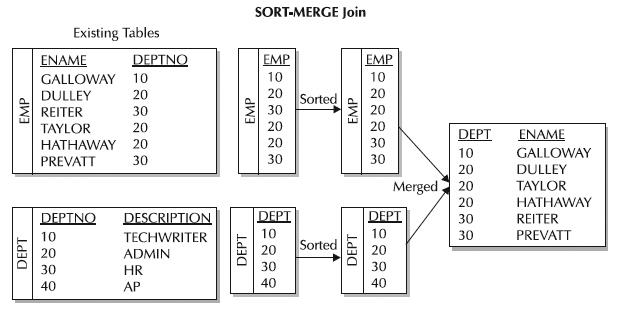
Синтаксис
Синтаксис Oracle PL/SQL оператора MERGE:
MERGE INTO table_A USING
{ table | view | subquery } ON ( condition )
WHEN MATCHED THEN merge_update_clause
WHEN NOT MATCHED THEN merge_insert_clause;
Параметры или аргумент
- schema
- схема базы данных.
- INTO
- используйте оператор INTO, чтобы указать целевую таблицу, которую вы обновляете или вставляете данные.
- table_A
- целевая таблица.
- t_alias
- алиас (псевдоним).
- USING { table | view | subquery }
- указывает источник данных, из которого нужно обновить или вставить данные в table_A. Это может быть таблица, представление или результат подзапроса.
- ON ( condition )
- указывает условие, при котором операция MERGE либо обновляет, либо вставляет данные. Для каждой строки table_A, для которой выполняется условие поиска, Oracle обновляет строку, используя соответствующие данные из исходной таблицы. Если условие не выполняется ни для одной строки, Oracle вставляет в table_A данные на основе соответствующей строки исходной таблицы.
- WHEN MATCHED | NOT MATCHED
- Используйте эти предложения, чтобы указать Oracle, как реагировать на результаты условия соединения в предложении ON. Вы можете указать эти два предложения в любом порядке.
- merge_update_clause
- определяет новые значения столбцов table_A. Oracle выполняет это обновление, если условие предложения ON истинно. Если предложение обновления выполняется, то активируются все триггеры обновления, определенные в table_A.
Пример merge_update_clause:Ограничения на обновление View
- Вы не можете указать DEFAULT при обновлении View.
- Вы не можете обновить столбец, на который есть ссылка в условии ON.
- merge_insert_clause
- определяет значения для вставки в столбец table_A, если условие предложения ON ложно. Если предложение вставки выполняется, то активируются все триггеры вставки, определенные в table_A.
Пример merge_insert_clause:Ограничение на слияние с View
Вы не можете указать DEFAULT при обновлении View.
Группы операторов SQL
Операторы базы SQL подразделяются на несколько основных групп по признаку типа задач, которые можно решить с их помощью.
DDL (Data Definition Language)
Представляют собой группу операторов для определения данных. Они работают с целыми таблицами. Такие операторы SQL используются в тех случаях, когда нужно внести в базу новую таблицу или, напротив, удалить старую. Они включают в себя следующие командные слова:
- CREATE — создание нового объекта в существующей базе.
- ALTER — изменение существующего объекта.
- DROP — удаление объекта из базы.
DML (Data Manipulation Language)
Эти операторы языка SQL предназначены для манипуляции данными. С их помощью меняется наполнение таблиц. Они позволяют изменять значение строк, столбцов и прочих атрибутов. Такие операторы SQL, например, позволяют удалить информацию о сотруднике, который больше не работает в компании, или исправить данные действующих специалистов. Эти операторы SQL представлены следующими командными словами:
- SELECT — позволяет выбрать данные в соответствии с необходимым условием.
- INSERT — осуществляют добавление новых данных.
- UPDATE — производит замену существующих данных.
- DELETE — удаление информации.
DCL (Data Control Language)
Это операторы SQL, предназначенные для определения доступа к данным. С их помощью можно закрыть или открыть для пользователей работу с базой. Такие операторы необходимы, чтобы ограничить кого-либо из сотрудников в доступе к информации или, наоборот, позволить работать с базой новому специалисту.
- GRANT— предоставляет доступ к объекту.
- REVOKE— аннулирует выданное ранее разрешение на доступ.
- DENY— запрет, который прекращает действие разрешения.
ТОП-30 IT-профессий 2023 года с доходом от 200 000 ₽
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в
IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее
будущее!
Скачивайте и используйте уже сегодня:
Александр Сагун
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 19648
TCL (Transaction Control Language)
Предназначен для управления транзакциями, то есть таким сочетанием команд, которые выполняются в определённом алгоритме. Транзакция проведена успешно, если все необходимые команды выполнены пошагово. Если же в какой-либо из них произошёл сбой, то вся операция, включая предыдущие команды, отменяется. Простым и понятным примером таких операторов SQL является проведение банковских платежей.
При этом вы сначала вводите сумму, а затем подтверждаете отправку платежа кодом, который вам присылает банк. Если операция не будет подтверждена, то транзакция отменится автоматически.
- BEGIN TRANSACTION — начало транзакции.
- COMMIT TRANSACTION — изменение команд транзакции.
- ROLLBACK TRANSACTION — отказ в транзакции.
