
Сочетания клавиш отладчика Transact-SQL
| Действие | SQL Server 2017 | SQL Server 2008 R2 |
|---|---|---|
| Начать или продолжить отладку | ALT + F5 | ALT + F5 |
| Остановить отладку | SHIFT + F5 | SHIFT + F5 |
| Шаг с заходом | F11 | F11 |
| Шаг с обходом | F10 | F10 |
| Шаг с выходом | SHIFT + F11 | SHIFT + F11 |
| Переход к определенной инструкции | SHIFT + ALT + F11 | Нет эквивалента |
| Установка следующей инструкции | Ctrl + 3 0 | Нет эквивалента |
| Отображение следующей инструкции | ALT + NUM | Нет эквивалента |
| Реализация команды Выполнить до курсора | CTRL + F10 | CTRL + F10 |
| Отобразить диалоговое окно Быстрая проверка |
CTRL + ALT + Q
либо SHIFT + F9 |
CTRL + ALT + Q |
| Переключить точку останова | F9 | F9 |
| Включение точки останова | CTRL + F9 | Нет эквивалента |
| Удаление точки останова Доступно только в окне Точки останова | ALT + F9, D | Нет эквивалента |
| Открытие диалогового окна Изменение меток точек останова . Доступно только в окне Точки останова | ALT + F9, L | Нет эквивалента |
| Удаление всех точек останова | CTRL + SHIFT + F9 | CTRL + SHIFT + F9 |
| Отобразить окно Точки останова | CTRL + ALT + B | CTRL + ALT + B |
| Приостановить все | CTRL + ALT + BREAK | CTRL + ALT + BREAK |
| Прерывание на функции | CTRL + B | Нет эквивалента |
| Отображение окна Контрольное значение 1 | CTRL+ALT+W, 1 | Нет эквивалента |
| Отображение окна Контрольное значение 2 | CTRL+ALT+W, 2 | CTRL+ALT+W, 1 |
| Отображение окна Контрольное значение 3 | CTRL+ALT+W, 3 | CTRL+ALT+W, 3 |
| Отображение окна Контрольное значение 4 | CTRL + ALT + W, 4 | CTRL + ALT + W, 4 |
| Отобразить окно Автоматические значения | CTRL + ALT + V, A | CTRL + ALT + V, A |
| Отобразить окно Локальные значения | CTRL + ALT + V, L | CTRL + ALT + V, L |
| Отобразить окно Интерпретация | CTRL + ALT + I | CTRL + ALT + I |
| Отобразить окно Стек вызовов | CTRL + ALT + C | CTRL + ALT + C |
| Отобразить окно Потоки | CTRL + ALT + H | CTRL + ALT + H |
| Отобразить окно Параллельные стеки | CTRL + SHIFT + D, S | Нет эквивалента |
| Отобразить окно Параллельные задачи | CTRL_SHIFT + D, K | Нет эквивалента |
Число прочитанных строк и Оценочное число строк к прочтению
В плане запроса есть два очень важных свойства Actual Number Of Rows и Estimated Number of Rows, действительное и оценочное число строк. Эти свойства, содержат информацию только о том, сколько строк вернул оператор чтения данных, но не сколько строк он действительно прочитал. Свойства Number of Rows Read и Estimated Number of Rows to be Read отвечают как раз на этот вопрос и позволяют понять, сколько строк в действительности прочитал или собирается прочитать сервер. Свойство ActualRowsRead (Number of Rows Read в SSMS) доступно начиная с SQL Server 2012 SP3, 2014 SP2, 2016 SP1. Свойство EstimatedRowsRead (Estimated Number of Rows to be Read в SSMS) доступно начиная с SQL Server 2016 SP1.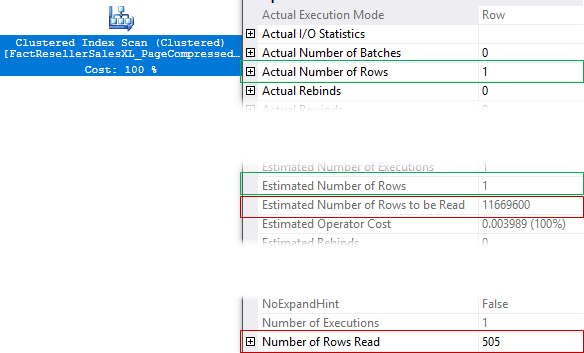
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
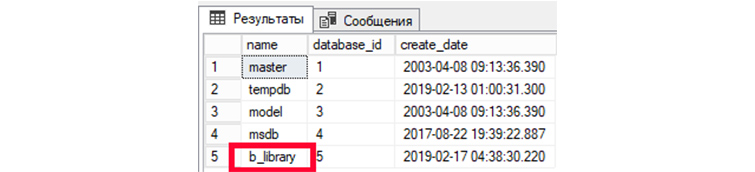
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_date FROM sys.databases;
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=’BASE TABLE’
 3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
SELECT * FROM tAuthors;
 4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
SELECT count(*) FROM tAuthors;
 5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
SELECT * FROM tAuthors ORDER BY AuthorId OFFSET 3 ROWS FETCH NEXT 2 ROWS ONLY;
 6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
SELECT * FROM tAuthors ORDER BY AuthorFirstName;
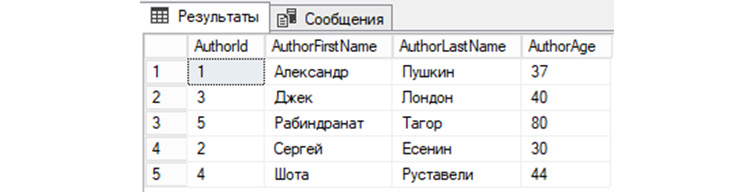 7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
7) Выведем из «tAuthors данные, предварительно по AuthorId отсортировав их по убыванию:
SELECT * FROM tAuthors ORDER BY AuthorId DESC;
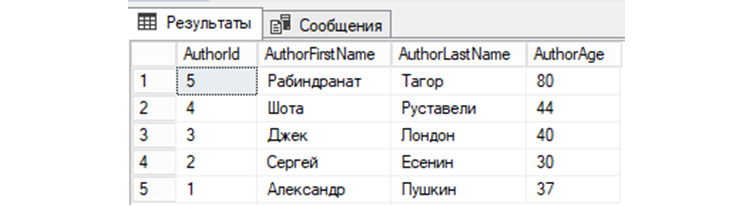
![]() Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
SELECT * FROM tAuthors WHERE AuthorFirstName=’Александр’;
 9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘се%’;
 10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘%ат’ ORDER BY AuthorId;
Видео курсы по схожей тематике:

SQL Базовый. Разбор ДЗ
Владимир Дымчук

MySQL Базовый
Андрей Бондаренко

How to SQL Базовый
Владимир Дымчук
 11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:
SELECT * FROM tAuthors WHERE AuthorId IN (2,4);
 12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
12) Выберем в «tAuthors» такую запись AuthorAge, значение которой — наибольшее:
SELECT max(AuthorAge) FROM tAuthors;
 13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
SELECT AuthorFirstName, AuthorLastName FROM tAuthors;
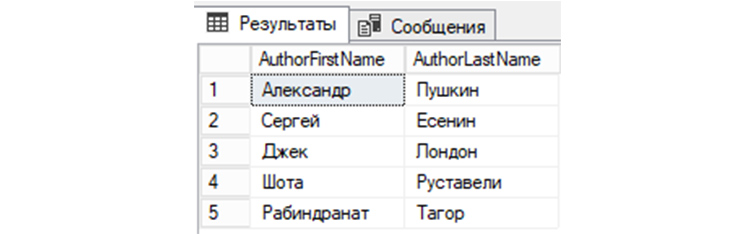 14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
SELECT AuthorId, AuthorFirstName, AuthorLastName FROM tAuthors WHERE AuthorId!=’3′;

INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД. Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
INSERT INTO tAuthors VALUES (‘Уильям’, ‘Шекспир’, ’51’);
Проверим:
SELECT * FROM tAuthors;

UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (AuthorId = 6). Значения изменим для полей имени, фамилии и возраста автора.



UPDATE tAuthors SET AuthorFirstName = ‘Лев’, AuthorLastName=’Толстой’, AuthorAge = ’82’ WHERE AuthorId = ‘6’;
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
SELECT * FROM tAuthors;
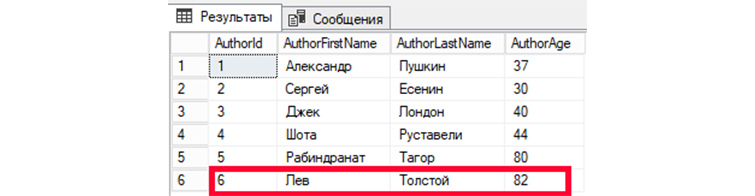
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где AuthorId = 5:
DELETE FROM tAuthors WHERE AuthorId = ‘5’;
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
SELECT * FROM tAuthors;
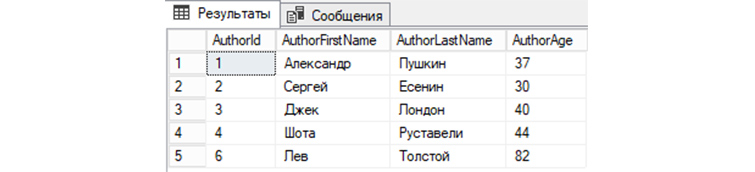
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors целиком, выполнив простой SQL запрос:
DROP TABLE tAuthors;
Далее рассмотрим сложные запросы SQL.
Сочетания клавиш для поиска
| Действие | SQL Server 2017 | SQL Server 2008 R2 |
|---|---|---|
| Отобразить диалоговое окно Найти | CTRL + F | CTRL + F |
| Отображение вкладки В файлах в диалоговом окне Найти . | ||
| Отображение определения выделенного символа. | F12 | Нет эквивалента |
| Отображение списка ссылок для выделенного символа. | SHIFT + F12 | Нет эквивалента |
| Отобразить диалоговое окно Заменить | CTRL + H | CTRL + H |
| Начать последовательный поиск. Введите последовательность символов, которую нужно найти, или нажмите CTRL + I для поиска тех же символов, что и в предыдущий раз. | CTRL + I | CTRL + I |
| Найти следующее вхождение искомой последовательности символов в текст | F3 | F3 |
| Найти предыдущее вхождение искомого текста | SHIFT + F3 | SHIFT + F3 |
| Найти следующее вхождение выделенного текста | CTRL + F3 | CTRL + F3 |
| Найти предыдущее вхождение выделенного текста | CTRL + SHIFT + F3 | CTRL + SHIFT + F3 |
| Отобразить диалоговое окно Заменить в файлах | CTRL + SHIFT + H | CTRL + SHIFT + H |
| Изменить направление поиска с уточнением критериев, чтобы он выполнялся от конца файла к началу | CTRL + SHIFT + I | CTRL + SHIFT + I |
| Установить или снять флажок Искать вверх в диалоговом окне Найти и заменить | ALT + F3, B | ALT + F3, B |
| Остановить выполнение операции Найти в файлах | ALT + F3, S | ALT + F3, S |
| Установить или снять флажок Искать слово в диалоговом окне Найти и заменить | ALT + F3, W | ALT + F3, W |
| Установить или снять флажок Шаблон в диалоговом окне Найти и заменить | ALT + F3, P | ALT + F3, P |
| Перемещение курсора в поле «Найти/Команда» на стандартной панели инструментов | CTRL + / | Нет эквивалента |
Сочетания клавиш для перемещения курсора
| Действие | SQL Server 2017 | SQL Server 2008 R2 |
|---|---|---|
| Переместить курсор на одну позицию влево | СТРЕЛКА ВЛЕВО | СТРЕЛКА ВЛЕВО |
| Переместить курсор на одну позицию вправо | СТРЕЛКА ВПРАВО | СТРЕЛКА ВПРАВО |
| Переместить курсор на одну позицию вверх | СТРЕЛКА ВВЕРХ | СТРЕЛКА ВВЕРХ |
| Переместить курсор на одну позицию вниз | СТРЕЛКА ВНИЗ | СТРЕЛКА ВНИЗ |
| Переместить курсор в начало строки | HOME | HOME |
| Переместить курсор в конец строки | END | END |
| Переместить курсор в начало документа | CTRL + HOME | CTRL + HOME |
| Переместить курсор в конец документа | CTRL + END | CTRL + END |
| Переместить курсор на один экран вверх | PAGE UP | PAGE UP |
| Переместить курсор на один экран вниз | PAGE DOWN | PAGE DOWN |
| Переместить курсор на одно слово вправо | CTRL + СТРЕЛКА ВПРАВО | CTRL + СТРЕЛКА ВПРАВО |
| Переместить курсор на одно слово влево | CTRL + СТРЕЛКА ВЛЕВО | CTRL + СТРЕЛКА ВЛЕВО |
| Возврат курсора к последнему элементу. | SHIFT + F8 | Нет эквивалента |
| Перемещение курсора в верхнюю часть документа | CTRL + PAGE UP | Нет эквивалента |
| Переход к предыдущей вкладке документа | CTRL + PAGE UP | |
| Перемещение курсора в нижнюю часть документа | CTRL + PAGE DOWN | Нет эквивалента |
| Переход к следующей вкладке документа | CTRL + PAGE DOWN | Нет эквивалента |
Сочетания клавиш для работы со справкой и электронной документацией
| Действие | SQL Server 2017 | SQL Server 2008 R2 |
|---|---|---|
| Справка |
F1
либо SHIFT + F1 |
F1 |
| Отображение электронной документации по SQL Server | CTRL + F1 | Нет эквивалента |
| Открытие диспетчера библиотек справки | CTRL + ALT + F1 | Нет эквивалента |
| Открытие веб-страницы центра ресурсов SQL Server | CTRL + ALT + F2 | Нет эквивалента |
| Отображение справки для текущего окна редактора | SHIFT + F1 | Нет эквивалента |
| Справка по разделу «Инструкции» | Нет эквивалента | CTRL + F1 |
| Выбрать в электронной документации вкладку «Оглавление» | Нет эквивалента | CTRL + ALT + F1 |
| Выбрать в электронной документации вкладку «Указатель» | Нет эквивалента | CTRL + ALT + F2 |
| Открыть в справочной системе окно поиска | Нет эквивалента | CTRL + ALT + F3 |
| Динамическая справка | Нет эквивалента | CTRL + ALT + F4 |
| Избранные разделы справки | Нет эквивалента | CTRL + ALT + F |
Информация о сливе данных в tempdb
Некоторые операторы плана, например, такие как Sort или Hash Match, требуют память во время выполнения запроса, однако, количество памяти рассчитывается в момент компиляции. В силу разных причин (например, неверной оценки числа предполагаемых строк), количество памяти может быть посчитано неверно. Если памяти было выделено меньше, чем нужно для выполнения, сервер вынужден сливать данные в tempdb (spill to tempdb), что замедляет выполнение запроса. Предупреждение о такой ситуации появилось в 2012 сервере, но начиная с SQL Server 2012 SP3, 2014 SP2, 2016 диагностическая информация была расширена и теперь включает в себя объем слитых и прочитанных данных, так что можно оценить степень бедствия и принять адекватные меры.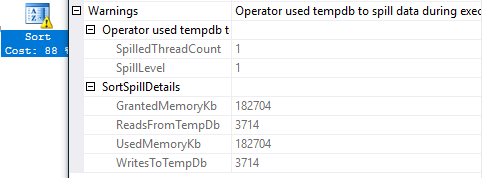
Нумерация строк
Чтобы пронумеровать строки, мы должны объявить переменную запроса. Продемонстрируем этот подход на примере простой таблицы, содержащей список работников предприятия ( employees ). Следующий запрос выбирает 5 работников из таблицы, присваивая им номера по порядку, начиная с 1:
В выше приведённом запросе мы:
- Определили переменную row_number и инициализировали её нулевым значением;
- Увеличивали её значение на 1 при каждой итерации запроса.
Другая техника, позволяющая достичь того же результата, заключается в создании вместо глобальной переменной производной таблицы и перекрёстном объединении этих двух таблиц. Пример такого запроса:
Обратите внимание на то, что для соблюдения правил синтаксиса у производной таблицы должен быть псевдоним
Возобновление нумерации в группах
Как нам задать отдельную нумерацию для каждой группы строк, объединённых выражением ORDER BY или GROUP BY ? Например, как имитировать следующий запрос:
Нам нужно сформировать список платежей, в котором каждому платежу будет соответствовать определённый порядковый номер. Для того чтобы получить требуемый результат, нам понадобятся две переменные: одна – с порядковым номером строки, другая – для хранения идентификатора клиента из предыдущей строки, чтобы сравнить его с текущим. Наш запрос будет выглядеть так:
Мы использовали оператор CASE для вычисления условия: если номер клиента остаётся прежним, мы увеличиваем номер строки на 1, в противном случае мы устанавливаем номер строки равным 1. Результат будет тем же, что и на выше приведённом скриншоте.
Теперь добьёмся того же результата, используя технику производной таблицы и перекрёстного запроса:
Итак, мы научились эмулировать нумерацию строк запроса в MySQL .
Данная публикация представляет собой перевод статьи « MySQL row_number Emulation » , подготовленной дружной командой проекта Интернет-технологии.ру
Изучение Transact-SQL продолжается и на очереди у нас функции ранжирования ROW_NUMBER, RANK, DENSE_RANK и NTILE, сейчас мы узнаем, что делают эти функции и зачем вообще они нужны, все как обычно будем рассматривать на примерах.

В языке Transact-SQL очень много различных функций, конструкций, например, PIVOT или INTERSECT, которые в принципе редко используются, их мы даже в нашем мини справочнике Transact-SQL не указывали, но знать, где и как их можно использовать нужно, так же, как и функции ранжирования или их еще называют функции нумерации. Поэтому сегодня давайте поговорим именно об этих функциях, и если говорить конкретно, то это функции: ROW_NUMBER, RANK, DENSE_RANK, NTILE.
И начнем мы, конечно же, с определения, что же вообще это за ранжирующие функции.
Установка экземпляра Microsoft SQL Server 2008
При установке экземпляра оставим набор компонентов и их детальную настройку за скобками, отметив только следующие моменты:
Для каждого компонента желательно создать отдельную учетную запись в Active Directory. Это необходимо для того, чтобы впоследствии эффективно распределять права, которые будут необходимы компонентам для сетевых взаимодействий, как то создание резервных копий, доступ к данным на удаленных компьютерах и т. п.
В качестве пути установки нового экземпляра Microsoft SQL Server следует использовать путь на дисковом массиве, предназначенном для файлов данных БД. Делается это по нескольким причинам, во-первых, папка экземпляра содержит системные базы данных и если мы решили хранить все базы данных на отдельном хранилище, то они не должны стать исключением
Во-вторых, скорость доступа к данным на дисковом массиве файлов данных максимальна, что также немаловажно для системных баз данных. Таким образом, мы полностью освободили системный диск сервера от данных, которые необходимы для работы экземпляра SQL-сервера и в случае необходимости легко можем очистить его и переустановить ОС.
Размещение tempdb на RAM-диске
Задача размещения системной базы данных tempdb на отдельном высокоскоростном хранилище хорошо известна администраторам баз данных. Дело в том, что эта база данных хранит временные таблицы SQL, необходимые для обработки сложных запросов, таким образом, от производительности операций с tempdb существенно зависит производительность всего экземпляра в целом.
Одним из способов увеличения скорости операций ввода-вывода с базой данных tempdb является размещение её файлов на RAM-диске. Для этого необходимо подобрать программное обеспечение, которое позволит создать в системе RAM-диск. На основе тестирования различных RAM-дисков (http://www.raymond.cc/blog/archives/2009/12/08/12-ram-disk-software-benchmarked-for-fastest-read-and-write-speed/) можно сделать вывод о том, что неплохой производительностью, а также бесплатностью с некоторыми ограничениями обладает RAM-диск от DataRam (http://memory.dataram.com/products-and-services/software/ramdisk). Ограничением является максимальный объем диска для бесплатной версии равный 4 Гб.
Естественно объема, определенного для файлов базы данных tempdb на RAM-диске может быть недостаточно для некоторых запросов и может возникнуть неприятная ситуация переполнения файлов базы данных. Для устранения этого необходимо разделить tempdb на файлы хранимые на RAM-диске и файлы размещенные на дисковых массивах. При этом размеры файлов RAM-диска следует установить в соответствии с размером RAM-диска и отключить авторасширение, а размеры файлов на дисковых массивах необходимо установить минимальными с включенным авторасширением. В виду того, что Microsoft SQL Server использует алгоритм round robin для записи в файлы баз данных, основная часть операций будет выполняться с файлами RAM-диска, однако же при их переполнении произойдет не сбой, а авторасширение файлов на дисковых массивах. Финальная настройка файлов tempdb может быть такой, как показана на рис. 3.
Рисунок 3. Файлы базы данных tempdb
Также необходимо настроить сохранение образа RAM-диска на дисковый массив при перезагрузке сервера, иначе база tempdb не сможет запуститься, что повлечет за собой невозможность запуска самого экземпляра SQL-сервера. Для хранения образа целесообразнее всего избрать дисковый массив с файлами данных БД.
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
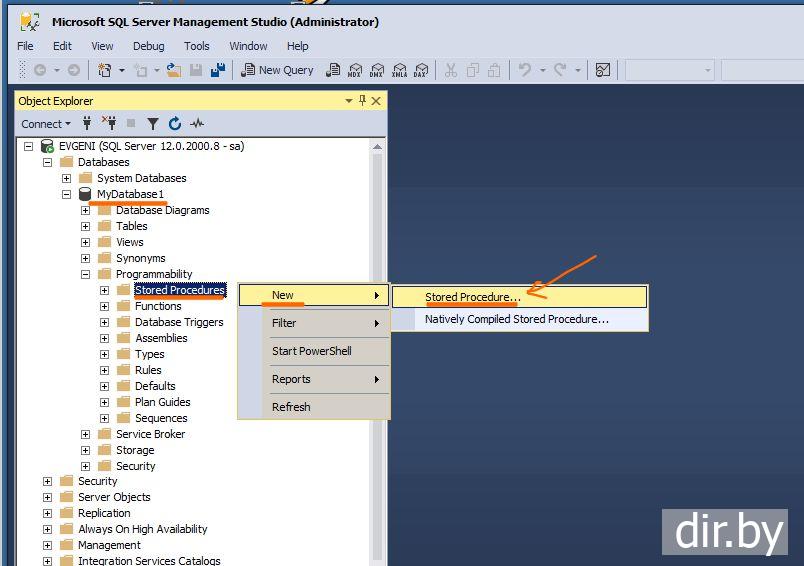
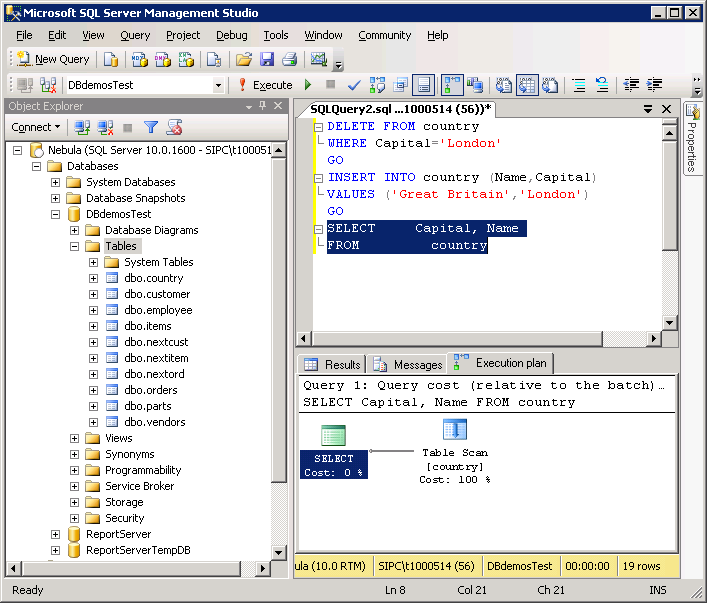
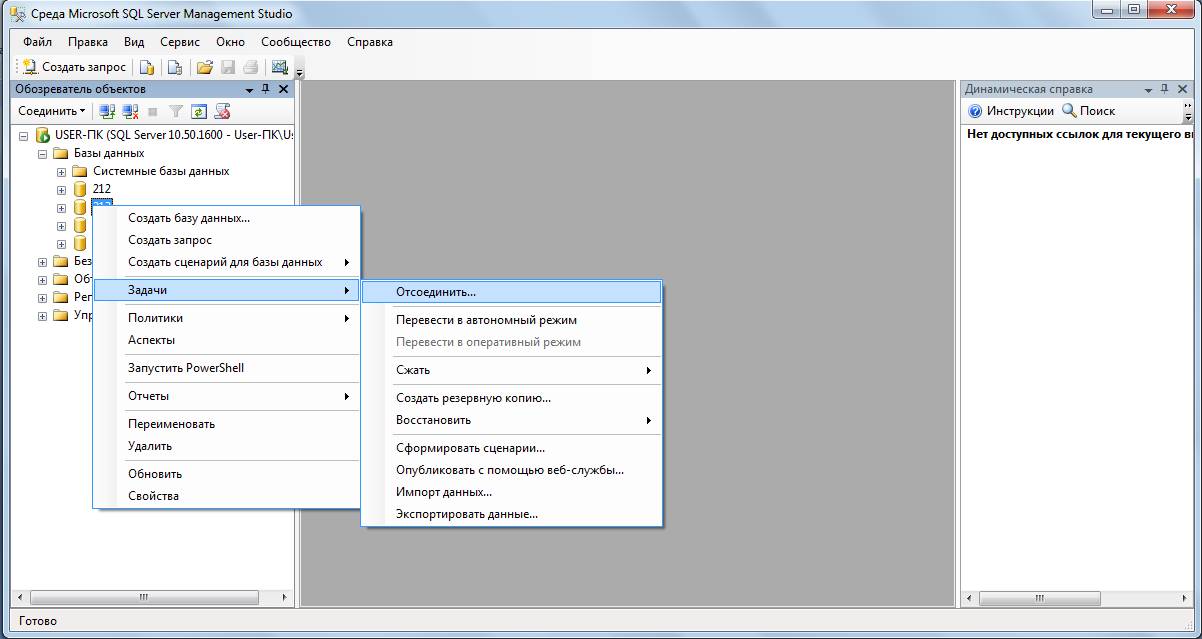
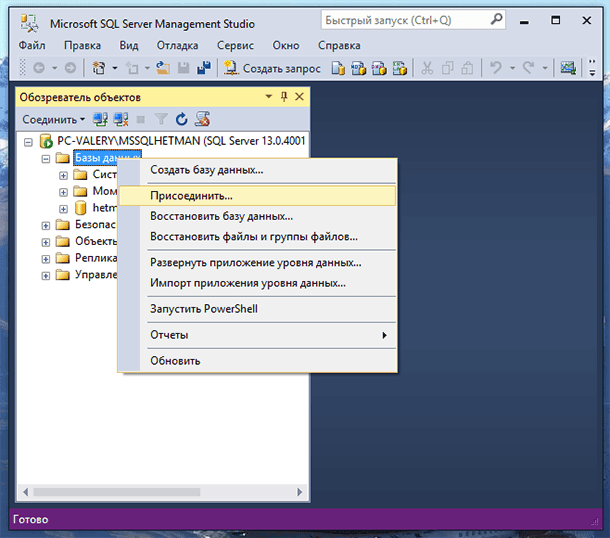
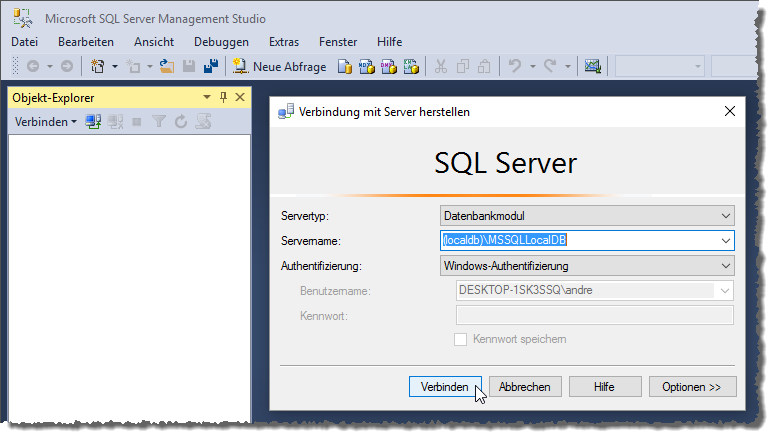
