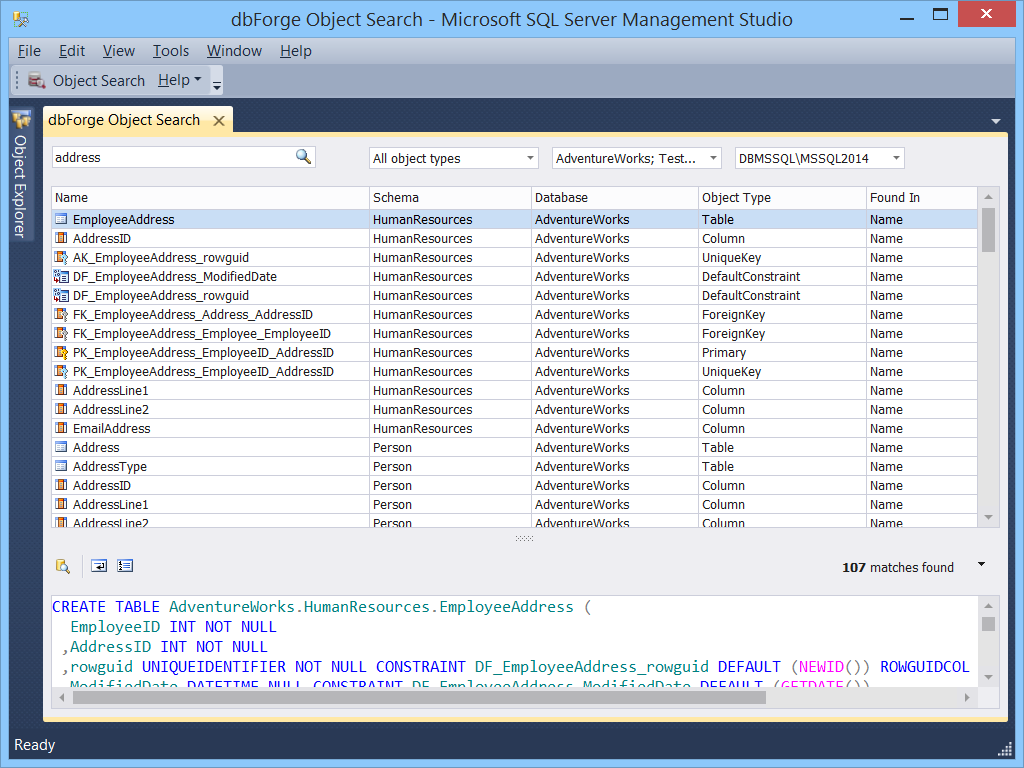
GUID as Primary Key
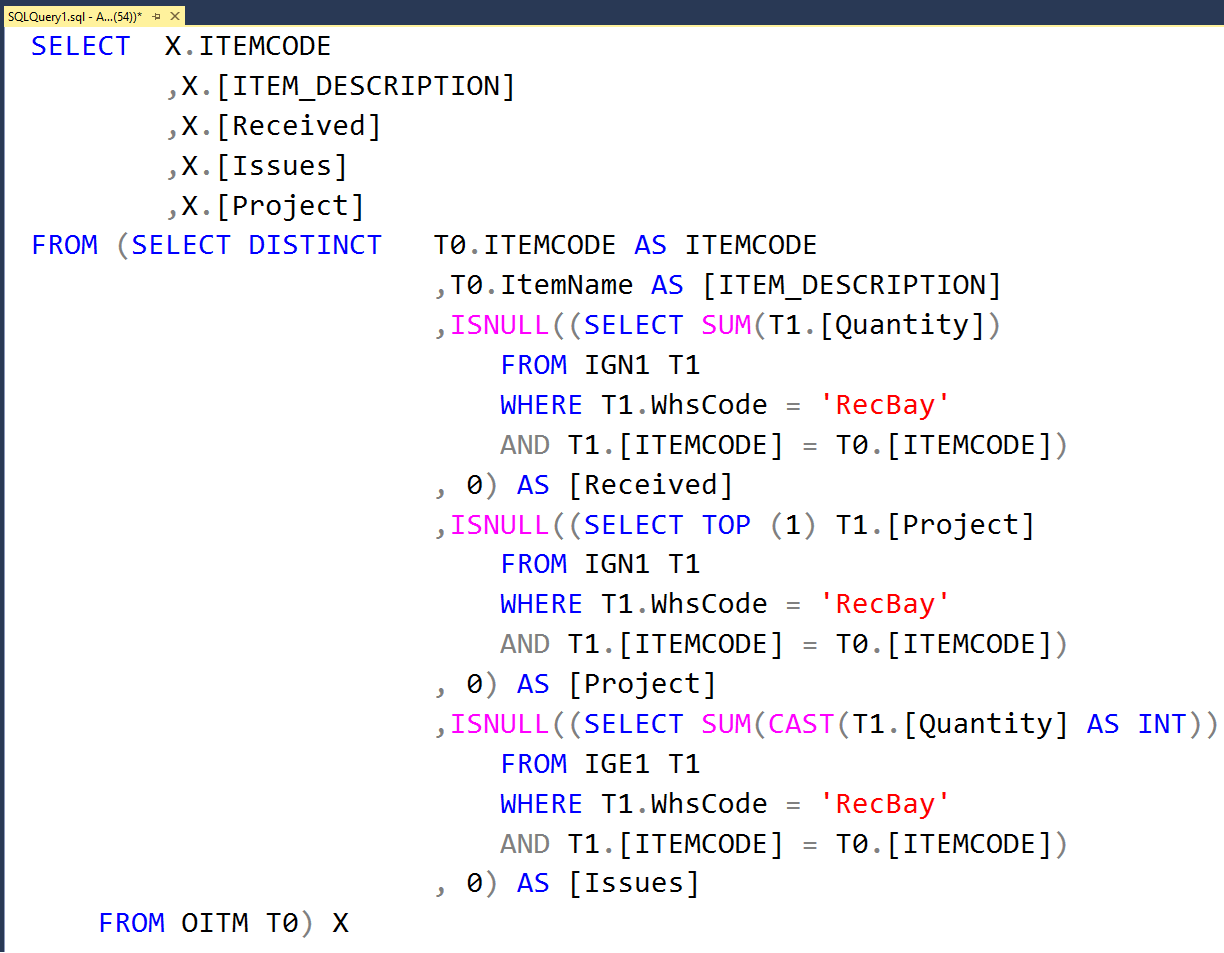
The idea is to create a unique value e.g a new productId, on one of the application layers without performing a round-trip to the database in order to ask for a new Id. So, the generated GUID value becomes a PK value for the new product in e.g Products table. The PK may be implemented as a unique non-clustered index. The index is likely to be highly fragmented since the generated GUIDs are completely random. Also, keep in mind that the PK is highly likely to be a part of one or more referential integrity constraints(Foreign Keys) in tables like e.g ProductInventory, ProductListPriceHistory, etc. Moreover, the Foreign keys may be, at the same time, part of the composite PKs on the foreign tables – Figure 7. This design may have a negative effect on many tables and the database performance in general.