- SAVE TRANSACTION — формирование промежуточной точки сохранения внутри операции.
SQL Server MERGE Syntax
The basic syntax of the MERGE statement is given below.
In this syntax,
- MERGE – keyword to instruct SQL of a MERGE operation.
- target_table – the table which is being updated.
- source_table– the table from which the target table is being updated.
- merge_condition – the condition on which the records (rows of information) of the two tables are matched for the merge. Usually the condition is specified on a primary key or unique key column.
- WHEN MATCHED – please refer above.
- update_statement – An UPDATE statement to update the data in the target table from the source table.
- WHEN NOT MATCHED BY TARGET please refer above.
- insert_statement – An INSERT statement to add unique records from the source table to target table.
- WHEN NOT MATCHED BY SOURCE – please refer above.
- THEN DELETE – A DELETE statement to delete unique records from the target table.
Атрибуты курсора для операций DML
Для доступа к информации о последней операции, выполненной командой SQL, Oracle предоставляет несколько атрибутов курсоров, неявно открываемых для этой операции. Атрибуты неявных курсоров возвращают информацию о выполнении команд INSERT, UPDATE, DELETE, MERGE или SELECT INTO. В этом разделе речь пойдет об использовании атрибутов SQL% для команд DML.
бедует помнить, что значения атрибутов неявного курсора всегда относятся к последней выполненной команде SQL, независимо от того, в каком блоке выполнялся неявный курсор. До открытия первого SQL-курсора сеанса значения всех неявных атрибутов равны NULL. (Исключение составляет атрибут %ISOPEN, который возвращает FALSE.) Значения, возвращаемые атрибутами неявных курсоров, описаны в табл. 1.
Таблица 1. Атрибуты неявных курсоров для команд DML

Давайте посмотрим, как эти атрибуты используются.
С помощью атрибута SQL%FOUND можно определить, обработала ли команда DML хотя бы одну строку. Допустим, автор издает свои произведения под разными именами, а записи с информацией обо всех книгах данного автора необходимо время от времени обновлять. Эту задачу выполняет процедура, обновляющая данные столбца author и возвращающая логический признак, который сообщает, было ли произведено хотя бы одно обновление:
Атрибут SQL%ROWCOUNT позволяет выяснить, сколько строк обработала команда DML. Новая версия приведенной выше процедуры возвращает более полную информацию:
Что такое T-SQL

Язык SQL – это стандарт, он реализован во всех реляционных базах данных, но у каждой СУБД есть расширение этого стандарта, так называемый диалект языка SQL.
И вот мы дошли до сути нашего сегодняшнего вопроса – что такое T-SQL.
T-SQL – это сокращенное название языка, а полное название Тransact-SQL, т.е. транзакционный SQL.







T-SQL обладает всеми возможностями языка SQL, однако предназначен он для решения задач программирования, не связанных с реляционными данными. Иными словами, на T-SQL Вы можете полноценно программировать, используя переменные, циклы, условные конструкции и другие возможности. T-SQL позволяет нам реализовывать сложные алгоритмы бизнес-логики в виде хранимых процедур и функций, тем самым создавая так называемые «программы» внутри базы данных.
Кроме этого, T-SQL упрощает написание SQL запросов за счет огромного количества встроенных системных функций, а также позволяет администрировать SQL Server и получать системную информацию с помощью системных представлений, процедур и функций.
На сегодня это все, надеюсь, материал был Вам интересен и полезен, до новых встреч!
Нравится36Не нравится1
Adding a Sort Transformation to the Data Flow
Another option for sorting data in the data flow is to use the transformation. When working with an component, you usually want to use the source component’s T-SQL query and advanced editor to sort the data. However, for other data sources, such as a text file, you won’t have this option. And that’s where the transformation comes in.
Delete the data path that connects the data source to the transformation by right-clicking the data path and then clicking .
Next, drag the transformation from the section of the to the data flow design surface, between the data source and the transformation, as shown in Figure 14.
Figure 14: Adding the transformation to the data flow
Drag the data path from the data source to the transformation. Then double-click the transformation to open the , shown in Figure 15.
Figure 15: Configuring the transformation
As you can see in the figure, at the bottom of the there is a warning message indicating that we need to select at least one column for sorting. Select the checkbox to the left of the column in the list. This adds the column to the bottom grid, which means the data will be sorted based on that column. By default, all other columns are treated as pass-through, which means that they’ll be passed down the data flow in their current state.
When we select a column to be sorted, the sort order and sort type are automatically populated. These can obviously be changed, but for our purposes they’re fine. You can also rename columns in the column by overwriting what’s in this column.
Once you’ve configured the sort order, click to close the .
We now need to connect the transformation to the transformation, so drag the data path from the transformation to the transformation, as shown in Figure 16.
Figure 16: Connecting the transformation to the transformation
That’s all we need to do to sort the data. For the customer data, we used the source component. For the territory data, we used a transformation. As far as the transformation is concerned, either approach is fine, although, as mentioned earlier, if you’re working with an component, using that component is usually the preferred method.
