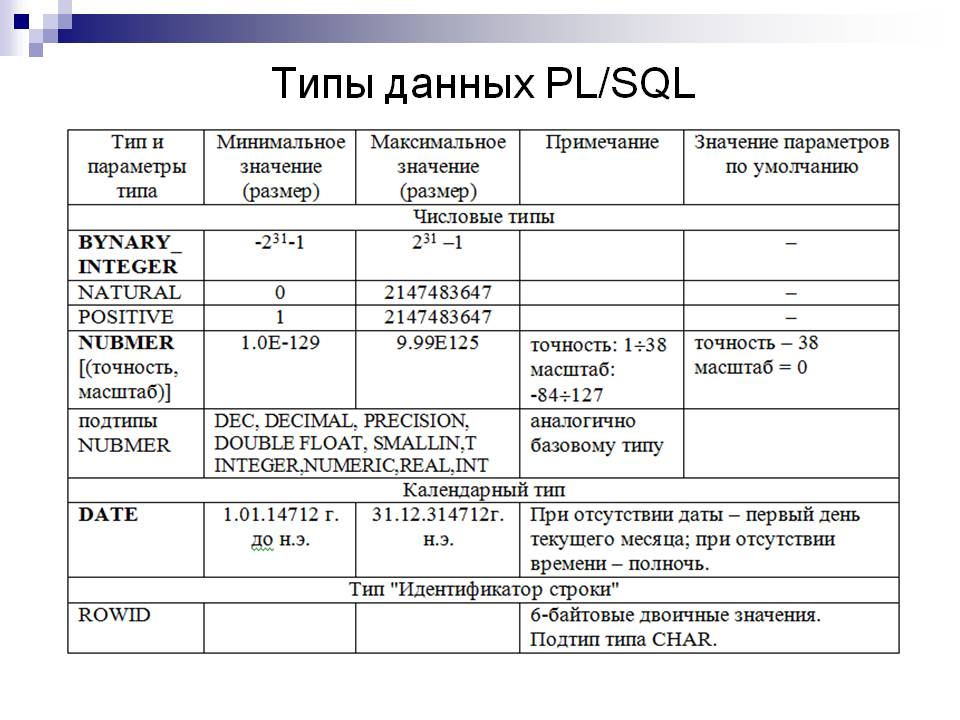
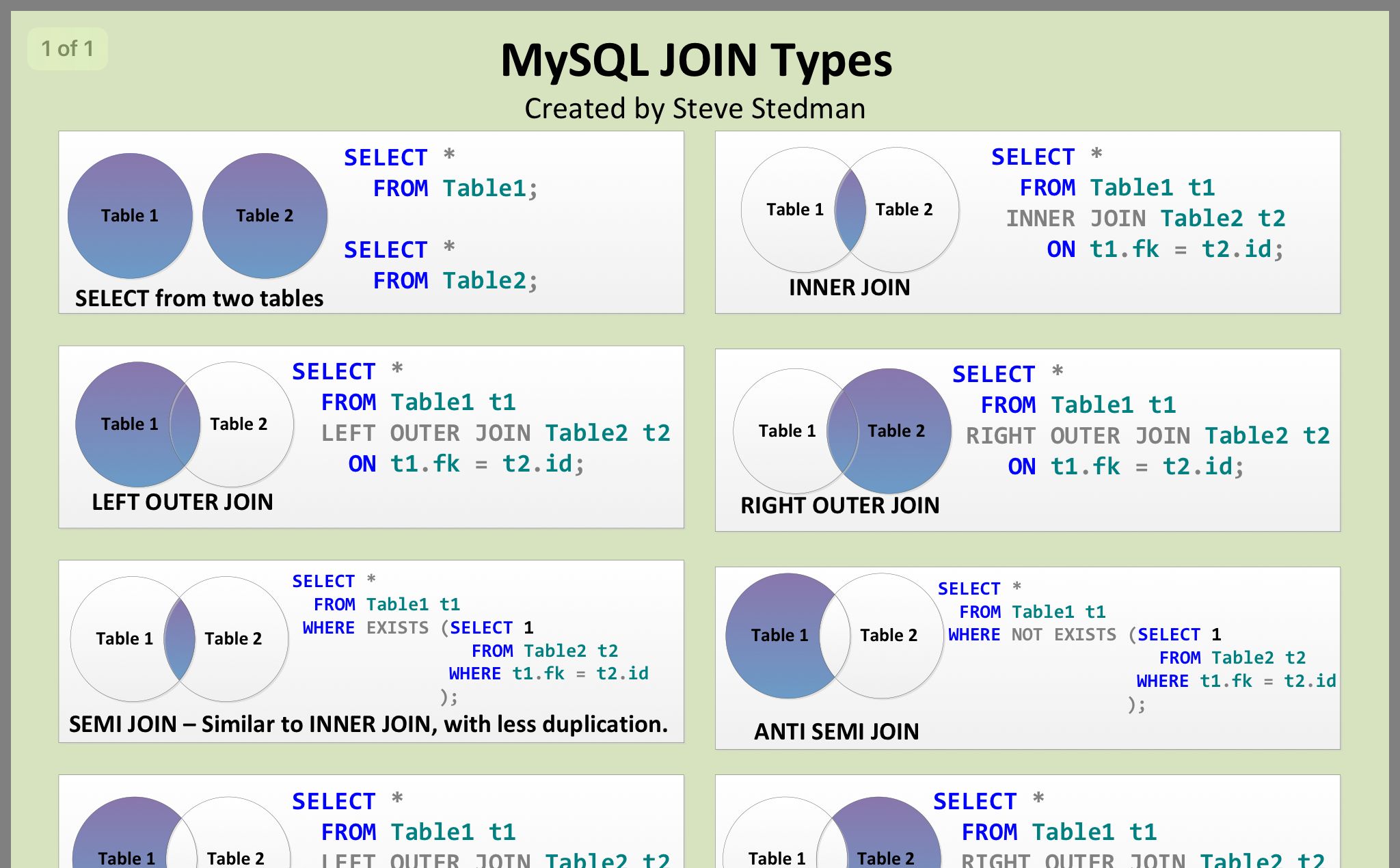
Введение в администрирование MySQL
С развитием систем баз данных процедуры инсталляции и использования MySQL становятся все проще. Судя по всему, именно простота работы с MySQL стала основной причиной широкой ее популярности среди пользователей. Особенно это относится к тем из них, которые не являются, да и не желают быть программистами. Безусловно, знания компьютерного профессионала могут оказаться весьма полезными, но для успешного использования MySQL быть опытным программистом вовсе не обязательно.
