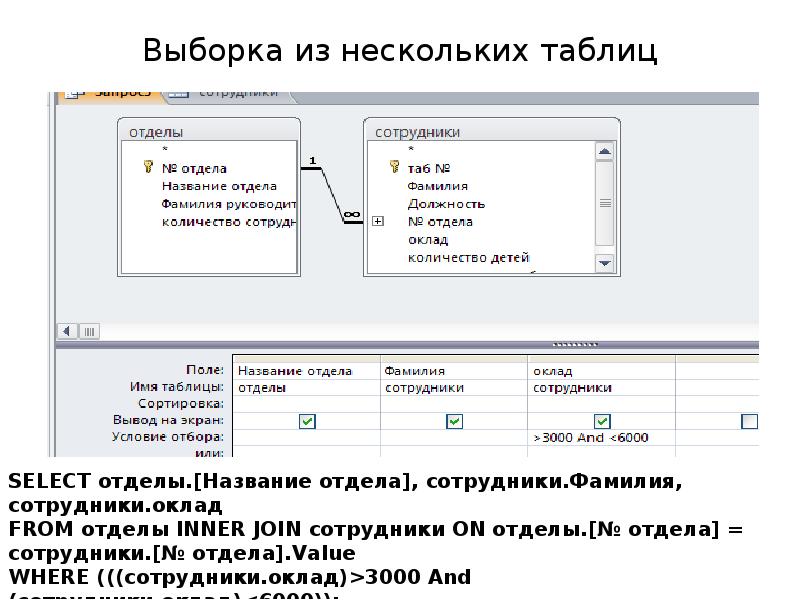
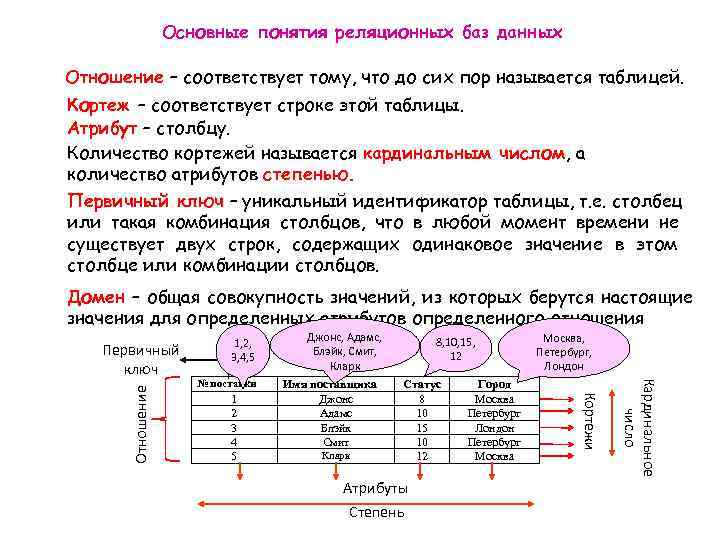
Примеры использования предикатов
Предикаты представляют собой выражения, принимающие истинностное значение. Они могут представлять собой как одно выражение, так и любую комбинацию из неограниченного количества выражений, построенную с помощью булевых операторов AND, OR или NOT. Кроме того, в этих комбинациях может использоваться SQL-оператор IS, а также круглые скобки для конкретизации порядка выполнения операций
Предикат в языке SQL может принимать одно из трех значений TRUE (истина), FALSE (ложь) или UNKNOWN (неизвестно). Исключение составляют следующие предикаты: NULL (отсутствие значения), EXISTS (существование), UNIQUE (уникальность) и MATCH (совпадение), которые не могут принимать значение UNKNOWN.
Правила комбинирования всех трех истинностных значений легче запомнить, обозначив TRUE как 1, FALSE как 0 и UNKNOWN как 1/2 (где то между истинным и ложным).
AND с двумя истинностными значениями дает минимум этих значений. Например, TRUE AND UNKNOWN будет равно UNKNOWN.
OR с двумя истинностными значениями дает максимум этих значений. Например, FALSE OR UNKNOWN будет равно UNKNOWN.
Отрицание истинностного значения равно 1 минус данное истинностное значение. Например, NOT UNKNOWN будет равно UNKNOWN.
Помимо этого, используются предикаты сравнения.
Предикат сравнения представляет собой два выражения, соединяемых оператором сравнения. Имеется шесть традиционных операторов сравнения: =, >, <, >=, <=, <>.
Данные типа NUMERIC (числа) сравниваются в соответствии с их алгебраическим значением.