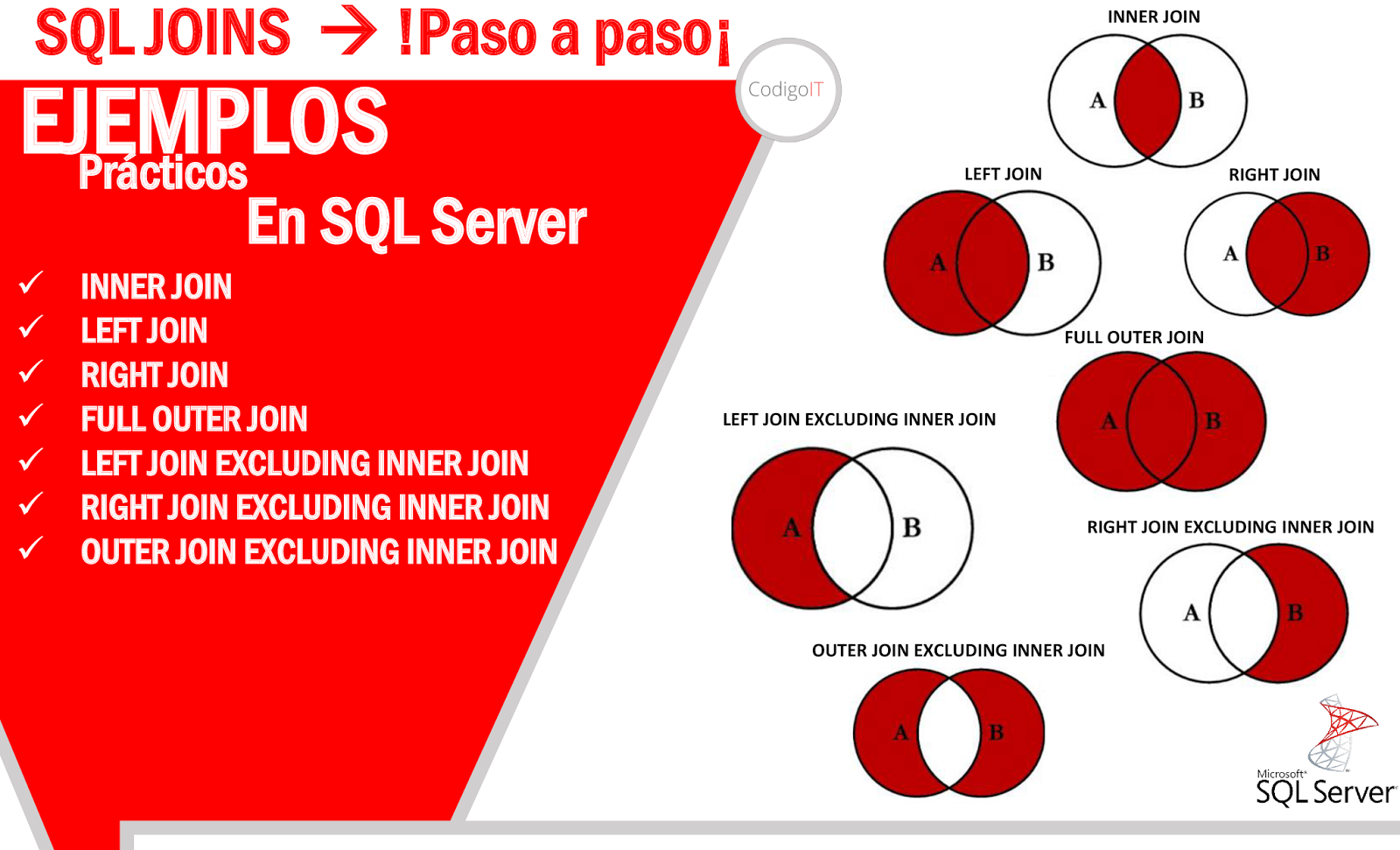
LEFT JOIN / RIGHT JOIN / FULL JOIN
LEFT JOIN, RIGHT JOIN и FULL JOIN считаются внешними соединениями (OUTER JOIN), поэтому у них также есть синонимы: LEFT OUTER JOIN, RIGHT OUTER JOIN и FULL OUTER JOIN.
LEFT JOIN и RIGHT JOIN отличаются от INNER JOIN тем, что к результирующей таблице добавляются строки не имеющие совпадений в соседней таблице. Если используется LEFT JOIN, добавляются все записи из таблицы указанной по левую сторону от оператора, если RIGHT JOIN, то из таблицы по правую сторону от оператора. В пару к таким строкам устанавливается значение NULL. Оба оператора не возможно использовать без какого-либо условия.
Это используется если, к примеру, надо вывести все доступные бренды машин, не зависимо от того указан у них цвет или нет:
Или все возможные цвета, независимо от того есть ли у брендов такой цвет в наличии:
Можно дополнить запрос условием на проверку несуществования соседних данных, и получить список записей, которые не имеют пары, при этом поля, которые необходимо вывести, можно указать, как и при обычном SELECT запросе:
FULL JOIN объединяет в себе LEFT JOIN и RIGHT JOIN.
В MySQL он используется без условий, результат использования этого оператора будет таким:
Но, при добавлении сравнения USING в MySQL, результат будет аналогичен INNER JOIN:
Другие условия с оператором FULL JOIN в MySQL использовать нельзя, по крайней мере на момент написания статьи.
