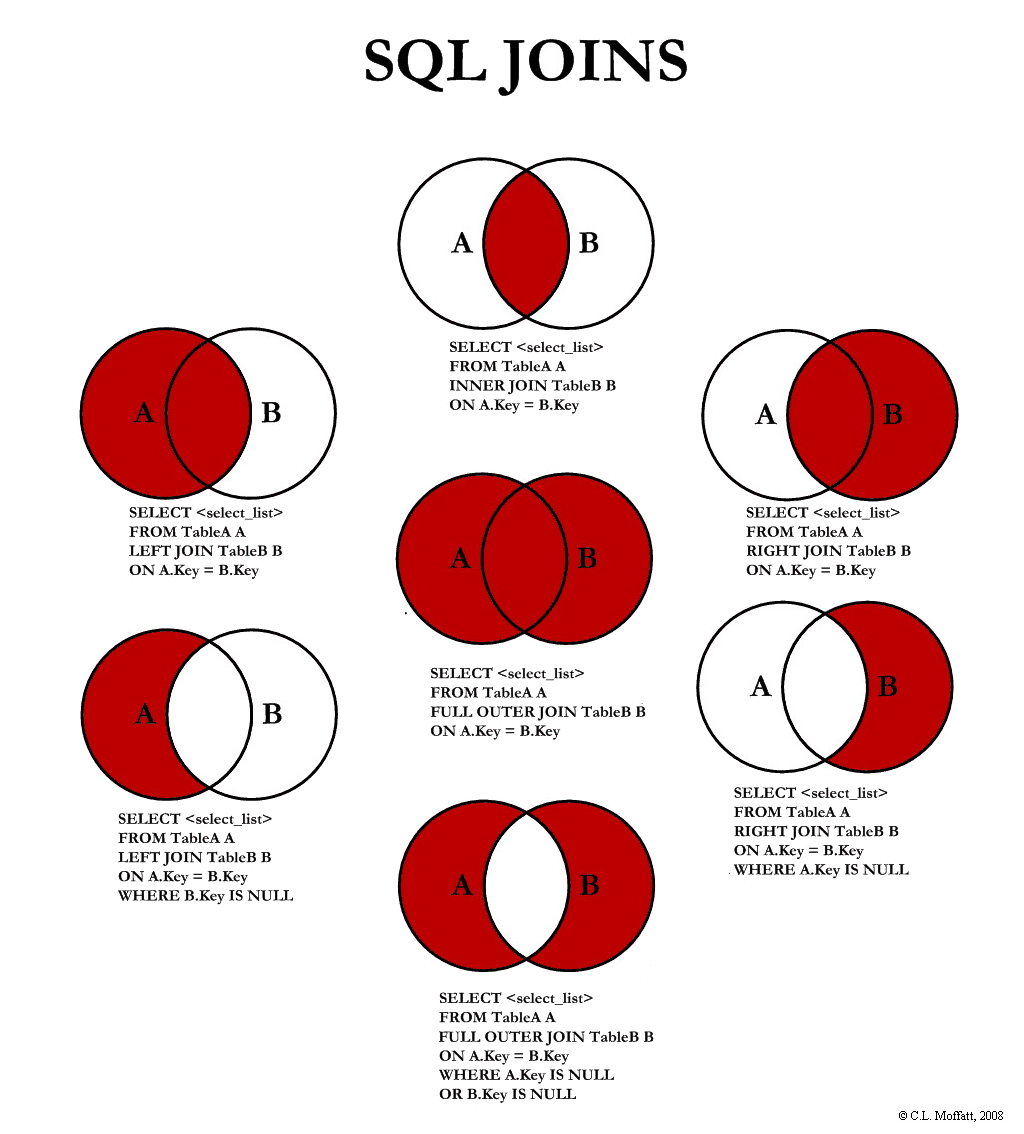
Пои создании перекрестного з апроса в режиме конструктора необходимо указать поля, значения которых будут заголовками столбцов и строк, а также поле, значения которого следует использовать в вычислениях. Для этого по команде Запрос / Перекрестный в бланк запроса добавляются строки Групповая операция и Перекрестная таблица. Строка Перекрестная таблица используется для определения роли поля в перекрестном запросе (Заголовки строк, Заголовки столбцов, Значение). Строка Групповая операция позволяет указать, какие именно вычисления необходимо произвести в перекрестном запросе.
SQL CROSS JOIN с примерами
В этой статье мы изучим концепцию SQL CROSS JOIN и подкрепим наши знания простыми примерами, которые объясняются иллюстрациями.
Введение
CROSS JOIN используется для создания парной комбинации каждой строки первой таблицы с каждой строкой второй таблицы. Этот тип соединения также известен как декартово соединение.
Предположим, что мы сидим в кофейне и решили заказать завтрак. Вскоре мы посмотрим на меню и начнем думать, какое сочетание еды и напитков может быть вкуснее. Наш мозг получит этот сигнал и начнет генерировать все комбинации еды и питья.
