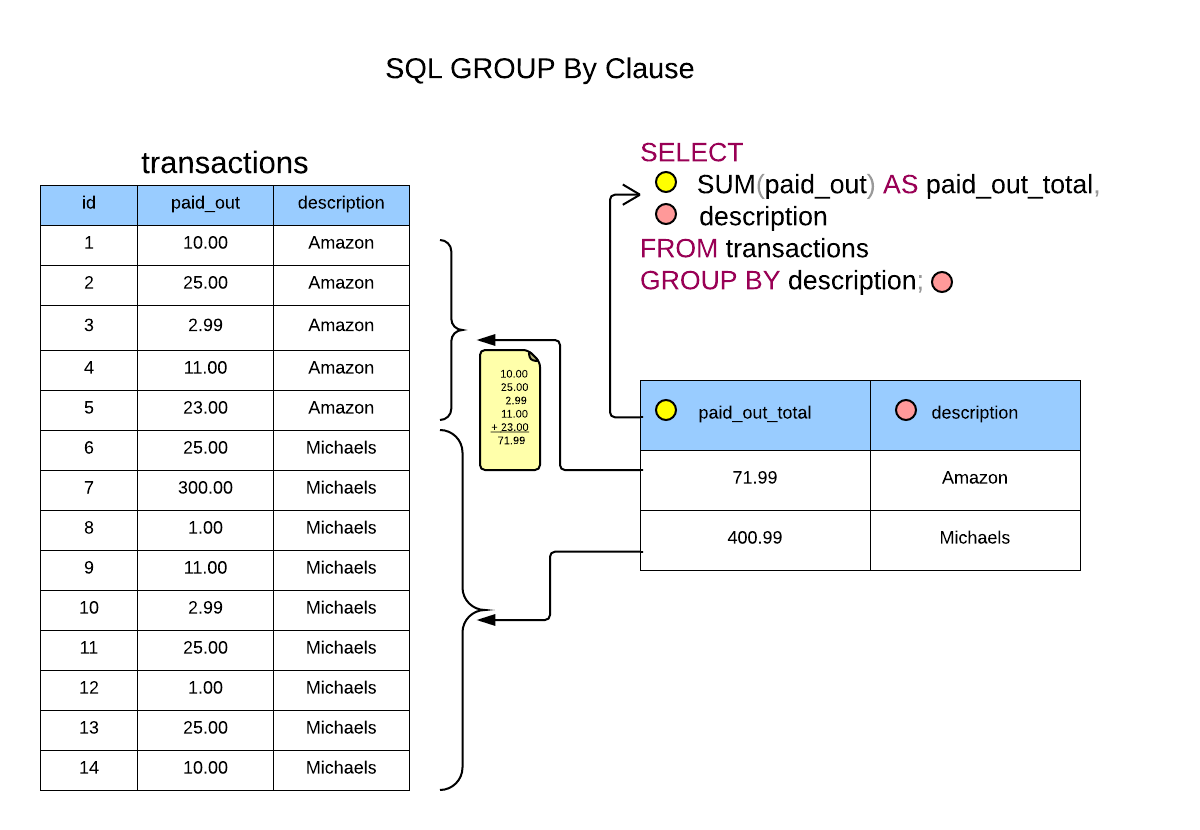
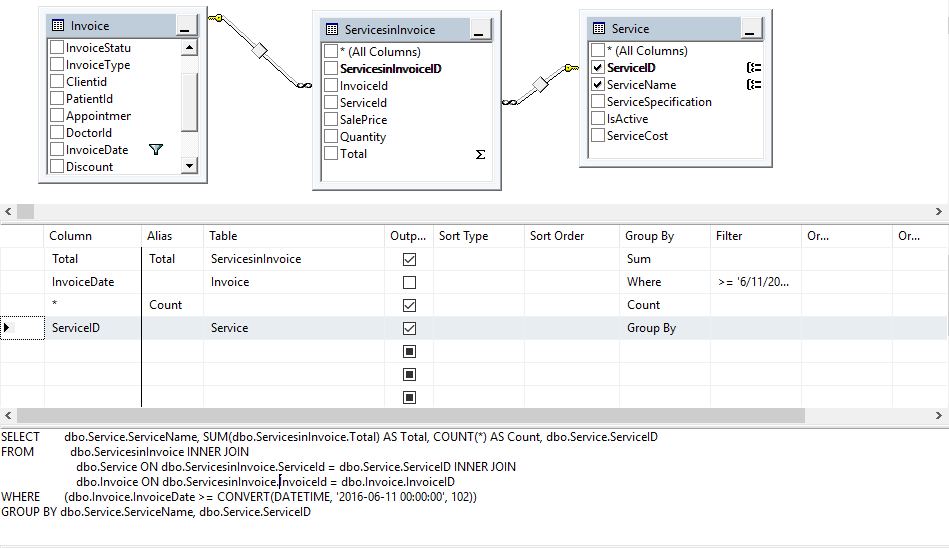
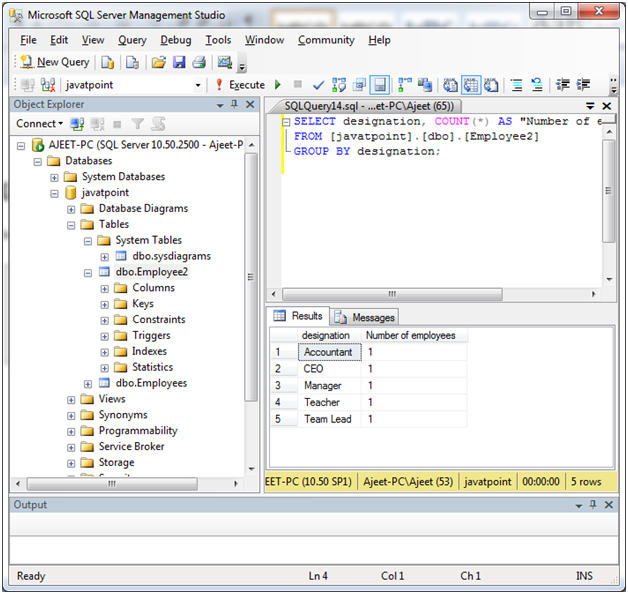
Использование конструкции GROUP BY с операцией GROUPING SETS
Операция GROUPING SETS позволяет распределять множество наборов столбцов по группам при вычислении агрегатных показателей вроде сумм. Ниже приведен пример, демонстрирующий применение этой операции для вычисления агрегатных показателей с их последующим распределением по трем таким группам: (year, region, item), (year, item) и (region, item). Операция GROUPING SETS устраняет необходимость в использовании неэффективных операций UNION ALL.