Создание таблиц directors и movies
Чтобы проиллюстрировать следующие виды объединений, мы воспользуемся примером с фильмами (movies) и режиссерами (movie directors).
Каждый фильм имеет режиссера, но это не является обязательным условием. Может быть ситуация, когда фильм уже анонсировали, но режиссер еще не выбран.
В нашей таблице directors будут храниться имена всех режиссеров, а в таблице movies — названия фильмов, а также отсылка к режиссеру (если он известен).
Давайте создадим эти таблицы и внесем в них необходимые данные:
CREATE TABLE directors( id SERIAL PRIMARY KEY, name TEXT NOT NULL ); INSERT INTO directors(name) VALUES (‘John Smith’), (‘Jane Doe’), (‘Xavier Wills’) (‘Bev Scott’), (‘Bree Jensen’); CREATE TABLE movies( id SERIAL PRIMARY KEY, name TEXT NOT NULL, director_id INTEGER REFERENCES directors ); INSERT INTO movies(name, director_id) VALUES (‘Movie 1’, 1), (‘Movie 2’, 1), (‘Movie 3’, 2), (‘Movie 4’, NULL), (‘Movie 5’, NULL);
У нас есть пять режиссеров и пять фильмов, причем для трех фильмов указаны режиссеры. У режиссера с ID 1 есть два фильма, а у режиссера с ID 2 — один фильм.
Running Your SSIS Package
Your SSIS package should now be complete. The next step is to run it to make sure everything is working as you expect. To run the package, click the button (the green arrow) on the menu bar.
If you ran the script I provided to populate your tables, you should retrieve 500 rows from the data source and 10 from the data source. Once the data is joined, you should end up with 500 rows in the table. Figure 21 shows the data flow after successfully running.
Figure 21: Running the SSIS package to verify the results
One other check we can do is to look at the data that has been inserted into the table. In SQL Server Management Studio (SSMS), run a statement that retrieves all rows from the table in the database. The first dozen rows of your results should resemble Figure 22.



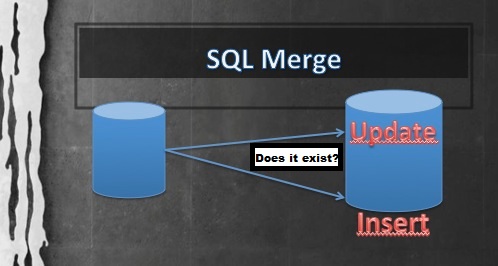
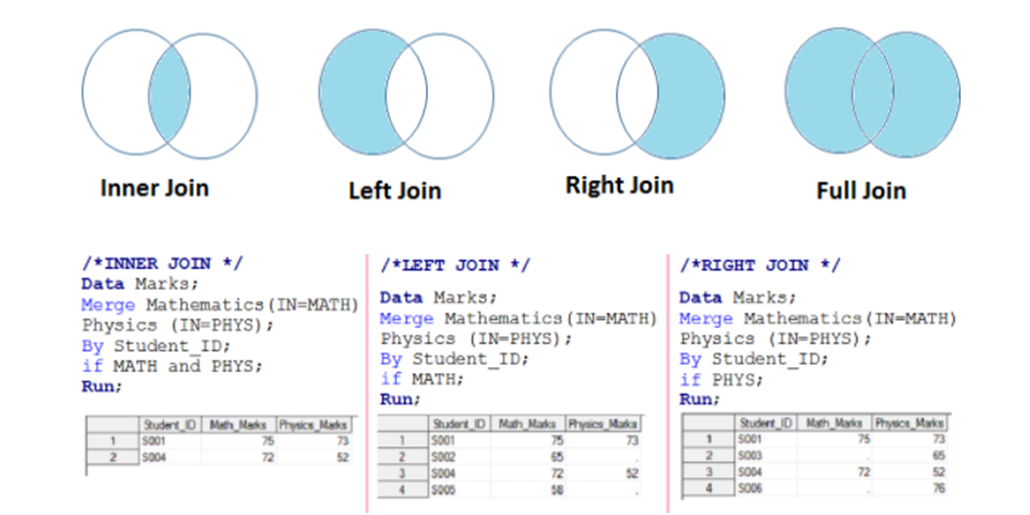

Figure 22: Partial results from retrieving the data in the table
Многотабличные запросы
Используя JOIN, можно объединять не только две таблицы, как было описано выше, но и гораздо больше. В MySQL 5.0 на сегодняшний день можно объединить вплоть до 61 таблицы. Помимо объединений разных таблиц, MySQL позволяет объединять таблицу саму с собой. Однако, в любом случае необходимо следить за именами столбцов и таблиц, если они будут неоднозначны, то запрос не будет выполнен.