Данные типа CHARACTER STRING (символьные строки) сравниваются в соответствии с их алфавитной последовательностью. Если a1a2…an и b1b2…bn — две последовательности символов, то первая «меньше» второй, если а1<b1, или а1=b1 и а2<b2 и т.д. Считается также, что а1а2…аn<b1b2…bm, если n<m и а1а2…аn=b1b2…bn, т.е. если первая строка является префиксом второй. Например, ‘folder'<‘for’, т.к. первые две буквы этих строк совпадают, а третья буква строки ‘folder’ предшествует третьей букве строки ‘for’. Также справедливо неравенство ‘bar’ < ‘barber’, поскольку первая строка является префиксом второй.
Данные типа DATETIME (дата/время) сравниваются в хронологическом порядке.
Данные типа INTERVAL (временной интервал) преобразуются в соответствующие типы, а затем сравниваются как обычные числовые значения типа NUMERIC.
Пример. Получить информацию о компьютерах, имеющих частоту процессора не менее 500 Мгц и цену ниже $800:
SELECT * FROM PC
WHERE speed >= 500 AND price < 800;
Запрос возвращает следующие данные (Таблица 6.):
Таблица 6. – Пример информационного запроса.
Существуют так же и другие предикаты, например, BETWEEN, IN, LIKE.
Имена столбцов, указанных в предложении SELECT, можно переименовать. Это делает результаты более читабельными, поскольку имена полей в таблицах часто сокращают с целью упрощения набора. Ключевое слово AS, используемое для переименования, согласно стандарту можно и опустить, т.к. оно неявно подразумевается.