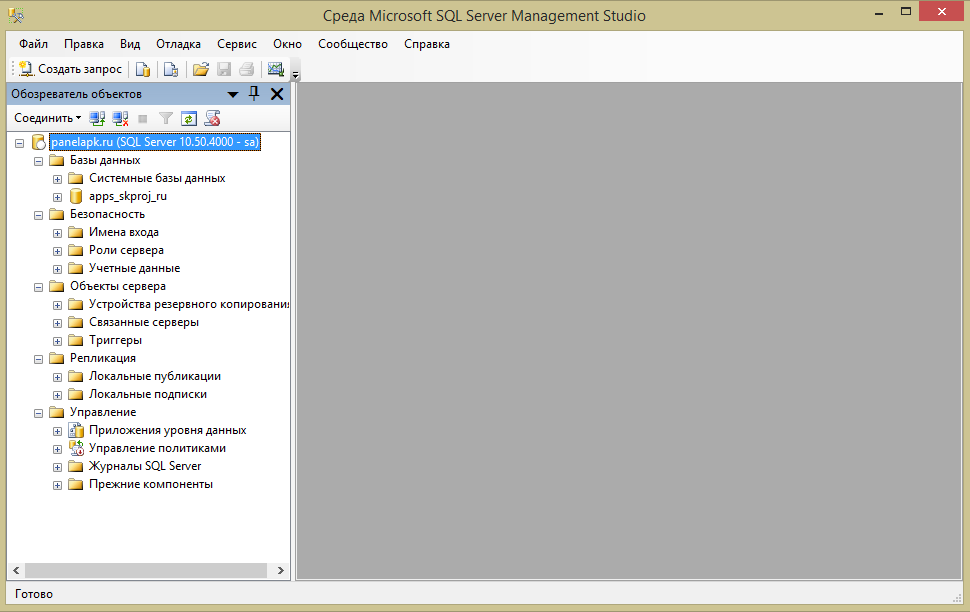
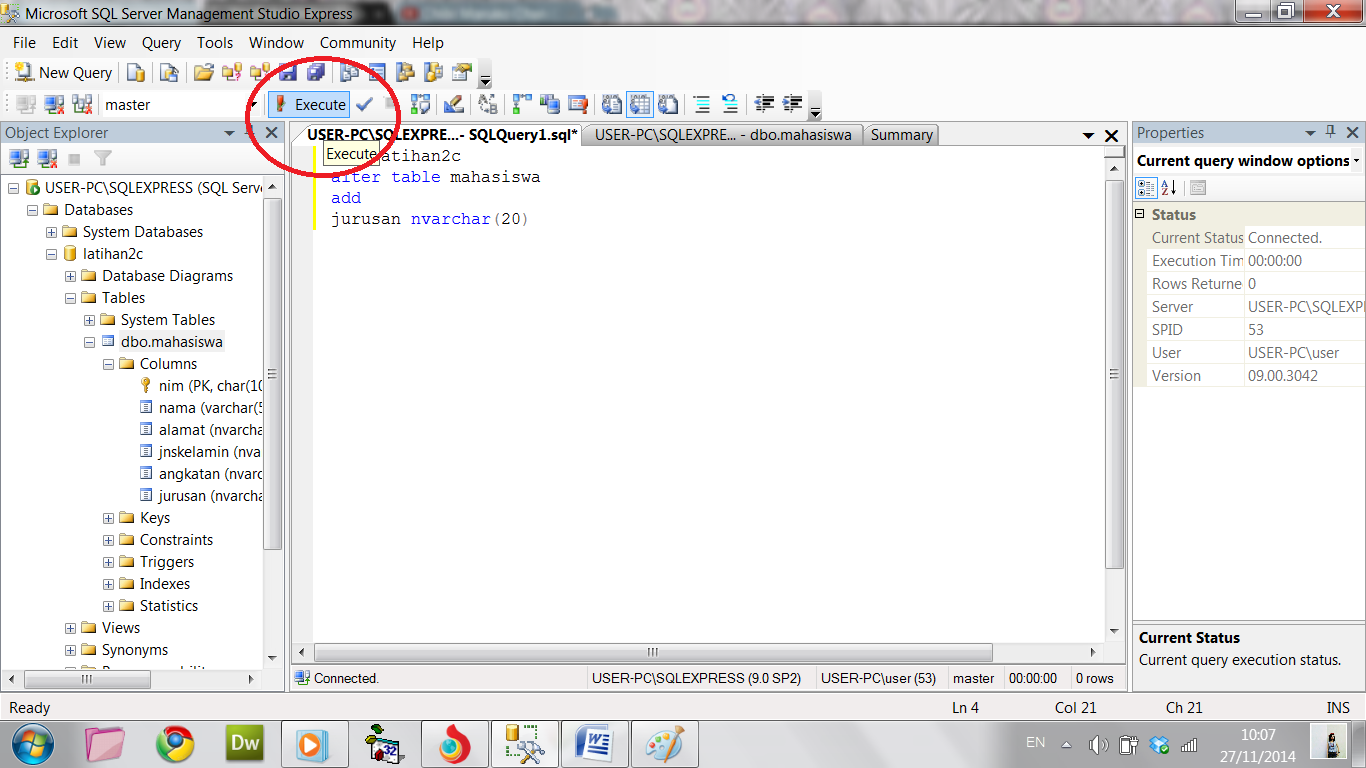
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
CREATE DATABASE b_library;
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library.
