Что такое конкатенация?
Конкатенация означает объединение двух вещей. Возможно, вы использовали его на языке программирования для объединения двух строк. Возможно, у вас есть переменные имени и фамилии, которые вы объединили в качестве переменной полного имени.
Конкатенация — очень полезный способ объединения двух строк в одну. PHP использует полную остановку для объединения строк, тогда как JavaScript и jQuery используйте знак плюс.
Конкатенация в SQL работает точно так же. Вы используете специальный оператор, чтобы объединить две вещи в одну. Вот пример в псевдокоде :
В языках программирования конкатенация облегчает чтение кода. Если вашему коду всегда требуется доступ к двум строкам, объединение их в одну облегчает запоминание и уменьшает длину кода.
Хотя переменные в SQL встречаются реже (но все еще используются), конкатенация по-прежнему необходима для возврата комбинированных результатов или для манипулирования данными.
Как объединить
Конкатенация очень проста в SQL. Хотя SQL является распространенным языком, отдельные механизмы баз данных реализуют функции различными способами. Хотя все эти примеры представлены на диалекте PostgreSQL, их легко перевести на другие варианты, просто выполнив поиск в сети «Конкатенация <YOUR_DATABASE_ENGINE>». Различные механизмы могут иметь разный синтаксис для конкатенации, но принцип остается тем же.
Возвращаясь к нашему примеру с именем, вот основной запрос выбора :

Здесь нет ничего сложного, поэтому давайте добавим в конкатенацию:

Как видите, эта конкатенация сработала отлично, но есть одна небольшая проблема. Полученное полное имя было сшито в точности как произведение обоих столбцов — между именами должен быть пробел!
К счастью, это легко исправить: просто вставьте пробел между ними:

Это базовые примеры, но вы должны увидеть, как работает конкатенация — это действительно так просто! Трубный оператор ( | ) используется дважды между предложениями. Ваш движок SQL знает, что каждая часть до и после этого символа должна быть объединена и рассматриваться как одна. Будьте осторожны, если вы используете оператор concat, но ничего не объединяете, вы получите ошибку.

Как упоминалось выше, в этих примерах используется вариант SQL PostgreSQL. Другие варианты могут использовать другой оператор или даже специальную функцию, которую вам нужно вызвать. На самом деле не имеет значения, как вы объединяете строки, если вы делаете это так, как ожидает ваш механизм базы данных.
Типы данных Access
Типы данных Access разделяются на следующие группы:
- Текстовый – максимально 255 байтов.
- Мемо — до 64000 байтов.
-
Числовой — 1,2,4 или 8 байтов.Для числового типа размер поля м.б. следующим:
- байт — целые числа от -0 до 255, занимает при хранении 1 байт
- целое — целые числа от -32768 до 32767, занимает 2 байта
- длинное целое — целые числа от -2147483648 до 2147483647, занимает 4 байта
- с плавающей точкой — числа с точностью до 6 знаков от –3,4*1038 до 3,4*1038, занимает 4 байта
- с плавающей точкой — числа с точностью от –1,797*10308 до 1,797*10308, занимает 8 байт
- Дата-время — 8 байтов
- Денежный — 8 байтов, данные о денежных суммах, хранящиеся с 4 знаками после запятой.
- Счетчик — уникальное длинное целое, генерируемое Access при создании каждой новой записи — 4 байта.
- Логический — логические данные 1бит.
- Поле объекта OLE — до 1 гигабайта, картинки, диаграммы и другие объекты OLE из приложений Windows. Объекты OLE могут быть связанными или внедренными.
- Гиперссылки — поле, в котором хранятся гиперссылки. Гиперссылка может быть либо типа UNC (стандартный формат для указания пути с включением сетевого сервера файлов), либо URL(адрес объекта, документа, страницы или объекта другого типа в Интернете или Интранете. Адрес URL определяет протокол для доступа и конечный адрес).
- Мастер подстановок — поле, позволяющее выбрать значение из другой таблицы Accesss или из списка значений, используя поле со списком. Чаще всего используется для ключевых полей. Имеет тот же размер, что и первичный ключ, являющийся также и полем подстановок, обычно 4 байта. (Первичный ключ – одно или несколько полей, комбинация значений которых однозначно определяет каждую запись в таблице Accesss. Не допускает неопределенных .Null. значений, всегда должен иметь уникальный индекс. Служит для связывания таблицы с вторичными ключами других таблиц).
UNHEX(str)
Выполняет обратную операцию HEX(str). То есть, он интерпретирует каждую пару шестнадцатеричных цифр в аргументе как число и преобразует его в символ, представленный номер. Полученные символы возвращаются в виде бинарной строки.
SQL> SELECT UNHEX('4D7953514C');
+---------------------------------------------------------+
| UNHEX('4D7953514C') |
+---------------------------------------------------------+
| SQL |
+---------------------------------------------------------+
1 row in set (0.00 sec)
Символы в строке аргумента должны быть шестнадцатеричные цифры: ‘0’ .. ‘9’, ‘A’ .. ‘F’, ‘а’ .. ‘е’. Если UNHEX() встречает любые не шестнадцатеричные цифры в аргументе, она возвращает NULL.
SPACE
С помощью функции SPACE можно создавать пробелы. В качестве единственного параметра нужно указать число, которое определяет количество возвращаемых пробелов. Работа функции идентична REPLICATE, если в качестве клонируемого символа указать пробел.