Например, запрос:
SELECT ram AS Mb, hd Gb
FROM PC
WHERE cd = ’24x’;
переименует столбец ram в Mb (мегабайты), а столбец hd — в Gb (гигабайты). Этот запрос возвратит объемы оперативной памяти и жесткого диска для тех компьютеров, которые имеют 24-скоростной CD-ROM (Таблица 7.):
Таблица 7. – Пример запроса SELECT AS.
Получение итоговых значений:
Существует возможность получения итоговых (агрегатных) функций. Стандартом предусмотрены следующие агрегатные функции (Таблица 8.):

Таблица 8 .– Описание (агрегатных) функций.
Все эти функции возвращают единственное значение. При этом, функции COUNT, MIN и MAX применимы к любым типам данных, в то время как SUM и AVG используются только для числовых полей. Разница между функцией COUNT(*) и COUNT() состоит в том, что вторая при подсчете не учитывает NULL-значения.
Пример. Найти минимальную и максимальную цену на персональные компьютеры:
SELECT MIN(price) AS Min_price, MAX(price) AS Max_price
FROM PC;
Результатом будет единственная строка, содержащая агрегатные значения (таблица 9.):
Таблица 9. – Строка содержащая (агрегатные) значения.
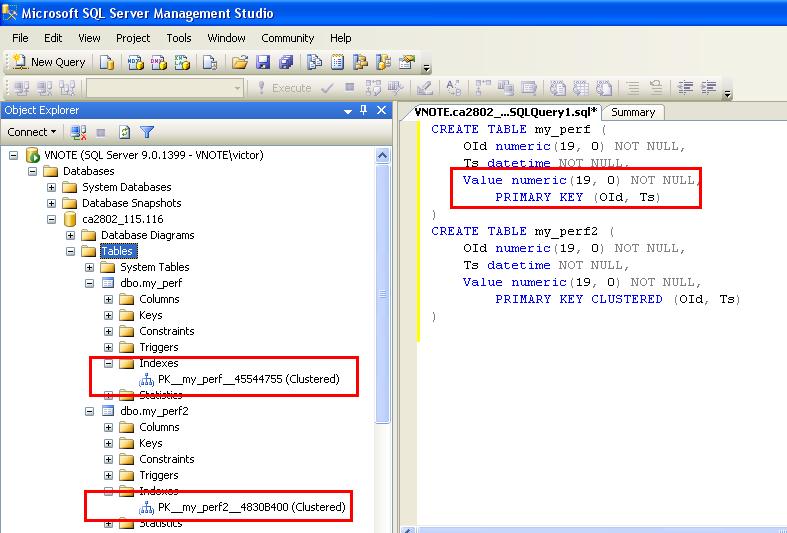
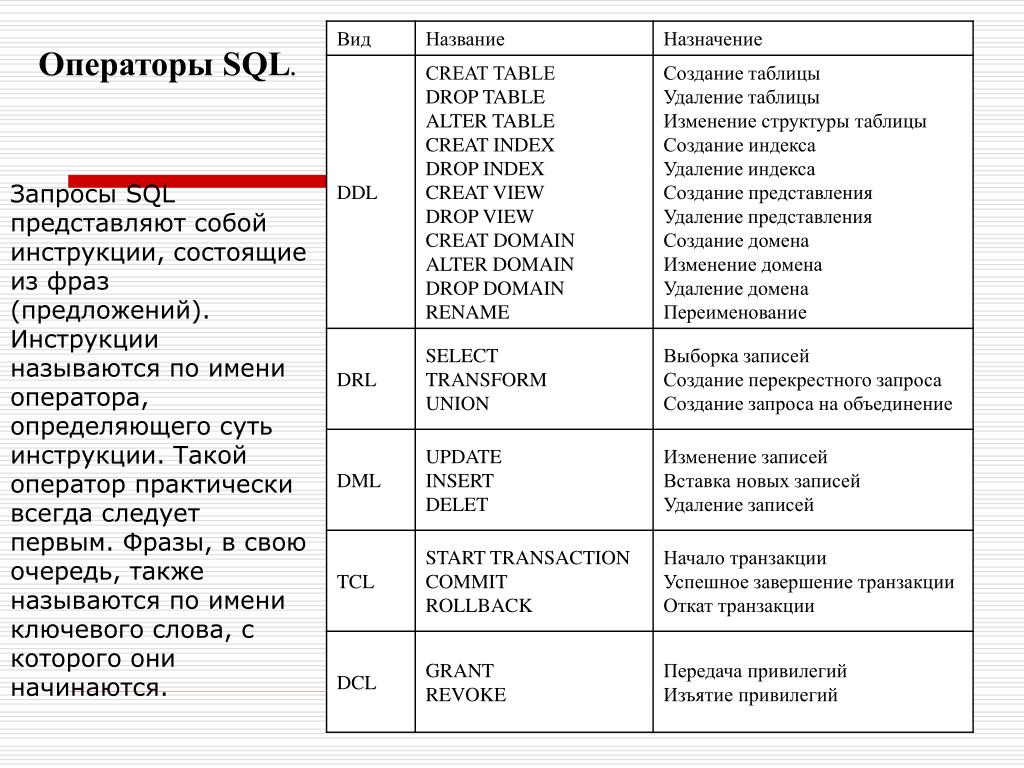


Для просмотра данных наиболее удобно использовать совместно значения оператора COUNT — счетчик (позволяет узнать количество записей в запросе), и оператора CURSOR — позволяет принимать не все записи сразу, а по одной (указанной пользователем).
