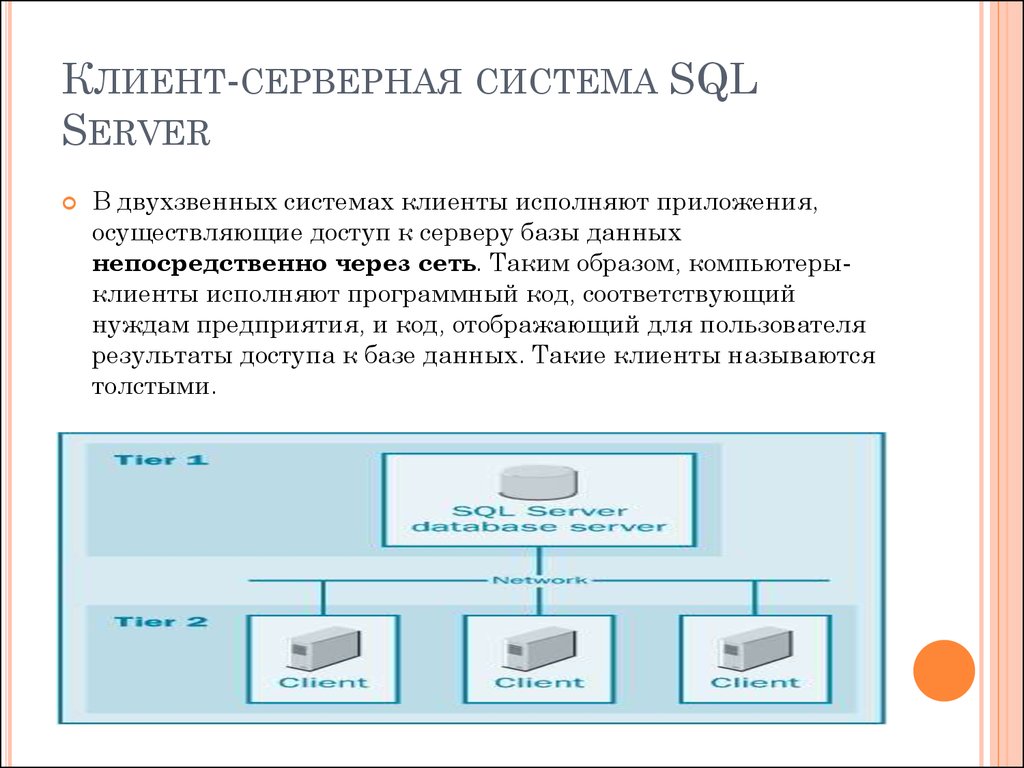
Алгоритмы создания индексов в «1С»
Способ №1Не выраженный. В этом варианте платформа сама формирует индексы, но лишь тогда, когда для каждого объекта метаданных существуют ключи (к примеру, код или ссылка). Способ №2Выраженный. Он дает возможность использовать три варианта создания индексов:1. Установить флажок «Индексировать» около значка «реквизиты»/«измерения». Используя функцию «Индексировать с дополнительным упорядочиванием» добавить индекс в строку «Код»/«Наименование» (это необходимо в начале проделать с динамичными списками).2. В раздел «Критерии отбора» вставить дополнительное поле.3. Использовать функцию «Индексировать по» для обозначения поля для индексации.
Create an Index
Syntax
The syntax for creating an index in SQL Server (Transact-SQL) is:
CREATE INDEX index_name
ON table_name ( column1 , ... column_n )
[ FILESTREAM_ON { filegroup | partition_scheme };
- UNIQUE
- Optional. Indicates that the combination of values in the indexed columns must be unique.
- CLUSTERED
- Optional. Indicates that the logical order determines the physical order of the rows in the table.
- NONCLUSTERED
- Optional. Indicates that the logical order does not determine the physical order of the rows in the table.
- index_name
- The name of the index to create.
- table_name
- The name of the table or view on which the index is to be created.
- column1, … column_n
- The columns to base the index.
- ASC | DESC
- The sort order for each of the columns.
- INCLUDE ( column1, … column_n )
- Optional. The columns that are not key columns to add to the leaf level of the nonclustered index.
- WHERE condition
- Optional. The condition to determine which rows to include in the index.
- ON partition_scheme ( column )
- Optional. Indicates that the partition schema determines the filegroups in which the partitions will be mapped.
- ON filegroup
- Optional. Indicates that the index will be created on the specified filegroup.
- ON default_filegroup
- Optional. Indicates the default filegroup.
- FILESTREAM_ON { filegroup | partition_scheme }
- Optional. Indicates where to place the FILESTREAM data for a clustered index.
Index Example
Let’s look at an example of how to create an index in SQL Server (Transact-SQL).
For example:
CREATE INDEX contacts_idx ON contacts (last_name);
In this example, we’ve created an index on the contacts table called contacts_idx. It consists of only one field — the last_name field.
We could also create an index with more than one field as in the example below:
CREATE INDEX contacts_idx ON contacts (last_name, first_name);
In this example, we’ve created an index on the contacts table called contacts_idx but this time, it consists of the last_name and first_name fields.
Since we have not specified ASC | DESC to each of the columns, the index is created with each of the fields in ascending order. We could modify our example and change the sort orders to descending as follows:
CREATE INDEX contacts_idx ON contacts (last_name DESC, first_name DESC);
This CREATE INDEX example will create the contacts_idx index with the last_name sorted in descending order and the first_name sorted in descending order.
UNIQUE Index Example
Next, let’s look at an example of how to create a unique index in SQL Server (Transact-SQL).
For example:
CREATE UNIQUE INDEX contacts_uidx ON contacts (last_name, first_name);
This example would create an index called contacts_uidx on that contacts table that consists of the last_name and first_name fields, but also ensures that the there are only unique combinations of the two fields.
You could modify this example further to make the unique index also clustered so that the physical order of the rows in the table is determined by the logical order of the index.
For example:
CREATE UNIQUE CLUSTERED INDEX contacts_uidx ON contacts (last_name, first_name);
ALTER Command to add and drop the PRIMARY KEY
You can add a primary key as well in the same way. But make sure the Primary Key works on columns, which are NOT NULL.
The following code block is an example to add the primary key in an existing table. This will make a column NOT NULL first and then add it as a primary key.
mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL; mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (i);
You can use the ALTER command to drop a primary key as follows −
mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY;
To drop an index that is not a PRIMARY KEY, you must specify the index name.
Displaying INDEX Information
You can use the SHOW INDEX command to list out all the indexes associated with a table. The vertical-format output (specified by \G) often is useful with this statement, to avoid a long line wraparound −
Try out the following example −
mysql> SHOW INDEX FROM table_name\G ........
Previous Page
Print Page
Next Page
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.91 от 17.01.2023
3 стартмани
178
Некластеризованный индекс:
Некластеризованный индекс — это особый тип индекса, в котором логический порядок индекса не совпадает с физическим порядком строк, хранящихся на диске. Конечный узел некластеризованного индекса не содержит страниц данных, а содержит информацию о строках индекса. Таблица может содержать до 249 индексов. По умолчанию ограничение уникального ключа создает некластеризованный индекс. В операции чтения некластеризованные индексы работают медленнее, чем кластеризованные индексы. Некластеризованный индекс содержит копию данных из проиндексированных столбцов, сохраненных в порядке, а также ссылки на фактические строки данных; указатели на кластерный список, если таковые имеются. Поэтому рекомендуется выбирать только те столбцы, которые используются в индексе, вместо использования *. Таким образом, данные могут быть получены непосредственно из дублирующего индекса. В противном случае кластерный индекс также используется для выбора оставшихся столбцов, если он создан.