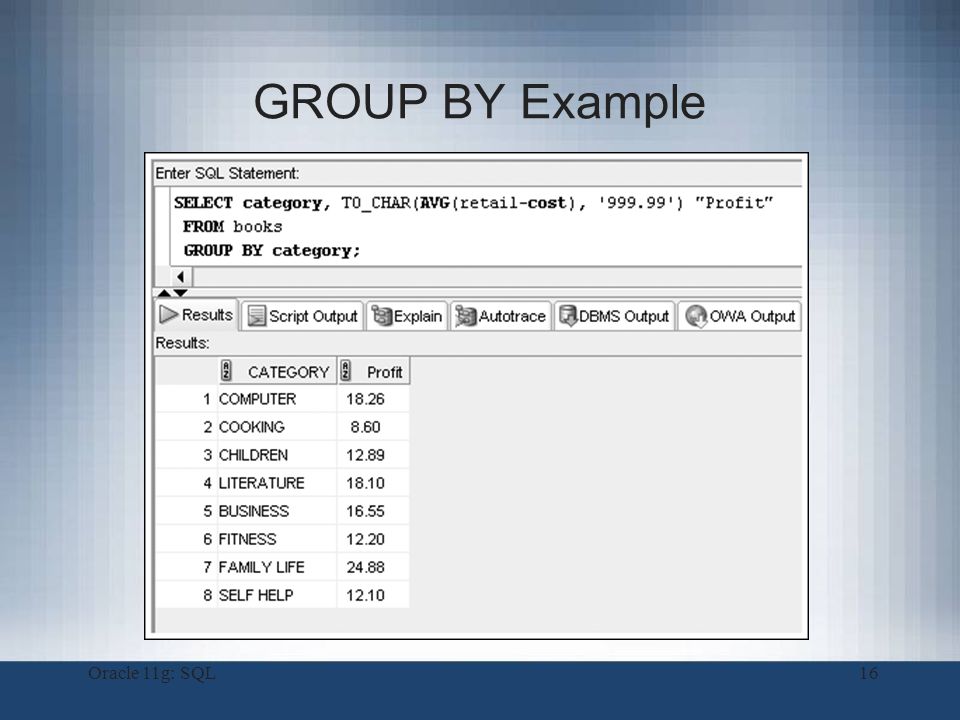
SQL> SELECT year, region, item, sum(sales) FROM regional_salesitem GROUP BY GROUPING SETS (( year, region, item), (year, item), (region, item));
SQL операторы AND, OR и BETWEEN
Эти операторы позволяют сделать запрос еще более конкретным, добавив дополнительные критерии в оператор WHERE.
Оператор AND принимает два условия, и оба они должны быть истинными, чтобы строка отображалась в результате.
Оператор OR принимает два условия, и любое из них должно быть истинным, чтобы строка отображалась в результате.
Оператор BETWEEN отфильтровывает определенный диапазон чисел или текста.
Мы также можем использовать эти операторы в сочетании друг с другом.
Скажем, наша таблица теперь такая:
| employee_id | first_name | last_name | country | salary | |
|---|---|---|---|---|---|
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Если бы мы использовали оператор, подобный приведенному ниже:
Мы получили бы такой вывод:
Это выбирает все поля, у строк которых есть employee_id от 3 до 7 и указана страна Germany.
SQL Оператор ORDER BY
Оператор ORDER BY сортирует по столбцам, упомянутым в операторе SELECT.
Он сортирует результаты и представляет их в алфавитном или числовом порядке по убыванию или возрастанию (по умолчанию — по возрастанию).
Мы можем указать направление сортировки с помощью команды: ORDER BY имя_столбца DESC | ASC.
В приведенном выше примере мы сортируем зарплаты сотрудников в команде инженеров и представляем их в порядке убывания числового значения.
Ordering Grouping Results
Groups aren’t returned in sorted order. In order to do this, you need to include the ORDER BY clause. Add the ORDER BY clause to the end of the SQL statement.
Modify this statement so it sorts the groups by SalesOrderID and CarrierTrackingNumber.
/*modify this statement*/
SELECT SalesOrderID, CarrierTrackingNumber, COUNT(1) as NumberofLines
FROM Sales.SalesOrderDetail
GROUP BY SalesOrderID, CarrierTrackingNumber;
/* Answer */ SELECT SalesOrderID, CarrierTrackingNumber, COUNT(1) as NumberofLines FROM Sales.SalesOrderDetail GROUP BY SalesOrderID, CarrierTrackingNumber ORDER BY SalesOrderID, CarrierTrackingNumber
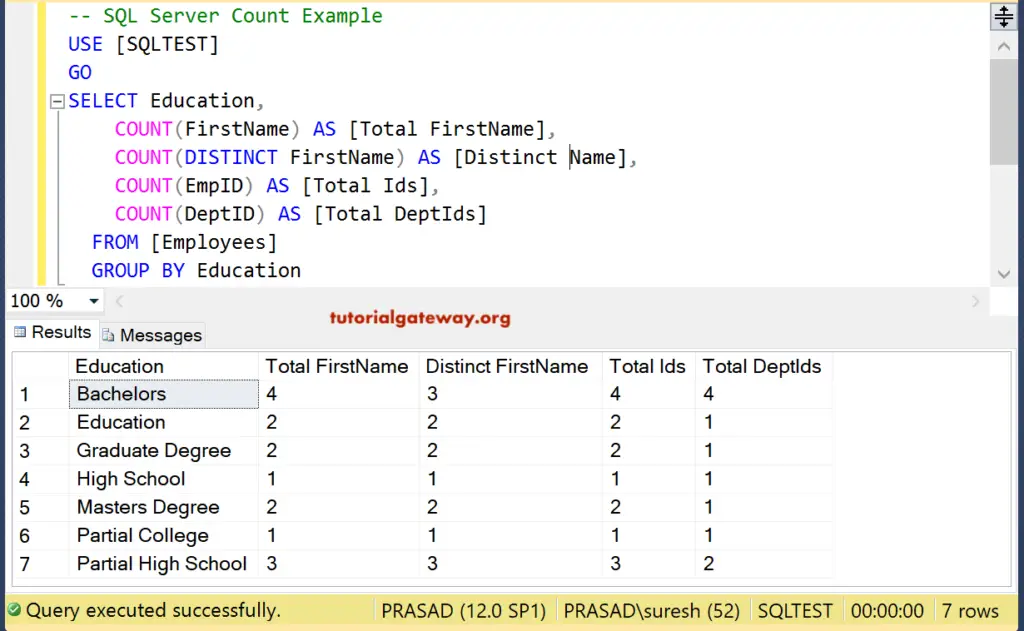
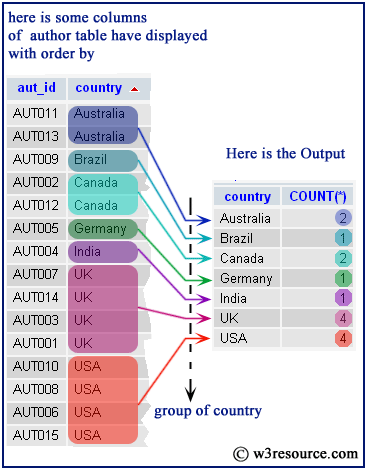
SQL GROUP BY Statement | Aggregate Functions
Aggregate functions are functions that take a set of rows as input and return a single value. In SQL we have five aggregate functions which are also called multirow functions as follows.
Advertisement
- : Returns the sum or total of each group.
- : Returns the number of rows of each group.
- : Returns the average and mean of each group.
- : Returns the minimum value of each group.
- : Returns the minimum value of each group.
For examples of SQL GROUP BY Statement, here we are considering some tables of school management systems:
The Records of above tables are as follow:Student Table
| student_id | studentname | admissionno | admissiondate | enrollmentno | date_of_birth | city | class_id | |
|---|---|---|---|---|---|---|---|---|
| 101 | reema | 10001 | 02-02-2000 | e15200002 | 02-02-1990 | reema@gmail.com | surat | 2 |
| 102 | kriya | 10002 | 04-05-2001 | e16200003 | 04-08-1991 | kriya@gmail.com | surat | 1 |
| 103 | meena | 10003 | 06-05-1999 | e15200004 | 02-09-1989 | meena@gmail.com | vadodara | 3 |
| 104 | carlin | 2001 | 04-01-1998 | e14200001 | 04-04-1989 | carli@gmail.com | vapi | 1 |
| 105 | dhiren | 2002 | 02-02-1997 | e13400002 | 02-02-1987 | dhiru@gmail.com | vapi | 2 |
| 106 | hiren | 2003 | 01-01-1997 | e13400001 | 03-03-1887 | hiren@gmail.com | surat | 2 |
| 107 | mahir | 10004 | 06-09-2000 | e15200003 | 07-09-1990 | mahi@gmail.com | vapi | 3 |
| 108 | nishi | 2004 | 02-04-2001 | e16200001 | 03-02-1991 | nishi@gmail.com | vadodara | 1 |
Result Table
| result_id | student_id | examname | examdate | subject | obtainmark | totalmarks | percentage | grade | status |
|---|---|---|---|---|---|---|---|---|---|
| 3001 | 101 | sem1 | 07-08-2001 | 1 | 80 | 100 | 80 | A+ | pass |
| 3002 | 101 | sem1 | 08-08-2001 | 2 | 76 | 100 | 76 | A+ | pass |
| 3003 | 102 | sem3 | 05-05-2000 | 3 | 67 | 100 | 67 | A | pass |
| 3004 | 102 | sem3 | 06-05-2000 | 4 | 89 | 100 | 89 | A+ | pass |
| 3005 | 102 | sem3 | 07-05-2000 | 5 | 90 | 100 | 90 | A+ | pass |
| 3006 | 103 | sem5 | 08-09-1998 | 6 | 55 | 100 | 55 | B | pass |
| 3007 | 103 | sem5 | 09-09-1998 | 7 | 30 | 100 | 30 | D | fail |
| 3008 | 103 | sem5 | 10-09-1998 | 8 | 34 | 100 | 34 | D | fail |
Subject Table
| subjectid | facultyname | subjectname | subjectcode |
|---|---|---|---|
| 1 | krishna | c | 1003 |
| 2 | rahul | cpp | 1004 |
| 3 | radha | asp | 1005 |
| 4 | meera | sql | 1006 |
| 5 | yasoda | cloud | 1007 |
| 6 | nadan | cg | 1008 |
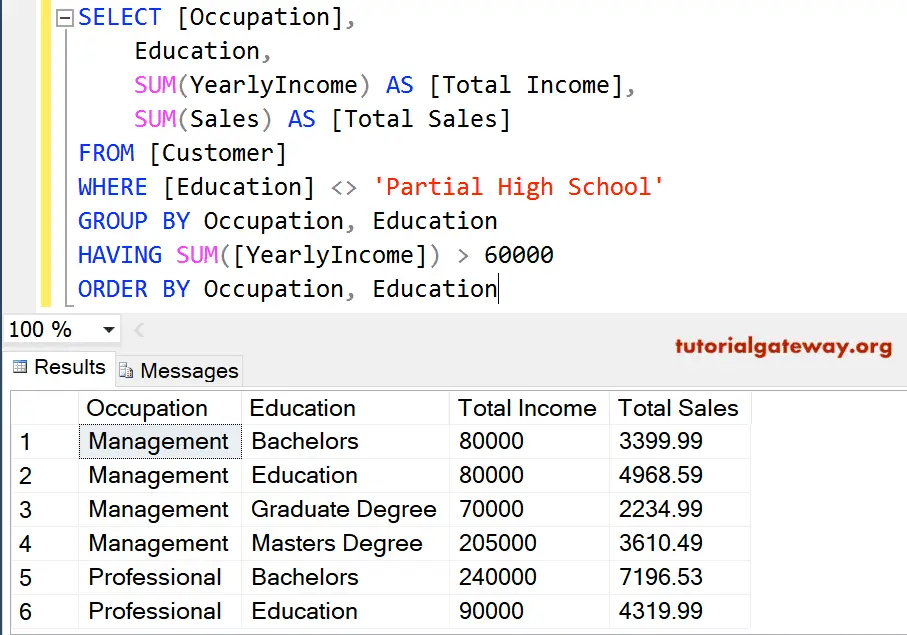
What Is The SQL GROUP BY Clause?
The GROUP BY clause is a clause in the SELECT statement. It allows you to create groups of rows that have the same value when using some functions (such as SUM, COUNT, MAX, MIN, and AVG).
Aggregate functions without a GROUP BY will return a single value.
If you want to find the aggregate value for each value of X, you can GROUP BY x to find it.
It allows you to find the answers to problems such as:
- The total number of sales per month
- The average salary of an employee per department
- The number of students enrolled per year
It goes towards the end of your SELECT query.
The SELECT statement could look like this:
It allows you to write queries like “select * from table group by column”.
The GROUP BY clause in the query is what we will be discussing in this article. We’ll also cover the HAVING clause as they are closely related.



Взаимосвязь PHP и MySQL
Приложения на базе языка программирования PHP, применяющие базу данных как способ хранения информации, функционируют значительно быстрее и эффективнее аналогов, построенных на файловой системе хранения. MySQL в этом случае выполняет необходимую работу с данными. Базы данных берут на себя заботу о безопасности информации и ее хранении и обработке. Извлечение и размещение контента осуществляется посредством использования всего одной строчки.
С аналогичной легкостью решаются задачи поиска в рамках сайта, разбиения на страницы, регистрации и авторизации пользователей. Несмотря на значительнее количество базовых систем, на основе которых могут быть сформированы веб-приложения, MySQL остается наиболее предпочтительной. Поддержка сервера MySQL составляет стандартный комплект поставки PHP. Поэтому связка PHP+MySQL воспринимается как неразрывная.
Подробнее
Предложение используется для определения групп выходных строк, к которым могут применяться агрегатные функции (, , , и ). Если это предложение отсутствует, и используются агрегатные функции, то все столбцы с именами, упомянутыми в , должны быть включены в агрегатные функции, и эти функции будут применяться ко всему набору строк, что удовлетворяют предикату запроса. В противном случае все столбцы списка , не вошедшие в агрегатные функции, должны быть указаны в предложении . В результате чего все выходные строки запроса разбиваются на группы, характеризуемые одинаковыми комбинациями значений в этих столбцах. После чего к каждой группе будут применены агрегатные функции. Для все значения трактуются как равные, т.е. при группировке по полю, содержащему -значения, все такие строки попадут в одну группу.
Если при наличии предложения , в предложении отсутствуют агрегатные функции, то запрос просто вернет по одной строке из каждой группы. Эту возможность, наряду с ключевым словом , можно использовать для исключения дубликатов строк в результирующем наборе.
Пример:
SELECT model, COUNT(model) AS Qty_model, AVG(price) AS Avg_price FROM PC GROUP BY model;
В этом запросе для каждой модели ПК определяется их количество и средняя стоимость. Все строки с одинаковыми значениями model (номер модели) образуют группу, и на выходе вычисляются кол-во значений и средняя цена для каждой группы. Результатом выполнения запроса будет следующая таблица:
|
Если бы в присутствовал столбец с датой, то можно было бы вычислять эти показатели для каждой конкретной даты. Для этого нужно добавить дату в качестве группирующего столбца, и тогда агрегатные функции вычислялись бы для каждой комбинации значений {модель, дата}.
Существует несколько определенных правил выполнения агрегатных функций.
-
Если в результате выполнения запроса не получено ни одной строки (или ни одной строки для данной группы), то исходные данные для вычисления любой из агрегатных функций отсутствуют. В этом случае результатом выполнения функций будет нуль, а результатом всех других функций — .Данное свойство может дать не всегда очевидный результат. Рассмотрим, например, такой запрос:
- a
- price
- PC
- price<
select 1 a where exists(select MAX(price) from PC where price<0) - Подзапрос в предикате EXISTS возвращает одну строку с NULL в качестве значения столбца. Поэтому, несмотря на то, что ПК с отрицательными ценами нет в базе данных, запрос в примере вернет 1.
- Аргумент агрегатной функции не может сам содержать агрегатные функции (функция от функции). То есть в простом запросе (без подзапросов) нельзя, скажем, получить максимум средних значений.
- Результат выполнения функции есть целое число (INTEGER). Другие агрегатные функции наследуют типы данных обрабатываемых значений.
- Если при выполнении функции будет получен результат, превышающий максимально возможное значение для используемого типа данных, возникает ошибка.
Итак, агрегатные функции, включенные в предложение запроса, не содержащего предложения , исполняются над всеми результирующими строками этого запроса. Если же запрос содержит предложение , каждый набор строк, который имеет одинаковые значения столбца или группы столбцов, заданных в предложении , составляют группу, и агрегатные функции выполняются для каждой группы отдельно.