An alternative approach may be to define GUID column as an Alternate Key* enforced by a unique NCI and to use INT or BIGINT along with the IDENTITY property or a Sequencer as a surrogate PK. The key can be enforced by the unique clustered index. This way we can avoid excessive fragmentation and enforce referential integrity in a more optimal way – Figure 7,rowguid column.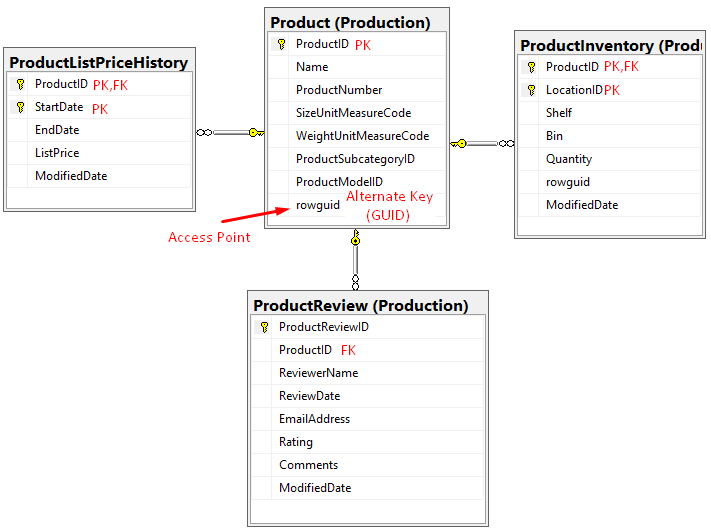
Figure 7, GUID column as an Alternate Key – Adventure Works
*Alternate Key represents column(s) that uniquely identify rows in a table. A table can have more than one column or combinations of columns that can uniquely identify every row in that table. Only one choice can be set as the PK. All other options are called Alternate Keys.
GUID values can be created by SQL Server during the INSERT operations. E.g Client code constructs a new product (product name, description, weight, color, etc..) and INSERTs the information(a new row) into the Products table. The NEWID() fn automatically creates and assigns a GUID value to the new row through a DEFAULT constraint on e.g ProductId column. Client code can also generate and supply GUID for the new product. The two methods can be mixed since the generated GUIDs are globally unique.
What I often see in different production environments is that the GUID values are used as PK values even if there is no need for the globally unique values.
Very few of them had better security in mind i.e It is safer to expose a GUID than a numeric value when querying DB through a public API. The exposed numeric value in the URL may potentially be used to harm the system. E.g http://myApp/productid/88765 can suggest that there is productId =88764 etc., but with a GUID value, these guesses will not be possible – Figure 7, data access point.
In most DB designs, at least in the ones I’ve had an opportunity to work on, GUIDs are used only because it was convenient from the application code design perspective.
When the application and the database become larger and more complex, these early decisions can cause performance problems. Usually, these problems are solved by, so-called quick fixes/wins. As the rule of thumb, the first “victim” of those “wins” is always data integrity e.g adding NOLOCK table hints everywhere, removing referential integrity(FK), replacing INNER JOINS with LEFT JOINS, etc. This inevitably leads to a new set of bugs that are not easy to detect and fix. This last paragraph may be too much, but this is what I am seeing in the industry.
