ROLLUP: Adding the “bottom line”
When creating reports, you will often need the “bottom line” which sums up what has been shown in the table. The way to do that in SQL is to use “GROUP BY ROLLUP”:
test=# SELECT country, product_name, sum(amount_sold)
FROM t_sales
GROUP BY ROLLUP (1, 2)
ORDER BY 1, 2;
country | product_name | sum
-----------+--------------+-----
Argentina | Hats | 111
Argentina | Shoes | 26
Argentina | | 137
Germany | Hats | 41
Germany | Shoes | 63
Germany | | 104
USA | Hats | 171
USA | Shoes | 202
USA | | 373
| | 614
(10 rows)
PostgreSQL will inject a couple of rows into the result. As you can see, “Argentina” returns 3 and not just 2 rows. The “product_name = NULL” entry was added by ROLLUP. It contains the sum of all argentinian sales (116 + 27 = 137). Additional rows are injected for both other countries. Finally, a row is added for the overall sales worldwide.
Often those NULL entries are not what people want to see, thus it can make sense to replace them with some other kind of entry. The way to do that is to use a subselect which checks for the NULL entry and does the replacement. Here’s how it works:
test=# SELECT CASE WHEN country IS NULL
THEN 'TOTAL' ELSE country END,
CASE WHEN product_name IS NULL
THEN 'TOTAL' ELSE product_name END,
sum
FROM (SELECT country, product_name, sum(amount_sold)
FROM t_sales
GROUP BY ROLLUP (1, 2)
ORDER BY 1, 2
) AS x;
country | product_name | sum
-----------+--------------+-----
Argentina | Hats | 111
Argentina | Shoes | 26
Argentina | TOTAL | 137
Germany | Hats | 41
Germany | Shoes | 63
Germany | TOTAL | 104
USA | Hats | 171
USA | Shoes | 202
USA | TOTAL | 373
TOTAL | TOTAL | 614
(10 rows)
As you can see, all NULL entries have been replaced with “TOTAL”, which in many cases is the more desirable way to display this data.
Предложение ORDER BY
Предложение ORDER BY определяет порядок сортировки строк результирующего набора, возвращаемого запросом. Это предложение имеет следующий синтаксис:
Соглашения по синтаксису
Порядок сортировки задается в параметре col_name. Параметр col_number является альтернативным указателем порядка сортировки, который определяет столбцы по порядку их вхождения в список выборки инструкции SELECT (1 — первый столбец, 2 — второй столбец и т.д.). Параметр ASC определяет сортировку в восходящем порядке, а параметр DESC — в нисходящем. По умолчанию применяется параметр ASC.
Имена столбцов в предложении ORDER BY не обязательно должны быть указаны в списке столбцов выборки. Но это не относится к запросам типа SELECT DISTINCT, т.к. в таких запросах имена столбцов, указанные в предложении ORDER BY, также должны быть указаны в списке столбцов выборки. Кроме этого, это предложение не может содержать имен столбцов из таблиц, не указанных в предложении FROM.
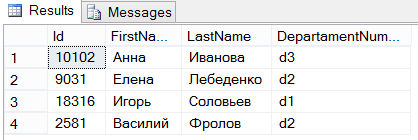
Как можно видеть по синтаксису предложения ORDER BY, сортировка результирующего набора может выполняться по нескольким столбцам. Такая сортировка показана в примере ниже:
В этом примере происходит выборка номеров отделов и фамилий и имен сотрудников для сотрудников, чей табельный номер меньше чем 20 000, а также с сортировкой по фамилии и имени. Результат выполнения этого запроса:
Столбцы в предложении ORDER BY можно указывать не по их именам, а по порядку в списке выборки. Соответственно, предложение в примере выше можно переписать таким образом:
Такой альтернативный способ указания столбцов по их позиции вместо имен применяется, если критерий упорядочивания содержит агрегатную функцию. (Другим способом является использование наименований столбцов, которые тогда отображаются в предложении ORDER BY.) Однако в предложении ORDER BY рекомендуется указывать столбцы по их именам, а не по номерам, чтобы упростить обновление запроса, если в списке выборки придется добавить или удалить столбцы. Указание столбцов в предложении ORDER BY по их номерам показано в примере ниже:
Здесь для каждого проекта выбирается номер проекта и количество участвующих в нем сотрудников, упорядочив результат в убывающем порядке по числу сотрудников.
Язык Transact-SQL при сортировке в возрастающем порядке помещает значения NULL в начале списка, и в конце списка — при убывающем.
Использование предложения ORDER BY для разбиения результатов на страницы
Отображение результатов запроса на текущей странице можно или реализовать в пользовательском приложении, или же дать указание осуществить это серверу базы данных. В первом случае все строки базы данных отправляются приложению, чьей задачей является отобрать требуемые строки и отобразить их. Во втором случае, со стороны сервера выбираются и отображаются только строки, требуемые для текущей страницы. Как можно предположить, создание страниц на стороне сервера обычно обеспечивает лучшую производительность, т.к. клиенту отправляются только строки, необходимые для отображения.
Для поддержки создания страниц на стороне сервера в SQL Server 2012 вводится два новых предложения инструкции SELECT: OFFSET и FETCH. Применение этих двух предложений демонстрируется в примере ниже. Здесь из базы данных AdventureWorks2012 (которую вы можете найти в исходниках) извлекается идентификатор бизнеса, название должности и день рождения всех сотрудников женского пола с сортировкой результата по названию должности в возрастающем порядке. Результирующий набор строк разбивается на 10-строчные страницы и отображается третья страница:
В предложении OFFSET указывается количество строк результата, которые нужно пропустить в отображаемом результате. Это количество вычисляется после сортировки строк предложением ORDER BY. В предложении FETCH NEXT указывается количество удовлетворяющих условию WHERE и отсортированных строк, которое нужно возвратить. Параметром этого предложения может быть константа, выражение или результат другого запроса. Предложение FETCH NEXT аналогично предложению FETCH FIRST.
Основной целью при создании страниц на стороне сервера является возможность реализация общих страничных форм, используя переменные. Эту задачу можно выполнить посредством пакета SQL Server.
Операторы работы с наборами
Кроме операторов, рассмотренных ранее, язык Transact-SQL поддерживает еще три оператора работы с наборами: UNION, INTERSECT и EXCEPT.