Допустим, что нам нужно вывести на экран поля фамилию и имя, разделенные 5-ю пробелами. Можно сделать так:
SELECT vcFamil+' '+vcName FROM tbPeoples
А можно воспользоваться функцией SPACE:
SELECT vcFamil+SPACE(5)+vcName FROM tbPeoples
Зачем нужна функция, когда можно воспользоваться без нее? Допустим, что вам нужно использовать 5 пробелов в нескольких местах большого сценария. Все легко решается без функций, но в последствии оказалось, что количество пробелов должно быть не 5, а 10. Придется пересматривать весь сценарий и корректировать пробелы. А если бы мы использовали SPACE в сочетании с переменными, то проблема решилась бы намного проще.
Рассмотрим пример, в котором множественные пробелы используются дважды и для задания количества используется переменная:
DECLARE @sp int SET @sp=10 SELECT vcFamil+SPACE(@sp)+vcName+SPACE(@sp)+vcSurName FROM tbPeoples
Теперь, достаточно только изменить значение переменной, и количество пробелов изменено во всем сценарии. А главное – что количество пробелов может быть определено динамически, на основе запросов к таблице.
Удаление пробелов из строки
Для удаления лишних пробелов из начала и конца строки в языке SQL есть три функции.
Функция LTRIM:
string
LTRIM
(str string
)
Удаляет с начала строки str пробелы и возвращает результат.
Функция RTRIM:
string
RTRIM
(str string
)
Также удаляет пробелы из строки str, только с конца. Обе функции поддерживают многобайтовые символы.
SELECT LTRIM (» текст «);
Результат: «текст »
SELECT RTRIM (» текст «);
Результат: » текст»
И третья функция TRIM позволяет сразу удалять пробелы из начала и из конца строки:
string
TRIM
([ string
FROM] str string
)
Параметр str обязательный, остальные параметры не обязательные. В случае если задан только один параметр str, то возвращает строку str удалив пробелы из начала и конца строки одновременно.





SELECT TRIM (» текст «);
Результат: «текст»
С помощью пара метра remstr можно задавать символы или подстроки, которые будут удаляться из начала и конца строки. С помощью управляющих параметров BOTH, LEADING, TRAILING можно задавать откуда будут удаляться символы:
- BOTH — удаляет подстроку remstr с начала и с конца строки;
- LEADING — удаляет remstr с начала строки;
- TRAILING — удаляет remstr с конца строки.
SELECT TRIM (BOTH «а» FROM «текст»);
Результат: «текст»
SELECT TRIM (LEADING «а» FROM «текстааа»);
Результат: «текстааа»
SELECT TRIM (TRAILING «а» FROM «ааатекст»);
Результат: «ааатекст»
Функция SPACE позволяет получить строку состоящую из определенного количества пробелов:
string
SPACE
(n integer
)
Возвращает строку, которая состоит из n пробелов.
Функция REPLACE нужна для замены заданных символов в строке
:
string REPLACE
(str string
, from_str string
, to_str string
)
Функция заменяет в строке str все подстроки from_str на to_str и возвращает результат. Поддерживает многобайтные символы.
SELECT REPLACE («замена подстроки», «подстроки», «текста»)
Результат: «замена текста»
Функция REPEAT:
string
REPEAT
(str string
, count integer
)
Функция возвращает строку, которая состоит из count повторений строки str. Поддерживает многобайтовые символы.
SELECT REPEAT («w», 3);
Результат: «www»
Функция REVERSE переворачивает строку:
string
REVERSE
(str string
)
Переставляет в строке str все символы с последнего на первый и возвращает результат. Поддерживает многобайтовые символы.
SELECT REVERSE («текст»);
Результат: «тскет»
Функция INSERT для вставки подстроки в строку:
string
INSERT
(str string
, pos integer
, len integer
, newstr string
)
Возвращает строку полученную в результате вставки в строку str подстроки newstr с позиции pos. Параметр len указывает сколько символов будет удалено из строки str, начиная с позиции pos. Поддерживает многобайтовые символы.
SELECT INSERT («text», 2, 5, «MySQL»);
Результат: «tMySQL»
«SELECT INSERT («text», 2, 0, «MySQL»);
Результат: «tMySQLext»
SELECT INSERT («вставка текста», 2, 7, «MySQL»);
Результат: «SELECT INSERT («вставка текста», 2, 7, «MySQL»);»
Если вдруг понадобиться заеменить в тексте все заглавные буквы на прописные, то можно воспользоваться одной из двух функций:
string
LCASE
(str string
) и string
LOWER
(str string
)
Обе функции заменяют в строке str заглавные буквы на прописные и возвращают результат. И та и другая поддерживают многобайтовые символы.
SELCET LOWER («АБВГДеЖЗиКЛ»);
Результат:»абвгдежзикл»
Если же наоборот необходимо прописные буквы заменить заглавными, то также можно применить одну из двух функцийй:
string
UCASE
(str string
) и string
UPPER (str string
)
Функции возвращают строку str, заменив все прописные символы на заглавные. Также поддерживают многобайтовые символы.
