
1.0 Введение
Назначение этого документа – представить и обсудить заявленную на патент технологию под названием (прим. переводчика: статья была написана в 2001 году, в предоставлении патента было отказано в январе 2005; сейчас архитектура Data Vault – общедоступна – FREE and PUBLIC DOMAIN). Data Vault – новый этап эволюции моделирования данных для хранилищ данных масштаба предприятия. Этот, сугубо технический документ, предназначен для аудитории, состоящей из проектировщиков данных, архитекторов данных и администраторов баз данных. Документ не предназначен для бизнес-аналитиков, менеджеров проектов и программистов. Рекомендуется, чтобы читатель обладал базовым уровнем знаний в области моделирования данных и хорошо понимал термины: таблицы, отношения, родитель, потомок, ключ (первичный / внешний), измерения и факты. Предметы обсуждения этой статьи следующие:
Определение Data Vault.
Краткая история моделирования данных для хранилищ.
Архитектурные проблемы существующих моделей хранилищ данных.
Важность архитектуры и дизайна для корпоративных хранилищ данных.
Компоненты Data Vault.
Решение существующих проблем архитектуры хранилищ данных.
Основы архитектуры Data Vault.
Возможные применения Data Vault.
Прочитав это документ, Вы можете узнать:
- Что такое Data Vault и какое она имеет значение.
- Как самому создать небольшое хранилище Data Vault.
- Какие перспективы хранилищ данных несостоятельны.
Слишком долго мы ждали структур данных, которые, наконец-то, приблизятся к приложениям искусственного интеллекта и приложениям интеллектуального анализа данных (). Большинство технологий интеллектуального анализа данных (data mining) требуют импортировать информацию в плоские файлы, чтобы соединить форму с функцией. К сожалению, объемы хранилищ данных растут быстро, и экспортировать эту информацию, предназначенную для интеллектуального поиска данных, становится все труднее. Просто не имеет смысла иметь эту неоднородность/разрыв между формой (структурой данных), функцией (искусственным интеллектом), и выполнением (осуществлением добычи данных).
Объединение формы, функции и выполнения имеет огромное значение для сообщества искусственного интеллекта (AI) и интеллектуального анализа данных. Найдена структура данных, которая математически обоснованно увеличивает возможность вернуть эти технологии к использованию баз данных, а не файлов. Модель Data Vault основана на математических принципах, которые позволяют ей быть расширяемой и способной к обработке огромных объемов информации. Эти архитектура и структура данных предназначены для обработки динамических меняющихся отношений между информацией.
Мы надеемся, что напряженное мышление в один прекрасный день инкапсулирует данные с функциями интеллектуального анализа данных, чтобы приблизиться к образцу «обладающей самосознанием» независимой информации, но это – пока только мечта. Но можно динамически формировать, понижать, и оценивать отношения между наборами данных. Таким образом, изменяя ландшафт возможностей модели данных, по существу, мы приводим в динамически меняющееся состояние (благодаря использованию интеллектуального анализа данных / искусственного интеллекта).
Благодаря реализации эталонной архитектуры (reference architecture) поверх структуры Data Vault функции, имеющие доступ к контенту, могут начать выполняться в параллельном и автоматическом режиме. Data Vault решает часть структурных проблем Корпоративного Хранилища Данных и проблемы хранения, причем, используя нормализованный, лучший в своем роде, подход. Эти концепции предоставляют целый ряд возможностей применения этой уникальной технологии.
«Вы должны стремиться делать то что, по Вашему мнению, Вы не сможете сделать»,
Элеонора Рузвельт.
Методы проектирования
Снизу вверх
При восходящем подходе сначала создаются витрины данных, чтобы предоставить отчеты и аналитические возможности для конкретных бизнес-процессов . Затем эти витрины данных можно интегрировать для создания всеобъемлющего хранилища данных. Архитектура шины хранилища данных в первую очередь является реализацией «шины», набора и согласованных фактов, которые являются измерениями, которые совместно используются (определенным образом) между фактами в двух или более витринах данных.
Нисходящий дизайн
Сверху вниз подход разработан с использованием нормированного предприятия модели данных . «Атомарные» данные, то есть данные с максимальной степенью детализации, хранятся в хранилище данных. Из хранилища данных создаются размерные витрины данных, содержащие данные, необходимые для определенных бизнес-процессов или конкретных отделов.
Гибридный дизайн
Хранилища данных (ХД) часто напоминают архитектуру концентратора и распределителя . Унаследованные системы, питающие склад, часто включают в себя управление взаимоотношениями с клиентами и планирование ресурсов предприятия, генерируя большие объемы данных. Чтобы объединить эти различные модели данных и облегчить процесс загрузки с преобразованием извлечения, хранилища данных часто используют оперативное хранилище данных, информация из которого анализируется в фактическую DW. Чтобы уменьшить избыточность данных, более крупные системы часто хранят данные нормализованным способом. Витрины данных для конкретных отчетов могут быть построены поверх хранилища данных.
База данных гибридного DW хранится в третьей нормальной форме, чтобы исключить избыточность данных . Однако обычная реляционная база данных неэффективна для отчетов бизнес-аналитики, где преобладает многомерное моделирование. Небольшие витрины данных могут делать покупки для данных из консолидированного хранилища и использовать отфильтрованные конкретные данные для таблиц фактов и требуемых измерений. DW представляет собой единый источник информации, из которого могут считываться витрины данных, предоставляя широкий спектр деловой информации. Гибридная архитектура позволяет заменить DW репозиторием управления основными данными, в котором может находиться рабочая (а не статическая) информация.
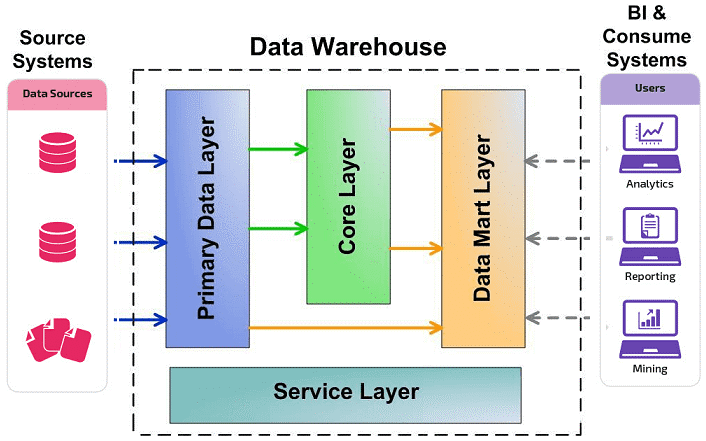
Компоненты моделирования хранилища данных следуют архитектуре концентратора и периферии. Этот стиль моделирования представляет собой гибридный дизайн, состоящий из лучших практик третьей нормальной формы и звездообразной схемы . Модель хранилища данных не является настоящей третьей нормальной формой и нарушает некоторые из ее правил, но это архитектура «сверху вниз» с конструкцией «снизу вверх». Модель хранилища данных предназначена строго для хранилища данных. Он не предназначен для доступа конечного пользователя, который при создании по-прежнему требует использования витрины данных или области выпуска на основе звездообразной схемы для бизнес-целей.
Немного про хранилища и витрины данных
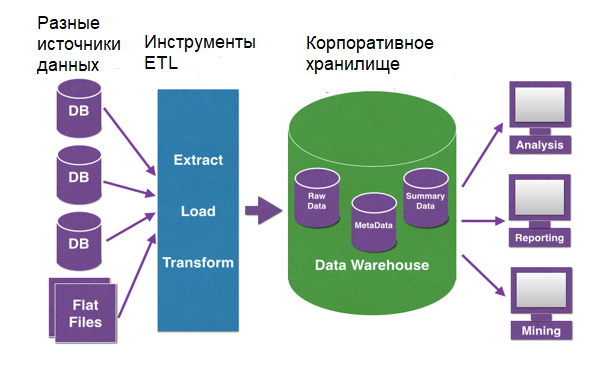
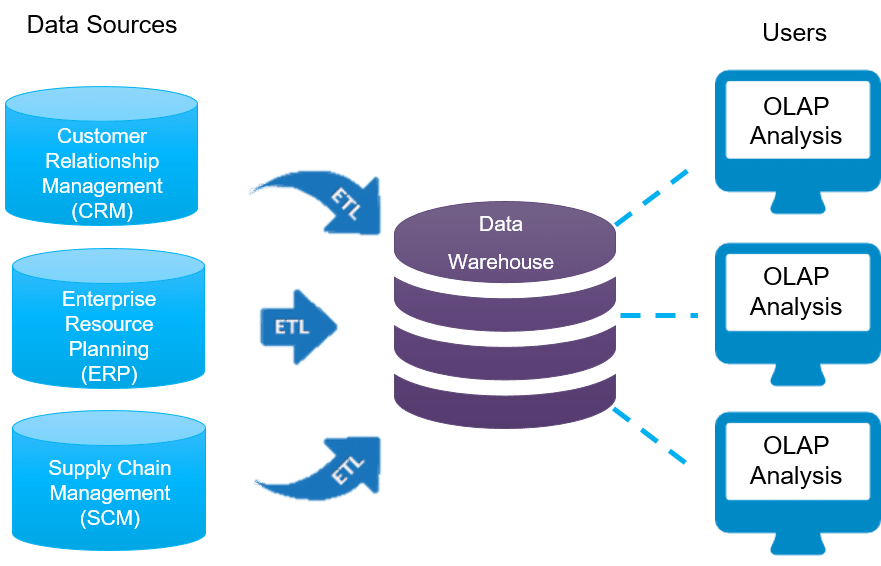
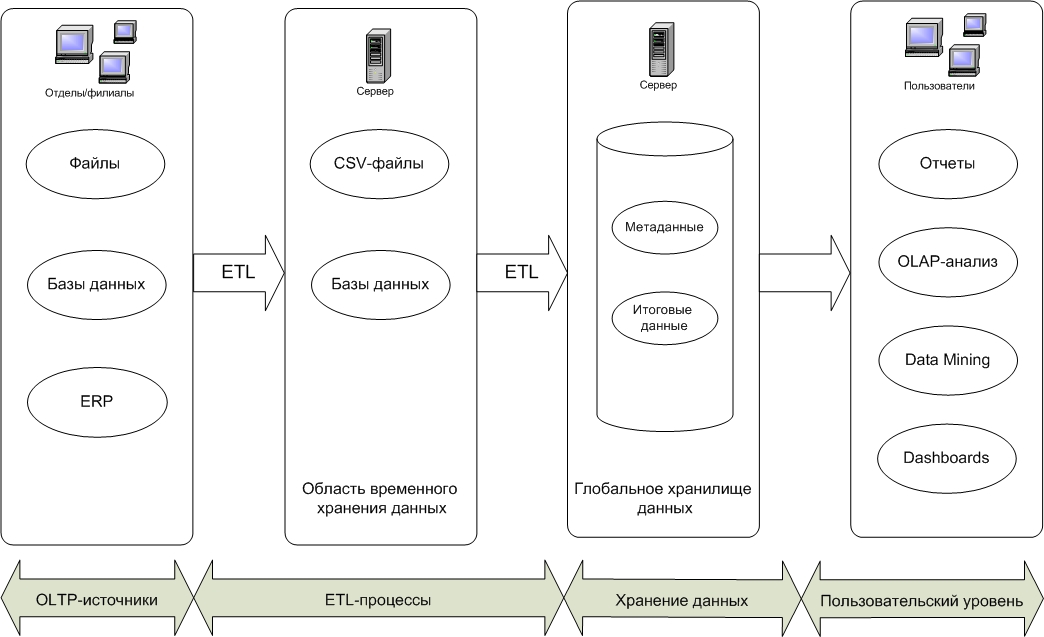
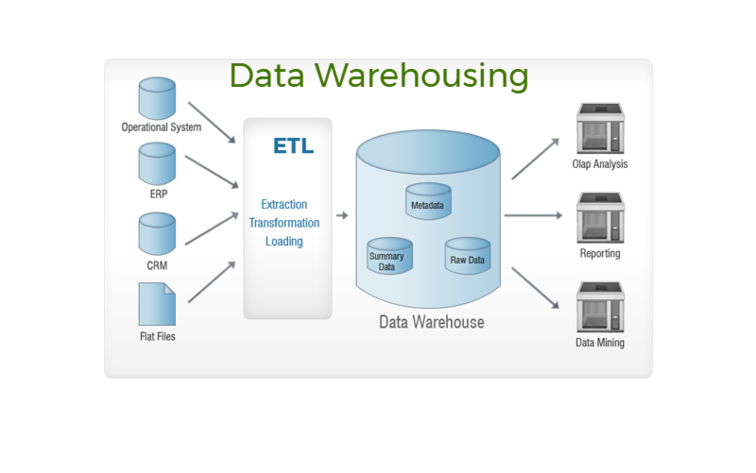
ETL часто рассматривают как средство переноса данных из различных источников в централизованное КХД. Однако КХД не связано с решением какой-то конкретной аналитической задачи, его цель — обеспечивать надежный и быстрый доступ к данным, поддерживая их хронологию, целостность и непротиворечивость. Чтобы понять, каким образом КХД связаны с аналитическими задачами и ETL, для начала обратимся к определению.
Корпоративное хранилище данных (КХД, DWH – Data Warehouse) – это предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчётов и бизнес-анализа с целью поддержки принятия решений в организации. Информация в КХД, как правило, доступна только для чтения. Данные из OLTP-системы копируются в КХД таким образом, чтобы при построении отчётов и OLAP-анализе не использовались ресурсы транзакционной системы и не нарушалась её стабильность. Есть два варианта обновления данных в хранилище :
- полное обновление данных в хранилище, когда старые данные удаляются, потом происходит загрузка новых данных. Процесс происходит с определённой периодичностью, при этом актуальность данных может несколько отставать от OLTP-системы;
- инкрементальное обновление, когда обновляются только те данные, которые изменились в OLTP-системе.
ETL-процесс позволяет реализовать оба этих способа. Отметим основные принципы организации КХД :
- проблемно-предметная ориентация, когда данные объединяются в категории и хранятся в соответствии с областями, которые они описывают, а не с приложениями, которые они используют;
- интегрированность – данные объединены так, чтобы они удовлетворяли всем требованиям предприятия в целом, а не конкретной бизнес-функции;
- некорректируемость – данные в КХД не создаются, а поступают из внешних источников, не корректируются и не удаляются;
- зависимость от времени – данные в хранилище точны и корректны только в том случае, когда они привязаны к некоторому промежутку или моменту времени.
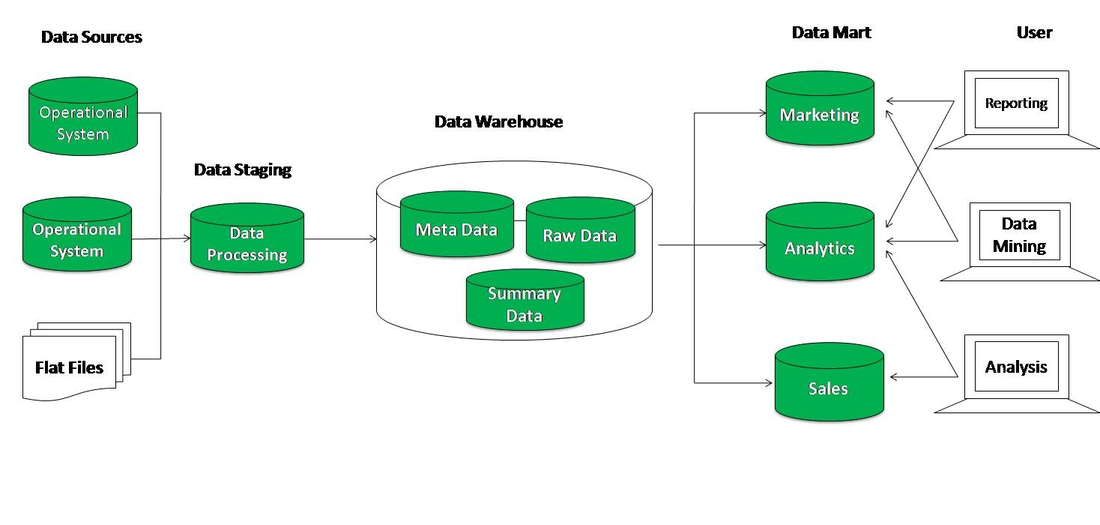
Витрина данных (Data Mart) представляет собой срез КХД в виде массива тематической, узконаправленной информации, ориентированного, например, на пользователей одной рабочей группы или департамента. Витрина данных, аналогично дэшборд-панели, позволяет аналитику увидеть агрегированную информацию в определенном временном или тематическом разрезе, а также сформировать и распечатать отчетные данные в виде шаблонизированного документа .
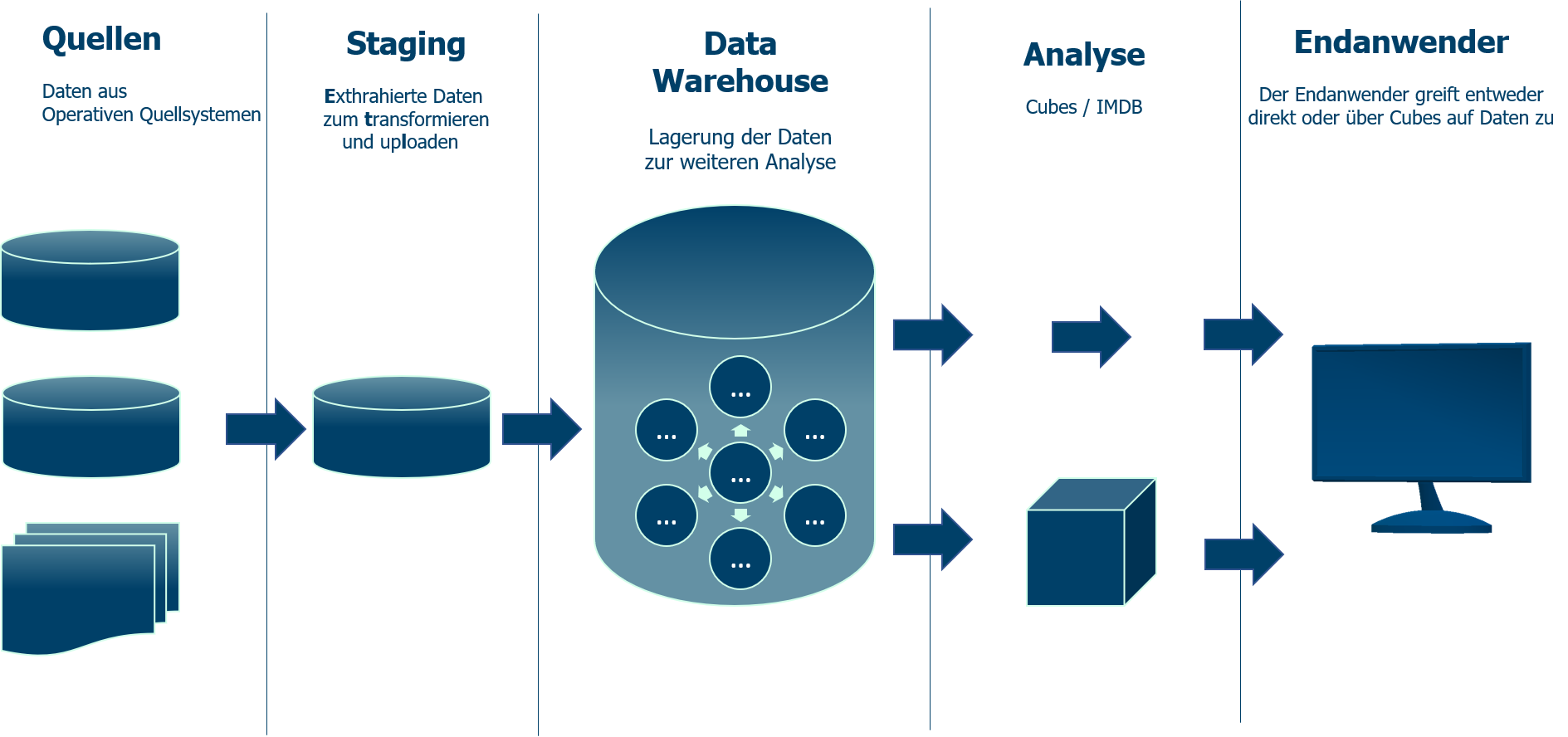
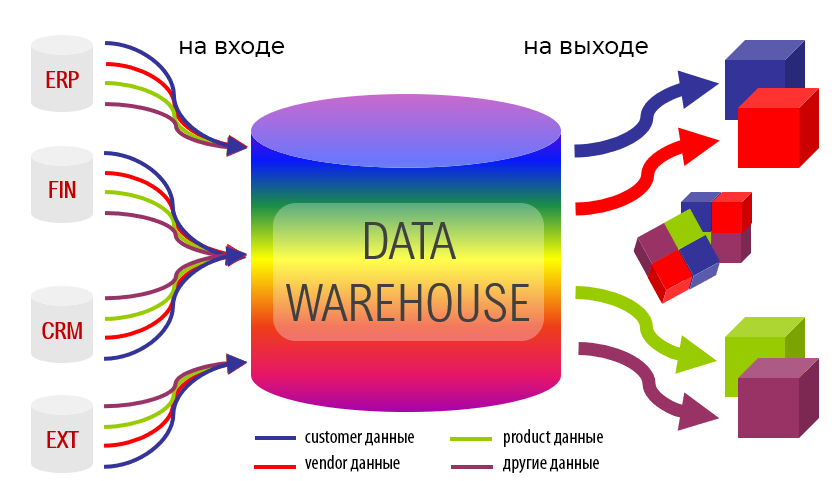

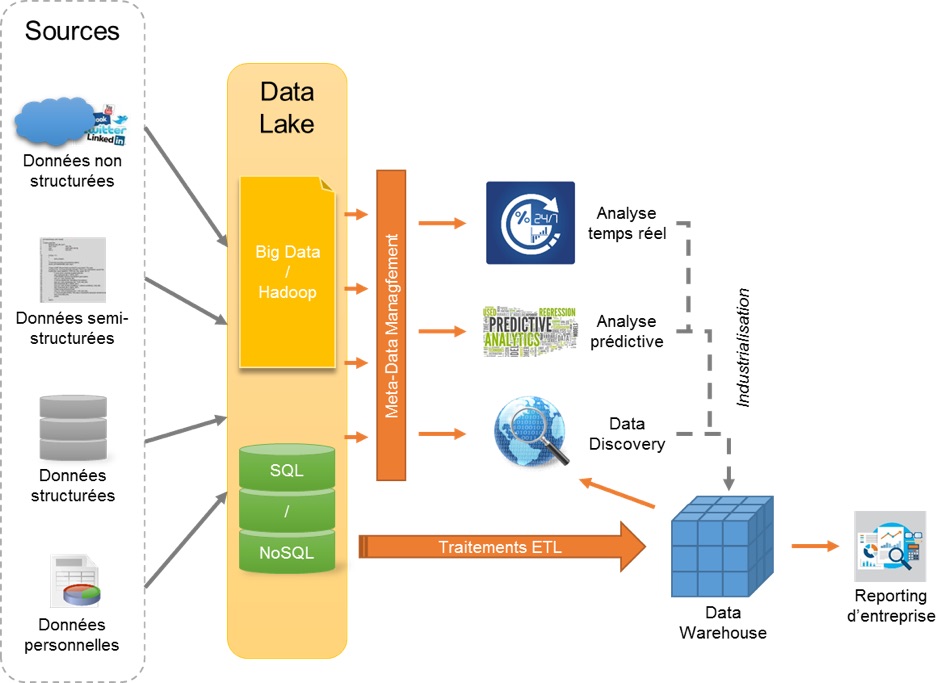
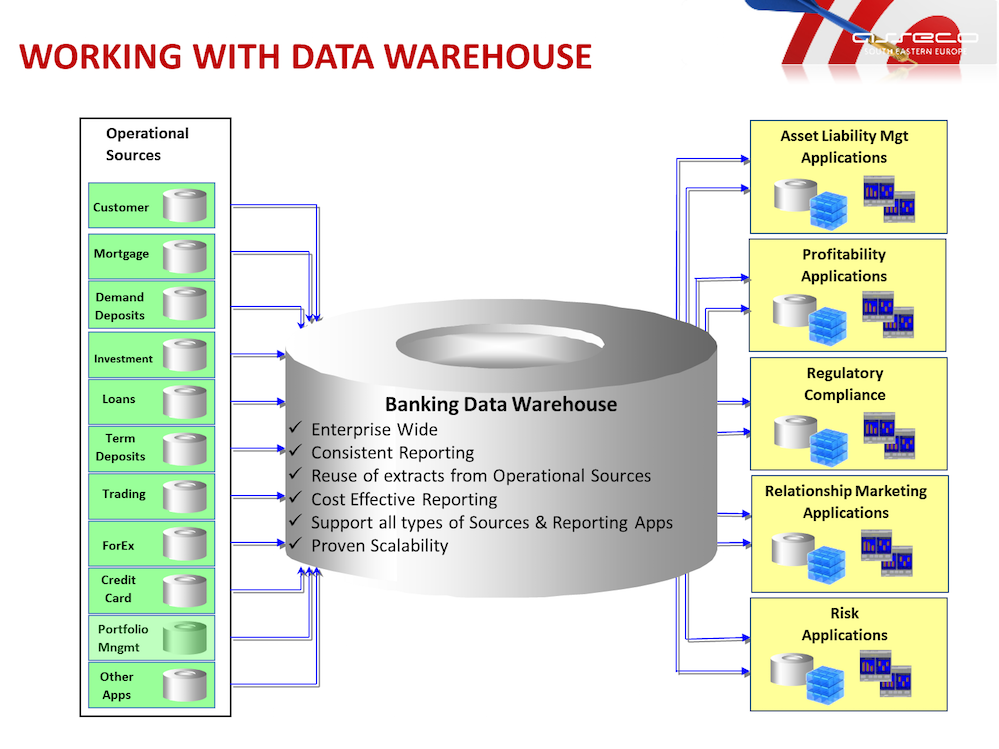
При проектировании хранилищ и витрин данных аналитику следует ориентироваться на возможности их прикладного использования и с учетом этого разрабатывать ETL-процессы
Например, если известно, что информация, поступающая из определенных подразделений, является самой важной и полезной, а также наиболее часто анализируется, то в регламент переноса данных в хранилище стоит внести соответствующие приоритеты. Это позволит ускорить работу с информацией, что особенно важно для data-driven организаций со сложной многоуровневой филиальной структурой и большим количеством подразделений
Преимущества
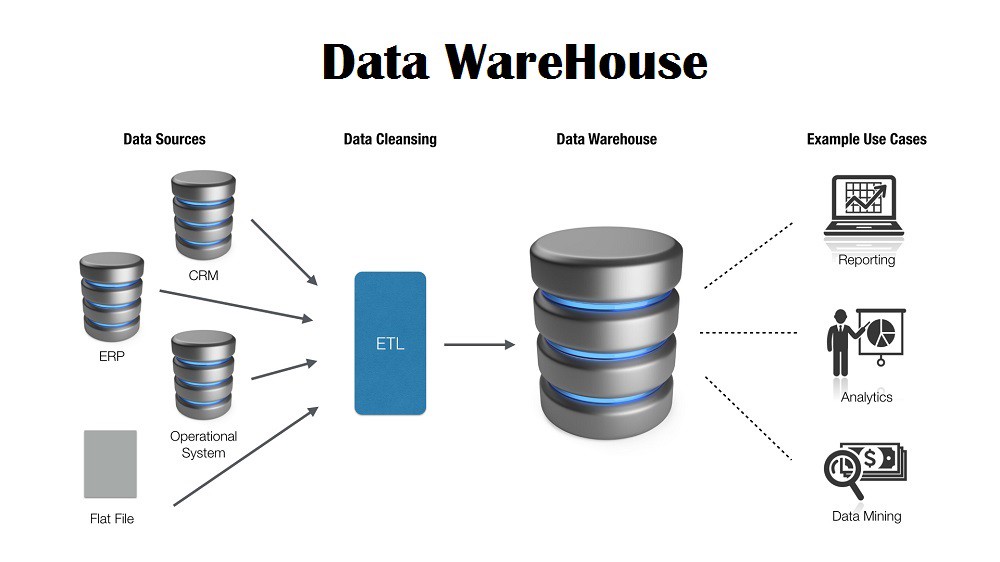
Хранилище данных хранит копию информации из исходных систем транзакций. Эта архитектурная сложность дает возможность:
- Интегрируйте данные из нескольких источников в единую базу данных и модель данных. Больше скопления данных в единую базу данных, чтобы можно было использовать единый механизм запросов для представления данных в ODS.
- Устранение проблемы конкуренции за блокировку уровня изоляции базы данных в системах обработки транзакций, вызванной попытками выполнения больших, длительных аналитических запросов в базах данных обработки транзакций.
- Сохраняйте , даже если системы исходных транзакций этого не делают.
- Интегрируйте данные из нескольких исходных систем, обеспечивая централизованное представление всего предприятия. Это преимущество всегда ценно, особенно когда организация выросла в результате слияния.
- Повышайте качество данных, предоставляя согласованные коды и описания, отмечая или даже исправляя неверные данные.
- Последовательно представляйте информацию организации.
- Обеспечьте единую общую модель данных для всех интересующих данных независимо от источника данных.
- Измените структуру данных, чтобы они были понятны бизнес-пользователям.
- Реструктурируйте данные так, чтобы они обеспечивали отличную производительность запросов даже для сложных аналитических запросов, не влияя на операционные системы .
- Повышайте ценность операционных бизнес-приложений, особенно систем управления взаимоотношениями с клиентами (CRM).
- Упростите написание запросов в поддержку принятия решений.
- Упорядочивайте повторяющиеся данные и устраняйте неоднозначность
Applications of Database
| Sector | Usage |
|---|---|
| Banking | Use in the banking sector for customer information, account-related activities, payments, deposits, loans, credit cards, etc. |
| Airlines | Use for reservations and schedule information. |
| Universities | To store student information, course registrations, colleges, and results. |
| Telecommunication | It helps to store call records, monthly bills, balance maintenance, etc. |
| Finance | Helps you to store information related stock, sales, and purchases of stocks and bonds. |
| Sales & Production | Use for storing customer, product and sales details. |
| Manufacturing | It is used for the data management of the supply chain and for tracking production of items, inventories status. |
| HR Management | Detail about employee’s salaries, deduction, generation of paychecks, etc. |
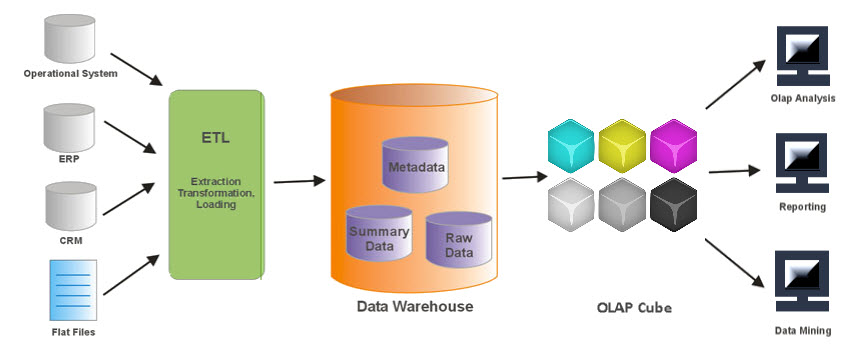
OLAP Tools
The database is designed (using a star or snowflake or any other approach), and the data is populated using ETL or ELT. Now we need to make sure that end users can analyze the data in any way they want. This is where OLAP tools come into play.
Many OLAP tools feature standard reports that can be generated and published by a number of users. Similarly, some users (i.e. power users) can also generate ad hoc reports using a canvas where objects can be dragged and dropped, i.e. filters can be added and a display format can be selected – tabular, pie chart, histogram, etc.
More sophisticated tools also provide what-if analyses: if the price was X instead of Y, what would have been the profit margin? The ability to extrapolate data and see how numbers could change in the future is another useful analytical feature.
OLAP tools like SAP BusinessObjects, IBM Cognos, and MicroStrategy have been around for decades. There are also new-gen Cloud-first OLAP tools like Kyligence and Microsoft Power BI.
OLAP System
OLAP handle with Historical Data or Archival Data. Historical data are those data that are achieved over a long period. For example, if we collect the last 10 years information about flight reservation, the data can give us much meaningful data such as the trends in the reservation. This may provide useful information like peak time of travel, what kind of people are traveling in various classes (Economy/Business) etc.
The major difference between an OLTP and OLAP system is the amount of data analyzed in a single transaction. Whereas an OLTP manage many concurrent customers and queries touching only an individual record or limited groups of files at a time. An OLAP system must have the capability to operate on millions of files to answer a single query.
| Feature | OLTP | OLAP |
|---|---|---|
| Characteristic | It is a system which is used to manage operational Data. | It is a system which is used to manage informational Data. |
| Users | Clerks, clients, and information technology professionals. | Knowledge workers, including managers, executives, and analysts. |
| System orientation | OLTP system is a customer-oriented, transaction, and query processing are done by clerks, clients, and information technology professionals. | OLAP system is market-oriented, knowledge workers including managers, do data analysts executive and analysts. |
| Data contents | OLTP system manages current data that too detailed and are used for decision making. | OLAP system manages a large amount of historical data, provides facilitates for summarization and aggregation, and stores and manages data at different levels of granularity. This information makes the data more comfortable to use in informed decision making. |
| Database Size | 100 MB-GB | 100 GB-TB |
| Database design | OLTP system usually uses an entity-relationship (ER) data model and application-oriented database design. | OLAP system typically uses either a star or snowflake model and subject-oriented database design. |
| View | OLTP system focuses primarily on the current data within an enterprise or department, without referring to historical information or data in different organizations. | OLAP system often spans multiple versions of a database schema, due to the evolutionary process of an organization. OLAP systems also deal with data that originates from various organizations, integrating information from many data stores. |
| Volume of data | Not very large | Because of their large volume, OLAP data are stored on multiple storage media. |
| Access patterns | The access patterns of an OLTP system subsist mainly of short, atomic transactions. Such a system requires concurrency control and recovery techniques. | Accesses to OLAP systems are mostly read-only methods because of these data warehouses stores historical data. |
| Access mode | Read/write | Mostly write |
| Insert and Updates | Short and fast inserts and updates proposed by end-users. | Periodic long-running batch jobs refresh the data. |
| Number of records accessed | Tens | Millions |
| Normalization | Fully Normalized | Partially Normalized |
| Processing Speed | Very Fast | It depends on the amount of files contained, batch data refresh, and complex query may take many hours, and query speed can be upgraded by creating indexes. |
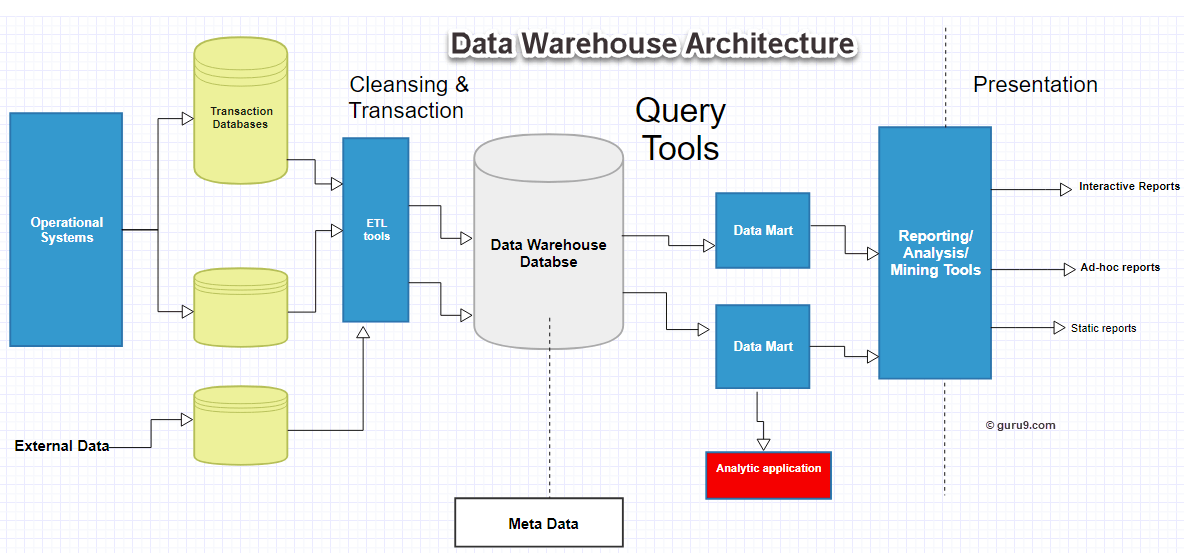
Next TopicData Warehouse Architecture
← prev
next →
Components of Data warehouse
Four components of Data Warehouses are:
Load manager: Load manager is also called the front component. It performs with all the operations associated with the extraction and load of data into the warehouse. These operations include transformations to prepare the data for entering into the Data warehouse.
Warehouse Manager: Warehouse manager performs operations associated with the management of the data in the warehouse. It performs operations like analysis of data to ensure consistency, creation of indexes and views, generation of denormalization and aggregations, transformation and merging of source data and archiving and baking-up data.
Query Manager: Query manager is also known as backend component. It performs all the operation operations related to the management of user queries. The operations of this Data warehouse components are direct queries to the appropriate tables for scheduling the execution of queries.
End-user access tools:
This is categorized into five different groups like 1. Data Reporting 2. Query Tools 3. Application development tools 4. EIS tools, 5. OLAP tools and data mining tools.
Comparison between Data warehouse and OLTP
| Data warehouse | OLTP | |
| System orientation |
It is a market-oriented database used by management for the decision making process. |
It is a customer-oriented database used by employees. |
| Data |
Data warehouse contains historical data which is aggregated and summarized. |
The data present in the transactional database is current data and too detailed. |
| Database Design |
Data warehouse follows star and snow flake schema model for designing the database. |
The database follows the entity-relationship(ER) database, model |
| Data Access |
The data warehouse has read-only access with complex queries. It does not support data access for day-to-day operations |
The OLTP database is accessible via simple queries. It is used for short transactions. OLTP requires mechanisms such as concurrency and recovery control. |
| Data View |
The information contained in the data warehouse comes from multiple data sources. It spans multiple database schemas. It requires multidimensional data view. |
The OTLP focuses mainly on current data. |
| Data Operations | Data warehouse requires a lot of scans | OLTP follows indexing and hashing on the primary key |
| Database size | The size of DW is more than terabytes of data | The size of OLTP ranges from few gigabytes to hundreds of gigabytes |
| Database records accessed | About millions of records can be accessed at one time. | About tens or hundreds of records can be accessed at one time. |
| Database Function | DW is used for information processing and analysis | OLTP is used for operational processing and transaction processing. |
| Data Query | DW information can be processed by complex queries | OLTP database operations can be accessed by simple queries |
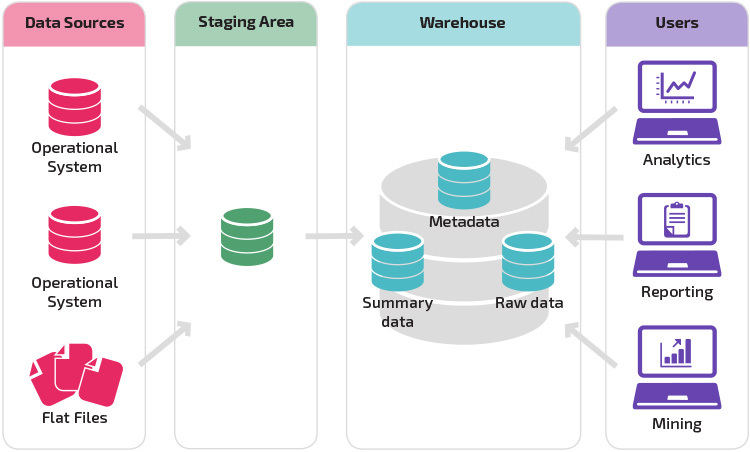
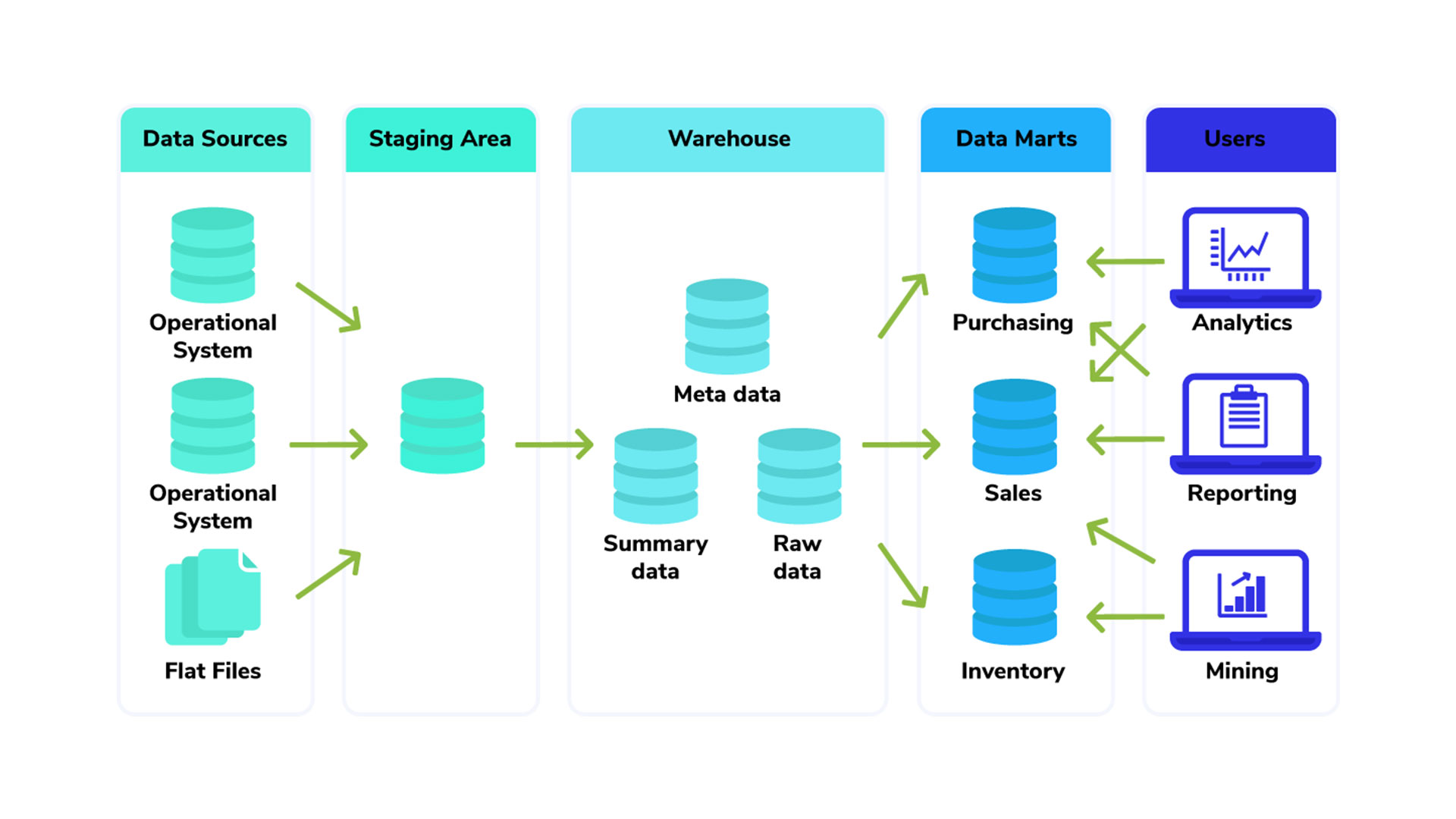
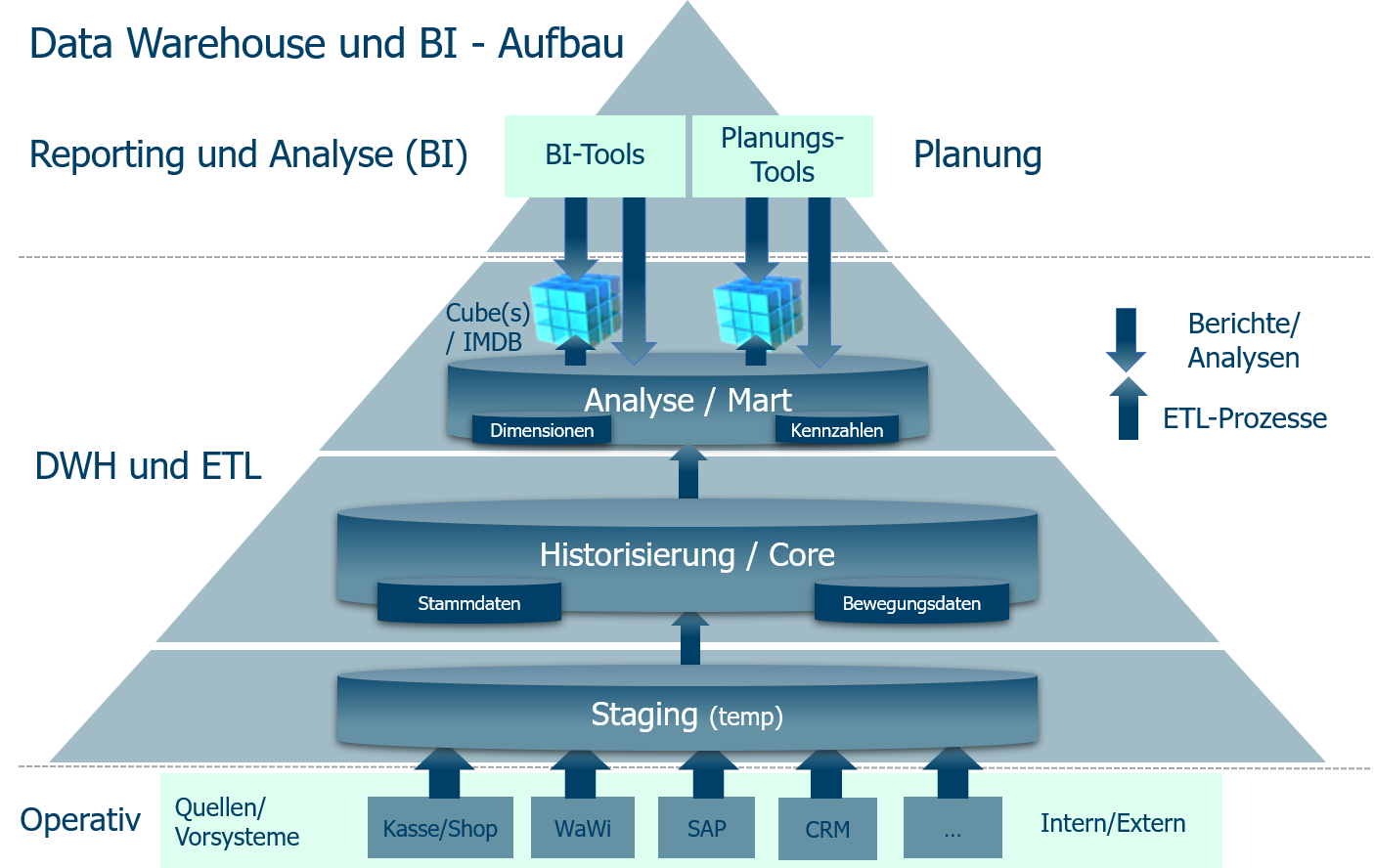