Оператор UNION
Оператор UNION объединяет результаты двух или более запросов в один результирующий набор, в который входят все строки, принадлежащие всем запросам в объединении. Соответственно, результатом объединения двух таблиц является новая таблица, содержащая все строки, входящие в одну из исходных таблиц или в обе эти таблицы.
Общая форма оператора UNION выглядит таким образом:
Параметры select_1, select_2, … представляют собой инструкции SELECT, которые создают объединение. Если используется параметр ALL, отображаются все строки, включая дубликаты. В операторе UNION параметр ALL имеет то же самое значение, что и в списке выбора SELECT, но с одним отличием: для списка выбора SELECT этот параметр применяется по умолчанию, а для оператора UNION его нужно указывать явно.
В своей исходной форме база данных SampleDb не подходит для демонстрации применения оператора UNION. Поэтому в этом разделе создается новая таблица EmployeeEnh, которая идентична существующей таблице Employee, но имеет дополнительный столбец City. В этом столбце указывается место жительства сотрудников.
Создание таблицы EmployeeEnh предоставляет нам удобный случай продемонстрировать использование предложения INTO в инструкции SELECT. Инструкция SELECT INTO выполняет две операции. Сначала создается новая таблица со столбцами, перечисленными в списке выбора SELECT. Потом строки исходной таблицы вставляются в новую таблицу. Имя новой таблицы указывается в предложении INTO, а имя таблицы-источника указывается в предложении FROM.
В примере ниже показано создание таблицы EmployeeEnh из таблицы Employee:
В этом примере инструкция SELECT INTO создает таблицу EmployeeEnh, вставляет в нее все строки из таблицы-источника Employee, после чего инструкция ALTER TABLE добавляет в новую таблицу столбец City. Но добавленный столбец City не содержит никаких значений. Значения в этот столбец можно вставить посредством среды Management Studio или же с помощью следующего кода:
Теперь мы готовы продемонстрировать использование инструкции UNION. В примере ниже показан запрос для создания соединения таблиц EmployeeEnh и Department, используя эту инструкцию:
Результат выполнения этого запроса:
Объединять с помощью инструкции UNION можно только совместимые таблицы. Под совместимыми таблицами имеется в виду, что оба списка столбцов выборки должны содержать одинаковое число столбцов, а соответствующие столбцы должны иметь совместимые типы данных. (В отношении совместимости типы данных INT и SMALLINT не являются совместимыми.)
Результат объединения можно упорядочить, только используя предложение ORDER BY в последней инструкции SELECT, как это показано в примере ниже. Предложения GROUP BY и HAVING можно применять с отдельными инструкциями SELECT, но не в самом объединении.
Запрос в этом примере осуществляет выборку сотрудников, которые или работают в отделе d1, или начали работать над проектом до 1 января 2008 г.
Оператор UNION поддерживает параметр ALL. При использовании этого параметра дубликаты не удаляются из результирующего набора.
Вместо оператора UNION можно применить оператор OR, если все инструкции SELECT, соединенные одним или несколькими операторами UNION, ссылаются на одну и ту же таблицу. В таком случае набор инструкций SELECT заменяется одной инструкцией SELECT с набором операторов OR.
Операторы INTERSECT и EXCEPT
Два других оператора для работы с наборами, INTERSECT и EXCEPT, определяют пересечение и разность соответственно. Под пересечением в данном контексте имеется набор строк, которые принадлежат к обеим таблицам. А разность двух таблиц определяется как все значения, которые принадлежат к первой таблице и не присутствуют во второй. В примере ниже показано использование оператора INTERSECT:
Язык Transact-SQL не поддерживает использование параметра ALL ни с оператором INTERSECT, ни с оператором EXCEPT. Использование оператора EXCEPT показано в примере ниже:
Следует помнить, что эти три оператора над множествами имеют разный приоритет выполнения: оператор INTERSECT имеет наивысший приоритет, за ним следует оператор EXCEPT, а оператор UNION имеет самый низкий приоритет. Невнимательность к приоритету выполнения при использовании нескольких разных операторов для работы с наборами может повлечь неожиданные результаты.
Функция SQL MAX
Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда
требуется определить максимальное значение среди всех значений столбца.
Пример 5.
Требуется узнать максимальную заработную плату сотрудников отдела с номером 42.
Для этого пишем следующий запрос:
Запрос вернёт значение 18352,80
Пришло время упражнения для самостоятельного решения
.
Пример 6.
Вновь работаем с двумя таблицами — Staff и Org.
Вывести название отдела и максимальное значение комиссионных, получаемых одним сотрудником в отделе,
относящемуся к группе отделов (Division) Eastern. Использовать JOIN (соединение таблиц)
.




![Sql [айти бубен]](https://wudgleyd.ru/wp-content/uploads/5/8/b/58b6d75feaf46f6bee75cfad79f2b537.png)

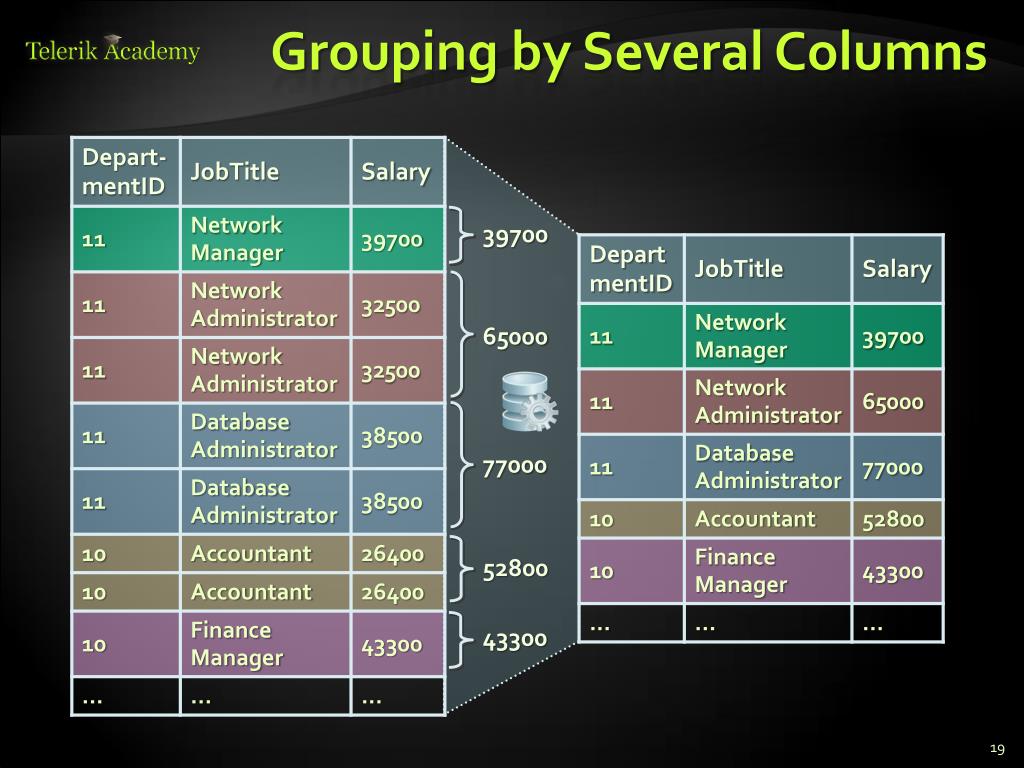
Работа с несколькими группами
Пока что мы работали с одной группировкой — по локациям. Что, если нам нужно разбить полученные группы на подгруппы?