Однако и полностью без управления MySQL работать также не может. Администратор должен хотя бы иногда проверять согласованность и эффективность ее работы и знать, что делать при возникновении проблем. Вся эта информация представлена далее
Этот курс посвящен рассмотрению различных аспектов администрирования MySQL . В этой лекции представлено описание всех основных вопросов, которыми необходимо владеть для успешного выполнения задач по администрированию инсталляцией MySQL. Она же включает краткий обзор всех обязанностей администратора. Инструкции по их выполнению рассматриваются в следующих лекциях.
Представленный далее в этой лекции длинный список обязанностей может не на шутку напугать начинающего или неопытного администратора. Каждая указанная в списке задача действительно очень важна, однако не стоит пробовать освоить их все сразу. Гораздо лучше использовать лекции этого курса в качестве справочного руководства, которое всегда под рукой и в которое при необходимости можно заглянуть.
Уже имеющие опыт работы администраторы могут заметить, что администрирование MySQL подобно администрированию других систем управления базами данных. Опыт администрирования других систем просто неоценим. В то же время, администрирование MySQL имеет свои уникальные особенности, которые и описываются в этом курсе.
Обзор задач администрирования
СУБД MySQL состоит из нескольких основных компонентов. Знание их сути и предназначения поможет лучше понять природу управляемой системы и принципы работы различных ее средств. Настоятельно рекомендуется потратить немного времени, чтобы хорошенько разобраться в представленном далее материале. Это значительно упростит дальнейшую работу. В частности, необходимо вникнуть в следующие аспекты работы MySQL.
LEFT
Задачу обрезание лишних символов из начала строки можно было бы решить и с использованием функции LEFT, которая возвращает указанное количество символов, начиная с 1-го. Функции нужно передать следующие два параметра:
- Поле, подстроку которого нужно получить;
- Количество символов.
Следующий пример формирует ФИО, в котором имя и отчество сокращены:
SELECT vcFamil+' '+left(vcName, 1)+'. '+left(vcSurName, 1)+'.' FROM tbPeoples
Поле «vcFamil» выводится полностью, а вот от имени и отчества выводится только один левый (первый) символ.
Теперь посмотрим, как можно было использовать LEFT для обрезания префикса ‘mr.’:
UPDATE tbPeoples
SET vcFamil=(case LEFT(vcFamil, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END)
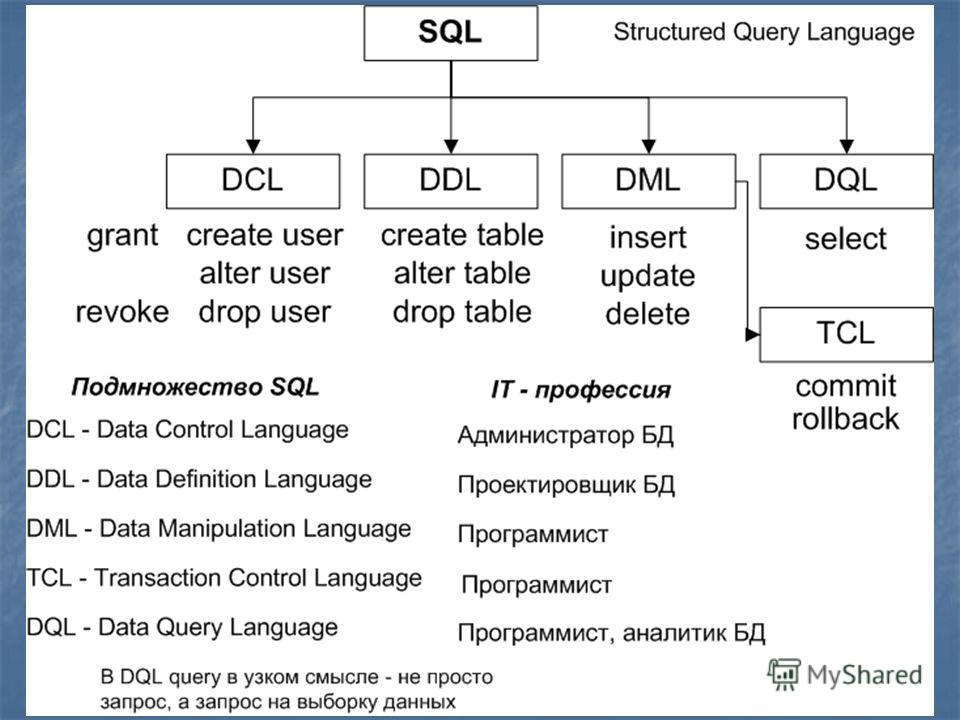
Основные правила синтаксиса языка SQL
- SQL не чувствителен к пробелам и переносам строк. Можно ставить сколько угодно пробелом и нажимать Enter для переноса строки, запрос эту информацию не учитывает
- SQL не чувствителен также к регистру букв. Можно написать SELECT или select, или Select. И даже SeLeCt. Это правило касается не только операторов, но и всего запроса.
- В запрос можно вставить комментарий. Иногда запросы бывают таким сложными и длинными, что даже сам автор не сразу понимает, где что написано, поэтому комментирование запросов SQL — очень нужный инструмент.