Синтаксис, используемый для создания некластеризованного индекса, аналогичен кластерному индексу. Однако ключевое слово «NONCLUSTERED» используется вместо «CLUSTERED» в случае некластеризованного индекса. Выполните следующий сценарий для создания некластеризованного индекса.
ИСПОЛЬЗОВАНИЕ
ИДТИ
SET ANSI_PADDING ON
ИДТИ
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС НА ,
(
ASC
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
ИДТИ
Вывод будет следующим.
Создание некластеризованного индекса для таблицы с именем «Сотрудник»
Записи таблицы сортируются по кластерному индексу, если он был создан. Этот новый некластеризованный индекс отсортирует таблицу в соответствии с ее определением и будет храниться в отдельном физическом адресе. Приведенный выше скрипт создаст индекс для столбца «NAME» таблицы Employee. Этот индекс будет сортировать таблицу в порядке возрастания столбца «Имя». Данные таблицы и индекс будут храниться в разных местах, как мы уже говорили ранее. Теперь выполните следующий скрипт для просмотра влияния нового некластеризованного индекса.
выберите имя от сотрудника
Вывод будет следующим.
По определению некластеризованного индекса в таблице «Сотрудник» он будет сортировать столбец «Имя» в порядке возрастания при выборе имени из таблицы.