Вспомните пример сценария, приведенный в начале статьи, с группировкой людей по цвету глаз и стране происхождения. Давайте попробуем найти число продаж каждого продукта в каждой отдельной локации (Например, сколько было продаж кофе, а сколько — бубликов на 1st Street, HQ и Downtown).
Для этого нам нужно добавить к нашему предложению GROUP BY второе группирующее условие:
SELECT … FROM sales GROUP BY location, product;
Добавив название еще одного столбца в наше предложение GROUP BY, мы разделили наши локационные группы на подгруппы по продуктам.
Поскольку теперь мы группируем также по столбцу product, мы можем вернуть результат при помощи нашего SELECT!
(Для облегчения чтения я добавил в запрос также предложения ORDER BY).
SELECT location, product FROM sales GROUP BY location, product ORDER BY location, product;
В результатах нашего нового группирования мы видим уникальные комбинации локаций и продуктов:
location | product ————+——— 1st Street | Bagel 1st Street | Coffee Downtown | Bagel Downtown | Coffee HQ | Bagel HQ | Coffee (6 rows)
Ну хорошо, у нас есть наши группы, а что мы будем делать с данными остальных столбцов?
Мы можем найти число продаж определенного продукта в каждой локации, используя все те же агрегатные функции:
SELECT location, product, COUNT(*) AS number_of_sales FROM sales GROUP BY location, product ORDER BY location, product; location | product | number_of_sales ————+———+—————— 1st Street | Bagel | 1 1st Street | Coffee | 1 Downtown | Bagel | 1 Downtown | Coffee | 1 HQ | Bagel | 2 HQ | Coffee | 2 (6 rows)
(Задание «со звездочкой»: найдите общую выручку (сумму) за каждый продукт в каждой локации).

GROUP BY
Let’s start be reminding ourselves how the clause works. An aggregate function takes multiple rows of data returned by a query and aggregates them into a single result row.
SELECT SUM(sales_value) AS sales_value FROM dimension_tab; SALES_VALUE ----------- 50528.39 1 row selected. SQL>
Including the clause limits the window of data processed by the aggregate function. This way we get an aggregated value for each distinct combination of values present in the columns listed in the clause. The number of rows we expect can be calculated by multiplying the number of distinct values of each column listed in the clause. In this case, if the rows were loaded randomly we would expect the number of distinct values for the first three columns in the table to be 2, 5 and 10 respectively. So using the column in the clause should give us 2 rows.
SELECT fact_1_id,
COUNT(*) AS num_rows,
SUM(sales_value) AS sales_value
FROM dimension_tab
GROUP BY fact_1_id
ORDER BY fact_1_id;
FACT_1_ID NUM_ROWS SALES_VALUE
---------- ---------- -----------
1 478 24291.35
2 522 26237.04
2 rows selected.
SQL>
Including the first two columns in the clause should give us 10 rows (2*5), each with its aggregated values.
SELECT fact_1_id,
fact_2_id,
COUNT(*) AS num_rows,
SUM(sales_value) AS sales_value
FROM dimension_tab
GROUP BY fact_1_id, fact_2_id
ORDER BY fact_1_id, fact_2_id;
FACT_1_ID FACT_2_ID NUM_ROWS SALES_VALUE
---------- ---------- ---------- -----------
1 1 83 4363.55
1 2 96 4794.76
1 3 93 4718.25
1 4 105 5387.45
1 5 101 5027.34
2 1 109 5652.84
2 2 96 4583.02
2 3 110 5555.77
2 4 113 5936.67
2 5 94 4508.74
10 rows selected.
SQL>
Including the first three columns in the clause should give us 100 rows (2*5*10).
SELECT fact_1_id,
fact_2_id,
fact_3_id,
COUNT(*) AS num_rows,
SUM(sales_value) AS sales_value
FROM dimension_tab
GROUP BY fact_1_id, fact_2_id, fact_3_id
ORDER BY fact_1_id, fact_2_id, fact_3_id;
FACT_1_ID FACT_2_ID FACT_3_ID NUM_ROWS SALES_VALUE
---------- ---------- ---------- ---------- -----------
1 1 1 10 381.61
1 1 2 6 235.29
1 1 3 7 270.7
1 1 4 13 634.05
1 1 5 10 602.36
1 1 6 7 538.41
1 1 7 5 245.87
1 1 8 8 435.54
1 1 9 8 506.59
1 1 10 9 513.13
...
2 5 1 14 714.84
2 5 2 13 686.56
2 5 3 13 579.5
2 5 4 10 336.87
2 5 5 5 215.17
2 5 6 4 268.72
2 5 7 14 667.22
2 5 8 7 451.29
2 5 9 8 365.24
2 5 10 6 223.33
100 rows selected.
SQL>
Примеры: Azure Synapse Analytics и Parallel Data Warehouse
Д. Базовое использование предложения GROUP BY
В следующем примере вычисляется общий объем всех продаж за каждый день. Выводится только одна строка, содержащая общий объем продаж по каждому дню.
Е. Базовое использование указания DISTRIBUTED_AGG
В этом примере показано указание запроса DISTRIBUTED_AGG для принудительного перемещения в таблице по столбцу перед выполнением статистического вычисления.