Так, если таблицу просто объединить саму на себя, то возникнет конфликт имён и запрос не выполнится.
| Код — Объединение таблицы саму на себя |
| mysql> SELECT * FROMnomenclatureJOINnomenclature; ERROR1066 (42000): Notuniquetable/alias: ‘nomenclature’ |
Обойти конфликт имён позволяет использование синонимов (alias) для имён таблиц и столбцов. В следующем примере внутреннее объединение будет работать успешнее:
| Код — Объединение таблицы саму на себя |
| mysql> SELECT * FROMnomenclatureJOINnomenclatureASt2; +—-+————+—-+————+ | id | name | id | name | +—-+————+—-+————+ | 1 | Книга | 1 | Книга | | 2 | Табуретка | 1 | Книга | | 3 | Карандаш | 1 | Книга | | 1 | Книга | 2 | Табуретка | | 2 | Табуретка | 2 | Табуретка | | 3 | Карандаш | 2 | Табуретка | | 1 | Книга | 3 | Карандаш | | 2 | Табуретка | 3 | Карандаш | | 3 | Карандаш | 3 | Карандаш | +—-+————+—-+————+9rowsinset (0.00sec) |
MySQL не накладывает ограничений на использование разных типов объединений в одном запросе, поэтому можно формировать довольно сложные конструкции:
| Код — Пример сложного объединения таблиц |
| mysql> SELECT * FROMnomenclatureASt1JOINnomenclatureASt2LEFTJOINnomenclatureASt3ONt1.id = t3.idANDt2.id = t1.id; +—-+————+—-+————+——+————+ | id | name | id | name | id | name | +—-+————+—-+————+——+————+ | 1 | Книга | 1 | Книга | 1 | Книга | | 2 | Табуретка | 1 | Книга | NULL | NULL | | 3 | Карандаш | 1 | Книга | NULL | NULL | | 1 | Книга | 2 | Табуретка | NULL | NULL | | 2 | Табуретка | 2 | Табуретка | 2 | Табуретка | | 3 | Карандаш | 2 | Табуретка | NULL | NULL | | 1 | Книга | 3 | Карандаш | NULL | NULL | | 2 | Табуретка | 3 | Карандаш | NULL | NULL | | 3 | Карандаш | 3 | Карандаш | 3 | Карандаш | +—-+————+—-+————+——+————+9rowsinset (0.00sec) |
Помимо выборок использовать объединения можно также и в запросах UPDATE и DELETE
Так, следующие три запроса проделывают одинаковую работу:
| Код — Многотаблицные обновления |
| mysql> UPDATEnomenclatureASt1, nomenclatureASt2SETt1.id = t2.idWHEREt1.id = t2.id; QueryOK, 0rowsaffected (0.01sec) Rowsmatched: 3Changed: 0Warnings: 0mysql> UPDATEnomenclatureASt1JOINnomenclatureASt2SETt1.id = t2.idWHEREt1.id = t2.id; QueryOK, 0rowsaffected (0.00sec) Rowsmatched: 3Changed: 0Warnings: 0mysql> UPDATEnomenclatureASt1JOINnomenclatureASt2USING(id) SETt1.id = t2.id; QueryOK, 0rowsaffected (0.00sec) Rowsmatched: 3Changed: 0Warnings: 0 |
Таким же образом работают и многтабличные удаления
| Код — Многотабличные удаления |
| mysql> DELETEt1FROMnomenclatureASt1JOINnomenclatureASt2USING(id) WHEREt2.id > 10; QueryOK, 0rowsaffected (0.02sec) |
Следует помнить, что при использовании многотабличных запросов на удаление или обновление данных, нельзя включать в запрос конструкции ORDER BY и LIMIT. Впрочем, это ограничение очень эффективно обходится при помощи временных таблиц, просто, надо это учитывать при модификации однотабличных запросов.
Изменение функций
Вы можете изменять функцию с помощью оператора ALTER FUNCTION. Общий вид для каждого варианта функции отличается. Давайте рассмотрим каждый из них.
1. Общий вид команды изменения скалярной функции:
ALTER FUNCTION function_name
( } ] )
RETURNS scalar_return_data_type
]
BEGIN
function_body
RETURN scalar_expression
END
2. Общий вид изменения функции, возвращающей таблицу:
ALTER FUNCTION function_name
( } ] )
RETURNS TABLE
]
RETURN select-stmt
3. Общий вид команды изменения функции с множеством операторов, возвращающей таблицу.
ALTER FUNCTION function_name
( } ] )
RETURNS @return_variable TABLE
]
BEGIN
function_body
RETURN
END
::=
{ ENCRYPTION | SCHEMABINDING }
:: =
( { column_definition | table_constraint } )
Следующий пример показывает упрощенный вариант команды, изменяющей функцию:
ALTER FUNCTION dbo.tbPeoples AS -- эовое тело функции
Notes
Следующие шаги происходят во время выполнения .
-
Выполнять любые триггеры для всех указанных действий, независимо от того, совпадают ли их предложения .
-
Выполните объединение исходной и целевой таблиц.Результирующий запрос будет оптимизирован обычным образом и выдаст набор строк с изменениями-кандидатами.Для каждой строки-кандидата изменений,
-
Оцените, является ли каждая строка или .
-
Проверяйте каждое условие в указанном порядке,пока одно из них не вернет true.
-
Когда условие возвращает истину,выполните следующие действия:
-
Выполните все триггеры , которые срабатывают для типа события действия.
-
Выполните указанное действие,вызывая любые проверочные ограничения на целевой таблице.
-
Выполните все триггеры , которые срабатывают для типа события действия.
-
-
-
Выполнять любые триггеры для указанных действий, независимо от того, происходят они на самом деле или нет. Это похоже на поведение , которая не изменяет ни одной строки.
