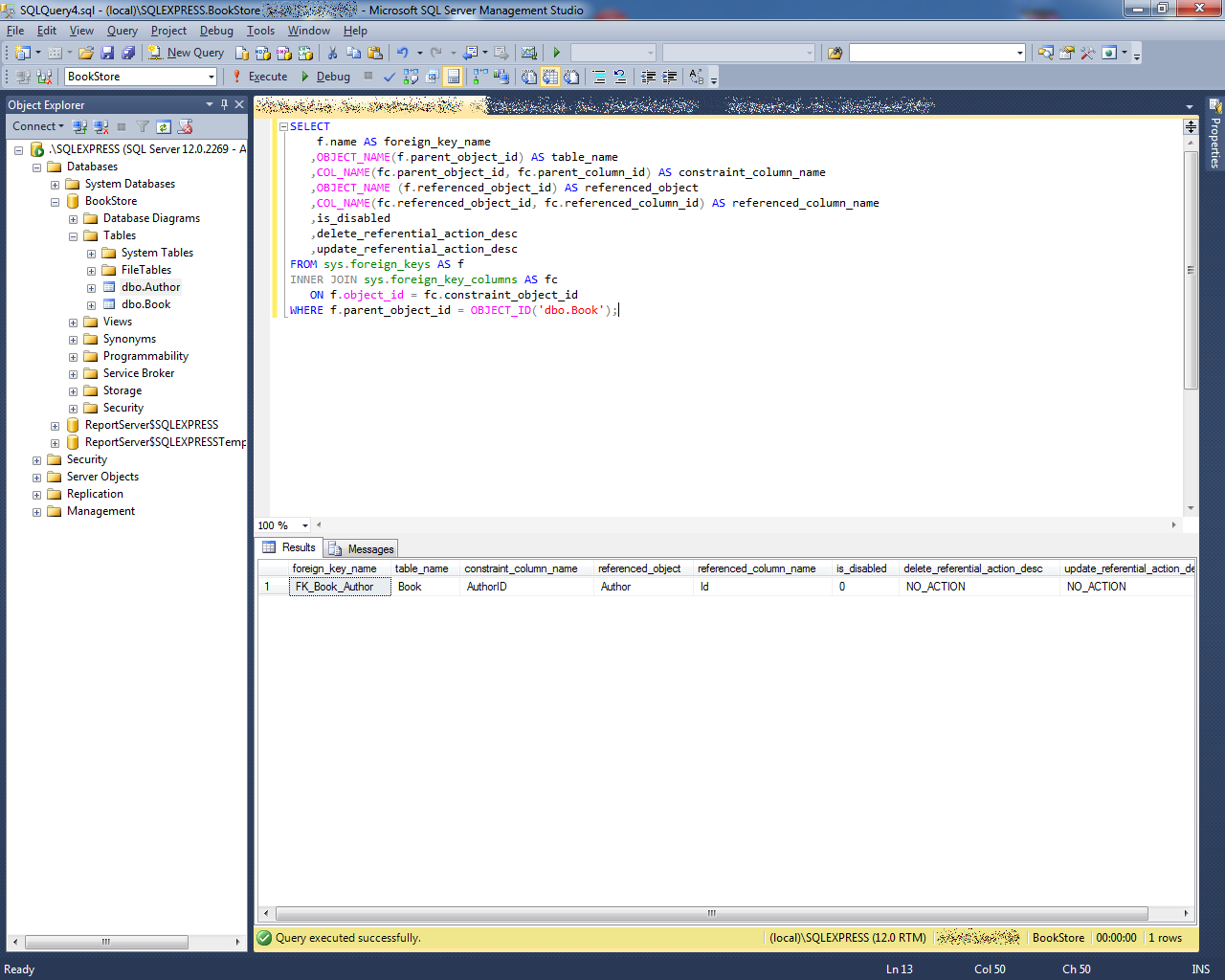
1НФ – первая нормальная форма
Первая нормальная форма (1НФ) выполняется, если все значения атрибутов (читай, колонок таблицы) атомарны, то есть неделимы.
Собственные типы данных СУБД считаются атомарными, исключение могут составлять массивы, в том числе символьные (текстовые) и байтовые. Следует также понимать, что атомарность может быть относительна выбранного взгляда со стороны предметной области и контекста. Например, телефонный номер в базе данных маркетинга содержится в одной колонке, тогда как у телефонных операторов он разделяется на номера АТС, шлейфов и т.п. Колонки для хранения комментариев, подлежащих последующей обработке приложением, также отчасти нарушают принцип атомарности.
По этой же причине не стоит рассматривать отдельно целую и дробные части действительного числа или даже пару «дата-время»: дальнейшая детализация не имеет смысла с точки зрения моделируемой области, где они атомарны.
Предположим, мы нарушили 1НФ и стали хранить фамилии, имена и отчества клиентов в одной колонке. Пока операторы вносили информацию, эта ошибка проектирования особенно не мешала, Однако, на следующем этапе понадобилась отчётность, в которой ФИО клиентов выводились бы в виде фамилии и инициалов. Оказалось, что некоторые записи вместо «Сидоров Петр Иванович» содержат «Петр Иванович Сидоров», в других отчества нет вовсе, в третьих фамилия двойная и не всегда записана через тире, в четвёртых после фамилий расставлены запятые. Эту проблему пришлось решать программированием совсем нетривиальной логики с элементами распознавания по словарю. Было потрачено много времени и средств, но в отчётности нет-нет да и проскакивали непонятные значения типа «Оглы П.Б.Б.».