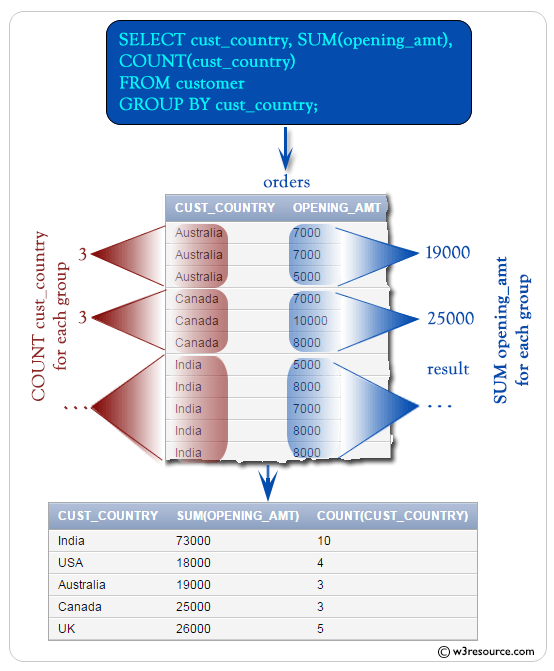
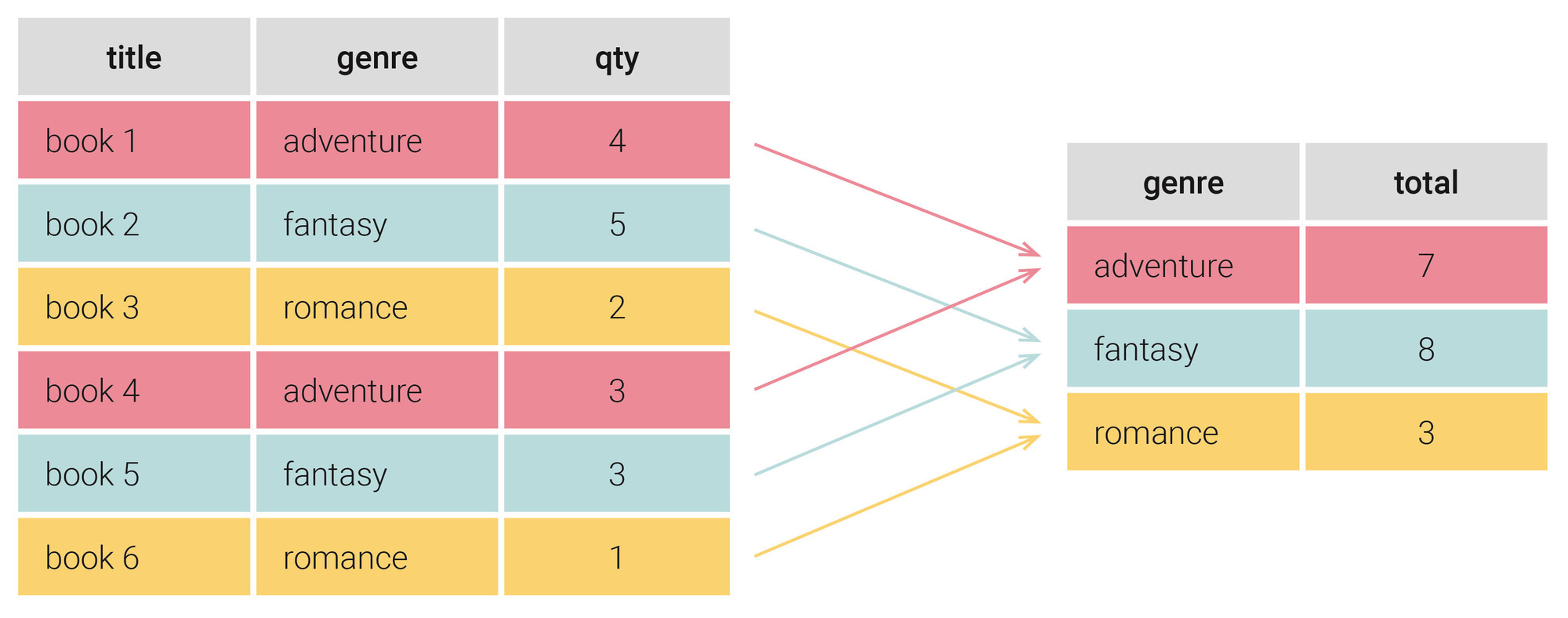
Aggregations (COUNT, SUM, AVG)
Once we’ve decided how to group our data, we can then perform aggregations on the remaining columns.
These are things like counting the number of rows per group, summing a particular value across the group, or averaging information within the group.
To start, let’s find the number of sales per location.
Since each record in our table is one sale, the number of sales per location would be the number of rows within each location group.
To do this we’ll use the aggregate function to count the number of rows within each group:
We use which counts all of the input rows for a group.
( also works with expressions, but it has slightly different behavior.)
Here’s how the database executes this query:
- — First, retrieve all of the records from the table
- — Next, determine the unique groups
- — Finally, select the location name and the count of the number of rows in that group
We also give this count of rows an alias using to make the output more readable. It looks like this:
The 1st Street location has two sales, HQ has four, and Downtown has two.
Here we can see how we’ve taken the remaining column data from our eight independent rows and distilled them into useful summary information for each location: the number of sales.
In a similar way, instead of counting the number of rows in a group, we could sum information within the group—like the total amount of money earned from those locations.
To do this we’ll use the function:
Instead of counting the number of rows in each group we sum the dollar amount of each sale, and this shows us the total revenue per location:
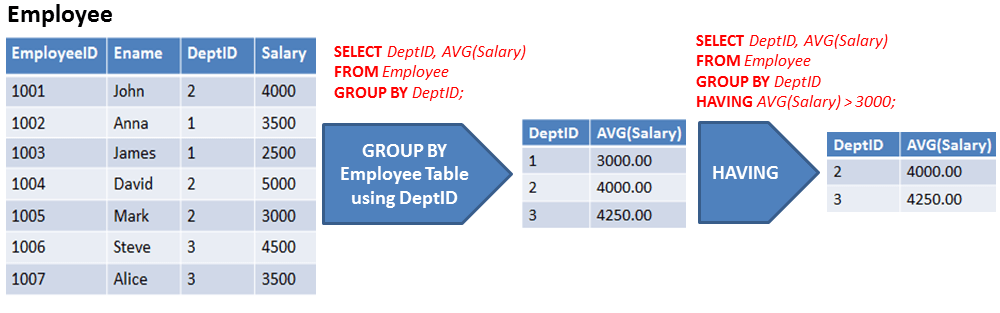
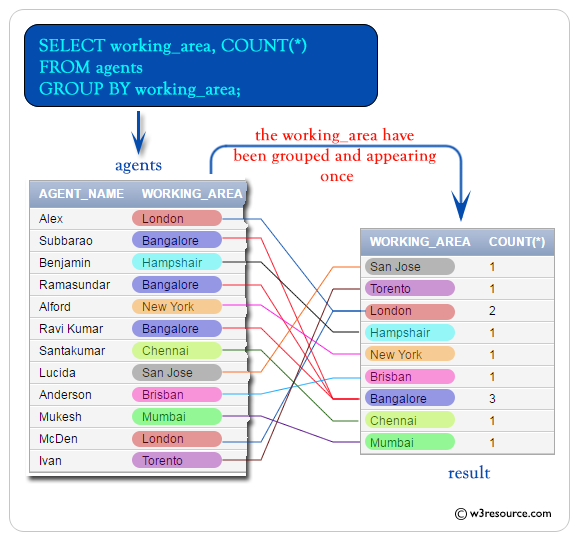
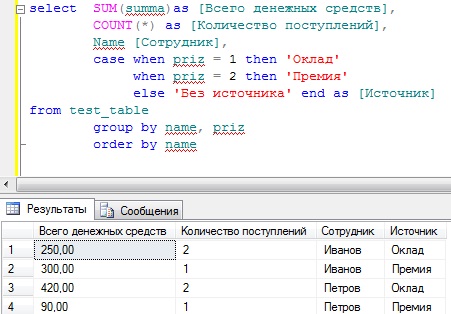
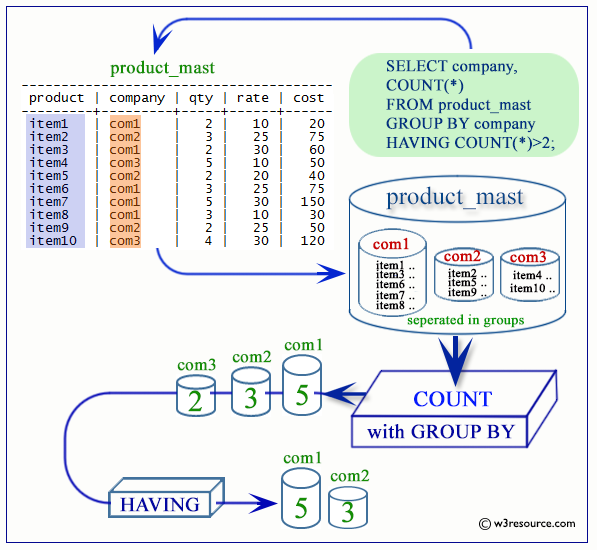
Операторы GROUP BY и HAVING
Последнее обновление: 19.07.2017
Для группировки данных в T-SQL применяются операторы GROUP BY и HAVING, для использования которых применяется следующий формальный синтаксис:
SELECT столбцы FROM таблица
GROUP BY
Оператор GROUP BY определяет, как строки будут группироваться.
