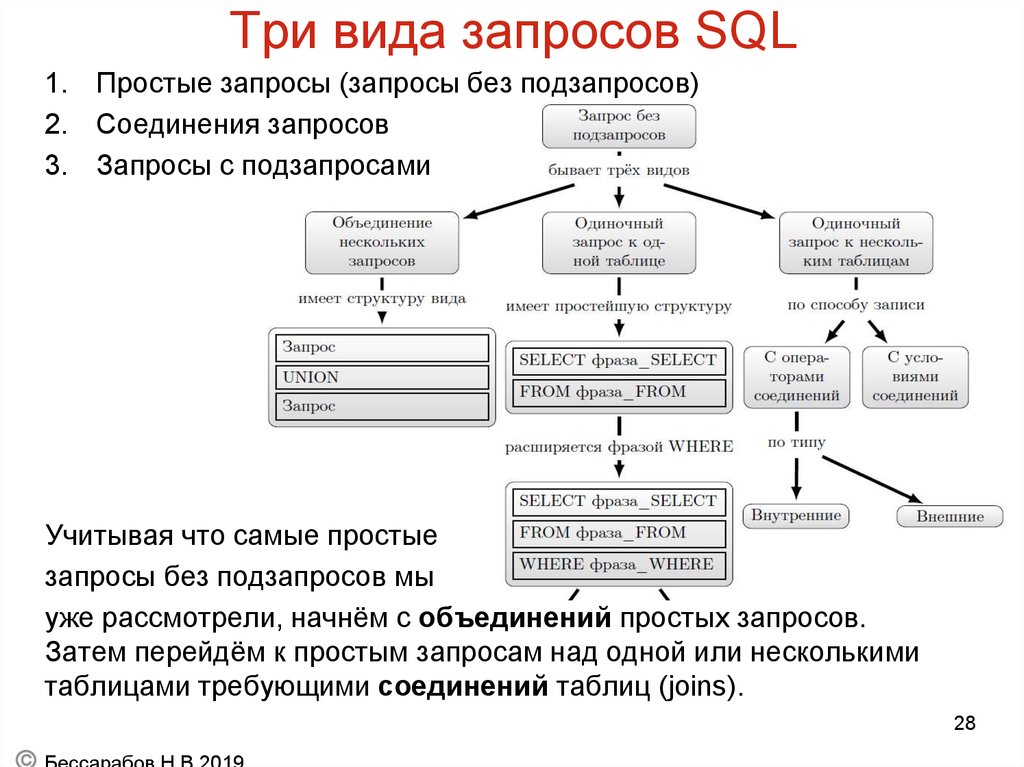
Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок ‘ом, мы задаем знаения ‘ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
делает то же самое, что раньше: выбирает строки. Вместо , который использовался при чтении, мы теперь используем . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос это просто запрос или без названий колонок. Серьезно. Как и в случае с и , блок остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это . Формат такой:
Где , , это названия колонок, а , и это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с , который заполняет всю таблицу «books»:
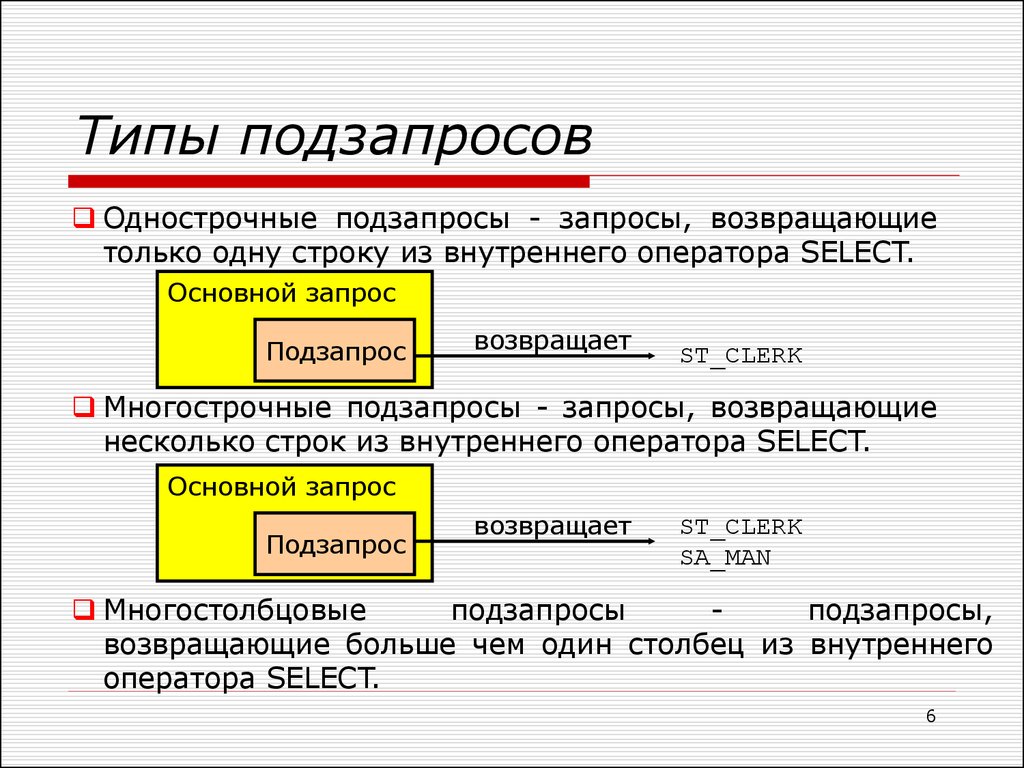
Подзапросы с заявлением DELETE
Подзапрос может быть использован в сочетании с DELETE как и с любыми другими заявлениями, упомянутых выше.
Базовый синтаксис выглядит следующим образом.
DELETE FROM TABLE_NAME (SELECT COLUMN_NAME FROM TABLE_NAME)
Пример
Предполагая, у нас есть таблица CUSTOMERS_BKP, которая является резервной копией таблицы Customers. Следующий пример удаляет записи из таблицы CUSTOMERS для всех клиентов, чей возраст больше или равен 37.
SQL> DELETE FROM CUSTOMERS
WHERE AGE IN (SELECT AGE FROM CUSTOMERS_BKP
WHERE AGE >= 37 );
Это будет влиять на одну строку и, наконец, таблица CUSTOMERS будет иметь следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Maxim | 35 | Moscow | 21000.00 | | 3 | Oleg | 33 | Rostov | 34000.00 | | 4 | Masha | 35 | Moscow | 34000.00 | | 5 | Ruslan | 34 | Omsk | 45000.00 | | 6 | Dima | 32 | SP | 45000.00 | | 7 | Roma | 34 | SP | 10000.00 | +----+----------+-----+-----------+----------+
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Вопрос 2. Уровень Middle
Этот вопрос не такой хитрый, как предыдущий, а вполне себе конкретный. Однако, он требует знания оконных функций и их тонкостей, а это исконное Middle требование.
Вопрос: В чем отличие функции от ?
Примечание Кстати говоря, по мотивам этого вопроса очень любят давать задачи на собеседованиях в разных вариациях: пронумеровать строки с одинаковыми значениями без разрывов, с разрывами и так далее. Так что потренируйтесь на досуге
По аналогии с функцией , оконные функции и служат для нумерации строк. Однако, делают они это немного иначе: строки с одинаковым значениям получают одинаковый ранг. Для ряда задач это логично: если у двух сотрудников одинаковая зарплата, мы не можем сказать, что кто-то из них первый, а кто-то второй. Они одинаковы. Но при таком подходе возникает проблема: а какой ранг должен получить следующий сотрудник? Например, если первые два были одинаковые и у них ранги 1, то сотрудник со второй зарплатой в компании должен иметь ранг 2 или 3?
Простые примеры использования SELECT
Синтаксис:
> SELECT <fields1> FROM <table>
* где fields1 — поля для выборки через запятую, также можно указать все поля знаком *; table — имя таблицы, из которой вытаскиваем данные; conditions — условия выборки; fields2 — поле или поля через запятую, по которым выполнить сортировку; count — количество строк для выгрузки.
* запрос в квадратных скобках не является обязательным для выборки данных.
> SELECT * FROM users
* в данном примере мы получаем список всех записей из таблицы users.
2. Выборка данных с объединением двух таблиц (JOIN)
SELECT u.name, r.* FROM users u JOIN users_rights r ON r.user_id=u.id
* в данном примере идет выборка данных с объединением таблиц users и users_rights. Объединяются они по полям user_id (в таблице users_rights) и id (users). Извлекается поле name из первой таблицы и все поля из второй.
3. Выборка с интервалом по времени и/или дате
Варианты запросов и примеров могут быть самые разные. Мы рассмотрим те, с которыми чаще всего приходилось иметь дело автору.
а) известна точка начала и определенный временной интервал:
> SELECT * FROM users WHERE date >= DATE_SUB(NOW(), INTERVAL 1 HOUR)
* будут выбраны данные за последний час (поле date).
б) известны дата начала и дата окончания:
> SELECT * FROM users WHERE date >= ‘2017-10-25’ AND date <= ‘2017-11-25’
* выбираем данные в промежутке между 25.10.2017 и 25.11.2017.
в) известны даты начала и окончания + время:
> SELECT * FROM users WHERE DATE(date) BETWEEN ‘2018-03-25 00:15:00’ AND ‘2018-04-25 15:33:09’;
* выбираем данные в промежутке между 25.03.2018 0 часов 15 минут и 25.04.2018 15 часов 33 минуты и 9 секунд.
г) вытаскиваем данные за определенные месяц и год:
> SELECT * FROM study WHERE MONTH(date) = 4 AND YEAR(date) = 2018
* извлечем данные, где в поле date присутствуют значения для апреля 2018 года.
д) текущая дата минут год:
> SELECT * FROM study WHERE date < (CURDATE() — INTERVAL 1 YEAR)
* мы получим данные, которые имеют в колонке date дату, старше одного года.
4. Выборка максимального, минимального и среднего значения
> SELECT max(area), min(area), avg(area) FROM country
* max — максимальное значение; min — минимальное; avg — среднее.
5. Использование длины строки
> SELECT * FROM users WHERE CHAR_LENGTH(name) = 5;
* данный запрос должен показать всех пользователей, имя которых состоит из 5 символов.
6. Использование лимитов (LIMIT)
Применяется для ограничения количества выводимых результатов. Синтаксис:
<основной запрос> LIMIT <число1>
* где число1 — сколько результатов вернуть; число2 — сколько результатов пропустить, необязательный параметр — если его не писать, то отсчет начнется с первой строки.
а) извлечь максимум 15 строк:
> SELECT * FROM users LIMIT 15;
б) выбрать строки с 16 по 25 (запрос со смещением):
> SELECT * FROM users LIMIT 15, 10;
* 15 строк пропускаем, 10 извлекаем.
Предложение SELECT
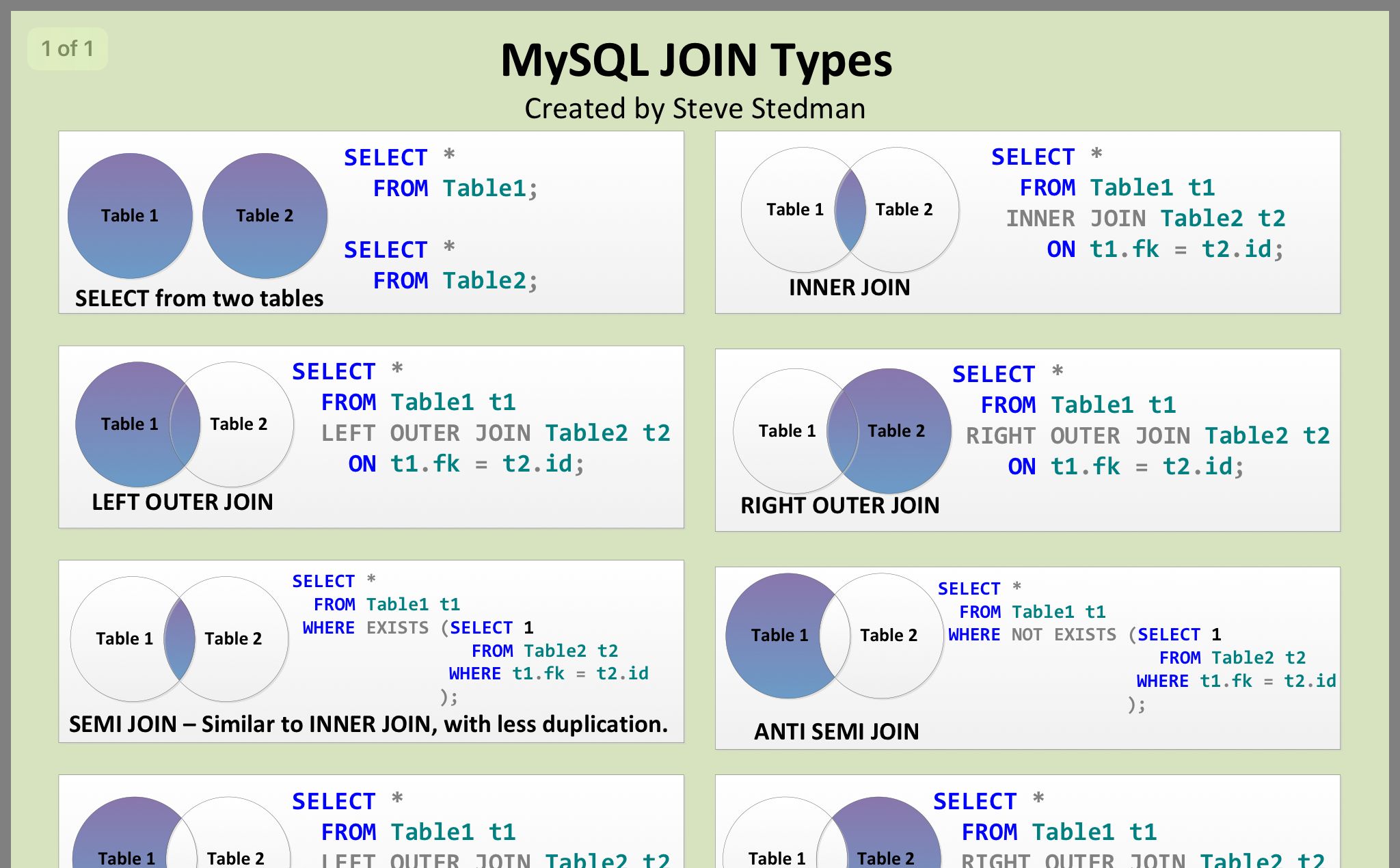
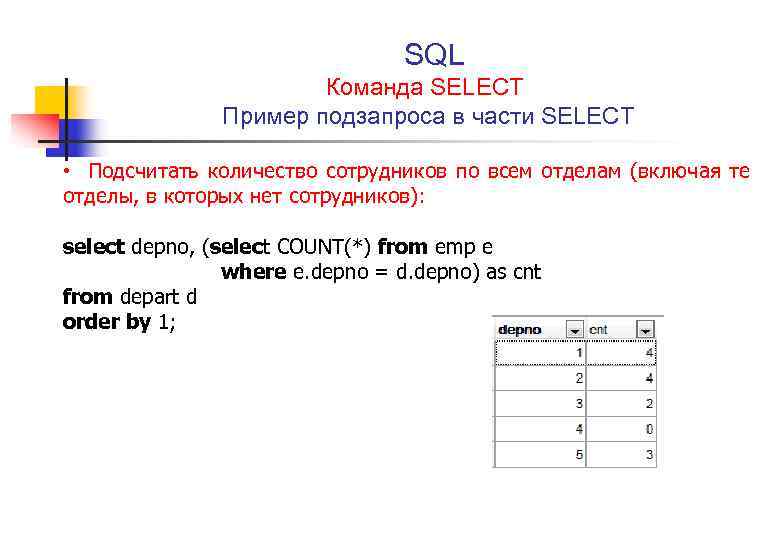
Подзапрос также можно найти в предложении SELECT. Они обычно используются, когда вы хотите получить расчет с использованием агрегатной функции, такой как функция SUM, COUNT, MIN или MAX, но вы не хотите, чтобы агрегированная функция применялась к основному запросу.
Например:
Transact-SQL
SELECT e1.last_name, e1.first_name,
(SELECT MAX(salary)
FROM employees e2
WHERE e1.employee_id = e2.employee_id) subquery2
FROM employees e1;
|
1 |
SELECTe1.last_name,e1.first_name, (SELECTMAX(salary) FROMemployeese2 WHEREe1.employee_id=e2.employee_id)subquery2 FROMemployeese1; |
В этом примере мы создали подзапрос в предложении SELECT следующим образом:
Transact-SQL
(SELECT MAX(salary)
FROM employees e2
WHERE e1.employee_id = e2.employee_id) subquery2
|
1 |
(SELECTMAX(salary) FROMemployeese2 WHEREe1.employee_id=e2.employee_id)subquery2 |
Подзапрос был с псевдонимом с именем subquery2. Это будет имя, используемое для ссылки на этот подзапрос или любое из его полей.
Трюк для размещения подзапроса в предложении select заключается в том, что подзапрос должен возвращать одно значение. Вот почему в подзапросе используется агрегирующая функция, такая как функция SUM, COUNT, MIN или MAX.
Работа в сервисе sql fiddle
Онлайн проверка sql запросов возможна при помощи сервиса sqlFiddle.