Следует отметить, что при добавлении к этому учёту клиентов- иностранцев, проектировщиков логической схемы БД не спасла бы и более структурированная форма из трёх колонок для раздельного хранения фамилий, имён и отчеств. Потому что это проблема уровня концептуального проектирования и соответствующих моделей: необходим синтез не привязанной к модели данных структуры, способной вмещать в себя комбинации имён людей разных стран и культур.
Описание нормализации
Нормализация — это процесс организации данных в базе данных, включающий создание таблиц и установление отношений между ними в соответствии с правилами, которые обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и несогласованные зависимости.
Избыточность данных приводит к непродуктивному расходованию свободного места на диске и затрудняет обслуживание баз данных. Например, если данные, хранящиеся в нескольких местах, потребуется изменить, в них придется внести одни и те же изменения во всех этих местах. Изменение адреса клиента гораздо легче реализовать, если в базе данных эти сведения хранятся только в таблице Customers и нигде больше.
Что такое «несогласованные зависимости»? Пользователь, которому нужно узнать, например, адрес определенного клиента, вполне обоснованно будет искать его в таблице Customers (клиенты), но искать в ней сведения о зарплате сотрудника, который работает с этим клиентом, не имеет смысла. Зарплата сотрудника связана с сотрудником (зависит от него), поэтому эти сведения следует хранить в таблице Employees (сотрудники). Несогласованные зависимости могут затруднять доступ к данным, так как путь к данным при этом может отсутствовать или быть неправильным.
Существует несколько правил нормализации баз данных. Каждое правило называется обычной формой. Если наблюдается первое правило, база данных считается в «первой обычной форме». Если выполняются первые три правила, база данных считается в третьей обычной форме. Хотя возможны и другие уровни нормализации, третья обычная форма считается наивысшим уровнем, необходимым для большинства приложений.
Как и в случае со многими другими формальными правилами и спецификациями, обеспечить полное соответствие реальным ситуациям не всегда возможно. Как правило, для выполнения нормализации приходится создавать дополнительные таблицы, и некоторые клиенты считают это нежелательным. Собираясь нарушить одно из первых трех правил нормализации, убедитесь в том, что в приложении учтены все связанные с этим проблемы, такие как избыточность данных и несогласованные зависимости.
В описаниях ниже приведены соответствующие примеры.
Нормализация базы данных и ее формы
Примечание: Во всех статьях текущей категории уроков по SQL используются примеры и задачи, основанные на учебной базе данных.
Приступая к изучению данного материала, рекомендуется ознакомиться с описанием учебной БД.
Материал этой статьи напрямую не относиться к изучению языка SQL, так как имеет отношение к проектированию баз данных (БД), но для общего понимания взаимосвязи хранимой в системе информации она будет полезна.
По поводу того, как должна быть спроектирована база нет 100% решения, потому что конкретный вариант может удовлетворять либо не удовлетворять различным бизнес-процессам и целям
Но не принимать во внимание элементарные правила нельзя, так как их соблюдение сохранит много времени, нервов и денег при работе с данными
Нормализация баз данных заключается в приведении структуры хранения данных к нормальным формам (NF). Всего таких форм существует 8, но часто достаточным является соблюдение первых трех. Рассмотрим их более подробно на примере учебной базы данных. Примеры будут строится по принципу «что было бы, если было иначе, чем сейчас».
Первая нормальная форма
Основным правилом первой формы является необходимость неделимости значения в каждом поле (столбце) строки – атомарность значений.
Рассмотрим таблицы сотрудников и телефонных линий.
Чтобы избавиться от связывающей таблицы «Сотрудники_Линии», мы могли бы записать идентификаторы сотрудников для каждой линии в виде перечня в дополнительном столбце:
Но подобная структура не является надежной. Представьте, что Вам необходимо поменять некоторым сотрудникам подключенные линии. Потребуется осуществить разбор составного поля, чтобы определить наличие id сотрудника в каждой записи линий, затем скорректировать перечень. Получается слишком сложный и долгий процесс для такой простой операции.
Организации структуры таблиц с применением дополнительной связывающей избавляет от подобных проблем.
Помимо атомарности к первой нормальной форме относятся следующие правила:
- Строки таблиц не должны зависеть друг от друга, т.е. первая запись не должна влиять на вторую и наоборот, вторая на третью и т.д. Размещение записей в таблице не имеет никакого значения.
- Аналогичная ситуация со столбцами записей. Их порядок не должен влиять на понимание информации.
- Каждая строка должна быть уникальна, поэтому для нее определяется первичный ключ, состоящий из одного либо нескольких полей (составной ключ). Первичный ключ не может повторяться в пределах таблицы и служит идентификатором записи.