Ж. Варианты синтаксиса для GROUP BY
Если в списке Select статистические вычисления, каждый столбец в списке Select должен быть включен в список GROUP BY. Вычисляемые столбцы в списке Select можно указать в списке GROUP BY (делать это необязательно). Ниже приведены примеры синтаксически правильных инструкций SELECT.
З. Использование GROUP BY с несколькими выражениями GROUP BY
В следующем примере группируются результаты с помощью нескольких критериев . Если в каждой группе есть подгруппы, которые могут отличаться по , для результирующего набора будет определено новое группирование.
И. Использование предложения GROUP BY с предложением HAVING
В следующем примере используется предложение , чтобы указать, какие группы, сформированные в предложении , должны быть включены в результирующий набор. В результаты будут включены только группы с датами заказов в 2004 году или более поздними.
General Remarks
How GROUP BY interacts with the SELECT statement
SELECT list:
- Vector aggregates. If aggregate functions are included in the SELECT list, GROUP BY calculates a summary value for each group. These are known as vector aggregates.
- Distinct aggregates. The aggregates AVG (DISTINCT column_name), COUNT (DISTINCT column_name), and SUM (DISTINCT column_name) are supported with ROLLUP, CUBE, and GROUPING SETS.
WHERE clause:
SQL removes Rows that do not meet the conditions in the WHERE clause before any grouping operation is performed.
HAVING clause:
SQL uses the having clause to filter groups in the result set.
ORDER BY clause:
Use the ORDER BY clause to order the result set. The GROUP BY clause does not order the result set.
NULL values:
If a grouping column contains NULL values, all NULL values are considered equal, and they are collected into a single group.
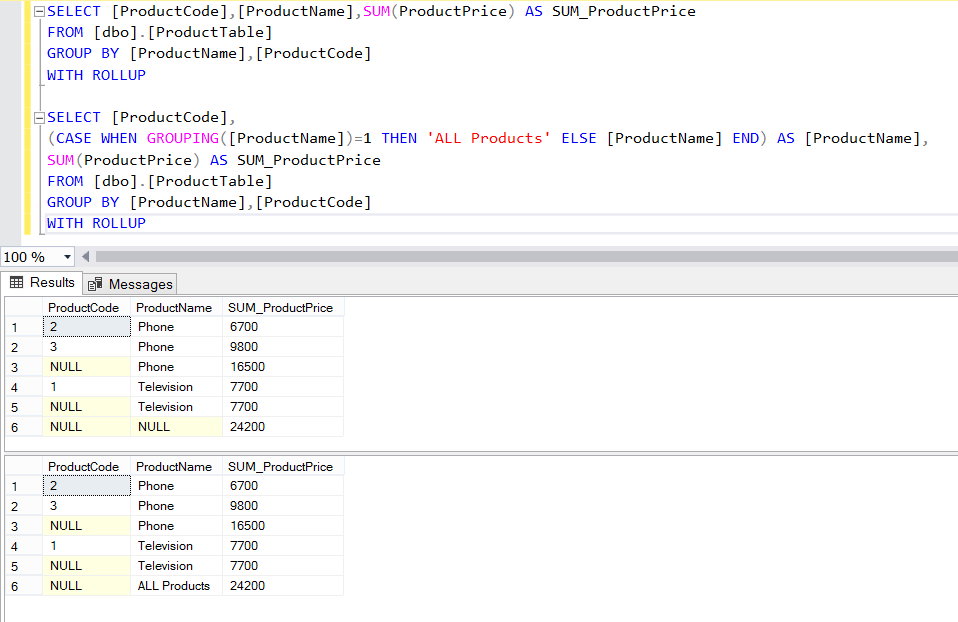
Использование конструкции GROUP BY с операцией ROLLUP
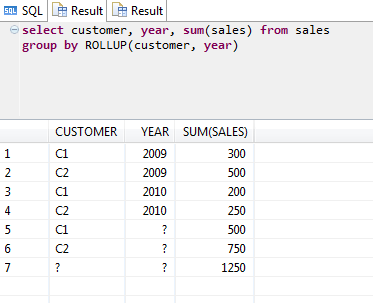
Как с помощью конструкции GROUP BY получать промежуточные итоговые значения (subtotals), уже было показано. За счет использования конструкции GROUP BY с операцией ROLLUP, однако, можно получать как промежуточные итоговые, так и общие суммарные (totals) значения и, следовательно, генерировать промежуточные агрегатные значения на любом уровне. Другими словами, операция ROLLUP позволяет получать агрегатные значения для каждой группы на отдельных уровнях. Промежуточные итоговые строки и конечные суммарные строки называются суперагрегатными строками (superaggregate rows).
В листинге ниже приведен пример применения конструкции GROUP BY с операцией ROLLUP.
SQL> SELECT Year,Country,SUM(Sales) AS Sales FROM Company_Sales GROUP BY ROLLUP (Year,Country); YEAR COUNTRY SALES ——— ——— ——- 1997 France 3990 1997 USA 13090 1997 17080 1998 France 4310 1998 USA 13900 1998 18210 1999 France 4570 1999 USA 14670 1999 19240 54530 /* Так выглядит конечное суммарное значение */ SQL>
Summary
So, in summary:
- Grouping is needed when working with aggregate functions.
- The SQL GROUP BY clause allows you to specify the columns to group by.
- The HAVING clause allows you to filter records after the GROUP BY is applied.
- ROLLUP lets you group by sets of columns, from right to left.
- CUBE lets you group by all combinations of columns.
- GROUPING SETS lets you specify the sets or subtotals you require.
- Composite grouping means you can use brackets to force several columns to be treated as a single unit for grouping.
- Concatenated grouping means you can specify different group types within the same GROUP BY clause, separated by a comma.
- The GROUPING function shows 1 if a row is a subtotal row and 0 if it is not.
- The GROUPING_ID function shows a number indicating what level of a group the row relates to.
- The GROUP_ID function shows 0 if the record is unique or 1 if it is a duplicate.
That’s how the GROUP BY clause and related keywords work.
