Управление пользователями
В PostgreSQL используется концепция ролей. Одну роль можно рассматривать как отдельного пользователя или как группу пользователей. Роли могут владеть объектами БД и выдавать разрешения другим ролям.
По умолчанию была создана роль postgres. Давайте создадим еще одну роль. Для этого из консоли системы выполняем команду:
createuser -P --interactive
Система запросит имя для новой роли, пароль, а также позволит настроить привилегии — например, нужно ли давать права суперпользователя или разрешать создавать другие роли и базы данных.
Если вы уже зашли в psql, то создать новую роль можно командой:
CREATE ROLE имя_новой_роли WITH LOGIN CREATEDB CREATEROLE; // В конце обязательно ставим ;
Затем задаем пароль:
\password имя_роли
Вывести список всех ролей можно командой /du. Кроме имен отобразятся привилегии каждого роли.
Чтобы закрыть список ролей, выполняем команду q.
Для удаления пользователя выполняем команду:
DROP ROLE имя_роли;
Это можно также сделать из консоли системы с помощью команды:
drop user имя_роли
Чтоб сменить пароль пользователя, подключаемся к psql с правами суперпользователя. Затем выполняем следующую команду:
ALTER USER имя_роли WITH PASSWORD 'новый_пароль';
Эта операция сохраняется в файле .psql_history вместе с паролем, который не будет зашифрован. В качестве дополнительной меры безопасности эту запись рекомендуется удалить. Файл обычно находится в директории /var/lib/postgresql.
Импорт и экспорт данных в PostgreSQL, гайд для начинающих
В процессе обучения аналитике данных у человека неизбежно возникает вопрос о миграции данных из одной среды в другую. Поскольку одним из необходимых навыков для аналитика данных является знание SQL, а одной из наиболее популярных СУБД является PostgreSQL, предлагаю рассмотреть импорт и экспорт данных на примере этой СУБД.
В своё время, столкнувшись с импортом и экспортом данных, обнаружилось, что какой-то более-менее структурированной инфы мало: этот момент обходят на всяких там курсах по аналитике, подразумевая, что это очень простые моменты, которым не следует уделять внимание. В данной статье приведены примеры импорта в PostgreSQL непосредственно самой базы данных в формате sql, а также импорта и экспорта данных в наиболее простом и распространенном формате .csv, в котором в настоящее время хранятся множество существующих датасетов
Формат .json хоть и является также очень распространенным, рассмотрен не будет, поскольку, по моему скромному мнению, с ним все-таки лучше работать на Python, чем в SQL
В данной статье приведены примеры импорта в PostgreSQL непосредственно самой базы данных в формате sql, а также импорта и экспорта данных в наиболее простом и распространенном формате .csv, в котором в настоящее время хранятся множество существующих датасетов. Формат .json хоть и является также очень распространенным, рассмотрен не будет, поскольку, по моему скромному мнению, с ним все-таки лучше работать на Python, чем в SQL.
1. Импорт базы данных в формате в PostgreSQL
Скачиваем (получаем из внутреннего корпоративного источника) файл с базой данных в выбранную папку. В данном случае путь:
Имя файла: demo-big-20170815
Далее понадобиться командная строка windows или SQL shell (psql). Для примера воспользуемся cmd. Переходим в каталог, где находится скачанная БД, командой cd C:\Users\User-N\Desktop\БД :
Далее выполняем команду для загрузки БД из sql-файла:
«C:\Program Files\PostgreSQL\10\bin\psql» -U postgres -f demo-big-20170815.sql
Где сначала указывается путь, по которому установлен PostgreSQL на компьютере, -U – имя пользователя, -f — название файла БД.
Отметим, что в зависимости от размера базы данных загрузка может занимать до нескольких десятков минут. Конец загрузки будет отмечен следующим видом:
Заходим в pgAdmin и наблюдаем там импортированную БД:
2. Импорт данных из csv-файла
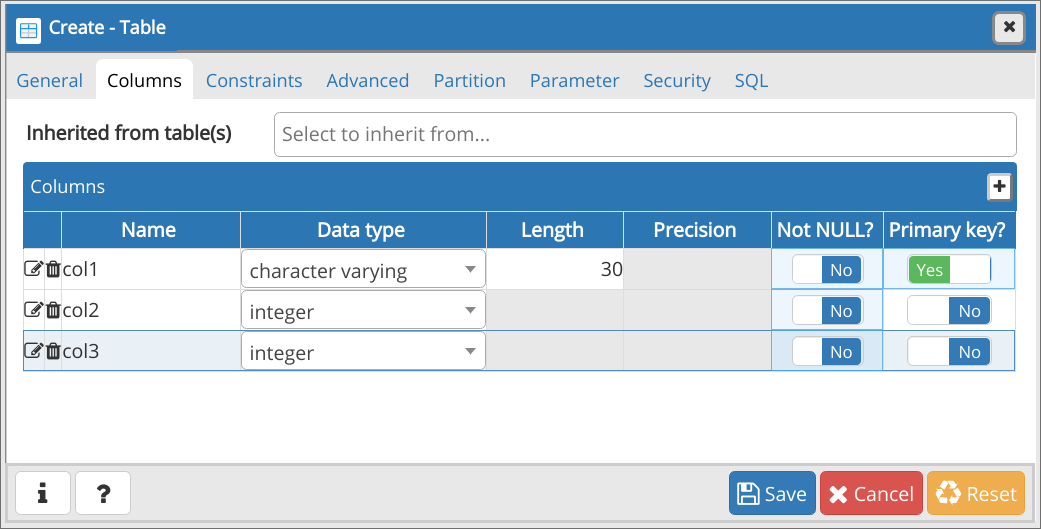
Предполагается, что у вас уже есть необходимый .csv-файл, и первое, что нужно сделать, это перейти pgAdmin и создать там новую базу данных. Ну или воспользоваться уже существующей, в зависимости от текущих нужд. В данном случае была создана БД airtickets.
В выбранной БД создается таблица с полями, типы которых должны соответствовать «колонкам» в выбранном .csv-файле.
Далее воспользуемся SQL shell (psql) для подключения к нужной БД и для подачи команд на импорт данных. При открытии SQL shell (psql) она стандартно спросит про имя сервера, имя подключаемой БД, порт и пользователя. Ввести нужно только имя БД и пароль пользователя, всё остальное проходим нажатием ентра. Создается подключение к нужной БД – airtickets.
Ну и вводим команды на импорт данных из файла:
\COPY tickets FROM ‘C:\Users\User-N\Desktop\CSV\ticket_dataset_MOW.csv’ DELIMITER ‘,’ CSV HEADER;
Где tickets – название созданной в БД таблицы, из – путь, где хранится .csv-файл, DELIMITER ‘,’ – разделитель, используемый в импортируемом .csv-файле, сам формат файла и HEADER , указывающий на заголовки «колонок».
Один интересный момент. Написание команды COPY строчными (маленькими) буквами привело к тому, что psql ругнулся, выдал ошибку и предложил написать команду прописными буквами.