Таким образом, триггеры операторов для типа события (скажем, ) будут запускаться всякий раз, когда мы указываем действие такого типа. Напротив, триггеры уровня строки будут срабатывать только для определенного типа выполняемого события . Таким образом, команда может запускать триггеры инструкций как для , так и для , даже если были запущены только триггеры строки .
Вы должны убедиться, что объединение создает не более одной строки изменения кандидата для каждой целевой строки. Другими словами, целевая строка не должна присоединяться к более чем одной строке источника данных. Если это так, то для изменения целевой строки будет использоваться только одна из строк изменения-кандидата; последующие попытки изменить строку вызовут ошибку. Это также может произойти, если триггеры строк вносят изменения в целевую таблицу, а строки, измененные таким образом, впоследствии также изменяются с помощью . Если повторяющееся действие является , это приведет к нарушению уникальности, а повторное или приведет к нарушению кардинальности; последнее поведение требуется стандартом SQL. Это отличается от исторического поведения соединений PostgreSQL в .и операторы , в которых вторая и последующие попытки изменить одну и ту же строку просто игнорируются.
Если в предложении отсутствует подпредложение , оно становится последним достижимым предложением такого типа ( или ). Если указано более позднее предложение такого типа, оно будет доказуемо недостижимым, и возникнет ошибка. Если не указано окончательное достижимое предложение любого типа, возможно, что для строки изменения-кандидата не будет предпринято никаких действий.
Порядок, в котором строки генерируются из источника данных, по умолчанию не определен. Source_query использовать для указания согласованного порядка, если это необходимо, что может понадобиться, чтобы избежать взаимоблокировок между параллельными транзакциями.
нет предложения . Действия , и не могут содержать предложения или .
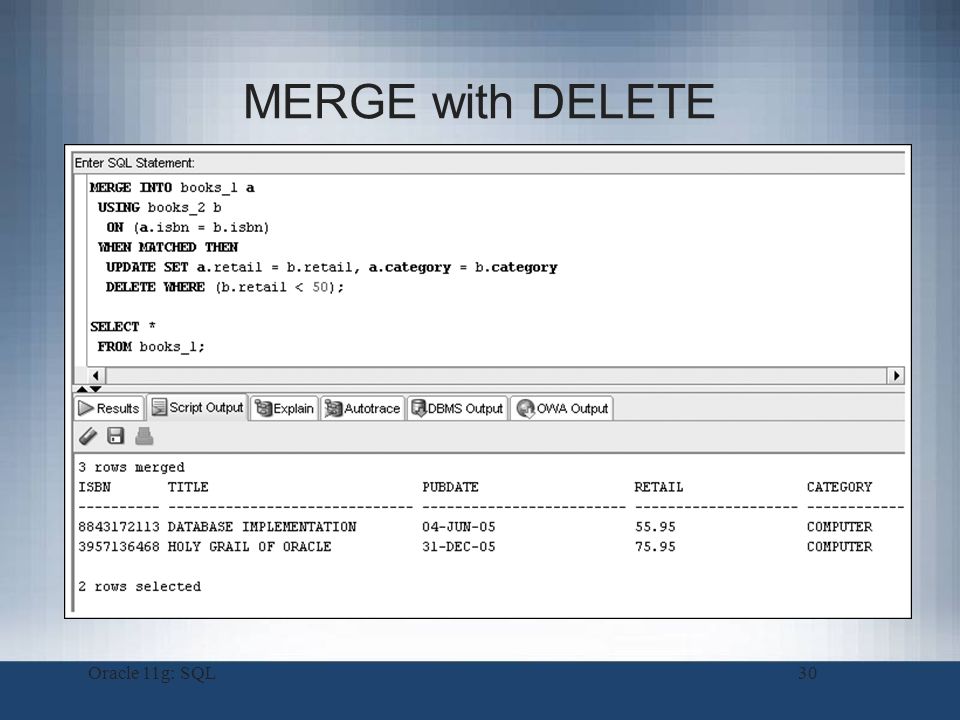
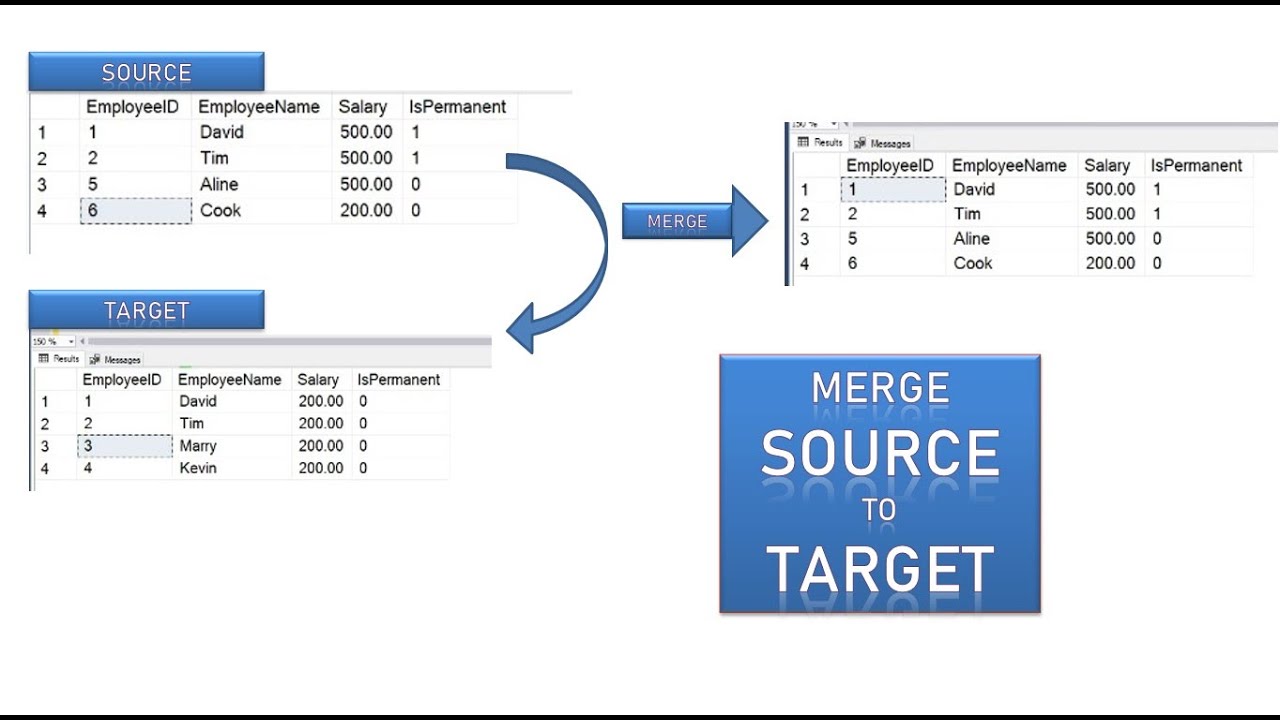
Using MERGE to update matched rows
WHEN MATCHED clause in SQL Server MERGE statement is used to update, delete the rows in the target table when the rows are matched with the source table based on the join condition. In this case, Locations is the target table, Locations_stage is the source table and the column LocationID is used in the join condition. Please refer to the below T-SQL script for updating matched rows using WHEN MATCHED clause.