ROLLUP Examples
The ROLLUP operator allows SQL Server to create subtotals and grand totals, while it groups data using the GROUP BY clause. For my first example let me use the ROLLUP operator to generator a grand total by PurchaseType by running this code:
USE tempdb; GO SELECT coalesce(PurchaseType,'GrandTotal') AS PurchaseType , Sum(PurchaseAmt) as SummorizedPurchaseAmt FROM PurchaseItem GROUP BY ROLLUP(PurchaseType);
When I run this code I get this output:
PurchaseType SummorizedPurchaseAmt -------------------- --------------------- Appliances 233018.28 Electrical 17057.75 Garden 5567.99 Hardware 24341.35 Kitchenware 8044.89 Lighting 345.11 Lumber 47725.04 Outdoor 14444.56 Paint 14218.23 GrandTotal 364763.20
By reviewing the output above you can see that this code created subtotals for all the different PurchaseTypes and then at the end produced a GrandTotal for all the PurchaseTypes combined. If you look at the code above, I got the PurchaseType of “Grand Total” to display by using the coalesce clause. Without the coalesce clause the PurchaceType column value would have been “Null’ for the grand total row.


Suppose I wanted to calculate the subtotals of ProductTypes by month, with a monthly total amount for all the products sold in the month. I could do that by running the following code:
USE tempdb; GO SELECT month(PurchaseDate) PurchaseMonth , CASE WHEN month(PurchaseDate) is null then 'Grand Total' ELSE coalesce(PurchaseType,'Monthly Total') end AS PurchaseType , Sum(PurchaseAmt) as SummorizedPurchaseAmt FROM PurchaseItem GROUP BY ROLLUP(month(PurchaseDate), PurchaseType); When I run this code I get this output: PurchaseMonth PurchaseType SummorizedPurchaseAmt ------------- -------------------- --------------------- 1 Electrical 12347.87 1 Hardware 9653.17 1 Monthly Total 22001.04 2 Kitchenware 4712.00 2 Lumber 43235.67 2 Paint 12987.01 2 Monthly Total 60934.68 3 Appliances 143141.38 3 Garden 2321.01 3 Lumber 3245.59 3 Outdoor 3331.59 3 Monthly Total 152039.57 4 Electrical 4709.88 4 Kitchenware 3332.89 4 Lighting 345.11 4 Monthly Total 8387.88 5 Appliances 89876.90 5 Garden 3246.98 5 Hardware 14688.18 5 Lumber 1243.78 5 Outdoor 11112.97 5 Paint 1231.22 5 Monthly Total 121400.03 NULL Grand Total 364763.20
Here I have included two columns in the ROLLUP clause. The first column was the month of the purchase, and the second column is PurchaseType. This allowed me to create the subtotals by ProductType by month, as well as Monthly Total amount at the end of every month. Additionally this code creates a Grant Total amount of all product sales at the end.
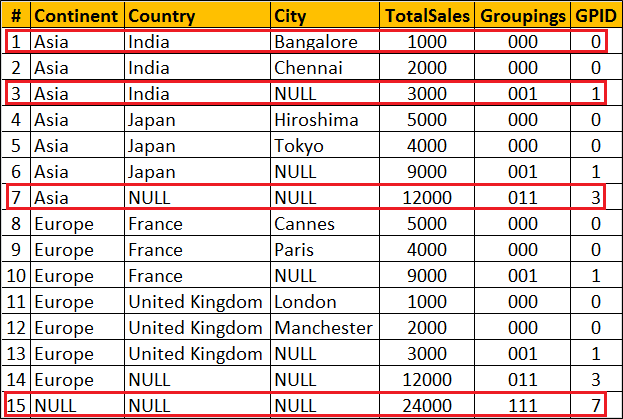
CUBE
In addition to the subtotals generated by the extension, the extension will generate subtotals for all combinations of the dimensions specified. If «n» is the number of columns listed in the , there will be 2n subtotal combinations.
SELECT fact_1_id,
fact_2_id,
SUM(sales_value) AS sales_value
FROM dimension_tab
GROUP BY CUBE (fact_1_id, fact_2_id)
ORDER BY fact_1_id, fact_2_id;
FACT_1_ID FACT_2_ID SALES_VALUE
---------- ---------- -----------
1 1 4363.55
1 2 4794.76
1 3 4718.25
1 4 5387.45
1 5 5027.34
1 24291.35
2 1 5652.84
2 2 4583.02
2 3 5555.77
2 4 5936.67
2 5 4508.74
2 26237.04
1 10016.39
2 9377.78
3 10274.02
4 11324.12
5 9536.08
50528.39
18 rows selected.
SQL>
As the number of dimensions increase, so do the combinations of subtotals that need to be calculated, as shown by the output of the following query, shown here.
SELECT fact_1_id,
fact_2_id,
fact_3_id,
SUM(sales_value) AS sales_value
FROM dimension_tab
GROUP BY CUBE (fact_1_id, fact_2_id, fact_3_id)
ORDER BY fact_1_id, fact_2_id, fact_3_id;
It is possible to do a partial cube to reduce the number of subtotals calculated. The output from the following partial cube is shown here.
SELECT fact_1_id,
fact_2_id,
fact_3_id,
SUM(sales_value) AS sales_value
FROM dimension_tab
GROUP BY fact_1_id, CUBE (fact_2_id, fact_3_id)
ORDER BY fact_1_id, fact_2_id, fact_3_id;
GROUPING SETS: The basic building blocks
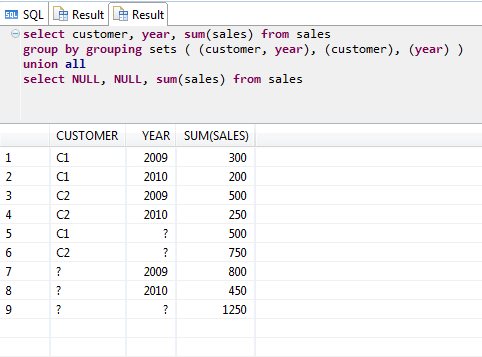
GROUP BY will turn every distinct entry in a column into a group. Sometimes you might want to do more grouping at once. Why is that necessary? Suppose you are processing a 10 TB table. Clearly, reading this data is usually the limiting factor in terms of performance. So reading the data once and producing more results at once is appealing. That’s exactly what you can do with GROUP BY GROUP SETS. Suppose we want to produce two results at once:
- GROUP BY country
- GROUP BY product_name
Here’s how it works:
test=# SELECT country, product_name, sum(amount_sold)
FROM t_sales
GROUP BY GROUPING SETS ((1), (2))
ORDER BY 1, 2;
country | product_name | sum
-----------+--------------+-----
Argentina | | 137
Germany | | 104
USA | | 373
| Hats | 323
| Shoes | 291
(5 rows)
In this case, PostgreSQL simply appends the results. The first three lines represent “GROUP BY country”. The next two lines contain the result of “GROUP BY product_name”. Logically, it’s the equivalent of the following query:
test=# SELECT NULL AS country , product_name, sum(amount_sold)
FROM t_sales
GROUP BY 1, 2
UNION ALL
SELECT country, NULL, sum(amount_sold)
FROM t_sales
GROUP BY 1, 2
ORDER BY 1, 2;
country | product_name | sum
-----------+--------------+-----
Argentina | | 137
Germany | | 104
USA | | 373
| Hats | 323
| Shoes | 291
(5 rows)
However, the GROUPING SETS version is ways more efficient because it only has to read the data once.