Заходим в pgAdmin и удостоверяемся, что данные были загружены.
3. Экспорт данных в .csv-файл
Предположим, нам надо сохранить таблицу airports_data из уже упоминаемой выше БД demo.
Для этого подключимся к БД demo через SQL shell (psql) и наберем команду, указав уже знакомые параметры разделителя, типа файла и заголовка:
\COPY airports_data TO ‘C:\Users\User-N\Desktop\CSV\airports.csv’ DELIMITER ‘,’ CSV HEADER;
Существует и другой способ экспорта через pgAdmin: правой кнопкой мыши по нужной таблице – экспорт – указание параметров экспорта в открывшемся окне.
4. Экспорт данных выборки в .csv-файл
Иногда возникает необходимость сохранить в .csv-файл не полностью всю таблицу, а лишь некоторые данные, соответствующие некоторому условию. Например, нам нужно из БД demo таблицы flights выбрать поля flight_id, flight_no, departure_airport, arrival_airport, где departure_airport = ‘SVO’. Данный запрос можно вставить сразу в команду psql:
Восстановление
Может понадобиться создать базу данных. Это можно сделать SQL-запросом:
=# CREATE DATABASE users WITH ENCODING=’UTF-8′;
* где users — имя базы; UTF-8 — используемая кодировка.
Если мы получим ошибку:
ERROR: encoding «UTF8» does not match locale «en_US»
DETAIL: The chosen LC_CTYPE setting requires encoding «LATIN1».
Указываем больше параметров при создании базы:
CREATE DATABASE users WITH OWNER ‘postgres’ ENCODING ‘UTF8’ LC_COLLATE = ‘ru_RU.UTF-8’ LC_CTYPE = ‘ru_RU.UTF-8’ TEMPLATE = template0;


Синтаксис:
psql <имя базы> < <файл с дампом>
Пример:
psql users < /tmp/users.dump
С авторизацией
При необходимости авторизоваться при подключении к базе вводим:
psql -U dmosk -W users < /tmp/users.dump
* где dmosk — имя учетной записи; опция W потребует ввода пароля.
Из файла gz
Сначала распаковываем файл, затем запускаем восстановление:
gunzip users.dump.gz
psql users < users.dump
Или одной командой:
zcat users.dump.gz | psql users
Определенную базу
Если резервная копия делалась для определенной базы, запускаем восстановление:
psql users < /tmp/database.dump
Если делался полный дамп (всех баз), восстановить определенную можно при помощи утилиты pg_restore с параметром -d:
pg_restore -d users cluster.bak
Определенную таблицу
Если резервная копия делалась для определенной таблицы, можно просто запустить восстановление:
psql users < /tmp/students.dump
Если делался полный дамп, восстановить определенную таблицу можно при помощи утилиты pg_restore с параметром -t:
pg_restore -a -t students users.dump
С помощью pgAdmin
Запускаем pgAdmin — подключаемся к серверу — кликаем правой кнопкой мыши по базе, для которой хотим восстановить данные — выбираем Восстановить:
Выбираем наш файл с дампом:
И кликаем по Восстановить:
Использование pg_restore
Данная утилита предназначена для восстановления данных не текстового формата (в одном из примеров создания копий мы тоже делали резервную копию не текстового формата).
Из бинарника:
pg_restore -Fc users.bak
Из тарбола:
pg_restore -Ft users.tar
С созданием новой базы:
pg_restore -Ft -C users.tar
Мы можем использовать опцию d для указания подключения к конкретному серверу и базе, например:
pg_restore -d «postgresql://dmosk_user:dmosk_pass@localhost/dmosk_base» -Fc users.bak
* в данном примере мы подключимся к локальной базе (localhost) с названием dmosk_base от пользователя dmosk_user с паролем dmosk_pass.
Мета-команды PostgreSQL
Теперь, когда ты все настроил и готов приступить к работе с базой данных, осталось разобрать несколько мета-команд.
Это не SQL запросы, а команды специфичные для PostgreSQL.
В других системах управления базами данных есть их аналоги, но их синтаксис немного отличается.
Всем мета-командам предшествует обратная косая черта , за которой следует фактическая команда.
Список всех баз данных
Чтобы получить список всех баз данных на сервере, ты можешь использовать команду .
Ввод этой мета-команды в оболочке Postgres выведет:
Это список всех имеющихся баз данных и служебная информация, такая как владелец базы данных, кодировка и права доступа.
На данный момент мы пока ничего не создали, а базы данных которые ты видишь на экране — создаются по умолчанию при установке Postgres.
- postgres — это просто пустая база данных.
- «template0» и «template1» — это служебные базы данных, которые служат шаблоном для создания новых баз.
Тебе пока не стоит беспокоиться о них. Если хочешь изучить все детали, то проверь официальную документацию.
Подключаемся к базе данных PostgreSQL
Некоторые команды SQL требуют, чтобы ты сначала вошел в базу данных (например, для создания новой таблицы).
Ты можешь выбрать, в какую базу данных входить, при запуске SQL Shell.
Когда ты находишься внутри оболочки (shell), то можешь использовать команду (или ), за которой следует имя
базы данных. Если бы у тебя была другая база данных под названием , то подключиться к ней можно было бы так:
Полностью в терминале у тебя получится что-то такое:
Обрати внимание, что приглашение оболочки изменилось с на. Это значит, что теперь ты
подключен к базе данных , а не
Получить список всех таблиц в базе данных
Как и в случае со списком существующих баз данных, ты можешь получить список таблиц внутри конкретной базы данных
с помощью команды .
Перед выполнением этой команды вам необходимо войти в базу данных.
Предположим, ты уже находишься внутри базы , и в ней есть таблица с именем. Набрав , ты
получишь следующее:
Ты можешь увидеть имя таблицы и некоторую другую информацию, такую как схема (мы обсудим схемы в более сложных
руководствах) и владельца.
Владелец (owner) — это пользователь, который создал таблицу.
Если ты создаешь других пользователей и используешь их для создания таблиц, то в последнем столбце будут именно они.
Список пользователей и ролей
Как ты уже знаешь, при установке Postgres создается суперпользователь с именем .
Список всех пользователей базы данных можно вывести на экран используя команду .




Обрати внимание, что первый столбец называется — роль (role name).
И весь вывод на экран называется “список ролей” (List of roles), а не список пользователей. В PostgreSQL пользователи и роли практически
одинаковы
В PostgreSQL пользователи и роли практически
одинаковы.
У ролей есть атрибуты, которые определяют их разрешения, такие как создание баз данных или даже создание
других новых ролей.
Любая роль с атрибутом LOGIN может рассматриваться, как пользователь.
Здесь мы видим только одну роль, суперпользователя по умолчанию.
В реальном мире все будет иначе, потому что использовать только суперпользователя все время опасно.
Вместо этого создают другие роли с меньшими привилегиями.