Use GUIDs with caution and with the cost-benefit in mind
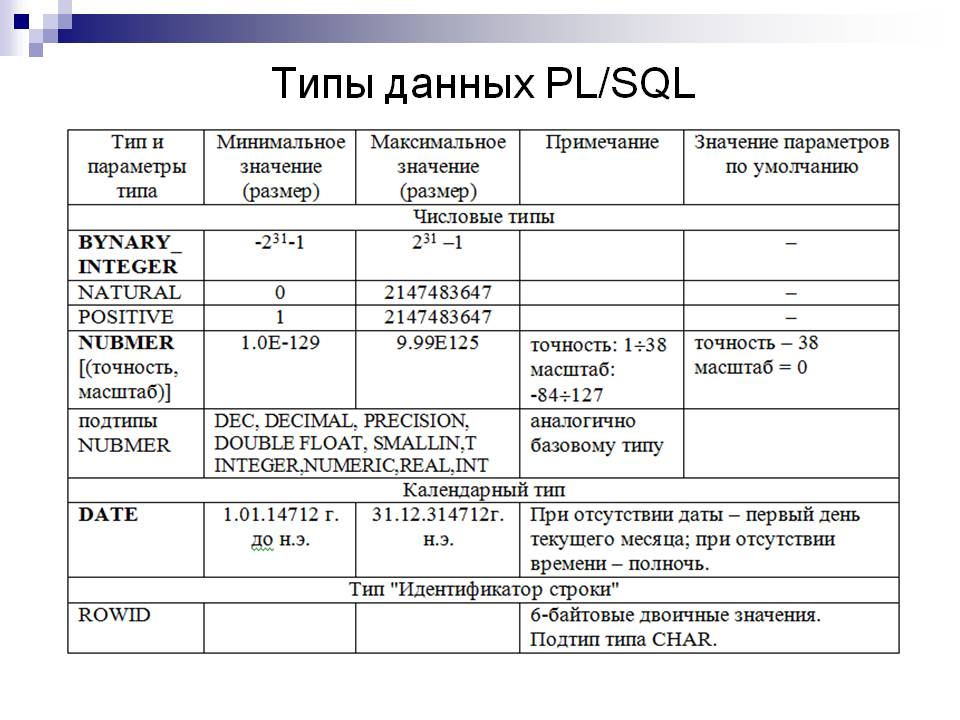
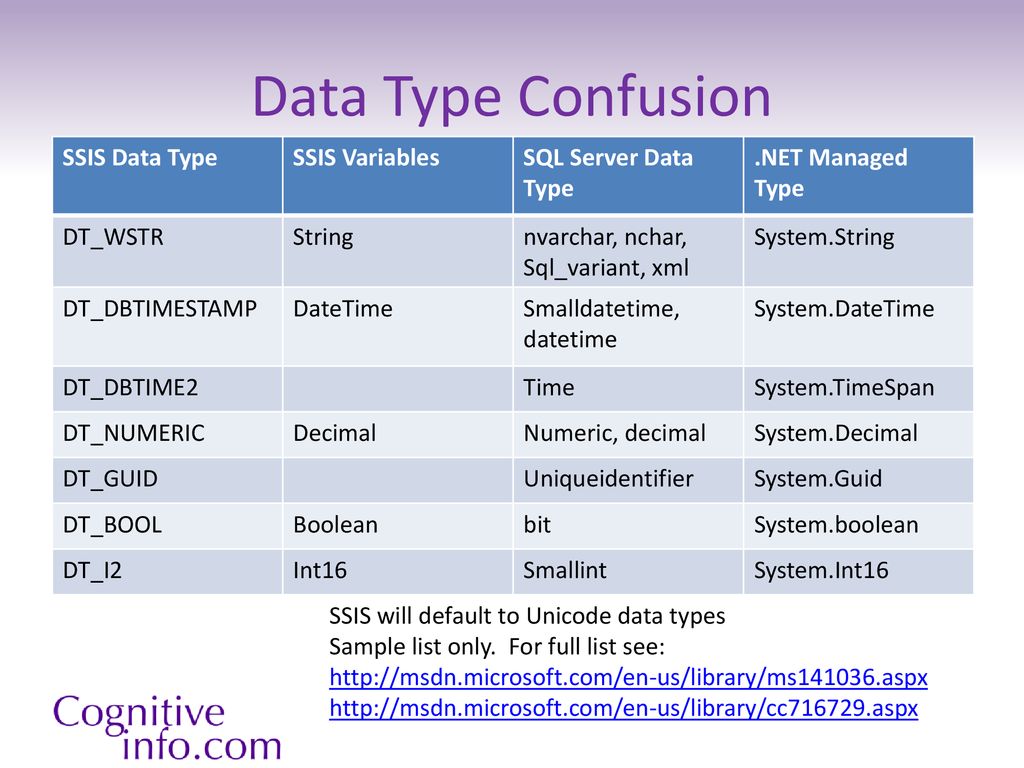
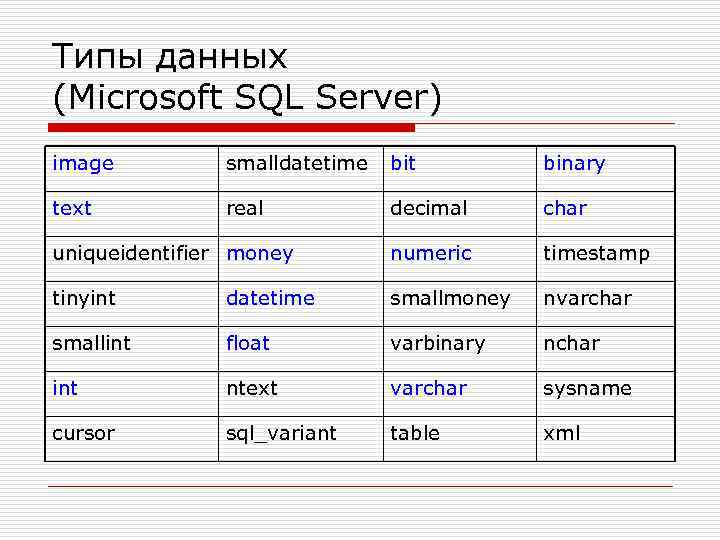
SQL Server, SSIS и Biml типы данных
Таблица ниже является упрощенной схемой связи между типами данныхSQL Server, SSIS и Biml.