Самый простой способ организации работы состоит из следующих этапов:
- В верхней части рабочей области сервиса выбираем язык: SQLite(WebSQL);
Открывшаяся рабочая область разделена визуально на 3 окна: левое — для кода создания таблиц и заполнения их данными, правое — для кода запросов, нижнее — для отображения результатов запросов. - В левое окно помещается код для создания таблиц и вставки в них данных (пример кода расположен ниже). Затем щелкается кнопка «Build Schema».
После того как схема построена (об этом сигнализирует надпись на зеленом фоне «Schema Ready»), в правое окошко вставляется код запроса и щелкается кнопка Run SQL.
Еще пример:
Теперь некоторые пункты рассмотрим подробнее.Создание таблиц:
Пример: создайте сразу три таблицы (teachers, lessons и courses); добавьте по нескольку значений в каждую таблицу.
* для тех, кто незнаком с синтаксисом — просто скопировать полностью код и вставить в левое окошко сервиса
* урок по созданию таблиц в языке SQL далее
/*teachers*/ CREATE TABLE `teachers` ( `id` INT(11) NOT NULL, `name` VARCHAR(25) NOT NULL, `code` INT(11), `zarplata` INT(11), `premia` INT(11), PRIMARY KEY (`id`) ); INSERT INTO teachers VALUES (1, 'Иванов',1,10000,500), (2, 'Петров',1,15000,1000) ,(3, 'Сидоров',1,14000,800), (4,'Боброва',1,11000,800); /*lessons*/ CREATE TABLE `lessons` ( `id` INT(11) NOT NULL, `tid` INT(11), `course` VARCHAR(25), `date` VARCHAR(25), PRIMARY KEY (`id`) ); INSERT INTO lessons VALUES (1,1, 'php','2015-05-04'), (2,1, 'xml','2016-13-12'); /*courses*/ CREATE TABLE `courses` ( `id` INT(11) NOT NULL, `tid` INT(11), `title` VARCHAR(25), `length` INT(11), PRIMARY KEY (`id`) ); INSERT INTO courses VALUES (1,1, 'php',54), (2,1, 'xml',72), (3,2, 'sql',25); |
В результате получим таблицы с данными:
Отправка запроса:
Для того чтобы протестировать работоспособность сервиса, добавьте в правое окошко код запроса.
Пример: при помощи запроса выберите все данные из таблицы teachers, касаемые учителя с фамилией Иванов
SELECT * FROM `teachers` WHERE `name` = 'Иванов'; |
На дальнейших уроках SQL будет использоваться та же схема, поэтому необходимо будет просто копировать схему и вставлять в левое окно сервиса.
Онлайн визуализации схемы базы данных
Для онлайн визуализации схемы базы данных можно воспользоваться сервисом https://dbdesigner.net/:
- Создать свой аккаунт (войти в него, если уже есть).
- Щелкнуть по кнопке Go to Application.
- Меню Schema -> Import.
- Скопировать и вставить в появившееся окно код создания и заполнения таблиц базы данных
Далее к уроку 0 Язык sql создание таблиц
Взаимосвязь PHP и MySQL
Приложения на базе языка программирования PHP, применяющие базу данных как способ хранения информации, функционируют значительно быстрее и эффективнее аналогов, построенных на файловой системе хранения. MySQL в этом случае выполняет необходимую работу с данными. Базы данных берут на себя заботу о безопасности информации и ее хранении и обработке. Извлечение и размещение контента осуществляется посредством использования всего одной строчки.
С аналогичной легкостью решаются задачи поиска в рамках сайта, разбиения на страницы, регистрации и авторизации пользователей. Несмотря на значительнее количество базовых систем, на основе которых могут быть сформированы веб-приложения, MySQL остается наиболее предпочтительной. Поддержка сервера MySQL составляет стандартный комплект поставки PHP. Поэтому связка PHP+MySQL воспринимается как неразрывная.
Стандартные типы
Турбо-Паскаль имеет четыре встроенных стандартных типа: integer (целое), real (вещественное), boolean (логический) и char (символьный).
Целочисленный тип (integer)
В Турбо-Паскале имеется пять встроенных целочисленных типов: shortint (короткое целое), integer (целое), longint (длинное целое), byte (длиной в байт) и word (длиной в слово). Каждый тип обозначает определенное подмножество целых чисел, как это показано в следующей Таблице.
Встроенные целочисленные типы.
|
Тип |
Диапазон |
Формат |
|
shortint |
-128 ..+127 |
8 битов со знаком |
|
integer |
-32768 .. 32767 |
16 битов со знаком |
|
longint |
-2147483648 +2147483647 |
32 бита со знаком |
|
byte |
0 .. 255 |
8 битов без знака |
|
word |
0 .. 65535 |
16 битов без знака |






Арифметические действия над операндами целочисленного типа осуществляются в соответствии со следующими правилами:
- Тип целой константы представляет собой встроенный целочисленный тип с наименьшим диапазоном, включающим значение этой целой константы.
- В случае бинарной операции (операции, использующей два операнда), оба операнда преобразуются к их общему типу перед тем, как над ними совершается действие. Общим типом является встроенный целочисленный тип с наименьшим диапазоном, включающим все возможные значения обоих типов. Например, общим типом для целого и целого длиной в байт является целое, а общим типом для целого и целого длиной в слово является длинное целое. Действие выполняется в соответствии с точностью общего типа и типом результата является общий тип.
- Выражение справа в операторе присваивания вычисляется независимо от размера переменной слева.