Пример:
SELECT UPPER («Абвгдежз»);
Результат: «АБВГДЕЖЗ»
Строковых функций в языке SQL немного больше, чем рассмотрено в данной статье. Но так как даже большинство рассмотренных здесь функций используются редко, я закончу их рассмотрение. В следующих статьях я постараюсь рассмотреть реальные практические примеры использования строковых функций SQL. Поэтому не забудьте подписаться на обновления блога . До новых встреч!
Основные строковые функции и операторы предоставляют разнообразные возможности и возвращают в качестве результата строковое значение. Некоторые строковые функции являются двухэлементными, что означает, что они могут работать одновременно с двумя строками. Стандарт SQL 2003 поддерживает строковые функции.
CONV(N, N from_base, to_base)
Преобразование числа между различными системами счисления. Возвращает строковое представление числа N, преобразованное из базового from_base в to_base. Возвращает NULL, если любой параметр NULL. Аргумент N интерпретируется как целое, но может быть указан в виде целого числа или строки. Минимальная база 2, а максимальная база 36. Если to_base отрицательное число, N рассматривается как число со знаком. В противном случае, N трактуется как беззнаковое. CONV() работает с 64-битной точностью.
SQL> SELECT CONV('a',16,2);
+---------------------------------------------------------+
| CONV('a',16,2) |
+---------------------------------------------------------+
| 1010 |
+---------------------------------------------------------+
1 row in set (0.00 sec)
REVERSE
Пару раз я встречался с необходимостью перевернуть строку задом наперед, и в этом мне помогла функция REVERSE. Ей нужно передать строку и результатом будет та же строка, только буквы будут идти в обратном порядке. Например, следующий запрос выводит все фамилии задом наперед:
SELECT REVERSE(vcFamil) FROM tbPeoples
В реальных приложениях полностью строку вы будете менять достаточно редко, а вот часть строки может меняться. Например, в следующем запросе в фамилии меняются местами первые два символа:
SELECT REPLACE(vcFamil,
LEFT(vcFamil, 2),
REVERSE(LEFT(vcFamil, 2))
)
FROM tbPeoples
Пример достаточно интересен тем, что лишний раз показывает, как использовать уже известные нам функции работы со строками. В результирующем наборе отображается результат работы функции REPLACE. Функции нужно передать:





![Sql [айти бубен]](https://wudgleyd.ru/wp-content/uploads/2/7/6/2767b43f5de3d0d226e64a94043ccc31.png)
- Название поля, где хранится фамилия;
- Первые два символа. Для получения первых двух символов используем уже знакомую нам функцию LEFT;
- В качестве строки, которая должна будет поставлена вместо первых двух символов фамилии, выступают те же два символа, только перевернутые.
Introduction
Many a time, SQL programmers are faced with a requirement to generate report-like resultsets directly from a Transact SQL query. In most cases, the requirement arises from the fact that there neither sufficient tools nor in-house expertise to develop tools that can extract the data as a resultset, and then massage the data in the desired display format. Quite often folks are confused about the potential of breaking relational fundamentals such as the First Normal Form or the scalar nature of typed values. (Talking about 1NF violations in a language like SQL which lacks sufficient domain support, allows NULLs and supports duplicates is somewhat ironic to begin with, but that is a topic which requires detailed explanations.)
By ‘Concatenating row values’ we mean this: You have a table, view or result that looks like this……and you wish to have a resultset like the one below:
In this example we are accessing the sample NorthWind database and using the following SQL
|
1 |
SELECTCategoryId,ProductName FROMNorthwind..Products |
The objective is to return a resultset with two columns, one with the Category Identifier, and the other with a concatenated list of all the Product Names separated by a delimiting character: such as a comma.
Concatenating column values or expressions from multiple rows are usually best done in a client side application language, since the string manipulation capabilities of Transact SQL and SQL based DBMSs are somewhat limited. However, you can do these using different approaches in Transact SQL, but it is best to avoid such methods in long-term solutions
EXPORT_SET(bits,on,off[,separator[,number_of_bits]])
Возвращает строку, что для каждого бита, установленного в значении бит, вы получаете на строку и для каждого бита не установлен в значении, вы не получите строку. Биты в битах рассматриваются справа налево (от низкого до бита высокого порядка). Строки добавляются к результату слева направо, отделены друг от друга разделительной полосой (по умолчанию является символ запятой.,.). Число битов задается NUMBER_OF_BITS (по умолчанию 64).