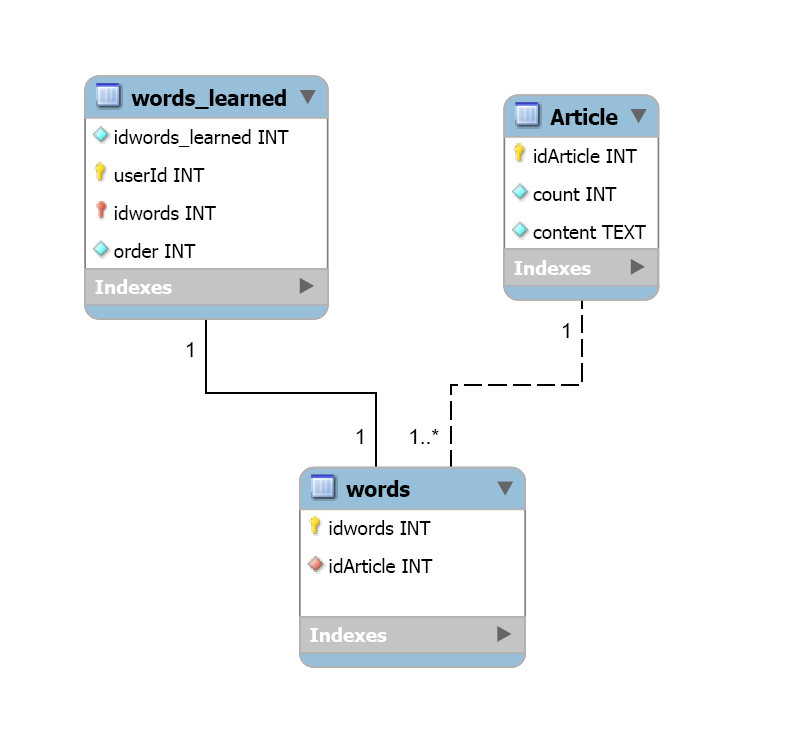
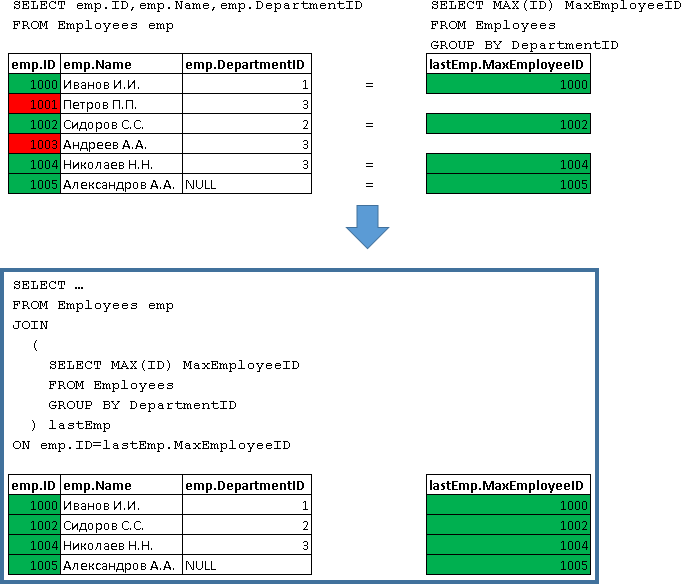
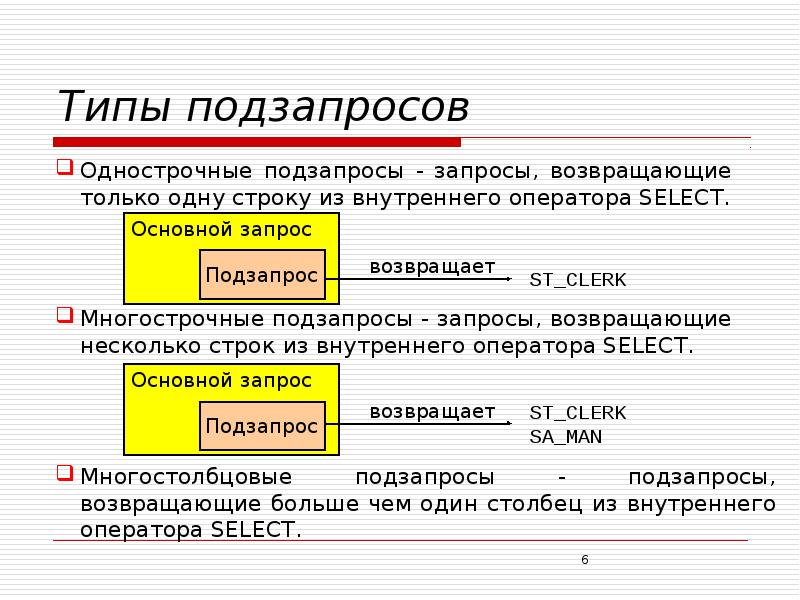
Подзапросы
На выходе подзапрос должен возвращать одно единственное значение (для страховки можно принудительно указывать LIMIT 1). Допускается использование подзапросов, которые на выходе выдают ряд значений, для оператора IN.
Операторы EXISTS, ANY(ANY и SOME абсолютно идентичны и являются взаимозаменяемыми),ALL умеют работать с множеством значений.
-
Пример. Использования подзапроса с оператором INSERT. В таблицу df_lcr_list передаются два значения(datestart и dateend), login_id ищется подзапросом по заранее известному имени пользователя, в таблицу вставляется текущее время.
INSERT INTO df_lcr_list (datestart,dateend,login_id, date_event) SELECT '20120405','20120405',id, now() FROM users WHERE login='username';
-
Пример. Использования подзапроса(subquery) с оператором UPDATE. Subquery выводит множество значений.
UPDATE accounts SET balance=0 WHERE uid IN (SELECT id FROM users WHERE email LIKE 'ltaixp1%');
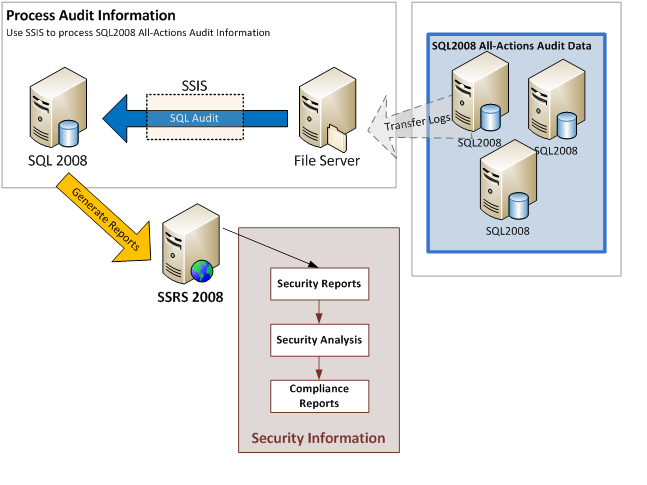
CDS Просмотр прав доступа на уровне строк с помощью языка управления данными (DCL)
В этом блоге я планирую пройти этапы и предварительные условия создания простого DCL (языка управления данными) для ограничения на уровне строк, настраиваемого представления CDS, созданного для аналитики / отчетности.