Чтобы вставить комментарий, в начале строки указываются два дефиса подряд, например:
— текст комментария
- Текстовые значения в фильтрах всегда берутся в одинарные кавычки. Например: Where City = ‘Paris’
- Элементы в блоках SELECT, FROM, GROUP BY и ORDER BY всегда разделяются запятой, а в блоках WHERE и HAVING — операторами AND или OR, в зависимости от от условий запроса.
Мы рассмотрели структуру и простые примеры SQL-запросов к базе данных.
SQL Оператор DELETE
SQL оператор DELETE используется для удаления одной или нескольких записей из таблицы.
Синтаксис
Синтаксис оператора DELETE в SQL:
Примечание
Вам не нужно перечислять поля в операторе DELETE, так как вы удаляете всю строку из таблицы.
Пример оператора DELETE с одним условием
Если вы запустите оператор DELETE без условий в предложении WHERE, все записи из таблицы будут удалены. В результате вы чаще всего будете включать предложение WHERE, по крайней мере с одним условием, в свой оператор DELETE.
Давайте начнем с простого примера запроса DELETE, который имеет одно условие в предложении WHERE.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Moscow |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Введите следующий оператор DELETE:
Будет удалена 1 запись. Снова выберите данные из таблицы поставщиков:
Вот результаты, которые вы должны получить:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
В этом примере удаляются все записи из таблицы suppliers , где supplier_name — Yandex.
Вы можете проверить количество строк, которые будут удалены. Вы можете определить количество строк, которые будут удалены, выполнив следующий запрос SELECT перед выполнением удаления:
Этот запрос вернет количество записей, которые будут удалены при выполнении оператора DELETE.
| COUNT(*) |
|---|
| 1 |
Пример — оператор DELETE с более чем одним условием
Вы можете иметь более одного условия в инструкции DELETE в SQL, используя либо условие AND, либо условие OR. Условие AND позволяет вам удалить запись, если все условия выполнены. Условие OR удаляет запись, если выполняется одно из условий.
Давайте рассмотрим пример использования оператора DELETE с двумя условиями с использованием условия AND. В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
Введите следующий оператор DELETE:
Будет удалены 3 записи. Снова выберите данные из таблицы products :
Вот результаты, которые вы получите:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
В этом примере удаляются все записи из таблицы products , у которых category_id равен 50, а product_name НЕ ‘Pear’.
Вы можете удалить записи в одной таблице на основе значений в другой таблице. Поскольку вы не можете перечислить более одной таблицы в предложении FROM при выполнении удаления, вы можете использовать предложение EXISTS.
SQL запросы на примерах
Предположим, у нас есть таблица Customers, в которой содержатся следующие столбцы:
CustomerID
CustomerName
ContactName
Address
City
PostalCode
Country
SumProd
1. Для первого примера воспользуемся только обязательными операторами запроса — SELECT и FROM.
Этот запрос выведет все столбцы (потому что в select указана *) и все строки из таблицы Customers.
2. Следующий пример выведет только те столбцы, которые мы выбрали:
Этот запрос выведет только столбцы CustomerName и City из таблицы Customers, и все строки по ним (всех покупателей по всем городам).
Казалось бы, что еще нужно? Выгрузили все данные, а дальше их можно и в эксель обработать. Но если в таблице сотни тысяч и миллионы строк, то такой способ не подходит. Поэтому нужно учиться фильтровать данные уже в запросе SQL.
3. Для следующего запроса добавляем необязательный элемент WHERE. Предыдущий пример вывел всех покупателей по всему миру, а это несколько миллионов строк… Что делать с таким огромным массивом и зачем он нужен, если нам нужны только покупатели из Парижа?

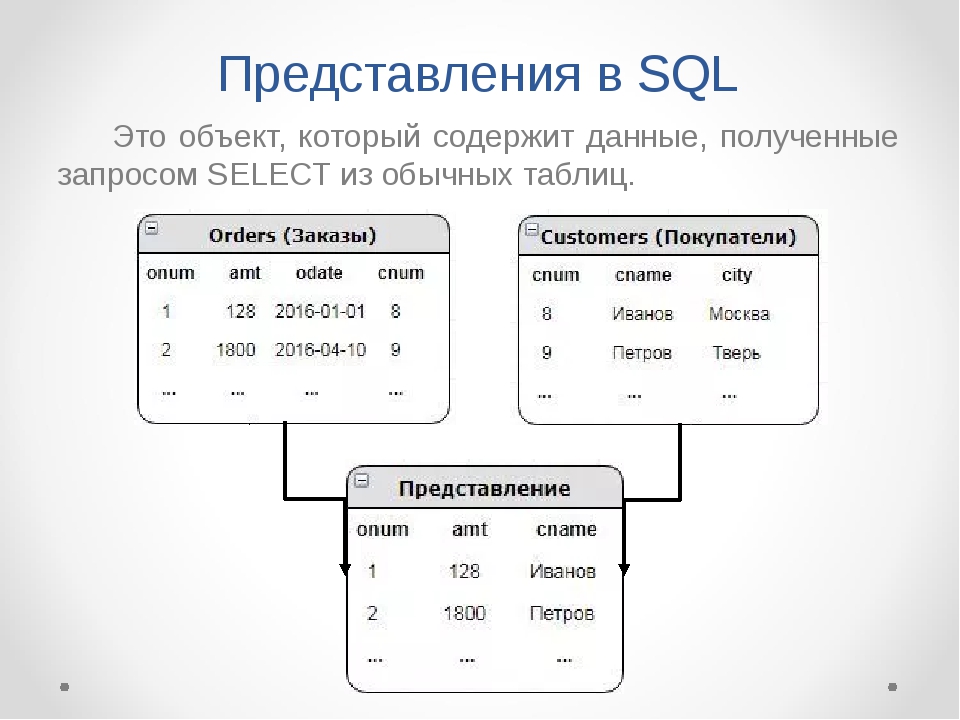



Модифицируем наш запрос:
Этот запрос выведет нам столбцы CustomerName и City, но только для тех строк, где City указан Paris.