На рисунке выше видно, что столбец «Имя» таблицы «Сотрудник» показан в порядке возрастания столбца «имя», хотя мы не упомянули предложение «Упорядочить по ASC» в предложении выбора. Это происходит из-за некластеризованного индекса в столбце «Имя», созданного в таблице «Сотрудник». Теперь, если запрос написан для получения имени, электронной почты, города и адреса конкретного человека. База данных сначала будет искать это конкретное имя в индексе, а затем извлекать соответствующие данные, что уменьшит время выборки запроса, особенно когда данные огромны.
выберите имя, адрес электронной почты, город, адрес сотрудника, где имя = ‘Aaaronboy Гутьеррес’
Заключение
Из приведенного выше обсуждения мы узнали, что кластеризованный индекс может быть только один, тогда как некластеризованный индекс может быть много. Кластерный индекс быстрее по сравнению с некластеризованным индексом. Кластерный индекс не использует дополнительное пространство для хранения, тогда как некластеризованному индексу требуется дополнительная память для их хранения. Если мы применяем ограничение первичного ключа к таблице, автоматически создается кластеризованный индекс. Более того, если мы применяем ограничение уникального ключа к любому столбцу, для него автоматически создается некластеризованный индекс. Некластеризованный индекс быстрее по сравнению с кластеризованным индексом для операций вставки и обновления. Таблица может не иметь некластеризованного индекса.
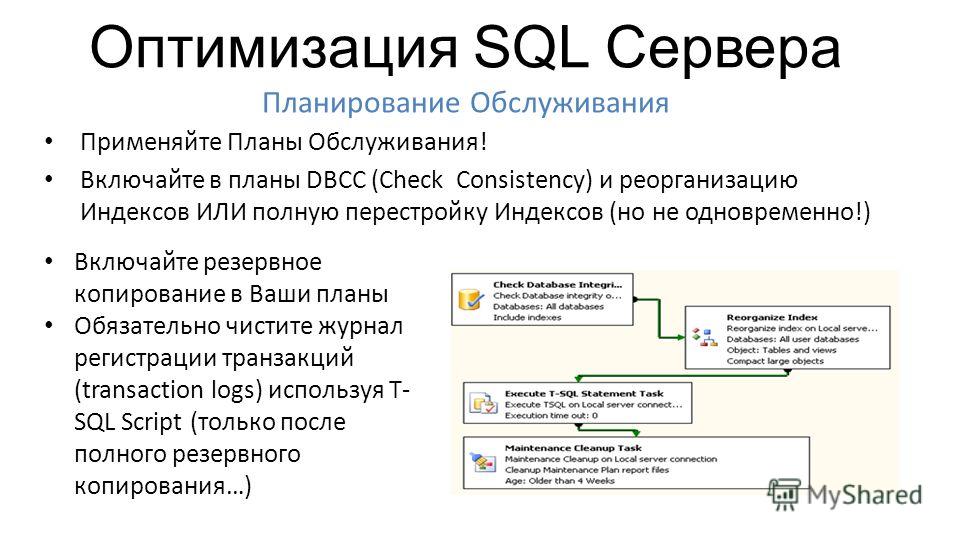
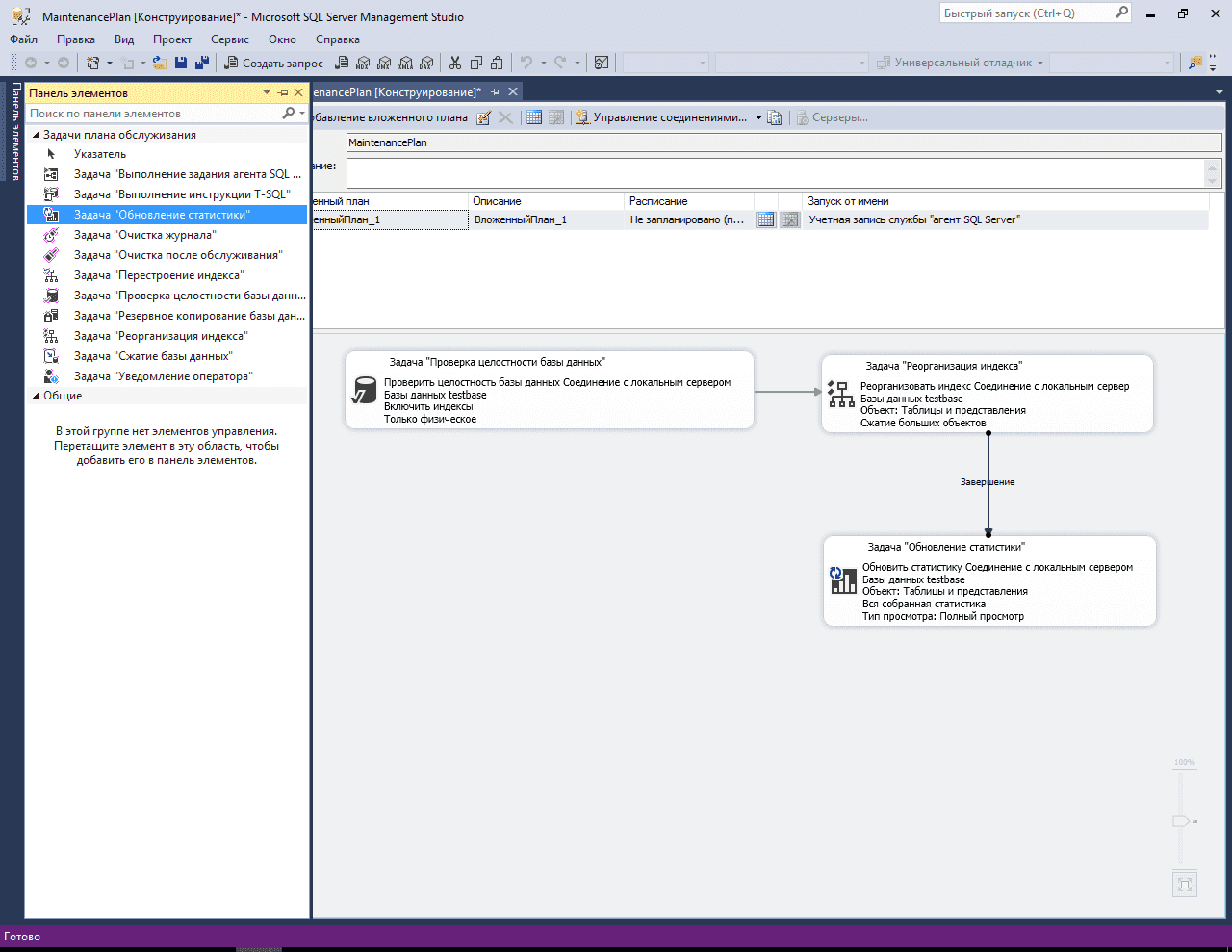
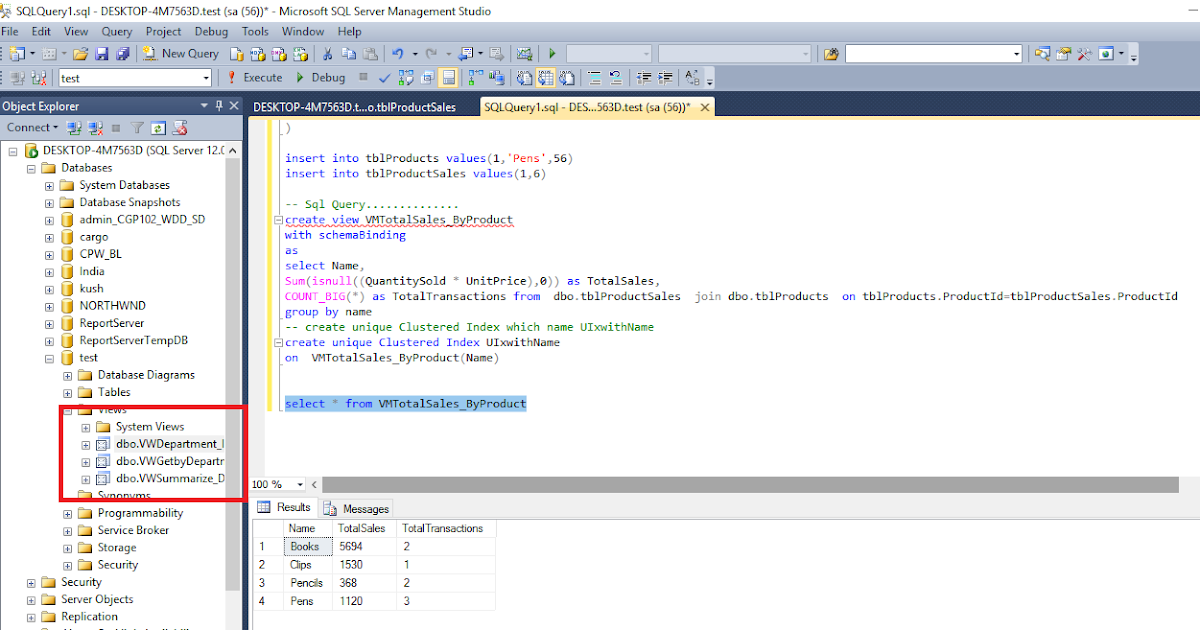
Настройка задания
В ранее созданный нами план обслуживания (статья «Резервное копирование транзакционного лога») добавим еще один субплан «EveryDayActivity» и назначим расписание его выполнения. Поскольку данный план обслуживания должен выполняться ежедневно (а точнее 6 раз в неделю, т.к. в один из дней недели мы будем выполнять другой, «Еженедельный» план), установим выполнение, например, с понедельника по субботу, в период времени когда пользовательская активность минимальна или ее нет (в моем случае 5:00 утра).
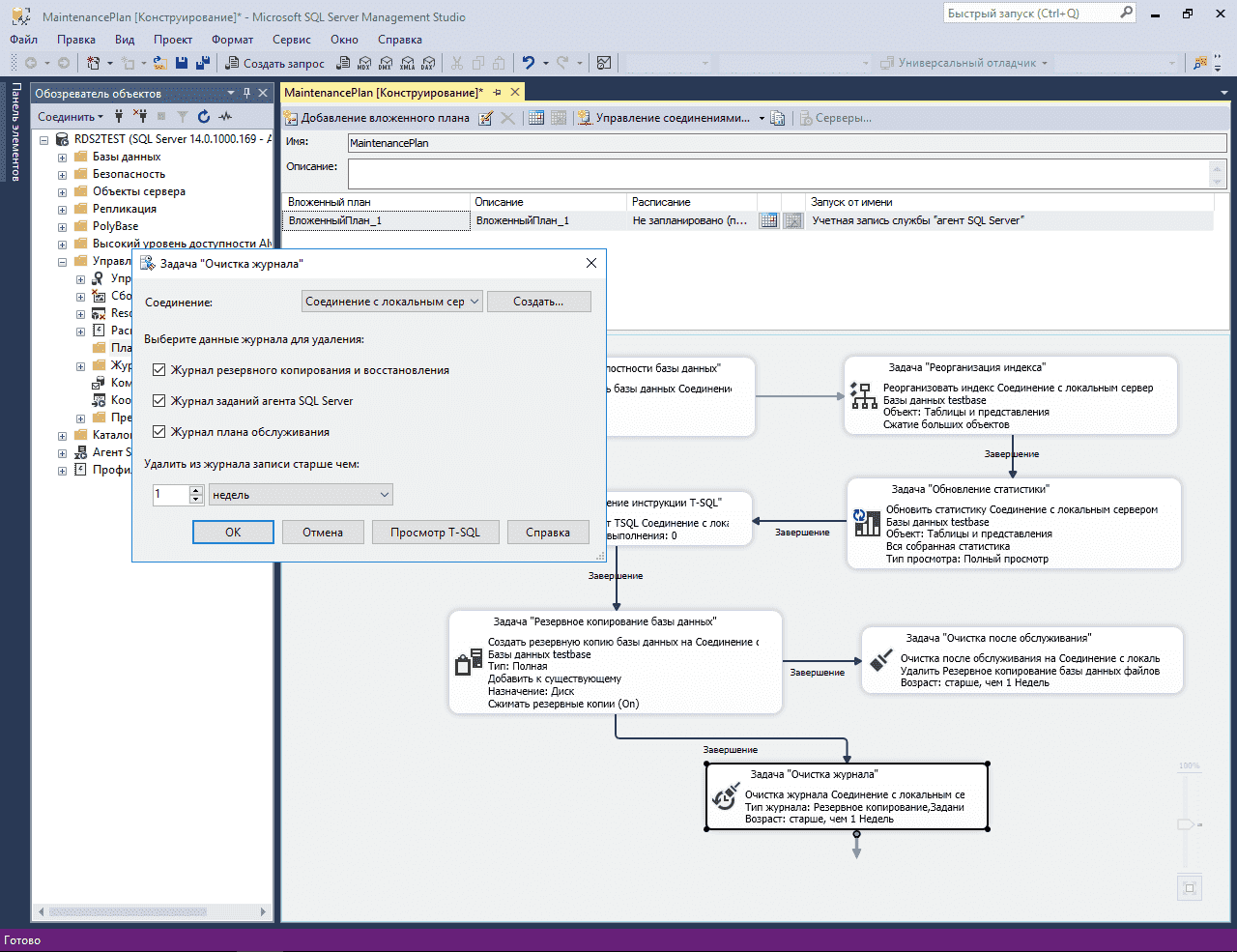

Свойства субплана «EveryDayActivity»Свойства расписания субплана «EveryDayActivity»
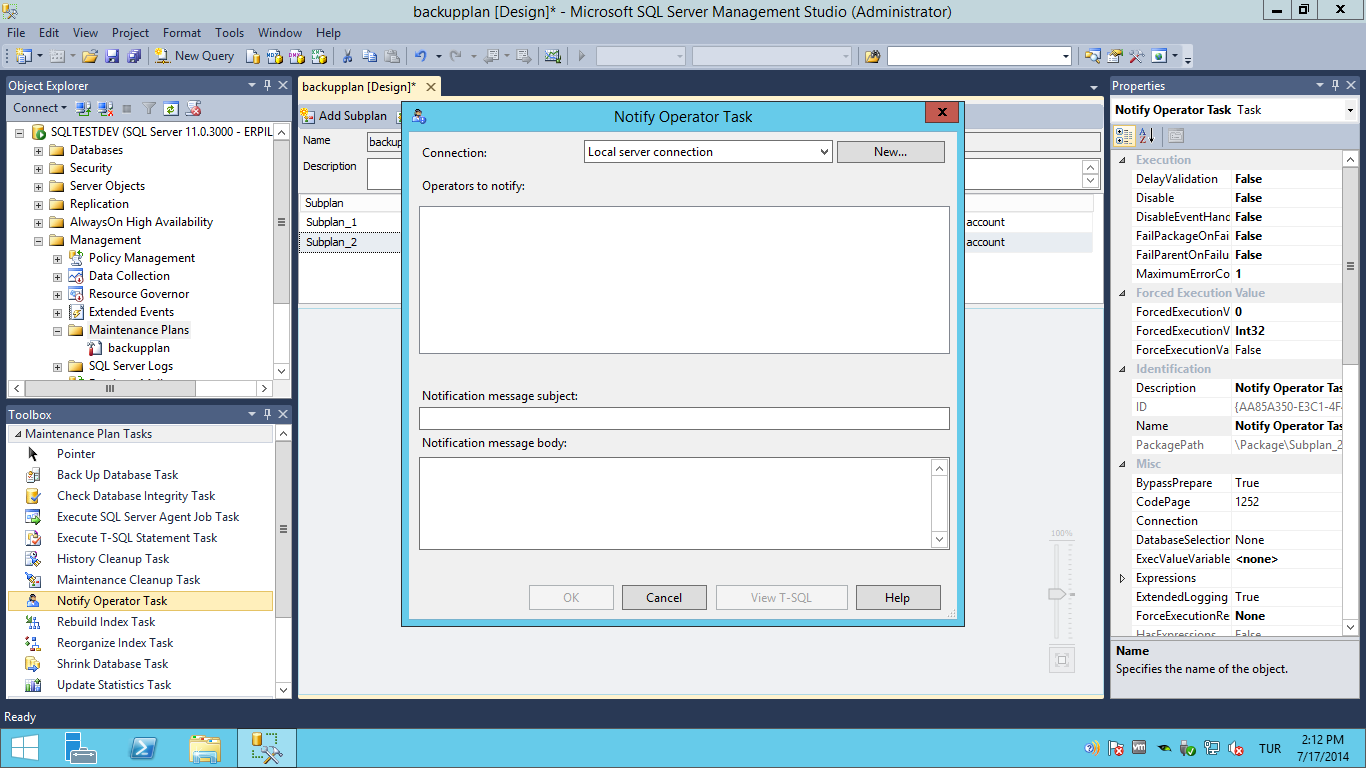
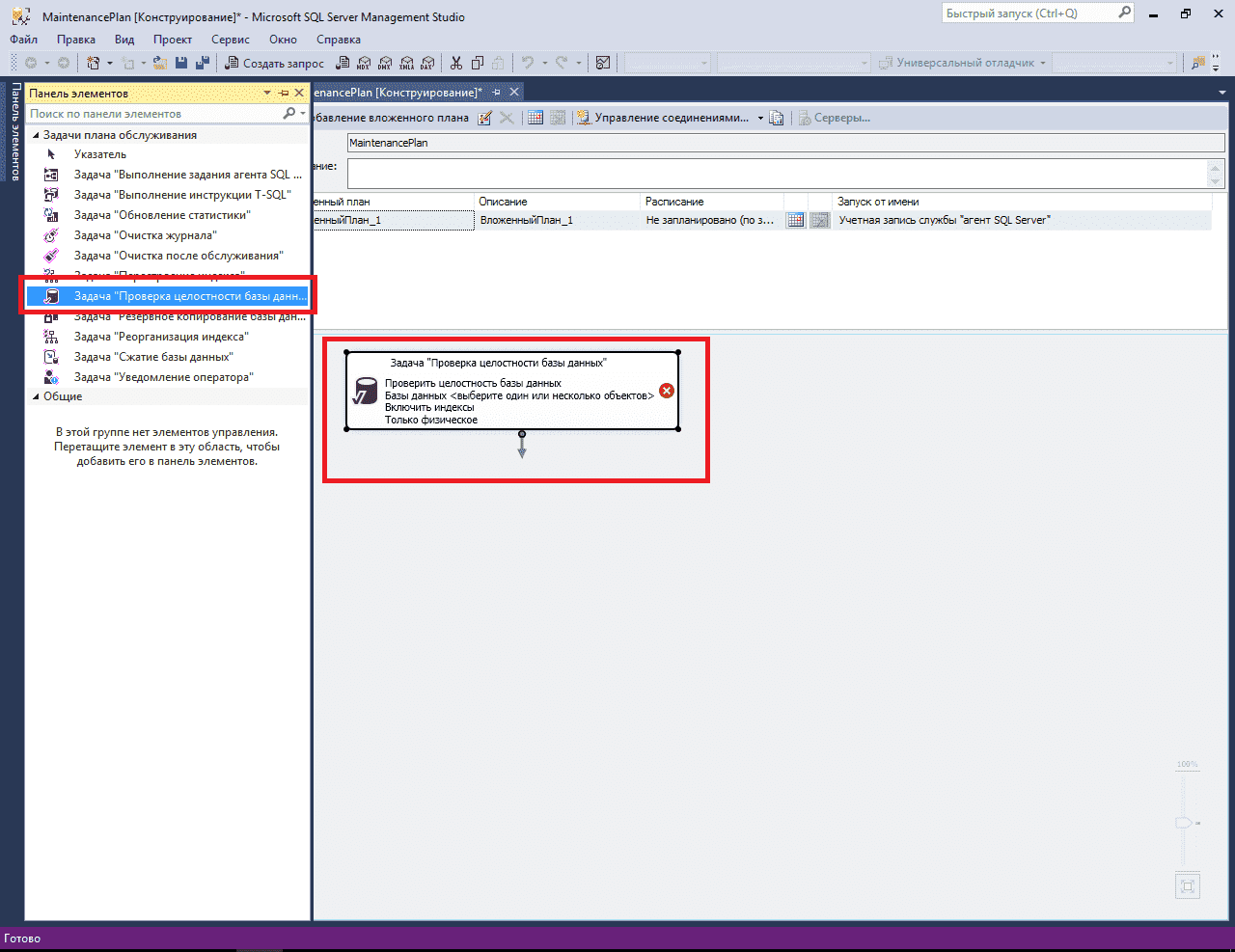
Далее, из панели инструментов Планов обслуживания перенесем задание «Реорганизация индекса» (Reorganize Index Task) в рабочую область субплана (т.е. добавим задание в наш субплан).