На следующем изображении показаны все комбинации меню, которые может генерировать наш мозг. SQL CROSS JOIN работает аналогично этому механизму, поскольку создает все парные комбинации строк таблиц, которые будут объединены.
«Пожалуйста, не волнуйтесь, даже если вы чувствуете себя немного голодным сейчас, вы можете есть все, что захотите, после прочтения нашей статьи».
Основная идея CROSS JOIN заключается в том, что она возвращает декартово произведение соединенных таблиц. В следующем совете мы кратко объясним декартово произведение;
Совет: Что такое декартово произведение?
Декартово произведение — это операция умножения в теории множеств, порождающая все упорядоченные пары заданных множеств. Предположим, что A — это множество, а элементами являются {a,b}, а B — это множество, а элементами являются {1,2,3}. Декартово произведение этих двух A и B обозначается AxB, и результат будет примерно следующим.
AxB = {(а, 1), (а, 2), (а, 3), (б, 1), (б, 2), (б, 3)}
Пример подзапроса SQL: SELECT
Предположим, вы хотите получить список студентов, занесённых в списки почёта, вы можете использовать подзапрос. Это предполагает, что информация о списках части находится в другой таблице.
Давайте воспользуемся примером, чтобы проиллюстрировать, как работают подзапросы SQL. Следующий запрос вернёт список всех клиентов, которые сделали заказ на сумму более 200 долларов:
Наш подзапрос возвращает следующее:
| name | address | loyalty_plan | id | |
| Katy | katy.l@gmail.com | Mountain View, CA | None | 4 |
| John | john.p@outlook.com | Boston, MA | None | 1 |
В первой строке мы выбираем каждый столбец из нашей таблицы клиентов. Затем мы указываем, что хотим получить только тех клиентов, чей идентификатор клиента находится в подзапросе. Наш подзапрос выбирает все уникальные идентификаторы клиентов из нашей таблицы заказов, где стоимость товара превышает 200 долларов. Записи, соответствующие этим условиям, включают этих клиентов в результаты.
Примеры сложных запросов к базе данных MS SQL
Сложные запросы SQL представляют из себя комбинации простых запросов. Выполняясь, простые запросы возвращают сгруппированные в промежуточные таблицы наборы данных. А сложный запрос уже манипулирует данными, полученными благодаря простым «подзапросам».
Сложные запросы получаются следующими способами:
- Помещением одного запроса в другой. В этом случае внешнее выражение будет называться основным запросом, а вложенное выражение – подзапросом.
- Применение с SQL запросами различных операторов объединения результатов выполнения подзапросов. Такие операторы называют реляционными.
Рассмотрим в SQL примеры сложных запросов.
Воспользуемся нашей предыдущей таблицей «tAuthors» и создадим дополнительно еще одну таблицу с книгами этих авторов – «tBooks. В качестве идентификатора авторов книг используем значение AuthorId из «tAuthors», а название книги – BookTitle.
Заполним «tBooks» такими книгами:
1) Сделаем выборку из БД всех книг, у которых имя автора – «Александр»:

2) Сделаем выборку данных из «tBooks» всех книг, авторами которых являются люди, с именами «Александр» или «Сергей»:
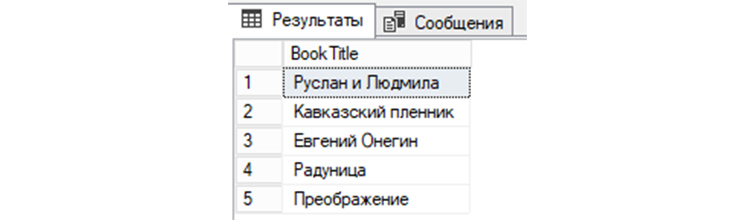
3) Сделаем выборку по книгам из таблицы «tBooks», у которых именами авторов являются НЕ «Сергей» и НЕ «Александр»:
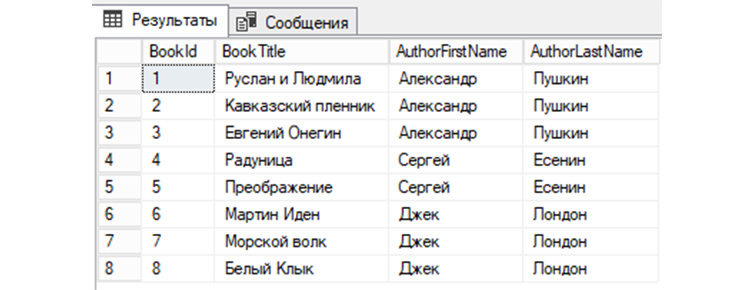
4) Возьмем таблицу «tBooks» и сделаем из нее выборку всех книг с указанием как имен, так и фамилий авторов этих книг из «tAuthors»: