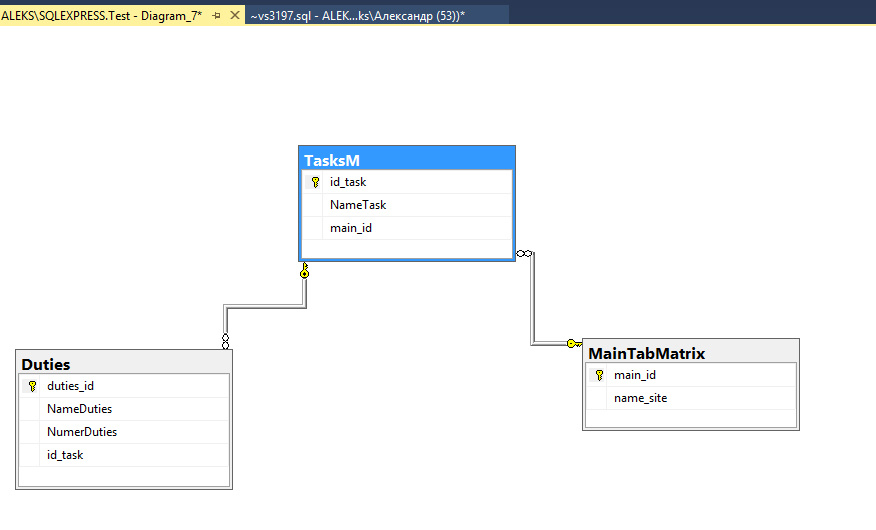
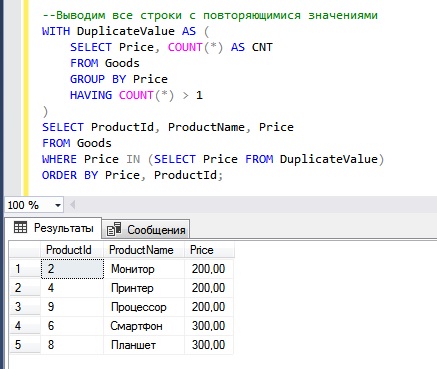
join + group by
Та же идея, что и в предыдущем случае, только реализована через самообъединение таблицы и группировку. Каждой строке сопоставляется набор строк с тем же user_id и большей или равной date_added, после группировки мы получаем для каждой строки (количество сообщений того же пользователя с большей датой добавления) + 1. Иными словами, если мы пронумеруем сообщения пользователя по убыванию date_added, то полученное число будет порядковым номером строки в этой нумерации.
select t1.* from
posts t1 join posts t2 on t1.user_id=t2.user_id and t2.date_added >= t1.date_addedgroup by t1.post_id having count(*) <=3;
Этот способ часто рекомендуют в интернете в качестве решения задачи (встречаются вариации с left join). Однако его производительность не самая оптимальная в сравнении с другими методами, рассмотренными в этой статье. Вероятно, причина популярности этого решения в том, что join многим интуитивно представляется более простым решением.
Обратите внимание: в режиме ONLY_FULL_GROUP_BY придется усложнять запрос: сначала выбрать нужные post_id, затем по ним дополнительным join извлечь остальные поля (подробнее см статью Группировка в MySQL). Простое перечисление всех полей в части group by в разы увеличивает время выполнения запроса
Строго говоря, этот способ как и предыдущий (с помощью зависимого подзапроса) можно использовать для выборки случайных строк из группы, но только в новых версиях, где есть поддержка обобщенных табличных выражений. Вместо исходной таблицы в запросе будет использоваться результат select posts.*, rand() new_col from posts, и сравнение не по полю date_added, а по new_col.
Будем считать, что варианты 1 и 2 не применимы для поиска случайных строк в группах, потому что:
- в старых версиях они действительно не применимы

- в новых их производительность будет существенно хуже по сравнению с иными доступными вариантами решений (см способы 4 и 6)
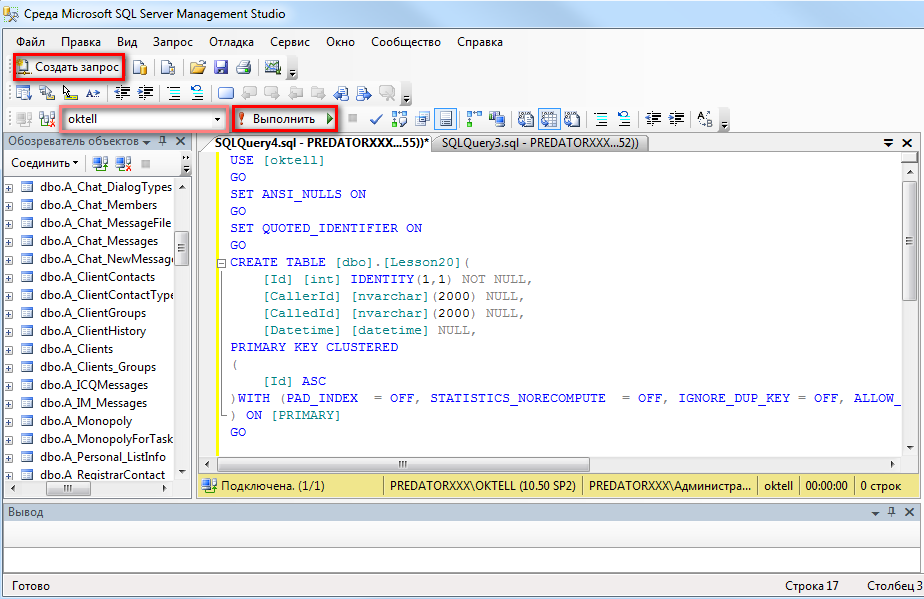
Оператор SQL DELETE и удаление всех данных из таблицы
Для удаления всех строк из таблицы применяется оператор SQL DELETE без условий, заданных в секции WHERE и
без любых других ограничей и условий, например, диапазона удаляемых строк. Таким образом, для удаления
всех строк синтаксис оператора DELETE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ИМЯ_ТАБЛИЦЫ
Пример 4. Чтобы удалить все данные из таблицы ADS, достаточно
написать следующий запрос:
DELETE FROM ADS
Если после выполнения этого запроса обратиться к таблице ADS при помощи оператора
SELECT, применяемого для получения выборки данных, то будет выведено сообщение о том, что эта
таблица не содержит данных.