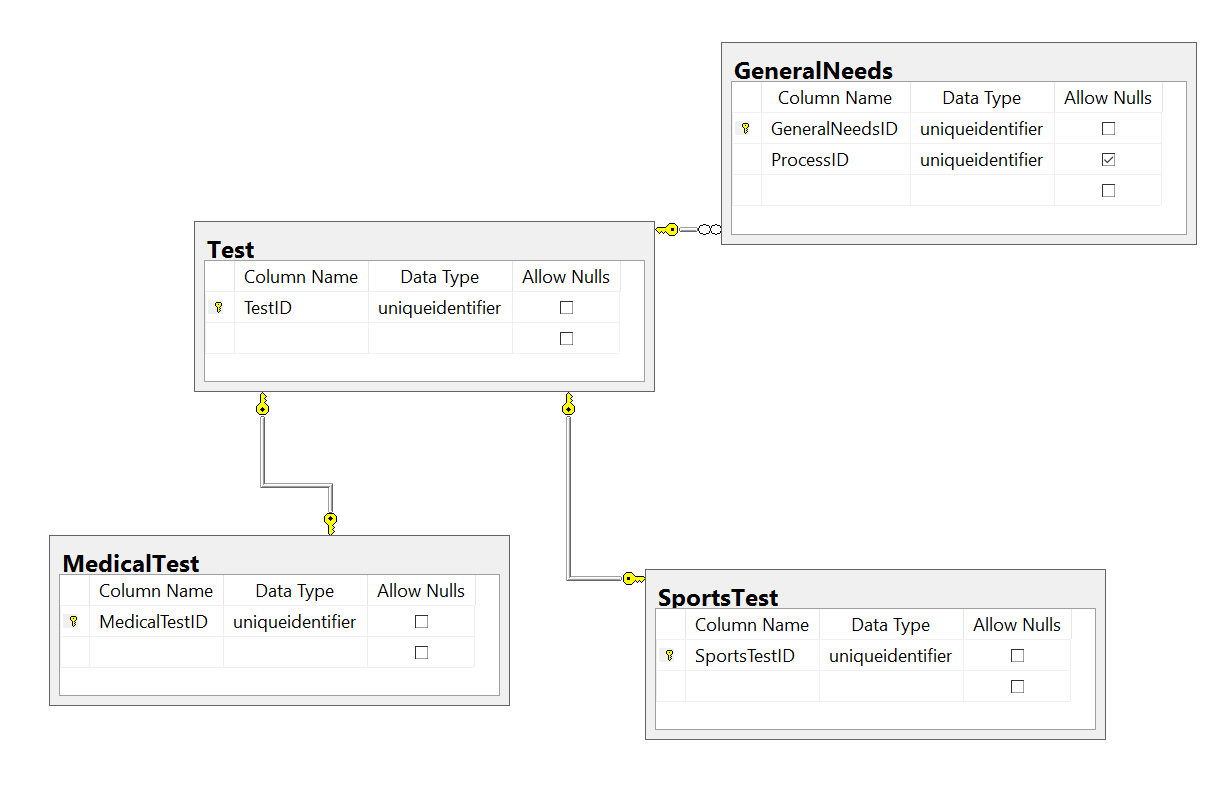
Вторая нормальная форма
Условием этой формы является отсутствие зависимости неключевых полей от части составного ключа.
Так как составной ключ в учебной базе наблюдается только в таблице «Сотрудники_Линии», то рассмотрим пример на ней.
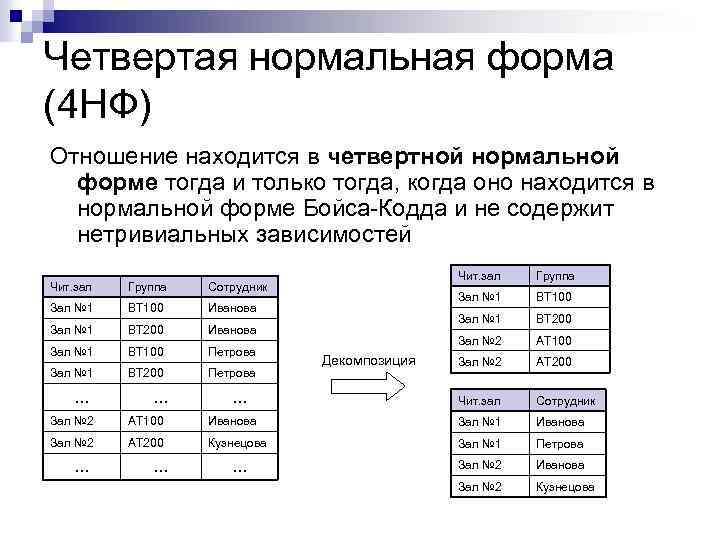
На представленной диаграмме столбцы описания и приоритета зависят от столбца «Линия», входящего в составной ключ. Это значит, что для каждой линии, подключенной разным сотрудникам, потребуется повторно указывать описание и приоритетность. Подобная структура приводит к избыточности данных.






Также велика вероятность возникновения противоречивой информации. Изменяя приоритет или описание для линии, можно по ошибке оставить некоторые строки не обработанными. В таком случае, для одного и того же идентификатора линии значения зависимых полей будут различными.
Если соблюдены правила первой нормальной формы, то создание таблицы «Линии» и перенос в нее зависимых столбцов удовлетворяет второй нормальной форме.
Третья нормальная форма
3NF схожа по логике с 2NF, но с некоторым отличием. Если 2 форма ликвидирует зависимости неключевых полей от части ключа, то третья нормальная форма исключает зависимость неключевых полей от других неключевых полей.
На приведенном примере таблицы сотрудников видно, что столбец «Супервайзер» имеет зависимость от столбца «Группа», а это значит, что при изменении значения поля группы, потребуется изменить значение поля супервайзера.
Все риски, которые были рассмотрены для 2NF, так же относятся к 3NF и устраняются переносом зависимых полей в отдельную таблицу.
Денормализация базы данных
Теория нормальных форм не всегда применима на практике. Например, неатомарные значения не всегда являются «злом», а иногда наоборот. Связано это с необходимостью дополнительного объединения (следовательно, затрат производительности системы) при выполнении запросов, особенно когда производится обработка большого массива информации.
Для баз данных, предназначенных для аналитики, часто выполняют денормализацию, чтобы укорить выполнение запросов.
Нарушения правил нормализации
Убедившись, что база данных в 3НФ поможет гарантировать надёжность и жизнеспособность, не нужно полностью нормализовывать все базу, с которыми вы работаете. Перед тем, как использовать эти методы, имейте ввиду, что это может иметь долгосрочные разрушающие последствия.
Две основных причины, чтобы нарушить правила нормализации — удобство и быстродействие. Меньшим число таблиц проще управлять, чем большим. Кроме того, из-за более сложного характера, нормализованные таблицы более медленные для обновления, изменения и выдачи данных. Вкратце, нормализация это сделка между целостностью/расширяемостью и простотой/скоростью. С другой стороны, есть достаточно способов чтобы улучшить производительность базы данных, но не так много способов чтобы исправить повреждённые данные, возникшие из-за плохого дизайна структуры.
Практика и опыт подскажут, как сделать модель базы данных, но лучше совершайте ошибки пробуя нормальные формы, хотя бы до тех пор, пока не поймете принцип.
Вторая нормальная форма
- Создайте отдельные таблицы для наборов значений, относящихся к нескольким записям.
- Свяжите эти таблицы с помощью внешнего ключа.
Записи могут зависеть только от первичного ключа таблицы (составного ключа, если необходимо). Возьмем для примера адрес клиента в системе бухгалтерского учета. Этот адрес необходим не только таблице Customers, но и таблицам Orders, Shipping, Invoices, Accounts Receivable и Collections. Вместо того чтобы хранить адрес клиента как отдельный элемент в каждой из этих таблиц, храните его в одном месте: или в таблице Customers, или в отдельной таблице Addresses.
Отношения
Отношения — это указатели, которые показывают, как соотносятся данные в одной таблице с данными в другой. Проще говоря, ссылка с одного столбца первой таблицы на другой столбец второй таблицы. Бывают трех видов — один-к-одному, один-к-многим, многие-к-многим.
Отношение один-к-одному означает что поле1 соотносится с полем2. Пример — у каждого человека свой номер паспорта. 1 человек- 1 паспорт. Тут отношение один-к-одному.
Один-к-многим указывает, что поле1 может соотносится как с полем2, так и с полем3, полемN… В книге приведён пример — у одного мужчины может быть много женщин и наоборот Автор юморист Один-к-многим самая распространённая связь между таблицами в нормализованных базах.
Отношение многие-к-многим бывает, когда нескольким значениям из одной таблицы соответствует несколько значений другой таблицы. Например, в категории блога может быть много постов, а у блога может быть много категорий. Еще такое отношение может встречаться в составных ключах. Такой связи следует избегать, поскольку она ведет к избыточности данных. В том-же вордпрессе категории и посты соотносятся через третью таблицу — wp_relationships.
На рисунке приведены условные обозначения всех трех отношений в нотации UML.
Создание структуры базы данных (схема) и отношений между таблицами можно ускорить, использую различные CASE-средства. В конце будет ссылка на mysql workbench, бесплатную кроссплатформенную программу.
Многозначные зависимости
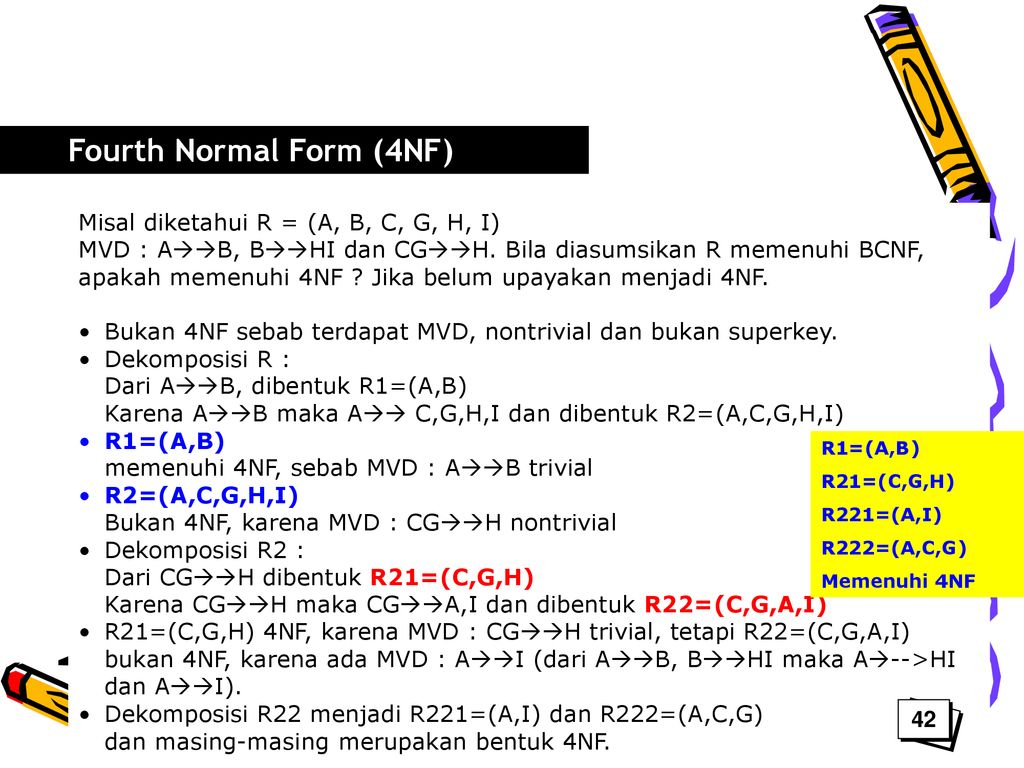
Если заголовки столбцов в таблице реляционной базы данных разделены на три непересекающиеся группы Икс, Y, и Z, то в контексте конкретной строки мы можем ссылаться на данные под каждой группой заголовков как Икс, у, и z соответственно. А многозначная зависимость Икс ↠{ displaystyle twoheadrightarrow}Y означает, что если мы выберем любой Икс фактически встречается в таблице (назовите этот выбор Иксc) и составить список всех Иксcyz комбинации, которые встречаются в таблице, мы обнаружим, что Иксc связан с тем же у записи независимо от z. Таким образом, по сути, наличие z не дает никакой полезной информации, чтобы ограничить возможные значения у.