Задача «Реорганизация индекса» в панели инструментов плана обслуживания
И, сразу после этого, двойным щелчком по заданию, откроем его свойства.
Данная задача имеет лишь небольшое количество настроек, тем не менее, рассмотрим их:
- «Базы данных» (Databases): в данном свойстве можно выбрать одну/несколько/все базы данных. Здесь выбор зависит от вашего желания, если план обслуживания создается общий для нескольких баз, можно выбрать все необходимые.
- «Объект» (Object): ограничивает набор данных в поле «Выбор» для отображения таблиц, представлений или обоих элементов. Для наших целей подходит значение «Таблица» (Table)
- «Выбор» (Selection): в данном поле можно выбрать конкретные таблицы, индексы которых, необходимо реорганизовать. Такая возможность может быть полезной, например, если есть таблицы с редко изменяемыми данными, а значит и индексы у них фрагментируются медленно, тогда в целях экономии времени на выполнение задания, можно исключить такие таблицы из ежедневного задания, но включить в еженедельное, например.
- «Сжатие больших объектов» (Compact large objects): сжимает большие объекты (LOB), по умолчанию установлено. Смысла отключать не имеет, разве что для сокращения времени выполнения задания.
Свойства задачи «Реорганизация индекса»
Таким образом, сейчас у нас должно быть одно задание в новом субплане:
Субплан «EveryDayActivity»
В следующих статьях будет рассмотрено добавление оставшихся заданий в ежедневный субплан плана обслуживания.
4.1 Корректировка таблиц-справочников
Таблицы-справочники содержат в себе основную информацию аэропорта. В
данном приложении это информация о покупателях, расписание полетов, экипаж
самолета, авиакомпании и марка самолета.
Для просмотра таблиц справочников необходимо выбрать соответвующий пункт
меню справочников (рисунок 4.1).
Рисунок 4.1 — Пункты меню для выбора таблиц-справочников
Каждую таблицу можно открыть (рисунок 4.2).
Рисунок 4.2 — Открытие справочника
Все записи можно изменить или добавить новую (рисунок 4.3).
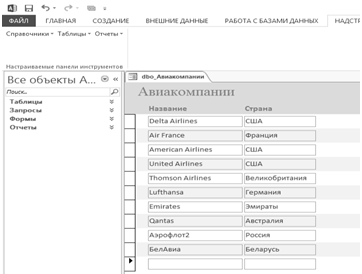
Рисунок 4.3 — Изменение и добавление записи
Помимо этого, запись из таблицы-справочника можно удалить (рисунок 4.5)
при отсутствия связанной записи в дочерней таблице. Перед удалением появится
информационное окно (рисунок 4.4).
Каскадное удаление не предусмотрено в данной БД для предотвращения потери
данных. Удалить запись можно при условии, если на эту запись не ссылаются
другие таблицы.
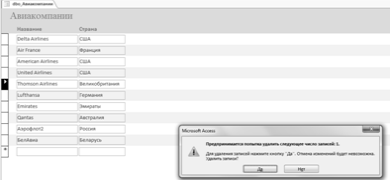
Рисунок 4.4 — Предупреждение об удалении записи
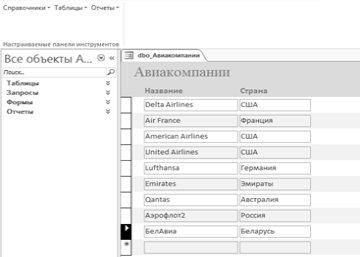
Рисунок 4.5 — Результат удаления записи
Создать индекс в PostgreSQL 9.3.13
В PostgreSQL команда CREATE INDEX создает индекс для указанного столбца (-ов) указанного отношения, который может быть таблицей или материализованным представлением. Индексы в основном используются для повышения производительности базы данных (хотя неправильное использование может привести к снижению производительности).
Синтаксис:
СОЗДАТЬ ИНДЕКС НА имя_таблицы
({column_name | (expression)} )
)]
Создать индекс в Oracle 11g
В Oracle CREATE INDEX оператор используется для создания индекса по:
- Один или несколько столбцов таблицы, многораздельной таблицы, организованной по индексу таблицы или кластера
- Один или несколько скалярных типизированных атрибутов объекта таблицы или кластера
- Таблица хранения вложенной таблицы для индексации столбца вложенной таблицы
Синтаксис:
СОЗДАТЬ INDEX индекс
ON {cluster_index_clause
| table_index_clause
| bitmap_join_index_clause
}
Создание индексов в SQL Server
Теперь посмотрим, как создавать индексы вручную. До этого момента мы использовали индексы, которые сервер создавал автоматически для первичного ключа и уникального поля. Сервер SQL автоматически создает индекс, когда создается ограничение PRIMARY KEY или UNIQUE, но бывает необходимость создать индекс на поле без этих ограничений.
Для создания индекса на произвольное поле используется оператор CREATE INDEX, а для удаления используется DROP INDEX. Вы должны быть владельцем базы данных или администратором, чтобы выполнять эти операторы.
Информация об индексах храниться в системной таблице sysindexes. В главе 2 мы научимся работать с таблицами и просматривать их содержимое. Просто ради интереса попробуйте просмотреть системную таблицу sysindexes. Только не вздумайте ее изменять вручную, системные таблицы можно только просматривать.
Лучше всего, если индекс создается на поле с маленьким типом данных, такой индекс будет более эффективным. Когда вы создаете кластерный индекс, все существующие не кластерные индексы перестраиваются, поэтому желательно в первую очередь создавать кластерный индекс.
В общем виде команда создания индекса выглядит следующим образом:
CREATE INDEX index_name
ON { table | view } ( column )
]
Чтобы удобнее было понять команду, я разбиваю ее на строчки. В первой строке указывается ключевые слова CREATE и INDEX, между которыми можно указать UNIQUE, чтобы индекс был уникальным и CLUSTERED или NONCLUSTERED, чтобы сделать индекс кластерным или не кластерным соответственно. После INDEX указывается имя индекса.