Оператору DELETE без условий и ограничений аналогичен оператор TRUNCATE TABLE. Он
также удаляет из таблицы все строки, но выполняется намного быстрее.
Пример 5. Запрос на удаление всех данных из таблицы ADS
при помощи оператора TRUNCATE TABLE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
TRUNCATE TABLE ADS
Примеры запросов к базе данных «Портал объявлений-1» есть также в уроках об
операторах INSERT, UPDATE, HAVING и UNION.
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Вызов функции
QHB позволяет вызывать функции с именованными параметрами с
использованием позиционной или именованной нотации. Именованная нотация
особенно полезна для функций, которые имеют большое количество
параметров, поскольку она делает ассоциации между параметрами и
фактическими аргументами более явными и надежными. В позиционной нотации
вызов функции записывается со значениями аргументов в том же порядке, в
котором они определены в объявлении функции. В именованной нотации
аргументы сопоставляются с параметрами функции по имени и могут быть
записаны в любом порядке.
В любой нотации параметры, которые имеют значения по умолчанию,
указанные в объявлении функции, вообще не должны записываться в вызове.
Но это особенно полезно в именованной нотации, поскольку любая
комбинация параметров может быть опущена; в то время как в позиционной
нотации параметры могут быть пропущены только справа налево.
QHB также поддерживает смешанную нотацию, которая объединяет позиционную
и именованную нотацию. В этом случае позиционные параметры записываются
первыми, а именованные параметры появляются после них.
Следующие примеры иллюстрируют использование всех трех обозначений,
используя следующее определение функции:
Функция concat_lower_or_upper имеет два обязательных параметра, и
. Кроме того, есть один необязательный параметр uppercase который по
умолчанию равен false. Входы и будут объединены и переведены в
верхний или нижний регистр в зависимости от параметра uppercase.
Остальные детали этого определения функции здесь не важны
(см. главу Расширение SQL для получения дополнительной информации).
Позиционная нотация — это традиционный механизм передачи аргументов
функциям в QHB. Примером является:
Все аргументы указаны в порядке. Результат — верхний регистр, поскольку
uppercase указан как true. Другой пример:
Здесь параметр uppercase пропущен, поэтому он получает значение по
умолчанию false, что приводит к выводу в нижнем регистре. В позиционной
нотации аргументы могут быть опущены справа налево, если они имеют
значения по умолчанию.
В именованной нотации имя каждого аргумента указывается с помощью
чтобы отделить его от выражения аргумента. Например:
Опять же, аргумент в uppercase был опущен, поэтому он неявно установлен
в значение false. Одно из преимуществ использования именованных
обозначений заключается в том, что аргументы могут быть указаны в любом
порядке, например:
Более старый синтаксис, основанный на , поддерживается для обратной совместимости:
Смешанная нотация объединяет позиционную и именованную нотацию. Однако,
как уже упоминалось, именованные аргументы не могут предшествовать
позиционным аргументам. Например:
В приведенном выше запросе аргументы и указываются позиционно, а
uppercase — именем. В этом примере это мало что добавляет, кроме
документации. С более сложной функцией, имеющей многочисленные параметры
со значениями по умолчанию, именованные или смешанные обозначения могут
сэкономить много времени и уменьшить вероятность ошибок.
Именованные и смешанные нотации вызовов в настоящее время не могут
использоваться при вызове агрегатной функции (но они работают, когда
агрегатная функция используется в качестве оконной функции).
LEFT
Задачу обрезание лишних символов из начала строки можно было бы решить и с использованием функции LEFT, которая возвращает указанное количество символов, начиная с 1-го. Функции нужно передать следующие два параметра:
- Поле, подстроку которого нужно получить;
- Количество символов.
Следующий пример формирует ФИО, в котором имя и отчество сокращены:
SELECT vcFamil+' '+left(vcName, 1)+'. '+left(vcSurName, 1)+'.' FROM tbPeoples
Поле «vcFamil» выводится полностью, а вот от имени и отчества выводится только один левый (первый) символ.
Теперь посмотрим, как можно было использовать LEFT для обрезания префикса ‘mr.’:
UPDATE tbPeoples
SET vcFamil=(case LEFT(vcFamil, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END)
Исходные данные для примеров
Сначала давайте я расскажу, какие данные я буду использовать в статье, чтобы Вы четко понимали и видели, какие результаты будут возвращаться, если выполнять те или иные действия.
Сразу скажу, что все данные тестовые.
Следующей инструкцией мы создаем таблицу Goods и добавляем в нее несколько строк, в некоторых из которых значение столбца Price будет повторяться.
Останавливаться на том, что делает та или иная инструкция, я не буду, так как это другая тема, если Вам интересно, можете более подробно посмотреть в следующих статьях:
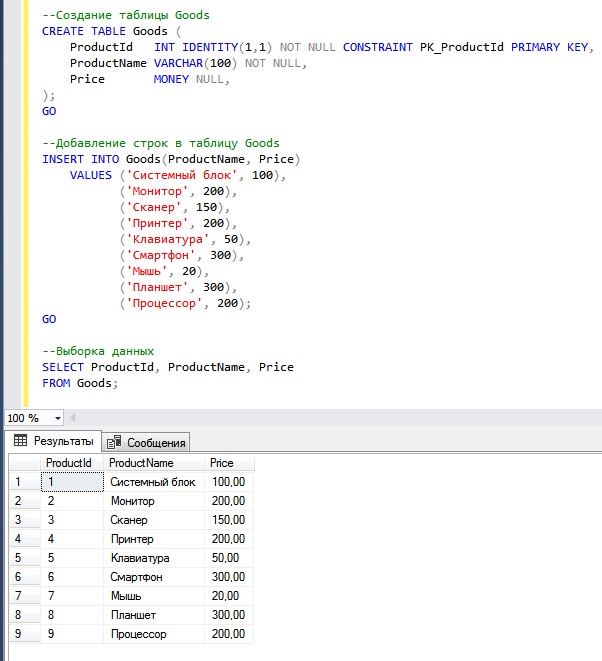
Вы видите, какие данные есть, именно к ним я буду посылать SQL запрос, который будет определять и выводить повторяющиеся значения в столбце Price.
Решения на основе CLR
Одно возможное решение на основе CLR (Common Language Runtime) по сути является одной из форм решения с использованием курсора. Разница в том, что вместо использования курсора T-SQL, который тратит много ресурсов на получение очередной строки и выполнение итерации, применяются итерации .NET SQLDataReader и .NET, которые работают намного быстрее. Одна из особенностей CLR которая делает этот вариант быстрее, заключается в том, что результирующая строка во временной таблице не нужна — результаты пересылаются напрямую вызывающему процессу. Логика решения на основе CLR похожа на логику решения с использованием курсора и T-SQL. Вот код C#, определяющий хранимую процедуру решения:
Чтобы иметь возможность выполнить эту хранимую процедуру в SQL Server, сначала надо на основе этого кода построить сборку по имени AccountBalances и развернуть в базе данных TSQL2012. Если вы не знакомы с развертыванием сборок в SQL Server, можете почитать раздел «Хранимые процедуры и среда CLR» в статье «Хранимые процедуры».
Если вы назвали сборку AccountBalances, а путь к файлу сборки — «C:\Projects\AccountBalances\bin\Debug\AccountBalances.dll», загрузить сборку в базу данных и зарегистрировать хранимую процедуру можно следующим кодом:
После развертывания сборки и регистрации процедуры можно ее выполнить следующим кодом:
Как я уже говорил, SQLDataReader является всего лишь еще одной формой курсора, но в этой версии затраты на чтение строк значительно меньше, чем при использовании традиционного курсора в T-SQL. Также в .NET итерации выполняются намного быстрее, чем в T-SQL. Таким образом, решения на основе CLR тоже масштабируются линейно. Тестирование показало, что производительность этого решения становится выше производительности решений с использованием подзапросов и соединений, когда число строк в секции переваливает через 15.
По завершении надо выполнить следующий код очистки:
Метод 1. Быстрый способ экспорта результатов запроса в CSV на SQL Server
Для начала запустите запрос, чтобы получить результаты.
Например, я выполнил простой запрос и получил следующую таблицу с небольшим количеством записей:
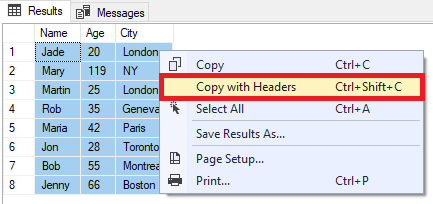
Чтобы быстро экспортировать результаты запроса, выберите все записи в вашей таблице (например, по рис. измените любую ячейку сетки, а затем используйте комбинацию клавиш Ctrl + A ):
После выбора всех записей щелкните правой кнопкой мыши любую ячейку в сетке и выберите « Копировать с заголовками ‘(или просто выберите «Копировать», если вы не хотите включать заголовки):
Откройте пустой файл CSV и вставьте результаты:
Вышеупомянутый метод может быть полезен для меньшего количества записей. Однако, если вы имеете дело с гораздо большими наборами данных, вы можете рассмотреть возможность использования второго метода ниже.

Задание псевдонимов для столбцов запроса
| ФИО | Дата приема | Дата рождения | ZP |
|---|---|---|---|
| Иванов Иван Иванович | 2015-04-08 | 1955-02-19 | 5000 |
| Петров Петр Петрович | 2015-04-08 | 1983-12-03 | 1500 |
| NULL | 2015-04-08 | 1976-06-07 | 2500 |
| NULL | 2015-04-08 | 1982-04-17 | 2000 |
| FullName1 | FullName2 | FullName3 |
|---|---|---|
| Иванов Иван Иванович | Иванов Иван Иванович | Иванов Иван Иванович |
| Петров Петр Петрович | Петров Петр Петрович | Петров Петр Петрович |
| NULL | Сидоров Сидор | Сидоров Сидор |
| NULL | Андреев Андрей | Андреев Андрей |
Основные арифметические операторы SQL
| Оператор | Действие |
|---|---|
| + | Сложение (x+y) или унарный плюс (+x) |
| — | Вычитание (x-y) или унарный минус (-x) |
| * | Умножение (x*y) |
| Деление (x/y) | |
| % | Остаток от деления (x%y). Для примера 15%10 даст 5 |
| ID | Name | Result1 | Result2 | Result3 |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 2500 | 2500 | 2500 |
| 1001 | Петров П.П. | 225 | 225 | 225 |
| 1002 | Сидоров С.С. | NULL | ||
| 1003 | Андреев А.А. | 600 | 600 | 600 |
| 1004 | Николаев Н.Н. | NULL | ||
| 1005 | Александров А.А. | NULL |
| ID | Name |
|---|---|
| 1000 | Иванов И.И. |
| 1004 | Николаев Н.Н. |
| 1002 | Сидоров С.С. |
Поиск подстроки в строке средствами sql
Для вычисления позиции подстроки в строке в языке sql существует несколько функций. Первая, которую мы рассмотрим, функция POSITION:
integer POSITION(substr string IN str string)
Возвращает номер позиции первого вхождения подстроки substr в строке str и возвращает 0 если подстрока не найдена. Функция POSITION может работать с многобайтовыми символами.
Пример:
SELECT POSITION (‘cd’ IN ‘abcdcde’);
Результат: 3
SELECT POSITION (‘xy’ IN ‘abcdcde’);
Результат: 0
Следующая функция LOCATE позволяет начинать поиск подстроки с определенной позиции:
integer LOCATE(substr string, str string, pos integer)
Возвращает позицию первого вхождения подстроки substr в строке str, начиная с позиции pos. Если параметр pos не задан, то поиск осуществляется с начала строки. Если подстрока substr не найдена, то возвращает 0. Поддерживает многобайтовые символы.
Пример:
SELECT LOCATE (‘cd’, ‘abcdcdde’, 5);
Результат: 5
SELECT LOCATE (‘cd’, ‘abcdcdde’);
Результат: 3
Аналогом функций POSITION и LOCATE является функция INSTR:
integer INSTR(str string, substr string)
Также как и функции выше возвращает позицию первого вхождения подстроки substr в строке str. Единственное отличие от функций POSITION и LOCATE то, что аргументы поменяны местами.
Далее рассмотрим функции, которые помогают получить подстроку.
Первыми рассмотрим сразу две функции LEFT и RIGHT, которые похожи по своему действию:
string LEFT(str string, len integer)string RIGHT(str string, len integer)
Функция LEFT возвращает len первых символов из строки str, а функция RIGHT столько же последних. Поддерживают многобайтовые символы.
Пример:
SELECT LEFT (‘Москва’, 3);
Результат: Мос
SELECT RIGHT (‘Москва’, 3);
Результат: ква
Далее рассмотрим одинаковые по итоговому результату функции SUBSTRING и MID:
string SUBSTRING(str string, pos integer, len integer)string MID(str string, pos integer, len integer)
Функции позволяют получить подстроку строки str длиною len символов с позиции pos. В случае если параметр len не задан, то возвращается вся подстрока начиная с позиции pos.
Пример:
SELECT SUBSTRING (‘г. Москва — столица России’, 4, 6);
Результат: Москва
SELECT SUBSTRING (‘г. Москва — столица России’, 4);
Результат: Москва — столица России
Примеры с функцией MID не привожу, потому что результаты будут аналогичные.
Интересная функция SUBSTRING_INDEX:
string SUBSTRING_INDEX(str string, delim string, count integer)
Функция возвращает подстроку строки str, полученную путем удаления символов, идущих после разделителя delim, находящимся в позиции count. Параметр count может быть как положительным, так отрицательным. Если count положительный, то отсчет позиции разделителя будет вестись слева и удаляться будут символы находящиеся справа от разделителя. Если count отрицательный, то отсчет позиции разделителя ведется справа и удаляются символы находящиеся слева от разделителя. Возможно, описание получилось слишком запутанным, но на примерах станет понятней.
Пример:
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, 1);
Результат: www
В данном примере функция находит, первое вхождения символа точки в строке «www.mysql.ru» и удаляет все символы, идущие после нее, включая сам разделитель.
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, 2);
Результат: www.mysql
Здесь функция ищет второе вхождение точки, удаляет все символы справа от нее и возвращает получившуюся подстроку. И еще один пример с отрицательным значением параметра count:
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, -2);
Результат: mysql.ru
В этом примере функция SUBSTRING_INDEX ищет вторую точку, отсчитывая позицию справа, удаляет символы слева от нее и выдает полученную подстроку.
Вставка значений с использованием оператора SET в MySQL
В MySQL дополнительно существует альтернативная конструкция для вставки значений в таблицу с
использованием оператора SET. Она похожа на конструкцию оператора UPDATE и имеет следующий синтаксис:
INSERT INTO ИМЯ_ТАБЛИЦЫ
SET
ИМЯ_СТОЛБЦА_1=ЗНАЧЕНИЕ,
ИМЯ_СТОЛБЦА_2=ЗНАЧЕНИЕ,
…,
ИМЯ_СТОЛБЦА_N=ЗНАЧЕНИЕ
В подобных запросах можно указывать имена не всех столбцов, при этом не указанные столбцы
принимают значения по умолчанию.
Пример 6. База данных и таблица —
те же, что и в предыдущих примерах.
Вставим в таблицу строку, при этом столбцы Units и Money примут значения по умолчанию:
INSERT INTO ADS
SET
Id=13,
Category=’Недвижимость’,
Part=’Гаражи’
В результате выполнения запроса в таблице появится новая строка:
| 13 | Недвижимость | Гаражи | NULL | NULL |
Многострочное обновление с переменными
Показанные до этого момента приемы вычисления нарастающих итогов гарантированно дают правильный результат. Описываемая в этом разделе методика неоднозначна, потому что основана на наблюдаемом, а не задокументированном поведении системы, кроме того она противоречит принципам релятивности. Высокая ее привлекательность обусловлена большой скоростью работы.
В этом способе используется инструкция UPDATE с переменными. Инструкция UPDATE может присваивать переменным выражения на основе значения столбца, а также присваивать значениям в столбцах выражение с переменной. Решение начинается с создания временной таблицы по имени Transactions с атрибутами actid, tranid, val и balance и кластеризованного индекса со списком ключей (actid, tranid). Затем временная таблица наполняется всеми строками из исходной БД Transactions, причем в столбец balance всех строк вводится значение 0,00. Затем вызывается инструкция UPDATE с переменными, связанными с временной таблицей, для вычисления нарастающих итогов и вставки вычисленного значения в столбец balance.
Используются переменные @prevaccount и @prevbalance, а значение в столбце balance вычисляется с применением следующего выражения:
Выражение CASE проверяет, не совпадают ли идентификаторы текущего и предыдущего счетов, и, если они равны, возвращает сумму предыдущего и текущего значений в столбце balance. Если идентификаторы счетов разные, возвращается сумма текущей транзакции. Далее результат выражения CASE вставляется в столбец balance и присваивается переменной @prevbalance. В отдельном выражении переменной prevaccount присваивается идентификатор текущего счета.
После выражения UPDATE решение представляет строки из временной таблицы и удаляет последнюю. Вот код законченного решения:
План этого решения показан на следующем рисунке. Первая часть представлена инструкцией INSERT, вторая — UPDATE, а третья — SELECT:
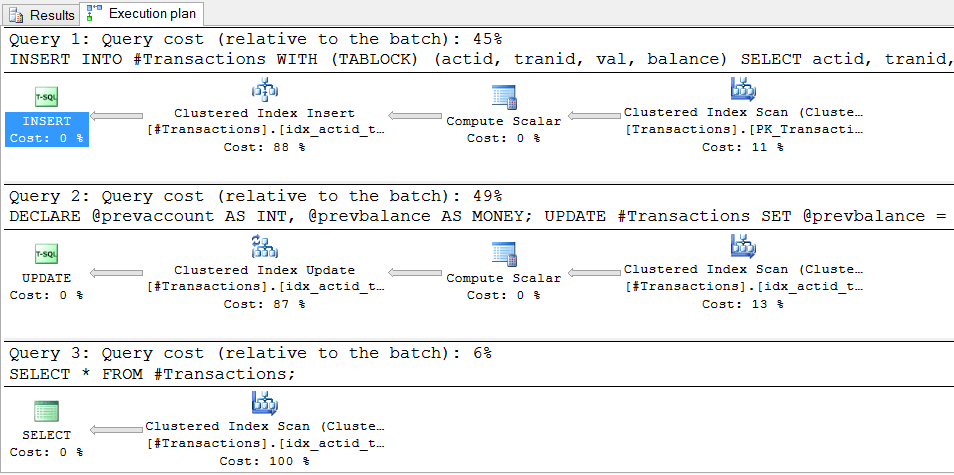
В этом решении предполагается, что при оптимизации выполнения UPDATE всегда будет выполняться упорядоченный просмотр кластеризованного индекса, и в решении предусмотрен ряд подсказок, чтобы предотвратить обстоятельства, которые могут помешать этому, например параллелизм. Проблема в том, что нет никакой официальной гарантии, что оптимизатор всегда будет посматривать в порядке кластеризованного индекса. Нельзя полагаться на особенности физических вычислений, когда нужно обеспечить логическую корректность кода, если только в коде нет логических элементов, которые по определению могут гарантировать такое поведение. В данном коде нет никаких логических особенностей, которые могли бы гарантировать именно такое поведение. Естественно выбор, использовать или нет этот способ, лежит целиком на вашей совести. Я считаю, что безответственно использовать его, даже если вы тысячи раз проверяли и «вроде бы все работает, как надо».
К счастью, в SQL Server 2012 этот выбор становится практически ненужным. При наличии исключительно эффективного решения с использованием оконных функций агрегирования не приходится задумываться о других решениях.
Выражения значения
Выражение значения используются в различных контекстах, таких как список
целей команды SELECT, в качестве новых значений столбцов в INSERT или
UPDATE или в условиях поиска в ряде команд. Результат вычисления
выражения значений иногда называют скаляром, чтобы отличить его от
результата табличного выражения (которое является таблицей). Поэтому
выражения значений также называют скалярными выражениями (или даже
просто выражениями). Синтаксис выражения позволяет вычислять значения из
примитивных частей, используя арифметические, логические, множественные
и другие операции.
Выражением значения может быть:
-
Постоянное или буквальное значение;
-
Ссылка на столбец;
-
Ссылка на позиционный параметр в теле определения функции или
подготовленного оператора; -
Выражение подзапроса;
-
Выражение выбора поля;
-
Вызов оператора;
-
Вызов функции;
-
Агрегатное выражение;
-
Вызов оконной функции;
-
Приведение типа;
-
Сортировка выражения;
-
Скалярный подзапрос;
-
Конструктор массива;
-
Конструктор строк.
-
Другое выражение значения в скобках (используется для группировки
подвыражений и переопределения приоритета).
В дополнение к этому списку, существует ряд конструкций, которые могут
быть классифицированы как выражения, но не следуют никаким общим
правилам синтаксиса. Как правило, они имеют семантику функции или
оператора и объясняются в соответствующем месте в главе Функции и операторы. Примером
является предложение IS NULL.



Константы уже обсуждались в разделе . В следующих подразделах обсуждаются остальные варианты.
На столбец можно ссылаться в виде:
correlation — это имя таблицы (возможно, дополненной именем схемы) или
псевдонима для таблицы, определенного с помощью предложения FROM. Имя
таблицы и разделяющая точка могут быть опущены, если имя столбца
уникально во всех таблицах, используемых в текущем запросе. (См. также
главу Запросы).
Ссылка на позиционный параметр используется для указания значения,
которое подается извне в оператор SQL. Параметры используются в
определениях функций SQL и в подготовленных запросах. Некоторые
клиентские библиотеки также поддерживают указание значений данных
отдельно от командной строки SQL, и в этом случае параметры используются
для ссылки на внешние значения данных. Форма ссылки на параметр:
Например, рассмотрим определение функции dept как:
Здесь $1 ссылка на значение первого аргумента функции при каждом её
вызове.
Если выражение дает значение типа массива, то конкретный элемент
значения массива можно извлечь, написав
или несколько смежных элементов («срез массива») можно извлечь, написав
(Здесь скобки должны появляться буквально). Каждый подзапрос сам
по себе является выражением, которое должно давать целочисленное
значение.
В общем случае массив expression должен быть заключен в скобки, но
круглые скобки могут быть опущены, когда выражение, которое должно быть
подписано, является просто ссылкой на столбец или позиционным
параметром. Кроме того, несколько подзапросов могут быть объединены,
если исходный массив является многомерным. Например:
Скобки в последнем примере обязательны. См. раздел Массивы для получения дополнительной информации о массивах.
Если выражение возвращает значение составного типа (тип строки), то конкретное
поле строки можно извлечь, написав
В общем случае выражение строки должно быть заключено в скобки, но их
можно опустить, если это просто ссылка на таблицу или позиционный параметр.
Например:
(Таким образом, полная ссылка на столбец на самом деле является просто частным
случаем синтаксиса выбора поля). Важный частный случай здесь — это извлечение
поля из столбца составного типа:
Здесь скобки нужны, чтобы показать, что compositecol — это имя столбца, а не
таблицы, или, во втором случае, что mytable — это имя таблицы, а не схемы.
Можно запросить все поля составного значения, написав :
Эта запись ведет себя по-разному в зависимости от контекста; подробную
информацию см. в разделе .
Существует три возможных синтаксиса для вызова оператора:
где маркер operator следует синтаксическим правилам раздел , или
является одним из ключевых слов AND, OR и NOT, или является
квалифицированным именем оператора в форме:
Какие конкретные операторы существуют и являются ли они унарными или
двоичными, зависит от того, какие операторы были определены системой или
пользователем. В главе Функции и операторы описываются встроенные операторы.
Фильтрация и сортировка данных
В качестве примера, исключим из таблицы данных студентов, чей возраст больше 23 лет. Существует множество способов решения подобного рода задач, включая циклы if-else, for или while (о них будет написана отдельная статья). Однако в нашем случае хватит простого фильтра, основанного на логическом операторе «<=» (меньше или равно). В квадратных скобках таблицы находится объект таблицы, по которому будет проводиться фильтрация:
Того же результата мы добьемся, если будем использовать логические операторы «>» (больше) и «!» (исключить):
Итак, мы получили финальную версию таблицы «voenvuz.final». Осталось лишь упорядочить столбцы:
И произвести сортировку данных по имени студентов, используя функцию order:
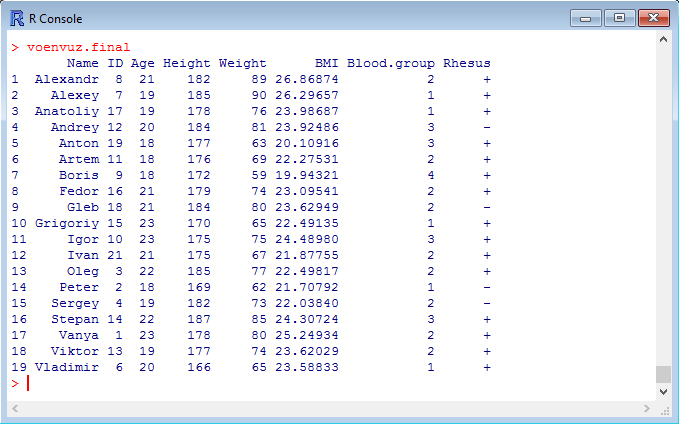
После завершения редактирования таблицы, обновим имена строк, т.к. сейчас они не соответствуют действительности, и выведем таблицу на экран, введя имя таблицы в консоль:
Сводка
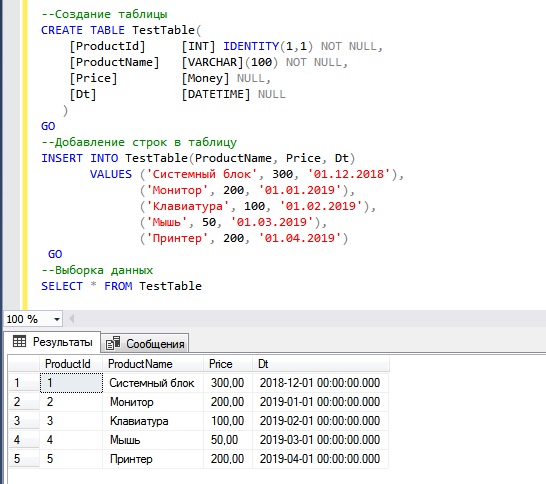
Существует два распространенных метода, которые можно использовать для удаления дублирующихся записей из SQL Server таблицы. Для демонстрации сначала создайте пример таблицы и данных:
Затем попробуйте следующие методы, чтобы удалить дублирующиеся строки из таблицы.