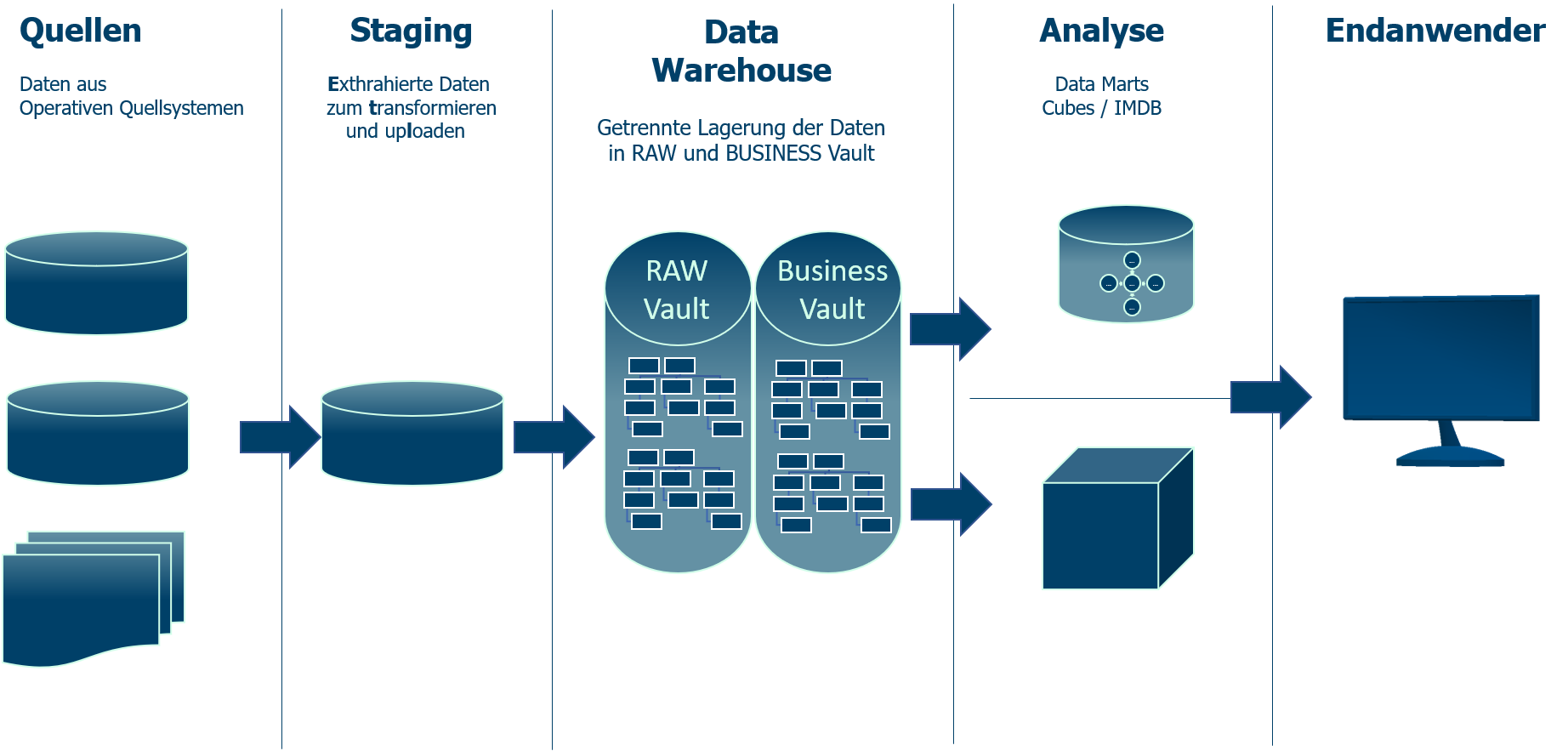
Методы проектирования хранилищ данных
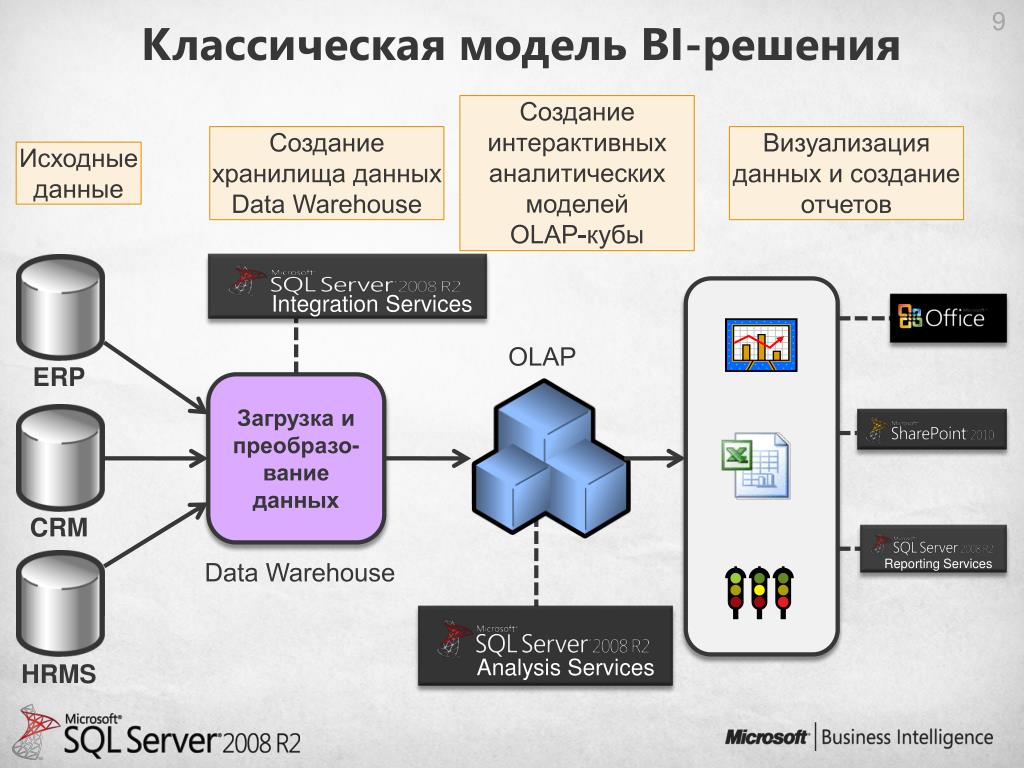
При разработке хранилища данных обычно используют две разные методологии, и на основе требований вашего проекта можно выбрать, какой из них больше подходит для вашего конкретного сценария. Эти методологии являются результатом исследований Билла Инмона и Ральфа Кимбалла.
Билл Инмон — Подход к проектированию хранилищ данных “сверху вниз”
Билла Инмонхж иногда называют также «отцом хранилищ данных»; его методология проектирования основана на подходе “сверху вниз” и определяет хранилище данных в соответствии со следующими принципами:
- Предметная ориентация. Данные в хранилище классифицируются на основе области, которую они описывают, следовательно, являются «предметными».
- Интегрированность. Данные интегрируются из различных источников и унифицируются по именам, измерениям, классификации для использования в хранилище данных, которое обеспечивает консолидированное представление данных предприятия, следовательно является интегрированным решением.
- Неизменяемость. Как только данные будут интегрированы \ загружены в хранилище данных, их можно будет только читать. Пользователи не смогут вносить изменения в данные, что делает данные неизменяемыми.
- Хронологичность. Наконец, данные хранятся в течение длительных периодов времени, количественно определяемых в годах, и имеют дату и временную метку, и поэтому они описываются как хронологические.
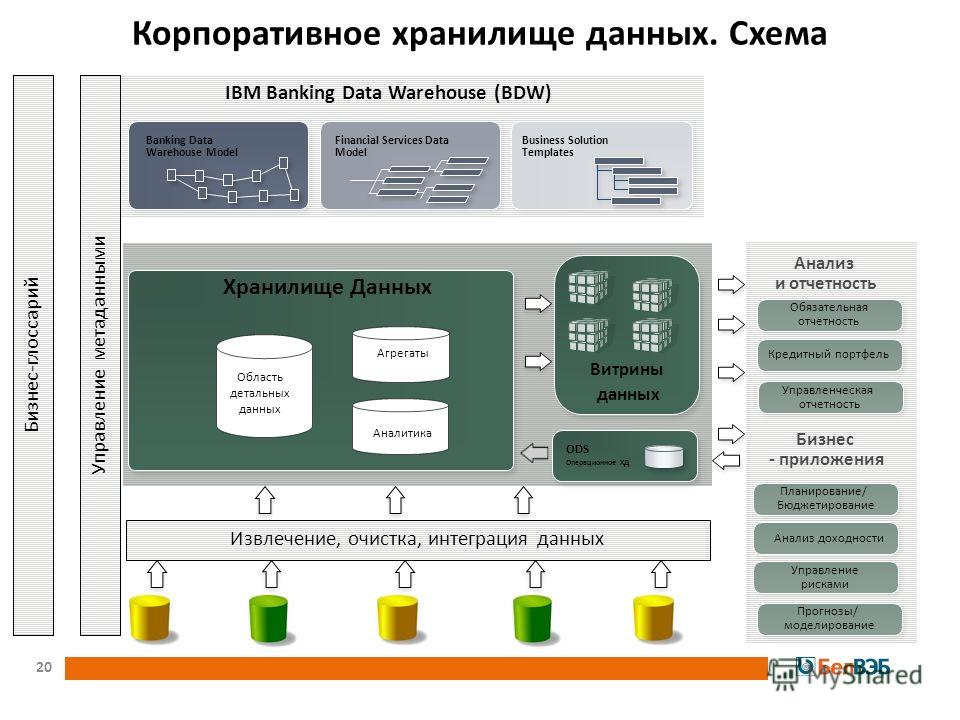
Билл Инмон увидел необходимость интегрировать данные из разных OLTP-систем в централизованный репозиторий (называемый хранилищем данных) по принципу «сверху вниз». Билл Инмон представил хранилище данных в центре «Корпоративной информационной фабрики» (CIF), которое обеспечивает логическую структуру для предоставления возможностей бизнес-аналитики (BI) и управления бизнесом.