Имя должно быть понятным, должно отображать, что это индекс и желательно, чтобы отражалось имя поля. Я рекомендую использовать для этого формат: «I_CL_Имя». Первая буква I, указывает на то, что это индекс. Затем я ставлю CL или UCL, что будет показывать кластерный или не кластерный индекс. И в самом конце перечисляются имена полей, которые индексируются. В данном случае только одно поле «vcName».
Во вторую строку я пишу ключевое слово ON, за которым идет имя таблицы и в скобках имена индексируемых полей.
Следующий пример создает кластерный индекс на колонку vcName:
CREATE CLUSTERED INDEX I_CL_vcName ON TestTable(vcName)
После имени колонки нужно указать направление сортировки индекса. Направление задается ключевыми словами ASC (возрастание) или DESC (убывание). Следующий пример создает не кластерный индекс по убыванию:
CREATE NONCLUSTERED INDEX I_CL_vcName ON TestTable(vcName DESC)
Теперь поговорим о удалении индексов. Можно удалять только созданные вами индексы. Для этого используется оператор DROP INDEX. Вы не можете использовать этот оператор для удаления индекса, который был автоматически создан на ограничения PRIMARY KEY или UNIQUE. Вы должны удалить ограничение, прежде чем удалять индекс. Нельзя удалять индексы системных таблиц.
Если удалить кластерный индекс, то все не кластерные индексы будут автоматически перестроены.
В общем виде команда удаления индекса выглядит следующим образом:
DROP INDEX 'table.index | view.index'
В следующем примере удаляется созданный нами ранее индекс:
DROP INDEX TestTable.I_CL_vcName
Ранее мы уже создавали индекс уникальности, но делали мы это только на этапе создания таблицы. Если она уже существует, то индекс уникальности можно добавить с помощью оператора CREATE UNIQUE INDEX.
Уникальный индекс гарантирует, что все данные в колонке с таким индексом – уникальны, и не содержат повторяющихся значений. Сервер SQL автоматически создает индекс, когда создается ограничение PRIMARY KEY или UNIQUE.
Сервер SQL проверяет дубликаты каждый раз, когда вы выполняете операторы INSERT или UPDATE. Если дубликат существует, то сервер отклоняет ваши операторы и возвращает сообщение об ошибке.
Если повторяющиеся значения существуют, когда вы создаете уникальный индекс, операция CREATE INDEX отклоняется. Сервер возвращает сообщение об ошибке с первым дубликатом, но могут существовать и еще дубликаты. Используйте следующий простой сценарий для любых таблиц, чтобы найти дублирующие значения в колонке.
SELECT индексная колонка, COUNT(индексная колонка) FROM имя таблицы GROUP BY индексная колонка HAVING COUNT (индексная колонка)>1 ORDER BY индексная колонка
Снова мы забегаем вперед, потому что запросы SELECT это тема следующей главы. Если вы не работали с SQL, то этот запрос еще не понятен для вас, но вернитесь к нему после прочтения второй главы, и все встанет на свои места.
Что такое индексы в базе данных?
Индекс
— это объект базы данных, который представляет собой структуру данных, состоящую из ключей, построенных на основе одного или нескольких столбцов таблицы или представления, и указателей, которые сопоставляются с местом хранения заданных данных. Индексы предназначены для более быстрого получения строк из таблицы, другими словами, индексы обеспечивают быстрый поиск данных в таблице, что значительно повышает производительность запросов и приложений. Индексы также могут быть использованы и для обеспечения уникальности строк таблицы, гарантируя тем самым целостность данных.
Sort
Сортировка является одной из наиболее дорогих операций, которые могут быть в плане выполнения, поэтому лучше избегать ее, насколько это возможно.
Простой способ избежать оператора сортировки – иметь данные, хранящиеся в предварительно упорядоченном виде. Это может быть выполнено созданием индекса с ключевыми столбцами, перечисленными в том же самом порядке, который использует оператор сортировки.
Если SQL Server должен выполнить сортировку одних и тех же данных в одном и том же порядке несколько раз в плане выполнения, то еще одним выходом является разбиение запроса на несколько этапов при использовании временных индексированных таблиц для сохранения данных между этапами. В таком случае, если вы будете повторно использовать временную таблицу в плане выполнения вашего запроса, то вы получите чистую экономию.
Почему данные сортируются по любому реквизиту?
Сразу скажу, что не по всем реквизитам можно сортировать, например, нельзя сортировать по реквизиту с типом “ХранилищеЗначений”. Если реквизит примитивного типа, то достаточно установить для свойства реквизита «Индексировать» значение «Индексировать» или «Индексировать с доп. упорядочиванием». А для реквизитов ссылочного типа, необходимо явно разрешить доступность сортировки программно. Например:
ЭлементыФормы.СправочникСписок.НастройкаПорядка.Контрагент.Доступность = истина;
или для всех реквизитов
Для каждого ТекЭлем из ЭлементыФормы.СправочникСписок.НастройкаПорядка Цикл ТекЭлем.Доступность = Истина;КонецЦикла;
причем в последнем случае сортировка будет даже у реквизитов со свойством “Индексировать” – “Не индексировать”
Недостаточно прав для комментирования
Составные индексы
Составные индексы используют более одной колонки в качестве ключевого значения. Создавайте составные индексы, когда две или более полей чаще всего используются для поиска в качестве ключа и если запрос ссылается только на все поля в составном индексе. Если запрос будет использовать не все поля, то индекс, скорей всего использоваться не будет.
Для примера, телефонный справочник является хорошим примером. Справочник организован по фамилии. Вместе с фамилией для поиска регулярно используется имя, потому что часто существует много записей для одной фамилии с разными именами и вполне логично создать индекс из фамилии и имени одновремнно.
Вы можете объединять до 16 колонок в составной индекс. Сумма длины всех колонок составного индекса должна быть менее 900 байт. При этом, все поля должны быть из одной таблицы.
Объявляйте сначала уникальные колонки. Первые колонки, описанные в операторе CREATE INDEX, имеют высший приоритет при сортировке. При поиске данных в таблице, ваш запрос должен будет обязательно ссылаться на первую колонку индекса, иначе индекс точно использоваться не будет.
Индекс на поля «Фамилия» и «Имя» это не то же самое, что индекс на поля «Фамилия» и «Имя». Эти индексы имеют разный порядок полей. Например, для первого случая сортировка будет следующей:
Фамилия Имя ----------------------------------------- Иванов Андрей Иванов Сергей Петров Андрей Петров Василий
Те же самые поля, но с индексом «Имя» и «Фамилия» будут отсортированы следующим образом:
Фамилия Имя ----------------------------------------- Иванов Андрей Петров Андрей Петров Василий Иванов Сергей
В данном случае главным является имя, и именно оно сортируется первым.
Составной индекс позволяет повысить производительность запросов и уменьшить количество индексов на таблицу. Производительность повышается за счет того, что сервер для поиска необходимых данных сканирует только один индекс.
Следующий пример создает не кластерный составной индекс для таблицы телефонного справочника
Обратите внимание, что поле «Фамилия» описывается первой, потому что она чаще всего является основой при выборке данных из таблицы:
CREATE UNIQUE NONCLUSTERED INDEX I_NCL_Фамилия_Имя ON (Фамилия, Имя)
Так как индекс уникальный, в таблицу нельзя будет записать двух людей с фамилией и именем Иванов Андрей.