Способ 1
Запустите следующий сценарий:
Этот скрипт принимает следующие действия в данном порядке:
- Перемещает один экземпляр любой дублирующейся строки в исходной таблице в дублирующую таблицу.
- Удаляет все строки из исходной таблицы, которые также находятся в дублирующей таблице.
- Перемещает строки в таблицу дубликатов обратно в исходную таблицу.
- Сбрасывает таблицу дубликата.
Этот метод прост. Однако для создания дублирующей таблицы в базе данных необходимо иметь достаточно места. Этот метод также накладные расходы, так как данные перемещаются.
Кроме того, если в вашей таблице есть столбец IDENTITY, при восстановлении данных в исходной таблице необходимо использовать set IDENTITY_INSERT ON.
Способ 2
Функция ROW_NUMBER, которая была представлена в Microsoft SQL Server 2005 г., значительно упрощает эту операцию:
Этот скрипт принимает следующие действия в данном порядке:
- Использует функцию для раздела данных на основе которых может быть один или несколько столбцов, разделенных запятой.
- Удаляет все записи, которые получили значение больше 1. Это значение указывает на то, что записи являются дубликатами.
Из-за выражения скрипт не сортировать разделимые данные на основе каких-либо условий. Если в логике удаления дубликатов необходимо выбрать, какие записи удалять, а какие хранить в соответствии с порядком сортировки других столбцов, для этого можно использовать выражение ORDER BY.
Как вывести значения столбца в строке через запятую на T-SQL? Microsoft SQL Server
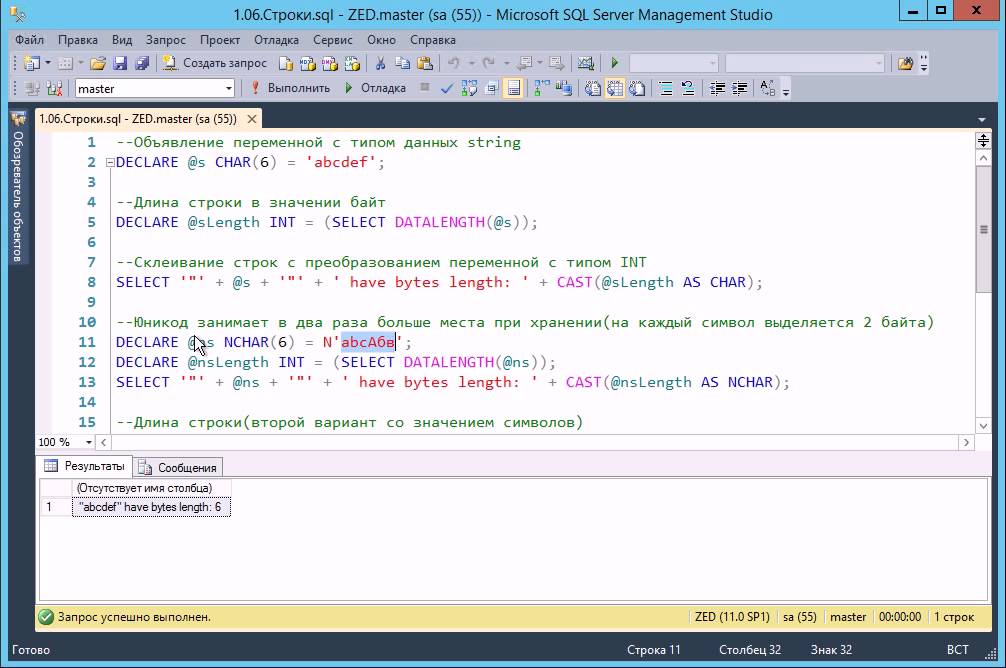
Когда работаешь с базой данных, пишешь SQL запросы или инструкции, может возникнуть необходимость получить в виде текстовой строки значения определенного столбца таблицы, где каждое значение будет отделяться разделителем, например, запятой или точкой с запятой. В этой статье я покажу, как реализовать это на языке T-SQL, т.е. как получить значения столбца в строке через запятую.