Таблица не включает все возможные комбинации и все виды типов данных, но полезна как быстрая ссылка при разработке и изучении Biml.
| SQL Server | SSIS Variables | SSIS Pipeline Buffer | OLE DB | ADO.NET | Biml |
|---|---|---|---|---|---|
| bigint | Int64 | DT_I8 | LARGE_INTEGER | Int64 | Int64 |
| binary | Object | DT_BYTES | — | Binary | Binary |
| bit | Boolean | DT_BOOL | VARIANT_BOOL | Boolean | Boolean |
| char | String | DT_STR | VARCHAR | StringFixedLength | AnsiStringFixedLength |
| date | Object | DT_DBDATE | DBDATE | Date | Date |
| datetime | DateTime | DT_DBTIMESTAMP | DATE | DateTime | DateTime |
| datetime2 | Object | DT_DBTIMESTAMP2 | DBTIME2 | DateTime2 | DateTime2 |
| datetimeoffset | Object | DT_DBTIMESTAMPOFFSET | DBTIMESTAMPOFFSET | DateTimeOffset | DateTimeOffset |
| decimal | Decimal | DT_NUMERIC | NUMERIC | Decimal | Decimal |
| float | Double | DT_R8 | FLOAT | Double | Double |
| geography | — | DT_IMAGE | — | Object | Object |
| geometry | — | DT_IMAGE | — | Object | Object |
| hierarchyid | — | DT_BYTES | — | Object | Object |
| image (*) | Object | DT_IMAGE | — | Binary | Binary |
| int | Int32 | DT_I4 | LONG | Int32 | Int32 |
| money | Object | DT_CY, DT_NUMERIC | CURRENCY | Currency | Currency |
| nchar | String | DT_WSTR | NVARCHAR | StringFixedLength | StringFixedLength |
| ntext (*) | String | DT_NTEXT | — | String | String |
| numeric | Decimal | DT_NUMERIC | NUMERIC | Decimal | Decimal |
| nvarchar | String | DT_WSTR | NVARCHAR | String | String |
| nvarchar(max) | Object | DT_NTEXT | — | — | String |
| real | Single | DT_R4 | FLOAT, DOUBLE | Single | Single |
| rowversion | Object | DT_BYTES | — | Binary | Binary |
| smalldatetime | DateTime | DT_DBTIMESTAMP | DATE | DateTime | DateTime |
| smallint | Int16 | DT_I2 | SHORT | Int16 | Int16 |
| smallmoney | Object | DT_CY, DT_NUMERIC | CURRENCY | Currency | Currency |
| sql_variant | Object | DT_WSTR, DT_NTEXT | — | Object | Object |
| table | Object | — | — | — | — |
| text (*) | Object | DT_TEXT | — | — | AnsiString |
| time | Object | DT_DBTIME2 | DBTIME2 | Time | Time |
| timestamp (*) | Object | DT_BYTES | — | Binary | Binary |
| tinyint | Byte | DT_UI1 | BYTE | Byte | Byte |
| uniqueidentifier | String, Object | DT_GUID | GUID | Guid | Guid |
| varbinary | Object | DT_BYTES | — | Binary | Binary |
| varbinary(max) | Object | DT_IMAGE | — | Binary | Binary |
| varchar | String | DT_STR | VARCHAR | String | AnsiString |
| varchar(max) | Object | DT_TEXT | — | — | AnsiString |
| xml | Object | DT_NTEXT | — | — | Xml |
(* Данные типы данных будут удалены в будущих версиях SQL Server.
Избегайте использование этих типов данных в новых проектах и, по возможности, измените их в текущих проектах.)
GUID as PK and the Clustered index key
Sometimes developers decide to use GUID values as a PK enforced by the clustered index. This means that the primary key column is at the same time the clustered index key. Data pages(leaf level) of a clustered index are logically ordered by the clustered index key values.
One of the reasons for this design may be the ability to easily merge data from different databases in the distributed database environment. The same idea can be implemented more efficiently using GUID as an alternative key as explained earlier.
More often, the design is inherited from SQL Server’s default behavior when the PK is created and automatically implemented as the clustered index key unless otherwise specified.
Using GUID as clustered index key leads to extensive page and index fragmentation. This is due to its randomness. E.g every time the client app inserts a new Product, a new row must be placed in a specific position i.e specific memory location on a data page. This is to maintain the logical order of the key values. The pages(nodes) are part of a doubly linked list data structure. If there is not enough space on the designated page for the new row, the page must be split into two pages to make the necessary space for the new row. The physical position of the newly allocated page (8KB memory space) in the data file does not follow the order of the index key (it is not physically next to the original page). This is known as logical fragmentation. Splitting data pages introduces yet another type of fragmentation, physical fragmentation which defines the negative effect of the wasted space per page after the split. The increased number of “half full” pages along with the process of splitting the pages has a negative impact on query performance.
The “potential collateral damage” of the decision to use GUID as clustered index key is non-unique non-clustered indexes.
A non-clustered index that is built on a clustered index, at the leaf level, contains row locators- the clustered index key values. These unique values are used as pointers to the clustered index structure and the actual rows – more information can be found here – The data Access Pattern section.
A non-unique NCI can have many duplicate index key values. Each of the key values is “coupled” with a unique pointer – in this case, a GUID value. Since GUID values are random the new rows can be inserted in any position within the range of the duplicated values. This introduces the fragmentation of the NCI. The more duplicated values, the more fragmentation.