Этот сверху-вниз дизайн обеспечивает высококонвертированное пространственное представление данных через витрины данных, поскольку все витрины данных загружаются из централизованного хранилища (DW). Проектирование «сверху вниз» также оказалось гибким для поддержки изменений в бизнесе, поскольку оно рассматривает организацию в целом, а не каждую функцию или бизнес-процесс организации. Создание новых витрин мерных данных в отношении данных, расположенных в хранилище данных, является относительно простой задачей. Несмотря на такие преимущества, существует и ряд проблем, связанных с подходом «сверху вниз»: поскольку он представляет собой очень крупный, широкомасштабный проект, поэтому первоначальные затраты на внедрение хранилища данных с использованием такой методологии значительны. Кроме того, проходит немало времени, прежде чем конечные пользователи начинают испытывать первоначальные преимущества решения, Помимо прочего, методология «сверху вниз» часто бывает негибкой и не реагирующей на меняющиеся потребности отдела или бизнес-процессов (проблема для сегодняшней динамично меняющейся среды) на этапе реализации.
Ральф Кимбалл — Подход к проектированию хранилища данных “снизу вверх”
Ральф Кимбалл — известный автор по вопросам хранения данных. Его методология дизайна называется многомерным моделированием или методологией Кимбалла
Она фокусируется на восходящем подходе, подчеркивая важность быстрого доступа пользователей к хранилищу данных. По его мнению, хранилище данных — это копия транзакционных данных, специально структурированных для аналитических запросов и отчетности и функционирования системы поддержки принятия решений
Согласно его методологии, сначала создаются витрины данных — для предоставления отчетов и аналитических возможностей для конкретных бизнес-процессов, а в дальнейшем эти витрины данных могут в конечном итоге объединяться вместе для создания всеобъемлющего хранилища корпоративных данных. Подход «снизу вверх» сосредоточен на каждом бизнес-процессе в один момент времени, поэтому инвестиции возвращаются так же быстро, как создается первый файл данных. Но, в случае не слишком тщательного планирования и чрезмерной концентрации на отдельном бизнес-процессе, вы рискуете не получить общую картину хранилища данных предприятия (если вы потеряли некоторые измерения или создали избыточные измерения).
Подход «снизу вверх» Ральфа Кимбалла предлагает создать бизнес-матрицу, которая должна содержать все общие элементы, используемые витринами данных, такие как согласованные или общие измерения, определенные для предприятия в целом. Благодаря этому, пользователь может проектировать и разрабатывать решения, которые поддерживают анализ в бизнес-процессах для перекрестных продаж.
2 место. PostgreSQL
Следующая по популярности OLTP-база: по сравнению с MySQL она больше соответствует стандарту SQL. Если MySQL в первую очередь ориентирована на стабильность, надежность и простоту, то PostgreSQL — на инновации и расширенную функциональность.
Будучи объектно-реляционной, PostgreSQL обеспечивает такие функции, как наследование таблиц и перегрузка функций. Поддерживает множество типов данных, включая JSON, XML, геопространственные данные, «ключ-значение» и другие.
Еще система расширяемая, можно воспользоваться одним из множества готовых расширений или создать собственное.
Рекомендуется для задач, где требуется многофункциональная БД, способная хранить массивные объемы данных и обрабатывать сложные запросы:
- построение небольших DWH (Data Warehouse) для аналитических систем;
- хранилище для геоинформационных систем — совместно с расширением PostGIS;
- основное хранилище для веб-приложений, мобильных приложений, игр.
Не рекомендуется для задач, где
- преобладают записи чтения— в таком случае предпочтительнее MySQL;
- требуется горизонтальное масштабирование;
- требуется OLAP-хранилище.
3 место. MongoDB
Одна из ведущих NoSQL-систем. MongoDB — документо-ориентированная: каждая строка представляет собой JSON или Binary JSON (BSON).
В базе данных используют язык запросов, он отличается от SQL и обеспечивает поиск по графам, а также географический, текстовый поиск и другие. Поддерживает распределенные ACID-транзакции. Благодаря горизонтальному масштабированию выдерживает очень высокие нагрузки.
Рекомендуется для задач, где используют полуструктурированные данные (JSON, XML), схема данных отсутствует или часто изменяется, а также требуется устойчивость к высоким нагрузкам:
- мобильные приложения,
- аналитика в реальном времени,
- CMS-системы,
- интернет вещей (IoT),
- электронная коммерция,
- игры.
Не рекомендуется для задач, где
- данные структурированы;
- в будущем могут понадобиться жесткие схемы данных и проверки на консистентность.