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
USE b_library;
В БД «b_library создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors ( AuthorId INT IDENTITY (1, 1) NOT NULL, AuthorFirstName NVARCHAR (20) NOT NULL, AuthorLastName NVARCHAR (20) NOT NULL, AuthorAge INT NOT NULL );
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES (‘Александр’, ‘Пушкин’, ’37’), (‘Сергей’, ‘Есенин’, ’30’), (‘Джек’, ‘Лондон’, ’40’), (‘Шота’, ‘Руставели’, ’44’), (‘Рабиндранат’, ‘Тагор’, ’80’);
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
SELECT * FROM tAuthors;
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Эксперимент
Эксперимент довольно прост:
- Открываем в 1С обработку «ЗаписьВРегистрВТранзакции» и встаем на модальном окне предупреждения
- В Management Studio выполняем SQL-запрос, он должен начать выполняться и «повиснуть» на выполнении
В результате этих действий в нашей базе данных выполняется запрос, который ожидает освобождения ресурса. Если бы было установлено время таймаута (а по умолчанию его нет), возникла бы ошибка превышения времени ожидания на блокировке.
Получение информации о текущих запросах
Текущее состояние нашей системы дает нам возможность выполнить запрос, который вернет информацию об исполняемых в данный момент запросах. В моем запросе будут использованы следующие динамические административные представления:
| Представление | Описание |
|---|---|
| dm_exec_requests | Возвращает сведения о каждом из запросов, выполняющихся в SQL Server |
| dm_exec_sql_text | Возвращает текст пакета SQL, который определен указанным параметром |
| dm_exec_query_plan | Возвращает события инструкции Showplan в XML-формате для пакета, указанного в дескрипторе плана |
Текст запроса приведен ниже, а также доступен во вложении к статье:
Текущие исполняемые запросы
SELECT
DB_NAME(er.database_id) AS DB_Name,
er.start_time,
er.session_id,
er.status,
er.command,
— performance:
er.reads+er.writes AS IO,
er.logical_reads,
er.cpu_time,
er.total_elapsed_time,
— waits:
er.blocking_session_id,
er.wait_type,
er.wait_time,
er.wait_resource,
— query:
qt.text,
qp.query_plan
FROM
sys.dm_exec_requests as er
CROSS APPLY sys.dm_exec_sql_text(er.sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(er.plan_handle) qp
WHERE
er.database_id = DB_ID(‘MyBase’)
|
1 |
SELECT DB_NAME(er.database_id)ASDB_Name, er.start_time, er.session_id, er.status, er.command, —performance er.reads+er.writes ASIO, er.logical_reads, er.cpu_time, er.total_elapsed_time, —waits er.blocking_session_id, er.wait_type, er.wait_time, er.wait_resource, —query qt.text, qp.query_plan FROM sys.dm_exec_requests aser CROSS APPLY sys.dm_exec_sql_text(er.sql_handle)qt CROSS APPLY sys.dm_exec_query_plan(er.plan_handle)qp WHERE er.database_id=DB_ID(‘MyBase’) |
В условии отбора «MyBase» — имя моей базы данных в СУБД. Результат запроса представлен на картинке ниже:
 Текущие исполняемые запросы
Текущие исполняемые запросы
У меня на картинке выведено 2 строки: первая (обведена красным цветом) — запрос, ожидающий освобождения ресурса; вторая — сам запрос получения информации об исполняемых запросах, поэтому ее разбирать не будем.