Это гарантирует, что никто не совершит нежелательных действий по ошибке.
Если у одной из ролей есть доступ только на чтение данных, то с помощью этой роли будет невозможно удалить таблицу или поле.
Шаг 2 — Настройка pgAdmin 4
Хотя pgAdmin был установлен на сервере, осталось несколько шагов, которые нужно выполнить, чтобы гарантировать, что в наличии все разрешения и конфигурации, необходимые для правильной работы с веб-интерфейсом.
Основной файл конфигурации pgAdmin с именем считывается перед любым другим файлом конфигурации. Его содержание можно использовать в качестве отправной точки для последующих настроек конфигурации, которые можно указать в других файлах конфигурации pgAdmin, но чтобы избежать непредвиденных ошибок, вы не должны редактировать файл самостоятельно. Мы внесем некоторые изменения конфигурации в новый файл с именем , который будет считываться непосредственно после основного файла.
Создайте этот файл сейчас, используя текстовый редактор. Мы будем использовать :
environments/my_env/lib/python3.6/site-packages/pgadmin4/config_local.py
Вот что делают эти пять директив:
- : данная директива определяет файл, в котором будут храниться журналы pgAdmin.
- : pgAdmin хранит данные о пользователях в базе данных SQLite, и эта директива указывает программному обеспечению PgAdmin на базу данных конфигурации. Поскольку этот файл находится в постоянной директории , ваши пользовательские данные после обновления не будут потеряны.
- : указывает, какая директория будет использоваться для хранения данных сеанса.
- : определяет, где pgAdmin будет хранить другие данные, например резервные копии и сертификаты безопасности.
- : установка значения для этой директивы говорит о том, что pgAdmin должен запускаться в режиме сервера, а не в режиме настольного компьютера.
Обратите внимание, что каждый из этих путей файла указывает на директории, созданные на шаге 1. После добавления этих строк сохраните и закройте файл (нажмите , а затем нажмите и )
После внесения этих изменений запустите скрипт установки pgAdmin, чтобы задать учетные данные для входа:
После добавления этих строк сохраните и закройте файл (нажмите , а затем нажмите и ). После внесения этих изменений запустите скрипт установки pgAdmin, чтобы задать учетные данные для входа:
После запуска этой команды вы увидите запрос на ввод адреса электронной почты и пароля. Они будут служить вашими учетными данными для последующего доступа к pgAdmin, обязательно запомните их или запишите:
После этого необходимо деактивировать вашу виртуальную среду:
Воспользуйтесь путями файла, которые вы указали в файле . Эти файлы хранятся в директориях, созданных на шаге 1, которые в настоящее время принадлежат вашему пользователю без прав root. Однако они должны быть доступны для пользователя и группы, которые запускают ваш веб-сервер. По умолчанию в Ubuntu 18.04 это пользователь и группа www-data, поэтому необходимо обновить разрешения для следующих директорий, чтобы предоставить www-data нужные права владения:
После этого настройку pgAdmin можно считать выполненной. Однако программа еще не обслуживается на вашем сервере, поэтому она остается недоступной. Для устранения данной проблемы мы настроим Apache для обслуживания pgAdmin, чтобы вы могли получить доступ к интерфейсу пользователя через браузер.
Editing postgresql.conf and pg_hba.conf from pgAdmin3
You can edit configuration files directly from pgAdmin, provided that
you installed the adminpack extension on your server. PostgreSQL
one-click installers generally create the adminpack extension. If itâs
present, you should see the Server Configuration menu enabled, as shown
in .
Figure 4-5. PgAdmin3 configuration file editor
If the menu is grayed out and you are connected to a PostgreSQL
server, either you donât have the adminpack installed on that server or you are not logged in as a
superuser. To install the adminpack run the SQL statement or use
the graphical interface for installing extensions, as shown in . Disconnect from the server
and reconnect; you should see the menu enabled.
Что нужно учесть при настройке ОС?
PostgreSQL, как и большинство приложений, зависит от параметров операционной системы. Для СУБД это особенно критично: производительность может ощутимо снизиться при некорректной настройке параметров.
Ключевыми являются следующие настройки:
-
vm.swappines:
Так регулируется процент памяти, при котором система начинает использовать swap-файл – область на диске, которая может быть использована системой как очень медленная оперативная память.
-
vm.overcommit_memory / vm.overcommit_ratio
Убираем перевыделение памяти по умолчанию: в значении vm.overcommit_memory=0 происходит эвристический анализ для определения выделяемой процессу памяти. Это дополнительная трата ресурсов, а острая нехватка памяти и большая конкуренция запустит процесс OOM Killer, при этом вы получите сообщения: “Out of Memory: Killed process 12345 (postgres)”.
Избежать этого поможет контроль перевыделения. Рекомендуем установить значение vm.overcommit_memory=2. Имейте в виду, что после установки этого параметра большую роль начнет играть значение vm.overcommit_ratio (число будет определять процент памяти, доступный для перевыделения, например, 50 для 4 Гб = 6 Гб) и наличие SWAP-файла. Для vm.overcommit_ratio универсальных значений нет: его обычно вычисляют исходя из доступной памяти и объема SWAP — overcommit_ratio < (RAM — swap) / RAM * 100.
Утилиты (программы) PosgreSQL:
- createdb и dropdb – создание и удаление базы данных (соответственно)
- createuser и dropuser – создание и пользователя (соответственно)
- pg_ctl – программа предназначенная для решения общих задач управления (запуск, останов, настройка параметров и т.д.)
- postmaster – многопользовательский серверный модуль PostgreSQL (настройка уровней отладки, портов, каталогов данных)
- initdb – создание новых кластеров PostgreSQL
- initlocation – программа для создания каталогов для вторичного хранения баз данных
- vacuumdb – физическое и аналитическое сопровождение БД
- pg_dump – архивация и восстановление данных
- pg_dumpall – резервное копирование всего кластера PostgreSQL
- pg_restore – восстановление БД из архивов (.tar, .tar.gz)
Примеры создания резервных копий:
Создание бекапа базы mydb, в сжатом виде
pg_dump -h localhost -p 5440 -U someuser -F c -b -v -f mydb.backup mydb
Создание бекапа базы mydb, в виде обычного текстового файла, включая команду для создания БД
pg_dump -h localhost -p 5432 -U someuser -C -F p -b -v -f mydb.backup mydb
Создание бекапа базы mydb, в сжатом виде, с таблицами которые содержат в имени payments
pg_dump -h localhost -p 5432 -U someuser -F c -b -v -t *payments* -f payment_tables.backup mydb
Дамп данных только одной, конкретной таблицы. Если нужно создать резервную копию нескольких таблиц, то имена этих таблиц перечисляются с помощью ключа -t для каждой таблицы.
pg_dump -a -t table_name -f file_name database_name
Создание резервной копии с сжатием в gz
pg_dump -h localhost -O -F p -c -U postgres mydb | gzip -c > mydb.gz
Список наиболее часто используемых опций:
- -h host — хост, если не указан то используется localhost или значение из переменной окружения PGHOST.