Сервер SQL предлагает опции, которые могут ускорить создание индекса, а также увеличить производительность индексов.
Руководство по созданию индексов
Хотя хорошо известно, что индексы повышают производительность базы данных,следует знать, как их заставить работать должным образом. Добавление ненужных или неподходящих индексов к таблице может даже привести к снижению производительности. Ниже предоставлены некоторые рекомендации по созданию эффективных индексов в базе данных Oracle.
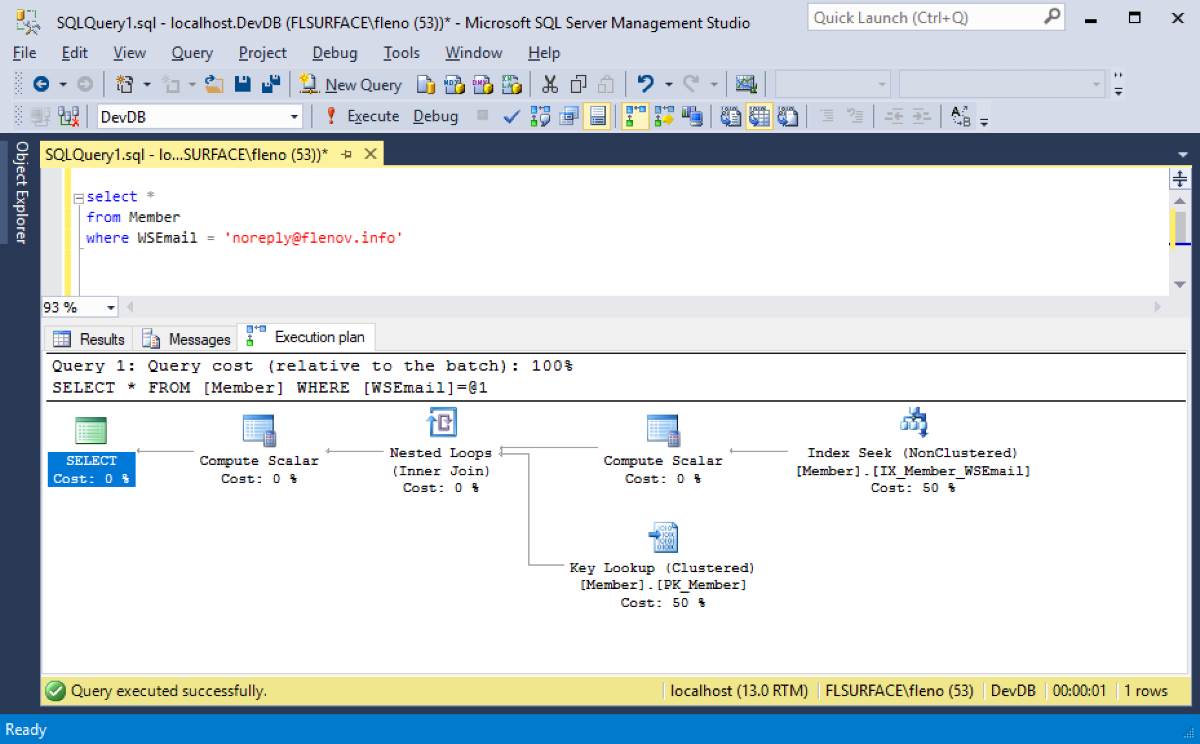
- Индексация имеет смысл, если нужно обеспечить доступ одновременно не более чем к 4–5% данных таблицы. Альтернативой использованию индекса для доступа к данным строки является полное последовательное чтение таблицы от начала до конца, что называется полным сканированием таблицы. Полное сканирование таблицы больше подходит для запросов, которые требуют извлечения большего процента данных таблицы. Помните, что применение индексов для извлечения строк требует двух операций чтения: индекса и затем таблицы.
- Избегайте создания индексов для сравнительно небольших таблиц. Для таких таблиц больше подходит полное сканирование. В случае маленьких таблиц нет необходимости в хранении данных и таблиц, и индексов.
- Создавайте первичные ключи для всех таблиц. При назначении столбца в качестве первичного ключа Oracle автоматически создает индекс по этому столбцу.
- Индексируйте столбцы, участвующие в многотабличных операциях соединения.
- Индексируйте столбцы, которые часто используются в конструкциях WHERE.
- Индексируйте столбцы, участвующие в операциях ORDER BY и GROUP BY или других операциях, таких как UNION и DISTINCT, включающих сортировку. Поскольку индексы уже отсортированы, объем работы по выполнению необходимой сортировки данных для упомянутых операций будет существенно сокращен.
- Столбцы, состоящие из длинно-символьных строк, обычно плохие кандидаты на индексацию.
- Столбцы, которые часто обновляются, в идеале не должны быть индексированы из-за связанных с этим накладных расходов.
- Индексируйте таблицы только с высокой селективностью. То есть индексируйте таблицы, в которых мало строк имеют одинаковые значения.
- Сохраняйте количество индексов небольшим.
- Составные индексы могут понадобиться там, где одностолбцовые значения сами по себе не уникальны. В составных индексах первым столбцом ключа должен быть столбец с максимальной селективностью.
Всегда помните золотое правило индексации таблиц: индекс таблицы должен быть основан на типах запросов, которые будут выполняться над столбцами этой таблицы. На таблице можно создавать более одного индекса; например, можно создать индекс на столбце X, или столбце Y, или обоих сразу, а также один составной индекс на обоих столбцах. Принимая правильное решение относительно того, какие индексы следует создавать, подумайте о наиболее часто используемых типах запросов данных таблицы.