|
1 |
MERGELocationsT USINGLocations_stageSONT.LocationID=S.LocationID WHENMATCHEDTHEN UPDATESETLocationName=S.LocationName; |
Rows with LocationID 1 and 3 are matched in the target and source table as per the join condition and the value of LocationName in the target was updated with the value of LocationName in the source table for both rows.
We can also use additional search condition along with “WHEN MATCHED” clause in SQL Server MERGE statement to update only rows that match the additional search condition.
|
1 |
IFEXISTS(SELECT1FROMSYS.TABLESwherename=’Locations_stage’) BEGIN DROPTABLELocations_stage END IFEXISTS(SELECT1FROMSYS.TABLESwherename=’Locations’) BEGIN DROPTABLELocations END CREATETABLEdbo.Locations( LocationIDintNULL, LocationNamevarchar(100)NULL ) GO CREATETABLEdbo.Locations_stage( LocationIDintNULL, LocationNamevarchar(100)NULL ) GO INSERTINTOLocationsvalues(1,’Richmond Road’),(2,’Brigade Road’),(3,’Houston Street’) INSERTINTOLocations_stagevalues(1,’Richmond Cross’),(3,’Houston Street’),(4,’Canal Street’) MERGELocationsT USINGLocations_stageSONT.LocationID=S.LocationID WHENMATCHEDANDT.LocationID=3THEN UPDATESETLocationName=S.LocationName; select*fromLocations |
We can see that the merge statement did not update the row with LocationID 1 as it did not satisfy the additional search condition specified along with the WHEN MATCHED clause.
At most, we can specify only two WHEN MATCHED clauses in the MERGE statement. If two WHEN MATCHED clauses are specified, one clause must have an update operation and the other one must use delete operation. Please refer to below T-SQL script for the example for the MERGE statement with two WHEN MATCHED clauses.



|
1 |
IFEXISTS(SELECT1FROMSYS.TABLESwherename=’Locations_stage’) BEGIN DROPTABLELocations_stage END IFEXISTS(SELECT1FROMSYS.TABLESwherename=’Locations’) BEGIN DROPTABLELocations END CREATETABLEdbo.Locations( LocationIDintNULL, LocationNamevarchar(100)NULL ) GO CREATETABLEdbo.Locations_stage( LocationIDintNULL, LocationNamevarchar(100)NULL ) GO INSERTINTOLocationsvalues(1,’Richmond Road’),(2,’Brigade Road’),(3,’Houston Street’) INSERTINTOLocations_stagevalues(1,’Richmond Cross’),(3,’Houston Street’),(4,’Canal Street’) MERGELocationsT USINGLocations_stageSONT.LocationID=S.LocationID WHENMATCHEDANDT.LocationID=3THEN DELETE WHENMATCHEDANDT.LocationID=1THEN UPDATESETLocationName=S.LocationName; |
Note: We cannot use the same DML operation in both WHEN MATCHED clauses.