- -p port — порт, если не указан то используется 5432 или значение из переменной окружения PGPORT.
- -u — пользователь, если не указан то используется текущий пользователь, также значение можно указать в переменной окружения PGUSER.
- -a, —data-only — дамп только данных, по-умолчанию сохраняются данные и схема.
- -b — включать в дамп большие объекты (blog’и).
- -s, —schema-only — дамп только схемы.
- -C, —create — добавляет команду для создания БД.
- -c — добавляет команды для удаления (drop) объектов (таблиц, видов и т.д.).
- -O — не добавлять команды для установки владельца объекта (таблиц, видов и т.д.).
- -F, —format {c|t|p} — выходной формат дампа, custom, tar, или plain text.
- -t, —table=TABLE — указываем определенную таблицу для дампа.
- -v, —verbose — вывод подробной информации.
- -D, —attribute-inserts — дамп используя команду INSERT с списком имен свойств.
Бекап всех баз данных используя команду pg_dumpall.
pg_dumpall > all.sql
Восстановление таблиц из резервных копий (бэкапов):
psql — восстановление бекапов, которые хранятся в обычном текстовом файле (plain text);
pg_restore — восстановление сжатых бекапов (tar);
Восстановление всего бекапа с игнорированием ошибок
psql -h localhost -U someuser -d dbname -f mydb.sql
Восстановление всего бекапа с остановкой на первой ошибке
psql -h localhost -U someuser —set ON_ERROR_STOP=on -f mydb.sql
Для восстановления из tar-арихива нам понадобиться сначала создать базу с помощью CREATE DATABASE mydb; (если при создании бекапа не была указана опция -C) и восстановить
pg_restore —dbname=mydb —jobs=4 —verbose mydb.backup
Восстановление резервной копии БД, сжатой gz
gunzip mydb.gz psql -U postgres -d mydb -f mydb
Перенос базы данных PostgreSQL с помощью экспорта и импорта
Можно извлечь базу данных PostgreSQL в файл сценария с помощью pg_dump и импортировать данные из этого файла в целевую базу данных с помощью psql.
Предварительные требования
Прежде чем приступить к выполнению этого руководства, необходимы следующие компоненты:
- с правилами брандмауэра, разрешающими доступ к этом серверу и его базам данных;
- установленная программа командной строки pg_dump;
- установленная программа командной строки psql.
Выполните приведенные ниже действия, чтобы экспортировать и импортировать базу данных PostgreSQL.
Создание файла сценария, содержащего загружаемые данные, с помощью pg_dump
Чтобы экспортировать имеющуюся базу данных PostgreSQL в локальную среду или на виртуальную машину в виде файла сценария SQL, выполните следующую команду:
Например, если имеется локальный сервер с базой данных testdb.
Импорт данных в целевую базу данных Azure для PostrgeSQL
Вы можете использовать командную строку psql с параметром —dbname (-d), чтобы импортировать данные в базу данных Azure для сервера PostrgeSQL и загрузить данные из SQL-файла.
Шаг 3 — Настройка Apache
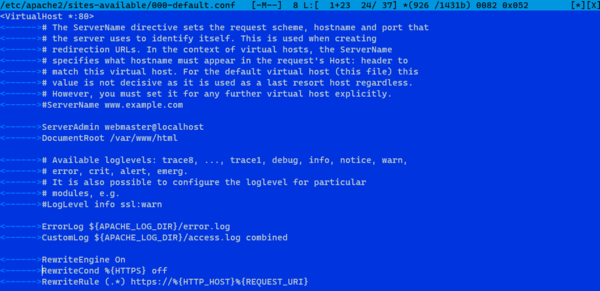
Веб-сервер Apache использует виртуальные хосты для инкапсуляции данных конфигурации и размещения сразу нескольких доменов на одном сервере. Если вы выполнили указания предварительного руководства для Apache, у вас уже может быть настроен пример виртуального хоста с именем , но на этом шаге мы создадим новый хост, откуда мы сможем обслуживать веб-интерфейс pgAdmin.
Сначала убедитесь, что вы находитесь в директории root:
Затем создайте новый файл в вашей директории с именем . Это будет файл виртуального хоста вашего сервера:
Добавьте следующее содержимое в файл, заменив выделенные части в соответствии с вашей собственной конфигурацией:
/etc/apache2/sites-available/pgadmin4.conf
Сохраните и закройте файл виртуального хоста. Затем воспользуйтесь скриптом для отключения файла виртуального хоста по умолчанию, :
Примечание: если вы выполнили требования предварительного руководства Apache, вы должны были отключить и настроить пример файла конфигурации виртуального хоста (с именем согласно требованиям). В этом случае вам нужно будет отключить файл виртуального хоста с помощью следующей команды:
Затем воспользуйтесь скриптом , чтобы активировать ваш файл виртуального хоста . В результате будет создана символьная ссылка из файла виртуального хоста в директории в директорию :
После этого проверьте на правильность синтаксис вашего файла конфигурации:
Если файл конфигурации в порядке, вы увидите сообщение . Если вы увидите ошибку в результатах, снова откройте файл и повторно проверьте, что ваш IP-адрес и пути файлов корректны, после чего запустите .


После появления вывода перезапустите службу Apache, чтобы она смогла прочитать ваш новый файл виртуального хоста:
pgAdmin теперь полностью установлен и настроен. Теперь мы перейдем к тому, как организовать доступ к pgAdmin из браузера, прежде чем подключать его к базе данных PostgreSQL.
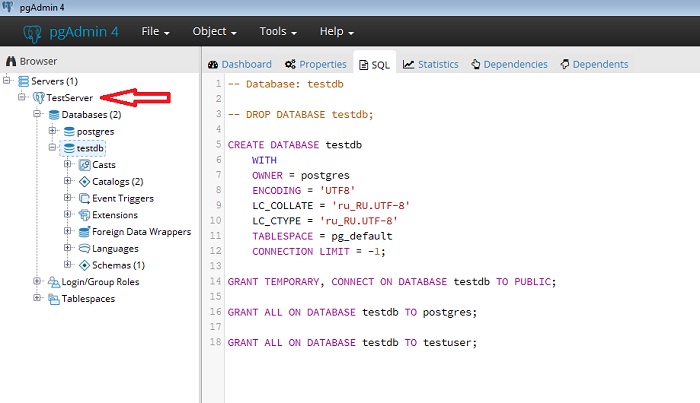
Создание дампа базы данных PostgreSQL в pgAdmin 4
Весь процесс переноса базы данных PostgreSQL достаточно простой, суть в следующем.
Нам необходимо создать копию нашей базы данных (дамп), затем создать пустую базу на нужном нам сервере и восстановить все данные, используя созданный ранее дамп.