Прикладные кейсы использования ETL-технологий
Рассмотрим пару типовых примеров использования ETL-систем .
Кейс 1. Прием нового сотрудника на работу, когда требуется завести учетную карточку во множестве корпоративных систем. В реальности в средних и крупных организациях этим занимаются специалисты разных подразделений, не скоординировав задачу между собой. Поэтому на практике часто возникают ситуации, когда принятый на работу сотрудник подолгу не может получить банковскую карту, потому что его учетная запись не была вовремя заведёна в бухгалтерии, а уже уволенные сотрудники имеют доступ к корпоративной почте и приложениям, т.к. их аккаунты не заблокированы в домене. ETL поможет быстро наладить взаимодействие между всеми корпоративными информационными системами.
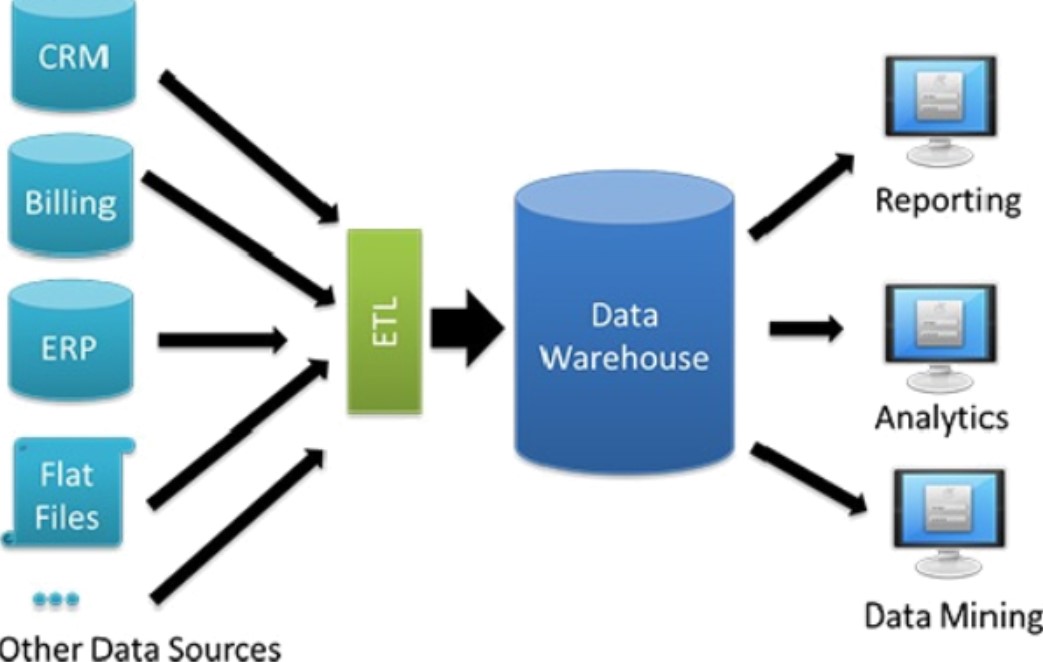
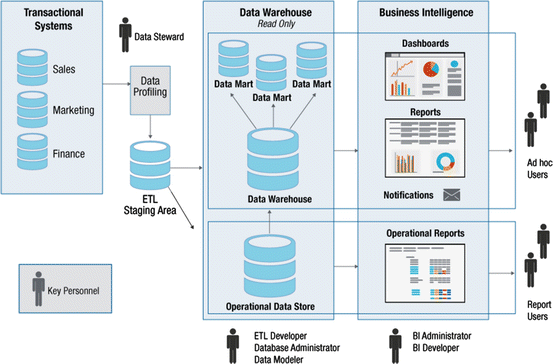
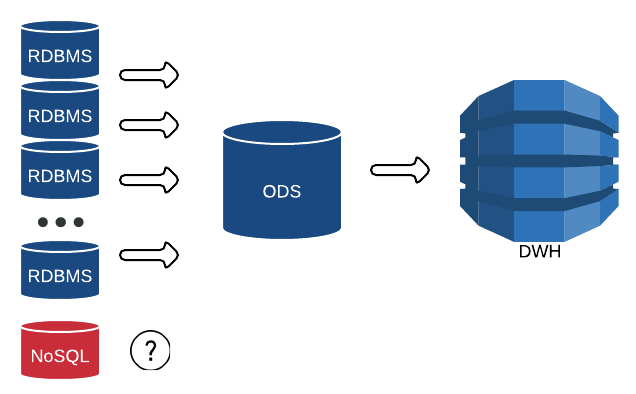
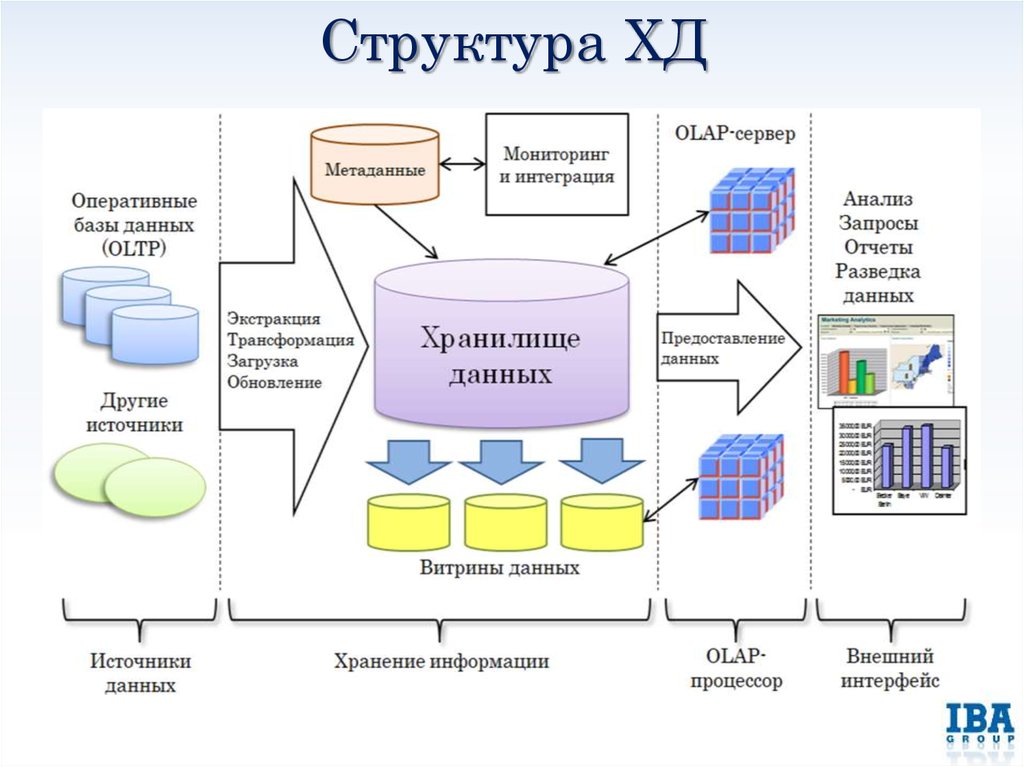
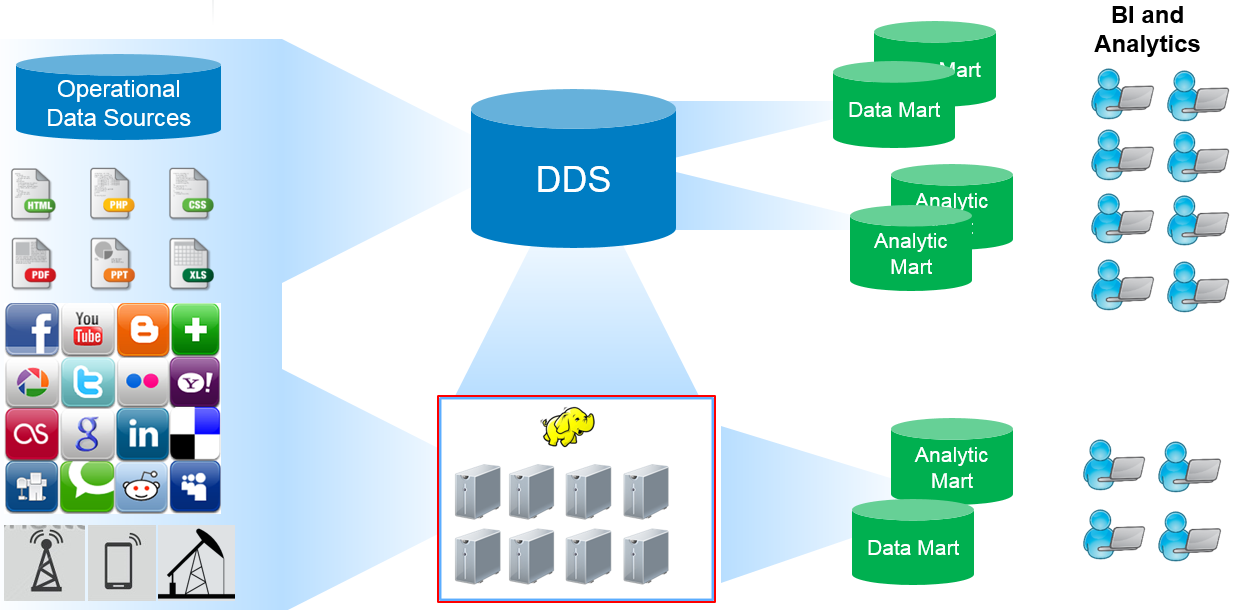
Аналогичным образом ETL-технологии помогут автоматизировать удаление аккаунтов сотрудника из всех корпоративных систем в случае увольнения. В частности, как только в HR-систему попадут данные о дате окончания карьеры сотрудника на этом месте работы, информация о необходимости блокировки его записи поступит контроллеру домена, его корпоративная почта автоматически архивируется, а почтовый ящик блокируется. Также возможен полуавтоматический режим с созданием заявки на блокировку в службу технической поддержки, например, Help Desk.
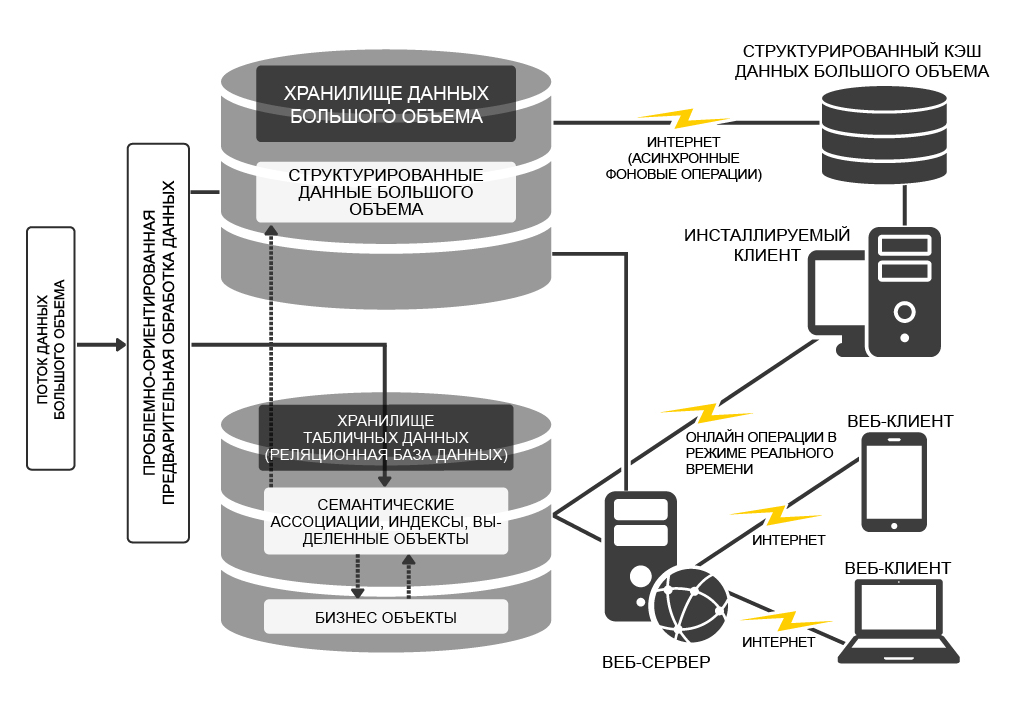
Кейс 2. Разноска платежей, когда при взаимодействии со множеством контрагентов необходимо сопоставить информацию в виде платёжных документов, с деньгами, поступившими на расчетный счёт. В реальности это два независимых потока данных, которые сотрудники бухгалтерии или операционисты связывают вручную. Далеко не все корпоративные финансовые системы имеют функцию автоматической привязки платежей.
Итак, информация о платежах поступает от платежной сети в зашифрованном виде, т.к. содержит персональные данные. Вторым потоком данных являются файлы в формате DBF, содержащие информацию о банках-контрагентах, которая требуется для геолокации платежа. Наконец, с минимальной задержкой в три банковских дня, приходят деньги и выписка с платежами, проведёнными через банк-партнёр. Отметим, что в реальности прямой связи между всеми этими данными нет: номера документов, указанные в реестрах от платёжной системы и банка, не совпадают, а из-за особенностей работы банка дата платежа, которая значится в выписке, может не соответствовать дате реальной оплаты, которая содержится в зашифрованном файле реестра.
Расшифровку данных можно включить в ETL-процесс, в результате чего получится текстовый файл сложной структуры, содержащий ФИО, телефон, паспортные данные плательщика, сумму и дату платежа, а также дополнительные технические данных, идентифицирующие транзакцию. Это как раз позволит связать платёж с данными из банковской выписки. Данные из реестра обогащаются информацией о банках-контрагентах (филиалах, подразделениях, городах и адресах отделений), после этого осуществляются их соответствие (мэппинг) к конкретным полям таблиц корпоративных информационных систем и загрузка в КХД. Обогащение уже очищенных данных происходит в рамках реляционной модели с использованием внешних ключей.
После прихода банковской выписки запускается ещё один ETL-процесс, задача которого состоит в сопоставлении ранее полученной информации о платежах с реально пришедшими деньгами. Поскольку выписки приходят из банка в текстовом формате, первым шагом трансформации является разбор файла, затем идет процесс автоматической привязки платежей с использованием информации, ранее загруженной в корпоративную систему из реестров платежей и банков. В процессе привязки происходит сравнение не только ключей, идентифицирующих транзакцию, но и суммы и ФИО плательщика, а также отделения банка. Также решается задача исправления неверной даты платежа, указанной в банковской выписке, на реальную дату его совершения.
В результате нескольких ETL-процессов получилась система автоматической привязки платежей, при этом основные затраты были связаны с не с разработкой программного обеспечения, а с проектированием и изучением форматов файлов. В редких случаях ручной привязки обогащение данных с помощью ETL-технологии существенно облегчает эту процедуру. В частности, наличие телефонного номера плательщика позволяет уточнить данные о платеже лично у него, а геолокация платежа даёт информацию для аналитических отчётов и позволяет более эффективно отслеживать переводы от партнёров-брокеров (рис. 4).
Рис. 4. Организация разноски платежей с помощью ETL