Операции совершаемые над целыми числами:
“+” — сложение
“-“ — вычитание
“*” — умножение
SQR — возведение в квадрат
DIV — после деления отбрасывает дробную часть
MOD — получение целого остатка после деления
ABS — модуль числа
RANDOM(X)-получение случайного числа от 0 до Х
Пример:
а:=100; b:=60; a DIV b результат - 1 а MOD b результат - 40
Описываются переменные целого типа следующим образом:
var список переменных: тип;
Например: var а,р,n:integer;
Вещественный тип(real)
К вещественному типу относится подмножество вещественных чисел, которые могут быть представлены в формате с плавающей запятой с фиксированным числом цифр. Запись значения в формате с плавающей запятой обычно включает три значения — m, b и e — таким образом, что m*bе, где b всегда равен 10, а m и e являются целочисленными значениями в диапазоне вещественного типа. Эти значения m и e далее определяют диапазон и точность вещественного типа.
Имеется пять видов вещественных типов: real, singlе, duble, exnende, comp. Вещественные типы различаются диапазоном и точностью связанных с ними значений
Диапазон и десятичные цифры для вещественных типов
|
Тип |
Диапазон |
Цифры |
|
Real Single Duble Extende comp |
2.9×10Е-39 до 1.7×10Е 38 1.5×10Е-45 до 3.4×10Е 38 5.0×10Е-324 до 1.7×10Е 308 3.4×10Е-493 до 1.1×10Е 403 -2Е 63 до 2Е 63 |
от 11 до 12 от 7 до 8 от 15 до 16 от 19 до 20 от 19 до 20 |
Операции совершаемые над вещественными числами:
- Все операции допустимые для целых чисел.
- SQRT(x)-корень квадратный из числа х.
- SIN(X), COS(X), ARCTAN(X).
- LN(X)-натуральный логарифм.
- EXP(X)-экспонента Х (ех).
- EXP(X*LN(A))-возведение в степень (Ах).
- Функции преобразования типов:
- TRUNC(X)-отбрасывает дробную часть;
- ROUND(X)-округление.
- Некоторые правила арифметических операций:
- Если в арифметическом действии встречаются числа типа real и integer, то результат будет иметь тип real.
- Все составные части выражения записываются в одну строку.
- Используются только круглые скобки.
- Нельзя подряд ставить два арифметических знака.
Описываются переменные вещественного типа следующим образом:
var список переменных: тип;
Например:
var d,g,k:real;
Символьный тип(char)
K типу char относится любой символ заключенный в апострофы. Для представления апострофа как символьную переменную, надо заключить его в апостроф:’’’’.
Каждый символ имеет свой код и номер. Порядковые номера цифр 0,1..9 упорядочены по возрастанию. Порядковые номера букв также упорядочены по возрастанию, но не обязательно следуют друг за другом.
К символьным данным применимы знаки сравнения:
> , < , >=, <=, <> .
Например: ‘A’ < ‘W’
Функции, которые применимы к символьным переменным:
- ORD(X) — определяет порядковый номер символа Х.
Пример:
ord(‘a’)=97;
- CHR(X) — определяет символ по номеру.
Пример:
chr(97)=’a’;
- PRED(X) — выдает символ, стоящий перед символом Х.
Пример:
pred(‘B’)=’A’;
- SUCC(X) — выдает символ, следующий после символа Х.
Пример:
succ(‘A’)=’B’;
PHP и MySQL
Еще раз хочу подчеркнуть, что запросы при создании интернет-проекта — это обычное дело. Чтобы их использовать в php-документах выполните такой алгоритм действий:
- Соединяемся с БД при помощи команды mysql_connect();
- Используя mysql_select_db() выбираем нужную БД;
- Обрабатываем запрос при помощи mysql_fetch_array();
- Закрываем соединение командой mysql_close().
Важно! Работать с БД не сложно. Главное — правильно написать запрос
Начинающие вебмастера подумают. А что почитать по этой теме? Хотелось бы порекомендовать книгу Мартина Грабера « SQL для простых смертных ». Она написана так, что новичкам все будет понятно. Используйте ее в качестве настольной книги.
Но это теория. Как же обстоит дело на практике? В действительности интернет-проект нужно не только создать, но еще и вывести в ТОП Гугла и Яндекса. В этом вас поможет видеокурс « Создание и раскрутка сайта ».
Запросы sql INNER JOIN
В предложении FROM может использоваться явная операция соединения двух и более таблиц.
Разберем пример. Имеем две таблицы: (учителя) и (уроки):
| teachers | lessons |
Пример: Выбрать имена учителей и проведенные уроки по курсам, которые они ведут
Решение:
Для этого необходимы обе таблицы:
SELECT t.name,t.code,l.course FROM teachers t INNER JOIN lessons l ON t.id=l.tid |

Результат:
В запросе буквы и являются псевдонимами таблиц (l) и (t).
Важно: Inner Join — выбираются значения только в случае присутствия в обеих таблицах
Задание 3_3
Указать фамилии студентов с оценкой 5 по курсу
Задание 3_4. . Вывести список фамилий и номеров телефонов студентов
Важно: Соединение таблиц может быть либо внутренним (), либо одним из внешних (). Служебное слово можно опускать, тогда при использовании просто слова имеется в виду внутреннее соединение ()
Sql left inner join 1. . Вывести фамилии всех преподавателей, названия и длительность курсов, которые они ведут (, , ) из таблиц и . Использовать внутреннее объединение
Sql left inner join 2. . Найти производителя, номер и цену каждого компьютера, имеющегося в базе данных.