А тривиальная многозначная зависимость Икс ↠{ displaystyle twoheadrightarrow}Y тот, где либо Y это подмножество Икс, или же Икс и Y вместе образуют весь набор атрибутов отношения.
А функциональная зависимость это частный случай многозначной зависимости. В функциональной зависимости Икс → Y, каждые Икс определяет ровно один год, не более одного.
Плюсы
Нормализация не является обязательной, но приносит следующие преимущества:
— упрощается процесс выборки. Речь идет об упрощении работы по составлению запросов, то есть пользователь сможет получать нужную информацию относительно простыми запросами;
— обеспечивается целостность данных. Можно говорить о минимизации искажения информации и снижении вероятности потери данных;
— улучшается масштабируемость. При соблюдении правил нормализации формируются благоприятные предпосылки к росту БД;
— отсутствует избыточность (data redundancy). Избыточность — известная проблема непродуктивного использования свободного места на жестком диске, затрудняющая обслуживание БД. В отдельных случаях эту проблему усугубляет и то, что в случае необходимости изменения записей однотипных данных, хранимых в нескольких местах (таблицах), пользователю придется вносить требуемые изменения везде, что весьма трудоемкое занятие. Гораздо проще сделать так, чтобы, к примеру, данные о городах хранились только в таблице Cities и нигде больше. Если подытожить вышесказанное, избыточность предполагает дублирование данных, а это не только усложняет работу с БД, но и увеличивает ее размер;
— отсутствие несогласованных зависимостей. Несогласованные зависимости затрудняют доступ к данным, ведь путь к такой информации может быть неправилен и нелогичен. В той же таблице Cities логично искать города, количество жителей и т. п., но не адреса и имена жителей — для этой информации уже нужна другая таблица — Citizens.
Как выполнить нормализацию?
Чтобы привести БД к нормальной форме, необходимо:
1. Объединить имеющиеся данные в группы.
2. Выяснить логические связи между группами. Чтобы обеспечить правильность связей, связываемые поля должны иметь один тип.
Если таблица не нормализована, она может хранить информацию о нескольких сущностях и включать в себя повторяющиеся столбцы, а они, в свою очередь, могут хранить дублируемые значения. Если же нормализована, то каждая таблица хранит информацию лишь об одной сущности.







При нормализации предполагается использование нормальных форм по отношению к структуре имеющихся данных. Есть несколько правил нормализации. Каждое из них носит название «нормальная форма» (НФ). Каждая такая форма, кроме первой, предполагает, что к данным уже применили предыдущую нормальную форму. При выполнении первого правила БД представлено в первой нормальной форме (1НФ), при выполнении трех правил — в третьей нормальной форме (3НФ).
Таких форм (уровней) — семь, однако на практике для большей части приложений вполне достаточно нормализовать БД до третьей нормальной формы (строго говоря, БД и будет считаться нормализованной, когда к ней применяется 3НФ и выше).
Да, обеспечить полное соответствие правилам и спецификациям — задача не всегда выполнимая, ведь для нормализации придется создавать дополнительные таблицы, а это не всегда приемлемо или не находит отклика у клиентов. Но если правила приходится нарушать, надо понимать, что все, связанные с этим проблемы, включая несогласованные зависимости и избыточность, будут учтены, и что это допустимо для приложения, не нарушит его работоспособность.
пример
Рассмотрим следующий пример:
| Ресторан | Разнообразие пиццы | Зона доставки |
|---|---|---|
| А1 Пицца | Толстая корка | Springfield |
| А1 Пицца | Толстая корка | Shelbyville |
| А1 Пицца | Толстая корка | Столица |
| А1 Пицца | Фаршированная корочка | Springfield |
| А1 Пицца | Фаршированная корочка | Shelbyville |
| А1 Пицца | Фаршированная корочка | Столица |
| Элитная пицца | Тонкая корка | Столица |
| Элитная пицца | Фаршированная корочка | Столица |
| Пицца Винченцо | Толстая корка | Springfield |
| Пицца Винченцо | Толстая корка | Shelbyville |
| Пицца Винченцо | Тонкая корка | Springfield |
| Пицца Винченцо | Тонкая корка | Shelbyville |
Каждая строка указывает на то, что данный ресторан может доставить определенное разнообразие пиццы в определенное место.