Выражения вложенного куба
Выражение вложенного куба может содержать идентификатор вложенного куба или инструкцию многомерных выражений, возвращающую вложенный куб. Если выражение вложенного куба содержит идентификатор вложенного куба, то это будет простое выражение. Если оно содержит инструкцию многомерных выражений, которая возвращает вложенный куб, то это сложная инструкция. Например, инструкция многомерных выражений SELECT возвращает вложенный куб и может использоваться там, где допустимы выражения вложенного куба, как показано в следующем примере:
SELECT .MEMBERS ON COLUMNS,
..MEMBERS ON ROWS
(SELECT . ON COLUMNS,
..& ON ROWS
Такое использование инструкции SELECT в предложении FROM называется также подзапросом выборки.
Другой типичный скрипт, где встречаются выражения вложенного куба, — это назначения с указанием области в скрипте многомерных выражений. В следующем примере используется инструкция SCOPE, чтобы ограничить назначение вложенным кубом, состоящим из .:
SCOPE(.);
Идентификатор вложенного куба отображается как Subcube_Name. в описаниях инструкций многомерных выражений в форме Бэкуса-Наура.
Подзапросы
На выходе подзапрос должен возвращать одно единственное значение (для страховки можно принудительно указывать LIMIT 1). Допускается использование подзапросов, которые на выходе выдают ряд значений, для оператора IN.
Операторы EXISTS, ANY(ANY и SOME абсолютно идентичны и являются взаимозаменяемыми),ALL умеют работать с множеством значений.
-
Пример. Использования подзапроса с оператором INSERT. В таблицу df_lcr_list передаются два значения(datestart и dateend), login_id ищется подзапросом по заранее известному имени пользователя, в таблицу вставляется текущее время.
INSERT INTO df_lcr_list (datestart,dateend,login_id, date_event) SELECT '20120405','20120405',id, now() FROM users WHERE login='username';
-
Пример. Использования подзапроса(subquery) с оператором UPDATE. Subquery выводит множество значений.
UPDATE accounts SET balance=0 WHERE uid IN (SELECT id FROM users WHERE email LIKE 'ltaixp1%');
The ROLLUP Operator
As mentioned earlier, the ROLLUP operator is used to calculate sub-totals and grand totals for a set of columns passed to the “GROUP BY ROLLUP” clause.
Let’s see how the ROLLUP clause helps us calculate the total salaries of the employees grouped by their departments and the grand total of the salaries of all the employees in the company. To do this we will work through a simple example query.
SELECT coalesce (department, 'All Departments') AS Department, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department)
In this code, we used the ROLLUP operator to calculate the grand total of the salaries of the employees from all the departments. However, for the grand total ROLLUP will return a NULL for department. To avoid this, we have used the “Coalesce” clause. This will replace NULL with the text “All Departments” and display the department name of each department in the Department column. For more details on using “Coalesce” see this article.
| Department | Salary_Sum |
| Finance | 16800 |
| HR | 20200 |
| IT | 21200 |
| Marketing | 18700 |
| Sales | 18700 |
| All Departments | 95600 |
Test Base
For the examples in this post, I will provide the base below so we can create a testing and demonstration environment.
Transact-SQL
IF (OBJECT_ID(‘tempdb..#Produtos’) IS NOT NULL) DROP TABLE #Produtos
CREATE TABLE #Produtos (
Codigo INT IDENTITY(1, 1) NOT NULL PRIMARY KEY,
Ds_Produto VARCHAR(50) NOT NULL,
Ds_Categoria VARCHAR(50) NOT NULL,
Preco NUMERIC(18, 2) NOT NULL
)
IF (OBJECT_ID(‘tempdb..#Vendas’) IS NOT NULL) DROP TABLE #Vendas
CREATE TABLE #Vendas (
Codigo INT IDENTITY(1, 1) NOT NULL PRIMARY KEY,
Dt_Venda DATETIME NOT NULL,
Cd_Produto INT NOT NULL