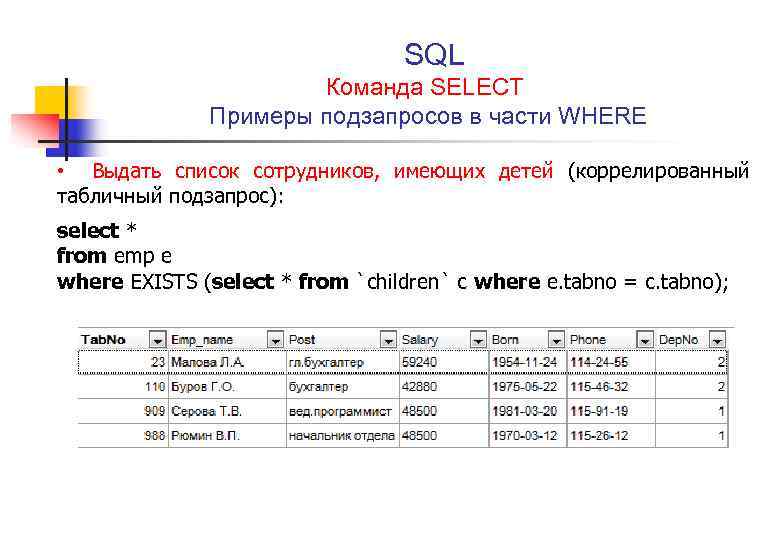
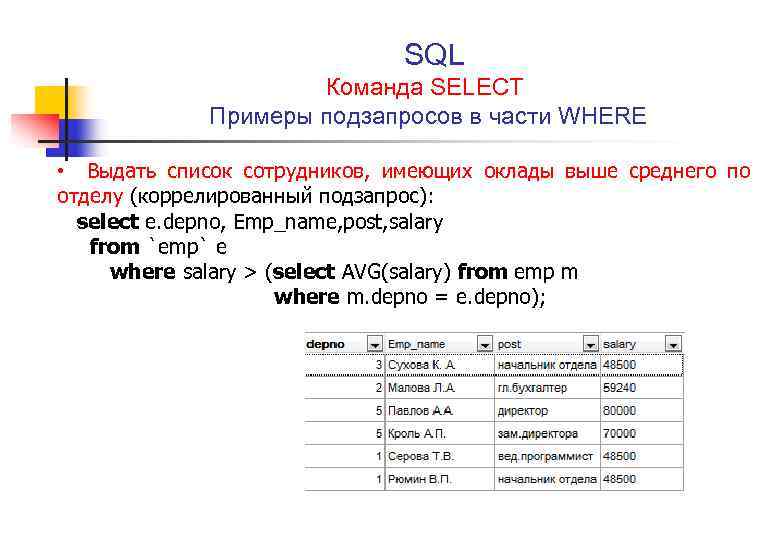


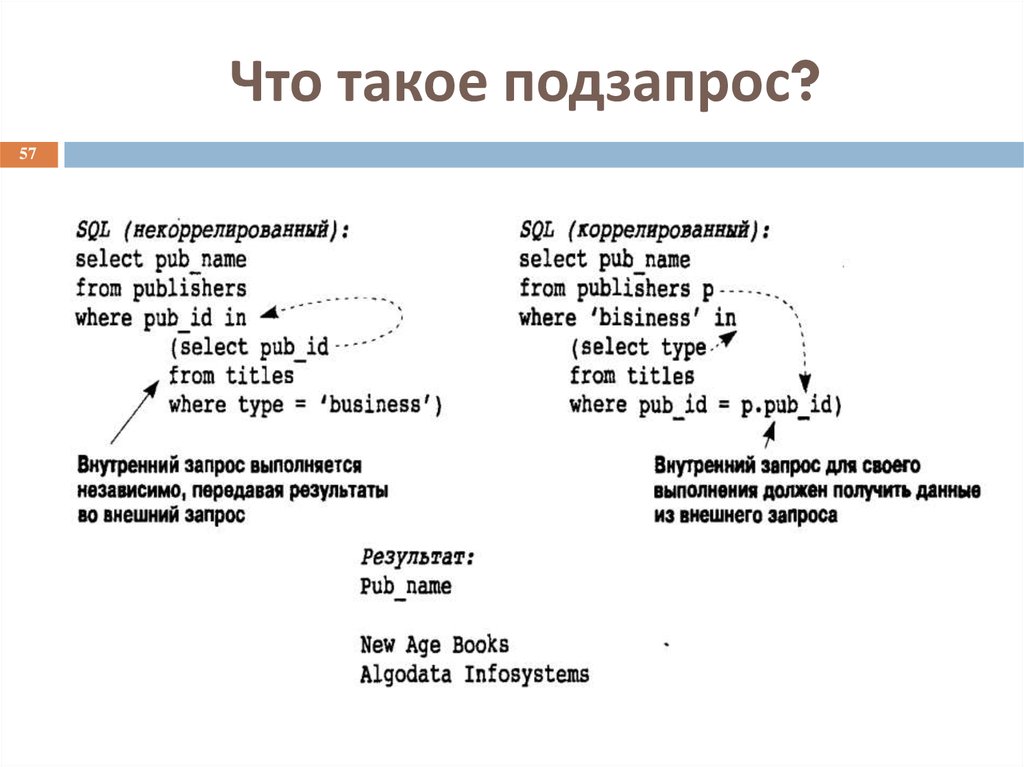
Соотнесенные (коррелирующие) подзапросы
Определение 1
Соотнесенный(коррелирующий) подзапрос – это подзапрос, который содержит ссылку на поля из внешнего запроса.

Пример 3
Пусть каждый абитуриент подал несколько заявлений на разные специальности. У заявления есть много атрибутов: форма обучения, приоритет, курс, специальность и т.д. Для каждого абитуриента нужно заявление, которое было подано им последним. (Допустим, абитуриент Василий Тапкин подал три заявления. Из этого списка необходимо только то заявление, которое было подано позже двух других.)
Найти такие заявления очень просто запросом с группировкой по коду абитуриента:
SELECT max(idapplication) FROM application group by idabiturient;
Но в результате мы получим только код заявления, в то время как нужно видеть все атрибуты заявления — форму, специальность, приоритет, курс и т.д. Добавлять «лишние» поля в групповые запросы крайне нежелательно. Поэтому задачу лучше всего решать с помощью соотнесенного подзапорса.
SELECT * FROM application outquery WHERE outquery.idapplication = (SELECT max(idapplication) FROM application innerquery where outquery.idabiturient=innerquery.idabiturient);
outquery и innerquery здесь являются псевдонимами для внешней и внутренней части.