The fragmentation can be “postponed” by using the FILLFACTOR setting. The setting instructs SQL Server what percentage of each data page should be used to store data. The “extra” free space per page can “delay” page splits. The FILLFACTOR value isn’t maintained when inserting new data. It is only effective when we create or rebuild an index. So once it’s full, and between the index rebuilds, the data page will be split again during the next insert.
Things are different with the sequential GUID. Sequential GUIDs are generated in ascending order. The “block” of compact, ever-increasing GUIDs is formed on a server and between the OS restarts. Sequential GUIDs created by the Client code on a different server will fall into a separate “block” of guids – see Figure 6. As mentioned before, sequential GUIDs can be created by SQL Server – NEWSEQUENTIALID() fn. initiated by a DEFAULT constraint and/or by the client code. The compact “blocks” of guids will reduce fragmentation.
Conclusion
In SQL Server, GUID is a 16byte binary value stored as UNIQUIEIDENTIFIER data type. NEWID() and NEWSEQUENTIALID() are the two system functions that can be used to create GUIDs in SQL server. The latter is not compliant with the RFC4122 standard. Both GUID types can be created by the client code using functions: UUidCreate(), UuidCreateSequential(). .NET sorts Guid values differently than SQL Server. UNIQUEIDENTIFIER data type re-shuffles first 8 bytes(the first three segments). .NET’s SqlGuid Struct represents a GUID to be stored or retrieved from a DB.
GUID values are often used as primary key/clustered index key values. The randomness of the GUID values introduces logical and physical data fragmentation, which then leads to query performance regression. Sequential GUIDs can reduce fragmentation but still need to be used carefully and with the cost-benefit approach in mind.
Thanks for reading.
Dean Mincic
Значение NULL
Значение null — это специальное значение, которое можно присвоить ячейке таблицы. Это значение обычно применяется, когда информация в ячейке неизвестна или неприменима. Например, если неизвестен номер домашнего телефона служащего компании, рекомендуется присвоить соответствующей ячейке столбца home_telephone значение null.
Если значение любого операнда любого арифметического выражения равно null, значение результата вычисления этого выражения также будет null. Поэтому в унарных арифметических операциях, если значение выражения A равно null, тогда как +A, так и -A возвращает null. В бинарных выражениях, если значение одного или обоих операндов A и B равно null, тогда результат операции сложения, вычитания, умножения, деления и деления по модулю этих операндов также будет null.
Если выражение содержит операцию сравнения и значение одного или обоих операндов этой операции равно null, результат этой операции также будет null.
Значение null должно отличаться от всех других значений. Для числовых типов данных значение 0 и значение null не являются одинаковыми. То же самое относится и к пустой строке и значению null для символьных типов данных.
Значения null можно сохранять в столбце таблицы только в том случае, если это явно разрешено в определении данного столбца. С другой стороны, значения null не разрешаются для столбца, если в его определении явно указано NOT NULL. Если для столбца с типом данных (за исключением типа TIMESTAMP) не указано явно NULL или NOT NULL, то присваиваются следующие значения:
-
NULL, если значение параметра ANSI_NULL_DFLT_ON инструкции SET равно on.
-
NOT NULL, если значение параметра ANSI_NULL_DFLT_OFF инструкции SET равно on.
Если инструкцию set не активировать, то столбец по умолчанию будет содержать значение NOT NULL. (Для столбцов типа TIMESTAMP значения null не разрешаются.)




Дополнительные соображения
Есть еще несколько вещей, которые стоит принять во внимание. В данной статье мы много времени уделили времени вставки значений в базу, но совершенно упустили из виду время формирования самого GUID, по сравнению с Guid.NewGuid()
Конечно, время формирования дольше. Я могу создать миллион произвольных GUID за 140 ms, но на создание последовательных уйдет 2800 ms, что в 20 раз медленнее.
Быстрые тесты показали, что львиная доля такого замедления приходится на использование сервиса RNGCryptoServiceProvider для генерирования произвольных данных. Переключение на System.Random снизило время выполнения до 400 ms. Я все еще не рекомендую этот способ из-за описанных опасностей.
Является ли такое замедление проблемой? Лично для себя я решил, что нет. До тех пор пока ваше приложение не использует интенсивные вставки данных (а тогда стоит рассмотреть саму целесообразность использования GUID), стоимость генерирования согласуется с временем работы самой базы и ее дальнейшей быстрой работы.
Другая возможная проблема: будут ли 10 байт достаточны для гарантирования уникальности? С учетом временного штампа это означает, что два любых GUID созданных в период больший чем несколько миллисекунд будут гарантированно разными. Но что с GUID, которые создаются действительно очень быстро в одном промежутке времени. В таком случае 10 байт дают нам оценку в 280, или 1,208,925,819,614,629,174,706,176 возможных комбинаций. Т.е. вероятность будет такой же как и то, что в этот момент ваша база данных и все бэкапы будут одновременно атакованы и уничтожены ордой диких свиней.
Последняя проблема, которая вас может заинтересовать, это то, что полученные GUID технически не совместимы со стандартом RFC 4122. Честно, я не думаю, что это большая проблема, я не знаю ни одной базы данных которая реально проверяет внутреннее устройство GUID и упущение версии GUID дает нам дополнительные байты для увеличения уникальности ключа.