Во-первых, я создал несколько представлений CDS в HANA studio. Представление CDS размерности типа в таблице MARA со связью с MAKT для получения описаний материалов.
Затем я построил простое представление CDS типа куб на таблице VBAP с очень небольшим количеством полей, связанное с измерением представления CDS материалов выше.Я не буду подробно рассказывать о том, что означает каждая аннотация. Существует множество блогов, объясняющих концепции CDS Views.
В этом примере я хочу ограничить данные на основе поля Группа материалов (VBAP-MATKL).
Ниже мой Cube CDS View, выбирающий данные из VBAP. Несколько замечаний:
- Нам нужна аннотация @ AccessControl.authorizationCheck: #CHECK . Это позволит проверить это представление CDS на предмет авторизации.
- Я создал псевдоним для MATKL, переименовав его в MaterialGroup . Это поле, которое мы будем использовать в DCL.
Ниже приведена моя исходная таблица, которая включает несколько значений для группы материалов:
Поскольку представления CDS существуют на уровне приложения, мы можем применить к нему традиционную безопасность PFCG, что является одним из основных преимуществ, поскольку нам не нужно также поддерживать безопасность БД HANA.
Итак, первым шагом является создание объекта полномочий в TCODE SU21.Я также создал новый класс объекта для этого примера:
В окне «Создать объект авторизации» укажите техническое имя и текст объекта:
Добавьте поле ACTVT и нажмите кнопку сохранения:
Вам будет предложено ввести пакет. Выберите свой пакет или сохраните как локальный объект, в соответствии с вашими требованиями:
Вы должны получить сообщение, подобное приведенному ниже:
Экран должен измениться, и вы сможете поддерживать разрешенные действия:
На экране «Разрешенные действия» выберите 03 — Отображение, поскольку это представление CDS для аналитических целей, и нам нужен только доступ к отображению.
Затем добавьте поле, которое необходимо авторизовать, в нашем случае Material Group (MATKL), и выполните те же шаги, что и выше, чтобы предоставить доступ к дисплею. Ваш объект авторизации должен выглядеть так:
Ваш объект авторизации должен выглядеть так:
Мы закончили создание объекта авторизации. Теперь нам нужно создать роли для его назначения. Итак, мы переходим в PFCG и создаем роль, давая ей имя и щелкая Single Role. Первая роль, которую я создам, будет ограничивать группу материалов YBF02:
В редакторе ролей я щелкнул вкладку «Авторизация», а затем внизу «Изменить данные авторизации»:
Я не выбирал никаких шаблонов:
На следующем экране я выбрал Вручную, чтобы добавить ранее созданный объект авторизации:
Добавляю объект авторизации и ставлю зеленую галочку:
У вас должен получиться экран, который выглядит так:
Нам нужно отредактировать авторизацию, щелкнув по карандашу рядом с каждым полем.Начнем с Activity. Убедитесь, что флажок рядом с Display установлен, затем нажмите save:
Затем щелкните карандашом рядом с группой материалов и сохраните разрешенное значение, затем нажмите «Сохранить»:
Ваша роль должна выглядеть так (игнорируйте два верхних объекта авторизации BC_A и RS):
Аналогичным образом, я создал другую роль, ограничивающую данные по группе материалов YBR01, выполнив те же шаги, что и выше:
Создав свои роли, я создал двух пользователей для тестирования каждой роли, пользователя YBR01_DLC и YBF02_DCL, каждый с соответствующими ролями:
YBR01_DCL:
Что такое Data-Driven тестирование?
Data-Driven тестирование (или «Тестирование, управляемое данными») — это система автоматизации, в которой данные для тестов хранятся в таблице, а входные значения считываются из файлов данных и сохраняются в различных тестовых сценариях. Это помогает избежать необходимости создавать отдельные тесты для каждого набора данных.
Система изолирует данные, поэтому один и тот же тестовый сценарий может использоваться для нескольких комбинаций входных данных. Входные данные могут храниться в форматах XLS, XML, CSV и в базе данных. Ниже несколько примеров типов тестирования, управляемого данными:
Key-driven: Динамические тестовые данные вводятся тестировщиком для повторного тестирования приложения с новыми входными значениями.File-driven (.txt, .doc): Повторное тестирование с использованием данных, хранимых в файле.Excel: Этот тест запускает сценарий для нескольких входных данных, которые хранятся в Excel-таблицах.