Решение
Таблицы кучи в SQL Server
Базовый синтаксис кучи в SQL Server
CREATE TABLE TestData (TestId integer, TestName varchar(255), TestDate date,
TestType integer, TestData1 integer,
TestData2 varchar(100), TestData3 XML,
TestData4 varbinary(max), TestData4_FileType varchar(3));
ALTER TABLE TestData REBUILD;
DROP TABLE TestData;
Кластеризованный индекс в SQL Server
Основной синтаксис кластеризованного индекса в SQL Server
CREATE CLUSTERED INDEX IX_TestData_TestId ON dbo.TestData (TestId); ALTER INDEX IX_TestData_TestId ON TestData REBUILD WITH (ONLINE = ON); DROP INDEX IX_TestData_TestId on TestData WITH (ONLINE = ON);
Некластеризованный индекс в SQL Server
Основной синтаксис некластеризованного индекса в SQL Server
CREATE INDEX IX_TestData_TestDate ON dbo.TestData (TestDate); ALTER INDEX IX_TestData_TestDate ON TestData REBUILD WITH (ONLINE = ON); DROP INDEX IX_TestData_TestDate on TestData;
Индексы поколоночного хранения в SQL Server
Основной синтаксис поколоночных индексов в SQL Server
CREATE CLUSTERED COLUMNSTORE INDEX CIX_TestData_TestType ON TestData.TestType WITH (DATA_COMPRESSION = COLUMNSTORE); ALTER INDEX CIX_TestData_TestType ON TestData REORG IX_TestData_TestDate; DROP INDEX CIX_TestData_TestType;
XML индексы в SQL Server
Основной синтаксис индекса XML в SQL Server
-- первичный индекс CREATE PRIMARY XML INDEX PXML_TestData_TestData3 ON TestData (TestData3); -- вторичные индексы CREATE XML INDEX XMLPATH_TestData_TestData3 ON TestData (TestData3) USING XML INDEX PXML_TestData_TestData3 FOR PATH; CREATE XML INDEX XMLPROPERTY_TestData_TestData3 ON TestData (TestData3) USING XML INDEX PXML_TestData_TestData3 FOR PROPERTY; CREATE XML INDEX XMLVALUE_TestData_TestData3 ON TestData (TestData3) USING XML INDEX PXML_TestData_TestData3 FOR VALUE;
Полнотекстовые индексы в SQL Server
Основной синтаксис полнотекстового индекса в SQL Server
-- перед созданием индекса требуется создать каталог CREATE FULLTEXT CATALOG fulltextCatalog AS DEFAULT; CREATE FULLTEXT INDEX ON dbo.TestData (TestData4 TYPE COLUMN TestData4_FileType) KEY INDEX PK_TestData WITH STOPLIST = SYSTEM; ALTER FULLTEXT CATALOG fulltextCatalog REBUILD; DROP FULLTEXT INDEX ON dbo.TestData;
Вариации индексов в SQL Server
Индекс на базе функций SQL Server (вычисляемые столбцы)
ALTER TABLE TestData ADD TestDatePlus7Days AS DATEADD(DAY,7,TestDate) PERSISTED; CREATE NONCLUSTERED INDEX IX_TestData_TestDate_Plus7Days ON TestData (TestDatePlus7Days);
Покрывающий индекс SQL Server
CREATE INDEX IX_TestData_TestDate_TestType_AllData on TestData (TestDate,TestType) INCLUDE (TestData1,TestData2,TestData3,TestData4); SELECT TestData1,TestData2,TestData3,TestData4 FROM TestData WHERE TestDate > current_timestamp-1 and TestType=1;
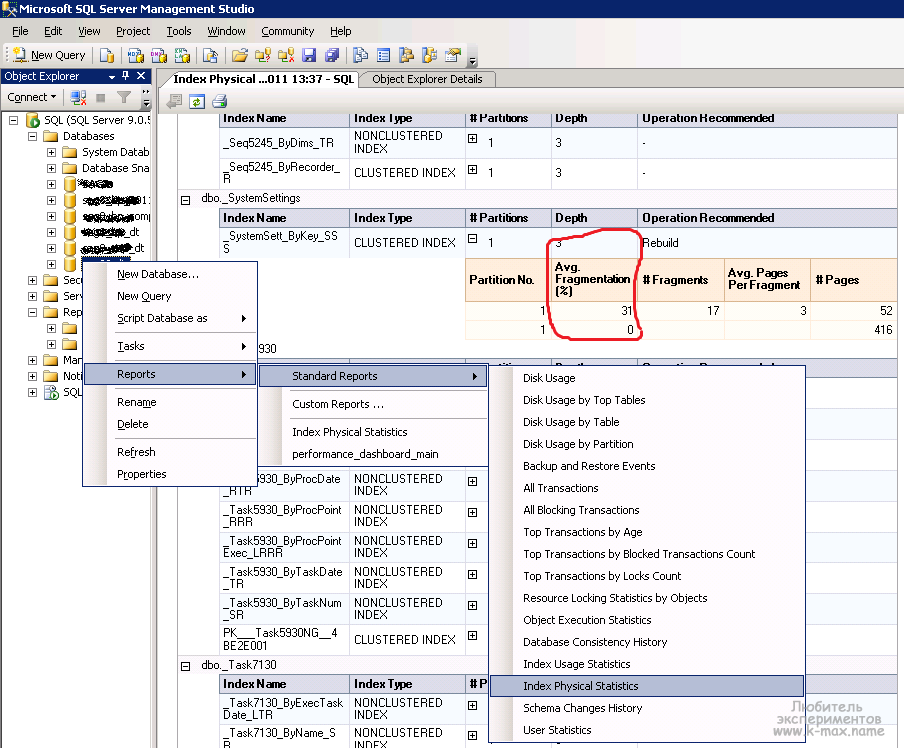
Обслуживание индексов в SQL Server
SELECT t.name AS TableName,i.name AS IndexName,
ROUND(avg_fragmentation_in_percent,2) AS avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ips
INNER JOIN sys.tables t on t. = ips.
INNER JOIN sys.indexes i ON (ips.object_id = i.object_id) AND (ips.index_id = i.index_id)
ORDER BY avg_fragmentation_in_percent DESC;
| REBUILD | REORG |
|---|---|
| требуется достаточно пространства для создания нового индекса | работает на месте, поэтому никакого дополнительного пространства не требуется |
| если процесс прерывается, требуется начинать заново | может продолжиться с того места, на котором процесс прервался |
| может выполняться онлайн или офлайн | всегда выполняется онлайн |
| генерирует больше записей в журнал, чем reorg | записывает в журнал только блоки, которые были реорганизованы |
| статистика обновляется автоматически | обновление статистики должно быть выполнено вручную |
5.2 Использование хранимых процедур
Таблица 5.2 — Хранимые процедуры
|
Название |
Назначение |
Где используется |
|
1 ИнфоПокупатель |
Поиск покупателя по ФИО |
Для отчета информации о покупателе |
Ниже приведен текст SQL,
создающий процедуры:
/*процедура для отображения информации о покупателе*/proc
ИнфоПокупательprocedure ИнфоПокупатель @ФИО varchar(40)ФИО,
ДатаРождения,
Цена,
Место,
ВесПокупатель,Билет,БагажПокупатель.КодПокупателя=Билет.КодПокупателяБилет.КодБилета=Багаж.КодБилетаФИО=@ФИО
Заключение
В результате было разработано база данных управлением аэропорта.
Приложение создано в среде MS Acces 2013 и MS SQL SERVER 2008.
В ходе выполнения создания приложения были выполнены следующие действия:
— База данных приведена к третьей нормальной форме;
— Разработаны процедуры, представления для выполнения действий
на сервере, чтобы снизить нагрузку на пользовательский компьютер;
— Сделан интуитивно понятливый интерфейс;
— Созданы печатные отчеты.
Данную базу данных можно легко изменять для выполнения самых разнообразных
задач.
Список
использованных источников
1 Винкоп, С. Использование Microsoft SQL Server 7.0 : специальное издание / С. Винкоп. — СПб. :
Издательский дом «Вильямс», 2001. — 816 с.
Хоторн, Р. Разработка баз данных Microsoft SQL Server 2000 на
примерах / Р. Хоторн. — М. : Бином, 2001. — 464 с.
Змитрович, А.И. Базы данных : учебное пособие для вузов /
А.И. Змитрович. — Мн. : Университетское, 1991. — 271 с.
Риордан, Р. Программирование в Microsoft SQL Server 2000. Шаг
за шагом / Р. Риордан. — М. : Эком, 2002. — 608 с.
Кренке, Д. Теория и практика построения баз данных / Д.
Кренке. — 8-е изд. — СПб. : Питер, 2003. — 800 с.