Например, сгруппируем товары по производителю
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer
Первый столбец в выражении SELECT — Manufacturer представляет название группы, а второй столбец — ModelsCount представляет результат функции Count,
которая вычисляет количество строк в группе.
Стоит учитывать, что любой столбец, который используется в выражении SELECT (не считая столбцов, которые хранят результат агрегатных функций),
должны быть указаны после оператора GROUP BY. Так, например, в случае выше столбец Manufacturer указан и в выражении SELECT, и в выражении
GROUP BY.
И если в выражении SELECT производится выборка по одному или нескольким столбцам и также используются агрегатные функции, то необходимо использовать
выражение GROUP BY. Так, следующий пример работать не будет, так как он не содержит выражение группировки:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products
Другой пример, добавим группировку по количеству товаров:
SELECT Manufacturer, ProductCount, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer, ProductCount
Оператор может выполнять группировку по множеству столбцов.
Если столбец, по которому производится группировка, содержит значение NULL, то строки со значением NULL составят
отдельную группу.
Следует учитывать, что выражение должно идти после выражения , но до выражения
:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price > 30000 GROUP BY Manufacturer ORDER BY ModelsCount DESC
Фильтрация групп. HAVING
Оператор HAVING определяет, какие группы будут включены в выходной результат, то есть выполняет фильтрацию групп.
Применение HAVING во многом аналогично применению WHERE. Только есть WHERE применяется к фильтрации строк, то HAVING используется для фильтрации групп.

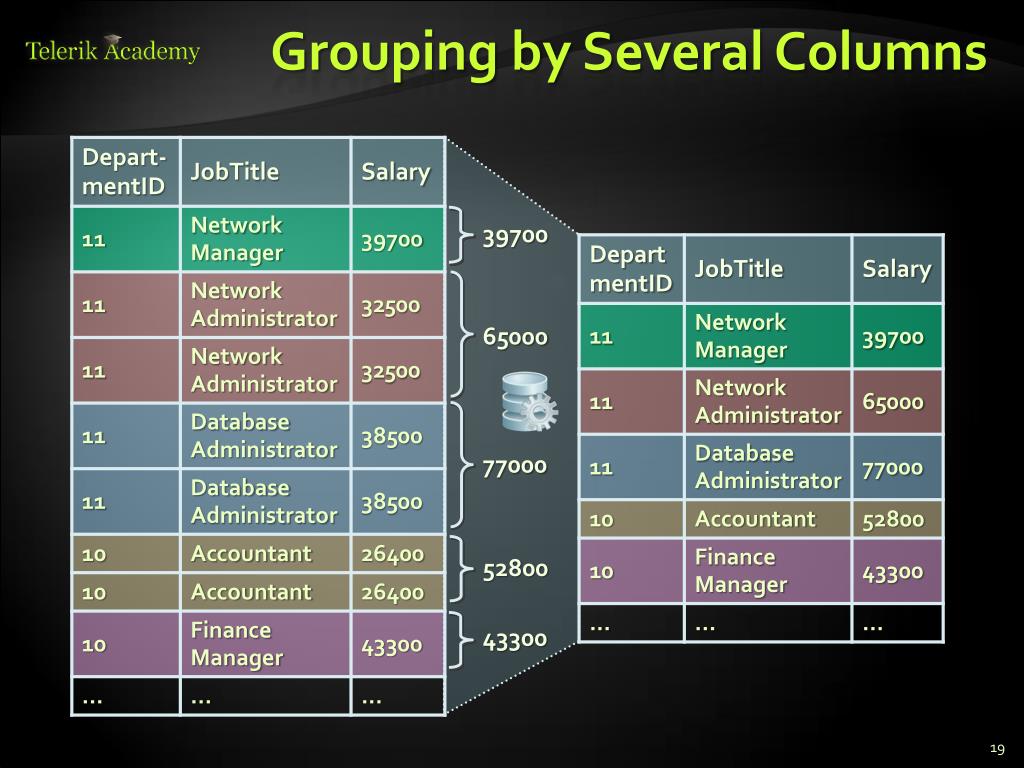


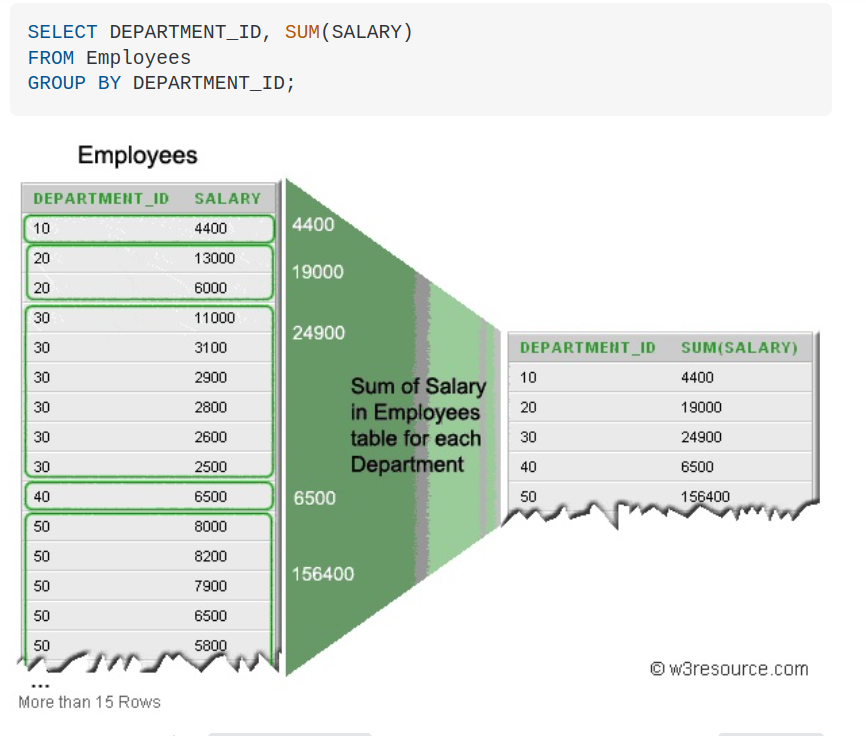

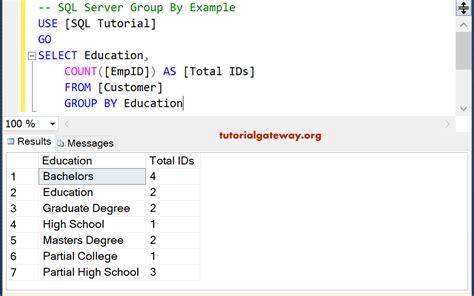
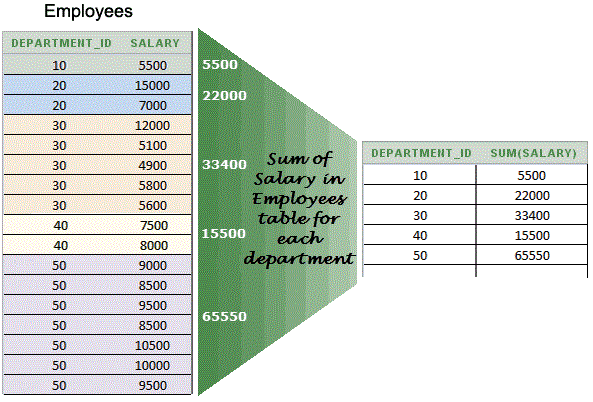
Например, найдем все группы товаров по производителям, для которых определено более 1 модели:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer HAVING COUNT(*) > 1
При этом в одной команде мы можем использовать выражения WHERE и HAVING:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING COUNT(*) > 1
То есть в данном случае сначала фильтруются строки: выбираются те товары, общая стоимость которых больше 80000. Затем выбранные товары
группируются по производителям. И далее фильтруются сами группы — выбираются те группы, которые содержат больше 1 модели.
Если при этом необходимо провести сортировку, то выражение ORDER BY идет после выражения HAVING:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING SUM(ProductCount) > 2 ORDER BY Units DESC
В данном случае группировка идет по производителям, и также выбирается количество моделей для каждого производителя (Models)
и общее количество всех товаров по всем этим моделям (Units). В конце группы сортируются по количеству товаров по убыванию.
НазадВперед
Next Steps