Все это можно сделать с нашего клиентского компьютера, используя pgAdmin 4, если, конечно же, целевой сервер нам доступен, если недоступен, то придётся каким-то другим образом переносить дамп базы данных на нужный сервер и, используя стандартные консольные утилиты, восстановить базу данных из дампа.
Кстати, стоит отметить, что pgAdmin 4 для экспорта/импорта баз данных использует как раз эти стандартные консольные утилиты, в частности pg_dump, pg_dumpall и pg_restore, которые по умолчанию входят в состав PostgreSQL.
pg_dump – утилита для экспорта баз данных PostgreSQL
pg_dumpall – утилита для экспорта кластера баз данных PostgreSQL (всех данных на сервере)
pg_restore – утилита восстановления баз данных PostgreSQL из файла архива
Таким образом, благодаря pgAdmin 4 нам не нужно писать и выполнять команды в командной строке, за нас все это делает pgAdmin 4, мы всего лишь будем пользоваться мышкой, настраивая все параметры в графическом интерфейсе.
Создать дамп базы данных PostgreSQL можно в нескольких форматах, в частности:
Специальный (Custom) – это пользовательский формат, который использует сжатие. Данный формат по умолчанию предлагается в pgAdmin 4 и рекомендован для средних и больших баз данных. Обычно архивные файлы в таком формате создают с расширением backup, однако можно использовать и другое расширение.
Tar (tar) – база данных выгружается в формат tar. Данный формат не поддерживает сжатие.