- Сначала внешним запросом выбирается очередная запись. Для этой записи определяется значение поля idabiturient. Это и будет outquery.idabiturient.
- Потом выполняется внутренний подзапрос с подстановкой, полученного на первом шаге, значения outquery.idabiturient. В результате получается максимальный номер заявления для данного абитуриента.
- Во внешнем запросе выбирается запись с полученным на втором шаге максимальным номером заявления.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_date FROM sys.databases;
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=’BASE TABLE’
3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
SELECT * FROM tAuthors;
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
SELECT count(*) FROM tAuthors;
5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
SELECT * FROM tAuthors ORDER BY AuthorId OFFSET 3 ROWS FETCH NEXT 2 ROWS ONLY;
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
SELECT * FROM tAuthors ORDER BY AuthorFirstName;
7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
SELECT * FROM tAuthors ORDER BY AuthorId DESC;
![]() Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
SELECT * FROM tAuthors WHERE AuthorFirstName=’Александр’;
9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘се%’;
10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘%ат’ ORDER BY AuthorId;
Видео курсы по схожей тематике:
SQL Базовый. Разбор ДЗ
Владимир Дымчук
MySQL Базовый
Андрей Бондаренко
How to SQL Базовый
Владимир Дымчук
11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
SELECT * FROM tAuthors WHERE AuthorId IN (2,4);
12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
SELECT max(AuthorAge) FROM tAuthors;
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
SELECT AuthorFirstName, AuthorLastName FROM tAuthors;
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
SELECT AuthorId, AuthorFirstName, AuthorLastName FROM tAuthors WHERE AuthorId!=’3′;
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД. Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
INSERT INTO tAuthors VALUES (‘Уильям’, ‘Шекспир’, ’51’);
Проверим:
SELECT * FROM tAuthors;
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.
UPDATE tAuthors SET AuthorFirstName = ‘Лев’, AuthorLastName=’Толстой’, AuthorAge = ’82’ WHERE AuthorId = ‘6’;
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
SELECT * FROM tAuthors;
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
DELETE FROM tAuthors WHERE AuthorId = ‘5’;
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
SELECT * FROM tAuthors;
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors целиком, выполнив простой SQL запрос:
DROP TABLE tAuthors;
Далее рассмотрим сложные запросы SQL.
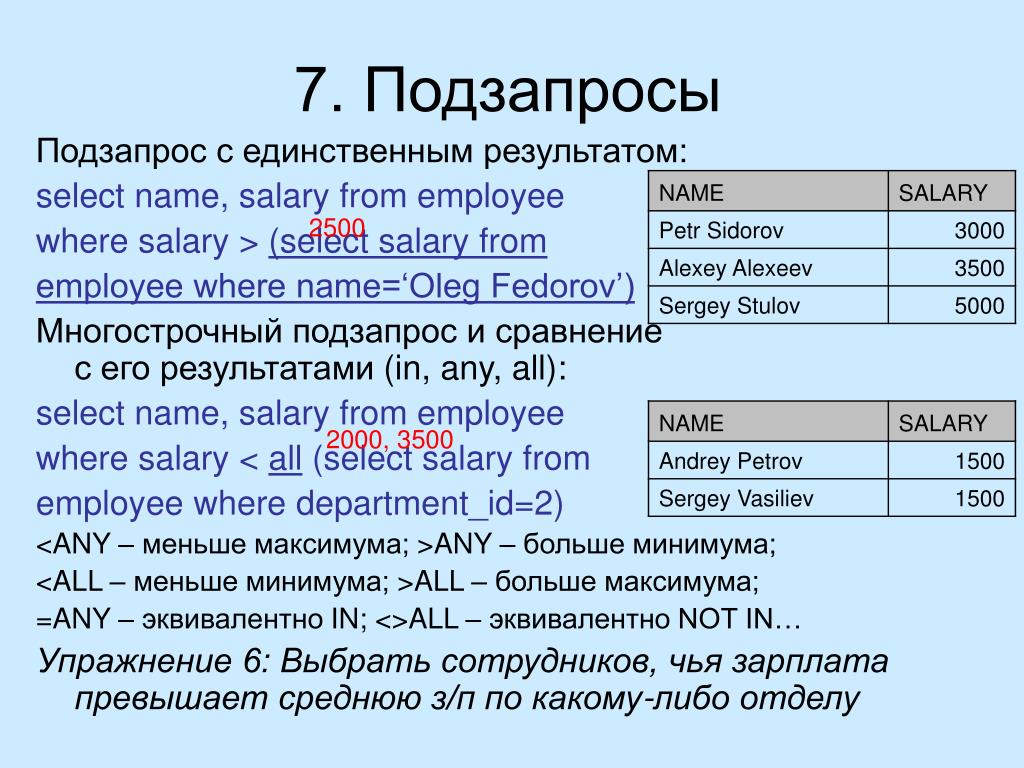
Вложенный запрос, возвращающий список значений
Если вложенный запрос может вернуть список значений, то синтаксис должен быть немного другим:

Здесь вместо знака равно в инструкции WHERE используется оператор IN, который будет сравнивать значение поля со списком значений.
Пример 2
Попробуем вывести список заявлений, поданных на математический факультет. Задача отличается от предыдущей тем, что на факультете несколько специальностей. Следовательно, нужно искать заявления, которые поданы не на одну специальность, а на целый список специальностей:
SELECT * FROM application WHERE application.idspec IN (select spec.idspec from spec where spec.idfacult=1);
- Вложенный запрос вернет нам список с кодами двух специальностей, которые находятся на факультете. Это будут специальности с кодами 1 и 6.
- После этого выполнится внешний запрос:
SELECT * FROM application WHERE application.idspec IN (1,6);
Он вернет список заявлений, поданных на специальности 1 и 6.