Data aggregation or summarization is one of the most important tasks and skills for anyone who manages data. From profit and loss statements to creating a perfect visualization of data, SQL Group By is the tool that allows us to do these kinds of tasks efficiently.
Now that you know how to aggregate and summarize data, it is time for you to start querying, manipulating, and visualizing all kinds of data to move forward in your journey to become an expert in SQL. If you liked this article and want to get certified, check out our Business Analyst Master’s Program as it will help you learn the A-Z of SQL as well.
Do you have any questions for us? Please mention them in the comment section of our “How to Aggregate Data Using Group By in SQL” article, and we’ll have our experts in the field answer them for you right away!
Функция SQL SUM
Функция SQL SUM возвращает сумму значений столбца таблицы базы данных. Она может применяться только
к столбцам, значениями которых являются числа. Запросы SQL для получения результирующей суммы
начинаются так:
SELECT SUM
(ИМЯ_СТОЛБЦА) …
После этого выражения следует FROM (ИМЯ_ТАБЛИЦЫ), а далее с помощью конструкции WHERE может быть
задано условие. Кроме того, перед именем столбца может быть указано DISTINCT, и это означает, что
учитываться будут только уникальные значения. По умолчанию же учитываются все значения (для этого
можно особо указать не DISTINCT, а ALL, но слово ALL не является обязательным).
Пример 1.
Есть база данных фирмы с данными о её подразделениях
и сотрудниках. Таблица Staff помимо всего имеет столбец с данными о заработной плате сотрудников. Выборка
из таблицы имеет следующий вид (для увеличения картинки щёлкнуть по ней левой кнопкой мыши):
Для получения суммы размеров всех заработных плат используем следующий запрос:
SELECT SUM
(Salary)
FROM
Staff
Этот запрос вернёт значение 287664,63.
А теперь . В упражнениях уже начинаем
усложнять задания, приближая их к тем, что встречаются на практике.
Пример — две таблицы в операторе FROM (INNER JOIN)
Давайте посмотрим, как использовать предложение FROM, чтобы INNER JOIN (объединить) вместе две таблицы.
В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
И таблица categories со следующими данными:
| category_id | category_name |
|---|---|
| 25 | Deli |
| 50 | Produce |
| 75 | Bakery |
| 100 | General Merchandise |
| 125 | Technology |
Выполните следующий SQL-оператор:
PgSQL
SELECT products.product_name, categories.category_name
FROM products
INNER JOIN categories
ON products.category_id = categories.category_id
WHERE product_name <> ‘Pear’;
|
1 2 3 4 5 |
SELECTproducts.product_name,categories.category_name FROMproducts INNER JOINcategories ONproducts.category_id=categories.category_id WHEREproduct_name<>’Pear’; |
Будет выбрано 5 записей. Вот результаты, которые вы должны получить:
| product_name | category_name |
|---|---|
| Banana | Produce |
| Orange | Produce |
| Apple | Produce |
| Bread | Bakery |
| Sliced Ham | Deli |
В этом примере оператора FROM используется объединение двух таблиц — products и categories. В этом случае мы используем FROM, чтобы указать INNER JOIN между таблицами products и categories на основе столбца category_id в обеих таблицах.