SQL> SELECT EXPORT_SET(5,'Y','N',',',4); +---------------------------------------------------------+ | EXPORT_SET(5,'Y','N',',',4) | +---------------------------------------------------------+ | Y,N,Y,N | +---------------------------------------------------------+ 1 row in set (0.00 sec)
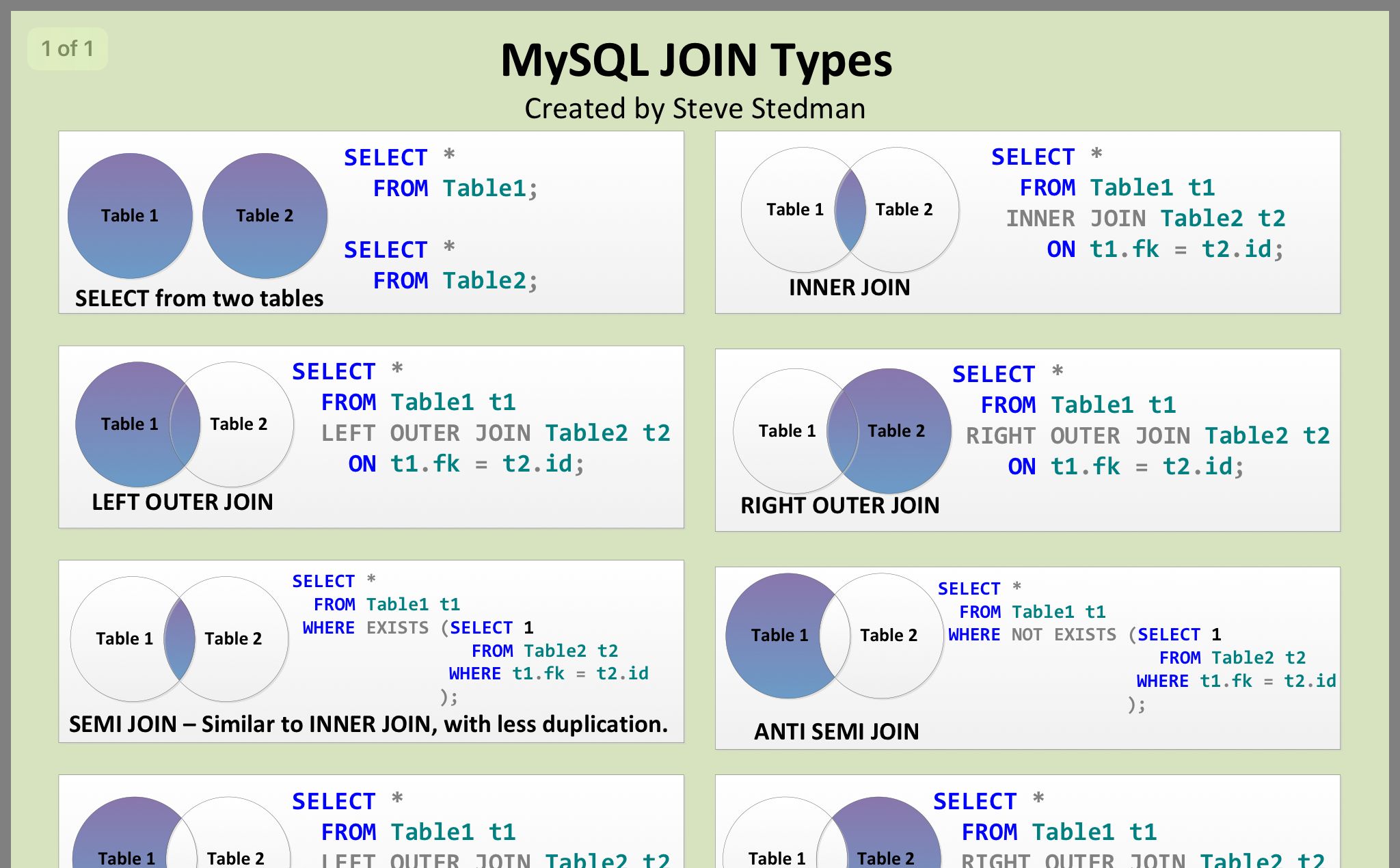
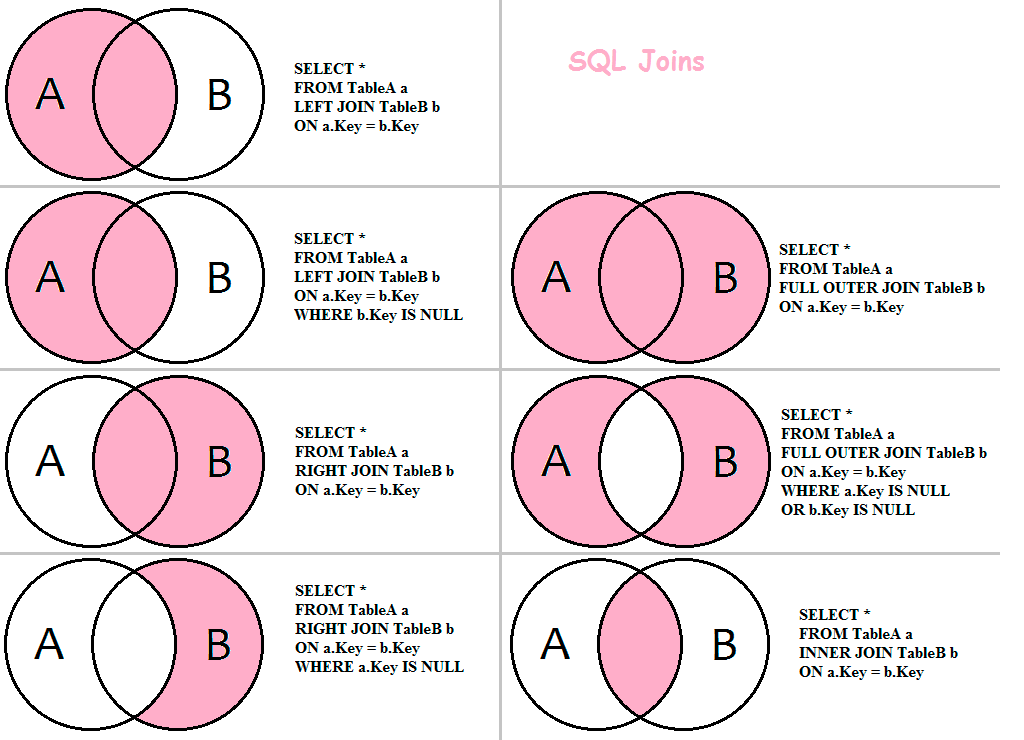
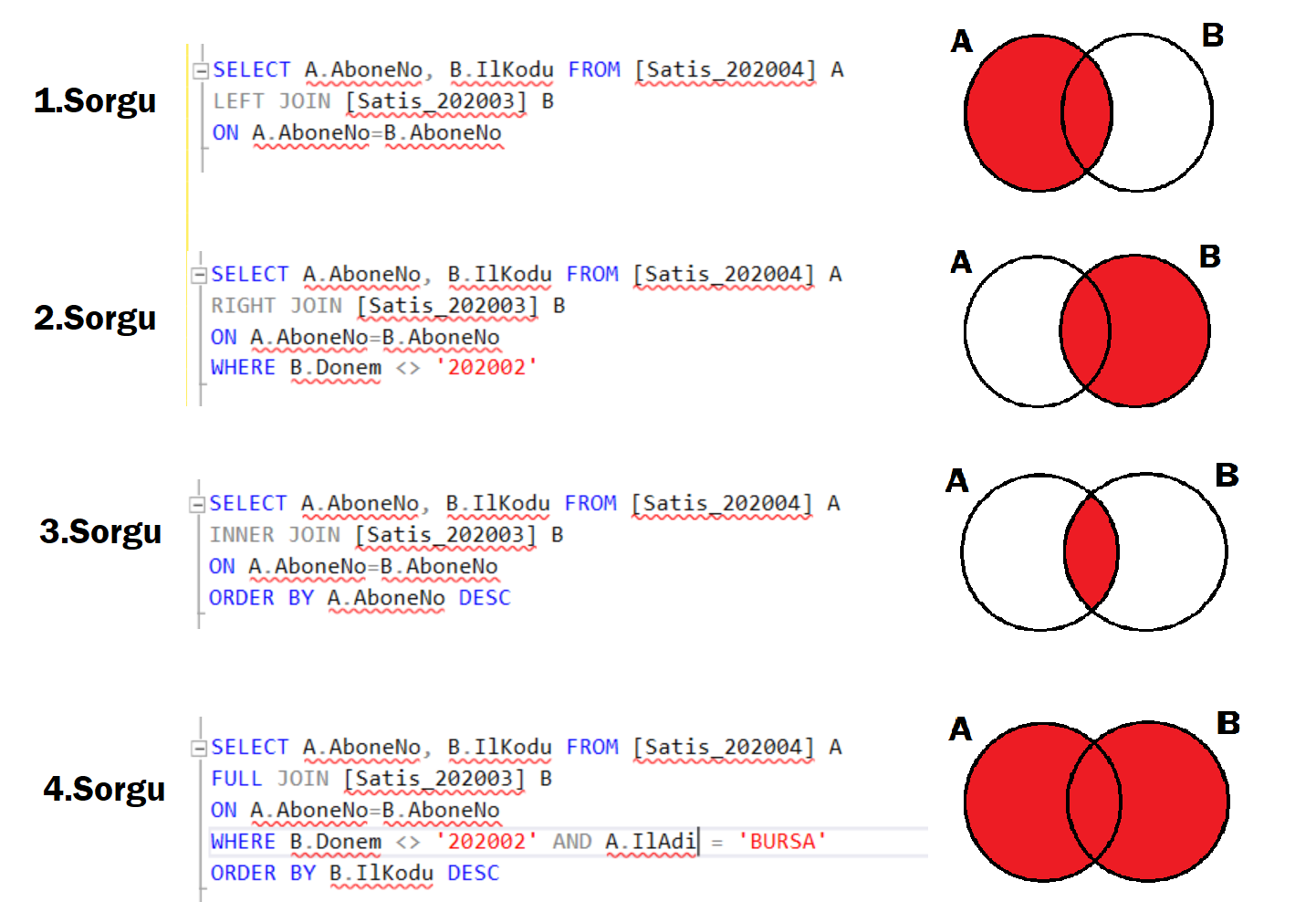
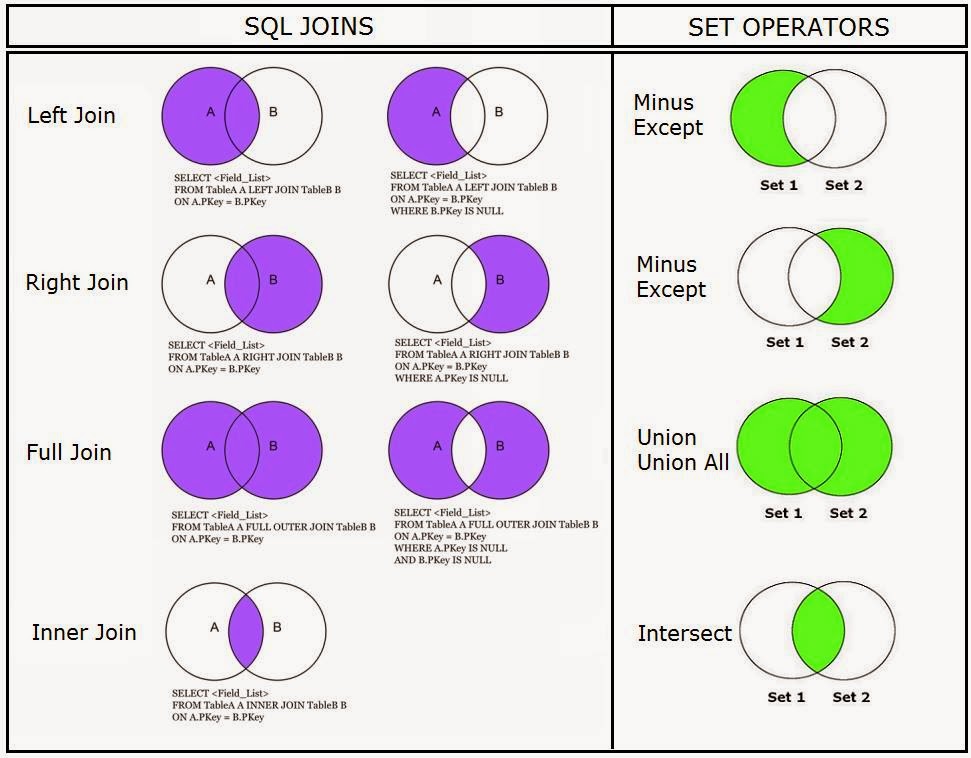
SELECT раздел JOIN
-
W3schools: SQL Joins
-
Какая разница между LEFT, RIGHT, INNER, OUTER JOIN?