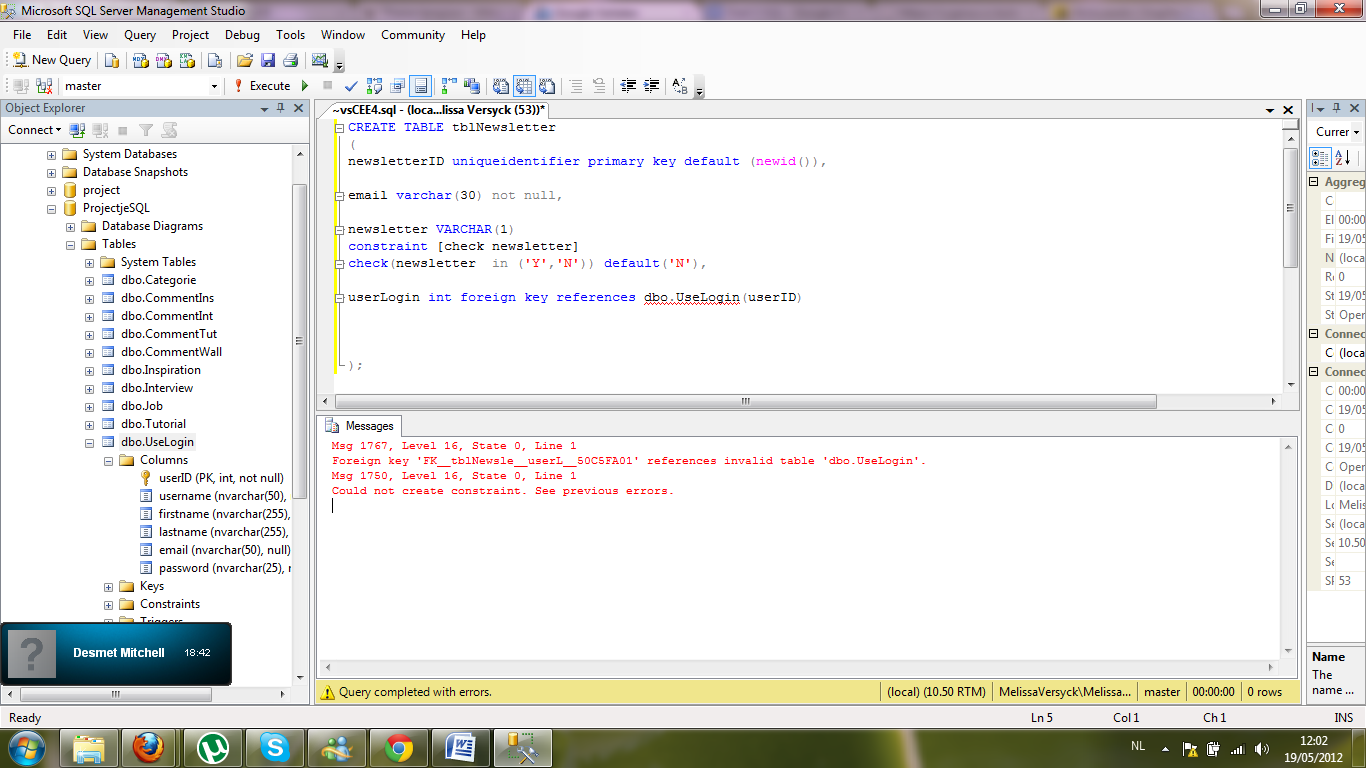
Reason #3. Number of Locks
When statement is being executed, Microsoft SQL Server is locking new data row by row or page by page thinking that the table might be accessed by concurrent query. If you are generating test database, there are no concurrent queries. So we may direct Microsoft SQL Server to lock whole table rather than page by page locking. Table hint locks the whole table at the beginning of execution.
SQL
create table ids(id uniqueidentifier); declare @ids table(id int identity) declare @guidCount int = 1000000; declare @n int = ; while @n < SQRT(@guidCount) begin insert @ids default values; set @n = @n + 1; end insert ids with(tablock) select NEWID() from @ids i1, @ids i2;
This code generates 1 000 000 guids in 500 ms! That’s really a great result. So one can see that this is very important to obtain a table lock before heavy execution. If you want to create even more guids — is the only solution. In my test environment (default Microsoft SQL 2008 settings), I can’t generate more than 10 millions guids without table lock. I get an error:
Msg 1204, Level 19, State 4, Line 10 The instance of the SQL Server Database Engine cannot obtain a LOCK resource at this time. Rerun your statement when there are fewer active users. Ask the database administrator to check the lock and memory configuration for this instance, or to check for long-running transactions.
Incremental Primary Keys
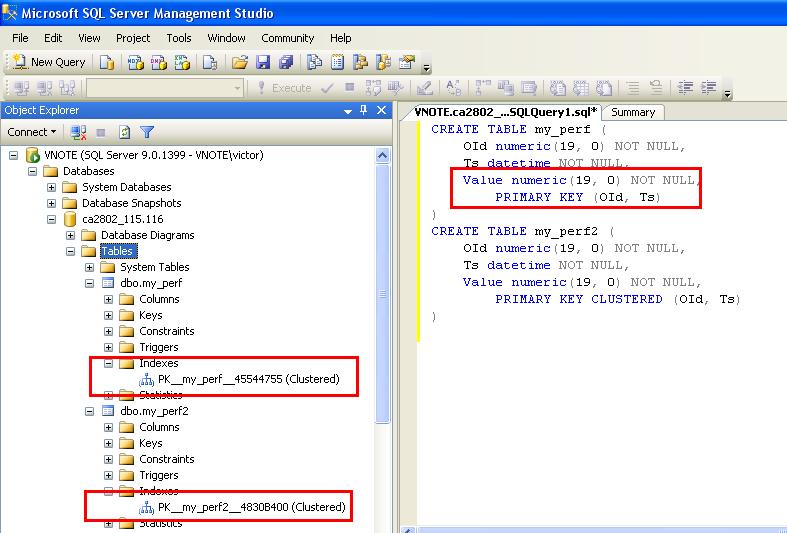
As you might guess, the cure for the random primary key anti-pattern is an incremental key pattern. With a uniqueidentifier data type, a sequential value can be assigned by SQL Server using the NEWSEQUENTIALID function (in a default constraint expression) or in application code using the UuidCreateSequential Win32 API call along with some byte swapping (code example below). Alternatively, one can use an integral data type (int, bigint, etc.) along with a value generated by an IDENTITY property or a SEQUENCE object. The advantage of an integral type is the reduced space requirements compared to a 16-byte uniqueidentifier. The advantage of a uniqueidentifier is that it can easily be generated in application code before database persistence without a database round trip, which is desirable for distributed applications and when keys of related tables are assigned in application code before writing to the database.