Простой (plain) – в данном случае база данных выгружается в обычный текстовый SQL-скрипт, в котором все объекты базы данных и непосредственно сами данные будут в виде соответствующих SQL инструкций. Данный скрипт можно легко отредактировать в любом текстовом редакторе и выполнить, используя Query Tool, как обычные SQL запросы. Данный формат рекомендован для небольших баз данных, а также для тех случаев, когда требуется внести изменения в дамп базы данных перед восстановлением.
Каталог (directory) – этот формат файла создает каталог, в котором для каждой таблицы и большого объекта будут созданы отдельные файлы, а также файл оглавления в машиночитаемом формате, понятном для утилиты pg_restore. Этот формат по умолчанию использует сжатие, а также поддерживает работу в несколько потоков.
В данном материале мы рассмотрим создание дампа в специальном формате, а также в формате обычного SQL скрипта, дело в том, что процесс восстановления базы данных из этих форматов в pgAdmin 4 немного отличается.
Создание дампа базы данных в сжатом формате
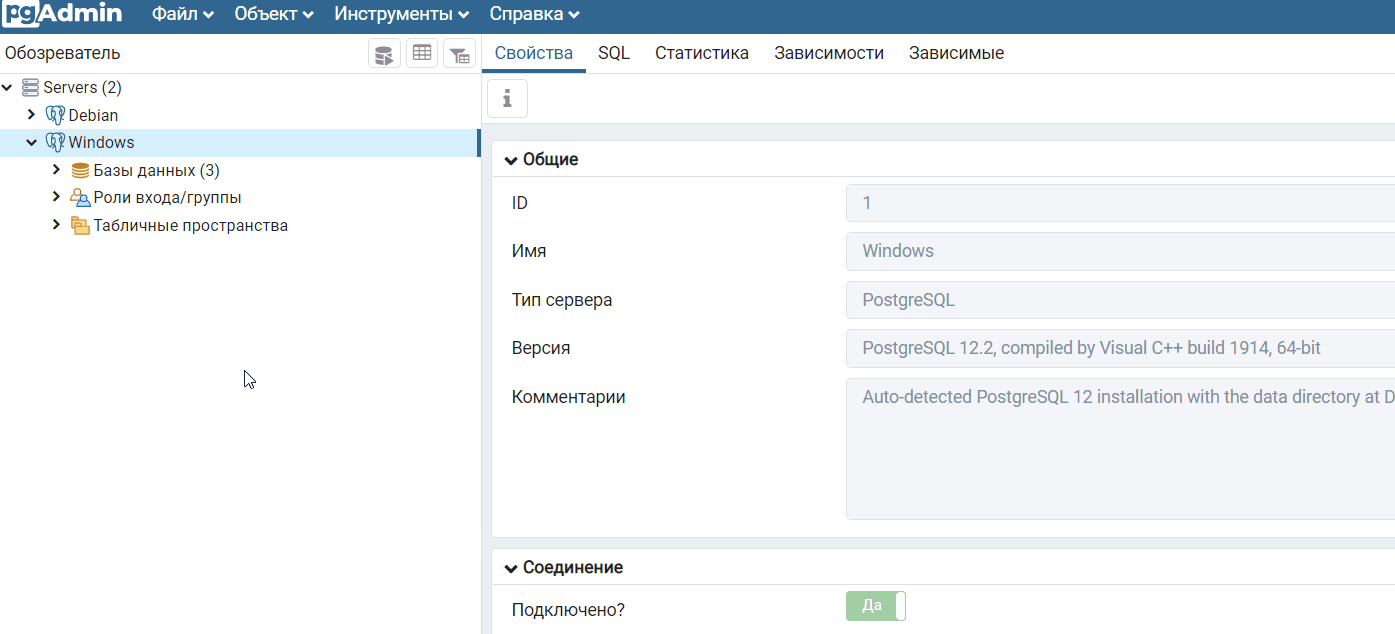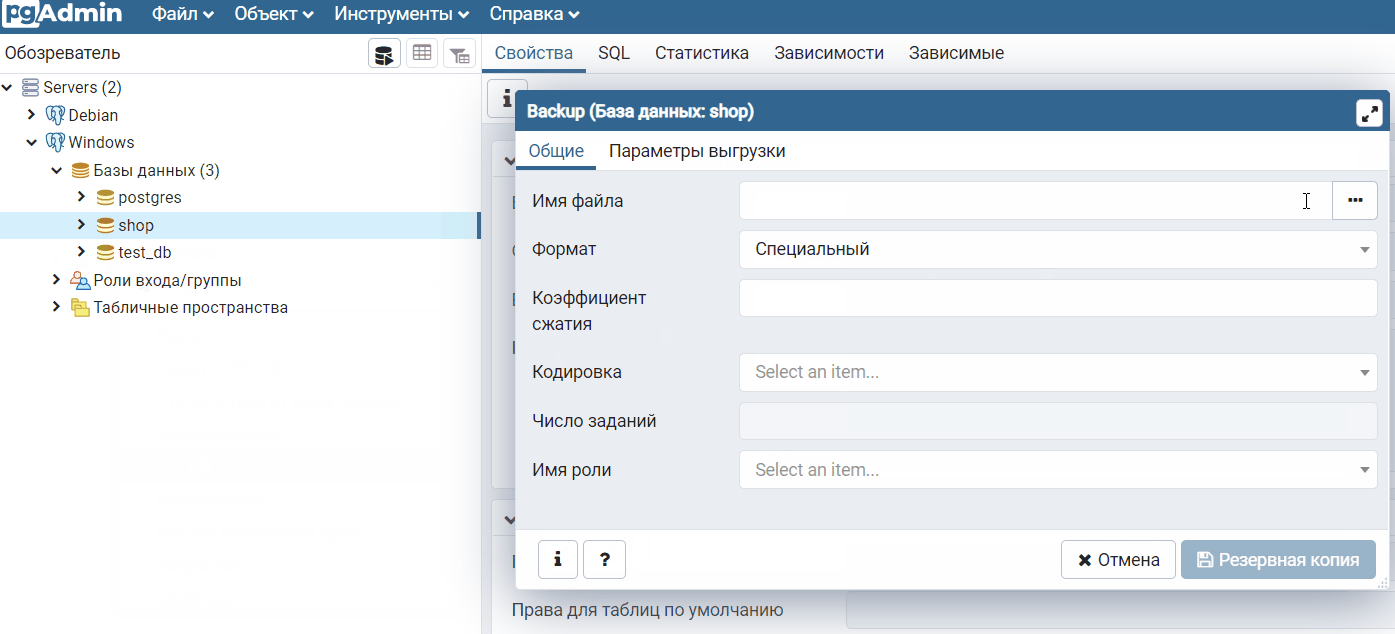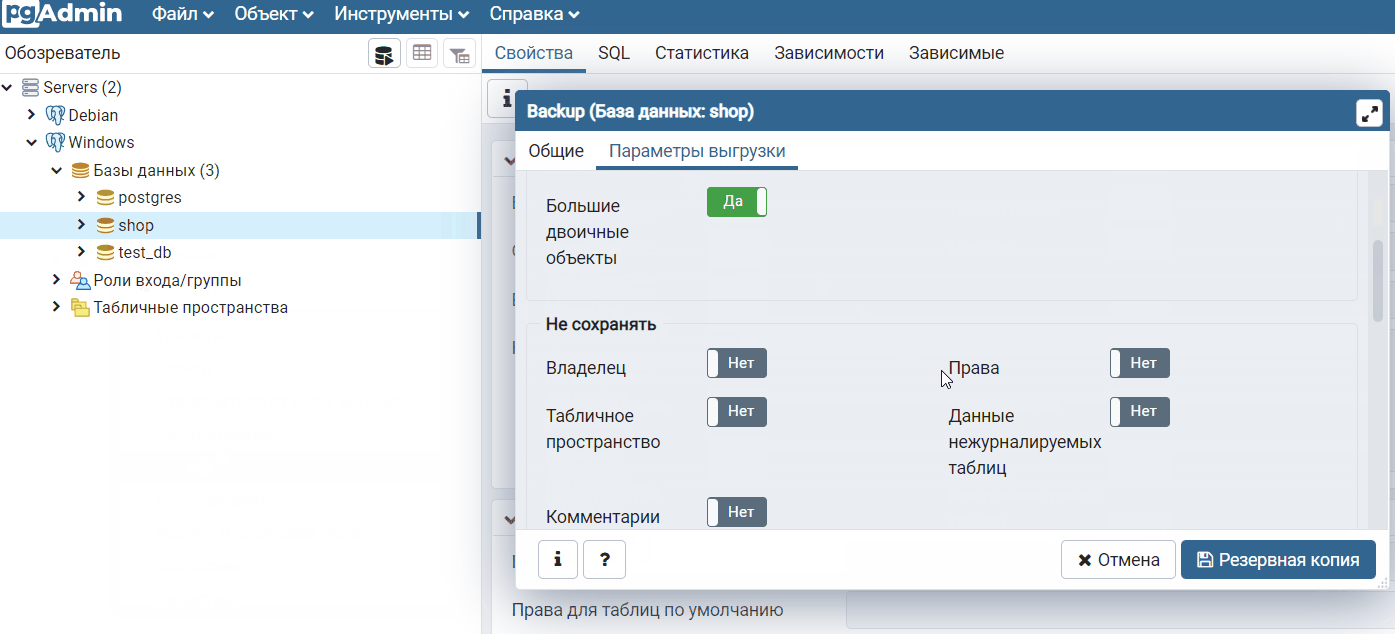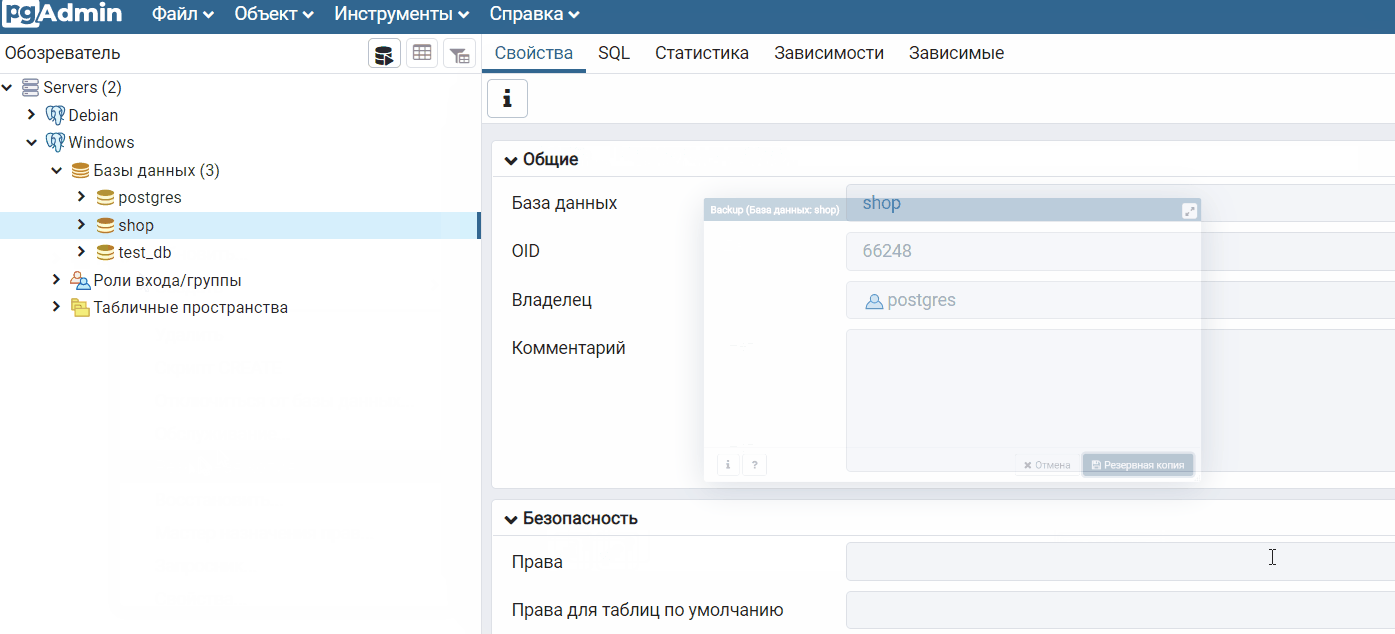
Чтобы создать дамп базы данных PostgreSQL в pgAdmin 4, необходимо в обозревателе выбрать нужную базу данных, я выбираю базу данных shop, далее необходимо вызвать контекстное меню правой кнопкой мыши и нажать на пункт «Резервная копия».