-
MySQL 1054 Unknown column ‘table1.id’ in ‘on clause’
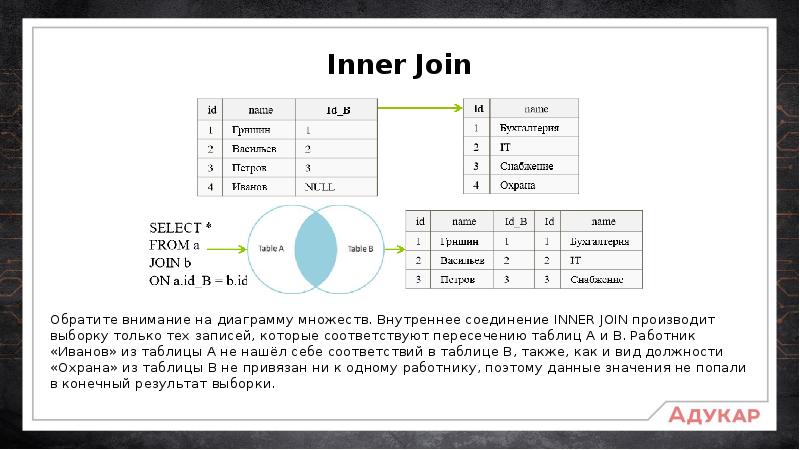
Простой JOIN (=пересечение JOIN =INNER JOIN ) — означает показывать только общие записи обоих таблиц. Каким образом записи считаются общими определяется полями в join- выражении. Например следующая запись: FROM t1 JOIN t2 ON t1.id = t2.id
означает что будут показаны записи с одинаковыми id, существующие в обоих таблицах.
- LEFT JOIN (или LEFT OUTER JOIN) означает показывать все записи из левой таблицы (той, которая идет первой в join- выражении) независимо от наличия соответствующих записей в правой таблице. Если записей нет в правой таблицы устанавливается пустое значение NULL.
- RIGHT JOIN (или RIGHT OUTER JOIN) действует в противоположность LEFT JOIN — показывает все записи из правой (второй) таблицы и только совпавшие из левой (первой) таблицы.
- Другие виды JOIN объединений: MINUS — вычитание; FULL JOIN — полное объединение; CROSS JOIN — “Каждый с каждым” или операция декартова произведения.
SELECT JOIN SUBSTRING
Пример работает для БД PostgreSQL 8.4. В разделе JOIN используется регулярное выражение (Шпаргалка RegExp: Метасимволы, Максимализм квантификатора, Алфавиты и блоки), аналогичное
SELECT SUBSTRING('XY1234Z', 'Y*({1,3})');
SELECT SUBSTRING('fly@gmail.com', '.*(@.*)$');
В листинге берутся три первые цифры из поля dst_number_bill и эти полученные цифры уже сравниваются.
SELECT cdr.id, cdr.nas_id, cdr.src_peer_id, peers.name, cdr.src_ip, cdr.src_number_bill, cdr.dst_number_bill,
df_lcrcode.destination, cdr.init_time, SUBSTRING(cdr.dst_number_bill, '({1,3})') as country_code
FROM cdr
LEFT JOIN peers ON cdr.src_peer_id=peers.id
LEFT JOIN df_lcrcode ON SUBSTRING(cdr.dst_number_bill, '({1,3})')=df_lcrcode.code
WHERE begin_time >= '2013-02-17 00:00:00' AND begin_time <= '2013-02-17 23:59:59' AND cause_local != 138
AND dst_ip = '0.0.0.0'
ORDER BY src_peer_id DESC LIMIT 10
SUBSTRING(str FROM pos FOR len)
Формы без аргумента len возвращает подстроку из строки str, начиная с позиции pos. Формы с аргументом len возвращают подстроку len символов из строки str, начиная с позиции pos. Формы, которые используют FROM являются стандартным синтаксисом SQL. Кроме того, можно использовать отрицательное значение для pos. В этом случае, начало подстроки len символов от конца строки, а не c началf. Отрицательное значение может быть использовано для pos в любом из форм этой функции.