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
![Sql [айти бубен]](https://wudgleyd.ru/wp-content/uploads/d/7/7/d775103d79eb1f3a24f72016ed04a038.jpeg)


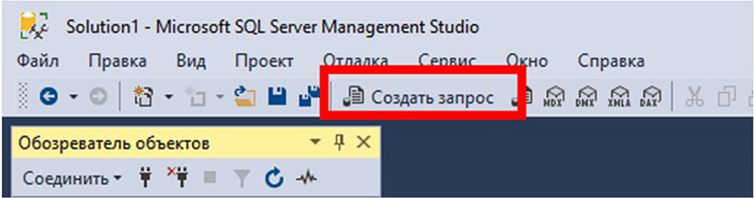
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
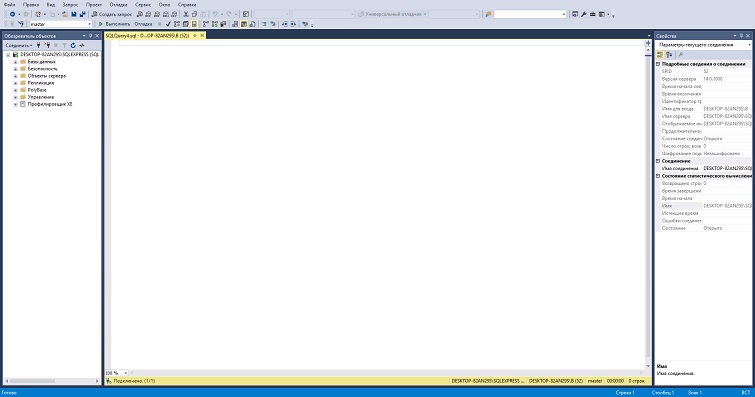
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
CREATE DATABASE b_library;
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library.
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
USE b_library;
В БД «b_library создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors ( AuthorId INT IDENTITY (1, 1) NOT NULL, AuthorFirstName NVARCHAR (20) NOT NULL, AuthorLastName NVARCHAR (20) NOT NULL, AuthorAge INT NOT NULL );
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES (‘Александр’, ‘Пушкин’, ’37’), (‘Сергей’, ‘Есенин’, ’30’), (‘Джек’, ‘Лондон’, ’40’), (‘Шота’, ‘Руставели’, ’44’), (‘Рабиндранат’, ‘Тагор’, ’80’);
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
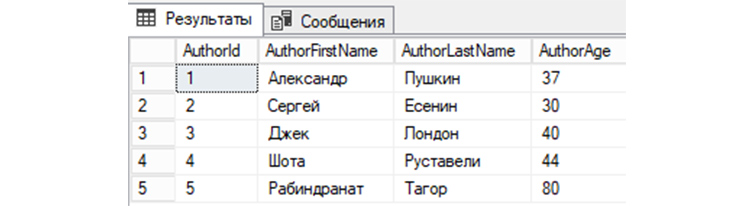
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
История
В начале 1970-х годов в компании IBM была разработана экспериментальная СУБД «System R» на основе языка SEQUEL (Structured English Query Language — структурированный английский язык запросов). Позже по юридическим соображениям язык SEQUEL был переименован в SQL. Когда в 1986 году первый стандарт языка SQL был принят ANSI (American National Standards Institute), официальным произношением стало — эс-кью-эл. Несмотря на это, даже англоязычные специалисты по прежнему часто называют SQL сиквел, вместо эс-кью-эл (по-русски также часто говорят «эс-ку-эль»). Целью разработки было создание простого непроцедурного языка, которым мог воспользоваться любой пользователь, даже не имеющий навыков программирования.
Собственно разработкой языка запросов занимались Чэмбэрлин (Chamberlin) и Рэй Бойс (Ray Boyce). Пэт Селинджер (Pat Selinger) занималась разработкой стоимостного оптимизатора (cost-based optimizer), Рэймонд Лори (Raymond Lorie) занимался компилятором запросов.
В году IBM объявила о своём первом основанном на SQL программном продукте — SQL/DS. Чуть позже к ней присоединились Oracle, Relational Technology и другие производители.
Первый стандарт языка SQL был принят ANSI (Американским национальным институтом стандартизации) в и ISO (Международной организацией по стандартизации) в (так называемый SQL level 1) и несколько уточнён в 1989 году (SQL level 2). Дальнейшее развитие языка поставщиками СУБД потребовало принятия в нового расширенного стандарта (ANSI SQL-92 или просто SQL-2). Следующим стандартом стал SQL-99. В настоящее время действует стандарт, принятый в 2003 году (SQL-3).