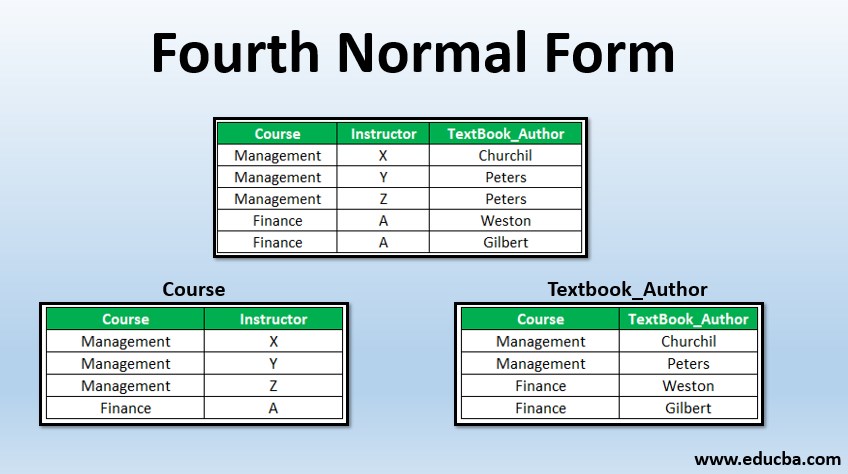
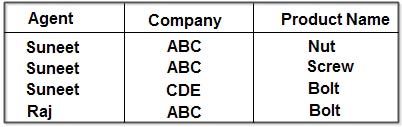
Таблица не имеет неключевых атрибутов, потому что ее единственный ключ — {Ресторан, Разнообразие пиццы, Зона доставки}. Следовательно, он соответствует всем нормальным формам вплоть до BCNF. Если мы предположим, однако, что на разновидности пиццы, предлагаемые рестораном, не влияет зона доставки (т. Е. Ресторан предлагает все разновидности пиццы, которые он готовит, во все области, которые он поставляет), то он не соответствует 4NF. Проблема в том, что в таблице есть две нетривиальные многозначные зависимости от атрибута {Restaurant} (который не является суперключом). Зависимости:
- {Ресторан} ↠{ displaystyle twoheadrightarrow} {Разнообразие пиццы}
- {Ресторан} ↠{ displaystyle twoheadrightarrow} {Зона доставки}
Эти нетривиальные многозначные зависимости от не суперключей отражают тот факт, что разновидности пиццы, которые предлагает ресторан, не зависят от областей, в которые ресторан доставляет. Такое положение вещей приводит к избыточность в таблице: например, нам трижды сказали, что A1 Pizza предлагает фаршированное тесто, и если A1 Pizza начнет производить пиццу с сырной корочкой, нам нужно будет добавить несколько строк, по одной для каждой зоны доставки A1 Pizza. Более того, ничто не мешает нам сделать это неправильно: мы можем добавить строки Cheese Crust для всех областей доставки A1 Pizza, кроме одной, тем самым не соблюдая многозначную зависимость {Restaurant} ↠{ displaystyle twoheadrightarrow} {Разнообразие пиццы}.
Чтобы исключить возможность этих аномалий, мы должны поместить факты о предлагаемых разновидностях в другую таблицу, а не факты о регионах доставки, в результате чего получим две таблицы, которые обе находятся в 4NF:
| Ресторан | Разнообразие пиццы |
|---|---|
| А1 Пицца | Толстая корка |
| А1 Пицца | Фаршированная корочка |
| Элитная пицца | Тонкая корка |
| Элитная пицца | Фаршированная корочка |
| Пицца Винченцо | Толстая корка |
| Пицца Винченцо | Тонкая корка |
| Ресторан | Зона доставки |
|---|---|
| А1 Пицца | Springfield |
| А1 Пицца | Shelbyville |
| А1 Пицца | Столица |
| Элитная пицца | Столица |
| Пицца Винченцо | Springfield |
| Пицца Винченцо | Shelbyville |
Напротив, если бы разновидности пиццы, предлагаемые рестораном, иногда действительно менялись от одной области доставки к другой, исходная таблица из трех столбцов удовлетворяла бы требованиям 4NF.
Рональд Феджин продемонстрировал, что всегда можно достичь 4НФ.Теорема Риссанена также применимо к многозначные зависимости.
Вторая нормальная форма
Для приведения таблиц ко второй нормальной форме (2НФ), приводимые таблицы должны быть уже в 1НФ. Нормализация должна проходить по порядку.
Теперь, во второй нормальной форме, должно быть соблюдено условие — любой столбец, который не является ключом (в том числе внешним), должен зависеть от первичного ключа. Обычно такие столбцы, имеющие значения, который не зависят от ключа, легко определить. Если данные, содержащиеся в столбце, не имеют отношения к ключу, который описывает строку, то их следует отделять в свою отдельную таблицу. В старую таблицу надо возвращать первичный ключ.
На рисунке выше и названия фильмов и имена актеров нарушают правила 2НФ (сами не являются ключами и не зависят от первичного ключа).
После всех преобразований, база данных с фильмами будет иметь минимум 4 таблицы.
Каждое имя режиссёра, название картины и имя актера хранится только один раз и все неключевые поля зависят от первичного ключа их собственной таблицы.
По факту, нормализация может быть утрированно названа процессом создания все новых и новых таблиц до тех пор, пока избыточность и повторения не будут полностью уничтожены.
Чтобы привести базу ко второй нормальной форме, надо:
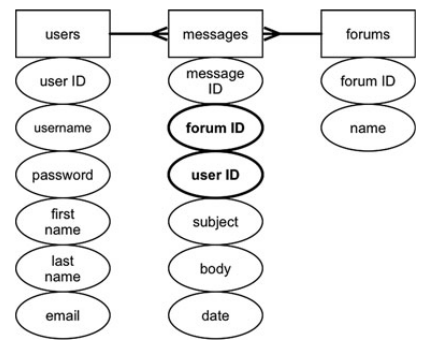
- Определить все столбцы, которые не находятся в прямой зависимости от первичного ключа этой таблицы. На рисунке выше у таблиц users и forums нет первичного ключа. У таблицы messages первичный ключ — message ID, от которого зависят все остальные поля этой таблицы.
- Создаем необходимые поля в таблицах users и forums, выделяем из существующих полей или создаем из новых первичные ключи.
- Создаем внешние ключи и обозначаем их отношения между таблицами. Конечным шагом нормализации до 2НФ будет являться выделение внешних ключей для связи с ассоциированными таблицами. Первичный ключ одной таблицы должен быть внешним ключом в другой. На рисунке снизу показана связь между ключами трех таблиц. Поле user ID таблицы messages является первичным ключом поля user ID таблицы users. Тип связи между ними — один ко многим. Один пользователь может оставить много сообщений, но у сообщения может быть только один пользователь. Такая же связь соединяет таблицы forums и messages через forum ID. У форума может быть много сообщений, но сообщение может находиться только в одном форуме.