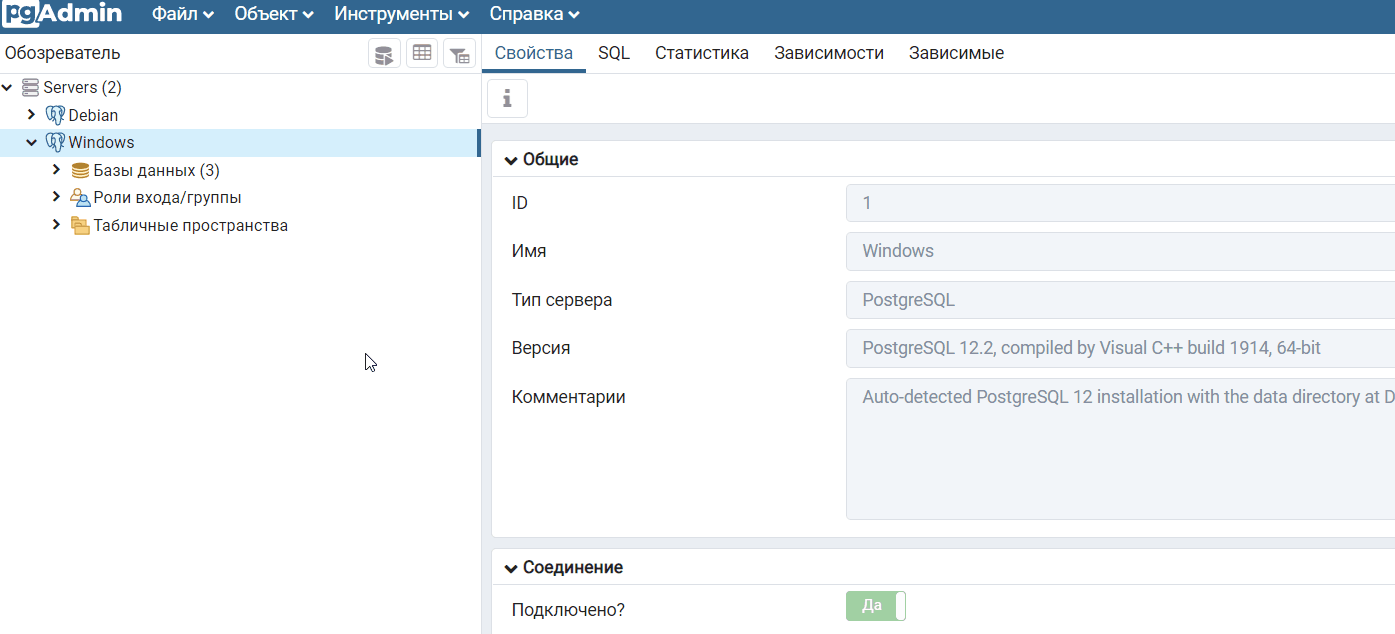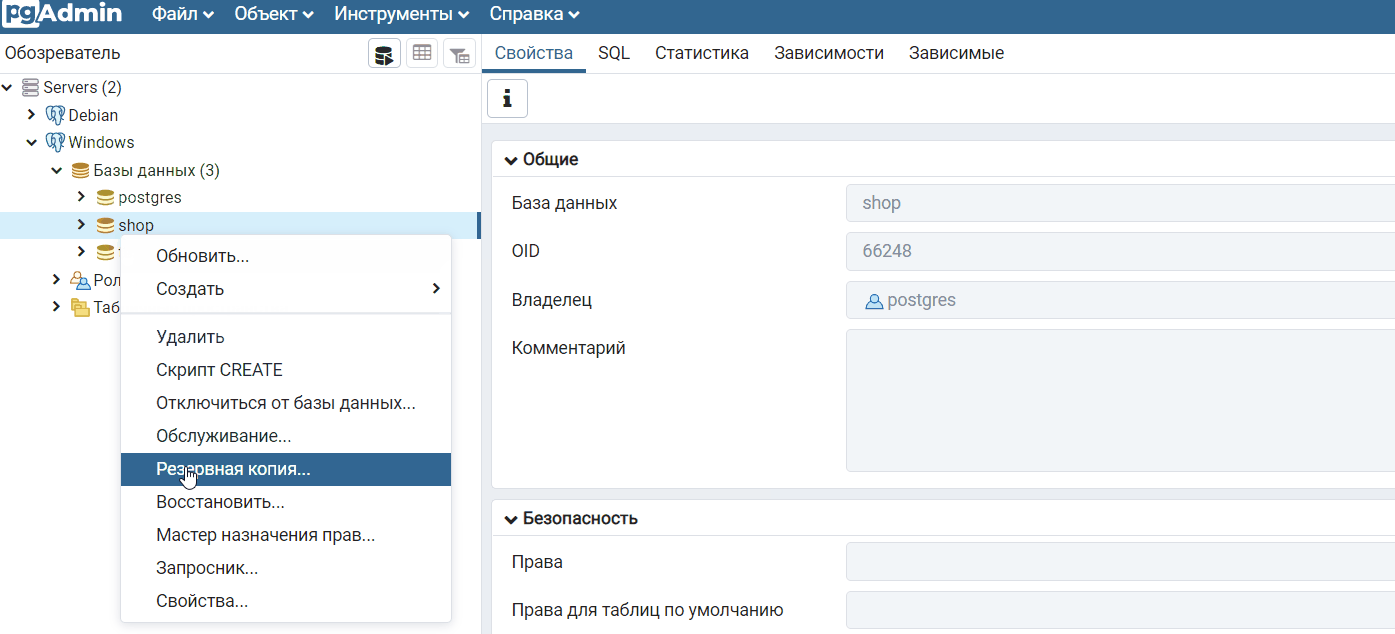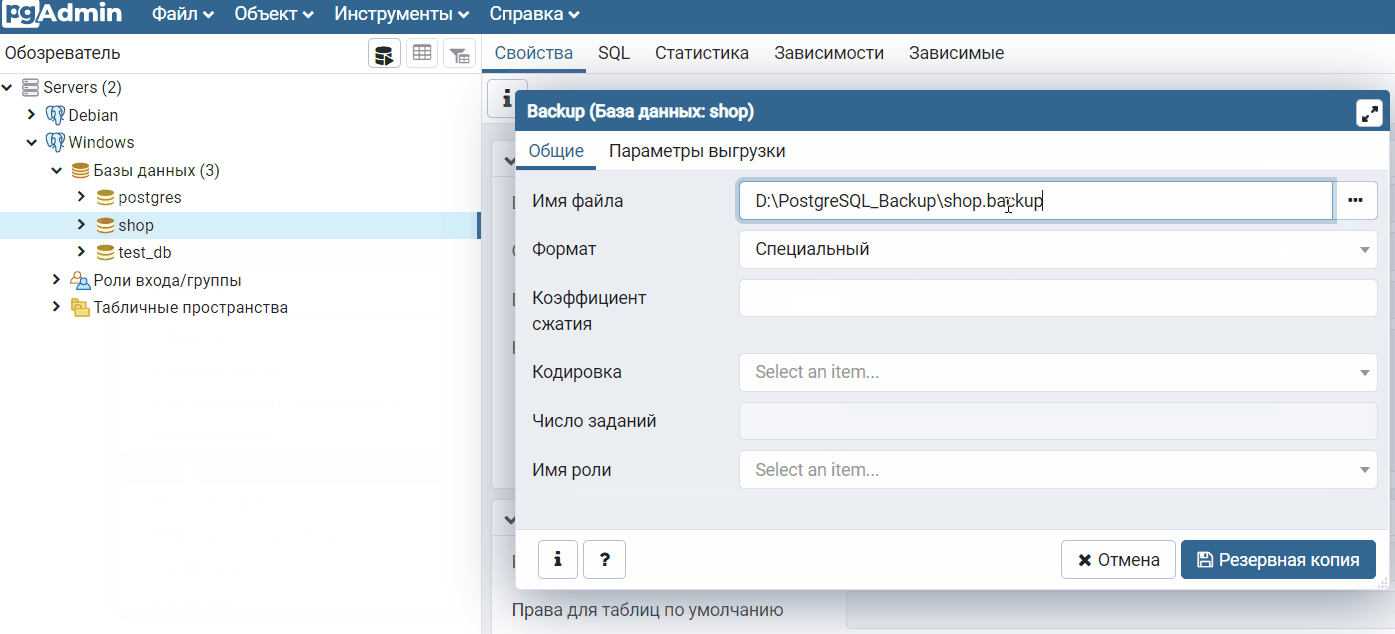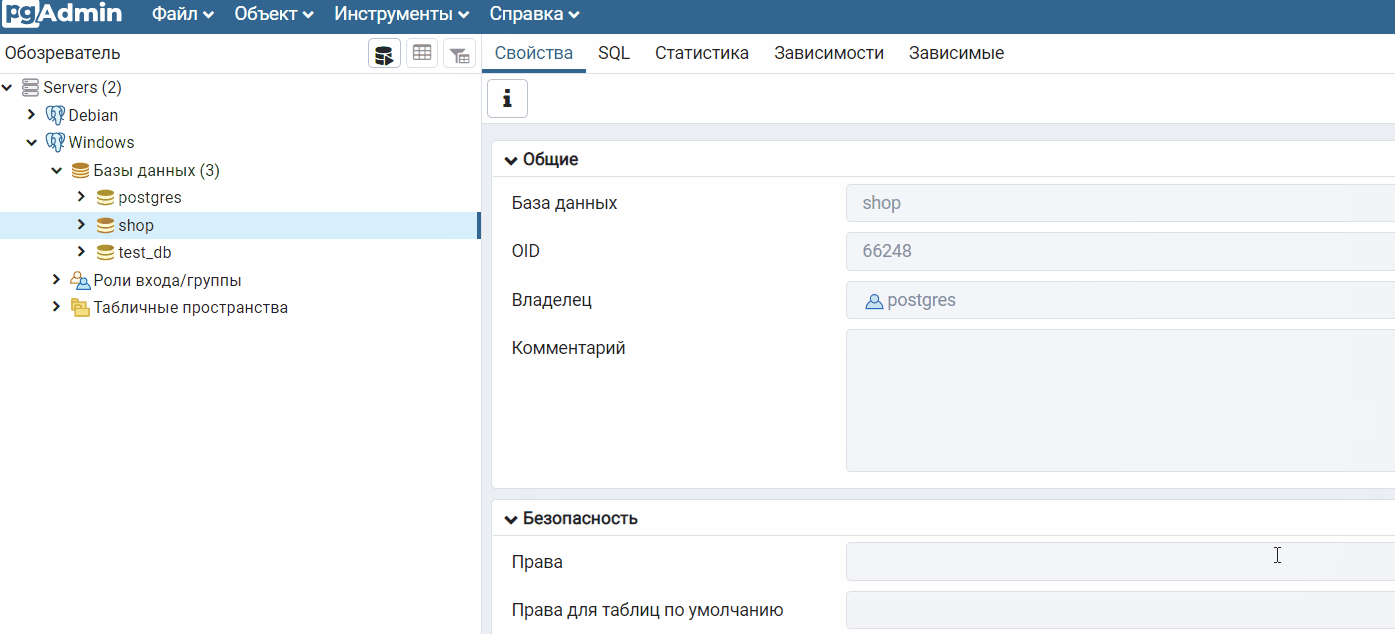
Затем всего лишь нужно указать имя архивного файла и путь к каталогу, где его сохранить, для этого можно использовать кнопку с тремя точками.
Формат «Специальный», как было отмечено ранее, предлагается по умолчанию, поэтому выбирать его не требуется.
Как я уже отмечал, обычно архив в таком формате создают с расширением backup, я так и поступаю, т.е. архив назову shop.backup и сохраню его в каталоге D:\PostgreSQL_Backup\.
В случае необходимости задать определенный уровень сжатия можно с помощью параметра «Коэффициент сжатия», поддерживаются значения от 0 до 9, где 0 – вообще не использовать сжатие, а 9 самый высокий уровень сжатия, по умолчанию используется умеренное сжатие.
В нашем случае база данных небольшая, поэтому мы можем оставить все по умолчанию.