Причем, столбец, по которому фильтруем (в данному случае, City), может и не содержаться в SELECT.
Данный запрос выведет просто имена покупателей, но только тех, кто проживает в Париже.
4. Для следующего примера используем сразу три новых понятия: вывод уникальных значений, функция и группировка столбцов.
Этот запрос выведет нам сумму продаж по всем городам Франции.
| City | SUM(SumProd) |
| Paris | 120020 |
| Marsel | 500000 |
| Strastburg | 40500 |
Теперь разберемся с новыми понятиями:
- DISTINCT — оператор, который выводит только уникальные значения из списка. В данной таблицу город Paris встречается много раз (т.к.покупателей оттуда много), но в таблицу он вышел только один раз — здесь помог оператор DISTINCT.
- SUM(SumProd) — это агрегатная функция. Здесь она суммирует продажи по указанному столбцу (City).
оператор GROUP BY — показывает, по какому столбцу будут сгруппированы данные.
И здесь мы понимаем, что необязательный элемент GROUP BY в данном случае становится обязательным (попробуйте выполнить этот запрос без него).
Дело в том, что группировка данных обязательна, если используются агрегатные функции.
И отсюда еще одно основное правило SQL-запросов: набор столбцов в SELECT и GROUP BY должен быть одинаковым. Агрегирующие функции в GROUP BY никогда не указываются.
5. Добавим оператор HAVING в наш запрос:
Оператор HAVING работает только со сгруппированными данными и указывается после GROUP BY. Чаще всего HAVING используют с числовыми значениями, как в данном случае. Мы выводим список городов Франции с сумму продаж по ним — но только тех городов, где суммы продаж превышает 100000.
Почему нельзя было указать это условие в операторе WHERE?
Дело в том, что WHERE работает с несгруппированными, “сырыми” данными из таблицы. Перебирает каждую строку. И если указать:
WHERE SumProd>100000,
то запрос будет искать это условие в каждой строке. А нам нужно отфильтровать уже сгруппированные по городам данные.
6. И наконец, добавим последний элемент запроса ORDER BY, который отсортирует выведенные данные в определенном порядке.
В данном случае, таблица будет отсортирована по столбцу City в алфавитном порядке от A до Z.
Если нужно отсортировать в обратном порядке, то используем элемент DESC:
ORDER BY City DESC
Теперь таблица отсортирована по столбцу City в порядке от Z до A.
Также можно использовать несколько столбцов для сортировки.
И в конце разберем основные правила синтаксиса языка SQL.
Рецепты для хворающих SQL-запросов
За прошедшее время вы уже воспользовались им более 6000 раз, но одна из удобных функций могла остаться незамеченной — это структурные подсказки, которые выглядят примерно так:
Прислушивайтесь к ним, и ваши запросы «станут гладкими и шелковистыми».
А если серьезно, то многие ситуации, которые делают запрос медленным и «прожорливым» по ресурсам, типичны и могут быть распознаны по структуре и данным плана.
В этом случае каждому отдельному разработчику не придется искать вариант оптимизации самостоятельно, опираясь исключительно на свой опыт — мы можем ему подсказать, что тут происходит, в чем может быть причина, и как можно подойти к решению. Что мы и сделали.
Давайте чуть подробнее рассмотрим эти кейсы — как они определяются и к каким рекомендациям приводят.
AdBlock похитил этот баннер, но баннеры не зубы — отрастут
Просмотр таблицы
Посмотреть на созданную таблицу можно с помощью команды SELECT * FROM <название таблицы>. Например:
# SELECT * FROM users;
fio | company | phone | email
----------------------------+---------------+-------------+----------------
Иванов Иван Алексеевич | ООО "Ромашка" | 89057362761 | ivanov@mail.ru
Донченко Иван Андреевич | ООО "Ромашка" | 89038276494 | dota@yandex.ru
Девин Алексей Владимирович | ООО "Начало" | 89069384782 | test@yandex.ru
(3 rows)
Можно вывести определённые колонки указав их вместо звездочки:
# SELECT fio, phone FROM users;
fio | phone
----------------------------+-------------
Иванов Иван Алексеевич | 89057362761
Донченко Иван Андреевич | 89038276494
Девин Алексей Владимирович | 89069384782
(3 rows)
Можно вывести определённые строки с помощью WHERE <условие>:
# SELECT * FROM users WHERE company = 'ООО "Ромашка"';
fio | company | phone | email
-------------------------+---------------+-------------+----------------
Иванов Иван Алексеевич | ООО "Ромашка" | 89057362761 | ivanov@mail.ru
Донченко Иван Андреевич | ООО "Ромашка" | 89038276494 | dota@yandex.ru
(2 rows)
В качестве условия можем указать, что значение в определённой колонке должно:
- чему-то равняется;
- быть больше или меньше определённого значения;
- содержать что-то;
- и другое.
Можем комбинировать эти методы, например:
# SELECT fio, phone FROM users WHERE company = 'ООО "Ромашка"';
fio | phone
-------------------------+-------------
Иванов Иван Алексеевич | 89057362761
Донченко Иван Андреевич | 89038276494
(2 rows)
А ещё можем отсортировать таблицу по какой-нибудь строке:
# SELECT fio, phone FROM users ORDER BY fio;
fio | phone
----------------------------+-------------
Девин Алексей Владимирович | 89069384782
Донченко Иван Андреевич | 89038276494
Иванов Иван Алексеевич | 89057362761
Условий может быть несколько, например ФИО должно содержать Иван, а телефон должен заканчиваться на 94:
# SELECT * FROM users WHERE fio ~ 'Иван' AND phone ~ '.*94$';
fio | company | phone | email
-------------------------+---------------+-------------+----------------
Донченко Иван Андреевич | ООО "Ромашка" | 89038276494 | dota@yandex.ru
Знак “~” – означает что значение должно содержать, а не равняться.
Также в примере выше я показал, что в условии можно использовать регулярные выражения.
Комбинировать условия можно с помощью AND и OR.
Команда ALTER TABLE в MySQL
Команда ALTER TABLE используется для осуществления изменений таблицы:
- Добавление колонок
- Удаление колонок
- Модификация колонок
- Изменения имени таблицы
- Изменения кодировки таблицы
- Добавление и удаление ограничений
Для дальнейших примеров будем использовать таблицу books из базы данных Bookstore, которую создали в одном из предыдущих постов.
Чтобы просмотреть изменения колонок в таблице, воспользуйтесь командой:SHOW COLUMNS FROM table_name;
Перед началом работ выберем базу данных, с которой будем работать.
<текстареа class=»crayon-plain print-no» data-settings=»dblclick» readonly=»» style=»-moz-tab-size:4; -o-tab-size:4; -webkit-tab-size:4; tab-size:4; font-size: 14px !important; line-height: 28px !important;»> USE Bookstore;
| 1 | USEBookstore; |
LTRIM и RTRIM
Функция LTRIM убирает все символы пробела в начале строки, а RTRIM убирает пробелы в конце строки. Допустим, что пользователь при вводе фамилии в самом начале случайно зацепил клавишу пробела. Получилось, что в базе хранится две фамилии:


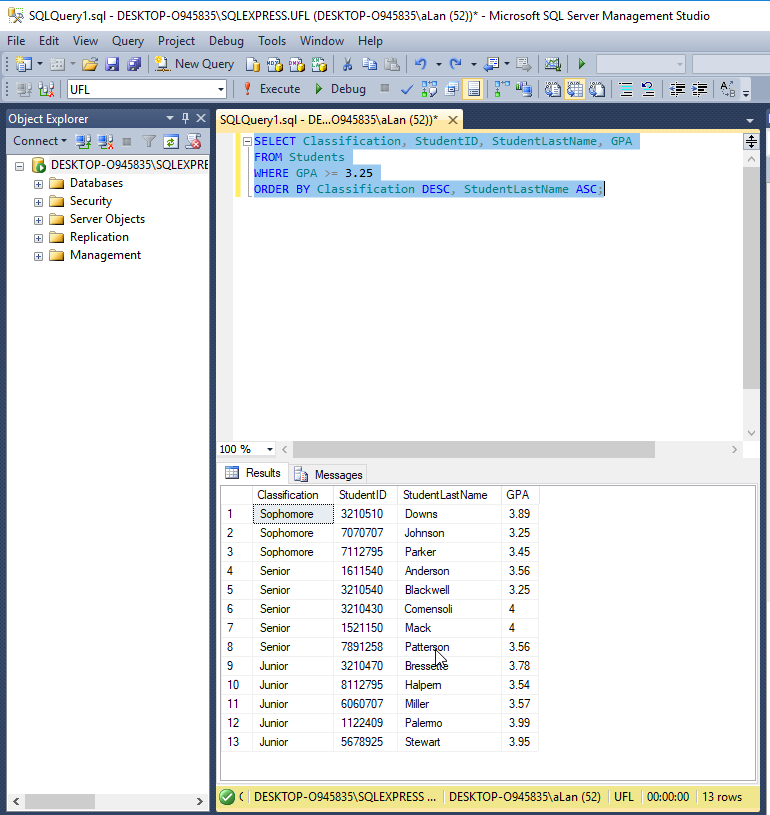




Иванов Иванов
Когда смотришь на эти фамилии, то видно, что вторая строка сдвинута вправо за счет пробела вначале. Это значит, что база данных будет воспринимать эти значения по-разному. Чтобы избавится от лишних пробелов, как раз используют функции LTRIM и RTRIM. Например:
SELECT *
FROM tbPeoples
WHERE LTRIM(vcFamil)=LTRIM(' Сидоров')
В этом примере поле «vcFamil» сравнивается с фамилией Сидоров, с пробелом в начале. Чтобы убрать пробел используется функция LTRIM. В следующем примере мы убираем и левые и правые пробелы:
-- Убрать лишние пробелы
SELECT *
FROM tbPeoples
WHERE vcFamil=LTRIM(RTRIM(' Сидоров '))
Если честно, то пробелы справа убираются сервером автоматически. Выполните следующий запрос и убедитесь сами:
SELECT * FROM tbPeoples WHERE vcFamil='Сидоров '
Если работник с фамилией Сидоров (без пробелов в конце) существует в таблице, и запрос отобразил его, то сервер автоматически убрал пробел.
PHP и MySQL
Еще раз хочу подчеркнуть, что запросы при создании интернет-проекта — это обычное дело. Чтобы их использовать в php-документах выполните такой алгоритм действий:
- Соединяемся с БД при помощи команды mysql_connect();
- Используя mysql_select_db() выбираем нужную БД;
- Обрабатываем запрос при помощи mysql_fetch_array();
- Закрываем соединение командой mysql_close().
Важно! Работать с БД не сложно. Главное — правильно написать запрос
Начинающие вебмастера подумают. А что почитать по этой теме? Хотелось бы порекомендовать книгу Мартина Грабера « SQL для простых смертных ». Она написана так, что новичкам все будет понятно. Используйте ее в качестве настольной книги.
Но это теория. Как же обстоит дело на практике? В действительности интернет-проект нужно не только создать, но еще и вывести в ТОП Гугла и Яндекса. В этом вас поможет видеокурс « Создание и раскрутка сайта ».