)
INSERT INTO #Produtos ( Ds_Produto, Ds_Categoria, Preco )
VALUES
( ‘Processador i7’, ‘Informática’, 1500.00 ),
( ‘Processador i5’, ‘Informática’, 1000.00 ),
( ‘Processador i3’, ‘Informática’, 500.00 ),
( ‘Placa de Vídeo Nvidia’, ‘Informática’, 2000.00 ),
( ‘Placa de Vídeo Radeon’, ‘Informática’, 1500.00 ),
( ‘Celular Apple’, ‘Celulares’, 10000.00 ),
( ‘Celular Samsung’, ‘Celulares’, 2500.00 ),
( ‘Celular Sony’, ‘Celulares’, 4200.00 ),
( ‘Celular LG’, ‘Celulares’, 1000.00 ),
( ‘Cama’, ‘Utilidades do Lar’, 2000.00 ),
( ‘Toalha’, ‘Utilidades do Lar’, 40.00 ),
( ‘Lençol’, ‘Utilidades do Lar’, 60.00 ),
( ‘Cadeira’, ‘Utilidades do Lar’, 200.00 ),
( ‘Mesa’, ‘Utilidades do Lar’, 1000.00 ),
( ‘Talheres’, ‘Utilidades do Lar’, 50.00 )
DECLARE @Contador INT = 1, @Total INT = 100
WHILE(@Contador <= @Total)
BEGIN
INSERT INTO #Vendas ( Cd_Produto, Dt_Venda )
SELECT
(SELECT TOP 1 Codigo FROM #Produtos ORDER BY NEWID()) AS Cd_Produto,
DATEADD(DAY, (CAST(RAND() * 364 AS INT)), ‘2017-01-01’) AS Dt_Venda
SET @Contador += 1
END
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
IF(OBJECT_ID(‘tempdb..#Produtos’)ISNOTNULL)DROPTABLE#Produtos CREATETABLE#Produtos ( CodigoINTIDENTITY(1,1)NOTNULLPRIMARYKEY, Ds_ProdutoVARCHAR(50)NOTNULL, Ds_CategoriaVARCHAR(50)NOTNULL, PrecoNUMERIC(18,2)NOTNULL ) IF(OBJECT_ID(‘tempdb..#Vendas’)ISNOTNULL)DROPTABLE#Vendas CREATETABLE#Vendas ( CodigoINTIDENTITY(1,1)NOTNULLPRIMARYKEY, Dt_VendaDATETIMENOTNULL, Cd_ProdutoINTNOTNULL ) INSERTINTO#Produtos (Ds_Produto,Ds_Categoria,Preco) VALUES (‘Processador i7′,’Informática’,1500.00), (‘Processador i5′,’Informática’,1000.00), (‘Processador i3′,’Informática’,500.00), (‘Placa de Vídeo Nvidia’,’Informática’,2000.00), (‘Placa de Vídeo Radeon’,’Informática’,1500.00), (‘Celular Apple’,’Celulares’,10000.00), (‘Celular Samsung’,’Celulares’,2500.00), (‘Celular Sony’,’Celulares’,4200.00), (‘Celular LG’,’Celulares’,1000.00), (‘Cama’,’Utilidades do Lar’,2000.00), (‘Toalha’,’Utilidades do Lar’,40.00), (‘Lençol’,’Utilidades do Lar’,60.00), (‘Cadeira’,’Utilidades do Lar’,200.00), (‘Mesa’,’Utilidades do Lar’,1000.00), (‘Talheres’,’Utilidades do Lar’,50.00) DECLARE@ContadorINT=1,@TotalINT=100 WHILE(@Contador<=@Total) BEGIN INSERTINTO#Vendas (Cd_Produto,Dt_Venda) SELECT (SELECTTOP1CodigoFROM#ProdutosORDERBYNEWID())ASCd_Produto, DATEADD(DAY,(CAST(RAND()*364ASINT)),’2017-01-01′)ASDt_Venda SET@Contador+=1 |
In a simple data grouping, just bringing the quantities filtering by category and product, we can return this view using the query below:
Transact-SQL
SELECT
B.Ds_Categoria,
B.Ds_Produto,
COUNT(*) AS Qt_Vendas,
SUM(B.Preco) AS Vl_Total
FROM
#Vendas A
JOIN #Produtos B ON A.Cd_Produto = B.Codigo
GROUP BY
B.Ds_Categoria,
B.Ds_Produto
ORDER BY
1, 2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT B.Ds_Categoria, B.Ds_Produto, COUNT(*)ASQt_Vendas, SUM(B.Preco)ASVl_Total FROM #VendasA JOIN#ProdutosBONA.Cd_Produto=B.Codigo GROUPBY B.Ds_Categoria, B.Ds_Produto ORDERBY 1,2 |
ROLLUP
ROLLUP – оператор Transact-SQL, который формирует промежуточные итоги для каждого указанного элемента и общий итог.
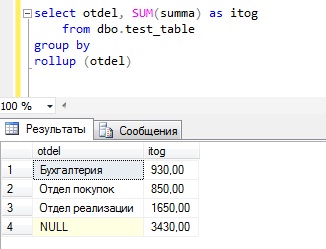
Для того чтобы понять, как работает данный оператор, предлагаю сразу перейти к примерам, и допустим, что нам необходимо получить сумму расхода на оплату труда по отделам и по годам, и сначала давайте попробуем написать запрос с группировкой без использования оператора ROLLUP.
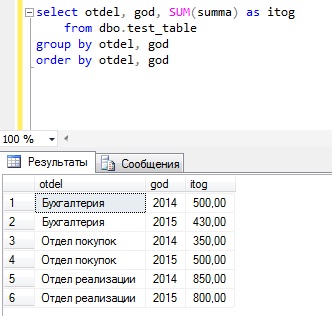
Как видите, группировка у нас получилась и в принципе мы видим что, например, в бухгалтерии в 2014 был такой расход, а 2015 такой, но иногда руководство хочет видеть и общую информацию, например, общий расход по каждому отделу. Для этих целей мы можем использовать оператор ROLLUP.