SQL> SELECT SUBSTRING('Quadratically',5);
+---------------------------------------------------------+
| SSUBSTRING('Quadratically',5) |
+---------------------------------------------------------+
| ratically |
+---------------------------------------------------------+
1 row in set (0.00 sec)
SQL> SELECT SUBSTRING('foobarbar' FROM 4);
+---------------------------------------------------------+
| SUBSTRING('foobarbar' FROM 4) |
+---------------------------------------------------------+
| barbar |
+---------------------------------------------------------+
1 row in set (0.00 sec)
SQL> SELECT SUBSTRING('Quadratically',5,6);
+---------------------------------------------------------+
| SUBSTRING('Quadratically',5,6) |
+---------------------------------------------------------+
| ratica |
+---------------------------------------------------------+
1 row in set (0.00 sec)
Применение
Ниже приведены примеры обрезки строк с использованием нескольких языков программирования. Все показанные реализации возвращают новую строку и не изменяют первоначальную переменную.
| Пример использования | Язык программирования |
|---|---|
| String.Trim([chars]) | C#, Visual Basic .NET, Windows PowerShell |
| std.string.strip(string) | D |
| (string-trim ‘(#\Space #\Tab #\Newline) string) | Common Lisp |
| (string-trim string) | Scheme |
| string.trim() | Java |
| Trim(String) | Паскаль |
| string.strip() | Python |
| strip(string [,option , char]) | REXX |
| string:strip(string [,option , char]) | Erlang |
| string.strip | Ruby |
| trim($string) | PHP |
| Trim(String) | QBasic, Visual Basic, Delphi |
| string trim $string | Tcl |
| ALLTRIM(String) | FoxPro |
Другие языки
В языках без встроенной функции trim(), для достижения сравнимой функциональности, обычно пишутся функции, выполняющие ту же задачу.
AWK
В AWK, для этого можно использовать регулярные выражения:
ltrim(v) = gsub(/^+/, "", v) rtrim(v) = gsub(/+$/, "", v) trim(v) = ltrim(v); rtrim(v)
или:
function ltrim(s) { sub(/^+/, "", s); return s }
function rtrim(s) { sub(/+$/, "", s); return s }
function trim(s) { return rtrim(ltrim(s)); }
JavaScript
Начиная с ECMAScript 5, в JavaScript появилась возможность использовать trim(). До её появления объекты String можно было расширять с помощью прототипа:
String.prototype.trim = function() {
return this.replace(/^\s+|\s+$/g, "");
}
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALL
ALTER
ALTER COLUMN
ALTER TABLE
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions:
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions:
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions:
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions:
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions:
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions:
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions:
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions:
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions:
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions:
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions:
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() означает объединить с сепаратором и особую форму CONCAT(). Первый аргумент является разделителем для остальных аргументов. Разделитель добавляется между строками, которые объединяются. Сепаратор может быть строкой, как и остальные аргументы. Если разделитель равен NULL, то результат будет NULL.
SQL> SELECT CONCAT_WS(',','First name','Last Name' );
+---------------------------------------------------------+
| CONCAT_WS(',','First name','Last Name' ) |
+---------------------------------------------------------+
| First name,Last Name |
+---------------------------------------------------------+
1 row in set (0.00 sec)
Булевы операторы и простые операторы сравнения
| AND | логическое И. Ставится между двумя условиями (условие1 AND условие2). Чтобы выражение вернуло True, нужно, чтобы истинными были оба условия |
|---|---|
| OR | логическое ИЛИ. Ставится между двумя условиями (условие1 OR условие2). Чтобы выражение вернуло True, достаточно, чтобы истинным было только одно условие |
| NOT | инвертирует условие/логическое_выражение. Накладывается на другое выражение (NOT логическое_выражение) и возвращает True, если логическое_выражение = False и возвращает False, если логическое_выражение = True |
| Условие | Значение |
|---|---|
| = | Равно |
| < | Меньше |
| > | Больше |
| <= | Меньше или равно |
| >= | Больше или равно |
| <> != |
Не равно |
| IS NULL | Проверка на равенство NULL |
|---|---|
| IS NOT NULL | Проверка на неравенство NULL |
expr REGEXP pattern
Эта функция выполняет соответствовать образцу выражение в отношении pattern. Возвращает 1, Если выражение соответствует pattern; в противном случае возвращает 0. Если какое-либо выражение или pattern имеет значение NULL, результатом будет NULL. Регулярное выражение не чувствительно к регистру, за исключением, когда используется с двоичными строками.
SQL> SELECT 'ABCDEF' REGEXP 'A%C%%'; +---------------------------------------------------------+ | 'ABCDEF' REGEXP 'A%C%%' | +---------------------------------------------------------+ | 0 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Другой пример:
SQL> SELECT 'ABCDE' REGEXP '.*'; +---------------------------------------------------------+ | 'ABCDE' REGEXP '.*' | +---------------------------------------------------------+ | 1 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Давайте посмотрим еще один пример:
SQL> SELECT 'new*\n*line' REGEXP 'new\\*.\\*line'; +---------------------------------------------------------+ | 'new*\n*line' REGEXP 'new\\*.\\*line' | +---------------------------------------------------------+ | 1 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Concatenate Rows using a Scalar Variable
You can concatenate rows into a single string by using Scalar Variable method, there are several ways to do it but one of the most known is COALESCE method.