USING ORDER BY
The function of the statement is to sort results in ascending or descending order based on the column(s) you specify in the query. Depending on the data type stored by the column you specify after it, will organize them in alphabetical or numerical order. By default, will sort results in ascending order; if you prefer descending order, however, you have to include the keyword in your query. You can also use the statement with , but it must come after in order to function properly. Similar to , must also come after the statement and clause. The general syntax for using is as follows:
ORDER BY syntax
Let’s continue with the sample data for the movie theater and practice sorting results with . Begin with the following query which retrieves values from the column and organizes those numerical values with an statement:
Since your query specified a column with numerical values, the statement organized the results by numerical and ascending order, starting with 25 under the column.
If you preferred to order the column in descending order, you would add the keyword at the end of the query. Additionally, if you wanted to order the data by the character values under , you would specify that in your query. Let’s perform that type of query using to order the column with character values in descending order. Sort the results even further by including a clause to retrieve the data on movies showing at 10:00 pm from the column:
This result set lists the four different movie showings at 10:00 pm in descending alphabetical order, starting from Top Gun Maverick to Downtown Abbey A New Era.
For this next query, combine the and statements with the aggregate function to generate results on the total revenue received for each movie. However, let’s say the movie theater miscounted the total guests and forgot to include special parties that had pre-purchased and reserved tickets for a group of 12 people at each showing.
In this query use and include the additional 12 guests at each movie showing by implementing the operator for addition and then adding to the . Make sure to enclose this in parenthesis. Then, multiply this total by the with the operator , and complete the mathematical equation by closing the parenthesis at the end. Add the clause to create the alias for the new column titled . Then, use to group results for each movie based on the data retrieved from the column. Lastly, use to organize the results under the new column in ascending order:
This result set tells us the total revenue for each movie with the additional 12 guest ticket sales and organizes the total ticket sales in ascending order from lowest to highest. From this, we learn that Top Gun Maverick received the most ticket sales, while Men received the least. Meanwhile, The Bad Guys and Downton Abbey A New Era movies were very close in total ticket sales.
In this section, you practiced various ways to implement the statement and how to specify the order you prefer, such as ascending and descending orders for both character and numerical data values. You also learned how to include the clause to narrow down your results, and performed a query using both the and statements with an aggregate function and mathematical equation.
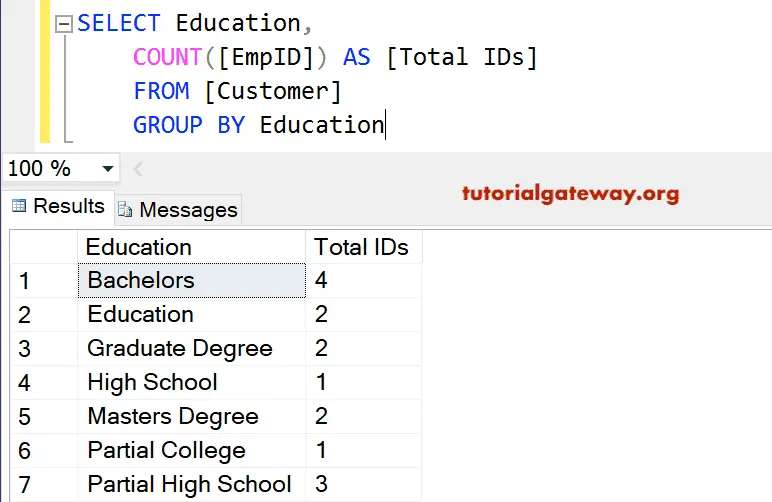
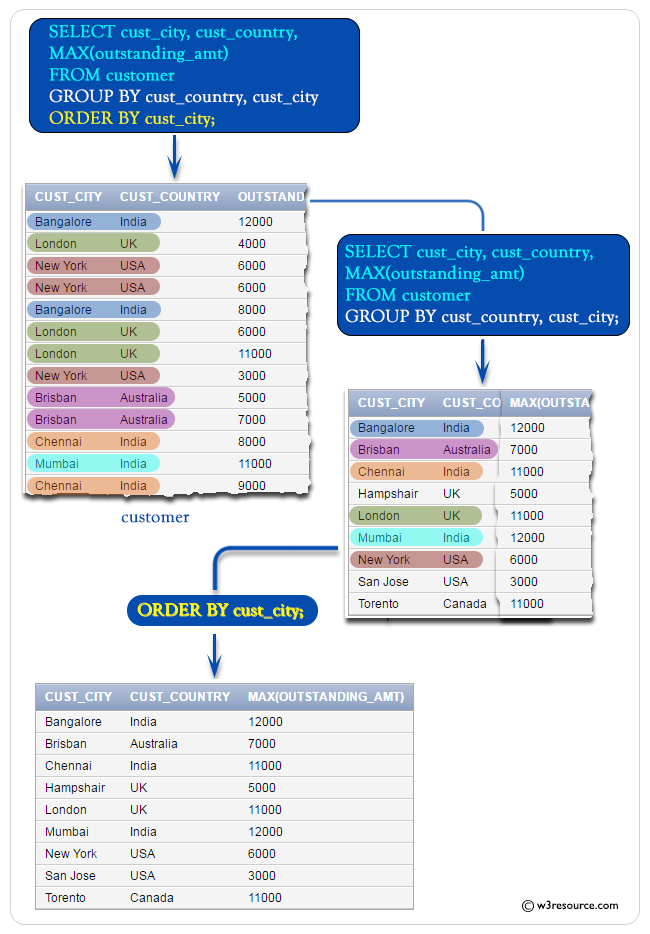
The SQL Server GROUP BY Clause
SELECT column_name , group_function(column_name) FROM table_name WHERE condition GROUP BY column_name
So far, each group function described here has treated the table as one large group of data. In most cases you need to divide the table into smaller groups, instead of getting the average salary of all employees in Employees table, you would rather see, for example, the average salary grouped by each department (what is the average salary of the HR department, IT department and so on).
You can use the SQL Server GROUP BY clause to divide the rows in a table into groups. Then you can use the group functions to retrieve summary information for each group.
SELECT department_id , AVG(salary) FROM employees GROUP BY department_id