Figure 2 shows the same test using a sequential key value. Over 2.2M rows were inserted in 15 minutes. As you can see, significant performance improvement is achieved with this trivial application change.
Figure 2: Incremental key insert performance
Listing 1 shows the T-SQL code I used for these performance tests and listing 2 contains the C# code (with the random GUID commented out). I generated the uniqueidentifier value via application code in the tests but performance with NEWID() is comparable to the first test and NEWSEQUENTIALID() is similar to the second test.
Listing 1: T-SQL scripts for test table and stored procedure
CREATE TABLE dbo.TestTable( TestKey uniqueidentifier NOT NULL CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED ,TestData char(8000) NOT NULL ); GO CREATE PROC dbo.InsertTestTable @TestKey uniqueidentifier ,@TestData char(8000) AS SET NOCOUNT ON; DECLARE @TotalRows int; --insert row INSERT INTO dbo.TestTable (TestKey, TestData) VALUES(@TestKey, @TestData); --update pmon counter for rowcount SELECT @TotalRows = rows FROM sys.partitions WHERE object_id = OBJECT_ID(N'TestTable') AND index_id = 1; EXEC sys.sp_user_counter1 @TotalRows; --for pmon row count RETURN @@ERROR; GO
Listing 2: C# insert test console application
using System;
using System.Data;
using System.Data.SqlClient;
using System.Runtime.InteropServices;
namespace UniqueIdentifierPerformanceTest
{
class Program
{
public static extern int UuidCreateSequential(ref Guid guid);
static string connectionString = @"Data Source=MyServer;Initial Catalog=MyDatabase;Integrated Security=SSPI";
static int rowsToInsert = 10000000;
static SqlConnection connection;
static SqlCommand command;
static void Main(string[] args)
{
int rowsInserted = 0;
using (connection = new SqlConnection(connectionString))
{
using (command = new SqlCommand("dbo.InsertTestTable", connection))
{
command.Connection = connection;
command.CommandType = CommandType.StoredProcedure;
command.Parameters.Add("@TestKey", SqlDbType.UniqueIdentifier);
command.Parameters.Add("@TestData", SqlDbType.Char, 8000);
connection.Open();
while (rowsInserted < rowsToInsert)
{
//random guid
//command.Parameters.Value = Guid.NewGuid();
//sequential guid
command.Parameters.Value = NewSequentialGuid();
command.Parameters.Value = "Test";
command.ExecuteNonQuery();
++rowsInserted;
//display progress every 1000 rows
if (rowsInserted % 1000 == 0)
{
Console.WriteLine(string.Format(
"{0} of {1} rows inserted"
, rowsInserted.ToString("#,##0")
, rowsToInsert.ToString("#,##0")));
}
}
}
connection.Close();
}
}
///
/// call UuidCreateSequential and swap bytes for SQL Server format
///
/// sequential guid for SQL Server
private static Guid NewSequentialGuid()
{
const int S_OK = 0;
const int RPC_S_UUID_LOCAL_ONLY = 1824;
Guid oldGuid = Guid.Empty;
int result = UuidCreateSequential(ref oldGuid);
if (result != S_OK && result != RPC_S_UUID_LOCAL_ONLY)
{
throw new ExternalException("UuidCreateSequential call failed", result);
}
byte[] oldGuidBytes = oldGuid.ToByteArray();
byte[] newGuidBytes = new byte;
oldGuidBytes.CopyTo(newGuidBytes, 0);
// swap low timestamp bytes (0-3)
newGuidBytes = oldGuidBytes;
newGuidBytes = oldGuidBytes;
newGuidBytes = oldGuidBytes;
newGuidBytes = oldGuidBytes;
// swap middle timestamp bytes (4-5)
newGuidBytes = oldGuidBytes;
newGuidBytes = oldGuidBytes;
// swap high timestamp bytes (6-7)
newGuidBytes = oldGuidBytes;
newGuidBytes = oldGuidBytes;
//remaining 8 bytes are unchanged (8-15)
return new Guid(newGuidBytes);
}
}
}
4.3 Генерация значений колонок
Различные
возможности позволяют вам генерировать значения колонок: тождеств (Identity), NEWID функция
и тип данных uniaueidentifier.
Использование свойства Identity
Вы можете
использовать свойство Identity (тождество) для
создания колонки, которая содержит сгенерированное системой следующее значение,
определяющее каждую строку, вставленную в таблицу. Тождественная колонка часто
используется в качестве значений первичного ключа.