A) COALESCE Method
As you can see in the following example, you have to start by declaring a varchar variable(This variable is going to be max as we don’t know the size of the variable that we are going to need), then proceed to declare the varchar variable inside the coalesce, proceed to concat the variable with the column then assign the coalesce to a variable.
A lot of people thinks that coalesce is concatenating the rows but that is fake, coalesce is helping us to keep trailing comma on the list as the varchar variable is empty.
/*WITHOUT GROUPING*/ /*WITH COALESCE*/ DECLARE @COUNTRIES VARCHAR(MAX); SELECT @COUNTRIES = COALESCE(@COUNTRIES + ', ' + CountryName, CountryName) FROM Application.Countries ORDER BY CountryName DESC; SELECT @COUNTRIES AS Countries;

As you can see we can use is null instead of coalesce and it is going to have the same effect.
B) CONCAT Method
1. Concatenate rows using CONCAT without grouping
Similar to coalesce method, but in this case we are not going to use coalesce, and we are going to use stuff function to get rid of the trim comma that is generated because of initial variable empty value.
/*WITHOUT GROUPING*/ /*WITH CONCAT*/ DECLARE @COUNTRIES VARCHAR(MAX); SELECT @COUNTRIES = CONCAT(@COUNTRIES ,', ') + CountryName FROM Application.Countries ORDER BY CountryName DESC; SELECT STUFF(@COUNTRIES,1,2,'') AS Countries;

2. Concatenate rows using CONCAT without grouping
Grouping this kind of function is hard, we have to start by creating a function for it, this function is going to retrieve country list by continent and use Coalesce Method (As it is the simplest one).
/*WITH GROUPING*/ /*CREATING FUNCTION*/ CREATE FUNCTION dbo.List(@CONTINENT VARCHAR(100)) RETURNS VARCHAR(MAX) AS BEGIN -- Defining Method DECLARE @COUNTRIES VARCHAR(MAX); SELECT @COUNTRIES = CONCAT(@COUNTRIES + ', ', '') + CountryName FROM Application.Countries WHERE Continent = @CONTINENT ORDER BY CountryName DESC; --Returning list RETURN @COUNTRIES; END;
We are going to invoke the function for every Continent that we have, you can simulate the same behavior by using cursors.
WITH C AS(
SELECT DISTINCT Continent
FROM Application.Countries
)
SELECT *
FROM C
CROSS APPLY (SELECT dbo.List(C.Continent) as List) D
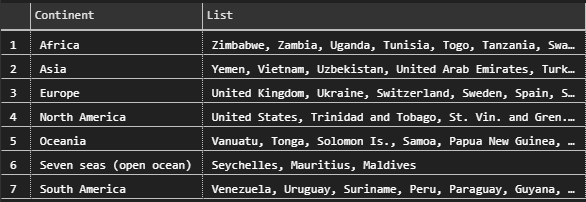
This function returns the same results that we have with the previous methods but it involves more effort.
Конкатенация с разделителем
Этот вид конкатенации в MySQL выполняется с помощью функции CONCAT_WS(), имеющей следующий синтаксис:
CONCAT_WS(‘символ_разделитель’, строка1, строка2…)
В этом случае между соединяемыми строками будет установлен символ-разделитель.
Пример 2
Например, в данном запросе в качестве разделителя используется запятая:
SELECT concat_ws(‘,’, fio,age,gender) as text1 FROM abiturient;
Результат:
Если в качестве разделителя использовать пустую строку, то результат будет полностью совпадать с результатом простой конкатенации. Если разделителем должен быть символ кавычки ‘, то его нужно экранировать обратным слешем – ‘\».







Пример 3
SELECT concat_ws(‘\», fio,age,gender) as text1 FROM abiturient;
TRIM([remstr FROM] str)
Возвращает строку str со все remstr префиксы или суффиксы удалены. Если ни один из спецификаторов BOTH, LEADING или TRAILING не заданы, предполагается, BOTH. remstr является необязательным и, если не указано, пробелы удаляются.
SQL> SELECT TRIM(' bar ');
+---------------------------------------------------------+
| TRIM(' bar ') |
+---------------------------------------------------------+
| bar |
+---------------------------------------------------------+
1 row in set (0.00 sec)
SQL> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');
+---------------------------------------------------------+
| TRIM(LEADING 'x' FROM 'xxxbarxxx') |
+---------------------------------------------------------+
| barxxx |
+---------------------------------------------------------+
1 row in set (0.00 sec)
SQL> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');
+---------------------------------------------------------+
| TRIM(BOTH 'x' FROM 'xxxbarxxx') |
+---------------------------------------------------------+
| bar |
+---------------------------------------------------------+
1 row in set (0.00 sec)
SQL> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
+---------------------------------------------------------+
| TRIM(TRAILING 'xyz' FROM 'barxxyz') |
+---------------------------------------------------------+
| barx |
+---------------------------------------------------------+
1 row in set (0.00 sec)