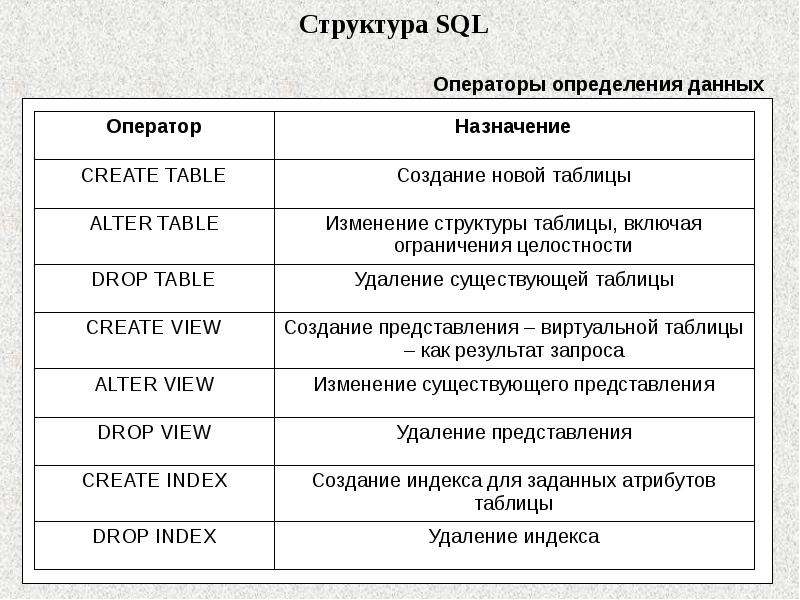
Среди достоинств использования (применения) SQL в прикладной сфере можно выделить следующие:
Независимость от конкретной СУБД
Несмотря на наличие диалектов и различий в синтаксисе, в большинстве своём тексты SQL запросов, содержащие DDL и DML, могут быть достаточно легко перенесены из одной СУБД в другую и наоборот. Существуют системы, разработчики которых изначально закладывались на применение по меньшей мере нескольких СУБД (например: система электронного документооборота Documentum может работать как с Oracle Database, так и с Microsoft SQL Server и IBM DB2)
Наличие стандартов
Наличие стандартов и набора тестов для выявления совместимости и соответствия конкретной реализации SQL общепринятому стандарту только способствует «стабилизации» языка.
Полноценность как языка для управления данными
С помощью SQL программист или пользователь может просматривать, изменять и удалять данные, что является основой самого понятия СУБД.
Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста.
Несмотря на наличие международного стандарта ANSI SQL-92, многие компании, занимающиеся разработкой СУБД (например, Oracle, Microsoft, MySQL AB, Borland), вносят изменения в язык SQL, применяемый в разрабатываемой СУБД, тем самым отступая от стандарта. Таким образом появляются специфичные для каждой конкретной СУБД диалекты языка SQL.
Команды языка управления транзакциями
Команды языка управления транзакциями ( TCL (Тгаnsасtiоn Соntrol Language) ) команды позволяют определить исход транзакции. Команды управления транзакциями управляют изменениями в базе данных, которые осуществляются командами манипулирования данными.Транзакция (или логическая единица работы) – неделимая с точки зрения воздействия на базу данных последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.COMMIT — заканчивает («подтверждает») текущую транзакцию и делает постоянными (сохраняет в базе данных) изменения, осуществленные этой транзакцией. Также стирает точки сохранения этой транзакции и освобождает ее блокировки. Можно также использовать эту команду для того, чтобы вручную подтвердить сомнительную распределенную транзакцию.ROLLBACK — выполняет откат транзакции, т.е. отменяет все изменения, сделанные в текущей транзакции. Можно также использовать эту команду для того, чтобы вручную отменить работу, проделанную сомнительной распределенной транзакцией. Понятие транзакции имеет непосредственную связь с понятием целостности базы данных. Очень часто база данных может обладать такими ограничениями целостности, которые просто невозможно не нарушить, выполняя только один оператор изменения БД. Например, невозможно принять сотрудника в отдел, название и код которого отсутствует в базе данных. В системах с развитыми средствами ограничения и контроля целостности каждая транзакция начинается при целостном состоянии базы данных и должна оставить это состояние целостными после своего завершения. Несоблюдение этого условия приводит к тому, что вместо фиксации результатов транзакции происходит ее откат (т.е. вместо оператора COMMIT выполняется оператор ROLLBACK), и база данных остается в таком состоянии, в котором находилась к моменту начала транзакции, т.е. в целостном состоянии. В связи со свойством сохранения целостности БД транзакции являются подходящими единицами изолированности пользователей, т.е., если с каждым сеансом работы с базой данных ассоциируется транзакция, то каждый пользователь начинает работу с согласованным состоянием базы данных, т.е. с таким состоянием, в котором база данных могла бы находиться, даже если бы пользователь работал с ней в одиночку.
SELECT раздел JOIN
-
W3schools: SQL Joins
-
Какая разница между LEFT, RIGHT, INNER, OUTER JOIN?