Подсказки:
- Другой способ приведения схемы к 2НФ — посмотреть на отношения между таблицами. Идеальный вариант — создать все отношения вида один-к-многим. Отношения вида многие-к-многим нуждаются в реструктуризации.
- Если взглянуть еще раз на таблицу movies-actors, то можно заметить, что она является промежуточной таблицей. Она превращает отношение многие-к-многим между movies и actors в один-к-многим. Можно вводить такие промежуточные таблицы, у которых все столбцы являются ключами. В таких таблицах не требуется свой собственный первичный ключ, поскольку он может быть комбинацией двух внешних ключей.
- Нормализованная должным образом таблица никогда не будет иметь повторяющихся рядов (двух и более рядов, значения которых не являются ключами и содержат совпадающие данные).
- Чтобы упростить нормализацию, помните, что при приведении к 1НФ вы ищете дубли горизонтально (дубли столбцов), а при приведении к 2НФ — вертикально (дубли рядов).
Нормальные Формы
Сообщество баз данных разработало серию руководящих принципов для обеспечения нормализации баз данных. Они называются нормальными формами и пронумерованы от одной (самая низкая форма нормализации, называемая первой нормальной формой или 1NF) до пяти (пятая нормальная форма или 5NF). В практических приложениях вы часто будете видеть 1NF, 2NF и 3NF вместе со случайными 4NF. Пятая нормальная форма встречается очень редко и не будет обсуждаться в этой статье.
Прежде чем мы начнем наше обсуждение нормальных форм, важно отметить, что они являются лишь руководящими принципами. Иногда возникает необходимость отклониться от них, чтобы соответствовать практическим требованиям бизнеса
Тем не менее, когда возникают изменения, необходимо оценить возможные последствия, которые они могут иметь в вашей системе, и учесть возможные несоответствия. Тем не менее, давайте рассмотрим нормальные формы.
Первая нормальная форма (1NF)
Первая нормальная форма (1NF) устанавливает основные правила для организованной базы данных:
- Удалите дублирующие столбцы из одной таблицы.
- Создайте отдельные таблицы для каждой группы связанных данных и идентифицируйте каждую строку уникальным столбцом или набором столбцов ( первичный ключ ).
Вторая нормальная форма (2NF)
Вторая нормальная форма (2NF) дополнительно обращается к концепции удаления дублирующих данных:
- Удовлетворить все требования первой нормальной формы.
- Удалите подмножества данных, которые применяются к нескольким строкам таблицы, и поместите их в отдельные таблицы.
- Создайте отношения между этими новыми таблицами и их предшественниками с помощью внешних ключей .
Третья нормальная форма (3NF)
Третья нормальная форма (3NF) идет еще на один важный шаг:
- Удовлетворить все требования второй нормальной формы.
- Удалите столбцы, которые не зависят от первичного ключа.
Нормальная форма Бойса-Кодда (BCNF или 3.5NF)
Нормальная форма Бойса-Кодда, также называемая «третьей и наполовину (3,5) нормальной формой», добавляет еще одно требование:
- Удовлетворяют всем требованиям третьей нормальной формы.
- Каждый определитель должен быть ключом-кандидатом .
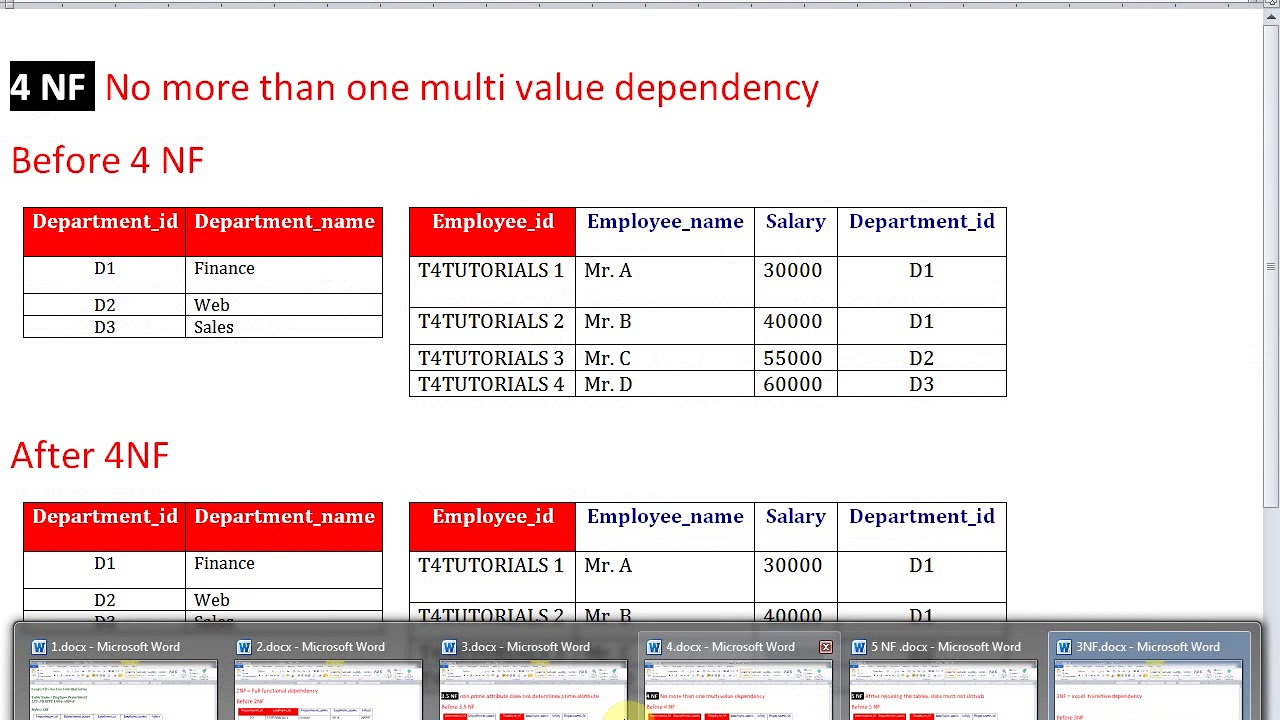
Четвертая нормальная форма (4NF)
Наконец, четвертая нормальная форма (4NF) имеет одно дополнительное требование:
- Удовлетворяют всем требованиям третьей нормальной формы.