В каких случаях может потребоваться получать значения столбца, разделенные запятой в строке? Например, самый простой вариант — это для реализации какой-нибудь динамической процедуры или инструкции (подробней об этой возможности языка T-SQL в материале – «Выполнение динамических T-SQL инструкций в Microsoft SQL Server»). Если приводить более конкретный пример, то на практике очень часто нужно реализовывать так называемый динамический PIVOT, для формирования аналитических отчетов. PIVOT, если кто не знает, — это оператор, с помощью которого можно формировать сводные таблицы, в частности осуществлять транспонирование таблицы (значения по горизонтали выводить по вертикали с агрегацией и группировкой).
Итак, давайте приступим.

Сравнение двух таблиц в Excel на наличие несовпадений значений
Пример 2. В Excel хранятся две таблицы, которые на первый взгляд кажутся одинаковыми. Было решено сравнить по одному однотипному столбцу этих таблиц на наличие несовпадений. Реализовать способ сравнения двух диапазонов ячеек.
Вид таблицы данных:

Для сравнения значений, находящихся в столбце B:B со значениями из столбца A:A используем следующую формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ выполняет поиск логического значения ИСТИНА в массиве логических значений, возвращаемых функцией СОВПАД (сравнивает каждый элемент диапазона A2:A12 со значением, хранящимся в ячейке B2, и возвращает массив результатов сравнения). Если функция ПОИСКПОЗ нашла значение ИСТИНА, будет возвращена позиция его первого вхождения в массив. Функция ЕНД возвратит значение ЛОЖЬ, если она не принимает значение ошибки #Н/Д в качестве аргумента. В этом случае функция ЕСЛИ вернет текстовую строку «есть», иначе – «нет».
Чтобы вычислить остальные значения «протянем» формулу из ячейки C2 вниз для использования функции автозаполнения. В результате получим:
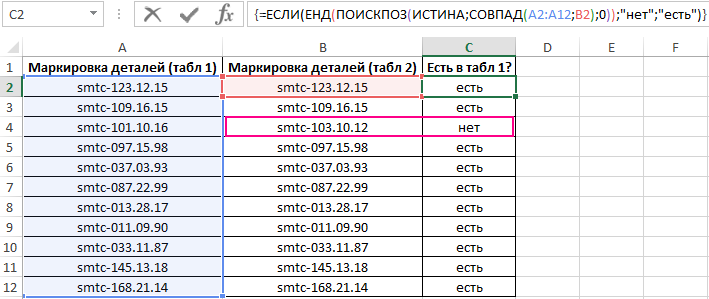
Как видно, третьи элементы списков не совпадают.
Обновление (UPDATE)
Синтаксис:
> UPDATE <table> SET <field>='<value>’ WHERE <conditions>
* где table — имя таблицы; field — поле, для которого будем менять значение; value — новое значение; conditions — условие (без него делать update опасно — можно заменить все данные во всей таблице).
Обновление с использованием замены (REPLACE):
UPDATE <table> SET <field> = REPLACE(<field>, ‘<что меняем>’, ‘<на что>’);
Примеры:
UPDATE cities SET name = REPLACE(name, ‘Масква’, ‘Москва’);
UPDATE cities SET name = REPLACE(name, ‘Масква’, ‘Москва’) WHERE country = ‘Россия’;
UPDATE cities SET name = REPLACE(name, ‘Ма’, ‘Мо’) WHERE name = ‘Масква’;
Если мы хотим перестраховаться, результат замены можно сначала проверить с помощью SELECT:
SELECT REPLACE(name, ‘Ма’, ‘Мо’) FROM cities WHERE name = ‘Масква’;
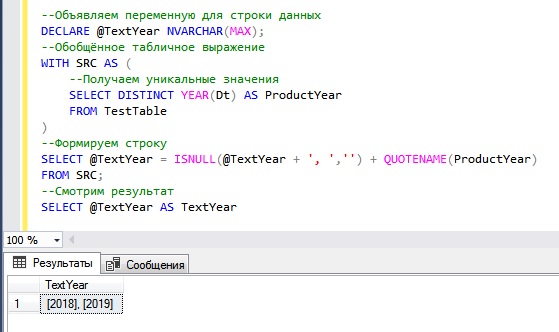
Пример 1 – выводим все значения столбца в строке через запятую
Давайте представим, что нам нужно получить все значения из столбца «Наименование товара» (ProductName) в виде текстовой строки с разделителем.
В примере ниже мы напишем простую SQL инструкцию, в которой мы сохраним в переменной строку из значений столбца, разделенных запятыми.

Суть данного метода проста, мы последовательно записываем в переменную значение за значением (то, что есть в переменной + текущее значение), по мере считывания данных из столбца, добавляя между значениями нужный нам разделитель.
Функцию ISNULL (проверка на NULL) мы использовали для того, чтобы определить, когда нам нужно вставлять первый разделитель, но в данном случае можно использовать и COALESCE, в чем разница можете почитать в статье «Функции COALESCE и ISNULL в T-SQL – особенности и основные отличия».
Функцию QUOTENAME мы используем для отделения каждого значения в строке, в нашем случае квадратными скобами. Это нужно для того, чтобы избежать ситуаций, когда в значении используются пробелы или другие символы. Если отделять значения не требуется, то эту функцию использовать необязательно, также можно вместо квадратных скобок указать другой символ в качестве выделения значения, например, кавычки, круглые или фигурные скобки и некоторые другие (необходимый символ указывается вторым параметром у функции QUOTENAME, по умолчанию квадратные скобки).