-
MySQL 1054 Unknown column ‘table1.id’ in ‘on clause’
Простой JOIN (=пересечение JOIN =INNER JOIN ) — означает показывать только общие записи обоих таблиц. Каким образом записи считаются общими определяется полями в join- выражении. Например следующая запись: FROM t1 JOIN t2 ON t1.id = t2.id
означает что будут показаны записи с одинаковыми id, существующие в обоих таблицах.
- LEFT JOIN (или LEFT OUTER JOIN) означает показывать все записи из левой таблицы (той, которая идет первой в join- выражении) независимо от наличия соответствующих записей в правой таблице. Если записей нет в правой таблицы устанавливается пустое значение NULL.
- RIGHT JOIN (или RIGHT OUTER JOIN) действует в противоположность LEFT JOIN — показывает все записи из правой (второй) таблицы и только совпавшие из левой (первой) таблицы.
- Другие виды JOIN объединений: MINUS — вычитание; FULL JOIN — полное объединение; CROSS JOIN — “Каждый с каждым” или операция декартова произведения.
SELECT JOIN SUBSTRING
Пример работает для БД PostgreSQL 8.4. В разделе JOIN используется регулярное выражение (Шпаргалка RegExp: Метасимволы, Максимализм квантификатора, Алфавиты и блоки), аналогичное


SELECT SUBSTRING('XY1234Z', 'Y*({1,3})');
SELECT SUBSTRING('fly@gmail.com', '.*(@.*)$');
В листинге берутся три первые цифры из поля dst_number_bill и эти полученные цифры уже сравниваются.
SELECT cdr.id, cdr.nas_id, cdr.src_peer_id, peers.name, cdr.src_ip, cdr.src_number_bill, cdr.dst_number_bill,
df_lcrcode.destination, cdr.init_time, SUBSTRING(cdr.dst_number_bill, '({1,3})') as country_code
FROM cdr
LEFT JOIN peers ON cdr.src_peer_id=peers.id
LEFT JOIN df_lcrcode ON SUBSTRING(cdr.dst_number_bill, '({1,3})')=df_lcrcode.code
WHERE begin_time >= '2013-02-17 00:00:00' AND begin_time <= '2013-02-17 23:59:59' AND cause_local != 138
AND dst_ip = '0.0.0.0'
ORDER BY src_peer_id DESC LIMIT 10
Операторы сравнения (Transact-SQL)
Операторы сравнения позволяют проверить, одинаковы ли два выражения. Операторы сравнения можно применять ко всем выражениям, за исключением выражений типов text, ntext и image. Операторы сравнения Transact-SQL приведены в следующей таблице:

Тип данных Boolean
Результат выполнения оператора сравнения имеет тип данных Boolean. Он может иметь одно из трех значений: TRUE, FALSE и UNKNOWN. Выражения, возвращающие значения типа Boolean, называются «логическими выражениями». В отличие от других типов данных SQL Server, тип Boolean не может быть типом столбца или переменной и не может быть возвращен в результирующем наборе.
Сводка
Хотя одной из сильных сторон U-SQL является работа с неструктурированными данными, хранящимися в файлах, она также может предоставлять структурированные представления неструктурированных данных, управлять структурированными данными в таблицах и предоставлять общую систему каталогов метаданных для организации структурированных данных и пользовательского кода, защиты и обеспечения их обнаружения.
Каждому объекту метаданных присваивается имя, а объекты располагаются в следующей иерархии объектов:
Объекты, включенные из контекста C#, такие как имена функций, классов, методов, предоставляемых сборками, не требуют имен объектов метаданных, но вместо этого ссылаются с помощью имен C# после того, как на сборки ссылаются имена объектов метаданных в скриптах.
В следующем примере мы используем концепции контекста статической базы данных и контекста статической схемы , которые определяют имена баз данных и схем по умолчанию, которые используются для разрешения имен, которые не являются полными во время компиляции и выполнения.
Все неквалифицированные имена объектов, привязанных к схеме (например, имена функций и таблиц) будут разрешаться в текущем контексте статической схемы в текущем контексте статической базы данных. Отдельные имена могут перезаписывать разрешение, используя многокомпонентные имена (так называемые полные имена). Например, T будет разрешен в текущем контексте, S.T разрешим имя объекта T в схеме S в текущем контексте статической базы данных, а D.S.T — имя объекта T в схеме S в базе данных D.
Обратите внимание, что имена внутри функций U-SQL разрешаются на основе контекста во время компиляции функции, а не динамического контекста во время использования. Все объекты метаданных, кроме учетных данных, создаются и управляются с помощью следующих инструкций DDL
Все объекты метаданных, кроме учетных данных, создаются и управляются с помощью следующих инструкций DDL.