When there is more than one row in the source table that matches the join condition, the update in SQL Server MERGE statement fails and returns error “The MERGE statement attempted to UPDATE or DELETE the same row more than once. This happens when a target row matches more than one source row. A MERGE statement cannot UPDATE/DELETE the same row of the target table multiple times. Refine the ON clause to ensure a target row matches at most one source row, or use the GROUP BY clause to group the source rows.”
|
1 |
IFEXISTS(SELECT1FROMSYS.TABLESwherename=’Locations_stage’) BEGIN DROPTABLELocations_stage END IFEXISTS(SELECT1FROMSYS.TABLESwherename=’Locations’) BEGIN DROPTABLELocations END CREATETABLEdbo.Locations( LocationIDintNULL, LocationNamevarchar(100)NULL ) GO CREATETABLEdbo.Locations_stage( LocationIDintNULL, LocationNamevarchar(100)NULL ) GO INSERTINTOLocationsvalues(1,’Richmond Road’),(2,’Brigade Road’),(3,’Houston Street’) INSERTINTOLocations_stagevalues(1,’Richmond Cross’),(3,’Houston Street’),(4,’Canal Street’),(1,’James Street’) MERGELocationsT USINGLocations_stageSONT.LocationID=S.LocationID WHENMATCHEDTHEN UPDATESETLocationName=S.LocationName; |
Описание табличных переменных MS SQL Server
Табличные переменные – это переменные с особым типом данных TABLE, которые используются для временного хранения результирующего набора данных в виде строк таблицы. Появились они еще в 2005 версии SQL сервера. Использовать такие переменные можно и в хранимых процедурах, и в функциях, и в триггерах, и в обычных SQL пакетах. Создаются табличные переменные так же, как и обычные переменные, путем их объявления инструкцией DECLARE.
Переменные такого типа предназначены в качестве альтернативы временным таблицам. Если говорить о том, что лучше использовать табличные переменные или временные таблицы, то однозначного ответа нет, у табличных переменных есть и плюсы, и минусы. Например, лично мне нравиться использовать табличные переменные, потому что их удобно создавать (т.е. объявлять) и не нужно думать об их удалении или очищение в конце инструкции, так как они автоматически очищаются (как и обычные переменные). Но при этом табличные переменные лучше использовать только тогда, когда Вы собираетесь хранить в них небольшой объём данных, в противном случае рекомендуется использовать временные таблицы.
Преимущества табличных переменных в Microsoft SQL Server
- Табличные переменные ведут себя как локальные переменные. Они имеют точно определенную область применения;
- Табличные переменные автоматически очищаются в конце инструкции, где они были определены;
- При использовании табличных переменных в хранимых процедурах повторные компиляции происходят реже, чем при использовании временных таблиц;
- Транзакции с использованием переменных TABLE продолжаются только во время процесса обновления соответствующей переменной. За счет этого табличные переменные реже подвергаются блокировке и требуют меньше ресурсов для ведения журналов регистрации.
Недостатки табличных переменных в MS SQL Server
- Запросы, которые изменяют переменные TABLE, не создают параллельных планов выполнения запроса;
- Переменные TABLE не имеют статистики распределения и не запускают повторных компиляций, поэтому рекомендуется использовать их для небольшого количества строк;
- Табличные переменные нельзя изменить после их создания;
- Табличные переменные нельзя создавать путем инструкции SELECT INTO;
- Переменные TABLE не изменяются в случае откатов транзакций, так как имеют ограниченную область действия и не являются частью постоянных баз данных.
Merge Conditions
Let’s go over what the various conditions mean:
MATCHED – these are rows satisfying the match condition. They are common to both the source and target tables. In our diagram, they are shown as green. When you use this condition in a merger statement you; most like being updating the target row columns with sourceTable column values.
NOT MATCHED – This is also known as NOT MATCHED BY TARGET; these are rows from the source table that didn’t match any rows in the target table. These rows are represented by the blue area above. In most cases that can be used to infer that the source Rows should be added to the targetTable.
NOT MATCHED BY SOURCE – these are rows in the target table that were never match by a source record; these are the rows in the orange area. If your aim is to completely synchronize the targetTable data with the source, then you’ll use this match condition to DELETE rows.
If you’re having trouble understanding how this works, consider the merge condition is like a join condition. ROWS in the green section represent rows that match the merge condition, rows in the blue section are those rows found in the SourceTable, but not in the target. The rows in the orange section are those rows found only in the target.
Give these matching scenarios, you’re able to easily incorporate add, remove, and update activities into a single statement to synchronize changes between two tables.
Let’s look at an Example.
Синтаксис
Есть два синтаксиса, которые вы можете использовать для создания комментария в SQL.
Синтаксис использования символов (два тире)
Синтаксис для создания комментария в SQL с использованием символов .
здесь пишется комментарий
Комментарий, начинающийся с символов , должен находиться в конце строки в вашем операторе SQL с разрывом строки после него. Этот метод комментирования может занимать только одну строку в вашем SQL и должен находиться в конце строки.
Синтаксис использования символов и
Синтаксис для создания комментария в SQL с использованием символов и . здесь пишется комментарий
Комментарий, который начинается с символа и заканчивается и может находиться в любом месте вашего SQL оператора. Этот метод комментирования может занимать несколько строк в вашем SQL.