Ниже приведу описания колонок результата запроса:
| Имя колонки | Описание |
|---|---|
| DB_Name | Имя базы данных к которой выполняется запрос |
| start_time | Отметка времени поступления запроса |
| session_id | Идентификатор сеанса, к которому относится данный запрос |
| status | Состояние запроса |
| command | Тип выполняемой команды |
| IO | Число операций чтения и записи, выполненных данным запросом |
| logical_reads | Число логических операций чтения, выполненных данным запросом |
| cpu_time | Время ЦП (в миллисекундах), затраченное на выполнение запроса |
| total_elapsed_time | Общее время, истекшее с момента поступления запроса (в миллисекундах) |
| blocking_session_id | Идентификатор сеанса, блокирующего запрос |
| wait_type | Если запрос в настоящий момент блокирован, в столбце содержится тип ожидания |
| wait_time | Если запрос в настоящий момент блокирован, в столбце содержится продолжительность текущего ожидания (в миллисекундах) |
| wait_resource | Если запрос в настоящий момент блокирован, в столбце указан ресурс, освобождения которого ожидает запрос |
| text | Текст поступившего запроса |
| query_plan | Предполагаемый план выполнения поступившего запроса |
Как включить заголовки столбцов при экспорте запроса результаты в CSV в SQL Server
Чтобы включить заголовки столбцов, перейдите в Инструменты , а затем выберите Параметры…

Затем нажмите Результаты запроса >> SQL Server >> Результаты в сетку ng>:
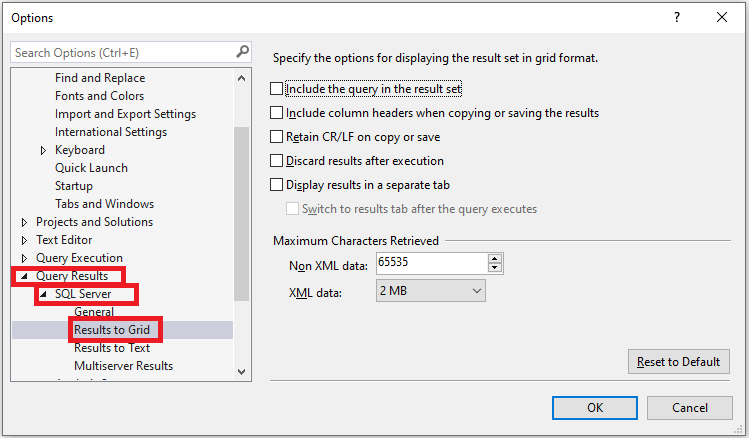
Установите флажок ‘ Включить заголовки столбцов при копировании или сохранении результатов ‘, а затем нажмите
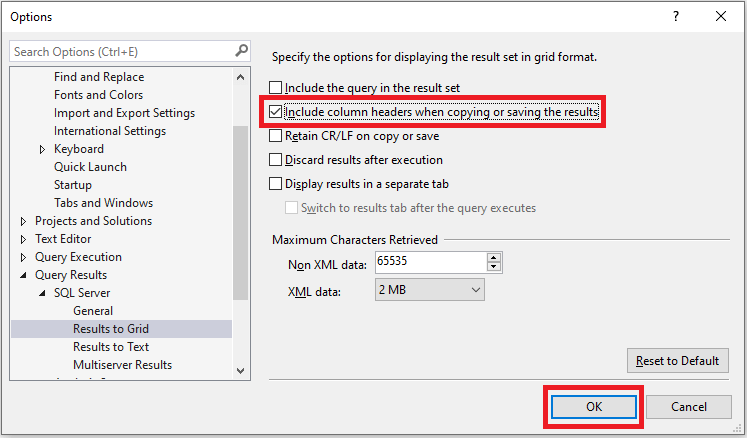
Теперь вам нужно перезапустить сервер SQL, чтобы изменения вступили в силу. .
Затем повторно запустите запрос, чтобы получить результаты:
Щелкните правой кнопкой мыши любую ячейку в самой сетке и выберите« Сохранить результаты как… »
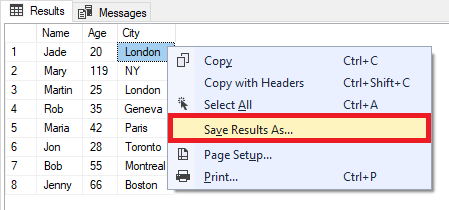
Введите имя для вашего CSV-файла и нажмите Сохранить :
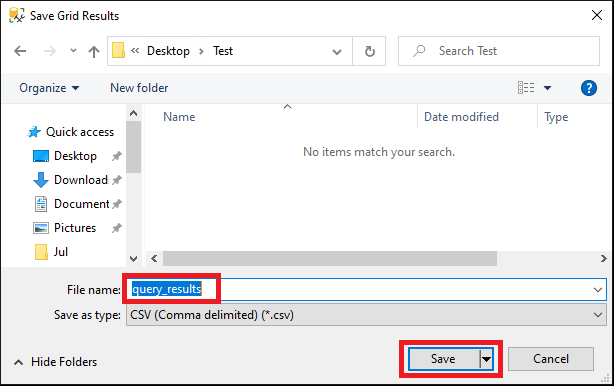
Ваш новый CSV-файл будет теперь содержат заголовки столбцов, идущие вперед:
Добавление номера строки для каждой записи в отчете или группе
Вы можете нумеровать элементы отчета. Например, в отчете о продажах по продуктам, возможно, потребуется «1» для начала первого элемента в группе «продукт», «2» — перед вторым элементом и т. д. Когда начинается следующая группа продуктов, счетчик начинается с, а «1» предшествует первому элементу.


Вы можете нумеровать элементы отчета с помощью вычисляемого элемента управления и задания его свойства Sum .
В области навигации щелкните отчет правой кнопкой мыши и выберите в контекстном меню пункт конструктор .
На вкладке Конструктор в группе Элементы управления щелкните Поле.
В области сведений отчета перетащите указатель, чтобы создать надпись, чтобы она была достаточно широкой, чтобы вместить самый большой номер элемента.
Например, если у вас есть заказы на 100, вам понадобится место по не менее трех символов (100). Если рядом с текстовым полем появится надпись, удалите ее, щелкнув ее и нажав клавишу DELETE. Если вы поместили надпись рядом с левым полем, она может быть скрыта под текстовым полем. С помощью маркера перемещения, расположенного в левом верхнем углу текстового поля, перетащите текстовое поле вправо, чтобы можно было видеть метку. Затем вы можете щелкнуть метку и нажать клавишу DELETE.
Выделите текстовое поле. Если страница свойств не отображается, нажмите клавишу F4.
Откройте вкладку все . В поле имя свойства введите имя, например ткститемнумбер.
Откройте вкладку Данные.
В поле свойства Сумма выберите вариант более группа.
В поле свойства » источник элемента управления » введите = 1.
Откройте вкладку Формат.
В поле свойства Формат введите #. (знак решетки, за которым следует точка).
Таким образом номер строки будет форматироваться точкой, следующей за числом.
Сохраните отчет и переключитесь в режим отчета, чтобы просмотреть результаты.