Больше никаких настроек в нашем случае делать нет необходимости, и мы можем нажать на кнопку «Резервная копия», чтобы запустить процесс создания дампа базы данных.
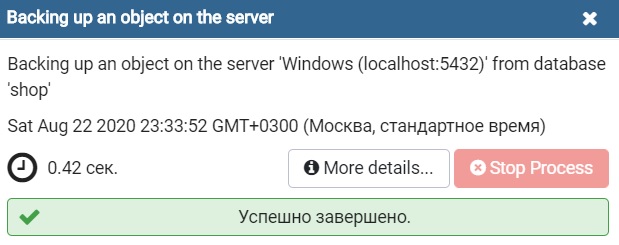
Когда появится сообщение «Успешно завершено», значит, процесс создания дампа базы данных PostgreSQL завершен успешно, в противном случае Вы будете получать сообщения о неуспешном завершении.
Создание дампа базы данных в простом формате SQL
В данном случае нам необходимо сделать практически все то же самое, только нужно выбрать формат «Простой» и дополнительно включить пару параметров, чтобы добавление данных осуществлялось с помощью обычных инструкций INSERT, а не с помощью команды COPY, которая используется по умолчанию.
Для этого переходим на вкладку «Параметры выгрузки» и включаем два параметра «Использовать команды INSERT» иINSERT с указанием столбцов», хотя данный параметр можно и не указывать.