оконные функции
Начиная с MariaDB 10.2 / MySQL 8 добавлена поддержка оконных функций. С помощью row_number() можно для каждого пользователя сделать отдельную нумерацию сообщений в порядке убывания даты. После чего выбрать те записи, у которых № меньше или равен 3.








select post_id, user_id, date_added, post_text from (select posts.*,
row_number() over (partition by user_id order by date_added desc) ifrom posts) t where i <= 3;
Производительность — двойное сканирование таблицы: сначала для нумерации (нет возможности ограничиться нумерацией только нескольких строк из группы), потом отбросить не удовлетворяющие условию where i <= 3.
Для случайных сообщений пользователя достаточно заменить сортировку по убыванию даты order by date_added desc на случайную — order by rand().
Множественные уровни вложенности
Каждый вложенный запрос, в свою очередь, может содержать один или более вложенных запросов. В инструкцию можно вложить любое количество вложенных запросов.
Следующий запрос осуществляет поиск сотрудников, занимающих должность менеджера по продажам.
Результирующий набор:
Самый глубоко вложенный запрос возвращает идентификаторы указанных сотрудников. Запрос уровнем выше оперирует с полученными идентификаторами и возвращает контактные идентификаторы сотрудников. Наконец, во внешнем запросе по полученным контактным идентификаторам извлекаются имена сотрудников.
Этот запрос также можно выразить с помощью соединения:
Примеры использования предикатов
Предикаты представляют собой выражения, принимающие истинностное значение. Они могут представлять собой как одно выражение, так и любую комбинацию из неограниченного количества выражений, построенную с помощью булевых операторов AND, OR или NOT. Кроме того, в этих комбинациях может использоваться SQL-оператор IS, а также круглые скобки для конкретизации порядка выполнения операций
Предикат в языке SQL может принимать одно из трех значений TRUE (истина), FALSE (ложь) или UNKNOWN (неизвестно). Исключение составляют следующие предикаты: NULL (отсутствие значения), EXISTS (существование), UNIQUE (уникальность) и MATCH (совпадение), которые не могут принимать значение UNKNOWN.
Правила комбинирования всех трех истинностных значений легче запомнить, обозначив TRUE как 1, FALSE как 0 и UNKNOWN как 1/2 (где то между истинным и ложным).
AND с двумя истинностными значениями дает минимум этих значений. Например, TRUE AND UNKNOWN будет равно UNKNOWN.
OR с двумя истинностными значениями дает максимум этих значений. Например, FALSE OR UNKNOWN будет равно UNKNOWN.
Отрицание истинностного значения равно 1 минус данное истинностное значение. Например, NOT UNKNOWN будет равно UNKNOWN.
Помимо этого, используются предикаты сравнения.
Предикат сравнения представляет собой два выражения, соединяемых оператором сравнения. Имеется шесть традиционных операторов сравнения: =, >, <, >=, <=, <>.
Данные типа NUMERIC (числа) сравниваются в соответствии с их алгебраическим значением.
Данные типа CHARACTER STRING (символьные строки) сравниваются в соответствии с их алфавитной последовательностью. Если a1a2…an и b1b2…bn — две последовательности символов, то первая «меньше» второй, если а1<b1, или а1=b1 и а2<b2 и т.д. Считается также, что а1а2…аn<b1b2…bm, если n<m и а1а2…аn=b1b2…bn, т.е. если первая строка является префиксом второй. Например, ‘folder'<‘for’, т.к. первые две буквы этих строк совпадают, а третья буква строки ‘folder’ предшествует третьей букве строки ‘for’. Также справедливо неравенство ‘bar’ < ‘barber’, поскольку первая строка является префиксом второй.
Данные типа DATETIME (дата/время) сравниваются в хронологическом порядке.
Данные типа INTERVAL (временной интервал) преобразуются в соответствующие типы, а затем сравниваются как обычные числовые значения типа NUMERIC.
Пример. Получить информацию о компьютерах, имеющих частоту процессора не менее 500 Мгц и цену ниже $800:
SELECT * FROM PC
WHERE speed >= 500 AND price < 800;
Запрос возвращает следующие данные (Таблица 6.):
Таблица 6. – Пример информационного запроса.
Существуют так же и другие предикаты, например, BETWEEN, IN, LIKE.
Имена столбцов, указанных в предложении SELECT, можно переименовать. Это делает результаты более читабельными, поскольку имена полей в таблицах часто сокращают с целью упрощения набора. Ключевое слово AS, используемое для переименования, согласно стандарту можно и опустить, т.к. оно неявно подразумевается.
Например, запрос:
SELECT ram AS Mb, hd Gb
FROM PC
WHERE cd = ’24x’;
переименует столбец ram в Mb (мегабайты), а столбец hd — в Gb (гигабайты). Этот запрос возвратит объемы оперативной памяти и жесткого диска для тех компьютеров, которые имеют 24-скоростной CD-ROM (Таблица 7.):
Таблица 7. – Пример запроса SELECT AS.
Получение итоговых значений:
Существует возможность получения итоговых (агрегатных) функций. Стандартом предусмотрены следующие агрегатные функции (Таблица 8.):
Таблица 8 .– Описание (агрегатных) функций.
Все эти функции возвращают единственное значение. При этом, функции COUNT, MIN и MAX применимы к любым типам данных, в то время как SUM и AVG используются только для числовых полей. Разница между функцией COUNT(*) и COUNT() состоит в том, что вторая при подсчете не учитывает NULL-значения.
Пример. Найти минимальную и максимальную цену на персональные компьютеры:
SELECT MIN(price) AS Min_price, MAX(price) AS Max_price
FROM PC;
Результатом будет единственная строка, содержащая агрегатные значения (таблица 9.):
Таблица 9. – Строка содержащая (агрегатные) значения.
Для просмотра данных наиболее удобно использовать совместно значения оператора COUNT — счетчик (позволяет узнать количество записей в запросе), и оператора CURSOR — позволяет принимать не все записи сразу, а по одной (указанной пользователем).