Когда SQL Server
автоматически предоставляет значение ключа, можно уменьшить затраты на
улучшение производительности. Это облегчает программирование, делает первичный
ключ коротким и уменьшает пользовательские транзакции.
Рассмотрите
следующие рекомендации для использования свойства Identity:
Только одна тождественная колонка разрешена в таблице;
Она должна использоваться с целочисленными типами данных.;
Оно не может обновляться;
Вы можете использовать ключевое слово IDENTITYCOL в
месте с именем колонки в запросе. Это позволяет вам ссылаться на колонку в
таблице со свойством Identity, не зная имени
колонки;
Не разрешает нулевые значения.
Вы можете
получить информацию о свойстве Identity
несколькими путями:
Две системные функции возвращают информацию о тождественной
колонке: IDENT_SEED (возвращает начальное значение) и IDENT_INCR (возвращает значение приращения);
Вы можете получить информацию о Identity
колонке, используя глобальную переменную @@identity,
которая определяет значение последней вставленной строки в тождественную
колонку в течение сессии;
Функция SCOPE_IDENTITY
возвращает последнее значение, вставленное в колонку в некоторых рамках. Рамки
определяются процедурой, триггером, функцией или batch;
Функция IDENTITY_INSERT
возвращает последнее значение, сгенерированное для определённой таблицы в любой
сессии или рамке.
Вы можете
управлять свойством Identity несколькими путями:
Вы можете позволить явно вставлять значения в тождественную
колонку таблицы с помощью установки свойства IDENTITY_INSERT в
значение ON. Когда это свойство
установлена, оператор INSERT должен указывать значение колонки.




Для проверки возможности изменения текущего тождественного поля
таблицы, вы можете использовать оператор DBCC CHECKIDENT.
Он позволяет вам сравнить текущее тождественное значение с максимальным
значением в тождественной колонке.
Тождественное свойство не обеспечивает уникальности. Для
уникальности создавайте уникальный индекс.
Следующий
пример создаёт таблицу с двумя колонками, StudentID
и Name. Свойство Identity
используется для автоматического увеличения в каждой строке колонки StudentID. Начальное значение устанавливается в 100, а
приращение в 5. Значения для этой колонки будут генерироваться в виде 100, 105,
110, 115 …
CREATE
TABLE
Class
(StudentID INT IDENTITY(100,5) NOT NULL,
Namt varchar (16))
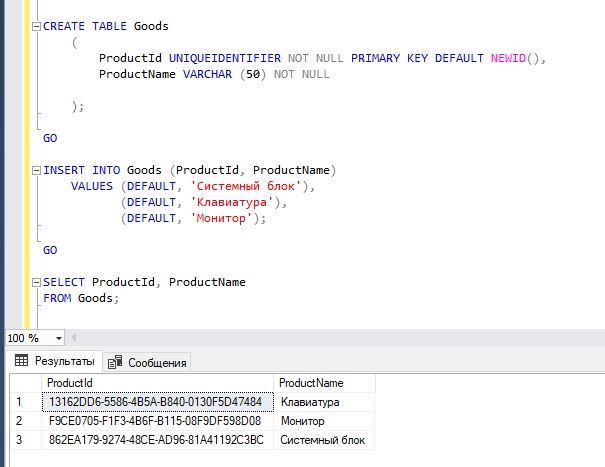
Использование функции NEWID и
уникального идентификатора
Тип данных uniqueidentifier (уникальный
идентификатор) и функция NEWID –
это две возможности, которые используются вместе. Используйте эти возможности,
когда данные сопоставляются из нескольких таблиц в одну большую таблице, когда
нужно обеспечить уникальность всех записей:
Тип данных uniqueidentifier хранит
число уникального идентификатора в виде 16-байт бинарной строки. Тип данных использует
для хранения глобальный уникальный идентификатор (GUID);
Функция NEWID
создаёт новое число уникального идентификатора, которое хранится в типе данных uniqueidentifier;
Тип данных uniqueidentifier не
генерирует автоматически новый ID для вставляемой
строки в отличие от свойства Identity.
Пример
Тип данных TIMESTAMP
Тип данных TIMESTAMP указывает столбец, определяемый как VARBINARY(8) или BINARY(8) , в зависимости от свойства столбца принимать значения null. Для каждой базы данных система содержит счетчик, значение которого увеличивается всякий раз, когда вставляется или обновляется любая строка, содержащая ячейку типа TIMESTAMP, и присваивает этой ячейке данное значение. Таким образом, с помощью ячеек типа TIMESTAMP можно определить относительное время последнего изменения соответствующих строк таблицы. (ROWVERSION является синонимом TIMESTAMP.)
Само по себе значение, сохраняемое в столбце типа TIMESTAMP, не представляет никакой важности. Этот столбец обычно используется для определения, изменилась ли определенная строка таблицы со времени последнего обращения к ней
Unique Identifier – A Globally Unique ID (GUID)
The uniqueidentifier type is used when you which to store a GUID (Globally Unique ID). The main purpose to create GUID is create an ID that is unique across many computers within a network.
Unique Identifiers take the form xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx where x represents a hexadecimal value (e.g. 0-F).
An example of an GUID is F22620D0-600E-4F0D-86E3-71250D1CE01E.
You can use the NEWID() function to generate GUID’s.
Here is an example:
Which when I ran it returned 0AFEBE69-7B1E-43F9-909E-35E7E32535B2. When you run it, it will create a different GUID as you’re running it on a different computer at another time.
Unique Identifiers are important to SQL as they’re used when replicating data.