- Отношение находится в 4NF, если оно не имеет многозначных зависимостей .
Помните, что эти рекомендации по нормализации являются накопительными. Чтобы база данных была в 2NF, она должна сначала соответствовать всем критериям базы данных 1NF.



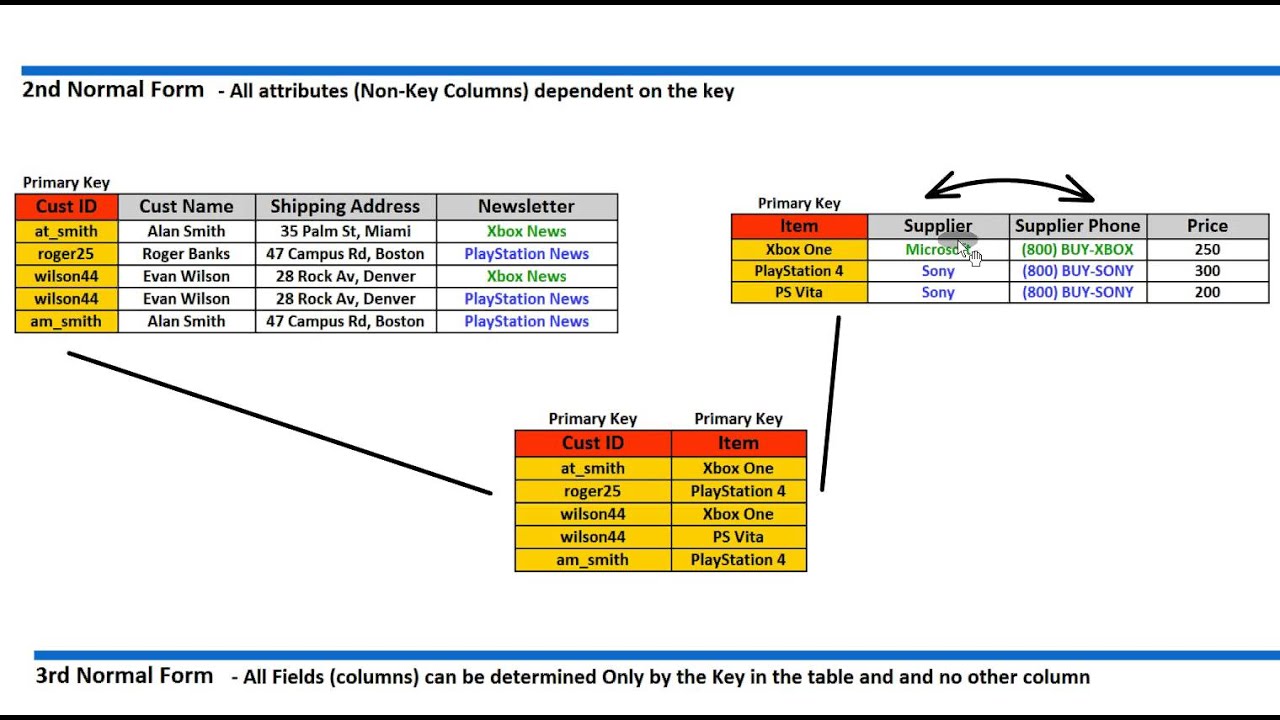




Третья нормальная форма.
База данных будет находиться в третьей нормальной форме, если она приведена ко второй нормальной форме и каждый не ключевой столбец независим друг от друга. Если следовать процессу нормализации правильно до этой точки, с приведением к 3НФ может и не возникнуть вопросов. Следует знать, что 3НФ нарушается, если изменив значение в одном столбце, потребуется изменение и в другом столбце. В примере с форумом (рисунок вверху), проблем с приведением к 3НФ не возникнет, но можно рассмотреть как образец гипотетическую ситуацию, где это может произойти.
Возьмём, как образец, одиночную таблицу, которая хранит некую информацию о бизнес клиентах: имя, фамилию, телефон, адрес, город, штат, почтовый индекс и все в этом духе. Такая таблица не будет находится в 3НФ, поскольку тут много полей будет взаимозависимо — улица будет зависеть от города, город от штата, почтовый индекс тоже под вопросом. Все эти поля будут подчинены друг другу, а не человеку, к которому относится эта запись.
Чтобы нормализовать такую базу, нужно создать по таблице для штатов, городов (с внешним ключом, ведущим в таблицу штатов) и для почтовых кодов. Все они будут ссылаться назад на клиентскую таблицу.
Если вы чувствуете, что все эти действия могут быть излишними, вы правы. Честно, в верхних уровнях нормализации часто нет необходимости. Смысл в том, что нужно стараться нормализовать базу данных, но иногда приходиться идти на уступки ради того, чтобы не допустить чрезмерного усложнения. Потребности приложения и структура данных в базе подскажут, насколько потребуется проводить процесс нормализации.
Как уже говорилось, пример с форумом уже достаточно нормализован, но все равно опишем шаги для нормализации для третьей нормальной формы, показав как исправить пример с клиентами.