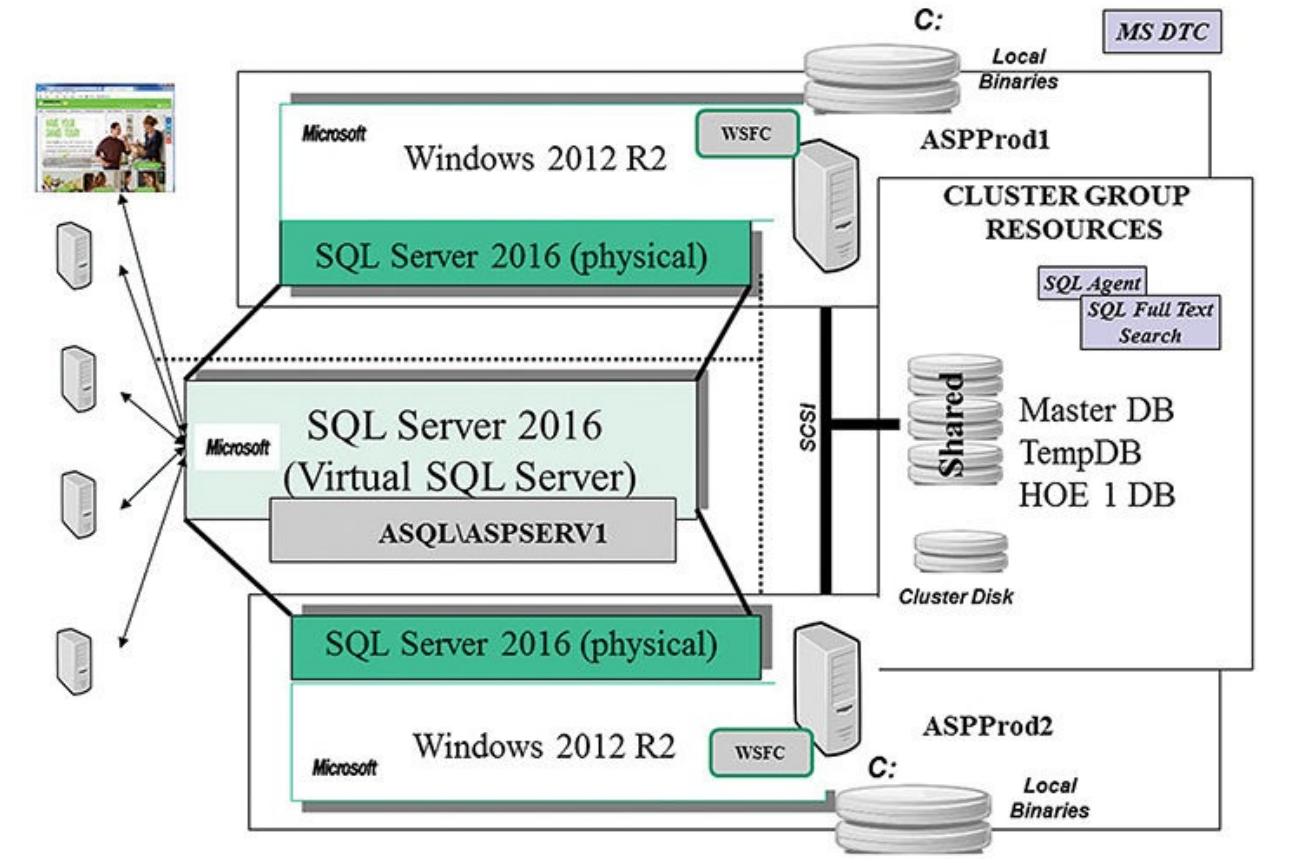

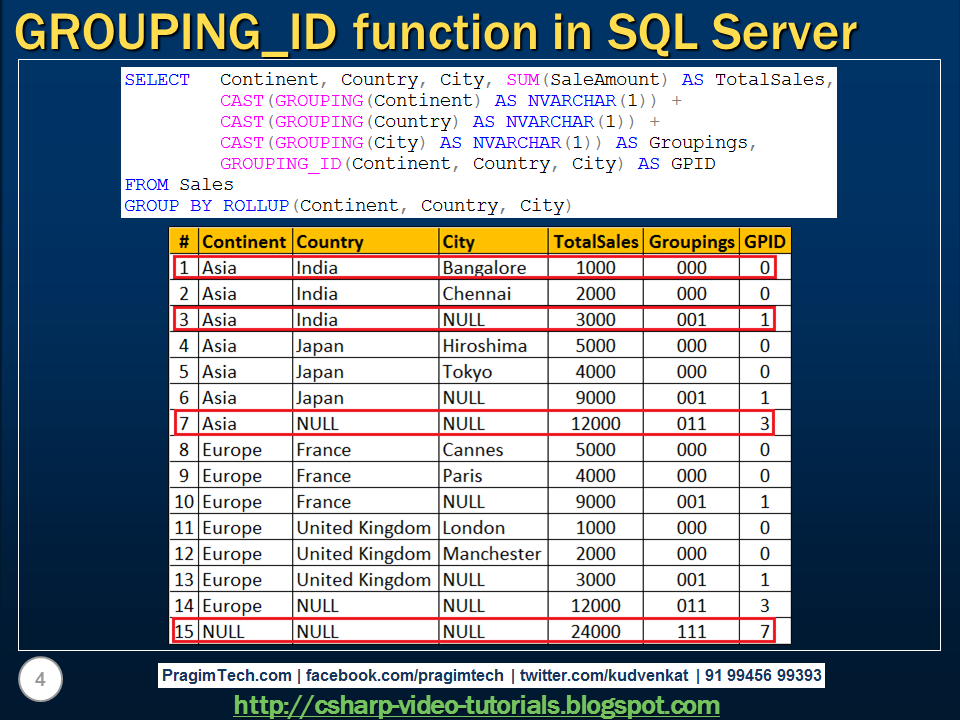




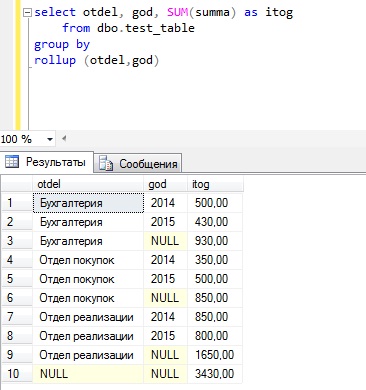
Строки со значением NULL и есть промежуточные итоги по отделам, а самая последняя строка общий итог. Согласитесь, что это уже более наглядно.
Можно также использовать rollup и с группировкой по одному полю, например:
Группировка по отделам с общим итогом

Группировка по годам с общим итогом
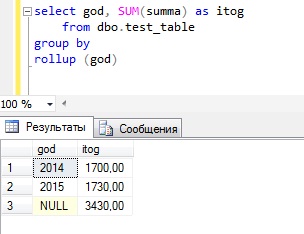
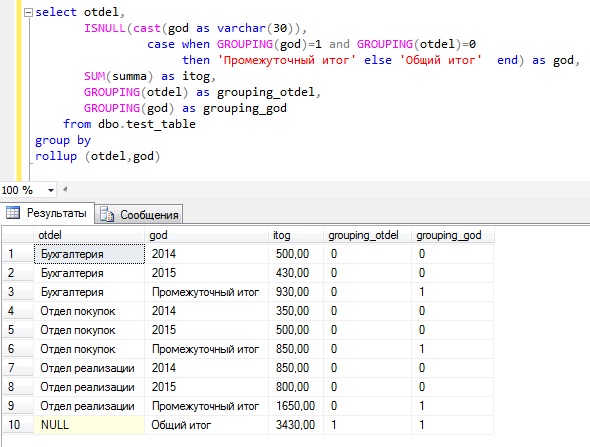
CUBE — оператор Transact-SQL, который формирует результаты для всех возможных перекрестных вычислений.
Давайте напишем практически такой же SQL запрос, только вместо rollup укажем cube и посмотрим на полученный результат.

В данном случае отличие от rollup заключается в том, что группировка и промежуточные итоги выполнены как для otdel, так и для god.