Защита порядковых номеров от обновления
Листинг 19: обновление столбца ID
USE tempdb; GO BEGIN TRAN UPDATE Sample SET ID = ID + 100; SELECT * FROM Sample; ROLLBACK TRAN; GO
Вывод кода из листинга 17Листинг 20: триггер AFTER UPDATE
USE tempdb
GO
CREATE TRIGGER trg_UpdateSample
ON Sample
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
DECLARE @OriginalID int
DECLARE @UpdatedID int
SELECT @OriginalID = FROM deleted
SELECT @UpdatedID = FROM inserted
IF @OriginalID @UpdatedID
BEGIN
RAISERROR('Failed: Update performed on ID column', 16, 1);
ROLLBACK TRANSACTION
END
END
GO
Листинг 21: Тестирование триггера, запрещающего обновление столбца ID
USE tempdb; GO UPDATE Sample SET ID = ID + 100 WHERE ID = 1; GO
Ошибка при выполнении кода из листинга 21
Как переименовать столбец с помощью ALTER TABLE
Вы можете переименовать столбец с помощью приведенного ниже кода. Вы выбираете таблицу с помощью ALTER TABLE имя_таблицы, а затем указываете, какой столбец переименовать и во что переименовать, с помощью RENAME COLUMN old_name TO new_name.
Давайте посмотрим на ту же таблицу, которую мы использовали в предыдущем примере:
| id | name | age | state | id_number | country | |
|---|---|---|---|---|---|---|
| 1 | Paul | 24 | Michigan | paul@example.com | NULL | United States |
| 2 | Molly | 22 | New Jersey | molly@example.com | NULL | United States |
| 3 | Robert | 19 | New York | robert@example.com | NULL | United States |
Чтобы избежать путаницы между столбцами id и id_number, давайте переименуем первый в user_id.
Сначала мы укажем таблицу с помощью ALTER TABLE users, а затем объявим имя столбца, чтобы оно изменилось на то, что мы хотим изменить, с помощью RENAME COLUMN id TO user_id.
После выполения запроса таблица будет выглядеть так:
| user_id | name | age | state | id_number | country | |
|---|---|---|---|---|---|---|
| 1 | Paul | 24 | Michigan | paul@example.com | NULL | United States |
| 2 | Molly | 22 | New Jersey | molly@example.com | NULL | United States |
| 3 | Robert | 19 | New York | robert@example.com | NULL | United States |
Если вы используете инструмент рефакторинга базы данных для изменения имени столбца вместо использования ALTER TABLE, он будет управлять всеми зависимостями и обновлять их с новым именем столбца.
Если у вас небольшая база данных, возможно, вам не о чем беспокоиться, но об этом важно помнить
Редактирование элементов таблицы
Иногда возникают ситуации, когда необходимо вставить в таблицу столбец или строку, изменить значение элемента или название колонки. Наша таблица — не исключение и нуждается в доработке.
Добавление строк
Добавим в таблицу данные о двух новых студентах: Иване и Олеге. Для этого необходимо создать новую структуру — список (list), В список мы по порядку вносим параметры, совпадающие со структурой таблицы (напомню, что в кавычках мы пишем нечисловые типы данных):
После, при помощи функции rbind (от англ. row bind, что дословно означает «связать строчки») мы объединим эти два списка с нашей таблицей:
Добавление столбцов
Теперь у нас в таблице два Ивана и два Олега. В данном случае хорошо было бы прописать для каждого студента свой идентификационный номер (ID), чтобы не запутаться, кто есть кто. Для этого создадим структуру, которая называется вектор (последовательность элементов одного типа). В него мы запишем последовательность от 1 до 22, так, чтобы у каждого из наших 22 студентов был свой уникальный ID:
Теперь объединим наш вектор с таблицей, воспользовавшись функцией cbind (от англ. column bind):
Не забудьте поменять тип данных нового столбца на символьный:
В качестве еще одного примера добавления новых столбцов с данными в таблицу, рассчитаем индекс массы тела (BMI) для каждого студента. Для этого, мы воспользуемся новым способом: напишем математическую формулу индекса на языке R и присвоим ей новое имя столбца «BMI» внутри нашей таблицы:
Проверьте, что получилось, используя уже знакомые нам функции head и str
Удаление строк и столбцов
Существует относительно «универсальная формула» для удаления элементов таблицы: new.data <- my.data Для того, чтобы корректно ее использовать необходимо запомнить несколько правил:
- После имени таблицы пространство внутри квадратных скобок следует разделить на две части запятой.
- Все, что находится до запятой, относится к строчкам, все что после — к столбцам.
- Поставьте минус перед номером столбца или номером строки, которую собираетесь удалить.
- Если таких элементов несколько, используйте функцию c(…): внутри скобок перечисление элементов через запятую.
В нашем случае, удалять из таблицы ничего не надо, но я покажу пару примеров, назвав «укороченные» таблицы именами «trash1», «trash2», «trash3», «trash4»:
Изменение имен столбцов и данных в ячейках:
Переименуем колонку «Rhesus.factor» на укороченное «Rhesus». Для этого нужно вызвать функцию names, написать в параметрах функции имя таблицы и номер столбца, и присвоить ему новое имя:
Изменение данные в ячейках таблицы не представляет особой сложности. В квадратных скобках прописываем координаты нужной ячейки (до запятой — строка, после запятой — столбец) и присваиваем новое значение:
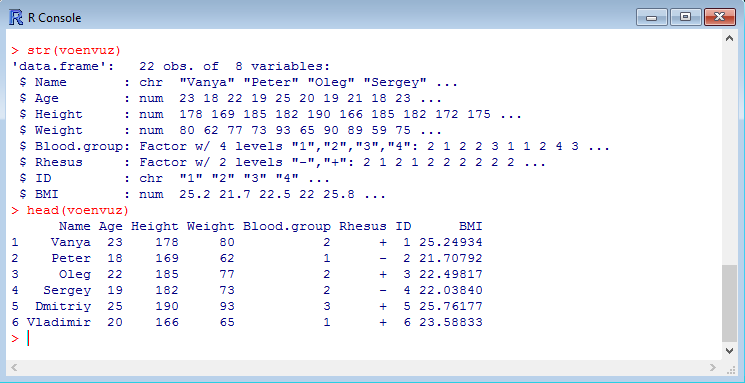
После всех наших манипуляций мы должны получить вот такую таблицу данных:
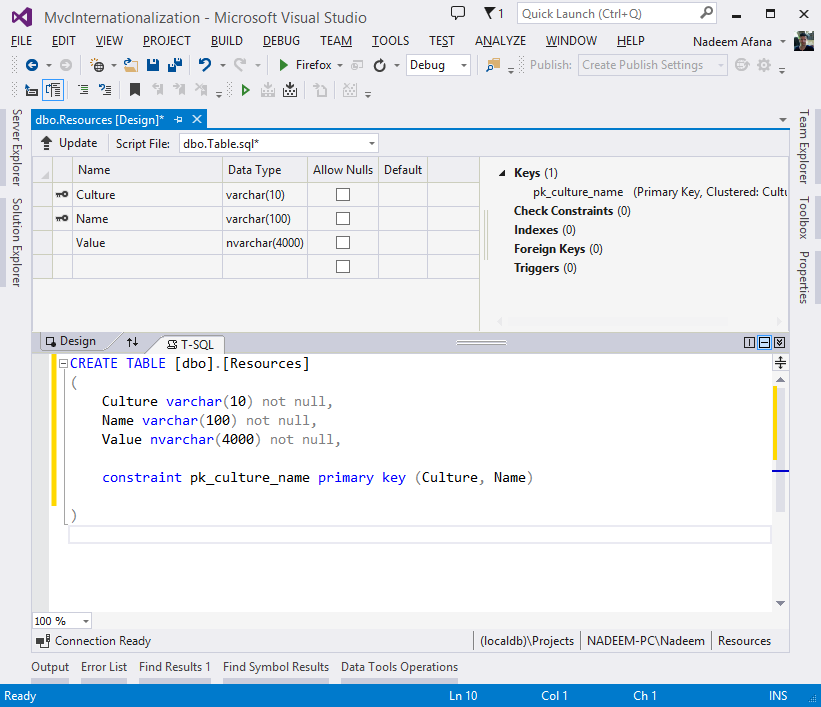
Изменение таблиц в конструкторе SQL Server Management Studio
Сначала я покажу, как изменяются таблицы с помощью графического интерфейса SQL Server Management Studio, а изменяются они точно так же, как и создаются, с помощью того же самого конструктора.
Чтобы открыть конструктор таблиц в среде SQL Server Management Studio, необходимо в обозревателе объектов найти нужную таблицу и щелкнуть по ней правой кнопкой мыши, и выбрать пункт «Проект». Увидеть список таблиц можно в контейнере «Базы данных -> Нужная база данных -> Таблицы».
В итоге откроется конструктор таблиц, где Вы можете добавлять, удалять или изменять столбцы таблицы.
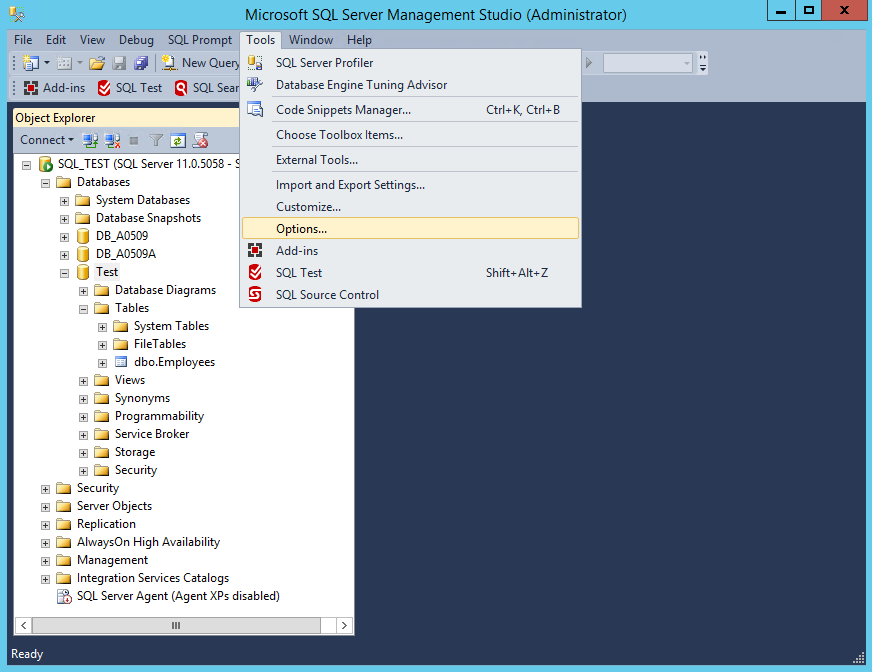
В случае если Вы работаете исключительно в конструкторе (если делать все то же самое с помощью T-SQL, то такая ошибка возникать не будет) и четко уверены в своих действиях, то этот параметр можно отключить. Для этого зайдите в меню «Сервис -> Параметры» и в разделе «Конструкторы -> Конструкторы таблиц и баз данных» снимите соответствующую галочку.
После чего данное ограничение будет снято, и Вы сможете вносить изменения в таблицы с помощью конструктора. При сохранении таблицы ошибок возникать уже не будет.




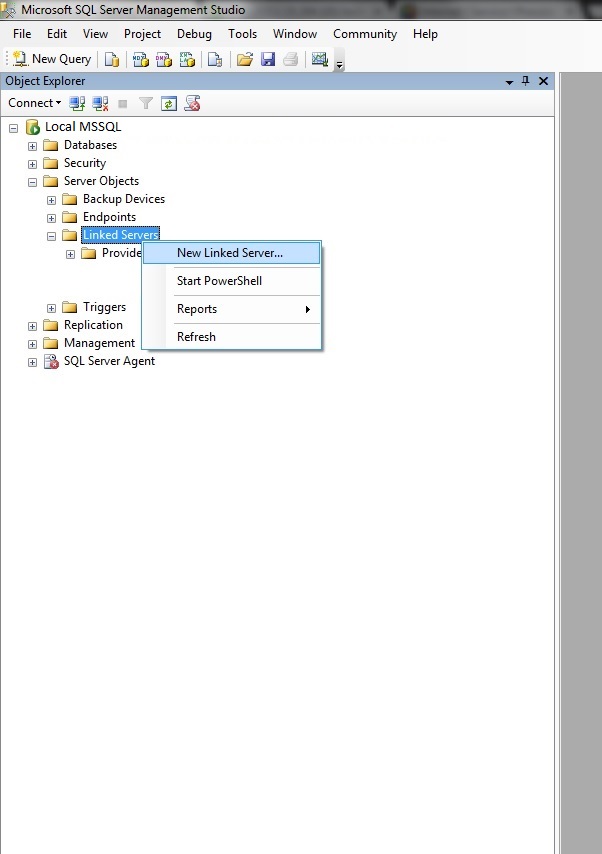

Как работать с конструктором, я думаю, понятно, например, для добавления нового столбца просто пишем название столбца в новую строку, выбираем тип данных и указываем признак, может ли данный столбец хранить значения NULL. Для сохранения изменений нажимаем сочетание клавиш «Ctrl+S» или на панели инструментов нажимаем кнопку «Сохранить» (также кнопка «сохранить» доступна и в меню «Файл», и в контекстном меню самой вкладки конструктора).
Для внесения изменений в существующие столбцы точно так же изменяем параметры, и сохраняем изменения.
Важно!
Во всех случаях, т.е
не важно с помощью конструктора или с помощью языка T-SQL, когда Вы будете вносить изменения в таблицы, в которых уже есть данные, важно понимать и знать, как эти изменения отразятся на существующих данных, и можно ли вообще применить эти изменения к данным
Например, изменить тип данных можно, только если он явно преобразовывается без потери данных или в столбце нет данных вообще. Допустим, если в столбце с типом данных VARCHAR(100) есть данные, при этом максимальная длина фактических данных в столбце, к примеру, 80 символов, то изменить тип данных, без потери данных можно только в сторону увеличения или уменьшения до 80 символов (VARCHAR(80)).
Также если в столбце есть данные, при этом он может принимать значение NULL, а Вы хотите сделать его обязательным, т.е. задать свойство NOT NULL, Вам сначала нужно проставить всем записям, в которых есть NULL, значение, например, то, которое будет использоваться по умолчанию, или уже более детально провести анализ для корректной простановки значений.
Еще стоит отметить, что даже просто добавить новый столбец, который не должен принимать значения NULL, не получится, если в таблице уже есть записи, в таких случаях нужно сначала добавить столбец с возможностью принятия значения NULL, потом заполнить его данными, и уже потом обновить данный параметр, т.е. указать NOT NULL.
Удаление столбцов из таблицы
В этой статье показано, как удалить столбцы таблицы в SQL Server с использованием SQL Server Management Studio (SSMS) или Transact-SQL.
При удалении столбца из таблицы удаляется сам столбец и все содержащиеся в нем данные.
Ограничения
Нельзя удалить столбец с ограничением CHECK. В первую очередь необходимо удалить ограничение.
Удалить столбец с ограничениями PRIMARY KEY, FOREIGN KEY или другими зависимостями можно только с использованием конструктора таблиц в SSMS. При использовании обозревателя объектов или Transact-SQL необходимо сначала удалить зависимости столбца.
Удаление столбцов с помощью обозревателя объектов
Ниже описаны действия по удалению столбцов с помощью обозревателя объектов в SSMS.
- В обозревателе объектов подключитесь к экземпляру компонента Компонент Database Engine.
- В обозревателе объектов найдите таблицу, из которой нужно удалить столбцы, и разверните ее, чтобы отобразить имена столбцов.
- Щелкните правой кнопкой мыши столбец, который необходимо удалить, и выберите команду Удалить.
- В диалоговом окне Удаление объекта нажмите кнопку ОК.
Если столбец содержит ограничения или другие зависимости, то в диалоговом окне Удаление объекта будет отображено сообщение об ошибке. Чтобы устранить проблему, удалите упомянутые ограничения.
Удаление столбцов с помощью конструктора таблиц
Ниже описаны действия по удалению столбцов с помощью конструктора таблиц в SSMS.
- В обозревателе объектов щелкните правой кнопкой мыши таблицу, из которой необходимо удалить столбцы, и выберите пункт Конструктор.
- Щелкните правой кнопкой мыши столбец, который надо удалить, и выберите из контекстного меню пункт Удалить столбец .
- Если столбец участвует в связи (FOREIGN KEY или PRIMARY KEY), то будет выдано сообщение с запросом на подтверждение удаления выбранных столбцов и их связей. выберите Yes (Да).
Удаление столбцов с помощью Transact-SQL
Вы можете удалять столбцы с помощью Transact-SQL в SSMS, Azure Data Studio или средств командной строки, таких как служебная программа sqlcmd.
В следующем примере демонстрируется удаление столбца.
Если столбец содержит ограничения или другие зависимости, то будет возвращено сообщение об ошибке. Чтобы устранить проблему, удалите упомянутые ограничения.
Дополнительные примеры см. в статье ALTER TABLE (Transact-SQL).
Следующие шаги
Дополнительные сведения об изменении таблиц, общих задачах и связанных с ними инструментах см. в следующих статьях:
Заключение
На этом завершаем наш урок по SQL. В нем мы постарались дать читателю несколько практических навыков, которые пригодятся при дальнейшем обучении. На самом деле язык SQL очень обширен. Описать все его возможности в одной статье не представляется возможным. Поэтому для построения карьеры успешного веб-разработчика необходимо развиваться дальше и изучать SQL более детально.
В сети существует один полезный инструмент, предназначенный для тестирования SQL запросов, вы можете использовать его в процессе обучения.
Оригинал статьи — http://tutorialzine.com/2016/01/learn-sql-in-20-minutes/